Meta Objective Guided Disambiguation for Partial Label Learning
Abstract
Partial label learning (PLL) is a typical weakly supervised learning framework, where each training instance is associated with a candidate label set, among which only one label is valid. To solve PLL problems, typically methods try to perform disambiguation for candidate sets by either using prior knowledge, such as structure information of training data, or refining model outputs in a self-training manner. Unfortunately, these methods often fail to obtain a favorable performance due to the lack of prior information or unreliable predictions in the early stage of model training. In this paper, we propose a novel framework for partial label learning with meta objective guided disambiguation (MoGD), which aims to recover the ground-truth label from candidate labels set by solving a meta objective on a small validation set. Specifically, to alleviate the negative impact of false positive labels, we re-weight each candidate label based on the meta loss on the validation set. Then, the classifier is trained by minimizing the weighted cross entropy loss. The proposed method can be easily implemented by using various deep networks with the ordinary SGD optimizer. Theoretically, we prove the convergence property of meta objective and derive the estimation error bounds of the proposed method. Extensive experiments on various benchmark datasets and real-world PLL datasets demonstrate that the proposed method can achieve competent performance when compared with the state-of-the-art methods.
Index Terms:
partial label learning, candidate label set, ground-truth label, disambiguation, meta-learning.I Introduction
With the increasing amounts of carefully labeled data used for training modern machine learning models, model performance has been greatly improved. Nevertheless, collecting a large number of precisely labeled training data is time-consuming and costly in many realistic applications, which imposes a trade-off between the classification performance and the labeling cost.
Partial label learning (PLL) is a commonly used weakly supervised learning framework, where each training example is associated with a set of candidate labels, among which only one corresponds to the ground-truth label[1, 2]. For example, as illustrate in Fig. 1a, in face image recognition (see Fig. 1a)[3, 4, 5], an image with multiple faces is often associated with textual description. One can treat each face detected from the image as an example and those names extracted from the associated textual description consist of the candidate label set of each example. In crowdsourcing image tagging (see Fig. 1b), an image would be assigned with different labels by labelers with different level of expertise. PLL has been successfully applied into numerous realistic applications, such as web mining [6, 7], Ecoinformatics[8], multimedia content analysis[9, 10], etc.


Partial label learning aims to train a multi-class classifier with partially labeled training examples, then utilize the classifier to automatically predict the ground-truth label for an unknown sample. The key challenge of PLL is that the learning algorithms cannot get access to the ground-truth label of training examples [1, 11, 12]. To mitigate this trouble, the most widely used strategy is disambiguation, i.e., identifying the ground-truth label from the candidate label set.
Most existing methods perform disambiguation for candidate labels based on prior knowledge. Among them, some methods utilize the regularization term to capture the noisy labels based on the sparsity assumption[13]; some methods assume that candidate labels are always instance-dependent (feature-dependent)[14]; some other works recover the ground-truth label matrix by maintaining the local consistency in the label space [15]. The manifold consistency encourages the similar instances to have the same labels.[15, 16]. There exist some other methods exploiting the outputs of model for recovering the true label information. These methods usually use the model outputs as a guidance to progressively identify the ground-truth labels. For instance, the method proposed in [17] re-weights the losses by the confidences of each candidate label. Some methods encourage the model to output a shaper confidence distribution so as to easily identify the most probable class label[18, 19, 20].
Despite the improvement of performance for PLL that these methods have achieved, there still exist two main challenges for learning a multi-class classifier on PLL datasets. On one hand, existing methods rely on prior knowledge, which is often unavailable in practical applications. For instance, the candidate set may not be sparse but composed of many noisy labels in practice, since the training examples may be seriously corrupted in extreme cases. Besides, in high-dimensional feature space, the smoothing assumption may lose effectiveness since it relies on the Euclidean distance. In these cases, the performance of the model often noticeably decreases due to the lack of prior information. On the other hand, the disambiguation methods based on model outputs often suffer from the over-fitting issue of noise labels hidden in the candidate set, particularly when there are a large number of noisy labels. The phenomenon often occurs at the early stage, since the model fails to obtain a desirable disambiguation performance at this time due to its insufficient training.
In this paper, we propose a more reliable and effective approach to perform disambiguation for candidate labels of training examples without any additional auxiliary assumptions. Specifically, we try to recover the true label information by designing a meta-objective on a very tiny validation set (a mini-batch), which can be collected in many practical tasks with small labeling cost. On one hand, we train a classification model by minimizing a confidence-weighted cross entropy loss.. On the other hand, the confidence of each candidate label is adaptively estimated in a meta fashion based on its meta-loss on a tiny validation set. Theoretically, we show that the model learned by the proposed method is always better than directly learning from partial-labeled data, and we further provide the estimation error bounds for the proposed method. Comprehensive experimental results validate that demonstrate that the proposed method shows superiority to the comparing methods on multiple synthetic and real-world datasets.
The rest of this article is organized as follows. Firstly, we overview the related work in the following section. Then the proposed method will be introduced in Section III. Section IV demonstrates theoretical properties of the proposed approach. Section V presents the experimental results, followed by the conclusion in Section VI.
II Related Work
Partial label learning aims to train a classifier model merely using ambiguously labeling training data, thereby reducing labeling cost in practice. The major difficulty of PLL is that the learning algorithms cannot directly get access to the ground-truth label of training examples since it is hidden in the candidate set [1, 11, 12]. To mitigate this issue, a large number of methods have been developed to handle partial labels by adopting the disambiguation strategy, which aims to identify the true label in the candidate set. Existing PLL methods can be roughly divided into three groups: average-based methods, identification-based methods, and disambiguation-free methods.
Averaging-based methods commonly treat all the candidate labels equally and distinguish the ground-truth label by averaging their modeling outputs. Cour et al.[1] proposed to decompose the partial label learning task into a series of binary classification and then employ SVM to solve them, which is a convex optimization approach named CLPL. Hüllermeier and Beringer [21] proposed a k-nearest neighbors method named PLNN, which distinguishes the ground-truth label by voting among the candidate labels of each neighboring sample. Zhang and Yu [16] proposed an instance-based method called IPAL, which averages the information of the candidate label from the neighboring instances to predict an unknown example. Tang and Zhang [22] proposed to enhance the disambiguation ability by simultaneously utilizing the confidences of candidate label and the weights of training samples. Overall, despite this kind of method can be easily implemented, it has the common drawback that the outputs of false positive labels may mislead the model during the iterative training process and decrease the robustness of learning models.
Identification-based methods progressively estimate the confidence of each candidate label, and then try to recover the ground-truth label from the candidate label set. Specifically, most existing PLL methods typically iteratively refine the confidence of the ground-truth by regarding it as a latent variable. These methods update model parameters by using the iteratively refined expectation maximization techniques, such as maximum likelihood [23, 2, 24], and maximum margin[18, 20, 25]. For instance, Nguyen and Caruana [18] try to maximize the margin between the output of non-candidate labels and the maximal output of candidate label. Feng and An [19] proposed SURE, which imposes the maximum infinity norm regularization on the modeling outputs to conduct pseudo-labeling and train models simultaneously, then automatically identify the ground-truth label with high confidence. The above methods are usually restricted to linear models, which suffers from the lack of strong learning ability. To exploit the powerful fitting ability of the deep neural network, Yao et al. [26] conducted a preliminary study on deep PLL. They proposed a PLL method named CNN [26], they utilize the entropy regularizer to make the prediction more discriminative and employ convolution neural networks (DCNNs) to improve the ability of feature representation. In Yao et al. [27], they proposed to train two networks collaboratively by utilizing a network-cooperation mechanism. Nevertheless, these methods mainly study the discrepancy between the false positive candidate labels and the ground-truth label but neglect the possibility of each candidate label can be the ground-truth label. To mitigate this issue, some methods try to estimate the confidence of each candidate label rather than directly identifying the ground-truth. For example, Lv et al. [17] proposed a progressive identification method named PRODEN, which identifies the true labels according to the output of classifier itself.
Different from aforementioned two disambiguation-based methods, disambiguation-free based methods directly learn from partially labeled data by making modifications to existing techniques. For instance, Zhang et al. [28] proposed a disambiguation-free PLL method called ECOC, which decomposes the PLL problem into many binary classification problems and uses Error-Correcting Output Codes (ECOC) coding matrix [10] to fit partially labeled data.
The proposed method performs disambiguation for candidate labels by designing a meta objective to guide the model training. The idea of using a meta objective to re-weight training examples has been widely applied to train a robust model in many real-world scenarios [29, 30, 31]. Similar to MAML[32], our method takes one gradient descent step on the meta-objective at each iteration. Besides, unlike these meta learning methods, our meta objective guided disambiguation method does not need any extra hyperparameters.
III The Proposed Approach
In this paper, we consider the problem of ordinary -class classification. Let be the feature space with -dimensional, be the target space with class labels. Besides, let be the training set with partial-labeled instances, where each instance is represented by a -dimensional feature vector , is its corresponding candidate label set. Let be the DNN model, where denotes the parameters.
In the following content, we describe our proposed Meta objective Guided Disambiguation (MoGD) framework for solving PLL problems in detail. Firstly, we develop a confidence-weighted objective function to handle partial-labeled examples; then, we propose to adaptively estimate the confidence of each candidate label in a meta-learning fashion. To reduce the computational cost, we alternatively update the confidences of candidate labels and the parameters of the neural network by using an online approximation strategy.
III-A Confidence-Weighted Objective Function
To solve PLL problems, the pioneer work [1] derives the partial cross entropy (PCE) loss, which computes the cross entropy (CE) loss for each candidate label. Formally, let denote the model output for instance , then we define the PCE loss as:
| (1) |
where denotes the labels vector, if ; , otherwise. For notational simplicity, we denote as the loss vector computed on . Accordingly, the PCE loss can be rewritten by .
Unfortunately, PCE loss regards all candidate labels as ground-truth labels and thus introduces noisy labels into model training. These noisy labels often mislead the model, which leads to a noticeable decrease in generalization performance. To mitigate the negative influence of noise labels, a label confidence vector is assigned to every example , where the confidence is use to estimate the probability that the example belongs to -th class. Obviously, if is not a candidate label, then we keep its confidence being 0 due to the fact that it cannot be a ground-truth label for example .
The confidence-weighted cross entropy loss can be formulated as follows:
| (2) |
In the ideal case, if we can accurately recover the confidences for ground-truth labels, then would be degenerated into the standard cross entropy, which yields that the disambiguation is achieved for candidate labels.
Nevertheless, it is hard to estimate the confidence precisely without any prior knowledge in many real-world scenarios. To mitigate this issue, we follow a meta-learning paradigm to design a disambiguation strategy based on a meta objective.
III-B Meta Objective Guided Disambiguation
In this subsection, we aim to estimate a optimal confidence distribution for every example in an meta-learning fashion. Towards this goal, we firstly measure the performance of confidence estimation based on a validation set, and then for each candidate label, we use the measurement as a guidance to adaptively estimate its confidence. The only need is a tiny clean validation set (e.g., a mini-batch of examples), which can be collected in many realistic tasks with small labeling cost.
Specifically, we denote as a validation set with examples available during the training phase. Here, for every validation example , we use superscript to distinguish it from training examples. It is noteworthy that every validation example has been annotated with its ground-truth label vector . Intuitively, the optimal confidences often leads to the best model such that minimizes the validation loss. Based on this intuition, we can treat the objective function on the validation set as guidance to optimize the confidences. The meta objective function can be formulated as follows:
| (3) |
where represents the loss of trained classifier on the validation set . In Section V, we discuss that the proposed method is influenced by the size of validation set, and the results show that the performance of MoGD is insensitive to the size of validation set.
We can adopt the alternative strategy to optimize variables and by updating one of the variables while fixing the other. The process continues until both of these two variables converge or exceed the maximum iteration. Unfortunately, it requires two nested loops to obtain optimal parameters, which is unbearable in many realistic tasks, especially when the deep model is used. To improve the training efficiency, inspired by the previous works [30], the online approximation strategy is used to obtain the optimal variables and . Specifically, to obtain the , motivated by the EM algorithm, we can initialize the confidences uniformly as follows:
| (4) |
Then, at every training iteration , given a mini-batch training samples , where denotes the mini-batch size, that satisfies . Then we can update the parameters based on the descent direction of the objective function on this mini-batch:
| (5) |
where is the step size with respect to .
Next we can seek the optimal confidence by minimizing the validation loss .
Based on the , we can take a single gradient descent step according to the direction of the meta-objective on the mini-batch validation samples to get a cheap estimate of , which can be formally written as:
| (6) |
where is the step size with respect to . To make sure the the expect loss non-negative, it requires us to guarantee each is non-negative:
| (7) |
In practice, for each training example, we normalize the confidences with respect to every class so that they sum to one:
| (8) |
Finally, we can optimize the model parameter by employing the gradient descent based on the latest updated confidences , which is described below:
| (9) |
We repeat these procedures until both of them converge or exceed the maximum epoch. The step-by-step pseudo-code of MoGD is shown in Algorithm 1.
IV Theoretical Analysis
In this section, we first analyze the convergence of MoGD, then establish the estimation error bounds.
IV-A Convergence
Different from optimization on a single-level problem, the proposed methods is a optimization problem with two-level objectives including Eq.(6) and Eq.(9). Following the analysis procedure in [30], we obtain the convergence results that both the training and meta objective function converges to the critical points under some mild conditions.
Definition 1
A function is said to be Lipschitz-smooth with constant if
Definition 2
has -bounded gradients if for all .
Theorem 1 (convergence)
Suppose that the meta loss function is Lipschitz-smooth with constant , and for training data , the training loss function have -bounded gradients. Then the validation loss always monotonically decreases with the iteration by employing our optimization method, i.e.,
Note that, the step size satisfies , where denotes the batch size of training, and denotes the number of classes.
Furthermore, if the gradient of validation loss becomes at iteration , the equality will hold, i.e.,
if and only if
IV-B Comparisons with Ordinary Methods
In the following content, we discuss the effectiveness of the proposed approach compared with ordinary PLL methods.
First, define the empirical risk as:
then we have the theorem below.
Theorem 2 (effectiveness)
Define is the model trained without using validation set, i.e.,
Then the empirical risk of that produced by MoGD is never worse than which trained merely utilizes original partial labeled examples, i.e., .
Proof:
First, we have
Suppose , obviously we can always set the weight of each label to its initial value, e.g., non-candidate label to zero and candidate label to one. Then we can obtain the . Therefore, is never worse than . ∎
| Dataset | # Train | # Test | # Feature | # Class | Model |
|---|---|---|---|---|---|
| Fashion-MNIST | 60000 | 10000 | 784 | 10 | Linear Model |
| CIFAR-10 | 50000 | 10000 | 3072 | 10 | ResNet, ConvNet |
| CIFAR-100 | 50000 | 10000 | 3072 | 100 | ResNet, ConvNet |
| Dataset | # Instance | # Feature | # Avg.Label | # Class | Domain | Model |
|---|---|---|---|---|---|---|
| Lost | 1122 | 108 | 2.23 | 16 | automatic face naming | Linear Model |
| BirdSong | 4998 | 38 | 2.18 | 13 | bird song classification | Linear Model |
| MSRCv2 | 1758 | 48 | 3.16 | 23 | object classification | Linear Model |
| Soccer Player | 17472 | 279 | 2.09 | 171 | automatic face naming | Linear Model |
| Yahoo! News | 22991 | 163 | 1.91 | 219 | automatic face naming | Linear Model |
IV-C Estimation Error Bounds
In this subsection, we establish the estimation error bounds for the proposed method.
We begin with several useful definitions and lemmas as follows.
Definition 3 (-cover)
For a set , if for satisfies , then is an -cover of .
Definition 4 (Rademacher Complexity)
Define is the underlying joint density of random variables . Let be a family of functions for empirical risk minimization, be Rademacher variables, then we can define the Rademacher complexity of over with example size as follows[33]:
Assume the meta-objective function is upper-bounded by and Lipschitz-smooth with a constant , i.e.,
For notational simplicity, we use and to denote empirical risk and generalization risk, respectively. Following prior works[17, 30, 34, 35], we summarized two lemmas as follows.
Lemma 2
Theorem 3 (estimation error bounds)
Let be the parameter of label confidence of the examples, which is bounded in a -dimensional unit ball. Let Then, the generalization risk can be defined as:
Let be the empirically optimal parameter in a candidate set , and let be the optimal parameter in the unit ball. Then, with a probability at least , we have,
where denotes the number of examples.
Proof:
where we used that by the definition of and . ∎
Theorem 3 guarantees that: , .
| Dataset | Method | ||||
|---|---|---|---|---|---|
| Fashion-MNIST | MoGD | ||||
| VALEN | |||||
| LWS | |||||
| PRODEN | |||||
| RC | |||||
| CC | |||||
| MSE | |||||
| EXP | |||||
| Fully Supervised | |||||
| Dataset | Method | ||||
|---|---|---|---|---|---|
| CIFAR-10 | MoGD | ||||
| VALEN | |||||
| LWS | |||||
| PRODEN | |||||
| RC | |||||
| CC | |||||
| MSE | |||||
| EXP | |||||
| Fully Supervised | |||||
| Dataset | Method | ||||
| CIFAR-100 | MoGD | ||||
| VALEN | |||||
| LWS | |||||
| PRODEN | |||||
| RC | |||||
| CC | |||||
| MSE | |||||
| EXP | |||||
| Fully Supervised | |||||
V Experiments
In this section, we conduct experiments on various datasets, and compare it with some state-of-the-art partial label learning algorithms to validate the effectiveness of MoGD.
V-A Experiment Setting
V-A1 Datasets
We perform experiments on three widely used benchmark image datasets, including Fashion-MNIST111https://github.com/zalandoresearch/fashion-mnist[36], CIFAR-10 and CIFAR-100 222https://www.cs.toronto.edu/~kriz/cifar.html [37] as well as five real-world PLL datasets, including Lost [1], BirdSong [38], MSRCv2 [24], Soccer Player [4], and Yahoo! News [39]. Table I and Table II summarize the detailed characteristics of these datasets, respectively.
Note that it requires to manually generate the candidate label sets for three image datasets, since they are supposed to be used for multi-class classification. We manually generate candidate labels for training examples from these datasets based on two different generation process, i.e., uniform generation process [17] and instance-dependent generation process [14].
Specifically, we generate candidate labels by flipping a negative label into false positive label with a flipping probability , where . In other words, we employ a binomial flipping strategy: for each training example, we conduct independent Bernoulli experiments, and each experiment determines whether a false positive label is generated with probability . To make sure all training example have two or more candidate labels, for the instance that there is none false positive labels generated, we randomly select a negative label and add it to the candidate label set. Similar to previous works[17, 40], we consider for Fashion-MNIST and CIFAR-10, and for CIFAR-100. Generally, a lager value of indicates a higher level of ambiguity of training examples.
To construct instance-dependent candidate labels, we follow the generating procedure used in [14]. Specifically, for an instance , let be the flipping probability of -th label, where denotes the original label vector. Then we use the prediction probability of a clean network trained on the clean labels to set the flipping probability of each negative label with , where denotes the negative label set of . In our experiments, we directly adopt the pre-trained model released by [14] to generate instance-dependent candidate labels.
V-A2 Compared methods
In order to validate the effectiveness of the proposed method, we first compare MoGD against the following five deep PLL methods on three image datasets:
-
•
VALEN[14]: An instance-dependent method which uses variational inference technique to iteratively estimate the latent label distribution during the training stage.
-
•
LWS[41]: A discriminative method which imposes a trade-off between losses on non-candidate labels and candidate labels.
-
•
PRODEN[17]: A progressive identification method which identifies the true labels according to the output of classifier itself.
-
•
RC[40]: A risk-consistent method which establishes the true risk estimator by employing the importance re-weighting strategy.
-
•
CC[40]: A classifier-consistent method which establishes the empirical risk estimator by employing the transition matrix and cross entropy loss.
The baseline methods:
- •
-
•
Fully Supervised: It trains a multi-class classifier based on ordinary labeled data and can be regarded as an upper bound of performance.
In addition, we also compare MoGD with eight classical PLL methods on five real-world datasets, including GA[43], CNN[26], SURE[19], CLPL[1], ECOC[28], PLSVM[18], PLNN[21], IPAL[16]. The details of these methods can be found in the related work section. In our experiments, the hyper-parameters are determined based on the recommended parameter settings in their original literature.
| Dataset | Method | ||||
|---|---|---|---|---|---|
| CIFAR-10 | MoGD | ||||
| VALEN | |||||
| LWS | |||||
| PRODEN | |||||
| RC | |||||
| CC | |||||
| MSE | |||||
| EXP | |||||
| Fully Supervised | |||||
| Dataset | Method | ||||
| CIFAR-100 | MoGD | ||||
| VALEN | |||||
| LWS | |||||
| PRODEN | |||||
| RC | |||||
| CC | |||||
| MSE | |||||
| EXP | |||||
| Fully Supervised | |||||
V-A3 Implementation Details
We employ multiple basic models, including linear model, 12-layer ConvNet[44] and Wide-ResNet-28[45] to show that the proposed approach is compatible with different learning models. Specifically, for Fashion-MNIST and five real-world datasets, we employ Linear Net as the backbone neural network while using ConvNet and ResNet for CIFAR-10 and CIFAR-100.
To make a fair comparison, we employ the same network architecture as the base model for all methods. For our method, we train the model based on a tiny validation set (a mini-batch). Specifically, before training, we randomly sample a mini-batch precisely labeled instances as the validation set. For the comparing methods, we add the validation examples into training set, which indicates that the classifier is trained on the original training examples and validation examples. Note that the comparing methods directly train the classifier with the validation examples, while MoGD only uses them for auxiliary disambiguation. Furthermore, the parameters are determined as suggested in their original papers. For CIFAR-10 and CIFAR-100, we perform a strong augmentation (containing Cutout [46] and random horizontal flip) for each training image as done in [47] 333https://github.com/kekmodel/FixMatch-pytorch. We employ the SGD optimizer [48] with the momentum of 0.9 to train the model for 500 epochs. For all experiments, we repeat independent experiments (with different random seeds) and report the average results and standard deviation. All experiments are carried on Pytorch 444https://pytorch.org/[49] with GeForce RTX 3080Ti GPUs.
| Method | Fashion-MNIST | CIFAR-10 |
|---|---|---|
| MoGD | ||
| VALEN | ||
| LWS | ||
| PRODEN | ||
| RC | ||
| CC |
| Lost | MSRCv2 | BirdSong | Soccer Player | Yahoo! News | |
|---|---|---|---|---|---|
| MoGD | |||||
| VALEN | |||||
| LWS | |||||
| PRODEN | |||||
| CNN | |||||
| GA | |||||
| SURE | |||||
| CLPL | |||||
| ECOC | |||||
| PLSVM | |||||
| PLNN | |||||
| IPAL |
V-B Experiments on Image Datasets
We first report the results of the experiments on three image datasets with uniform candidate labels.
Table III demonstrates the comparison results on Fashion-MNIST with linear models. We consider flipping probability . As shown in the table, it can be observed that: 1) MoGD consistently outperforms all comparing methods. 2) Even compared to fully supervised learning, the results show that MoGD achieves competitive performance. In particular, with , our method has a very small performance decrease (less than ), even with , the performance drop of MoGD is less than , respectively, when compared to fully supervised learning.
Table IV and Table V report the comparing results on CIFAR-10 and CIFAR-100 with ConvNet and Resnet, respectively. From the results, it can be observed that:
-
1.
MoGD achieves the best performance on all cases with various flipping probabilities.
-
2.
MoGD achieves comparable performance compared with fully supervised learning with low flipping probabilities on CIFAR-10 and CIFAR-100, e.g., with the ConvNet backbone, the performance drop of on CIFAR-10 () and on CIFAR-100 ().
-
3.
MoGD outperforms the comparing methods with a large performance gap on CIFAR-100. For example, by using the ConvNet backbone, our method outperforms the second best method PRODEN by , , , and with flipping probabilities , respectively.
-
4.
MoGD achieves a relatively small performance drop as flipping probabilities increase. On the contrary, the comparing methods like LWS, VALEN, MSE and EXP work well on low flipping probabilities, while achieving a significant performance drop with the increase of flipping probabilities.
These experimental results convincingly validate that MoGD can achieve favorable disambiguation ability for candidate labels. The results on CIFAR-100 demonstrate that MoGD show stronger robustness against the comparing methods.
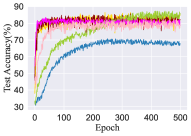
Moreover, we analyze the convergence properties of these methods. Fig. 2 illustrates the performance curves of different methods with regard to test accuracy with the increase of epoch. From the figures, we can see that MoGD can quickly converge with about 40 epochs. Comparing methods like VALEN and LWS converge relatively slowly.
Besides the uniform candidate labels, we also compare these methods on Fashion-MNIST and CIFAR-10 with instance-dependent candidate labels. Table VI shows that the proposed approach achieves the best performance in all cases. In particular, MoGD outperforms the second best method with and accuracy on Fashion-MNIST and CIFAR-10, respectively.
V-C Experiments on Real-World Datasets
We also conduct experiments on five real-world PLL datasets to evaluate the practical usefulness of MoGD. Specifically, for all methods, we perform five-fold cross-validation. We use the same Linear model and employ the SGD optimizer [48] with a momentum of to train the model for epochs. Table VII shows the comparison results between MoGD and comparing methods. From the results, it can observed that our method outperforms all comparing methods on BirdSong, Soccer Player and Yahoo! News. In particular, MoGD outperforms the second best method LWS and accuracy on Soccer Player and Yahoo! News, respectively. Although the performance of our method is lower than that of some methods on Lost and MSRCv2, it is still acceptable and higher than that of most comparing methods.
V-D Study On the Size of Validation Set
In this section, we conduct experiments to study the influence of the size of validation data by comparing the performance of our method with different validation set size. Fig. 3 illustrates the test accuracy curves of MoGD as the size of the validation set changes among on the CIFAR-10, on CIFAR-100 and on the two real-world datasets include Soccer Player and Yahoo! News. From the figures, the performance of MoGD is also satisfactory when the size of the validation set is relatively small, such as 128 for CIFAR-10, 256 for CIFAR-100, 100 for Yahoo! News, and 200 for Soccer Player. In fact, the meta objective on the validation set can encourage the classifier net to precisely estimate the confidence of the candidate label, which is similar to the effect of a regularization term. This phenomenon suggests that, in practical applications, one can precisely annotate a few examples in advance to improve the classification performance.







VI Conclusion
In this paper, we propose a novel framework for partial label learning by achieving disambiguation for candidate labels in a meta-learning manner. Different from the previous methods, we utilize the meta-objective on a tiny clean validation set to adaptively estimate the confidence of each candidate label without extra assumptions of data. Then we optimize the multi-class classifier by minimizing a confidence-weighted objective function. To improve the training efficiency, we iteratively update these two objective functions by using an online approximation strategy. We validate the effectiveness of MoGD both theoretically and experimentally. In theory, we prove that the model trained by MoGD is never worse than merely learning from partial-labeled data. Extensive experiments on commonly used benchmark datasets and real-world datasets demonstrate that MoGD is superior to the state-of-the-art methods. In the future, we will focus on studying other more powerful learning models to further enhance the performance of MoGD algorithm.
References
- [1] T. Cour, B. Sapp, and B. Taskar, “Learning from partial labels,” The Journal of Machine Learning Research, vol. 12, pp. 1501–1536, 2011.
- [2] R. Jin and Z. Ghahramani, “Learning with multiple labels,” Advances in neural information processing systems, vol. 15, 2002.
- [3] M. Guillaumin, T. Mensink, J. Verbeek, and C. Schmid, “Automatic face naming with caption-based supervision,” in 2008 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2008, pp. 1–8.
- [4] Z. Zeng, S. Xiao, K. Jia, T.-H. Chan, S. Gao, D. Xu, and Y. Ma, “Learning by associating ambiguously labeled images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 708–715.
- [5] Y.-C. Chen, V. M. Patel, R. Chellappa, and P. J. Phillips, “Ambiguously labeled learning using dictionaries,” IEEE Transactions on Information Forensics and Security, vol. 9, no. 12, pp. 2076–2088, 2014.
- [6] L. Feng and B. An, “Partial label learning by semantic difference maximization.” in IJCAI, 2019, pp. 2294–2300.
- [7] J. Luo and F. Orabona, “Learning from candidate labeling sets,” Advances in neural information processing systems, vol. 23, 2010.
- [8] Y. Zhou, J. He, and H. Gu, “Partial label learning via gaussian processes,” IEEE transactions on cybernetics, vol. 47, no. 12, pp. 4443–4450, 2016.
- [9] C.-H. Chen, V. M. Patel, and R. Chellappa, “Matrix completion for resolving label ambiguity,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 4110–4118.
- [10] T. G. Dietterich and G. Bakiri, “Solving multiclass learning problems via error-correcting output codes,” Journal of artificial intelligence research, vol. 2, pp. 263–286, 1994.
- [11] J. Wang and M.-L. Zhang, “Towards mitigating the class-imbalance problem for partial label learning,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 2427–2436.
- [12] M.-L. Zhang, B.-B. Zhou, and X.-Y. Liu, “Partial label learning via feature-aware disambiguation,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 1335–1344.
- [13] G. Lyu, S. Feng, Y. Li, Y. Jin, G. Dai, and C. Lang, “Hera: partial label learning by combining heterogeneous loss with sparse and low-rank regularization,” ACM Transactions on Intelligent Systems and Technology (TIST), vol. 11, no. 3, pp. 1–19, 2020.
- [14] N. Xu, C. Qiao, X. Geng, and M.-L. Zhang, “Instance-dependent partial label learning,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [15] N. Xu, J. Lv, and X. Geng, “Partial label learning via label enhancement,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 5557–5564.
- [16] M.-L. Zhang and F. Yu, “Solving the partial label learning problem: An instance-based approach,” in Twenty-fourth international joint conference on artificial intelligence, 2015.
- [17] J. Lv, M. Xu, L. Feng, G. Niu, X. Geng, and M. Sugiyama, “Progressive identification of true labels for partial-label learning,” in International Conference on Machine Learning. PMLR, 2020, pp. 6500–6510.
- [18] N. Nguyen and R. Caruana, “Classification with partial labels,” in Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, 2008, pp. 551–559.
- [19] L. Feng and B. An, “Partial label learning with self-guided retraining,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 3542–3549.
- [20] F. Yu and M.-L. Zhang, “Maximum margin partial label learning,” in Asian conference on machine learning. PMLR, 2016, pp. 96–111.
- [21] E. Hüllermeier and J. Beringer, “Learning from ambiguously labeled examples,” Intelligent Data Analysis, vol. 10, no. 5, pp. 419–439, 2006.
- [22] C.-Z. Tang and M.-L. Zhang, “Confidence-rated discriminative partial label learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, no. 1, 2017.
- [23] Y. Grandvalet, Y. Bengio et al., “Learning from partial labels with minimum entropy,” CIRANO, Tech. Rep., 2004.
- [24] L. Liu and T. Dietterich, “A conditional multinomial mixture model for superset label learning,” Advances in neural information processing systems, vol. 25, 2012.
- [25] J. Chai, I. W. Tsang, and W. Chen, “Large margin partial label machine,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 7, pp. 2594–2608, 2019.
- [26] Y. Yao, J. Deng, X. Chen, C. Gong, J. Wu, and J. Yang, “Deep discriminative cnn with temporal ensembling for ambiguously-labeled image classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 12 669–12 676.
- [27] Y. Yao, C. Gong, J. Deng, and J. Yang, “Network cooperation with progressive disambiguation for partial label learning,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2020, pp. 471–488.
- [28] M.-L. Zhang, F. Yu, and C.-Z. Tang, “Disambiguation-free partial label learning,” IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 10, pp. 2155–2167, 2017.
- [29] M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, “Meta-learning for semi-supervised few-shot classification,” arXiv preprint arXiv:1803.00676, 2018.
- [30] M. Ren, W. Zeng, B. Yang, and R. Urtasun, “Learning to reweight examples for robust deep learning,” in International conference on machine learning. PMLR, 2018, pp. 4334–4343.
- [31] M.-K. Xie, F. Sun, and S.-J. Huang, “Partial multi-label learning with meta disambiguation,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 1904–1912.
- [32] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in International conference on machine learning. PMLR, 2017, pp. 1126–1135.
- [33] M. Mohri, A. Rostamizadeh, and A. Talwalkar, Foundations of machine learning. MIT press, 2018.
- [34] L.-Z. Guo, Z.-Y. Zhang, Y. Jiang, Y.-F. Li, and Z.-H. Zhou, “Safe deep semi-supervised learning for unseen-class unlabeled data,” in International Conference on Machine Learning. PMLR, 2020, pp. 3897–3906.
- [35] T. Ishida, G. Niu, W. Hu, and M. Sugiyama, “Learning from complementary labels,” Advances in neural information processing systems, vol. 30, 2017.
- [36] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017.
- [37] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” 2009.
- [38] F. Briggs, X. Z. Fern, and R. Raich, “Rank-loss support instance machines for miml instance annotation,” in Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, 2012, pp. 534–542.
- [39] M. Guillaumin, J. Verbeek, and C. Schmid, “Multiple instance metric learning from automatically labeled bags of faces,” in European conference on computer vision. Springer, 2010, pp. 634–647.
- [40] L. Feng, J. Lv, B. Han, M. Xu, G. Niu, X. Geng, B. An, and M. Sugiyama, “Provably consistent partial-label learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 10 948–10 960, 2020.
- [41] H. Wen, J. Cui, H. Hang, J. Liu, Y. Wang, and Z. Lin, “Leveraged weighted loss for partial label learning,” in International Conference on Machine Learning. PMLR, 2021, pp. 11 091–11 100.
- [42] L. Feng, T. Kaneko, B. Han, G. Niu, B. An, and M. Sugiyama, “Learning with multiple complementary labels,” in International Conference on Machine Learning. PMLR, 2020, pp. 3072–3081.
- [43] T. Ishida, G. Niu, A. Menon, and M. Sugiyama, “Complementary-label learning for arbitrary losses and models,” in International Conference on Machine Learning. PMLR, 2019, pp. 2971–2980.
- [44] S. Laine and T. Aila, “Temporal ensembling for semi-supervised learning,” arXiv preprint arXiv:1610.02242, 2016.
- [45] S. Zagoruyko and N. Komodakis, “Wide residual networks,” arXiv preprint arXiv:1605.07146, 2016.
- [46] T. DeVries and G. W. Taylor, “Improved regularization of convolutional neural networks with cutout,” arXiv preprint arXiv:1708.04552, 2017.
- [47] K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li, “Fixmatch: Simplifying semi-supervised learning with consistency and confidence,” Advances in Neural Information Processing Systems, vol. 33, pp. 596–608, 2020.
- [48] H. Robbins and S. Monro, “A stochastic approximation method,” The annals of mathematical statistics, pp. 400–407, 1951.
- [49] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol. 32, 2019.