Make Bipedal Robots Learn How to Imitate
Abstract
Bipedal robots do not perform well as humans since they do not learn to walk like we do. In this paper we propose a method to train a bipedal robot to perform some basic movements with the help of imitation learning (IL) in which an instructor will perform the movement and the robot will try to mimic the instructor movement. To the best of our knowledge, this is the first time we train the robot to perform movements with a single video of the instructor and as the training is done based on joint angles the robot will keep its joint angles always in physical limits which in return help in faster training. The joints of the robot are identified by OpenPose architecture and then joint angle data is extracted with the help of angle between three points resulting in a noisy solution. We smooth the data using Savitzky-Golay filter and preserve the Simulatore data anatomy. An ingeniously written Deep Q Network (DQN) is trained with experience replay to make the robot learn to perform the movements as similar as the instructor. The implementation of the paper is made publicly available.
Index Terms:
Imitation Learning, Bipedal Robots, Pybullet Simulator, OpenAI.I Introduction
Humans learn to perform any specific task through various supervised, unsupervised, reinforcement, and semi-supervised techniques. Reinforcement learning is the way of learning by past experiences, for example consider a simulation environment in which a simulated agent will try to learn to play a game of chess, agent will have all the knowledge of the way chess pieces move and is called as action space for each iteration the agent will perform a move and the get reward as +1 if he cuts opponents piece, -1 if he land into dangerous situation and 0 if nothing happens based on the reward and observation i.e. current position of all chess pieces agent will perform next move and slowly learns how to play chess and win. This kind of learning is more unsupervised, IL is a type of reinforcement learning where the learning agent tries to mimic the teacher. Human beings prefer IL [1] as we involuntarily employ it in our life irrespective of the success. We refer to the human or trainable agents (if we talk in reinforcement learning domain) gathering behaviour, expertise or way of completing any given task by observing an instructor or any other skilled agent doing it, this method of learning is getting popular because it eases teaching complex tasks without exhausting the resources. Number of possible scenarios in a complex application such as human-computer interaction [2], self-driving cars [3], augmented reality [4], generative adversarial networks [5], and robot related tasks is vast and insane. Robots are classified according to their movements such as wheeled (uses wheels to move) [6], tracked (uses tank like tracks to move) [7], quadruped (move on four legs) [8], and biped (move on two legs) [9]. A lot of research is going into IL in bipedal robots [10, 11] due to the reduced computational cost. If we consider an environment in which multiple agents are trying to climb to the top of the mountain, let us consider a random agent (Agent-22)with the ability of IL learn maneuvers that are likely to be useful for the task. Agent-22 learns by the reinforcement learning approach along with a referring database for agent to refer and adjust its actions to learn the task faster without an exploration and exploitation problem [12]. Bipedal robots utilize a human-like pair of legs to move around, they are different from humanoid robots [13] as the bipedal may or may not have a complete human like torso, but humanoid must have. Cassie [14] and Atlas [15] are examples of bipedal and humanoid robots respectively used for research. Making a bipedal learn any specific task is easy but the problem increases with a higher number of tasks. The domain increases so the variables on which the robot will depend would increase. Training a bipedal to walk with human-like gait is a tedious task and we address this issue in this paper. The contributions of the paper are as follows:
-
•
Extract joint angles for various movements of the bipedal robot using a single video.
-
•
Train a DQN to predict the joint angles for the movement in OpenAI gym environment
We minimize the data reliability and large duration for training while extracting the joint angles data from a single video and then processing it to train DQN. The organization of the paper is as follows: Section II discusses the state-of-the-art approaches in the field of IL, Section III describes the working of the proposed approach, Section IV shows the experimental results and finally Section V concludes the paper.
II Related Works
Learning in humans is very diverse and subject to the task, we focus on implying IL to the bipedal robot POPPY [16]. One of the areas kept in mind while creating this bipedal is to provide researchers a low-cost machine to test their experiments. Poppy is a 25-degree of freedom (DOF) humanoid robot which is very less when compared to humans. It has much lower DOF than humans who have 244 DOF but it mimics all the major joints a human will engage whenever performing a movement such as walking, sprinting, kicking. Whenever we humans move or perform a set of actions to complete a movement like sprinting we engage a lot of muscles, activate a lot of joints, apply forces and torque in varying manner to the body joints [17] there are many variables that come into play, humans use active dynamics walking style i.e. while activating muscles for movement we consume energy in form of ATP (Adenosine triphosphate)[18] similarly in robots they consume power in form of electricity from battery, fuel cells etc.
Bipedal robots utilise passive dynamic walking style [19] in which they do not consume any power while walking while simply going down the slope. This passive dynamic walking style saves energy but motion of bipedal is limited as it can only move in a specific direction and can not avoid obstacles. Ohta et al. [20] demonstrated a technique that can transform passive to active dynamic walking providing better control. Simulations for training a bipedal to walk is a tedious task, if we desire to make a bipedal learn to perform a movement with the help of neural networks like a simple feed-forward network (FNN) [21] it is a grueling task for the network. IL [1, 22] helps in this scenario as it is a supervised learning. In traditional supervised learning training data represents features and labels, whereas in IL training data demonstrate action and state. The state represents the position with respect to the world and velocities of the joints and action consist of a list of joint angles further the subject will perform in complete duration of movement in the scenario we are discussing. While training the agent mimics the movement performed by the subject or demonstrator. Learning in IL can be performed through mainly two classes behavioral cloning (BC) [23, 24] and inverse reinforcement learning (IRL) [25].
In BC, computer programs reproduce human behaviour or sub-cognitive skills of the human while performing a movement [26], demonstrator perform the movement his or her action (joint angles and position) and the situation arise from that action (states) are recorded are used as input to train the agent, the agent will try to mimic the behaviour in learning process. BC is inefficient in complex tasks. In the IRL model of IL a reward function is being devised from the optimal behaviour of the demonstrator [26], the devised reward function performance for training an agent will solely depend on how precise and clean movement is performed by the demonstrator.
Humans use a lot of muscles while walking and mimicking but it is a difficult task in robots hence researchers develop a small bipedal robot [27] and made it walk in forward direction with a constant speed using a single condition that robot gait must be efficient as human gait. Ames [28] utilise human walking gait data to develop human-inspired control for walking of a bipedal robot while 57 muscles are engaged that lead to highly non-linear dynamics and forces acting on the muscles that sum up to hundreds of DOF. The authors created human-inspired controllers that utilizes time-based joint angles as output from human walking gait, processed and fed into a controller to control the robot. Learning algorithms were not used in this approach. Schuitema et al. [29] use a simple reinforcement learning algorithm to develop a controller for a passive dynamic walking robot and to maintain the balance of the bipedal while walking distorted due to disturbances. A feedback control loop is used as a hip actuation mechanism and an imbalance of the bipedal calculates the variables included and provided to the controller. First the algorithm is tested while simulating and then the mechanical prototype is made and finally tested.
Dadashi et al. [30] proposed an algorithm where the primal Wasserstein distance between the expert and the agent state-action distributions is minimized, Ho and Ermon [31] use Shannon-Jensen divergence, and Fu et al. [32] use Kullback-Leibler divergence to match state-action distribution of agent to the expert. Using similarity measures for IL shows promising results but the practical implementation requires fine tuning of a lot of hyperparameters and parameters approximations. Wang et al. [33] use Markov Decision Process [34] for generation of pose prediction sequence of a human from an image. Ho and Ermon [31] present a generative adversarial network to train the agent for IL. The discriminator must be very fine tuned according to the problem in order to improve the performance of the algorithm. Christiano et al. [35] propose a deep neural network based reinforcement learning from human preferences approach to perform the IL. This model can learn to imitate with minimal hours of human training data. Authors tested the performance of this method on Atari games and have satisfying results. Lepetit et al. [36] use Perspective-n-points (PnP) to find camera-to-robot pose. This method works flawlessly for articulated robots but does not work for bipedal or high DOF robots and Lee et al. [37] propose an algorithm to find joint positions of an articulated robot using a single image.
We propose to generate major joint angles with a single video of experts while performing movement with help of OpenPose architecture and then training a DQN to generate joint angles similar to the original input to make bot perform movement similar to expert demonstrator. While training we consider the physical limitations or joint limits of the robot so that the movement cannot be clipped.
III Proposed Methodology
Fig. 1 explains the approach where the joint angles data are extracted with the help of OpenPose [38], smoothed after that with the help of DQN [39], and the robot is trained to perform the movement.

We use a color image as input to a network that produces 2D locations of the joints or anatomical keypoints of the human body such as [shoulder, elbow, knee, waist, head]. These points are connected to form a vector that represent limb with the help of PAFs (Part Affinity Fields) [40] that encode the degree of union between points or joints. This is a bottom-up approach for detecting human pose in which, first the body parts are detected and then they are grouped together to form a complete human based on the PAFs. Fig. 2 shows the neural architecture for the OpenPose

.
Branch network produces PAF’s where refers to the neural network in branch 1 for summarizing in stage 1. In each successive stage original image features IF and predicted PAF’s from previous are chained to produce precise predictions,
| (1) |
where is total number of PAF stages in the network. After producing precisely refined PAF’s prediction the process is repeated for confidence map detection starting from the most updated PAF prediction.
| (2) |
where is the total number of confidence map stages. loss is calculated between the estimated predictions and the ground truth maps and fields, loss functions for the PAF branch at stage and loss function of confidence map branch at stage are:
| (3) |
| (4) |
where is ground truth PAF and is ground truth confidence map and B is a binary mask with when the label is not present in the ground truth, the loss function is used to guide the network to predict the PAF’s of body in branch 1 and confidence maps in branch 2 iteratively in precise manner. The overall loss function becomes:
| (5) |
PAF preserves location and orientation of the detected keypoints and predict the connection between the limbs whether they are from same person or different person, each PAF is a 2D vector field for each limb in this 2D vector field a 2D vector encodes the direction of points from one point of limb to another. After extracting the keypoints or anatomically important joints of a person angle between the joints is calculated, output of the pose estimation network is locations of joints of human in sequence ’nose’, ’neck’, ’r-shoulder’, ’r-elbow’, ’r-wrist’, ’l-shoulder’, ’l-elbow’, ’l-wrist’, ’r-hip’, ’r-knee’, ’r-ankle’, ’l-hip’, ’l-knee’, ’l-ankle’, ’r-eye’, ’l-eye’, ’r-ear’, ’l-ear’ and locations of these keypoints is defined as,
| (6) |
where and are the pixel locations of the keypoint from above mentioned joints. In this experiment we used ’r-shoulder’, ’r-elbow’, ’r-wrist’, ’l-shoulder’, ’l-elbow’, ’l-wrist’, ’r-hip’, ’r-knee’, ’r-ankle’, ’l-hip’, ’l-knee’, ’l-ankle’. Shoulder joint angle is angle between a point vertically downwards to the shoulder joint and elbow joint for both left and right shoulder, elbow joint angle is angle between shoulder and wrist for both right and left arm, hip joint angle is angle between a point vertically downwards hip joint and knee joint for both hip joints, knee joint angle is angle between hip joint and ankle joint for both left and right legs. We have three points and and angle between three points is:
| (7) |
where and are slopes of two line formed by joining , and , respectively. After all the major joint angles are recorded and saved, the joint values are used as input to an OpenAI gym [41] environment to make the bot learn and perform the movement. The environment has the Poppy Humanoid robot [16] as the agent, initially the shoulder joints of the robot are not in optimal standing human condition the arms were stretching away from the torso. Hence, we replaced all the RPY (roll, pitch and yaw) values to zero in the URDF ( Universal Robot Description Format ) file of the robot. Bot joint positions with respect to the world and joint forces are considered as state and the smoothed data of the joint angles obtained from above mentioned method are considered as actions. Joint angles data is smoothed by applying Savitzky-Golay [42] filter using local least squares polynomial approximation without distorting signal tendency. Consider joint angles of the right shoulder over a period of milliseconds. The smoothed joint angle is given by the formula:-
| (8) |
where is smoothed data point, is the value of quadratic polynomial used for smoothing if then 7-point quadratic polynomial is used and for , is the data angle of index from original data and are convolutions coefficient and are the elements of the matrix
| (9) |
where is a vandermonde matrix in which row of has values . After smoothing the data we create a DQN that makes the bipedal robot POPPY learn to imitate the instructor. In DQN states are given as input to the neural network and Q-value of all possible action at that time is generated as output, as in reinforcement learning we do not know the target value there will be too much forking between the two if we use a single network to calculate predicted value and target value. To solve this issue we use two neural network one to approximate the Q-value functions and other as target network to estimate the target, however the architecture of target network is similar to the prediction network but with fixed weights the weights of the target network changes after every b iterations (b- a hyperparameter) to train smoothly as it will keep the target value fixed for a little while, weights are copied from the prediction network after b iterations. Experience gained from the training is stored while training in the form of (state, action, reward, next-state).
| Number of Networks | 2 |
| Number of layers in each network | 5 |
| Activation Function | tanh/ReLU |
| Optimizer | Adam |
| Input Dimensions | 28 |
| Output Dimensions | 25 |
| Number of Hidden Layer Neurons | 768 |
| Learning Rate | 0.001 |
| Batch Size | 64 |
| Number of Epochs | 500 |
We use two types of neural networks CNN and FNN for training and testing networks. The hyper parameters are given in Table I, activation functions used are hyperbolic tan and ReLU by CNN and FNN respectively.
IV Experimental Results
We develop an OpenAI Gym [41] environment with the help of PyBullet [44] physics simulator to simulate the real world scenario while training the bot. Joint angles data is collected from a video of a person walking from Endless Reference with the help of OpenPose. The full implementation of the experiments in the paper is available here.





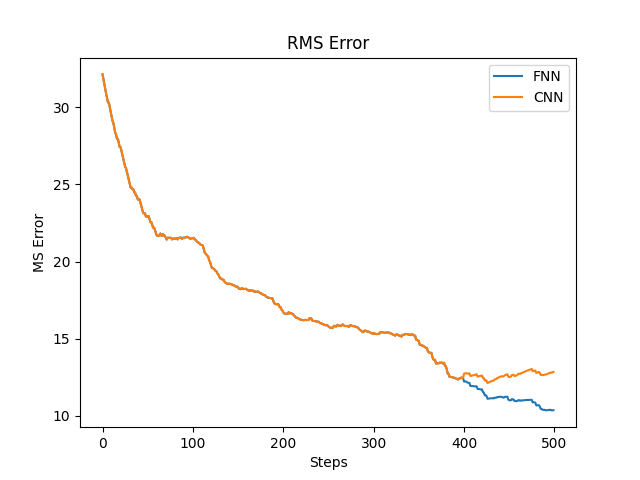












Fig. 3 shows the output of OpenPose with all major joints and connection between them as a skeleton and provides a noisy collected data because of some sudden movements of the instructor (person in video). We see absence of detected keypoints from the video so the data must be smoothed out as this data will lead to distortion in training of the agent. Savitzky-Golay filter is being used to smoothen the data, this filter will remove the sudden spikes in the data while keeping the data integrity as in Fig. 4.
Joint angles produced by these networks will be further known as F.Angles and C.Angles for output of FNN and CNN respectively.
| F.Shoulder | F.Elbow | F.Thigh | F.Knee | C.Shoulder | C.Elbow | C.Thigh | C.Knee | |
| Case-1 | -0.15 | -0.18 | 0.01 | 0.41 | 1.23 | 1.03 | 2.15 | 1.96 |
| Case-2 | 0.17 | 0.21 | -0.14 | 0.36 | -1.36 | 2.00 | 1.98 | -0.75 |
| Case-3 | 0.20 | -0.19 | 0.24 | 0.31 | 2.93 | 1.84 | 2.45 | 2.66 |
| Case-4 | -0.13 | 0.16 | -0.19 | 0.53 | 2.88 | -1.53 | 2.26 | -2.98 |
| F.Shoulder | F.Elbow | F.Thigh | F.Knee | C.Shoulder | C.Elbow | C.Thigh | C.Knee | |
| Case-1 | 1.80 | 1.54 | 1.33 | 1.40 | 4.57 | 2.54 | 6.86 | 4.02 |
| Case-2 | 2.08 | 1.92 | 3.47 | 2.12 | 12.90 | 12.81 | 9.51 | 11.28 |
| Case-3 | 5.02 | 1.03 | 2.34 | 1.59 | 15.61 | 18.04 | 12.50 | 12.66 |
| Case-4 | 6.03 | 1.96 | 2.17 | 2.53 | 22.88 | 21.03 | 21.26 | 22.98 |
Fig. 5 shows four test cases to validate the proposed approach. We looked at (1) Adult male walking in normal condition, (2) Adult female walking in normal condition, (3) Adult male walking with long strides, and (4) Adult female walking with long strides. First column of Fig. 5 shows the original input joint angles used for training for all four test cases, second column shows plot of F.Angles, third column shows plot of C.Angles and the last column shows plots of root mean square (RMS). We conclude from Fig. 5 that the FNN predicts joint angles more accurately than CNN. The plots in the second column are smoother when compared to the plots in the third column and similar to the original input. When we compare a small timestamp from both second and third column plots we see that joint angle transitions are smooth and there are no fluctuations whereas in third column plots joint angle transitions have fluctuations which lead to shivers in output movement.
Average mean angle error is the difference of average of the predicted left and right joint angles of the body and average of training input of left and right joint angles. Positive average mean angle error depicts the predicted joint angles are smaller or equal to the original joint angles and vice versa. Table II shows average mean angle error of joints. While analysing the data in Table II it seems that the values of F.Shoulder, F.Elbow, F.Thigh, F.Knee are much closer to zero which means the joint angle prediction is approximately equal, while values for C.Shoulder, C.Elbow, C.Thigh, C.Knee are far from zero compared to F. values.
Table III shows the Euclidean distance between the predicted joint angles and the original joint angles that is used for training for both the networks. F. values have lower euclidean distance which means the input and predicted are very much similar but for the C. values the euclidean distance has higher values which shows that the input and predicted are distant from each other.


We consider joint angles as the sole variable to perform IL due to unavailability of the desired data. Fig. 6 and Fig. LABEL:cnn_outpu shows the plot of joint angles produced by FNN and CNN respectively after training for both the left and right side of the body. The left part of the plot is the input joint angles and right part of the graph is output joint angles. While comparing these two figures it seems that the output of F.Angles are much similar to the input angles used to train compared to the C.Angles as shown in the bottom left plot of Fig. LABEL:cnn_outpu. Fig. 5, 6, and LABEL:cnn_outpu shows that the joint angles are totally different from the input angles. The prediction of F.Angles is comparatively similar to the original input data than C.Angles. This also shows that FNN performs better than CNN in this scenario. There will be some scenarios when we have to feed the input as an image instead of joint angles data in those cases CNN may perform better than FNN. Fig. 8 shows the mean squared error (MSE) and root mean squared error (RMSE) for the training of both the networks, MSE loss is plotted on left side of axis and RMSE loss is plotted on right side of axis due to range variation of both losses.

The curves in Fig. 8 shows that the loss is decreasing over a number of epochs and there is no sudden drop in loss which means the algorithm is learning instead of remembering the demonstrated action.
V Conclusions
In this paper we made an agent learn to perform specific movement as demonstrated by the instructor using IL, first data generation is done by OpenPose, a video is fed to the OpenPose network frame by frame and the joint angles are extracted and stored in text files after this step data smoothing is done by Savitzky-Golay filter. Data is then fed to a DQN with a target network made to predict the values of original joint angles data. We used two networks for training and inferred that the performance of FNN performs better to give joint angles similar to the original data. The proposed approach works well for the slow movements such as walking and jogging in a computationally cost effective manner using a single video as the training data. In future with 3D-Data generation and other network architecture more complex movements similar to the instructor can be imitated. The data generated would be 2D joint angles and their position in 2D space. 3D data generation would constitute joint angles, positions, and velocity of joints in 3D space giving rise to more realistic training.
References
- [1] T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, and J. Peters, “An Algorithmic Perspective on Imitation Learning,” Foundations and Trends in Robotics, vol. 7, no. 1-2, p. 1–179, 2018.
- [2] P. Booth, An Introduction to Human-computer Interaction. Erlbaum, 1989.
- [3] M. Daily, S. Medasani, R. Behringer, and M. Trivedi, “Self-Driving Cars,” Computer, vol. 50, no. 12, pp. 18–23, 2017.
- [4] R. T. Azuma, “A Survey of Augmented Reality,” Presence: Teleoperators and Virtual Environments, vol. 6, no. 4, pp. 355–385, 08 1997.
- [5] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adversarial Nets,” 2014.
- [6] G. Klančar, A. Zdešar, S. Blažič, and I. Škrjanc, “Chapter 1 - Introduction to Mobile Robotics,” in Wheeled Mobile Robotics, G. Klančar, A. Zdešar, S. Blažič, and I. Škrjanc, Eds., 2017, pp. 1–11.
- [7] Z. Xu and P. Ma, “A Wall-Climbing Robot for Labelling Scale of Oil Tank’s Volume,” Robotica, vol. 20, no. 2, p. 209–212, Mar. 2002.
- [8] F. Gao, C. Qi, Q. Sun, X. Chen, and X. Tian, “A Quadruped Robot with Parallel Mechanism Legs,” in ICRA, 2014, pp. 2566–2566.
- [9] C. C. G. B. G. A. Y. Aoustin, Bipedal Robots and Walking. John Wiley & Sons, Ltd, 2009, ch. 1, pp. 1–45.
- [10] S. Schaal, “Is Imitation Learning the Route to Humanoid Robots?” Trends in Cognitive Sciences, vol. 3, no. 6, pp. 233–242, 1999.
- [11] C. Nehaniv and K. Dautenhahn, Imitation and Social Learning in Robots, Humans and Animals: Behavioural, Social and Communicative Dimensions. Cambridge University Press, 01 2007.
- [12] A. K. Gupta, K. G. Smith, and C. E. Shalley, “The Interplay Between Exploration and Exploitation,” Academy of Management Journal, vol. 49, no. 4, pp. 693–706, 2006.
- [13] S. Saeedvand, M. Jafari, H. S. Aghdasi, and J. Baltes, “A Comprehensive Survey on Humanoid Robot Development,” The Knowledge Engineering Review, vol. 34, p. e20, 2019.
- [14] Y. Gong, R. Hartley, X. Da, A. Hereid, O. Harib, J.-K. Huang, and J. Grizzle, “Feedback Control of a Cassie Bipedal Robot: Walking, Standing, and Riding a Segway,” CoRR, vol. abs/1809.07279, 2018.
- [15] G. Nelson, A. Saunders, and R. Playter, The PETMAN and Atlas Robots at Boston Dynamics. Springer Netherlands, 01 2019, pp. 169–186.
- [16] M. Lapeyre, “Poppy: Open-source, 3D Printed and Fully-modular Robotic Platform for Science, Art and Education,” Ph.D. dissertation, University of Bordeaux, France, 2014.
- [17] J. Schulkin, “Evolutionary Basis of Human Running and Its Impact on Neural Function,” Frontiers in Systems Neuroscience, vol. 10, p. 59, 2016.
- [18] A. Santanasto, P. Coen, N. Glynn, K. Conley, S. Jubrias, F. Amati, E. Strotmeyer, R. Boudreau, B. Goodpaster, and A. Newman, “The Relationship between Mitochondrial Function and Walking Performance in Older Adults with A Wide Range of Physical Function,” Experimental Gerontology, vol. 81, 04 2016.
- [19] T. McGeer, “Passive Dynamic Walking,” The International Journal of Robotics Research, vol. 9, no. 2, pp. 62–82, 1990.
- [20] H. Ohta, M. Yamakita, and K. Furuta, “From Passive to Active Dynamic Walking,” International Journal of Robust and Nonlinear Control, vol. 11, no. 3, pp. 287–303, 2001.
- [21] D. Dai, W. Tan, and H. Zhan, “Understanding the Feedforward Artificial Neural Network Model From the Perspective of Network Flow,” CoRR, vol. abs/1704.08068, 2017.
- [22] A. Hussein, M. M. Gaber, E. Elyan, and C. Jayne, “Imitation Learning: A Survey of Learning Methods,” ACM Comput. Surv., vol. 50, no. 2, Apr. 2017.
- [23] F. Torabi, G. Warnell, and P. Stone, “Behavioral Cloning from Observation,” in IJCAI, 2018, p. 4950–4957.
- [24] N. Gavenski, J. Monteiro, R. Granada, F. Meneguzzi, and R. C. Barros, “Imitating Unknown Policies via Exploration,” in BMVC, 2020.
- [25] A. Y. Ng and S. Russell, “Algorithms for Inverse Reinforcement Learning,” in ICML, 2000, pp. 663–670.
- [26] C. Sammut, “Behavioral Cloning,” in Encyclopedia of Machine Learning. New York: Springer, 2010, pp. 93–97.
- [27] S. H. Collins and A. Ruina, “A Bipedal Walking Robot with Efficient and Human-Like Gait,” in ICRA, 2005, pp. 1983–1988.
- [28] A. D. Ames, “Human-Inspired Control of Bipedal Walking Robots,” IEEE Transactions on Automatic Control, vol. 59, no. 5, pp. 1115–1130, 2014.
- [29] E. Schuitema, D. G. E. Hobbelen, P. P. Jonker, M. Wisse, and J. G. D. Karssen, “Using A Controller based on Reinforcement Learning for A Passive Dynamic Walking Robot,” in ICHR, 2005, pp. 232–237.
- [30] R. Dadashi, L. Hussenot, M. Geist, and O. Pietquin, “Primal Wasserstein Imitation Learning,” CoRR, vol. abs/2006.04678, 2021.
- [31] J. Ho and S. Ermon, “Generative Adversarial Imitation Learning,” in NIPS, vol. 29, 2016.
- [32] J. Fu, K. Luo, and S. Levine, “Learning Robust Rewards with Adversarial Inverse Reinforcement Learning,” CoRR, vol. abs/1710.11248, 2018.
- [33] B. Wang, E. Adeli, H. Chiu, D. Huang, and J. C. Niebles, “Imitation Learning for Human Pose Prediction,” in ICCV, 2019, pp. 7123–7132.
- [34] R. S. Sutton and A. G. Barto, Introduction to Reinforcement Learning, 1st ed. MIT Press, 1998.
- [35] P. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep Reinforcement Learning from Human Preferences,” in NIPS, vol. 30, 2017.
- [36] V. Lepetit, F. Moreno-Noguer, and P. Fua, “EPnP: An Accurate Solution to the PnP Problem,” IJCV, vol. 81, 02 2009.
- [37] T. E. Lee, J. Tremblay, T. To, J. Cheng, T. Mosier, O. Kroemer, D. Fox, and S. Birchfield, “Camera-to-Robot Pose Estimation from a Single Image,” in ICRA, 2020.
- [38] Z. Cao, G. Hidalgo Martinez, T. Simon, S. Wei, and Y. A. Sheikh, “OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,” IEEE TPAMI, vol. 43, no. 1, pp. 172–186, 2021.
- [39] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing Atari With Deep Reinforcement Learning,” in NIPS Deep Learning Workshop, 2013.
- [40] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields,” in CVPR, 2017, pp. 1302–1310.
- [41] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “OpenAI Gym,” CoRR, vol. abs/1606.01540, 2016.
- [42] A. Savitzky and M. J. E. Golay, “Smoothing and Differentiation of Data by Simplified Least Squares Procedures,” Analytical Chemistry, vol. 36, no. 8, pp. 1627–1639, 1964.
- [43] T. Hester, M. Vecerik, O. Pietquin, M. Lanctot, T. Schaul, B. Piot, D. Horgan, J. Quan, A. Sendonaris, I. Osband, G. Dulac-Arnold, J. Agapiou, J. Leibo, and A. Gruslys, “Deep Q-learning From Demonstrations,” in AAAI, 2018, pp. 3223–3230.
- [44] E. Coumans and Y. Bai, “PyBullet, A Python Module for Physics Simulation for Games, Robotics and Machine Learning,” http://pybullet.org, 2016–2019.