Meta Deformation Network: Meta Functionals for Shape Correspondence
Abstract
We present a new technique named Meta Deformation Network for 3D shape matching via deformation, in which a deep neural network maps a reference shape onto the parameters of a second neural network whose task is to give the correspondence between a learned template and query shape via deformation. We categorize the second neural network as a meta-function, or a function generated by another function, as its parameters are dynamically given by the first network on a per-input basis. This leads to a straightforward overall architecture and faster execution speeds, without loss in the quality of the deformation of the template. We show in our experiments that Meta Deformation Network leads to improvements on the MPI-FAUST Inter Challenge over designs that utilized a conventional decoder design that has non-dynamic parameters.
Keywords:
dynamic neural networks, shape registration, shape correspondence1 Introduction
In the pairwise 3D shape correspondence problem, a program is given two query shapes and is asked to compute all pairs of corresponding points between the two shapes. Recent works [7],[5] yielded improved results on pairwise 3D shape correspondence by aligning a template point cloud with individual query shapes, which gives a correspondence relationship between the template and each query shape. After the correspondence between the template and each query shape was obtained, this information was used to infer the correspondence between the two query shapes. This approach usually employed an encoder-decoder design with the encoder generating a feature embedding that captures the characteristics of the query shape . is then fed into the decoder along with the of points on the template shape as input in order to output a set of points representing the deformation of the template into the query shape. Every point in the template is said to be in correspondence with the point on the query shape that is nearest to its deformation. Originally named in [12], we refer to this decoder scheme as Latent Vector Concatenation (LVC), since the input to the decoder is the concatenation of individual 3-D coordinates and the latent vector .
Although LVC is widely used in recent works to represent or deform 3-D shapes, [14],[7],[8],[19],[5], in this paper, we investigate the possibility of an alternative decoder structure and compare it against LVC on the task of computing correspondence for human 3-D scans. Specifically, we evaluate an alternative decoder design scheme that uses only the template point cloud as input but has dynamic parameters that are predicted by a neural network from and also outputs the deformed template points. We call this architecture Meta Deformation Network because the deformation process is carried out by a neural network whose parameters are not independent but generated by another neural network. The decoder could be thought of as a second-order function that is defined or generated by another function. This formulation leads to a speedup in training and testing, and the results on the MPI-FAUST Inter correspondence challenge show that the meta decoder yields improved correspondence accuracy over a similar design [5] that employs an LVC decoder.
2 Related Works
2.1 Dynamic Neural Networks
Dynamic Neural Networks are a design in which one network is trained to predict the parameters of another network in test-time in order to give the second network higher adaptability. The possibility of using dynamic networks on 2-D and more recently 3-D data has been researched by several of authors. [17], [9], [1], [3] applied dynamic convolutional kernels to 2-D images to input-aware single-image super-resolution, short-range weather prediction, one-shot character classification and tracking, few-shot video frame prediction, respectively. These tasks demanded highly adaptive behaviors from the neural networks, and they show improvements when using dynamic neural networks over conventional methods that used static-parameter convolutional kernels. [10] was one of the first works to apply the idea of dynamically generated parameters to the 3-D domain, where it achieved state-of-the-art results on single-image 3D reconstruction on ShapeNet-core [4] compared to conventional methods in [20], [6], [16]. We are motivated by these works to further investigate the potential of dynamic neural networks. We build on previous studies by examining the effectiveness of dynamic neural networks for 3-D shape correspondence in which both the input shapes and output correspondence are of a 3-dimensional nature.
2.2 3-D Shape Correspondence
The registration of and correspondence among 3-D structures with non-rigid geometrical variations is a problem that has been extensively studied and one in which machine-learned based methods have had great success. MPI-FAUST [2] is a widely used benchmark for finding correspondence between pairs of 3-D scans of humans with realistic noises and artifacts as a result of scanning real-world humans. There are various approaches to the task. [10] used a Siamese structure to learn compact descriptors of input shapes and using functional maps [13] to solve for inter-shape correspondences. [21] fitting query meshes to a pre-designed part-based model (”stitched puppet”) and aligning the models for the two query scans to get correspondence. [7] took a simpler approach, by choosing a set of points to be a template and getting inter-shape correspondences by computing the query shapes’ individual correspondences to the common template, effectively factoring the problem of computing correspondence between two unknown shapes into two problems each involving the correspondence between a known template and an unknown shape. This method proved to give the best correspondence accuracy on FAUST and is the inspiration for the training procedure of our method, the Meta Deformation Network. [7] obtains correspondence between a template and a query shape by using a multi-layer perceptron to deform the points on templates into the shape of the query and obtaining correspondence by Euclidean proximity between the deformed points of the template and actual points on the query shape. However, holds fixed parameters and takes a latent vector concatenated with template points as input. By contrast, our Meta Deformation Network has a decoder that holds dynamic parameters, which adds more flexibility and adaptability of the deformation with respect to different query shapes.
3 Network Design

3.1 Architecture Overview
A graphical description of the Meta Deformation Network is shown in fig. 1. We used a simplified version of the PointNet [15] encoder following [7], which we will denote as , to output a feature vector of size 1024 from a set of points from the query shape . L independent MLPs, each denoted , then takes as input outputs , the predicted optimal parameters for layer of the meta decoder . If layer of has input neurons and output neurons, then is a vector of size since we define the forward-pass for each layer of g as
| (1) |
where denotes element-wise multiplication, and is the pre-activation output. Note that we place a scaling term in addition to the typical feed-forward calculation of an MLP with the intuition that it facilitates the learning of (reasoning behind this intuition is given in 3.5).
With computed, the meta decoder takes as input a point outputs a 3-D residual vector that will shift to the location of the corresponding point on the query shape . Note that the input layer to is only a vector of 3 elements, which leads to a major speed up over a decoder that uses the LVC input, which take in a vector of size if using an . The difference in time is greater as the resolution of the template increases because the deformation computation is repeated times to get the respective for all .
In all experiments, we pick ’s structure and for every layer of except the last, which has since it outputs a 3 dimensional translation vector for each input point .
3.2 Encoder
We used a simplified variant of the PointNet feature encoder [15]. The encoder, denoted , applies a shared 3-layered MLP of output sizes to each point to obtain a local feature of size where is the number of points chosen from the template and is equal to in all experiments. It then applies max-pooling along the first dimension to obtain a primitive global feature vector of size , which is refined by a 2-layered MLP of output sizes to become the final global feature embedding . Formally,
| (2) |
We pick for all of our experiments.
3.3 Parameter Predictor for Meta Decoder
Having defined operations performed by each layer of , we define a set of 1-layered MLPs (or more accurately, SLPs), which we will denote as , that maps the global feature embedding to . Formally,
| (3) | |||
So has an input size of and an output size that matches the number of parameters needed for the layer of (see the calculation above eq. 1 in 3.1).


3.4 Learnable Template
Following [5], instead of choosing a template prior to training and making it permanently fixed, we initialize our template with a subsampled scan (so that ) from the MPI-FAUST training dataset and learns a translation vector for each original point on the template . So . This allows the network to learn an template that results in the best deformation correspondence during training. The chosen template initialization is depicted in fig 2. In test-time, we hold the template fixed by fixing the learned translation vectors . Note that in test-time, if a high-resolution template is desired, we will no longer be able to use the learned translation vectors because each is learned specifically for . We will not have a dense set of translation vectors for every point in if we wish to use a high-resolution version (i.e. ) of the initial template in test-time.
3.5 Meta Decoder
We formulate each layer of as a customized version of a fully-connected layer (from eq. 1),
| (1) |
The full network outputs a residual vector for every input point which will take it to the location of the corresponding point . Formally,
| (4) | |||
Optimizing correspondence among query shapes is equivalent to minimizing the distance between and for every query shape. Thus, the formulations above leads to a straightforward supervised training loss with just a single term when training for correspondence.
3.6 Training and Losses
Since is predicted, we only need to update the parameters of and in train-time. Let be the set of all query shapes in the training dataset, this gives the following supervised optimization problem, which is the same equation used in [7]:
| (5) | |||
Note that in the supervised case we assume having knowledge of the ground-truth location of the point in correspondence with for all . However, we do not need any explicit information on the correspondence among the query shapes themselves as it is implicitly given by the correspondence with a common template.



We adopt augmented SURREAL dataset by created T. Groueix et al. [7] using SMPL [11] and SURREAL [18], containing 229,984 meshes of synthetic humans in various poses for training and 200 for validation. Samples of the training data are shown in fig. 3. We train the model using ADAM with at a learning rate of for epochs and then for epochs. This takes around hours on a machine with a GTX 1080 Ti and a 6-core Intel CPU.
4 Inferencing Correspondences
4.1 Optimizing Query Shape Rotation
As in [7], we use a procedure during testing to improve the deformation before the optimization of the latent vector . Before calculating the correspondence, we rotate each query shape by selecting different pitch and yaw angles so that the deformation of the template given the rotated has the smallest Chamfer distance to the rotated . (When returning the correspondence output, we apply the inverse rotation matrices to recover the pre-rotation predicted locations).
| (6) |
where stands for the counterclockwise rotation matrix around the axis by angle (yaw), stands for the counterclockwise rotation matrix around the axis (pitch) by angle , and denotes the set of points after applying the pitch and yaw rotation matrices to every point in . In practice, we try every combination of where , . The intervals are discrete with strides and respectively for and . This leads to a total of tries during which we remember the pair that gives the best deformation and replace with .
4.2 Latent Vector Optimization
As 6.1 illustrates, using directly as the feature embedding produces suboptimal deformations. To mitigate this problem, during testing only, we use as an initialization for and optimizes over for 3000 iterations using ADAM at a learning rate of to implicitly find the that minimizes the Chamfer distance between the deformation and the query shape . We do not perform this step in training as we reduces training speed and we want to train the encoder to predict feature embeddings directly. The Chamfer loss given and is defined as:
| (7) |
4.3 Finding Pairwise Correspondences
We use the algorithm presented in [7] to optimize over and find the correspondence between a pair of 3-D shapes, shown here in algorithm 1. Note that although we only compute correspondence between two shapes for the FAUST-Inter challenge, the same algorithm can easily be extended to predict correspondence across multiple shapes with an execution time linear to the number of query shapes by matching each shape to the common template.
5 Analysis on the Characteristics of the ”Meta” Decoder
5.1 Defining the Meta Decoder
In a Latent Vector Concatenation decoder construction, a fixed-parameter decoder takes as input the coordinates of a template point concatenated with the feature embedding representing the query shape and outputs the predicted coordinates of the corresponding point in the query shape. Since we predict pairwise correspondence based on the query shapes’ individual correspondences to the common template, the quality of the template deformation was crucial to the correspondence accuracy. In LVC, because the decoder has fixed parameters and needs to accurately deform all points on the template into corresponding points on various query shapes when given only and as input, its structure is often complex in terms of the number of trainable parameters, which could leads to problems like lengthy training times and the overfitting. Denoting the feature encoder as and the decoder as , this leads to the formulation:
| (8) | ||||
| (9) |
Where and are jointly optimized during training.
Our approach simplifies the structure of the decoder by formulating it as a concise dynamic multi-layer perceptron, that is, a MLP whose parameters are dynamically and uniquely determined by another neural network for each input. Denoting the encoder f and the dynamic decoder g, we have:
| (10) | ||||
| (11) |
Because is determined by f, we only need to optimize during training. Note that the decoder computes a location residual instead of the coordinates of the actual deformed point that corresponds to . We found that predicting the residual was an easier task to learn for the network.
5.2 Mathematical differences between LVC and Meta Decoder
Although they perform different tasks, the neural networks in [7], [15], and [14] have all employed as an LVC decoder that is an MLP with non-dynamic parameters. E. Mitchell pointed out in [12] that this formulation is equivalent to having a MLP that has fixed input and weights but a variable bias. Consider a case in which needs to deform a template into query shapes, then the LVC deformation decoder would take in of concatenated with a feature embedding representing the query shape . Such is the case in [7]. Let vector be the concatenation of and , that is, , then the first layer of the LVC MLP decoder will perform the following operation:
| (12) |
where is the pre-activation output, is the fixed weights matrix, and is the fixed bias. We can rewrite as the sum of two vectors and where and
| (13) |
Note that are fixed with regards to and only z changes with different , so the only term that varies with the query shape is . Thus, can be seen as a dynamic bias predicted from query shapes for the first layer, which has fixed weights and input (points on the template were fixed in test-time). Using the concatenation of and as input is therefore equivalent to having an MLP that has fixed input, weights, and biases, except that a variable bias term is added to layer 1’s pre-activation output that depends on . The low adaptability of the LVC decoder prevents it from producing high-quality deformations with a concise structure.
In the case of the meta decoder, we set all parameters of to be dynamic. With this approach, the input is simply a 3-D vector , and the first layer of the decoder MLP performs the operation
| (14) |
where are given by . The process is similar for subsequent layers. As a result, all parameters of are dynamic a function of the query shape . Defining ’s parameters to be a function of offers the decoder more flexibility in computing the optimal translation that deforms the template into diverse query shapes. We also include an element-wise scaling factor in the formulation of to facilitate the learning of , which maps to . To see this, suppose that a particular output neuron of needs to be changed in order to compute the optimal deformation. Multiplying by has the same effect on the output as scaling all elements in the first row of by , but is an easier change to predict for since it requires predicting a single number instead of multiple numbers to capture this change. Overall, the meta decoder has fully adaptive parameters to different query shapes. By contrast, the LVC decoder has only a variable bias in the output of the first layer and fixed parameters everywhere else. The enhanced adaptability of with respect to query shapes allows it to produce better deformations of the template with fewer parameters and at higher speeds.
6 Experiment Results
We test the Meta Deformation Network on the MPI-FAUST Inter and Intra Subject Challenges. The ”inter” challenge contains 40 pairs of 3D scans of real people with each pair consisting of two different people at different poses. In test-time, to get the optimal deformation, we use as an initialization for the feature embedding , and optimizes over for 3000 iterations using ADAM at a learning rate of to implicitly find the that minimizes the Chamfer distance between the deformation and the query shape .
6.1 Unoptimized Deformations












We show the deformation of the template into the query shapes before the optimization of , and compare Meta Deformation Network against the non-meta deformation network developed by T. Deprelle et al. in [5]. The figures are included in fig. 4.
Both approaches give a reasonable unoptimized deformation of a template into the query shape, though both suffer from varying amounts of distortions and imprecision from the actual query shape. The optimization step depicted in 6.2 over improves the quality of the deformation.
6.2 Feature Embedding Optimization





We also test how sensitive the quality of the template deformation is to different numbers of optimization steps for . We qualitatively demonstrate that the deformation continues to improve in quality as is optimized for more iterations, but the marginal gain diminishes as the number of iterations increases, with the difference between 1,000 and 3,000 iterations hardly noticeable (See fig. 5).
The imprecision of the unoptimized deformation suggests that our ShapeNet encoder is unable to produce an optimal feature embedding that fully captures the characteristics of the query shape; the unoptimized deformation has a more generic structure lacking details of the person’s body shape, which the post-optimization deformation is able to capture. The relatively weak encoding power of our simplified ShapeNet encoder, can be alleviated by optimizing over given as its initialization. Also note that although the query shape has incomplete data around the person’s feet, our decoder has learned to reconstruct the missing parts from the input.
6.3 Quantitative Assessment
| Method | FAUST-Inter Mean Error (cm) |
|---|---|
| Deep functional maps [13] | 4.82 |
| Stitched Puppet [21] | 3.12 |
| 3D-CODED w/. Learned 3D Translation Template [5] | 3.05 |
| 3D-CODED w/. Learned 3D Deformed Template [5] | 2.76 |
| Meta Deformation Network (Ours) | 2.97 |
Though the Meta Deformation Network did not surpass the state-of-the-art performance, it showed an improvement over 3D-CODED w/. Learned 3D Translation Template, an approach that is comparable to ours in that it shares the same simplified PointNet encoder design and also applies a learnable translation matrix to the points of the base template, with the difference being that it its LVC decoder has fixed parameters. This shows quantitatively that having the meta decoder produces more accurate correspondences on FAUST-Inter than does a static-parameter decoder (while also having speedier execution).
6.4 Transference onto Unseen Templates
| Template used in inferencing | FAUST-Iter Mean Error (cm) |
|---|---|
| Learned Template (6890 Vertices) | 3.07 |
| Unseen Template (176K Vertices) | 2.97 |

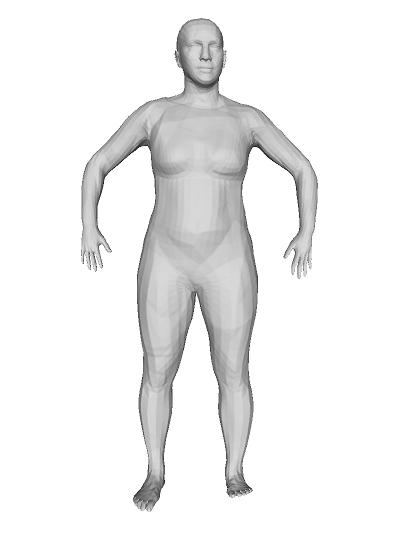

In the training step, we have trained a feature encoder and a parameter mapper to enable to predict deformations from a known template into unseen query shapes. Here, we also test how well the model performs when given a template and query shapes that are both unseen in training. We run an experimental setup where we find the rotation matrices and the feature embedding initialization for using the learned template but swaps in a different, higher-resolution template for the optimization step and subsequent correspondence calculation. The learned template contains 6,890 vertices while the unseen template contains slightly over 176,000 vertices. A visualization is given in fig. 6. The visual results is consistent with table 2, with little difference in error rate between using a learned template and a high-resolution unseen template.
Results from table 2 suggest that is able to transfer the learned predictions for when operates on a different template. As a result, the meta decoder adapts wells operating on a template that is different from the one used in training and takes advantage of the higher resolution of the new template to produce more accurate correspondences. The high adaptability of the Meta Decoder Network suggests the possibility of variations of the model that use a dynamic template in addition to the dynamic decoder, which we desire to research in future works.
6.5 Training and Testing Speeds
| Method | Time per training iteration(s) |
|---|---|
| 3D-CODED w/. Learned 3D Translation Template [7] | 0.1964 |
| Meta Deformation Network (Ours) | 0.1259 |
| Method | Time per pairwise corr. (s) |
|---|---|
| 3D-CODED w/. Learned 3D Translation Template [7] | 286.42 |
| Meta Deformation Network (Ours) | 273.66 |
We compare the training and testing speeds of the Meta Deformation Network against those of 3D-CODED, which has the same encoder structure but uses an LVC decoder. We train both models on the same Extended SURREAL dataset created by [7].
We find that the Meta Deformation Network took less time to carry out an iteration of training (table 3) with a batch size set of 32, yet it yields improved accuracy (table 1) on the FAUST Inter challenge than did the model from [5] that also had a translation-based learnable template.
For testing, we evaluate the time a model takes to compute the correspondence for one pair of 3D scans from FAUST Inter. In testing, our model took less time to finish. Here the difference was less dramatic than in training, which we think was due to the under-utilization of the computer’s hardware in both methods due to the the latent vector optimization with a batch size of 1. See table 4.
7 Conclusion
Meta Deformation Network is the first implementation of a meta decoder used in a 3-D to 3-D task aim at solving correspondences. It has an encoder-meta-decoder design in which all parameters of the decoder are inferred from a given query shape during both training and testing to improve the deformation of the template. The meta decoder enjoys more adaptability when deforming the template into query shapes compared to the LVC decoder [5] with the same encoder. As suggested by testing the Meta Deformation Network on the FAUST-Inter challenge, the meta decoder achieves better correspondence accuracy with the added benefit of speedier training and inferencing.
References
- [1] Bertinetto, L., Henriques, J.F., Valmadre, J., Torr, P.H.S., Vedaldi, A.: Learning feed-forward one-shot learners (2016)
- [2] Bogo, F., Romero, J., Loper, M., Black, M.J.: FAUST: Dataset and evaluation for 3D mesh registration. In: Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). IEEE, Piscataway, NJ, USA (Jun 2014)
- [3] Brabandere, B.D., Jia, X., Tuytelaars, T., Gool, L.V.: Dynamic filter networks (2016)
- [4] Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: Shapenet: An information-rich 3d model repository (2015)
- [5] Deprelle, T., Groueix, T., Fisher, M., Kim, V.G., Russell, B.C., Aubry, M.: Learning elementary structures for 3d shape generation and matching (2019)
- [6] Fan, H., Su, H., Guibas, L.: A point set generation network for 3d object reconstruction from a single image (2016)
- [7] Groueix, T., Fisher, M., Kim, V.G., Russell, B.C., Aubry, M.: 3d-coded : 3d correspondences by deep deformation (2018)
- [8] Groueix, T., Fisher, M., Kim, V.G., Russell, B.C., Aubry, M.: Atlasnet: A papier-mâché approach to learning 3d surface generation (2018)
- [9] Klein, B., Wolf, L., Afek, Y.: A dynamic convolutional layer for short rangeweather prediction. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4840–4848 (June 2015). https://doi.org/10.1109/CVPR.2015.7299117
- [10] Littwin, G., Wolf, L.: Deep meta functionals for shape representation (2019)
- [11] Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia) 34(6), 248:1–248:16 (Oct 2015)
- [12] Mitchell, E., Engin, S., Isler, V., Lee, D.D.: Higher-order function networks for learning composable 3d object representations (2019)
- [13] Ovsjanikov, M., Ben-Chen, M., Solomon, J., Butscher, A., Guibas, L.: Functional maps: A flexible representation of maps between shapes. ACM Transactions on Graphics - TOG 31 (07 2012). https://doi.org/10.1145/2185520.2185526
- [14] Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: Deepsdf: Learning continuous signed distance functions for shape representation (2019)
- [15] Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation (2016)
- [16] Richter, S.R., Roth, S.: Matryoshka networks: Predicting 3d geometry via nested shape layers (2018)
- [17] Riegler, G., Schulter, S., Rüther, M., Bischof, H.: Conditioned regression models for non-blind single image super-resolution. In: 2015 IEEE International Conference on Computer Vision (ICCV). pp. 522–530 (Dec 2015). https://doi.org/10.1109/ICCV.2015.67
- [18] Varol, G., Romero, J., Martin, X., Mahmood, N., Black, M.J., Laptev, I., Schmid, C.: Learning from synthetic humans. In: CVPR (2017)
- [19] Yang, Y., Feng, C., Shen, Y., Tian, D.: Foldingnet: Point cloud auto-encoder via deep grid deformation (2017)
- [20] Zeng, W., Karaoglu, S., Gevers, T.: Inferring point clouds from single monocular images by depth intermediation (2018)
- [21] Zuffi, S., Black, M.J.: The stitched puppet: A graphical model of 3d human shape and pose. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2015)