Machine Learning Methods for
Spectral Efficiency Prediction in Massive MIMO Systems
Abstract
Channel decoding, channel detection, channel assessment, and resource management for wireless multiple-input multiple-output (MIMO) systems are all examples of problems where machine learning (ML) can be successfully applied. In this paper, we study several ML approaches to solve the problem of estimating the spectral efficiency (SE) value for a certain precoding scheme, preferably in the shortest possible time. The best results in terms of mean average percentage error (MAPE) are obtained with gradient boosting over sorted features, while linear models demonstrate worse prediction quality. Neural networks perform similarly to gradient boosting, but they are more resource- and time-consuming because of hyperparameter tuning and frequent retraining. We investigate the practical applicability of the proposed algorithms in a wide range of scenarios generated by the Quadriga simulator. In almost all scenarios, the MAPE achieved using gradient boosting and neural networks is less than 10%.
keywords:
MIMO, Precoding, Machine Learning, Gradient Boosting, Neural Networks.1 Introduction
Wireless multiple-input multiple-output (MIMO) technology is the subject of extensive theoretical and practical research for next-generation cellular systems [40, 15], which consider multiuser MIMO as one of the core technologies [16]. A considerable research effort has been dedicated to performance evaluation of MIMO systems in realistic cellular environments [8]. One of the most important features in mobile systems is to provide much higher rate data services to a large number of users without corresponding increase in transmitter power and bandwidth [38]. The efficiency of communication systems is traditionally measured in terms of spectral efficiency (SE), which is directly related to the channel capacity in bit/s. This metric indicates how efficiently a limited frequency spectrum is utilized [12].
Evaluation of the channel capacity for the MIMO system in terms of SE has attracted considerable research interest in the past decades [9, 33]. The cell averaged SE is an important parameter for evaluating performance of cellular systems, and it is often obtained by using sophisticated system-level simulations. For traditional cellular systems, the cell-wide SE was studied [1]. The problem of user scheduling in 5G systems requires fast SE computations [6, 20], which can be enabled using machine learning (ML) methods [34].
Advanced ML techniques are capable of providing simple and efficient solutions, given that complicated phases of design and training are completed. ML has recently been applied to power-control problems in wireless communications. In [32] a deep neural network for optimizing the averaging SE is constructed for a system serving a few dozens of users. The neural network structure can be reused [43] for solving an energy-efficiency problem. In [35] the joint data and pilot non-convex power optimization for maximum SE in multi-cell Massive MIMO systems is studied. In [30] deep learning (DL) is used to solve max-min and max-prod power allocation (PA) problems in downlink of Massive MIMO. In [44, 7] the PA problem in cell-free Massive MIMO is solved using DL, which is closely related to the SE evaluation.
Recently the application of neural networks to massive MIMO got significant attention in the literature. Neural networks can be applied to channel decoding, detection, channel estimation, and resource management [41]. A supervised neural-network-based approach for precoding (predicting precoding matrix using the dataset of (channel matrix , precoding matrix ) pairs) for the multiple-input and single-output (MISO) systems is proposed. Also, a mixed problem statement is considered where precoding is computed via a conventional iterative scheme, while the neural network predicts optimal per-user power allocation, which is utilized in the iterative scheme. In [14] an unsupervised neural-network-based approach for precoding in a MIMO system is proposed, where a neural network predicts the precoding based on a channel matrix, and spectral efficiency is used as the loss function directly, so there is no need to provide precoding as targets during training. There are several attempts [11, 34, 29] to predict signal to interference-and-noise-ratio (SINR), which is closely related to predicting SE, but these studies are very limited and take into account only the power distributions of users, but not a channel, precoding, detection matrices.
Although the aforementioned studies deal with problem statements that are somewhat comparable to the problem we solve, there is still a lot of potential for research. Firstly, these works mostly do not describe data generation, so it is unclear whether their results are applicable in practice. In contrast, we study the applicability of ML models in a wider range of Quadriga scenarios. Secondly, the previous research only describes a basic approach for solving the problem and does not study the influence of different neural network architectures, i. e. transformers, and does not consider other efficient machine learning algorithms, e. g. gradient boosting or linear models, that may contribute a lot to the quality of the solution. We include the mentioned algorithms and architectures in our experiments. Finally, all of the works above do not focus on SE prediction, while we consider it as one of our goals. To our knowledge, the prediction of SE using ML for a detailed MIMO model has not been previously studied.
The remainder of the paper is organized as follows. In Section 2 we describe a Massive MIMO system model, particular precoding methods, quality measures, types of detection matrices, and power constraints. In Section 3 we consider the problem of spectral efficiency estimation using machine learning methods. In Section 4 we describe channel dataset, algorithm features, and standard machine learning approaches including linear models, neural networks, and gradient boosting algorithms. Section 5 contains numerical results and Section 6 concludes the paper. Appendix Section 7 contains results for a transformer-based method.
2 MIMO System Background
We consider a precoding problem in multi-user massive MIMO communication in 5G cellular networks. In such system, a base station has multiple transmitting antennas that emit signals to several users simultaneously. Each user also has multiple receiving antennas. The base station measures the quality of channel between each transmitter and receiver. This is known as channel state information. The precoding problem is to find an appropriate weighting (phase and gain) of the signal transmission in such a way that the spectral efficiency is maximum at the receiver. We consider the following downlink multi-user linear channel:
| (1) |
In this model, we have users and we would like to transmit symbols to -th user. Hence in total we would like to transmit a vector , where . First, we multiply the vector being transmitted by a precoding matrix , where is the total number of transmitting antennas on the base station. Then we transmit the precoded signal to all users. Suppose that -th user has receiving antennas and is a channel between -th user antennas and antennas on the base station. Then -th user receives , where is Gaussian noise. Finally, -th user applies a detection for transmitted symbols by multiplying the received vector by a detection matrix . The vector of detected symbols for the -th users is denoted by . The whole process of symbol transmission is presented in Fig. 1 [3]. Usually, in downlink the numbers of symbols being transmitted, user antennas, and base station antennas are related as .


2.1 Precoding Methods
We denote a concatenation of user channel matrices as . Then we make a singular-value decomposition of each matrix as , where is a unitary matrix, is a diagonal matrix and is a semi-unitary matrix. In such way we obtain the decomposition: . For each we denote a sub-matrix with rows corresponding to the largest singular values from . We denote a concatenation of all as .
There are some well-known heuristic precoding algorithms [21, 26, 42, 39, 25]:
| (2) | |||
| (3) |
The diagonal matrix is a column-wise power normalization of precoding matrix, is a scalar power normalization constant for meeting per-antenna power constraints (8). Normalization by constant is done as the last step, after normalization by . The value is a variance of Gaussian noise during transmission (1). We also consider LBFGS precoding optimization scheme [5].
2.2 Quality Functions
The base station chooses an optimal precoding matrix based on measured channel , which maximizes the so-called Spectral Efficiency (SE) [37, 10, 2]. Function of SE is closely related to Signal-to-Interference-and-Noise Ratio and is expressed as :
| (4) |
The set of symbol indexes targeted to -th user is denoted as :
| (5) | |||
| (6) |
where is a precoding for the -th symbol, is a detection vector of the -th symbol, is a variance of Gaussian noise (1). The total power of transmitting antennas without loss of generality is assumed to be equal to one.
Additionally, we consider the function of Single-User SINR (SUSINR) :
| (7) |
The formula (7) describes channel quality for the specified user without taking into account the others. The matrix contains all singular values of on the main diagonal: , and is a diagonal sub-matrix of consisting of largest singular values of the -th user, and are the corresponding elements of [3].
2.3 Power Constraints
It is important to note that each transmitting antenna has a restriction on power of the transmitter. Assuming all the symbols being transmitted are properly normalized, this results in the following constraints on the precoding matrix :
| (8) |
The total power is assumed to be equal to one.
2.4 Detection Matrices
A detection matrix is specific to each user. Below we consider the main detection algorithms: MMSE and MMSE-IRC. In the case of MMSE, the detection matrix is calculated as [18]:
| (9) |
where matrix is estimated using pilot signals on the user side.
3 Spectral Efficiency Prediction Problem
3.1 Machine Learning Background
In this subsection, we give a background on machine learning (ML) tasks and methods. In ML, we are given a training dataset of pairs (input object , target ). The problem is to learn an algorithm (also called prediction function) that predicts target for any new object . Usually , however, complex inputs could also be used. Conventionally used targets include (regression problem) or (classification problem, is the number of classes). We are also given a set of testing objects, , and a metric that measures the quality of predicting target for new objects. This metric should satisfy the problem-specific requirements and could be non-differentiable. Summarizing, in order to use machine learning methods we need to specify objects, targets, metrics, and collect the dataset of (object, target) pairs.
3.2 Objects and Targets
Firstly, we consider the problem of predicting the SE: given antennas at the base station, users with antennas and symbols each, and set of channel matrices (input object), the problem is to predict the spectral efficiency SE (4) that could be achieved with some precoding algorithm (precoding is not modeled in this problem). We assume that , , for all are fixed, while the number of users could be variable. Since is fixed, each object , which serves as an input for our ML algorithms, can be represented by three dimensional tensor .
3.3 Metric
Since spectral efficiency prediction is a regression problem, we can use metrics known from this class of tasks. Namely, we use Mean Average Percentage Error (MAPE):
| (10) |
where is the spectral efficiency computed using specific precoding, and is spectral efficiency predicted by the algorithm for the -th object .
3.4 Problem Statement and Research Questions
Given the dataset , our goal is to train an algorithm that predicts spectral efficiency SE based on the object . The algorithm may also take additional information as input, e. g. the level of noise or SUSINR value. We also consider an alternative problem statement with user-wise spectral efficiency prediction. Our research questions are as follows:
-
•
Can we predict the spectral efficiency (average or user-wise) with acceptable quality, e. g. with error on the test dataset, which is an order of magnitude less than the value we predict, i. e. (10)?
-
•
Which machine learning algorithm out of the considered classes (linear models, gradient boosting, neural networks) is the most suitable for working with channel data?
4 Proposed Methods
4.1 Channel Dataset
To obtain a dataset for this problem, we generate input channel matrices , find precoding for each case using a certain precoding scheme, fixed for this particular dataset, and compute the target spectral efficiency SE using (4). To generate channel coefficients, we use Quadriga [17], an open-source software for generating realistic radio channel matrices. We consider two Quadriga scenarios, namely Urban and Rural. For each scenario, we generate random sets of user positions and compute channel matrices for the obtained user configurations. We describe the generation process in detail in our work [3].
In the majority of the experiments, we consider three precoding algorithms: Maximum Ratio Transmission (MRT) [21], Zero Forcing (ZF) [42] and LBFGS Optimization [5]. The first two classic algorithms are quite simple, while the last one achieves higher spectral efficiency, however being slower. We provide proof-of-concept results for Interference Rejection Combiner (IRC) SE (11) [28].
4.2 Algorithm Features
We consider well-known machine learning algorithms for regression task, namely linear models, gradient boosting, and fully connected neural networks. We rely on the following pipeline:
-
1.
Take an object as input (and possibly other inputs, e. g. SUSINR).
-
2.
Extract a feature vector representation based on the raw input .
-
3.
Apply the algorithm to feature vector to obtain .
Further, we discuss how to obtain feature extraction procedure and prediction function . Motivated by the exact formulas for the case of Maximum Ratio and Zero-Forcing precoding, we select the following default features from the Singular Value Decomposition (SVD) of the matrix, where is the number of users, and is the -th user number of layers:
-
•
– singular values;
-
•
- pairwise layer correlations, .
It can be shown that spectral efficiency (4), which is the value being predicted, depends only on the squares of the first singular values of of all users and the correlations between the first layers of all possible user pairs, which justifies this choice of default features.
There are several issues with these features: 1) the number of features is variable, as the number of users varies among different objects in the dataset, while the aforementioned ML models take a feature vector of fixed size as input 2) the target objective, SE, is invariant to permutation of users, hence there should be a symmetry in feature representations. To address these issues, we propose two modifications of the default features.
Firstly, we introduce symmetry with respect to user permutations by sorting the feature values along with user indices. For singular values, we sort users by the largest singular value. For pairwise correlations, we sort pairs of users by the largest correlation value of their layers.
Secondly, we alleviate the issue with a variable number of users by introducing polynomial features. For a sequence of features, we can apply symmetric polynomial transformation, obtaining fixed number of features :
Therefore, in the following experiments, we consider 3 types of features: default, sorted, polyk. In some experiments, we also use a SUSINR as an additional feature. Models which are trained on default and sorted features require a dataset with a fixed number of users =const, while polyk features allow us to train models on a dataset with variable number of users between objects , which is a significant advantage. After extracting features, we use three ML algorithms: linear models, gradient boosting, and fully-connected neural networks. These algorithms are described in Section 4.3.
4.3 Machine Learning Methods Used for Predicting SE
In this work, we rely on the three most commonly used machine learning algorithms: linear models, gradient boosting, and neural networks. We discuss the positive and negative sides of these algorithms along with the description of how we apply them to 5G data. We compare all the results obtained by these models in Sec. 5.
4.3.1 Linear Models
We begin by evaluating simple linear regression models. Linear models are very fast and memory-efficient and, being applied over a well-chosen feature space, could achieve high results in practice. Inspired by the fact that SUSINR is linear with respect to squares of singular values, we suppose that considering linear models is reasonable in our setting. We use the Scikit-learn implementation of linear regression and particularly, class LassoCV which tunes the regularization hyperparameter using cross-validation.
Linear models are one of the simplest and fastest supervised learning algorithms. Linear models work with data represented in matrix form where each object is represented by a feature vector: . The dimensionality is fixed and the same for all objects. A linear model predicts the target for the input object with a linear function . In this prediction function, parameters (also called weights) are unknown and need to be found based on the training data . Usually, this is achieved by optimizing a loss function that measures the penalty of predicting target with algorithm .
4.3.2 Gradient Boosting
We proceed by evaluating an out-of-the-box gradient boosting model, a simple, but efficient nonlinear model. Gradient boosting is considered in as one of the best-performing algorithms for regression tasks. Moreover, gradient boosting is fast and does not require a lot of memory to store trained models. We use the CatBoost [27] implementation of gradient boosting. The hyperparameters of our model are listed in Tab. 2.
Gradient boosting processes input data and combines the predictions of several base algorithms , which are usually decision trees. The final prediction function is a weighted sum of base learners . Such algorithms are trained one by one, and each following algorithm tries to improve the prediction of the already built composition.
Boosting models, as well as linear models, are suitable only for the data with a fixed feature vector dimensionality. That is always the case for polyk features, while default and sorted features require a fixed number of users in pairing.
4.3.3 Neural Networks
Finally, we consider fully-connected neural networks. Their strength is the ability to capture complex nonlinear dependencies in data. In deep learning, the prediction function , called neural network, is constructed as a composition of differentiable parametric functions: where parameters are learned via the optimization of criteria . The distinctive feature of neural networks is the wide range of architectures, i. e. different compositions , that can be chosen given the specifics of the particular problem.
However, the drawback of neural networks is that they require careful hyperparameter tuning, i. e. they usually achieve low results in out-of-the-box configuration. Thus, in practice, gradient boosting is often preferred over neural networks. Still, we conduct experiments using neural networks as well, to estimate their capabilities of processing channel data and obtaining reasonable prediction quality. One more drawback of neural networks is that they are slower than classic ML algorithms such as linear models or boosting, and require more memory to store parameters. But there are several techniques aimed at reducing the time and memory complexity of the trained models [22, 23, 24, 13].
Another important issue regarding neural networks is tuning their hyperparameters, which is essential for their performance. We train our fully-connected neural networks using SGD with momentum as it performed better than another popular optimization algorithm, Adam [19]. The mini-batch has a size 32. We choose the learning rate using a search on the grid , minimizing the train mean squared error. This is how we ensure the network does not underfit, i. e. is capable of recognizing train objects. However, it could overfit, i. e. memorize train data without learning actual dependencies in the data. To avoid it, we utilize standard regularization techniques: weight decay and dropout. We tune their hyperparameters using grid search, minimizing MAPE on the held-out set.
For neural networks, we normalize input data, both features, and targets, as it is essential for training convergence. Specifically, for each feature and target, we compute the mean and standard deviation over the training data, subtract the mean values from the elements of all the feature vectors, and divide by the standard deviation. This procedure needs to be done for both training and testing data, with the mean and standard deviation being computed over training data. For computing metrics, we scale the target values back to the original scale.
5 Experimental Results






This section contains the results for linear models, gradient boosting and neural networks. Firstly, we fix the number of users and analyze how our ML algorithms work for different precoding methods in different scenarios. Then we show how the results change for different values of and experiment with the solutions based on polynomial features in the case of variable number of users. We also measure time and memory complexity of the proposed algorithms. Finally, we apply the proposed approaches to the task of user-wise SE prediction. In all of our experiments, train data size and test data size .
The results for linear models and gradient boosting for different precoding methods and in different scenarios are shown in Figs. (2, 3, 4). Linear models demonstrate reasonable prediction quality. On the other hand, gradient boosting solutions provide significantly more accurate predictions. In terms of features, the best solutions are obtained using sorted features and polynomial features with the degree three. The results are only shown for a fixed number of users, , but all the results hold for other considered values of (2 and 8 users).

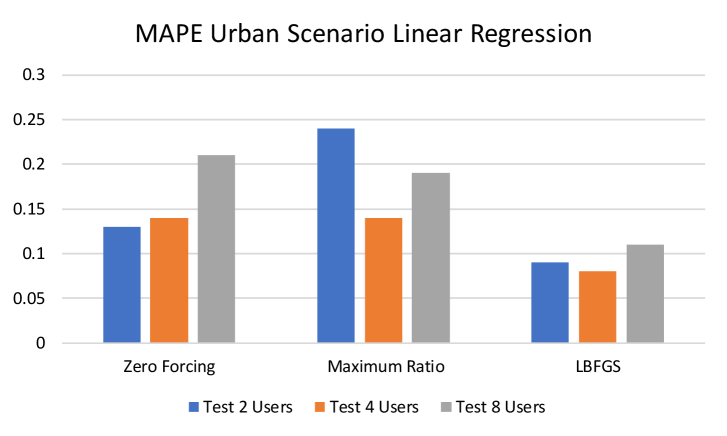

In Fig. 5, we compare the results of the best-proposed models (boosting on sorted and polynomial features with the degree three) for different values of . In this experiment, all models are trained on datasets with a fixed number of users and then are tested with the same number of users. The results show that the proposed algorithms perform well for all the considered numbers of users.
The dimensionality of polynomial features is independent of the number of users , therefore we can train all methods with polynomial features on the data with variable . In Fig. 6 we show the results of such an experiment. We train all models on a combined train dataset with a variable number of users (2, 4, and 8) and then test them on the test data with the fixed number of users. From the results we conclude that gradient boosting successfully tackles this problem for all precoding methods.
5.1 Time and Memory Complexity
| Number of | Zero-Forcing | Preprocessing | Boosting | Boosting |
|---|---|---|---|---|
| Users | ground truth | features | features | |
| {2} | 0.42 | 0.02 | 0.021 | 0.091 |
| {4} | 0.78 | 0.05 | 0.023 | 0.092 |
| {8} | 2.17 | 0.174 | 0.032 | 0.11 |
| {2, 4, 8} | 1.12 | 0.08 | - | 0.097 |
In Tab. 1, we report the inference time of our best models, namely boosting algorithms with sorted and polynomial features, and of several reference algorithms, e. g. the computational time of true SE values for the Zero-Forcing precoding method. We observe that the time complexity of gradient boosting (including preprocessing) is an order smaller than the time of computing true SE values for the Zero-Forcing algorithm.
5.2 User-Wise SE Prediction
In the previous experiments for SE prediction, we predicted SE for the whole pairing of users, i.e. averaged SE. Now, we wish to verify whether it is also possible to obtain reasonable prediction quality for each user separately since it can be useful in practice for selecting modulation coding scheme for each user [4]. We define the target SEu for each user as SE before averaging by the users: .
The features for user-wise SE prediction are the same as for the case of average SE prediction. For each user, we once again use the corresponding singular values, correlations between the chosen user’s layers and the layers of other users, and additional features, such as noise power or equivalently SUSINR. These features characterize the relation of one particular user to all other users.
The results for the Urban scenario, 2/4/8 users (separate models) are shown in Fig. 7. Note that MAPE values in these experiments are not comparable to the values from previous sections, because of different target spaces. The results show that the gradient boosting approach outperforms the linear regression approach, for all considered user counts and precoding algorithms.

5.3 SE-IRC Prediction
We also provide the results for SE-IRC [28] prediction based on MMSE-IRC detection (11), to verify that our method is robust to the change of the detection. For the case of MMSE-IRC, the detection matrix is calculated as:
| (11) |
where the matrix is related to unit symbol variance and is calculated as follows:
| (12) |
The results for the Urban scenario, 2/4/8 users (separate models) are shown in Fig. 7. From this results we conclude that the LBFGS-IRC composition of precoding and detection allows us to obtain better prediction quality with gradient boosting in comparison with other precoding schemes except MRT for all considered user counts.
5.4 Results for Fully-Connected Neural Networks
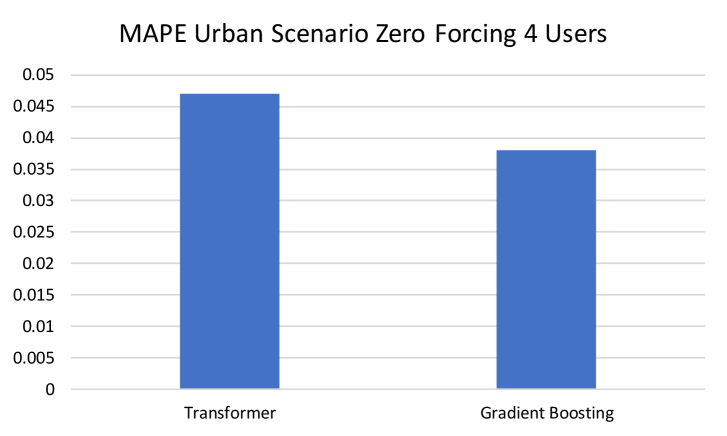
To test whether neural networks could improve feature-based spectral efficiency prediction, we train a fully-connected neural network on the default features, for the Urban scenario, 4 users, Zero Forcing precoding method. We consider one and three hidden layers configurations with 200 neurons at each layer. Our results show that while linear models provide MAPE of 0.0679, and gradient boosting – of 0.0383, the one-/three-layer neural networks achieve MAPE of 0.0371 / 0.0372 (see Fig. 8).
Thus, we conclude that using fully-connected neural networks is comparable to using gradient boosting in terms of prediction quality, while the tuning of network hyperparameters and the training procedure itself require significantly more time and memory than those of the other methods. However, these experiments showed that neural networks are in general applicable to channel data.

6 Conclusion
To summarize, in this paper we consider the problem of spectral efficiency prediction using machine learning methods. We looked at three methods of forming feature vector representations for user channel data. We compared several machine learning algorithms, namely linear models, gradient boosting, and fully connected neural networks. We found that gradient boosting applied to sorted objects provides the best results, while linear models achieve lower quality. The neural networks perform similarly to boosting, but require more time and effort to set up. In almost all cases, prediction quality reaches MAPE below 10% using gradient boosting and neural networks. This valuable result will allow us to significantly improve the quality of MIMO wireless communication in the future.
Acknowledgements
Authors are grateful to Dmitry Kovkov and Irina Basieva for discussions.
Funding
The work is funded by Huawei Technologies.
References
- [1] M.S. Alouini and A.J. Goldsmith, Area spectral efficiency of cellular mobile radio systems, IEEE Transactions on vehicular technology 48 (1999), pp. 1047–1066.
- [2] H.P. Benson, Maximizing the ratio of two convex functions over a convex set, Naval Research Logistics (NRL) 53 (2006), pp. 309–317.
- [3] E. Bobrov, B. Chinyaev, V. Kuznetsov, H. Lu, D. Minenkov, S. Troshin, D. Yudakov, and D. Zaev, Adaptive Regularized Zero-Forcing Beamforming in Massive MIMO with Multi-Antenna Users (2021).
- [4] E. Bobrov, D. Kropotov, and H. Lu, Massive MIMO adaptive modulation and coding using online deep learning algorithm, IEEE Communications Letters (2021).
- [5] E. Bobrov, D. Kropotov, S. Troshin, and D. Zaev, Finding better precoding in massive MIMO using optimization approach, CoRR abs/2107.13440 (2021). Available at https://arxiv.org/abs/2107.13440.
- [6] R. Chataut and R. Akl, Channel Gain Based User Scheduling for 5G Massive MIMO Systems, in 2019 IEEE 16th International Conference on Smart Cities: Improving Quality of Life Using ICT & IoT and AI (HONET-ICT). IEEE, 2019, pp. 049–053.
- [7] C. D’Andrea, A. Zappone, S. Buzzi, and M. Debbah, Uplink power control in cell-free massive MIMO via deep learning, in 2019 IEEE 8th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP). IEEE, 2019, pp. 554–558.
- [8] A. Farajidana, W. Chen, A. Damnjanovic, T. Yoo, D. Malladi, and C. Lott, 3GPP LTE downlink system performance, in GLOBECOM 2009-2009 IEEE Global Telecommunications Conference. IEEE, 2009, pp. 1–6.
- [9] G.J. Foschini and M.J. Gans, On limits of wireless communications in a fading environment when using multiple antennas, Wireless personal communications 6 (1998), pp. 311–335.
- [10] J.Y. Gotoh and H. Konno, Maximization of the ratio of two convex quadratic functions over a polytope, Computational Optimization and Applications 20 (2001), pp. 43–60.
- [11] Y. Guo, C. Hu, T. Peng, H. Wang, and X. Guo, Regression-based uplink interference identification and SINR prediction for 5G ultra-dense network, in ICC 2020-2020 IEEE International Conference on Communications (ICC). IEEE, 2020, pp. 1–6.
- [12] F. Héliot, M.A. Imran, and R. Tafazolli, On the energy efficiency-spectral efficiency trade-off over the mimo rayleigh fading channel, IEEE Transactions on Communications 60 (2012), pp. 1345–1356.
- [13] G. Hinton, O. Vinyals, and J. Dean, Distilling the Knowledge in a Neural Network (2015).
- [14] H. Huang, W. Xia, J. Xiong, J. Yang, G. Zheng, and X. Zhu, Unsupervised learning-based fast beamforming design for downlink MIMO, IEEE Access 7 (2018), pp. 7599–7605.
- [15] H. Huh, G. Caire, H.C. Papadopoulos, and S.A. Ramprashad, Achieving ”Massive MIMO” spectral efficiency with a not-so-large number of antennas, IEEE Transactions on Wireless Communications 11 (2012), pp. 3226–3239.
- [16] H. Huh, A.M. Tulino, and G. Caire, Network MIMO with linear zero-forcing beamforming: Large system analysis, impact of channel estimation, and reduced-complexity scheduling, IEEE Transactions on Information Theory 58 (2011), pp. 2911–2934.
- [17] S. Jaeckel, L. Raschkowski, K. Börner, and L. Thiele, QuaDRiGa: A 3-D multi-cell channel model with time evolution for enabling virtual field trials, IEEE Transactions on Antennas and Propagation 62 (2014), pp. 3242–3256.
- [18] M. Joham, W. Utschick, and J.A. Nossek, Linear transmit processing in mimo communications systems, IEEE Transactions on signal Processing 53 (2005), pp. 2700–2712.
- [19] D.P. Kingma and J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
- [20] X. Liu and X. Wang, Efficient antenna selection and user scheduling in 5G massive MIMO-NOMA system, in 2016 IEEE 83rd Vehicular Technology Conference (VTC Spring). IEEE, 2016, pp. 1–5.
- [21] T.K. Lo, Maximum ratio transmission 2 (1999), pp. 1310–1314.
- [22] E. Lobacheva, N. Chirkova, and D. Vetrov, Bayesian sparsification of recurrent neural networks, arXiv preprint arXiv:1708.00077 (2017).
- [23] E. Lobacheva, N. Chirkova, and D. Vetrov, Bayesian Sparsification of Gated Recurrent Neural Networks (2018).
- [24] D. Molchanov, A. Ashukha, and D. Vetrov, Variational Dropout Sparsifies Deep Neural Networks (2017).
- [25] L.D. Nguyen, H.D. Tuan, T.Q. Duong, and H.V. Poor, Multi-user regularized zero-forcing beamforming, IEEE Transactions on Signal Processing 67 (2019), pp. 2839–2853.
- [26] C.B. Peel, B.M. Hochwald, and A.L. Swindlehurst, A vector-perturbation technique for near-capacity multiantenna multiuser communication-part I: channel inversion and regularization, IEEE Transactions on Communications 53 (2005), pp. 195–202.
- [27] L. Prokhorenkova, G. Gusev, A. Vorobev, A.V. Dorogush, and A. Gulin, CatBoost: Unbiased Boosting with Categorical Features, in Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA. Curran Associates Inc., NIPS’18, 2018, p. 6639–6649.
- [28] B. Ren, Y. Wang, S. Sun, Y. Zhang, X. Dai, and K. Niu, Low-complexity mmse-irc algorithm for uplink massive mimo systems, Electronics Letters 53 (2017), pp. 972–974.
- [29] O. Rozenblit, Y. Haddad, Y. Mirsky, and R. Azoulay, Machine learning methods for sir prediction in cellular networks, Physical Communication 31 (2018), pp. 239–253.
- [30] L. Sanguinetti, A. Zappone, and M. Debbah, Deep learning power allocation in massive MIMO, in 2018 52nd Asilomar conference on signals, systems, and computers. IEEE, 2018, pp. 1257–1261.
- [31] J. Snoek, H. Larochelle, and R.P. Adams, Practical bayesian optimization of machine learning algorithms, Advances in neural information processing systems 25 (2012).
- [32] H. Sun, X. Chen, Q. Shi, M. Hong, X. Fu, and N.D. Sidiropoulos, Learning to optimize: Training deep neural networks for wireless resource management, in 2017 IEEE 18th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC). IEEE, 2017, pp. 1–6.
- [33] E. Telatar, Capacity of multi-antenna Gaussian channels, European transactions on telecommunications 10 (1999), pp. 585–595.
- [34] R. Ullah, S.N.K. Marwat, A.M. Ahmad, S. Ahmed, A. Hafeez, T. Kamal, and M. Tufail, A machine learning approach for 5g sinr prediction, Electronics 9 (2020), p. 1660.
- [35] T. Van Chien, E. Bjornson, and E.G. Larsson, Sum spectral efficiency maximization in massive MIMO systems: Benefits from deep learning, in ICC 2019-2019 IEEE International Conference on Communications (ICC). IEEE, 2019, pp. 1–6.
- [36] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L.u. Kaiser, and I. Polosukhin, Attention is All you Need, in Advances in Neural Information Processing Systems, I. Guyon, U.V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, eds., Vol. 30. Curran Associates, Inc., 2017.
- [37] S. Verdú, Spectral efficiency in the wideband regime, IEEE Transactions on Information Theory 48 (2002), pp. 1319–1343.
- [38] D. Wang, J. Wang, X. You, Y. Wang, M. Chen, and X. Hou, Spectral efficiency of distributed MIMO systems, IEEE Journal on Selected Areas in Communications 31 (2013), pp. 2112–2127.
- [39] Z. Wang and W. Chen, Regularized zero-forcing for multiantenna broadcast channels with user selection, IEEE Wireless Communications Letters 1 (2012), pp. 129–132.
- [40] J. Wannstrom, LTE-advanced, Third Generation Partnership Project (3GPP) (2013).
- [41] W. Xia, G. Zheng, Y. Zhu, J. Zhang, J. Wang, and A.P. Petropulu, A deep learning framework for optimization of MISO downlink beamforming, IEEE Transactions on Communications 68 (2019), pp. 1866–1880.
- [42] T. Yoo and A. Goldsmith, On the optimality of multiantenna broadcast scheduling using zero-forcing beamforming, IEEE Journal on selected areas in communications 24 (2006), pp. 528–541.
- [43] A. Zappone, M. Di Renzo, M. Debbah, T.T. Lam, and X. Qian, Model-aided wireless artificial intelligence: Embedding expert knowledge in deep neural networks towards wireless systems optimization, arXiv preprint arXiv:1808.01672 (2018).
- [44] Y. Zhao, I.G. Niemegeers, and S.H. De Groot, Power allocation in cell-free massive mimo: A deep learning method, IEEE Access 8 (2020), pp. 87185–87200.
7 Appendix. Transformer-Based Method

In this section, we focus on a transformer state-of-the-art model, which has been successfully applied to the tasks of text, image, audio processing [36]. The transformer model is well-suited for processing channel data since it supports the variable number of input elements (users/layers in our case).
Our transformer-based architecture is illustrated in Fig. 9. It takes singular vectors and singular values of all layers of all users as input. Specifically, the transformer’s input has a shape , where is the number of users in pairing, is -th user number of symbols () and is the number of antennas at the base station (). The shape appears because the real and imaginary parts of -sized singular vectors, and also a singular value are combined in one layer representation. After applying the transformer, the output has a shape , where is the hyperparameter. We then apply fully-connected layer to each of the -dimensional transformer outputs and obtain the output of a shape .
We consider two approaches in our experiments. The first option is to apply an arbitrary simple transformation, e. g. averaging over values, to map the matrix to the scalar and then train the model so that this scalar approximates spectral efficiency. The second option is to use additional supervision.
When we generate data, there is an intermediate step where we compute layer-wise spectral efficiencies: , so that they are later averaged to obtain the mean spectral efficiency (4). Thus, we can train our transformer so that it would predict these layer-wise spectral efficiencies of shape . To obtain the final spectral efficiency (4) we use simple averaging.
When transformers are applied to sequences, positional encodings are often used to encode the order of the elements. Since our input data is order-free, we do not use positional encodings. We train our transformer model using the Adam optimization algorithm. We use the standard transformer’s dropout with dropout rate selected from based on the performance on the held-out dataset. Hyperparameters of the model were selected using Bayesian optimization [31].
Same as for fully-connected neural networks, we also use data normalization for transformers. Using proper normalization is essential for neural networks, otherwise, training would be unstable or even diverge. For normalization purposes mean and standard deviation values are computed over all layers of all users. The procedure is the same as for fully-connected networks.
In the experiments in Fig. 10 the transformer has 3 layers, , the scenario is Urban, the number of users is 4, Zero Forcing precoding method is used. With proper data normalization, the transformer achieved MAPE of 0.047, and gradient boosting achieved 0.038. We also experimented with larger transformers, and they did not achieve lower error.
| auto_class_weights | None |
|---|---|
| bayesian_matrix_reg | 0.1 |
| best_model_min_trees | 1 |
| boost_from_average | True |
| boosting_type | Plain |
| bootstrap_type | MVS |
| border_count | 254 |
| classes_count | 0 |
| depth | 6 |
| eval_metric | MAPE |
| feature_border_type | GreedyLogSum |
| grow_policy | SymmetricTree |
| iterations | 1000 |
| l2_leaf_reg | 3 |
| leaf_estimation_backtracking | AnyImprovement |
| leaf_estimation_iterations | 1 |
| leaf_estimation_method | Exact |
| learning_rate | 0.03 |
| loss_function | MAE |
| max_leaves | 64 |
| min_data_in_leaf | 1 |
| model_shrink_mode | Constant |
| model_shrink_rate | 0 |
| model_size_reg | 0.5 |
| nan_mode | Min |
| penalties_coefficient | 1 |
| posterior_sampling | False |
| random_seed | 228 |
| random_strength | 1 |
| rsm | 1 |
| sampling_frequency | PerTree |
| score_function | Cosine |
| sparse_features_conflict_fraction | 0 |
| subsample | 0.8 |
| task_type | CPU |
| use_best_model | False |