Making Bias Amplification in Balanced Datasets Directional and Interpretable
Abstract
Most of the ML datasets we use today are biased. When we train models on these biased datasets, they often not only learn dataset biases but can also amplify them — a phenomenon known as bias amplification. Several co-occurrence-based metrics have been proposed to measure bias amplification between a protected attribute (e.g., gender) and a task (e.g., cooking). However, these metrics fail to measure biases when is balanced with . To measure bias amplification in balanced datasets, recent work proposed a predictability-based metric called leakage amplification. However, leakage amplification cannot identify the direction in which biases are amplified. In this work, we propose a new predictability-based metric called directional predictability amplification (DPA). DPA measures directional bias amplification, even for balanced datasets. Unlike leakage amplification, DPA is easier to interpret and less sensitive to attacker models (a hyperparameter in predictability-based metrics). Our experiments on tabular and image datasets show that DPA is an effective metric for measuring directional bias amplification. The code will be available soon.
1 Introduction
Machine learning models should perform fairly across demographics, genders, and other groups. However, ensuring fairness is challenging when training datasets are biased, as is the case with many datasets. For instance, in the imSitu dataset [12], of the images labeled “cooking” feature females, indicating a gender bias that women are more likely to be associated with cooking than men [14]. Given a biased training set, it is not surprising for a model to learn these dataset biases. Surprisingly, models not only learn dataset biases but can also amplify them [14, 10, 13]. In the example from imSitu, where females and cooking co-occurred of the time, bias amplification occurs when of the images predicted as cooking feature females.
Several metrics have been proposed to measure bias amplification between a protected attribute (e.g., gender), denoted as , and a task (e.g., cooking), denoted as [14, 10, 13]. If and co-occur more frequently than random in the training dataset, these metrics measure the increase in co-occurrence between the predictions of and . For instance, if the co-occurrence between “females” () and “cooking” () is in the training dataset and at test time, the bias amplification value is .
These metrics imply that if a protected attribute and task are balanced in the training dataset, there are no dataset biases to amplify. However, simply balancing a protected attribute with a pre-defined task does not ensure an unbiased dataset. Biases may emerge from unannotated parts of the dataset.
Suppose we balance imSitu such that of the images labeled “cooking” feature females. In this case, gender is balanced with respect to cooking. Now, assume that cooking objects in imSitu, like hairnets, are not annotated. If most of the cooking images with females have hairnets, while most of the cooking images with males do not, the model may learn a spurious correlation between hairnets, cooking, and females. Hence, the model may more often predict the presence of a female when cooking images have hairnets in the test set, leading to bias amplification between females and cooking. However, since gender appears balanced with respect to the cooking labels, current metrics would report bias amplification.
Wang et al. [11] identified that metrics measuring bias through co-occurrences between a protected attribute and a task failed to account for biases emerging from unannotated elements. They proposed a term called “leakage” to measure bias amplification, even when a dataset’s protected attribute is balanced with a task. Leakage measures how predictable the protected attribute is from the ground truth labels of task (dataset leakage) and from the model predictions of task (model leakage). Wang et al. [11] describe bias amplification as the difference between dataset leakage () and model leakage (). and are quantified using an attacker model that predicts the protected attribute.
In this work, we refer to Wang et al.’s [11] method of calculating bias amplification as leakage amplification. Leakage amplification was an important step toward measuring bias amplification in balanced datasets. However, it has the following limitations:
-
1.
Leakage amplification lacks direction. In the cooking example, we need to identify if the model amplifies the bias towards predicting only women as cooking () or towards predicting all cooks as women ().
-
2.
Leakage amplification is unbounded. Leakage amplification does not have a bounded range of values since it is the absolute difference between and . This makes leakage amplification values hard to interpret.
-
3.
Leakage amplification does not measure the relative change in biases. In a slightly biased dataset (e.g., ), a bias amplification of (to ) is a larger relative increase compared to the same amplification in a highly biased dataset (e.g., to ). Since leakage amplification calculates the absolute difference between and , it gives the same bias amplification value of for both datasets.
-
4.
Leakage amplification is sensitive to the choice of attacker model. The choice of attacker model influences and , and consequently, leakage amplification values. An attacker model with poor predictability of the protected attribute will yield very different results for and , compared to one with high predictability.
We propose a new metric called Directional Predictability Amplification () that addresses the limitations of leakage amplification. The contributions of are:
-
1.
is the only metric that can measure directional bias amplification in a balanced dataset.
-
2.
is bounded and interpretable.
-
3.
measures the relative change of predictability (as opposed to an absolute change of predictability in leakage amplification).
-
4.
is minimally sensitive to attacker models.
2 Related Work
Co-occurence for Bias Amplification
Men Also Like Shopping () [14] proposed the first metric for bias amplification. The proposed metric measured the co-occurrences between protected attributes and task . For any pairs that showed a positive correlation (i.e., the pair occurred more frequently than independent events) in the training dataset, it measured how much the positive correlation increased in model predictions.
Wang et al. [10] generalized the metric to also measure negative correlation (i.e., the pair occurred less frequently than independent events). Further, Wang et al. [10] changed how the positive bias is defined by comparing the independent and joint probability of a pair. But, both [14] and Wang et al. [10] could only work for pairs where , were singleton sets (e.g., {Basketball} & {Male}). Zhao et al. [13] extended the metric proposed by Wang et al. [10] to allow pairs where , are non-singleton sets (e.g., {Basketball, Sneakers} & {African-American, Male}).
Lin et al. [4] proposed a new metric called bias disparity to measure bias amplification in recommender systems. Foulds et al. [2] measured bias amplification using the difference in “differential fairness”, a measure of the difference in co-occurrences of pairs across different values of . Seshadri et al. [8] measured bias amplification for text-to-image generation using the increase in percentage bias in generated vs. training samples.
Bias Amplification in Balanced Datasets
Wang et al. [11] identified that [14] failed to measure bias amplification for balanced datasets. They proposed a metric that we refer to as leakage amplification that could measure bias amplification in balanced datasets. While some of the previously discussed metrics [2, 8, 4, 13] can measure bias amplification in a balanced dataset, these metrics do not work for continuous variables, because they use co-occurrences to quantify biases.
Leakage amplification quantifies biases in terms of predictability, i.e., how easily a model can predict the protected attribute from a task . Attacker functions () are trained to predict the attribute () from the ground-truth observations of the task () and model predictions of the task (). The relative performance of on vs. represents the leakage of information from to .
As the attacker function can be any kind of machine learning model, it can process continuous inputs, text, and images. This flexibility gives leakage amplification a distinct advantage over co-occurrence-based bias amplification metrics. Subsequent work used leakage amplification for quantifying bias amplification in image captioning [3].
Capturing Directionality in Bias Amplification
While previous metrics including leakage amplification [11] could detect the presence of bias, they could not explain its causality or directionality. Wang et al. [10] was the first to introduce a directional bias amplification metric, . However, the metric only works for unbalanced datasets. Zhao et al. [13] proposed a new metric, , to measure directional bias amplification for multiple attributes and balanced datasets. However, the metric cannot distinguish between positive and negative bias amplification, as shown in section A. This lack of sign awareness makes unsuitable for many use cases.
In summary, no existing metric can measure the positive and negative directional bias amplification in a balanced dataset, as shown in Table 1.
3 Leakage Amplification
Before introducing our metric, we explain the formulation and limitations of the leakage amplification metric proposed by Wang et al. [11].
3.1 Formulation
To measure the leakage of an attribute () from a task (), Wang et al. [11] trained an attacker function () that takes as input to predict . The performance of the attacker is measured using a quality function (). Previous works [11, 3] used accuracy and F1-scores for . Wang et al. [11] describe dataset leakage () as:
| (1) |
Similarly, model leakage () is decribed as:
| (2) |
where and represent the ground truth and model predictions for the task, respectively. is trained on task observations from the dataset, while is trained on task predictions from the model.
Leakage amplification measures the increase of leakage in model predictions compared to the leakage in the dataset:
| (3) |
Model predictions () are not accurate and might have errors. These errors might create a difference in leakage values, which could be misinterpreted as bias. To prevent conflation of errors with bias, Wang et al. [11] introduced a similar error rate in using random perturbations. If the model predictions are accurate, they randomly flipped of labels in . As the bias in can vary significantly between two random perturbations, they measured bias amplification using confidence intervals. This quality equalization prevents conflation of model biases and errors.
3.2 Limitations
3.2.1 Incompatible with directionality
In leakage amplification, as seen in equation 1, the attacker function tries to model the relationship of . Hence, we can approximate equation 1 as:
| (4) |
| (5) |
We observe that leakage amplification approximates differences in probability with fixed posteriors. This is different from Wang et al’s [10] definition of directionality where fixed priors are used. Wang et al. [10] defined their metric in the following manner:
| (6) |
where,
| (7) |
| (8) |
For , measures the change in with respect to , i.e., change in the conditional probability of vs. with respect to a fixed prior . Similarly, for , measures change in the conditional probability of vs. with respect to a fixed prior .
In leakage amplification, unlike , the posterior is fixed. To measure directionality, we need fixed priors. Thus, leakage amplification does not align with existing definitions of directionality.
3.2.2 Variable bounds
Leakage amplification is the difference between and (equation 3). Hence, the range for leakage amplification is bounded in the interval . However, the max and min values for and are dependent on the choice of quality function . Depending on the choice of , we can have completely different leakage amplification values for the same input. This makes leakage amplification values hard to interpret.
3.2.3 Does not measure relative amplification
Leakage amplification does not account for the magnitude of biases in the dataset (). Let us understand this using two cases. In the first case, we are working with a slightly biased dataset . In the second case, we are working with a significantly biased dataset . We train two identical models on these datasets to get predictions and respectively. Let us assume we are using accuracy for . Suppose we get the following values: = (slightly biased), = (highly biased), = , = .
Leakage amplification treats both cases as equivalent. Although the relative increase in bias in the first case ( 0.09) is greater than the second case ( 0.06), both cases will report the same bias amplification value ().
3.2.4 Sensitive to attacker model hyperparameters
The performance of attacker functions (usually neural networks) directly impacts leakage amplification values. Since neural network performance is sensitive to the hyperparameter settings, leakage amplification values are too.
4 Directional Predictability Amplification
We propose our new metric, Directional Predictability Amplification () that addresses the previously mentioned limitations of leakage amplification.
4.1 Formulation
As noted in section 3.2.1, Wang et al’s [11] formula for leakage amplification is not compatible with directionality as it has fixed posteriors, not priors. We define predictability () using fixed priors.
We define the predictability of from , which represents the dataset bias for direction, as:
| (9) |
We define the predictability of from , which represents the model bias for direction, as:
| (10) |
We define the predictability of from , which represents the dataset bias for direction, as:
| (11) |
We define the predictability of from , which represents the model bias for direction, as:
| (12) |
represents an attacker function that takes as input and tries to predict . represents an attacker function that takes as input and tries to predict .
While leakage amplification computed the difference between and , we normalize the difference in predictability using their sum.
4.2 Benefits
The new formulation gives the following benefits:
Directionality
For , we keep the prior fixed by giving as input for both attacker models (). Similarly, for , we keep the prior fixed by giving as input for both attacker models (). Hence, our method follows Wang et al.’s [10] definition of directionality.
Fixed Bounds
For any chosen quality function (such that its range is or [0, ]), the range of is restricted to (-1,1). This normalization fixes the issue of unbounded values in leakage amplification.
While selecting , users must ensure that represents worst possible performance by the attacker function (i.e., low predictability or no bias), and the upper bound represents best possible performance by the attacker function (i.e., high predictability or significant bias). This is true for most typical choices for quality functions such as accuracy or F1 score, but not for certain losses like cross-entropy.
Relative Amplification
The normalization in not only gives a bounded range but also considers the original bias in the dataset. To demonstrate this shift in behavior, we plot the relation between leakage amplification and at different values of dataset bias () in Figure 1. For , we plot the relation between and at different values of dataset bias ().
We observe that the slope for leakage amplification remains constant irrespective of the value of . On the other hand, for we observed higher slopes between and , for smaller values of and vice-versa. Hence, in nearly balanced datasets (smaller ), reports high bias amplification even for small increases in bias. For highly biased datasets (higher ), reports a small bias amplification value for a similar increase in biases.

Attacker Robustness
Normalization also helps in improving the robustness of to different hyperparameters of the attacker model. Since we use the same type of attacker for both and , the changes in hyperparameters impact their performance in similar ways. We show that taking the normalized difference of and is more robust in section B.
5 Experiment Setup
We performed experiments using tabular (COMPAS [1]) and image (COCO [5]) datasets to compare to previous bias amplification metrics.
5.1 COMPAS Experiment
COMPAS [1] is a dataset containing information about individuals who have been previously arrested. Each entry is associated with 52 features. We used five features: age, juv_fel_count, juv_misd_count, juv_other_count, priors_count.
We limited the dataset to 2 races (Caucasian or African-American) which we used as the protected attribute (). The task () was recidivism (i.e. if the person was arrested again for a crime in the next 2 years). Hence, and .
We created balanced and unbalanced versions of the COMPAS dataset. For the unbalanced dataset, we sampled all available COMPAS instances (attributes, race labels, and recidivism labels) for each of the four and pairs. For the balanced dataset, we sampled an equal number of instances across the four and pairs. The counts for the and pairs in the unbalanced dataset are shown in the top-left quadrant of Table 2(a), while the counts for the balanced dataset are shown in the top-right quadrant of Table 2(b).
We trained a decision tree model on the unbalanced and the balanced COMPAS datasets. Each model predicts a person’s race () and recidivism () based on the selected features. We measured the bias amplification caused by each model in two directions: bias amplification caused by race () on recidivism (), referred to as , and the bias amplification caused by recidivism () on race (), referred to as . We compared our proposed metric, , to previous metrics and . For , we used a 3-layer dense neural network (with a hidden layer of size 4 and sigmoid activations) as the attacker model for both directions. Following [11], we evaluated each bias amplification metric on the training set predictions.
5.2 COCO Experiment
Next, we explore how different bias amplification metrics are impacted in as a model’s reliance on task-associated objects to predict gender increases. We used the gender-annotated version of the COCO dataset released by Wang et al. [11]. Each image is labeled with both gender () and object categories (. For the purpose of the experiment, we sampled 2 sub-datasets, “Unbalanced” and “Balanced”. The balanced dataset is subject to the following constraint.
| (15) |
Where represents the number of images of a male person performing task , represents the number of images of a female person performing task . As these constraints are hard to satisfy, only a subset of 12 objects or tasks are used in the final dataset. This results in a dataset of 6156 images (3078 male and 3078 female images).
We used the same 12 objects for the unbalanced case but relaxed the constraint from Equation 15 as shown in equation 16. This results in a dataset of 15743 images (8885 male and 6588 female images)
| (16) |
For each dataset, we have 4 versions: one original and three perturbed versions wherein the person in the image is masked using different techniques (i.e., partially masking segment, completely masking segment, completely masking bounding box), as shown in Table 4. We trained a separate VGG16 [9] (pre-trained on ImageNet-1K [7]) for 12 epochs for each of the 8 cases (4 versions for both balanced and unbalanced datasets). We measure the feature attribution of the model using Gradient-Shap [6]. This allows us to measure the attribution of different image elements and compare it with bias amplification reported by various metrics.
6 Results
| Method | Unbalanced | Balanced | ||
| DPA (ours) | ||||
| Dataset Split | Metric | Original | Partial Masked | Segment Masked | Bounding-Box Masked |
| Image |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/orignal.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/partial.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/segment.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/bb.png)
|
|
| Attribution Map |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/orig_gs1.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/partial_gs1.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/segment_gs1.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f23a9722-485e-40fc-b172-2c743a4f998e/bb_gs1.png)
|
|
| Unbalanced | Attribution Score | ||||
| Balanced | Attribution Score | ||||
While interpreting results, note that a co-occurrence-based metric like and a predictability-based metric like may sometimes give different results. This is because they measure bias amplification in different ways.
classifies each pair in the dataset as a majority or minority pair using equation 7. It only measures if the counts of the majority pair increased (positive bias amplification) or decreased (negative bias amplification) in the model predictions or vice-versa.
, like [11], does not select a majority or a minority pair. It measures the change in the task distribution given the attribute (and vice-versa). For instance, if and are binary, measures if the absolute difference in counts between and increased (positive bias amplification) or decreased (negative bias amplification) in the model predictions. Both and offer different yet valuable insights into bias amplification.
6.1 COMPAS Results
6.1.1 Unbalanced COMPAS dataset
The bias amplification scores for the unbalanced case are shown in the first two columns of Table 3.
:
For , when , the count of the majority class decreased from in the dataset to in the model predictions. Similarly, when , the count of the majority class decreased from in the dataset to in the model predictions. Since the count of the majority classes decreased in the model predictions, reported a negative bias amplification in .
For , when , the difference in counts between and increased from () in the dataset to () in the model predictions. However, when , the difference in counts between and decreased from () in the dataset to () in the model predictions. Since the decrease in bias when is larger than the increase in bias when (), we might naively assume a negative bias amplification in .
This naive assumption does not account for the conflation of model errors and model biases. As noted in 3.1, the quality equalization step in leakage prevents the conflation of the model’s errors and biases. The model has a low accuracy when predicting (approx. ); hence, of instances in are perturbed to match the model’s accuracy. As a result, the biases in the perturbed are lesser than , indicating a positive bias amplification. The positive score reported by is not an incorrect result. It is the low model accuracy that misleadingly suggests a negative bias amplification.
also reports a positive bias amplification of the same magnitude as . But, this positive value is the result of not being able to distinguish between positive and negative amplification, as shown in Appendix A.
:
For , when , the count of the majority class decreased from in the dataset to in the model predictions. Similarly, when , the count of the majority class decreased from in the dataset to in the model predictions. Since the count of the majority classes decreased in the model predictions, reported negative bias amplification in .
For , when , the difference in counts between and decreased from () in the dataset to () in the model predictions. Similarly, when , the difference in counts between and decreased from () in the dataset to () in the model predictions. Since the overall count difference decreased in the model predictions, reported negative bias amplification in .
reported positive bias amplification as it cannot capture negative bias amplification. It only measures the magnitude of bias amplification but not its sign.
6.1.2 Balanced COMPAS Dataset
The bias amplification scores for the balanced case are shown in the last two columns of Table 3.
:
Since assumes a balanced dataset to be unbiased, reported zero bias amplification in . For , when , the difference in counts between and increased from () in the dataset to () in the model predictions. Similarly, when , the difference in counts between and increased from () in the dataset to () in the model predictions. Since the overall count difference increased in the model predictions, reported positive bias amplification in .
:
Since the dataset is balanced, reported zero bias amplification in . For , when , the difference in counts between and increased from () in the dataset to () in the model predictions. Similarly, when , the difference in counts between and increased from () in the dataset to () in the model predictions. Since the overall count difference increased in the model predictions, reported positive bias amplification in .
reported positive bias amplification as it only looks at the magnitude of amplification scores.


6.2 COCO Results
In Table 4, the “attribution score” is a measure of the contribution of non-person image elements in the model’s prediction of a person’s gender. To calculate the attribution score, we take the normalized attribution map created using Gradient-Shap [6] and mask the values for the person’s segment (similar to the segment-masked case). We add the remaining values and average across all images in the dataset to get the final score.
The unbalanced section in Table 4 shows that all metrics report increasing scores as the attribution score increases. It makes intuitive sense that as the model relies more on the background objects (including task-associated objects) to predict gender, the bias of tasks on gender (i.e., ) increases.
But, in Table 4’s balanced section, this trend no longer holds for . reports a constant zero bias amplification despite the model’s increasing reliance on background objects to predict gender. Thus, for balanced datasets, continues to report zero bias amplification despite changes in model biases.
Thus, is the most reliable metric as it avoids pitfalls such as ’s inability to work with “balanced” datasets and ’s inability to distinguish positive and negative bias amplification.
7 Discussion
7.1 Different metrics interpret bias amplification differently
As we observed in Section 6, each metric reported a different value for bias amplification. This makes it challenging for users to decide which metric to use when measuring bias amplification.
To understand the behavior of each metric, we simulated the following scenario. Consider a dataset with a protected attribute (where or ) and task (where or ). Initially, we have the same probability () for each pair. To introduce bias in the dataset, we modify the probabilities for specific groups. We add a term to the group {, } and subtract it from {, }. Here, ranges from to in steps of . This setup creates a dataset that is balanced only when ; as moves away from (in either direction), the dataset becomes increasingly unbalanced. We follow the same setup to simulate the model predictions.
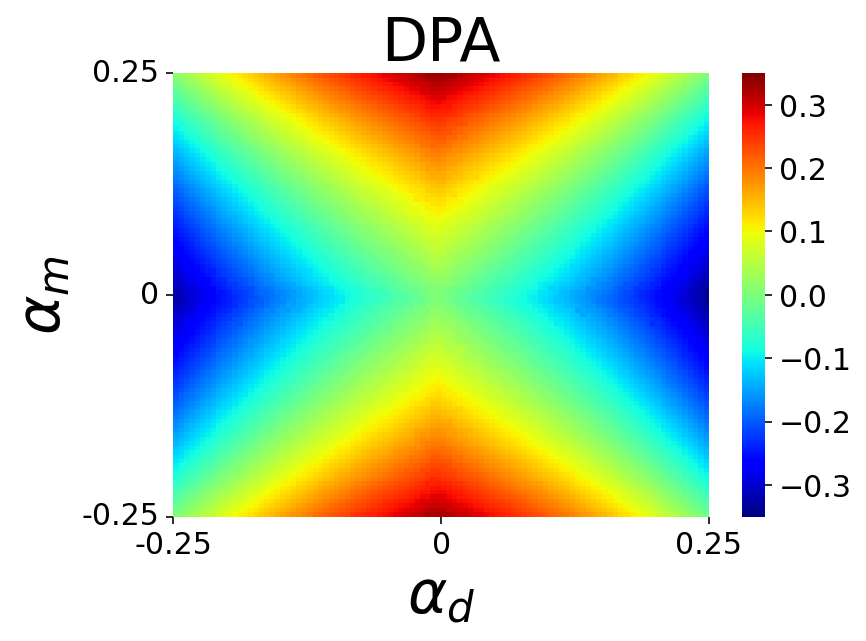
With ranging from to , we create different versions of the dataset and model predictions, influenced by and , respectively. For each metric, we plot a heatmap of the reported bias amplification scores. Each pixel in the heatmap represents the bias amplification score for a specific {dataset, model} pair.
Figure 2 shows the heatmaps for all metrics. Figures 2(a) and 2(b) display the bias amplification heatmaps for and , respectively. These heatmaps look similar, suggesting that both metrics show similar behavior. However, (Figure 2(a)) shows a distinct vertical green line in the center, indicating that when the dataset is balanced ( on the X-axis), bias amplification remains at , regardless of changes in model’s bias (indicated by varying values on the Y-axis). In contrast, (Figure 2(b)) accurately detects non-zero bias amplification whenever there is a shift in bias in either the dataset or model predictions. Thus, is a more reliable metric for measuring bias amplification. (as shown in Figure 2(c)) reports positive bias amplification in all scenarios, making it an unreliable metric.
7.2 Should we always use DPA?
While is generally the most reliable metric for measuring bias amplification, there are cases where is more suitable. Consider a job hiring dataset: men () and women () apply for a job. Out of these, men and women are hired (), while the rest are rejected (). Since the acceptance rate for women () is higher than for men (), sees this as a bias. In contrast, interprets this as an unbiased scenario because the same number of men and women are hired. In situations like this, where (acceptance) is almost always less frequent than (rejections), may be a better fit, as it considers a dataset unbiased only if the -to- ratio is the same for both genders.
In another scenario, imagine a dataset of men () and women (), where each person is either indoors () or outdoors (). It would make more sense to call this dataset unbiased when there are an equal number of instances for all and pairs. In this case, is a better metric, as it treats a dataset as unbiased when all and combinations have equal representation. and each measure distinct types of bias. The choice of metric depends on the specific bias we aim to address.
8 Conclusion
In this work, we showed how our novel predictability-based metric () can measure directional bias amplification, even for balanced datasets. We also showed how is easy to interpret and minimally sensitive to attacker models. is the only reliable directional metric for balanced datasets. It should be used in unbalanced datasets with an accurate understanding of the type of biases an end-user wants to measure.
References
- Angwin et al. [2022] Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. Machine bias. In Ethics of Data and Analytics, pages 254–264. Auerbach Publications, 2022.
- Foulds et al. [2020] James R. Foulds, Rashidul Islam, Kamrun Naher Keya, and Shimei Pan. An intersectional definition of fairness. In 2020 IEEE 36th International Conference on Data Engineering (ICDE), pages 1918–1921, 2020.
- Hirota et al. [2022] Yusuke Hirota, Yuta Nakashima, and Noa Garcia. Quantifying societal bias amplification in image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13450–13459, 2022.
- Lin et al. [2019] Kun Lin, Nasim Sonboli, Bamshad Mobasher, and Robin Burke. Crank up the volume: preference bias amplification in collaborative recommendation, 2019.
- Lin et al. [2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Lundberg and Lee [2017] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2017.
- Russakovsky et al. [2015] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015.
- Seshadri et al. [2023] Preethi Seshadri, Sameer Singh, and Yanai Elazar. The bias amplification paradox in text-to-image generation. arXiv preprint arXiv:2308.00755, 2023.
- Simonyan and Zisserman [2015] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition, 2015.
- Wang and Russakovsky [2021] Angelina Wang and Olga Russakovsky. Directional bias amplification. In International Conference on Machine Learning, pages 10882–10893. PMLR, 2021.
- Wang et al. [2019] Tianlu Wang, Jieyu Zhao, Mark Yatskar, Kai-Wei Chang, and Vicente Ordonez. Balanced datasets are not enough: Estimating and mitigating gender bias in deep image representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5310–5319, 2019.
- Yatskar et al. [2016] Mark Yatskar, Luke Zettlemoyer, and Ali Farhadi. Situation recognition: Visual semantic role labeling for image understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5534–5542, 2016.
- Zhao et al. [2023] Dora Zhao, Jerone Andrews, and Alice Xiang. Men also do laundry: Multi-attribute bias amplification. In Proceedings of the 40th International Conference on Machine Learning, pages 42000–42017. PMLR, 2023.
- Zhao et al. [2017] Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. Men also like shopping: Reducing gender bias amplification using corpus-level constraints. arXiv preprint arXiv:1707.09457, 2017.
Supplementary Material
Appendix A explanation
To understand why cannot differentiate between positive bias amplification and negative bias amplification (i.e.) bias reduction, let us take a look at its formulation.
| (17) |
where,
and,
| (18) |
Following [13], M represents the attribute groups and G represents the task groups.
From Equation 17, we get
| (19) |
Appendix B Attacker Robustness
To prove the normalization improves robustness, we conduct the following experiment:
We define . We define and in the following manner:
| (20) |
| (21) |
Here represents any degree polynomial of and . To demonstrate positive bias amplification, we want to be a better predictor of , compared to . Hence, we set .
As the attacker needs to model a simple polynomial function, we use a simple Fully Connected Network as the attacker. The attacker has varying depths and width with a combination of TanH and ReLU activations. We used the inverse of RMSE loss for quality function. Figure 3 shows the reported value of non-normalized and normalized DPA for different values of . Table 5 lists the parameters used for this experiment.

In Figure 3, non-normalized showed unstable bias amplification values with high variance across different models. On the other hand, normalized DPA show a relatively stable bias amplification value with minimal variance across models of different sizes. Hence, we conclude that normalized is more robust to changes in model hyperparameters.