Meta Pattern Concern Score: A Novel Evaluation Measure with Human Values for Multi-classifiers
Abstract
While advanced classifiers have been increasingly used in real-world safety-critical applications, how to properly evaluate the black-box models given specific human values remains a concern in the community. Such human values include punishing error cases of different severity in varying degrees and making compromises in general performance to reduce specific dangerous cases. In this paper, we propose a novel evaluation measure named Meta Pattern Concern Score based on the abstract representation of probabilistic prediction and the adjustable threshold for the concession in prediction confidence, to introduce the human values into multi-classifiers. Technically, we learn from the advantages and disadvantages of two kinds of common metrics, namely the confusion matrix-based evaluation measures and the loss values, so that our measure is effective as them even under general tasks, and the cross entropy loss becomes a special case of our measure in the limit. Besides, our measure can also be used to refine the model training by dynamically adjusting the learning rate. The experiments on four kinds of models and six datasets confirm the effectiveness and efficiency of our measure. And a case study shows it can not only find the ideal model reducing 0.53% of dangerous cases by only sacrificing 0.04% of training accuracy, but also refine the learning rate to train a new model averagely outperforming the original one with a 1.62% lower value of itself and 0.36% fewer number of dangerous cases.
Index Terms:
Machine Learning, Classification, Evaluation Measure, Human Value.I Introduction
A classifier is a learned model that approximates a specific target function to sort given input into predicted output [1]. Through processing labeled data, supervised algorithms enable advanced classifiers to learn the key features needed for constructing accurate predictions automatically [2]. While such simplicity lays a solid foundation for the widespread implementation of classifiers nowadays, it also makes the model learning a black-box process that is hard to be flexibly and properly evaluated.
Currently, there are two types of metrics commonly used in practice to assess the quality of learning-based classifiers. One is the evaluation measure based on confusion matrix [3], which provides people a certain degree of freedom to define the specific learning objective with different statistics of the output results, like Precision and Recall. However, as such statistical values are always discrete, evaluation measures are insensitive to slight improvements in the model [4]. Also, since there is a gap between observed results in existing data and the underlying posterior probability distribution [5], these evaluation measures are considered theoretically incomplete in assessing the generalization ability of the model. The other type of metric is the loss value serving as the optimization objective in model training [6]. While researchers have proven that losses do not suffer from the issues above [4, 7], they are always fixedly predefined upon the probabilistic prediction scores of all the classes, and as a result, lack the flexibility to be customized for different tasks.
With more and more classifiers used in safety-critical areas such as self-driving [8] and healthcare [9], just uniformly assessing different models built for different tasks is gradually found to be limited and unsatisfying. This is because, beyond the general performance, there are usually some specific human values to be concerned with and weighed in such areas. For instance, the mistakes to recognize a red light respectively as yellow and green have completely different degrees of severity in real-world traffic [10]. In this paper, we mainly focus on introducing two kinds of human values into multi-classifiers. Firstly, many specific cases in our human society are not just black-or-white, so instead of equally punishing all kinds of incorrect predictions with different destructiveness, we allow assigning specific weights individually for every single error case. In this way, we can specify which kinds of errors should be strictly punished, and which are relatively tolerable. Secondly, in order to satisfy some safety-critical requirements in practice, we would rather make certain compromises in overall performance to reduce specific dangerous cases. For this purpose, we introduce a threshold to indicate the concession we can make in the confidence of prediction, to leave enough space to search for model parameters that are better under the given requirements.
Based on these ideas, we propose a novel evaluation measure named Meta Pattern Concern Score (MPCS) for multi-classification. We design this measure for the following targets: 1) it can be flexibly customized for different tasks to find better models given the human values mentioned; 2) it is still qualified enough to serve as a general evaluation measure, which means the models found should also be fine under assessments of the common metrics; 3) it should reduce the impact of the two inherent drawbacks of existing evaluation measures mentioned. Specifically, we take the basic idea of the confusion matrix to design an abstract representation for the probabilistic prediction result, to specify different punishments for every single kind of incorrect prediction. At the same time, through introducing the adjustable fine-grained interval into the representation, we make MPCS approximating to cross entropy loss in the limit. In other words, cross entropy can be viewed as a special case of MPCS. In this way, we not only make it inherit certain mathematical completeness and work effectively as general metrics, but also reduce the insensitivity caused by the discrete value. Finally, in addition to the evaluation, although the abstract representation makes MPCS non-differentiable, which means it can not directly serve as the loss, we can still use it to refine the training by dynamically adjusting the learning rate according to its value.
The experiments on four different kinds of models and six reality and synthetic datasets confirm that MPCS is as effective and computationally efficient as the common metrics in the evaluation of multi-classifiers. A specific case study in MNIST shows that given customized requirements, MPCS can not only accordingly pick out the ideal model better than the one selected by the common metrics without violating them too much, but also improve the training process to newly train a better model. Specifically, it can pick a model with 0.53% fewer dangerous misclassifications by just sacrificing 0.04% of training accuracy, or directly train a new model averagely outperforming the original one with a 1.62% lower value of MPCS and 0.36% fewer number of dangerous cases, which can be especially useful in real-world safety-critical applications.
II Background
II-A Common Metrics for Classification
A number of metrics have been proposed to train and pick out the desired classifier. For one thing, the evaluation measures based on simple observations and statistics of the output results such as classification accuracy rate are widely used. Most of these measures are derived from the confusion matrix, a structure to illustrate the results obtained from a classifier [3]. Given a -class classification task, let be the number of samples actually belonging to the -th class while that are classified into the -th class, the confusion matrix can be defined as . Given a target positive label , there are four different situations namely “True Positive” (TP ), “False Negative” (FN ), “False Positive” (FP ) and “True Negative” (TN ) [11], with which a series of evaluation measures are defined as follows:
For another, the objective of model training is to find the optimal parameters to minimize the value of global loss function over the whole training dataset [6]:
| (1) |
where denotes the specific loss value computed from sample with parameters . So naturally, how well the objective is met can serve as a metric of model quality. Given a model having fully connected final layer with the softmax activation, the supervised labels in the format of one-hot, and the probability outputs predicted by , the famous loss mean squared error (MS) and the cross entropy error (CE) commonly used in classification [12] can be denoted as:
| (2) |
| (3) |
II-B Drawbacks of Existing Metrics
The two kinds of metrics mentioned above both have their own advantages in contrast, while they also struggle with different dilemmas. Compared with loss value, confusion matrix-based evaluation measures have advantages in the ability of flexible customization. Through the various combinations of TP, FN, FP and TN, evaluation measures allow one to define the objective in an intuitive and direct format according to the specific application. For instance, as the over-abundance of negative examples is commonly seen in information retrieval, recommendation systems and social network analysis [13], one of the reasonable metrics in such situations is the Precision who can measure the ability of the classifier not to label as positive a sample that is negative, so that the always-negative classifier will not be over-valued.
Nevertheless, evaluation measures directly refer to the classification results, which brings some potential problems. For one thing, each element in the confusion matrix is essentially a number of classification results having specific actual and predicted labels, which means the values of all the evaluation measures based on the confusion matrix are discrete. As a consequence, they are insensitive to slight improvements in model parameters and only vary discontinuously and abruptly when the prediction results of some samples change [4]. This can be especially disappointing in the latter stages of model training. For another, evaluation measures heavily focus on the existing data, while the ideal model is expected to reliably classify previously unseen objects in the real world. So what really matters is, according to the Bayesian classification theory, how well the model approximates the underlying posterior probability distribution [14]. Researchers have shown that improving observed accuracy rates and improving posterior probability estimation are not entirely synonymous [5]. In fact, efforts to improve posterior probability estimation may yield lower accuracy rates in the known dataset, but lead to better performance on future reality tasks.
The problems mentioned above are actually the important reasons why loss is proposed [4]. Carefully designed loss functions ensure the gradient of most parameters is not in the training process, so as to guide the continuous optimization of the model. And for the latter problem mentioned, the theoretical relationship between Bayesian posterior probability estimation and MS cost functions had also been explored and widely adopted [7]. However, squared error assumes Gaussian target data, which is violated given the discrete targets used to train classifiers. Besides, it can be found from (2) that MS is likely to be dominated by a few outlier data points that have particularly large errors in practice.
As a log-linear error function based on the maximum likelihood estimate approach [12] that is impacted much less by these further problems, CE gradually became more popular in classification tasks to date. However, entropy-based measures are specifically designed for binary targets at the beginning, so when CE is applied in multi-classification tasks, it has to treat all the classes except the class with the correct label as a collective concept “incorrect class”, without considering the distinction between them. What’s worse, CE merely takes the probability of the correct label in the prediction results into error calculation, which means that of the incorrect labels, which are certainly more in quantity in every single output of multi-classification and may also impact the prediction effectiveness, are totally ignored.
All in all, there is indeed an uncharted territory: is the bias between the two kinds of metrics irreconcilable? Empirically, if we consider the multi-classification task from a similar perspective as the confusion matrix, but construct a specific formula with the mathematical principle closer to the loss, it is likely that a metric can be proposed with not only the customizability just as the former but also the theoretical completeness inherited from the latter at the same time. We take this idea into consideration when specifically designing the formula of our own evaluation measure.
III Meta Pattern Concern Score
In the past section, from the perspective of basic technology, we discussed the ideas and issues to be concerned with for our design. In this section, we first rely on two real-world scenarios to illustrate and describe the motivation and intuitive scheme to take the two kinds of human values into consideration, and then accordingly propose our novel evaluation measure, Meta Pattern Concern Score (MPCS).
III-A Considering Human Values in MPCS
The two scenarios to be talked about come from a typical safety-critical task, Traffic Light Recognition, which is important regarding the traffic participants’ safety in autonomous driving [15]. Note that this task usually involves a variety of technologies in practice, but for convenience here we just simplify it as a 3-class classification problem.
The first scenario happens when a red light shows, where there are two different kinds of misclassifications according to the specific prediction result. If it is classified as a green light, the autonomous vehicle will be incorrectly allowed to proceed, which may endanger both its passengers and others, and as a result, totally unacceptable. While if the light is predicted to be yellow, which means “stop, unless it is unsafe to do so” [10], at least in most cases the car will stop and not break the traffic rules. So it is obviously inappropriate to treat both of the errors with the same severity, which is, however, what the traditional metrics do.
Since this kind of scenario with negative classes having different damages is commonly seen in practice, it would make sense to design for it. But before providing formal definitions and descriptions in section III-B, showing our idea in an intuitive way firstly might be found helpful. As mentioned previously, CE is only affected by the predicted value of the correct label. Just as shown in Fig. 1, this is marked as follows: the significance of the correct class “Red” is , while that of others is assigned to be to represent no influence. On the other hand, the MS and all the evaluation measures from confusion matrix treat the prediction as either True or False, respectively corresponding to and in the “Others” line.
In our idea, we mark instead of for the incorrect prediction “Yellow” to represent it is relatively less destructive. What’s more, we assign that of the “Red” to be , which is basically a compromise between CE and other metrics. Specifically, we neither ignore negative classes completely nor make each of them as important as the positive class, while we set that the positive class and the whole of negative classes are of equal significance. These marked values correspond to a concept to be formally defined later in our measure called concern degree.

| Training Size | Classifier | Prediction Result | Number of Sample | Prediction Confidence | Cross Entropy Loss |
|---|---|---|---|---|---|
| 100 | A | Correct | 99 | 0.99 | 0.741920 |
| Wrong | 1 | 0.49 | |||
| B | Correct | 100 | 0.98 | 0.877392 | |
| Wrong | 0 | - |

The second scenario is presented aiming to illustrate the significance to introduce a threshold for the concession in prediction confidence. As shown in Table I, there are two classifiers trained for a task with a training size of 100 and the loss CE. The classifier A makes a mistake in one of the input samples, predicting the probability of the correct label to be only , while the classifier B makes correct predictions in the whole dataset. However, the confidence of all the correct predictions of classifier A is , while that of B is . In this case, it is indeed that the CE value of classifier A is less than that of B, but does that really mean A is a better choice? At least in our simplified Traffic Light Recognition case, the answer is no because it is the failure of prediction that is more intolerable compared with the minor weakness of confidence in such a safety-critical task. Note that although here we take CE as an instance, MS and other loss functions also have the same problem to different extents.
To deal with this problem, we can set a threshold value for the confidence and keep the model from being punished in specific samples once the confidence value of the correct label exceeds it. In our idea shown in Fig. 2, we further divide the entire confidence field into several intervals according to the granularity determined by the threshold, and calculate the punishment of a specific confidence value based on the distance between the interval it falls into and the interval representing the highest confidence.
III-B Detailed Design of MPCS
In this section, we propose the specific definition of MPCS, and provide a detailed process to calculate its value. As shown in Fig. 3, the calculation process can be divided into three parts. The first part is about running the multi-classifier and normalizing its results to the probabilistic distribution using softmax. The second part is where the two constructors extract and build meta patterns from the processed results. Finally, in the third part, concern degrees and interval punishments are calculated given specific human values, and the MPCS on the entire dataset is accordingly acquired.

To begin with, to realize our idea, it is not sufficient enough to merely take the label with the highest confidence into account. However, considering all the labels may also lead to a lot of unnecessary computational time costs. So we introduce a hyper-parameter to indicate the top- classes in the order of confidence decreasing to be considered according to the practical task. With denoting a specific label in a classification task, the prediction pattern is defined as a vector with length :
| (4) |
where the value of is between one and the number of classes of the task.
To realize the idea described in Fig. 2, we divide the confidence field into intervals and determine the confidence level of a specific label under an input sample by the interval in which its confidence value falls and whether the label is the correct one or not. The confidence pattern is defined as a vector with length that must be the same as in one task:
| (5) |
in which denotes the confidence level of the label . Given a hyper-parameter and the correct label , and let be the confidence of label , can be calculated as follows:
| (6) |
Notice that there is a correspondence between each pair of elements in the same position of and in any specific sample. As a pair of the two patterns can be used to record the key information to uniquely represent any specific output of the classifier, we always refer to them together. The meta pattern is an abstract representation of the probabilistic prediction result of multi-classifiers, which is defined as the combination of the corresponding prediction pattern and confidence pattern .
Then it is time to recall the idea shown in Fig. 1. We introduce a release list as a hyper-parameter with every single element indicating a less destructive situation in practice, as well as a factor to indicate that in what extent the concern of them could be released. In every single data sample, for every label selected into its , there are three kinds of values of the corresponding element in its concern degree depending on whether the label is the correct one and whether it exists in any element of release list together with the correct label if not. Given a prediction pattern , its concern degree can be defined as a vector with the same length :
| (7) |
Given the correct label , a release list with representing any element of it, and a release factor , can be calculated as:
| (8) |
Input: Classifier , Dataset , Release List , Release Factor , Hyper-parameters and
Output: Meta Pattern Concern Score
| ID | Model | Dataset | Spearman Similarity | ||||
| ACC | F1 | MCC | MS | CE | |||
| Exp. 1 | MLP | IRIS | -0.9091 | -0.9092 | -0.9011 | 0.9873 | 0.9827 |
| Exp. 2 | DIGITS | -0.9886 | -0.9936 | -0.9935 | 0.9989 | 0.9989 | |
| Exp. 3 | MNIST | -0.9881 | -0.9886 | -0.9880 | 0.9880 | 0.9841 | |
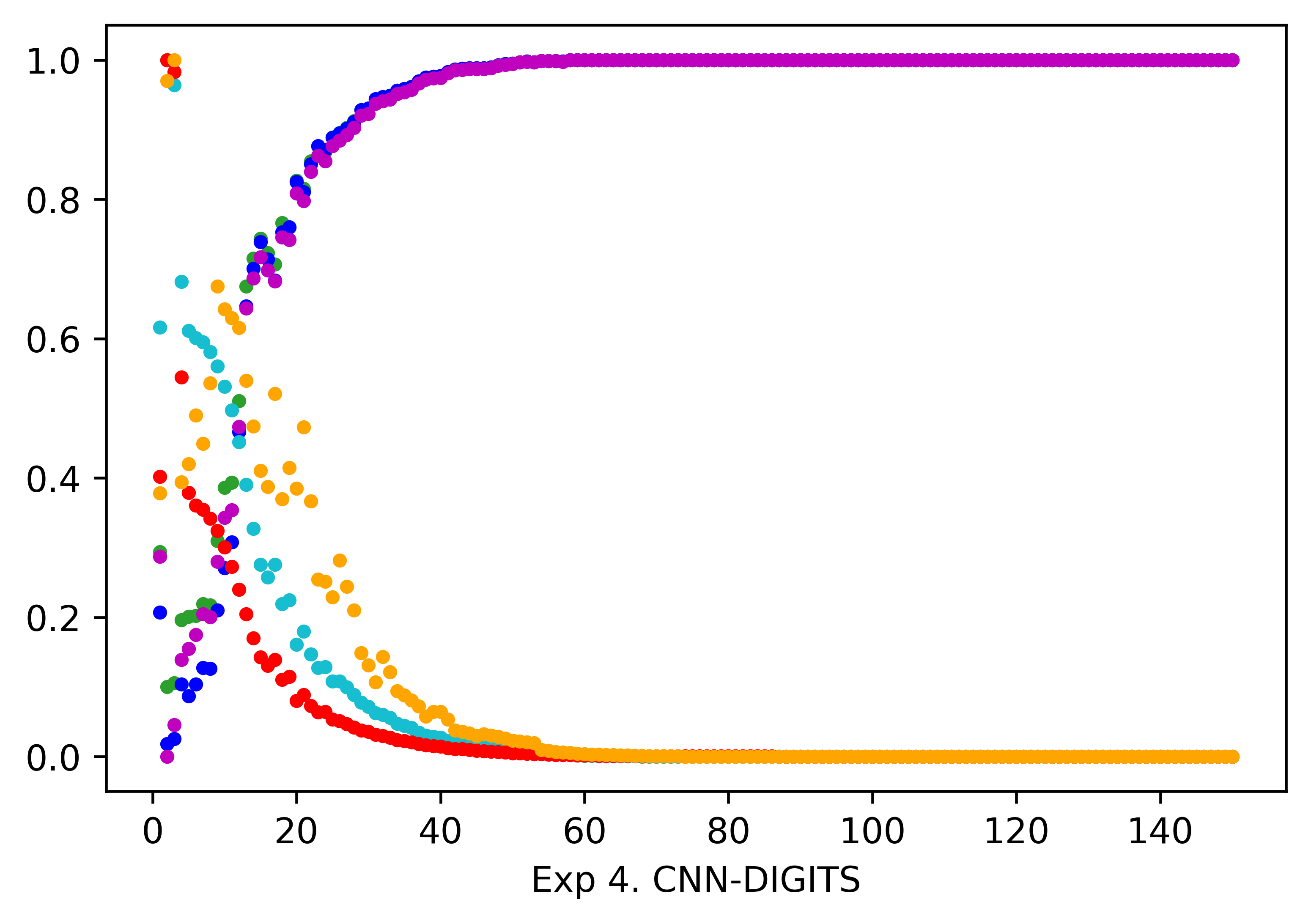
| Exp. 4 | CNN | DIGITS | -0.9106 | -0.9106 | -0.9107 | 0.9547 | 0.9547 |
| Exp. 5 | MNIST | -0.9231 | -0.9229 | -0.9220 | 0.9299 | 0.9168 | |
| Exp. 6 | RNN | UCR-CT | -0.9576 | -0.9549 | -0.9587 | 0.9618 | 0.9619 |
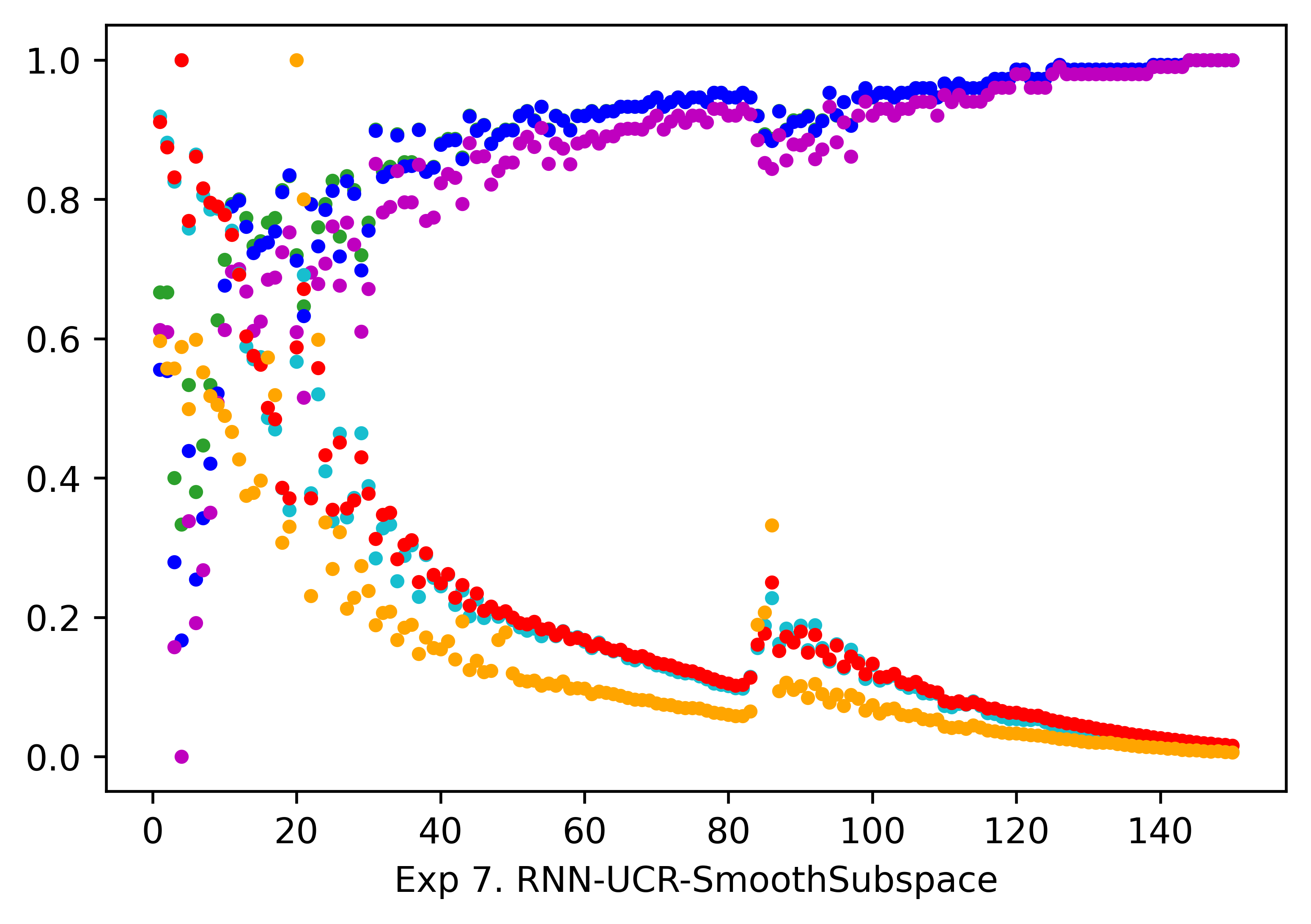
| Exp. 7 | UCR-SS | -0.9846 | -0.9844 | -0.9827 | 0.9929 | 0.9928 | |
| Exp. 8 | LSTM | UCR-SS | -0.9382 | -0.9352 | -0.9373 | 0.9700 | 0.9718 |
| Exp. 9 | ADD | -0.9721 | -0.9735 | -0.9706 | 0.9815 | 0.9862 | |
| Exp. 10 | MNIST | -0.9757 | -0.9754 | -0.9760 | 0.9774 | 0.9763 | |








Now we can propose our evaluation measure MPCS based on the above definitions. To calculate the interval punishment, given confidence pattern , we select the function just as CE to convert the interval distance into a concrete punishment value. Then with the concern degree , the meta pattern concern score of the classification result of every single sample can be calculated as:
| (9) |
where and respectively represents the -th element in the and , and , are the hyper-parameters defined previously. An important characteristic to be noticed is that MPCS approximates CE in the limit of and . In other words, CE can be viewed as a special case of MPCS under the limit condition. We illustrate the whole process of MPCS calculation in Algorithm 1, including the construction of meta pattern (line 3-5, 8), the calculation of concern degree (line 6-7, 9-17) and interval punishment (line 18-20), and the calculation of the MPCS value in the whole dataset (line 21-24).
IV Evaluation and Discussion
In this section, we first evaluate MPCS in general effectiveness and efficiency, and then illustrate its specific advantages in introducing the human values by a case study. Finally, we also discuss the contribution of MPCS based on the experiment results. The code and detailed experiment records are available on our Github repository: https://github.com/FlaAI/MPCS.
IV-A Experimental Setup
There are six datasets from four sources used in the experiments, namely the IRIS and DIGITS from scikit-learn [16], the MNIST, the pedestrian counting dataset CT and the smooth subspace clustering dataset SS from UCR time-series archive [17], and the synthetic Autonomous Driving Dataset (ADD) generated by the Scenic scenario programming language and the Carla simulator [18]. Different models, including Multi-Layer Perceptron (MLP), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM), are adopted and Adam is chosen as the optimizer uniformly. The Accuracy, score, MCC, MS and CE mentioned in section II-A are the benchmarks adopted. The experiments are implemented with Python 3.8.8, and PyTorch 1.10.1.


IV-B General Effectiveness and Efficiency
In this section, we evaluate MPCS in two general aspects. For one thing, through the comparison of the value and trend between MPCS and the benchmark metrics, we verify its effectiveness as an evaluation measure in the training process of multi-classifier. For another, by illustrating the time cost of MPCS calculation, we clarify that it has considerable efficiency as the benchmark metrics.
IV-B1 Effectiveness
Inspired by the evaluation method adopted in [19], we use the spearman correlation coefficient to calculate the similarity value between MPCS and the benchmarks, and regard this kind of relationship as the verification of its effectiveness. We illustrate the results in Table II with corresponding figures as a supplement in Fig. 4. From the results, we can find that all the similarity values exceed , and more than half of them are even above , based on which we can give an empirical inference that MPCS is highly correlated with the benchmark metrics, so it can indeed serve as an evaluation measure with practical significance.
| ID | Time Cost () | |||||
| ACC | F1 | MCC | MS | CE | MPCS | |
| Exp. 1 | 0.28 | 1.76 | 2.01 | 0.49 | 0.49 | 4.27 |
| Exp. 2 | 0.33 | 1.62 | 2.79 | 0.59 | 0.49 | 13.66 |
| Exp. 3 | 26.15 | 50.21 | 88.63 | 33.88 | 33.74 | 497.49 |
| Exp. 4 | 31.56 | 32.98 | 33.90 | 31.80 | 35.55 | 43.98 |
| Exp. 5 | 692.03 | 696.62 | 702.07 | 693.26 | 788.27 | 710.92 |
| Exp. 6 | 7.25 | 8.34 | 8.17 | 7.26 | 7.59 | 7.08 |
| Exp. 7 | 21.30 | 22.27 | 22.34 | 21.39 | 22.43 | 22.40 |
| Exp. 8 | 38.92 | 40.05 | 39.99 | 39.04 | 40.07 | 38.89 |
| Exp. 9 | 228.87 | 230.86 | 232.93 | 229.05 | 245.07 | 230.59 |
| Exp. 10 | 2672.93 | 2703.11 | 2746.43 | 2685.93 | 2927.46 | 2802.63 |
IV-B2 Efficiency
We verify the efficiency of MPCS by comparing its computational time cost with the benchmark metrics. Specifically, we calculate them in the whole training dataset for every turn of the training process with a total of 150 turns and take the average time cost as the final results. As illustrated in Table III, it can be found that the time costs of all the metrics are about the same order of magnitude in general, which is especially clear in relatively complex models.
IV-C Specific Advantages given Human Values
So far we have confirmed that MPCS can work as a general evaluation measure, but the particular benefits it can bring given specific human values have not been discussed. In this section, we use a case study to illustrate how to use MPCS to introduce human values into the evaluation and even the learning of the multi-classifier. We build the case with MLP and MNIST like Exp. 3, and determine the less destructive misclassifications according to the t-SNE projection [20], a technique that can plot 2D embeddings for high-dimensional datasets while keeping the distance between the samples the same. To be specific, if the incorrect prediction result of a sample is adjacent to its correct label in the projected clusters, this mistake is less destructive compared to confusing non-adjacent labels. So we pick all that kinds of mistakes, which are framed in red in Fig. 5, into the release list . Notice that here we just take this as an example since its meaning is relatively simple to understand, while actually the release condition can be customized according to any specific complex requirements in practice.
IV-C1 MPCS for Evaluation
We train MLP using CE for 150 epochs and record the model parameters from each epoch as different candidates, then respectively use different metrics to pick out the optimal models among them. The , and of MPCS is set to be 0.5, 5 and 200 here. In this case, all the metrics except MPCS pick out the same model, and the prediction results of the two models are respectively shown in Fig. 5 as the form of the confusion matrix. As can be calculated from the two confusion matrices, although the total number of misclassification of the model picked by the MPCS (5128) is greater than that of the model picked by other metrics (5108), the number of destructive cases of the former (2605) is less than that of the latter (2621). In other words, we pick out a model that trades off training accuracy from to for a reduced destructive rate from to by applying MPCS. This result can especially make sense in real-world safety-critical applications.




IV-C2 MPCS for Learning
In addition to the evaluation, we also explore how to introduce the human values into the learning by MPCS. Since the abstract representation makes MPCS non-differentiable, which means it can not be directly used as a loss, we can just introduce it to refine the training process by dynamically adjusting the learning rate according to its value. This is because the loss is basically a punishment to be learned, so for a smaller (i.e. better) MPCS value gotten, we can reduce the punishment by a proportionately smaller learning rate of the current turn. In Fig. 6, we record the change of the Accuracy in training and test set, the MPCS value and the number of destructive samples among the model learning with and without MPCS respectively. With MPCS introduced, the newly trained model averagely outperforms the original one with a 1.62% lower MPCS value and 0.36% fewer number of destructive samples. At the same time, there are even slight improvements under the Accuracy measure as well, namely 0.04% and 0.03% for training and test data.
IV-D Contributions
With all the results shown above, now we are ready to answer what can MPCS contribute to the community. For the first time, we provide a general idea to introduce two kinds of specific human values into the evaluation and even Learning of multi-classifiers. Different from common metrics having a fixed form all the time, the MPCS allows people to flexibly declare what they care more about the model in different practices, and try to cater to their specific will to pick out the optimal model, under the premise of not violating the common metrics too much and having a similar time cost as them.
On the other hand, technically speaking, MPCS is designed regarding the advantages of the existing two common kinds of metrics. Specifically, it provides an abstract view of model output to enable customization as the confusion matrix-based evaluation measures, and calculates its value in a way that approximates CE in the limit to make the picked model approximate the posterior probability distribution as much as possible like the loss. And for the negative labels, MPCS neither ignores them completely like CE, nor gives them the same importance as MS, while it adopts a compromise to avoid their shortcomings and makes the assessment more reasonable. Although MPCS can still not avoid discrete values in non-limit conditions, not only the granularity is adjustable, but also the extent of discreteness is much lower than the confusion matrix-based measures in general.
V Conclusion
In this paper, to acquire better multi-classifiers given specific human values, we proposed a novel evaluation measure called Meta Pattern Concern Score. It not only achieves considerable effectiveness and efficiency as common metrics in general tasks, but also shows particular advantages under given human values. The MPCS is expected to support the customized evaluation and even training of multi-classifiers in real-world practice, especially in safety-critical areas with various human values to be considered. In the future, we plan to evaluate and refine several existing applications by using MPCS customized for them, to make them safer and more trustworthy for the public.
References
- [1] T. M. Mitchell and T. M. Mitchell, Machine learning. McGraw-hill New York, 1997, vol. 1, no. 9.
- [2] F. Chollet, Deep learning with Python. Simon and Schuster, 2021.
- [3] A. Luque, A. Carrasco, A. Martín, and A. de Las Heras, “The impact of class imbalance in classification performance metrics based on the binary confusion matrix,” Pattern Recognition, vol. 91, pp. 216–231, 2019.
- [4] S. Weidman, Deep learning from scratch: building with python from first principles. O’Reilly Media, 2019.
- [5] D. M. Kline and V. L. Berardi, “Revisiting squared-error and cross-entropy functions for training neural network classifiers,” Neural Computing & Applications, vol. 14, no. 4, pp. 310–318, 2005.
- [6] C. Chen, H. Xu, W. Wang, B. Li, B. Li, L. Chen, and G. Zhang, “Communication-efficient federated learning with adaptive parameter freezing,” in 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS). IEEE, 2021, pp. 1–11.
- [7] M. Hung, M. Hu, M. Shanker, and B. Patuwo, “Estimating posterior probabilities in classification problems with neural networks,” International Journal of Computational Intelligence and Organizations, vol. 1, no. 1, pp. 49–60, 1996.
- [8] E. Soares, P. Angelov, B. Costa, and M. Castro, “Actively semi-supervised deep rule-based classifier applied to adverse driving scenarios,” in 2019 international joint conference on neural networks (IJCNN). IEEE, 2019, pp. 1–8.
- [9] A. Lucieri, M. N. Bajwa, S. A. Braun, M. I. Malik, A. Dengel, and S. Ahmed, “On interpretability of deep learning based skin lesion classifiers using concept activation vectors,” in 2020 international joint conference on neural networks (IJCNN). IEEE, 2020, pp. 1–10.
- [10] HMG, “The traffic signs regulations and general directions 2016,” 2016.
- [11] D. M. Ibrahim, N. M. Elshennawy, and A. M. Sarhan, “Deep-chest: Multi-classification deep learning model for diagnosing covid-19, pneumonia, and lung cancer chest diseases,” Computers in biology and medicine, vol. 132, p. 104348, 2021.
- [12] R. Das and S. Chaudhuri, “On the separability of classes with the cross-entropy loss function,” arXiv preprint arXiv:1909.06930, 2019.
- [13] P. Flach and M. Kull, “Precision-recall-gain curves: Pr analysis done right,” Advances in neural information processing systems, vol. 28, 2015.
- [14] R. O. Duda, P. E. Hart et al., Pattern classification and scene analysis. Wiley New York, 1973, vol. 3.
- [15] C. Fernández, C. Guindel, N.-O. Salscheider, and C. Stiller, “A deep analysis of the existing datasets for traffic light state recognition,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018, pp. 248–254.
- [16] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
- [17] H. A. Dau, A. Bagnall, K. Kamgar, C.-C. M. Yeh, Y. Zhu, S. Gharghabi, C. A. Ratanamahatana, and E. Keogh, “The ucr time series archive,” IEEE/CAA Journal of Automatica Sinica, vol. 6, no. 6, pp. 1293–1305, 2019.
- [18] M. Zhang, D. Du, M. Zhang, L. Zhang, Y. Wang, and W. Zhou, “A meta-modeling approach for autonomous driving scenario based on sttd.” International Journal of Software & Informatics, vol. 11, no. 3, 2021.
- [19] T. Baluta, Z. L. Chua, K. S. Meel, and P. Saxena, “Scalable quantitative verification for deep neural networks,” in 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 312–323.
- [20] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008.