MemoNav: Selecting Informative Memories for Visual Navigation
Abstract
Image-goal navigation is a challenging task, as it requires the agent to navigate to a target indicated by an image in a previously unseen scene. Current methods introduce diverse memory mechanisms which save navigation history to solve this task. However, these methods use all observations in the memory for generating navigation actions without considering which fraction of this memory is informative. To address this limitation, we present the MemoNav, a novel memory mechanism for image-goal navigation, which retains the agent’s informative short-term memory and long-term memory to improve the navigation performance on a multi-goal task. The node features on the agent’s topological map are stored in the short-term memory, as these features are dynamically updated. To aid the short-term memory, we also generate long-term memory by continuously aggregating the short-term memory via a graph attention module. The MemoNav retains the informative fraction of the short-term memory via a forgetting module based on a Transformer decoder and then incorporates this retained short-term memory and the long-term memory into working memory. Lastly, the agent uses the working memory for action generation. We evaluate our model on a new multi-goal navigation dataset. The experimental results show that the MemoNav outperforms the SoTA methods by a large margin with a smaller fraction of navigation history. The results also empirically show that our model is less likely to be trapped in a deadlock, which further validates that the MemoNav improves the agent’s navigation efficiency by reducing redundant steps.
1 Introduction
Human beings plan their routes by recalling detailed experiences of the past [37, 35, 23]. When we get into a new environment, the first thing is usually to explore our surroundings to get familiar with the scene layout. This exploration behavior enables us to quickly plan new routes with the help of the so-called working memory [39, 12].
Recent neuroscience research [29, 24, 6] has found that working memory is essential for organizing goal-directed behaviors including navigation, as it maintains task-relevant information. Several models [13, 12, 3] of working memory have been constructed to explain the relationships among short-term memory (STM), long-term memory (LTM), and working memory (WM). Particularly, the model by Cowan et al. [12] (shown in the Appendix) demonstrates that the human brain selects short-term memory as part of working memory by focusing attention on task-relevant experiences to avoid distractions. It is also noticed that working memory is not a simple extension of short-term memory, but an incorporation of selected short-term memory and long-term memory in goal-oriented tasks [3].
Inspired by the above neuroscience research, we propose a MemoNav for image-goal visual navigation (ImageNav) agents, which is built upon a SoTA topological map-based method VGM [20]. The MemoNav simulates the working memory mechanism of the human brain and improves the agent’s ability to complete multi-goal navigation tasks. Recently, a number of ImageNav methods [20, 9, 8, 14, 19] have introduced memory mechanisms. According to the structure of memory, these methods can be classified into three categories: (a) metric map-based methods [8, 11] that reconstruct local top-down maps and aggregate them into a global map, (b) stacked memory-based methods [27, 25, 14] that stack the past observations and pose sensor data in chronological order, and (c) topological map-based methods [20, 9, 4, 32] that store sparse landmark features in the graph nodes. Comparatively speaking, the metric map-based methods store every detail of the scene, thus consuming large memory when the agent encounters large scenes; the stacked memory-based methods utilize all past data without differentiating useful information and noise; the topological map-based methods benefit from the memory sparsity of topological maps, but still suffer from all memory computation without considering the contribution of each graph node.
To overcome these limitations, the MemoNav enables the agent to flexibly retain informative navigation experience. In our design, the MemoNav utilizes the aforementioned three types of memory: STM, LTM, and WM. STM represents the local node features in a topological map; LTM is a global node continuously aggregating short-term memory; WM incorporates the informative fraction of the STM and the LTM. Technically, the MemoNav consists of four steps: map update, selective forgetting, memory encoding and decoding, and action generation. (1) Firstly, the map update module stores landmark features on the map as the STM. (2) To incorporate informative STM into the WM, a selective forgetting module temporarily removes nodes whose attention scores assigned by the memory decoder rank below a predefined percentage. After forgetting, the navigation pipeline will not compute the forgotten node features at subsequent time steps. To assist the STM, we add a global node [1, 5] to the map as the LTM. The global node links to all map nodes and continuously aggregates the features of these nodes at each time step. (3) The retained STM and the LTM form the WM, which is then processed by a GATv2 [7] encoder. Afterward, two Transformer [38] decoders use the embeddings of the goal image and the current observation to decode the processed WM. (4) Lastly, the decoded features are used for generating navigation actions.
The MemoNav enables the agent to utilize task-relevant experiences to find a short path to the goal without being intervened by misleading information. With the synergy of these three types of memory, the MemoNav achieves considerable progress in multi-goal ImageNav tasks. The results show that compared with the SoTA method [20], the MemoNav increased the success rate by 5%, 9%, and 3% on 2-goal, 3-goal, and 4-goal test datasets, respectively. The main contributions of this paper are as follows:
-
•
We propose the MemoNav, which utilizes a forgetting module to select informative short-term memory stored in the topological map for generating navigation actions.
-
•
We introduce a global node to represent long-term memory as a supplement to the short-term memory.
-
•
We evaluate the proposed model on a multi-goal task. The results demonstrate that our model outperforms the SoTA baseline by a large margin on a multi-goal task.
2 Related Work
ImageNav models based on topological maps. Cognitive research [40, 15, 17] suggests that humans save landmark features in their memory for navigation, instead of detailed scene layouts. Several methods [32, 4, 9, 20, 10] utilize this theory and propose topological memory for visual navigation. SPTM [32] is an early attempt to use topological maps in ImageNav. It proposes a semi-parametric topological memory that is pre-built before navigation. Beeching et al. [4] introduced a graph processing method inspired by dynamic programming-based shortest path algorithms. This method also needs to explore the scene in advance. NTS [9] and VGM [20] incrementally build the topological map during navigation. VGM uses no pose sensor data and is more robust to sensor noise than NTS. The two methods utilize all features in the map, while the MemoNav flexibly utilizes the informative fraction of these features.
Memory mechanisms for reinforcement learning. Several studies [30, 21, 36, 22] draw inspiration from memory mechanisms of the human brain and design reinforcement learning models for reasoning over long time horizons. Ritter et al. [30] proposed an episodic memory storing state transitions for navigation tasks. Lampinen et al. [21] presented hierarchical attention memory as a form of “mental time-travel” [37], which means recovering goal-oriented information from past experiences. Unlike this method, our model retains such information via a novel forgetting module. Expire-span [36] predicts life spans for each memory fragment and permanently deletes expired ones. Our model is different from it in that we restore forgotten memory if the agent returns to visited places. The most similar work is WMG [22] which also uses theories of working memory. However, its memory capacity is fixed. In contrast, our model retains a certain proportion of short-term memory in the working memory and adjusts the memory capacity when the navigation episode contains more goals.
3 Background
3.1 Task Definition
We consider image-goal navigation (ImageNav) in this paper. As shown in Figure 1 (left), the objective of the agent is to learn a policy to reach a target, given an image that contains a view of the target and a series of observations, , captured during the navigation. At the beginning of navigation, the agent receives an RGB image, , of the target. At each time step, it captures an RGB-D panoramic image, of the current location and generates a navigational action. Following [20], any additional sensory data, e.g. GPS and IMU, are not available.

3.2 Brief Review of Visual Graph Memory
The MemoNav is mainly built upon VGM [20], which is briefly introduced below.
VGM incrementally builds a topological map from the agent’s past observations where and denote nodes and edges, respectively. The node features (STM) are generated from observations by a pretrained encoder where denotes the dimension of feature and the number of nodes at time .
VGM updates the map in two steps: localization and graph update. Localization is implemented by calculating embedding similarity. VGM first uses to map the current observation to an embedding , and then calculates the similarities between and each node feature . If the similarity of a node is higher than a threshold , this node is seen as near the agent. Graph Update depends on three cases. (i) If the agent is localized at the last node, the map will not be updated. (ii) If the localized node is different from the last one, a new edge connecting these two nodes will be created, and the feature of the localized node will be replaced with the new embedding. (iii) If the agent fails to be localized, a new node with the current observation embedding will be created, and a new edge will connect this new node with the last node.
VGM utilizes a three-layer graph convolutional network (GCN) to process the topological map and obtain the encoded memory (i.e., a sequence of feature vectors). Before the first layer, VGM fuses each feature of a node with the target image embedding using a linear layer.
The encoded memory is then decoded by two Transformer decoders, and . takes the current observation embedding as the query and the feature vectors of the encoded memory as the keys and values, generating a feature vector . Similarly, takes the target embedding as the query and generates . Lastly, an LSTM-based policy network takes as input the concatenation of , and , and outputs an action distribution.
4 Method
In this section, We expand the definition of ImageNav and describe our MemoNav designed for multi-goal navigation tasks.
4.1 Multi-goal ImageNav
Single-goal tasks are not sufficient for thoroughly evaluating the potential of memory mechanisms, since finding a single goal may not need all navigation history. Hence, it remains unclear which fraction of navigation history is useful for finding the goal. To further investigate how memory mechanisms assist the agent in exploring the environment and locating the target, we borrow the idea of MultiON [41] and collect multi-goal test datasets (an example in Figure 1). In a multi-goal task, the agent navigates to an ordered sequence of destinations in the environment. We place the final target within the vicinity of previous ones to form a loop. By letting the agent return to visited places, we are able to test whether memory mechanisms can help the agent plan a short path. If not, the agent will probably waste its time re-exploring the scene or traveling randomly.

4.2 Model Components
The MemoNav comprises three key components: the forgetting module, the global node, and the GATv2-based memory encoder. We show the pipeline of the MemoNav in Figure 2 and describe these components in the remainder of this section.
4.2.1 Working Memory Mechanism via Selective Forgetting
VGM (Section 3.2) decodes all STM in the map, thus introducing redundancy. Inspired by previous studies on the forgetting mechanisms of animal brains [23, 26, 31, 35, 37], we devise a forgetting module that instructs the agent to forget uninformative experiences. Here, ‘forgetting’ means that nodes with attention scores lower than a threshold are temporarily excluded from the navigation pipeline. This means of forgetting via attention is evidenced by research [2, 16] revealing that the optimal performance of working memory relies on humans’ ability to focus attention on task-relevant information and to avoid distractions. In Figure 3, we visualize the attention scores calculated in for the encoded STM. The figure shows that the agent assigns high attention scores to nodes close to targets while paying little to no attention to remote ones. This phenomenon indicates that not all node features in the STM are helpful and that it is more efficient to incorporate a small number of them in the WM for navigation.
With these insights, we propose a selective forgetting module that helps to select STM to form WM according to the attention scores the goal embedding assigns to all nodes in . Each time finishes decoding, the agent temporarily ‘forgets’ a fraction of nodes whose scores rank below a predefined percentage . In other words, these nodes will be disconnected from their neighbors, and not be processed by the navigation pipeline at the subsequent time steps. If the agent returns to a forgotten node, this node will be added to the map and processed by the pipeline again. In a multi-goal task, once the agent has reached a target, all forgotten nodes will be restored, as the nodes that are uninformative for finding the last target may lead the agent to the next one.
The proposed forgetting mechanism is used in a plug-and-play manner. Our default model sets as 20%. We train our model without forgetting in order for it to learn to assign high attention scores to the informative fraction of STM. When evaluating and deploying the agent, we switch on the forgetting mechanism. With this mechanism, the agent can selectively incorporate the most informative STM in the WM, while avoiding misleading experiences.
4.2.2 Long-term Memory Generation

In addition to STM, knowledge from LTM also forms part of WM [13]. Inspired by ETC [1] and LongFormer [5], we add a zero-initialized global node to the topological map as the LTM. This global node is respawned at the beginning of each episode and continuously fuses the STM via memory encoding (Figure 2 (e)), thereby storing past observations of the agent. Moreover, the global node acts as the LTM in that it contains a scene-level feature. A recent study [28] suggests that embodied agents must learn higher-level representations of the 3D environment. From this viewpoint, the LTM stores a high-level spatial representation of the scene by aggregating local node features.
Another merit of the LTM is facilitating feature fusing. The topological map is divided into several sub-graphs when forgotten nodes are removed. Consequently, direct message passing between the nodes separated in different sub-graphs no longer exists. The global node links to every node in the map, thereby acting as a bypath that facilitates feature fusing between these isolated sub-graphs.
4.2.3 GATv2-based Memory Processor
To generate LTM from STM that is dynamically updated by the agent, we change the backbone of the memory encoder in VGM (Section 3.2) from GCN to GATv2 [7]. GATv2 differs from GCN [18] in that the weights for neighboring nodes are derived from node features, instead of the Laplacian matrix.
Brody et al. [7] claimed that GATv2 is powerful when different nodes have different rankings of neighbors. This is exactly the case in multi-goal ImageNav: the extents to which different nodes contribute to leading the agent to the goal are diverse. When the LTM aggregates the STM via the attention mechanism in GATv2, the STM features that contain information about the target or a path leading to the target should obtain high attention, while those of irrelevant places should receive lower attention. Furthermore, the node features in the STM are dynamically updated during navigation, as the agent replaces these features with new ones when revisiting these nodes. Therefore, the dynamic attention mechanism of GATv2 is more suitable for processing the STM that dynamically varies during navigation.
Combining the STM , LTM and GATv2-based processor , the memory processing is formulated as follows:
| (1) |
where represents the layer number, the encoded working memory, and the processor parameters. denotes concatenation along the sequence dimension.
After the processing of GATv2, the decoders and take as keys and queries, generating and , which fuse both LTM and STM.
5 Experiments
5.1 Simulation Settings
All experiments are conducted in the Habitat [33] simulator with the Gibson [42] scene dataset. Following VGM [20], we train all models with 72 scenes, and evaluate them on a public 1-goal dataset [25] that comprises 1400 episodes for 14 unseen scenes. For a fair comparison, 1007 sampled episodes are used for evaluating our model on 1-goal tasks, while 1400 episodes are used for conducting ablation studies. In addition, we generate 700-episode datasets for a multi-goal task by ourselves (see the Appendix). The difficulty of an episode is indicated by the number of goals 111The 1-goal difficulty level here denotes the hard level in the public test dataset All baselines and our model are trained on the 1-goal dataset and tested on other difficulty levels.
The action space of the agent consists of four options: stop, forward, turn_left, and turn_right. When the agent performs a forward action, the agent moves 0.25m forward. A turning action rotates the agent by 10 degrees. The agent is allowed to take at most 500 steps in either 1-goal or multi-goal tasks. The agent succeeds in an episode if it performs stop within a 1m radius of each target location. The agent fails if it performs stop anywhere else or runs out of time step budget.
5.2 Training Techniques
Following VGM [20], we first train the agent using imitation learning, minimizing the negative log-likelihood of the ground-truth actions. Next, we finetune the agent’s policy with proximal policy optimization (PPO) [34] to improve the exploratory ability of the agent. The reward setting and auxiliary losses remain the same as in VGM. All our models are obtained on a TITAN RTX GPU.
5.3 Baselines
We compare the proposed model with baselines that also utilize memory mechanisms. Random is an agent taking random actions with oracle stopping. ANS [8] and Exp4nav [11] are metric map-based models proposed for the task of exploration. They are adapted for ImageNav in the experiments of VGM [20]. SMT [14] stacks past observations in chronological order and uses a Transformer decoder to further process them. Neural Planner [4] needs to explore the scene first to pre-build a topological map. Once the map is built, this method performs a hierarchical planning strategy to generate navigation actions. NTS [9] incrementally builds a topological map without pre-exploring. Its navigation strategy follows two steps: a global policy samples a subgoal, and then a local policy takes navigational actions to reach the subgoal. VGM [20] (see Section 3.2) is the baseline the MemoNav is built on. The quantitative results of these baselines on 1-goal tasks are from [20]. We re-evaluate VGM and report the new results.
5.4 Evaluation Metrics
In 1-goal tasks, the success rate (SR) and success weighted by path length (SPL) [2] are used. In a multi-goal task, we borrow two metrics from [41]: the Progress (PR) and progress weighted by path length (PPL). PR is the fraction of goals that are successfully reached, equal to the SR for 1-goal tasks. PPL indicates navigation efficiency and is defined as , where is the total number of test episodes, and are the shortest path distance to the final goal via midway ones, and the actual path length taken by the agent, respectively.
5.5 Quantitative Results
| Methods | Memory Type | SR | SPL | Methods | Memory Type | SR | SPL |
|---|---|---|---|---|---|---|---|
| Random | - | 0.17 | 0.05 | Neural Planner [4] | graph | 0.42 | 0.27 |
| ANS [8] | metric map | 0.30 | 0.11 | NTS [9] | graph | 0.43 | 0.26 |
| Exp4nav [11] | metric map | 0.47 | 0.39 | VGM [20] | graph | 0.75 | 0.58 |
| SMT [14] | stack | 0.56 | 0.40 | MemoNav (ours) | graph | 0.78 | 0.54 |
| Methods | 2-goal | 3-goal | 4-goal | |||
|---|---|---|---|---|---|---|
| PR | PPL | PR | PPL | PR | PPL | |
| Random | 0.05 | 0.01 | 0.03 | 0.00 | 0.02 | 0.00 |
| VGM [20] | 0.45 | 0.18 | 0.33 | 0.08 | 0.28 | 0.05 |
| MemoNav (ours) | 0.50 | 0.17 | 0.42 | 0.09 | 0.31 | 0.05 |
Comparison on 1-goal tasks. Table 1 shows that the proposed method outperforms all the baselines in SR on the 1-goal dataset. Compared with the metric map-based methods (Exp4nav [11] and Neural Planner [4]), our model enjoys a large improvement in SR (from 0.47 to 0.78) and SPL (from 0.39 to 0.54). The two baselines require pre-built maps but exhibit lower SR and SPL. This is partly because the explored areas fail to cover the target place. Compared with VGM [20], our model exhibits a slight performance gain, increasing the SR by 0.03 while using 20% fewer node features. This result indicates that VGM uses redundant past observations that probably interfere with the agent’s navigation. In contrast, our agent uses the informative fraction of these observation, obtaining a higher success rate with less past information. The SPL slightly decreases, probably because the agent forgets a certain proportion of explored places and spends more time re-exploring.
Comparison on a multi-goal task. In Table 2, we compare the MemoNav with VGM [20] on a multi-goal task. As the difficulty level rises from 1 goal to 4 goals, both methods witness drops in the navigation success rate, but the MemoNav is more robust and more competent to complete a multi-goal task. At the 2-goal level, the MemoNav outperforms VGM in PR by 0.05 (11.1%). When the number of goals increases to 3, the performance gap widens: the improvement in PR rises to 0.09 (27.2%). At the 4-goal level, the two methods both perform worse, but our method still surpasses VGM in PR by a noticeable margin of 0.03 (10.7%).
5.6 Ablation Studies and Analysis
| Components | 1-goal | 2-goal | 3-goal | 4-goal | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GATv2 | LTM | FG20% | SR | SPL | PR | PPL | PR | PPL | PR | PPL | |
| 1 | 0.621 | 0.494 | 0.449 | 0.178 | 0.329 | 0.080 | 0.276 | 0.054 | |||
| 2 | ✓ | 0.618 | 0.533 | 0.452 | 0.193 | 0.377 | 0.080 | 0.307 | 0.060 | ||
| 3 | ✓ | 0.617 | 0.521 | 0.489 | 0.207 | 0.385 | 0.092 | 0.311 | 0.057 | ||
| 4 | ✓ | 0.611 | 0.478 | 0.472 | 0.187 | 0.327 | 0.079 | 0.279 | 0.056 | ||
| 5 | ✓ | ✓ | 0.617 | 0.527 | 0.491 | 0.202 | 0.403 | 0.098 | 0.301 | 0.056 | |
| 6 | ✓ | ✓ | 0.623 | 0.462 | 0.496 | 0.163 | 0.417 | 0.084 | 0.313 | 0.050 | |
| 7 | ✓ | ✓ | ✓ | 0.610 | 0.461 | 0.498 | 0.171 | 0.421 | 0.087 | 0.314 | 0.049 |
The performance gain of each proposed component. We ablate the three key components described in Section 4.2, and show the results in Table 3. Comparing rows 2, 3, and 4 with row 1 (VGM), we can see that the LTM brings the largest improvement over the baseline at the 2, 3, and 4-goal levels among the three components. For example, the LTM brings an increase in PR by 0.056 at the 3-goal level. Although applying the forgetting module only achieves improvements at the 2 and 4-goal levels, its cooperation with the LTM witnesses a significant increase in the SR/PR at the 1, 2, and 3-goal levels. More importantly, compared with VGM (row 1), the synergy of the three components (row 7) increases the PR by 0.049 (10.9%), 0.092 (21.9%), 0.038 (13.8%) at the 2, 3 and 4-goal levels respectively. These results demonstrate that the three components are helpful for solving long-time navigation tasks with multiple sequential goals.
The importance of the LTM. Table 4 presents the results of ablation experiments that demonstrate the importance of the LTM (described in Section 4.2.2). The first ablation (row 2) is to replace the feature in the LTM with that of a randomly selected node in the STM once the GATv2 encoding is finished so that the LTM is disabled. Row 2 shows that the agent’s performance decreases at all difficulty levels compared with the full model (row 1). Furthermore, when the LTM feature is not incorporated into the WM (row 3), the performance also deteriorates. In summary, the LTM stores a scene-level feature essential for improving the success rate.
| Methods | 1-goal | 2-goal | 3-goal | 4-goal | |||||
|---|---|---|---|---|---|---|---|---|---|
| SR | SPL | PR | PPL | PR | PPL | PR | PPL | ||
| 1 | Ours | 0.610 | 0.461 | 0.498 | 0.171 | 0.421 | 0.087 | 0.314 | 0.049 |
| 2 | Ours w. random replace | 0.602 | 0.365 | 0.464 | 0.122 | 0.373 | 0.065 | 0.306 | 0.046 |
| 3 | Ours w.o. decoding LTM | 0.604 | 0.456 | 0.492 | 0.169 | 0.393 | 0.083 | 0.309 | 0.048 |


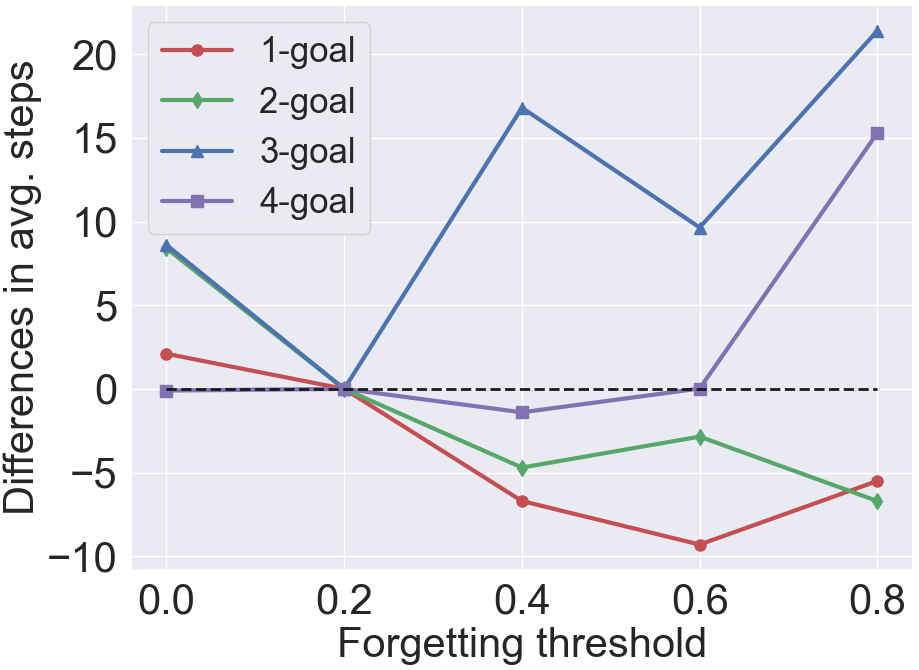
The correlation between the difficulty level and forgetting threshold. We evaluate our model with different forgetting thresholds used by the WM (see Section 4.2.1). The results are shown in Figure 4. For clarity, the figure shows the performance differences between our default model (row 7 in Table 3) and the variants. The four levels exhibit different trends: when increases (i.e., a larger fraction of STM is not incorporated into the WM), our model first witnesses increases and then drops in the SR/PR and SPL/PPL at the 3 and 4-goal levels while enjoying slight gains in these metrics at the 1 and 2-goal levels. At the 1-goal level, our model obtains the highest SR and SPL when , which means that a large fraction of node features in the map are useless when the navigation task is easy. A similar trend can also be seen at the 2-goal level. In contrast, our model exhibits an increase in the PR (from 0.313 to 0.321) and PPL (from 0.049 to 0.050) at the 4-goal level when rises from 0% to 40%. However, if rises to 80%, the two metrics see a precipitous decline, and the agent takes more than 20 steps to complete the tasks. These results suggest that excluding unimportant STM from the WM improves navigation performance in multi-goal navigation tasks. However, excluding an excessive fraction forces the agent not to utilize what it has explored, thus reducing the navigation efficiency.

5.7 Visualization Results
To observe how the MemoNav improves the navigation performance, we show example episodes of VGM and our model at the four difficulty levels in Fig 5 (more examples are provided in the Appendix). We can see that the MemoNav agent takes fewer steps and its trajectories are smoother. VGM tends to spend a large proportion of time going in circles in narrow pathways. For instance, the 1st and 3rd columns in Figure 5 show that the VGM agent is trapped in a bottleneck connecting two rooms, while our agent uses the time steps wasted by VGM to efficiently explore the scene. This comparison shows that the MemoNav is more capable of avoiding deadlock.

We next draw a histogram of the normalized path lengths of successful episodes for VGM and our model to further investigate to what degree our model avoids deadlock. The normalized path length is calculated as where and are defined in Section 5.4. indicates how many extra steps the agent takes compared to the shortest path. A larger represents a less efficient navigation episode. Figure 6 shows that the histogram of our model exhibits a less heavier-tailed distribution, especially on the 3-goal dataset. This distribution means that our model has fewer episodes with an extremely large number of steps. This result agrees with the visualization in Figure 5 , as it suggests that our model utilizes goal-relevant navigation history stored in the WM to reduce the number of wasted steps.
Analyzing these results, the reason why our model helps the agent escape from loops is twofold. Firstly, the WM excludes misleading node features and reduces the interference of irrelevant past observations. Secondly, the LTM provides the agent with a scene-level context that helps it locate the target from a global view.
6 Conclusion
This paper proposes MemoNav, a memory mechanism for ImageNav. This model flexibly retains the informative fraction of the short-term navigation memory via a forgetting module. We also add an extra global node to the topological map as a long-term memory that aggregates features in the short-term memory. The retained short-term memory and the long-term memory form the working memory that is used for generating action, Our model is only trained on a 1-goal dataset. Nevertheless, it is capable of solving a multi-goal navigation task. The results show that the MemoNav outperforms the baselines in 1-goal and multi-goal tasks and is more capable of escaping from deadlock.
Acknowledgements
We would like to acknowledge Yuxi Wang, Yuqi Wang, Lue Fan, He Guan, Jiawei He, Zeyu Wang and the anonymous reviewers for their help, comments and suggestions.
Licenses for Referenced Datasets
References
- Ainslie et al. [2020] J. Ainslie, S. Ontanon, C. Alberti, V. Cvicek, Z. Fisher, P. Pham, A. Ravula, S. Sanghai, Q. Wang, and L. Yang. Etc: Encoding long and structured inputs in transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 268–284, 2020.
- Anderson et al. [2018] P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V. Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva, et al. On evaluation of embodied navigation agents. arXiv preprint arXiv:1807.06757, 2018.
- Baddeley [2012] A. Baddeley. Working memory: theories, models, and controversies. Annual review of psychology, 63:1–29, 2012.
- Beeching et al. [2020] E. Beeching, J. Dibangoye, O. Simonin, and C. Wolf. Learning to plan with uncertain topological maps. In ECCV 2020-16th European Conference on Computer Vision, pages 1–24, 2020.
- Beltagy et al. [2020] I. Beltagy, M. E. Peters, and A. Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- Blacker et al. [2017] K. J. Blacker, S. M. Weisberg, N. S. Newcombe, and S. M. Courtney. Keeping track of where we are: Spatial working memory in navigation. Visual Cognition, 25(7-8):691–702, 2017.
- Brody et al. [2022] S. Brody, U. Alon, and E. Yahav. How attentive are graph attention networks? In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=F72ximsx7C1.
- Chaplot et al. [2020a] D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, and R. Salakhutdinov. Learning to explore using active neural slam. In International Conference on Learning Representations (ICLR), 2020a.
- Chaplot et al. [2020b] D. S. Chaplot, R. Salakhutdinov, A. Gupta, and S. Gupta. Neural topological slam for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12875–12884, 2020b.
- Chen et al. [2021] K. Chen, J. K. Chen, J. Chuang, M. Vázquez, and S. Savarese. Topological planning with transformers for vision-and-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11276–11286, 2021.
- Chen et al. [2019] T. Chen, S. Gupta, and A. Gupta. Learning exploration policies for navigation. In International Conference on Learning Representations, 2019. URL https://openreview.net/pdf?id=SyMWn05F7.
- Cowan [2008] N. Cowan. What are the differences between long-term, short-term, and working memory? Progress in brain research, 169:323–338, 2008.
- Ericsson and Kintsch [1995] K. A. Ericsson and W. Kintsch. Long-term working memory. Psychological review, 102(2):211, 1995.
- Fang et al. [2019] K. Fang, A. Toshev, L. Fei-Fei, and S. Savarese. Scene memory transformer for embodied agents in long-horizon tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 538–547, 2019.
- Foo et al. [2005] P. Foo, W. H. Warren, A. Duchon, and M. J. Tarr. Do humans integrate routes into a cognitive map? map-versus landmark-based navigation of novel shortcuts. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(2):195, 2005.
- Fukuda and Vogel [2009] K. Fukuda and E. K. Vogel. Human variation in overriding attentional capture. Journal of Neuroscience, 29(27):8726–8733, 2009.
- Gillner and Mallot [1998] S. Gillner and H. A. Mallot. Navigation and acquisition of spatial knowledge in a virtual maze. Journal of cognitive neuroscience, 10(4):445–463, 1998.
- Kipf and Welling [2017] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR), 2017.
- Kumar et al. [2018] A. Kumar, S. Gupta, D. Fouhey, S. Levine, and J. Malik. Visual memory for robust path following. Advances in neural information processing systems, 31, 2018.
- Kwon et al. [2021] O. Kwon, N. Kim, Y. Choi, H. Yoo, J. Park, and S. Oh. Visual graph memory with unsupervised representation for visual navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15890–15899, 2021.
- Lampinen et al. [2021] A. Lampinen, S. Chan, A. Banino, and F. Hill. Towards mental time travel: a hierarchical memory for reinforcement learning agents. Advances in Neural Information Processing Systems, 34, 2021.
- Loynd et al. [2020] R. Loynd, R. Fernandez, A. Celikyilmaz, A. Swaminathan, and M. Hausknecht. Working memory graphs. In International Conference on Machine Learning, pages 6404–6414. PMLR, 2020.
- Manning [2021] J. R. Manning. Episodic memory: Mental time travel or a quantum “memory wave” function? Psychological review, 128(4):711, 2021.
- Mansouri et al. [2015] F. A. Mansouri, M. G. Rosa, and N. Atapour. Working memory in the service of executive control functions. Frontiers in Systems Neuroscience, 9:166, 2015.
- Mezghani et al. [2021] L. Mezghani, S. Sukhbaatar, T. Lavril, O. Maksymets, D. Batra, P. Bojanowski, and K. Alahari. Memory-augmented reinforcement learning for image-goal navigation. arXiv preprint arXiv:2101.05181, 2021.
- Nematzadeh et al. [2020] A. Nematzadeh, S. Ruder, and D. Yogatama. On memory in human and artificial language processing systems. In Proceedings of ICLR Workshop on Bridging AI and Cognitive Science, 2020.
- Pashevich et al. [2021] A. Pashevich, C. Schmid, and C. Sun. Episodic transformer for vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15942–15952, 2021.
- Ramakrishnan et al. [2022] S. K. Ramakrishnan, T. Nagarajan, Z. Al-Halah, and K. Grauman. Environment predictive coding for visual navigation. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=DBiQQYWykyy.
- Ravizza et al. [2021] S. M. Ravizza, T. J. Pleskac, and T. Liu. Working memory prioritization: Goal-driven attention, physical salience, and implicit learning. Journal of Memory and Language, 121:104287, 2021.
- Ritter et al. [2021] S. Ritter, R. Faulkner, L. Sartran, A. Santoro, M. Botvinick, and D. Raposo. Rapid task-solving in novel environments. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=F-mvpFpn_0q.
- Sabandal et al. [2021] J. M. Sabandal, J. A. Berry, and R. L. Davis. Dopamine-based mechanism for transient forgetting. Nature, 591(7850):426–430, 2021.
- Savinov et al. [2018] N. Savinov, A. Dosovitskiy, and V. Koltun. Semi-parametric topological memory for navigation. In International Conference on Learning Representations, 2018.
- Savva et al. [2019] M. Savva, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9339–9347, 2019.
- Schulman et al. [2017] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Suddendorf et al. [2009] T. Suddendorf, D. R. Addis, and M. C. Corballis. Mental time travel and the shaping of the human mind. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1521):1317–1324, 2009.
- Sukhbaatar et al. [2021] S. Sukhbaatar, D. Ju, S. Poff, S. Roller, A. Szlam, J. Weston, and A. Fan. Not all memories are created equal: Learning to forget by expiring. In International Conference on Machine Learning, pages 9902–9912. PMLR, 2021.
- Tulving [1985] E. Tulving. Memory and consciousness. Canadian Psychology/Psychologie canadienne, 26(1):1, 1985.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wallace [1960] A. Wallace. Plans and the structure of behavior . george a. miller, eugene galanter, karl h. pribram. American Anthropologist, 62(6):1065–1067, 1960.
- Wang and Spelke [2002] R. F. Wang and E. S. Spelke. Human spatial representation: Insights from animals. Trends in cognitive sciences, 6(9):376–382, 2002.
- Wani et al. [2020] S. Wani, S. Patel, U. Jain, A. Chang, and M. Savva. Multion: Benchmarking semantic map memory using multi-object navigation. Advances in Neural Information Processing Systems, 33:9700–9712, 2020.
- Xia et al. [2018] F. Xia, A. R. Zamir, Z. He, A. Sax, J. Malik, and S. Savarese. Gibson env: Real-world perception for embodied agents. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 9068–9079, 2018.
Checklist
-
1.
For all authors…
- (a)
-
(b)
Did you describe the limitations of your work? [Yes] Refer to Section 5.6 for the discussion about how the forgetting module probably undermines navigation efficiency. Additional description of the limitations of the proposed model is placed in the supplementary materials.
-
(c)
Did you discuss any potential negative societal impacts of your work? [N/A]
-
(d)
Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes]
-
2.
If you are including theoretical results…
-
(a)
Did you state the full set of assumptions of all theoretical results? [N/A]
-
(b)
Did you include complete proofs of all theoretical results? [N/A]
-
(a)
-
3.
If you ran experiments…
-
(a)
Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [Yes] Refer to the supplementary materials for detailed instructions of how to reproduce the results, which include hyperparameters, implementation details and data generation process.
-
(b)
Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? [Yes]
-
(c)
Did you report error bars (e.g., with respect to the random seed after running experiments multiple times)? [No] We decided not to report error bars with respect to multiple random seeds, since multiple experiments on training the proposed model and the baselines exhibit large performance diversity. In addition, training the proposed model and the baselines is time-consuming and expensive.
-
(d)
Did you include the total amount of compute and the type of resources used (e.g., type of GPUs, internal cluster, or cloud provider)? [Yes] See the supplementary materials.
-
(a)
-
4.
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
-
(a)
If your work uses existing assets, did you cite the creators? [Yes]
-
(b)
Did you mention the license of the assets? [Yes]
-
(c)
Did you include any new assets either in the supplemental material or as a URL? [N/A]
-
(d)
Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [N/A]
-
(e)
Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [N/A]
-
(a)
-
5.
If you used crowdsourcing or conducted research with human subjects…
-
(a)
Did you include the full text of instructions given to participants and screenshots, if applicable? [N/A]
-
(b)
Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
-
(c)
Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [N/A]
-
(a)
Appendix A Appendix
A.1 Open-sourced Code
We have open-sourced the implementation of the MemoNav, which can be found at: *
A.2 Limitations
While the MemoNav witnesses a large improvement in the navigation success rate in multi-goal navigation tasks, it still encounters limitations. The proposed forgetting module is a post-processing method, as it has to obtain the attention scores of the decoder before deciding which nodes are to be forgotten. Future work can explore trainable forgetting modules. The second limitation is that our forgetting module does not reduce memory footprint, since the features of the forgotten nodes still exist in the map for localization. Moreover, the forgetting threshold in our experiments is fixed. Future work can merge our idea with Expire-span [36] to learn an adaptive forgetting threshold.
A.3 Representative Models of Human Memory
Cowan et al. [12] proposed a typical model describing the relationships among long-term memory (LTM), short-term memory (STM), and working memory (WM) of the human brain. According to their definitions, LTM is a large knowledge base and a record of prior experience; STM reflects faculties of the human mind that hold a limited amount of information in a very accessible state temporarily; WM includes part of STM and other processing mechanisms that help to utilize STM. Cowan et al. designed a framework depicting how WM is formed from STM and LTM (shown in Figure 7). This framework demonstrates that STM is derived from a temporarily activated subset of LTM. This activated subset may decay as a function of time unless it is refreshed. The useful fraction of STM is incorporated into WM via an attention mechanism to avoid misleading distractions. Subsequent work by Baddeley et al. [3] suggests that the central executive manipulates memory by incorporating not only part of STM but also part of LTM to assist in making a decision.
We draw inspirations from the work by Cowan et al. [12] and Baddeley et al. [3] and reformulate the agent’s navigation experience as the three types of memory defined above. The agent’s current observations are analogous to STM since they are temporarily stored in the topological map; the global node aggregates graph node features and saves navigation history, thereby acting as LTM; the forgetting module retains the goal-relevant fraction of STM and incorporates the retained STM and LTM into WM, which is then input to the policy network.

A.4 Implementation Details
A.4.1 Model Architecture
| Param | Meaning | Value | ||
| The pre-trained encoder used for map update | ResNet18 | |||
| The dimension of node feature | 512 | |||
|
ResNet18 | |||
| The number of GATv2 layers | 3 | |||
| The number of decoder heads | 4 |
The structure of the memory encoding and decoding module (Figure 2(e) in the main paper) in the MemoNav remains the same as in the VGM [20] and is shown in Figure 8. We maintain the module hyper-parameters specified in the supplementary of the VGM paper and list them in Table 5 for convenience.

A.4.2 Implementation of the MemoNav
The forgetting module on the MemoNav requires the attention scores generated in the decoder . Therefore, our model needs to calculate the whole navigation pipeline before deciding which fraction of the STM should be retained. This lag means that the retained STM is incorporated into the WM at the next time step. The pseudo-code of the MemoNav is shown in Algorithm 1
A.4.3 Training Details
We follow the two-step training routine and maintain the training hyper-parameters shown in Table 5 of the VGM paper [20]. Our model is trained using imitation learning for 20k steps. Afterward, we finetune our model using PPO [34] for 10M steps. Due to the performance fluctuation intrinsic to reinforcement learning, the model at the 10M-th step is probably not the best. Therefore, we evaluate all checkpoints in the step range [9M, 10.4M] and select the best one. Our model compared with the baselines is the checkpoint at the 9.4M-th step.
A.4.4 Details of Collecting Multi-goal Datasets
We follow the format of the public 1-goal dataset in [25] and create 2-goal, 3goal, and 4-goal test datasets on the Gibson [42] scene dataset. We generate 50 samples for each of the 14 test scenes. In each sample, we randomly choose target positions while still following five rules: (1) no obstacles appear inside a circle with a radius of 0.75 meters centered at each target; (2) the distance between two successive targets is no more than 10 meters; (3) all targets are placed on the same layer without altitude differences. (4) all targets are reachable from each other. (5) The final target is placed near a certain previous one with the distance between them smaller than 1.5 meters. The distributions of the total geodesic distances for the three difficulty levels are shown in Figure 9.
A.4.5 Compute Requirements
We utilize an RTX TITAN GPU for training and evaluating our models. The imitation learning phase takes 1.5 days to train while the reinforcement learning takes 5 days.
The computation in the GATv2-based encoder and the two Transformer decoders occupy the largest proportion of the run-time of the MemoNav. The computation complexity of the encoder and the decoders are and , respectively. Using the forgetting module with a percentage threshold , the computation complexity of the MemoNav can be flexibly decreased by reducing the number of nodes to .

A.5 Extra Ablation Studies
We conduct extra ablation experiments on the forgetting module in the MemoNav to further investigate how its design affects the agent’s navigation performance. The results are shown in Table 6.
The origin of the attention scores used by the forgetting module. The forgetting module in the MemoNav removes the uninformative STM according to the attention scores generated in , as described in Section 4.2.1. We change these scores to those generated in . The result (row 2) shows that using the attention scores generated in as in , which means that the two decoders can both decide which fraction of the STM is informative. We choose since it brings larger performance gains.
The effectiveness of the forgetting module. This ablation investigates whether it is effective to exclude the STM with attention scores ranking below the predefined percentage . In this experiment,the forgetting module excludes a random fraction of the STM. We test this ablation model over five random seeds and report the average metrics. The result (row 3) shows that incorporating a random fraction of the STM into the WM leads to decreases in all metrics, which validates the effectiveness of our design for retaining informative STM.
Training the MemoNav with the forgetting module. As described in Section 4.2.1, the MemoNav is trained without the forgetting module. Here, we test the performance of the MemoNav trained with this module. The result (row 3) shows that training the MemoNav with the forgetting module leads to worse performance at the four difficulty levels.
| Methods | 1-goal | 2-goal | 3-goal | 4-goal | |||||
|---|---|---|---|---|---|---|---|---|---|
| SR | SPL | PR | PPL | PR | PPL | PR | PPL | ||
| 1 | Ours | 0.610 | 0.461 | 0.498 | 0.171 | 0.421 | 0.087 | 0.314 | 0.049 |
| 2 | Ours w. att. scores | 0.616 | 0.453 | 0.513 | 0.175 | 0.413 | 0.084 | 0.323 | 0.051 |
| 3 | Ours w. Random STM | 0.597 | 0.446 | 0.479 | 0.153 | 0.391 | 0.081 | 0.307 | 0.048 |
| 4 | Ours w. Training forgetting | 0.601 | 0.416 | 0.462 | 0.132 | 0.375 | 0.068 | 0.266 | 0.039 |
A.6 Extra Visualization Results
We demonstrate more examples of multi-goal episodes in Figure 10. The agent efficiently explores the scenes and finds sequential goals using the informative fraction of the node features in the map. These examples show that the MemoNav agent focuses high attention only on a small fraction of nodes and excludes nodes that are far away from the current goal. For example, in the 3-goal example, the agent forgets the topmost node when navigating to the 1st goal since this node is the farthest from the goal; the agent forgets the nodes at the bottom left corner when navigating to the 2nd and 3rd goals since these nodes are remote and uninformative. The comparison with the baseline for these examples is recorded in the supplementary videos.
We present examples of failed episodes in Figure 10 and record the proportions of various failure modes at all difficulty levels. The failure modes can mainly be categorized into four types: Stopping mistakenly, Missing the goal, Not close enough, and Over-exploring. The mode Stopping mistakenly (34.2%) means that the agent implements stop at the wrong place. The mode Missing the goal (13.5%) means that the agent has observed the goal but passes it. The mode Not close enough (3.2%) means that the agent attempts to reach the goal it sees but implements stop outside the successful range. The mode Over-exploring (49.1%) means that the agent spends too much time exploring open areas without any goals. The largest probability lies in Over-exploring cases, most of which occur when the agent explores a large proportion of the scene but still fails to get close to the target area in a limited time.


A.7 The Variation of the LTM
To investigate how the feature in the LTM changes during navigation, we calculate the L2 distance between the features at every two successive time steps and show the curves for two examples in Figure 11. The two curves show similar trends: the L2 difference rapidly increases and then gradually converges to 0 while several peaks appear. To understand why the LTM variation shows such a trend, we visualize the agent’s observations at the time steps of the peaks in Figure 11. Comparing these observations, we can see that the trend of the LTM variation exhibits two traits: (1) the LTM feature remains stable (the L2 difference is close to 0) if the agent is traveling in visited areas. For instance, in the 2-goal example (top row), the L2 difference steadily decreases in during which the agent turns around and travels to visited areas; (2) the LTM feature significantly changes (a peak appears) if the agent captures novel views of the scene. For instance, in the 3-goal example (bottom row), the L2 difference curve exhibits peaks at when the agent passes a corner and at when the agent observes a novel open area. These results indicate that the LTM focuses higher attention on the agent’s novel observations when aggregating the STM and stores the agent’s exploration experience.
