Meta-Gating Framework for Fast and Continuous Resource Optimization in Dynamic Wireless Environments
Abstract
With the great success of deep learning (DL) in image classification, speech recognition, and other fields, more and more studies have applied various neural networks (NNs) to wireless resource allocation. Generally speaking, these artificial intelligent (AI) models are trained under some special learning hypotheses, especially that the statistics of the training data are static during the training stage. However, the distribution of channel state information (CSI) is constantly changing in the real-world wireless communication environment. Therefore, it is essential to study effective dynamic DL technologies to solve wireless resource allocation problems. In this paper, we propose a novel framework, named meta-gating, for solving resource allocation problems in an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. The proposed framework, consisting of an inner network and an outer network, aims to adapt to the dynamic wireless environment by achieving three important goals, i.e., seamlessness, quickness and continuity. Specifically, for the former two goals, we propose a training method by combining a model-agnostic meta-learning (MAML) algorithm with an unsupervised learning mechanism. With this training method, the inner network is able to fast adapt to different channel distributions because of the good initialization. As for the goal of ‘continuity’, the outer network can learn to evaluate the importance of inner network’s parameters under different CSI distributions, and then decide which subset of the inner network should be activated through the gating operation. Additionally, we theoretically analyze the performance of the proposed meta-gating framework. Simulation results demonstrate that the proposed meta-gating framework can well achieve the three important goals compared with existing state-of-the-art algorithms.
Index Terms:
Dynamic wireless environment, meta-learning, continual learning, resource allocation, neural network.I Introduction
Resource allocation plays an essential role in wireless communications. However, most of them are formulated as NP-hard non-convex problems, which are computationally challenging to solve. With the great success of deep learning (DL) in image classification, speech recognition, and other fields, various neural networks (NNs) are recently applied to solve resource allocation problems in wireless networks[1, 2, 3, 4]. In [1] and [2], the deep neural networks (DNNs) trained by the unsupervised learning method were employed to solve the power control problem for sum-rate maximization. The authors in [3] have designed a convolutional neural network (CNN) to optimize the transmit power in device-to-device (D2D) networks. Recently, graph neural networks (GNNs) have been widely applied to solve resource allocation problems because of their good representation ability for wireless networks[5, 6, 7, 8]. In [5], a GNN trained by the unsupervised learning method was applied to address the link scheduling in D2D networks. The authors in [6] have developed a GNN to solve the beamformer design problem in the multi-antenna systems. In [7, 8], GNNs were designed to optimally allocate resources across a set of transceiver pairs in a wireless network. However, all aforementioned NNs are trained under some special hypotheses, in particular that the statistics of the training data are static. Unfortunately, the real-world wireless environment is dynamic and constantly changing, such as the distribution of channel state information (CSI) may change over periods. It is known that the NN-based methods in existing works usually suffer from severe performance degradation when the environment changes, i.e., when the real-time data follows a different distribution from that used in the training phase[12]. Besides, if one chooses to retrain the entire NN once the environment changes, the re-training process would incur overwhelming overhead especially for highly dynamic wireless networks.[9]. Thus, it is worth studying how to effectively optimize the resources in such a dynamic wireless environment.
Recently, transfer learning (TL)[15] has been widely employed to handle dynamic data in wireless resource allocation problems such as power control[10] and beamformer design[11]. However, once an NN model has adapted to the new environment by using TL, it would degrade or even overwrite the previously learned model, and thus the performance in the previous environment degrades significantly[16, 17], which is termed as the catastrophic forgetting (CF) phenomenon. Besides, the performance of TL largely depends on the selection of the pre-trained model. Motivated by these challenges, we summarize the difficulties of dealing with the resource allocation problems in a dynamic wireless environment as: How to achieve good performances under different CSI distributions without CF.
To achieve good performance under different CSI distributions, meta-learning[13, 14] is a potential technique, where a good model initialization learned from a large amount of data with different distributions can help achieve good performance and fast adapt to new samples. The efficiency of meta-learning techniques in processing the new samples has been extensively studied in resource allocation problems[11, 18, 19]. In [11], a downlink beamformer design based on meta-learning has been proposed to enable fast adaptation to a new testing wireless environment. In [18], the authors aimed to fast adapt to new network topology with limited data for the power control problem. Specifically, the ordinary black-box meta-learning technique has been improved by using the modular meta-learning, which can optimize a series of modules and quickly re-combine them when solving a new task. The authors in [19] summarized the applications of meta-learning-based methods in wireless networks. However, the aforementioned works mainly focus on the improvement of fast adaption of meta-learning but the CF challenge is not considered.
As for the CF phenomenon, it can be potentially solved by the continual learning (CL)[26, 27], which aims to incrementally learn new knowledge without forgetting previously learned knowledge. There have been a great number of works studying the CL and they can be roughly classified into three categories, i.e., regularization based methods[9, 28], dynamic NN architecture based methods[21, 22], and memory box based methods[24, 25]. Among the aforementioned three categories, the first one is the most popular since the latter two would increase the training overhead due to the increase in the number of neurons or the size of the memory box. Specifically, the regularization based methods mainly study how to evaluate the importance of parameters and select less-important parameters to be modified in response to new data. This parameter evaluation and selection process is termed as selective plasticity in corresponding work. However, the design of selective plasticity in the aforementioned regularization based methods highly depend on the manual hyperparameter adjustment, which is impractical in practical applications. Therefore, it is necessary to apply the learning ability of NNs to achieve the goal of ‘learning to continually learn’. Inspired by the neuromodulatory processes of CL in human brain, there have been several papers on enabling the selective plasticity of NNs by using neuromodulation-based techniques [35, 36], making the aforementioned goal possible.
In this paper, we take the classic sum-rate maximization (SRM) problem in the -user interference network as example to study the dynamic DL technology. Specifically, we consider an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains stationary within each period. Then, we develop a novel framework named meta-gating to overcome the aforementioned difficulties by achieving the following three important goals, where the former two are proposed for fulfilling good performance under different CSI distributions and the third goal is for overcoming the CF problem.
-
•
Seamlessness: The proposed method can achieve good sum-rate performance over all periods, which means that the sum-rate variance should be small enough so that it is unaware of changes in the CSI distribution.
-
•
Quickness: The proposed method should well adapt to the new wireless environment with few training samples.
-
•
Continuity: The proposed method can achieve good sum-rate performance in a new wireless environment without forgetting what has learned in previous environments/periods. Besides, it should not depend on the manual hyperparameter adjustment.
The proposed meta-gating framework consists of an inner network and an outer network. Specifically, for the former two goals, we propose a dual-loop training method by combining the model-agnostic meta-learning (MAML) algorithm with the unsupervised training. With such a design, the inner network is able to achieve good sum-rate performance on different channel distributions through a few number of stochastic gradient descent (SGD) iterations because of the suitable initialization. As for the goal of ‘continuity’, we adopt the regularization method and design an element-wise gating operation to multiply the outputs of the inner and outer networks, aiming to evaluate the importance of inner network’s parameters under different CSI distributions and then decide which subset of the inner network should be activated. Thus, it results in selective plasticity of the inner network by affecting its back propagation, where the selective plasticity is the core of regularization based methods in CL.
In summary, the main contributions of this work are highlighted as follows.
-
•
We propose a general framework to enable NNs to solve the resource allocation problems in a dynamic wireless environment, including the network architecture and the training method. The proposed framework can achieve three important goals, i.e., seamlessness, quickness, and continuity, to satisfy the requirements of a dynamic wireless environment via meta-learning and continual learning.
-
•
The proposed framework is model-agnostic, i.e, the inner and outer networks can be implemented as any NN models. Specifically, except that the number of outputs of the inner and outer networks need to be the same, the inner and outer networks have no other constraints, e.g., the kind of NNs, the number of neurons in the hidden layer, and the number of hidden layers.
-
•
We provide rigorous analysis for the proposed framework in terms of the testing performance and generalization ability. Furthermore, in order to mathematically explain the CF problem, we propose a metric named channel distribution similarity (CDS) to measure the similarities between channels under different distributions.
The rest of the paper is organized as follows. The problem formulation and the meta-gating framework are given in Section II-A. Section II-B introduces the comprehensive process of meta-gating framework for resource allocation problem. The theoretical analysis is introduced in Section IV. Section V presents the simulation results and performance analysis. Finally, this paper is concluded in Section VI.
II Problem Formulation and the Meta-Gating Framework
II-A Problem Formulation
We consider an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. Scenarios with the considered dynamic environment can be widely found in practice. For example, when a user drives from indoor to outdoor or moves from a highly dense place to an open place within a period of time, the CSI distribution will change accordingly (e.g., from Rayleigh fading with NLoS to Rician fading with LoS). Mathematically, we formulate the resource allocation problem in such a dynamic environment as follows
| (1a) | ||||
| s.t. | (1b) | |||
where random variable represents the instantaneous CSI (i.e., inputs of the NN-based models), denotes its corresponding instantaneous resource allocation strategy (i.e., outputs of the NN-based models), function evaluates the instantaneous performance of strategy , and is a vector utility function to constrain the strategy . Let represent the channel distributions in all periods, where denotes the specific channel distribution in period .
Problem aims to maximize the expectation of the evaluation function to achieve good performance in an episodically dynamic wireless environment, i.e. find a strategy to maximize function under constraints in each period.
II-B Overview of the Proposed Meta-Gating Framework
In this subsection, we present the overall architecture of the proposed meta-gating framework and its training method for solving Problem .
II-B1 Architecture of the Meta-Gating Framework

As mentioned in Section I, we attempt to utilize the learning ability of NNs to achieve the selective plasticity. Therefore, a dual-network structure is proposed, where the outer network extracts the characteristics of each CSI distribution. It aims to ensure the performance of the inner network under the previous CSI distribution when the inner network adapts to samples from a new CSI distribution. Specifically, as shown in Fig. 1, the proposed meta-gating network consists of an inner network, an outer network, and a non-linear layer, where both inner and outer networks are implemented as general NNs. Except that the number of outputs of the inner and outer networks need to be the same, there are no other constraints, e.g., the kind of NNs, the number of neurons in the hidden layer and the number of hidden layers. The inner and outer networks are connected through the gating operation, which refers to as element-wise multiplication of the output vectors of the inner and outer networks. After the multiplication, the results are input to the non-linear layer to obtain the final outputs.
II-B2 Training Procedure
In this part, to achieve aforementioned three important goals, we design a training procedure for the proposed meta-gating framework, which is based on the model-agnostic meta-learning (MAML) algorithm[23] and the unsupervised learning.

Different from the general DL where the wireless networks with different channel states can be directly used as different training samples, the training sample in the proposed training method refers to as a task. Specifically, one task consists of a support set and a query set as shown in Fig. 2, both containing the samples in general DL. The samples in each support set and query set are randomly selected from the different channel distributions.
The proposed training procedure consists of an inner loop and an outer loop, where the inner loop is employed to update the inner network parameters on the support set and the outer loop is for updating the outer network parameters on the query set. Specifically, the parameters of the inner network are optimized by Adam optimizer[29] for iterations on the support set with the loss function . During each of these forward propagation, the outputs of the inner network are gated, i.e. element-wisely multiplied, by the outputs of the outer network, which enables selective activation of the inner network by modifying its ultimate outputs during the forward propagation. Moreover, the gating to the inner network influences the update of the Adam optimizer and would result in selective plasticity during back propagation. After inner loop iterations, the parameters of the inner networks on task are denoted by , which will be used in the subsequent outer loop. As for the outer loop, the parameters of the outer network are updated with the query sets and a meta loss , which is calculated based on and . The detailed training procedure of the proposed meta-gating framework is summarized in Algorithm 1.
Following the aforementioned training procedure, the framework can well achieve aforementioned three goals and the reasons are as follows. First, the proposed framework can achieve the fast adaptation with small amount of samples because of the suitable initialization obtained by the MAML method. Thus, the proposed training method can well achieve the goal of ‘seamlessness’ and ‘quickness’. Secondly, the selective plasticity is achieved by the gating operation. Specifically, the importance of model parameters in response to different CSI distributions is different. The outer network is trained by the outer loop of Algorithm 1 with tasks from multiple CSI distributions. Therefore, the outer network can learn to evaluate the importance of inner network’s parameters under different CSI distributions, and then decide which subset of the inner network should be activated. By the gating operation, the meta-learned outer network can convey the decision to the inner network and thus indirectly influence the back propagation of the inner network. In this way, the inner network can perform well under both the previous and current CSI distribution, so as to overcome the CF problem.111Similarly, the graceful forgetting ability can be achieved by adjusting the learning abilities of inner network and outer networks, e.g, increasing the number of layers of the inner network within a certain range or adding a mask to the gating operation between the inner and outer network. The testing procedure of the proposed framework is summarized in Algorithm 2.
III Meta-Gating Framework for Resource Allocation Problem
In this section, we take the SRM problem in a -user interference network as an example to concretize , , and in Problem . Then, for the aforementioned example, two widely-used network models: GNN and CNN are adopted with the proposed meta-gating framework to further demonstrate its model-agnostic property.
III-A System Model of K-User Interference Network

As depicted in Fig. 3, there are transceiver pairs where each transmitter and receiver are equipped with and one antennas, respectively. It is assumed that transmissions on the transceiver pairs occur simultaneously using the same frequency band. Let denote the beamformer of the -th transmitter and denote the transmit signal. The received signal at receiver is , where denotes the direct channel vector between the -th transceiver pair, denotes the interference channel vector from transmitter to receiver , and denotes the additive noise following the complex Gaussian distribution .
Then, the signal-to-interference-plus-noise ratio (SINR) of receiver is expressed as
| (2) |
The optimization goal is to find the optimal beamformer matrix to maximize the sum rate, i,e., .
Finally, Problem in this example can be concretized as
| (3a) | ||||
| s.t. | (3b) | |||
where denotes the weight for the -th transceiver pair and represents the maximum transmit power of each transmitter.
III-B Meta-Gating GNN for Problem
III-B1 Scenario Modeling
In this part, we first model the wireless environment as a graph, and then formulate Problem as a graph optimization problem.
In general, the wireless environment can be modeled as a weighted directed graph with both node and edge features. Formally, a graph can be represented as a four tuple , where is the set of nodes and is the set of edges. For each node in , function maps it to its corresponding feature vector. For each edge in , it has a corresponding weight .


Following the modeling in [6], our considered system in Fig. 3 can be modeled as a graph model in Fig. 4(a), where the -th transceiver pair is treated as the -th node in the graph. Moreover, the node feature matrix is given by , and the weight matrix is given by
| (4) |
where vector is a zero vector with a size of .
Then the SINR in (2) can be rewritten with the notations , , and as follows
| (5) |
Finally, Problem in each period can be reformulated as
| (6a) | ||||
| s.t. | (6b) | |||
III-B2 Forward Propagation
As depicted in Fig. 4(b), the input data of meta-gating GNN is the graph model in Fig. 4(a) and the final outputs are the optimal beamformer matrix in each period. Both inner and outer networks are implemented as wireless communication graph convolution network (WCGCN) [6], which belongs to the message passing graph neural network (MPGNN). Before introducing the WCGCN model, we first describe the mechanism of MPGNN. Specifically, the update process (key operation of GNNs) of the -th layer at node in an MPGNN is describe as
| (7) |
where represents the hidden state of the -th layer at node , is the input node feature vector of node , denotes the neighbors of node , and is the input edge feature vector of edge . Moreover, is the function that aggregates information from the neighbors of node and is the function that combines the aggregated information with its own information, which can be seen in Fig. 4(b). Furthermore, can be further simplified by applying NNs as follows
| (8) |
where is implemented by some simple functions, such as and , and is the existing NN structure.
In the WCGCN model, is utilized as function , and two different multi-layer perceptrons (MLPs) are applied to function and , respectively. Thus, its update process of node can be expressed as . Then, the forward propagation of node in the proposed meta-gating GNN can be expressed as
| (9) | ||||
| (10) | ||||
| (11) |
where is the input node feature, is the weight matrix that represents the input edge feature, and denote the number of layers in the inner and outer networks, respectively, is a differentiable normalization function in the non-linear layer, and denotes the element-wise multiplication operation.
III-B3 Back Propagation
Due to the lack of an optimal solution to Problem , unsupervised training that directly maximizes the sum rate is applied for solving the considered problem. The loss function to be minimized can be written as
|
|
(12) |
III-B4 Complexity Analysis
For the meta-gating GNN, the inner and outer networks are implemented by WCGCNs. The complexity of WCGCN is , where is the number of layers of WCGCN, denotes the size of edge set, and denotes the size of node set. Therefore, the complexity of the proposed framework is .
III-C Meta-Gating CNN for Problem
III-C1 Scenario Modeling


CNN has been widely used in DL, e.g., it can extract spatial features from an image for classification. In a wireless environment, CNN is generally utilized to exploit the spatial features in channel state. It is because that the nearby receiver plays more significant role in determining the beamformer of the -th transmitter. Besides, CNN has fewer number of trainable parameters compared to DNN and can greatly reduce the training overhead. Based on this, we model in Problem as a picture-like pixel structure, as shown in Fig. 5(a).
III-C2 Forward Propagation
As depicted in Fig. 5(b), the input data of meta-gating CNN is the picture-like pixel structure and the final outputs are the the optimal beamformer matrix in each period. Both inner and outer networks are implemented as general CNNs[31]. The forward propagation in the proposed framework can be expressed as
| (13) | ||||
| (14) | ||||
| (15) |
where , and denote the -th and -th hidden state of the inner network and the outer network, respectively. and represent the outputs of the inner and outer networks, respectively. represents the rectified linear unit layer to prevent the negative values, represents the fully-connected layer, and denotes the max-pooling operation. is a differentiable normalization function, and denotes the final outputs. and represent the layer number of the inner and outer networks, respectively, and represents the convolution layer that performs two-dimensional spatial convolution of the input data. The size of the convolution layer is denoted as and its depth is set to .
III-C3 Back Propagation
Similarly, we employ the unsupervised training for the considered problem and the loss function to be minimized can be written as
| (16) |
III-C4 Complexity Analysis
For the meta-gating CNN, the inner and outer networks are implemented by CNNs. The complexity of CNN is , where is the number of layers of CNN, denotes the output size of -th layer, represents the size of convolution kernel, and is the number of channels in the -th layer. Therefore, the complexity of the proposed framework is , where and denote the output size of inner and outer networks, respectively.
IV Theoretical Analysis of the Meta-Gating Framework
In this section, we theoretically analyze the performance of the proposed meta-gating framework. Specifically, we first propose a metric named CDS to measure the distances between different channel distributions, which is employed to explain the CF phenomenon between different channel distributions in the following simulation part. Then, we analyze the impact of the number of update round, , to demonstrate that the value of cannot be chosen too large, which exactly satisfies the requirement of fast adaptation. Finally, we analyze the generalization ability of the proposed framework in terms of the gradient of its loss function with respect to the trained parameters.
IV-A Distances Between Different Channel Distributions

In this part, CDS is designed to measure the difference between channel distributions from parameter space. It is because that the outputs of NN-based model on different input data distributions may not be quite different, even if the distances between input data distributions are large. Therefore, the influence of different data distributions on the outputs of NN-based model cannot be judged only from the input data space. Based on the above analysis, we don’t need to obtain the absolute value of the distances between different channel distributions. Instead, we need to measure the impact of different distributions on the output of NN-based model with the same initialization. In the following, we present the detailed mechanism of CDS. Specifically, we assume that a pre-trained model adapts to a channel distribution starting from and moves to the final solution by performing SGD iterations steps. Then, the parameters’ adaptive trajectory to channel distribution starting from is defined as the sequence of iterations, which is denoted as . To alleviate the challenges in dealing with trajectories of multiple steps in a parameter space of a very high dimension, the trajectory direction vector can be defined as
| (17) |
Fig. 6 presents the SGD update trajectories for the pre-trained model to adapt to channel distribution and channel distribution , respectively. Based on the above analysis, CDS is finally defined as the inner product between their direction vectors.
| (18) |
Compared with the KL-divergence that only measures the distances between different distributions from the input data space, the proposed metric measures from the model parameters space. It takes the characteristics of the model into consideration so that the impact of different data distributions on the output of NN-based model can be well judged.
IV-B Impact of the Number of Update Round——Fast Adaptation
In this part, we focus on the impact of the number of update round, , on the performance of the proposed meta-gating framework.
We denote the dataset of channel as , where the number of testing samples is denoted as . Assume that we run gradient descent steps on to obtain the updated model for channel . Let and denote the initializations of inner and outer networks, respectively, and both are learned from the proposed training method. represents the optimal model parameters of the channel . As a premise, we first introduce some necessary definitions.
Definition 1
Definition 2
Excess Risk. ER, where denotes the expected loss on .
It evaluates the loss difference between and the optimal model on all samples with all channels , and a smaller value means a better . In the following, excess risk is used to analyze the influence of the number of update round , i.e., the testing performance of fast adaption to new samples.
Theorem 1
(Testing Performance Analysis). Suppose that the loss function is -Lipschitz continuous and -smooth w.r.t. both the inner and outer network parameters ( and ). Assume that obeys and denote . Then for any and with size , we have
| (19) |
The detailed proof can be found in Appendix A. Theorem 1 demonstrates that the excess risk ER of the channel-specific updated model for channel is mainly determined by three key factors, i.e., the testing sample number (more precisely, the size of the support set in the testing samples), the value of , and the expected loss between the adapted parameter and the optimal model . Note that, a larger leads to a smaller upper bound for the first term in (19). However, in order to reduce the overhead, the amount of online update data should not be too large, thus, cannot be too large. Besides, an intuitive way to reduce the excess risk is to increase the value of which however increases the upper bound of the first term. It is because that is usually slightly larger than given a small learning rate . Therefore, to make a fair trade-off between the first and second terms in (19), should not be large, which accords with the impact of the number round in the following simulation parts of Section V.
IV-C First-Order Optimality Analysis——Generalization Ability
To measure the testing performance of the adapted parameters in terms of first-order optimality, we first introduce the expected population gradient.
Definition 3
Expected Population Gradient. Let EPG denote the gradient of the loss function on all samples and all channels .
In the following, we will apply this expected population gradient as the metric to measure the testing performance of so as to verify the generalization ability of learned initializations .
Theorem 2
(First-order Optimality Analysis). Suppose that the loss function is -Lipschitz continuous and -smooth w.r.t. both the inner and outer network parameters ( and ). Assume that obeys and denote . Then for any and with size , we have
| (20) |
The detailed proof can be found in Appendix B. Theorem 2 reveals the importance of the empirical gradient on determining the expected population gradient EPG. Specifically, when the learned initializations are close to the first-order stationary points of the empirical risk , a small value of (a few gradient descent steps) can already guarantee a very small gradient of the adapted parameters . Besides, the value of is small and the testing samples are usually sufficient, which has been proved in Theorem 1. Therefore, the first term of (20) is also small. Finally, the proposed framework is proved to have a good generalization ability because of the small value of EPG.
V Simulation Results
In this section, we conduct simulations to demonstrate the effectiveness of the proposed meta-gating framework. All codes are implemented in Python 3.9 with Pytorch 1.8.0 and we consider the following benchmarks for comparison, where the channel state samples refer to the samples from one specific CSI distribution.
-
•
Joint (Joint Training): It updates the model using all channel state samples.
-
•
Mismatch: It trains the model under one of the channel state samples.
-
•
TL (Transfer Learning): It trains the pre-trained model only using the current channel state samples, where the pre-trained model was trained under a given channel distribution.
-
•
EWC (Elastic Weight Consolidation): It adds a penalty term to the loss function so as to prevent large changes in those parameters that are important to previous samples. The importance of the parameters is judged by the Fisher information matrix[9].
-
•
WoGate: It updates model via traditional MAML method, i.e., without gating operation in the proposed framework.
V-A Simulation Results on Meta-Gating GNN
We consider transceiver pairs within an area, where the transmitters are generated uniformly in the aforementioned area and the receivers are generated uniformly within from their corresponding transmitters. We adopt the channel model in [32] as follows
| (21) |
where denotes the large-scale fading including the path loss and shadowing, and denote the transmit and receive directions, respectively. We adopt the large-scale fading model in [33] and generate the following three standard types of channel distributions as the sequential input data.
-
•
Channel 1: and each channel state is generated according to a standard normal distribution, i.e.,
(22) -
•
Channel 2: dB, both and are uniformly generated from , and each channel state is generated according to the Gaussian distribution with dB -factor, i.e.,
(23) -
•
Channel 3: , the shadow fading in is set as normal distribution with a standard deviation of dB, and each channel state is generated the same as Channel 1.
We generate tasks as the training samples for Algorithm 1, where the support set and the query set in each task are composed by and channel state samples, respectively. Note that the channel state samples in each support set and query set are randomly selected from the three aforementioned channels. It is noticed that tasks here are equivalent to channel state samples in general DL, which is sufficient to obtain a good model. As for the testing stage, channel state samples are generated for each channel, where we randomly split of these samples into support set for inner network’s fine-tune process, and the rest into query set. Besides, we set the batch size of training samples and the number of adaptation samples as and , respectively. Furthermore, we adopt the Adam optimizer with a learning rate of to optimize the outer network and a learning rate of to optimize the inner network in the training stage. The Adam optimizer with a learning rate of is adopted to fine-tune the inner network in the testing stage.
Finally, in order to compare the sum-rate performance under different channel distributions, we normalize the sum rate by the weighted minimum mean-square error (WMMSE) algorithm [30], which is termed as the ‘Normalized Sumrate’ in the following simulation results. The WMMSE algorithm is a classic optimization-based algorithm for sum-rate maximization in the -user interference network and is usually used as an upper bound for such problems. In this section, we run WMMSE for iterations with the random initialization and take this value for normalization. The system parameters and network parameters are summarized in Table I and Table II, respectively.
| Parameter | Value |
| Transceiver pairs, | |
| Area length, | m |
| # of Transmitter antennas, | |
| Transceiver pairs distance, , | m, m |
| Noise power, | dB |
| Maximum transmit power, | w |
| Weight for the -th transceiver pair, | 1 |
| Parameter | Value |
| Type of NN | WCGCN[6] |
| Number of layers in outer and inner networks | , |
| MLPs in outer/inner network | {, , }, {, , } |
| Nonlinear function, |
V-A1 Three Important Goals
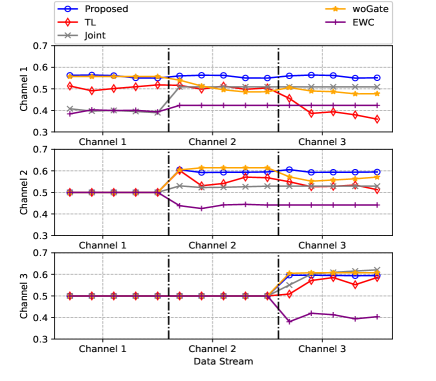
(i) Seamlessness. Fig. 8 compares the proposed meta-gating framework with the above benchmark algorithms on the sum-rate performance, where the channel state samples in ‘Mismatch’ are collected from . Obviously, applying a model trained under one distribution to test the samples on another distribution does lead to a quite large sum-rate performance loss. Moreover, we can observe that the sum-rate performance of our meta-gating framework is better than that of TL under the premise of the same number of fine-tune samples, update rounds, and optimizer. It is mainly because that the proposed framework has better initializations compared to the TL and thus achieves better sum-rate performance using only a small number of update rounds. Besides, compared with TL, the MAML algorithm can obtain a suitable model initialization for all three channels. Thus, the average sum-rate performance is better than that of TL.
Similar with the TL, the sum-rate performance of ‘WoGate’ on and are affected by the online update according to the previous channel state samples, which can be seen from the gap between ‘proposed’ and ‘woGate’. In the proposed framework, the inner network updates according to the current channel sample data, where only part of the model parameters that are selected by the meta-learned outer network will be updated. Therefore, the proposed framework can still achieve good sum-rate performance on the current channel state sample and is not largely affected by the previous channel state samples.
Table III presents the variance of the sum-rate performance among different channel distributions under different methods. It can be observed that the proposed framework has the smallest variance, indicating that the sum-rate performance on different channel distributions is basically similar. Therefore, the proposed framework can well achieve the goals of ‘seamlessness’.


| Method | (Channel 1, Channel 2) | (Channel 2, Channel 3) |
| TL | ||
| EWC | ||
| Joint | ||
| WoGate | ||
| Proposed |
Furthermore, we compare the sum-rate performance of the proposed meta-gating framework under different values of maximum transmit power , and the results are depicted in Fig. 8. From the figure, the proposed framework achieves good sum-rate performance under different , i.e., the sum-rate performance is basically the same as the WMMSE algorithm. Moreover, Table IV presents the variances of the normalized sum rate among different channel distributions under different values of . From the table, these variances are all quite small which further highlights the advantage of the proposed meta-gating framework in terms of ‘seamlessness’.


| (W) | ||||
| Variance |
(ii) Quickness. Fig. 10 depicts the impact of different values of on the sum-rate performance. From the figure, the proposed framework only needs a small value of to achieve good sum-rate performance under each channel distribution ( in this simulation scenario). It is mainly because that the proposed meta-gating framework has good model initializations via the proposed training procedure. Besides, we can see that the sum-rate performance under different channel distributions first increases and then decreases with the increase of . The degradation of the sum-rate performance is mainly caused by the severe overfitting on the small amount of adaptation samples . In fact, the fine-tune process with small amount of samples exactly achieves the goal of ‘quickness’, where the value of is small to avoid serious overfitting phenomenon. The simulation results are consistent with the theoretical analysis in Section IV-B.
(iii) Continuity. Fig. 10 depicts the ‘continuity’ capability of different methods. Specifically, it shows the sum-rate performance of the proposed framework on (the vertical axis) after updating according to the (the horizontal axis). In order to clearly illustrate the capability for continuous adaptation of different methods, we set the value of the normalized sum rate in as when . From the figure, the sum-rate performance of TL on the previous channel suffers from a significant degradation when it adapts to the following new channel distribution. It is mainly because that the model in TL is only fine-tuned on the latest new samples. After learning the knowledge of new samples, the knowledge from the previous model may be altered or even overwritten, which thus results in significant performance deterioration on the previous samples. Similar results can be seen from ‘WoGate’. On the other hand, the proposed meta-gating framework utilizes the outer network to evaluate the importance of inner network’s parameters under different CSI distributions and then decide which subset of the inner network should be activated through the gating operation. Therefore, it can ensure the capability for continuous adaptation.
| Channel pair | (1,2) | (2,3) | (3,1) |
| CDS |
According to the analysis in Section IV, we compute the similarity between the considered three channel distributions and the results are given in Table V. From the table, the distance between and is the largest, indicating that the distribution between these two channels are quite different. Therefore, it will cause the largest performance loss in when the model is updated according to the samples in in TL. Moreover, the CDS metric shown in Table V can explain the capability for continuous adaptation of the EWC method in Fig. 10. Specifically, channel samples under each distribution are sequentially input during the EWC training stage. In order not to forget the knowledge learned on , the update of model’s parameters on will be affected by the consolation operation, where the distance between and is the largest. Therefore, it finally leads to poor sum-rate performance on .
Furthermore, Fig. 12 compares the capability for continuous adaptation of the proposed meta-gating framework under different values of . From the figure, the proposed framework achieves the good capability for continuous adaptation under each value of , i.e., the sum-rate performance on does not largely degrade when the model is updated according to the samples of the . It further indicates the advantage of the proposed framework in terms of ‘continuity’.


V-A2 Performance Comparison with TL
It is quite important for TL to select a suitable pre-train model since the model initializations make great influence on the adaptation. Fig. 12 presents the impact of different pre-train models on the sum-rate performance, where TL1, TL2, and TL3 represent the models trained with the samples of , , and as pre-train models, respectively. Since there does exist differences between each channel distribution, the sum-rate performance with different pre-train models will be quite different. In contrast, the proposed meta-gating framework achieves a better sum-rate performance because of its adaptivity on different channel distributions.


V-A3 Performance Comparison with EWC
The performance of the EWC method largely depends on the coefficient of the penalty term, . To verify it, we test the sum-rate performance on each channel distribution and the capability for continuous adaptation with , which can be seen in Fig. 13. It is observed that a large value of can indeed improve the sum-rate performance on the previous channel, i.e., enhance the capability for continuous adaptation of the model, but with the cost of significant sum-rate performance loss on the current channel. Therefore, it is important for the EWC method to select an appropriate value of , which is the disadvantage of the EWC method. Different from the EWC method that needs to be manually implemented, the proposed meta-gating framework can continuously achieve the good sum-rate performance because of the proposed training procedure and the gating operation.
V-A4 Scalability
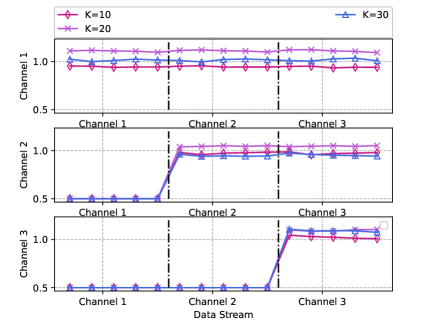
In this part, we test the sum-rate performance and the capability for continuous adaptation with different numbers of users (, and ) in the same area with radius m, where the number of update round is chosen as . As depicted in Fig. 15 and Table VI, the proposed meta-gating framework achieves good sum-rate performances with different numbers of users and the variances of the normalized sum rate among different channel distributions under different numbers of users are all quite small, which further highlights the advantage of the proposed meta-gating framework in terms of ‘seamlessness’. Besides, as shown in Fig. 15, the proposed framework achieves the good capability for continuous adaptation with different numbers of users, i.e., the sum-rate performance on does not largely degrade when the model is updated according to the samples of the . These results demonstrate the good scalability of the proposed framework with more practical simulation scenario settings.

| Variance |
V-B Simulation Results on Meta-Gating CNN
In this part, we present the performance of meta-gating CNN on Problem to demonstrate that the proposed framework is model-agnostic. Since the main purpose of this simulation part is to verify the model-agnostic nature of the proposed framework, we only consider a special case of Problem with . Then, three standard types of random channels following the settings in [20] are denoted as , and . Specifically, follows the Rayleigh fading, follows the Rician fading, and follows the Geometric fading.
Geometric fading: All transceiver pairs are randomly distributed in an area, as
| (24) |
where denotes the small-scale fading coefficient follows (0, 1), is the distance between the -th transmitter and the -th receiver.
The data generation procedure is the same as that in Section V-A and we again normalize the sum rate by using the WMMSE algorithm in order to compare the sum-rate performance under different channel distributions, which is expressed as the ‘Normalized Sumrate’ in the following simulation results. The system parameters and the network parameters are summarized in Table VII and Table VIII, respectively.
| Parameter | Value |
| Transceiver pairs, | |
| Noise power, | dB |
| Maximum transmit power, | w |
| Area length, | m |
| Parameter | Value |
| Type of Neural Network | CNN |
| Number of layers in outer and inner networks | , |
| Number of channels in outer and inner networks | {}{}, {}{} |
| Kernel size in outer and inner networks | , |
| Stride and padding in the convolution layer | , |
| Nonlinear function, |
V-B1 Three Important Goals
(i) Seamlessness. Fig. 16 compares the proposed meta-gating framework with other benchmark algorithms on the sum-rate performance. The proposed meta-gating framework has the best sum-rate performance on each channel distribution compared to the benchmark algorithms due to its better model initializations. Table IX presents the variance of the sum-rate performance among each channel distribution with different methods. It can be observed that the proposed framework has quite small variance, which indicates that the proposed framework can achieve similar sum-rate performances on different channel distributions. Therefore, it can well achieve the goals of ‘seamlessness’. These results are similar as those observed in Fig. 8 and Table III.

| Method | (Channel 1, Channel 2) | (Channel 2, Channel 3) |
| TL | ||
| EWC | ||
| Joint | ||
| WoGate | ||
| Proposed |
(ii) Quickness. Fig. 18 depicts the impact of different values of on the sum-rate performance, where the similar conclusion can be concluded as those in Fig. 10.
(ii) Continuity. Fig. 18 depicts the capability for continuous adaptation of different methods and we set the value of the normalized sum rate in as when . Similarly, we compute the similarity among these three channels, which can be seen in Table X. From the table, the distance between and is the largest. Therefore, it would cause a large performance loss in when the model is updated according to the samples in in TL, as shown in Fig. 18.

| Channel pair | (1,2) | (2,3) | (3,1) |
| CDS |
To conclude, simulation results demonstrate that the proposed framework is model-agnostic, i.e., it can well achieve three goals compared with the state-of-the-art algorithms on the proposed problem for both CNN and GNN models.
V-B2 Generalization Ability
To verify Theorem 2 with simulation experiments, we test the sum-rate performances on the Nakagami- channels. The reason why we apply the Nakagami- channel is that it is a more general fading channel model and the Nakagami fading can be transformed into a variety of fading models by changing the value of (e.g., it can be degenerated into Rayleigh fading when ). Specifically, we randomly generate four kinds of channels where and follows a uniform distribution between in the training stage. Similarly, we generate four kinds of channels in the testing stage, where the latter two kinds of channels are unseen channels following the Nakagami- distribution with different values of from the training stage.
Table XI presents the sum-rate performances of joint training method and proposed framework in both seen and unseen channels with different values of . It is observed that the proposed framework achieves a similar sum-rate performance with the joint training method on seen channels but significantly outperforms the joint training method on unseen channels, where the sum-rate performance gaps are further depicted in Fig. 19. It is mainly because that the joint training method only focuses on the distribution on the seen channels, but the proposed framework can better take further optimizations into account because of the dual-loop optimization for better model initializations.
| /w | Seen | Unseen | |||
| Channel 1 | Channel 2 | Channel 3 | Channel 4 | ||
| Proposed | |||||
| Joint | |||||
| Proposed | |||||
| Joint | |||||
| Proposed | |||||
| Joint | |||||

VI Conclusions
In this paper, we have proposed a general meta-gating framework for solving wireless resource allocation problems in an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. Specifically, the proposed framework includes an inner network and an outer network, and they are connected through the gating operation. The proposed dual-loop training method is developed to achieve the goals of ‘seamlessness’ and ‘quickness’ by combining the MAML algorithm with the unsupervised training method. As for the goal of ‘continuity’, the outer network learns to evaluate the importance of inner network’s parameters under different CSI distributions and then decide which subset of the inner network should be activated. Therefore, it enables the selective plasticity of the inner network. Additionally, we have theoretically analyzed the performance of the proposed meta-gating framework. Finally, simulation results have demonstrated that the proposed meta-gating framework can well adapt to the dynamic wireless environment via achieving three important goals compared with several existing state-of-the-art algorithms.
Appendix A Proof of Theorm 1
Lemma 1
Assume that function is -smooth in . If , then it holds for any channel and any parameters that
| (25) |
where denotes the learned initializations of the inner network and .
Lemma 2
| (26) | ||||
| (27) |
Then, we can obtain the following bound for any
| (28) |
The proof of the aforementioned two lemmas can be found in [34].
Then, we can obtain the following upper bound according to Lemma 2 as follows:
| (29) | |||
| (30) | |||
| (31) |
Note that . Then, we take the expectation on both sides of (31) on to finally obtain
| (32) | |||
Appendix B Proof of Theorm 2
Consider a fixed channel and its associated random dataset with size . Then, we perform gradient steps to obtain the adapted parameter . We can show the following inequality:
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) |
Here, ① comes from Lemma 2.
References
- [1] Q. Hou, M. Lee, G. Yu, and Z. Zhou, “Multicell power control under QoS requirements with CNet,” IEEE Commun. Lett., vol. 26, no. 6, pp. 1308-1312, Jun. 2022.
- [2] F. Liang, C. Shen, W. Yu, and F. Wu, “Towards optimal power control via ensembling deep neural networks,” IEEE Trans. Commun., vol. 68, no. 3, pp. 1760–1776, Mar. 2020.
- [3] W. Lee, M. Kim, and D. Cho, “Deep power control: Transmit power control scheme based on convolutional neural network,” IEEE Commun. Lett., vol. 22, no. 6, pp. 1276–1279, Jun. 2018.
- [4] D. Wen, P. Liu, G. Zhu, Y. Shi, J. Xu, Yonina C. Eldar, and S. Cui, “Task-Oriented Sensing, Computation, and Communication Integration for Multi-Device Edge AI” arXiv preprint arXiv:2207.00969, 2022.
- [5] M. Lee, G. Yu, and G. Y. Li, “Graph embedding based wireless link scheduling with few training samples,” IEEE Trans. Wireless Commun., vol. 20, no. 4, pp. 2282 – 2294, Apr. 2021.
- [6] Y. Shen, Y. Shi, J. Zhang, and K. B. Letaief, “Graph neural networks for scalable radio resource management: Architecture design and theoretical analysis,” IEEE J. Sel. Areas Commun., vol. 39, no. 1, pp. 101–115, Jan. 2021.
- [7] M. Eisen and A. Ribeiro, “Large scale wireless power allocation with graph neural networks,” in 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC). IEEE, 2019, pp. 1–5.
- [8] M. Eisen and A. Ribeiro, “Optimal wireless resource allocation with random edge graph neural networks,” IEEE Trans. Signal Process., vol. 68, pp. 2977–2991, Apr. 2020.
- [9] J. Kirkpatrick, et al., “Overcoming catastrophic forgetting in neural networks,” in Proc. PNAS, 2017, pp. 3521–3526.
- [10] Y. Shen, Y. Shi, J. Zhang, and K. B. Letaief, “Transfer learning for mixed-integer resource allocation problems in wireless networks,” in Proc. IEEE Int. Conf. Commun. (ICC), Shanghai, China, 2019, pp. 1-6.
- [11] Y. Yuan, G. Zheng, K. -K. Wong, B. Ottersten, and Z. -Q. Luo, “Transfer learning and meta learning-based fast downlink beamforming adaptation,” IEEE Trans. Wireless Commun., vol. 20, no. 3, pp. 1742-1755, Mar. 2021.
- [12] Y. Shen, Y. Shi, J. Zhang, and K. B. Letaief, “LORM: Learning to optimize for resource management in wireless networks with few training samples,” IEEE Trans. Wireless Commun., vol. 19, no. 1, pp. 665–679, Jan. 2020.
- [13] T. Hospedales, A. Antoniou, P. Micaelli, and A. Storkey, “Meta-learning in neural networks: A survey,” CoRR, vol. abs/2004.05439, 2020. [Online]. Available: http://arxiv.org/abs/2004.05439
- [14] S. Thrun and L. Pratt, “Learning To learn: Introduction and overview,” in Learning To Learn, 1998.
- [15] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Trans. Knowl. Data Eng., vol. 22, no. 10, pp. 1345–1359, Oct. 2010.
- [16] G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter, “Continual lifelong learning with neural networks: A review,” Neural Networks, vol. 113, pp. 54–71, Feb. 2019.
- [17] M. McCloskey and N. J. Cohen, “Catastrophic interference in connectionist networks: The sequential learning problem,” in Psychol. Learn Motiv., Elsevier, 1989, vol. 24, pp. 109–165.
- [18] I. Nikoloska and O. Simeone, “Modular meta-learning for power control via random edge graph neural networks,” IEEE Trans. Wireless Commun., 2022, doi: 10.1109/TWC.2022.3195352.
- [19] O. Simeone, S. Park, and J. Kang, “From learning to meta-learning: Reduced training overhead and complexity for communication systems,” in Proc. 6G Wireless Summit (6G SUMMIT). Virtual, 2020, pp. 1–5.
- [20] H. Sun, W. Pu, X. Fu, T. -H. Chang, and M. Hong, “Learning to continuously optimize wireless resource in a dynamic environment: A bilevel optimization perspective,” IEEE Trans. Signal Process., vol. 70, pp. 1900-1917, Jan. 2022.
- [21] Andrei A Rusu, et al., “Progressive neural networks,” arXiv preprint arXiv:1606.04671, 2016.
- [22] J. Yoon, E. Yang, J. Lee, and S. J. Hwang, “Lifelong learning with dynamically expandable networks,” arXiv preprint arXiv:1708.01547, 2017.
- [23] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in Proc. ICML, 2017, pp. 1126–1135.
- [24] D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for continual learning,” in Advances in Neural Information Processing Systems, 2017, pp. 6467–6476.
- [25] H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,” in NIPS, 2017, pp. 2990–2999.
- [26] A. Pentina and C. Lampert, “Lifelong learning with non-i.i.d. tasks”, in Advances Neural Inf. Process. Syst., 2015, pp. 1540–1548.
- [27] D. L. Silver, Q. Yang, and L. Li, “Lifelong machine learning systems: Beyond learning algorithms,” in Proc. AAAI Spring Symp., 2013, pp. 49–55.
- [28] F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” in ICML, 2017, pp. 3987–3995.
- [29] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proc. 3rd Int. Conf. Learn. Represent. (ICLR), 2014, pp. 1–6.
- [30] Q. Shi, M. Razaviyayn, Z.-Q. Luo, and C. He, “An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel,” IEEE Trans. Signal Process., vol. 59, no. 9, pp. 4331–4340, Sep. 2011.
- [31] S. Albawi, T. A. Mohammed, and S. Al-Zawi, “Understanding of a convolutional neural network,” in Proc. Int. Conf. Eng. Technol. (ICET), 2017, pp. 1–6.
- [32] Y. He, Y. Cai, H. Mao, and G. Yu, “RIS-assisted communication radar coexistence: Joint beamforming design and analysis,” IEEE J. Sel. Areas Commun., vol. 40, no. 7, pp. 2131-2145, Jul. 2022.
- [33] Y. Shi, J. Zhang, and K. B. Letaief, “Group sparse beamforming for green cloud-RAN,” IEEE Trans. Wireless Commun., vol. 13, no. 5, pp. 2809–2823, May 2014.
- [34] P. Zhou, Y. Zou, X. Yuan, J. Feng, C. Xiong, and S Hoi, “Task similarity aware meta learning: Theory-inspired improvement on MAML”, in Conf. Uncertainty in Artificial Intelligence, 2021, pp. 23–33.
- [35] A. Soltoggio, J. A. Bullinaria, C. Mattiussi, P. Drr, and D. Floreano, “Evolutionary advantages of neuromodulated plasticity in dynamic, reward-based scenarios”. in Proc. 11th Int. Conf. Artif. Life (Alife XI), 2008, pp. 569–576, Cambridge, MA. MIT Press.
- [36] A. Soltoggio, K. O. Stanley, and S. Risi, “Born to learn: The inspiration, progress, and future of evolved plastic artificial neural networks,” Neural Netw., vol. 108, pp. 48–67, 2018.
- [37] P. Zhou, X. Yuan, H. Xu, S. Yan, and J. Feng. “Efficient meta learning via minibatch proximal update,” In Proc. Conf. Neural Information Processing Systems, 2019.
- [38] K. Mikhail, B. Maria-Florina, and T. Ameet. “Adaptive gradient-based meta-learning methods,” In Proc. Conf. Neural Information Processing Systems, 2019.