MAFF-Net: Filter False Positive for 3D Vehicle Detection with Multi-modal Adaptive Feature Fusion
Abstract
3D vehicle detection based on multi-modal fusion is an important task of many applications such as autonomous driving. Although significant progress has been made, we still observe two aspects that need to be further improvement: First, the specific gain that camera images can bring to 3D detection is seldom explored by previous works. Second, many fusion algorithms run slowly, which is essential for applications with high real-time requirements(autonomous driving). To this end, we propose an end-to-end trainable single-stage multi-modal feature adaptive network in this paper, which uses image information to effectively reduce false positive of 3D detection and has a fast detection speed. A multi-modal adaptive feature fusion module based on channel attention mechanism is proposed to enable the network to adaptively use the feature of each modal. Based on the above mechanism, two fusion technologies are proposed to adapt to different usage scenarios: PointAttentionFusion is suitable for filtering simple false positive and faster; DenseAttentionFusion is suitable for filtering more difficult false positive and has better overall performance. Experimental results on the KITTI dataset demonstrate significant improvement in filtering false positive over the approach using only point cloud data. Furthermore, the proposed method can provide competitive results and has the fastest speed compared to the published state-of-the-art multi-modal methods in the KITTI benchmark.
I INTRODUCTION
Background. Since 3D vehicle detection is a crucial part of perception in autonomous driving, a lot of research work has been invested in the industry and academia. 3D detection can be achieved through images, lidar point clouds or multi-modal data. In this study, we consider the fusion problem of lidar point clouds and RGB images. Point clouds provide very accurate depth information, but are accompanied by low resolution and texture information. On the other hand, images have ambiguous depth information but can provide fine-grained texture and color information. This provides an attractive research opportunity for how to design a model that can take full advantages of the two types of data.
Reality. As a pioneering attempt of fusion methods, MV3D proposed a multi-view fusion mechanism to explore multi-modal collaboration methods. Based on this method, AVOD and ContFuse further proposed more diverse fusion pipelines to improve the performance of 3D detection. However, some recently published methods such as PointPillars[1], Second[2], PointRCNN[3], PartA2[4], STD[5] and 3DSSD[6] significantly outperform these methods using only lidar point clouds. In fact, despite some recent fusion studies[7, 8, 9, 10, 11], the top methods on the KITTI[12] leaderboard are still lidar only[13, 14, 15]. Does this mean that the 3D point cloud is sufficient for 3D detection? Or is there any way for RGB images to effectively supplement 3D detection?

Analysis. The answer is clear by analyzing the characteristics of point cloud data and RGB image data. Consider the two examples in Fig. 1, where the hierarchical trees in the left and the object clusters in the right are very similar to vehicles in the lidar modality. This makes it difficult to distinguish specific objects using only point clouds. But, the above objects are easy to distinguish in the image, which shows that adding images to the point cloud network can help effectively reduce 3D false positive(FP). However, in the currently published fusion methods, almost no attention has been paid to the specific effects of images for 3D detection, especially in eliminating FP. In this research, we focus on the false positive filtering effect of images for 3D vehicle detection: we hope that when the image is fused with the point cloud, FP can be effectively reduced without reducing true positive(TP).
Challenges. However, how to effectively integrate 2D images into the 3D detection pipeline is still an open question. A naive way is to directly concatenate the raw RGB feature to the 3D point cloud feature, because the point-to-pixel correspondence can be established through projection. However, the image often has noise information such as occlusion and truncation. In these cases, the wrong image feature will be obtained after 3D points are projected onto the image. Therefore, simply using point-wise projected image features will degrade the performance of 3D detection. Moreover, we also notice that the detection speeds of current fusion methods are generally slow. The reasons for the slow speed are: (i) the fusion methods generally adopt a two-stage way that uses ROI-pooling[16] to fuse the image with the point cloud; (ii) the fusion methods usually use 2D detection or segmentation tasks to obtain high-level image features, and then fuse the features with the point cloud. The second way is equivalent to doing a 2D task first and then doing 3D task, which slows down the speed of the 3D detection.
Contributions. In this paper, to address the above challenges, we design a multi-modal adaptive feature fusion network named MAFF-Net based on the successful PointPillars architecture. It is an end-to-end single-stage fusion 3D detection method, which only uses the raw RGB features and does not rely on the high-level features of any 2D tasks. It is also able to eliminate the interference information of two modalities through channel-wise attention module, so that the network can make full use of the advantages of image and point cloud features, to achieve the purpose that reducing FP and reserving TP at the same time.
Specifically, we have developed two fusion technologies: (i) PointAttentionFusion(PAF): This is a relatively fast and simple fusion method where the corresponding projection image features and 3D point features are concatenated to obtain preliminary mixed features, which are used as the input of point-wise channel attention module to learn the channel-wise importance of point cloud and image features. The learned attention features and the original modal features are then concatenated to obtain the final point-wise fusion feature, which is then jointly processed by the PointPillars pipelines. (ii) DenseAttentionFusion(DAF): In this technology, point cloud and image features are divided into three types of pillar-wise features: point cloud feature, image feature, and point cloud image feature that is obtained by appending RGB feature to the point cloud feature. The above three features are concatenated and sent to the pillar-wise channel attention module to generate attention feature. Finally, the attention feature is concatenated with the previous three modalities features to form the pillar-wise fusion feature, which is further used by the subsequent 2D CNN network. Compared with the DenseAttentionFusion, PointAttentionFusion is more concise, so it is faster and more suitable for eliminating some simple false detections. DenseAttentionFusion is a complex and dense fusion method. Its performance is better than PointAttentionFusion and it is more effective for some difficult false detections.
The main contributions of this study are summarized as follows:
-
•
This paper proposes an end-to-end trainable single-stage multi-modal fusion method for reducing 3D false positive.
-
•
This paper proposes two different fusion techniques based on channel attention mechanism for different usage scenarios.
-
•
Experiments on the KITTI dataset demonstrate that the proposed method can effectively reduce false positive while maintaining true positive. It achieves competitive results compared with the published state-of-the-art fusion methods with a fast detection speed of 32 Hz.
-
•
Extensive analysis and visualization are conducted to understand the design principles of the proposed method and the usefulness of the attention mechanism for multi-modal fusion.
II RELATED WORK
II-A 3D Vehicle Detection based on Point Cloud
3D vehicle detection using only point clouds can be roughly divided into 3 types: Bird’s Eye View(BEV)-based, Voxel-based, and Point-based. BEV-based methods[17, 18] first use rules[19] to convert the point cloud into the BEV form, and then uses the 2D CNN network for learning and prediction[20]. Voxel-based methods divides the point cloud space into regularly arranged voxel blocks, use rules[21, 22, 23] or neural networks[24, 25] to encode the voxels, and then adopt 3D or 2D convolution[2, 26, 4, 27, 28] for 3D detection. PointPillars[1] further simplified voxels into pillars, realizing a real-time one-stage 3D detection method. The voxel-based methods are conducive to accurate 3D proposal generation but are also limited by the receptive field of 2D/3D convolution. The point-based method mainly uses PointNet[29, 30] technology to encode 3D points, and then uses more strategies[3, 5, 6] to process 3D points to achieve the purpose of accurately predicting 3D vehicles. Most of these point-based methods are based on the PointNet series, which makes the receptive fields of point cloud feature learning more flexible. Recently, there has been a trend of fusing point-based and voxel-based methods[15, 13] to utilize the best of two worlds, thereby improving 3D detection performance.
II-B 3D Vehicle Detection based on Multi-modal Fusion

In order to take advantages of the camera and lidar sensors, various fusion methods have also been proposed. MV3D[31] is a pioneering work in the fusion method. It combines the lidar BEV representation, front view and image together, and proposes a two-stage network. AVOD[32] fuses the features of the BEV and the image in the middle layer of the convolution to predict 3D objects. ContFuse[33] uses continuous convolution to fuse images and lidar features on different resolutions. MMF adds ground estimation and depth estimation to the fusion framework, and learns better fusion feature representations while jointly learning multi-tasks. [34, 35, 36] first use camera images to generate proposals and then exploit some methods to process the lidar points in these regions to generate 3D objects. [10, 37] use 2D tasks (detection or segmentation) to obtain the feature representations of the image, then fuse these feature representations with the point cloud, and finally use the architecture of VoxelNet to process the fused features.
Although various multi-modal fusion methods have been proposed, they have seldom paid attention to the specific gains brought by the image for 3D detection and the detection speeds are often very slow. In this study, we focus on using images to eliminate the FP of 3D vehicle detection and hope to obtain a fast multi-modal fusion method.
III Proposed Method
In this section, we introduce the proposed single-stage point cloud and image feature fusion 3D vehicle detector MAFF-Net in detail.
III-A Raw RGB Input
Compared with lidar point clouds, images have rich color and texture information, which is very effective for overcoming the false detection of point clouds, especially the background false detection. In this paper, we only use the raw RGB features of the image as the input of MAFF-Net. MAFF-Net does not rely on any 2D annotation information and the high-level features of any 2D tasks.
III-B PointPillars
The PointPillars structure is used as the base 3D detection network for two main reasons: (i) it achieves a good balance between speed and performance: with excellent performance, it has a very fast detection speed. A lot of work in academia and industry is also based on this algorithm[27, 28, 38, 39, 40, 41]. (ii) It provides a natural and effective interface for fusing image features at different granularities in 3D space such as points and pillars. The network used in this study is described in [1]. For completeness, this section briefly reviews PointPillars. This algorithm consists of three modules: (i) a Pillar Feature Net(PFN); (ii) 2D Convolutional Neural Networks; (iii) a Detection Head.
PFN is a feature learning network designed to encode raw point clouds for individual pillars. All non-empty pillars are encoded by PFN and share the same network parameters. The encoded features are scattered back to the original pillar positions to construct a pseudo-image. The pseudo-image features are forwarded through a series of 2D convolutional blocks to extract high-level features. The features are then used by a detection head to generate the targets.
III-C Multimodal Adaptive Feature Fusion(MAFF)
In this study, two concise technologies that can fuse raw RGB data with the point cloud data are proposed to filter false positive in 3D detection.
PointAttentionFusion(PAF): This is an early and simple fusion approach in which each 3D point is aggregated through an image feature and two attention features to achieve the adaptive fusion features. Fig. 3 presents the procedure of this technology.
The method first uses the calibration matrix to project each 3D point onto the image, and the projected image features can be obtained according to the corresponding projection location index. Note that these features are the raw RGB features. In order to make the projected image features and point cloud features compatible, a simple fully connected network called is applied to map the image features to appropriate dimensions. The is composed of a set of blocks and each block consists of a linear layer, a BN layer, and a ReLU layer. Next, the point cloud features and the mapped image features are concatenated channel-wise to obtain point-wise extended features. However, since the image has many noise factors, such as occlusion, truncation, etc., the extended features will introduce interference information.
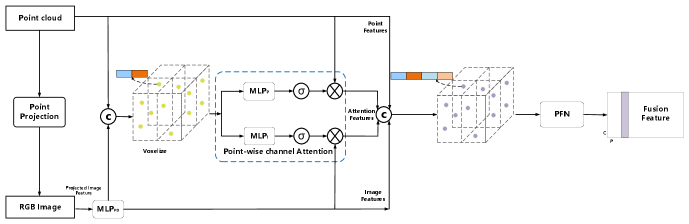
To address this issue, we adopt the point-wise channel attention module, which uses expanded features to adaptively estimate the importance of each type of features in a channel-wise manner. First, feed the extended features into a fully connected layer that includes a linear layer, a ReLU layer, and a linear layer. Then output the feature weights through a sigmoid, and finally multiply the weights with the corresponding features in a channel-wise manner to get the attention features. The above process is used to process the point cloud features and image features respectively. The specific forms of channel attention are as follows:
| (1) | ||||
where and represent point cloud and image features, respectively, and are the corresponding point-wise attention features, is the extended point image features, is the sigmoid activation function and is the element-wise product operator. After obtaining the attention features, concatenate , , and channel-wise to get the point-wise fusion feature. Then divide the 3D point cloud space into pillars, followed by grouping the points to pillars. Finally, the simplified version of PointNet is adopted to generate the pillar-wise fusion features.
The advantage of this method is that since the fusion method is simple and the added networks are all shallow networks, the approach can achieve fast detection speed. Moreover, the approach can learn to summarize useful information from both modalities through PFN layer because of the early stage fusion strategy.
DenseAttentionFusion(DAF): In contrast to PointAttentionFusion that fuses features in a concise manner, DenseAttentionFusion employs a relatively complex fusion strategy, where features are divided into three forms and fused together. As shown in Fig. 4, the three features are the point cloud features, the image features, and the extended point image features described in PointAttentionFusion.
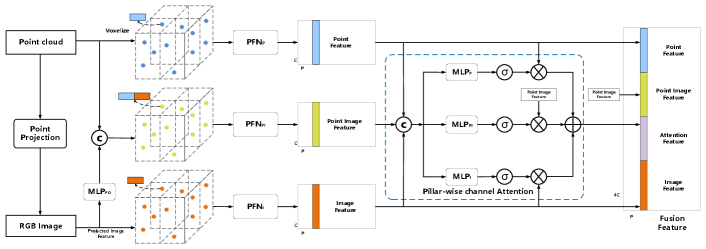
In PointAttentionFusion, only extended point image features is used for subsequent work. However, after PFN learning, the feature is equivalent to the global features of the point cloud and the image. This feature will lose some characteristics of the original two modalities. Thus, a naive approach would be to put the original point cloud features and image features back into the global features. However, due to the noise information of the image features and the redundancy of the three features, blindly fusing the three features will introduce lots of interference information, resulting in the degradation of detection performance. In the following, we describe a novel dense attention fusion method that effectively combines the three types of features.
First, after projecting 3D points onto the image, the corresponding RGB features can be obtained. The RGB features have two uses, one is to expand the point cloud features in the same way as PointAttentionFusion to obtain the point cloud image features, and the other can regard this point-wise image feature as another feature form of 3D points. In this way, we can obtain point cloud features, point cloud image mixed features, and projected image features. Because the above three features are all in point-wise form, they can use the and coordinates of the 3D point to perform pillar operations, respectively. Here, we can get the pillar representations of three different features, and then three PFNs with the same structure are adopted to encode the pillars to generate three type of pillar-wise features.
Next, we use the pillar-wise channel attention module to adaptively estimate the importance of each pillar feature. The above three features are concatenated together as the input of this module. The attention features of the three features are estimated by the following attention maps:
| (2) | ||||
where , and represent the pillar-wise point cloud, point image and image features, respectively, is the concatenated feature of the above three features, , and are the corresponding pillar-wise attention features, is the pillar-wise attention features that need to be obtained, is the sigmoid activation function and represents the element-wise product operator. After obtaining the attention features, concatenate , , , and channel-wise to get the pillar-wise fusion features.
Although DenseAttentionFusion is a relatively complex fusion strategy, it has the following advantages. First, it fully retains the original characteristics of the three features of point cloud, image, and point cloud image, while minimizing the noise impact of each feature. This makes its detection performance better than PointAttentionFusion. Second, the fusion is based on Pillars features, which can reduce the dependence on the availability of high-resolution 3D points.
III-D Training Details
Network Architecture: For the fairness of comparison, we keep most of the settings of PointPillars as described in [1] except for some newly added module structures. According to the type of fusion, the input and output dimensions of the PFN layers and the MLP layers are different. Note that, except for the input dimensions, the structure of 2D convolutional network in the proposed MAFF-Net is the same as PointPillars.
For PointAttentionFusion, the configuration of image dimension prediction is (3,96,16). The and in the attention module have (9+16,25,9) and (9+16,25,16) configurations respectively, where 9 is the dimension of the point cloud feature and 16 is the dimension of the image feature. Next, the configuration of PFN layer is (9+16+9+16,64), which leads to the input dimension of the subsequent 2D convolutional network is 64.
For DenseAttentionFusion, the configuration of is the same as the in PointAttentionFusion. , and have configurations of (16, 64), (9+16, 64) and (3, 64) respectively. The configuration of the three MLPs in the attention module are all (64*3, 64*3, 64), but their weights are not shared. The final fusion feature is combined by four types of features, so its dimension is 64*4, which leads to the input dimension of the 2D convolutional network is 64*4.
Loss: We use the same loss functions described in PointPillars. The loss function is divided into 3 types, namely the localization regression loss , the classification loss , and the orientation loss . uses SmoothL1 function to define the loss for , uses focal loss, and uses a softmax classification loss. The overall loss function can be defined as:
| (3) |
where , and is the number of positive anchors.
Data Augmentation: Our two fusion methods both project the 3D points to the image in a point-wise manner, so all the data augmentation methods of PointPillars can be used, which is similar to PointPainting[9]. Data augmentation adopts sample objects from database, augment ground truths independently, and perform global augmentations for the whole point cloud and all boxes.
IV EXPERIMENTS
IV-A Dataset and Metric
Dataset and Implementation: This study uses the KITTI benchmark dataset [12] to evaluate the proposed fusion method, which includes 7481 training samples and 7518 testing samples. There are three levels of difficulty: easy, moderate and hard, which are assessed based on the object height in image, occlusion and truncation. The rank of leaderboard is based on the moderate result. We follow the general approach proposed by [31] to split the training samples into a training set of 3712 samples and a validation set of 3769 samples. The proposed MAFF-Net is compared with previously published method on the car category. Inference of the entire network is carried out on Tesla V100 GPU. The code of PointPillars used in this study comes from (httP://github.com/nutonomy/second.pytorch).
Metric: The metric of KITTI is defined by average precision(AP) on 40 recall positions of the Precision/Recall curve [42] with IoU=0.7. This metric is a good indicator of the overall performance, but it cannot effectively reflect the details of the performance, such as the FP that we are concerned about. To show the performance of filtering FP, a simple way can be used: for each recall position, the number of TP is the same. According to the formula of precision , when TP remains unchanged, the less FP, the higher precision. Thus, the precision at a single recall position can reflect the performance of the algorithm processing FP. In this study, we use precision of five recall positions () to verify the proposed method performance for filtering FP. The reason for choosing these positions is that the scores of detection at these positions are generally at a medium level and it is difficult to filter vehicles only using the score threshold, which will lead to many FP.
| Method | Recall=0.725 | Recall=0.75 | Recall=0.775 | Recall=0.8 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| easy | moderate | hard | mAP | easy | moderate | hard | mAP | easy | moderate | hard | mAP | easy | moderate | hard | mAP | |
| PointPillars | 95.17 | 86.21 | 81.75 | 87.71 | 94.29 | 83.68 | 77.41 | 85.13 | 93.49 | 79.99 | 71.39 | 81.62 | 92.41 | 73.86 | 66.03 | 77.44 |
| MAFF-Net(PAF) | 96.48 | 87.56 | 82.83 | 88.96 | 96.16 | 85.25 | 78.91 | 86.78 | 95.34 | 81.58 | 73.31 | 83.41 | 94.44 | 75.69 | 67.99 | 79.37 |
| MAFF-Net(DAF) | 95.64 | 88.35 | 83.53 | 89.17 | 95.03 | 86.08 | 80.11 | 87.07 | 94.23 | 83.05 | 73.56 | 83.61 | 93.49 | 78.08 | 68.82 | 80.13 |
| Improvement | +1.31 | +2.13 | +1.78 | +1.46 | +1.87 | +2.40 | +2.69 | +1.94 | +1.86 | +3.06 | +2.17 | +1.99 | +2.03 | +4.22 | +2.79 | +2.69 |
IV-B Evaluation on KITTI Validation Set
Evaluation on filtering FP. Table I shows the comparison of the 3D detection performance of PointPillars and MAFF-Net at different recall positions. The performance of each position has been significantly improved. As recall increases (in this case, the detection score decreases and FP is easier to increase), the improvement of mAP gradually increases. For the moderate category that is concerned on the KITTI benchmark, when the recall is 0.8, the proposed fusion method improves the performance by 4.22%. For a single recall position, only reducing FP can improve performance because of the same number of TP. Therefore, the performance improvement on each single recall position shows that MAFF-Net is effective for filtering FP.
| Method | Score Threshold = 0.4 | Score Threshold = 0.1 | ||||
|---|---|---|---|---|---|---|
| TP | FP | FP(BG) | TP | FP | FP(BG) | |
| PointPillars | 8606 | 4428 | 2346 | 8783 | 26237 | 22403 |
| MAFF-Net(PAF) | 8636 | 4080 | 2018 | 8802 | 24446 | 20478 |
| MAFF-Net(DAF) | 8627 | 3933 | 1906 | 8811 | 23330 | 19585 |
| Improvement number/rate | - | -495 | -440 | - | -2907 | -2818 |
In order to reflect the performance of filtering FP more intuitively, Table II lists the number of TP and FP for the 3D vehicle detection under different score thresholds. When the score are 0.4 and 0.1, the FP are reduced by 11.18% and 11.08%, respectively, and the FP caused by the background are reduced by 18.75% and 12.58%, respectively. It shows that the proposed two fusion methods can effectively reduce FP while slightly improving TP, especially for reducing FP caused by background.
| Method | 3D(Car) | BEV(Car) | ||||
|---|---|---|---|---|---|---|
| easy | moderate | hard | easy | moderate | hard | |
| PointPillars(baseline) | 87.79 | 78.44 | 74.06 | 92.55 | 88.32 | 86.52 |
| MAFF-Net(PointFusion) | 89.02 | 77.76 | 74.51 | 93.55 | 87.52 | 84.78 |
| MAFF-Net(PAF) | 88.86 | 79.30 | 74.71 | 93.10 | 89.25 | 86.67 |
| MAFF-Net(DenseFusion) | 88.05 | 77.20 | 73.73 | 93.10 | 87.21 | 84.29 |
| MAFF-Net(DAF) | 88.88 | 79.37 | 74.68 | 93.23 | 89.31 | 86.61 |
Analysis of the attention mechanisms. We visualize the point cloud features in DenseAttentionFusion before () and after () using attention, as shown in Figure 6. After using the attention module, the background area is fully suppressed, so that the geometric shape of the vehicles can be highlighted. Moreover, for some objects that are similar to the vehicle in 3D structure, the attention module can eliminate some of their shapes, so that their 3D structures are no longer similar to the vehicle.
In order to further show the role of the attention module, Table III shows the performance comparison of the KITTI validation set with and without the attention module. When the attention module is not used, compared to PointPillars, the two fusion methods have improved performance in the easy category, but the performance in the moderate and hard categories decreases. In the moderate and hard categories, interference information is very serious. In these cases, when the point cloud is projected to the image, it will get the wrong image features, which will lead to the degradation of detection performance. After adding the attention module, the MAFF-Net is able to adapt to the weight of each modal feature, thereby improving the detection performance.


The visualization of Detection Results. Figure 5 provides a qualitative analysis of some 3D detection results. It can be observed from Figure 5 that the 3D structures of many false detection objects are similar to that of vehicles, such as the hierarchical tree clusters on the left side of the second column image, the object clusters on the right side of the third column image, and wall and fence on the left side of the fourth column image. These conditions will make it difficult for the lidar point cloud to distinguish the objects. However, MAFF-Net can effectively reduce the above false detection objects by using image information, which demonstrates the effectiveness of the proposed algorithm.
IV-C Evaluation on KITTI Testing Set
We evaluate the proposed MAFF-Net with DenseAttentionFusion on the KITTI testing set by submitting the test results to the official server. The results are summarized in Table IV. It can be observed that MAFF-Net with DenseAttentionFusion can have competitive results compared with other state-of-the-art multimodal fusion algorithms. The proposed method has the fastest speed, achieves top rank in one category and 2nd rank in three categories within the fusion methods. It is worth pointing out that the results of the test set we submitted(PointPillars(baseline)) using the code given in PointPillars[1] are not ideal, for example, it is lower than the original PointPillars 1.1% in the 3D moderate category. However, even if only the low-performance PointPillars are used, the detection performance of MAFF-Net is still better than the original PointPillars in most categories. In 3D moderate, MAFF-Net is 1.9% higher than PointPillars (baseline) and 0.7% higher than PointPillars. Therefore, if a more powerful point cloud backbone network can be used, MAFF-Net will achieve better performance.
| Method | 3D(Car) | BEV(Car) | Speed | ||||
|---|---|---|---|---|---|---|---|
| easy | moderate | hard | easy | moderate | hard | (Hz) | |
| MV3D[31] | 74.97 | 63.63 | 54.00 | 86.62 | 78.93 | 69.80 | 2.80 |
| AVOD-FPN[32] | 83.07 | 71.76 | 65.73 | 90.99 | 84.82 | 79.62 | 10.00 |
| ContFuse[33] | 83.68 | 68.78 | 61.67 | 94.07 | 85.35 | 75.88 | 16.70 |
| F-ConvNet[35] | 87.36 | 76.39 | 66.69 | 91.51 | 85.84 | 76.11 | 2.1 |
| F-pointnet[34] | 82.19 | 69.79 | 60.59 | 91.17 | 84.67 | 74.77 | 5.90 |
| PI-RCNN[11] | 84.37 | 74.82 | 70.03 | 91.44 | 85.81 | 81.00 | 10.00 |
| PointPillars[1] | 82.58 | 74.31 | 68.99 | 90.07 | 86.56 | 82.81 | 62.00 |
| PointPillars(baseline) | 83.11 | 73.12 | 67.73 | 90.06 | 86.64 | 79.19 | 62.00 |
| MAFF-Net(DAF) | 85.52 | 75.04 | 67.61 | 90.79 | 87.34 | 77.66 | 24.00 |
V CONCLUSION
In this paper, we have explored how RGB images can assist 3D vehicle detection and proposed an end-to-end single-stage feature adaptive fusion network by extending the recently proposed PointPillars, to achieve fast speed and effectively eliminate false positive. Based on the channel attention mechanism, we propose two fusion techniques: PointAttentionFusion uses the channel attention mechanism to perform point-wise feature fusion of the two modalities; DointAttentionFusion converts the image and point cloud into three modalities, and then performs pillar-wise feature fusion of multi-modalities. Researchers can choose different fusion methods according to actual needs. Evaluation on the KITTI dataset demonstrates significant improvement in filtering false positive over the approach that uses only a single modality. Furthermore, the proposed method yields competitive results and has the fastest speed compared to the published state-of-the-art multi-modal methods in the KITTI benchmark. In the future, we plan to explore how images can bring more performance enhancements to 3D vehicle detection and the gains images can bring to multi-class detection networks.
References
- [1] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 12 697–12 705.
- [2] Y. Yan, Y. Mao, and B. Li, “Second: Sparsely embedded convolutional detection,” Sensors, vol. 18, no. 10, p. 3337, 2018.
- [3] S. Shi, X. Wang, and H. Li, “Pointrcnn: 3d object proposal generation and detection from point cloud,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 770–779.
- [4] S. Shi, Z. Wang, J. Shi, X. Wang, and H. Li, “From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [5] Z. Yang, Y. Sun, S. Liu, X. Shen, and J. Jia, “Std: Sparse-to-dense 3d object detector for point cloud,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 1951–1960.
- [6] Z. Yang, Y. Sun, S. Liu, and J. Jia, “3dssd: Point-based 3d single stage object detector,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 040–11 048.
- [7] J. H. Yoo, Y. Kim, J. S. Kim, and J. W. Choi, “3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection,” arXiv preprint arXiv:2004.12636, 2020.
- [8] M. Liang, B. Yang, Y. Chen, R. Hu, and R. Urtasun, “Multi-task multi-sensor fusion for 3d object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7345–7353.
- [9] S. Vora, A. H. Lang, B. Helou, and O. Beijbom, “Pointpainting: Sequential fusion for 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 4604–4612.
- [10] V. A. Sindagi, Y. Zhou, and O. Tuzel, “Mvx-net: Multimodal voxelnet for 3d object detection,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7276–7282.
- [11] L. Xie, C. Xiang, Z. Yu, G. Xu, Z. Yang, D. Cai, and X. He, “Pi-rcnn: An efficient multi-sensor 3d object detector with point-based attentive cont-conv fusion module.” in AAAI, 2020, pp. 12 460–12 467.
- [12] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012, pp. 3354–3361.
- [13] S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “Pv-rcnn: Point-voxel feature set abstraction for 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 529–10 538.
- [14] Z. Liang, M. Zhang, Z. Zhang, X. Zhao, and S. Pu, “Rangercnn: Towards fast and accurate 3d object detection with range image representation,” arXiv preprint arXiv:2009.00206, 2020.
- [15] C. He, H. Zeng, J. Huang, X.-S. Hua, and L. Zhang, “Structure aware single-stage 3d object detection from point cloud,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 873–11 882.
- [16] R. Girshick, “Fast r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1440–1448.
- [17] M. Simony, S. Milzy, K. Amendey, and H.-M. Gross, “Complex-yolo: An euler-region-proposal for real-time 3d object detection on point clouds,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 0–0.
- [18] J. Redmon and A. Farhadi, “Yolo9000: better, faster, stronger,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7263–7271.
- [19] B. Yang, W. Luo, and R. Urtasun, “Pixor: Real-time 3d object detection from point clouds,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 7652–7660.
- [20] Y. Zeng, Y. Hu, S. Liu, J. Ye, Y. Han, X. Li, and N. Sun, “Rt3d: Real-time 3-d vehicle detection in lidar point cloud for autonomous driving,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 3434–3440, 2018.
- [21] D. Z. Wang and I. Posner, “Voting for voting in online point cloud object detection.” in Robotics: Science and Systems, vol. 1, no. 3, 2015, pp. 10–15 607.
- [22] M. Engelcke, D. Rao, D. Z. Wang, C. H. Tong, and I. Posner, “Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 1355–1361.
- [23] B. Li, “3d fully convolutional network for vehicle detection in point cloud,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 1513–1518.
- [24] Y. Zhou and O. Tuzel, “Voxelnet: End-to-end learning for point cloud based 3d object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4490–4499.
- [25] P. Yun, L. Tai, Y. Wang, C. Liu, and M. Liu, “Focal loss in 3d object detection,” IEEE Robotics and Automation Letters, vol. 4, no. 2, pp. 1263–1270, 2019.
- [26] H. Yi, S. Shi, M. Ding, J. Sun, K. Xu, H. Zhou, Z. Wang, S. Li, and G. Wang, “Segvoxelnet: Exploring semantic context and depth-aware features for 3d vehicle detection from point cloud,” in 2020 International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 2274–2280.
- [27] Z. Liu, X. Zhao, T. Huang, R. Hu, Y. Zhou, and X. Bai, “Tanet: Robust 3d object detection from point clouds with triple attention.” in AAAI, 2020, pp. 11 677–11 684.
- [28] M. Ye, S. Xu, and T. Cao, “Hvnet: Hybrid voxel network for lidar based 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 1631–1640.
- [29] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 652–660.
- [30] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” in Advances in neural information processing systems, 2017, pp. 5099–5108.
- [31] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 1907–1915.
- [32] J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. Waslander, “Joint 3d proposal generation and object detection from view aggregation,” IROS, 2018.
- [33] M. Liang, B. Yang, S. Wang, and R. Urtasun, “Deep continuous fusion for multi-sensor 3d object detection,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 641–656.
- [34] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 918–927.
- [35] Z. Wang and K. Jia, “Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 1742–1749.
- [36] K. Shin, Y. P. Kwon, and M. Tomizuka, “Roarnet: A robust 3d object detection based on region approximation refinement,” in 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019, pp. 2510–2515.
- [37] J. Dou, J. Xue, and J. Fang, “Seg-voxelnet for 3d vehicle detection from rgb and lidar data,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 4362–4368.
- [38] H. Kuang, B. Wang, J. An, M. Zhang, and Z. Zhang, “Voxel-fpn: Multi-scale voxel feature aggregation for 3d object detection from lidar point clouds,” Sensors, vol. 20, no. 3, p. 704, 2020.
- [39] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 621–11 631.
- [40] Y. Zhou, P. Sun, Y. Zhang, D. Anguelov, J. Gao, T. Ouyang, J. Guo, J. Ngiam, and V. Vasudevan, “End-to-end multi-view fusion for 3d object detection in lidar point clouds,” in Conference on Robot Learning, 2020, pp. 923–932.
- [41] Y. Wang, A. Fathi, A. Kundu, D. Ross, C. Pantofaru, T. Funkhouser, and J. Solomon, “Pillar-based object detection for autonomous driving,” arXiv preprint arXiv:2007.10323, 2020.
- [42] A. Simonelli, S. R. Bulo, L. Porzi, M. López-Antequera, and P. Kontschieder, “Disentangling monocular 3d object detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 1991–1999.