Making Better Use of Bilingual Information for
Cross-Lingual AMR Parsing
Abstract
Abstract Meaning Representation (AMR) is a rooted, labeled, acyclic graph representing the semantics of natural language. As previous works show, although AMR is designed for English at first, it can also represent semantics in other languages. However, they find that concepts in their predicted AMR graphs are less specific. We argue that the misprediction of concepts is due to the high relevance between English tokens and AMR concepts. In this work, we introduce bilingual input, namely the translated texts as well as non-English texts, in order to enable the model to predict more accurate concepts. Besides, we also introduce an auxiliary task, requiring the decoder to predict the English sequences at the same time. The auxiliary task can help the decoder understand what exactly the corresponding English tokens are. Our proposed cross-lingual AMR parser surpasses previous state-of-the-art parser by 10.6 points on Smatch F1 score. The ablation study also demonstrates the efficacy of our proposed modules.
1 Introduction
Abstract Meaning Representation (AMR) Banarescu et al. (2013) is a rooted, labeled, acyclic graph representing sentence-level semantic of text. Nodes in the graph are concepts in the texts and edges in the graph are relations between concepts. Since AMR abstracts away from syntax and preserves only semantic information, it can be applied to many semantic related tasks such as summarization Liu et al. (2015); Liao et al. (2018), paraphrase detection Issa et al. (2018), machine translation Song et al. (2019) and so on.
Previous works on AMR parsing mainly focus on English, since AMR is designed for English texts and parallel corpus of non-English texts and AMRs are scarce. Early work of AMR announces that AMR is biased towards English and is not an interlingua Banarescu et al. (2013). Besides, some studies show that aligning AMR with non-English language is not always possible Xue et al. (2014); Hajic et al. (2014). However, recent studies Damonte and Cohen (2018); Blloshmi et al. (2020) show that AMR parsers are able to recover AMR structures when there are structural differences between languages, which demonstrate that it is capable to overcome many translation divergences. Therefore, it is possible for us to parse texts in target (non-English) languages into AMRs.
Another problem of cross-lingual AMR parsing is the scarcity of parallel corpus. Unlike machine translation or sentiment classification which have abundant resources on the Internet, we can only get non-English text and AMR pairs by human annotation. Damonte and Cohen (2018) align a non-English token with an AMR node if they can be mapped to the same English token to construct training set. They further train a transition-based parser using the synthetic training set. They also attempt to translate test set into English and apply an English AMR parser. Blloshmi et al. (2020) build training data in two ways. One of the approaches is that they use gold parallel sentences and generate synthetic AMR annotations with the help of an English AMR parser. Another approach is to use gold English-AMR pairs and get non-English texts by a pre-trained machine translation system. They further use a sequence-to-graph parser Zhang et al. (2019a) to train a cross-lingual AMR parser.
According to Blloshmi et al. (2020), a cross-lingual AMR parser may predict the concepts less specific and accurate than the gold concepts. Therefore, we propose a new model introducing machine translation to enable our parser to predict more accurate concepts. In particular, we first build our training data similar to Blloshmi et al. (2020), translating English texts into target languages. Our basic model is a sequence-to-sequence model, rather than the sequence-to-graph model used in Blloshmi et al. (2020), since in English AMR parsing, sequence-to-sequence models can achieve state-of-the-art result with enough data for pre-training Xu et al. (2020). While training, we introduce bilingual input by concatenating translated target language texts and English texts as inputs. As for inference stage, the bilingual input is the concatenation of translated English texts and target language texts. We hope that our model can predict more accurate concepts with the help of the English tokens, while it can still preserve the meaning of the original texts if there are semantic shifts in the translated English texts. Besides, during training process, we also introduce an auxiliary task, requiring the decoder to restore English input tokens, which also aims at enhancing the ability of our parser to predict concepts. Our parser outperforms previous state-of-the-art parser XL-AMR Blloshmi et al. (2020) on LDC2020T07 dataset Cai and Knight (2013) by about 10.6 points of Smatch F1 score on average, which demonstrates the efficacy of our proposed cross-lingual AMR parser.
Our main contributions are summarized as follows:
-
•
We introduce bilingual inputs and an auxiliary task to a seq2seq cross-lingual AMR parser, aiming to enable the parser to make better use of bilingual information and predict more accurate concepts.
-
•
Our parser surpasses the best previously reported results of Smatch F1 score on LDC2020T07 by a large margin. The results demonstrate the effectiveness of our parser. Ablation studies show the usefulness of the model modules. Codes are public available 111https://github.com/headacheboy/cross-lingual-amr-parsing.
-
•
We further carry out experiments to investigate the influence of incorporating pre-training models into our cross-lingual AMR parser.
2 Related Work
Abstract Meaning Representation (AMR) Banarescu et al. (2013) parsing is becoming popular recently. Some of previous works Flanigan et al. (2014); Lyu and Titov (2018); Zhang et al. (2019a) solve this problem with a two-stage approach. They first project words in sentences to AMR concepts, followed by relation identification. Transition-based parsing is applied by Wang et al. (2015b, a); Damonte et al. (2017); Liu et al. (2018); Guo and Lu (2018); Naseem et al. (2019); Lee et al. (2020). They align words with AMR concepts and then take different actions based on different processed words to link edges or insert new nodes. Due to the recent development in sequence-to-sequence model, several works employ it to parse texts into AMRs Konstas et al. (2017); van Noord and Bos (2017); Ge et al. (2019); Xu et al. (2020). They linearize AMR graphs and leverage character-level or word-level sequence-to-sequence model. Sequence-to-graph model is proposed to enable the decoder to better model the graph structure. Zhang et al. (2019a) first use a sequence-to-sequence model to predict concepts and use a biaffine classifier to predict edges. Zhang et al. (2019b) propose a one-stage sequence-to-graph model, predicting concepts and relations at the same time. Cai and Lam (2020) regard AMR parsing as dual decisions on input sequences and constructing graphs. They therefore propose a sequence-to-graph method by first mapping an input words to a concept and then linking an edge based on the generated concepts. Recently, pre-training models have been proved to perform well in AMR parsing Xu et al. (2020). Lee et al. (2020) employ a self-training method to enhance a transition-based parser, which achieves the state-of-the-art Smatch F1 score in English AMR parsing.
Vanderwende et al. (2015) first carry out research of cross-lingual AMR parsing. They parse texts in target language into logical forms as a pivot, which are then parsed into AMR graphs. Damonte and Cohen (2018) attempt to project non-English words to AMR concepts and use a transition-based parser to parse texts to AMR graphs. They also attempt to automatically translate non-English texts to English and exploit an English AMR parser. Blloshmi et al. (2020) try to generate synthetic training data by a machine translation system or an English AMR parser. They conduct experiments with a sequence-to-graph model in different settings, trying to find a best way to train with synthetic training data. Different from Blloshmi et al. (2020), we treat cross-lingual AMR parsing as a sequence-to-sequence transduction problem and improve seq2seq models with bilingual input and auxiliary task.
3 Problem Setup
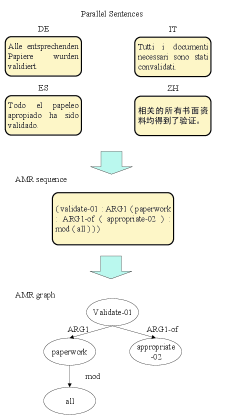
Cross-lingual AMR parsing is the task of parsing non-English texts into AMR graphs corresponding to their English translation. In this task, nodes in AMR graphs are still English words, PropBank framesets or AMR keywords, which are the same as the original design of AMR.
Figure 1 shows an example of cross-lingual AMR parsing. We define as an input sample in language l and is the -th token of it. is the corresponding AMR sequence derived from the AMR graph, and is the -th token. The model should predict the AMR sequence first and then transform the sequence into a graph.
4 Our Proposed Model

Figure 2 shows the training and inference processes of our proposed model. The basic model we adopt is Transformer Vaswani et al. (2017) encoder-decoder model, since Xu et al. (2020) show that it can achieves state-of-the-art result in English AMR parsing. We introduce the bilingual input to our model. When training the model, the bilingual input contains original English text and translated text in non-English target language, which may not be very accurate. During inference, the bilingual input is composed of translated English text and original text in target language. With the help of bilingual input, our model can better understand and preserve the semantics of target language texts, and predict more accurate concepts according to the translated English texts. Apart from predicting AMR sequences, the model is also required to predict the English input texts as an auxiliary objective, which can further help the model learn the exact meaning of input tokens and predict their corresponding concepts more accurately.
We will first introduce the way we obtain training data and the pre-processing and post-processing process in Section 4.1 and Section 4.2, followed by introducing the basic sequence-to-sequence model, the bilingual input and the auxiliary task.
4.1 Synthetic Training Data
Blloshmi et al. (2020) propose two methods to generate parallel training data, namely parallel sentences - silver AMR graphs and gold AMR graphs - silver translations. The first approach means that we exploit human annotated parallel corpus of target languages and English and use an English parser to get the corresponding AMR graphs. The second approach means that we exploit human annotated English-AMR pairs and use a machine translation system to get texts in target languages. According to Blloshmi et al. (2020), model training with data generated by gold English-AMR pairs performs better. We thus exploit this approach (i.e., gold AMR graphs - silver translations) to generate our data for training and validation.
4.2 Pre-Processing and Post-Processing
Following van Noord and Bos (2017), we first remove variables, since variables are only used to identify the same node in a graph and contain no semantic information, which may do harm to the model training process. We also remove wiki links (:wiki), since sequence-to-sequence model may link to non-existing objects of Wikipedia. As for co-referring nodes, we simply duplicate the concepts. It transforms an AMR graph into a tree. The final linearized AMR is the pre-order traversal of the tree.
In post-processing, we should restore a predicted AMR sequence without variables, wiki links and co-referring nodes to a AMR graph. Following van Noord and Bos (2017), We first restore variables and prune duplicated nodes, which brings co-reference back to the AMR sequence. van Noord and Bos (2017) use DBpedia Spotlight to restore wiki links. However, same entity in different language is linked to different pages in DBpedia, which makes it difficult for cross-lingual AMR parser to restore the wiki linking the entity in English. Different from van Noord and Bos (2017), we restore a wiki link of a certain name if this name corresponds to the wiki link in training set.
4.3 Sequence-to-Sequence Model
After pre-processing, both input texts and output AMRs are sequences. Hence we are able to apply a sequence-to-sequence model to accomplish cross-lingual AMR parsing. We use Transformer Vaswani et al. (2017), one of the most popular sequence-to-sequence model as our basic model.
In order to be compatible with pre-training XLM-R Conneau et al. (2020a) model, the tokenizer and input vocabulary we used is the same as XLM-R. Subword unit such as byte pair encoding (BPE) Sennrich et al. (2016) is commonly used to reduce the size of vocabulary. Thus, we exploit BPE to get our output vocabulary.
| Training | Development | Test | |
|---|---|---|---|
| Number | 36521 | 1368 | 1371 |
4.4 Bilingual Input
AMR concepts heavily rely on the corresponding English texts. According to Damonte and Cohen (2018), a simple method that first translates the test set into English and then applies an English AMR parser can outperform their cross-lingual AMR parser. However, machine translation may introduce semantic shifts, which may do harm to the generation of AMRs.
We therefore introduce the bilingual input. Since we do not have gold parallel corpus, we use machine translation to get the bilingual input. During training, we concatenate the translated text in target language mentioned in Section 4.1 and the original English text as bilingual input. At the inference stage, we take the bilingual input by concatenating original target language texts and the translated English text. The model can better understand and preserve the semantic meanings of the input bilingual text. It can also predict more correct concepts, since the English tokens are also provided.
4.5 Auxiliary Task
AMR concepts are composed of English words and Propbank frames. According to Blloshmi et al. (2020), roughly 60% of nodes in AMR 2.0 (LDC2017T10) are English words. What’s more, Propbank predicates are similar to English words, such as predicate publish-01 and word publish. We argue that if the decoder can restore the input tokens in English precisely, it can predict the corresponding concepts appropriately.
We thus design an auxiliary task, requiring the decoder to predict the English input sequence. Inspired by multilingual machine translation Johnson et al. (2017), we add a new BOS token indicating that the model should predict the English sequences instead of AMR sequences. The decoder predicting English sequences share the same weights as the decoder predicting AMR sequences.
The final loss function is the weighted sum of loss functions of these two tasks: - the loss of AMR sequence prediction and - the loss of English sentence prediction. We adopt the cross-entropy loss for both tasks.
5 Implementation Details
The coefficient of is 1, while the coefficient of is 0.5. We use Adam optimizer Kingma and Ba (2015) to optimize the final loss function. The number of transformer layers in both encoder and decoder is 6. The embedding size and hidden size are both 512 and the size of feed-forward network is 2048. The head number of multi-head attention is 8. We follow Vaswani et al. (2017) to tune the learning rate each step and the warmup step is 4000. The learning rate for decoder at each step is half of this learning rate. Following Blloshmi et al. (2020), we use machine translation system OPUS-MT Tiedemann and Thottingal (2020) to get our bilingual input. We use all data from different languages to train our model and the final model is able to parse sentences in different languages.
6 Experiments
6.1 Dataset
| DE | IT | ES | ZH | AVG | |
|---|---|---|---|---|---|
| AMREager | 39.0 | 43.0 | 42.0 | 35.0 | 39.8 |
| XL-AMR (Mul) | 49.9 | 53.5 | 53.2 | 41.0 | 49.4 |
| XL-AMR (Mul*) | 52.1 | 56.7 | 56.2 | - | - |
| XL-AMR (Lang) | 51.6 | 56.7 | 56.1 | 43.1 | 51.9 |
| XL-AMR (Bi) | 53.0 | 58.1 | 58.0 | 41.5 | 52.7 |
| Translate-test | 60.4 | 62.1 | 63.3 | 53.7 | 59.9 |
| Ours | 64.0 | 65.4 | 67.3 | 56.5 | 63.3 |
| AMREager | XL-AMR | Ours | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | DE | IT | ES | ZH | DE | IT | ES | ZH | DE | IT | ES | ZH |
| Smatch | 39.1 | 43.2 | 42.1 | 34.6 | 53.0 | 58.1 | 58.0 | 43.1 | 64.0 | 65.4 | 67.3 | 56.5 |
| Unlabeled | 45.0 | 48.5 | 46.6 | 41.1 | 57.7 | 63.4 | 63.0 | 48.9 | 68.1 | 69.6 | 71.2 | 61.0 |
| No WSD | 39.2 | 42.5 | 42.2 | 34.7 | 53.2 | 58.4 | 58.4 | 43.2 | 64.4 | 65.9 | 67.8 | 56.7 |
| Reentrancies | 18.6 | 25.7 | 27.2 | 15.9 | 39.9 | 46.1 | 46.6 | 34.7 | 47.9 | 49.3 | 51.3 | 41.4 |
| Concepts | 44.9 | 52.3 | 53.3 | 39.9 | 58.0 | 64.7 | 65.9 | 48.0 | 69.3 | 72.1 | 75.0 | 61.3 |
| Named Ent. | 63.1 | 67.7 | 65.7 | 67.9 | 66.0 | 70.0 | 66.2 | 60.6 | 79.3 | 79.5 | 80.2 | 76.2 |
| Wikification | 49.9 | 50.6 | 44.5 | 46.8 | 60.9 | 67.0 | 63.1 | 54.5 | 74.0 | 74.9 | 73.9 | 68.1 |
| Negation | 18.6 | 22.3 | 19.8 | 6.8 | 11.7 | 29.2 | 23.4 | 12.8 | 47.1 | 52.6 | 55.6 | 36.6 |
| SRL | 29.4 | 34.3 | 35.9 | 27.2 | 47.9 | 54.7 | 55.2 | 41.3 | 57.3 | 60.1 | 62.1 | 50.7 |
The released test set, LDC2020T07, contains four translations of test set of AMR 2.0, including German (DE), Italian (IT), Spanish (ES) and Chinese(ZH).
As is mentioned in Section 4.1, we translate the sentences in a gold English-AMR dataset to get training and development data with OPUS-MT. We use AMR 2.0 as our gold English-AMR dataset. We also translate test sets in German, Italian, Spanish and Chinese back to English as input texts. The statistics of AMR 2.0 are shown in Table 1.
6.2 Evaluation Metric
Smatch Cai and Knight (2013) is the evaluation metric of AMR parsing. In this evaluation metric, AMR graph is regarded as several triples. Smatch counts the numbers of matched triples and outputs the score based on total numbers of triples of two AMR graphs. We use the Smatch scripts available online 222https://github.com/sheng-z/stog.
6.3 Main Results
| S2S | S2S + Bilingual Input | S2S + Auxiliary | Full Model | ||||
|---|---|---|---|---|---|---|---|
| F1 | F1 | F1 | F1 | ||||
| Smatch | 53.1 | 57.5 | 4.4 | 58.6 | 5.5 | 63.3 | 10.2 |
| Unlabeled | 57.7 | 59.2 | 1.5 | 58.9 | 1.2 | 67.5 | 9.8 |
| No WSD | 53.4 | 59.2 | 5.8 | 58.9 | 5.5 | 63.7 | 10.3 |
| Reentrancies | 38.4 | 41.9 | 3.5 | 42.7 | 4.3 | 47.5 | 9.1 |
| Concepts | 57.3 | 66.4 | 9.1 | 62.7 | 5.4 | 69.4 | 12.1 |
| Named Ent. | 73.7 | 75.0 | 1.3 | 77.2 | 3.5 | 78.8 | 5.1 |
| Wiki | 62.1 | 69.0 | 6.9 | 69.2 | 7.1 | 72.7 | 10.6 |
| Negation | 32.9 | 44.1 | 11.2 | 39.5 | 6.6 | 48.0 | 15.1 |
| SRL | 47.4 | 52.1 | 4.7 | 52.2 | 4.8 | 57.6 | 10.2 |
We compare our model with previous works and baseline methods including:
-
•
AMREager. This is the model proposed by Damonte and Cohen (2018). They assume that if a word in target language is aligned with the word in English and the English word aligns with AMR concept , can be aligned with . Based on this assumption, they project AMR annotations to target languages and further train a transition-based AMR parser Damonte et al. (2017) as in English.
-
•
XL-AMR. This is the model proposed by Blloshmi et al. (2020). When conducting experiments of their best model, they first generate synthetic training and validation data by machine translation. They then train an AMR parser on target language with a sequence-to-graph parser. They experiment XL-AMR with many different settings: language specific setting, bilingual setting and multilingual setting. Language specific setting means that they only use target language data to train the model. Bilingual setting represents training with target language data and English data. Multilingual setting represents training with data in all languages. They also experiment multilingual setting except Chinese data because they found training with Chinese data will lower the results.
-
•
Translate-test. This method first translates target language texts into English and uses an English AMR parser to predict the final AMR graphs. For fair comparison, we choose the sequence-to-sequence model as the English AMR parser. The encoder, decoder and hyper-parameters of these modules are the same as those in our model. We use only English texts as input and do not apply the auxiliary task in the training of English parser. Note that this baseline is not compared in Blloshmi et al. (2020) and we show it is a very strong baseline.

The comparison results are shown in Table 2. Our model outperforms previous best model XL-AMR in different settings by a large margin. As for languages that share similarity with English, namely German, Italian, Spanish, our proposed model achieves substantial improvement on Smatch F1 score by about 10 points. When it comes to languages that has linguistic differences with English, namely Chinese, our model performs better, surpassing XL-AMR by 13.4 points on Smatch F1 score. The Translate-test method is a strong baseline because of the quality of machine translation. It outperforms previous reported results by a large margin, which reveals that English information is significantly beneficial to AMR prediction. In this work, our model also surpasses this method by 3.4 points and achieves the new state-of-the-art results.
Table 3 lists the fine-grained evaluation results of AMREager, the best XL-AMR model and our model. Our proposed model achieves substantially higher performance by about 10 points for each fine-grained task except Negation. As for Negation, our model achieves over 20 points higher than XL-AMR. These results demonstrates that our model not only predicts better concepts but also predicts better relations between concepts.
6.4 Ablation Study
In order to verify the effectiveness of the bilingual input and the auxiliary task in our model, we carry out several ablation experiments.
Table 4 shows the Smatch score and fine-grained results of ablation study. Compared with the basic sequence-to-sequence model, the bilingual input can improve the Smatch F1 score by 4.4 points on average. The introduction of auxiliary task brings 5.5 points improvement of Smatch on average. Our full model makes use of both bilingual input and auxiliary task at the same time, improving Smatch scores by 10.2 points, which indicates that each module is very beneficial to the performance of our model.
Fine-grained results further demonstrate the effectiveness of our modules. As Table 4 shows, F1 score for Concepts improves substantially, which demonstrates that our proposed modules can actually help the parser predict more accurate concepts. Besides, fine-grained evaluation Negation achieves the highest improvement, revealing that our proposed modules enable the parser to understand the semantics of the input texts better.
6.5 Effect of Pre-trained Models on Cross-Lingual AMR Parsing

| Model | DE | IT | ES | ZH | AVG |
|---|---|---|---|---|---|
| Full Model | 64.0 | 65.4 | 67.3 | 56.5 | 63.3 |
| + XLM-R | 66.1 | 67.9 | 69.6 | 57.9 | 65.4 |
| + dec | 64.9 | 66.7 | 68.5 | 57.4 | 64.4 |
| + XLM-R & dec | 68.3 | 70.0 | 71.9 | 59.6 | 67.5 |

Recently, pre-training models on cross-lingual tasks have been proposed. Pre-training models, such as mBert Devlin et al. (2019), XLM Conneau and Lample (2019), XLM-R Conneau et al. (2020b) and mBart Liu et al. (2020) achieve state-of-the-art results on many tasks such as machine translation, cross-lingual natural language inference and so on. In our experiment, we exploit XLM-R Conneau et al. (2020b) as the input embeddings of the model.
When training an English AMR parser, Xu et al. (2020) first pre-train the model on large scale synthetic data and fine-tune it on gold English-AMR data. Since cross-lingual AMR parsing shares the same output formats with AMR parsing, we can employ the decoder of Xu et al. (2020) to initialize our decoder and further finetune the cross-lingual AMR parser.
Results are listed in Table 5. The performance of our parser with XLM-R embedding improves by 2.1 points on Smatch score, while our parser finetuning pre-trained AMR decoder achieves 1.1 points improvement. We further employ both XLM-R embedding and pre-trained AMR decoder and the average Smatch score is 67.5. The results show that pre-trained cross-lingual embeddings like XLM-R as well as the pre-trained decoder can help the parser predict better AMR graphs.
7 Analysis
Figure 3 shows several AMRs parsed by models with and without auxiliary task. The AMR predicted by model without auxiliary task misses many concepts, while our full model predicts them correctly. What’s more, our full model can predict relations of concepts more accurately as well. For example, the full model adds ARG0 between hamper-01 and problem, retaining semantic information of the original sentence. The model trained without auxiliary task predicts the relation ARG2 instead, changing the meaning of the original sentence.
Another example in Figure 5 shows the efficacy of bilingual inputs. The AMR parsed by basic sequence-to-sequence model does not contain correct semantics. This model predicts many erroneous concepts such as launch-01, possible-01. Besides, the semantics of original sentence did not lose power is changed into have no electricity. The AMR produced by sequence-to-sequence model with bilingual input is almost correct except missing of concept silo. This example reveals that our bilingual input enables the parser to predict more accurate concepts and preserve the semantics of the sentence.
We also show an attention heatmap of an example in test set in Figure 4. This attention pattern shows that our parser can predict AMR tokens based on English translation (e.g. recommend-01) and based on both English and Spanish tokens (e.g. good-02).
8 Conclusion
In this paper, we focus on cross-lingual AMR parsing. Previous works have deficiency in predicting correct AMR concepts. We thus introduce bilingual inputs as well as an auxiliary task to predict more accurate concepts and their relations in AMR graphs. Empirical results on data in German, Italian, Spanish and Chinese demonstrate the efficacy of our proposed method. We also conduct ablation study to further verify the significance of the bilingual inputs and auxiliary task. For future work, we will attempt to adapt other methods used in English AMR parsing to cross-lingual AMR parsing, such as pre-training and self-training.
Acknowledgments
This work was supported by National Natural Science Foundation of China (61772036), Beijing Academy of Artificial Intelligence (BAAI) and Key Laboratory of Science, Technology and Standard in Press Industry (Key Laboratory of Intelligent Press Media Technology). We appreciate the anonymous reviewers for their helpful comments. Xiaojun Wan is the corresponding author.
References
- Banarescu et al. (2013) Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. 2013. Abstract meaning representation for sembanking. In Proceedings of the 7th linguistic annotation workshop and interoperability with discourse, pages 178–186.
- Blloshmi et al. (2020) Rexhina Blloshmi, Rocco Tripodi, and Roberto Navigli. 2020. Enabling cross-lingual amr parsing with transfer learning techniques. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2487–2500.
- Cai and Lam (2020) Deng Cai and Wai Lam. 2020. AMR parsing via graph-sequence iterative inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1290–1301, Online. Association for Computational Linguistics.
- Cai and Knight (2013) Shu Cai and Kevin Knight. 2013. Smatch: an evaluation metric for semantic feature structures. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 748–752.
- Conneau et al. (2020a) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020a. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451, Online. Association for Computational Linguistics.
- Conneau et al. (2020b) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Édouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020b. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451.
- Conneau and Lample (2019) Alexis Conneau and Guillaume Lample. 2019. Cross-lingual language model pretraining. In Advances in Neural Information Processing Systems, pages 7059–7069.
- Damonte and Cohen (2018) Marco Damonte and Shay B Cohen. 2018. Cross-lingual abstract meaning representation parsing. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1146–1155.
- Damonte et al. (2017) Marco Damonte, Shay B Cohen, and Giorgio Satta. 2017. An incremental parser for abstract meaning representation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 536–546.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
- Flanigan et al. (2014) Jeffrey Flanigan, Sam Thomson, Jaime G Carbonell, Chris Dyer, and Noah A Smith. 2014. A discriminative graph-based parser for the abstract meaning representation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1426–1436.
- Ge et al. (2019) Donglai Ge, Junhui Li, Muhua Zhu, and Shoushan Li. 2019. Modeling source syntax and semantics for neural amr parsing. In IJCAI, pages 4975–4981.
- Guo and Lu (2018) Zhijiang Guo and Wei Lu. 2018. Better transition-based amr parsing with a refined search space. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1712–1722.
- Hajic et al. (2014) Jan Hajic, Ondřej Bojar, and Zdenka Uresova. 2014. Comparing czech and english amrs. In Proceedings of Workshop on Lexical and Grammatical Resources for Language Processing, pages 55–64.
- Issa et al. (2018) Fuad Issa, Marco Damonte, Shay B Cohen, Xiaohui Yan, and Yi Chang. 2018. Abstract meaning representation for paraphrase detection. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 442–452.
- Johnson et al. (2017) Melvin Johnson, Mike Schuster, Quoc V Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, et al. 2017. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Transactions of the Association for Computational Linguistics, 5:339–351.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
- Konstas et al. (2017) Ioannis Konstas, Srinivasan Iyer, Mark Yatskar, Yejin Choi, and Luke Zettlemoyer. 2017. Neural amr: Sequence-to-sequence models for parsing and generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 146–157.
- Lee et al. (2020) Young-Suk Lee, Ramón Fernandez Astudillo, Tahira Naseem, Revanth Gangi Reddy, Radu Florian, and Salim Roukos. 2020. Pushing the limits of amr parsing with self-learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 3208–3214.
- Liao et al. (2018) Kexin Liao, Logan Lebanoff, and Fei Liu. 2018. Abstract meaning representation for multi-document summarization. In Proceedings of the 27th International Conference on Computational Linguistics, pages 1178–1190.
- Liu et al. (2015) Fei Liu, Jeffrey Flanigan, Sam Thomson, Norman Sadeh, and Noah A Smith. 2015. Toward abstractive summarization using semantic representations. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1077–1086.
- Liu et al. (2018) Yijia Liu, Wanxiang Che, Bo Zheng, Bing Qin, and Ting Liu. 2018. An amr aligner tuned by transition-based parser. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2422–2430.
- Liu et al. (2020) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics, 8:726–742.
- Lyu and Titov (2018) Chunchuan Lyu and Ivan Titov. 2018. Amr parsing as graph prediction with latent alignment. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 397–407.
- Naseem et al. (2019) Tahira Naseem, Abhishek Shah, Hui Wan, Radu Florian, Salim Roukos, and Miguel Ballesteros. 2019. Rewarding smatch: Transition-based amr parsing with reinforcement learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4586–4592.
- van Noord and Bos (2017) Rik van Noord and Johan Bos. 2017. Neural semantic parsing by character-based translation: Experiments with abstract meaning representations. Computational Linguistics in the Netherlands Journal, 7:93–108.
- Sennrich et al. (2016) Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725.
- Song et al. (2019) Linfeng Song, Daniel Gildea, Yue Zhang, Zhiguo Wang, and Jinsong Su. 2019. Semantic neural machine translation using amr. Transactions of the Association for Computational Linguistics, 7:19–31.
- Tiedemann and Thottingal (2020) Jörg Tiedemann and Santhosh Thottingal. 2020. Opus-mt–building open translation services for the world. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, pages 479–480.
- Vanderwende et al. (2015) Lucy Vanderwende, Arul Menezes, and Chris Quirk. 2015. An amr parser for english, french, german, spanish and japanese and a new amr-annotated corpus. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, pages 26–30.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Wang et al. (2015a) Chuan Wang, Nianwen Xue, and Sameer Pradhan. 2015a. Boosting transition-based amr parsing with refined actions and auxiliary analyzers. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 857–862.
- Wang et al. (2015b) Chuan Wang, Nianwen Xue, and Sameer Pradhan. 2015b. A transition-based algorithm for amr parsing. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 366–375.
- Xu et al. (2020) Dongqin Xu, Junhui Li, Muhua Zhu, Min Zhang, and Guodong Zhou. 2020. Improving amr parsing with sequence-to-sequence pre-training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2501–2511.
- Xue et al. (2014) Nianwen Xue, Ondrej Bojar, Jan Hajic, Martha Palmer, Zdenka Uresova, and Xiuhong Zhang. 2014. Not an interlingua, but close: Comparison of english amrs to chinese and czech. In LREC, volume 14, pages 1765–1772. Reykjavik, Iceland.
- Zhang et al. (2019a) Sheng Zhang, Xutai Ma, Kevin Duh, and Benjamin Van Durme. 2019a. Amr parsing as sequence-to-graph transduction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 80–94.
- Zhang et al. (2019b) Sheng Zhang, Xutai Ma, Kevin Duh, and Benjamin Van Durme. 2019b. Broad-coverage semantic parsing as transduction. arXiv preprint arXiv:1909.02607.