capbtabboxtable[][\FBwidth]
Masked autoencoders are effective solution to transformer data-hungry
Abstract
Vision Transformers (ViTs) outperforms convolutional neural networks (CNNs) in several vision tasks with its global modeling capabilities. However, ViT lacks the inductive bias inherent to convolution making it require a large amount of data for training. This results in ViT under performing CNNs on small datasets like medicine and science. We experimentally found that masked autoencoders (MAE) can make the transformer focus more on the image itself, thus alleviating the data-hungry issue of ViT to some extent. Yet the current MAE model is too complex resulting in over-fitting problems on small datasets. This leads to a gap between MAEs trained on small datasets and advanced CNNs models still. To this end, we investigate how to reduce the decoder complexity in MAE and find a more suitable architectural configuration for it with small datasets. Besides, we additionally design a location prediction task and a contrastive learning task to introduce localization and invariance characteristics for MAE. Our contrastive learning task not only enables the model to learn high-level visual information, but also allows the training of MAE’s class token, which is not considered in most MAE improvement efforts. Extensive experiments on standard small datasets and medical datasets with few samples show that our method can achieve the state-of-the-art performance compared with the current popular masked image modeling (MIM) and vision transformers for small datasets. The code and models are available at https://github.com/Talented-Q/SDMAE.
1 Introduction
CNNs were once dominant in computer vision by the characteristics of localization, translation invariance and hierarchy of convolution. Since Dosovitskiy et al.[13] introduced transformer from the field of natural language processing (NLP) to computer vision domain, a series of visual transformer works[49, 68, 61, 4, 23, 17] represented by ViT have been developed rapidly in recent years. ViTs have emerged as an alternative to convolution in several vision tasks with its powerful global modeling capabilities.

Although ViTs have shown such excellent performance in the field of computer vision, the lack of induction bias of CNNs in transformers causes them to need to learn these properties from large-scale datasets. For example, ViT and its variants are typically trained using large-scale datasets such as ImageNet-1k/22k [9] or JFT-300M [45], which contains 303 million images. However, many subjects, such as medicine and science, are not equipped with large-scale datasets due to privacy protection, limited exploration equipment and other factors. This makes them fail to train a transformer network with good analysis capability. Therefore, methods that can train a good transformer on small datasets are particularly important.
To make ViTs perform better on small datasets, Lee et al.[33] proposed Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) to enhance the local induction bias of ViT. Hassani et al.[20] designed a more compact ViT architecture to suppress the issue of model over-fitting on small datasets. Gani et al.[15] introduce local, invariant, and hierarchical properties to ViT by designing self-supervised tasks. Despite the fact that all these approaches improve ViT performance on small datasets to some extent, they all used smaller ViT configuration models. This prevents them from achieving uniformity in ViT training on large and small datasets. We prefer to find a training method that does not require changes to the ViT configuration in small dataset.
Recently MAE[21] has effectively improved the performance of ViT downstream tasks by recovering the mask tokens pixel information. While MAE has been applied to many visual tasks, to our knowledge, no work has been done to investigate whether MAE can solve the data-hungry issue of transformer. We argue that MAE can somewhat reduce the dependence of ViT models with standard configuration on large-scale datasets by focusing on the images themselves. To verify this conjecture, we train the standard MAE on a representative small dataset Tiny-ImageNet[48]. Figure 1 demonstrates that MAE effectively improves the performance of ViT on small datasets, but still falls short of the advanced CNN. This is due to the fact that the standard configuration of the MAE decoder is too complex for small datasets suppressing the performance of the ViT encoder. Therefore, we conduct a lot of decoder weakening experiments to find an architecture configuration for MAE’s decoder that is more suitable for small datasets. In addition, we design a location prediction task as well as a contrastive learning task for MAE to introduce the localization and invariance features of CNNs. Our location prediction task consists only of a tiny location predictor with negligible parameters and without any human assisted labeling. Our contrastive learning task also allows MAE to learn advanced semantic information about the images and to train class token specifically for MAE. This is because MAE and its refinement efforts often do not have a training task specifically for class token in the pre-training design. However, class token is indispensable in the fine-tuning phase, so a pre-training task for class token is necessary. We combine this masked image modeling with the above designs and call it Small Dataset Masked Autoencoders (SDMAE).
Later experimental results show that our SDMAE exhibits state-of-the-art performance on standard small datasets Tiny-ImageNet[48], CIFAR-100[30], CIFAR-10[30] and SVHN[37] in comparison to vision transformers for small datasets and advanced CNNs. Moreover, SDMAE is superior to the popular MIM on these datasets. This indicates that SDMAE is more suitable for standard configuration of ViT models trained on small datasets. Besides, SDMAE excels in medical diagnostic tasks with small datasets. This further demonstrates the effectiveness of SDMAE in the practical application on small datasets.
To sum up, our method has the following contributions:
-
•
To the best of our knowledge, our SDMAE is the first work to study MAE training ViT on a small dataset. We found the optimal decoder configuration for MAE through extensive experiments to solve the over-fitting problem of MAE decoder on small datasets. Moreover, since our SDMAE does not change the ViT configuration, it achieves unification of ViT training on both large-scale and small datasets.
-
•
We design a tiny predictor with negligible parameters to perform the location prediction task of unmasked tokens based on the properties of MAE random masks. This task introduces the localization feature of CNNs for ViT.
-
•
Our contrastive learning task design in SDMAE not only introduces CNNs invariant features to ViT, but also enables MAE to train class token and learn high-level semantic information of images. Training of class token is not considered in the MAE and most of its improvement efforts.
2 Related Work
2.1 Convolutional Neural Networks
CNNs play a leading role in the field of computer vision depending on their inductive bias characteristics. LeCun first established the rudiment of convolutional neural network training in [32]. The proposal of AlexNet[31] further promoted the development of CNNs. Szegedy et al. proposed that GoogleNet[46] greatly improved the utilization of computer resources by increasing the depth of CNN. Simonyan et al.[44] studied the depth of CNNs to reduce the parameters of convolution model. He et al.[22] solved the vanishing gradient problem of CNNs by residual linking, thus designing a more compact ResNet. Huang et al.[25] designed an efficient DenseNet by implementing feature reuse through dense connection. EfficientNet[47] uses composite coefficients to uniformly scale all dimensions of the model, greatly improving the accuracy and efficiency of CNNs. Liu et al.[40] reviewed the CNNs design space from the perspective of transformer through a large amount of experiments and proposed ConvNext with higher accuracy. In recent years, CNNs are still the preferred choice for researchers to study small datasets through the characteristics of locality, translation invariance and hierarchy.

2.2 Vision Transformers for small datasets
Vision Transformers outstanding in many mainstream visual tasks, such as image classification[39, 55, 8, 3, 53, 52, 58, 36, 51], semantic segmentation[69, 11, 54, 29, 63, 34, 65, 18], and object detection[62, 27, 59, 67, 35, 70], depending on its global modeling characteristics. Matsoukas et al.[43] proved that ViTs can also replace CNNs in the medical field. However, due to the lack of inductive bias of CNNs, ViTs needs a lot of data for training. To solve this issue, Lee et al.[33] proposed Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA) for ViTs. Hassani et al.[20] analyzed the structure of ViTs and improved the representation learning ability of ViTs on small datasets by modifying the ViTs architecture. Liu et al.[38] designed a relative position prediction task to regularize ViTs training on small datasets. Gani et al.[15] introduced the inductive bias attribute of CNNs for ViTs through self-supervised task design. The research of El Nouby et al.[14] indicates that large-scale datasets are not necessary for the self-supervised pre-training task of the standard configuration ViT model. Therefore, we want to find a self-supervised method that can train standard configuration ViT models well on small datasets in order to achieve uniform ViT training on large and small datasets.
2.3 Masked Image Modeling
MIM enables the transformer to better learn image representation by recovering the masked tokens. Bao et al. introduced BERT[10] in NLP into the field of computer vision and designed BEiT[1]. Compared with the previous ViTs pre training methods, this model has achieved better results. He et al. proposed MAE[21], which greatly improves the model efficiency while enhancing the performance of ViT. Xie et al. considered the structure design of MIM and proposed SimMIM[57] with only one layer of MLP decoder. Chen et al. proposed SdAE[7] by combining self-distillation with MIM. Dong et al. designed BootMAE[12] to force ViTs to fully learn high-level and low-level visual information in the pre-training stage. Chen et al.[5] designed alignment tasks for the encoder to enhance its representation learning ability. Huang et al.[26] introduced contrastive learning to enhance the discriminability of MAE. Xiao et al.[56] also used MAE in multi label thorax disease classification research. Although the improvement of MAE has shown excellent performance, we think that there are still two issues that have been ignored. First of all, in order to improve MAE, some works has compromised the advantage of MAE’s low computation. Second, the class token, which is crucial in MAE fine-tuning, is ignored in the design of pre-training tasks.
3 Method
In this section we first review the specific process of MAE in 3.1. Then we experimentally choose the best configuration for MAE’s decoder on small datasets in 3.2. Finally in 3.3 and 3.4 we introduce the SDMAE location prediction task and the contrastive learning task, respectively. The overview of SDMAE is shown in Figure 2.
3.1 Preliminaries

Figure 3 illustrates the specific flow of MAE. MAE is mainly composed of two core designs, the asymmetric encoder-decoder architecture and the high proportion of random masks. Given an input image , it is first divided into N patches by a convolution with stride P, and Next all patches are flattened to one-dimensional sequential tokens , where . Then MAE masks these tokens randomly according to the masking ratio . At this moment we obtain the visible token set and the masked token set , where .
The MAE encoder then linearly maps the visible tokens and adds holistic positional embeddings for them. After a series of transformer blocks, we get the encoding of the visible tokens. Then MAE uses masked tokens composed of learnable vectors to learn the low-level visual information of the image. are merged with in the correct order to get full token set The MAE decoder also adds positional embeddings to and feeds them to several transformer blocks to get the final output . MAE eventually selects the tokens of the masked region from to predict the original set of masked tokens after normalization. The decoder maps to through the multi-layer perception (MLP) thus achieving dimension alignment with . Overall the final prediction process can be expressed as:
| (1) |
where denotes normalization and is the mean squared error[2].
3.2 Decoder Weakening

We found through our experiments that MAE trained on small datasets, while largely reducing ViT’s dependence on data volume, still fall short of the current state-of-the-art CNNs. We speculate that this is due to the over-complication of the standard configuration MAE decoder, which causes an over-fitting problem that ultimately inhibits the performance of the ViT encoder.
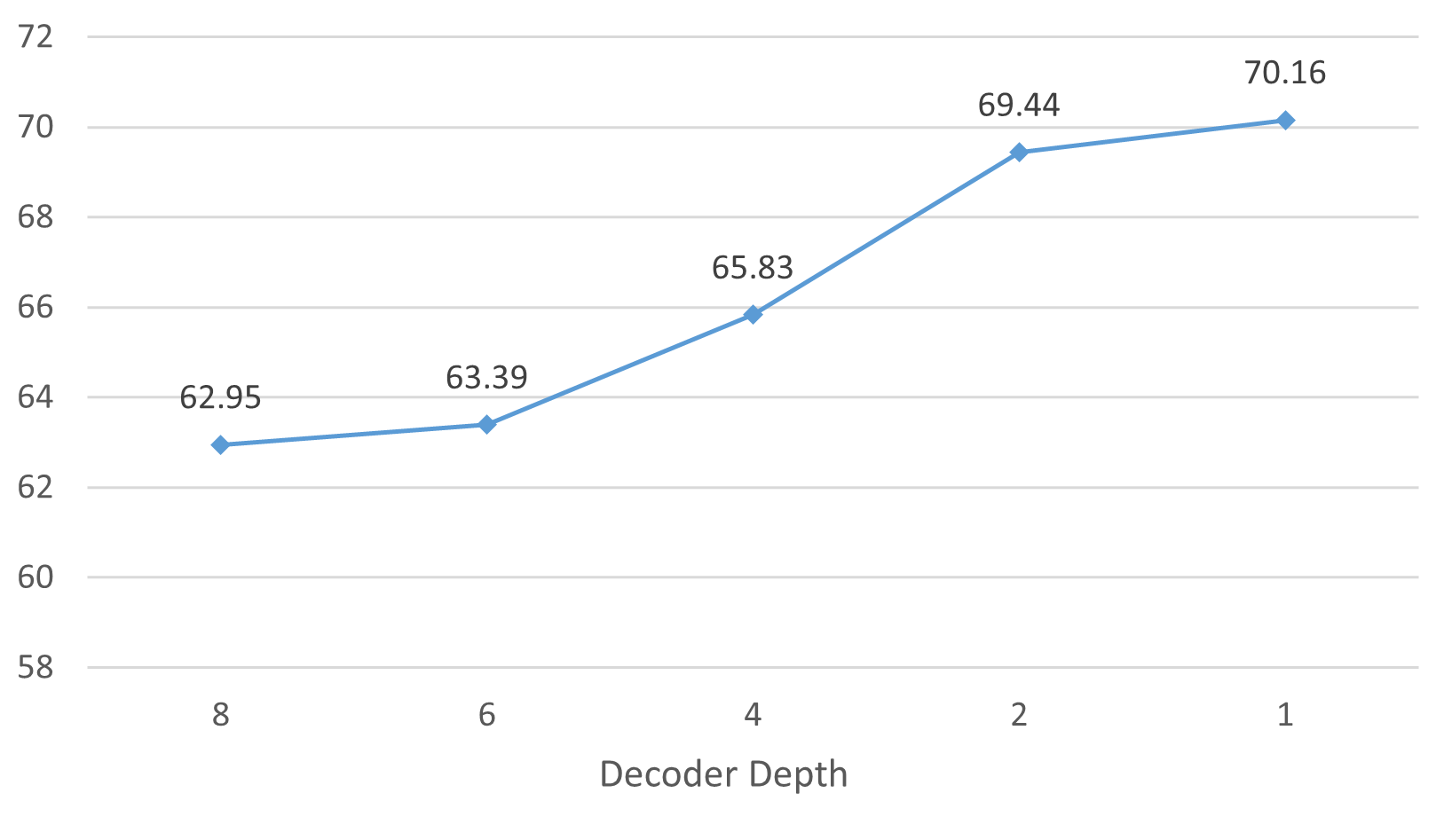
To solve this problem, we weaken the decoder in both dimensionality and depth directions respectively to find the most suitable decoder configuration for MAE training on small datasets. Figure 4 show the influence of decoder dimension and depth on MAE training on small datasets, respectively. We can find that the performance of MAE on small datasets keeps improving when the decoder dimension and depth are reduced. This validates our conjecture that the standard configuration MAE decoder over-fits on small datasets.
However, we continue to weaken the decoder and find that the performance of MAE starts to deteriorate instead. We consider that this is caused by the fact that the decoder complexity of MAE is no longer sufficient to recover the image at this time. We can see from Figure 5 that the predicted image quality becomes very poor when the MAE decoder is extremely weakened. This suggests that we cannot continuously weaken the decoder. Therefore, our SDMAE eventually selects a decoder configuration with a depth of 1 and an embedding dimension of 128. We supplement it in section 4.3.

3.3 Location Prediction Task
The goal of our location prediction task is to introduce spatially localized information for ViT without using additional manual annotations. It is due to the nature of the MIM random mask that our SDMAE can easily achieve this task. Specifically, MAE divides the image sequential tokens into visible token set and masked token set by random masks with mask ratio . Affected by this operation, the position of each token in the visible token set no longer matches the normal position in the image. Thus, we can predict the location of the encoded visible token set in the sequential tokens of the image and thus make the encoder learn the spatial local information of the image.

We implement the above task with a tiny predictor with negligible parameters. Our location predictor consists of only two MLP in a squeezed form. Figure 6 shows the specific details of the location predictor. We assume that the position index of each token of the visible token set in the image sequential tokens is , and the location predictor has prediction result for each token in (Note that the here does not contain the class token). However, there is a large numerical difference between and , so we cannot simply regress them by mean squared error. Therefore, the details of our approach are to map to an -dimensional vector and then regress the maximum index in the -dimensional vector against . And the overall location prediction loss function can be further formulated as:
| (2) |
where represents the operation that returns the index of the last dimensional maximum.
3.4 Contrastive Task
To introduce the feature of invariance of CNNs, we design the contrastive task for MAE. Most current MAE combined with contrastive learning efforts[5, 60] tend to have the following two issues. First, they encode the full image in addition to the set of visible tokens. This inevitably increases the amount of model computation and defeats the original purpose of MAE efficient computation. Second, class token plays a crucial role in the fine-tuning process of MAE. However, the class token of MAE and its improvement works are not involved in the task during the pre-training phase. Therefore, it is necessary to design a contrastive learning task that keeps the MAE computation efficient while involving the class token.
Given an input image , we apply different intensities of data-augment to it to obtain and . We encode only the set of visible tokens for these two images to obtain , . This greatly improves the computational efficiency of SDMAE. Then our decoder recovers the full set of tokens for both images. This process can be depicted as:
| (3) |
where and are the learnable mask tokens for the strong and weak data augmented images, respectively. represents the merge operation, and is the decoder of SDMAE.
Next and are encoded again by two small encoders with two transformer blocks and , and is the momentum encoder for . This can be specified as:
| (4) |
where is the parameter of and is the parameter of . is the momentum update weight. To implement the asymmetric structure design for contrastive learning, we only project one of the above codes. Our projection layer consists of two expansive fully connected layers. Finally, we extract class token from the output of the encoder and projection layer of the two images respectively for contrastive training. This process is calculated as:
| (5) |
where denotes projector and represents the extract class token operation. Our contrastive losses can be written as:
| (6) |
Where is a temperature hyper-parameter.
3.5 Loss Function
We select mask area tokens and from and respectively to predict the original set of masked tokens and . The whole reconstruction loss can be expressed as:
| (7) |
The total loss of SDMAE is recorded as:
| (8) |
Where and are hyperparameters for location prediction loss and contrastive loss respectively. Unless otherwise specified, in the following experiments, We default .
4 Experiments
We conduct image classification experiments on several standard small datasets. In addition, we also perform diagnostic work on image-sparse medical datasets to validate the performance of SDMAE in practical applications with small datasets. We next compare SDMAE with current state-of-the-art algorithms in these tasks. We then conduct an ablation study on the core designs of SDMAE.
4.1 Image Classification on small datasets
Settings.
For small dataset image classification experiments, we evaluate SDMAE on four datasets, Tiny-ImageNet (T-IN)[48], CIFAR-100[30], CIFAR-10[30] and SVHN[37]. Please see Appendix A for a detailed description of the dataset. The top-1 accuracy on four datasets is reported. We follow with the detailed settings for the pre-training and fine-tuning phases:
-
•
pre-training. We use AdamW[41] with a base learning rate of 1e-3 to pre-train SDMAE for 300 epochs. The learning rate scheduler adopts cosine decay with 40 epochs of linear warm-up. SDMAE employs 64 batches of 224 resolution images as input. The mask ratio and weight decay we set to 0.75 and 0.05, respectively. For the model architecture we choose the standard configuration ViT-Base as the encoder. For the data augmentation scheme, we follow MoCo v3[6].
-
•
fine-tuning. We use 100 epochs and 20 epochs for linear warm-up fine-tuning scheme. Furthermore, we have added a drop path rate of 0.1. We followed the data augmentation scheme of the MAE[21] fine-tuning phase, and the rest of the settings were kept consistent with the pre-training phase.
| Method | #FLOPs(M) | CIFAR-10 | CIFAR-100 | SVHN | T-IN |
|---|---|---|---|---|---|
| ResNet56[22] | 506.2 | 95.7 | 76.36 | 97.73 | 58.77 |
| ResNet110[22] | 1020 | 96.37 | 79.86 | 97.85 | 62.96 |
| EffecientNet B0[47] | 123.9 | 94.66 | 76.04 | 97.22 | 66.79 |
| MobileNet V3[24] | 233.2 | 81.52 | 51.74 | 91.48 | 36.56 |
| ShuffleNet V2[42] | 591 | 82.21 | 51.44 | 91.88 | 35.46 |
| ViT-Tiny[13] | 189.8 | 93.58 | 73.81 | 97.82 | 57.07 |
| ViT-Base[13] | 16863.6 | 91.91 | 67.52 | 97.8 | 56.52 |
| SL-ViT[33] | 199.2 | 94.53 | 76.92 | 97.79 | 61.07 |
| SL-Cait[33] | 623.3 | 95.8 | 80.3 | 98.2 | 67.1 |
| SL-PiT w/o [33] | 280.4 | 94.96 | 77.08 | 97.94 | 60.31 |
| SL-PiT w/ [33] | 322.9 | 95.88 | 79 | 97.93 | 62.91 |
| SL-Swin w/o [33] | 247 | 95.3 | 78.13 | 97.88 | 62.7 |
| SL-Swin w/ [33] | 284.9 | 95.93 | 79.99 | 97.92 | 64.95 |
| CCT-7/3×1[20] | 1190 | 96.53 | 80.92 | - | - |
| Drloc-ViT[38] | 189.8 | 81 | 58.29 | 94.02 | 42.33 |
| Drloc-Swin[38] | 239.6 | 83.89 | 66.23 | 94.23 | 48.66 |
| Drloc-CaiT[38] | 472 | 82.2 | 56.32 | 19.59 | 45.95 |
| SSL-ViT[15] | 353.1 | 96.41 | 79.15 | 98.03 | 63.36 |
| SSL-Swin[15] | 479.2 | 96.18 | 80.95 | 98.01 | 65.13 |
| SSL-CaiT[15] | 944.1 | 96.42 | 80.79 | 98.18 | 67.46 |
| Ours | 20164.7 | 96.57 | 82 | 98.3 | 72.24 |
Comparison with CNNs and ViTs for small datasets.
Table 1 shows the results of SDMAE compared with ViTs models for small datasets and advanced CNNs. SDMAE successfully helps the standard configuration of ViT models to significantly outperform CNNs on four small datasets. SDMAE also achieves state-of-the-art performance compared to current works on ViTs trained on small datasets. +1.08% for SDMAE(82%) over CCT[20] on CIFAR-100, +5.1% for SDMAE(72.2%) over SL-CaiT[50] on Tiny-ImageNet, +0.1% for SDMAE(98.3%) over SL-CaiT on SVNH and +0.8% for SDMAE(96.6%) over SL-CaiT on CIFAR-10.
| Method | pre-train epochs | CIFAR-10 | CIFAR-100 | SVHN | T-IN |
|---|---|---|---|---|---|
| MAE[21] | 300 | 93.41 | 75.15 | 97.66 | 62.95 |
| i-MAE[64] | 1000 | 92.34 | 69.5 | - | 61.13 |
| ConvMAE[16] | 300 | 90.9 | 73.19 | 96.94 | 62.26 |
| SimMIM[57] | 300 | 68.17 | 66.4 | 96.02 | 49.86 |
| BEiT[1] | 300 | 82.82 | 70.29 | 81.23 | 48.44 |
| Ours | 300 | 96.57 | 82 | 98.3 | 72.24 |
Comparison with MIM for small datasets.
We show the results of comparing SDMAE with the currently popular MIM model on four small datasets in Table 2. Compared with several MIMs, our SDMAE shows superior performance on small datasets. +9.29% for SDMAE(72.2%) over MAE[21] and +9.98% for SDMAE over ConvMAE[16] on Tiny-ImageNet. This suggests that our SDMAE is more suitable for training standard configuration ViT models on small datasets than other MIMs. Figure 7 shows training efficiency of SDMAE in comparison to other MIMs during the fine-tuning stage.

4.2 Medical Image Diagnosis with small datasets
| Method | Resolution | APTOS 2019 | COVID-19 |
|---|---|---|---|
| ResNet110[22] | 71.85 | 56.5 | |
| EffecientNet B0[47] | 73.49 | 53 | |
| MAE[21] | 82.79 | 60.5 | |
| ConvMAE[16] | 80.6 | 58 | |
| SSL-ViT[15] | 56.28 | 60.5 | |
| Drloc-ViT[38] | 74.59 | 59.5 | |
| DIRA[19] | 58.19 | 58.5 | |
| Medical MAE[56] | 76.77 | 60 | |
| Ours | 83.06 | 61 |
Settings.
To validate the performance of SDMAE in real-world applications with small datasets, we apply it to medical diagnostic work. We selected APTOS 2019[28] and COVID-19[66], which contain fewer images, for evaluation. APTOS 2019 contains only 3662 images. For COVID-19, we use only 546 images for training. For more details on the use of the medical datasets, please see Appendix A. The pre-training and fine-tuning phase settings are kept consistent with the image classification experiments.

Results.
We quantitatively and qualitatively demonstrate the results of applying SDMAE to a small dataset of medical diagnoses. Table 3 shows that SDMAE shows state-of-the-art results compared to advanced medical diagnostic algorithms, MIMs and CNNs, and small datasets ViTs. This shows that our SDMAE can indeed be effective in real-world applications with small datasets. We use the attention visualization in Figure 8 to show the regions that SDMAE focuses on in the medical datasets.
4.3 Ablation Study
In this section, we investigate the optimal decoder configuration for SDMAE and focus on verifying the effectiveness of the location prediction task as well as the comparative task in SDMAE. We mainly used the image classification task on Tiny-ImageNet for their ablation study.


Decoder configuration.
Based on the phenomena we observe in Section 3.2, we test the classification results on Tiny-ImageNet for a range of combinations of depth and embedding dimensions. Since a decoder with embedding dimension 32 can severely damage the predicted image, we do not investigate the decoder configuration with embedding dimension 32 anymore. Figure 9 shows the experimental results. We can observe that SDMAE presents the best results when using a decoder configuration with a depth of 1 embedding dimension of 128.
| Location Prediction Task | Contrastive Task | Top-1 Acc |
| ✗ | ✗ | 70.59 |
| ✗ | ✓ | 70.94 |
| ✓ | ✗ | 71.22 |
| ✓ | ✓ | 72.24 |
Location Prediction Task.
We report the ablation results for the location prediction task in Table 4. It can be found that when SDMAE does not perform the location prediction task, the performance of the standard configuration ViT on Tiny-ImageNet decreases by 1.3%. This shows that the location prediction task is essential to help the ViT in SDMAE capture local spatial information. Therefore, we conclude that it is necessary for ViT to design tasks related to local information in small datasets training.
Contrastive Task.
Table 4 shows the ablation results of the contrastive task in SDMAE. We see that when we cancel the SDMAE comparison task, its top-1 accuracy on Tiny-ImageNet decreased significantly. This is due to the cancellation of the contrastive task, which makes SDMAE unable to learn the invariance of CNNs, and the lack of specific task constraints on class token in the pre-training stage.
4.4 Visualization
To demonstrate the image prediction performance of SDMAE, we show the prediction results on Tiny-ImageNet in Figure 10. We can see that even though SDMAE weakens the decoder, it still successfully predicts the image. See Appendix B for more forecast results.
5 Conclusion
In this paper, we propose a method to efficiently train ViT on small datasets by MAE, which is called small dataset masked autoencoders (SDMAE). We first solve the over-fitting issue of MAE decoder on small data sets experimentally and present a decoder configuration for SDMAE that is suitable for training on small datasets. Since SDMAE does not require changing the configuration of the ViT model, it achieves unification of ViT training on both large and small datasets. Secondly, we also propose a location prediction task as well as a contrastive task to introduce the properties of localization and invariance of CNNs. Our contrastive task design successfully reduces the computational cost of MAE improvement work combined with contrastive learning and considers the training of class token in the pre-training phase. Numerous experiments have shown that SDMAE significantly improves the quality of learning representations on small datasets with standard configuration of ViT. Our SDMAE achieves state-of-the-art performance on both several standard small datasets and image-sparse medical datasets. This indicates that SDMAE is an effective means to solve transformer data-hungry.
Acknowledge
This work was supported by Public-welfare Technology Application Research of Zhejiang Province in China under Grant LGG22F020032, and Key Research and Development Project of Zhejiang Province in China under Grant 2021C03137.
References
- [1] Hangbo Bao, Li Dong, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
- [2] Eric Bauer and Ron Kohavi. An empirical comparison of voting classification algorithms: Bagging, boosting, and variants. Machine learning, 36(1):105–139, 1999.
- [3] Chun-Fu Chen, Rameswar Panda, and Quanfu Fan. Regionvit: Regional-to-local attention for vision transformers. arXiv preprint arXiv:2106.02689, 2021.
- [4] Chun-Fu Richard Chen, Quanfu Fan, and Rameswar Panda. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF international conference on computer vision, pages 357–366, 2021.
- [5] Xiaokang Chen, Mingyu Ding, Xiaodi Wang, Ying Xin, Shentong Mo, Yunhao Wang, Shumin Han, Ping Luo, Gang Zeng, and Jingdong Wang. Context autoencoder for self-supervised representation learning. arXiv preprint arXiv:2202.03026, 2022.
- [6] Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9640–9649, 2021.
- [7] Yabo Chen, Yuchen Liu, Dongsheng Jiang, Xiaopeng Zhang, Wenrui Dai, Hongkai Xiong, and Qi Tian. Sdae: Self-distillated masked autoencoder. In European Conference on Computer Vision, pages 108–124. Springer, 2022.
- [8] Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, and Chunhua Shen. Twins: Revisiting the design of spatial attention in vision transformers. Advances in Neural Information Processing Systems, 34:9355–9366, 2021.
- [9] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [10] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [11] Jian Ding, Nan Xue, Gui-Song Xia, and Dengxin Dai. Decoupling zero-shot semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11583–11592, 2022.
- [12] Xiaoyi Dong, Jianmin Bao, Ting Zhang, Dongdong Chen, Weiming Zhang, Lu Yuan, Dong Chen, Fang Wen, and Nenghai Yu. Bootstrapped masked autoencoders for vision bert pretraining. In European Conference on Computer Vision, pages 247–264. Springer, 2022.
- [13] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [14] Alaaeldin El-Nouby, Gautier Izacard, Hugo Touvron, Ivan Laptev, Hervé Jegou, and Edouard Grave. Are large-scale datasets necessary for self-supervised pre-training? arXiv preprint arXiv:2112.10740, 2021.
- [15] Hanan Gani, Muzammal Naseer, and Mohammad Yaqub. How to train vision transformer on small-scale datasets? arXiv preprint arXiv:2210.07240, 2022.
- [16] Peng Gao, Teli Ma, Hongsheng Li, Jifeng Dai, and Yu Qiao. Convmae: Masked convolution meets masked autoencoders. arXiv preprint arXiv:2205.03892, 2022.
- [17] Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze. Levit: a vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12259–12269, 2021.
- [18] Xiaoqing Guo, Jie Liu, Tongliang Liu, and Yixuan Yuan. Simt: Handling open-set noise for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7032–7041, 2022.
- [19] Fatemeh Haghighi, Mohammad Reza Hosseinzadeh Taher, Michael B Gotway, and Jianming Liang. Dira: Discriminative, restorative, and adversarial learning for self-supervised medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20824–20834, 2022.
- [20] Ali Hassani, Steven Walton, Nikhil Shah, Abulikemu Abuduweili, Jiachen Li, and Humphrey Shi. Escaping the big data paradigm with compact transformers. arXiv preprint arXiv:2104.05704, 2021.
- [21] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022.
- [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [23] Byeongho Heo, Sangdoo Yun, Dongyoon Han, Sanghyuk Chun, Junsuk Choe, and Seong Joon Oh. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11936–11945, 2021.
- [24] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1314–1324, 2019.
- [25] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- [26] Zhicheng Huang, Xiaojie Jin, Chengze Lu, Qibin Hou, Ming-Ming Cheng, Dongmei Fu, Xiaohui Shen, and Jiashi Feng. Contrastive masked autoencoders are stronger vision learners. arXiv preprint arXiv:2207.13532, 2022.
- [27] Zhenchao Jin, Dongdong Yu, Luchuan Song, Zehuan Yuan, and Lequan Yu. You should look at all objects. In European Conference on Computer Vision, pages 332–349. Springer, 2022.
- [28] Kaggle. Aptos 2019 blindness detection, 2019.
- [29] Namyup Kim, Dongwon Kim, Cuiling Lan, Wenjun Zeng, and Suha Kwak. Restr: Convolution-free referring image segmentation using transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18145–18154, 2022.
- [30] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [31] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6):84–90, 2017.
- [32] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- [33] Seung Hoon Lee, Seunghyun Lee, and Byung Cheol Song. Vision transformer for small-size datasets. arXiv preprint arXiv:2112.13492, 2021.
- [34] Liulei Li, Tianfei Zhou, Wenguan Wang, Jianwu Li, and Yi Yang. Deep hierarchical semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1246–1257, 2022.
- [35] Wentong Li, Yijie Chen, Kaixuan Hu, and Jianke Zhu. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1829–1838, 2022.
- [36] Wei Li, Xing Wang, Xin Xia, Jie Wu, Xuefeng Xiao, Min Zheng, and Shiping Wen. Sepvit: Separable vision transformer. arXiv preprint arXiv:2203.15380, 2022.
- [37] Zhibin Liao and Gustavo Carneiro. Competitive multi-scale convolution. arXiv preprint arXiv:1511.05635, 2015.
- [38] Yahui Liu, Enver Sangineto, Wei Bi, Nicu Sebe, Bruno Lepri, and Marco Nadai. Efficient training of visual transformers with small datasets. Advances in Neural Information Processing Systems, 34:23818–23830, 2021.
- [39] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021.
- [40] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11976–11986, 2022.
- [41] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [42] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), pages 116–131, 2018.
- [43] Christos Matsoukas, Johan Fredin Haslum, Magnus Söderberg, and Kevin Smith. Is it time to replace cnns with transformers for medical images? arXiv preprint arXiv:2108.09038, 2021.
- [44] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [45] Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE international conference on computer vision, pages 843–852, 2017.
- [46] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015.
- [47] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019.
- [48] Amirhossein Tavanaei. Embedded encoder-decoder in convolutional networks towards explainable ai. arXiv preprint arXiv:2007.06712, 2020.
- [49] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021.
- [50] Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 32–42, 2021.
- [51] Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. Maxvit: Multi-axis vision transformer. arXiv preprint arXiv:2204.01697, 2022.
- [52] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 568–578, 2021.
- [53] Wenxiao Wang, Lu Yao, Long Chen, Binbin Lin, Deng Cai, Xiaofei He, and Wei Liu. Crossformer: A versatile vision transformer hinging on cross-scale attention. arXiv preprint arXiv:2108.00154, 2021.
- [54] Yuchao Wang, Haochen Wang, Yujun Shen, Jingjing Fei, Wei Li, Guoqiang Jin, Liwei Wu, Rui Zhao, and Xinyi Le. Semi-supervised semantic segmentation using unreliable pseudo-labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4248–4257, 2022.
- [55] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, and Lei Zhang. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22–31, 2021.
- [56] Junfei Xiao, Yutong Bai, Alan Yuille, and Zongwei Zhou. Delving into masked autoencoders for multi-label thorax disease classification. arXiv preprint arXiv:2210.12843, 2022.
- [57] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9653–9663, 2022.
- [58] Rui Yang, Hailong Ma, Jie Wu, Yansong Tang, Xuefeng Xiao, Min Zheng, and Xiu Li. Scalablevit: Rethinking the context-oriented generalization of vision transformer. arXiv preprint arXiv:2203.10790, 2022.
- [59] Zhendong Yang, Zhe Li, Xiaohu Jiang, Yuan Gong, Zehuan Yuan, Danpei Zhao, and Chun Yuan. Focal and global knowledge distillation for detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4643–4652, 2022.
- [60] Kun Yi, Yixiao Ge, Xiaotong Li, Shusheng Yang, Dian Li, Jianping Wu, Ying Shan, and Xiaohu Qie. Masked image modeling with denoising contrast. arXiv preprint arXiv:2205.09616, 2022.
- [61] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zi-Hang Jiang, Francis EH Tay, Jiashi Feng, and Shuicheng Yan. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 558–567, 2021.
- [62] Mohsen Zand, Ali Etemad, and Michael Greenspan. Objectbox: From centers to boxes for anchor-free object detection. In European Conference on Computer Vision, pages 390–406. Springer, 2022.
- [63] Jiaming Zhang, Kailun Yang, Chaoxiang Ma, Simon Reiß, Kunyu Peng, and Rainer Stiefelhagen. Bending reality: Distortion-aware transformers for adapting to panoramic semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16917–16927, 2022.
- [64] Kevin Zhang and Zhiqiang Shen. i-mae: Are latent representations in masked autoencoders linearly separable? arXiv preprint arXiv:2210.11470, 2022.
- [65] Yifan Zhang, Bo Pang, and Cewu Lu. Semantic segmentation by early region proxy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1258–1268, 2022.
- [66] Jinyu Zhao, Yichen Zhang, Xuehai He, and Pengtao Xie. Covid-ct-dataset: a ct scan dataset about covid-19. arXiv preprint arXiv:2003.13865, 490, 2020.
- [67] Yizhou Zhao, Xun Guo, and Yan Lu. Semantic-aligned fusion transformer for one-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7601–7611, 2022.
- [68] Daquan Zhou, Bingyi Kang, Xiaojie Jin, Linjie Yang, Xiaochen Lian, Zihang Jiang, Qibin Hou, and Jiashi Feng. Deepvit: Towards deeper vision transformer. arXiv preprint arXiv:2103.11886, 2021.
- [69] Tianfei Zhou, Wenguan Wang, Ender Konukoglu, and Luc Van Gool. Rethinking semantic segmentation: A prototype view. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2582–2593, 2022.
- [70] Wenzhang Zhou, Dawei Du, Libo Zhang, Tiejian Luo, and Yanjun Wu. Multi-granularity alignment domain adaptation for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9581–9590, 2022.
Appendix
Appendix A Datasets
| Dataset | Train size | Test size | Classes |
|---|---|---|---|
| CIFAR-100 | 50000 | 10000 | 100 |
| CIFAR-10 | 50000 | 10000 | 10 |
| SVHN | 73257 | 26032 | 10 |
| Tiny ImageNet | 100000 | 10000 | 200 |
| APTOS 2019 | 3662 | 1928 | 5 |
| COVID-19 | 546 | 200 | 2 |
In the classification experiment of small datasets, we select Tiny-ImageNet[48], CIFAR-100[30], CIFAR-10[30] and SVHN[37] as the compared datasets. In real-world medical diagnosis application, we choose Aptos 2019[28] and COVID-19[66] as our benchmark datasets. The specific distribution of the datasets is shown in Table 5.
CIFAR-100: The CIFAR-100 dataset consists of 32×32 RGB images in real-world. Each class has 600 images, 500 of which are used as training sets and 100 as test sets. The 100 classes in CIFAR-100 are divided into 20 superclasses. Each image has a fine label and a coarse label.
CIFAR-10: The CIFAR-10 dataset consists of 60,000 32×32 color images of 10 classes, with 6000 images for each class. It is divided into 50,000 training images and 10,000 test images. Its 10 categories are aircraft, cars, birds, cats, deer, dogs, frogs, horses, boats and trucks.
SVHN: Street View Door Number (SVHN) dataset is a door number extracted from Google Street View images. Its style is similar to MNIST[32], and it is also divided into 10 categories. However, it contains a larger order of magnitude of marking data, which is used for a more difficult practical problem of recognizing characters and numbers in natural scene images. It contains a total of 73257 training images and 26032 test images.
Tiny-ImageNet: Tiny ImageNet aims to let users solve the problem of image classification as much as possible. It contains 100000 images of 200 classes (500 for each class) downsized to 64×64 colored images. Each class has 500 training images, 50 validation images and 50 test images.

APTOS 2019: The task of APTOS 2019 is to classify images of diabetes retinopathy into five categories of severity. It uses 3662 high-resolution retinal images as the training set and 1928 images as the test set. Figure 11(a) shows some examples of APTOS 2019.
COVID-19: It contains the clinical manifestations of COVID-19 from 216 patients. It has a total of 746 CT images, specifically divided into negative and positive. We randomly select 297 negative images and 249 positive images as the training set, and the rest are all test set images. We also show some images of COVID-19 dataset in Figure 11(b).
Appendix B More Results
