11email: [email protected]
22institutetext: South China Agricultural University, GuangDong, China
22email: [email protected] 33institutetext: Beijing University Of Technology, Beijing, China
33email: [email protected] 44institutetext: Department of Human Centered Computing, Faculty of Information Technology, Monash University, Melbourne, Australia
44email: [email protected]
Memory Matching is not Enough: Jointly Improving Memory Matching and Decoding for Video Object Segmentation
Abstract
Memory-based video object segmentation methods model multiple objects over long temporal-spatial spans by establishing memory bank, which achieve the remarkable performance. However, they struggle to overcome the false matching and are prone to lose critical information, resulting in confusion among different objects. In this paper, we propose an effective approach which jointly improving the matching and decoding stages to alleviate the false matching issue. For the memory matching stage, we present a cost aware mechanism that suppresses the slight errors for short-term memory and a shunted cross-scale matching for long-term memory which establish a wide filed matching spaces for various object scales. For the readout decoding stage, we implement a compensatory mechanism aims at recovering the essential information where missing at the matching stage. Our approach achieves the outstanding performance in several popular benchmarks (i.e., DAVIS 2016&2017 Val (92.4%&88.1%), and DAVIS 2017 Test (83.9%)), and achieves 84.8%&84.6% on YouTubeVOS 2018&2019 Val.
Keywords:
Video Object Segmentation False Matching Alleviation Compensatory Decoding
1 Introduction
Video object segmentation (VOS) is a fundamental procedure for many multimedia applications, such as special effects editing in movies, robot interaction, and smart camera surveillance, which requires instance segmentation of objects of interest in videos. The work in this paper focuses on semi-supervised VOS, which completes instance segmentation of the remaining frames based on multiple instances given in the first frame. Recently, matching-based approaches have gained popularity, wherein the basic idea is to establishing and maintaining a memory to store previous frames and their corresponding masks. These stored memories are then matched with the query frame to generate a memory readout, and finally produce masks of the target objects from the memory readout.
Memory matching essentially relates to the accuracy in generating the target object masks, which becomes a crucial component in improving the accuracy of VOS tasks. Early matching-based methods such as STM [13] and its variants [2, 16, 18] employ attention mechanisms to achieve matching between query frames and the memory. Such methods treat all the memory units with equal importance, without special design regarding the individual memory unit in the process. Inspired by the human cognitive process where there is a distinctive difference between short-term and long-term memories, current memory matching methods treat short-term and long-term memory differently in VOS. Long-term memory stores multiple historical frames, and records the change across frames in a coarse-grained manner. The objects in long-term memory may have different scales, so the long-term matching mechanism should not be limited to a single-scale. Short-term memory focuses on the adjacent frames, which are similar with each other, meaning the variations are fine-grained. Thus, the short-term matching mechanism must capture the variants sufficiently.
Some state-of-the-art methods (i.e., AOT [27], variants of AOT [25, 29], and XMem [1]) divide long-term and short-term memory, these methods still have limitations: As shown in Fig. 1(a), the AOT [27] and XMem [1] produce results with slight errors in the impact of the short-term memory insufficiency (Frame 5 in Fig. 1(a)), the later frames (Frame 31 & 78 in Fig. 1(a)) present object confusion and crucial information loss. On the one hand, they employ single-scale attention in long-term memory, which makes them exhibit rapid performance degradation in handling multiple objects, especially undergoing different morphological changes simultaneously. On the other hand, these methods also need to improve in matching short-term memory. For example, AOT [27] and its variants [25, 29] implement the local correlation attention, which may lose critical information when the morphological changes occur outside the local memory unit’s perceptive field. In addition, slight errors in short-term memory matching accumulate in long-term memory, which can be fatal for VOS methods that rely on long-term memory.
In this paper, we propose an improved memory matching mechanism, including cost-aware matching for short-term memory and cross-scale matching for long-term memory. Cost-aware matching mechanism focuses on a stronger relationship between corresponding pixels of adjacent frames. Inspired by optical flow prediction methods [19, 20, 7], we construct the cost volume for the query frame and the previous frame. Cost volume is a vector that stores the matching degree of corresponding pixels between two frames [4]. After patch embedding the cost volume, we introduce a group of learnable query tokens for collecting coarse-grained spatial variations. Furthermore, to explore fine-grained details, we construct a spatial readout head via SS-attention [3]. Note that cost volume in our cost-aware matching is a global relationship of pixels in adjacent frames which is different from the neighborhood correlation of short-term transformer in AOT [27] and its variants [25, 29]. We implement multiple scales for long-term memory and more effective models objects of various scales simultaneously within a matching block. Our improved memory mechanism reduces the accumulation of slight errors in short-term memory and adequately adapts the objects of various spatial morphology in the previous frames.
Matching-based VOS methods inevitably produce false matches [13, 2, 1], which may lead to object confusion (see XMem in Fig. 1(a)) or missing objects (see AOT in Fig. 1(a)). However, matching-based methods usually focus solely on improving memory matching, and they implement a naive FPN [8] for decoding (e.g., STCN [2], HMMN [18] and RMNet [23]), lacking consideration of modifying the decoding process. AOT [27] and XMem [1] make extensive modifications for memory matching, the problem of false matches still exists. Unlike fully supervised segmentation that understands rich semantics, semi-supervised VOS requires more the low-level semantic feature prompt of target objects. We argue that suppressing false matches requires improving memory matching and improving decoding process. There is significant potential for improving the decoding process. For instance, AOML [5] achieves excellent performance by designing bi-decoders for online learning VOS. CFBI [26] and CFBI+ [28] emphasizes separating the foreground and background in decodng process to improve matching. They have an explicit foreground-background embedding feature and low-level feature incorporation, which are beneficial for distinguishing the foreground from the background. Such explicit foreground-background distinction still struggle to overcome the false matching problem. Our paper aims to give a more suitable and comprehensive answer, which jointly improves both stages and rethinks all details toward reducing the false matching instead of the simple foreground-background distinction.
Therefore, we propose a compensatory decoding mechanism (as shown in Fig. 1(c)), which consists of three steps, 1) pre-decoding, 2) context embedding, and 3) post-decoding. The initial memory readout inevitably lose some critical information and looking twice at the original image effectively compensates such losses; thus, we embed a context embedding process in the decoding stage to force the encoder to look at the query frame one more time, which supplements the critical information lost in the memory matching stage. Pre-decoding provides a guiding prompt for context embedding, and the post-decoding generates the final segmentation masks. The compensatory decoding mechanism not only sufficiently embeds the critical information of the target objects but also suppresses the false matches in the initial memory readout to some extent.
The mainly contributions of this paper are summarized as:
-
•
Different existing methods, we improve the matching and decoding stages in a jointly paradigm, which give a more suitable and comprehensive answer to alleviate false matching issue.
-
•
We propose a improved mechanisms for the memory matching stage. Cost-aware matching in short-term memory prompts the network to perceive changes between two frames more adequately. Cross-scale matching in long-term memory prompts the network to explore the variations in different scaled objects.
-
•
We propose a novel compensatory decoding mechanism that can suppress false matches and supplement the crucial information loss of target objects for the readout decoding stage.
-
•
Our approach achieves state-of-the-art performance in several popular benchmarks (i.e., DAVIS 2016&2017 Val (92.4%&88.1%), and DAVIS 2017 Test (83.9%)), and achieves 84.8%&84.6% on YouTubeVOS 2018&2019 Val with the specific training strategy.
2 Related Work
Semi-supervised Video Object Segmentation In semi-supervised VOS, according to the object masks given in the first frame of the video, the corresponding object is segmented in the remaining video frames. The mainstream of semi-supervised VOS methods can be roughly divided into online fine-tuning and methods without fine-tuning. In the methods without fine-tuning, matching based is the popular study branch.
Matching based Methods Matching-based is an VOS method without fine-tuning that has achieved notable success, and the proposal in this paper is focus on the matching based methods. STM [13] introduces a spatio-temporal network to establish the matching relationship between the current frame (query frame) and all historical frames (memory), which can be roughly divided into three stages: query embedding, memory matching, and readout decoding. The following matching-based methods almost focus on improving the memory matching stage. Some methods [6, 9, 17] focus on designing novel memory structures, such as HMMN [18], which designs a hierarchical memory structure. In addition, some methods [2, 16, 23] proposed novel matching mechanisms, such as STCN [2] proposed utilizing negative squared euclidean distance to calculate the affinity of matching, and KMN [16] introduced gaussian kernel to reduce the non-locality of matching. All the above methods treat all memories fairly, which makes the performance of the memory model have a bottleneck. Recently, some state-of-the-art methods such as AOT [27] and its variants (AOST [25], DeAOT [29]), XMem [1] distinguish memory between long and short term to improve the inference performance. However, there are still significant improvements possibilities for these methods. On the one hand, the design of this long-short term matching mechanism does not fully adapt to multi-scale objects and ignores part of the crucial inter-frame changes. In this paper, we propose an improved long short-term memory matching mechanism that outperforms these methods in performance. On the other hand, we argue that "memory matching is not enough", and previous methods have neglected the effect of improvements on the readout decoding for semi-supervised VOS.
3 Methodology
3.1 Proposal Overview
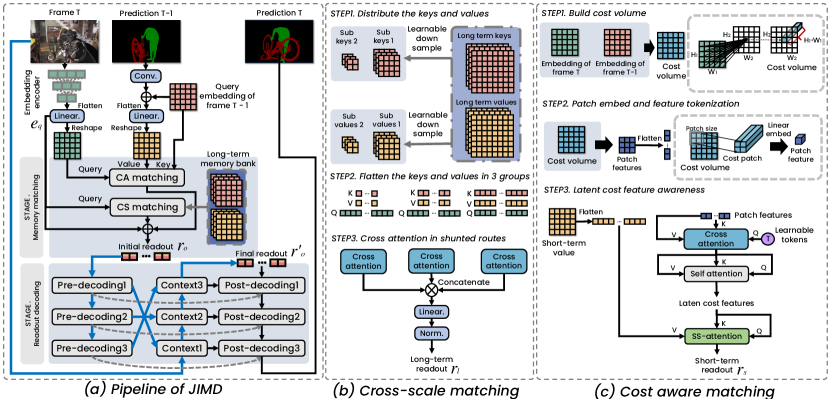
We propose an effective approach to alleviate the false matching issue from the memory matching and readout decoding stages. We name this proposal as Jointly Improve Matching and Decoding (JIMD) in the following content. The pipeline of JIMD is illustrated in 2. JIMD sequentially processes each frame for a video clip. For the current frame , we extract the backbone features from the embedding encoder and then input into a linear layer to obtain the embedding query feature . Then we implement the cost volume matching for short-term memory, and employ the cross scale matching for the long-term memory to obtain two matching readout results (i.e., and ). Initial readout feature can be formulated as: . We firstly decode the for guiding the context block to extract the information form source frame. We obtain the final readout feature after embedding the source context into the initial readout . Finally, we decode the readout feature and upsample into the object masks. During the entire procedure, JIMD maintains two sets of memory data, which are long-term and short-term memories. The short-term memory is stacked into the long-term memory at intervals, and the memory data is stored as key & value. Memory value is generated by fusing the previous embedding feature and the mask feature from the ID module, which is borrowed from AOT [27]. Here, we implement a convolution with kernel size of and stride of 16 to encode the masks of frame as the identify encoder.
3.2 Cross-Scale in Long-Term Matching
Long-term memory records the change across frames in a coarse-grained manner (e.g., an object may have multiple morphologies across frames or multiple scale objects in the same frame). Introducing cross-scale in long-term memory is beneficial to match targets with variable scales. Therefore, we shunt the keys and values, downsampling the long-term memory keys and values at different scales. Let the and denote all previous keys and values in long-term memory. As shown in 2, we employ three spatial rates for non-local matching. The downsample is a convolution layer with the decreasing kernel size as illustrated in 2. Here, we denote as the spatial rate for downsampling:
| (1) | |||
| (2) |
We perform cross-attention with after obtaining keys and values of different sizes:
| (3) |
Three attention results are concatenated, then projected as the readout feature of long-term memory:
| (4) |
where is the linear norm layer. This shunting matching benefits the long-term memory and performs well in handling multi-scale cases.
3.3 Cost-Aware Matching
The purpose of the short-term memory matching mechanism is to learn the changes in adjacent frames, which is crucial for VOS. If the short-term memory matching produces inaccurate masks that are used in generating values for the next round, it would lead to a vicious circle process. Representing the changes in adjacent frames is essential for effective short-term memory matching, it requires more larger local receptive field but with a low computational cost increasement. We construct a cost volume to represent the interframe variations and tokenize the cost volume with patch embedding. Then we implement the multi-head attention mechanism to produce the latent cost features that involve critical variations. Finally, the SS-attention [3] generates the readout feature with the latent cost features and the previous frame’s value. We construct cost-aware matching as a transformer architecture, as shown in 2.
Cost Volume Generation. The first step of short-term memory matching requires the generation of initial information representing the variations between adjacent frames. Instead of the local correlation matching in AOT [27] and its variants [25, 29] with high computational cost, we build a global 4D cost volume for and , the volume is constructed through dot product operations. Here, and donate the ’s height and width, and donate the ’s height and width. As shown in the bottom right corner of 2, each 2D sub-map in cost volume can be regarded as the visual similarity between the source pixel and all target pixels, and is derived from the of the previous frame. We patch embed the cost volume, which divides the cost volume into multiple patches according to the patch size, and perform feature embedding on each patch, as shown in the upper right corner of 2. We define the number of the patches as , embedding dimension as , the patch embedding features as:
| (5) |
Patch Features Tokenization. For complicated variations between adjacent frames, we need to pay more attention to the patches relating to the target objects. To achieve this goal, we introduce a set of learnable tokens to extract the patch features that contains latent critical variations, where is the token number and is the tokens’ embedding dimension. We implement a cross-attention, which applies the learnable tokens as query, patch embedding features as the key and value:
| (6) |
Then we apply a multi-head self-attention to output the latent cost features . The latent cost features implicitly represent critical variants between adjacent frames.
Producing Readout Feature. We implement the SS-attention [3], which focus more on capturing spatial features to produce short-term readout result :
| (7) |
where is the frame value, and there is a final fusion for attention output and . After the cost-aware matching, the short-term readout feature sufficiently capture the fine-grained variations between adjacent frames.
3.4 Compensatory Decoding
We observe that only improving the memory matching is insufficient in solving the object confusion and missing; thus, we propose a new compensatory decoding mechanism to further resolve the issues. As shown in 3, the compensatory decoding process consists of three steps, 1) pre-decoding, 2) context embedding, and 3) post-decoding. Pre-decoding aims to obtain a set of upsampled intermediate results as the guide spatial prompt in context embedding. Context embedding gradually recovers the lost critical features in the initial memory readout by embedding the frame and spatial prompt feature, resulting a final readout feature . In post-decoding, we generate the mask prediction base on the final readout feature and the skip-connections from context embedding.

Context Embedding. Context block (CB) applies the same residual network layer as the encoder and three context blocks form a cascaded structure. Prompt features and the residual encoder output fuse as in each cascade:
| (8) |
where is the residual layer. is the input to the next CB as well as the skip connection for post-decoding, which contains richer semantic information than the query feature from embedding encoder. Critical information of the target objects is sufficiently embedded into the final readout feature , and the false matches in the initial memory readout are suppressed.
Recursive Decoding Process. Inspired by [15], we introduce the "looking and thinking twice" idea into memory readout decoding, namely recursive decoding, which consists of pre-decoding and post-decoding. Recursive decoding process shares weights in upsample blocks (UP, as shown in 3), which is essential for improving readout decoding due to seeing both the pre-decoded features and the context compensated features. Let and denote pre-decoding and post-decoding outputs, is the cascading level. The implementation of UP can be formally defined as follows:
| (9) |
where is the upsample rate, here is equal to 2. Spatial pooling block (SP, as shown in 3) produce the spatial prompt feature in pre-decoding step, which is implemented via atrous spatial pyramid pooling block (ASPP). In post-decoding step, we implement an adaptive weighting block (AW, as shown in 3) in each cascaded UP block to fuse context features and pre-decoding features. We apply a convolution with a kernel size equal to 1 as the AW block. The adaptive weighting process formulates as:
| (10) |
| (11) |
where is the weight of the post-decoding output. Then is the input of the next cascaded UP block.
| DAVIS 2017 test-dev | DAVIS 2017 val | DAVIS 2016 val | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | FPS | |||||||||
| (CVPR′2018) RGMP [12] | 52.8 | 51.3 | 54.4 | 66.7 | 64.8 | 68.6 | - | 68.8 | 68.6 | 68.9 |
| (CVPR′2019) FEELVOS [21] | 57.8 | 55.1 | 60.4 | 71.6 | 69.1 | 74.0 | 2.0 | 81.7 | 81.1 | 82.2 |
| (ICCV′2019) STM [13] | 72.2 | 69.3 | 75.2 | 81.7 | 79.2 | 84.3 | - | 89.4 | 88.7 | 90.1 |
| (ECCV′2020) CFBI [26] | 74.8 | 71.1 | 78.5 | 81.9 | 79.1 | 84.6 | 5.9 | 89.4 | 88.3 | 90.5 |
| (CVPR′2021) RMNet [23] | 75.0 | 71.9 | 78.1 | 83.5 | 81.0 | 86.0 | - | 88.8 | 88.9 | 88.7 |
| (ECCV′2020) KMN [16] | 77.2 | 74.1 | 80.3 | 82.8 | 80.0 | 85.6 | 4.2 | 90.5 | 89.5 | 91.5 |
| CFBI+ [28] | 78.0 | 74.4 | 81.6 | 82.9 | 80.1 | 85.7 | 5.6 | 89.9 | 88.7 | 91.1 |
| (ICCV′2021) HMMN [18] | 78.6 | 74.7 | 82.5 | 84.7 | 81.9 | 87.5 | 10.0 | 90.8 | 89.6 | 92.0 |
| (NeurIPS′2021) AOT-L [27] | 79.6 | 75.9 | 83.3 | 84.9 | 82.3 | 87.5 | 18.0 | 91.1 | 90.1 | 92.1 |
| (NeurIPS′2021) STCN [2] | 79.9 | 76.3 | 83.5 | 85.3 | 82.0 | 88.6 | 20.2 | 91.7 | 90.4 | 93.0 |
| AOST-L [25] | 79.9 | 76.2 | 83.6 | 85.6 | 82.6 | 88.5 | 17.5 | 92.1 | 90.6 | 93.6 |
| (NeurIPS′2022) DeAOT-L [29] | 80.7 | 76.9 | 84.5 | 85.2 | 82.2 | 88.2 | 19.8 | 92.3 | 90.5 | 94.0 |
| (ECCV′2022) XMem †[1] | 81.0 | 77.4 | 84.5 | 86.2 | 82.9 | 89.5 | 22.6 | 91.5 | 90.4 | 92.7 |
| (CVPR′2023) ISVOS †[22] | 82.8 | 79.3 | 86.2 | 87.1 | 83.7 | 90.5 | - | 92.6 | 91.5 | 93.7 |
| JIMD (ours) | 83.9 | 80.3 | 87.4 | 88.1 | 85.2 | 91.0 | 13.2 | 92.4 | 90.6 | 94.2 |
4 Experiments
4.1 Implementation Details
Training. We deploy the ResNet50 as the backbone for embedding encoder. Following popular matching-based VOS methods [13, 2, 26], we employ the two-stage training strategy. In the first training stage, the model is pre-trained on static datasets from AOT [27], where objects with masks are augmented (e.g., flip, shift, crop) and randomly synthesized onto the backgrounds. In the second training stage, we perform training on real videos. For the evaluation of DAVIS [14], we use the training sets of DAVIS and YouTube, while for the evaluation of YouTubeVOS [24], we only use the YouTube training set. The embedding encoder is frozen in the second training stage to avoid overfitting to the seen object categories. All modules apply the learning rates from initial 2e-4 then the learning rates gradually decay to 2e-5 in a polynomial manner. We employ the cross entropy loss and soft jaccard loss [11] to train the model. During training, we use an input size of and a batch size of 8, which is distributed on 4 RTX3090 GPUs. Note that our method do not adopt the BL30K for training in the following reports.
Inference. Our method uses a resolution of 480p by inference. Following common matching-based methods, we set the update frequency of memory to 5 (i.e., every five frames stack the short-term memory in long-term memory). For a fair comparison, we do not employ the multi-scale inference trick on val/test datasets.
4.2 Datasets and Metrics
We evaluate our method on the five most popular VOS task benchmark datasets, consisting of a single-object dataset (DAVIS2016-val) and four multi-object datasets (DAVIS2017-val, DAVIS2017-test, YouTube2018-val, YouTube2019-val). A total of 971 real videos incorporated in the evaluation. We evaluate our method by region similarity (i.e., ) and contour accuracy (i.e., ). In YouTubeVOS, there are additional 26 unseen categories; thus we separately report the score and the score for "seen classes" in training set and "unseen classes" that are not. is the global average score of all metrics. We submit the val/test results on official online evaluation servers for a fair comparison.
4.3 Compare with the State-of-the-Art Methods
Quantitative Comparison. As shown in Table 1, we compare the performance of our method with up-to-date methods on a series of DAVIS datasets. Compared with the state-of-the-art memory matching-based methods (i.e., XMem [1]), we achieve a 2.9% and 1.9% J&F improvement on DAVIS2017 Test and DAVIS2017 Val, respectively. Compared with the latest understanding-based method (i.e., ISVOS [22]), we improve the J&F by 1.1% and 1% on DAVIS2017 Test&Val, respectively. Our method achieves the top ranking of F performance on DAVIS 2016 single object performance, DAVIS2017 Test&Val multiple objects performance. On the Youtube dataset validation, for a fair comparison, we only adopt YouTubeVOS’s train-set for training and compare it with XMem [1] schemes using the same training data. As shown in Table 3, even without any fancy training and inference tricks, our method still achieves excellent performances in YouTube2018&2019.
Unseen Categories. Youtube dataset needs to evaluate the performance of unseen categories in training, as shown in Table 3; our method outperforms other methods under the metrics of unseen categories. Our proposed compensatory decoding stage generates guide information in pre-decoding that can more discriminatively help segment unseen category objects.
Qualitative Results. We visualize some video segmentation results in evaluation, including some common VOS challenge cases (i.e., tremendous motion, object reappearance, similar objects confusion), and compare them with two state-of-the-art matching-based methods AOT-L [27] and XMem [1], as shown in Fig. 4. Our method is superior to the other two methods in obtaining object details. We can see that AOT-L [27] and XMem [1] make obvious errors when the human body appears in drastic motions. XMem [1] is more prone to errors when dealing with objects of different scales (e.g., the rope and the human body in the Col 5 and 6 of Fig. 4). Furthermore, we compare the classical method STM [13] based on memory matching for a long span. Our method does not have object confusion after multiple similar objects are occluded, indicating that the proposed jointly improving method is helpful in overcoming the challenge of similar objects.

4.4 Ablation Studies
We improve the memory matching stage and the decoding stage separately, achieving cost-aware matching (CA) and cross-scale matching (CS) in the memory matching stage and compensatory decoding (CD) in the decoding stage. In order to evaluate the effectiveness of the three improvements, we conduct separate experiments on JIMD for each modification and explore the improvement performance of their combination. All ablation studies are evaluated on DAVIS2017 Val split. The corresponding modules used by the baseline in Table 3 (i.e., long short-term matching modules, decoding process) are replaced by AOST-L [25] (a evolution method of AOT-L [27]), as shown in the first row of Table 3.
Impact of Memory Matching Mechanism. As shown from Row 2 to Row 4 in Table 3, both our cost-aware and cross-scale in the memory matching stage play positive roles when compensatory decoding is removed. The improvement of cross-scale matching is more conducive to improving regional similarity (i.e., ), and cost-aware matching improves both metrics and edge accuracy (i.e., ). Cross-scale matching has more powerful matching for objects of different scales in the video and thus is beneficial to improve region similarity. Cost-aware constructs the cost volume for learning, explores the changes between two frames, and therefore is more effective for preserving object details and edge features. Cost-aware matching also improves the inference speed (FPS) in Col 7 of Table 3, which abandons the calculation of neighbourhood cross-correlation in short-term memory and constructs the pixel relationship by dot product that is more efficient. We can observe that the combined improvement strategy of cost-aware and cross-scale improves J by 2.6% and F by 2% compared to the baseline.
| CFBI | 81.4 | 81.1 | 85.8 | 75.3 | 83.4 | |
|---|---|---|---|---|---|---|
| CFBI+ | 82.8 | 81.8 | 86.6 | 77.1 | 85.6 | |
| AOT-L | 84.1 | 83.7 | 88.5 | 78.1 | 86.1 | |
| STCN | 84.3 | 83.2 | 87.9 | 79.0 | 87.3 | |
| XMem | 84.4 | 83.7 | 88.5 | 78.2 | 87.2 | |
| JIMD (ours) | 84.8 | 83.7 | 88.7 | 79.1 | 87.6 | |
| CFBI | 81.0 | 80.6 | 85.1 | 75.2 | 83.0 | |
| CFBI+ | 82.6 | 81.7 | 86.2 | 77.1 | 85.2 | |
| AOT-L | 84.1 | 83.5 | 88.1 | 78.4 | 86.3 | |
| STCN | 84.2 | 82.6 | 87.0 | 79.4 | 87.7 | |
| XMem | 84.3 | 83.6 | 88.0 | 78.5 | 87.1 | |
| JIMD (ours) | 84.6 | 82.9 | 87.8 | 79.7 | 87.9 |
| CD | CS | CA | FPS | |||
|---|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | 85.6 | 82.6 | 88.5 | 17.5 |
| ✗ | ✓ | ✗ | 86.1 | 83.5 | 88.6 | 15.7 |
| ✗ | ✗ | ✓ | 87.3 | 84.3 | 90.3 | 17.8 |
| ✗ | ✓ | ✓ | 87.7 | 84.8 | 90.5 | 14.3 |
| ✓ | ✗ | ✗ | 87.6 | 84.9 | 90.2 | 17.1 |
| ✓ | ✓ | ✗ | 87.7 | 85.0 | 90.3 | 13.6 |
| ✓ | ✗ | ✓ | 87.9 | 85.0 | 90.8 | 15.0 |
| ✓ | ✓ | ✓ | 88.1 | 85.2 | 91.0 | 13.2 |
| Method | |||||
|---|---|---|---|---|---|
| CD-Basline | 87.6 | 84.9 | 90.2 | ||
|
86.4(1.2) | 83.5 (1.4) | 89.3 (0.9) | ||
| CD w/o AW | 87.4 | 84.6 | 90.1 | ||
| CD w/o SP | 87.1 | 84.6 | 89.6 |
Impact of Decoding Mechanism. Compensatory decoding provides an essential information supplement for matching readout results and suppresses false matching to a certain extent by implementing context embedding compensation in the decoding stage. Row 5 of Table 3 demonstrates the improvement of compensatory decoding over the baseline. To study the binding function effect in compensatory decoding, as shown in Table 5, we remove three implements or modules (i.e., context compensation (Context), adaptive weighting (AW), and spatial block (SP)) and evaluate the gains separately. CD-Baseline in Table 5 for the experimental setup in the 5th row of Table 3. On the context removal setting, we simultaneously remove the share-weighted recursive decoder and replace it with two decoders in the cascade that do not share weights. As shown in Table 5, after removing context comparison, we can observe the most significant drop in performance (i.e., 1.4% drop in and 0.9% drop in ). Therefore, context compensation is vital in improving the decoding stage. Furthermore, we migrate our decoding improved mechanism to other existing matching-based methods, as shown in Table 5, which indicates the feasibility and the plug-and-play potential of our compensatory decoding.
Impact of Matching and Decoding Improved Jointly. The contribution of this paper is to explore the role of joint improvement of memory matching and decoding. Rows 6 to 8 from Table 3 show the gain of the matching and decoding jointly improving mechanisms. We can see that the combination of either CD & CA or CD & CS has a more substantial positive effect than the memory matching improved alone. Therefore, we believe the joint improvement of memory matching and decoding proposed in this paper is crucial to the matching-based VOS approach.

Visualize the Readout Features. We visually compared the readout features with AOT [27] as shown in Fig. 5. After cost-aware and cross-scale matching, our initial readout results are significantly better than AOT [27]. We can see that our initial readout still has false matching area at the right wheel of the bike. However, after context embedding, the final readout results suppress false matches and increase some high-response features. This suggests that our approach of jointly improving the matching and decoding stages could facilitate producing more accurate and precise masks.
5 Conclusion
This paper proposes a network JIMD that jointly improves the memory matching and decoding stages to address the issue of false matching. We design an improved mechanism for the memory matching stage consisting of cost-aware matching and cross-scale matching for short-term and long-term memory. Cost-aware matching in short-term memory prompts the network to perceive changes between two frames more adequately. Cross-scale matching in long-term memory prompts the network to explore the variations in different scaled objects. For the readout decoding stage, we propose a novel compensatory decoding mechanism that can suppress false matches and supplement the crucial information loss of target objects. We conduct extensive experiments on the effectiveness of joint improvement, and results on popular benchmarks demonstrate that JIMD outperforms existing matching-based methods. Therefore, JIMD has considerable potential to be applied to multimedia applications in the future.
Acknowledgments. This project was supported by the key R&D project of Guangzhou (202206010091) and the fund of Southern Marine Science and Engineering Guangdong Laboratory (Zhanjiang)(ZJW-2023-04).
References
- [1] Cheng, H.K., Schwing, A.G.: XMem: Long-term video object segmentation with an atkinson-shiffrin memory model. In: ECCV (2022)
- [2] Cheng, H.K., Tai, Y.W., Tang, C.K.: Rethinking space-time networks with improved memory coverage for efficient video object segmentation. In: Advances in Neural Information Processing Systems. vol. 34, pp. 11781–11794 (2021)
- [3] Chu, X., Tian, Z., Wang, Y., Zhang, B., Ren, H., Wei, X., Xia, H., Shen, C.: Twins: Revisiting the design of spatial attention in vision transformers. In: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W. (eds.) Advances in Neural Information Processing Systems. vol. 34, pp. 9355–9366. Curran Associates, Inc. (2021)
- [4] Gelautz, M.: Short papers_. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 35(2) (2013)
- [5] Guo, P., Zhang, W., Li, X., Zhang, W.: Adaptive online mutual learning bi-decoders for video object segmentation. IEEE Transactions on Image Processing 31, 7063–7077 (2022)
- [6] Hu, L., Zhang, P., Zhang, B., Pan, P., Xu, Y., Jin, R.: Learning position and target consistency for memory-based video object segmentation pp. 4144–4154 (2021)
- [7] Huang, Z., Shi, X., Zhang, C., Wang, Q., Cheung, K.C., Qin, H., Dai, J., Li, H.: Flowformer: A transformer architecture for optical flow. In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVII. pp. 668–685. Springer (2022)
- [8] Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
- [9] Lu, X., Wang, W., Danelljan, M., Zhou, T., Shen, J., Van Gool, L.: Video object segmentation with episodic graph memory networks pp. 661–679 (2020)
- [10] Mei, J., Wang, M., Lin, Y., Liu, Y.: Transvos: Video object segmentation with transformers. arXiv preprint arXiv:2106.00588 (2021)
- [11] Nowozin, S.: Optimal decisions from probabilistic models: the intersection-over-union case. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 548–555 (2014)
- [12] Oh, S.W., Lee, J.Y., Sunkavalli, K., Kim, S.J.: Fast video object segmentation by reference-guided mask propagation. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7376–7385 (2018)
- [13] Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J.: Video object segmentation using space-time memory networks. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9225–9234 (2019)
- [14] Pont-Tuset, J., Perazzi, F., Caelles, S., Arbeláez, P., Sorkine-Hornung, A., Van Gool, L.: The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675 (2017)
- [15] Qiao, S., Chen, L.C., Yuille, A.: Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10213–10224 (2021)
- [16] Seong, H., Hyun, J., Kim, E.: Kernelized memory network for video object segmentation. In: Computer Vision – ECCV 2020. pp. 629–645 (2020)
- [17] Seong, H., Hyun, J., Kim, E.: Video object segmentation using kernelized memory network with multiple kernels. IEEE transactions on pattern analysis and machine intelligence (2022)
- [18] Seong, H., Oh, S.W., Lee, J.Y., Lee, S., Lee, S., Kim, E.: Hierarchical memory matching network for video object segmentation. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 12869–12878 (2021)
- [19] Sun, D., Yang, X., Liu, M.Y., Kautz, J.: Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 8934–8943 (2018)
- [20] Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. pp. 402–419. Springer (2020)
- [21] Voigtlaender, P., Chai, Y., Schroff, F., Adam, H., Leibe, B., Chen, L.C.: Feelvos: Fast end-to-end embedding learning for video object segmentation. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9473–9482 (2019)
- [22] Wang, J., Chen, D., Wu, Z., Luo, C., Tang, C., Dai, X., Zhao, Y., Xie, Y., Yuan, L., Jiang, Y.G.: Look before you match: Instance understanding matters in video object segmentation. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 0–0 (2023)
- [23] Xie, H., Yao, H., Zhou, S., Zhang, S., Sun, W.: Efficient regional memory network for video object segmentation. In: CVPR (2021)
- [24] Xu, N., Yang, L., Fan, Y., Yang, J.: Youtube-vos: Sequence-to-sequence video object segmentation. In: Computer Vision – ECCV 2018. pp. 603–619 (2018)
- [25] Yang, Z., Miao, J., Wang, X., Wei, Y., Yang, Y.: Associating objects with scalable transformers for video object segmentation. arXiv preprint arXiv:2203.11442 (2022)
- [26] Yang, Z., Wei, Y., Yang, Y.: Collaborative video object segmentation by foreground-background integration. In: Computer Vision – ECCV 2020. pp. 332–348. Springer International Publishing (2020)
- [27] Yang, Z., Wei, Y., Yang, Y.: Associating objects with transformers for video object segmentation. In: Advances in Neural Information Processing Systems. vol. 34, pp. 2491–2502 (2021)
- [28] Yang, Z., Wei, Y., Yang, Y.: Collaborative video object segmentation by multi-scale foreground-background integration. IEEE Transactions on Pattern Analysis and Machine Intelligence 44(9), 4701–4712 (2022)
- [29] Yang, Z., Yang, Y.: Decoupling features in hierarchical propagation for video object segmentation. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Information Processing Systems. vol. 35, pp. 36324–36336. Curran Associates, Inc. (2022)