Maximal co-occurrence nonoverlapping sequential rule mining
Abstract
The aim of sequential pattern mining (SPM) is to discover potentially useful information from a given sequence. Although various SPM methods have been investigated, most of these focus on mining all of the patterns. However, users sometimes want to mine patterns with the same specific prefix pattern, called co-occurrence pattern. Since sequential rule mining can make better use of the results of SPM, and obtain better recommendation performance, this paper addresses the issue of maximal co-occurrence nonoverlapping sequential rule (MCoR) mining and proposes the MCoR-Miner algorithm. To improve the efficiency of support calculation, MCoR-Miner employs depth-first search and backtracking strategies equipped with an indexing mechanism to avoid the use of sequential searching. To obviate useless support calculations for some sequences, MCoR-Miner adopts a filtering strategy to prune the sequences without the prefix pattern. To reduce the number of candidate patterns, MCoR-Miner applies the frequent item and binomial enumeration tree strategies. To avoid searching for the maximal rules through brute force, MCoR-Miner uses a screening strategy. To validate the performance of MCoR-Miner, eleven competitive algorithms were conducted on eight sequences. Our experimental results showed that MCoR-Miner outperformed other competitive algorithms, and yielded better recommendation performance than frequent co-occurrence pattern mining. All algorithms and datasets can be downloaded from https://github.com/wuc567/Pattern-Mining/tree/master/MCoR-Miner.
Index Terms:
Sequential pattern mining, sequential rule mining, rule-antecedent, co-occurrence pattern, maximal rule miningI Introduction
As an important method of knowledge discovery [1], sequential pattern mining (SPM) [2] aims to mine sub-sequences (patterns) that meet certain conditions from sequence datasets [3]. A variety of SPM methods have been derived for different mining requirements, such as order-preserving SPM for time series [4], SPM for large-scale databases [5, 6], episode pattern mining [7], spatial co-location pattern mining [8, 9], contrast SPM [10, 11], negative SPM [12, 13], high utility SPM [14], high average-utility SPM [15, 16, 17], outlying SPM [18], three-way SPM [19, 20], co-occurrence SPM [21, 22], and SPM with gap constraints [23]. One of the disadvantages of traditional SPM is that it only considers whether a given pattern occurs within a sequence and ignores the repetition of the pattern in the sequence [24]. For example, the support (number of occurrences) of a pattern in sequence is one according to traditional SPM, despite the pattern occurring more than once in the sequence. From this example, we see that repetition is ignored in traditional SPM, meaning that some interesting patterns will be lost [25].
To solve this issue, gap constraint SPM was proposed [26], which can be expressed as p = with = (or p = …), where and are integers indicating the minimum and maximum wildcards between and , respectively [27, 28]. For example, pattern means that there are zero to three wildcards between and . Repetitions of patterns can be useful in terms of capturing valuable information from sequences, and gap constraint SPM therefore has many applications, such as septic shock prediction for ICU patients [29], keyphrase extraction [30], missing behaviors analysis [31], and pyramid scheme pattern mining [32]. However, gap constraint SPM is not only difficult to solve, but also has many forms, such as periodic gaps SPM [33], disjoint SPM [34], one-off SPM [35], and nonoverlapping SPM [23]. Previous research work has shown that the nonoverlapping SPM avoids the production of many redundant patterns [24]; for example, under the nonoverlapping condition, the pattern occurs twice in sequence .
Unfortunately, current schemes based on gap constraint SPM can only mine all of the frequent patterns. Compared with rule mining, frequent pattern mining is not suitable for making predictions or recommendations. Rule mining [36] focuses on mining rules such as p q, which means that if pattern p occurs in the sequence, pattern q is likely to appear afterward with a probability higher than or equal to a given confidence, i.e., p q . However, in cases where users only want to find the rules with the same antecedent p, then mining all the strong rules is not only time-consuming and laborious, but also meaningless. For example, in a recommendation problem, researchers hope to discover potential rules from historical data and use the recent events to predict future events. Obviously, it is valuable to discover rules with the same recent events instead of all rules. This kind of rule is called co-occurrence rule and is more meaningful. For clarification, an illustrative example is as follows.
Example 1.
Suppose we have a sequence s = , a gap constraint = [0,3], and a predefined support threshold minsup = 3. According to nonoverlapping SPM, there are 12 frequent patterns: {, , , , , , , , , , , }. Moreover, if we continue to set the minimum confidence threshold mincf = 0.7, there are 11 rules: { , , , , , , , , , , }. Obviously, it is difficult for users to apply these excessive numbers of frequent patterns and rules.
However, if we have a prefix-pattern (or antecedent) p = , the number of frequent super-patterns and rules will be reduced. The details are shown as follows. We know that p = occurs four times in sequence s, since the subsequence is and the subsequences , , and are also . Thus, the support of p in s is four. Similarly, we know that the subsequences , , and are all . Thus, the support of pattern in s is three, which is not less than = 3. Hence, the pattern is a frequent co-occurrence pattern of p = . Furthermore, is a co-occurrence rule whose confidence is 3/4 = 0.75 = 0.7. Similarly, we know that patterns and are frequent, and that and are co-occurrence rules. Hence, there are only three co-occurrence patterns of pattern p, , , and , and three co-occurrence rules , , and , which means that the number of frequent patterns and rules is greatly reduced.
Inspired by the maximal SPM, the concept of maximal co-occurrence rules (MCoRs) is developed to further decrease the number of co-occurrence rules. For instance, if a rule p r is an MCoR, then we know that p q is also a co-occurrence rule, where pattern q is the prefix pattern of r. Moreover, if the pattern w is a superpattern of r, then p w is not a co-occurrence rule. From the above examples, we see that it is meaningful to investigate MCoR mining. The main contributions of this paper are as follows.
-
1.
To avoid mining irrelevant patterns and obtain better recommendation performance, we develop MCoR mining, which can mine all MCoRs with the same rule-antecedent, and we propose the MCoR-Miner algorithm.
-
2.
In MCoR mining, the user does not need to set the support threshold, since it can be automatically calculated based on the support of the rule-antecedent and the minimum confidence threshold.
-
3.
To improve support calculation, MCoR-Miner consists of three parts: a preparation stage, candidate pattern generation, and a screening strategy to improve efficiency.
-
4.
To validate the performance of MCoR-Miner, eleven competitive algorithms and eight datasets are selected. Our experimental results verify that MCoR-Miner outperforms the other competitive algorithms and yields better recommendation performance than frequent SPM.
II Related work
The aim of SPM is to find subsequences (patterns) in a sequence database that meet the given requirements [37]. SPM methods are commonly used for data mining, since their results are intuitive and interpretable [38, 39]. Traditional SPM mainly focuses on frequent pattern mining, which means the mined patterns have high frequency. To reduce the number of patterns, top- SPM [12], closed SPM [40], and maximal SPM [41] were developed, all of which require that the data are static rather than dynamic. To overcome this drawback, incremental SPM [42] and window SPM [43] methods were explored. However, the research community noticed that rare patterns were of great significance in the field, and rare pattern mining was also proposed [44]. In addition, to discover missing events, negative SPM methods such as e-NSP [45] and e-RNSP [46] were designed. An approach called high utility SPM was also designed [47, 48], which can discover patterns with low frequency but high utility [49, 50].
Most SPM methods can be seen as classical SPM [51], since these methods only consider whether a pattern occurs within a sequence, while repetitive SPM deeply considers the number of occurrences of a pattern in the sequence [33]. For example, suppose we have two sequences: s1=aabbaaba and s2=abcbc. According to classical SPM, the support of pattern aba in s1 and s2 is one, since pattern aba occurs in sequence s1=aabbaaba, but does not occur in sequence s2. Thus, classical SPM neglects the fact that pattern aba occurs in sequence s1=aabbaaba more than once, while repetitive SPM considers the number of occurrences. Another significant difference is that classical SPM focuses on mining patterns in sequences with itemsets, while repetitive SPM mainly aims to mine patterns in sequences with items [52]. For example, (ab)(bc)(a)(bd)(ad) is a sequence with itemsets, and each itemset has many ordered items. If all itemsets in a sequence have only one item, then the sequence is a sequence with items. Thus, a sequence with items can be seen as a special case of a sequence with itemsets. The sequences with items are used in many fields, such as DNA sequence, protein sequence, clickstreams, and commercial data.
Note that repetitive SPM is similar to episode mining [53]. The differences are three-fold. First, episode mining deals with one sequence, while repetitive SPM processes one or more sequences. Second, episode mining aims to mine patterns in an event sequence, where an event sequence can be represented by (,), (,), (,), where is an event set, and is the occurrence time of . In contrast, in repetitive SPM, the sequences do not have the occurrence time. Third, in episode mining, can be a set, while in repetitive SPM, the sequence consists of items, rather than sets.
Compared with classical SPM, repetitive SPM not only is more challenging, but also has many forms: general form (no condition) [33], disjoint [52], one-off [54], and nonoverlapping forms [55]. Note that the disjoint form was called the nonoverlapping form in some studies [46, 34], which is far different from the nonoverlapping form in this study. To clarify the difference between disjoint and nonoverlapping, an illustrative example is shown as follows.
Example 2.
Suppose we have a sequence s=aabbaaba and a pattern p=a[0,1]b[0,1]a.
In the disjoint form [46, 34], the first position of an occurrence is greater than the last position of its previous occurrence. Thus, there are two occurrences: 1,3,5 and 6,7,8. Note that 1,3,5 and 2,4,6 do not satisfy the disjoint form, since the first position of occurrence 2,4,6 2 is less than 5, which is the last position of 1,3,5.
In the nonoverlapping form [24], each item cannot be reused by the same , but can be reused by different . Thus, there are three occurrences: 1,3,5,2,4,6, and 6,7,8. Note that 2,4,6, and 6,7,8 satisfy the nonoverlapping form, since matches in 2,4,6, and matches in 6,7,8.
Recently, various applications for SPM with gap constraints were investigated. For example, top- contrast nonoverlapping SPM was proposed, in which the mined patterns can be used as features for a sequence classification task [10]. To discover low frequency but high average utility patterns, high average utility one-off SPM [49] and nonoverlapping SPM [56] were developed. To discover missing events, a one-off negative SPM was proposed, which could be used to predict the future trend in traffic flow [13]. Inspired by three-way decisions [19, 57], nonoverlapping three-way SPM [20] was designed to mine the patterns to which users pay the most attention, and can effectively mine patterns composed of strong-interest and medium-interest items.
Most of these schemes aim to discover all of the patterns that satisfy the predefined constraints. However, in general, these methods will discover numerous patterns. Although top- SPM [10], nonoverlapping closed SPM [40], and nonoverlapping maximal SPM [41] can reduce the number of patterns, users may not be interested in many of the patterns that are discovered. However, these mining methods fail to reveal the relationship between patterns. Rule mining is an effective method in discovering the relationship between patterns [36]. There are many rule mining methods such as association rule mining [58], sequential rule mining [36], episode rule mining [59], and order-persevering rule mining [60]. Similar to pattern mining, there are many methods to reduce the redundant rules, such as maximum consequent and minimum antecedent [61], top-k rule mining [58], closed rule mining, and maximal rule mining [60]. Nevertheless, in some cases, users know a prefix pattern advance, and they want to discover its super-patterns. This is called co-occurrence pattern mining [62]. Based on the co-occurrence patterns, co-occurrence rules can be further explored to reveal the relationships between the prefix patterns and their super-patterns. Although we can mine all patterns at first, and then filter out useless patterns with different prefixes, this approach will increase the running time [63].
In summary, although the use of SPM with gap constraints can make the mining results more meaningful, the mining results of this scheme are not targeted. In order to make the mining results more suitable for recommendations, based on the special needs of users, we present a scheme inspired by co-occurrence SPM [64] and maximal nonoverlapping SPM [41], called MCoR mining.
III Problem definitions
Definition 1.
(Sequence) A sequence s with length is denoted by s = , where (1 ) , represents a set of items in sequence s, and the size of can be expressed as .
Definition 2.
(Sequence database) A sequence database with length is a set of sequences, denoted by = {, , }.
Definition 3.
(Pattern) A pattern p with length is denoted by p = (or abbreviated as p = with = , where and are integers indicating the minimum and maximum wildcards between and , respectively.
Definition 4.
(Occurrence and nonoverlapping occurrence) Suppose we have a sequence s = and a pattern p = . = , , , is an occurrence of pattern p in sequence s if and only if = , = , , = (0 ) and . We assume there is also another occurrence = , , , . and are two nonoverlapping occurrences if and only if for any , .
Example 3.
Suppose we have a sequence s = and a pattern p = . According to the gap constraint [0,3], all occurrences of p in s are 1,2, 1,4, 5,6, 5,8, 11,14, 13,14 and 13,16. 1,2 and 1,4 do not satisfy the nonoverlapping condition, since 1 appears in these two occurrences in the same position. Thus, there are four nonoverlapping occurrences of p in s, which are 1,2, 5,6, 11,14, and 13,16.
Note that there are many different methods to calculate the nonoverlapping occurrences and the results may be different, such as NETLAP [65], NETGAP [24], Netback [41], DFOM [56]. For example, besides two nonoverlapping occurrences 1,2 and 5,6, 1,4 and 5,8 are also two nonoverlapping occurrences. Although the results may be different, this problem has been theoretically proved to be solved in polynomial time [65]. More importantly, it has been shown that there are four different ways to find the nonoverlapping occurrences, finding the maximal occurrences in the rightmost leaf-root way, finding the maximal occurrences in the rightmost root-leaf way, finding the minimal occurrences in the leftmost leaf-root way, and finding the minimal occurrences in the leftmost root-leaf way [66]. In this example, 1,2 and 5,6 are called minimal nonoverlapping occurrences [56], while 1,4 and 5,8 are called maximal nonoverlapping occurrences [65]. In this paper, we search for the minimal nonoverlapping occurrences.
Definition 5.
(Support) The support of pattern p in sequence s is the number of nonoverlapping occurrences, represented by . The support of pattern p in sequence database is the sum of the supports in each sequence, i.e., = .
Definition 6.
(Frequent pattern) If the support of pattern p in sequence s or is no less than the minimum support threshold , then pattern p is a frequent pattern.
Definition 7.
(Prefix pattern, subpattern, and superpattern). Given two patterns p = and q = () with = [], if and only if = , = , , and = , then pattern p is the prefix pattern of pattern q. Moreover, pattern p is a subpattern of pattern q, and pattern q is a superpattern of pattern p.
Example 4.
Given two patterns p = and q = , pattern p is the prefix pattern of pattern q.
Definition 8.
(Co-occurrence pattern, co-occurrence rule, rule antecedent, rule consequent, and confidence) Suppose we have a pattern q=p·r = , where p = and r = . The pattern r is a co-occurrence pattern of p, and p r is a co-occurrence rule, where p and r are the rule antecedent and consequent, respectively. The ratio of the supports of patterns q and p is called the confidence of the sequential rule p r, and is denoted by conf(p r) = sup(p·r,)/sup(p,). The confidence indicates the probability of occurrence of pattern r when pattern p occurs.
Definition 9.
(Maximal co-occurrence pattern) Suppose we have a pattern q. If one of its superpattern r is a frequent co-occurrence pattern, then pattern q is not a maximal co-occurrence pattern; otherwise, pattern q is a maximal co-occurrence pattern.
Definition 10.
(Strong co-occurrence rule and MCoR) If p r is greater than or equal to the predefined threshold , i.e., p r , then p r is a strong co-occurrence rule. Suppose p r is a strong co-occurrence rule. For any superpattern w of pattern r, if p w is not a strong co-occurrence rule, then p r is an MCoR.
MCoR mining: Given a sequence s or sequence dataset , , and prefix pattern p, the aim of MCoR mining is to discover all MCoRs.
Example 5.
From Example 1, we know that and are two co-occurrence rules. Rule is not an MCoR, while rule is an MCoR, since the pattern is the prefix pattern of and for any superpattern of , such as , is not a strong co-occurrence rule.
The symbols used in this paper are shown in Table I.
| Symbol | Description |
|---|---|
| s | A sequence with length |
| A sequence database with sequences | |
| p | A pattern with length |
| The minimum and maximum wildcards, respectively | |
| The number of occurrences of p in s | |
| The number of occurrences of p in | |
| The set of items in sequence database | |
| The minimum support threshold | |
| The predefined confidence threshold | |
| p r | A co-occurrence rule |
| conf(p r) | The confidence of the co-occurrence rule p r |
IV Proposed algorithm
In this section, we propose MCoR-Miner, an algorithm designed to discover all MCoRs. MCoR mining is based on nonoverlapping SPM whose main issue is support calculation. Therefore, support calculation is a key aspect of MCoR mining illustrated in Section IV-A. In addition to support calculation, MCoR-Miner has three parts: preparation stage, candidate pattern generation, and screening strategy. The framework of MCoR-Miner is shown in Fig. 1.

IV-A Support calculation
Given a sequence and a pattern with gap constraints, the calculation of its support is a pattern matching task [65]. From Definition 4, we know that all nonoverlapping occurrences are a subset of all occurrences, and these occurrences can be expressed using a Nettree structure. Wu et al. [65] first theoretically proved that calculating the nonoverlapping occurrences can be solved in polynomial-time. Some state-of-the-art algorithms, such as NETLAP-Best [65] and NETGAP [24], initially create a Nettree and then iteratively prune useless nodes to find all nonoverlapping occurrences on the Nettree. The time complexities of NETLAP-Best and NETGAP are both , where , , and are the length of pattern and sequence, and , respectively. Since pruning these useless nodes will consume a lot of time, Netback [41] was proposed to improve the efficiency, in which a Nettree is first created and a backtracking strategy is then employed to find all nonoverlapping occurrences on the Nettree. The time complexity of NetBack is reduced to . Although a Nettree can intuitively represent all occurrences, it contains a lot of useless information when representing all nonoverlapping occurrences, such as useless nodes and parent-child relationships. To further improve the efficiency, DFOM [56] was proposed; this algorithm does not need to create a whole Nettree, and employs depth-first search and backtracking strategies to find all nonoverlapping occurrences. One of the shortcomings of DFOM is that it employs a sequential searching strategy to find the feasible child nodes of each current node. The time complexity of DFOM is , since DFOM also employs the depth-first and backtracking strategies without creating a whole Nettree. To overcome this drawback, we propose a depth-first search and backtracking with indexes algorithm, called DBI, which employs an indexing mechanism to avoid sequential searching. Example 6 illustrates the principle of DFOM [56].
Example 6.
We use the same sequence s = as in Example 3 and a pattern p = . Fig. 2 illustrates the occurrences searching process of DFOM. We know that = . Thus, DFOM sequentially searches for in sequence s. Now, DFOM creates a root, labeled node 1, since = = . According to the depth-first search strategy, DFOM sequentially searches for in sequence s after node 1 with gap constraints , since = . We know that = . Thus, DFOM creates a child of node 1, labeled node 2. Since = , DFOM sequentially searches for in sequence s after node 2 with gap constraints . Unfortunately, there is no between and . Hence, using a backtracking strategy, DFOM backtracks node 1 to find a new child. We know that is , which is not equal to = , and DFOM, therefore, continues to search. We know that is which is equal to = . Thus, DFOM finds a new child of node 1, labeled node 4. Following a depth-first search strategy, DFOM searches for in sequence s after node 4 with gap constraints , since = . It is easy to see that and are not equal to . Since = is equal to and the gap between positions 7 and 4 is 2, this satisfies the gap constraints . Thus, DFOM finds a new child of node 4, labeled node 7. Since the length of p is three, DFOM finds an occurrence 1,4,7. Now, DFOM continues to search for a new root. Since , , and are not equal to , these characters are ignored. Since is , DFOM finds a new root, labeled node 5. By iterating the above process, DFOM finds a new nonoverlapping occurrence 5,6,9. Finally, occurrence 11,14,15 is found.

From Example 6 and Fig. 2, we know that the main drawback of DFOM is its sequential search. To overcome this shortcoming, DBI uses index arrays to store the positions of each character. Example 7 illustrates the principle of DBI.

Example 7.
We use the same sequence s = and pattern p = as in Example 6. DBI uses index arrays to store the positions of each character, as shown in Fig. 3. Fig. 4 shows the occurrences searching process of DBI. Since = , DBI gets the first element in the array , which is position 1. Thus, DBI creates a root, labeled node 1. Following a depth-first search strategy, since = , DBI gets the first element in the array , which is 2, and the gap between positions 2 and 1 is zero, which satisfies the gap constraints . Thus, DBI creates a child of node 1, labeled node 2. According to a depth-first search strategy, since = , DBI gets the first element in the array , which is position 7. The gap between positions 7 and 2 is four, which does not satisfy the gap constraints . According to the backtracking strategy, DBI backtracks node 1 to find a new child. We know that the second element of the array is position 4, which satisfies the gap constraints . Thus, DBI creates a child of node 1, labeled node 4. Now, DBI selects the first element of the array , which is position 7, and it satisfies the gap constraints . Hence, DBI obtains the occurrence 1,4,7. Then, DBI gets the second element of array , which is position 5. By iterating the above process, DBI obtains the occurrence 5,6,9. Finally, 11,14,15 is found.
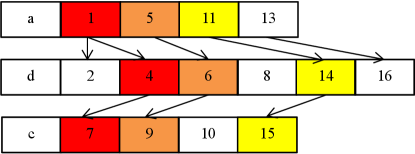
From Example 7, we know that DBI first creates level nodes according to the index arrays of pattern p. Then, based on the index arrays, DBI adopts the depth-first search and backtracking strategies to iteratively find the minimal nonoverlapping occurrences. The pseudocode of DBI is shown in Algorithm 1. The main steps of DBI are as follows.
-
Step 1:
DBI selects the first element in the index array of as the current node, and set the current level as the first level (Lines 1 to 3).
-
Step 2:
DBI gets the first unused element in the next level as the child node of the current node, and the distance between the current node and the child node satisfies the gap constraints =[] (Lines 5 to 10).
-
Step 3:
If DBI successfully finds the child node, then the child node is selected as the current node and the next level is set as the current level. Otherwise, DBI backtracks to the parent node of the current node and searches for the next child node (Lines 11 to 17).
-
Step 4:
Iterate Step 3 until DBI reaches the -th level or the first level. If DBI reaches the -th level, then DBI finds an occurrence, i.e., ++ (Lines 19 to 21).
-
Step 5:
DBI selects the next element in the index array of as the current node, and sets the current level as the first level.
-
Step 6:
Iterate Steps 2 to 5 until all elements in the index array of are checked.
Theorem 1.
The time and space complexities of DBI are both , where , , and are the lengths of pattern and sequence, and the size of , respectively.
Proof.
It is easy to know that the size of the index array of each item is , since the length of the sequence is , and the size of items is . To calculate the support, there are index arrays. We know that each element in the index arrays can be used at most once, which means that DBI visits these elements one by one. Hence, the time and space complexities of DBI are both .
IV-B Preparation stage
In this section, we propose two strategies: filtering strategy and minimum support strategy to avoid some redundant support calculations. We first propose the filtering strategy.
Filtering strategy. If the support of pattern p in sequence s is zero, then sequence s can be pruned.
Theorem 2.
Filtering strategy is correct and complete.
Proof.
We know that the nonoverlapping SPM satisfies anti-monotonicity [24], which means that the support of a superpattern is no greater than that of its sub-pattern. If = 0, then we can safely say that = 0, where pattern q is a superpattern of pattern p, since the nonoverlapping SPM satisfies the anti-monotonicity condition and sequence s can therefore be pruned. Hence, the filtering strategy is correct and complete.
Moreover, based on this anti-monotonicity, we further propose a minimum support strategy.
Minimum support strategy. If the support of a pattern q in is less than , then pattern q and its superpatterns can be pruned, where = .
Theorem 3.
Minimum support strategy is correct and complete.
Proof.
Suppose a rule p r is a strong co-occurrence rule, i.e., p r) = ·/ . Then, · , which means that the support of pattern p·r is greater than or equal to . Thus, for MCoR mining, users do not need to set , since it can be automatically calculated based on . Hence, the minimum support strategy is correct and complete.
In the preparation stage, we propose the SDB-Filt algorithm whose pseudocode is shown in Algorithm 2. The main steps of SDB-Filt are as follows.
-
Step 1:
Select a sequence s in .
-
Step 2:
SDB-Filt employs the DBI algorithm to calculate .
-
Step 3:
If is zero, then sequence s can be shrunk according to filtering strategy. Otherwise, sequence s is stored in a shrunk database , and the support is updated, i.e., gets + (Lines 4 to 7).
-
Step 4:
Iterate Steps 1 to 3 until all sequences are calculated.
-
Step 5:
After getting , SDB-Filt calculates according to the minimum support strategy (Line 9).
IV-C Candidate pattern generation
There are two strategies that are commonly used for generating candidate patterns: the enumeration tree strategy and the pattern join strategy. Many nonoverlapping SPM methods have adopted the pattern join strategy to generate candidate patterns, such as NOSEP [24] and NTP-Miner [20], since it can effectively reduce the candidate patterns compared to the enumeration tree strategy. However, the pattern join strategy uses all frequent patterns with length to generate candidate patterns with length , which means that we need to mine all of the frequent patterns. Obviously, a brute-force algorithm is used to mine all frequent patterns and then pattern q and its superpatterns are found among them. We therefore adopt the enumeration tree strategy. In the classical enumeration tree strategy, if pattern q is a frequent pattern, then all patterns q· are candidate patterns, where is any item in sequence s.
To reduce the number of candidate patterns, we first propose the FET strategy and then present the BET strategy.
The FET strategy: If pattern q is a frequent pattern and is any frequent item in sequence s, then all patterns q· are candidate patterns.
Example 8 demonstrates the advantage of the FET strategy.
Example 8.
Suppose we have a sequence s = = , a pattern q = , and = 3. From sequence s, we know that all of the items are {}. According to the classical enumeration tree strategy, there are four candidate patterns based on pattern q: , , , and . However, we know that the supports of patterns , , , and are four, two, four, and six, respectively. Thus, the frequent items are {}, since = 3. Hence, according to FET, there are only three candidate patterns based on pattern q: , , and . This example shows that the FET strategy has better performance than the classical enumeration tree strategy.
To further reduce the number of candidate patterns, inspired by the pattern join strategy, we propose the BET strategy as follows.
The BET strategy: We discover all frequent patterns with length two and store them in set . If is the last item of q, and pattern is a frequent pattern with length two, i.e. , then pattern r = q· is a candidate pattern.
Example 9 illustrates the advantage of the BET strategy.
Example 9.
We use the same scenario as in Example 8. We know that the frequent items are {}. We can then generate nine candidate patterns with length two {, , , , , , , , } using the pattern join strategy. It is then easy to see that the frequent candidate patterns with length two are ad, ca, cd, dc, and dd. From Example 8, we see that there are only three candidate patterns based on pattern q using the FET strategy: , , and . Pattern cannot be pruned by the BET strategy, since pattern is a frequent pattern with length two, while pattern can be pruned by the BET strategy, since pattern is not a frequent pattern with length two. Similarly, pattern cannot be pruned. Thus, only two candidate patterns are generated by the BET strategy. This example demonstrates that the BET strategy outperforms the FET strategy. A comparison of the candidate patterns is given in Fig. 5.



Theorem 4.
Both FET and BET strategies are correct and complete.
Proof.
As mentioned above, the nonoverlapping SPM satisfies anti-monotonicity [24]. Thus, the support of a superpattern is no greater than that of its sub-pattern. Therefore, if item is infrequent, then the pattern q· is infrequent. Hence, the FET strategy is correct and complete. Similarly, we know that the BET strategy is also correct and complete.
IV-D Screening strategy
Obviously, it is easy for us to obtain strong co-occurrence sequential rules based on the frequent co-occurrence patterns. Moreover, we can discover the maximal strong co-occurrence rules based on the maximal co-occurrence patterns. The simplest method is to mine all frequent co-occurrence patterns, and then discover the maximal co-occurrence patterns among them. This method can be seen as a brute-force method. To improve the performance, we propose a screening strategy to discover the maximal co-occurrence patterns. The principle is as follows.
Screening strategy: Suppose we have a pattern q. If one of its superpatterns r is a frequent co-occurrence pattern, then pattern q is not a maximal co-occurrence pattern; otherwise, q is a maximal co-occurrence pattern.
Theorem 5.
Screening strategy is correct and complete.
Proof.
According to the definition of the maximal co-occurrence pattern, for a pattern q, if one of its superpattern r is a frequent co-occurrence pattern, then pattern q is not a maximal co-occurrence pattern; otherwise, pattern q is a maximal co-occurrence pattern. The screening strategy discovers the maximal co-occurrence patterns based on the definition of the maximal co-occurrence pattern. Hence, the screening strategy is correct and complete.
We store all frequent co-occurrence patterns in a stack. Suppose pattern q is the top element of the stack. We generate the candidate patterns based on pattern q using the BET strategy, and then we use the DBI algorithm to calculate the supports of the candidate patterns. If candidate pattern r is a frequent co-occurrence pattern, then we store pattern r in the stack; otherwise, pattern q is a maximal co-occurrence pattern and is stored in the set . We check all patterns in the stack until it is empty. Example 10 illustrates the principle of the screening strategy.
Example 10.
Suppose we have a sequence s = = , p = , and = 3. Suppose the top element of the stack is pattern q = . According to the BET strategy, there are two candidate patterns based on pattern q: and . We know that the support of pattern is two. This means that cannot be stored in the stack, since it is not a frequent co-occurrence pattern. Moreover, we know that the support of pattern is three. The pattern is therefore stored in the stack, since it is a frequent co-occurrence pattern. Meanwhile, pattern q is not a maximal co-occurrence pattern, since it has a frequent co-occurrence superpattern . Now, the top element of the stack is pattern which has two candidate patterns according to the BET strategy: and . It is then easy to see that the supports of patterns and are both one. Hence, the pattern is a maximal co-occurrence pattern, since all its superpatterns are not frequent co-occurrence patterns. The advantage of the screening strategy is that the maximal co-occurrence patterns can be discovered without a brute-force search process.
IV-E MCoR-Miner
We introduce the MCoR-Miner algorithm whose pseudocode is shown in Algorithm 3. MCoR-Miner has the following main steps.
-
Step 1:
Use SDB-Filt to calculate the support of pattern p, i.e., ; prune the sequence s whose support is zero; and calculate = (Lines 1 to 2).
-
Step 2:
Traverse to find all frequent items and store them in (Line 3).
-
Step 3:
Generate candidate pattern set using the pattern join strategy (Line 4).
-
Step 4:
Calculate the support of each pattern in set and store the frequent patterns in (Line 5).
-
Step 5:
Store pattern p in stack (Line 6).
-
Step 6:
Obtain the top element pattern q of stack (Line 8).
-
Step 7:
Generate all candidate co-occurrence patterns of pattern q using frequent items and store them in set (Lines 10 to 13).
-
Step 8:
Use BET to prune candidate patterns (Line 14).
-
Step 9:
Use the DBI algorithm to calculate the support of each pattern r in (Line 15).
-
Step 10:
If pattern r is a frequent co-occurrence pattern, then pattern r is stored in stack (Lines 16 to 19).
-
Step 11:
If all patterns r are not frequent co-occurrence patterns, then pattern q is a maximal co-occurrence pattern and is stored in set (Lines 22 to 24).
-
Step 12:
Iterate Steps 6 to 11, until the stack is empty.
-
Step 13:
Generate maximal strong rules based on .
Theorem 6.
The space and time complexities of MCoR-Miner are and , where , , , and are the number of candidate patterns, the maximal length of candidate patterns, the total length of shrunk sequence database, and the size of , respectively.
Proof.
The time and space complexities of scanning the sequence database to obtain its index arrays are . It is easy to know that the space complexity of SDB-Filt is . The time complexity of SDB-Filt is , since the time complexity of DBI is and SDB-Filt checks all sequences, where . The space complexity of is , since the size of all frequent items is no greater than all items. Thus, the time complexity of Line 3 is . The time and space complexities of Line 4 are . The time complexity of Line 5 is , since there are candidate patterns, and the length of each candidate pattern is two. The space complexity of storing frequent patterns with length two is . Suppose MCoR-Miner checks candidate patterns and the maximal length of candidate patterns is . The space complexity of storing these candidate patterns is , and the time complexity of calculating the supports of these candidate patterns is . Hence, the space complexity of MCoR-Miner is =, since generally , , , , and are much smaller than . The time complexity of MCoR-Miner is =, since and are much smaller than and , respectively.
V Experimental results and analysis
To validate the performance of MCoR-Miner, we consider the following eight research questions (RQs).
-
RQ1:
Does MCoR-Miner yield better performance than other state-of-the-art algorithms in terms of mining co-occurrence patterns?
-
RQ2:
Does DBI give better performance than other state-of-the-art algorithms in terms of support calculation?
-
RQ3:
Can the filtering strategy reduce the number of support calculations in MCoR-Miner?
-
RQ4:
Can the FET and BET strategies reduce the number of candidate patterns, and when can BET achieve better performance?
-
RQ5:
What is the effect of the screening strategy?
-
RQ6:
Does MCoR-Miner have better scalability?
-
RQ7:
How do different parameters affect the performance of MCoR-Miner?
-
RQ8:
What is the performance of MCoR-Miner for recommendation tasks?
To answer RQ1, we select NOSEP, DFOM-All, and DBI-All to verify the performance of MCoR-Miner on the problem of co-occurrence pattern mining. In response to RQ2, we propose NETGAP-MCoR, Netback-MCoR, and DFOM-MCoR to explore the effect of DBI, as described in Section V-B. To address RQ3, we propose MCoR-NoFilt to investigate the effect of the filtering strategy, as presented in Section V-B. To answer RQ4, we apply two algorithms, MCoR-AET and MCoR-FET, to verify the effects of the FET and BET strategies, as described in Section V-B. To solve RQ5, we propose MCoR-NoScr to validate the effect of the screening strategy in Section V-B. To answer RQ6, we explore the scalability of MCoR-Miner, as presented in Section V-C. To address RQ7, we explore the effects of different gap constraints and minimum confidence thresholds on the running time of MCoR-Miner in Section V-D. To answer RQ8, we report the performances of MCoR-Miner in terms of confidence, recall, and F1-score in section V-E. All experiments were conducted on a computer with an Intel(R) Core(TM)i7-10870H processor, 32 GB of memory, the Windows 10 operating system, and VS2022 as the experimental environment. All algorithms and datasets can be downloaded from https://github.com/wuc567/Pattern-Mining/tree/master/MCoR-Miner.
V-A Benchmark datasets and baseline algorithms
We used eight datasets shown in Table II as test sequences.
| Dataset | Type | Number of sequence | Length | |
|---|---|---|---|---|
| GAMESALE1 | Commerce | 12 | 39 | 16,446 |
| BABYSALE2 | Commerce | 6 | 949 | 29,971 |
| TRANSACTION3 | Commerce | 31 | 4,661 | 32,851 |
| MOVIE4 | Commerce | 20 | 4,988 | 741,132 |
| MSNBC5 | Clickstream | 17 | 200,000 | 948,674 |
| SARS6 | Bio-sequence | 4 | 426 | 29,751 |
| SARS-Cov-27 | Bio-sequence | 4 | 428 | 29,903 |
| HIV8 | Bio-sequence | 20 | 1 | 10,000 |
To report the performance of the MCoR-Miner algorithm, four experiments were designed, and nine competitive algorithms were selected.
-
1.
NOSEP [24], DFOM-All [56], and DBI-All: To verify that it is necessary to use a special algorithm to discover frequent co-occurrence patterns, we selected two state-of-the-art algorithms: NOSEP [24] and DFOM [56], where NOSEP can mine all frequent patterns. DFOM-All and DBI-All can also discover all frequent patterns, which employed the DFOM and DBI algorithms to calculate the support, respectively. We can then find the frequent co-occurrence patterns among all frequent patterns. Based on the above analysis, we know that the time complexities of NOSEP, DFOM-All, and DBI-All are , , and , respectively, where () and are the number of all frequent patterns and .
-
2.
NETGAP-MCoR [24], Netback-MCoR [41], and DFOM-MCoR [56]: To explore the running performance of DBI, three competitive algorithms were proposed: NETGAP-MCoR, Netback-MCoR, and DFOM-MCoR. The three competitive algorithms employed three state-of-the-art algorithms NETGAP [24], Netback [41], and DFOM [56] to calculate the support, respectively. Other strategies, such as filtering, FET, BET, and screening, are the same as MCoR-Miner. Based on the above analysis, we know that the time complexities of NETGAP-MCoR, Netback-MCoR, and DFOM-MCoR are , , and , respectively.
-
3.
MCoR-NoFilt: To demonstrate the performance of the filtering strategy, MCoR-NoFilt was proposed, which did not employ the filtering strategy but is otherwise the same as MCoR-Miner. The time complexity of MCoR-NoFilt is , while that of MCoR-Miner is , where and () are the lengths of the original and shrunk sequence databases, respectively.
-
4.
MCoR-AET and MCoR-FET: To investigate the performance of the BET strategy, we proposed MCoR-AET and MCoR-FET, which used all items and frequent items to generate candidate patterns, respectively. The time complexities of MCoR-AET and MCoR-FET are and , respectively, where () and are the numbers of candidate patterns. Note that can be smaller than , since MCoR-Miner needs to calculate candidate patterns with length two, and in some cases, it cannot prune candidate patterns using the BET strategy.
-
5.
MCoR-NoScr: To assess the performance of the screening strategy, we used MCoR-NoScr, which did not include the screening strategy. The time complexity of MCoR-NoScr is almost the same as that of MCoR-Miner.
-
6.
CoP-Miner: To verify the recommendation performance, CoP-Miner was proposed, which can mine all frequent patterns with the predefined prefix pattern, and employed the same strategies as MCoR-Miner. The time complexity of CoP-Miner is , where () is the number of all frequent patterns.
V-B Efficiency
To determine the necessity of co-occurrence pattern mining, we selected NOSEP, DFOM-All, and DBI-All as the competitive algorithms. Moreover, to verify the performance of the DBI algorithm and the filtering, BET, and screening strategies, we employed NETGAP-MCoR, Netback-MCoR, DFOM-MCoR, MCoR-NoFilt, MCoR-AET, MCoR-FET, and MCoR-NoScr as the competitive algorithms. Eight datasets were selected. Since the characteristics of these datasets are significantly different, for example in terms of different number of characters and sequences, we set different parameters as shown in Table III. Comparisons of the running time and memory usage are shown in Tables IV and V, respectively. The main indicators of mining results, such as the number of CoRs and MCoRs are shown in Table VI.
| Dataset | Prefix | Gap constraint | Minimum confidence |
|---|---|---|---|
| GAMESALE | [0,8] | 0.3 | |
| BABYSALE | [0,8] | 0.2 | |
| TRANSACTION | [0,3] | 0.3 | |
| MOVIE | [0,3] | 0.5 | |
| MSNBC | [0,8] | 0.3 | |
| SARS | [0,3] | 0.6 | |
| SARS-Cov-2 | [0,3] | 0.6 | |
| HIV | [0,3] | 0.3 |
| GAMESALE | BABYSALE | TRANSACTION | MOVIE | MSNBC | SARS | SARS-Cov-2 | HIV | |
|---|---|---|---|---|---|---|---|---|
| NOSEP | 47.95 | 152.55 | 10.20 | 77.66 | - | 95.47 | 133.12 | 211.98 |
| DFOM-All | 2.47 | 12.33 | 2.11 | 5.78 | - | 9.07 | 10.00 | 84.28 |
| DBI-All | 0.92 | 8.38 | 0.45 | 4.13 | 15.72 | 6.56 | 8.28 | 1.48 |
| NetGAP-MCoR | 16.17 | 113.00 | 2.80 | 50.16 | 587.91 | 2.80 | 2.75 | 7.74 |
| Netback-MCoR | 15.89 | 112.17 | 2.70 | 46.53 | 582.67 | 2.58 | 2.60 | 7.78 |
| DFOM-MCoR | 1.88 | 11.34 | 0.70 | 5.25 | 97.38 | 3.60 | 3.13 | 5.11 |
| MCoR-NoFilt | 0.66 | 5.53 | 1.00 | 4.08 | 215.83 | 2.81 | 2.97 | 0.13 |
| MCoR-AET | 0.70 | 7.14 | 3.88 | 16.22 | 25.92 | 1.56 | 1.42 | 0.02 |
| MCoR-FET | 0.59 | 5.94 | 0.47 | 5.25 | 24.17 | 1.55 | 1.41 | 0.02 |
| MCoR-NoScr | 0.63 | 5.80 | 0.48 | 4.11 | 16.52 | 3.13 | 2.97 | 0.13 |
| MCoR-Miner | 0.42 | 5.36 | 0.38 | 4.00 | 16.08 | 2.34 | 2.66 | 0.11 |
| GAMESALE | BABYSALE | TRANSACTION | MOVIE | MSNBC | SARS | SARS-Cov-2 | HIV | |
|---|---|---|---|---|---|---|---|---|
| NOSEP | 32.1 | 203.3 | 908.1 | 1092.5 | 1183.2 | 106.2 | 106.5 | 19.4 |
| DFOM-All | 22.0 | 195.7 | 903.7 | 971.2 | 1188.0 | 95.1 | 95.4 | 20.2 |
| DBI-All | 14.4 | 16.9 | 21.6 | 38.5 | 230.7 | 17.6 | 17.6 | 14.1 |
| NetGAP-MCoR | 23.7 | 25.8 | 24.8 | 163.1 | 404.9 | 25.2 | 25.2 | 19.6 |
| Netback-MCoR | 26.7 | 18.8 | 35.7 | 187.2 | 263.9 | 27.8 | 27.4 | 20.3 |
| DFOM-MCoR | 15.9 | 18.7 | 22.8 | 40.0 | 226.0 | 15.8 | 15.9 | 15.9 |
| MCoR-NoFilt | 16.7 | 19.6 | 25.0 | 41.1 | 445.8 | 17.6 | 24.3 | 23.0 |
| MCoR-AET | 16.0 | 18.8 | 24.5 | 43.9 | 232.4 | 17.2 | 17.2 | 16.0 |
| MCoR-FET | 24.0 | 26.4 | 30.5 | 47.8 | 238.80 | 14.9 | 14.8 | 13.4 |
| MCoR-NoScr | 20.8 | 32.1 | 30.3 | 47.4 | 239.0 | 24.3 | 16.9 | 15.8 |
| MCoR-Miner | 13.6 | 16.5 | 20.8 | 38.0 | 228.8 | 17.4 | 26.6 | 21.5 |
| GAMESALE | BABYSALE | TRANSACTION | MOVIE | MSNBC | SARS | SARS-Cov-2 | HIV | |
| Number of CoRs | 36 | 98 | 4 | 4 | 12 | 2 | 2 | 3 |
| Number of MCoRs | 20 | 47 | 2 | 1 | 1 | 2 | 2 | 3 |
| Number of filtered sequences | 642 | 1,350 | 104,787 | 288 | 49,163,184 | 28 | 28 | 0 |
| Number of non-filtered sequences | 11,877 | 425,700 | 21,060 | 79,520 | 1,236,816 | 11,900 | 11,956 | 472 |
| Number of all items | 12 | 6 | 30 | 20 | 17 | 4 | 4 | 20 |
| Number of frequent items | 10 | 5 | 4 | 3 | 15 | 4 | 4 | 20 |
| Number of BET items | 27 | 15 | 4 | 2 | 1 | 13 | 13 | 286 |
| Number of BET items under non-filtered | 27 | 15 | 6 | 2 | 24 | 13 | 13 | 286 |
| Number of candidate patterns pruned by BET | 149 | 70 | 9 | 8 | 168 | 0 | 0 | 8 |
| Number of candidate patterns nonpruned by BET | 221 | 425 | 11 | 7 | 27 | 12 | 12 | 72 |
These results give rise to the following observations.
-
1.
Maximal co-occurrence rule mining can effectively reduce the number of rules. From Table VI, on BABYSALE, there are 98 co-occurrence rules, while there are 47 maximal co-occurrence rules. The same phenomenon can be found on all the other datasets. This is because as shown in Example 5, both and are rules, and is a maximal rule, while rule is not a maximal rule. This means that MCoR mining can effectively reduce the number of rules.
-
2.
It is necessary to explore the co-occurrence pattern mining, since MCoR-Miner is significantly faster than NOSEP [24] and DFOM-All [56], and in particular is faster than DBI-All. For example, on GAMESALE, NOSEP and DFOM-All take 47.95s and 2.47s, respectively, while MCoR-Miner takes 0.42s, meaning that MCoR-Miner is about 100 times faster than NOSEP, and six times faster than DFOM-All. Moreover, DBI-all takes 0.92s, which is slower than MCoR-Miner. These phenomena can be found on the other datasets. The reasons for this are twofold. Firstly, MCoR-Miner employs a more efficient algorithm, called DBI, to calculate the support compared to NOSEP and DFOM-All. As mentioned in Section IV-A, we know that NOSEP has to create a whole Nettree to calculate the support. However, a Nettree contains many redundant nodes and parent-child relationships. Although DFOM can overcome this disadvantage, it uses a sequential searching strategy to find feasible child nodes of the current node, which is an inefficient method. In contrast, DBI is equipped with an indexing mechanism to avoid sequential searching, meaning that MCoR-Miner is significantly faster than NOSEP and DFOM-All. Secondly, although both DBI-All and MCoR-Miner employ DBI to calculate the support, DBI-All runs slower than MCoR-Miner. The reason for this is that the three algorithms have to discover all of the patterns, and since many of these are not targeted patterns, all three algorithms have to filter out these useless patterns. The experimental results therefore indicate that it is necessary to explore the co-occurrence pattern mining.
-
3.
MCoR-Miner runs faster than NETGAP-MCoR, Netback-MCoR, and DFOM-MCoR on all datasets, which indicates the efficiency of DBI. For example, from Table IV, we can see that on BABYSALE, MCoR-Miner takes 5.36s, while NETGAP-MCoR, Netback-MCoR, and DFOM-MCoR take 113.00s, 112.17s, and 11.34s, respectively. Thus, MCoR-Miner is obviously faster than NETGAP-MCoR and Netback-MCoR, and is about twice as fast as DFOM-MCoR. The reasons are as follows. The four algorithms adopt different methods to calculate the support. NETGAP-MCoR and Netback-MCoR have to create the whole Nettree which contain many useless nodes and parent-child relationships. Therefore, their time complexities are higher than those of DFOM-MCoR and MCoR-Miner. Although DFOM-MCoR does not create the whole Nettree, DFOM adopts a sequential searching strategy to find feasible child nodes of the current node, which is inefficient. Hence, MCoR-Miner outperforms NETGAP-MCoR, Netback-MCoR, and DFOM-MCoR.
-
4.
MCoR-Miner runs faster than MCoR-NoFilt on all datasets, which indicates the effectiveness of the filtering strategy. According to Table IV, on BABYSALE, MCoR-Miner takes 5.36s, while MCoR-NoFilt takes 5.53s. This phenomenon can also be found on all the other datasets. The reason for this is that some useless sequences are filtered out. For example, from Table VI, we see that 1350 sequences are filtered out when minimg all rules, which means that it is not necessary to calculate the support for these 1350 sequences, and hence the running performance is improved. The filtering strategy can reduce not only the number of sequences, but also the number of frequent patterns with length two, which means that it can reduce the number of candidate patterns with length more than two. For example, on the TRANSACTION dataset, there are only four patterns under the filtering strategy, but six under the non-filtering strategy, meaning that more time is needed to discover all the rules. All in all, the filtering strategy is effective, and MCoR-Miner outperforms MCoR-NoFilt.
-
5.
MCoR-Miner runs faster than MCoR-AET and MCoR-FET on GAMESALE, BABYSALE, TRANSACTION, MOVIE, and MSNBC, but slower than MCoR-AET and MCoR-FET on SARS, SARS-Cov-2, and HIV, which indicates that the BET strategy has certain advantages and limitations. We choose two typical datasets to illustrate the reason for this. 1) Taking GAMESALE as an example, we see that there are 12 items and 10 frequent items. Thus, there are 10 10=100 candidate patterns with length two. After checking these 100 candidate patterns, we have 27 frequent patterns with length two. Using these 27 patterns, 149 candidate patterns are pruned by the BET strategy, and 221 candidate patterns are not according to Table VI. Thus, by adding 100 times support calculations for candidate patterns with length two, MCoR-Miner can avoid 149 times support calculations for candidate patterns. Hence, MCoR-Miner can improve the running performance on GAMESALE. 2) Taking HIV as another example, we see that there are 20 frequent items. Thus, there are 2020=400 candidate patterns with length two. After checking these 400 candidate patterns, we have 286 frequent patterns with length two. Of these 286 patterns, only eight candidate patterns are pruned by the BET strategy, and 72 are not according to Table VI. Thus, by adding 400 times support calculations for candidate patterns with length two, MCoR-Miner can avoid only eight times support calculations for candidate patterns. The running time is therefore increased. Thus, the experimental results show that the BET strategy has some limitations on the Bio-sequence datasets. Hence, our methods, MCoR-Miner or MCoR-FET, can obtain better performance in all cases.
-
6.
MCoR-Miner runs faster than MCoR-NoScr on all datasets, which indicates the effectiveness of the screening strategy. For example, on TRANSACTION, MCoR-Miner requires 0.38s, while MCoR-NoScr requires 0.48s. This phenomenon can be found on all the other datasets. The reason for this is as follows. The difference between the two algorithms is that MCoR-Miner is equipped with the screening strategy, while MCoR-NoScr is not. Thus, the results indicate that the screening strategy is an effective way to reduce the running time, and hence MCoR-Miner outperforms MCoR-NoScr.
-
7.
From Table V, we notice that MCoR-Miner consumes less memory when mining patterns. For example, on GAMESALE, MCoR-Miner consumes 13.6Mb memory, which is less than the other competitive algorithms. This result can be found on most of the datasets. In particular, MCoR-Miner consumes less memory than NOSEP and DFOM-All algorithms. This is because in order to calculate the support, NOSEP needs to create a whole Nettree, which contains a lot of useless information. Although DFOM overcomes this drawback, it uses the sequential searching strategy to find feasible child nodes of the current node, which is not efficient. However, MCoR-Miner uses the DBI algorithm, which is equipped with the indexing mechanism to avoid sequential searching. Hence, MCoR-Miner consumes less memory.
In summary, MCoR-Miner achieves better running performance and memory consumption performance than other competitive algorithms.
V-C Scalability
To validate the scalability of MCoR-Miner, we selected MSNBC as the experimental dataset, since it was the largest dataset in Table II. Moreover, we created MSNBC1, MSNBC2, MSNBC3, MSNBC4, MSNBC5, and MSNBC6, which were one, two, three, four, five, and six times the size of MSNBC, respectively. We set = , = 0.3, and the prefix pattern was . Comparisons of running time and memory usage are shown in Figs. 6 and 7, respectively.


The results give rise to the following observations.
From Figs. 6 and 7, we know that the running time and the memory usage of MCoR-Miner both show linear growth with the increase of the size of the dataset. For example, the size of MSNBC6 is six times that of MSNBC1. MCoR-Miner takes 16.08s on MSNBC1, and 92.52s on MSNBC6, giving 92.52/16.08=5.75. The memory usage of MCoR-Miner is 1358.8Mb on MSNBC6, and 228.8Mb on MSNBC1, giving 1358.8/228.8 = 5.94. Thus, the growth rates of the running time and memory usage are slightly lower than the increase of the dataset size. This phenomenon can be found on all the other datasets. These results indicate that the time and space complexities of MCoR-Miner are positively correlated with the dataset size. More importantly, we can see that MCoR-Miner is more than 10 times faster than MCoR-NoFilt, and that the memory usage of MCoR-NoFilt is more than twice that of MCoR-Miner. We therefore draw the conclusion that MCoR-Miner has strong scalability, since the mining performance does not degrade with the increase of the dataset size.
V-D Influence of parameters
We assessed the effects of different gap constraints and minimum confidence on the number of rules and running time.
V-D1 Influence of different gap constraints
To analyze the influence of different gap constraints on the number of rules and running time of MCoR-Miner, we selected GAMESALE as the experimental dataset, and MCoR-NoFilt, MCoR-AET, MCoR-FET, and MCoR-NoScr as the competitive algorithms. The prefix pattern was and the minimum confidence was 0.3. The gap constraints were [0,5], [0,6], [0,7], [0,8], [0,9], and [0,10]. A comparison of the running time is shown in Fig. 8 and the numbers of mined CoRs and MCoRs mined are shown in Table LABEL:Comparison_of_number_of_CoRs_and_MCoRs_with_different_gaps.

| gap= | gap= | gap= | gap= | gap= | gap= | |
|---|---|---|---|---|---|---|
| [0,5] | [0,6] | [0,7] | [0,8] | [0,9] | [0,10] | |
| Number of CoRs | 8 | 14 | 20 | 36 | 63 | 134 |
| Number of MCoRs | 6 | 10 | 12 | 20 | 34 | 63 |
These results give rise to the following observations.
With the increase of the gap, the running time and number of CoRs and MCoRs are increased. For example, when gap=[0,8], MCoR-Miner takes 0.17s, and mines eight CoRs and six MCoRs, whereas when gap=[0,8], MCoR-Miner takes 0.42s, and mines 36 CoRs and 20 MCoRs. This phenomenon can be found on all the other algorithms. The reason is as follows. We know that with the increase of the gap, the support of a pattern increases. Thus, more patterns can be found, and each co-occurrence pattern corresponds to a CoR. Hence, more CoRs and MCoRs can be found and the running time also increases. MCoR-Miner outperforms the other competitive algorithms for any gap constraints.
V-D2 Influence of different minimum confidence
To report the influence of different minimum confidences on the number of rules and running time of MCoR-Miner, we selected GAMESALE as the experimental dataset, and MCoR-NoFilt, MCoR-AET, MCoR-FET, and MCoR-NoScr as the competitive algorithms. The prefix pattern was and the gap constraints was [0,8]. We set the minimum confidence to 0.16, 0.20, 0.24, 0.28, 0.32, and 0.36. A comparison of the running time is shown in Fig. 9 and the numbers of CoRs and MCoRs mined are shown in Table VIII.

| mincf | mincf | mincf | mincf | mincf | mincf | |
|---|---|---|---|---|---|---|
| =0.16 | =0.20 | =0.24 | =0.28 | =0.32 | =0.36 | |
| Number of CoRs | 796 | 246 | 100 | 49 | 27 | 17 |
| Number of MCoRs | 431 | 134 | 53 | 25 | 15 | 9 |
The results give rise to the following observations.
With the increase of minimum confidence, the running time and numbers of CoRs and MCoRs are decreased. For example, when = 0.16, MCoR-Miner takes 18.45s, and mines 796 CoRs and 431 MCoRs, whereas when = 0.36, MCoR-Miner takes 0.30s, and mines 17 CoRs and nine MCoRs. This phenomenon can be found on the other algorithms. The reason is as follows. For a certain prefix pattern, the minimum support threshold increases with the increase of . Thus, few patterns can be frequent patterns, and each co-occurrence pattern corresponds to a CoR. Hence, fewer CoRs and MCoRs can be found and the running time also decreases. MCoR-Miner outperforms the other competitive algorithms for any minimum confidence.
V-E MCoR-Miner for recommendation
The recommendation task is to provide the recommendation schemes based on the discovered potential rules with the same given antecedent p. To investigate the recommendation performance of MCoR-Miner, we compare the recommendation performance of co-occurrence pattern mining and rule mining. Therefore, we employed CoP-Miner as the competitive algorithm and selected the commerce datasets: GAMESALE, BABYSALE, TRANSACTION, and MOVIE. The first 80% of the sequences were used as the training set, and the remaining 20% as the testing set. The parameters used for training are shown in Table IX.
| Dataset | Prefix | Gap | for | for |
|---|---|---|---|---|
| constraint | MCoR-Miner | CoP-Miner | ||
| GAMESALE | [0,3] | 0.39 | 400 | |
| BABYSALE | [0,3] | 0.40 | 300 | |
| TRANSACTION | [0,3] | 0.40 | 100 | |
| MOVIE | [0,3] | 0.40 | 150000 |
To evaluate the performance of recommendation based on the co-occurrence rules, in addition to confidence, there are three commonly used criteria: precision = , recall = , and F1-score = , where is the number of correct recommendations, is the number of incorrect recommendations, and is the number of relevant items that are not included in the recommendation list. Taking GAMESALE as an example, we see that there are two maximal co-occurrence rules in the training set for MCoR-Miner: { , }, which means that if a user purchases item , then MCoR-Miner will recommend items and to the user. In the testing set, all of the patterns of length two with the prefix pattern are , , , , , and , with supports 110, 108, 139, 281, 126, and 83, respectively. Therefore, in this example, is 420, since the sum of the supports for patterns and is 139 + 281 = 420. FP is zero, since MCoR-Miner recommends items and , and in the test set, the next-item actually can be , , , , , and , which means that items and are both in these items, i.e., MCoR-Miner has no error recommendation. is 427, since the sum of the supports for patterns , , , and is 110+ 108 + 126+ 83 = 427. Thus, the precision, recall, and F1-score of MCoR-Miner on the testing set are 420/(420+0) = 1, 420/(420+427) = 0.4959, and 210.4959/(1+0.4959) = 0.6630, respectively. Comparisons of the confidence, recall, and F1-score results are shown in Figs. 10, 11, and 12, respectively.



The results indicate that our method has the following advantages.
-
1.
MCoR-Miner can effectively prune the co-occurrence rules with low confidence. For example, Fig.10 shows that the confidence for each maximal co-occurrence rule mined by MCoR-Miner is larger than 0.39, while the confidence for many of the co-occurrence patterns mined by CoP-Miner is less than 0.39, and the lowest is only 0.14. This is because MCoR-Miner discovers rules with high confidence and high frequency, while CoP-Miner only discovers rules with high frequency. Thus, MCoR-Miner can effectively prune co-occurrence patterns with low confidence, and the recommendation confidence is improved.
-
2.
More importantly, MCoR-Miner has better performance for recommendation task than CoP-Miner. For example, from Figs. 11 and 12, on GAMESALE, the recall and F1-score of MCoR-Miner are 0.4959 and 0.6630, respectively, which are higher than those of CoP-Miner. This phenomenon can also be found on the other datasets, meaning that MCoR-Miner yields better recommendation performance than CoP-Miner.
-
3.
MCoR-Miner is a sequential rule-based recommendation method that is more interpretable than the learning-based recommendation method. The reason is as follows. MCoR-Miner discovers the rules with high confidence by calculating the support of patterns in the training set. Taking GAMESALE as an example, the supports of patterns , , and are 1917, 970, and 763, respectively. Thus, MCoR-Miner generates two rules: { , }, whose confidences are 0.51 and 0.40, respectively. Therefore, MCoR-Miner has better interpretability. However, for a learning-based recommendation method, the recommendation model is very complex, and cannot be expressed intuitively by a mathematical formula.
In summary, MCoR-Miner has better recommendation performance than CoP-Miner. More importantly, MCoR-Miner can form effective recommendation schemes, which can help decision-makers make correct decisions.
VI CONCLUSION
In nonoverlapping SPM or nonoverlapping sequential rule mining, if the prefix pattern or rule-antecedent is known, it is not necessary to discover all patterns or rules and then filter out irrelevant patterns or rules. This problem is called co-occurrence pattern mining or co-occurrence rule mining. To avoid discovering irrelevant patterns and to obtain better recommendation performance, and inspired by the concept of maximal pattern mining, we investigate MCoR mining. Unlike classical rule mining, which requires two parameters, minimum confidence and minimum support, MCoR mining does not need the minimum support, since it can be automatically calculated based on the support of the rule-antecedent and the minimum confidence. To effectively discover all MCoRs with the same rule-antecedent, we propose the MCoR-Miner algorithm. In addition to the support calculation, MCoR-Miner consists of three parts: preparation stage, candidate pattern generation, and screening strategy. To effectively calculate the support, we propose the DBI algorithm, which adopts depth-first search and backtracking strategies equipped with an indexing mechanism. MCoR-Miner uses the filtering strategy to prune the sequences without the rule-antecedent to avoid useless support calculation. It adopts the FET and BET strategies to reduce the number of candidate patterns, and employs the screening strategy to avoid finding the maximal rules by brute force. To evaluate the performance of MCoR-Miner, eleven competitive algorithms were implemented, and eight datasets were considered. Our experimental results showed that MCoR-Miner yielded better running performance and scalability than the other competitive algorithms. More importantly, compared with frequent co-occurrence pattern mining, MCoR-Miner had better recommendation performance.
In this paper, we focus on the nonoverlapping maximal co-occurrence rule mining. The nonoverlapping sequential pattern mining is a kind of repetitive sequential pattern mining. We know that there are some similar mining methods, such as one-off sequential pattern mining and disjoint sequential pattern mining. Different mining methods will lead to different mining results. The one-off and disjoint maximal co-occurrence rule mining deserve further exploration. Moreover, for a specific mining task, which mining method is the best is worth further study. More importantly, the sequence studied in this paper is a special sequence, which means that the sequence consists of items. However, general sequence consists of itemsets, each of which has many ordered items. It is valuable to investigate frequent repetitive pattern mining and repetitive rule mining in general sequence database.
Acknowledgement
This work was partly supported by National Natural Science Foundation of China (61976240, 62120106008), National Key Research and Development Program of China (2016YFB1000901), and Natural Science Foundation of Hebei Province, China (Nos. F2020202013).
References
- [1] X. Wu, X. Zhu, and M. Wu. ”The Evolution of Search: Three Computing Paradigms,” ACM Trans. Manag. Inf. Syst., vol. 13, no. 2, pp. 20, 2022.
- [2] C. H. Mooney and J. F. Roddick, “Sequential pattern mining–approaches and algorithms,” ACM Computing Surveys, vol. 45, no. 2, pp. 1-39, 2013.
- [3] W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao, and P. S. Yu, “A survey of parallel sequential pattern mining,” ACM Trans. Knowl. Discov. Data, vol. 13, no. 3, pp. 25: 1-34, 2019.
- [4] Y. Wu, Q. Hu, Y. Li, L. Guo, X. Zhu, and X. Wu, “OPP-Miner: Order-preserving sequential pattern mining for time series,” IEEE Trans. Cybern., DOI: 10.1109/TCYB.2022.3169327, 2022.
- [5] J. C. W. Lin, Y. Djenouri, and G. Srivastava, “Efficient closed high-utility pattern fusion model in large-scale databases,” Information Fusion, vol. 76, pp.122-132, 2021.
- [6] G. Srivastava, J. C. W. Lin, X. Zhang, and Y. Li, “Large-scale high-utility sequential pattern analytics in Internet of Things,” IEEE Internet of Things Journal, vol. 8, no.16, pp. 12669-12678, 2021.
- [7] X. Ao, H. Shi, J. Wang, L. Zuo, H. Li, and Q. He, “Large-scale frequent episode mining from complex event sequences with hierarchies,” ACM Trans. Intell. Syst. Technol., vol. 10, no. 4, pp. 1-26, 2019.
- [8] L. Wang, X. Bao, and L. Zhou, “Redundancy reduction for prevalent co-location patterns,” IEEE Trans. Knowl. Data Eng., vol. 30, no. 1, pp. 142-155, 2018.
- [9] L. Wang, Y. Fang, and L. Zhou, “Preference-based spatial co-location pattern mining,” Series Title: Big Data Management, Springer Singapore, DOI: 10.1007/978-981-16-7566-9, 2022.
- [10] Y. Wu, Y. Wang, Y. Li, X. Zhu, and X. Wu, “Top-k self-adaptive contrast sequential pattern mining,” IEEE Trans. Cybern., vol. 52, no. 11, pp. 11819-11833, 2022.
- [11] Q. Li, L. Zhao, Y. Lee, and J. Lin. “Contrast pattern mining in paired multivariate time series of a controlled driving behavior experiment,” ACM Trans. Spatial Algorithms Syst., vol. 6, no. 4, pp. 1-28, 2020.
- [12] X. Dong, P. Qiu, J. Lv, L. Cao, and T. Xu, “Mining top-k useful negative sequential patterns via learning,” IEEE Trans. Neural Networks Learn. Syst., vol. 30, no. 9, pp. 2764-2778, 2019.
- [13] Y. Wu, M. Chen, Y. Li, J. Liu, Z. Li, J. Li, and X. Wu. “ONP-Miner: One-off negative sequential pattern mining,” ACM Trans. Knowl. Discov. Data, DOI: 10.1145/3549940, 2022.
- [14] W. Gan, J. C. W. Lin, P. Fournier-Viger, H.-C. Chao, V. S. Tseng, P. S. Yu, “A survey of utility-oriented pattern mining,” IEEE Trans. Knowl. Data Eng., vol. 33, no. 4, pp. 1306-1327, 2021.
- [15] T. C. Truong, H. V. Duong, B. Le, P. Fournier-Viger, “Efficient vertical mining of high average-utility itemsets based on novel upper-bounds,” IEEE Trans. Knowl. Data Eng., vol. 31, no. 2, pp. 301-314, 2019.
- [16] W. Song, L. Liu, and C. Huang. “Generalized maximal utility for mining high average-utility itemsets,” Knowl. Inf. Syst., vol. 63, pp. 2947–2967, 2021.
- [17] J. C. W. Lin, T. Li, M. Pirouz, J. Zhang, and P. Fournier-Viger, “High average-utility sequential pattern mining based on uncertain databases,” Knowl. Inf. Syst., vol. 62, no. 3, pp: 1199-1228, 2020.
- [18] T. Wang, L. Duan, G. Dong, and Z. Bao, “Efficient mining of outlying sequence patterns for analyzing outlierness of sequence data,” ACM Trans. Knowl. Discov. Data, vol. 14, no. 5, pp. 62, 2020.
- [19] F. Min, Z. Zhang, W. Zhai, and R. Shen, “Frequent pattern discovery with tri-partition alphabets,” Inf. Sci., vol. 507, pp. 715-732, 2020.
- [20] Y. Wu, L. Luo, Y. Li, L. Guo, P. Fournier-Viger, X. Zhu, and X. Wu, “NTP-Miner: Nonoverlapping three-way sequential pattern mining,” ACM Trans. Knowl. Discov. Data, vol. 16, no. 3, pp. 51, 2022.
- [21] D. Amagata and T. Hara, “Mining top-k co-occurrence patterns across multiple streams,” IEEE Trans. Knowl. Data Eng., vol. 29, no. 10, pp. 2249-2262, 2017.
- [22] H. Duong, T. Truong, A. Tran, and B. Le, “Fast generation of sequential patterns with item constraints from concise representations,” Knowl. Inf. Syst., vol. 62, no. 6, pp. 2191-2223, 2020.
- [23] Y. Wang, Y. Wu, Y. Li, F. Yao, P. Fournier-Viger, and X Wu. “Self-adaptive nonoverlapping sequential pattern mining,” Appl. Intell. , vol. 52, no. 6, pp. 6646-6661, 2021.
- [24] Y. Wu, Y. Tong, X. Zhu, and X. Wu, “NOSEP: Nonoverlapping sequence pattern mining with gap constraints,” IEEE Trans. Cybern., vol. 48, no. 10, pp. 2809-2822, 2018.
- [25] Y. H. Ke, J. W. Huang, W. C. Lin, and B. P. Jaysawal, “Finding possible promoter binding sites in DNA sequences by sequential patterns mining with specific numbers of gaps,” IEEE ACM Trans. Comput. Biol. Bioinform., vol. 18, no. 6, pp. 2459-2470, 2020.
- [26] M. Zhang, B. Kao, D. Cheung, and K. Yip, “Mining periodic patterns with gap requirement from sequences,” ACM Trans. Knowl. Discov. Data, vol. 1, no. 2, pp. 7, 2007.
- [27] Q. Shi, J. Shan, W. Yan, Y. Wu, and X. Wu, “NetNPG: Nonoverlapping pattern matching with general gap constraints,” Appl. Intell. , vol. 50, no. 6, pp. 1832-1845, 2020.
- [28] C. Li, Q. Yang, J. Wang, and M. Li, M, “Efficient mining of gap-constrained subsequences and its various applications,” ACM Trans. Knowl. Discov. Data, vol. 6, no. 1, pp. 2:1-39, 2012.
- [29] S. Ghosh, J. Li, L. Cao, and K. Ramamohanarao, “Septic shock prediction for ICU patients via coupled HMM walking on sequential contrast patterns,” Journal of Biomedical Informatics, no. 66, pp. 19-31, 2017.
- [30] F. Xie, X. Wu, and X. Zhu, “Efficient sequential pattern mining with wildcards for keyphrase extraction,” Knowl. Based Syst., vol. 115, pp. 27-39, 2017.
- [31] W. Wang and L. Cao, “VM-NSP: Vertical negative sequential pattern mining with loose negative element constraints,” ACM Trans. Inf. Syst., vol. 39, no. 2, pp. 1-27, 2021.
- [32] W. Wang, J. Tian, F. Lv, G. Xin, Y. Ma, and B. Wang, “Mining frequent pyramid patterns from time series transaction data with custom constraints,” Computers & Security, vol. 100, pp. 102088, 2021.
- [33] Y. Wu, L. Wang, J. Ren, W. Ding, and X. Wu, “Mining sequential patterns with periodic wildcard gaps,” Appl. Intell., vol. 41, no. 1, pp. 99-116, 2014.
- [34] O. Ouarem, F. Nouioua, and P. Fournier-Viger, “Mining episode rules from event sequences under non-overlapping frequency,” Intern. Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems. Springer, Cham, pp. 73-85, 2021.
- [35] Y. Wu, X. Wang, Y. Li, L. Guo, Z. Li, J. Zhang, and X. Wu, “OWSP-Miner: Self-adaptive one-off weak-gap strong pattern mining,” ACM Trans. Manag. Inf. Syst., vol. 13, no. 3, pp. 25, 2022.
- [36] P. Fournier-Viger, C.-W. Wu, V.S. Tseng, L. Cao, R. Nkambou, “Mining partially-ordered sequential rules common to multiple sequences,” IEEE Trans. Knowl. Data Eng., vol. 27, no. 8, pp. 2203-2216, 2015.
- [37] J. S. Okolica, G. L. Peterson, R. F. Mills, and M. R. Grimaila, “Sequence pattern mining with variables,” IEEE Trans. Knowl. Data Eng., vol. 32, no. 1, pp. 177-187, 2020.
- [38] J. D. Smedt, G. Deeva, and J. D. Weerdt, “Mining behavioral sequence constraints for classification,” IEEE Trans. Knowl. Data Eng., vol. 32, no. 6, pp. 1130-1142, 2020.
- [39] P. Ma, Y. Wu, Y. Li, L. Guo, H. Jiang, X. Zhu, and X. Wu, “HW-Forest: Deep forest with hashing screening and window screening,” ACM Trans. Knowl. Discov. Data, vol. 16, no. 6, pp. 123, 2022.
- [40] Y. Wu, C. Zhu, Y. Li, L. Guo, and X Wu, “NetNCSP: Nonoverlapping closed sequential pattern mining,” Knowl. Based Syst., vol. 196, pp. 105812, 2020.
- [41] Y. Li, S. Zhang, L. Guo, J. Liu, Y. Wu, and X. Wu, “NetNMSP: Nonoverlapping maximal sequential pattern mining,” Appl. Intell. , vol. 52, pp. 9861–9884, 2022.
- [42] J. C. W. Lin, M. Pirouz, Y. Djenouri, C. F. Cheng, and U. Ahmed, “Incrementally updating the high average-utility patterns with pre-large concept,” Appl. Intell. , vol. 50, no. 11, pp. 3788-3807, 2020.
- [43] Y. Baek, U. Yun, H. Kim, H. Nam, H. Kim, J. C. W. Lin, B. Vo, and W. Pedrycz, “RHUPS: Mining recent high utility patterns with sliding window-based arrival time control over data streams,” ACM Trans. Intell. Syst. Technol., vol. 12, no. 2, pp. 16:1-16:27, 2021.
- [44] Y. S. Koh, and S. D. Ravana, “Unsupervised rare pattern mining: a survey,” ACM Trans. Knowl. Discov. Data, vol. 10, no. 4, pp. 1-29, 2016.
- [45] L. Cao, X. Dong, and Z. Zheng, “e-NSP: Efficient negative sequential pattern mining,” Artificial Intelligence, vol. 235, pp. 156-182, 2016.
- [46] X. Dong, Y. Gong, and L. Cao, “e-RNSP: An efficient method for mining repetition negative sequential patterns,” IEEE Trans. Cybern., vol. 50, no. 5, pp. 2084-2096, 2020.
- [47] J. C. W. Lin, Y. Djenouri, G. Srivastava, Y. Li, and P. S. Yu, “Scalable mining of high-utility sequential patterns with three-tier MapReduce model,” ACM Trans. Knowl. Discov. Data, vol. 16, no. 3, pp. 1-26, 2022.
- [48] W. Gan, J. C. W. Lin, J. Zhang, P. Fournier-Viger, H. C. Chao, and P. S. Yu, “Fast utility mining on sequence data,” IEEE Trans. Cybern., vol. 51, no. 2, pp. 487-500, 2021.
- [49] Y. Wu, R. Lei, Y. Li, L. Guo, and X. Wu, “HAOP-Miner: Self-adaptive high-average utility one-off sequential pattern mining,” Expert Syst. Appl., vol. 184, pp. 115449, 2021.
- [50] M.S. Nawaz, P. Fournier-Viger, U. Yun, Y. Wu, and W. Song. Mining high utility itemsets with hill climbing and simulated annealing. ACM Trans. Manag. Inf. Syst., vol. 13, no. 1, pp. 4, 2022.
- [51] W. Gan, J. C. W. Lin, J. Zhang, H. Yin, P. Fournier-Viger, H. C. Chao, P. S. Yu, “Utility mining across multi-dimensional sequences,” ACM Trans. Knowl. Discov. Data, vol. 15, no. 5, pp. 82 ,2021.
- [52] P. Fournier-Viger, W. Gan, Y. Wu, M. Nouioua, W. Song, T. Truong, and H. Duong, “Pattern mining: Current challenges and opportunities,” DASFAA 2022 International Workshops, pp 34–49, 2022.
- [53] P. Fournier-Viger, M. S. Nawaz, Y. He, Y. Wu, F. Nouioua, and U. Yun, “MaxFEM: Mining maximal frequent episodes in complex event sequences,” International Conference on Multi-disciplinary Trends in Artificial Intelligence , pp 86–98, 2022.
- [54] Y. Li, L. Yu, J. Liu, L. Guo, Y. Wu, and Xindong Wu, “NetDPO: (delta, gamma)-approximate pattern matching with gap constraints under one-off condition,” Appl. Intell. , vol. 52, no. 11, pp 12155-12174, 2022.
- [55] Y. Wu, Z. Yuan, Y. Li, L. Guo, P. Fournier-Viger, and Xindong Wu, “NWP-Miner: Nonoverlapping weak-gap sequential pattern mining,” Inf. Sci., vol. 588, pp. 124-141, 2022.
- [56] Y. Wu, M. Geng, Y. Li, L. Guo, Z. Li, P. Fournier-Viger, X. Zhu, and X. Wu, “HANP-Miner: High average utility nonoverlapping sequential pattern mining,” Knowl. Based Syst., vol. 229, pp. 107361, 2021.
- [57] J. Zhan, J. Ye, W. Ding, and P. Liu, “A novel three-way decision model based on utility theory in incomplete fuzzy decision systems,” IEEE Trans. Fuzzy Syst., vol. 30, no. 7, pp. 2210 - 2226, 2022.
- [58] X. Liu, X. Niu, and P. Fournier-Viger, “Fast Top-K association rule mining using rule generation property pruning,” Appl. Intell., vol. 51, no. 4, pp. 2077-2093, 2021.
- [59] X. Ao, P. Luo, J. Wang, F. Zhuang, and Q. He, “Mining precise-positioning episode rules from event sequences,” IEEE Trans. Knowl. Data Eng., vol. 30, no. 3, pp. 530-543, 2017.
- [60] Y. Wu, X. Zhao, Y. Li, L. Guo, X. Zhu, P. Fournier-Viger, and X. Wu, “OPR-Miner: Order-preserving rule mining for time series,” IEEE Trans. Knowl. Data Eng., DOI: 10.1109/TKDE.2022.3224963, 2022.
- [61] R. Wang, W. Ji, M. Liu, X. Wang, J. Weng, S. Deng, S. Gao, and C. Yuan, “Review on mining data from multiple data sources,” Pattern Recognition Letters, vol. 109, pp 120-128, 2018.
- [62] S. Saleti and R. B. V. Subramanyam, “A novel mapreduce algorithm for distributed mining of sequential patterns using co-occurrence information,” Appl. Intell. , vol. 49, no. 1, pp. 150-171, 2019.
- [63] G. Huang, W. Gan, and P. S. Yu, ”TaSPM: Targeted Sequential Pattern Mining,” arXiv preprint arXiv:2202.13202, 2022.
- [64] M. Celik, S. Shekhar, J. P. Rogers, and J. A. Shine, “Mixed-drove spatiotemporal co-occurrence pattern mining,” IEEE Trans. Knowl. Data Eng., vol. 20, no. 10, pp. 1322-1335, 2008.
- [65] Y. Wu, C. Shen, H. Jiang, and X. Wu, “Strict pattern matching under non-overlapping condition,” Sci. China Inf. Sci., vol. 60, no. 1, pp. 012101, 2017.
- [66] Y. Wu, X. Liu, W. Yan, L. Guo, and X. Wu, “Efficient algorithm for solving strict pattern matching under nonoverlapping condition,” Journal of Software, vol. 32, no. 11, pp. 3331-3350, 2021.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/636cf195-7eb3-451d-8ed9-f56fab8a654d/ly.png) |
Yan Li received the PhD degree in Management Science and Engineering from Tianjin University, Tianjin, China. She is an associate professor with Hebei University of Technology. Her current research interests include data mining and supply chain management. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/636cf195-7eb3-451d-8ed9-f56fab8a654d/zhangchang.jpg) |
Chang Zhang received the master degree in the School of Economics and Management from the Hebei University of Technology, Tianjin, China. His current research interests include data mining and machine learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/636cf195-7eb3-451d-8ed9-f56fab8a654d/lijie.jpg) |
Jie Li received the Ph.D. degree in electrical engineering from the Hebei University of Technology, Tianjin, China, in 2002. She is currently a Professor with the School of Economics and Management, Hebei University of Technology. Her research interests include Big Data analytics in smart health care, business, and finance. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/636cf195-7eb3-451d-8ed9-f56fab8a654d/songwei.png) |
Wei Song received his Ph.D. degree in Computer Science from University of Science and Technology Beijing, Beijing, China, in 2008. He is a professor with the School of Information Science and Technology at North China University of Technology. His research interests are in the areas of data mining and knowledge discovery. He has published more than 40 research papers in refereed journals and international conferences. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/636cf195-7eb3-451d-8ed9-f56fab8a654d/zhenlianqi.png) |
Zhenlian Qi received the Ph.D. in Environmental Science and Engineering, Harbin Institute of Technology, Harbin, China in 2020. She was a postdoc with Guangdong University of Technology, from 2020 to 2022. She is currently an Associate Professor with Guangdong Eco-Engineering Polytechnic, Guangzhou, China. Her research interests include environmental engineering, eco-big data, and data analytics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/636cf195-7eb3-451d-8ed9-f56fab8a654d/wyx.png) |
Youxi Wu received the Ph.D. degree in Theory and New Technology of Electrical Engineering from the Hebei University of Technology, Tianjin, China. He is currently a Ph.D. Supervisor and a Professor with the Hebei University of Technology. He has published more than 30 research papers in some journals, such as IEEE TKDE, IEEE TCYB, ACM TKDD, ACM TMIS, SCIS, INS, JCST, KBS, EWSA, JIS, Neurocomputing, and APIN. He is a senior member of CCF and a member of IEEE. His current research interests include data mining and machine learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/636cf195-7eb3-451d-8ed9-f56fab8a654d/wxd.png) |
Xindong Wu received the Ph.D. degree from the University of Edinburgh, Edinburgh, U.K. He is a Yangtze River Scholar with the Hefei University of Technology, Hefei, China. His current research interests include data mining, big data analytics, knowledge based systems, and Web information exploration. Dr. Wu was an Editor-in-Chief of IEEE Transactions on Knowledge and Data Engineering (TKDE) (2005-2008) and is the Steering Committee Chair of the IEEE International Conference on Data Mining and the Editor-in-Chief of Knowledge and Information Systems. He is a Fellow of the American Association for the Advancement of Science and IEEE. |