rrred \addauthorjwbrown \addauthorarred \addauthorbcblue \addauthordmtblue
Mean Estimation in Banach Spaces
Under Infinite Variance and Martingale Dependence
Abstract
We consider estimating the shared mean of a sequence of heavy-tailed random variables taking values in a Banach space. In particular, we revisit and extend a simple truncation-based mean estimator by Catoni and Giulini. While existing truncation-based approaches require a bound on the raw (non-central) second moment of observations, our results hold under a bound on either the central or non-central th moment for some . In particular, our results hold for distributions with infinite variance. The main contributions of the paper follow from exploiting connections between truncation-based mean estimation and the concentration of martingales in 2-smooth Banach spaces. We prove two types of time-uniform bounds on the distance between the estimator and unknown mean: line-crossing inequalities, which can be optimized for a fixed sample size , and non-asymptotic law of the iterated logarithm type inequalities, which match the tightness of line-crossing inequalities at all points in time up to a doubly logarithmic factor in . Our results do not depend on the dimension of the Banach space, hold under martingale dependence, and all constants in the inequalities are known and small.
1 Introduction
Mean estimation is perhaps the most important primitive in the statistician’s toolkit. When the data is light-tailed (perhaps sub-Gaussian, sub-Exponential, or sub-Gamma), the sample mean is the natural estimator of this unknown population mean. However, when the data fails to have finite moments, the naive plug-in mean estimate is known to be sub-optimal.
The failure of the plug-in mean has led to a rich literature focused on heavy-tailed mean estimation. In the univariate setting, statistics such as the thresholded/truncated mean estimator [40, 21], trimmed mean estimator [35, 29], median-of-means estimator [34, 22, 2], and the Catoni M-estimator [5, 42] have all been shown to exhibit favorable convergence guarantees. When a bound on the variance of the observations is known, many of these estimates enjoy sub-Gaussian rates of performance [26], and this rate gracefully decays when only a bound on the th central moment is known for some [3].
In the more challenging setting of multivariate heavy-tailed data, modern methods include the geometric median-of-means estimator [33], the median-of-means tournament estimator [28], and the truncated mean estimator [6]. We provide a more detailed account in Section 1.2.
Of the aforementioned statistics, the truncated mean estimator is by far the simplest. This estimator, which involves truncating observations to lie within an appropriately-chosen ball centered at the origin, is extremely computationally efficient and can be updated online, very desirable for applied statistical tasks. However, this estimator also possesses a number of undesirable properties. First, it is not translation invariant, with bounds that depend on the raw moments of the random variables. Second, it requires a known bound on the th moment of observations for some , thus requiring that the observations have finite variance. Third, bounds are only known in the setting of finite-dimensional Euclidean spaces — convergence is not understood in the setting of infinite-dimensional Hilbert spaces or Banach spaces.
The question we consider here is simple: are the aforementioned deficiencies fundamental to truncation-based estimators, or can they be resolved with an improved analysis? The goal of this work is to show that the latter is true, demonstrating how a truncation-based estimator can be extended to handle fewer than two central moments in general classes of Banach spaces.
1.1 Our Contributions
In this work, we revisit and extend a simple truncation-based mean estimator due to Catoni and Giulini [6]. Our estimator works by first using a small number of samples to produce a naive mean estimate, say through a sample mean. Then, the remaining sequence of observations is truncated to lie in an appropriately-sized ball centered at this initial mean estimate. These truncated samples are then averaged to provide a more robust estimate of a heavy-tailed mean.
While existing works study truncation-based estimators via PAC-Bayesian analyses [6, 11, 24], we find it more fruitful to study these estimators using tools from the theory of Banach space-valued martingales. In particular, by proving a novel extension of classical results on the time-uniform concentration of bounded martingales due to Pinelis [36, 37], we are able to greatly improve the applicability of truncation-based estimators. In particular, our estimator and analysis improves over that in [6] in the following ways:
-
1.
The analysis holds in arbitrary 2-smooth Banach spaces instead of just finite-dimensional Euclidean space. This not only includes Hilbert spaces but also the commonly-studied and spaces for .
-
2.
Our results require only a known upper bound on the conditional central th moment of observations for some , and are therefore applicable to data lacking finite variance. Existing bounds for truncation estimators, on the other hand, require a bound on the non-central second moment.
-
3.
Our bounds are time-uniform and hold for data with a martingale dependence structure. We prove two types of inequalities: line-crossing inequalities, which can be optimized for a target sample size, and non-asymptotic law of the iterated logarithm (LIL) type inequalities, which match the tightness of the boundary-crossing inequalities at all times simultaneously up to a doubly logarithmic factor in the sample size.
-
4.
We show that our estimator exhibits strong practical performance, and that our derived bounds are tighter than existing results in terms of constants. We run simulations which demonstrate that, for appropriate truncation diameters, the distance between our estimator and the unknown mean is tightly concentrated around zero.
Informally, if we assume that the central th moments of all observations are conditionally bounded by , and we let denote our estimate after samples, then we show that
As far as we are aware, the only other estimator to obtain the same guarantee in a similar setting is Minsker’s geometric median-of-means [33]. (While he doesn’t state this result explicitly, it is easily derivable from his main bound—see Appendix B for the details.) Minsker also works in a Banach space, but assumes that it is separable and reflexive, whereas we will assume that it is separable and smooth. While we obtain the same rates, we feel that our truncation-style estimator has several benefits over geometric median-of-means. First, it is computationally lightweight and easy to compute exactly. Second, our line-crossing inequalities do not require as many tuning parameters to instantiate (eg choice of , , or ; see Section B). Third, we handle martingale dependence while Minsker does not. Finally, our analysis is significantly different from Minsker’s—and from existing analyses of other estimators under heavy-tails—and may be of independent interest.
1.2 Related Work
Section 1.1 discussed the relationship between this paper and the two most closely related works of Catoni and Giulini [6] and Minsker [33]. We now discuss how our work is related to the broader literature, none of which addresses our problem directly, but tackles simpler special cases of our problem (e.g., assuming more moments or boundedness, or with observations in Hilbert spaces or Euclidean spaces).
Heavy-tailed mean estimation under independent observations.
Truncation-based (also called threshold-based) estimators have a rich history in the robust statistics literature, dating back to works from Tukey, Huber, and others [21, 40]. These estimators have either been applied in the univariate setting or in as in Catoni and Giulini [6]. A related estimator is the so-called trimmed-mean estimator, which removes extreme observations and takes the empirical mean of the remaining points [35, 29]. For real-valued observations with finite variance, the trimmed-mean has sub-Gaussian performance [35].
Separately, Catoni and Giulini [5] introduce an approach for mean estimation in based on M-estimators with a family of appropriate influence functions. This has come to be called “Catoni’s M-estimator.” It requires at least two moments and fails to obtain sub-Gaussian rates. It faces the the additional burden of being less computationally efficient. A series of followup works have improved this estimator in various ways: Chen et al. [7] extend it to handle a -th moment for for real-valued observations, Gupta et al. [15] refine and sharpen the constants, and Mathieu [32] studies the optimality of general M-estimators for mean estimation.
Another important line of work on heavy-tailed mean estimation is based on median-of-means estimators [34, 22, 2]. These estimators generally break a dataset into several folds, compute a mean estimate on each fold, and then compute some measure of central tendency amongst these estimates. For real-valued observations, Bubeck et al. [3] study a median-of-means estimator that holds under infinite variance. Their estimator obtains the same rate as ours and Minsker’s. Most relevant for our work is the result on geometric median-of-means due to Minsker [33], which can be used to aggregate several independent mean estimates in general separable Banach spaces. In Hilbert spaces, when instantiated with the empirical mean under a finite variance assumption, geometric median-of-means is nearly sub-Gaussian (see discussion in Section 1.1). We compare our threshold-based estimator extensively to geometric median-of-means in the sequel and demonstrate that we obtain the same rate of convergence.
Another important result is the multivariate tournament median-of-means estimator due to Lugosi and Mendelson [28]. For i.i.d. observations in with shared covariance matrix (operator) , then Lugosi and Mendelson [28] show this estimator can obtain the optimal sub-Gaussian rate of . However, this result requires the existence of a covariance matrix and does not extend to a bound on the -th moment for , which is the main focus of this work.
While the original form of the tournament median-of-means estimator was computationally inefficient (with computation hypothesized to be NP-Hard in a survey by Lugosi and Mendelson [26]), a computationally efficient approximation was developed by Hopkins [17], with followup work improving the running time [8]. Tournament median-of-means was extended to general norms in [27], though the authors note that this approach is still not computationally feasible. Median-of-means style approaches have also been extended to general metric spaces [20, 9]. Of the above methods, only the geometric median-of-means estimator can handle observations that lack finite variance.
Sequential concentration under martingale dependence.
Time-uniform concentration bounds, or concentration inequalities that are valid at data-dependent stopping times, have been the focus of significant recent attention [18, 19, 44]. Such results are often obtained by identifying an underlying nonnegative supermartingale and then applying Ville’s inequality [41], a strategy that allows for martingale dependence quite naturally. This approach is also used here. Wang and Ramdas [42] extend Catoni’s M-estimator to handle both infinite variance and martingale dependence in , while Chugg et al. [11] give a sequential version of the truncation estimator in , though they require a central moment assumption and finite variance. The analyses of both Catoni and Giulini [6] and Chugg et al. [11] rely on so-called “PAC-Bayes” arguments [4, 12]. Intriguingly, while we analyze a similar estimator, our analysis avoids such techniques and is much closer in spirit to Pinelis-style arguments [36, 37].
Howard et al. [18, 19] provide a general collection of results on time-uniform concentration for scalar processes, which in particular imply time-uniform concentration results for some heavy-tailed settings (e.g. symmetric observations). Likewise, Whitehouse et al. [44] provide a similar set of results in . While interesting, we note that these results differ from our own in that they are self-normalized, or control the growth of a process appropriately normalized by some variance proxy (here a mixture of adapted and predictable covariance). The results also don’t apply when only a bound on the th moment is known, and the latter set of results have explicit dependence on the ambient dimension .
Concentration in Hilbert and Banach Spaces.
There are several results related to concentration in infinite-dimensional spaces. A series of works has developed self-normalized, sub-Gaussian concentration bounds in Hilbert spaces [43, 1, 10] based on the famed method of mixtures [13, 14]. These results have not been extended to more general tail conditions. Significant progress has been made on the concentration of bounded random variables in smooth and separable Banach spaces. Pinelis [36, 37] presented a martingale construction for bounded observations, thus enabling dimension-free Hoeffding and Bernstein inequalities. Dimension-dependence is replaced by the smoothness parameter of the Banach space, which for most practical applications (in Hilbert spaces, say) equals one. These results were strengthened slightly by Howard et al. [18]. Recently, Martinez-Taboada and Ramdas [31] gave an empirical-Bernstein inequality in Banach spaces, also using a Pinelis-like construction. Our work adds to this growing literature by extending Pinelis’ tools to the heavy-tailed setting.
1.3 Preliminaries
We introduce some of the background and notation required to state our results. We are interested in estimating the shared, conditional mean of a sequence of random variables living in some separable Banach space . Recall that a Banach space is a complete normed vector space; examples include Hilbert spaces, sequence spaces, and spaces of functions. We make the following central assumption.
Assumption 1.
We assume are a sequence of -valued random variables adapted to a filtration such that
-
(1)
, for all and some unknown , and
-
(2)
for some known constants and .
The martingale dependence in condition (1) above is weaker than the traditional i.i.d. assumption, requiring only a constant conditional mean. This is useful in applications such as multi-armed bandits, where we cannot assume that the next observation is independent of the past. Meanwhile, condition (2) allows for infinite variance, a weaker moment assumption than past works studying concentration of measure in Banach spaces (e.g., [33, 36, 37]). In Appendix C we replace condition (2) with a bound on the raw moment (that is, ) for easier comparison with previous work. We note that other works studying truncation-based estimators have exclusively considered the setting where observations admit covariance matrices [11, 6, 26]. We focus on in this work, but it is likely our techniques could be naturally extended to the setting. We leave this as interesting future work.
In order obtain concentration bounds, we must assume the Banach space is reasonably well-behaved. This involves assuming that is it both separable and smooth. A space is separable if it contains a countable, dense subset, and a real-valued function is -smooth if, for all , , , and
| (1.1) |
We assume that the norm is smooth in the above sense.
Assumption 2.
We assume that the Banach space is both separable and -smooth, meaning that the norm satisfies (1.1).
Assumption 2 is common when studying Banach spaces [36, 37, 18, 31]. We emphasize that is not akin to the dimension of the space. For instance, infinite-dimensional Hilbert spaces have and and spaces have for . Thus, bounds which depend on are still dimension-free.
Notation and background.
For notational simplicity, we define the conditional expectation operator to be for any . If is some stochastic process, we denote the -th increment as for any . For any process or sequence , denote by the first values: . We say the process is predictable with respect to filtration , if is -measurable for all . Our analysis will make use of both the Fréchet and Gateaux derivatives of functions in a Banach space. We do not define these notions here but instead refer to Ledoux and Talagrand [25].
Outline.
Section 2 provides statements of the main results. Our main result, Theorem 2.1, is a general template for obtaining bounds (time-uniform boundary-crossing inequalities in particular) on truncation-style estimators. Corollary 2.2 then instantiates the template with particular parameters to obtain tightness for a fixed sample size. Section 3 is dedicated to the proof of Theorem 2.1. Section 4 then uses a technique known as “stitching” to extend our line-crossing inequalities to bounds which shrink to zero over time at an iterated logarithm rate. Finally, Section 5 provides several numerical experiments demonstrating the efficacy of our proposed estimator in practice.
2 Main Result
Define the mapping
| (2.1) |
Clearly, is just the projection of onto the unit ball in . Likewise, is the projection of onto the ball of radius in . We note that the truncated observations are themselves random variables, which are adapted to the underlying filtration .
As we discussed in Section 1.1, previous analyses of truncation-style estimators have relied on a bound on the raw second moment. To handle a central moment assumption, we will center our estimator around a naive mean estimate which has worse guarantees but whose effects wash out over time.
To formalize the above, our estimate of at time will be
| (2.2) |
where is a naive mean estimate formed using the first samples and is some fixed hyperparameter. Defining when , we observe that is the usual truncation estimator, analyzed by Catoni and Giulini [6] in the fixed-time setting and Chugg et al. [11] in the sequential setting. To state our result, define
| (2.3) |
which depends on the Holder conjugate of . Note that for all . In fact, , , and is decreasing in . We also define the constant
| (2.4) |
which depends on the geometry and smoothness of the Banach space . In a Hilbert space (for which ), the variance of our supermartingale increments can be more easily bounded. If the norm is not induced by an inner product, then suffers an extra factor of four. Note that .
Our main result is the following template for bounding the deviations of assuming some sort of concentration of around .
Theorem 2.1 (Main result).
Let be random variables satisfying Assumption 1 which lie in some Banach space satisfying Assumption 2. Suppose we use the first samples to construct which satisfies, for any ,
| (2.5) |
for some function . Fix any . Decompose as where . Then, for any , with probability , simultaneously for all , we have:
| (2.6) |
The guarantee provided by Theorem 2.1 is a line-crossing inequality in the spirit of [18]. That is, if we multiply both sides by , it provides a time-uniform guarantee on the probability that the left hand side deviation between and ever crosses the line parameterized by the right hand side of (2.6). If we optimize the value of for a particular sample size , the bound will remain valid for all sample sizes, but will be tightest at and around . To obtain bounds that are tight for all simultaneously, one must pay an additional iterated logarithmic price in . To accomplish this, Section 4 will deploy a carefully designed union bound over geometric epochs—a technique known as “stitching” [19]. However, for practical applications where the sample size is known in advance, we recommend Theorem 2.1 and its corollaries.
Next we provide a guideline on choosing in Theorem 2.1. The proof is straightforward but is provided in Appendix A for completeness.
Corollary 2.2.
In Theorem 2.1, consider taking
| (2.7) |
Then, with probability at least , we have
In particular, as long as , and , we have
| (2.8) |
This is the desired rate per the discussion in Section 1.1, matching the rate of other estimators which hold under infinite variance. In particular, it matches the rates of Bubeck et al. [3] in scalar settings and Minsker [33] in Banach spaces.
Now let us instantiate Theorem 2.1 when we take to be either the sample mean or Minsker’s geometric median-of-means. The latter provides a better dependence on but at an additional computational cost. As we’ll see in Section 5, this benefit is apparent for small sample sizes, but washes out as grows. The details of the proof can be found in Appendix A.
Corollary 2.3.
Let satisfy Assumption 2 and satisfy Assumption 1. For some , let be the empirical mean of the first observations. Given , decompose it as for any . Then, with probability ,
| (2.9) |
where . If, on the other hand, is the geometric median-of-means estimator with appropriate tuning parameters, then with probability ,
| (2.10) |
3 Proof of Theorem 2.1
We will prove a slightly more general result that reduces to Theorem 2.1 in a special case. Throughout this section, fix two -predictable sequences, and . Define
| (3.1) |
If we take to be constant and to be -measurable, then . We will make such a substitution at the end of this analysis to prove the desired result. However, working with the more general process (2.2) has advantages. In particular, it allows us to consider sequences of predictable mean-estimates, if desired.
Our preliminary goal is to find a process such that the process
| (3.2) |
is upper bounded by a nonnegative supermartingale; in other words; in recent parlance, it is an e-process [38]. Applying Ville’s inequality will then give us a time-uniform bound on the deviation of the process in terms of . We will let
| where | (3.3) |
is a weighted measure of the deviation of the naive estimates from . Since it is difficult to reason about the difference between and directly, we introduce the proxy
| (3.4) |
and argue about and . We then bound the difference using the triangle inequality.
3.1 Step 1: Bounding
We need the following analytical property of , which will be useful in bounding the truncation error with fewer than two moments. We note that the following lemma was used by Catoni and Giulini [6] for . We prove the result for .
Lemma 3.1.
For any and , we have that
Proof.
Fix . It suffices to show that for all . For the result is obvious. For , we need to do a bit of work. First, note that , and that both and are continuous. Further, we only have precisely when . Let this value of be . This immediately implies that for . To check the inequality for all , it suffices to check that . We verify this by direct computation. First, . Likewise, we have that . Taking ratios, we see that
proving the desired result. ∎
We can now proceed to bounding .
Lemma 3.2.
Let be a -valued random variable and suppose . Let be -predictable and be as in (3.4). Then:
Proof.
Since is predictable, we may treat it as some constant when conditioning on . Using Holder’s inequality, write
where . The second expectation on the right hand side can be bounded using Minkowski’s inequality and the fact that is convex for :
| (3.5) |
Next, by Lemma 3.1, we have for any .
In particular, selecting , we have
where as defined in (2.3). Piecing everything together, we have that
Therefore, recalling that , we have , which is the desired result. ∎
3.2 Step 2: Bounding
We can now proceed to bounding where
| (3.6) |
and is as in (3.4). Note that is a martingale with respect to . The following proposition is the most technical result in the paper. It follows from a modification of the proof of Theorem 3.2 in Pinelis [37], combined with a Bennett-type inequality for 2-smooth separable Banach spaces presented in Pinelis [37, Theorem 3.4]. We present the full result here, even those parts found in Pinelis’ earlier work, for the sake of completeness.
Proposition 3.3.
Proof.
Fix some and let . We first observe that
by definition of . Let . If is a Hilbert space with inner product (which induces ), then
Otherwise, we have
where the penultimate inequality uses that and the final inequality follows from Jensen’s inequality. Therefore, we can write
| (3.7) |
where if is induced by an inner product, and otherwise. We note that this extra factor of 4 is responsible for the two cases in the definition of in (2.4). Carrying on with the calculation, write
| (3.8) |
where the final inequality follows by the same argument used to prove (3.5) in Lemma 3.2. We have shown that the random variable is bounded and its second moment (conditioned on the past) can be controlled, which opens the door to Pinelis-style arguments (see Pinelis [37, Theorem 3.4] in particular). Define the function by
In principle, the norm function need not be smooth, and so the same applies to . However, Pinelis [37] proved that one may assume smoothness of the norm without loss of generality (see Pinelis [37, Remark 2.4]). Thus, a second order Taylor expansion yields
Observe that
where the first inequality follows from the proof of Theorem 3.2 in Pinelis [37] and Theorem 3 in Pinelis [36], and the second inequality is obtained in view of .
Next, by the chain rule, we have
where denotes the Gateaux derivative of with respect to at in the directon of . The final equality follows from the fact that is itself a martingale with respect to . Thus, leveraging that , we have
where (i) is obtained in view of , (ii) is obtained from (3.8) (and also using that in a Hilbert space), and (iii) follows from for all . Since was arbitrary, rearranging yields that the process defined by is a nonnegative supermartingale. Noting that yields the claimed result. ∎
3.3 Step 3: Bounding
We now combine Lemma 3.2 and Proposition 3.3 to write down an explicit form for the supermartingale in (3.2).
Lemma 3.4.
Let and be as in Proposition 3.3. Then, the process defined by
is bounded above by a nonnegative supermartingale with initial value .
Proof.
We are finally ready to prove Theorem 2.1, which follows as a consequence of the following result.
Proposition 3.5.
Proof.
Let where is as in Lemma 3.4. By Ville’s inequality (Section 1.3), . Let . By assumption, . Set so that . We take the sequence of predictable values in Lemma 3.4 to be constant and set for all . On the event we have for all . That is, with probability ,
| (3.11) |
and
| (3.12) |
Substituting (3.12) into (3.11) and dividing both sides by gives the desired result. ∎
4 Law of the Iterated Logarithm Rates
In the previous section, we derived a time-uniform, line-crossing inequality that controlled (with high probability) the deviation between a truncated mean estimator and the unknown mean. This inequality was parameterized by a scalar/truncation level , which, when optimized appropriately, could guarantee a width of with probability at least for a preselected sample size . However, in many settings, one may not know a target sample size in advance and may wish to observe the data sequentially and stop adaptively at a data-dependent stopping time.
To generalize our bound to an anytime-valid setting (i.e., one where the sample size is not known in advance and may be data-dependent), we use a technique known as stitching [19]. This involves deploying Theorem 2.1 once per (geometrically spaced) epoch, and then using a carefully constructed union bound to obtain coverage simultaneously for all sample sizes.
The idea is to apply Theorem 2.1 once per geometrically spaced epoch with different parameters and in each epoch. We then take a union bound over epochs. Due to the time-uniformity of Theorem 2.1, the resulting estimator can be updated within the epoch, not only at their boundaries. The bound depends on a “stitching function” which satisfies and a parameter which determines the geometric spacing of the epochs, which are the intervals . For simplicity we take .
Theorem 4.1 (Stitching).
A few words are in order before we prove Theorem 4.1. As we discussed above, the idea is to apply a different estimator in each epoch . That is, the number of observations we set aside for the naive estimate in epoch is . (One could replace by any where grows slower than .) The bound holds for all so that we avoid various trivialities about defining the naive estimate . Finally, note that to get iterated logarithm rates, can be any polynomial which satisfies (e.g., ).
Proof of Theorem 4.1.
We will apply Theorem 2.1 once in every epoch for . In epoch we apply the estimator , where is fixed. For any , Theorem 2.1 provides the guarantee that
where
| (4.3) |
(Here the two terms above have split into ). Let so that . Note that corresponds to the epoch in which belongs, i.e., . Therefore,
It remains to select so that decreases at the desired rate. Choose
where , , and . With this choice, (4.3) becomes
Now, since for , , and , we have
Further, and , so
Noticing that by the same reasoning, we have
as claimed. ∎
As was done with Theorem 2.1, one can instantiate Theorem 4.1 with particular estimators to achieve specific rates. For instance, if is the plug-in mean estimate, then we can take (see (A.1) in Appendix A for a formal argument) so . If, in addition, we take say for , we achieve a final rate of
| (4.4) |
which loses only an iterated logarithm factor compared to the line-crossing inequality presented in Section 2. For , this asymptotic width is optimal by the law of the iterated logarithm [16, 39]. For , such a law does not necessarily exist—it depends on whether the distribution is in the domain of partial attraction of a Gaussian [23, 30]. Thus, while we cannot claim asymptotic optimality in this case, we note that our result extends and compliments recent efforts to obtain confidence sequences with iterated logarithm rates to the case of infinite variance (e.g., [19, 42, 11]).
For the purposes of constructing time-uniform bounds in practice, it’s worth tracking the constants throughout the proof of Theorem 4.1. Doing so, we obtain a width of
| (4.5) |
where and .
5 Bound Comparison and Simulations
In the above sections, we argued that the truncated mean estimator, when appropriately optimized, could obtain a distance from the true mean of with high probability. In particular, this rate matched that of the geometric median-of-means estimator due to Minsker [33]. In this section, we study the empirical instead of theoretical performance of our bounds and estimator.
Comparing Tightness of Bounds
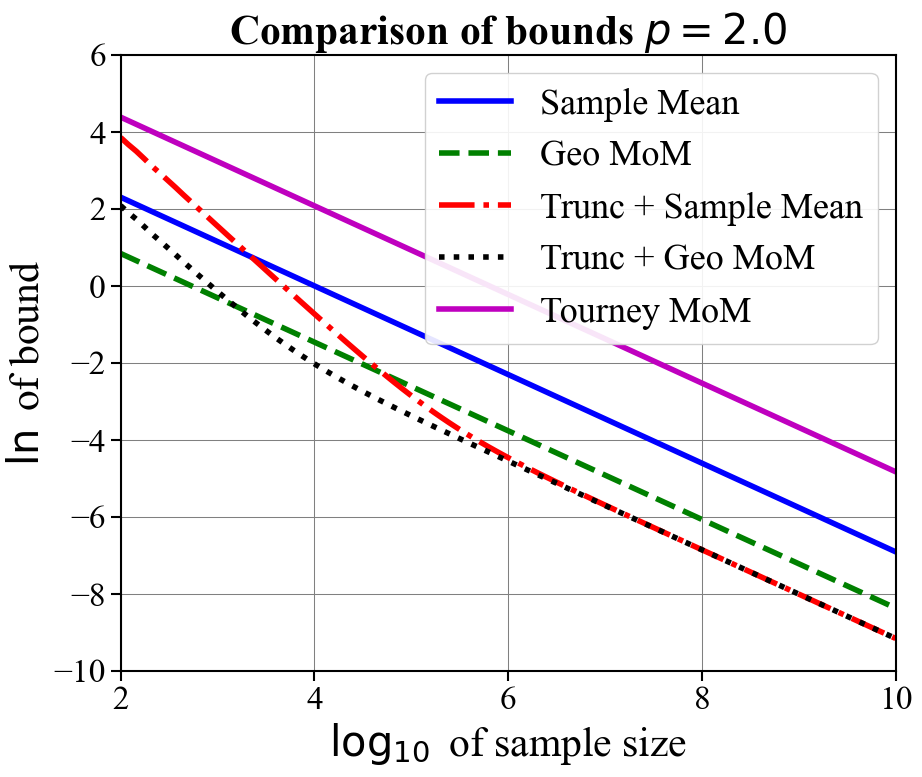
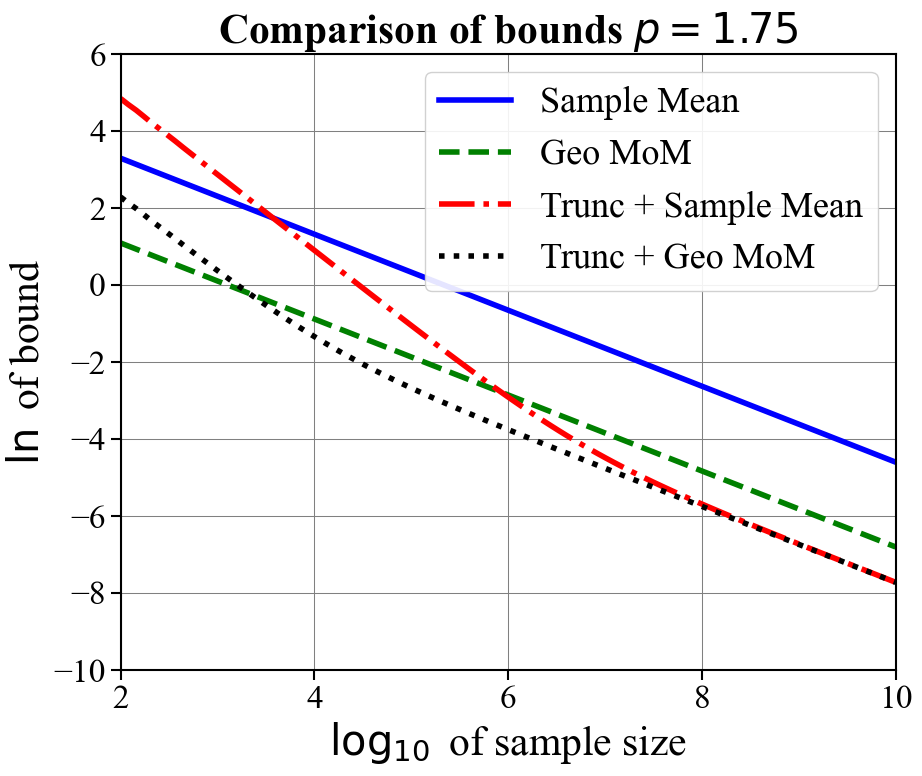
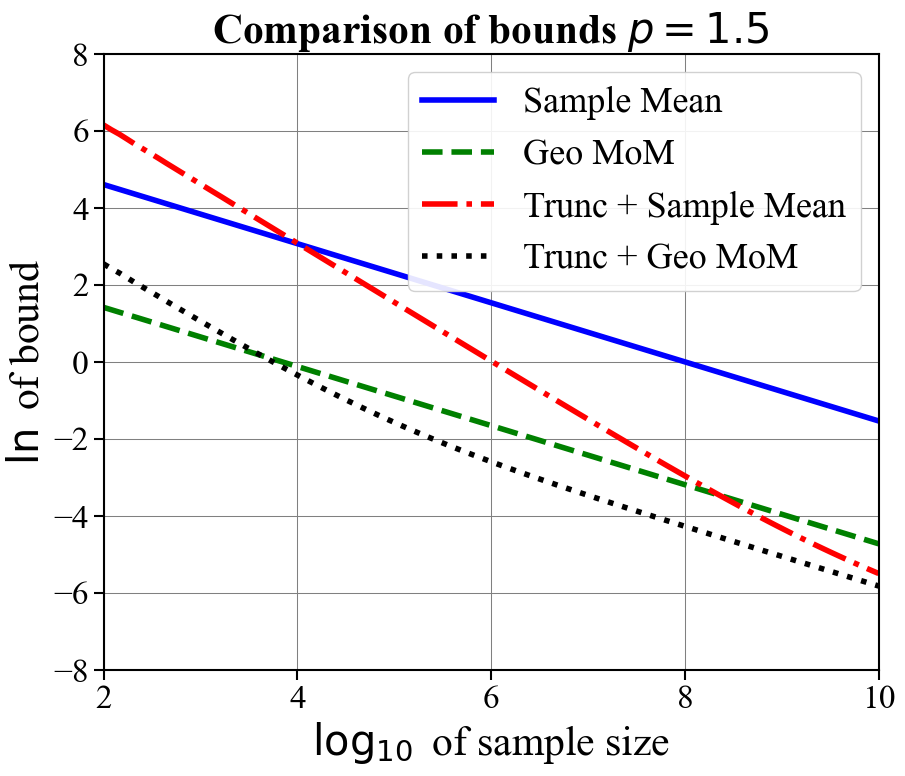
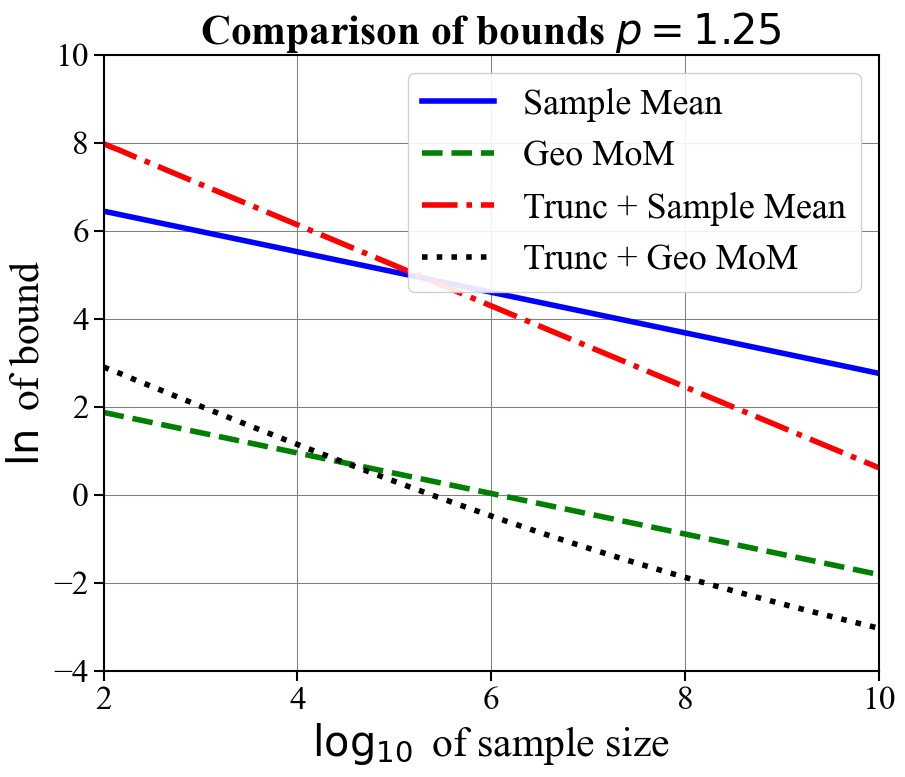
In Figure 1, we compare the confidence bounds obtained for our truncation-based estimators optimized for a fix sample size (Corollary 2.3) against other bounds in the literature. Namely, we compare against geometric median-of-means [33], the sample mean, and (in the case a shared covariance matrix exists for observations) the tournament median-of-means estimator [28]. We plot the natural logarithm of the bounds against the logarithm base ten of the sample sizes for and for . We assume and . For truncation-based estimates, we assume samples are used to produce the initial mean estimate and the remaining are used for the final mean estimate. We plot the resulting bounds for when the initial mean estimate is either computed using the sample mean or geometric median-of-means. For the tournament median-of-means estimate, we assume observations take their values in for , and that the corresponding covariance matrix is the identity .
As expected, all bounds have a slope of when is large, indicating equivalent dependence on the sample size. For all values of , the truncation-based estimator using geometric median-of-means as an initial estimate obtains the tightest rate once moderate sample sizes are reached ( or ). When , much larger sample sizes are needed for truncation-based estimates with a sample mean initial estimate to outperform geometric median means (needing samples for ). For (i.e., finite variance) the tournament median-of-means estimate, despite achieving optimal sub-Gaussian dependence on and , performs worse than even the naive mean estimate. This is due to prohibitively large constants. These plots suggest that the truncation-based estimate is a practical and computationally efficient alternative to approaches based on median-of-means.
Performance of Estimators on Simulated Data
In Figure 2, we examine the performance of the various mean estimators by plotting the distance between the estimates and the true mean. To do this, we sample i.i.d. samples for in the following way. First, we sample i.i.d. directions from the unit sphere. Then, we sample i.i.d. magnitudes from the Pareto II (or Lomax) distribution with .111If , the has inverse polynomial density . The learner then observes , and constructs either a geometric median estimate, a sample mean estimate, or a truncated mean estimate.
To compute the number of folds for geometric median-of-means, we follow the parameter settings outlined in Minsker [33] and assume a failure probability of (although we are not constructing confidence intervals, the failure probability guides how to optimize the estimator). See Appendix B for further discussion on this estimator. Once again, we consider the truncated mean estimator centered at both the sample mean and a geometric median-of-means estimate. We always use samples to construct the initial estimate, and produce a plot for hyperparameter .
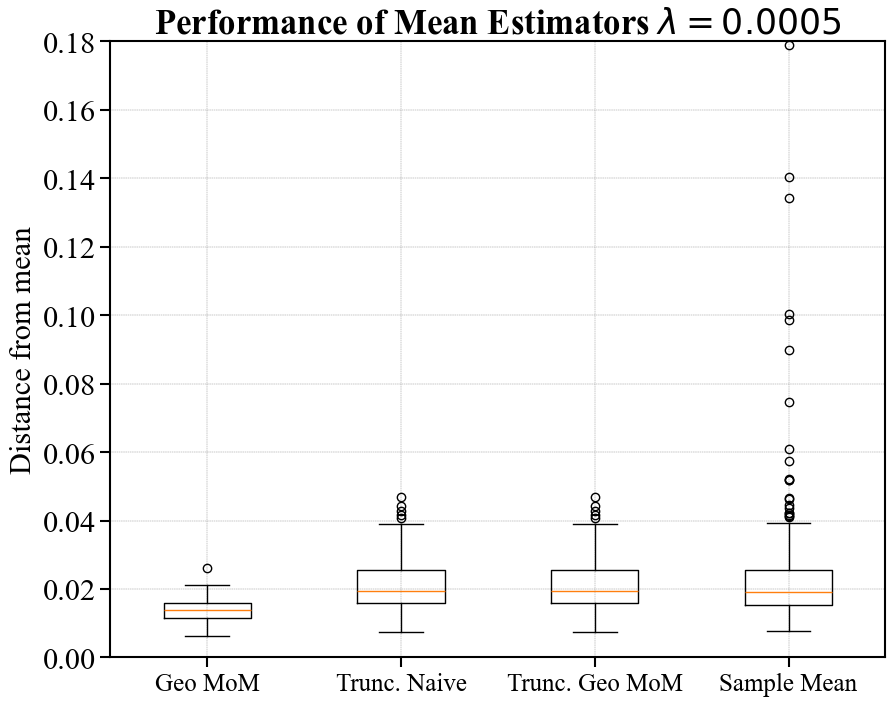
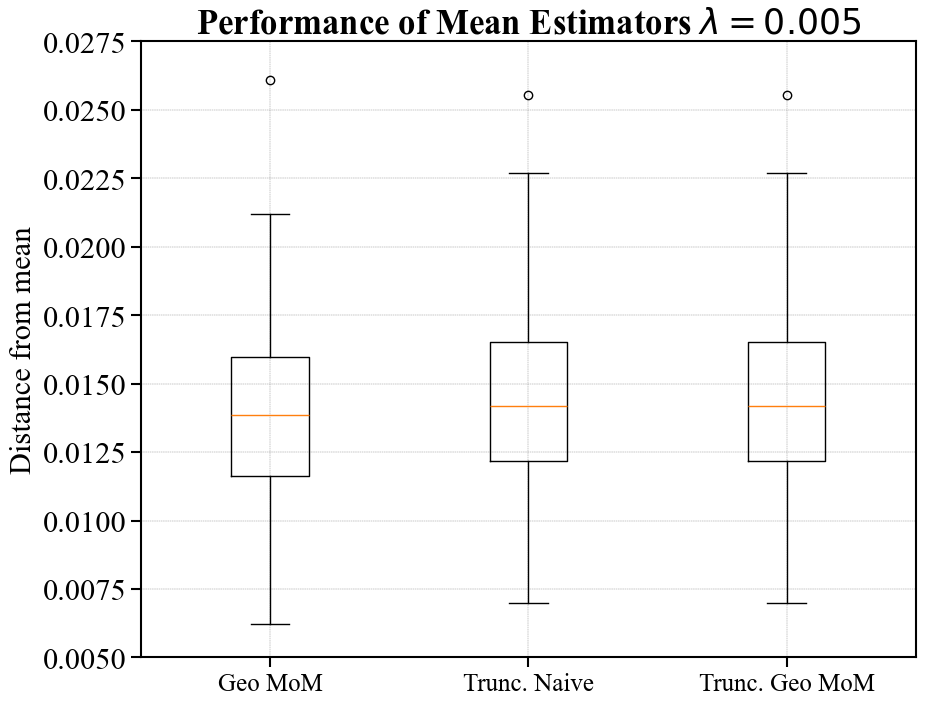
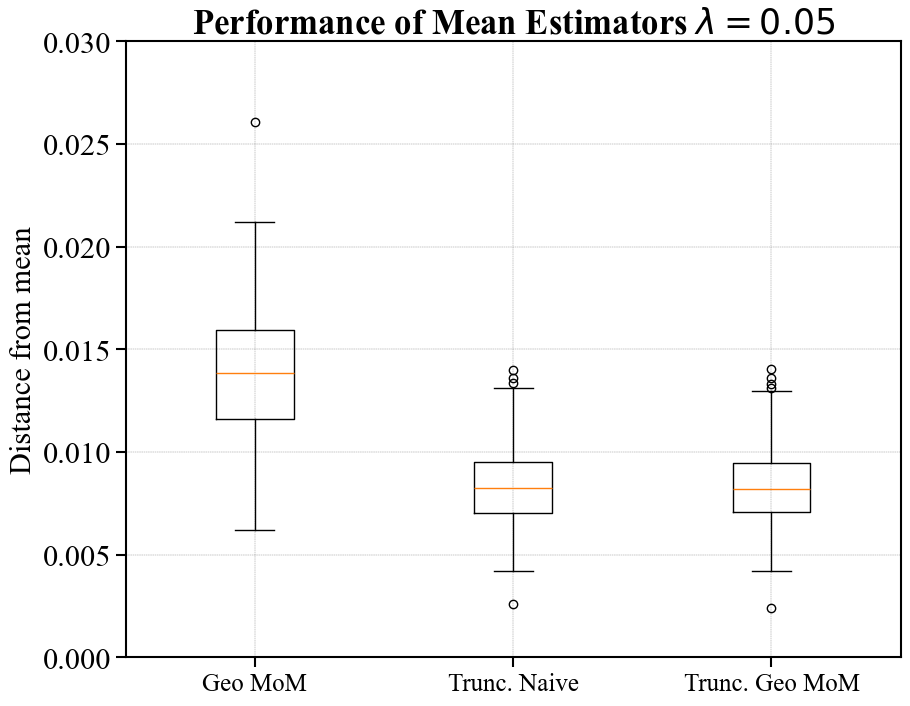
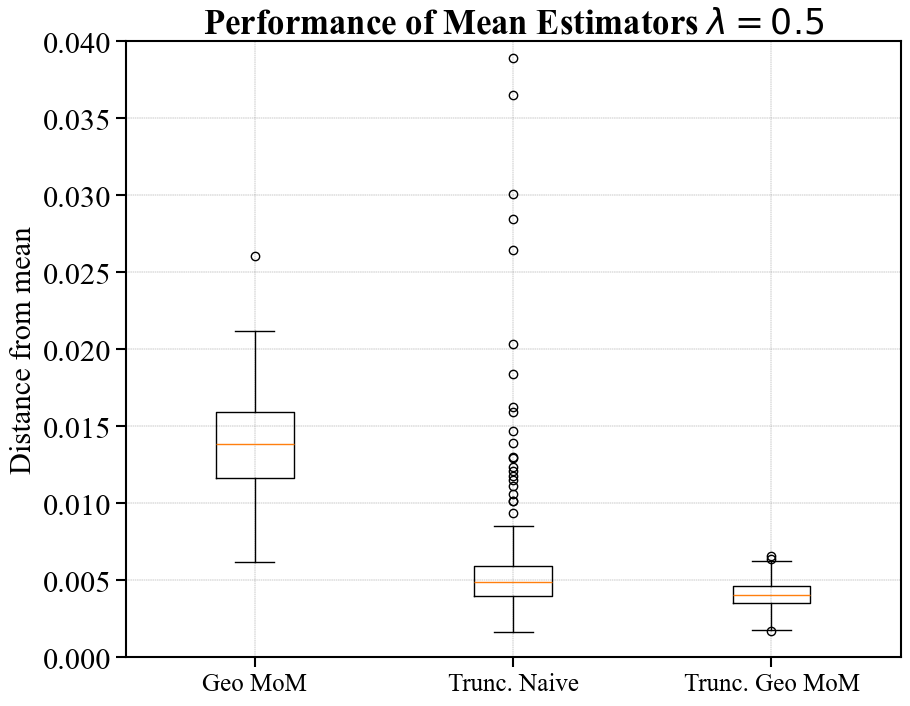
We construct these estimators over 250 independent runs and then construct box and whisker plots summarizing the empirical distance between the estimators and the true mean. The boxes have as a lower bound the first quartile , in the middle the sample median , and at the top the third quartile . The whiskers of the plot are given by the largest and smallest point falling within , respectively. All other points are displayed as outliers. We only include the sample mean in the first plot as to not compress the empirical distributions associated with other estimates.
As expected, the sample mean suffers heavily from outliers. For (corresponding to truncation at large radii), the geometric median-of-means estimate is roughly two times closer to the mean than either truncation-based estimate. In the setting of aggressive truncation (), the truncated mean estimator centered at the geometric median-of-means initial estimate offers a significantly smaller distance to the true mean than just geometric median-of-means alone. The truncated estimate centered at the sample mean performs similarly for , but suffers heavily from outliers when . Interestingly, the recommended truncation level for optimizing tightness at samples is per Corollary 2.2. Our experiments reflect that one may want to truncate more aggressively than is recommended in the corollary. In practice, one could likely choose an appropriate truncation level through cross-validation.
6 Summary
In this work, we presented a novel analysis of a simple truncation/threshold-based estimator of a heavy-tailed mean in smooth Banach spaces, strengthening the guarantees on such estimators that currently exist in the literature. In particular, we allow for martingale dependence between observations, replace the assumption of finite variance with a finite -th moment for , and let the centered -th moment be bounded instead of the raw -th moment (thus making the estimator translation invariant). Our bounds are also time-uniform, meaning they hold simultaneously for all sample sizes. We provide both a line-crossing inequality that can be optimized for a particular sample size (but remains valid at all times), and a bound whose width shrinks to zero at an iterated logarithm rate. Experimentally, our estimator performs quite well compared to more computationally intensive methods such as geometric median-of-means, making it an appealing choice for practical problems.
References
- Abbasi-Yadkori [2013] Yasin Abbasi-Yadkori. Online learning for linearly parametrized control problems. PhD thesis, University of Alberta, 2013.
- Alon et al. [1996] Noga Alon, Yossi Matias, and Mario Szegedy. The space complexity of approximating the frequency moments. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, pages 20–29, 1996.
- Bubeck et al. [2013] Sébastien Bubeck, Nicolo Cesa-Bianchi, and Gábor Lugosi. Bandits with heavy tail. IEEE Transactions on Information Theory, 59(11):7711–7717, 2013.
- Catoni [2007] Olivier Catoni. PAC-Bayesian supervised classification: the thermodynamics of statistical learning. arXiv preprint arXiv:0712.0248, 2007.
- Catoni and Giulini [2017] Olivier Catoni and Ilaria Giulini. Dimension-free PAC-Bayesian bounds for matrices, vectors, and linear least squares regression. arXiv preprint arXiv:1712.02747, 2017.
- Catoni and Giulini [2018] Olivier Catoni and Ilaria Giulini. Dimension-free PAC-Bayesian bounds for the estimation of the mean of a random vector. arXiv preprint arXiv:1802.04308, 2018.
- Chen et al. [2021] Peng Chen, Xinghu Jin, Xiang Li, and Lihu Xu. A generalized Catoni’s M-estimator under finite -th moment assumption with . Electronic Journal of Statistics, 15(2):5523–5544, 2021.
- Cherapanamjeri et al. [2019] Yeshwanth Cherapanamjeri, Nicolas Flammarion, and Peter L Bartlett. Fast mean estimation with sub-Gaussian rates. In Conference on Learning Theory, pages 786–806. PMLR, 2019.
- Cholaquidis et al. [2024] Alejandro Cholaquidis, Emilien Joly, and Leonardo Moreno. GROS: A general robust aggregation strategy. arXiv preprint arXiv:2402.15442, 2024.
- Chowdhury and Gopalan [2017] Sayak Ray Chowdhury and Aditya Gopalan. On kernelized multi-armed bandits. In International Conference on Machine Learning, pages 844–853. PMLR, 2017.
- Chugg et al. [2023a] Ben Chugg, Hongjian Wang, and Aaditya Ramdas. Time-uniform confidence spheres for means of random vectors. arXiv preprint arXiv:2311.08168, 2023a.
- Chugg et al. [2023b] Ben Chugg, Hongjian Wang, and Aaditya Ramdas. A unified recipe for deriving (time-uniform) PAC-Bayes bounds. Journal of Machine Learning Research, 24(372):1–61, 2023b.
- de la Peña et al. [2004] Victor H de la Peña, Michael J Klass, and Tze Leung Lai. Self-normalized processes: exponential inequalities, moment bounds and iterated logarithm laws. The Annals of Probability, 32(3), 2004.
- de la Peña et al. [2007] Victor H de la Peña, Michael J Klass, and Tze Leung Lai. Pseudo-maximization and self-normalized processes. Probability Surveys, 4:172–192, 2007.
- Gupta et al. [2024] Shivam Gupta, Samuel Hopkins, and Eric Price. Beyond Catoni: Sharper rates for heavy-tailed and robust mean estimation. In The Thirty Seventh Annual Conference on Learning Theory, pages 2232–2269. PMLR, 2024.
- Hartman and Wintner [1941] Philip Hartman and Aurel Wintner. On the law of the iterated logarithm. American Journal of Mathematics, 63(1):169–176, 1941.
- Hopkins [2020] Samuel B Hopkins. Mean estimation with sub-Gaussian rates in polynomial time. The Annals of Statistics, 48(2):1193–1213, 2020.
- Howard et al. [2020] Steven R Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform Chernoff bounds via nonnegative supermartingales. Probability Surveys, 17:257–317, 2020.
- Howard et al. [2021] Steven R Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform, nonparametric, nonasymptotic confidence sequences. The Annals of Statistics, 49(2):1055–1080, 2021.
- Hsu and Sabato [2016] Daniel Hsu and Sivan Sabato. Loss minimization and parameter estimation with heavy tails. Journal of Machine Learning Research, 17(18):1–40, 2016.
- Huber [1981] Peter J Huber. Robust statistics. Wiley Series in Probability and Mathematical Statistics, 1981.
- Jerrum et al. [1986] Mark R Jerrum, Leslie G Valiant, and Vijay V Vazirani. Random generation of combinatorial structures from a uniform distribution. Theoretical Computer Science, 43:169–188, 1986.
- Kesten [1972] Harry Kesten. The 1971 rietz lecture sums of independent random variables–without moment conditions. The Annals of Mathematical Statistics, pages 701–732, 1972.
- Langford and Shawe-Taylor [2002] John Langford and John Shawe-Taylor. PAC-Bayes & margins. Advances in Neural Information Processing Systems, 15, 2002.
- Ledoux and Talagrand [2013] Michel Ledoux and Michel Talagrand. Probability in Banach Spaces: Isoperimetry and processes. Springer Science & Business Media, 2013.
- Lugosi and Mendelson [2019a] Gábor Lugosi and Shahar Mendelson. Mean estimation and regression under heavy-tailed distributions: A survey. Foundations of Computational Mathematics, 19(5):1145–1190, 2019a.
- Lugosi and Mendelson [2019b] Gábor Lugosi and Shahar Mendelson. Near-optimal mean estimators with respect to general norms. Probability theory and related fields, 175(3):957–973, 2019b.
- Lugosi and Mendelson [2019c] Gábor Lugosi and Shahar Mendelson. Sub-Gaussian estimators of the mean of a random vector. The Annals of Statistics, 47(2):783–794, 2019c.
- Lugosi and Mendelson [2021] Gabor Lugosi and Shahar Mendelson. Robust multivariate mean estimation: the optimality of trimmed mean. Annals of Statistics, 2021.
- Maller [1980] RA Maller. On the law of the iterated logarithm in the infinite variance case. Journal of the Australian Mathematical Society, 30(1):5–14, 1980.
- Martinez-Taboada and Ramdas [2024] Diego Martinez-Taboada and Aaditya Ramdas. Empirical Bernstein in smooth Banach spaces. arXiv preprint arXiv:2409.06060, 2024.
- Mathieu [2022] Timothée Mathieu. Concentration study of M-estimators using the influence function. Electronic Journal of Statistics, 16(1):3695–3750, 2022.
- Minsker [2015] Stanislav Minsker. Geometric median and robust estimation in Banach spaces. Bernoulli, pages 2308–2335, 2015.
- Nemirovskij and Yudin [1983] Arkadij Semenovič Nemirovskij and David Borisovich Yudin. Problem complexity and method efficiency in optimization. 1983.
- Oliveira and Orenstein [2019] Roberto I Oliveira and Paulo Orenstein. The sub-Gaussian property of trimmed means estimators. Technical Report, IMPA, 2019.
- Pinelis [1992] Iosif Pinelis. An approach to inequalities for the distributions of infinite-dimensional martingales. In Probability in Banach Spaces, 8: Proceedings of the Eighth International Conference, pages 128–134. Springer, 1992.
- Pinelis [1994] Iosif Pinelis. Optimum bounds for the distributions of martingales in Banach spaces. The Annals of Probability, pages 1679–1706, 1994.
- Ramdas and Wang [2024] Aaditya Ramdas and Ruodu Wang. Hypothesis testing with e-values. arXiv preprint arXiv:2410.23614, 2024.
- Robbins [1970] Herbert Robbins. Statistical methods related to the law of the iterated logarithm. The Annals of Mathematical Statistics, 41(5):1397–1409, 1970.
- Tukey and McLaughlin [1963] John W Tukey and Donald H McLaughlin. Less vulnerable confidence and significance procedures for location based on a single sample: Trimming/winsorization 1. Sankhyā: The Indian Journal of Statistics, Series A, pages 331–352, 1963.
- Ville [1939] Jean Ville. Etude critique de la notion de collectif. Gauthier-Villars Paris, 1939.
- Wang and Ramdas [2023] Hongjian Wang and Aaditya Ramdas. Catoni-style confidence sequences for heavy-tailed mean estimation. Stochastic Processes and Their Applications, 163:168–202, 2023.
- Whitehouse et al. [2023a] Justin Whitehouse, Aaditya Ramdas, and Steven Z Wu. On the sublinear regret of GP-UCB. Advances in Neural Information Processing Systems, 36:35266–35276, 2023a.
- Whitehouse et al. [2023b] Justin Whitehouse, Zhiwei Steven Wu, and Aaditya Ramdas. Time-uniform self-normalized concentration for vector-valued processes. arXiv preprint arXiv:2310.09100, 2023b.
Appendix A Omitted Proofs
Proof of Corollary 2.2.
Taking as in (2.7) it’s easy to see that the width obeys
If we have and if then . Further, if then . So under these conditions we have
as desired. ∎
Proof of Corollary 2.3.
Let be the empirical mean on the first observations. By Markov and Jensen’s inequality,
| (A.1) |
Therefore, taking suffices to guarantee that . Using the binomial expansion (and assuming is large enough such that ), write
Therefore, taking as in (2.7) and applying Corollary 2.2, with probability ,
as claimed. For the proof of (2.10), we use a very similar argument but use the error rate of geometric median-of-means given in Appendix B. In particular, in this case we may take
which, when plugged into the previous display, gives the desired result. ∎
Appendix B Geometric Median-of-Means in Banach Spaces
While Minsker [33] studied mean estimation in smooth Banach spaces, his examples weren’t stated explicitly for Banach spaces nor for the case of infinite variance. Here we show that his geometric median-of-means estimator, when paired with empirical mean, achieves rate , the same as our rate.
Minsker [33, Theorem 3.1] provides the following bound. Let be a collection of independent estimators of the mean . Fix . Let and be such that for all , , we have
| (B.1) |
Let be the geometric median, defined as
Then
| (B.2) |
where
and
We will optimize Minsker’s bound by taking the same optimization parameters as in his paper. That is, we will set and and will set the number of naive mean estimators to be given by
which provides an overall failure probability of at most Markov’s and Jensen’s inequalities (as in Appendix A, see (A.1)) together yield
if we take
Therefore, we obtain that with probability ,
Appendix C Noncentral moment bounds
For completeness, we state our bound when we assume only a bound on the raw (uncentered) -th moment of the observations. This was the setting studied by Catoni and Giulini [6]. We replace assumption 1 with the following:
Assumption 3.
We assume are a sequence of -valued random variables adapted to a filtration such that
-
(1)
, for all and some unknown , and
-
(2)
for some known and some known constant .
With only the raw moment assumption, we do not try and center our estimator. Instead we deploy . With this estimator we obtain the following result, which achieves the same rate as Catoni and Giulini [6] and Chugg et al. [11].
Theorem C.1.
Let be random variables satisfying Assumption 3 which live in some Banach space satisfying Assumption 2. Fix any . Then, for any , with probability , simultaneously for all , we have:
| (C.1) |
Moreover, if we want to optimize the bound at a particular sample size and we set
then with probability ,
| (C.2) |
Proof.
Apply Theorem 2.1 with and . Then note that we can take for all since by Jensen’s inequality. ∎