MetaKRec: Collaborative Meta-Knowledge Enhanced Recommender System
Abstract
Knowledge graph (KG) enhanced recommendation has demonstrated improved performance in the recommendation system (RecSys) and attracted considerable research interest. Recently the literature has adopted neural graph networks (GNNs) on the collaborative knowledge graph and built an end-to-end KG-enhanced RecSys. However, the majority of these approaches have three limitations: (1) treat the collaborative knowledge graph as a homogeneous graph and overlook the highly heterogeneous relationships among items, (2) lack of design to explicitly leverage the rich side information, and (3) overlook the rich knowledge in user preference.
To fill this gap, in this paper, we explore the rich, heterogeneous relationship among items and propose a new KG-enhanced recommendation model called Collaborative Meta-Knowledge Enhanced Recommender System (MetaKRec). In particular, we focus on modeling the rich, heterogeneous semantic relationships among items and construct several collaborative Meta-KGs to explicitly depict the relatedness of the items under the guidance of meta-knowledge. In addition to the knowledge obtained from KG, we leverage user knowledge that extracts from user preference to construct the Meta-KGs. The constructed Meta-KGs can capture the knowledge from both the knowledge graph and user preference. Furthermore. we utilize a light convolution encoder to recursively integrate the item relationship in each collaborative Meta-KGs. This scheme allows us to explicitly gather the heterogeneous semantic relationships among items and encode them into the representations of items. In addition, we propose channel attention to fuse the item and user representations from different Meta-KGs. Extensive experiments are conducted on four real-world benchmark datasets, demonstrating significant gains over the state-of-the-art baselines on both regular and cold-start recommendation settings.
I Introduction
Knowledge graph (KG) enhanced recommendation is becoming increasingly popular due to its significant performance gains over traditional recommendation. The benefit mainly results from better user/item representation learned with knowledge graph side information, since that side information is able to alleviate cold-start issues in the recommendation. We illustrate the book recommendation task as a toy example in Figure 1: Tom bought the books “Harry Potter” and “The Old Man and The SEA”. Without the knowledge graph information, it is not clear if “Hemingway: Life and Death of a Giant” should be recommended to Tom. By taking the information in the knowledge graph, we know that “Hemingway: Life and Death of a Giant” depict the life of “Ernest Hemingway” who authors the “The Old Man and The SEA”. We can recommend “Hemingway: Life and Death of a Giant” to Tom based because he may be interested in the life of “Ernest Hemingway”. In addition, taking the KG into consideration also brings explainability, for example, the reason “Harry Potter” and “Fantastic Beasts” are similar is that they are written by the same author. Therefore study Knowledge graph (KG) enhanced recommendation is a nontrivial research question.
The key to KG-enhanced recommendation is to effectively incorporate the KG-side information for learning qualitative user/item representation. Existing works can be classified into two categories: feature-engineered approaches and end-to-end approaches. Feature-engineered approaches benefit from prior knowledge learned from analytic work and explicitly model the KG side information. In earlier research [1, 2, 3], KG triplets are used to create embeddings, which are then used to enrich item representations by treating them as prior or content knowledge. To better characterization of user-item connections, several follow-up research [4, 5, 6] extend the interactions with multi-hop edges from user to item. However, feature-engineered approaches usually require heavy human efforts to obtain good features. On the other hand, the end-to-end approaches [7, 8, 9, 10] aim to implicitly model the KG side information by building end-to-end trained graph neural networks (GNNs) [11, 12, 13] on the constructed Collaborative Knowledge Graph (CKG). The basic idea is to utilize the information aggregation strategy, which can successfully capture multi-hop structures and encode them into representations. However, the majority of these approaches have some limitations: (1) treat the collaborative knowledge graph as a homogeneous graph and overlook the highly heterogeneous relationship among items; (2) lack of design to explicitly leverage the rich side information. (3) overlook the rich knowledge in user preference. Thus it requires finding a solution that can overcome these limitations.
The collaborative Knowledge Graph (CKG) contains abundant heterogeneous relationships between items. Two items can be linked together through different relationships, providing fruitful information to enhance the recommender system. An illustration is shown in Figure 1. Similar items can be linked to the same entity by different kinds of relationships, e.g., we can observe two triples: (“Old Man and The Sea”, “written by”, “Ernest Hemingway”) and (“Ernest Hemingway”,“Protagonist in”,“Hemingway: Life and Death of a Giant”). The two books are linked to “Hemingway” by different relationships. Users who purchased “Old Man and The Sea” will likely be interested in “Hemingway: Life and Death of a Giant” because it depicts the life of the author of “Old Man and The Sea”. Two items that share the same relationship with one entity tend to be similar. E.g., the book “Harry Potter” and “Fantastic Beasts” are both linked to the fantasy category. Tom, who purchased “Harry Potter”, is also likely to be interested in “Fantastic Beasts” which belongs to the same category. Items can also be similar if they share similar semantic information over the knowledge graph even if they are not directly linked, e.g., “Old Man and The Sea” does not have a link to “Harry Potter”. But they are also similar in the sense that they are both the author’s most popular books. The unlinked entity similarity can be captured by the knowledge graph embedding method. Item similarity can also be revealed by users’ co-purchase behavior. E.g., Eva may be interested in “Harry Potter” because it is co-purchased with “Fantastic Beasts” by Jane. Thus, we can find similar items by the high co-purchase similarity or Top K co-purchased items. We can also alleviate the cold-start problem from the relational links in the knowledge graph. E.g., we can recommend the non-interacted “Hemingway: Life and Death of a Giant” to Tom because it shows the life of the author of “Old Man and The Sea”. Thus, it requires incorporating these heterogeneous relationships into the representation of learning of the items.
Based on the above motivation, we propose the Collaborative Meta-Knowledge Graph Enhanced Recommender System (MetaKRec ), a novel KG-enhanced recommendation model that explores the rich heterogeneity link between items. To represent the relatedness of the items under the guidance of the meta-graph, we build a variety of collaborative Meta-KGs with a specific emphasis on modeling the rich, diverse semantic connections among items. Additionally, we develop a simple convolution encoder to recursively incorporate the item connection in every shared Meta-KG. With the help of this technique, we can explicitly collect and encode the many semantic links between things. We also propose channel attention to combine the user and item representations from several Meta-KGs. Extensive experiments on four real-world benchmark datasets show considerable improvements (to be added) over the state-of-the-art baselines for both regular and cold-start recommendation settings. We open sourced MetaKRec at https://github.com/YangLiangwei/MetaKRec.
The key contributions are summarized as follows:
-
•
We first put forward Collaborative Meta-Knowledge Graphs to explicitly encode prior Meta-knowledge as edges between items. It is flexible to transform from both knowledge graphs and historical interactions.
-
•
We propose channel attention that can fuse information from different Collaborative Meta-Knowledge Graphs. It is effective to achieve better performance by combining different Collaborative Meta-Knowledge Graphs.
-
•
We propose MetaKRec , and validate its effectiveness on real-world datasets. It achieves the best performance under both normal and cold-start settings.

II Preliminaries
This section gives the required preliminaries for MetaKRec , including the problem formulation and graph neural network.
II-A Problem Formulation
For a knowledge graph enhanced recommender system, we have a set of users , a set of items , and a set of entities . Historical user-item interactions are represented as a user-item bipartite graph , where if has purchased , otherwise . Besides , we also have a knowledge graph as side information for items. The knowledge graph is typically formed by entities and the relationships among them. is represented by subject-property-object triple facts [14]: , where each triple represents the relation between and is .
Collaborative Knowledge Graph [7] is built by unifying and . Firstly, we set the item-entity alignment function that maps item as entity in the knowledge graph. Then user-item interaction is transformed into two triples and . Based on the previous alignment, the collaborative knowledge graph is represented by . Then the task is formulated to predict the adoption probability given that contains both historical interactions and the knowledge graph.

II-B Graph Neural Network
Graph neural network (GNN) is a deep learning method applied to graph-structured data. It has been tested to be effective in a wide range of graph-related tasks such as protein function prediction [15], group identification [16] as well as recommender system [17, 18, 19]. GNN is based on the homophily assumption [20] on graphs. It indicates nodes connected in a graph are similar to each other. GNN models homophily by directly aggregating embedding from neighbors to the center neighbor, which is formulated as:
| (1) |
where is node ’s embedding in -th layer, is ’s neighbors, aggregates neighbors’ embedding into a single vector in layer , and is the function to combine neighborhood representation and the center node’s embedding. Different selection of and leads to different kinds of GNN layers, such as GCN [21], GAT [22], and GIN [23].
III Method
This section presents the proposed MetaKRec , which includes parts. 1) Collaborative Meta-KG construction based on . 2) Graph convolution on the Collaborative Meta-KGs. 3) Channel attention module aggregating embedding learned from different meta-kg channels, and 4) Prediction module to predict the probability based on learned embedding. The main framework is also shown in Fig. 2.
III-A Collaborative Meta-KG Construction
Directly enhancing the recommender system by the original collaborative knowledge graph has two drawbacks. 1) The edges between items and entities are still sparse. Message-passing on the sparse graph is neither efficient nor effective. 2) The learning of entity embedding burdens the training procedure. To tackle the two drawbacks, we propose to construct Collaborative Meta-KG (CMKG) from the original collaborative knowledge graph , which is defined as:
Definition III.1
Collaborative Meta-KG, , where indicates the meta-edges between items built from knowledge graph. Each contains the historical user-item interactions and the specific item similarity extracted from the knowledge graph.
is constructed from . Based on explicit meta-knowledge, we encode the knowledge graph as multiple . In this way, we drop the entities in KG and encode the KG information as edges directly between items in . This leads to denser interactions and enables a direct message-passing between items. As shown in Fig. 3, we generate from the knowledge graph:
-
•
: Two items are similar when connected to the same entity. E.g., we transform relation in to a direct edge in .
-
•
: Two items are more similar if they are connected to the same entity under the same relation. E.g., we transform relation in to a direct edge in .
-
•
: Items are similar if they share similar semantic meanings in the knowledge graph. To this end, we obtain the entities embedding by training a TransE [24] model on the knowledge graph. Then we build edges between two items if the cosine similarity of their TransE embedding is larger than a threshold . E.g., we build an edge between and because their cosine similarity on TransE embedding is larger than a threshold .
We can also generate from the user-item interactions. MetaKRec generates based on co-purchase behavior:
-
•
: Items are similar if they share similar common users. We compute the Jaccard similarity between item pairs based on interacted users. Item’s user neighborhood is more similar with a higher Jaccard similarity. E.g., we construct an edge between in because their Jaccard similarity is larger than .
-
•
: Based on Jaccard similarity, we construct the edge between one item and its Top K most similar items. E.g., we construct in because is in ’s Top K similar items.

All share the historical user-item interactions and differ from the edges between items. Different utilizes different information sources and Meta Knowledge. , , are built based on knowledge graph. and are built based on user-item interaction graph. The can be built based on different kinds of Meta Knowledge. In MetaKRec , we illustrate the building method in differently. It is flexible enough to contain more information by transforming the Meta Knowledge into item similarities.
III-B Light Graph Convolution Encoder
Light graph convolution [25] (LGC) has been shown effective on the user-item bipartite graph. The direct embedding passing between users and items explicitly aggregates the collaborative filtering signal. MetaKRec applies LGC on each generated in Section III-A.
The embedding layer is built before the convolution to represent the users and items. The embedding layer is a look-up table that maps user/item ID to a dense vector:
| (2) |
where is the -dimensional vector to represent a user/item. The embedding indexed from the loop-up table is before the graph convolution. Then they are fed into the light graph convolution to aggregate neighbor’s information:
| (3) |
where can represent both user and item in , is the neighbor set of node . The LGC can be stacked in several layers, and we omit the notation for layers for simplicity. We perform the convolution separately for each . After the convolution, we have for node .
III-C Channel Attention
Each is one channel for model to encode KG information. Different channels encode node embedding from different , and contain different information. The channel attention module is a readout function to aggregate the embedding learned on different :
| (4) | ||||
| (5) |
where is the attention weight learned for , and is calculated by:
| (6) |
where is the parameter to compute attention weight. The channel attention module learns different weights for different channels to optimize the loss function. It can effectively combine information extracted from different .
III-D Prediction
The aggregated embedding for and contain information from different , and we compute the dot product as the probability that will purchase :
| (7) |
We randomly sample one negative item over the whole item set for each positive interaction and compute the Bayesian Personalized Ranking (BPR) loss [26] for optimization:
| (8) |
where is the randomly sampled negative item, is the regularization hyper-parameter, and contains all the parameters.
III-E Model Parameter Analysis
| Model | Parameters |
|---|---|
| KGAT | |
| KGIN | |
| MetaKRec |
We compare the parameter size of MetaKRec with KG-enhanced recommendation models. The comparison is shown in Table I. represent the user, item, entity and relation set, respectively. is the intent set in KGIN. is the number of layers and is the embedding size. MetaKRec has the fewest parameters, and it only needs the user and item embedding table. All the other KG-enhanced methods need much more parameters to represent the entities. MetaKRec abandons the redundant design of entity embedding and enables direct aggregation between items. As shown in Table III, MetaKRec achieves the best performance with the fewest parameters. It testifies the MetaKRec is effective and efficient.
IV Experiment
Extensive experiments are conducted on real-world datasets to answer the following research questions (RQs):
-
•
RQ1: Is MetaKRec effective in knowledge graph enhanced recommendation?
-
•
RQ2: What are the results on different Collaborative Meta-KGs?
-
•
RQ3: Can MetaKRec cope with the cold-start recommendation by considering more side information?
-
•
RQ4: What is the influence of different experiment setting on MetaKRec ?
IV-A Experiment Setting
IV-A1 Datasets
To test the performance of MetaKRec , we select four datasets with knowledge graphs as side information during the evaluation. The data statistics are shown in Table II. The size of four datasets varies from small to large, which are introduced as follows:
-
•
Music [27]: It contains musician listening information of the Last.fm online platform 111https://www.last.fm/.
-
•
Book [27]: It contains the rating from users to books of the Book-Crossing platform 222https://www.bookcrossing.com/.
-
•
Amazon [28]: It is a widely used dataset for studying e-commerce recommendations from Amazon platform 333https://www.amazon.com/. To ensure the data quality, -core setting is adopted, i.e., each user/item has at least interactions.
-
•
Yelp [28]: It is a dataset from Yelp platform 444https://www.yelp.com/, where users can check in and rate local businesses such as restaurants and bars. We also apply -core setting to ensure data quality.
All the datasets contain both user-item interactions and the related knowledge graph.
| Dataset | Music | Book | Amazon | Yelp |
|---|---|---|---|---|
| Users | 1,872 | 17,860 | 45,113 | 15,959 |
| Items | 3,846 | 14,967 | 24,695 | 43,214 |
| Interactions | 42,348 | 139,746 | 426,503 | 341,211 |
| Density | 0.59% | 0.05% | 0.038% | 0.049% |
| Entities | 3,846 | 77,891 | 113,269 | 134,175 |
| Relations | 60 | 25 | 39 | 42 |
IV-A2 Baselines
To make a thorough comparison, different kinds of methods are selected as baselines:
-
•
FM [29]: It is a supervised learning algorithm based on linear regression and matrix factorization.
-
•
FM-KG [7]: It adds the knowledge graph entity connection vector to enrich the item feature before the factorization machine.
-
•
GCN [21]: It is the most widely used graph neural network. It makes a direct GCN convolution on the user-item bipartite graph to obtain node embedding.
-
•
SGConv [30]: It simplifies the convolution of multiple GCN layers by multiplying the graph Laplacian matrix.
-
•
LightGCN [25]: It is the state-of-the-art recommender method. By removing the linear transform and non-linear activation, LightGCN achieves faster training and higher accuracy.
-
•
KGAT [7]: It is a graph neural network-based method that utilizes the knowledge graph as edges between items and entities. It trains directly on the knowledge in an end-to-end fashion.
-
•
KGIN [8]: It models the intent behind user-item interactions by combining different relations in the knowledge graph. It also designs a new information aggregation scheme to integrate the related sequences of long-range connectivity.
FM and FM-KG are two traditional methods. GCN, SGConv, and LightGCN are GNN-based methods. KGAT and KGIN are two knowledge graph-enhanced methods.
IV-A3 Metrics
To measure MetaKRec ’s performance, Recall and NDCG are adopted as the metrics. Recall measures the fraction of retrieved users’ truly interested items, and NDCG measures the model’s ranking quality of the retrieved items. For each metric, we compare the results on top-10 and top-20 recommendations.
| Dataset | Metric | FM | FM-KG | GCN | SGConv | LightGCN | KGAT | KGIN | MetaKRec | Improv. |
|---|---|---|---|---|---|---|---|---|---|---|
| Music | R@10 | 0.04805 | 0.11771 | 0.15700 | 0.17326 | 0.18966 | 0.17248 | 0.16244 | 0.20809 | 9.72% |
| R@20 | 0.09051 | 0.18290 | 0.22449 | 0.24911 | 0.27453 | 0.25043 | 0.26026 | 0.29053 | 5.83% | |
| N@10 | 0.03658 | 0.07741 | 0.10864 | 0.12299 | 0.13635 | 0.11557 | 0.10729 | 0.14698 | 7.80% | |
| N@20 | 0.05197 | 0.09916 | 0.13042 | 0.14768 | 0.16422 | 0.14220 | 0.13856 | 0.17433 | 6.16% | |
| Book | R@10 | 0.05522 | 0.06017 | 0.05914 | 0.06146 | 0.06302 | 0.04329 | 0.04394 | 0.07137 | 2.63% |
| R@20 | 0.06531 | 0.07341 | 0.07775 | 0.07971 | 0.09120 | 0.05166 | 0.06033 | 0.09987 | 9.51% | |
| N@10 | 0.04274 | 0.04993 | 0.05858 | 0.04539 | 0.06518 | 0.04002 | 0.04146 | 0.06842 | 4.97% | |
| N@20 | 0.04606 | 0.05453 | 0.06553 | 0.05343 | 0.07623 | 0.04396 | 0.04735 | 0.07962 | 4.45% | |
| Amazon | R@10 | 0.00760 | 0.03540 | 0.04393 | 0.04907 | 0.04379 | 0.03459 | 0.04581 | 0.05106 | 4.06% |
| R@20 | 0.01027 | 0.06030 | 0.07176 | 0.07894 | 0.06804 | 0.06129 | 0.07306 | 0.08618 | 9.17% | |
| N@10 | 0.00582 | 0.02200 | 0.02883 | 0.03420 | 0.02867 | 0.02252 | 0.02950 | 0.03466 | 1.35% | |
| N@20 | 0.00812 | 0.03070 | 0.03844 | 0.04470 | 0.03717 | 0.03149 | 0.03908 | 0.04645 | 3.91% | |
| Yelp | R@10 | 0.00400 | 0.01067 | 0.02468 | 0.02524 | 0.02465 | 0.02402 | 0.02034 | 0.02830 | 12.12% |
| R@20 | 0.00668 | 0.01777 | 0.04339 | 0.04291 | 0.04510 | 0.03749 | 0.03687 | 0.04884 | 8.29% | |
| N@10 | 0.00488 | 0.00945 | 0.02619 | 0.02596 | 0.02621 | 0.02247 | 0.01994 | 0.02839 | 8.32% | |
| N@20 | 0.0063 | 0.01322 | 0.03579 | 0.03552 | 0.03676 | 0.03001 | 0.02872 | 0.03880 | 8.41% |
IV-A4 Hyper-parameter Setting
We randomly split the datasets into training (), validation (), and test (). We tune hyper-parameters on the validation set and report experimental results on the test set. Adam is used as the optimizer. For all methods, we tune the learning rate and weight-decay within {0.1, 0.05, 0.01, 0.005, 0.001}, {1e-1, 1e-2, 1e-3, 1e-4, 1e-5, 1e-6}, respectively. For a fair comparison, we fix the embedding size as and the negative sample rate as for all methods. To avoid overfitting, we early stop the training if the model’s performance on the validation set does not improve in epochs.
| ID | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|
| 0.17464 | 0.25524 | 0.12244 | 0.14927 | |
| 0.17831 | 0.25015 | 0.12228 | 0.14626 | |
| 0.18958 | 0.27885 | 0.13087 | 0.16054 | |
| 0.17910 | 0.24578 | 0.12619 | 0.14930 | |
| 0.16501 | 0.23598 | 0.11773 | 0.14127 | |
| MetaKRec | 0.20810 | 0.29053 | 0.14699 | 0.17433 |
| Improv. | 9.77% | 4.19% | 12.32% | 8.59% |
| ID | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|
| 0.05356 | 0.06893 | 0.05493 | 0.06167 | |
| 0.05356 | 0.06893 | 0.05494 | 0.06167 | |
| 0.05917 | 0.08145 | 0.06364 | 0.07209 | |
| 0.05356 | 0.06888 | 0.05491 | 0.06157 | |
| 0.05432 | 0.06889 | 0.05134 | 0.05893 | |
| MetaKRec | 0.07138 | 0.09988 | 0.06843 | 0.07962 |
| Improv. | 20.64% | 22.63% | 7.53% | 10.44% |
| ID | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|
| 0.03940 | 0.06911 | 0.02637 | 0.03650 | |
| 0.04184 | 0.06973 | 0.02699 | 0.03662 | |
| 0.03762 | 0.06676 | 0.02535 | 0.03522 | |
| 0.03739 | 0.06679 | 0.02463 | 0.03438 | |
| 0.04050 | 0.06883 | 0.02798 | 0.03762 | |
| MetaKRec | 0.05106 | 0.08619 | 0.03467 | 0.04646 |
| Improv. | 22.04% | 23.61% | 23.91% | 23.50% |
| ID | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|
| 0.02280 | 0.04130 | 0.02366 | 0.03314 | |
| 0.02672 | 0.04369 | 0.02654 | 0.03546 | |
| 0.02703 | 0.04316 | 0.02790 | 0.03665 | |
| 0.02570 | 0.04423 | 0.02657 | 0.03603 | |
| 0.02731 | 0.04465 | 0.02663 | 0.03610 | |
| MetaKRec | 0.02831 | 0.04885 | 0.02840 | 0.03880 |
| Improv. | 3.66% | 9.41% | 1.79% | 5.87% |







IV-B Overall Experiment (RQ1)
The overall comparison of the datasets is shown in Table III. We can have the following observations:
-
•
MetaKRec consistently outperforms the runner-up on all datasets. The improvement is over on all Music and Yelp datasets metrics. The huge improvement validates the effectiveness of our model.
-
•
MetaKRec always beats LightGCN by a large margin. As MetaKRec and LightGCN use the same Light Graph Convolution layer, the improvement is largely brought by the KG information. It shows MetaKRec greatly enhances the recommender system by KG side information.
-
•
KG-enhanced recommender systems (KGAT, KGIN) do not necessarily perform better than models that utilize only user-item bipartite graphs (SGConv, LightGCN). It indicates the collaborative filtering signal on the bipartite graph is most important to achieve accurate recommendations while the knowledge graph is sided information.
-
•
Among all the KG enhanced methods, MetaKRec always achieves the best performance. It reveals that collaborative meta-kg graphs can effectively transform the knowledge graph as side information to enhance the recommender system.
IV-C Evaluation on different Collaborative Meta-KGs (RQ2)
We then test the model’s performance on different Collaborative Meta-KGs. Experiment results on datasets are illustrated in Tables IV, V, VI, VII respectively. From the tables, we can have the following observations. 1) The combined model that utilizes all the Collaborative Meta-KGs always achieves the best performance. The improvement on the Amazon dataset is over compared with the runner-up. It shows different Collaborative Meta-KGs acquire different information and can complement each other to achieve a better performance in a joint effort. 2) The performance of each Collaborative Meta-KG does not deteriorate much compared with the joint model. It reveals the collaborative filtering signal between user-item interactions is the most important during building an effective recommender system. The knowledge graph can be utilized as side information to enhance the recommendation performance.
IV-D Cold-start Experiment (RQ3)
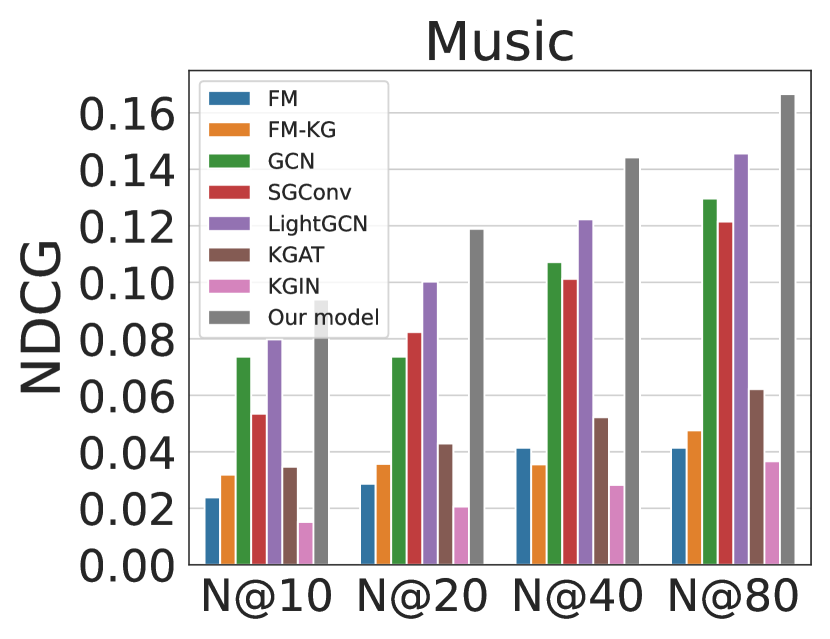
Cold-start is a severe problem in recommender systems. Without enough user-item interactions, it is difficult to obtain an informative representation. This experiment evaluates the model’s performance under the cold-start setting, where we randomly keep only user interaction for each item in the training set. Here we select Recall and NDCG @ as evaluation metrics.
Experiment results on Recall are shown in Fig. 4, and results on NDCG are shown in Fig. 5. From the results, we can observe that MetaKRec achieves the best performance on both Recall and NDCG over all datasets. Compared with the runner-up, the improvement of MetaKRec on Yelp dataset is over . On Amazon and Music datasets, MetaKRec surpasses the second best over . The lowest improvement on Book dataset is more than . The huge improvement on all datasets validates MetaKRec can effectively utilize knowledge graph as side information to cope with the cold-start recommendation problem.
We can also observe that the performance of KGAT and KGIN are even worse than the simple GCN model under the cold-start setting. It shows knowledge graph can not always provide informative information for cold-start items. The complex design of KGAT and KGIN do not contribute to better performance. With fewer parameters, MetaKRec achieves very huge improvement over other KG-enhanced models.
IV-E Hyper-parameter Study (RQ4)
In this experiment, we explore the influence of different experiment settings on MetaKRec . Two influential hyper-parameters are studied: 1) The number of graph convolution layers, and 2) Channel combination methods.
IV-E1 Number of convolution layers








In this experiment, we keep all the other hyper-parameters fixed, and observe the performance change with the increasing of convolution layer numbers. Experiment results on Recall@10 are shown in Fig. 6 and NDCG@10 are shown in Fig. 7. We can observe that both the metrics on datasets show a downward trend. Although there are occasional increases, MetaKRec always achieves the best performance when the number of layers is . MetaKRec transforms the knowledge graph into direct edges between items, which enables a direct message-passing between item pairs by using just single graph convolution. With more layers, the over-smoothing problem [31] exacerbates in MetaKRec because it builds lots of edges between items. One node will be smoothed by much more neighbors with the constructed edges. The results suggest we do not need to increase the complexity by stacking more convolution layers when utilizing MetaKRec . A simple layer convolution can achieve the best performance.
IV-E2 Channel combination methods
This experiment tests the channel combination methods. We keep all the other hyper-parameters fixed and only change the channel attention module to see the influence on performance. We show the changes on Recall@10 in Fig. 8 and NDCG@10 in Fig. 9. In both figures, “Mean” indicates we combine different embedding tables by a mean pooling layer, and “Concat” indicates we first concat all the embedding tables and transform them to the previous embedding size by a linear layer. From the experiment results, we can observe that “Attention” always achieves the best performance except for the NDCG@10 on Yelp dataset. On Music and Amazon dataset, “Attention” surpasses the other two methods by a large margin. It validates the channel attention design in MetaKRec , and the attention can effectively fuse the embedding table learned from different Collaborative Meta-KGs.
V Related Work
In this section, we introduce the related work of MetaKRec , which includes Meta Path/Graph learning and KG enhanced recommender system.








V-A Meta Path/Graph Learning
Meta Path/Graph is a kind of powerful learning method on graph data, and it has attracted much research attention in recent years [32, 33]. To evaluate the relevance of different-typed objects, Shi et al. [34] proposed HeteSim to measure the relevance of any object pair under an arbitrary meta path. Meta path-based methods are widely used on graph embedding. Meta-path2vec [35] designed a meta-path-based random walk and utilized skip-gram to perform graph embedding. Sun et al. [36] proposed meta-graph-based network embedding models, which simultaneously considered the hidden relations of all meta information of a meta-graph. Qiu et al. [37] provided the theoretical connections between skip-gram-based network embedding algorithms and the theory of graph Laplacian and presented the NetMF method as well as its approximation algorithm for computing network embedding. Fan et al. [38] proposed a HIN embedding model metagraph2vec to learn the low-dimensional representations for the nodes in HIN, where both the HIN structures and semantics are maximally preserved for malware detection. Fan et al. [39] also introduced an attributed heterogeneous information network (AHIN) to model the rich semantics and complex relations among multi-typed entities and designed different metagraphs to formulate the relatedness between buyers and products. The HeCo proposed by Wang et al. [40] employed network schema and meta-path views to collaboratively supervise each other, moreover, a view mask mechanism was designed to further enhance the contrastive performance.
Unlike previous works, we design meta graphs, particularly for knowledge graph enhanced recommendation. We propose Collaborative Meta Knowledge Graph that explicitly utilizes information from both knowledge graph and user-item interactions. The construction method is also not limited to paths or graph structures, which is flexible enough to encode different kinds of prior knowledge.
V-B KG Enhanced Recommender System
KG contains rich entity and relationship information, which can be used as auxiliary information to supplement the relationship between users and items, thus making the recommender system more effective, accurate, and explainable [41]. KG enhanced recommender system also receives much research attention [42, 43, 44]. KTUP [2] and CFKG [1] jointly learn recommendation and knowledge graph completion tasks by the shared embedding table. KGCN [27] is the pioneering work to take the advantage of GNN over knowledge graph to obtain an informative item embedding table. KGNN-LS [45] learns the influence of the knowledge graph on users and transforms KG into a user-specific weighted graph before GNN aggregation. Wang et al. [7] creatively propose the KGAT method, using two designs of recursive embedding propagation and attention-based aggregation to fully use the high-order information in KG to achieve the purpose of enhanced recommendation. Then they propose the KGIN [8] method, which provides a new aggregation scheme to extract useful information about user intent and encode them into user and item representations. ATBRG [46] generates subgraphs for specific user-item pairs and uses a the relation-aware extractor layer to extract informative relations for aggregation. DSKReG [47] samples on useful relations over knowledge graph by gumble softmax, and reconstructs a preference aware aggregation graph before GNN.
All previous researches rely on models to learn informative information from the complex knowledge graph with multiple kinds of relations. Unlike them, MetaKRec utilizes prior meta knowledge over knowledge graphs to construct different meta graphs to enhance recommendation. The reliable human-defined meta-knowledge decreases the noise and enables a simple model to achieve the best performance.
VI Conclusion and Future Work
In this paper, we research utilizing meta knowledge to enhance the KG-based recommender system. We propose constructing Collaborative Meta Knowledge Graphs to use prior meta-knowledge on the knowledge graphs and user-item interaction graphs. We make the construction based on different kinds of meta-knowledge and present MetaKRec that can effectively utilize knowledge graph to enhance recommendation. Experiment results on real-world datasets validate the effectiveness of MetaKRec . Cold-start experiment also shows MetaKRec can effectively utilize knowledge graph information to alleviate the cold-start problem. This work shows that the explicit usage of prior meta knowledge can benefit the KG-enhanced recommendation.
As for future work, we point out research directions. 1) Research on fusing prior meta-knowledge on other models. It is better to use meta knowledge to provide explicit signals when the relations are too complex for the model to learn. 2) Exploring how to construct explicit meta knowledge into deep learning models. In this paper, we propose the construction of Collaborative Meta-KG to encode meta-knowledge as edges between items. Researchers can also explore other methods to encode the meta knowledge in different scenarios.
VII Acknowledgements
Shen Wang, Liangwei Yang and Philip S. Yu are supported in part by NSF under grants III-1763325, III-1909323, III-2106758, SaTC-1930941. Jibing Gong, Shaojie Zheng, Shuying Du are funded in Hebei Natural Science Foundation of China under grant F2022203072.
References
- [1] Q. Ai, V. Azizi, X. Chen, and Y. Zhang, “Learning heterogeneous knowledge base embeddings for explainable recommendation,” Algorithms, vol. 11, no. 9, p. 137, 2018.
- [2] Y. Cao, X. Wang, X. He, Z. Hu, and T.-S. Chua, “Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences,” in The world wide web conference, 2019, pp. 151–161.
- [3] W. Ma, M. Zhang, Y. Cao, W. Jin, C. Wang, Y. Liu, S. Ma, and X. Ren, “Jointly learning explainable rules for recommendation with knowledge graph,” in The world wide web conference, 2019, pp. 1210–1221.
- [4] X. Wang, D. Wang, C. Xu, X. He, Y. Cao, and T.-S. Chua, “Explainable reasoning over knowledge graphs for recommendation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 5329–5336.
- [5] Y. Xian, Z. Fu, S. Muthukrishnan, G. De Melo, and Y. Zhang, “Reinforcement knowledge graph reasoning for explainable recommendation,” in Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval, 2019, pp. 285–294.
- [6] B. Hu, C. Shi, W. X. Zhao, and P. S. Yu, “Leveraging meta-path based context for top-n recommendation with a neural co-attention model,” in Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 1531–1540.
- [7] X. Wang, X. He, Y. Cao, M. Liu, and T.-S. Chua, “Kgat: Knowledge graph attention network for recommendation,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 950–958.
- [8] X. Wang, T. Huang, D. Wang, Y. Yuan, Z. Liu, X. He, and T.-S. Chua, “Learning intents behind interactions with knowledge graph for recommendation,” in Proceedings of the Web Conference 2021, 2021, pp. 878–887.
- [9] H. Wang, F. Zhang, M. Zhang, J. Leskovec, M. Zhao, W. Li, and Z. Wang, “Knowledge-aware graph neural networks with label smoothness regularization for recommender systems,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 968–977.
- [10] Z. Wang, G. Lin, H. Tan, Q. Chen, and X. Liu, “Ckan: collaborative knowledge-aware attentive network for recommender systems,” in Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, 2020, pp. 219–228.
- [11] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [12] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” Advances in neural information processing systems, vol. 30, 2017.
- [13] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” arXiv preprint arXiv:1710.10903, 2017.
- [14] Y. Cao, X. Wang, X. He, Z. Hu, and T.-S. Chua, “Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences,” in The world wide web conference, 2019, pp. 151–161.
- [15] R. You, S. Yao, H. Mamitsuka, and S. Zhu, “Deepgraphgo: graph neural network for large-scale, multispecies protein function prediction,” Bioinformatics, vol. 37, no. Supplement_1, pp. i262–i271, 2021.
- [16] M. Yang, Z. Liu, L. Yang, X. Liu, C. Wang, H. Peng, and P. S. Yu, “Ranking-based group identification via factorized attention on social tripartite graph,” arXiv preprint arXiv:2211.01830, 2022.
- [17] L. Yang, Z. Liu, Y. Dou, J. Ma, and P. S. Yu, “Consisrec: Enhancing gnn for social recommendation via consistent neighbor aggregation,” in Proceedings of the 44th international ACM SIGIR conference on Research and development in information retrieval, 2021, pp. 2141–2145.
- [18] Z. Liu, L. Yang, Z. Fan, H. Peng, and P. S. Yu, “Federated social recommendation with graph neural network,” ACM Transactions on Intelligent Systems and Technology (TIST), 2021.
- [19] L. Yang, Z. Liu, Y. Wang, C. Wang, Z. Fan, and P. S. Yu, “Large-scale personalized video game recommendation via social-aware contextualized graph neural network,” in Proceedings of the ACM Web Conference 2022, 2022, pp. 3376–3386.
- [20] M. Newman, Networks. Oxford university press, 2018.
- [21] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. [Online]. Available: https://openreview.net/forum?id=SJU4ayYgl
- [22] J. Du, S. Zhang, G. Wu, J. M. F. Moura, and S. Kar, “Topology adaptive graph convolutional networks,” CoRR, vol. abs/1710.10370, 2017. [Online]. Available: http://arxiv.org/abs/1710.10370
- [23] K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?” in 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. [Online]. Available: https://openreview.net/forum?id=ryGs6iA5Km
- [24] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” Advances in neural information processing systems, vol. 26, 2013.
- [25] X. He, K. Deng, X. Wang, Y. Li, Y. Zhang, and M. Wang, “Lightgcn: Simplifying and powering graph convolution network for recommendation,” in Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, 2020, pp. 639–648.
- [26] S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Thieme, “BPR: bayesian personalized ranking from implicit feedback,” in UAI 2009, Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, June 18-21, 2009, J. A. Bilmes and A. Y. Ng, Eds. AUAI Press, 2009, pp. 452–461.
- [27] H. Wang, M. Zhao, X. Xie, W. Li, and M. Guo, “Knowledge graph convolutional networks for recommender systems,” in The world wide web conference, 2019, pp. 3307–3313.
- [28] R. He and J. McAuley, “Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering,” in proceedings of the 25th international conference on world wide web, 2016, pp. 507–517.
- [29] S. Rendle, “Factorization machines,” in 2010 IEEE International conference on data mining. IEEE, 2010, pp. 995–1000.
- [30] F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Simplifying graph convolutional networks,” in International conference on machine learning. PMLR, 2019, pp. 6861–6871.
- [31] K. Zhou, X. Huang, Y. Li, D. Zha, R. Chen, and X. Hu, “Towards deeper graph neural networks with differentiable group normalization,” Advances in neural information processing systems, vol. 33, pp. 4917–4928, 2020.
- [32] Y. Chang, C. Chen, W. Hu, Z. Zheng, X. Zhou, and S. Chen, “Megnn: Meta-path extracted graph neural network for heterogeneous graph representation learning,” Knowledge-Based Systems, vol. 235, p. 107611, 2022.
- [33] X. Li, D. Ding, B. Kao, Y. Sun, and N. Mamoulis, “Leveraging meta-path contexts for classification in heterogeneous information networks,” in 2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 2021, pp. 912–923.
- [34] C. Shi, X. Kong, Y. Huang, S. Y. Philip, and B. Wu, “Hetesim: A general framework for relevance measure in heterogeneous networks,” IEEE Transactions on Knowledge and Data Engineering, vol. 26, no. 10, pp. 2479–2492, 2014.
- [35] Y. Dong, N. V. Chawla, and A. Swami, “metapath2vec: Scalable representation learning for heterogeneous networks,” in Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 2017, pp. 135–144.
- [36] L. Sun, L. He, Z. Huang, B. Cao, C. Xia, X. Wei, and S. Y. Philip, “Joint embedding of meta-path and meta-graph for heterogeneous information networks,” in 2018 IEEE international conference on big knowledge (ICBK). IEEE, 2018, pp. 131–138.
- [37] J. Qiu, Y. Dong, H. Ma, J. Li, K. Wang, and J. Tang, “Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec,” in Proceedings of the eleventh ACM international conference on web search and data mining, 2018, pp. 459–467.
- [38] Y. Fan, S. Hou, Y. Zhang, Y. Ye, and M. Abdulhayoglu, “Gotcha-sly malware! scorpion a metagraph2vec based malware detection system,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 253–262.
- [39] Y. Fan, Y. Ye, Q. Peng, J. Zhang, Y. Zhang, X. Xiao, C. Shi, Q. Xiong, F. Shao, and L. Zhao, “Metagraph aggregated heterogeneous graph neural network for illicit traded product identification in underground market,” in 2020 IEEE International Conference on Data Mining (ICDM). IEEE, 2020, pp. 132–141.
- [40] X. Wang, N. Liu, H. Han, and C. Shi, “Self-supervised heterogeneous graph neural network with co-contrastive learning,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 1726–1736.
- [41] Q. Guo, F. Zhuang, C. Qin, H. Zhu, X. Xie, H. Xiong, and Q. He, “A survey on knowledge graph-based recommender systems,” IEEE Transactions on Knowledge and Data Engineering, 2020.
- [42] K. Zhou, W. X. Zhao, S. Bian, Y. Zhou, J.-R. Wen, and J. Yu, “Improving conversational recommender systems via knowledge graph based semantic fusion,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 1006–1014.
- [43] C. Chen, M. Zhang, W. Ma, Y. Liu, and S. Ma, “Jointly non-sampling learning for knowledge graph enhanced recommendation,” in Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2020, pp. 189–198.
- [44] H. Wang, F. Zhang, M. Zhao, W. Li, X. Xie, and M. Guo, “Multi-task feature learning for knowledge graph enhanced recommendation,” in The world wide web conference, 2019, pp. 2000–2010.
- [45] H. Wang, F. Zhang, M. Zhang, J. Leskovec, M. Zhao, W. Li, and Z. Wang, “Knowledge-aware graph neural networks with label smoothness regularization for recommender systems,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 968–977.
- [46] Y. Feng, B. Hu, F. Lv, Q. Liu, Z. Zhang, and W. Ou, “Atbrg: Adaptive target-behavior relational graph network for effective recommendation,” in Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2020, pp. 2231–2240.
- [47] Y. Wang, Z. Liu, Z. Fan, L. Sun, and P. S. Yu, “Dskreg: Differentiable sampling on knowledge graph for recommendation with relational gnn,” in Proceedings of the 30th ACM International Conference on Information & Knowledge Management, 2021, pp. 3513–3517.