Maximum-Likelihood-Estimate Hamiltonian learning via efficient and robust quantum likelihood gradient
Abstract
Given the recent developments in quantum techniques, modeling the physical Hamiltonian of a target quantum many-body system is becoming an increasingly practical and vital research direction. Here, we propose an efficient strategy combining maximum likelihood estimation, gradient descent, and quantum many-body algorithms. Given the measurement outcomes, we optimize the target model Hamiltonian and density operator via a series of descents along the quantum likelihood gradient, which we prove is negative semi-definite with respect to the negative-log-likelihood function. In addition to such optimization efficiency, our maximum-likelihood-estimate Hamiltonian learning respects the locality of a given quantum system, therefore, extends readily to larger systems with available quantum many-body algorithms. Compared with previous approaches, it also exhibits better accuracy and overall stability toward noises, fluctuations, and temperature ranges, which we demonstrate with various examples.
I Introduction
Understanding the quantum states and the corresponding properties of a given quantum Hamiltonian is a crucial problem in quantum physics. Many powerful numerical and theoretical tools have been developed for such purposes and made compelling progress [1, 2, 3, 4, 5]. On the other hand, with the rapid experimental developments of quantum technology, e.g., near-term quantum computation [6, 7] and simulation [8, 9, 10, 11, 12, 13, 14], it is also vital to explore the inverse problem, e.g., Hamiltonian learning - optimize a model Hamiltonian characterizing a quantum system with respect to the measurement results. Given the knowledge and assumption of a target system, researchers have achieved many resounding successes modeling quantum Hamiltonians with physical pictures and phenomenological approaches [15, 16]. However, such subjective perspectives may risk biases and are commonly insufficient on detailed quantum devices. Therefore, the explorations for objective Hamiltonian learning strategies have attracted much recent attention [17, 18, 19, 20, 21, 22, 23, 24, 25].
There are mainly two categories of Hamiltonian-learning strategies, based upon either quantum measurements on a large number of (identical copies of) quantum states, e.g., Gibbs states or eigenstates [17, 18, 19, 20, 21, 22], or initial states’ time evolution dynamics [23, 24, 25, 26], corresponding to the target quantum system. For example, given the measurements of the correlations of a set of local operators, the kernel of the resulting correlation matrix offers a candidate model Hamiltonian [17, 18, 19]. On the other hand, while established theoretically, most approaches suffer from elevated costs and are limited to small systems in experiments or numerical simulations [19, 20, 27, 28]. Besides, there remains much room for improvements in stability towards noises and temperature ranges.
Maximum likelihood estimation (MLE) is a powerful tool that parameterizes and then optimizes the probability distribution of a statistical model so that the given observed data is most probable. MLE’s intuitive and flexible logic makes it a prevailing method for statistical inference. Adding to its wide range of applications, MLE has been applied successfully to quantum state tomography[29, 30, 31, 32, 33], providing the most probable quantum states given the measurement outputs.
Inspired by MLE’s successes in quantum problems, we propose a general MLE Hamiltonian learning protocol: given finite-temperature measurements of the target quantum system in thermal equilibrium, we optimize the model Hamiltonian towards the MLE step-by-step via a “quantum likelihood gradient”. We show that such quantum likelihood gradient, acting collectively on all presenting operators, is negative semi-definite with respect to the negative-log-likelihood function and thus provides efficient optimization. In addition, our strategy may take advantage of the locality of the quantum system, therefore allowing us to extend studies to larger quantum systems with tailored quantum many-body ansatzes such as Lanczos, quantum Monte Carlo (QMC), density matrix renormalization group (DMRG), and finite temperature tensor network (FTTN) [34, 35] algorithms in suitable scenarios. We also demonstrate that MLE Hamiltonian learning is more accurate, less restrictive, and more robust against noises and broader temperature ranges. Further, we generalize our protocol to measurements on pure states, such as the target quantum systems’ ground states or quantum chaotic eigenstates. Therefore, MLE Hamiltonian learning enriches our arsenal for cutting-edge research and applications of quantum devices and experiments, such as quantum computation, quantum simulation, and quantum Boltzmann machines [36].
We organize the rest of the paper as follows: In Sec. II, we review the MLE context and introduce the MLE Hamiltonian learning protocol; especially, we show explicitly that the corresponding quantum likelihood gradient leads to a negative semi-definite change to the negative-log-likelihood function. Via various examples in Sec. III, we demonstrate our protocol’s capability, especially its robustness against noises and temperature ranges. We generalize the protocol to quantum measurements of pure states in Sec. IV and Appendix D, with consistent results for exotic quantum systems such as quantum critical and topological models. We summarize our studies in Sec. V with a conclusion on our protocol’s advantages (and limitations), potential applications, and future outlooks.
II Maximum-likelihood-estimate Hamiltonian learning
To start, we consider an unknown target quantum system in thermal equilibrium, and measurements of a set of observables on its Gibbs state , where is the inverse temperature. Given a sufficient number of measurements of the operator , the occurrence time of the eigenvalue approaches:
| (1) |
where denotes the statistics of the outcome , and is the corresponding projection operator to the sector. Our goal is to locate the model Hamiltonian for the quantum system, which commonly requires the presence of all ’s terms in the measurement set .
Following previous MLE analysis [29, 30, 31, 32, 33], the statistical weight of any given state is:
| (2) |
upto a trivial factor, where is the total number of measurements. For Hamiltonian learning, we search for (the set of parameters of) the MLE Hamiltonian , whose Gibbs state maximizes the likelihood function in Eq. 2. The maximum condition for Eq. 2 can be re-expressed as:
| (3) |
see Appendix A for a detailed review. Solving Eq. 3 is a nonlinear and nontrivial problem, for which many algorithms have been proposed [31, 30, 32, 33]. For example, we can employ iterative updates until Eq. 3 is fulfilled [31]. These algorithms mostly center around the parameterization and optimization of a quantum state , whose cost is exponential in the system size. Besides, such iterative updates do not guarantee that the quantum state remains a Gibbs form, especially when the measurements are insufficient to uniquely determine the state (e.g., large noises or small numbers of measurements and there are many quantum states satisfying Eq. 3). Consequently, extracting from further adds up to the inconvenience.
Considering that the operator has the same operator structure as the Hamiltonian, we take an alternative stance for the Hamiltonian learning task and update the candidate Hamiltonian , i.e., the model parameters, collectively and iteratively. In particular, we integrate the corrections to the Hamiltonian coefficients to the operator , which offers such a quantum likelihood gradient (Fig. 1):
| (4) |
where is the learning rate - a small parameter controlling the step size. We denote for short here afterwards. Compared with previous Hamiltonian extractions from MLE quantum state tomography, the update in Eq. 4 possesses several advantages in Hamiltonian learning. First, we can utilize the Hamiltonian structure (e.g., locality) to choose suitable numerical tools (e.g., QMC and FTTN) and even calculate within the subregions - we circumvent the costly parametrization of the quantum state . Also, the update guarantees a state in its Gibbs form. Last but not least, we will show that for , such a quantum likelihood gradient in Eq. 4 yields a negative semi-definite contribution to the negative-log-likelihood function, guaranteeing the MLE Hamiltonian (upto a trivial constant) at its convergence and an efficient optimization toward it.

Theorem: For , , the quantum likelihood gradient in Eq. 4 yields a negative semi-definite contribution to the negative-log-likelihood function .
Proof: We note that upto linear order in :
| (5) | |||||
where and are the adjoint action of the Lie algebra. The first and third lines are based on the Zassenhaus formula[37] and the Baker-Hausdorff formula [37], respectively, while the second line neglects terms above the linear order of .
Following this, we can re-express the quantum state in Eq. 4 as:
| (6) |
where we have used as a direct consequence of ’s definition in Eq. 3.
Subsequently, after introducing the quantum likelihood gradient, the negative-log-likelihood function becomes:
| (7) | |||||
where we keep terms upto linear order of in the expansion.
On the other hand, we can establish the following inequality:
| (8) | |||||
where is the partition function, is the Frobenius norm of matrix , and the non-negative definiteness of allows . The inequality in the fourth line follows the Cauchy-Schwarz inequality.
We note that the equality - the convergence criteria of our MLE Hamiltonian learning protocol - is established if and only if:
| (9) |
which implies the conventional MLE optimization target in Eq. 3. We can also establish such consistency from our iterative convergence 111In practice, given sufficient measurements, we have dictating the quantum likelihood gradient at the iteration’s convergence. following Eq. 4:
| (10) |
where we have used the commutation relation between the Hermitian operators and following .
Finally, combining Eq. 7 and Eq. 8, we have shown that is a negative semi-definite quantity, which proves the theorem.
We conclude that the quantum likelihood gradient in Eq. 4 offers an efficient and collective optimization towards the MLE Hamiltonian, modifying all model parameters simultaneously. For each step of quantum likelihood gradient, the most costly calculation is on , or more precisely, the expectation value from . Fortunately, this is a routine calculation in quantum many-body physics and condensed matter physics with various tailored candidate algorithms under different scenarios. For example, we may resort to the FTTN, or the QMC approaches, which readily apply to much larger systems than brute-force exact diagonalization. Thus, we emphasize that MLE Hamiltonian learning works with evaluations of the expectation values of quantum states instead of the more expensive quantum states themselves in their entirety.
Interestingly, MLE Hamiltonian learning also allows a more local stance. For a given Hamiltonian, the necessary expectation value of its Gibbs state takes the form:
| (11) |
where is the reduced density operator defined upon a relatively local subsystem still containing . The effective Hamiltonian of the subregion contains the existing terms within the subsystem and the effective interacting terms from the trace operation [39]. According to the conclusions of the quantum belief propagation theory [40, 39], the locality of the interaction in the latter term , where () denotes the current (model-dependent critical) inverse temperature, is the distance between a specific site in the bulk of and the boundary of the subregion , and is the maximum acting distance(diameter) of a single operator in the original Hamiltonian(similar to the k-local in the next section). Thus, when (especially when ), is exponentially localized around the boundary of , and the effective Hamiltonian in the bulk of remains the same as that of the original of the entire system. Therefore, we may further boost the efficiency of MLE Hamiltonian learning by redirecting the expectation-value evaluations of the global quantum system to that of a series of local patches, as we will show in the next section.
In summary, given the quantum measurements of a thermal (Gibbs) state: , , and , we can perform MLE Hamiltonian learning to obtain the MLE Hamiltonian via the following steps (Fig. 1):
-
1)
Initialization/Update:
For initialization, start with a random model Hamiltonian :
(12) or an identity Hamiltonian.
-
2)
Evaluate the properties of the quantum state:
(14) with suitable numerical methods.
-
3)
Check for convergence: loop back to step 1) to update, , if the relative entropy is above a given threshold ; otherwise, terminate the process, and the final is the result for the MLE Hamiltonian. Here, is the theoretical minimum of the negative-log-likelihood function:
(15)
In practice, in Eq. 4 is singular for small values of and may become numerically unstable, which requires a minimal or dynamical learning rate to maintain the range of quantum likelihood gradient properly. Instead, we may employ a re-scaled version of :
| (16) |
where is a monotonic tuning-function:
| (17) |
which maps its argument in to a finite range . Such a re-scaled regularizes the quantum likelihood gradient and allows a simple yet relatively larger learning rate for more efficient MLE Hamiltonian learning. We also have , therefore as we approach convergence. We will mainly employ for our examples in the following sections.
In addition to the negative-log-likelihood function , we also consider the Hamiltonian distance as another criterion on the quality of Hamiltonian learning:
| (18) |
where and are the (vectors of) coefficients 222We typically perform MLE Hamiltonian learning and update the model Hamiltonian on the projection-operator basis; therefore, we transform the Hamiltonian back to the original, ordinary operator basis before evaluations. of the target Hamiltonian and the learned Hamiltonian after iterations, respectively. However, we do not recommend ( for short) as convergence criteria as is generally unknown aside from benchmark scenarios [28].
III Example models and results
In this section, we demonstrate the performance of the MLE Hamiltonian learning protocol. For better numerical simulations, we consider the -local Hamiltonians, with operators acting non-trivially on no more than contiguous sites in each direction. For example, for a 1-dimensional spin- system, a -local operator for takes the form or , , where denotes the spin operator. In particular, we focus on general 1D quantum spin chains with , taking the following form:
| (19) |
where denotes the spin operator on site , . There are 2-local operators under the open boundary condition, where is the system size. We generate the model parameters randomly following a uniform distribution in . This Hamiltonian , specifically the model parameters , will be our target for MLE Hamiltonian learning. As the protocol’s inputs, we simulate quantum measurements of all 2-local operators on the Gibbs states of numerically via exact diagonalization on small systems and FTTN for large systems. For the latter, we use a tensor network ansatz called the “ancilla” method [34], where we purify a Gibbs state with some auxiliary qubits , and obtain from a maximally-entangled state via imaginary time evolution. In addition, given a large number of Trotter steps, the imaginary time evolution operator is decomposed into Trotter gates’ product as . Here, we set the Trotter step , for which the Trotter errors of order show little impact on our protocol’s accuracy. Without loss of generality, we employ the integrated FTTN algorithm in the ITensor numerical toolkit [35], and set the number of measures for all operators in our examples for simplicity.

As we demonstrate in Fig. 2, MLE Hamiltonian learning obtains the target Hamiltonians with high accuracy and efficiency under various settings of system sizes and inverse temperatures . Besides, instead of the original quantum likelihood gradient in Eq. 3, we may obtain a faster convergence with the re-scaled in Eq. 16 and a larger learning rate, as we discuss in Appendix B. In the following numerical examples, we use the re-scaled quantum likelihood gradient and set for the tuning function in Eq. 17. Within the given iterations, not only have we achieved results (Hamiltonian distance and relative entropy ) comparable to, if not exceeding, previous methods [19] for systems and straightforwardly, but we have also achieved satisfactory consistency ( and ) for large systems and low temperatures that were previously inaccessible.
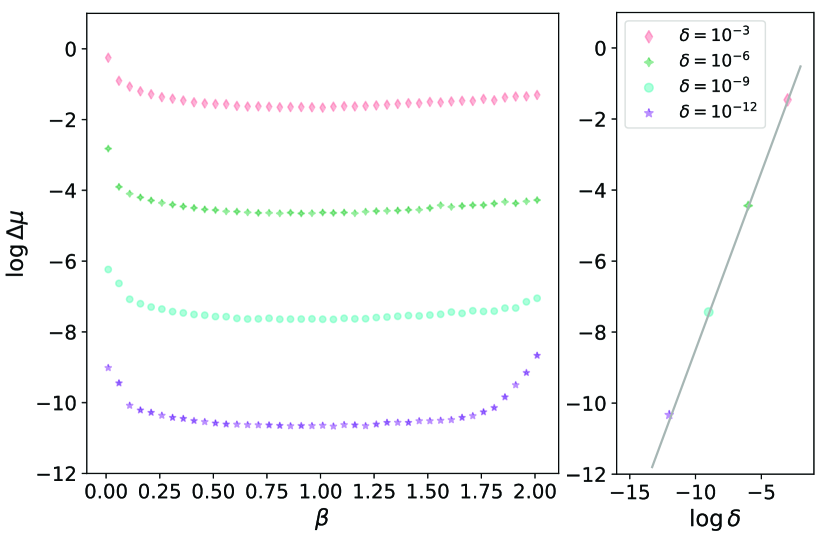
MLE Hamiltonian learning is also relatively robust against temperature and noises, two key factors impacting accuracy in Hamiltonian learning. For illustration, we include random errors following Gaussian distribution with zero mean and standard deviation to all quantum measurements: . We note that such may also depict the quantum fluctuations [19, 21] from a finite number of measurements . We also focus on smaller systems with and employ exact diagonalization to avoid confusion from potential Trotter error of the FTTN ansatz[34]. We summarize the results in Fig. 3.
Most previous algorithms on Hamiltonian learning have a rather specific applicable temperature range. For example, the high-temperature expansion of only works in the limit [42, 43]. Besides, gradient descent on the log partition function, despite a convex optimization, performs well in a narrow temperature range [20]. The gradient of this algorithm is proportional to the inverse temperature, so the algorithm’s convergence slows at high temperatures. Also, the gradient descent algorithm cannot extend to the limit - the ground state, while our protocol is directly applicable to the ground states of quantum systems, as we will generalize and justify later.
MLE Hamiltonian learning is also more robust to noises, with an accuracy of Hamiltonian distance across a broad temperature range at noise strength . Such noise level is hard to realize in practice; nevertheless, it is necessary to safeguard the correlation matrix method [17, 19, 44]. Even so, due to the uncontrollable spectral gap, the correlation matrix method is susceptible to high temperature, and its accuracy drastically decreases to at . In comparison, MLE Hamiltonian learning is more versatile, with an approximately linear dependence between its accuracy and the noise strength across a broad range of temperatures and noise strengths, saturating the previous bound [20]; see the right panel of Fig. 3. We also provide more detailed comparisons between the algorithms in Appendix C.

Despite efficient quantum likelihood gradient and applicable quantum many-body ansatz, the computational cost of MLE Hamiltonian learning still increases rapidly with the system size . Fortunately, as stated above in Eq. 11, we may resort to calculations on local patches, especially for low dimensions and high temperatures due to their quasi-Markov property. In particular, when (), the difference between the cutoff Hamiltonian and the effective Hamiltonian in a local subregion , , should be weak, short-ranged, and localized at ’s boundary [40, 39]; therefore, for those operators adequately deep inside , we can use , the Gibbs state defined by , to estimate the corresponding ; see illustration in Fig. 4 upper panel.
For example, we apply MLE Hamiltonian learning on systems, where we iteratively calculate the necessary expectation values on different local patches of size . We also choose different cut-offs , and evaluate for those operators at least away from the boundaries and sufficiently deep inside the subregion , so that the effective potential may become negligible. We also employ a sufficient number of local patches to guarantee full coverage of necessary observables - operators outside or in are obtainable from another local patch , as shown in the upper panel of Fig. 4, and so on so forth. Both the target system and the local patches for MLE Hamiltonian learning are simulated via FTTN. We have no problem achieving convergence, and the resulting Hamiltonians’ accuracy, the Hamiltonian distance versus the inverse temperature , is summarized in the lower panel of Fig. 4. Indeed, the local-patch approximation is more reliable at higher temperatures, as well as with larger subsystems and cutoffs, albeit with rising costs. We also note that we can achieve much larger systems with the local patches than we have demonstrated.
IV MLE Hamiltonian learning for pure eigenstates
In addition to the Gibbs states, MLE Hamiltonian learning also applies to measurements of certain eigenstates of target quantum systems:
1. The ground states are essentially the limit of the Gibbs states. However, due to the order-of-limit issue, the requirement of the theorem on Gibbs states forbids a direct extension to the ground states. In the Appendix D, we offer rigorous proof of the effectiveness of quantum likelihood gradient based on ground-state measurements, along with several nontrivial MLE Hamiltonian learning examples on quantum critical and topological ground states. We note that Ref. 45 offers preliminary studies on pure-state quantum state tomography, inspiring this work.
2. A highly-excited eigenstate of a (non-integrable) quantum chaotic system is believed to obey the eigenstate thermalization hypothesis (ETH), that its density operator behaves locally indistinguishable from a Gibbs state in thermal equilibrium [46]:
| (20) |
where is an effective temperature determined by the energy expectation value . As MLE Hamiltonian learning only engages local operators, its applicability directly generalizes to such eigenstates following ETH.
3. In general, ETH applies to eigenstates in the center of the spectrum of quantum chaotic systems, while low-lying eigenstates are too close to the ground state to exhibit ETH [47]. However, in the rest of the section, we demonstrate numerically that MLE Hamiltonian learning still works well for low-lying eigenstates.
We consider the 1D longitudinal-transverse-field Ising model [46, 47] as our target quantum system:
| (21) |
where the system size is . We set , , and . The quantum system is strongly non-integrable under such settings. Previous studies mainly focused on eigenstates in the middle of the energy spectrum. In contrast, we pick the first excited state - a typical low-lying eigenstate considered asymptotically integrable and ETH-violating [47] - for quantum measurements (via DMRG) and then MLE Hamiltonian learning for its candidate Hamiltonian (via FTTN).

We summarize the results in Fig. 5. Further, the model Hamiltonian we established is approximately equivalent to the target quantum Hamiltonian at an (inverse) temperature [46], which we have absorbed into the unit of our . Therefore, we have accurately established the model Hamiltonian and derived the effective temperature consistent with previous results [46] for a low-lying excited eigenstate not necessarily following ETH. The physical reason for quantum likelihood gradient applicability in such states is an interesting problem that deserves further studies.
V Discussions
We have proposed a novel MLE Hamiltonian learning protocol to achieve the model Hamiltonian of the target quantum system based on quantum measurements of its Gibbs states. The protocol updates the model Hamiltonian iteratively with respect to the negative-log-likelihood function from the measurement data. We have theoretically proved the efficiency and convergence of the corresponding quantum likelihood gradient and demonstrated it numerically on multiple non-trivial examples, which show more accuracy, better robustness against noises, and less temperature dependence. Indeed, the accuracy is almost linear to the imposed noise amplitude, thus inverse proportional to the square root of the number of samples, the asymptotic upper bound[20]. Further, MLE Hamiltonian learning directly rests on the Hamiltonians and their physical properties instead of direct and costly access to the quantum many-body states. Consequently, we can resort to various quantum many-body ansatzes in our systematic quantum toolbox and even local-patch approximation when the situation allows. These advantages allow applications to larger systems and lower temperatures with better accuracy than previous approaches. On the other hand, while our protocol is generally applicable for learning any Hamiltonian, its advantages are most apparent for local Hamiltonians, where various quantum many-body ansatzes and local-patch approximation shine. Despite such limitations, we note that the physical systems are characterized by local Hamiltonians in a significant proportion of scenarios.
In addition to the Gibbs states, we have generalized the applicability of MLE Hamiltonian learning to eigenstates of the target quantum states, including ground states, ETH states, and even selected cases of low-lying excited states. We have also provided theoretical proof of quantum likelihood gradient rigor and convergence in the Appendix D, along with several other numerical examples.
Our strategy may apply to the entanglement Hamiltonians and the tomography of the quantum states under the maximum-likelihood-maximum-entropy assumption [48]. Besides, our algorithm may also provide insights into the quantum Boltzmann machine [36] - a quantum version of the classical Boltzmann machine with degrees of freedom that obey the distribution of a target quantum Gibbs state. Instead of brute-force calculations of the loss function derivatives with respect to the model parameters or approximations with the gradients’ upper bounds, our protocol provides an efficient optimization that updates the model parameters collectively.
Acknowledgement:- We thank insightful discussions with Jia-Bao Wang. We acknowledge support from the National Key R&D Program of China (No.2021YFA1401900) and the National Science Foundation of China (No.12174008 & No.92270102). The calculations of this work are supported by HPC facilities at Peking University.
References
- Lanczos [1950] C. Lanczos, An iteration method for the solution of the eigenvalue problem of linear differential and integral operators, Journal of Research of the National Bureau of Standards 45, 255 (1950).
- White [1992] S. R. White, Density matrix formulation for quantum renormalization groups, Phys. Rev. Lett. 69, 2863 (1992).
- Schollwoeck and Germany Institute for Advanced Study Berlin [2011] U. Schollwoeck and . B. Germany Institute for Advanced Study Berlin, Wallotstrasse 19, The density-matrix renormalization group in the age of matrix product states, Annals of Physics (New York) 326, 10.1016/j.aop.2010.09.012 (2011).
- Foulkes et al. [2001] W. M. C. Foulkes, L. Mitas, R. J. Needs, and G. Rajagopal, Quantum monte carlo simulations of solids, Rev. Mod. Phys. 73, 33 (2001).
- Zhang and Liu [2019] X. W. Zhang and Y. L. Liu, Electronic transport and spatial current patterns of 2d electronic system: A recursive green’s function method study, AIP Advances 9, 115209 (2019).
- Nielsen and Chuang [2002] M. A. Nielsen and I. Chuang, Quantum computation and quantum information (2002).
- Nayak et al. [2008] C. Nayak, S. H. Simon, A. Stern, M. Freedman, and S. Das Sarma, Non-abelian anyons and topological quantum computation, Rev. Mod. Phys. 80, 1083 (2008).
- Buluta and Nori [2009] I. Buluta and F. Nori, Quantum simulators, Science 326, 108 (2009).
- Georgescu et al. [2014] I. M. Georgescu, S. Ashhab, and F. Nori, Quantum simulation, Rev. Mod. Phys. 86, 153 (2014).
- Barthelemy and Vandersypen [2013] P. Barthelemy and L. M. K. Vandersypen, Quantum dot systems: a versatile platform for quantum simulations, Annalen der Physik 525, 808 (2013).
- Browaeys and Lahaye [2020] A. Browaeys and T. Lahaye, Many-body physics with individually controlled rydberg atoms, Nature Physics 16, 132 (2020).
- Scholl et al. [2021] P. Scholl, M. Schuler, H. J. Williams, A. A. Eberharter, D. Barredo, K.-N. Schymik, V. Lienhard, L.-P. Henry, T. C. Lang, T. Lahaye, A. M. Läuchli, and A. Browaeys, Quantum simulation of 2d antiferromagnets with hundreds of rydberg atoms, Nature 595, 233 (2021).
- Ebadi et al. [2022] S. Ebadi, A. Keesling, M. Cain, T. T. Wang, H. Levine, D. Bluvstein, G. Semeghini, A. Omran, J.-G. Liu, R. Samajdar, X.-Z. Luo, B. Nash, X. Gao, B. Barak, E. Farhi, S. Sachdev, N. Gemelke, L. Zhou, S. Choi, H. Pichler, S.-T. Wang, M. Greiner, V. Vuletić, and M. D. Lukin, Quantum optimization of maximum independent set using rydberg atom arrays, Science 376, 1209 (2022).
- Bluvstein et al. [2021] D. Bluvstein, A. Omran, H. Levine, A. Keesling, G. Semeghini, S. Ebadi, T. T. Wang, A. A. Michailidis, N. Maskara, W. W. Ho, S. Choi, M. Serbyn, M. Greiner, V. Vuletić, and M. D. Lukin, Controlling quantum many-body dynamics in driven rydberg atom arrays, Science 371, 1355 (2021).
- Bistritzer and MacDonald [2011] R. Bistritzer and A. H. MacDonald, Moiré bands in twisted double-layer graphene, Proceedings of the National Academy of Sciences 108, 12233 (2011).
- Bardeen et al. [1957] J. Bardeen, L. N. Cooper, and J. R. Schrieffer, Theory of superconductivity, Phys. Rev. 108, 1175 (1957).
- Qi and Ranard [2019] X.-L. Qi and D. Ranard, Determining a local Hamiltonian from a single eigenstate, Quantum 3, 159 (2019).
- Dupont et al. [2019] M. Dupont, N. Macé, and N. Laflorencie, From eigenstate to hamiltonian: Prospects for ergodicity and localization, Phys. Rev. B 100, 134201 (2019).
- Bairey et al. [2019] E. Bairey, I. Arad, and N. H. Lindner, Learning a local hamiltonian from local measurements, Phys. Rev. Lett. 122, 020504 (2019).
- Anshu et al. [2021] A. Anshu, S. Arunachalam, T. Kuwahara, and M. Soleimanifar, Sample-efficient learning of interacting quantum systems, Nature Physics 17, 931 (2021).
- Zhou and Zhou [2022] J. Zhou and D. L. Zhou, Recovery of a generic local hamiltonian from a steady state, Phys. Rev. A 105, 012615 (2022).
- Turkeshi et al. [2019] X. Turkeshi, T. Mendes-Santos, G. Giudici, and M. Dalmonte, Entanglement-guided search for parent hamiltonians, Phys. Rev. Lett. 122, 150606 (2019).
- Valenti et al. [2022] A. Valenti, G. Jin, J. Léonard, S. D. Huber, and E. Greplova, Scalable hamiltonian learning for large-scale out-of-equilibrium quantum dynamics, Phys. Rev. A 105, 023302 (2022).
- Wenjun Yu [2022] Z. H. X. Y. Wenjun Yu, Jinzhao Sun, Practical and efficient hamiltonian learning (2022), arXiv:2201.00190 .
- Hsin-Yuan Huang [2022] D. F. Y. S. Hsin-Yuan Huang, Yu Tong, Learning many-body hamiltonians with heisenberg-limited scaling (2022), arXiv:2210.03030 .
- Frederik Wilde [2022] I. R. D. H. R. S. J. E. Frederik Wilde, Augustine Kshetrimayum, Scalably learning quantum many-body hamiltonians from dynamical data (2022), arXiv:2209.14328 .
- Wang et al. [2017] J. Wang, S. Paesani, R. Santagati, S. Knauer, A. A. Gentile, N. Wiebe, M. Petruzzella, J. L. O’Brien, J. G. Rarity, A. Laing, and M. G. Thompson, Experimental quantum hamiltonian learning, Nature Physics 13, 551 (2017).
- Carrasco et al. [2021] J. Carrasco, A. Elben, C. Kokail, B. Kraus, and P. Zoller, Theoretical and experimental perspectives of quantum verification, PRX Quantum 2, 010102 (2021).
- Hradil [1997] Z. Hradil, Quantum-state estimation, Phys. Rev. A 55, R1561 (1997).
- Řeháček et al. [2007] J. Řeháček, Z. c. v. Hradil, E. Knill, and A. I. Lvovsky, Diluted maximum-likelihood algorithm for quantum tomography, Phys. Rev. A 75, 042108 (2007).
- Lvovsky [2004] A. I. Lvovsky, Iterative maximum-likelihood reconstruction in quantum homodyne tomography, Journal of Optics B: Quantum and Semiclassical Optics 6, S556 (2004).
- Teo et al. [2012] Y. S. Teo, B. Stoklasa, B.-G. Englert, J. Řeháček, and Z. c. v. Hradil, Incomplete quantum state estimation: A comprehensive study, Phys. Rev. A 85, 042317 (2012).
- Fiurášek and Hradil [2001] J. Fiurášek and Z. c. v. Hradil, Maximum-likelihood estimation of quantum processes, Phys. Rev. A 63, 020101 (2001).
- Feiguin and White [2005] A. E. Feiguin and S. R. White, Finite-temperature density matrix renormalization using an enlarged hilbert space, Phys. Rev. B 72, 220401 (2005).
- Fishman et al. [2022] M. Fishman, S. R. White, and E. M. Stoudenmire, The ITensor Software Library for Tensor Network Calculations, SciPost Phys. Codebases , 4 (2022).
- Amin et al. [2018] M. H. Amin, E. Andriyash, J. Rolfe, B. Kulchytskyy, and R. Melko, Quantum boltzmann machine, Phys. Rev. X 8, 021050 (2018).
- Kimura [2017] T. Kimura, Explicit description of the Zassenhaus formula, Progress of Theoretical and Experimental Physics 2017, 10.1093/ptep/ptx044 (2017), 041A03.
- Note [1] In practice, given sufficient measurements, we have dictating the quantum likelihood gradient at the iteration’s convergence.
- Kuwahara et al. [2020] T. Kuwahara, K. Kato, and F. G. S. L. Brandão, Clustering of conditional mutual information for quantum gibbs states above a threshold temperature, Phys. Rev. Lett. 124, 220601 (2020).
- Bilgin and Poulin [2010] E. Bilgin and D. Poulin, Coarse-grained belief propagation for simulation of interacting quantum systems at all temperatures, Phys. Rev. B 81, 054106 (2010).
- Note [2] We typically perform MLE Hamiltonian learning and update the model Hamiltonian on the projection-operator basis; therefore, we transform the Hamiltonian back to the original, ordinary operator basis before evaluations.
- Jeongwan Haah [2021] E. T. Jeongwan Haah, Robin Kothari, Optimal learning of quantum hamiltonians from high-temperature gibbs states (2021), arXiv:2108.04842 .
- Rudinger and Joynt [2015] K. Rudinger and R. Joynt, Compressed sensing for hamiltonian reconstruction, Phys. Rev. A 92, 052322 (2015).
- Tim J. Evans [2019] S. T. F. Tim J. Evans, Robin Harper, Scalable bayesian hamiltonian learning (2019), arXiv:1912.07636 .
- Jia-Bao Wang [2022] Y. Z. Jia-Bao Wang, Single-shot quantum measurements sketch quantum many-body states (2022), arXiv:2203.01348 .
- Garrison and Grover [2018] J. R. Garrison and T. Grover, Does a single eigenstate encode the full hamiltonian?, Phys. Rev. X 8, 021026 (2018).
- Kim et al. [2014] H. Kim, T. N. Ikeda, and D. A. Huse, Testing whether all eigenstates obey the eigenstate thermalization hypothesis, Phys. Rev. E 90, 052105 (2014).
- Teo et al. [2011] Y. S. Teo, H. Zhu, B.-G. Englert, J. Řeháček, and Z. c. v. Hradil, Quantum-state reconstruction by maximizing likelihood and entropy, Phys. Rev. Lett. 107, 020404 (2011).
- Rahmani et al. [2015] A. Rahmani, X. Zhu, M. Franz, and I. Affleck, Phase diagram of the interacting majorana chain model, Phys. Rev. B 92, 235123 (2015).
- Gong et al. [2017] S.-S. Gong, W. Zhu, J.-X. Zhu, D. N. Sheng, and K. Yang, Global phase diagram and quantum spin liquids in a spin- triangular antiferromagnet, Phys. Rev. B 96, 075116 (2017).
- Zhang et al. [2012] Y. Zhang, T. Grover, A. Turner, M. Oshikawa, and A. Vishwanath, Quasiparticle statistics and braiding from ground-state entanglement, Phys. Rev. B 85, 235151 (2012).
Appendix A Maximum condition for MLE
A general quantum state takes the form of a density operator:
| (22) |
where , , and is a set of orthonormal basis. The search for the quantum state that maximizes the likelihood function:
| (23) |
can be converted to the optimization problem:
| (24) |
It is hard to solve this semi-definite programming problem directly and numerically. Instead, forgoing the non-negative definiteness, we adopt the Lagrangian multiplier method:
| (25) |
where is a Lagrangian multiplier. Given Eq. 22, we obtain the following solution:
| (26) |
and . Combining Eq. 22 and Eq. 26, we obtain the maximum condition:
| (27) |
We note that Eq. 26 does not guarantee the positive semi-definiteness of the density operator. Instead, one may search within the density-operator space (the space of positive semi-definite matrix with unit trace) to locate the MLE quantum state fulfilling Eq. 26 or Eq. 27. For the Hamiltonian learning task in this work, the search space is naturally the space of Gibbs states (under selected quantum many-body ansatz).
Appendix B MLE Hamiltonian learning with rescaling function
In this appendix, we compare the MLE Hamiltonian learning with the quantum likelihood gradient and the re-scaled counterpart . As we state in the main text, regularizes the gradient, allowing us to employ a larger learning rate , which leads to a faster convergence (Fig. 6) and a higher accuracy (Tab. 1) given identical number of iterations.

| , | , | , | |
|---|---|---|---|
Appendix C Comparisons between Hamiltonian learning algorithms
In this appendix, we compare different Hamiltonian learning algorithms, including the correlation matrix (CM) method [17, 19], the gradient descent (GD) method [20], and the MLE Hamiltonian learning (MLEHL) algorithm, by looking into some of their numerical results and performances. We consider general 2-local Hamiltonians in Eq. 10 in the main text for demonstration and measurements over all the 2-local operators (instead of all 4-local operators as in Ref. [19]).
We summarize the results in Fig. 7: the accuracy of CM is unstable and highly sensitive to temperature; while GD performs similarly to the proposed MLEHL algorithm at low temperatures, its descending gradient becomes too small at high temperatures to allow a satisfactory convergence within the given maximum iterations.

We also compare the convergence rates of the MLEHL and GD algorithms with the same learning rate. As in Fig. 8, the MLEHL algorithm exhibits a faster convergence and a smaller computational cost, which is similar under both algorithms for each iteration.

Appendix D Hamiltonian learning from ground state
In this appendix, we prove the effectiveness of the quantum likelihood gradient based on measurements of the target quantum system’s ground state and provide several nontrivial numerical examples, including 1D quantum critical states and 2D topological states.
D.1 Proof for ground-state-based quantum likelihood gradient
Given a sufficient number measurements of the operator on the non-degenerate ground state of a target system , we obtain a number of outcomes as the eigenvalue of as:
| (28) |
where , and is the projection operator of the eigenvalue .
Our MLE Hamiltonian learning follows the iterations:
| (29) |
where is the non-degenerate ground state of .
Theorem: For , the quantum likelihood gradient in Eq. 29 yields a negative semi-definite contribution to the negative-log-likelihood function following Eq. 2 in the main text.
Proof: At the linear order in , we may treat the addition of to at the iteration as a perturbation:
| (30) |
where is the Green’s function in the iteration:
| (31) |
where is the projection operator orthogonal to the ground space , and is the ground state energy. Keeping terms upto the linear order of in the log expansion of the negative-log-likelihood function, we have:
| (32) |
where difference takes the form:
| (33) |
Here, because denotes the energy for eigenstates other than the ground state. Our iteration converges when the equality in Eq. 33 is established. This happens when is an eigenstate of , consistent with the MLE condition (or ).
Finally, combining Eq. 32 and Eq. 33, we have shown that is a negative semi-definite quantity, which proves the theorem.
One potential complication to the proof is that Eq. 30 needs to assume there is no ground-state level crossing or degeneracy after adding the quantum likelihood gradient. A potential remedy is to keep some low-lying excited states together with the ground state and compare them for maximum likelihood, especially for steps with singular behaviors. Otherwise, we can only hope such transitions are sparse, especially near convergence, and they establish a new line of iterations heading toward the same convergence. A more detailed discussion is available in Ref. 45.
D.2 Example: CFT ground state of Majorana fermion chain
Here, we consider the spinless 1D Majorana fermion chain model of length as an example [49]:
| (34) |
where is the Majorana fermion operator obeying:
| (35) |
and and are model parameters. This model presents a wealth of nontrivial quantum phases under different . We focus on the model parameters in , where the ground state of Eq. 34 is a CFT composed of a critical Ising theory () and a Luttinger liquid ().

Through the definition of the complex fermions followed by the Jordan-Wigner transformation:
| (36) | |||||
where is the complex fermion number operator, we map Eq. 34 to a 3-local spin chain of length :
| (37) |
We employ quantum measurements on the ground state of this Hamiltonian, based on which we carry out our MLE Hamiltonian learning protocol. Here, we evaluate the ground-state properties via exact diagonalization. The numerical results for two cases of are in Fig. 9. We achieve successful convergence and satisfactory accuracy on the target Hamiltonian. The relative entropy’s instabilities are mainly due to the ground state’s level crossing and degeneracy.
D.3 Example: alternative Hamiltonian for ground state
We have seen that MLE Hamiltonian learning can retrieve the unknown target Hamiltonians via quantum measurements of its Gibbs states, even its ground states. For pure states, however, one interesting byproduct is that the relation between Hamiltonian and eigenstates is essentially many-to-one. Therefore, it is possible to obtain various candidate Hamiltonians sharing the same ground state as the original target , especially by controlling the operator/observable set. Here, we show such numerical examples.

As our target quantum system, we consider the transverse field Ising model (TFIM) of length :
| (38) |
at its critical point . Its ground state is . However, instead of the operators presenting in , we employ a different operator set for ’s quantum measurements:
| (39) |
We evaluate the ground-state properties via DMRG.
The subsequent MLE Hamiltonian learning results are in Fig. 10. Since we obtain a candidate Hamiltonian with the operators in Eq. 39 and destined to differ from , the Hamiltonian distance is no longer a viable measure of its accuracy. Instead, we introduce the ground-state fidelity , where () is the ground state of (). Interestingly, while the relative entropy shows full convergence, the fidelity jumps between and . This is understandable, as the quantum system is gapless, and the ground and low-lying excited states have similar properties under quantum measurements.
D.4 Example: two-dimensional topological states
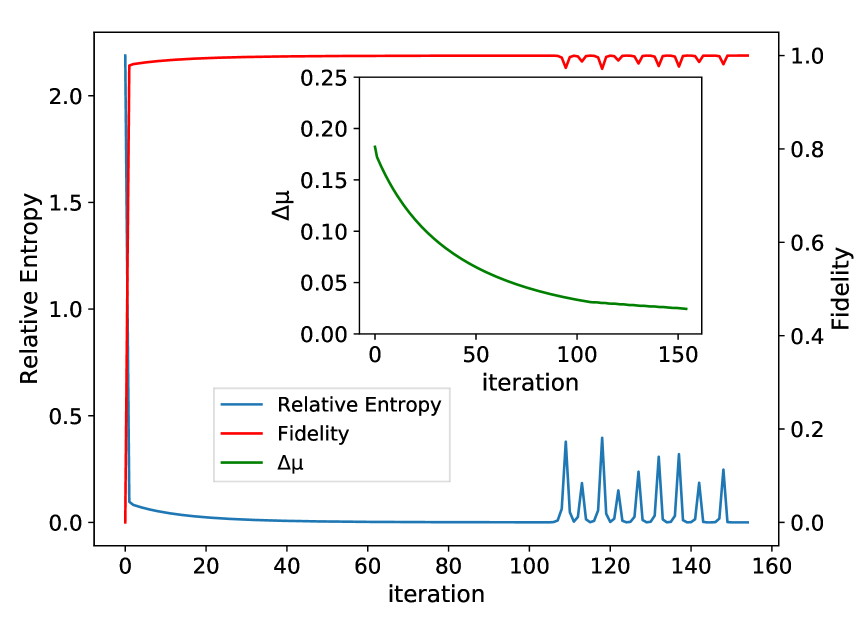
Here, we consider MLE Hamiltonian learning on two-dimensional topological quantum systems. In particular, we consider the chiral spin liquid (CSL) on a triangular lattice:
| (40) |
where the first and second terms are Heisenberg interactions, and the last term is a three-spin chiral interaction. Previous DMRG studies have established ’s ground state as a CSL under the model parameters , , and [50], which we set as the parameters of the target Hamiltonian. Here, we employ exact diagonalization on a system. Based upon entanglement studies of the lowest-energy eigenstates, we verify that both the modular matrix corresponding to rotations and the entanglement entropy fit well with a CSL topological phase[51]. Subsequently, we perform MLE Hamiltonian learning based on quantum measurements of the ground state, focusing on the operators presenting in . We summarize the results in Fig. 11. The Hamiltonian distance indicates a stable converging accuracy, yet the relative entropy and the fidelity witness certain instabilities. Indeed, being a topological phase means ground-state degeneracy - competing low-energy eigenstates with global distinctions yet similar local properties.