Machine Learning practices and infrastructures
Abstract.
Machine Learning (ML) systems, particularly when deployed in high-stakes domains, are deeply consequential. They can exacerbate existing inequities, create new modes of discrimination, and reify outdated social constructs. Accordingly, the social context (i.e. organisations, teams, cultures) in which ML systems are developed is a site of active research for the field of AI ethics, and intervention for policymakers. This paper focuses on one aspect of social context that is often overlooked: interactions between practitioners and the tools they rely on, and the role these interactions play in shaping ML practices and the development of ML systems. In particular, through an empirical study of questions asked on the Stack Exchange forums, the use of interactive computing platforms (e.g. Jupyter Notebook and Google Colab) in ML practices is explored. I find that interactive computing platforms are used in a host of learning and coordination practices, which constitutes an infrastructural relationship between interactive computing platforms and ML practitioners. I describe how ML practices are co-evolving alongside the development of interactive computing platforms, and highlight how this risks making invisible aspects of the ML life cycle that AI ethics researchers’ have demonstrated to be particularly salient for the societal impact of deployed ML systems.
1. Introduction
It follows from the notion that Machine Learning (ML) systems ought to be thought of as sociotechnical systems (Selbst et al., 2019)—i.e. systems that are socially constructed, requiring both human actors and machines to work (Emery, 1993)—that the social context in which an ML system is researched, developed, and deployed is likely to shape the characteristics of that system. Given the increasing rate of ML system deployment in high-stakes domains, and widespread evidence of ML systems failing to meet societal expectations (e.g. Buolamwini and Gebru, 2018; Obermeyer and Mullainathan, 2019; Koenecke et al., 2020; Shelby et al., 2022), a key question for the ML field relates to infrastructuralisation and its implications for ML practices and deployed ML systems. This paper begins to address this question by attending to one aspect of social context—interactions between ML practitioners and the tools they use to research, build, and deploy ML systems—and demonstrating the relevance of this context to concerns raised by AI ethics researchers.
The social context of ML system development has been studied in the emerging AI ethics field (e.g. Hopkins and Booth, 2021; Li et al., 2021; Bessen et al., 2022; Deshpande and Sharp, 2022). However, relatively little attention has been paid to tracing the relationship between specific material features of this context and the characteristics of ML systems that are developed (Langenkamp and Yue, 2022). That is, the role of material things (e.g. software tools, office layouts, computer interfaces, network connections), which themselves are socially constructed, alongside social things (e.g. people, beliefs, norms) in shaping ML systems merits closer scrutiny. In this paper, I consider one aspect of this sociomaterial context of ML system development: the use of interactive computing platforms (e.g. Jupyter Notebooks and Google Colaboratory) during ML model development and evaluation. I explore the structure of these platforms and their use by ML practitioners, and consider the ways in which this use may contribute to conventions of ML practices. This exploration serves to illustrate the importance for the AI ethics field of attending both to the sociomaterial context of ML system development generally, and to the role of interactive computing platforms, in particular. The research question to which this exploration is addressed is: how are interactive computing platforms used in ML practices?
To answer this question I developed a probabilistic topic model of user-contributed questions on the Stack Exchange forums related to ML and the use of interactive computing platforms. Stack Exchange forums were selected due to their wide use by data and computer scientists, software engineers, and technologists generally (Anderson et al., 2012; Barua et al., 2014). Alongside this I undertook qualitative text analysis of a small sample of Stack Exchange questions. I find that interactive computing platforms are used in a range of ML practices, particularly in the data curation and processing, and model training and evaluation stages of ML system development. I highlight the role of interactive computing platforms in learning practices, and in practices of coordination across multiple infrastructures. To interpret these findings I draw on sociological studies of infrastructures and practices, particularly the work of sociologists Susan Leigh Star (Star, 1989; Star and Ruhleder, 1996; Star, 1999; Bowker and Star, 2000) and Elizabeth Shove (Shove, 2003, 2016; Watson and Shove, 2022), and cultural anthropologist Brian Larkin (Larkin, 2013, 2020). I conclude that learning and coordination roles are indicative of an infrastructural relationship between ML practitioners and interactive computing platforms, which renders some of the aspects of ML systems development that AI ethics discourse has highlighted as particularly consequential (e.g. the importance of training dataset provenance (Gebru et al., 2021; Denton et al., 2021)) as invisible to ML practitioners. As such, this paper contributes an empirical snapshot of the use of interactive computing platforms in ML practices, and argues for a renewed focus in the field of AI ethics on the emergence of digital platform infrastructures in the ML ecosystem.
2. Related work
2.1. The sociomaterial context of Machine Learning practices
As ML systems have become objects of sociological interest (e.g. Burrell, 2016; Dourish, 2016; Kitchin, 2014; Mackenzie, 2015), the social context in which ML systems are researched, developed, commissioned, and deployed has garnered increased attention in diverse fields from Human-Computer Interaction (Holstein et al., 2019; Madaio et al., 2022), to Science and Technology Studies (Christin, 2017), to public policy (Krafft et al., 2020). In this paper, I refer to sociomaterial context rather than social context to signal a particular focus on the intertwining of socially-constructed material things—specifically, interactive computing platforms—in ML practices. As Paul Leonardi et al. (Leonardi and Barley, 2008; Leonardi et al., 2012; Leonardi, 2012) have argued, a sociomaterial perspective highlights how the material is socially constructed, and the social is enacted through material forms. A sociomaterial perspective invites us to consider the material things that ML practitioners enrol in their day-to-day work, alongside other aspects of the social context, and the contribution of these things to the stablisation of ML practices. In this context, material refers to the “properties of a technological artifact that do not change, by themselves, across differences in time and context” (Leonardi et al., 2012, p.7)—for interactive computing platforms, and software generally, this includes their user interfaces and layouts, their core capabilities, and their dependencies (Redström, 2005). My understanding of practices is informed by social practice theory (Rouse, 2007; Bourdieu, 2020; Sloane and Zakrzewski, 2022), which conceptualises practices as routinised ways of understanding and performing social activities (Ingram et al., 2007), and highlights that multiple practices can co-exist within the same cultural setting (Rouse, 2007, p.646). Machine Learning practices are thus the constitutive matter of ‘doing’ ML. Some practices (e.g. Agile meeting processes) may be widely shared across cultures and organisations, and others (e.g. the use of specific software) may vary dramatically from practitioner to practitioner.
In the field of AI ethics, a sociomaterial perspective has been used to highlight the challenges of translating AI ethics research into ML practices. Michael Veale and Reuben Binns (Veale and Binns, 2017), for instance, studied how statistical measures of fairness can be implemented within the practical constraints of limited access to data on protected characteristics, finding that new institutional arrangements will be necessary to support industry implementation of statistical measures of fairness that depend on access to sensitive data (cf. Beutel et al., 2019; Bogen et al., 2020). Veale and Binns argue for future empirical research on the “messy, contextually-embedded and necessarily sociotechnical” challenge of building ‘fairer’ ML systems (Veale and Binns, 2017, p.13). Veale et al. (Veale et al., 2018) subsequently conducted an empirical study of ML practitioners in public sector organisations and their engagement with ethics issues during ML system development for high-stakes decision making, finding that while practitioners have a high degree of awareness regarding ethical issues, they lack the necessary tools and organisational support to use this awareness in their ML practices. Mona Sloane and Janina Zakrzewski (Sloane and Zakrzewski, 2022), who also situate their work within social practice theory, provide a more expanded overview of AI ethics practices, through an empirical study of the operationalisation of ethics in German AI startups. Sloane and Zakrzewski develop an anatomy of AI ethics practices, which they suggest can be used as a framework to inform improvements to ML system development practices. Relevantly, the anatomy includes ‘ethics materials’, defined as “concrete objects, processes, roles, tools or infrastructures focused on ‘AI ethics”’ (Sloane and Zakrzewski, 2022, p.5). Holstein et al. (Holstein et al., 2019) provide further support for the importance of ethics materials, through their empirical study of ML practitioners working in product teams in large technology firms to develop ‘fairer’ ML systems, which found that practitioners lack the tools needed to identify and address ethics issues that arise during ML system development. Finally, Will Orr and Jenny Davis (Orr and Davis, 2020) highlight how ML practices include the diffusion of responsibility for ethics during ML system development. Orr and Davis found a “pattern of ethical dispersion” amongst practitioners: practitioners perceive themselves to be the inheritors of ethical parameters from more powerful actors (regulators, clients, employers), which their expertise translates into the characteristics of systems they develop, which are then handed over to users and clients, who assume ongoing responsibility (Orr and Davis, 2020, p.7). These studies, along with other empirical explorations of ML practice (e.g. Vakkuri et al., 2020; Hopkins and Booth, 2021; Rakova et al., 2021; Ryan et al., 2021; Krafft et al., 2020; Kaur et al., 2020) and several workshops focused on the research-to-practice gap (Baxter et al., 2020; Barry et al., 2020; Szymielewicz et al., 2020), have prompted calls for better support for practitioners attempting to operationalise AI ethics principles in their ML practices (Morley et al., 2020; Schaich Borg, 2021; Schiff et al., 2021).
This study complements and inverts these empirical studies of AI ethics in ML practices. Rather than moving from the social to the sociomaterial, this study moves from the material to the sociomaterial. That is, rather than starting with interviews (e.g. Orr and Davis, 2020; Sloane and Zakrzewski, 2022; Holstein et al., 2019; Veale et al., 2018; Hopkins and Booth, 2021; Rakova et al., 2021; Ryan et al., 2021) or surveys (e.g. Vakkuri et al., 2020; Krafft et al., 2020) of practitioners to explore their understanding and operationalisation of AI ethics in ML practices, the study begins with material artefacts that practitioners use and produce in the course of their ML practices, and explores what light these artefacts may shed on the translation of AI ethics to ML practices. A similar approach is followed by Max Langenkamp and Daniel Yue (Langenkamp and Yue, 2022) in their study of open source ML software use, which consists of a review of code repositories on GitHub to establish the breadth of open source use followed by interviews with practitioners to provide further context. That study takes a broad perspective, exploring trends across open source software use. In contrast, this study takes a narrow perspective, exploring how a specific category of software tool is used in ML practices.
2.2. Interactive computing platforms and Machine Learning practices
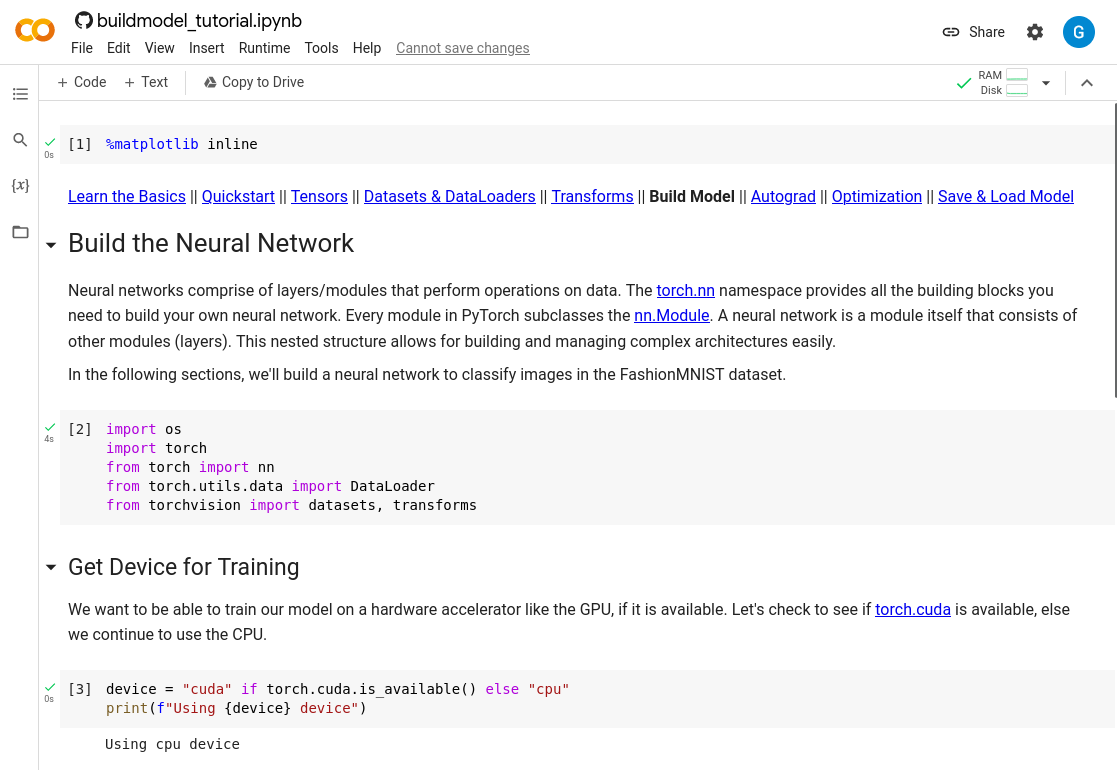
The specific material artefacts this study starts with are interactive computing platforms (ICPs), also referred to as ‘computational notebooks’ (Rule et al., 2018; Chattopadhyay et al., 2020), ‘literate programming tools’ (Pimentel et al., 2019) or ‘integrated development environments’ (Zhang et al., 2020). Two widely used ICPs are the open-source Jupyter Notebook and Google Colab, Google’s extension of Jupyter Notebook, designed to integrate with other Google services.111Available at https://jupyter.org/ and https://research.google.com/colaboratory/. Figure 1 shows an example Jupyter Notebook.
Technically, an ICP is an interactive shell for a programming language, such as Python (Perez and Granger, 2007). The shell enables users to write and interact with code fragments—called ‘cells’—alongside natural language, and to assemble series of cells into a notebook, which can be shared with others—much in the same way that a word processor enables a user to assemble an editable document and share that with others. The notebook can be thought of as a computational narrative, which enables one to read and interact with a sequence of code alongside a narrative description of what the code does (Kluyver et al., 2016)—hence, the terms ‘literate programming tools’ and ‘computational notebooks’. However, crucially, an ICP presents itself as only a shell: all but the most rudimentary code fragments depend on access to libraries of existing code, which a user must import into the shell environment. Similarly, particularly in the context of ML, data must be imported into the shell for the code to operate on and a compute resource must be accessed to process operations. Numerous digital infrastructures support importing code into a notebook, including the code repository GitHub,222See https://github.com/. in which many repositories include a notebook to demonstrate common use cases of the code (Rule et al., 2018), PyPi,333See https://pypi.org/. which indexes and hosts Python-based code packages, and HuggingFace,444See https://huggingface.co/. which indexes and hosts ML training and evaluation datasets and models. In this study, interactive computing platform is thus preferred, as the infrastructural implications of ‘platform’ are a critical aspect of what defines these tools: ICPs are highly networked arrangements, one part of a circular web of infrastructures and inter-dependencies (the Internet, cloud computing, programming languages and libraries).
Interactive computing platforms pre-date the widespread adoption of ML techniques in applied settings. Indeed, their motivating design goal was to support reproducible science (Kluyver et al., 2016; Perez and Granger, 2007; Granger and Pérez, 2021) (see, e.g. (Beg et al., 2021; Randles et al., 2017) for discussions of their effectiveness at meeting this goal). However, as ML techniques have become ubiquitous, and data scientists have become widespread in industry, interactive computing platforms have become widely enrolled in ML practices. Commentators thus describe ICPs as the “tool of choice” for data scientists (Perkel, 2018), and practitioners vigorously debate the merits and drawbacks of using ICPs in applied settings (e.g. Ufford et al., 2018; Brinkmann, 2021; Grus, 2018; Mueller, 2018; Howard, 2020).
Interactive computing platforms have also become objects of study in several fields adjacent to AI ethics. Human-Computer Interaction studies have developed empirical accounts of the way users interact with ICPs, focusing particularly on the role of ICPs in collaborations (Zhang et al., 2020; Wang et al., 2019) and in data science (Rule et al., 2018; Kery et al., 2018). Of particular relevance, Adam Rule et al. (Rule et al., 2018) conducted three studies of the use of ICPs by data scientists, which included a large-scale review of notebooks on GitHub and interviews with data scientists and found that ICPs tend to be used by data scientists during data exploration phases of a project, rather than for constructing and sharing detailed explanations of data analysis. Studies in the field of Software Engineering have also focused on documenting the use of ICPs, focusing particularly on ICPs as a site to study trends in code use (Wang et al., 2020) and reuse (Koenzen et al., 2020; Pimentel et al., 2019), and on the their potential as educational tools (Tan, 2021). Similarly, in the field of Computational Science, several studies have considered the role ICPs can play in supporting reproducible science (Beg et al., 2021; Brown et al., 2021; Juneau et al., 2021). This study provides a different perspective on ICP use, by considering ML practices in particular, and interpreting these practices through the lens of sociological studies of infrastructure, which shifts the focus of the study away from the individual user-notebook relationship and towards the broader relationship of ML practitioners to the suite of infrastructures involved in ML practices.
3. Studying infrastructures & practices
Studying the relationship between practices and infrastructures can be vexed. Infrastructures may be functionally invisible to the social groups who make use of them in daily practices (Star, 1999), as I consider further in Section 6.2. Further, infrastructures often span multiple practices across different social groups, which, particularly in the context of digital infrastructures, may not be geographically proximate (Bowker et al., 2009). And, practices themselves are not purely infrastructural—as Shove et al. (Shove et al., 2012) argue, they bring together infrastructures and other materials, competencies, and ways of knowing.
Sociological studies of infrastructures have orientated themselves around the broad aim of rendering infrastructures, and their sociopolitical commitments, visible (Bowker et al., 2009). Ethnographic methods–historically, fieldwork and participant observation; more recently, multi-site studies–have been used to empirically document infrastructures (Silvast and Virtanen, 2019). Star (Star, 1999), for instance, advocates studying moments of breakdown in infrastructures, seeing these as instances where infrastructures become visible to social groups. Star (Star, 1999) also observes that infrastructures are often learned as part of group membership, directing attention to moments of transience in social groups (discussed further in Section 6.1). However, digital infrastructures present particular challenges: one cannot physically access online communities, and the number of physical sites is at least as large as the user-base of the infrastructure (Bowker et al., 2009).555Although outside the scope of this paper, an additional emerging challenge is automated personalisation of digital infrastructures, which makes obtaining a general view of the infrastructure challenging (Troeger and Bock, 2022). ICPs do not currently afford personalisation in this way.
In this study, I build on Star’s insights by focusing, as a path towards understanding ICPs and their relationship to ML practices, on moments where ML practitioners are either experiencing ICP breakdowns or limitations in their own ICP capabilities. In particular, and reflecting the challenge of direct observation of digital infrastructure use, the primary data source used are the questions asked by ML practitioners on popular online forums. This is supplemented with analysis of ICP affordances and inter-dependencies. This approach follows in the spirit of other studies of digital infrastructure, such as Plantin et al.’s (Plantin et al., 2018a) analysis of the documentation and inter-dependencies of the Figshare platform and Andre Brock’s (Brock, 2018) analysis of Black Twitter through analysis of Twitter interfaces and user generated content, although the study presented here is narrower in scope.
4. Method
This study consisted of an empirical study of user-generated content on the Stack Exchange forums, supported by a close reading of a small number of exemplars texts (Jacobs and Tschötschel, 2019). In particular, a Structured Topic Model (STM) (Roberts et al., 2013, 2014, 2016, 2019) of user-generated questions about ML and the use of interactive computing platforms on Stack Exchange forums was estimated.666See (Isoaho et al., 2021; Nikolenko et al., 2017; Lindstedt, 2019; Mohr and Bogdanov, 2013) for overviews of topic modelling in the social sciences, and (Brookes and McEnery, 2019; Baumer and McGee, 2019) for more critical perspectives. A similar approach has been used in a number of studies of Stack Exchange forums (Ahmad et al., 2018), for instance to identify challenges practitioners face in developing ML systems more generally (Alshangiti et al., 2019) or themes in questions asked by mobile application developers (Rosen and Shihab, 2016) or themes in privacy-related (Tahaei et al., 2020) or security-related questions (Yang et al., 2016).777Code to reproduce pre-processing steps and the topic model described below, are available at https://github.com/gberman-aus/aies_23_topic_modelling.
4.1. Corpus development and description
English-language Stack Exchange community forums, specifically Stack Overflow, Cross Validated, Data Science, Computer Science, and Software Engineering were mined for relevant questions. Stack Exchange claims to be the world’s largest programming community.888See https://stackexchange.com/ to access Stack Exchange and its forums. Stack Overflow is broadly focused on computer programming. Cross Validated is a more specialised forum, focused on statistics and data analysis. Software Engineering is a similarly specialised forum, focused on software systems development. Finally, Data Science and Computer Science are relatively small forums, focused on data and computer science respectively. However, reflecting the ubiquity of ML techniques in computing, questions related to ML occur in all of these forums, and, as all of these forums are user-moderated, their boundaries and scope are dynamic. As of October 2022, its most popular forum, Stack Overflow, had over 19 million registered users, who contribute, edit, and moderate questions and answers on the forum.999This estimate is based on a query of the Stack Exchange Data Dump. See (Baltes and Diehl, 2019; Barua et al., 2014) for studies of Stack Overflow usage. Previous research demonstrates that Stack Overflow is enmeshed in software engineering and data science practices (e.g. Treude and Wagner, 2019; Baltes and Diehl, 2019; An et al., 2017; Abdalkareem et al., 2017; Nasehi et al., 2012; Ford et al., 2016), and that ML techniques are a rapidly growing topic of discussion on the forum (Alshangiti et al., 2019). The Stack Exchange forums share data structures101010A detailed description of the database schema used across forums is provided by Stack Exchange on their forum about the Stack Exchange network, appropriately named Meta Stack Exchange, accessible at https://meta.stackexchange.com/questions/2677/database-schema-documentation-for-the-public-data-dump-and-sede. and interface layouts, with annoymised user questions, answers, and comments from all Stack Exchange forum made available for querying and research through the Stack Exchange Data Dump (e.g. Yang et al., 2016; Rosen and Shihab, 2016; Alshangiti et al., 2019).111111The Stack Exchange Data Dump can be accessed at: https://archive.org/details/stackexchange. The database is updated weekly.
Questions related to ML and interactive computing platforms were extracted from the Stack Exchange forums listed above on 23 November, 2022. Four example questions are shown in Figure 2. To identify relevant questions the topical tags associated with every question were leveraged. Through manual review of the forums, and queries of the Stack Exchange Data Dump, ICP tags and ML related tags were identified.121212In studies of more niche topics only one tag has been used (Tahaei et al., 2020), however, as in (Alshangiti et al., 2019), manual review demonstrated that there are no over-arching ML or ICP tags. These tags are listed in Appendix A. Having identified relevant ML and ICP tags, two datasets were extracted from the Stack Exchange Data Dump: all questions on the selected forums with at least one ML related tag (a large dataset consisting of questions), and all questions on these forum with at least one ICP related tag (a smaller dataset of questions). The ML tagged questions were filtered by the presence of an ICP term (leaving questions), and ICP tagged questions were filtered by ML terms (leaving questions). This procedure resulted in two datasets with some substantial overlap. After de-duplication, a final dataset of ML and ICP related questions was left; this dataset became the corpus used to estimate a STM topic model..131313A significant advantage of the R package relied upon is that it enables manual setting of the random seeds used during the model training process—ensuring a higher degree of reproducability is possible.




4.2. Estimation of the topic model
STM is a probabilistic, mixed-membership topic model, which extends the widely-used Latent Dirichlet Allocation model by enabling the inclusion of metadata—here, the tags associated with questions and question creation date—in the model training process (see (Lindstedt, 2019; Roberts et al., 2014) for introductions to STM). To prepare the corpus for topic modelling, pre-processing was undertaken using the R package (Roberts et al., 2019) (see (Grimmer et al., 2022; Wesslen, 2018) for discussion of pre-processing procedures). Title and body fields for questions were concatenated into a single column. Questions on Stack Exchange forums are formatted using markdown, and often include large snippets of computer code. All code snippets and markdown were removed from questions. Code snippets were retained for subsequent analysis. Html symbols (e.g. ‘"’), special characters (e.g. ‘'’), punctuation, and superfluous white spaces were removed from questions. Questions were converted to lowercase. Frequently occurring words with little topic predictive value (’stopwords’) were removed from questions. Words in the questions were stemmed (i.e. converted to their root form). The creation date of questions was converted into a numerical format.
STM requires the researcher to set the number of latent topics () to identify in a corpus. As such, selecting the optimal value for is an important decision, and requires testing a wide range of values (Grimmer and Stewart, 2013). Additional hyper-parameters can also be optimised, and different pre-processing regimes can also be tested against each other (Grimmer et al., 2022; Maier et al., 2018). Given the preliminary nature of the study, values from to , at intervals of were experimented with. The package’s built in multi-model testing feature was used: for each value of , up to model runs, with a maximum of iterations each, were tested to ensure model stability.
To select an optimal value of two evaluation metrics were used: exclusivity and semantic coherence (Roberts et al., 2014). Exclusivity is a measure of the difference in key words associated with each topic, whilst semantic coherence is a measure of how internally consistent each topic’s key words are (Wesslen, 2018). These measures tend to pull in opposite directions: exclusivity is likely to be optimised by increasing the number of topics, whilst semantic coherence can be optimised by decreasing the number of topics (Roberts et al., 2014). An optimal number of topics for social science research can be found by plotting exclusivity against semantic coherence for a range of values, and then choosing a value at which neither measure dominates (Roberts et al., 2014). However, there is no ‘right’ value for (Quinn et al., 2010); the aim is to find a value of that enables meaningful interpretation (Grimmer and Stewart, 2013; Roberts et al., 2014; Syed and Spruit, 2017). In this instance, as can be seen in Figure 4 in the Appendix, models with values of around represented an optimal trade off between exclusivity and semantic coherence. After inspection of keywords associated with each topic and representative questions, the model with a value of was selected.
4.3. Interpretation of the topic model
To interpret the results of the topic model Yotam Ophir and Dror Walter’s (Ophir et al., 2020; Walter and Ophir, 2019) three step process was followed. First, I qualitatively interpreted the topics identified through review of the most probable words associated with each topic (Figure 3(a)). Second, I analysed the relationships between topics by calculating their correlation, with a positive correlation indicating a high likelihood of two topics being found together in the one Stack Exchange question (Roberts et al., 2016, 2019). Third, I used a community detection algorithm to identify clusters of topics and broader themes across the corpus (Figure 3(b)). In particular, I used the Newman-Girvan method for community structure detection (Newman and Girvan, 2004), with the result being three clusters of topics. After review of the probable terms associated with topics within each cluster and representative questions, I labeled these clusters: infrastructure and inter-dependencies, data manipulation, and model training. As an additional final step, I made use of STM’s ability to calculate the impact of covariates on topic prevalence to analyse the expected proportion of individual topics (Figure 3(c)) and clusters of topics over time (Figure 3(d)).
Throughout the above steps I moved between analysis of the topic model itself and deeper review of full Stack Exchange question and answer threads that are representative of particular topics or clusters of topics. Here, I adapted the approach of Paul DiMagggio, Manish Nag, and David Blei (DiMaggio et al., 2013), who, after training a topic model, identify topics of interest and then undertake analysis of the most representative texts for those topics. In particular, I identified the Stack Exchange questions with the highest probability for each topic, and the questions with the combined highest average probability across topics within each cluster. For these highly representative questions, within each topic cluster I further sorted the questions by their view count on the Stack Exchange forums (Figures 8 - 8 in the Appendix), enabling me to identify questions that were both highly representative of a given topic cluster and highly viewed on the Stack Exchange forum.
5. Findings
The topic model of Stack Exchange questions discussing interactive computing platforms and ML demonstrates that interactive computing platforms are implicated in a wide range of ML practices. ML practices are often conceptualised within a life cycle framework, with stages of ML development moving from problem formulation, to data curation and processing, to model training and evaluation, to model deployment and ongoing monitoring (e.g. Ashmore et al., 2022; Lee and Singh, 2021; Polyzotis et al., 2018, 2017; Morley et al., 2020). Figure 3(a) shows the most probable terms associated with each topic, and the expected proportion of each topic across the corpus. Unsurprisingly, given the corpus focus on ICPs, the two topics most widely represented in the dataset— and —are associated with Google Colab and Jupyter Notebook respectively. The most probable terms for most other topics are associated with many of the ML development stages, particularly data curation and processing (e.g. see key terms for topics , , and ), and model training and evaluation (e.g. see key terms for topics , , , and ). The deeper review of identified topics and representative questions highlights two inter-related themes, which address the study’s research question regrading use of ICPs in ML practices: the use of ICPs as learning laboratories; and, their role as coordination hubs across ML infrastructures.
5.1. Learning laboratories for Machine Learning
Interactive computing platforms serve as ML practice learning laboratories: they enable users to experiment with each other’s code and publicly-available datasets, learn how code functions through line-by-line interactions, and redeploy code in their own use cases. ICPs are thus part of the sociomaterial context for what Louise Amoore has described as the “partial, iterative and experimental” nature of ML practices (Amoore, 2019), which is also reflected in Langenkamp and Yue’s broader study of open source tools (Langenkamp and Yue, 2022).141414For an extended description of the relationship between learning practices and digital infrastructures see (Guribye, 2015).
Figure 1 shows an example of an ICP used as a learning laboratory, drawn from a tutorial for PyTorch, an ML-focused high-level programming language. Figure 2(b) shows an example of a Stack Overflow question, titled ‘Keras, how do I predict after I trained a model?”, which also reflects the use of an ICP as a learning laboratory. This is one of the four most viewed questions from the data manipulation cluster of topics. The author of this question appears to be engaged in a learning practice: they describe themselves as “playing with” the dataset, and write that they have “read about” saving a trained model, but are now struggling to use the saved model in a prediction task. Not shown in Figure 2(b) are the community answers the author received.151515The full question, including community provided answers can be seen as: https://stackoverflow.com/questions/37891954/keras-how-do-i-predict-after-i-trained-a-model. Each answer also includes a code snippet, demonstrating a solution. Similarly, the question “FailedPreconditionError: Attempting to use uninitialized in Tensorflow” (Figure 2(c)), one of the most viewed questions in the model training cluster, includes a code snippet that is “from the TensorFlow tutorial”, which the author is attempting to use with “digit recognition data from Kaggle”. In both these questions users’ learning is through an ICP, and is focused on understanding how to achieve a specific task using the Application Programming Interface (API) of a particular high-level programming library.
When ML practitioners use interactive computing platforms as learning laboratories they engage in practices of code and data reuse. The author of the Stack Overflow question discussed above notes they are “playing with the reuters-example dataset”, which is a publicly-available dataset used in topic modelling and text classification tasks (Lewis, 1997), and provides a code snippet to illustrate the point at which they require assistance. Within ML practices reuse of publicly available datasets, such as the Reuters dataset for text classification or the ImageNet dataset for computer vision is well documented (Denton et al., 2021). Patterns of dataset reuse can be found across the corpus: the Reuters dataset is referend in questions; ImageNet dataset is mentioned in questions; and, the MNIST handwritten digits dataset is mentioned in . Indirect evidence of code and data reuse in ML practices can also be found by reviewing the code snippets included in questions in the corpus. As discussed in Section 4, during pre-processing code snippets were isolated from the text of questions on which the topic model was trained. Of all questions, 89.7% include a code snippet. Because the corpus consists of questions about using ICPs, many of these code snippets represent the point at which a user of an ICP has become stuck while trying to attempt to an ML related task. This is illustrated by the question titled “How to load CSV file in Jupyter?”, shown in Figure 2(d). Here, the author of the question has included in the body of their question a screenshot of their Jupyter Notebook. As can be seen, the first cell in this notebook begins with the function, which is how specific programming libraries or sub-libraries are imported into the ICP. In this case, the author has imported , a mathematical functions library, and , a data analysis library. More broadly, the code snippets included in questions shed light on the substance of code that is entered into ICPs during ML related tasks. By calculating the frequency of the terms that immediately follow the function, widely used programming libraries can be identified (see Figure 5 in the Appendix). Among the most frequently mentioned programming libraries in code snippets are: ‘Sequential’, ‘Dense’, and ‘Model’ (specific components from Keras, a high-level library for deep learning); ’cv2’ (a computer vision high-level library); and, ‘PyTorch’ (an alternative to TensorFlow).
The code snippet in the question titled “FailedPreconditionError: Attempting to use uninitialized in Tensorflow”, shown in Figure 2(c), illustrates the significance of functions for extending the abilities of ICPs both as learning laboratories and more generally. The code snippet includes the line:
Across the corpus, questions reference TensorFlow’s GradientDescentOptimizer. Gradient Descent is a type of optimisation algorithm used during training of a neural network (Ruder, 2017). This line of code enables the user to access the TensorFlow library’s operationalisation of gradient descent algorithms through its API—alleviating the need for the user to code their own gradient descent algorithm. While TensorFlow is only one of a number of similar software libraries available, the volume of posts ( of all questions) in the corpus in which TensorFlow is mentioned, and the two most probable terms in topic (‘import’ and ‘tensorflow’), provides some indication of its widespread use in ICPs and ML practices.




5.2. Coordination hubs for ML infrastructures
Assembling an ML workflow is a complex task, requiring coordination of multiple infrastructures. Interactive computing platforms serve as coordination hubs, through which networks of infrastructures are assembled to support ML practices. Reflecting this, as shown in Figure 3(d), the cluster of topics associated with infrastructure and inter-dependencies accounts for a significantly greater proportion of questions in the corpus than the cluster of topics associated with model training. The most viewed questions within the infrastructure and inter-dependencies cluster reveal the infrastructural coordination that is at the heart of many ML practices.
One of the most viewed questions within the infrastructure and inter-dependencies cluster is titled “Can I run Keras model on gpu?” (Figure 2(a)).161616See https://stackoverflow.com/questions/45662253/can-i-run-keras-model-on-gpu for the full question and its answer thread. Keras is a high-level API designed to support deep learning techniques.171717See https://keras.io/ for an introduction to Keras. Keras is integrated into TensorFlow, and enables users to build a wide range of neural networks—Keras makes it easier and more efficient to complete deep learning tasks within TensorFlow. A GPU—Graphics Processing Unit—is a specialised microprocessor, which in many computing systems works alongside the more general-purpose Central Processing Unit (CPU) microprocessor. Whilst the GPU-CPU arrangement predates the emergence of Deep Learning, it turns out that GPU microprocessors are better suited to performing many of the computations required to train a neural network than CPUs. The author of this question is attempting to assemble a system that consists of a “Tensorflow backend” and a “Keras model”, interacted with through a “Jupyter notebook”, and run on their computer’s GPU. The highest scoring answer recommends installing CUDA, which is an additional parallel programming platform designed to enable GPUs to be used for non-graphics processing tasks, such as model training. This answer provides hyperlinks to additional resources for installing CUDA and checking that TensorFlow is running properly on a GPU. Above this answer are two further user comments also linking to additional resources. As such, the author of this question is assembling a system that involves at least five interdependent layers: GPU, CUDA, TensorFlow, Keras, Juypter Notebook. The author is fortunate, however, as their aim is to train their model within “36 hours”, which suggests that either they have access to a powerful GPU, or they are training a model with a relatively small dataset (for instance, as part of a learning exercise). In industrial or research settings, training a neural network requires access to much greater compute resources, which requires users to access a cloud resource, such as Amazon Web Services, and adds at least one additional layer of complexity to the system.
The key words associated with topics within the infrastructure and inter-dependencies cluster (shown in Figure 3(a)) provide an additional perspective on the infrastructural coordination required to support ML tasks. In descending order of representation in the corpus, these topics are: , , , , , , , , and . As already observed, topics and relate to Google Colab and Jupter Notebook, two ICPs. Meanwhile, topic includes ‘import’ and ‘tensorflow’ as the two most probable terms. Topic includes ‘gpu’, ‘cpu’, and ‘cuda’ as probable terms. Topic includes ‘tensorflow’ and ‘tpu’, which is a reference to Tensor Processing Units, which are a new generation of GPUs specifically designed to support TensorFlow. The presence of these topics, and their close correlations, as shown in Figure 3(b), indicate that coordination between infrastructures is widely discussed on Stack Exchange. Finally, Figure 3(d) shows the expected proportion of topic (Google Colab) compared to topic (Jupyter Notebook) over time. The topic model estimates that since 2017 questions related to Google Colab have increased compared to questions related to Jupyter Notebook. Significantly, a key point of difference between these two platforms is that Google Colab has been designed to integrate directly into Google’s cloud compute infrastructure, and is used as the platform of choice in TensorFlow and Keras tutorials.
6. Discussion
In this study, the intertwining of interactive computing platforms in ML practices was explored. The findings indicate that ICPs are learning laboratories—tools by which users experiment with and learn ML practices through line-by-line interaction with others’ code and publicly available datasets, facilitated by the APIs provided by high-level programming languages. The findings show also that ICPs are coordination hubs—sites at which multiple different infrastructures are brought together to support ML practices, such as model training or data processing. Given the role ICPs play as coordination hubs for ML practices, they can be conceptualised as an emerging form of ‘digital infrastructure’—an essential and widely participated in sociotechnical system (Plantin and Punathambekar, 2019; Bowker et al., 2009). Conceptualising ICPs in this way enables existing theorising about infrastructures to inform consideration of the sociopolitical significance of ICP use in ML practices, and helps connect ICP use to concerns raised in AI ethics discourse. To illustrate this, in the following subsections I consider how Brian Larkin’s review of anthropological practices for studying infrastructure (Larkin, 2013) and Susan Leigh Star’s description of the properties of infrastructure (Star, 1999) can apply to ICPs. In each subsection I conclude with a brief reflection on implications for AI ethics discourse.
6.1. An emerging infrastructural relationship
As material objects, Larkin describes infrastructures as “built networks that facilitate the flow of goods, people, or ideas” (Larkin, 2013, p.328). At the same time, infrastructures are systems that support the functioning of other objects, and it is these objects that users of an infrastructure experience; we experience hot water, not plumbing (Larkin, 2013, p.329). Star describes this characteristic of infrastructure as ‘transparency’: for users of an infrastructure, the tasks associated with it seem easy and straightforward—transparent (Star, 1999). Star, however, understands infrastructures as relational. Transparency is not an inherent characteristic of a sociotechnical system, but rather a characteristic of an infrastructural relationship between a sociotechnical system and its users.
The topic model of Stack Exchange questions is a snapshot of an emerging infrastructural relationship: as ML practitioners use ICPs as coordination hubs, facilitating flows of data and code across networks of disparate resources (compute capacity, programming languages, datasets, etc.), they are forming an infrastructural relationship with the platform. The platform itself recedes into the background and the objects that the platform enables to function—predictive models—come into the foreground. This is why ICPs excel as learning laboratories for ML. The affordances of the ICP, however, continue to have efficacy even as the platform itself becomes transparent: the affordances enable and constrain users, and in doing so help configure practices associated with the ML techniques that the platform enables (Davis and Chouinard, 2016; Davis, 2020).
Star’s understanding of infrastructures as relational also highlights the relationship between infrastructures and groups: infrastructures are “learned as part of membership” (Star, 1999, p.381). This conceptualisation of the relationship between infrastructures and group membership appears to align closely to the burgeoning infrastructural relationship between ML practitioners and ICPs. As the topic model interpretation illustrates, ML practitioners learn to use an ICPs as part of the process of becoming ‘ML practitioners’. Star highlights that shared use of common infrastructures among practitioners helps reinforce their identity as a distinct group (Star, 1999). Non-members, meanwhile, encounter infrastructures as things they need to learn to use in order to integrate into a group. Note, for example, the author’s phrasing in the Stack Overflow question shown in Figure 2(d): “I’m new and studying machine learning… I’m getting problems about loading the CSV File into the Jupyter Notebook”. ‘ML practitioner’ is an ill-defined term frequently used in AI ethics discourse as a catchall for describing the data scientists, software engineers, and product managers who work on the research and development of ML systems. From an infrastructural perspective, however, the term can also be thought of symbolising a new set of infrastructural relations: where previously data scientists, software engineers, etc., each worked within their own suites of tools, increasingly they use shared infrastructure, such as ICPs, enabling the collapsing of distinctions between these professional roles that is indicated in the term ‘ML practitioner’.
6.1.1. Implications for AI ethics
A stream of AI ethics research has focused on the development of software and management tools to support ML practitioners (see (Morley et al., 2020) for an overview). For this stream, ICPs may be a constraint, in so far as tool adoption is often held to be dependent on integration with existing ML infrastructure and practices (e.g. Hardt et al., 2021; Gebru et al., 2021). Alternatively, the affordances of ICPs may offer new opportunities for future tool development. The grammar of ICP interactions may be applied to the design of tools intended to prompt practitioner reflection. The open source Fairlearn library, for example, provides example ICP notebooks181818See https://fairlearn.org/v0.8/auto_examples/index.html. to demonstrate library uses.
More broadly, however, as ICPs contribute to the configuring of ML practices, they shape the space in which AI ethics are situated. Here, Britt Paris’s (Paris, 2021) reflections on the relationship between Internet infrastructure and constructions of time are instructive. ICPs, like the Internet at large, imagine particular temporal relations. ICPs, in particular, are premised on speed: the staccato call-and-response of user inputs and computer outputs helps configures a working environment in which the value of ML practices resides in their speed and efficiency. In this sense, conceptualising ICPs as ML infrastructure presents as a challenge to calls from AI ethics researchers for greater reflexivity in ML (e.g. Fish and Stark, 2021; Weinberg, 2022).
6.2. Visible and invisible infrastructures
As material objects, infrastructures are designed, and reflect, at least in part, the intentions of the designer. Yet, at the same time, infrastructures are “built on an installed base”, often following paths of development laid down by preceding infrastructures (Star, 1999, p.382). And, infrastructures are often caught in circular webs of relations with other infrastructures: computers rely on the electricity grid to function, and the functioning of the modern electricity grid is reliant on computers (Larkin, 2013). Infrastructures therefore cannot be understood in isolation, in the same way that they cannot be designed in isolation. The role ICPs play as coordination hubs reflect this: they are built on top of the networked and decentralised infrastructures of the Internet, programming languages, and computing. In doing so, ICPs augment and extend these pre-existing infrastructures, both following path dependencies established by these infrastructures and charting new paths for future infrastructures (cf. Winner, 1980).
Larkin highlights that infrastructures also serve a ‘poetic’ function (Larkin, 2013). Larkin draws on linguist Roman Jakobson’s concept of poetics (Jakobson, 1960), which holds that in some speech acts the palpable qualities of speech (roughly, sound patterns) have primary importance over representational qualities (i.e. meaning). Infrastructures, argues Larkin, can have a poetic function, not reflected in the declared intentions of designers, nor in their technical capabilities (Larkin, 2013). Researchers of infrastructure, then, must take seriously the aesthetic aspects of infrastructure, and consider how infrastructures not only reflect the declared intention of those who build them, but also their (undeclared) interests. Larkin’s description of the poetics of infrastructure mirrors Jenna Burrell’s critique of blithe descriptions of algorithms as ’opaque’, which ignore the ways the appearance of opaqueness in an algorithmic system can reflect the politics of the institutions who operate them (Burrell, 2016). In this context, a significant line of future inquiry pertains to the different politics and interests reflected in the two ICPs identified as widely used by the topic model: Jupyter Notebook and Google Colab.
For Larkin, the aesthetic aspects of infrastructure include the way infrastructures may at times appear transparent or invisible (Larkin, 2013). Here, Larkin takes issue with Star’s description of infrastructures as ‘invisible’. Star describes this characteristic of infrastructure as ”becoming visible upon breakdown” (Star, 1999, p.382). By standardising interactions between material objects, users, and other infrastructures, infrastructures become transparent to users, and, when this transparency becomes routine, the infrastructure itself appears invisible. Questions asked on Stack Exchange can thus be interpreted as instances of ML infrastructure becoming visible. To Larkin, however, the claim that infrastructures are invisible can only ever be partially valid: what the affordances of infrastructures make visible and invisible is both an outcome a system’s technical capabilities and its poetic functions. Larkin and Star’s debate on invisibility thus helps shed light on the mechanism by which ICPs become implicated in the characteristics of ML systems that are developed through their use. As infrastructural systems, ICPs standardise a particular form of presenting and interacting with code—the ‘notebook’ layout of descriptive and computation cells described in Section 2.2—and this standardisation renders some aspects of ML system development more visible to ML practitioners than others.
Shifts in the aspects of ML system development that are transparent to ML practitioners can have significant impacts on practitioners’ understanding of ML technologies. As discussed in Section 5.1, ICPs support iterative experimentation with the APIs of high-level programming languages, which often occurs through probing and re-purposing of code written by others. Iterative experimentation with the API of a high-level programming language, however, is unlikely to reveal the full range of decisions that the creators of an API have made in operationalising a particular ML algorithm or technique. The point of Keras’ Tokenizer function (shown in the code snippet in the Stack Overflow question in Figure 2(b)) is that it enables users to convert the text in a corpus into a series of integers (‘embeddings’), so that computations (e.g. topic modelling) can be run on the corpus. The function enables users to choose whether or not to convert text to lowercase, but because the function has a default setting, this choice is not necessary—by default any call of the Tokenizer function will convert text to lowercase before conversion to numerical form.191919See https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer for the Tokenizer documentation. This may seem inconsequential, but it can have a significant downstream impact: converting a corpus to lowercase means that the verb ‘stack’ and proper noun ‘Stack’ will be embedded as semantically identical.
As APIs of high-level programming languages become more sophisticated, particularly as they start to incorporate pre-trained models for common ML tasks (e.g. image classification, object detection and labelling, sentiment detection), the choices obfuscated by the API become more consequential. The TensorFlow Object Detection notebook202020Accessible at https://www.tensorflow.org/hub/tutorials/tf2_object_detection. uses a CenterNet pre-trained model which was trained on the Common Objects in Context dataset (Lin et al., 2015). This dataset includes labels for categories of objects, including ‘plate’, ‘cup’, ‘fork’, ‘knife’, ‘spoon’, and ‘bowl’ (but not, for instance, ‘chopstick’), and it is these objects that the CenterNet model can detect in images. This sequence of choices, and the constraints each choice imports into the ML system, are not surfaced by experimentation with the API in an ICP; the infrastructural relationship between ML practitioners and ICPs renders transparent code reuse, but leaves detailed code knowledge opaque.
6.2.1. Implications for AI ethics
At stake in AI ethics discourse are questions of legitimacy. Arising from the recognition that code operationalises and reifies particular interpretations of essentially contested social constructs (Jacobs and Wallach, 2021; Moss, 2022; Bowker and Star, 2000) is the challenge of locating where and how coding decisions are currently made, and where they ought to be made. What, if any, categories of gender ought to be included as labels in an image dataset (Keyes, 2018)? High-level APIs, interacted with through ICPs, obscure these decisions, and in doing so further entrench them in ML practices: what is unknown to ML practitioners is unquestioned. In this sense, the infrastructural relationship between practitioners and ICPs is an example of social arrangements helping configure ML practices as ’black boxes’ (Burrell, 2016), and is thus a new challenge to the efforts of AI ethics researchers to embed accountability for decision making in ML development (Cooper et al., 2022).
6.3. Development of infrastructures over time
The role of coordination hub lends ICPs and the web of other infrastructures they are related to (compute resources, code repositories, etc.) a semblance of hierarchical coherence. But, while infrastructures may be presented as coherent, hierarchical structures, they are rarely built or managed in this way. Indeed, Jupyter Notebook began life as an open-source project focused on scientific computing within the Python programming language, before being adopted and adapted by ML practitioners and industry (Granger and Pérez, 2021). In this sense, the emergence of ICPs as infrastructure reflects a familiar process of adaptation and translation (cf. Hughes, 1987). Relevantly, Star highlights that infrastructures are fixed in modular increments (Star, 1999, p.382), with “conventions of practice” co-evolving alongside the development of the infrastructure itself (Star, 1999). Here, Elizabeth Shove’s work on the co-evolution of infrastructures and practices offers a potential framework by which to explore how ICPs and ML practices co-evolve (Shove, 2003, 2016).
Watson and Shove argue that infrastructural relations and practices co-evolve through processes of aggregation and integration (Watson and Shove, 2022). Aggregation refers to “the ways in which seemingly localised experiences and practices combine and, in combining, acquire a life of their own” (Watson and Shove, 2022, p.2). Individual ML practitioners, for example, each develop their own approach to coordinating the different layers of infrastructure needed to support ML tasks. However, as individuals share their approaches, and these coalesce into conventions, the conventions themselves shape future infrastructure development. The convention of using GPUs for model training, for example, creates the demand needed to justify the development of more specialised TPUs. Integration refers to ways that policies, processes, and artefacts at the level of the overarching infrastructure are “brought together in the performance of practices enacted across multiple sites (Watson and Shove, 2022, p.2). Google, for example, sets various policies regarding the availability of Google’s GPU resources to users of Google Colab. These policy decisions (e.g. the decision to offer limited free access to GPUs) in turn are integrated into individual users’ ML practices—top-down policy decisions help inform the future development of conventions of practice, but do not determine them. For the field of AI ethics, the framework of aggregation and integration offers a path towards understanding how norms in ML practices, such as the use of particular operationalisations of fairness metrics, co-evolve as a product of both the integration of particular fairness approaches into high-level programming languages and the aggregation of local approaches to ‘managing’ ethics issues into shared practices.
6.3.1. Implications for AI ethics
Conceptualising interactive computing platforms as an emerging form of ‘digital infrastructure’ situates them alongside other digital ’platforms’ that have coalesced into infrastructures (e.g. WeChat (Plantin and de Seta, 2019), Facebook (Plantin et al., 2018b; Helmond et al., 2019; Helmond, 2015), and Google (Plantin et al., 2018b)). The prominence of these digital infrastructures in mediating contemporary life has led to the development of the platform governance field (Gorwa, 2019b).212121Similarly, the emergence of earlier information infrastructures led to the development of the internet governance field (Hofmann et al., 2017) and information infrastructure studies (Bowker and Star, 2000). Platform governance researchers have explored how digital infrastructures attempt to exercise governance over their users, and how digital infrastructures themselves can be more effectively governed. Robert Gorwa, for example, has studied the governance of online content, particularly user-generated content on digital platforms (Gorwa, 2019a). As Gorwa argues, there is an increasing nexus between AI ethics discourse and platform governance discourse: algorithmic systems, particularly predictive ML systems, are core components of the governance regimes of digital infrastructures (Gorwa, 2020). Tarleton Gillespie, for example, critiques the positioning of ML tools as the solution to social media content moderation (Gillespie, 2020). ICPs advance this nexus, but in the reverse direction: as the platforms have developed from software tools for scientific computing to general purpose coordination hubs for ML practices they have begun to integrate affordances more commonly associated with digital platforms. Google Colab, for example, integrates directly into Google Drive—a widely used cloud storage and file sharing platform. We can interpret this integration as an effort to cultivate network effects (Belleflamme, 2018): if I care about sharing my notebook with others, then it makes sense that I will seek out the ICP that integrates directly with the file sharing system most of my colleagues use. But, to the extent that a notebook is ‘content’, and the extent that this content may include ML models that have been shown to cause significant social harm, ICP operators have so far eluded responsibility for this content. For the field of AI ethics, then, the potential for ICP operators to exercise governance functions over ICP users may be worth further consideration.
7. Limitations
Conceptually, as Eric Baumer and Micki McGee (Baumer and McGee, 2019) argue, topic modelling risks using a statistical model of a corpus to speak on behalf of a social group. This risk is compounded by the fact that the social group who generates content that enters a corpus (in this study, people who ask questions on Stack Exchange forums) may not be representative of the social group of interest to the study (here, ML practitioners). Relevantly, among the Stack Overflow user base, as of 2016, only 5.8% of contributors were female (Ford et al., 2016). Additionally, while there are versions of Stack Overflow in multiple languages, only the English-language version has been used in this study. As such, future research will need to validate the extent to which the practices identified in this study are representative of ML practitioners.
The focus of Stack Exchange questions also presents a fundamental limitation for studies of ML practitioners. Stack Exchange questions are points of trouble—they represent moments when a user has been unable to complete a task. As such, it may be the case that there are a range of practices that are not represented in the Stack Exchange corpus, simply because they are practices so familiar they do not necessitate asking any questions. Given the discussion on transparency and infrastructures in Section 6.1, this means Stack Exchange questions can only offer a partial account of infrastructural relationships. There are also limitations inherent in the pre-processing and model training process outlined in Section 4.2. In particular, stemming of words may have reduced the semantic depth of the topic model, as may have removal of code snippets from the corpus. The validation of topic models is an ongoing area of research (Maier et al., 2018; Grimmer et al., 2022). As this is a preliminary study, no attempt has been made to externally validate the accuracy of the topics identified (e.g. through comparing the latent topics identified by the topic model to coded themes identified by expert human reviewers of the same corpus, as in (Mimno et al., 2011)). More broadly, the approach taken in this study will benefit from complementary qualitative studies to both validate and contextualise findings (e.g. ethnographic studies of practitioners in multiple social contexts (Forsythe, 1993)).
8. Conclusion
Interactive computing platforms, such as Jupyter Notebook and Google Colab, are widely used by ML practitioners. In this paper, I conducted a topic model analysis of user-contributed questions on the Stack Exchange forums related to interactive computing platforms and ML. I found interactive computing platforms are used by ML practitioners in two categories of practices: in learning practices, particularly to support probing and reuse of others’ code; and, in coordination practices, to help marshal the various infrastructures needed to enact ML tasks. I argued that these practices constitute an emerging infrastructural relationship between ML practitioners and interactive computing platforms, in which both the platforms and ML practices are co-evolving. I highlighted several consequences of this infrastructuralisation, in terms of configuring the space in which AI ethics operates and responds to, designing interventions in ML practices, making visible the operationalisation in code of social constructs, and the platform power of ICP operators. As the ML field advances, a pressing issue is therefore the relationship between the social context ICPs form part of and the characteristics of ML systems that are developed. Tracing these relations is critical for resisting the enclosure of AI ethics by a set of social arrangements that may themselves be contributing to the production and deployment of harmful ML systems.
Acknowledgements.
This research is part of a larger PhD research project, supported by the Australian Government Research Training Program Scholarship. I acknowledge feedback generously provided by Jochen Trumpf, Jenny Davis, Ben Hutchinson, Kate Williams, Charlotte Bradley, Ned Cooper, Kathy Reid, and the anonymous reviewers.References
- (1)
- Abdalkareem et al. (2017) Rabe Abdalkareem, Emad Shihab, and Juergen Rilling. 2017. On Code Reuse from StackOverflow: An Exploratory Study on Android Apps. Information and Software Technology 88 (Aug. 2017).
- Ahmad et al. (2018) Arshad Ahmad, Chong Feng, Shi Ge, and Abdallah Yousif. 2018. A Survey on Mining Stack Overflow: Question and Answering (Q&A) Community. Data Technologies and Applications 52, 2 (Jan. 2018).
- Alshangiti et al. (2019) Moayad Alshangiti, Hitesh Sapkota, Pradeep K. Murukannaiah, Xumin Liu, and Qi Yu. 2019. Why Is Developing Machine Learning Applications Challenging? A Study on Stack Overflow Posts. In 2019 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). IEEE, Porto de Galinhas, Recife, Brazil.
- Amoore (2019) Louise Amoore. 2019. Doubt and the Algorithm: On the Partial Accounts of Machine Learning. Theory, Culture & Society 36, 6 (Nov. 2019).
- An et al. (2017) Le An, Ons Mlouki, Foutse Khomh, and Giuliano Antoniol. 2017. Stack Overflow: A Code Laundering Platform?. In 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER).
- Anderson et al. (2012) Ashton Anderson, Daniel Huttenlocher, Jon Kleinberg, and Jure Leskovec. 2012. Discovering Value from Community Activity on Focused Question Answering Sites: A Case Study of Stack Overflow. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, Beijing China.
- Ashmore et al. (2022) Rob Ashmore, Radu Calinescu, and Colin Paterson. 2022. Assuring the Machine Learning Lifecycle: Desiderata, Methods, and Challenges. Comput. Surveys 54, 5 (June 2022).
- Baltes and Diehl (2019) Sebastian Baltes and Stephan Diehl. 2019. Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects. Empirical Software Engineering 24, 3 (June 2019).
- Barry et al. (2020) Marguerite Barry, Aphra Kerr, and Oliver Smith. 2020. Ethics on the Ground: From Principles to Practice. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery.
- Barua et al. (2014) Anton Barua, Stephen W. Thomas, and Ahmed E. Hassan. 2014. What Are Developers Talking about? An Analysis of Topics and Trends in Stack Overflow. Empirical Software Engineering 19, 3 (June 2014).
- Baumer and McGee (2019) Eric P. S. Baumer and Micki McGee. 2019. Speaking on Behalf of: Representation, Delegation, and Authority in Computational Text Analysis. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. ACM, Honolulu HI USA.
- Baxter et al. (2020) Kathy Baxter, Yoav Schlesinger, Sarah Aerni, Lewis Baker, Julie Dawson, Krishnaram Kenthapadi, Isabel Kloumann, and Hanna Wallach. 2020. Bridging the Gap from AI Ethics Research to Practice. Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (2020).
- Beg et al. (2021) Marijan Beg, Juliette Taka, Thomas Kluyver, Alexander Konovalov, Min Ragan-Kelley, Nicolas M. Thiéry, and Hans Fangohr. 2021. Using Jupyter for Reproducible Scientific Workflows. Computing in Science & Engineering 23, 2 (2021).
- Belleflamme (2018) Paul Belleflamme. 2018. Platforms and Network Effects. In Handbook of Game Theory and Industrial Organization, Volume II, Luis Corchón and Marco Marini (Eds.). Edward Elgar Publishing.
- Bessen et al. (2022) James Bessen, Stephen Michael Impink, and Robert Seamans. 2022. The Cost of Ethical AI Development for AI Startups. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. ACM, Oxford United Kingdom.
- Beutel et al. (2019) Alex Beutel, Jilin Chen, Tulsee Doshi, Hai Qian, Allison Woodruff, Christine Luu, Pierre Kreitmann, Jonathan Bischof, and Ed H. Chi. 2019. Putting Fairness Principles into Practice: Challenges, Metrics, and Improvements. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’19). Association for Computing Machinery, New York, NY, USA.
- Bogen et al. (2020) Miranda Bogen, Aaron Rieke, and Shazeda Ahmed. 2020. Awareness in Practice: Tensions in Access to Sensitive Attribute Data for Antidiscrimination. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery.
- Bourdieu (2020) Pierre Bourdieu. 2020. Outline of a Theory of Practice. In The New Social Theory Reader. Routledge.
- Bowker et al. (2009) Geoffrey C. Bowker, Karen Baker, Florence Millerand, and David Ribes. 2009. Toward Information Infrastructure Studies: Ways of Knowing in a Networked Environment. In International Handbook of Internet Research, Jeremy Hunsinger, Lisbeth Klastrup, and Matthew Allen (Eds.). Springer Netherlands, Dordrecht.
- Bowker and Star (2000) Geoffrey C. Bowker and Susan Leigh Star. 2000. Sorting Things out: Classification and Its Consequences. MIT Press.
- Brinkmann (2021) Demetrios Brinkmann. 2021. Jupyter Notebooks In Production?
- Brock (2018) André Brock. 2018. Critical Technocultural Discourse Analysis. New Media and Society 20, 3 (2018).
- Brookes and McEnery (2019) Gavin Brookes and Tony McEnery. 2019. The Utility of Topic Modelling for Discourse Studies: A Critical Evaluation. Discourse Studies 21, 1 (Feb. 2019).
- Brown et al. (2021) Duncan A. Brown, Karan Vahi, Michela Taufer, Von Welch, and Ewa Deelman. 2021. Reproducing GW150914: The First Observation of Gravitational Waves From a Binary Black Hole Merger. Computing in Science Engineering 23, 2 (March 2021).
- Buolamwini and Gebru (2018) Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency. PMLR, 77–91.
- Burrell (2016) Jenna Burrell. 2016. How the Machine ‘thinks’: Understanding Opacity in Machine Learning Algorithms. Big Data and Society 3, 1 (2016).
- Chattopadhyay et al. (2020) Souti Chattopadhyay, Ishita Prasad, Austin Z. Henley, Anita Sarma, and Titus Barik. 2020. What’s Wrong with Computational Notebooks? Pain Points, Needs, and Design Opportunities. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. ACM, Honolulu HI USA.
- Christin (2017) Angèle Christin. 2017. Algorithms in Practice: Comparing Web Journalism and Criminal Justice. Big Data & Society 4, 2 (Dec. 2017).
- Cooper et al. (2022) A. Feder Cooper, Emanuel Moss, Benjamin Laufer, and Helen Nissenbaum. 2022. Accountability in an Algorithmic Society: Relationality, Responsibility, and Robustness in Machine Learning. In 2022 ACM Conference on Fairness, Accountability, and Transparency. ACM, Seoul Republic of Korea.
- Davis (2020) Jenny L Davis. 2020. How artifacts afford: The power and politics of everyday things. MIT Press.
- Davis and Chouinard (2016) Jenny L. Davis and James B. Chouinard. 2016. Theorizing Affordances: From Request to Refuse. Bulletin of Science, Technology & Society 36, 4 (2016).
- Denton et al. (2021) Emily Denton, Alex Hanna, Razvan Amironesei, Andrew Smart, and Hilary Nicole. 2021. On the Genealogy of Machine Learning Datasets: A Critical History of ImageNet. Big Data & Society 8, 2 (July 2021).
- Deshpande and Sharp (2022) Advait Deshpande and Helen Sharp. 2022. Responsible AI Systems: Who Are the Stakeholders?. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. ACM, Oxford United Kingdom.
- DiMaggio et al. (2013) Paul DiMaggio, Manish Nag, and David Blei. 2013. Exploiting Affinities between Topic Modeling and the Sociological Perspective on Culture: Application to Newspaper Coverage of U.S. Government Arts Funding. Poetics 41, 6 (Dec. 2013).
- Dourish (2016) Paul Dourish. 2016. Algorithms and Their Others: Algorithmic Culture in Context. Big Data and Society 3, 2 (2016).
- Emery (1993) Fred Emery. 1993. Characteristics of Socio-Technical Systems. In The Social Engagement of Social Science, Volume 2, Eric Trist, Hugh Murray, and Beulah Trist (Eds.). University of Pennsylvania Press, Philadelphia.
- Fish and Stark (2021) Benjamin Fish and Luke Stark. 2021. Reflexive Design for Fairness and Other Human Values in Formal Models. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. ACM, Virtual Event USA.
- Ford et al. (2016) Denae Ford, Justin Smith, Philip J. Guo, and Chris Parnin. 2016. Paradise Unplugged: Identifying Barriers for Female Participation on Stack Overflow. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. ACM, Seattle WA USA.
- Forsythe (1993) Diana E. Forsythe. 1993. Engineering Knowledge: The Construction of Knowledge in Artificial Intelligence. Social Studies of Science 23, 3 (Aug. 1993).
- Gebru et al. (2021) Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for Datasets. Commun. ACM 64, 12 (Dec. 2021).
- Gillespie (2020) Tarleton Gillespie. 2020. Content Moderation, AI, and the Question of Scale. Big Data and Society 7 (2020).
- Gorwa (2019a) Robert Gorwa. 2019a. The Platform Governance Triangle: Conceptualising the Informal Regulation of Online Content. Internet Policy Review 8, 2 (June 2019).
- Gorwa (2019b) Robert Gorwa. 2019b. What Is Platform Governance? Information, Communication & Society 22, 6 (May 2019).
- Gorwa (2020) Robert Gorwa. 2020. Towards Fairness, Accountability, and Transparency in Platform Govvernance. AoIR Selected Papers of Internet Research (Feb. 2020).
- Granger and Pérez (2021) Brian Granger and Fernando Pérez. 2021. Jupyter: Thinking and Storytelling with Code and Data. Preprint.
- Grimmer et al. (2022) Justin Grimmer, Roberts. Margaret E., and Stewart, Brandon M. 2022. Text as Data: A New Framework for Machine Learning and the Social Sciences. Princeton.
- Grimmer and Stewart (2013) Justin Grimmer and Brandon M. Stewart. 2013. Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts. Political Analysis 21, 3 (2013).
- Grus (2018) Joel Grus. 2018. I Don’t like Notebooks.: Jupyter Notebook Conference & Training: JupyterCon. https://conferences.oreilly.com/jupyter/jup-ny/public/schedule/detail/68282.html
- Guribye (2015) Frode Guribye. 2015. From Artifacts to Infrastructures in Studies of Learning Practices. Mind, Culture, and Activity 22, 2 (April 2015).
- Hardt et al. (2021) Michaela Hardt, Xiaoguang Chen, Xiaoyi Cheng, Michele Donini, Jason Gelman, Satish Gollaprolu, John He, Pedro Larroy, Xinyu Liu, Nick McCarthy, Ashish Rathi, Scott Rees, Ankit Siva, ErhYuan Tsai, Keerthan Vasist, Pinar Yilmaz, Muhammad Bilal Zafar, Sanjiv Das, Kevin Haas, Tyler Hill, and Krishnaram Kenthapadi. 2021. Amazon SageMaker Clarify: Machine Learning Bias Detection and Explainability in the Cloud. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. ACM, Virtual Event Singapore.
- Helmond (2015) Anne Helmond. 2015. The Platformization of the Web: Making Web Data Platform Ready. Social Media and Society 1, 2 (2015).
- Helmond et al. (2019) Anne Helmond, David B. Nieborg, and Fernando N. van der Vlist. 2019. Facebook’s Evolution: Development of a Platform-as-Infrastructure. Internet Histories 3, 2 (April 2019).
- Hofmann et al. (2017) Jeanette Hofmann, Christian Katzenbach, and Kirsten Gollatz. 2017. Between Coordination and Regulation: Finding the Governance in Internet Governance. New Media & Society 19, 9 (Sept. 2017).
- Holstein et al. (2019) Kenneth Holstein, Jennifer Wortman Vaughan, Hal Daumé, Miroslav Dudík, and Hanna Wallach. 2019. Improving Fairness in Machine Learning Systems: What Do Industry Practitioners Need?. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems.
- Hopkins and Booth (2021) Aspen Hopkins and Serena Booth. 2021. Machine Learning Practices Outside Big Tech: How Resource Constraints Challenge Responsible Development. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. Association for Computing Machinery.
- Howard (2020) Jeremy Howard. 2020. Creating Delightful Libraries and Books with Nbdev and Fastdoc.
- Hughes (1987) Thomas P. Hughes. 1987. The Evolution of Large Technological Systems. The social construction of technological systems: New directions in the sociology and history of technology 82 (1987).
- Ingram et al. (2007) Jack Ingram, Elizabeth Shove, and Matthew Watson. 2007. Products and Practices: Selected Concepts from Science and Technology Studies and from Social Theories of Consumption and Practice. Design Issues 23, 2 (2007).
- Isoaho et al. (2021) Karoliina Isoaho, Daria Gritsenko, and Eetu Mäkelä. 2021. Topic Modeling and Text Analysis for Qualitative Policy Research. Policy Studies Journal 49, 1 (Feb. 2021).
- Jacobs and Wallach (2021) Abigail Z. Jacobs and Hanna Wallach. 2021. Measurement and Fairness. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery.
- Jacobs and Tschötschel (2019) Thomas Jacobs and Robin Tschötschel. 2019. Topic Models Meet Discourse Analysis: A Quantitative Tool for a Qualitative Approach. International Journal of Social Research Methodology 22, 5 (Sept. 2019).
- Jakobson (1960) Roman Jakobson. 1960. Linguistics and Poetics. In Style in Language. MIT Press, MA.
- Juneau et al. (2021) Stéphanie Juneau, Knut Olsen, Robert Nikutta, Alice Jacques, and Stephen Bailey. 2021. Jupyter-Enabled Astrophysical Analysis Using Data-Proximate Computing Platforms. Computing in Science Engineering 23, 2 (March 2021).
- Kaur et al. (2020) Harmanpreet Kaur, Harsha Nori, Samuel Jenkins, Rich Caruana, Hanna Wallach, and Jennifer Wortman Vaughan. 2020. Interpreting Interpretability: Understanding Data Scientists’ Use of Interpretability Tools for Machine Learning. Conference on Human Factors in Computing Systems - Proceedings (2020).
- Kery et al. (2018) Mary Beth Kery, Marissa Radensky, Mahima Arya, Bonnie E. John, and Brad A. Myers. 2018. The Story in the Notebook: Exploratory Data Science Using a Literate Programming Tool. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. ACM, Montreal QC Canada.
- Keyes (2018) Os Keyes. 2018. The Misgendering Machines: Trans/HCI Implications of Automatic Gender Recognition. Proceedings of the ACM on Human-Computer Interaction 2, CSCW (2018).
- Kitchin (2014) Rob Kitchin. 2014. Big Data, New Epistemologies and Paradigm Shifts. Big Data & Society 1, 1 (April 2014).
- Kluyver et al. (2016) Thomas Kluyver, Benjamin Ragan-Kelley, Fernando Pérez, Brian Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, Jessica Hamrick, Jason Grout, Sylvain Corlay, Paul Ivanov, Damián Avila, Safia Abdalla, Carol Willing, and Jupyter development team. 2016. Jupyter Notebooks – a Publishing Format for Reproducible Computational Workflows. In 20th International Conference on Electronic Publishing (01/01/16), Fernando Loizides and Birgit Scmidt (Eds.). IOS Press.
- Koenecke et al. (2020) Allison Koenecke, Andrew Nam, Emily Lake, Joe Nudell, Minnie Quartey, Zion Mengesha, Connor Toups, John R Rickford, Dan Jurafsky, and Sharad Goel. 2020. Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences 117, 14 (2020), 7684–7689.
- Koenzen et al. (2020) Andreas P. Koenzen, Neil A. Ernst, and Margaret-Anne D. Storey. 2020. Code Duplication and Reuse in Jupyter Notebooks. In 2020 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE.
- Krafft et al. (2020) P. M. Krafft, Meg Young, Michael Katell, Karen Huang, and Ghislain Bugingo. 2020. Defining AI in Policy versus Practice. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society. Association for Computing Machinery.
- Langenkamp and Yue (2022) Max Langenkamp and Daniel N. Yue. 2022. How Open Source Machine Learning Software Shapes AI. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. ACM, Oxford United Kingdom.
- Larkin (2013) Brian Larkin. 2013. The Politics and Poetics of Infrastructure. Annual Review of Anthropology 42 (2013).
- Larkin (2020) Brian Larkin. 2020. 7. Promising Forms: The Political Aesthetics of Infrastructure. In The Promise of Infrastructure, Nikhil Anand, Akhil Gupta, and Hannah Appel (Eds.). Duke University Press.
- Lee and Singh (2021) Michelle Seng Ah Lee and Jatinder Singh. 2021. Risk Identification Questionnaire for Detecting Unintended Bias in the Machine Learning Development Lifecycle. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. ACM, Virtual Event USA.
- Leonardi (2012) Paul M. Leonardi. 2012. Materiality, Sociomateriality, and Socio-Technical Systems: What Do These Terms Mean? How Are They Related? Do We Need Them? SSRN Scholarly Paper ID 2129878. Social Science Research Network, Rochester, NY.
- Leonardi and Barley (2008) Paul M. Leonardi and Stephen R. Barley. 2008. Materiality and Change: Challenges to Building Better Theory about Technology and Organizing. Information and Organization (2008).
- Leonardi et al. (2012) Paul M Leonardi, Bonnie A Nardi, and Jannis Kallinikos. 2012. Materiality and Organizing: Social Interaction in a Technological World. Oxford University Press, Oxford.
- Lewis (1997) David D. Lewis. 1997. UCI Machine Learning Repository: Reuters-21578 Text Categorization Collection Data Set. https://archive.ics.uci.edu/ml/datasets/reuters-21578+text+categorization+collection
- Li et al. (2021) Lan Li, Tina Lassiter, Joohee Oh, and Min Kyung Lee. 2021. Algorithmic Hiring in Practice: Recruiter and HR Professional’s Perspectives on AI Use in Hiring. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. Association for Computing Machinery.
- Lin et al. (2015) Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. 2015. Microsoft COCO: Common Objects in Context. arXiv:arXiv:1405.0312
- Lindstedt (2019) Nathan C. Lindstedt. 2019. Structural Topic Modeling For Social Scientists: A Brief Case Study with Social Movement Studies Literature, 2005–2017. Social Currents 6, 4 (Aug. 2019).
- Mackenzie (2015) Adrian Mackenzie. 2015. The Production of Prediction: What Does Machine Learning Want? European Journal of Cultural Studies 18, 4-5 (2015).
- Madaio et al. (2022) Michael Madaio, Lisa Egede, Hariharan Subramonyam, Jennifer Wortman Vaughan, and Hanna Wallach. 2022. Assessing the Fairness of AI Systems: AI Practitioners’ Processes, Challenges, and Needs for Support. Proceedings of the ACM on Human-Computer Interaction 6, CSCW1 (March 2022).
- Maier et al. (2018) Daniel Maier, A. Waldherr, P. Miltner, G. Wiedemann, A. Niekler, A. Keinert, B. Pfetsch, G. Heyer, U. Reber, T. Häussler, H. Schmid-Petri, and S. Adam. 2018. Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology. Communication Methods and Measures 12, 2-3 (April 2018).
- Mimno et al. (2011) David Mimno, Hanna Wallach, Edmund Talley, Miriam Leenders, and Andrew McCallum. 2011. Optimizing Semantic Coherence in Topic Models. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing.
- Mohr and Bogdanov (2013) John W. Mohr and Petko Bogdanov. 2013. Introduction—Topic Models: What They Are and Why They Matter. Poetics 41, 6 (Dec. 2013).
- Morley et al. (2020) Jessica Morley, Luciano Floridi, Libby Kinsey, and Anat Elhalal. 2020. From What to How: An Initial Review of Publicly Available AI Ethics Tools, Methods and Research to Translate Principles into Practices. Science and Engineering Ethics 26, 4 (Aug. 2020).
- Moss (2022) Emanuel Moss. 2022. The Objective Function: Science and Society in the Age of Machine Intelligence. arXiv:2209.10418 [cs]
- Mueller (2018) Alexander Mueller. 2018. 5 Reasons Why Jupyter Notebooks Suck. https://towardsdatascience.com/5-reasons-why-jupyter-notebooks-suck-4dc201e27086
- Nasehi et al. (2012) Seyed Mehdi Nasehi, Jonathan Sillito, Frank Maurer, and Chris Burns. 2012. What Makes a Good Code Example?: A Study of Programming Q&A in StackOverflow. In 2012 28th IEEE International Conference on Software Maintenance (ICSM).
- Newman and Girvan (2004) M. E. J. Newman and M. Girvan. 2004. Finding and Evaluating Community Structure in Networks. Physical Review E 69, 2 (Feb. 2004).
- Nikolenko et al. (2017) Sergey I. Nikolenko, Sergei Koltcov, and Olessia Koltsova. 2017. Topic Modelling for Qualitative Studies. Journal of Information Science 43, 1 (Feb. 2017).
- Obermeyer and Mullainathan (2019) Ziad Obermeyer and Sendhil Mullainathan. 2019. Dissecting Racial Bias in an Algorithm That Guides Health Decisions for 70 Million People. In Proceedings of the Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery.
- Ophir et al. (2020) Yotam Ophir, Dror Walter, and Eleanor R Marchant. 2020. A Collaborative Way of Knowing: Bridging Computational Communication Research and Grounded Theory Ethnography. Journal of Communication 70, 3 (June 2020).
- Orr and Davis (2020) Will Orr and Jenny L. Davis. 2020. Attributions of Ethical Responsibility by Artificial Intelligence Practitioners. Information Communication and Society 23, 5 (2020).
- Paris (2021) Britt S Paris. 2021. Time Constructs: Design Ideology and a Future Internet. Time & Society 30, 1 (Feb. 2021).
- Perez and Granger (2007) Fernando Perez and Brian E. Granger. 2007. IPython: A System for Interactive Scientific Computing. Computing in Science & Engineering 9, 3 (2007).
- Perkel (2018) Jeffrey M. Perkel. 2018. Why Jupyter Is Data Scientists’ Computational Notebook of Choice. Nature 563, 7729 (Nov. 2018).
- Pimentel et al. (2019) João Felipe Pimentel, Leonardo Murta, Vanessa Braganholo, and Juliana Freire. 2019. A Large-Scale Study about Quality and Reproducibility of Jupyter Notebooks. In 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR). IEEE.
- Plantin and de Seta (2019) Jean Christophe Plantin and Gabriele de Seta. 2019. WeChat as Infrastructure: The Techno-Nationalist Shaping of Chinese Digital Platforms. Chinese Journal of Communication 12, 3 (2019).
- Plantin et al. (2018a) Jean-Christophe Plantin, Carl Lagoze, and Paul N Edwards. 2018a. Re-Integrating Scholarly Infrastructure: The Ambiguous Role of Data Sharing Platforms. Big Data & Society 5, 1 (Jan. 2018).
- Plantin et al. (2018b) Jean Christophe Plantin, Carl Lagoze, Paul N. Edwards, and Christian Sandvig. 2018b. Infrastructure Studies Meet Platform Studies in the Age of Google and Facebook. New Media and Society 20, 1 (2018).
- Plantin and Punathambekar (2019) Jean Christophe Plantin and Aswin Punathambekar. 2019. Digital media infrastructures: pipes, platforms, and politics. Media, Culture and Society 41, 2 (2019), 163–174.
- Polyzotis et al. (2017) Neoklis Polyzotis, Sudip Roy, Steven Euijong Whang, and Martin Zinkevich. 2017. Data Management Challenges in Production Machine Learning. Proceedings of the ACM SIGMOD International Conference on Management of Data Part F1277 (2017).
- Polyzotis et al. (2018) Neoklis Polyzotis, Sudip Roy, Steven Euijong Whang, and Martin Zinkevich. 2018. Data Lifecycle Challenges in Production Machine Learning: A Survey. ACM SIGMOD Record 47, 2 (Dec. 2018).
- Quinn et al. (2010) Kevin M. Quinn, Burt L. Monroe, Michael Colaresi, Michael H. Crespin, and Dragomir R. Radev. 2010. How to Analyze Political Attention with Minimal Assumptions and Costs. American Journal of Political Science 54, 1 (Jan. 2010).
- Rakova et al. (2021) Bogdana Rakova, Jingying Yang, Henriette Cramer, and Rumman Chowdhury. 2021. Where Responsible AI Meets Reality: Practitioner Perspectives on Enablers for Shifting Organizational Practices. Proceedings of the ACM on Human-Computer Interaction 5, CSCW1 (April 2021).
- Randles et al. (2017) Bernadette M. Randles, Irene V. Pasquetto, Milena S. Golshan, and Christine L. Borgman. 2017. Using the Jupyter Notebook as a Tool for Open Science: An Empirical Study. In 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL). IEEE.
- Redström (2005) Johan Redström. 2005. On Technology as Material in Design. Design Philosophy Papers 3, 2 (June 2005).
- Roberts et al. (2016) Margaret E. Roberts, Brandon M. Stewart, and Edoardo M. Airoldi. 2016. A Model of Text for Experimentation in the Social Sciences. J. Amer. Statist. Assoc. 111, 515 (July 2016).
- Roberts et al. (2019) Margaret E. Roberts, Brandon M. Stewart, and Dustin Tingley. 2019. Stm: An R Package for Structural Topic Models. Journal of Statistical Software 91 (Oct. 2019).
- Roberts et al. (2013) Margaret E. Roberts, Brandon M. Stewart, Dustin Tingley, and Edoardo M. Airoldi. 2013. The Structural Topic Model and Applied Social Science. In Advances in Neural Information Processing Systems Workshop on Topic Models: Computation, Application, and Evaluation, Vol. 4. Harrahs and Harveys, Lake Tahoe.
- Roberts et al. (2014) Margaret E. Roberts, Brandon M. Stewart, Dustin Tingley, Christopher Lucas, Jetson Leder-Luis, Shana Kushner Gadarian, Bethany Albertson, and David G. Rand. 2014. Structural Topic Models for Open-Ended Survey Responses. American Journal of Political Science 58, 4 (2014).
- Rosen and Shihab (2016) Christoffer Rosen and Emad Shihab. 2016. What Are Mobile Developers Asking about? A Large Scale Study Using Stack Overflow. Empirical Software Engineering 21, 3 (June 2016).
- Rouse (2007) Joseph Rouse. 2007. Practice Theory. In Philosophy of Anthropology and Sociology. Elsevier.
- Ruder (2017) Sebastian Ruder. 2017. An Overview of Gradient Descent Optimization Algorithms. (2017). arXiv:1609.04747 [cs.LG]
- Rule et al. (2018) Adam Rule, Aurélien Tabard, and James D. Hollan. 2018. Exploration and Explanation in Computational Notebooks. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, New York, NY, USA.
- Ryan et al. (2021) Mark Ryan, Josephina Antoniou, Laurence Brooks, Tilimbe Jiya, Kevin Macnish, and Bernd Stahl. 2021. Research and Practice of AI Ethics: A Case Study Approach Juxtaposing Academic Discourse with Organisational Reality. Science and Engineering Ethics 27, 2 (2021).
- Schaich Borg (2021) Jana Schaich Borg. 2021. Four Investment Areas for Ethical AI: Transdisciplinary Opportunities to Close the Publication-to-Practice Gap. Big Data & Society 8, 2 (July 2021).
- Schiff et al. (2021) Daniel Schiff, Bogdana Rakova, Aladdin Ayesh, Anat Fanti, and Michael Lennon. 2021. Explaining the Principles to Practices Gap in AI. IEEE Technology and Society Magazine 40, 2 (June 2021).
- Selbst et al. (2019) Andrew D. Selbst, Danah Boyd, Sorelle A. Friedler, Suresh Venkatasubramanian, and Janet Vertesi. 2019. Fairness and Abstraction in Sociotechnical Systems. In Proceedings of the Conference on Fairness, Accountability, and Transparency (Atlanta, GA, USA) (FAT* ’19). Association for Computing Machinery, New York, NY, USA, 59–68.
- Shelby et al. (2022) Renee Shelby, Shalaleh Rismani, Kathryn Henne, Ajung Moon, Negar Rostamzadeh, Paul Nicholas, N’mah Yilla, Jess Gallegos, Andrew Smart, Emilio Garcia, and Gurleen Virk. 2022. Sociotechnical Harms: Scoping a Taxonomy for Harm Reduction. (Oct. 2022). arXiv:2210.05791 [cs.HC]
- Shove (2003) Elizabeth Shove. 2003. Comfort, Cleanliness and Convenience : The Social Organization of Normality. Berg.
- Shove (2016) Elizabeth Shove. 2016. Matters of Practice. In The Nexus of Practices (1st ed.). Routledge.
- Shove et al. (2012) Elizabeth Shove, Mika Pantzar, and Matt Watson. 2012. The Dynamics of Social Practice: Everyday Life and How It Changes. SAGE, Los Angeles.
- Silvast and Virtanen (2019) Antti Silvast and Mikko J. Virtanen. 2019. An Assemblage of Framings and Tamings: Multi-Sited Analysis of Infrastructures as a Methodology. Journal of Cultural Economy 12, 6 (Nov. 2019).
- Sloane and Zakrzewski (2022) Mona Sloane and Janina Zakrzewski. 2022. German AI Start-Ups and “AI Ethics”: Using A Social Practice Lens for Assessing and Implementing Socio-Technical Innovation. In 2022 ACM Conference on Fairness, Accountability, and Transparency. ACM, Seoul Republic of Korea.
- Star (1989) Susan Leigh Star. 1989. The Structure of Ill-Structured Solutions: Boundary Objects and Heterogeneous Distributed Problem Solving. In Distributed Artificial Intelligence. Elsevier.
- Star (1999) Susan Leigh Star. 1999. The Ethnography of Infrastructure. American behavioral scientist 43, 3 (1999).
- Star and Ruhleder (1996) Susan Leigh Star and Karen Ruhleder. 1996. Steps Toward an Ecology of Infrastructure: Design and Access for Large Information Spaces. Information Systems Research 7, 1 (March 1996).
- Syed and Spruit (2017) Shaheen Syed and Marco Spruit. 2017. Full-Text or Abstract? Examining Topic Coherence Scores Using Latent Dirichlet Allocation. In 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA). IEEE.
- Szymielewicz et al. (2020) Katarzyna Szymielewicz, Anna Bacciarelli, Fanny Hidvegi, Agata Foryciarz, Soizic Pénicaud, and Matthias Spielkamp. 2020. Where Do Algorithmic Accountability and Explainability Frameworks Take Us in the Real World? From Theory to Practice. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery.
- Tahaei et al. (2020) Mohammad Tahaei, Kami Vaniea, and Naomi Saphra. 2020. Understanding Privacy-Related Questions on Stack Overflow. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems.
- Tan (2021) Chiin-Rui Tan. 2021. The Nascent Case for Adopting Jupyter Notebooks as a Pedagogical Tool for Interdisciplinary Humanities, Social Science, and Arts Education. Computing in Science Engineering 23, 2 (March 2021).
- Treude and Wagner (2019) Christoph Treude and Markus Wagner. 2019. Predicting Good Configurations for GitHub and Stack Overflow Topic Models. In 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR). IEEE, Montreal, QC, Canada.
- Troeger and Bock (2022) Jasmin Troeger and Annekatrin Bock. 2022. The Sociotechnical Walkthrough – a Methodological Approach for Platform Studies. Studies in Communication Sciences 22, 1 (June 2022).
- Ufford et al. (2018) Michelle Ufford, M Pacer, Mathew Seal, and Kyle Kelley. 2018. Beyond Interactive: Notebook Innovation at Netflix.
- Vakkuri et al. (2020) Ville Vakkuri, Kai-Kristian Kemell, Joni Kultanen, and Pekka Abrahamsson. 2020. The Current State of Industrial Practice in Artificial Intelligence Ethics. IEEE Software 37, 4 (July 2020).
- Veale and Binns (2017) Michael Veale and Reuben Binns. 2017. Fairer Machine Learning in the Real World: Mitigating Discrimination without Collecting Sensitive Data. Big Data & Society 4, 2 (Dec. 2017).
- Veale et al. (2018) Michael Veale, Max Van Kleek, and Reuben Binns. 2018. Fairness and Accountability Design Needs for Algorithmic Support in High-Stakes Public Sector Decision-Making. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. ACM, New York, NY, USA.
- Walter and Ophir (2019) Dror Walter and Yotam Ophir. 2019. News Frame Analysis: An Inductive Mixed-method Computational Approach. Communication Methods and Measures 13, 4 (Oct. 2019).
- Wang et al. (2019) April Yi Wang, Anant Mittal, Christopher Brooks, and Steve Oney. 2019. How Data Scientists Use Computational Notebooks for Real-Time Collaboration. Proceedings of the ACM on Human-Computer Interaction 3, CSCW (Nov. 2019).
- Wang et al. (2020) Jiawei Wang, Li Li, and Andreas Zeller. 2020. Better Code, Better Sharing: On the Need of Analyzing Jupyter Notebooks. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: New Ideas and Emerging Results.
- Watson and Shove (2022) Matt Watson and Elizabeth Shove. 2022. How Infrastructures and Practices Shape Each Other: Aggregation, Integration and the Introduction of Gas Central Heating. Sociological Research Online (Jan. 2022).
- Weinberg (2022) Lindsay Weinberg. 2022. Rethinking Fairness: An Interdisciplinary Survey of Critiques of Hegemonic ML Fairness Approaches. Journal of Artificial Intelligence Research 74 (May 2022).
- Wesslen (2018) Ryan Wesslen. 2018. Computer-Assisted Text Analysis for Social Science: Topic Models and Beyond. arXiv:1803.11045 [cs]
- Winner (1980) Langdon Winner. 1980. Do Artifacts Have Politics? In The Whale and the Reactor a Search for Limits in an Age of High Technology. Vol. 109. The MIT Press.
- Yang et al. (2016) Xin-Li Yang, David Lo, Xin Xia, Zhi-Yuan Wan, and Jian-Ling Sun. 2016. What Security Questions Do Developers Ask? A Large-Scale Study of Stack Overflow Posts. Journal of Computer Science and Technology 31, 5 (Sept. 2016).
- Zhang et al. (2020) Amy X. Zhang, Michael Muller, and Dakuo Wang. 2020. How Do Data Science Workers Collaborate? Roles, Workflows, and Tools. Proceedings of the ACM on Human-Computer Interaction 4, CSCW1 (May 2020).
Appendix A List of tags used in query of the Stack Exchange Data Dump
Interactive computing platform tags: colab, google-colaboratory, ipython, ipython-notebook, ipywidgets, jupyter, jupyter-lab, jupyter-notebook, jupyterhub, pyspark.
Machine Learning tags: artificial-intelligence, backpropagation, caffe, classification, cnn, computer-vision, conv-neural-network, convolutional-neural-network, deep-learning, feature-selection,
image-processing, keras, lstm, machine-learning, machine-learning-model, neural-network, neural-networks, nlp, nltk, opencv, optimization, predictive-modelling, predictive-models, pytorch, random-forest, regression, scikit-learn, spacy, stanford-nlp, svm, tensorflow, tensorflow2.0.
Appendix B Topic model visualisations
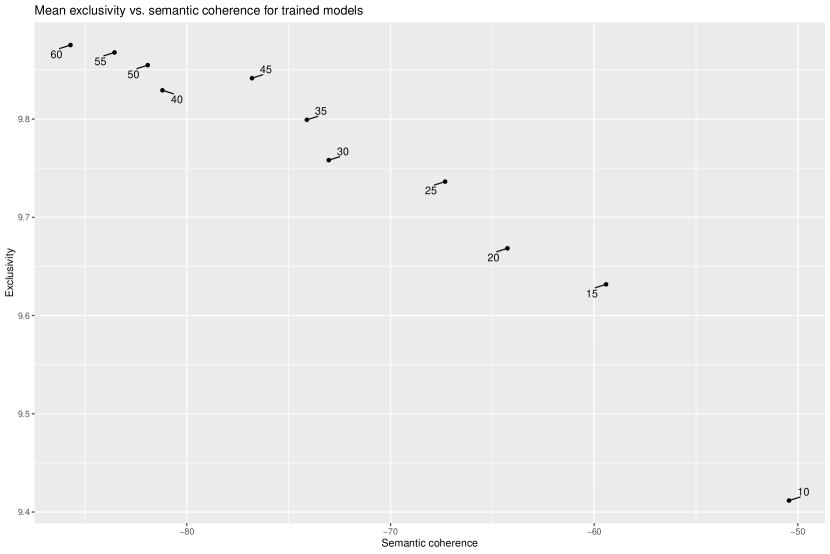

Appendix C Representative questions by topic cluster