MalDetConv: Automated Behaviour-based Malware Detection Framework Based on Natural Language Processing and Deep Learning Techniques
Abstract
The popularity of Windows attracts the attention of hackers/cyber-attackers, making Windows devices the primary target of malware attacks in recent years. Several sophisticated malware variants and anti-detection methods have been significantly enhanced and as a result, traditional malware detection techniques have become less effective. This work presents MalBehavD-V1, a new behavioural dataset of Windows Application Programming Interface (API) calls extracted from benign and malware executable files using the dynamic analysis approach. In addition, we present MalDetConV, a new automated behaviour-based framework for detecting both existing and zero-day malware attacks. MalDetConv uses a text processing-based encoder to transform features of API calls into a suitable format supported by deep learning models. It then uses a hybrid of convolutional neural network (CNN) and bidirectional gated recurrent unit (CNN-BiGRU) automatic feature extractor to select high-level features of the API Calls which are then fed to a fully connected neural network module for malware classification. MalDetConv also uses an explainable component that reveals features that contributed to the final classification outcome, helping the decision-making process for security analysts. The performance of the proposed framework is evaluated using our MalBehavD-V1 dataset and other benchmark datasets. The detection results demonstrate the effectiveness of MalDetConv over the state-of-the-art techniques with detection accuracy of 96.10%, 95.73%, 98.18%, and 99.93% achieved while detecting unseen malware from MalBehavD-V1, Allan and John, Brazilian, and Ki-D datasets, respectively. The experimental results show that MalDetConv is highly accurate in detecting both known and zero-day malware attacks on Windows devices.
keywords:
Malware , dynamic analysis , malware detection , Convolutional neural network, API Calls , word embedding , machine learning , deep learning1 Introduction
As Internet-based applications continue to shape various businesses around the globe, malware threats have become a severe problem for computing devices such as desktop computers, smartphones, local servers, remote servers, and IoT devices. It is expected that by 2023 [1] the total number of devices connected to IP networks will be around 29.3 billion, while predictions show that internet of things (IoT) devices in use will be more than 29 billion in 2030 [2], resulting in a massive interconnection of various networked devices. As the number of connected devices continues to rise exponentially, this has also become a motivating factor for cyber-criminals to develop new advanced malware programs that disrupt, steal sensitive data, damage, and exploit various vulnerabilities. The widespread use of different malware variants makes the existing security systems ineffective whereby, millions of devices are infected by various forms of malware such as worms, ransomware, backdoors, computer viruses, and Trojans[3] [4]. Accordingly, there has been a significant increase of new malware targeting Windows devices, i.e., the number of malware samples increased by 23% (9.5 million) [5] from 2020 to 2021. About 107.27 million new malware samples were created to compromise windows devices in 2021, showing an increase of 16.53 million samples over 2020 with an average of 328,073 malware samples produced daily [5].
The application of signature-based malware detection systems such as anti-virus programs that rely on a database of signatures extracted from the previously identified malware samples is prevalent. In static malware analysis, signatures are malware’s unique identities which are extracted from malware without executing the suspicious program [6] [7].
Some of the static-based malware analysis techniques were implemented using printable strings, opcode sequences, and static API calls[8], [9] [10]. As signature-based systems rely on previously seen signatures to detect malware threats, they have become ineffective due to a huge number of new malware variants coming out every day [11]. Moreover, static-based techniques are unable to detect obfuscated malware (malware with evasion behaviours) [12] [13]. Such obfuscated malware includes Agent Tesla, BitPaymer, Zeus Panda, and Ursnif, to name a few [14].
Dynamic or behaviour-based malware detection technique has addresses the above shortcoming observed in the signature-based techniques. In contrast to signature-based techniques, dynamic-based techniques can detect both obfuscated and zero-day malware attacks. They are implemented based on the dynamic malware analysis approach which allows monitoring the suspicious program’s behaviours and vulnerability exploits by executing it in a virtual environment [15]. Dynamic analysis can reveal behavioural features such as running processes, registry key changes, web browsing history (such as DNS queries), malicious IP addresses, loaded DLLs, API calls, and changes in the file system [16] [3]. Hence, the dynamic analysis produces the best representation of malware behaviour since in many cases the behaviour of malware remain the same despite many variants it may have. As malware can use API calls to perform different malicious activities in a compromised system, tracing API calls reveals how a particular executable file behaves [17] [8]. Accordingly, Vemparala et al.’s work [17] demonstrated that the dynamic-based malware detection model outperforms the static model in many cases, after comparing their performance using extracted dynamic API calls and static sequence of opcodes features. This work is focused on analyzing dynamic-based API call sequences to identify malware.
Existing techniques for dynamic-based malware detection have used machine learning (ML) algorithms to successfully identify malware attacks. These algorithms learn from given data and make predictions on new data. over the last decade, the use of ML-based models has become more prevalent in the field of cybersecurity such as malware detection [18] [19]. Decision Trees (DT), Support Vector Machine (SVM), J48, K-nearest neighbour (KNN), Random Forest (RF), and Naïve Bayes are the most popular ML algorithms which are used to build malware detection [8] [3] [19]. However, conventional machine learning techniques rely on manual feature extraction and selection process, which requires human expert domain knowledge to derive relevant or high-level patterns/features to be used to represent a set of malware and benign files. This process is known as manual feature engineering and is time-consuming and error-prone as it depends on a manual process, considering the current plethora of malware production. Deep learning (DL) algorithms have also emerged for malware detection [20] [21]. Deep neural networks (DNNs) [22], recurrent neural networks (RNNs) [23], autoencoders [24], convolutional neural networks (CNNs) [25] [26], and Deep Belief Networks (DBNs) [27] are examples of DL algorithms that have been used in dynamic malware analysis [28] [29]. Different from conventional ML techniques, DL algorithms can perform automatic feature extraction [24].
On the other hand, the majority of existing ML and DL-based techniques operate as black boxes [30] [31] [3]. These models receive input which is processed through a series of complex operations to produce as the predicted outcome/output. Nevertheless, these operations cannot be interpreted by humans, as they fail to provide human-friendly insights and explanations, for example, which features contributed to the final predicted outcome [30] [31]. Therefore, by using explainable modules researchers and security analysts can derive more insight from the detection models and understand the logic behind the predictions [32]. The interpretation of the model’s outcome can help to assess the quality of the detection model in order to make the correct decision.
Motivation and Contributions
Extracting behavioural features from malware executable files is a very critical task as malware can damage organizational resources such as corporate networks, confidential information, and other resources when they escape the analysis environment. Hence, obtaining a good and up-to-date behavioural representation of malware is a challenging task [33]. In the case of API calls, having a good representation of API call features from benign and malware programs also remains a challenge as the number of API calls made by malware executable files is relatively long which makes their analysis and processing difficult [28]. In addition, some of the previous techniques have used API calls to detect malicious executable files. Such API call-based malware detection techniques include the ones presented in [28] [34] [35] [36] and [29]. Unfortunately, none of the previous work has attempted to reveal API call features that contributed to the final prediction/classification outcome. Practically, it is ideal to have a machine learning or deep learning model that can detect the presence of malicious files with high detection accuracy. However, the prediction of such a model should not be blindly trusted, but instead, it is important to have confidence about the features or attributes that contributed to the prediction.
In order to improve the performance of existing malware detection techniques, this work proposes MalDetConv, a new automated framework for detecting both known and zero-day malware attacks based on natural language processing (NLP) and deep learning techniques. The motivation for using deep learning is to automatically identify unique and high relevant patterns from raw and long sequences of API calls which distinguishes malware attacks from benign activities, while NLP techniques allow producing numerical encoding of API call sequences and capturing semantic relationships among them. More specifically, MalDetConv uses an encoder based on NLP techniques to construct numerical representations and embedding vectors (dense vectors) of each API call based on their semantic relationships. All generated embedding vectors are then fed to a CNN module to automatically learn and extract high-level features of the API calls. The final features generated by CNN are then passed to a bidirectional gated recurrent unit (BiGRU) feature learning module to capture more dependencies between features of API calls and produce more relevant features. We believe that combining CNN and BiGRU creates a hybrid automatic feature extractor that can effectively capture relevant features that can be used in detecting malicious executable files. Finally, features generated by the BiGRU module are fed to a fully connected neural network (FCNN) module for malware classification. We have also integrated LIME into our framework to make it explainable [37]. LIME is a framework for interpreting machine learning and deep learning black box models proposed by Ribeiro et al. [32]. It allows MaldetConv to produce explainable predictions, which reveal feature importance, i.e., LIME produces features of API calls that contributed to the final prediction of a particular benign or malware executable file. Explainable results produced by LIME can help cybersecurity analysts or security practitioners to better understand MalDetConv’s predictions and to make decisions based on these predictions. The experimental evaluations conducted using different datasets show better performance of the MalDetConv framework over other state-of-the-art techniques based on API call sequences. Specifically, the following are the contributions of this work.
-
1.
This work contributes ”MalBehavD-V1”, a new behavioural dataset of API call sequences extracted from benign and malware executable files. We have used the MalBehavD-V1 dataset to evaluate the proposed framework and our dataset is made publicly available for use by the research community. Our dataset contains behaviours of 1285 new malware samples that appeared in the second quarter of 2021 and were not analyzed by the previous works.
-
2.
We designed and implemented the MalDetConv framework using an NLP-based encoder for API calls and a hybrid automatic feature extractor based on deep learning techniques.
-
3.
MalDetConv uses LIME to provide explainable predictions which are essential for security analysts to identify interesting API call features which contributed to the prediction.
-
4.
Detailed experimental evaluations confirm the superiority of the proposed framework over existing when detecting unseen malware attacks with an average of 97.48% in the detection accuracy obtained using different datasets of API calls. Our framework outperforms existing techniques such as the ones proposed in [34] [38] [29].
Structure: The remainder of this paper is structured as follows. Section 2 presents the background and Section 3 discusses the related works. Section 4 presents the proposed method while Section 5 discusses the experimental results. Section 6 presents limitations and future work. The conclusion of this work is provided in Section 7.
2 Background
This section discusses the prevalence of malware attacks in the Windows operating system (OS), Windows application programming interface (Win API), and malware detection using API calls. Moreover, it provides brief background on deep learning techniques, such as convolutional neural networks and recurrent neural networks.
2.1 High Prevalence of Malware Attacks on Windows platforms
Malware production is increasing enormously with millions of threats targeting Windows OS. Developed by Microsoft, Windows is the most widely used and distributed desktop OS with the highest global market share [39]. The distribution of this OS market share can also be viewed in Figure 1. Consequently, its popularity and widespread usage give many opportunities to cybercriminals to create various malware applications (malicious software) against Windows-based systems or devices [40] [41].

2.2 Windows API
The Windows application programming interface (API), also known as Win32 API, is a collection of all API functions that allow windows-based applications/programs to interact with the Microsoft Windows OS (Kernel) and hardware [42] [43] [44]. Apart from some console programs, all windows-based applications must employ Windows APIs to request the operating system to perform certain tasks such as opening and closing a file, displaying a message on the screen, creating, writing content to files, and making changes in the registry. This implies that both system resources and hardware cannot be directly accessed by a program, but instead, programs need to accomplish their tasks via the Win32 API. All available API functions are defined in the dynamic link libraries (DLLs), i.e., in .dll files included in C:\Windows\System32\*.For example, many commonly used libraries include Kernel32.dl, User32.dll, Advapi32.dll, Gdi32.dll, Hal.dll, and Bootvid.dll [45].
2.3 API calls Monitoring
Generally, any windows-based program performs its task by calling some API functions. This functionality makes Win32 API one of the important and core components of the Windows OS as well as an entry point for malware programs targeting the windows platform, since the API also allows malware programs to execute their malicious activities. Therefore, monitoring and analyzing Windows API call sequences gives the behavioural characteristics that can be used to represent benign and malware programs [46] [47]. API calls analysis reveals a considerable representation of how a given malware program behaves. Therefore, monitoring the program’s API call sequences is by far one of the most effective ways to observe if a particular executable program file has malicious or normal behaviours [48] [49] [50] [51] [34].
2.4 Deep Learning Algorithms
Deep learning (DL) techniques are subsets of machine learning techniques that use artificial neural network architectures to learn and discover interesting patterns and features from data. DL network architectures can handle big datasets with high dimensions and perform automatic extraction of high-level abstract features without requiring human expertise in contrast to ML techniques [52] [53]. DL algorithms are designed to learn from both labeled and unlabeled datasets and produce highly accurate results with low false-positive rates [54]. By using a hierarchical learning process, deep learning algorithms can generate high-level complex patterns from raw input data and learn from them to produce intelligent classification model which performs classification tasks, making deep models valuable and effective for big data manipulation. The multi-layered structure adopted by deep learning algorithms gives them the ability to learn relevant data representations through which low-level features are captured by lower layers and high-level abstract features are extracted by higher layers [55] [56]. The next section introduces CNN and recurrent neural networks, which are some of the popular categories of DL algorithms.
2.4.1 Convolutional Neural Network
Convolutional neural network (CNN) is a category of deep learning techniques that gained popularity over the last decades. Inspired by how the animal visual cortex is organized [57] [58], CNN was mainly designed for processing data represented in grid patterns such as images. CNN has been successfully used to solve computer vision problems [59] and has attracted significant interest across various image processing domains such as radiology [60]. Convolutional neural networks (CNNs) are developed to automatically learn and extract high-level feature representation from low patterns of raw datasets. The architecture of the CNN technique has three main components or layers that are considered its main building blocks (see Figure 2). These components include the convolutional layer, pooling layer, and fully connected layer (also known as the dense layer). The convolution layer and pooling layers are responsible for feature extraction and selection/reduction while the dense layer receives the extracted features as input, learns from them, and then performs classification which gives the output, e.g., a class of a given instance.
CNN differs from the existing conventional machine learning techniques as follows.
-
1.
Most of the current traditional machine learning techniques are based on manual or hand-crafted feature extraction and selection techniques which are followed by the learning and classification stages performed by the machine learning classier [36].
-
2.
In contrast, CNN network architectures do not use manual crafted-feature extraction and selection as they can automatically perform both operations and produce high-level feature representations through convolution and pooling operations [60].
- 3.
CNN can have single or multiple convolution and pooling layers, with the convolution layer being its core component. The goal of the convolutional layer is to learn different high-level feature representations from the input data using several learnable parameters called filters or kernels which generate different feature maps through convolution operations. During convolution, the defined filters are convolved to a window of the same size from input data which extracts features from different positions of the input. The element-wise multiplication is performed between the filter and each input window size. Strides and padding are also important parameters of the convolutional layer [61]. Stride is the defined step to which the filter should be moved over the input (horizontally or vertically) for 2-D data. In the case of 1-D input data, the filter moves in one direction (horizontally) with stride. Padding allows producing feature maps with a size similar to the input data and helps to protect the boundary information from being lost as the filter moves over the input data, with zero-padding being the most used method. The convolved results are passed to a non-linear activation function before being fed to the next layer.

The pooling layer (also known as the sub/down-sampling layer) selects a small region of each output feature map from the convolution and sub-samples them to generate a single reduced output feature map. Max-overtime pooling, average/mean pooling, and min pooling are different examples of pooling techniques. Note that the pooling operation reduces the dimension of input data and results in a few parameters to be computed in the upper layers, making the network less complex while keeping relevant feature representation at the same time [62].
The next layer (considered the last layer of CNN) is a fully connected neural network (FCNN) layer that receives the pooling layer’s output as input and performs classification/predictions. It is an artificial neural network with hidden layers and an output layer that learn and perform classification through forward propagation and backpropagation operations. Hence, a typical CNN model can be viewed as an integration of two main blocks, namely, feature extraction and selection block, and classification block. One dimensional CNN (1-D CNN) is a version of 2-D CNNs and has been recently presented in various studies [63] [64] [65] [66]. All these studies have proven that 1-D CNNs are preferable for certain applications and are advantageous over their 2-D counterparts when handling 1-D signals. One dimensional (1D) represents data with one dimension such as times series data and sequential data. Another recent study has mentioned that 1-D CNNs are less computationally expensive compared to 2-D CNNs and do not require graphics processing units (GPUs) as they can be implemented on a standard computer with a CPU and are much faster than 2-D CNNs [67]. 1-D CNN architectures have been also successful in modeling various tasks such as solving natural language processing (NLP) problems. For example, in the previous work, CNNs were successfully applied to perform text/documents classification [64] [68] [69] and sentiments classification [70].
2.4.2 Recurrent neural networks
A Recurrent neural network (RNN) is a type of DL network architecture which is suitable for modeling sequential data. RNN uses a memory function that allows them to discover important patterns from data. However, traditional/classic RNNs suffer from vanishing gradients (also known as gradient explosion) and are unable to process long sequences [71]. To address this problem, Hochreiter et al. [72] proposed Long short-term memory (LSTM), an improved RNN algorithm that performs well on long sequences. The Gated Recurrent Unit (GRU) was later implemented by Chao et al. [73] based on the LSTM. As depicted in Figure 3, a GRU network uses a reset gate and update gate to decide which information needs to be passed to the output. A reset gate is used to determine which information to forget in the hidden state of the previous time step/moment, where the information in the previous time step will be forgotten when the value of the reset gate is close to 0, otherwise it will be retained if the value is close to 1. The update gate decides how much information needs to be passed to the current hidden state. GRU operations are computed using mathematical equations in (1), (2),(3), and (4).
| (1) |
| (2) |
| (3) |
| (4) |

In Figure 3, , , and denote the update gate, reset gate, candidate hidden state of the currently hidden node and current hidden state, respectively. The symbol denotes the Sigmoid activation, is the current input, is the hyperbolic tangent activation function, and are weights matrices to be learned, is the Hadamard product of the matrix, while and denotes the bias. The values of and are between 0 and 1 and when modeling sequences the reset gate operates on to record all necessary information in the memory content. The information to be forgotten in the current memory content is determined by the reset gate after obtaining the Hadamard product [74]. All important information is recorded by through the input information and reset gate. The update gate acts on and and forwards it to the next unit. As it can be seen from equation 4, the expression decides which information needs to be forgotten and then the associated information in the memory content is updated. Hence, the required information to be retained is decided by at and via the update gate. Every hidden layer of the GRU network has a reset and update gate which are separated, and based on the current input information and the information from the previous time-step, layers produce different dependent relationships among features. GRU uses a simple network architecture and has shown better performance over regular LSTMs [75]. Bidirectional GRU (BiGRU) is a variant of GRU that models information in two directions (right and left direction) [76]. Accordingly, studies have shown better performance with reversed sequences, making it ideal to model sequences in both directions in some cases [76].
3 Related Works
This section presents related works on static and behaviour-based malware detection. However, all works that use images of binary files and hybrid malware detection techniques that use a combination of static and behavioural features are beyond the scope of this literature. In addition, works that do not use windows executable files for experimental analysis are also not included in this section.
3.1 Static and Dynamic-based malware detection techniques
There have been significant efforts in the recent works on malware detection through static and behaviour-based analysis. Static API calls extracted after disassembling benign and malware executables with IDA Pro Disassembler were mined using a hybrid of SVM wrapper and filter methods [10]. Different subsets of features selected by the SVM wrapper were combined with feature subsets generated by the filter method to construct a good representation of API call features and the final feature set was then employed to build different hybrid SVM-based malware detection models. While the model performs well when classifying malware based on API call features, there is no clear approach for selecting filters, which can affect the overall performance, especially for the hybrid methods. The work presented by Naik [7] has implemented a fuzzy-import hashing approach to measure similarity between malware and benign files and their results were further compared with YARA rules. The dataset with four ransomware families namely, WannaCry, Locky, Cerber Ransomware, and CryptoWall was used to evaluate the performance of their proposed approach. YARA rules were generated from strings extracted from these ransomware samples and different Fuzzy-Import Hashing approaches (SDHASH, IMPHASH, SSDEEP, etc.,) were tested. The results reveal that there is a high similarity between ransomware from the same family and a high dissimilarity between ransomware from different families. API calls and API calls’ statistics extracted from binary files through the static malware analysis were used in the detection model proposed in Huda et al.’s work [77]. The step-wise binary logistic regression (SBLR) model was applied to select a subset of specific features and thereafter, the Decision Tree and SVM algorithms were trained and tested to detect malicious activities. While the focus of their work was to reduce the computation complexity, this technique depends on a linear approach which can affect the overall detection accuracy of the proposed model. An instruction sequence-based malware detection framework was proposed in Fan et al.’s work [78] where sequences were extracted from executable samples and malicious sequential patterns were discovered using a sequence mining approach that works in combination with All-Nearest Neighbour (ANN) classifier. Based on the experimental results, this method can identify malicious patterns from given suspicious executable programs with improved detection accuracy.
A signature-based malware detection approach was implemented using deep autoencoders in [24]. An opcode sequence analysis method was used to construct a static-based method that effectively detects malware attacks [9]. Opcode sequences were statically extracted from 32-bit and 64-bit Windows EXE files and the occurrence of each opcode was computed using the term frequency-inverse document frequency (TF–IDF) to obtain a feature set that was used to train KNN, Decision Tree, Adaboost, RF, Bagging and backpropagation neural networks detection models. A total of 20,000 files (malware and benign) was used in the experiment and k-fold cross-validation was used to evaluate the performance of the proposed methods. The results reveal that their malware detection systems can identify and classify different malware attacks with the better performance achieved by the Adaboost model. Logistic regression was used to learn relevant features (to perform domain knowledge operation) from raw bytes to reveal the best byte n-grams features which were further employed to train the Random Forest and Extra Random Trees using the JSAT library [79]. Furthermore, they have also built a long short-term memory (LSTM) and fully connected neural networks detection approach using raw bytes and Keras library [80]. Their performance evaluation shows that neural network models trained on raw bytes features without performing explicit feature generation can outperform the performance of domain knowledge methods that fully depends on constructing explicit features from raw bytes extracted from PE headers [79]. D’Onghia et al. [81] proposed Apícula, a static analysis-based tool that uses the Jaccard index to identify malicious API calls presented in bytes streams such as network traffic, object code files, and memory dumps. The work presented by Kundu et al. [82] has improved the performance of a Light Gradient Boosted Machine (LightGBM) approach for detecting and classifying malicious software using two datasets, the Microsoft EMBER dataset and another private dataset collected from an anti-virus company. The optimization (hyper-parameter tuning) was performed using Microsoft Neural Network Intelligence (NNI) and AutoGluon-Tabular (AutoGluon) automated machine learning frameworks. The AutoGluon was released by Amazon and has been implemented with various ML algorithms including KNN, LightGBM, and Multi-Layer Perceptron (MLP). The results obtained after performing different empirical analyses demonstrate that there is an improvement in tuned models compared to the baseline models. Kale et al.’s [83] used opcode sequences from EXE files to build malware detection approaches based on RF, SVM, KNN, and CNN where feature extraction and representation were performed using different techniques such as Word2Vec, BERT, HMM2Vec, and ELMo. Yeboah et al.[84] proposed a CNN-based approach that detects malicious files using operational code (opcode).
Nevertheless, cybercriminals can easily modify the executable binary file’s code and disguise a small piece of encrypted malicious code, which can be decrypted during its execution/runtime [85]. Such malicious code can even be downloaded remotely and get inserted into the program while running. Accordingly, the work presented by [86] has also revealed that it is possible for encrypted and compressed code to be decrypted and unpacked when loaded into memory during runtime. Additionally, some sophisticated malware uses more than two stages to attack the victim’s systems. For instance, malware designed to target specific platforms such as Windows OS will first check if it is running in the targeted OS. Once detected, a malicious payload can automatically be downloaded from the cybercriminal’s server and get loaded into memory to perform malicious tasks. Malware with the ability to evade antivirus and utilizes it to transfer users’ stolen confidential information from the comprised users without any notice was reported in [85]. Recently advanced malware variants use varieties of sophisticated evasion techniques including obfuscation, dead code insertion, and packing [87] [88] to evade static-based malware detection, making them more vulnerable and unable to detect new sophisticated malware attacks. Fortunately, the dynamic malware analysis approach can handle obfuscated malware and consequently, many of the recent works were focused on dynamics-based approaches/techniques. The work proposed by Vemparala et al. [17] extracted API call sequences through dynamic analysis and employed them to train and test both hidden Markov Models and Profile Hidden Markov Models to observe the efficiency of the dynamic analysis approach while detecting malware. Their study has used a dataset of seven malware types with some malware programs such as Zbot and Harebot that have the capability of stealing confidential information. The results from their experiment show that the HMM-based malware detection approach using behavioural/dynamic sequences of API calls outdoes both static and hybrid-based detection techniques. Nevertheless, the authors have used an outdated dataset, which can prevent the model from identifying new sophisticated malware attacks, considering the rapid scale of different malware variants.
The work in [47] has adopted the DNA sequence alignment approach to design a dynamic analysis-based method for malware detection. Common API call features were dynamically extracted from different categories of malware. Their experimental outcome has revealed that some of the malicious files possess common behaviours/functions despite their categories, which may be different. In addition, their study has also indicated that unknown or new malware can be detected by identifying and matching the presence of certain API calls or function calls as malware programs perform malicious activities using almost similar API calls. However, the limitation of DNA sequence approaches is that they are prone to consuming many resources and require high execution time, making them computationally expensive, considering the high volume of the emerging malware datasets. Seven dynamic features, namely, API calls, mutexes, file manipulations/operations, changes in the registry, network operations/activities, dropped files, and printable string information (PSI) were extracted from 8422 benign and 16489 malware using the Cuckoo sandbox [8]. PSI features were processed using a count-based vector model (count vectorization approach) to generate a feature matrix representing each file and thereafter, truncated singular value decomposition was utilized to reduce the dimension of each generated matrix. Furthermore, they have computed Shannon entropy over PSI and API call features to determine their randomness. Using PSI features, their model has achieved the detection accuracy of 99.54% with the Adaboost ensemble model while the accuracy of 97.46% was yielded with the Random Forest machine learning classifier. However, while their method shows an improvement in the accuracy of the detection model using PSI features, it is worth mentioning that the count vectorization model applied while processing features does not preserve semantic relationship/linguistic similarity between features or word patterns [89] [90]. The count vectorization model is unable to identify the most relevant or less relevant features for the analysis, i.e., only words/features with a high frequency of occurrence in a given corpus are considered as the most statistically relevant words.
Cuckoo sandbox was used to generate behavioural features of benign and malware files during their execution time in the work carried out in [91]. They have used Windows API calls to implement a Random Forest-based malware detection and classification approach that achieved the detection accuracy of 98%. Malicious features were extracted from about 80000 malware files including four malware categories, namely, Trojans, rootkit, adware, and potentially unwanted programs (PUPs) downloaded from VirusTotal and VirusShare malware repository. The detection model was tested on 42000 samples and the results show an improvement in the detection of malware attacks. However, looking at the detection outcome, this approach only performs well when detecting Trojans. For instance, it achieved the true positive rate (TPR) of 0.959 when detecting and classifying Trojans while the TPR of 0.777, 0.858, and 0.791 were achieved while detecting rootkit, adware, and PUPs, respectively. In the work presented by Suaboot et al. [28] a subset of relevant features was extracted from API call sequences using a sub-curve Hidden Markov Model (HMM) feature extractor. Benign and malware samples were executed in the Cuckoo sandbox to monitor their activities while executing in a clean isolated environment residing in Windows 7-32 bits machine. The API call features selected from the behavioural reports of each executable program file (benign and malware) were then used to train and test a behaviour-based malware detection model. Only six malware families (Keyloggers, Zeus, Rammit, Lokibot, Ransom, and Hivecoin) with data exfiltration behaviours were used for the experimental evaluation. Different machine learning algorithms such as Random Forest (RF), J48, and SVM were evaluated, and the RF classifier achieved better prediction with an accuracy average of 96.86% compared to other algorithms. Nevertheless, their method was only limited to evaluating executable program files, which exfiltrates confidential information from the compromised systems. In addition, with 42 benign and 756 malware executable programs which were used in the experimental analysis, there is a significant class imbalance in their dataset which could lead to the model failing to predict and identify samples from minority classes despite its good performance.
A backpropagation neural networks (BPNNs) approach for malware detection was proposed in [92]. The proposed BPNNs–based approach learns from features extracted from benign and malware behavioural reports to classify malware attacks. A dataset of 13600 malware executable files was collected from Kafan Forum and the dataset has ten malware families which were labeled using Virscan. They also have used the HABO online behaviour-based system, which captures the behaviours of each file and generates a behavioural report having all activities performed by the executable file. Behavioural features such as mutexes, modified registry keys, and created processes, to name a few, were used to train and test the proposed BPNNs approach to perform binary classification, which led to the accuracy of 99%. Note the BPNN was built using a sub-behavioural feature generated based on a count-based method which is limited to using an occurrence matrix that does not provide any relationship between the selected sub-behavioural feature set. Malware attacks can be detected using the detection techniques implemented based on the longest common substring and longest common subsequence methods suggested in [93]. Both methods were trained on behavioural API calls, which were captured from 1500 benign and 4256 malware files during dynamic analysis. A Malware detection approach based on API calls monitored by the Cuckoo sandbox was designed in the work proposed by Kyeom et al. [94]. The analysis was carried out using 150 malware belonging to ten malware variants and the detection was achieved by computing similarity between files based on the extracted sequence of API calls features using the proposed sequence alignment approach. Their results also show that similar behaviours of malware families can be found by identifying a common list of invoked API call sequences generated during the execution of executable program. Unfortunately, this method cannot suitable for high-speed malware attacks detection as it fully relies on the pairwise sequence alignment approach, which introduces overheads. The work in [95] has proposed multiple instance-based learning (MIL) approach that exploits the performance of several machine learning classifiers (SVM, KNN, RF, etc.) to detect malicious binary files. The MIL was trained using different dynamic features such as network communication (operations), the structure of file paths, registry, mutexes, keys, and error messages triggered by the operating system. Behaviours of benign and malicious files were monitored in the sandbox and a similarity-based method was used in combination with clustering which allows similar systems resources to be grouped together. MIL has achieved a detection accuracy of 95.6% while detecting unknown malware files.
Several graph-based techniques for malware detection were proposed in the previous studies [96] [97] [98] [99] [100] and [101], to mention a few. All of these approaches have used graphs to represent behaviours of executable files and the detection models learned from the generated graphs. Nevertheless, the complexity of graph matching is one of the major issues with graph-based techniques, i.e., as the graph’s size increases the matching complexity, the detection accuracy of a given detection model decreases [8]. Grouping a common sequence of API calls in a single node is often applied to decrease the matching complexity of graphs. Although this approach does not yield better detection accuracy, it is harder for a cyber attacker to modify the behaviours of a malware detection model based on the graph method [99]. NLP techniques were applied to analyze/mine the sequence of API calls in the malware detection approach implemented in [102]. The API calls were processed using the n-gram method and the weights were assigned to each API call feature using the term frequency-inverse document frequency (TF-IDF) model. The main goal of the TF-IDF is to map n-grams of API calls into numerical features that are used as input to machine learning or deep learning algorithms. Given an input of behavioural report extracted from malware and benign files in a dynamic isolated environment, the TF-ID, processes the report to generate feature vectors by taking into account the relative frequency of available n-grams in the individual behavarioural report compared to the total number of the report in the dataset. The work in [38] has also relied on TF-IDF to compute input features for machine learning algorithms (CART, ETrees KNN, RF, SVM, XGBoost, and Ensemble). Another previous work in [23] has used LSTM and TF-IDF model to build a behaviour-based malware detection using API call sequences extracted with cuckoo sandbox in a dynamic analysis environment.
The work in [33] has used the term frequency-inverse document frequency to process printable strings extracted from malware executable files after dynamic analysis. TF-IDF and Anti-colony optimization (Swarm algorithm) were used to implement a behavioural graph-based malware detection method based on dynamic features of API calls extracted from executable [29]. Unfortunately, like the count vectorization model, the TF-IDF text processing model does not reveal or preserve the semantic relationship/similarity that exists between words. In the case of malware detection, this would be the similarity between API calls or another text-based feature such as file name, dropped messages, network operations such as contacted hostnames, web browsing history, and error message generated while executing the executable program file. Liu and Wang have [103] used Bidirectional LSTM (BLSTM) to Build an API call-based approach that classifies malware attacks with an accuracy of 97.85%. ALL sequences of API calls were extracted from 21,378 and were processed using the word2vec model. In Li et al. [104] a graph convolutional network (GCN) model for malware classification was built using sequences of API calls. Features were extracted using principal component analysis (PCA) and Markov Chain. A fuzzy similarity algorithm was employed by Lajevardi [105] to develop dynamic-based malware detection techniques based on API calls. Maniath et al. [106] proposed an LSTM-based model that identifies ransomware attacks based on Behavioural API calls from Windows EXE files generated through dynamic analysis in the Cuckoo sandbox. Chen et al.’s work [107] proposed different malware detection techniques based on CNN, LSTM, and bidirectional LSTM models. These models were trained on raw API sequences and parameters traced during the execution of malware and benign executable files. An ensemble of ML algorithms for malware classification based on API call sequences was recently implemented in the work presented in [108]. Convolutional neural networks and BiLSTM were used to develop a malware classification framework based on sequences of API calls extracted from executables files [21]. Two detests were used by Dhanya et al. [109] to evaluate the performance of various machine learning-based ensemble models (AdaBoost, Random Forest, Gradient descent boosting, XGBoost, Stacking, and Light GBM) for malware detection. Their study has also evaluated DL algorithms such as GRU, Graph Attention Network, Graph Convolutional Network, and LSTM. The work proposed in [110] has employed a dataset of API invocations, Registry keys, files/directory operations, dropped files, and embedded strings features extracted using the Cuckoo sandbox to implement a particle swarm-based approach that classifies ransomware attacks. Jing et al. [111] proposed Ensila, an ensemble of RNN, LSTM, and GRU for malware detection which was trained and evaluated on dynamic features of API calls.
3.2 API calls Datasets
Some of the previous studies presented above have generated datasets of API calls and have made them public for the research community focusing on malware detection. Examples of such datasets include the ones presented in [112], [113], [47] and [114]. Nevertheless, many existing studies did not share their datasets and as result, a few datasets are publicly available for the research community. The existing datasets are also outdated as they are not regularly updated to include new behavioural characteristics of malware. This situation hinders the development and evaluation of new malware detection models as building these models requires updated datasets having the necessary behavioural characteristics of new malware variants. Therefore, to contribute to the existing challenge related to the availability of benchmark datasets [33], this work generates a new behavioural dataset of API calls based on Windows executable files of malware and benign using the Cuckoo sandbox.
More specifically, we generate MalbehavD-V1, a new dataset that has the behavioural characteristics of current emerging malware such as ransomware, worms, Viruses, Spyware, backdoor, adware, keyloggers, and Trojans which appeared in the second quarter of 2021. The dataset has been processed to remove all inconsistencies/noise, making it ready to be used for evaluating the performance of deep learning models. The dataset is labeled and the hash value for each file has been included to avoid duplication of files while extending the dataset in the future, which makes it easier to include behavioural characteristics of newly discovered malware variants in the dataset or combine the dataset with any of the existing datasets of API calls extracted from Windows PE files through dynamic analysis. More details on the dataset generation are presented in Section 4 and the dataset can be accessed from the GitHub repository in [115].
4 Proposed MalDetConv Framework
The development of the proposed framework is mainly based on the dynamic malware analysis using natural language processing, convolutional neural networks, and the bidirectional gated recurrent unit. The benign and malware program’s dynamic/behavioural reports are created by analysing sequences of API calls in the Cuckoo sandbox. Given a program’s API call sequences represented in form of text, the proposed method uses an encoder based on the word embedding model to build dense vector representations of each API call which are further fed to a CNN-BiGRU automatic hybrid feature extractor. The architecture of the proposed framework is depicted in Figure 4 and consists of six main components/modules, namely, executable files collection module, behaviour monitoring module, pre-processing module, embedding module, hybrid automatic feature extraction module, and classification module. In the next section, we present the function of each module and how all modules inter-operate to detect malicious EXE files.

4.1 Executable File Collection Module
It is often challenging to find an up-to-date dataset of API calls of Windows executable files. For this reason, we have generated a new dataset of API calls which is used for the experimental evaluations. Different sources of malware executable files such as Malheur [116], Kafan Forum [92], Danny Quist [117], Vxheaven [10], MEDUSA [118], and Malicia [119] were used in the previous studies. Unfortunately, these repositories are not regularly updated to include new malware samples. Hence, we have collected malware executable samples from VirusTotal [120], the most updated and the world’s largest malware samples repository. Nevertheless, considering millions of malware samples available in the repository, processing all malware samples is beyond the scope of this study. Thus, only malware samples submitted in the second quarter of 2021 were collected. We were given access to a Google drive folder having the malicious EXE files which are shared by VirusTotal. Benign samples were collected from CNET site[121]. The VirusTotal online engine was used to scan each benign EXE file to ensure that all benign samples are clean. A total number of 2800 EXE files were collected to be analyzed in an isolated analysis environment using the dynamic analysis approach. However, we experienced issues while executing some files, resulting in a dataset of 2570 files (1285 benign and 1285 malware) that were successfully executed and analyzed to generate our MalbehavD-V1 benchmark dataset. Some benign files were excluded as they were detected as malicious by some of the anti-malware programs in the VirusTotal online engine [122] while some malware files did not run due to compatibility issues. The next sub-Sections (4.2 and 4.3) present the steps followed to generate the dataset.
4.2 Behaviour Monitoring Module
Monitoring and capturing sequences of API calls from benign and malware executable files through dynamic analysis mostly rely on the use of a sandbox environment as an analysis testbed. This is because automated sandboxes can monitor behaviours of malware executable programs during runtime while preventing them from damaging the host system or production environment. As shown in Figure 5, our isolated environment consists of the main host, host machine, Cuckoo sandbox, virtualization software, and virtual machines (VMs). The main host is a Windows 10 Enterprise edition (64bit) with direct access to the Internet. Considering that some very advanced malware can escape the sandbox analysis environment which could lead to serious damage and a disastrous situation when malware infects the production systems, we have used Oracle VirtualBox, one of the leading virtualization software to isolate the main host and the analysis environment which fully resides in Ubuntu 20.04.3 LTS (Focal Fossa) host machine. More specifically, Oracle VirtualBox 6.1 was installed on Windows 10 main host machine, and then Ubuntu host machine was installed inside the VirtualBox environment.
The Cuckoo sandbox [123] and its dependency software including required analysis modules were installed on the Ubuntu machine. We have installed another VirtualBox that manages all Windows 7 Professional 64-bit SP1 analysis VMs on the Ubuntu machine. A set of software was installed on each virtual machine and some security settings were disabled to make them more vulnerable to malware attacks. Examples of such software include Adobe reader 9.0, Java runtime environment (JRE 7), .NET Framework 4.0, Python 2.7 (32 bit), Pillow 2.5.3 (Python Imaging Library, 32 bit), Microsoft Office, and Cuckoo sandbox guest agent (32 bit). Python allows the Cuckoo guest agent to run while the pillow provides imaging functions such as taking screenshots. The cuckoo agent resides in each Windows VM under the Startup sub-directory. This allows the agent to automatically start whenever the VM boots up. A shared folder was configured in the Windows virtual machine to get all the above files, however, it was disabled after installing each file as some advanced malware looks for the shared folder to discover if they are running in a virtual environment or sandbox. As the Cuckoo guest agent must monitor each file’s behaviours while running and send all captured data back to the host, an Internet connection is needed between the Windows analysis VMs and Ubuntu host machine. Thus, we have set the network adaptor to ”host-only Adaptor” in the VirtualBox to allow the network traffic to only be routed between the Windows virtual machines and Ubuntu host machine without reaching the main host (Windows 10 Enterprise host machine).
The architecture of the analysis environment is mainly based on nested virtualization technology which allows deploying nested virtual machines in the same host. It is also important to note the hardware virtualization on each VirtualBox was set to “enable nested paging” while the paravirtualization interface was set to default. After installing all required software in the Windows 7 VMs, a clean snapshot of each virtual machine was taken and saved. This snapshot is used to restore the virtual machine to its clean state after the analysis of each executable program file. Cuckoo sandbox was configured to generate a behavioural report of each EXE file in JSON format, and each report was further processed to extract relevant features of API calls. A typical structure of JSON report from our dynamic analysis is presented in Figure 7 while details on a complete analysis workflow are given in Figure 6 which describes how each file is monitored by the Cuckoo sandbox at runtime. .


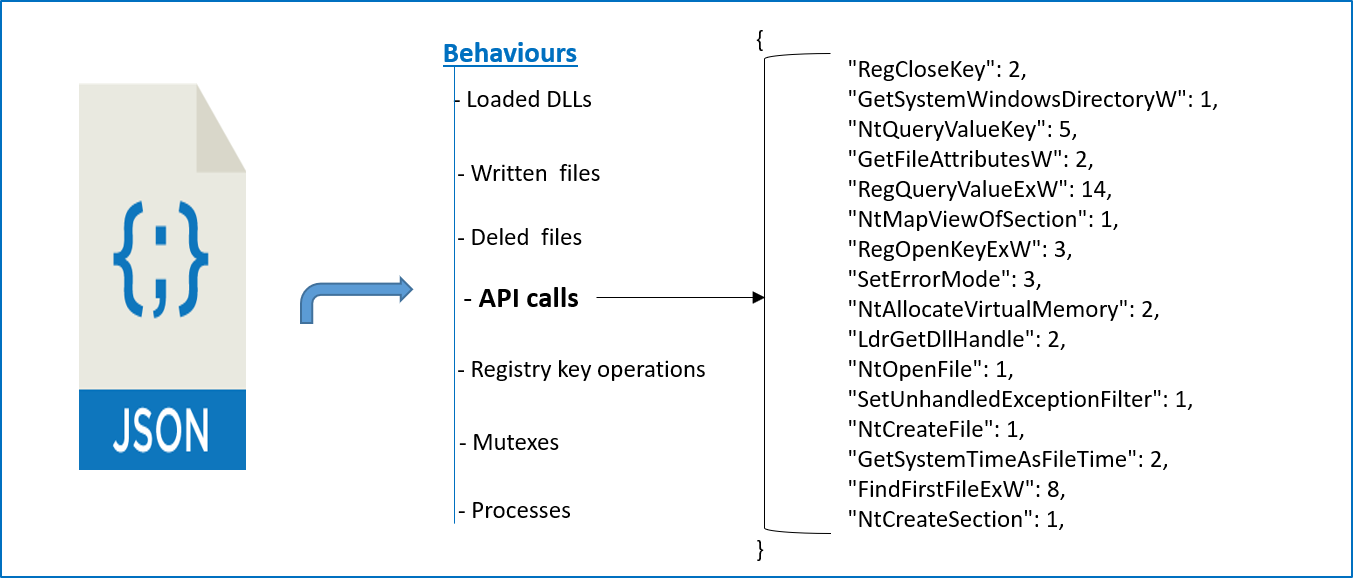
Accordingly, the behavioural reports generated during our dynamic malware analysis reveal that some sophisticated malware can use different API calls that potentially lead to malicious activities. For instance, Table 1 presents some of the API calls used by ae03e1079ae2a3b3ac45e1e360eaa973.virus, which is a ransomware variant. This ransomware ends up locking the comprised device (Windows VM in our analysis) and demands for a ransom to be paid in BitCoins in order to get access back to the system. This variant encrypts the hard drive’s contents and makes them inaccessible. We have also observed that recent malware variants possess multiple behaviours and can perform multiple malicious activities after compromising the target, making detection difficult.
| Malicious API call | Description of API Call |
|---|---|
| WriteConsoleW | Malware uses this API call to establish a command line console. |
| NtProtectVirtualMemory | This API call was used by the malware to allocate read-write memory usually to unpack itself. |
| CreateProcessInternalW | A process created a hidden Windows to hide the running process from the task manager. This API call allows the malicious program to spawn a new process from itself which is usually observed in packers that use this method to inject actual malicious code in memory and execute them using CreateProcessInternalW. |
| Process32FirstW | The malware used this API to search running processes potentially to identify processes for sandbox evasion, code injection, or memory dumping/live image capturing. |
| FindWindowA | The malware used this API to check for the presence of known Windows forensics tools and debuggers that might be running in the background. |
4.3 API Calls Pre-processing Module
The pre-processing of the behavioural report for each analyzed EXE file is performed at this stage. The pre-processing involves organizing and cleaning the raw features from the behavioural reports to make them suitable for training and testing the classification algorithm. After generating all JSON behavioural reports, they are stored in a local directory in the host machine. A typical JSON report contains various objects storing different data and all behavioural features are located under the “Behaviours” object in each JSON report. However, we are only interested in extracting sequences of API calls of benign and malware executable program files. As JSON stores raw features of API calls, they are not supported by deep learning algorithms. Hence, they must be processed to obtain a numerical representation of each PE file’s API call features that is supported by deep learning models.
The processing involves two main stages. The first stage involves processing all JSON reports to generate a comma separate value (CSV) file. Figure 8 presents various steps that are performed to accomplish the first processing stage. The second stage deals with processing the CSV file to generate a numerical representation of each feature and construct the embedding matrix which is fed to the proposed CNN-BiGRU hybrid automatic feature extractor. When a CSV file containing sequences of API calls that represent benign or malware program files is fed to the proposed framework, the pre-processing module transforms this CSV file into a pandas data frame which is much easier to process. A list of labels that are encoded in binary (1,0), with 1 representing each row of malware and 0 representing each row of benign is loaded and then appended to the data frame to obtain a new data frame with labeled features.
In the next step, the data are shuffled and passed to a splitting function which splits the dataset into training and test sets. All sequences of API calls (in both training and test set) are tokenized using the Tokenizer API from the Keras framework to generate a unique integer encoding of each API call. Thereafter, all encoded sequences are given the same length and padded where necessary (zero padding is used). This is very important for CNN as it requires all inputs to be numeric and all sequences to have the same length. The encoded sequences are fed to the embedding layer which builds a dense vector representation of each API call and then all vectors are combined to generate an embedding matrix which is used for CNNs. More specifically, all steps performed in the second pre-processing stage are presented in Figure 9 and further details are provided in subSection 4.6. Additionally, details on the API call embedding are presented in Section 4.4.


4.4 Embedding Module
This section first introduces word embedding and then provides details on the Keras embedding layer which is used to construct embedding vectors of API calls in this work.
4.4.1 Word Embedding
In NLP, word embedding is a group of techniques used to map sequences of words/sentences in a given vocabulary into numerical dense vectors supported by most of the deep learning models[124] [125] and [126]. Word embedding techniques reduce the dimensionality of text and can produce features that are more relevant or informative compared to the original raw dataset from which they are generated [127]. Count-based models and predictive models (often referred to as neural probabilistic language models) are two main categories of word embedding [90]. Counted-based models such as Count vectorization and term frequency-inverse document frequency (TF-IDF) represent word features into vectors with extremely high dimensions (which creates sparse vectors and time complexity) while in predictive models, word features are represented in small learned and dense embedding vectors. Word2Vec is one of the best predictive word embedding models for word representation [126] [127]. Word embeddings have gained popularity due to their frequent use as the first processing layer that processes word encoded features in deep learning models [128]. This success was mainly achieved based on continuous bag-of-words (CBOW) and skip-gram models, which are two Word2Vec embedding models that produce efficient high-quality distributed word feature vector representations where words with similar meanings are grouped based on their semantic/contextual relationships [126]. Categorizing word vectors based on their meaning produce an initial correlation of word features for deep learning models.
Word embedding models are often used when dealing with NLP classification problems. For instance, some recent works have applied Word2Vec in modeling text and documents, classifying sentiments and learning semantic information in DNS [129] [130] [131] [132] [133] [134]. Hence, our API calls feature vector representation approach is linked to these studies, however, in this work, we do not use existing pre-trained NLP-based word embedding models citemikolov2013efficient [135] because word similarities in API call sequences are dissimilar with ordinary English. Thereby, we use the direct embedding layer provided by the Keras DL framework to automatically learn and generate API calls embedding vectors. The direct embedding allows the knowledge to be incorporated inside the detection model, i.e., the whole knowledge of MalDeConv is incorporated in one component, which is different from the previous techniques).
4.4.2 Keras Embedding Layer
As the Keras embedding layer can be used to train embeddings while building the classification model [136] [137], we have used it to generate embedding vectors of API Calls. The word embedding layer in Keras provides an efficient way to generate word embeddings with dense representation where similar words have similar encoding (i.e., this layer can be used to represent both words and sequences of words using dense vector representations). Therefore, the embedding layer learns the embedding of API calls during model training. We treat each API call sequence extracted from each benign and malware EXE file as a sentence. The embedding layer requires all input of API calls to be integer encoded, the reason why each API call was represented by a unique integer using the Keras API Tokenizer during the pre-processing steps (see Section 4.3). Therefore, the embedding layer is first initialized with random weights, and thereafter, it learns the embedding of all API calls in the dataset. To achieve this, the Keras embedding layer uses the continuous bag-of-words model to build embedding vectors of each API call and requires three parameters to be specified. These parameters include which specifies the vocabulary size in the API calls data. For instance, if the API calls data has integer encoded values between 0-1000, then the vocabulary size would be 1001 API calls. The second parameter is the which denotes the size of the vector space in which words/tokens of API calls are embedded (i.e., it specifies/defines the size of each word’s output vector from the embedding layer). For example, it can be of dimensions 10, 20, 100, or even larger. In this work, different values of are tested to obtain the suitable dimension of the output. Hence, this value is empirically chosen after testing different values and in our case, we have set the to 100. Finally, the last parameter is the , which is the length of the input of each API call sequence. For instance, if a sequence of API calls extracted from a malware file has 60 API calls, its input length would be 60. As there are many sequences with different lengths in the dataset, all sequences are processed to have the same , value. The embedding layer concatenates all generated embedding vectors of API calls to form an embedding matrix which is used as input to the hybrid feature extractor.
4.5 Hybrid Automatic Feature Extraction Module
The next component of the proposed framework is the CNN-BiGRU hybrid automatic feature extractor, and its architecture is presented in Figure4 and 10. More formally, our binary classification problem of benign and malware’s API call sequences with MalDetConv can be addressed as follows.
4.5.1 CNN feature extractor
The CNN API feature extractor is designed based on the CNN text classification model presented in Kim’s work [64]. As it can be viewed from Figure 4, the architecture of CNN is made up of two main components, namely, the convolutional layer and the pooling layer. Below we discuss how the CNN feature extractor is designed, the function of each component, and how they interact to perform the extraction of high-level features of API calls. Given a sequence of API calls extracted from the behavioural report of benign or malware, let’s denotes a -dimensional API call vector representing the API call in where is the dimension of the embedding vector. Therefore, a sequence consisting of API calls from a single JSON report can be constructed by concatenating individual API calls using the expression in (5) where the symbol denotes the concatenation operator and is the length of the sequence.
| (5) |
We have padded sequences (where necessary) using zero padding values to generate API calls matrix of dimensions having number of tokens of API call with embedding vectors of length . Padding allows sequences to have a fixed number of tokens (the same fixed length is kept for all sequences) which is very important as CNN cannot work with input vectors of different lengths. We have set to a fixed length. To identify and select high relevant/discriminative features from raw-level features of API calls word embedding vectors, the CNN feature extractor performs a set of transformations to the input sequential vector through convolution operations, non-linear activation, and pooling operations in different layers. These layers interact as follows.
The convolutional layer relies on defined filters to perform convolutional operations to the input vectors of API calls. This allows the convolutional layer to extract discriminative/unique features of API call vectors that correspond to every filter and feature map from the embedding matrix. As the CNN convolutional filters extract features from different locations/positions in the embedding vectors (embedding matrix), the extracted features have a lower dimension compared to the original sequences/features. Hence, mapping high dimensional features to lower-dimensional features while keeping highly relevant features (i.e, it reduces the dimension of features). Positions considered by filters while convolving to the input are independent for each API call and semantic associations between API calls that are far apart in the sequences are captured at higher layers. We have applied a filter to generate a high-level feature representation, with moving/shifting over the embedding matrix based on a stride to construct a feature map which is computed using the expression in (8). It is important to mention that the multiplication operator (*) which is in the equation (6) denotes the convolutional operation (achieved by performing element wise multiplication) which represents API call vectors from to (which means rows at a time) from which is covered by the defined filter using the stride. To make the operation faster, we have kept stride to a value of 1, however, various strides can be adapted as well. Moreover, in the equation (6), the bias value is denoted by .
| (6) |
CNN supports several activation functions such as hyperbolic tangent, Sigmoid, and rectified linear unit (ReLU). In this work, we have used ReLU, which is represented by in (6). Once applied to each input , the ReLu activation function introduces non-linearity by caping/turning all negative values to zero. This operation is achieved using the expression in (7). This activation operation speeds up the training of the CNN model, however, it does not produce significant difference in the model’s classification accuracy.
| (7) |
After convolving filters to the entire input embedding matrix, the out is a feature map corresponding to each convolutional operation and is obtained using the expression in (8).
| (8) |
The convolutional layer passes its output to the pooling layer which performs further operations to generate a new feature representation by aggregating the received values. This operation is carried out using some well-known statistical techniques such as computing the mean or average, finding the maximum value, and applying the L-norm. One of the advantages of the pooling layer is that, it has the potential to prevent the model’s overfitting, reducing the dimensionality of features and producing sequences of API call features with the same fixed lengths. In this work, we have used max pooling [64] [138] which performs the pooling operation over each generated feature map and then selects the maximum value associated with a particular filter output feature map. For instance, having a feature map , the max-pooling operation is performed by the expression in (9) and the same operation is applied to each feature map.
| (9) |
The goal is to capture the most high-level features of API calls (the ones with the maximum/highest value for every feature map). Note that the selected value from each feature map corresponds to a particular API call feature captured by the filter while convolving over the input embedding matrix. All values from the pooling operations are aggregated together to produce a new reduced feature matrix which is passed to the next feature extractor (BiGRU).
4.5.2 BiGRU feature extractor
Features generated by CNN have a low-level semantic compared to the original ones. Fortunately, gated recurrent units can be applied to the intermediate feature maps generated by CNN. Hence, we use the BiGRU module to capture more relevant features of API calls, i.e., the final features maps of API calls generated by the CNN feature extractor are fed to the BiGRU feature which models sequences in both directions, allowing the model to capture high dependencies across the API features maps produced by CNN. The out consists of relevant information/features which are passed to a flatten layer.
4.5.3 Flatten layer
The flatten layer is used to convert/flatten the multi-dimensional input tensors produced by the BiGRU automatic feature extractor into a single dimension (a one-dimensional array/vector) which is used as input to the next layer. That is, the output of the BiGRU is flattened to create a single feature vector that is fed to the fully connected neural network module for malware classification.
4.5.4 Classification Module
In our case, the classification module consists of a fully connected neural network (FCNN)/an artificial neural network’s component with hidden layers and a ReLU activation function, and finally the output layer with a sigmoid activation function. The hidden layer neurons/units receive the input features from the flattening layer and then compute their activations using the expression in (10) with being the matrix of weights between the connections of the input neurons and hidden layer neurons while represents the biases. We have used the dropout regularization technique to prevent the FCNNs from overfitting the training data, i.e., a dropout rate of 0.2 was used after each hidden layer, which means that at each training iteration, 20% of the connection weights are randomly selected and set to zero. Dropout works by randomly dropping out/disabling neurons and their associated connections to the next layer, preventing the network’s neurons from highly relying on some neurons and forcing each neuron to learn and to better generalize on the training data [139].
| (10) |
In addition, we have used the binary-cross entropy [140] to computer the classification error/loss and the learning weights are optimized by Adaptive Moment Estimation (Adam) optimizer [141] [142]. Cross-entropy is a measure of the difference between two probability distributions for a given set of events or random variables and it has been widely used in neural networks for classification tasks. On the other hand, Adam works by searching for the best weights and bias parameters which contribute to minimizing the computed gradient from the error function (binary-cross entropy in this case). Note that the network learning weights are updated through backpropagation operations. For the sigmoid function, we have used the binary logistic regression (see equation (11).
| (11) |
| (12) |
After computing the activation, the classification outcome (the output) is computed by the above expression in (12). In addition, a simplified architecture of the proposed hybrid automatic feature extractor and classification module is presented in Figure 10. Our CNN network has 2 convolutional layers and 2 pooling layers which are connected to a BiGRU layer. The best parameters for the filter size were determined using the grid search approach. The next component to the BiGRU layer is the FCNN (with hidden layers and output layer) which classifies each EXE file as benign or malicious based on extracted features of API calls (see Figure10(A-1). All network parameters and configurations at each layer are presented in Figure 10 (A-2).


4.6 Malware detection with MalDetConv
Given a JSON report containing features of API call sequences representing benign or malware executable programs, the proposed framework performs classification based on all steps described in the previous Sections. First, each JSON file is processed to extract raw sequences of API call features which are followed by encoding each sequence of API calls to obtain an encoded integer representation for each API call. Thereafter, all encoded features are passed to the embedding layer which builds embedding vectors and then concatenates them to generate API calls embedding matrix which is passed to the CNN-BiGRU hybrid automatic feature extractor. The CNN module has filters that convolve to the embedding matrix to select high-level features through convolution operations. The selected features are aggregated together to generate a feature map which is passed to the pooling layer to generate high-level and compact feature representation through max pooling operations. The output from the last pooling layer is passed to a BiGRU layer to capture dependencies between features of API call and constructs more relevant features which are flattened by the flatten layer and then passed to a fully connected neural network module which performs classification. A complete workflow is depicted in Figure 11.
5 Experimental Results and Discussion
Various experimental results are presented and discussed in this Section. The results presented in this section are based on a binary classification problem of benign and malware executable program files in the Windows systems.
5.1 Experimental Setup and Tools
The proposed framework was implemented and tested in a computer running Windows 10 Enterprise edition (64bit) with Intel(R) Core (TM) i7-10700 CPU @ 2.90GHz, 16.0 GB RAM, NVIDIA Quadro P620, and 500 GB for the hard disk drive. The framework was implemented in Python programming language version 3.9.1 using TensorFlow 2.3.0 and Keras 2.7.0 frameworks and other libraries such as Scikit-learn, NumPy, Pandas, Matplotlib, Seaborn, LIME, and Natural Language Toolkit (NLTK) have been also used. All these libraries are freely available for public use and can be accessed from PiPy [144], the Python package management website. The proposed framework was trained and tested using sequences of API call features extracted from Windows EXE files.
5.2 Training and Testing Dataset
Our generated dataset (MalbehavD-v1) was employed to evaluate the performance of the MalDetConv framework. As we wanted the proposed framework to learn and be tested on a variety of different datasets, we have also collected other existing datasets of malicious and normal API calls for our experimental analysis. These datasets include the ones in [47] [114], API calls datasets presented in [112] and [143]. Using all these datasets allows us to assess the performance of the proposed framework while detecting malware attacks.Note that these datasets are freely available for public use. We have used 70% of each data for training while the remaining portion (30%) was used for testing and details on each dataset are presented in Table 2.
5.3 Performance Evaluation of MalDetConv
Different metrics such as precision (P), recall (R), F1-Score, and accuracy were measured to evaluate the performance of the proposed framework. The computations of these metrics are presented in equations (13), (14), (15), and (16), with TP, TN, FP, and FN indicating True Positives, True Negatives, False Positives, and False Negatives, respectively. Additionally, we have also measured the execution time taken while training and testing MalDetConv.
| (13) |
| (14) |
| (15) |
| (16) |
| n | Training Accuracy ( %) | Testing Accuracy ( %) |
|---|---|---|
| 20 | 99.17% | 93.77% |
| 40 | 99.44% | 94.03% |
| 60 | 99.72% | 95.19% |
| 80 | 99.56 % | 95.45% |
| 100 | 99.72% | 96.10% |
| n | Predicted Class | Precision | Recall | F1-Score |
| 20 | Benign | 0.9128 | 0.9692 | 0.9401 |
| Malware | 0.9664 | 0.9055 | 0.9350 | |
| 40 | Benign | 0.9386 | 0.9434 | 0.9410 |
| Malware | 0.9420 | 0.9370 | 0.9395 | |
| 60 | Benign | 0.9467 | 0.9589 | 0.9527 |
| Malware | 0.9574 | 0.9449 | 0.9511 | |
| 80 | Benign | 0.9515 | 0.9589 | 0.9552 |
| Malware | 0.9577 | 0.9501 | 0.9539 | |
| 100 | Benign | 0.9521 | 0.9717 | 0.9618 |
| Malware | 0.9705 | 0.9554 | 0.9602 |
5.3.1 Classification Results
The MalDetConv framework was trained and tested on different datasets to observe how effective it is while detecting/classifying unknown malicious activities. Hence, various evaluations were carried out, and the classification results are presented in this Section. As mentioned in the previous sub-Section 5.2, we evaluate MalDetConv on API call sequences extracted from Windows EXE files through the dynamic analysis approach. We have also compared the performance of MalDetConv against other state-of-the-art techniques presented in the previous works, which reveals its effectiveness and ability to handle both existing and newly emerging malware attacks over its counterparts. Accordingly, Table 3 shows the training and testing classification accuracy achieved by MalDetConv on our dataset (MalbehavD-v1). Different lengths (n) of API call sequences were considered to evaluate their effects on the performance. From the results, we could see that MalDetConv successfully classified malicious activities and benign activities with the accuracy of 96.10% where . The lowest accuracy (93.77%) was obtained using the lengths of 20. Interestingly, the testing accuracy varies in accordance with the value of , revealing the effect of the API call sequence’s length on the performance, i.e., as increases, the accuracy also increases. This is shown by the accuracy improvement of 2.33% obtained by increasing the value of from 20 to 100.
Table 4 presents the precision, recall, and F1-score obtained while testing MalDetConv, which demonstrates better performance while detecting both malware and benign on unseen data. For instance, the precision of 0.9128 and 0.9664 was obtained using the length of the API call sequence of 20 for benign and malware detection, respectively. Similarly, using the same length (n=20) the MalDetConv achieves the recall of 0.9055 and F1-Score of 0.9350 for malware detection. The precision values obtained using different values of (20, 40, 60, 80, and 100) demonstrate a better performance of the MalDetConv framework when distinguishing between malware and benign activities (positive and negative classes). That is, our framework has a good measure of separability between both classes (performs well in identifying malware attacks) and can deal with long sequences. The higher the value of precision (with 1 being the highest), the better performance of a given detection model. It is also important to highlight that in many cases the precision increases as increases.

Figure 12 presents the execution time taken by the MalDetConv framework which shows that increasing results in a high training time (see Figure 12). However, the testing time is low, and it does not dramatically increase, which again proves the effectiveness of MalDetConv in terms of malware detection time.
| Detection Method | Precision | Recall | F1-Score |
|---|---|---|---|
| MLP | 0.9459 | 0.9186 | 0.9321 |
| LSTM | 0.9491 | 0.9291 | 0.9390 |
| BiLSTM | 0.9375 | 0.9449 | 0.9412 |
| CNN | 0.9678 | 0.9475 | 0.9576 |
| GRU | 0.9521 | 0.9396 | 0.9458 |
| BiGRU | 0.9671 | 0.9265 | 0.9464 |
| MalDetConv | 0.9705 | 0.9554 | 0.9602 |
We have also implemented other DL models and compared their performance with MalDetConv. The detection results on unseen EXE files (API call sequences) presented in Table 5 and Figure 13 indicate better precision, recall and F1-Score, and accuracy of the proposed framework, compared to the existing deep learning models. MalDetConv outperforms multilayer perceptron (MLP), LSTM, BiLSTM, GRU, BiGRU, and CNN using the MalbehavD-v1 dataset. MLP achieves the Accuracy of 93.38%, LSTM (94.03%), BiLSTM (94.16%), and CNN (95.84%). The highest improvement gap in detection accuracy of 2.72% (96.1-93.38) is observed between the performance of MLP and MalDetConv.

| Dataset | Predicted Class | Precision | Recall | F1-Score |
| Allan and John | Benign | 1.0000 | 0.7667 | 0.8679 |
| Malware | 0.9504 | 1.0000 | 0.9745 | |
| Brazilian | Benign | 0.9621 | 0.9656 | 0.9638 |
| Malware | 0.9884 | 0.9872 | 0.9878 | |
| Ki-D | Benign | 1.0000 | 0.9524 | 0.9756 |
| Malware | 0.9993 | 1.0000 | 0.9996 |

| Dataset | Techniques/Framework | Feature Vectorization Approach | ML/DL Algorithm | Detection Accuracy |
| Allan and John | MalDy [38] | TF-IDF | XGBoost | 95.18% |
| MalDetConv | Word2Vec-CBOW | CNN-BiGRU | 95.73% | |
| MalBehavD-V1 | MalDy [38] | TF-IDF | XGBoost | 95.59% |
| MalDetConv | Word2Vec-CBOW | CNN-BiGRU | 96.10% | |
| Brazilian | MalDy [38] | TF-IDF | KNN | 97.60% |
| Amer et al. [29] | TF-IDF+word2vec | Swarm intelligence algorithm | 95.4% | |
| Ceschin et al. [145] | TF-IDF | Random Forest | 98.00% | |
| MalDetConv | Word2Vec-CBOW | CNN-BiGRU | 98.18% | |
| ki-D | Amer and Zelinka [34] | Word embedding and clustering similarity | Markov chain model | 99.90% |
| Ki et al. [47] | DNA Sequence Alignment | API call matching algorithm | 99.80% | |
| Tran and Sato [102] | TF-IDF | Support Vector Machine (SVM) | 96.18% | |
| MalDetConv | Word2Vec-CBOW | CNN-BiGRU | 99.93% |
Table 6 shows the classification results of MalDetConv on existing datasets of API calls (Allan and John, Brazilian, and Ki-D datasets). Using Allan and John’s dataset, MalDetConv detects unseen malware with a precision of 0.9504 and detects benign files’ activities with a precision of 1.0000. A precision of 0.9884 was obtained by MalDetConv on the Brazilian dataset while with the Ki-D dataset, MalDetConv performed with a precision of 0.9993. The detection results presented in Table obtained by measuring all metrics (precision, recall, and F1-score) 6, demonstrate better performance of MalDetConv on both small and large datasets. Looking at the training time presented in Figure 14, there is an increase in the training time as the size of the dataset increases. For instance, the execution time of 30.4494 seconds was taken while training MalDetConv on Allan and John’s dataset, and the testing time of 0.1107 seconds was taken while testing the framework on unseen samples. In addition, the training time of 664.2249 seconds was taken to train MalDetConv on the Brazilian dataset. Nevertheless, a few seconds (1.083) were taken to test the model on the test set. The huge gap in the execution time is mainly due to the size of the dataset. It is worth mentioning that the detection results were generated on the test set (30% of each dataset) and the length of the API call sequence of 100. Despite the training time which tends to be high for large datasets, it is worth mentioning that the MalDetConv framework does not take a huge amount of time to detect malware attacks, which is a necessity for any robust and efficient anti-malware detection system.

We have also examined the performance of the MalDetConv framework against other existing NLP-based frameworks/techniques based on API calls extracted from EXE files and comparative results are presented in Table 7. First, we compared MalDetConv against Maldy[38], an existing framework based on NLP and machine learning techniques. Using our dataset, Maldy achieved the detection accuracy of 95.59% with XGBoost while MalDetConv achieved 96.10%, creating an improvement of 0.51% (96.10%-95.59%) detection accuracy made by MalDetConv. The detection improvement of 0.55% (95.73% - 95.18%) was achieved by MalDetConv over the Maldy framework using Allan and John’s dataset. Additionally, MalDetConv detection also outperforms the Maldy on Ki-D and Brazilian datasets. Compared with the malware detection technique presented by Amer and Zelinka [34], MalDetConv obtained an improvement of 0.3% (99.93% - 99.90%) on Ki-D dataset. Moreover, there is an improvement of 0.13% (99.93% - 99.80%) in the detection accuracy achieved over the technique implemented by Ki et al. [47] using the Ki-D dataset, 0.58% (98.18%-97.60%) over Ceschin et al.’s [145] detection technique achieved using the Brazilian dataset and an improvement of 3.75% (99.93%-96.18%) over the detection technique presented by Tran and Sato [102]. MalDetConv has also outperformed the performance of a malware detection technique presented by Amer et al. [29], with an improvement of 2.76% (98.18%-95.40%) in the accuracy achieved using the Brazilian dataset. Figure 15 also depicts the comparison between MalDetConv against the above techniques. The overall performance achieved in various experiments shows that the MalDetConv framework can potentially identify and detect malware attacks with a high precision and detection accuracy, giving our framework the ability to deal with different malware attacks on Windows platforms.


5.3.2 Understanding MalDetConv Prediction With LIME
It is often complicated to understand the prediction/classification outcome of deep learning models given the many parameters they use when making a prediction. Therefore, in contrast to the previous malware detection techniques based on API calls, we have integrated LIME [32] into our proposed behaviour-based malware detection framework which helps to understand predictions. The local interpretable model-agnostic explanations (LIME) is an automated framework/library with the potential to explain or interpret the prediction of deep learning models. More importantly, in the case of text-based classification, LIME interprets the predicted results and then reveals the importance of the most highly influential words (tokens) which contributed to the predicted results.This works well for our proposed framework as we are dealing with sequences of API calls that represent malware and benign files. It is important to mention that the LIME framework was chosen because it is open source, has a high number of citations and the framework has been highly rated on GitHub.

Figure 16 shows how LIME works to provide an explanation/interpretation of a given prediction of API call sequence. LIME explains the framework’s predictions at the data sample level, allowing security analysts/end-users to interpret the framework’s predictions and make decisions based on them. LIME works by perturbing the input of the data samples to understand how the prediction changes i.e., LIME considers a deep learning model as a black box and discovers the relationships between input and output which are represented by the model [32] [146]. The output produced by LIME is a list of explanations showing the contributions of each feature to the final classification/prediction of a given data sample. This produces local interpretability and allows security practitioners to discover which API call feature changes (in our case) will have the most impact on the predicted output. LIME computes the weight probabilities of each API call in the sequence and highlights individual API calls that led to the final prediction of a particular sequence of API calls representing malware or benign EXE file.
For instance, in Figure 17, the Process32NextW, NtDelayExecution, Process32FirstW, CreateToolhelp32Snapshot, and NtOpenProcess are portrayed as the most API calls contributing to the final classification of the sequence as “malicious” while SearchPathW, LdrGetDllHandle, SetFileAttributesW, and GetUserNameW API calls are against the final prediction. Another example showing Lime output is presented in Figure 18 where API calls features that led to the correct classification of a benign file are assigned weight probabilities which are summed up to give the total weight of 0.99. API calls such as IsDebuggerPresent, FindResourceW, and GetSystemWindowsDir are among the most influential API calls that contribute to the classification of the sequence/file into its respective class (benign in this case).
The screenshots of lime explanations presented in Figures 17 and 18 are generated in HTML as it generates clear visualizations than other visualization tools such as matplotlib. In addition, the weights are interpreted by applying them to the prediction probability. For instance, if API calls IsDebuggerPresent and FindResourceW are removed from the sequences, we expect MalDetConv to classifier the benign sequence with the probability of 0.99-0.38-0.26= 0.37. Ideally, the interpretation/explanation produced by Lime is a local approximation of the MalDetConv framework’s behaviours, allowing to reveal what happened inside the black box. Note that in Figure 18, the tokens under “Text with highlighted words”, represent the original sequences of API while the number before each API call (e.g., 0 for RegCreateKeyExW) corresponds to its index in the sequence. The highlighted tokens show those API calls which contributed to the classification of the sequence. Thus, having this information, a security analyst can decide whether the model’s prediction should be trusted or not.
6 Limitations and Future Work
We have covered Windows 7 OS EXE files (malware and benign) in this research work. In our future work, we intend to evaluate the performance of the proposed framework on the latest versions of Windows OS such as Windows 10 or Windows 11 and other Windows file formats such as PowerShell scripts. Our dataset of API calls (MalBehavD-V1) will be extended to include more features from newly released malware variants. We also plan to evaluate the proposed framework on API call features extracted in the Android applications where API calls features will be extracted from APK files through dynamic analysis. Although, currently we can explain the results using LIME, but, in some cases LIME can be unstable as it depends on the random sampling of new features/perturbed features [37]. LIME ignores correlations between features as data points are sampled from a Gaussian distribution[37]. Therefore, we plan to explore and compare explanation insights produced by other frameworks such as Anchor[147] and ELI5 [148] which also interpret deep learning models.
7 Conclusion
This work has presented a dynamic malware detection framework, MalDetConv. In addition, a new dataset of API call sequences, namely, MalBehavD-V1, are also presented, which is extracted from benign and malware executable program files. The analysis was performed in a virtual isolated environment powered by the Cuckoo sandbox. The proposed framework is mainly based on natural language processing and deep learning techniques. The Keras Tokenizer APIs and embedding layer were used to perform feature vectorization/representation of API call sequences which generate embedding vectors of each API and group them based on their semantic relationships. MalDetConv uses a CNN-BiGRU module to perform automatic extraction and selection of high-relevant features that are fed to a fully connected neural network component for the classification of each sequence of API calls. The performance of MalDetConv was evaluated using the newly generated dataset (MalBehavD-V1) and some of the well-known datasets of API calls presented in the previous works. The experimental results prove the potential of MalDetConv over existing techniques based on API calls extracted from EXE files. The experimental results show high detection accuracy and better precision achieved by MalDetConv on both seen and unseen data. This provides the confidence that this framework can successfully identify and classify newly emerging malware attacks based on their behaviours. Moreover, MalDetConv achieved high detection accuracy on both small and large datasets, making it the best framework able to deal with the current malware variants. To address the problem of model interpretability encountered in most of the deep learning-based techniques, the LIME module was integrated into MalDetConv, enabling our framework to produce explainable predictions. The MalDetConv framework can be deployed in high-speed network infrastructures to detect both existing and new malware in a short time, with high accuracy and precision.
References
- [1] Cisco, Cisco annual internet report (2018–2023) white paper (2020).
- [2] Statista, Iot connected devices worldwide 2019-2030 — statista, https://www.statista.com/statistics/1183457/iot-connected-devices-worldwide/, (Accessed on 08/04/2022).
- [3] P. Maniriho, A. N. Mahmood, M. J. M. Chowdhury, A study on malicious software behaviour analysis and detection techniques: Taxonomy, current trends and challenges, Future Generation Computer Systems 130 (2022) 1–18. doi:https://doi.org/10.1016/j.future.2021.11.030.
- [4] B. Jovanovic, A not-so-common cold: Malware statistics in 2022, https://dataprot.net/statistics/malware-statistics/, (Accessed on 06/14/2022) (2022).
- [5] A. Drapkin, Over 100 million pieces of malware were made for windows users in 2021, https://tech.co/news/windows-users-malware, (Accessed on 06/14/2022).
- [6] S.-H. Zhang, C.-C. Kuo, C.-S. Yang, Static pe malware type classification using machine learning techniques, in: 2019 International Conference on Intelligent Computing and its Emerging Applications (ICEA), IEEE, 2019, pp. 81–86. doi:https://doi.org/10.1109/ICEA.2019.8858297.
- [7] N. Naik, P. Jenkins, N. Savage, L. Yang, T. Boongoen, N. Iam-On, Fuzzy-import hashing: A static analysis technique for malware detection, Forensic Science International: Digital Investigation 37 (2021) 301139. doi:https://doi.org/10.1016/j.fsidi.2021.301139.
- [8] J. Singh, J. Singh, Detection of malicious software by analyzing the behavioral artifacts using machine learning algorithms, Information and Software Technology 121 (2020). doi:https://doi.org/10.1016/j.infsof.2020.106273.
- [9] Z. Sun, Z. Rao, J. Chen, R. Xu, D. He, H. Yang, J. Liu, An opcode sequences analysis method for unknown malware detection, in: Proceedings of the 2019 2nd international conference on geoinformatics and data analysis, 2019, pp. 15–19. doi:https://doi.org/10.1145/3318236.3318255.
- [10] S. Huda, J. Abawajy, M. Alazab, M. Abdollalihian, R. Islam, J. Yearwood, Hybrids of support vector machine wrapper and filter based framework for malware detection, Future Generation Computer Systems 55 (2016) 376–390. doi:https://doi.org/10.1016/j.future.2014.06.001.
- [11] M. Alazab, S. Venkataraman, P. Watters, Towards understanding malware behaviour by the extraction of api calls, in: 2010 Second Cybercrime and Trustworthy Computing Workshop, 2010, pp. 52–59. doi:10.1109/CTC.2010.8.
- [12] I. Zelinka, E. Amer, An ensemble-based malware detection model using minimum feature set, MENDEL 25 (2) (2019) 1–10. doi:10.13164/mendel.2019.2.001.
- [13] Maldae: Detecting and explaining malware based on correlation and fusion of static and dynamic characteristics, Computers & Security 83 (2019) 208–233. doi:https://doi.org/10.1016/j.cose.2019.02.007.
- [14] Obfuscated files or information, technique t1027 - enterprise — mitre att&ck®, https://attack.mitre.org/techniques/T1027/, (Accessed on 07/08/2022).
- [15] N. Udayakumar, S. Anandaselvi, T. Subbulakshmi, Dynamic malware analysis using machine learning algorithm, in: 2017 International Conference on Intelligent Sustainable Systems (ICISS), IEEE, 2017, pp. 795–800. doi:https://doi.org/10.1109/ISS1.2017.8389286.
- [16] W. Han, J. Xue, Y. Wang, Z. Liu, Z. Kong, MalInsight: A systematic profiling based malware detection framework, Journal of Network and Computer Applications 125 (2019) 236–250. doi:https://doi.org/10.1016/j.jnca.2018.10.022.
- [17] S. Vemparala, F. D. Troia, C. A. Visaggio, T. H. Austin, M. Stamp, Malware detection using dynamic birthmarks (2019). arXiv:1901.07312.
- [18] G. Apruzzese, M. Colajanni, L. Ferretti, A. Guido, M. Marchetti, On the effectiveness of machine and deep learning for cyber security, in: 2018 10th International Conference on Cyber Conflict (CyCon), 2018, pp. 371–390. doi:10.23919/CYCON.2018.8405026.
- [19] D. Gibert, C. Mateu, J. Planes, The rise of machine learning for detection and classification of malware: Research developments, trends and challenges, Journal of Network and Computer Applications 153 (2020). doi:10.1016/j.jnca.2019.102526.
- [20] B. Bostami, M. Ahmed, Deep Learning Meets Malware Detection: An Investigation, 2020, pp. 137–155. doi:10.1007/978-3-030-35642-2_7.
- [21] C. Li, Q. Lv, N. Li, Y. Wang, D. Sun, Y. Qiao, A novel deep framework for dynamic malware detection based on api sequence intrinsic features, Computers & Security 116 (2022) 102686.
- [22] T. Kim, B. Kang, M. Rho, S. Sezer, E. G. Im, A multimodal deep learning method for android malware detection using various features, IEEE Transactions on Information Forensics and Security 14 (3) (2018) 773–788.
- [23] F. O. Catak, A. F. Yazı, O. Elezaj, J. Ahmed, Deep learning based sequential model for malware analysis using windows exe api calls, PeerJ Computer Science 6 (2020) e285. doi:https://doi.org/10.7717/peerj-cs.285.
- [24] S. S. Tirumala, M. R. Valluri, D. Nanadigam, Evaluation of Feature and Signature based Training Approaches for Malware Classification using Autoencoders, in: 2020 International Conference on COMmunication Systems and NETworkS(COMSNETS), 2020, pp. 1–5. doi:https://doi.org/10.1109/COMSNETS48256.2020.9027373.
- [25] A. Sharma, P. Malacaria, M. Khouzani, Malware detection using 1-dimensional convolutional neural networks, in: 2019 IEEE European Symposium on Security and Privacy Workshops (EuroS PW), 2019, pp. 247–256.
- [26] R. Feng, S. Chen, X. Xie, G. Meng, S.-W. Lin, Y. Liu, A performance-sensitive malware detection system using deep learning on mobile devices, IEEE Transactions on Information Forensics and Security 16 (2021) 1563–1578. doi:10.1109/TIFS.2020.3025436.
- [27] K. Alrawashdeh, C. Purdy, Ransomware detection using limited precision deep learning structure in fpga, in: NAECON 2018 - IEEE National Aerospace and Electronics Conference, 2018, pp. 152–157.
- [28] J. Suaboot, Z. Tari, A. Mahmood, A. Y. Zomaya, W. Li, Sub-curve HMM: A malware detection approach based on partial analysis of API call sequences, Computers & Security 92 (2020) 1–15. doi:https://doi.org/10.1016/j.cose.2020.101773.
- [29] E. Amer, A. Samir, H. Mostafa, A. Mohamed, M. Amin, Malware detection approach based on the swarm-based behavioural analysis over api calling sequence, in: 2022 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), IEEE, 2022, pp. 27–32.
- [30] R. Moraffah, M. Karami, R. Guo, A. Raglin, H. Liu, Causal interpretability for machine learning-problems, methods and evaluation, ACM SIGKDD Explorations Newsletter 22 (1) (2020) 18–33. doi:https://doi.org/10.1145/3400051.3400058.
- [31] N. Mehrabi, F. Morstatter, N. Saxena, K. Lerman, A. Galstyan, A survey on bias and fairness in machine learning, arXiv preprint arXiv:1908.09635 (2019).
- [32] M. T. Ribeiro, S. Singh, C. Guestrin, ” why should i trust you?” explaining the predictions of any classifier, in: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 2016, pp. 1135–1144.
- [33] M. Mimura, R. Ito, Applying nlp techniques to malware detection in a practical environment, International Journal of Information Security 21 (2) (2022) 279–291.
- [34] E. Amer, I. Zelinka, A dynamic Windows malware detection and prediction method based on contextual understanding of API call sequence, Computers & Security 92 (2020). doi:https://doi.org/10.1016/j.cose.2020.101760.
- [35] R. Sihwail, K. Omar, K. A. Z. Ariffin, S. Al Afghani, Malware detection approach based on artifacts in memory image and dynamic analysis, Applied Sciences 9 (18) (2019). doi:https://doi.org/10.3390/app9183680.
- [36] J. Singh, J. Singh, A survey on machine learning-based malware detection in executable files, Journal of Systems Architecture (2020). doi:https://doi.org/10.1016/j.sysarc.2020.101861.
- [37] C. Molnar, Interpretable machine learning, Lulu. com, 2020.
- [38] E. B. Karbab, M. Debbabi, Maldy: Portable, data-driven malware detection using natural language processing and machine learning techniques on behavioral analysis reports, Digital Investigation 28 (2019) S77–S87. doi:https://doi.org/10.1016/j.diin.2019.01.017.
- [39] Operating system market share, https://netmarketshare.com/operating-system-market-share.aspx?options, (Accessed on 11/04/2021).
- [40] A. Drapkin, Over 100 million pieces of malware were made for windows users in 2021, https://tech.co/news/windows-users-malware, (Accessed on 04/10/2022).
- [41] T. Boris, Windows users beware: 95% of ransomware attacks target microsoft’s os [google report] — tech times, https://www.techtimes.com/articles/266728/20211015/windows-users-ransomware-attack-windows-ransomware-windows-microsoft-google-report.htm#:~:text=Windows%20users%20have%20been%20the,of%20Google%2C%20VirusTotal%2C%20reported., (Accessed on 04/10/2022).
- [42] M. A. Stenne, Quick introduction to windows api,, https://users.physics.ox.ac.uk/~Steane/cpp_help/winapi_intro.htm, (Accessed on 05/14/2021).
- [43] G. B. P. Silberschatz Abraham, Gagne Greg, Operating System Concepts, 10th Edition, Wiley, 2018.
- [44] D. Uppal, R. Sinha, V. Mehra, V. Jain, Exploring behavioral aspects of api calls for malware identification and categorization, in: 2014 International Conference on Computational Intelligence and Communication Networks, 2014, pp. 824–828. doi:10.1109/CICN.2014.176.
- [45] Microsoft, Programming reference for the win32 api - win32 apps — microsoft docs, https://docs.microsoft.com/en-us/windows/win32/api/, (Accessed on 06/01/2021).
- [46] B. I. A. B. Ammar Ahmed E. Elhadi, Mohd Aizaini Maarof, Improving the Detection of Malware Behaviour Using Simplified Data Dependent API Call Graph, International Journal of Security and Its Applications 7 (2013) 29–42.
- [47] Y. Ki, E. Kim, H. K. Kim, A novel approach to detect malware based on api call sequence analysis, International Journal of Distributed Sensor Networks 11 (6) (2015). doi:https://doi.org/10.1155/2015/659101.
- [48] S. Gupta, H. Sharma, S. Kaur, Malware characterization using windows api call sequences, in: International Conference on Security, Privacy, and Applied Cryptography Engineering, 2016, pp. 271–280. doi:https://doi.org/10.1007/978-3-319-49445-6_15.
- [49] Y. Zhao, B. Bo, Y. Feng, C. Xu, B. Yu, A feature extraction method of hybrid gram for malicious behavior based on machine learning, Security and Communication Networks 2019 (2019). doi:https://doi.org/10.1155/2019/2674684.
-
[50]
M. Alaeiyan, S. Parsa, M. Conti,
Analysis
and classification of context-based malware behavior, Computer
Communications 136 (2019) 76–90.
doi:https://doi.org/10.1016/j.comcom.2019.01.003.
URL https://www.sciencedirect.com/science/article/pii/S0140366418300410 - [51] Y. Ding, X. Xia, S. Chen, Y. Li, A malware detection method based on family behavior graph, Computers & Security 73 (2018) 73–86. doi:https://doi.org/10.1016/j.cose.2017.10.007.
- [52] N. Sharma, R. Sharma, N. Jindal, Machine learning and deep learning applications-a vision, Global Transitions Proceedings 2 (1) (2021) 24–28, 1st International Conference on Advances in Information, Computing and Trends in Data Engineering (AICDE - 2020). doi:https://doi.org/10.1016/j.gltp.2021.01.004.
- [53] S. Yuan, X. Wu, Deep learning for insider threat detection: Review, challenges and opportunities, Computers & Security 104 (2021) 102221. doi:https://doi.org/10.1016/j.cose.2021.102221.
- [54] M. M. Najafabadi, F. Villanustre, T. M. Khoshgoftaar, N. Seliya, R. Wald, E. Muharemagic, Deep learning applications and challenges in big data analytics, Journal of big data 2 (1) (2015) 1–21. doi:https://doi.org/10.1186/s40537-014-0007-7.
- [55] M. F. Rafique, M. Ali, A. S. Qureshi, A. Khan, A. M. Mirza, Malware classification using deep learning based feature extraction and wrapper based feature selection technique (2020). arXiv:1910.10958.
- [56] A. Pinhero, A. M L, V. P, C. Visaggio, A. N, A. S, A. S, Malware detection employed by visualization and deep neural network, Computers & Security 105 (2021) 102247. doi:https://doi.org/10.1016/j.cose.2021.102247.
- [57] D. H. Hubel, T. N. Wiesel, Receptive fields and functional architecture of monkey striate cortex, The Journal of physiology 195 (1) (1968) 215–243.
- [58] K. Fukushima, Neural network model for a mechanism of pattern recognition unaffected by shift in position-neocognitron, IEICE Technical Report, A 62 (10) (1979) 658–665.
- [59] S. Khan, H. Rahmani, S. A. A. Shah, M. Bennamoun, A guide to convolutional neural networks for computer vision, Synthesis Lectures on Computer Vision 8 (1) (2018) 1–207.
- [60] A. S. Lundervold, A. Lundervold, An overview of deep learning in medical imaging focusing on mri, Zeitschrift für Medizinische Physik 29 (2) (2019) 102–127. doi:https://doi.org/10.1016/j.zemedi.2018.11.002.
- [61] K. O’Shea, R. Nash, An introduction to convolutional neural networks, arXiv preprint arXiv:1511.08458 (2015).
- [62] R. Yamashita, M. Nishio, R. K. G. Do, K. Togashi, Convolutional neural networks: an overview and application in radiology, Insights into imaging 9 (4) (2018) 611–629.
- [63] S. Kiranyaz, T. Ince, M. Gabbouj, Real-time patient-specific ecg classification by 1-d convolutional neural networks, IEEE Transactions on Biomedical Engineering 63 (3) (2015) 664–675.
- [64] Y. Kim, Convolutional neural networks for sentence classification (2014). arXiv:1408.5882.
- [65] A. Fesseha, S. Xiong, E. D. Emiru, M. Diallo, A. Dahou, Text classification based on convolutional neural networks and word embedding for low-resource languages: Tigrinya, Information 12 (2) (2021) 52.
- [66] O. Avci, O. Abdeljaber, S. Kiranyaz, B. Boashash, H. Sodano, D. J. Inman, Efficiency validation of one dimensional convolutional neural networks for structural damage detection using a shm benchmark data, in: Proc. 25th Int. Conf. Sound Vib.(ICSV), 2018, pp. 4600–4607.
- [67] S. Kiranyaz, O. Avci, O. Abdeljaber, T. Ince, M. Gabbouj, D. J. Inman, 1d convolutional neural networks and applications: A survey, Mechanical systems and signal processing 151 (2021) 107398. doi:https://doi.org/10.1016/j.ymssp.2020.107398.
- [68] P. Wang, B. Xu, J. Xu, G. Tian, C.-L. Liu, H. Hao, Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification, Neurocomputing 174 (2016) 806–814. doi:https://doi.org/10.1016/j.neucom.2015.09.096.
- [69] R. Johnson, T. Zhang, Effective use of word order for text categorization with convolutional neural networks (2015). arXiv:1412.1058.
- [70] F. Liu, L. Zheng, J. Zheng, Hienn-dwe: A hierarchical neural network with dynamic word embeddings for document level sentiment classification, Neurocomputing 403 (2020) 21–32. doi:https://doi.org/10.1016/j.neucom.2020.04.084.
- [71] H. M. Lynn, S. B. Pan, P. Kim, A deep bidirectional gru network model for biometric electrocardiogram classification based on recurrent neural networks, IEEE Access 7 (2019) 145395–145405.
- [72] S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (8) (1997) 1735–1780.
- [73] K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, Y. Bengio, Learning phrase representations using rnn encoder-decoder for statistical machine translation, arXiv preprint arXiv:1406.1078 (2014).
- [74] R. A. Horn, C. R. Johnson, Matrix analysis, Cambridge university press, 2012.
- [75] J. Chung, C. Gulcehre, K. Cho, Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, arXiv preprint arXiv:1412.3555 (2014).
- [76] V. Vukotić, C. Raymond, G. Gravier, A step beyond local observations with a dialog aware bidirectional gru network for spoken language understanding, in: Interspeech, 2016.
- [77] S. Huda, J. Abawajy, M. Abdollahian, R. Islam, J. Yearwood, A fast malware feature selection approach using a hybrid of multi-linear and stepwise binary logistic regression, Concurrency and Computation: Practice and Experience 29 (23) (2017) e3912. doi:https://doi.org/10.1002/cpe.3912.
- [78] Y. Fan, Y. Ye, L. Chen, Malicious sequential pattern mining for automatic malware detection, Expert Systems with Applications 52 (2016) 16–25. doi:https://doi.org/10.1016/j.eswa.2016.01.002.
- [79] E. Raff, J. Sylvester, C. Nicholas, Learning the pe header, malware detection with minimal domain knowledge, in: Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, 2017, pp. 121–132.
- [80] Getting started, https://keras.io/getting_started/, (Accessed on 07/24/2022).
- [81] M. D’Onghia, M. Salvadore, B. M. Nespoli, M. Carminati, M. Polino, S. Zanero, Apícula: Static detection of api calls in generic streams of bytes, Computers & Security (2022) 102775.
- [82] P. P. Kundu, L. Anatharaman, T. Truong-Huu, An empirical evaluation of automated machine learning techniques for malware detection, in: Proceedings of the 2021 ACM Workshop on Security and Privacy Analytics, 2021, pp. 75–81. doi:https://doi.org/10.1145/3445970.3451155.
- [83] A. S. Kale, V. Pandya, F. Di Troia, M. Stamp, Malware classification with word2vec, hmm2vec, bert, and elmo, Journal of Computer Virology and Hacking Techniques (2022) 1–16.
- [84] P. N. Yeboah, H. B. Baz Musah, Nlp technique for malware detection using 1d cnn fusion model, Security and Communication Networks 2022 (2022).
- [85] A. Klein, I. Kotler, The Adventures of AV and the Leaky Sandbox: A SafeBreach Labs Research, Tech. rep. (2017).
- [86] L. Martignoni, M. Christodorescu, S. Jha, Omniunpack: Fast, generic, and safe unpacking of malware, in: Twenty-Third Annual Computer Security Applications Conference (ACSAC 2007), 2007, pp. 431–441. doi:10.1109/ACSAC.2007.15.
- [87] Ç. Yücel, A. Koltuksuz, Imaging and evaluating the memory access for malware, Forensic Science International: Digital Investigation 32 (2020). doi:10.1016/j.fsidi.2019.200903.
- [88] Y. Ye, T. Li, D. Adjeroh, S. S. Iyengar, A survey on malware detection using data mining techniques, ACM Computing Surveys 50 (3) (2017) 1–40. doi:https://doi.org/10.1145/3073559.
- [89] S. Saket, (9) count vectorizer vs tfidf vectorizer — natural language processing — linkedin, https://www.linkedin.com/pulse/count-vectorizers-vs-tfidf-natural-language-processing-sheel-saket/, (Accessed on 10/03/2021).
- [90] A. Mandelbaum, A. Shalev, Word embeddings and their use in sentence classification tasks (2016). arXiv:1610.08229.
- [91] R. S. Pirscoveanu, S. S. Hansen, T. M. T. Larsen, M. Stevanovic, J. M. Pedersen, A. Czech, Analysis of Malware Behavior: Type Classification using Machine Learning, in: 2015 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), 2015. doi:https://doi.org/10.1109/CyberSA.2015.7166115.
- [92] Z.-P. Pan, C. Feng, C.-J. Tang, Malware Classification Based on the Behavior Analysis and Back Propagation Neural Network, in: 3rd Annual International Conference on Information Technology and Applications (ITA 2016), Vol. 7, 2016, pp. 1–5. doi:https://doi.org/10.1051/itmconf/20160702001.
- [93] F. Mira, A. Brown, W. Huang, Novel malware detection methods by using lcs and lcss, in: 2016 22nd International Conference on Automation and Computing (ICAC), 2016, pp. 554–559. doi:https://doi.org/10.1109/IConAC.2016.7604978.
- [94] I. K. Cho, T. G. Kim, Y. J. Shim, M. Ryu, E. G. Im, Malware analysis and classification using sequence alignments, Intelligent Automation & Soft Computing 22 (3) (2016) 371–377. doi:https://doi.org/10.1080/10798587.2015.1118916.
- [95] J. Stiborek, T. Pevny, M. Rehak, Multiple instance learning for malware classification, Expert Systems with Applications 93 (2018) 346–357. doi:https://doi.org/10.1016/j.eswa.2017.10.036.
- [96] T. Wüchner, A. Cisłak, M. Ochoa, A. Pretschner, Leveraging compression-based graph mining for behavior-based malware detection, IEEE Transactions on Dependable and Secure Computing 16 (1) (2019) 99–112. doi:10.1109/TDSC.2017.2675881.
- [97] S. Jha, M. Fredrikson, M. Christodoresu, R. Sailer, X. Yan, Synthesizing near-optimal malware specifications from suspicious behaviors, in: 2013 8th International Conference on Malicious and Unwanted Software: ”The Americas” (MALWARE), 2013, pp. 41–50. doi:10.1109/MALWARE.2013.6703684.
- [98] K. Blokhin, J. Saxe, D. Mentis, Malware similarity identification using call graph based system call subsequence features, in: 2013 IEEE 33rd International Conference on Distributed Computing Systems Workshops, 2013, pp. 6–10. doi:10.1109/ICDCSW.2013.55.
- [99] A. Hellal, F. Mallouli, A. Hidri, R. K. Aljamaeen, A survey on graph-based methods for malware detection, in: 2020 4th International Conference on Advanced Systems and Emergent Technologies, 2020, pp. 130–134. doi:10.1109/IC_ASET49463.2020.9318301.
- [100] Y. Ding, X. Xia, S. Chen, Y. Li, A malware detection method based on family behavior graph, Computers & Security 73 (2018) 73–86. doi:https://doi.org/10.1016/j.cose.2017.10.007.
- [101] X. Pei, L. Yu, S. Tian, Amalnet: A deep learning framework based on graph convolutional networks for malware detection, Computers & Security 93 (2020) 101792. doi:https://doi.org/10.1016/j.cose.2020.101792.
- [102] T. K. Tran, H. Sato, Nlp-based approaches for malware classification from api sequences, in: 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), 2017, pp. 101–105. doi:10.1109/IESYS.2017.8233569.
- [103] Y. Liu, Y. Wang, A robust malware detection system using deep learning on api calls, in: 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), IEEE, 2019, pp. 1456–1460.
- [104] S. Li, Q. Zhou, R. Zhou, Q. Lv, Intelligent malware detection based on graph convolutional network, The Journal of Supercomputing 78 (3) (2022) 4182–4198.
- [105] A. M. Lajevardi, S. Parsa, M. J. Amiri, Markhor: malware detection using fuzzy similarity of system call dependency sequences, Journal of Computer Virology and Hacking Techniques 18 (2) (2022) 81–90.
- [106] S. Maniath, A. Ashok, P. Poornachandran, V. Sujadevi, P. Sankar A.U., S. Jan, Deep learning lstm based ransomware detection, in: 2017 Recent Developments in Control, Automation & Power Engineering (RDCAPE), 2017, pp. 442–446.
- [107] X. Chen, Z. Hao, L. Li, L. Cui, Y. Zhu, Z. Ding, Y. Liu, Cruparamer: Learning on parameter-augmented api sequences for malware detection, IEEE Transactions on Information Forensics and Security 17 (2022) 788–803.
- [108] M. Sukul, S. A. Lakshmanan, R. Gowtham, Automated dynamic detection of ransomware using augmented bootstrapping, in: 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), 2022, pp. 787–794.
- [109] L. Dhanya, R. Chitra, A. A. Bamini, Performance evaluation of various ensemble classifiers for malware detection, Materials Today: Proceedings (2022).
- [110] M. S. Abbasi, H. Al-Sahaf, M. Mansoori, I. Welch, Behavior-based ransomware classification: A particle swarm optimization wrapper-based approach for feature selection, Applied Soft Computing 121 (2022) 108744.
- [111] C. Jing, Y. Wu, C. Cui, Ensemble dynamic behavior detection method for adversarial malware, Future Generation Computer Systems 130 (2022) 193–206.
- [112] N. Allan, J. Ngubiri, Windows pe api calls for malicious and benigin programs, https://www.researchgate.net/publication/336024802_Windows_PE_API_calls_for_malicious_and_benigin_programs?channel=doi&linkId=5d8b6a4e92851c33e9395c89&showFulltext=true, (Accessed on 12/16/2021).
- [113] F. Ceschin, F. Pinage, M. Castilho, D. Menotti, L. S. Oliveira, A. Gregio, The need for speed: An analysis of brazilian malware classifiers, IEEE Security & Privacy 16 (6) (2018) 31–41.
- [114] Github - leocsato/detector_mw: Optimizer for malware detection. api calls sequence of benign files are provided., https://github.com/leocsato/detector_mw, (Accessed on 12/15/2021).
- [115] P. Maniriho, Malbehavd-v1: A new dataset of api calls extracted from windows pe files of benign and malware, https://github.com/mpasco/MalbehavD-V1, (Accessed on 04/07/2022).
- [116] K. Rieck, P. Trinius, C. Willems, T. Holz, Automatic analysis of malware behavior using machine learning, Journal of Computer Security 19 (4) (2011) 639–668. doi:DOI:10.3233/JCS-2010-0410.
- [117] K. Sethi, B. K. Tripathy, S. K. Chaudhary, P. Bera, A Novel Malware Analysis for Malware Detection and Classification using Machine Learning Algorithms, in: SIN ’17: Proceedings of the 10th International Conference on Security of Information and Networks, 2017, pp. 107–116. doi:https://doi.org/10.1145/3136825.3136883.
- [118] V. P. Nair, H. Jain, Y. K. Golecha, M. S. Gaur, V. Laxmi, Medusa: Metamorphic malware dynamic analysis usingsignature from api, in: Proceedings of the 3rd International Conference on Security of Information and Networks, 2010, pp. 263–269. doi:https://doi.org/10.1145/1854099.1854152.
- [119] A. Nappa, M. Z. Rafique, J. Caballero, The malicia dataset: identification and analysis of drive-by download operations, International Journal of Information Security 14 (1) (2015) 15–33. doi:https://doi.org/10.1007/s10207-014-0248-7.
- [120] Virustotal - home, https://www.virustotal.com/gui/home/upload, (Accessed on 09/29/2021).
- [121] Free software downloads and reviews for windows, android, mac, and ios – cnet download, https://download.cnet.com/, (Accessed on 12/15/2021).
- [122] Virustotal - home, https://www.virustotal.com/gui/home/upload, (Accessed on 08/04/2022).
- [123] Cuckoo sandbox - automated malware analysis, https://cuckoosandbox.org/, (Accessed on 05/14/2021).
- [124] S. S. Birunda, R. K. Devi, A review on word embedding techniques for text classification, in: Innovative Data Communication Technologies and Application, Springer, 2021, pp. 267–281. doi:https://doi.org/10.1007/978-981-15-9651-3_23.
- [125] X. Rong, word2vec parameter learning explained (2016). arXiv:1411.2738.
- [126] T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space (2013). arXiv:1301.3781.
- [127] A. Chandak, W. Lee, M. Stamp, A comparison of word2vec, hmm2vec, and pca2vec for malware classification (2021). arXiv:2103.05763.
- [128] K. Sarkar, Recent trends in natural language processing using deep learning — medium, https://medium.com/@kanchansarkar/recent-trends-in-natural-language-processing-using-deep-learning-a1469fbd2ef, (Accessed on 05/20/2021) (2017).
- [129] N. Pittaras, G. Giannakopoulos, G. Papadakis, V. Karkaletsis, Text classification with semantically enriched word embeddings, Natural Language Engineering (2020) 1–35doi:10.1017/S1351324920000170.
- [130] P. F. Muhammad, R. Kusumaningrum, A. Wibowo, Sentiment analysis using word2vec and long short-term memory (lstm) for indonesian hotel reviews, Procedia Computer Science 179 (2021) 728–735, 5th International Conference on Computer Science and Computational Intelligence 2020. doi:https://doi.org/10.1016/j.procs.2021.01.061.
- [131] R. P. Nawangsari, R. Kusumaningrum, A. Wibowo, Word2vec for indonesian sentiment analysis towards hotel reviews: An evaluation study, Procedia Computer Science 157 (2019) 360–366, the 4th International Conference on Computer Science and Computational Intelligence (ICCSCI 2019) : Enabling Collaboration to Escalate Impact of Research Results for Society. doi:https://doi.org/10.1016/j.procs.2019.08.178.
- [132] R. A. Stein, P. A. Jaques, J. F. Valiati, An analysis of hierarchical text classification using word embeddings, Information Sciences 471 (2019) 216–232. doi:https://doi.org/10.1016/j.ins.2018.09.001.
- [133] W. López, J. Merlino, P. Rodríguez-Bocca, Learning semantic information from internet domain names using word embeddings, Engineering Applications of Artificial Intelligence 94 (2020) 103823. doi:https://doi.org/10.1016/j.engappai.2020.103823.
- [134] F. Enríquez, J. A. Troyano, T. López-Solaz, An approach to the use of word embeddings in an opinion classification task, Expert Systems with Applications 66 (2016) 1–6. doi:https://doi.org/10.1016/j.eswa.2016.09.005.
- [135] J. Pennington, R. Socher, C. D. Manning, Glove: Global vectors for word representation, in: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
- [136] J. Brownlee, Deep learning for natural language processing: develop deep learning models for your natural language problems, 2017.
- [137] Embedding layer, https://keras.io/api/layers/core_layers/embedding/#embedding-layer, (Accessed on 12/14/2021).
- [138] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, P. Kuksa, Natural language processing (almost) from scratch, Journal of machine learning research 12 (ARTICLE) (2011) 2493–2537.
- [139] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, R. Salakhutdinov, Dropout: a simple way to prevent neural networks from overfitting, The journal of machine learning research 15 (1) (2014) 1929–1958.
- [140] S. Jadon, A survey of loss functions for semantic segmentation, in: 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), IEEE, 2020, pp. 1–7.
- [141] D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
- [142] M. Yaqub, J. Feng, M. S. Zia, K. Arshid, K. Jia, Z. U. Rehman, A. Mehmood, State-of-the-art cnn optimizer for brain tumor segmentation in magnetic resonance images, Brain Sciences 10 (7) (2020) 427.
- [143] Github - fabriciojoc/brazilian-malware-dataset: Dataset containing thousands of malware and goodware collected in the brazilian cyberspace over years., https://github.com/fabriciojoc/brazilian-malware-dataset, (Accessed on 12/16/2021).
- [144] Pypi, Pypi · the python package index, https://pypi.org/, (Accessed on 08/22/2021).
- [145] F. Ceschin, F. Pinage, M. Castilho, D. Menotti, L. S. Oliveira, A. Gregio, The need for speed: An analysis of brazilian malware classifiers, IEEE Security Privacy 16 (6) (2018) 31–41. doi:10.1109/MSEC.2018.2875369.
- [146] L. Hulstaert, Understanding model predictions with lime — by lars hulstaert — towards data science, https://towardsdatascience.com/understanding-model-predictions-with-lime-a582fdff3a3b, (Accessed on 07/03/2022).
- [147] M. T. Ribeiro, S. Singh, C. Guestrin, Anchors: High-precision model-agnostic explanations, in: AAAI Conference on Artificial Intelligence (AAAI), 2018.
- [148] MIT, Github - teamhg-memex/eli5: A library for debugging/inspecting machine learning classifiers and explaining their predictions, https://github.com/TeamHG-Memex/eli5, (Accessed on 07/16/2022).