Measuring Adversarial Robustness using a Voronoi-Epsilon Adversary
Abstract
Previous studies on robustness have argued that there is a tradeoff between accuracy and adversarial accuracy. The tradeoff can be inevitable even when we neglect generalization. We argue that the tradeoff is inherent to the commonly used definition of adversarial accuracy, which uses an adversary that can construct adversarial points constrained by -balls around data points. As gets large, the adversary may use real data points from other classes as adversarial examples. We propose a Voronoi-epsilon adversary which is constrained both by Voronoi cells and by -balls. This adversary balances between two notions of perturbation. As a result, adversarial accuracy based on this adversary avoids a tradeoff between accuracy and adversarial accuracy on training data even when is large. Finally, we show that a nearest neighbor classifier is the maximally robust classifier against the proposed adversary on the training data.
1 Introduction
By applying a carefully crafted, but imperceptible perturbation to input images, so-called adversarial examples can be constructed that cause classifiers to misclassify the perturbed inputs (Szegedy et al., 2013). Defense methods like adversarial training (Madry et al., 2017) and certified defenses (Wong & Kolter, 2018) against adversarial examples have often resulted in decreased accuracies on clean samples (Tsipras et al., 2018). Previous studies have argued that the tradeoff between accuracy and adversarial accuracy may be inevitable in classifiers (Tsipras et al., 2018; Dohmatob, 2018; Zhang et al., 2019).
1.1 Problem Settings
Problem setting.
Let be a nonempty input space and be a set of possible classes. Data points and corresponding classes are sampled from a joint distribution . The distribution should satisfy the condition that is unique for all . The set of the data points is denoted as . is a nonempty finite set. A classifier assigns a class label from for each point . is a classification loss of the classifier provided an input and a label .
1.2 Adversarial Accuracy (AA)
Adversarial accuracy is a commonly used measure of adversarial robustness of classifiers (Madry et al., 2017; Tsipras et al., 2018). It is defined by an adversary region , which is an allowed region of the perturbations for a data point .
Definition 1 (Adversarial accuracy).
Given an adversary that is constrained to an adversary region , adversarial accuracy is defined as follows.
The choice of will determine the adversarial accuracy that we are measuring. Commonly considered adversary region is , which is a -ball around a data point based on a distance metric (Biggio et al., 2013; Madry et al., 2017; Tsipras et al., 2018; Zhang et al., 2019).
Definition 2 (Standard adversarial accuracy).
When the adversary region is , we refer to the adversarial accuracy as standard adversarial accuracy (SAA) . For SAA, we denote as .
This adversary region is based on an implicit assumption that there might be an adequate single epsilon that perturbed samples do not change their classes. However, this assumption has some limitations. We explain that in the next section.
1.3 The Tradeoff Between Accuracy and Standard Adversarial Accuracy
The usage of -ball-based adversary can cause the tradeoff between accuracy and adversarial accuracy. When the two clean samples and with have different classes, the increase of standard adversarial accuracy requires misclassification. We illustrate this with a toy example.
1.3.1 Toy Example
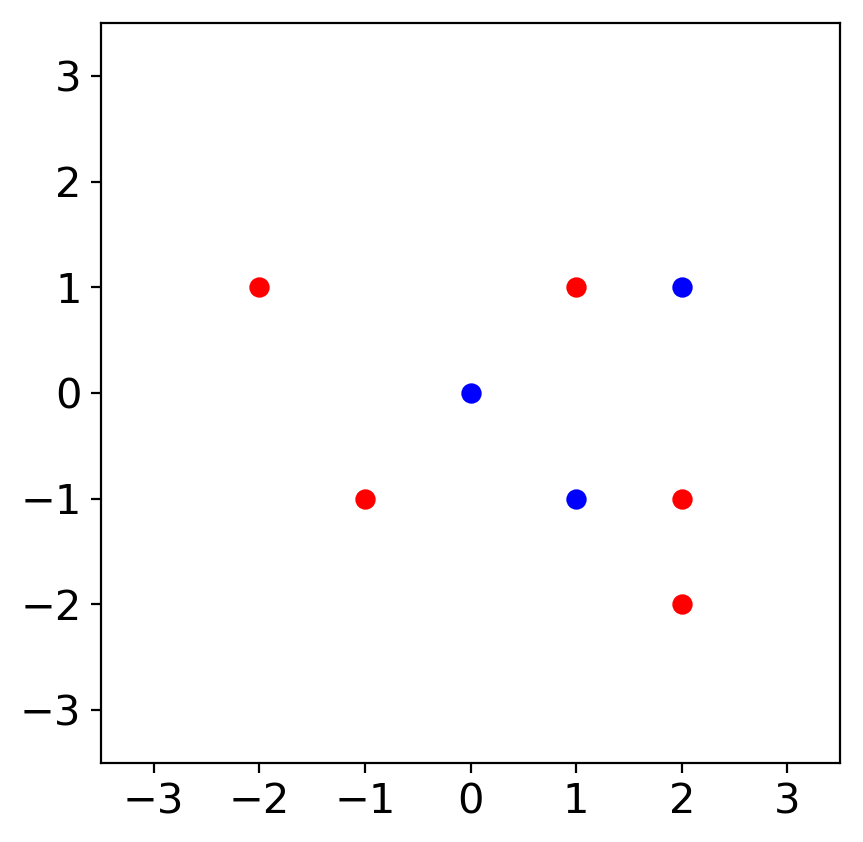
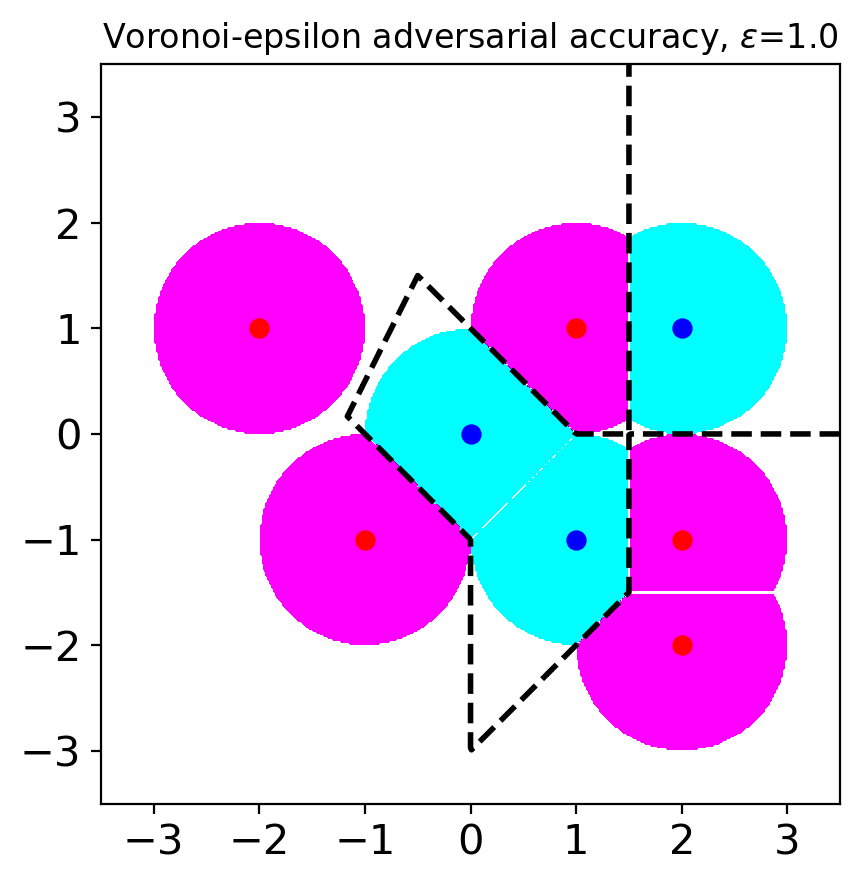
Let us consider an example visualized in Figure 1(a). The input space is . There are only two classes and , i.e., . We use the norm as a distance metric in this example.
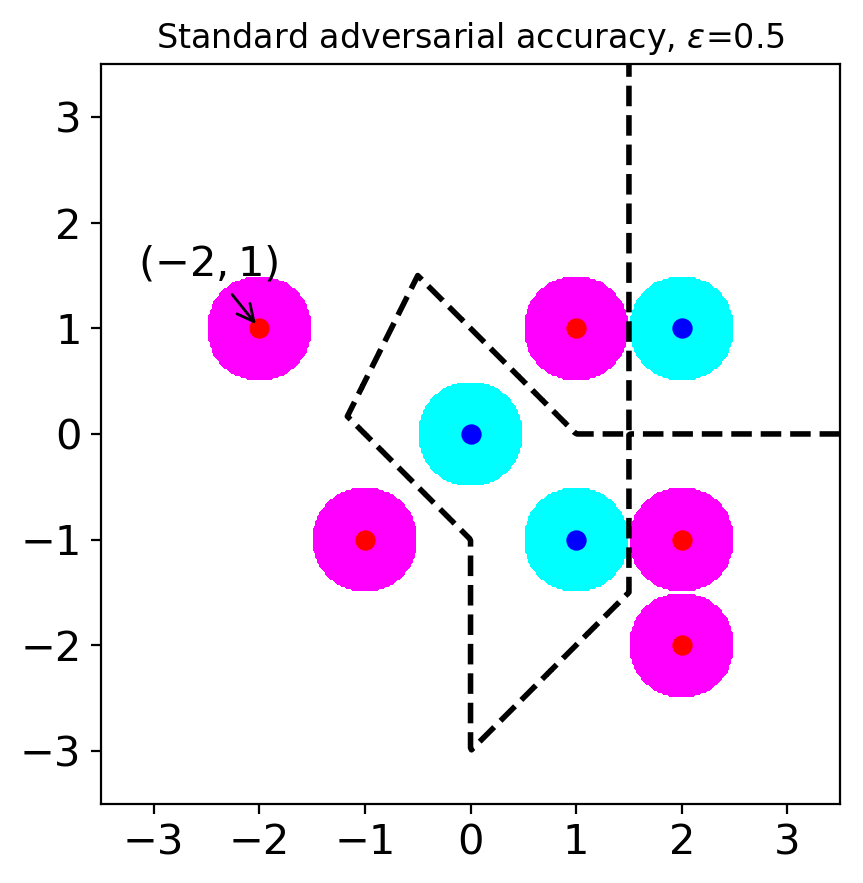
Let us consider a situation when (see Figure 1(c)). In this case, clean samples can also be considered as adversarial examples. For example, the point can be considered as an adversarial example originating from the point . If we choose a robust model based on SAA, we might choose a model with excessive invariance. For example, we might choose a model that predicts points belong to (including the point ) have class A. Or, we can choose a model that predicts points belong to (including the point ) have class B. In either case, the accuracy of the chosen model is smaller than . This situation explains the tradeoff between accuracy and standard adversarial accuracy when large is used. It originates from the overlapping adversary regions from the samples with different classes.
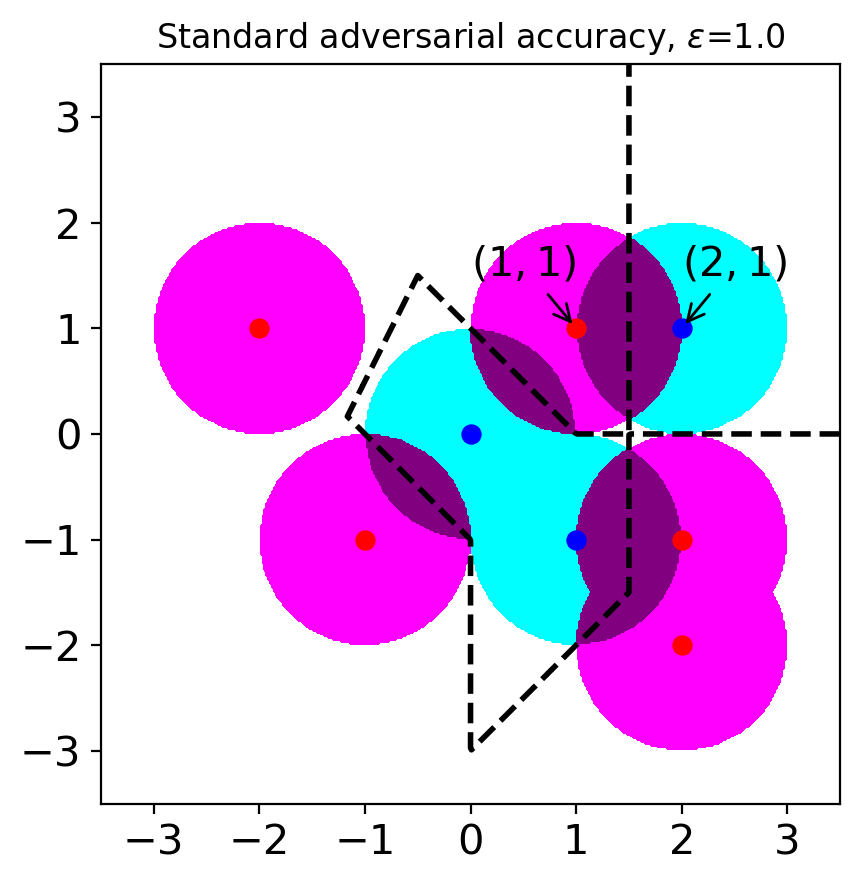
To avoid the tradeoff between accuracy and adversarial accuracy, one can use small values. Actually, a previous study has argued that commonly used values are small enough to avoid the tradeoff (Yang et al., 2020b). However, when small values are used, we can only analyze local robustness, and we need to ignore robustness beyond the chosen . For instance, let us consider our example when (see Figure 1(b)). In this case, we ignore robustness on . Models with local but without global robustness enable attackers to use large values to fool the models. Ghiasi et al. (2019) have experimentally shown that even models with certified local robustness can be attacked by attacks with large values. Note that their attack applies little semantic perturbations even though the perturbation norms measured by norms are large.
These limitations motivate us to find an alternative way to measure robustness. The contributions of this paper are as follows.
-
•
We propose Voronoi-epsilon adversarial accuracy (VAA) that avoids the tradeoff between accuracy and adversarial accuracy. This allows the adversary regions to scale to cover most of the input space without incurring a tradeoff. To our best knowledge, this is the first work to achieve this without an external classifier. (In Section A.3, we introduce formulas for adversary regions that can be used to estimate VAA.)
-
•
We explain the connection between SAA and VAA. We define global Voronoi-epsilon robustness as a limit of the Voronoi-epsilon adversarial accuracy. We show that a nearest neighbor (1-NN) classifier maximizes global Voronoi-epsilon robustness.
2 Voronoi-Epsilon Adversarial Accuracy (VAA)
Our approach restricts the allowed region of the perturbations to avoid the tradeoff originating from the definition of standard adversarial accuracy. This is achieved without limiting the magnitude of and without using an external model. We want to have the following property to avoid the tradeoff.
| (1) |
When Property (1) holds for the adversary region, we no longer have the tradeoff as for . In other words, a clean sample cannot be an adversarial example originating from another clean sample. We propose a new adversary called a Voronoi-epsilon adversary that combines the Voronoi-adversary introduced by Khoury & Hadfield-Menell (2019) with an -ball-based adversary. This adversary is constrained to an adversary region where is the (open) Voronoi cell around a data point . consists of every point in that is closer than any . Then, Property (1) holds as for .
Based on a Voronoi-epsilon adversary, we define Voronoi-epsilon adversarial accuracy (VAA).
Definition 3 (Voronoi-epsilon adversarial accuracy).
When a Voronoi-epsilon adversary is used for the adversary, we refer to the adversarial accuracy as Voronoi-epsilon adversarial accuracy (VAA) . For VAA, we denote as .
Note that VAA is only defined on a fixed set of data points . As we do not know the distribution , in practice, the fact that VAA is not defined on the whole input space does not matter.
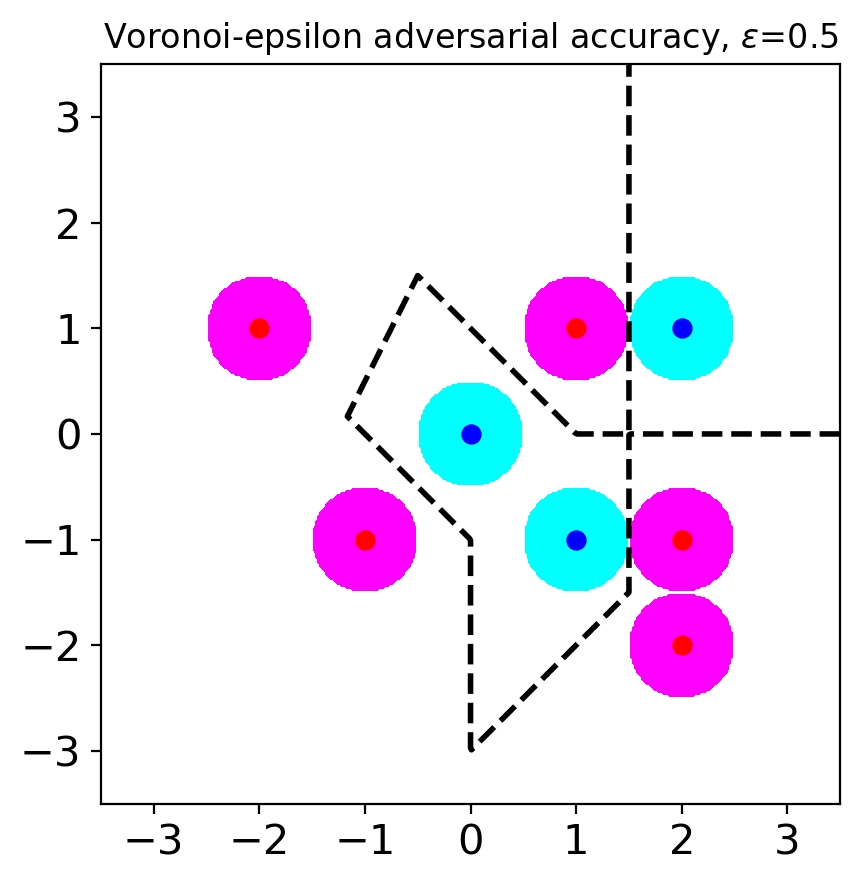
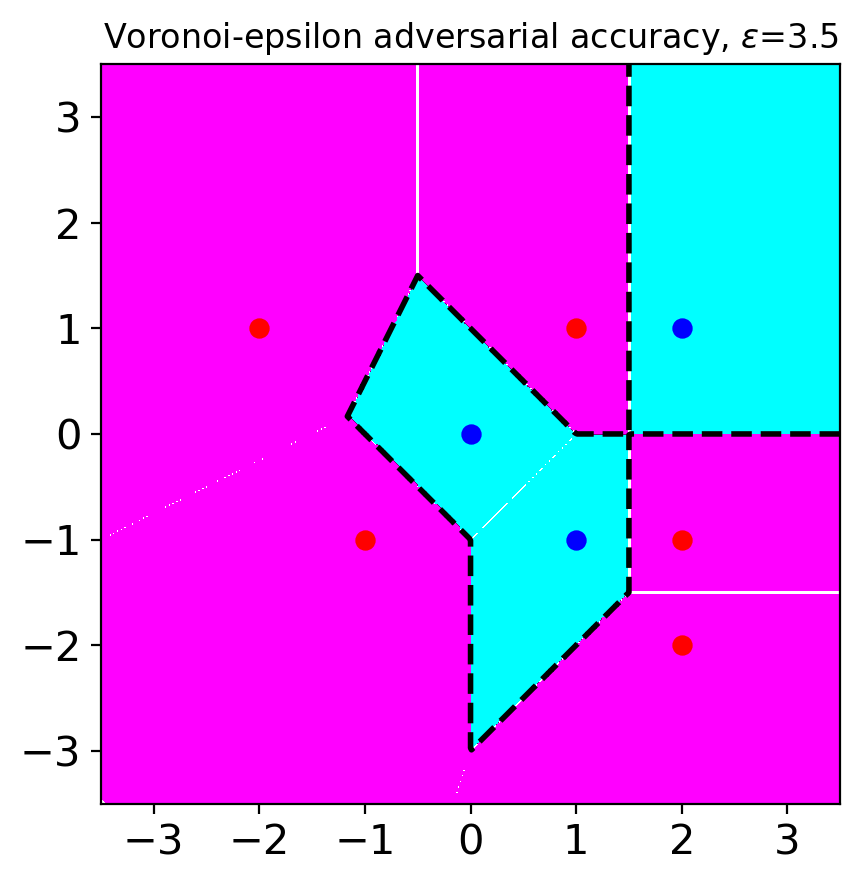
Figure 2 shows the adversary regions for VAA with varying values. When , the regions are same with SAA except for the points and . Even when is large (), there is no overlapping adversary region, which was a source of the tradeoff in SAA. Therefore, when we choose a robust model based on VAA, we can get a model that is both accurate and robust. Figure 2(c) shows the single nearest neighbor (1-NN) classifier would maximize VAA. The adversary regions cover most of the points in for large .
Observation 1.
Let be the nearest distance of the data point pairs, i.e., . Then, the following equivalence holds.
| (2) |
Observation 1 shows that VAA is equivalent to SAA for sufficiently small values. This indicates that VAA is an extension of SAA that avoids the tradeoff when is large. The proof of the observation is in Section A.5. We point out that equivalent findings were also mentioned in Yang et al. (2020a; b); Khoury & Hadfield-Menell (2019).
As explained in Section 1.3.1, studying the local robustness of classifiers has a limitation. Attackers can attack models with only local robustness by using large values. The absence of a tradeoff between accuracy and VAA enables us to increase values and to study global robustness. We define a measure for global robustness using VAA.
Definition 4 (Global Voronoi-epsilon robustness).
Global Voronoi-epsilon robustness is defined as
Global Voronoi-epsilon robustness considers the robustness of classifiers for most points in (all points except for Voronoi boundary , which is the complement set of the unions of Voronoi cells.). We derive the following theorem from global Voronoi-epsilon robustness.
Theorem 1.
A single nearest neighbor (1-NN) classifier maximizes global Voronoi-epsilon robustness on training data. 1-NN classifier is a unique classifier that satisfies this except for Voronoi boundary .
Note that Theorem 1 only holds for exactly the same data under the exclusive class condition as mentioned in the problem settings Problem setting. It does not take into account generalization. The proof of the theorem is in A.6.
3 Discussion
In this work, we address the tradeoff between accuracy and adversarial robustness by introducing the Voronoi-epsilon adversary. Another way to address this tradeoff is to use a Bayes optimal classifier (Suggala et al., 2019; Kim & Wang, 2020). Since this is not available in practice, a reference model must be used as an approximation. In that case, the meaning of adversarial robustness is dependent on the choice of the reference model. VAA removes the need for a reference model by using the data point set and the distance metric to construct adversary. This is in contrast to Khoury & Hadfield-Menell (2019) who used Voronoi cell-based constraints (without -balls) for an adversarial training purpose, but not for measuring adversarial robustness.
By avoiding the tradeoff with VAA, we can extend the study of local robustness to global robustness. Also, Theorem 1 implies that VAA is a measure of agreement with the 1-NN classifier. For sufficiently small values, SAA is also a measure of agreement with the 1-NN classifier because SAA is equivalent to VAA as in Observation 1. This implies that many defenses (Goodfellow et al., 2014; Madry et al., 2017; Zhang et al., 2019; Wong & Kolter, 2018; Cohen et al., 2019) with small values unknowingly try to make locally the same predictions with a 1-NN classifier.
In our analysis, we do not consider generalization, and robust models are known to often generalize poorly (Raghunathan et al., 2020). The close relationship between adversarially robust models and the 1-NN classifier revealed by Theorem 1 highlights a possible avenue to explore this phenomenon.
Acknowledgments
We thank Dr. Nils Olav Handegard, Dr. Yi Liu, and Jungeum Kim for the helpful feedback. We also thank Dr. Wieland Brendel for the helpful discussions.
References
- Biggio et al. (2013) Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nelson, Nedim Šrndić, Pavel Laskov, Giorgio Giacinto, and Fabio Roli. Evasion attacks against machine learning at test time. In Joint European conference on machine learning and knowledge discovery in databases, pp. 387–402. Springer, 2013.
- Cohen et al. (2019) Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. In International Conference on Machine Learning, pp. 1310–1320. PMLR, 2019.
- Dohmatob (2018) Elvis Dohmatob. Limitations of adversarial robustness: strong No Free Lunch Theorem. arXiv:1810.04065 [cs, stat], October 2018. URL http://arxiv.org/abs/1810.04065. arXiv: 1810.04065.
- Ghiasi et al. (2019) Amin Ghiasi, Ali Shafahi, and Tom Goldstein. Breaking certified defenses: Semantic adversarial examples with spoofed robustness certificates. In International Conference on Learning Representations, 2019.
- Goodfellow et al. (2014) Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Khoury & Hadfield-Menell (2019) Marc Khoury and Dylan Hadfield-Menell. Adversarial training with Voronoi constraints. arXiv preprint arXiv:1905.01019, 2019.
- Kim & Wang (2020) Jungeum Kim and Xiao Wang. Sensible adversarial learning, 2020. URL https://openreview.net/forum?id=rJlf_RVKwr.
- Madry et al. (2017) Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- Raghunathan et al. (2020) Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John Duchi, and Percy Liang. Understanding and mitigating the tradeoff between robustness and accuracy. arXiv preprint arXiv:2002.10716, 2020.
- Suggala et al. (2019) Arun Sai Suggala, Adarsh Prasad, Vaishnavh Nagarajan, and Pradeep Ravikumar. Revisiting adversarial risk. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 2331–2339. PMLR, 2019.
- Szegedy et al. (2013) Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- Tsipras et al. (2018) Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy. arXiv preprint arXiv:1805.12152, 2018.
- Wong & Kolter (2018) Eric Wong and Zico Kolter. Provable defenses against adversarial examples via the convex outer adversarial polytope. In International Conference on Machine Learning, pp. 5286–5295. PMLR, 2018.
- Yang et al. (2020a) Yao-Yuan Yang, Cyrus Rashtchian, Yizhen Wang, and Kamalika Chaudhuri. Robustness for non-parametric classification: A generic attack and defense. In International Conference on Artificial Intelligence and Statistics, pp. 941–951. PMLR, 2020a.
- Yang et al. (2020b) Yao-Yuan Yang, Cyrus Rashtchian, Hongyang Zhang, Russ R Salakhutdinov, and Kamalika Chaudhuri. A closer look at accuracy vs. robustness. Advances in Neural Information Processing Systems, 33, 2020b.
- Zhang et al. (2019) Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric P Xing, Laurent El Ghaoui, and Michael I Jordan. Theoretically principled trade-off between robustness and accuracy. arXiv preprint arXiv:1901.08573, 2019.
Appendix A Appendix
A.1 List of Notation
| A perturbation budget. | |
| The dimension of the input space. | |
| The nonempty input space. . | |
| The set of possible classes. | |
| A corresponding class of a clean data point . | |
| The joint distribution. . | |
| The set of data points. We assume it is a nonempty finite set. | |
| The classifier that we want to analyze. . | |
| A classification loss of the classifier provided an input and a label . | |
| An adversary region which is an allowed region of the perturbations for a data point . It can be depend on a perturbation budget . | |
| The indicator function. and . | |
| Adversarial accuracy. | |
| The distance metric that is used for measuring adversarial robustness. It is not limited to norms. It can be a learned metric or more complex distance. | |
| An -ball around a sample . Mathematically, . | |
| The allowed regions of the perturbations for standard adversarial accuracy around a data point . . | |
| Standard adversarial accuracy using a perturbation budget . In other words, the adversarial accuracy when the adversary region is . | |
| The (open) half-space closer to than . Mathematically, . | |
| The (open) Voronoi cell of a sample . Mathematically, . | |
| The allowed regions of the perturbations for Voronoi-epsilon adversarial accuracy around a data point . . | |
| The Voronoi-epsilon adversarial accuracy using perturbation budget . In other words, the adversarial accuracy when the adversary region is . | |
| The complement set of a set . For , . | |
| Voronoi boundary based on . It is the complement set of the unions of Voronoi cells. . | |
| Global Voronoi-epsilon robustness. | |
| The number of data points. | |
| The allowed regions of the perturbations for the lower bound of Voronoi-epsilon adversarial accuracy around a data point . When , . When , . |
| The allowed regions of the perturbations for the upper bound of Voronoi-epsilon adversarial accuracy around a sample . When , . When , . | |
| The lower bound of Voronoi-epsilon adversarial accuracy using perturbation budget . It is defined as the adversarial accuracy when the adversary region for a data point is . | |
| The upper bound of Voronoi-epsilon adversarial accuracy using perturbation budget . It is defined as the adversarial accuracy when the adversary region for a data point is . |
A.2 List of Abbreviation
| AA | Adversarial accuracy. |
| SAA | Standard adversarial accuracy. |
| VAA | Voronoi-epsilon adversarial accuracy. |
| 1-NN | Single nearest neighbor. |
| LB | Lower bound. |
| UB | Upper bound. |
A.3 Adversary Region
Voronoi-epsilon adversarial accuracy (VAA) uses . We introduce upper and lower bounds of using nearest neighbors of a data point . These bounds enable to calculate approximate upper and lower bounds of VAA.
Lemma 1.
When is the number of data points, let be the sorted neighbors of a data point . Mathematically, . Then, the following relations hold for a fixed number . {fleqn}
| (3) |
| (4) |
| (5) |
When , we can calculate VAA using relations (3) and (4). The relation (5) of Lemma 1 enables to calculate the lower and upper bound of VAA when . When , we denote the leftmost set in the relation (5) as and the rightmost set as . (When , we set .) Figure 3 visualizes the relationship . The proof of the lemma is in Section A.4.
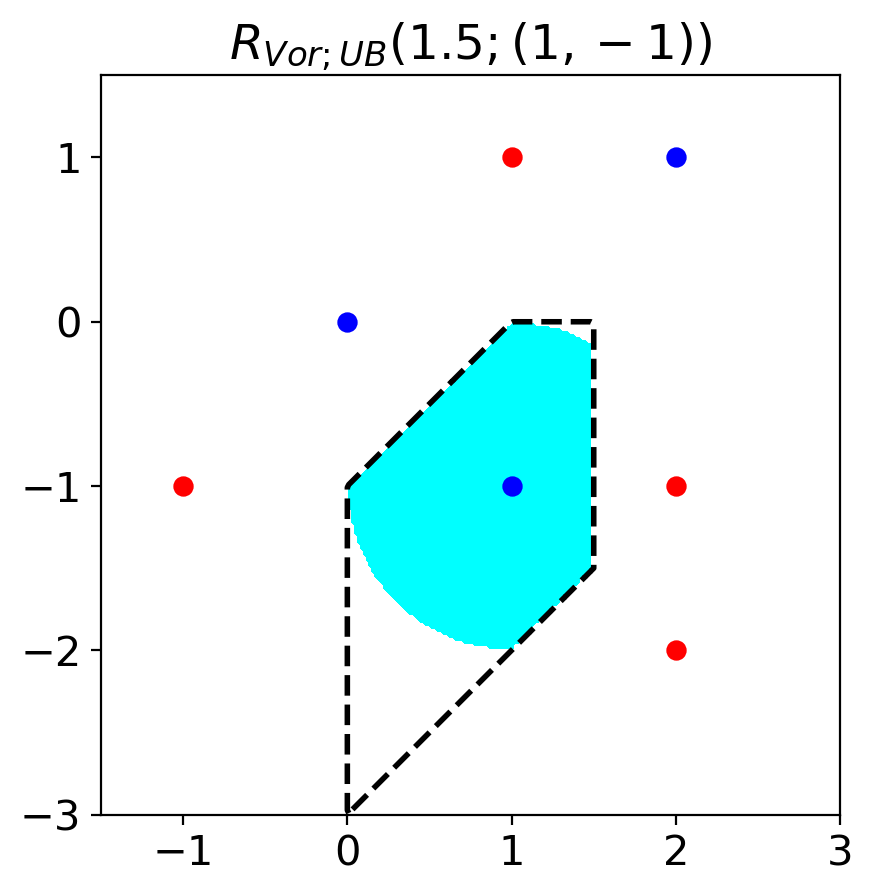
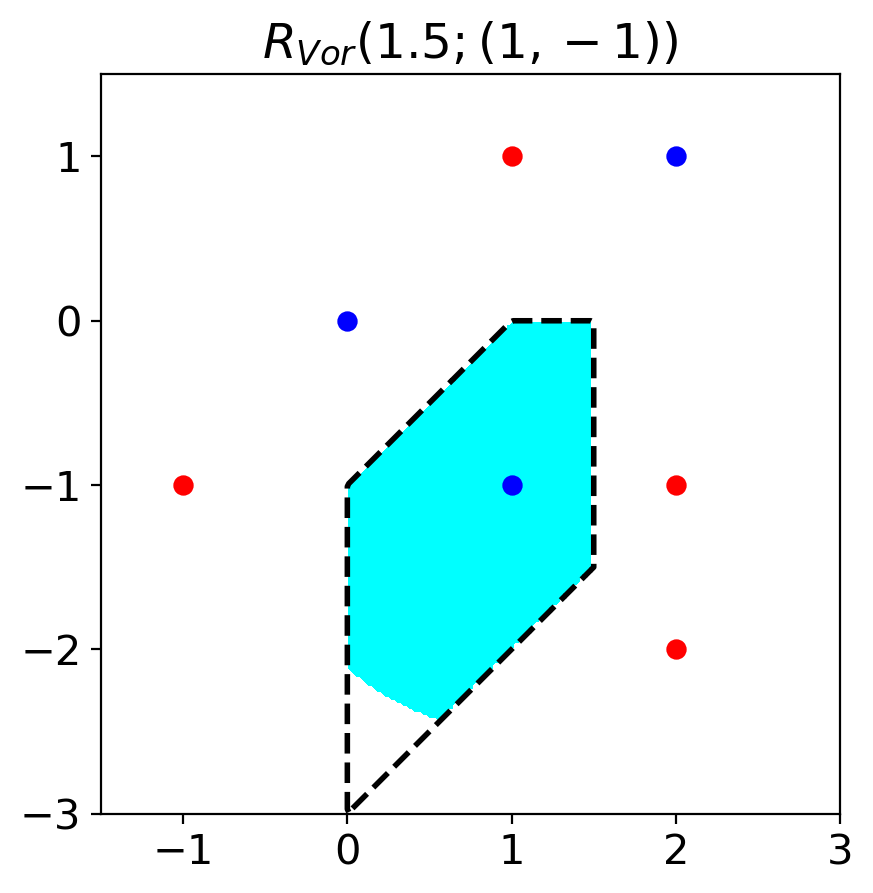
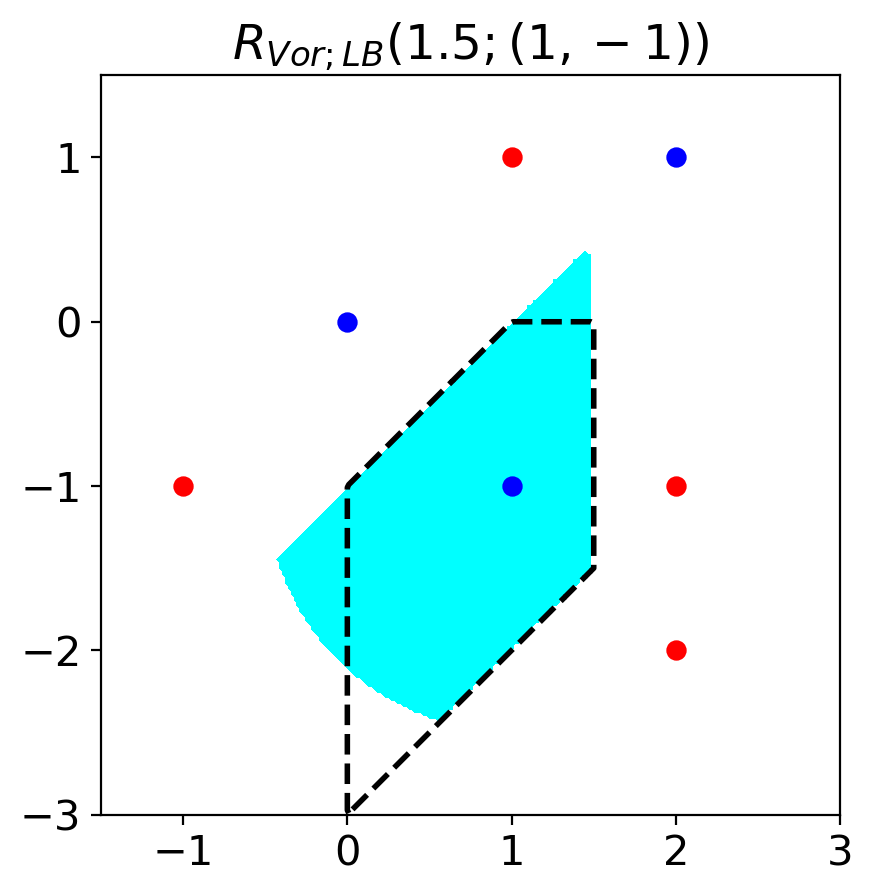
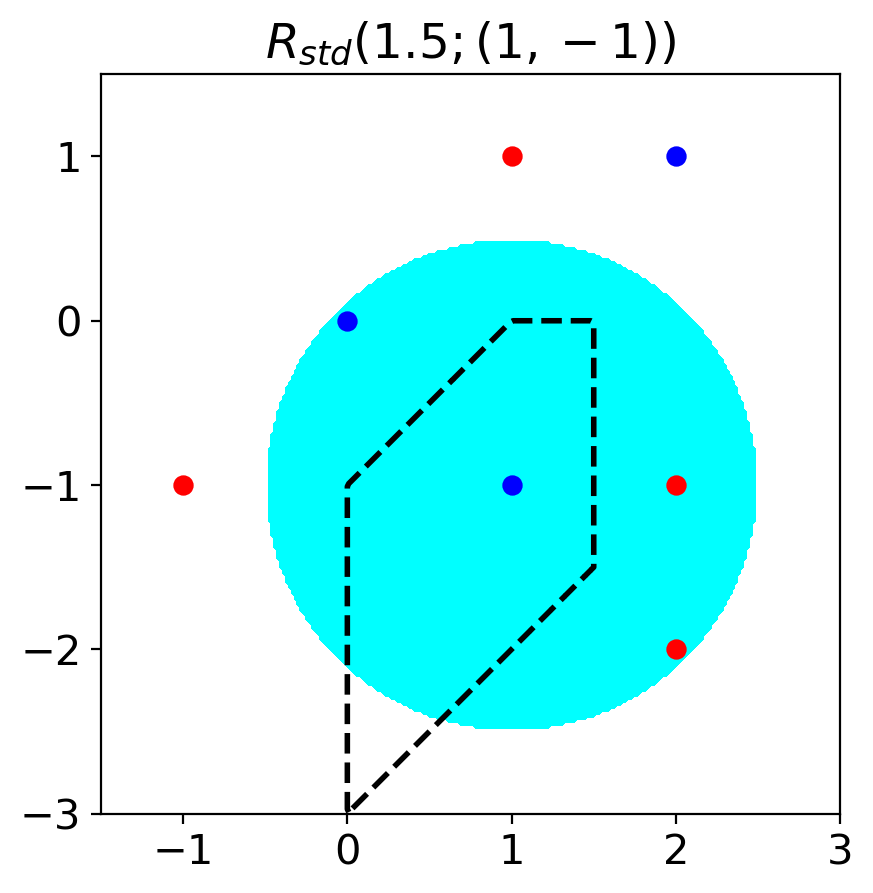
Proposition 1.
is defined as the adversarial accuracy when the allowed regions of perturbation is . is defined as the adversarial accuracy when the allowed regions of perturbation is . Then, the following relation holds.
| (6) |
The proof of Proposition 1 is in Section A.5.
A.4 Proof of Lemma 1
Proof.
Relation (3)
First, we consider when .
Let . Then, .
.
Due to the triangle inequality, .
When we combine the above inequalities, .
Then, . Thus, .
Hence, and .
Relation (4)
Now, we consider when .
is obvious as .
We only need to proof .
Let . Then, .
for .
Due to the triangle inequality, .
When we combine the above inequalities, for
.
Then, for .
We got and we proved .
Relation (5)
Finally, we consider when .
(i)
:
Let . Then, .
Through similar process used in the proof of Relation (3) and Relation (4), we have for .
Then, for .
We got and we proved (i).
(ii)
:
It is obvious as and .
∎
A.5 Proof of Observation 1 and Proposition 1
Proof.
Observation 1
.
When , . Thus, due to the relation (3) in Lemma 1.
Then,
is same with as .
Proposition 1
First, we consider a data point and let be the sorted neighbors of .
Let , , , and .
(i) When :
from the definition.
from the relations (3) and (4).
Then, as .
(ii) When :
from the relation (5).
from the definition.
Then, as .
From (i) and (ii), .
We finished the proof of the relation (6)
as , , , and .
∎
A.6 Proof of Theorem 1
To proof Theorem 1, we introduce the following lemma.
Lemma 2.
By changing and , that satisfies can fill up except for . In other words, .
Proof.
Lemma 2
Let .
.
.
Let . Then, and .
.
We proved .
∎
Now, we proof Theorem 1.
Proof.
Part 1
First, we prove that a 1-NN classifier maximizes global Voronoi-epsilon robustness. We denote the 1-NN classifier as and calculate its global Voronoi-epsilon robustness.
For a data point , let .
.
As , is unique nearest data point in and thus .
When , .
. Thus, takes the maximum global Voronoi-epsilon robustness .
Part 2
Now, we prove that if maximizes global Voronoi-epsilon robustness, then becomes the 1-NN classifier except for Voronoi boundary .
Let be a function that maximizes global Voronoi-epsilon robustness.
From the last part of the part 1, when we calculate global Voronoi-epsilon robustness of , it should satisfy the equation .
For a data point and , .
Thus, for a data point and , where and .
for . In other words, is a decreasing function.
( for a , then it is a contradictory to as is a decreasing function.).
where .
As the calculation is based on the finite set , () where .
As are the worst case adversarially perturbed samples, i.e., samples that output mostly
different from , where .
By changing and , that satisfies can fill up except for
( Lemma 2). Hence, is equivalent to except
for Voronoi boundary .
∎