Machine learning based Photometric Redshifts for Galaxies in the North Ecliptic Pole Wide field: catalogs of spectroscopic and photometric redshifts
Abstract
We perform an MMT/Hectospec redshift survey of the North Ecliptic Pole Wide (NEPW) field covering 5.4 square degrees, and use it to estimate the photometric redshifts for the sources without spectroscopic redshifts. By combining 2572 newly measured redshifts from our survey with existing data from the literature, we create a large sample of 4421 galaxies with spectroscopic redshifts in the NEPW field. Using this sample, we estimate photometric redshifts of 77755 sources in the band-merged catalog of the NEPW field with a random forest model. The estimated photometric redshifts are generally consistent with the spectroscopic redshifts, with a dispersion of 0.028, an outlier fraction of 7.3 %, and a bias of . We find that the standard deviation of the prediction from each decision tree in the random forest model can be used to infer the fraction of catastrophic outliers and the measurement uncertainties. We test various combinations of input observables, including colors and magnitude uncertainties, and find that the details of these various combinations do not change the prediction accuracy much. As a result, we provide a catalog of 77755 sources in the NEPW field, which includes both spectroscopic and photometric redshifts up to z2. This dataset has significant legacy value for studies in the NEPW region, especially with upcoming space missions such as JWST, Euclid, and SPHEREx.
1 Introduction
Estimating galaxy redshifts is one of the most important tasks in extragalactic astronomy and cosmology (e.g., Davis & Peebles, 1983; Strauss & Willick, 1995; Ilbert et al., 2006a). The redshifts are generally derived from spectroscopic observations with high precisions. Large spectroscopic surveys including SDSS (Almeida et al., 2023), HectoMAP (Sohn et al., 2023), and the DESI (DESI Collaboration et al., 2024) provide an extensive sample of spectroscopic redshift measurements. However, obtaining a statistically large sample of spectroscopic redshifts requires a considerable amount of telescope time and resources, limiting the number of objects with available spectroscopic redshifts.
Photometric redshifts are an alternative proxy for spectroscopic redshifts (e.g., Baum, 1957; Puschell et al., 1982). The photometric redshifts of galaxies are conventionally estimated based on the comparison between the photometry (e.g., across optical wavelengths) and the spectral energy distribution (SED) models (e.g., Puschell et al., 1982; Arnouts et al., 1999; Benítez, 2000; Bolzonella et al., 2000; Ilbert et al., 2006b). Photometric redshifts are generally less precise with the typical uncertainty of at (e.g., Ho et al., 2021), which is larger than that of spectroscopic redshifts, at (e.g., Ahumada et al., 2020). Photometric redshift estimation is often confused because the photometric SED can be explained by the model SED shifted with various redshifts (e.g., Tanaka, 2015). Thus, recent photometric redshift measurements are based on multi-band photometry; for example, Laigle et al. (2016) derive the photometric redshifts of the objects in the COSMOS field using 36 bands.
More recently, various machine learning techniques have been employed to refine the photometric redshift measurements (Salvato et al., 2019; Pasquet et al., 2019; Schuldt et al., 2021; Henghes et al., 2022; Luo et al., 2024). For example, the neural network model (e.g., Cavuoti et al., 2012; Lee & Shin, 2021) transforms photometric data into a target label with the applications of tensor (or matrix) operators and non-linear functions. It finds the optimal tensors that generate the most accurate target label with the training set (Hopfield, 1982; Lee & Shin, 2021). Another example is a Gaussian process based on the assumption that an output for input is described by a joint Gaussian distribution with a mean and a covariance matrix . The Gaussian process constructs the distribution of based on the training set and predicts for a new input (Rasmussen & Williams, 2006). As an example application of the Gaussian process to the photometric redshift estimation, Leistedt & Hogg (2017) combines the SED fitting with the Gaussian process on the flux-redshift space to estimate the photometric redshift.
Here, we construct a random forest model (Breiman, 2001; James et al., 2021) to derive photometric redshifts. The random forest model is a supervised learning that identifies an underlying function from the training set consisting of pairs of well-defined input features (e.g., photometry) and a target label (e.g., photometric redshift). The random forest technique has a simple prediction process. Our random forest photometric redshift estimation model requires a small training set and a short training time.
We test our random forest model and derive the photometric redshifts for the sources from the survey of AKARI North Ecliptic Pole Wide (NEPW) Field. AKARI was an infrared astronomy satellite launched in 2006 (Murakami et al., 2007) which produced an all-sky survey. Due to its orbit, it has especially high visibility around the ecliptic pole regions. It repeatedly observed the area around the NEP centered at R.A.=, Dec.=, with its nine filters from near- to mid-infrared wavelengths (Matsuhara et al., 2006). This wavelength range covers the emission from polycyclic aromatic hydrocarbon (PAH) emission, a useful feature for studying dusty star-forming galaxies.
The combination of AKARI photometric data with redshifts allows us to obtain valuable insights into the star formation history of galaxies (Matsuhara et al., 2006), the physical modeling of the spectral energy distribution of galaxies (Kim et al., 2019), and the metallicity-PAH relation of star-forming galaxies (Shim et al., 2023). Moreover, the band-merged catalog of the NEPW field (Kim et al., 2021b) becomes an important basis for studying the properties of infrared-bright galaxies, including the infrared luminosity functions (Goto et al., 2019), the nuclear activity of AGN-host galaxies (Chiang et al., 2019; Wang et al., 2020; Santos et al., 2021; Poliszczuk et al., 2021; Chen et al., 2021), the star formation model of high- galaxies (Barrufet et al., 2020), the infrared sources without optical counterparts (Toba et al., 2020), the identification of galaxy clusters (Huang et al., 2021), the merger-driven star formation activity (Kim et al., 2021a), and optical/near-infrared identifications of X-ray sources (Miyaji et al., 2024). Constructing a large sample of galaxies with redshift measurements is critical to the study of listed subjects.
Based on the multi-band photometry and the compilation of existing spectroscopy of the NEPW sources, we construct the random forest model to estimate the photometric redshifts. We also apply the random forest model to provide homogenous measurements of photometric redshifts for the sources in the NEPW field. The extended catalog of the NEPW field including the photometric redshifts will be an important basis for future studies of galaxy evolution based on optical and NIR/MIR photometry. This paper is organized as follows; we describe the photometric and spectroscopic data we use in Section 2. We then demonstrate our photometric redshift measurement process based on the random forest model in Section 3. We discuss the accuracy and significance of our photometric redshift measurements in Section 4. We conclude in Section 5.
2 The Data Sets
2.1 Input photometry
The basement for our photometric redshift measurement is multi-band photometry of the sources in the NEPW field. AKARI observes the NEPW field with its nine filters in near- and mid-infrared ranges (e.g., N2, N3, and N4; Matsuhara et al., 2006; Lee et al., 2009; Kim et al., 2012) and detects 91681 sources. Based on the AKARI observations, our team constructs the band-merged catalog for the NEPW field (Kim et al., 2021b) by cross-matching the sources detected in AKARI NEPW surveys and other follow-up observations.
We select 26-band photometry from the NEPW band-merged catalog to measure photometric redshifts following Ho et al. (2021). From the original NEPW band-merged catalog including 42-band photometry, Ho et al. (2021) used 26-band photometry for the photometric redshift estimates based on the spectral energy distribution (SED) fitting technique. To make a fair comparison, we also use the following 26-band photometry. In the optical range, the photometry with the highest number of observed sources comes from Subaru/HSC observations (Goto et al., 2017; Oi et al., 2021). They provide complete photometry for 77755 sources at g, r, i, z, and Y. In addition to Subaru/HSC photometry, there is photometry from the CFHT/MegaCam u*/g/r/i/z (Hwang et al., 2007; Oi et al., 2014), CFHT/MegaPrime u* (Huang et al., 2020), and the Maidanak/SNUCAM B/R/I (Jeon et al., 2010). In the infrared range, AKARI N2, N3, and N4 photometry is available for most sources. The infrared photometry in CFHT/WIRcam Y/J/Ks (Oi et al., 2014), the KPNO/FLAMINGOS J/H (Jeon et al., 2014), Spitzer IRAC1/2 (Werner et al., 2004; Jarrett et al., 2011; Nayyeri et al., 2018), and WISE W1/W2 (Wright et al., 2010; Jarrett et al., 2011) bands are also available. We note that most sources in the NEPW band-merged catalog miss photometry in some bands because the depths and spatial coverages of the observations are different. Table 1 (and Figure 3) in Ho et al. (2021) summarizes the photometric bands we use for our photometric redshift estimation.
2.2 Spectroscopic data and redshift measurement
We compile spectroscopic redshifts from the previous observations (Shim et al., 2013; Takagi et al., 2010; Shogaki et al., 2018; Kim et al., 2018; Díaz Tello et al., 2017; Oi et al., 2017; Ohyama et al., 2018). We also add new spectroscopic redshifts based on our own spectroscopic observations for the NEPW field.
| Field | R.A. | Decl. | Date | Exposure | Number of | Number of |
|---|---|---|---|---|---|---|
| (deg, J2000) | (deg, J2000) | (seconds) | Targets | Measured Redshifts | ||
| NEPc20_2 | 269.068 | 65.67054 | 2020 Oct 7 | 3600 | 260 | 160 |
| NEPc20_1 | 270.168 | 66.50360 | 2020 Oct 11 | 3600 | 258 | 221 |
| NEPc21_1 | 271.897 | 67.13100 | 2021 Oct 2 | 3352 | 248 | 148 |
| NEPc21_3 | 270.943 | 65.75491 | 2021 Oct 2 | 3600 | 251 | 153 |
| NEPc21_2 | 268.411 | 67.05496 | 2021 Oct 3 | 3600 | 259 | 214 |
| NEPc21_4 | 271.514 | 65.93796 | 2021 Oct 3 | 2880 | 258 | 130 |
| NEPc21_5 | 270.212 | 67.36748 | 2021 Nov 12 | 3600 | 254 | 194 |
| NEPa22_1 | 267.752 | 66.58976 | 2022 Mar 2 | 4140 | 259 | 168 |
| NEPa22_2 | 272.282 | 66.47379 | 2022 Apr 4 | 3600 | 260 | 210 |
| NEPa22_3 | 269.848 | 65.64594 | 2022 Apr 25 | 3600 | 256 | 102 |
| NEPa22_4 | 268.531 | 65.88472 | 2022 Apr 28 | 4800 | 261 | 205 |
| NEPa22_5 | 270.413 | 67.35335 | 2022 Apr 29 | 4800 | 255 | 199 |
| NEPa22_6 | 271.777 | 65.95914 | 2022 May 3 | 4860 | 256 | 183 |
| NEPa22_7 | 268.609 | 67.12775 | 2022 May 4 | 3960 | 225 | 196 |
| NEPa22_8 | 270.048 | 66.53124 | 2022 May 4 | 2400 | 254 | 132 |
We first obtain 1985 spectroscopic redshifts from the NEPW band-merged catalog (Kim et al., 2021b). Most of the spectroscopic redshifts in the catalog are originated from Shim et al. (2013). Shim et al. (2013) observe the NEPW field with MMT/Hectospec and WIYN/Hydra. Based on the visual inspection, Shim et al. (2013) provide 1796 reliable redshift measurements, including 6 Milky Way stars, 233 AGNs, 1522 galaxies, and 35 unidentified sources due to the low signal-to-noise ratios. The other spectroscopic redshifts are from Keck/DEIMOS (Takagi et al., 2010; Shogaki et al., 2018; Kim et al., 2018), Gran Telescope Canarias (GTC)/OSIRIS (Díaz Tello et al., 2017), Subaru/FMOS (Oi et al., 2017), and AKARI/SPICY (Ohyama et al., 2018) observations.
We conduct our own spectroscopic survey with MMT/Hectospec to increase the number of spectroscopic redshifts in the NEPW field. Our survey was carried out from 2020 to 2022 as a part of the K-GMT science program (PI: Ho Seong Hwang). Hectospec is a multi-object optical spectrograph with 300 fed fibers for MMT (Fabricant et al., 2005). It covers the wavelength range of 3500 Å - 10000 Å with a spectral resolution of R1000-2000. The main targets of our survey were AKARI selected galaxies with -band magnitudes brighter than 21 mag. We additionally obtained spectra for the galaxies that are bright in r-band, but not detected in . We reduced the Hectospec spectra based on the HSRED reduction pipeline111The description on the pipeline at http://www.mmto.org/hsred-reduction-pipeline/.
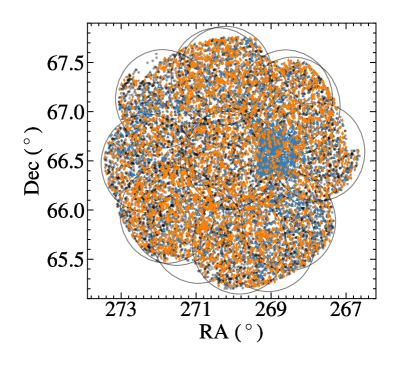
Table 1 summarizes our spectroscopic survey of the NEPW field with MMT/Hectospec. In our 15 visits to the NEPW, we observed 3835 sources ( 250 sources per field). Figure 1 illustrates the spatial distribution of the NEPW sources. Our survey uniformly covers the NEPW regions and almost triples the number of sources with optical spectra.
To measure the redshift from the reduced spectrum, we develop a new Python package, RVSNUpy, based on a cross-correlation technique (T. Kim et al. 2025 in preparation). The code implements the algorithm that was originally used for IRAF/RVSAO (Kurtz & Mink, 1998); it first subtracts the continuum of a given spectrum and cross-correlates the continuum-subtracted spectrum against the various template spectra, including absorption- and emission-line dominated templates in the rest frame. Because the cross-correlation signal is maximized when the phases of the template and the given spectrum are most similar, RVSNUpy determines the peak of the cross-correlation signal as the redshift of the given spectrum. RVSNUpy also provides the -value from Tonry & Davis (1979), which indicates the significance of the cross-correlation signals. We explain the details of RVSNUpy in our forthcoming paper (T. Kim et al. in preparation).
We measure the redshifts of the observed sources with RVSNUpy based on all prepared templates and determine the final redshifts as follows. First, we select reliable redshift measurements with derived based on absorption-line-dominated templates and derived based on emission-line-dominated templates. Second, we prioritize the measurements based on the absorption-line-dominated templates over the emission-line-dominated templates because the absorption lines originate from the stars in the galaxies. Lastly, we prioritize the measurements with the higher -value. We finally obtained 2572 reliable redshift measurements.
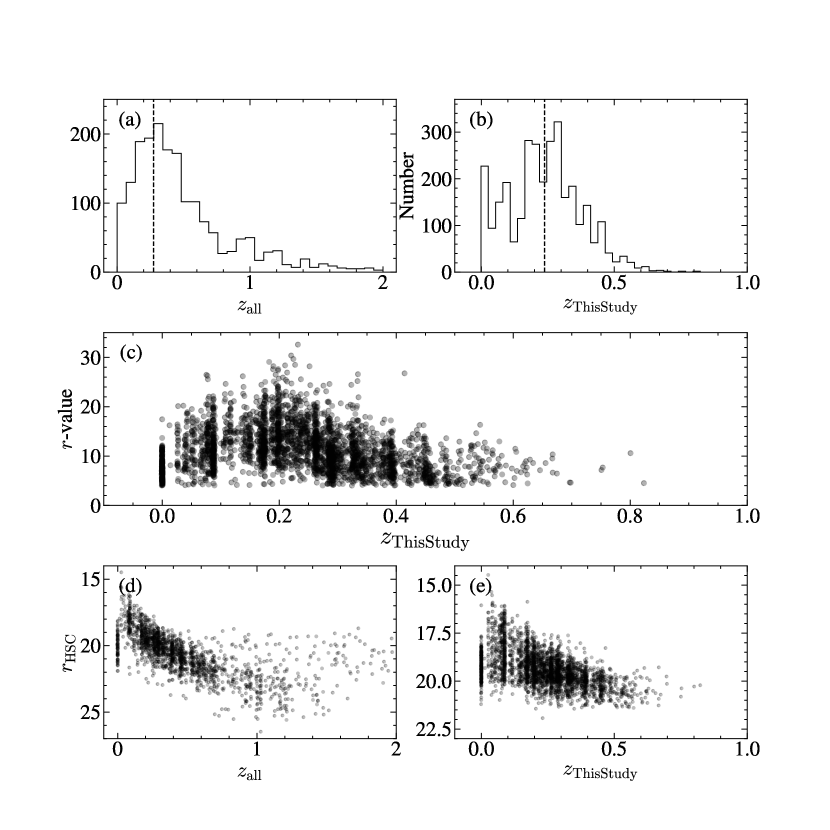
Figure 2 (a) shows the distributions of 4467 spectroscopic redshifts in the combined NEPW spectroscopic catalog. Figure 2 (b) displays the distribution of 2572 redshifts we obtained from our own spectroscopic survey. The new redshifts are mostly at . Figure 2 (c) shows the value distribution as a function of redshift. Our new redshift measurements are all reliable with . Figure 2 (d) and (e) show the Subaru/HSC band magnitude as a function of spectroscopic redshift. The vertical concentrations of galaxies at similar redshifts indicate clustering of galaxies. Our spectroscopic sample includes galaxies in . The median redshift of our spectroscopic sample is 0.274. For our photometric redshift estimation, we select 4421 galaxies at because the number of high-z galaxies is too small for our random forest applications.
3 Photometric redshift with a random forest
We build a random forest machine learning model to estimate photometric redshifts. We first describe the decision tree which is a basis for our random forest model in Section 3.1. In Section 3.2, we construct the random forest model to estimate the photometric redshifts based on our NEPW photometric dataset. In Section 3.3, we compare the photometric redshift measurements based on our random forest model with the redshift measurements based on spectroscopy and SED-fitting. In Section 3.4, we describe methods to determine the reliabilities and uncertainties of the photometric redshift measurements. In Section 3.5, we present our value-added NEPW photometric redshift catalog based on our random forest model.
3.1 Decision tree
The decision tree (James et al., 2021) is a supervised learning that makes a prediction based on the partition of an input data space. The decision tree is often employed for both classification and regression. Here, we briefly explain the regression process based on the decision tree used for estimating photometric redshifts.
Developing the decision tree requires a training set containing input features and a target value. In our photometric redshift estimation, the input features are multi-band photometry of the galaxies in the NEPW field, and the target values are their spectroscopic redshifts. The decision tree first divides the training set into two groups that have similar target values. Specifically, the decision tree computes the similarity of the target values in the two groups, which we refer to as RSS:
| (1) |
Here, is the target value of th element in a group divided by the decision tree and is the mean of in the group. For the first step of the decision tree (), there is only one group (i.e., ) for the training set. As we increase the depth () of the tree, there are more and smaller groups, like the branches stemming out from a single tree.
At each depth, the decision tree determines the boundary in the input feature space for grouping that minimizes the RSS. In other words, the decision tree tests different groupings by changing the boundary in the input feature space and finds the grouping with the lowest RSS value. In our case, the decision tree tests grouping based on magnitude, magnitude uncertainty, and color distributions in multi-band photometry, selecting the grouping that minimizes the RSS value. By repeating this grouping, the decision tree splits the training sample into more groups that have similar target values within a narrower range.
As the depth of the decision tree increases, the groups capture more detailed relations between the input features and the target values, enabling more accurate prediction. However, the decision tree grouping becomes too specific to the training data when the depth is too large (i.e., overfitting). Then, the model prediction based on the decision tree becomes less accurate for the new data with slightly different input feature space. Thus, the optimal depth of the decision tree needs to be determined empirically depending on the purpose of the model (see Section 3.2).
Once the decision tree is constructed, the prediction for the target values is available with a new input dataset with the same input features. In our case, the new input dataset including the photometry of galaxies goes through the decision tree and returns the spectroscopic redshift prediction based on the decision tree.
3.2 Construction of our random forest model
Random forest is a machine learning algorithm that combines multiple decision trees to make a robust prediction. A single decision tree generally has an accuracy lower than other machine learning models because of its simple structure. Combining multiple models to construct a structured model can help improve prediction accuracy. The random forest bootstraps the training set to construct sub-training sets and generates a decision tree for each sub-training set (Breiman, 2001; James et al., 2021). Each decision tree uses only randomly selected features at each partitioning step. The random selection of features ‘decorrelates’ the decision trees and improves regression performance. The random forest then returns the average of outputs from all decision trees as its final output.
We construct a random forest model to predict photometric redshifts. We use the scikit-learn (Pedregosa et al., 2011) and follow the approach222https://www.astroml.org/book_figures/chapter9/fig_photoz_forest.html from Vanderplas et al. (2012). The input photometric dataset lists 56 input features, including the 26 magnitudes and their uncertainties, and four Subaru/HSC colors (i.e., g-r, r-i, i-z, z-Y). We use colors only from Subaru/HSC because they provide complete photometry for most sources.
Many galaxies in the NEPW band-merged catalog (Kim et al., 2021b) do not have full 26 magnitudes and their uncertainties. We replace the missing photometry data with a dummy value of 1000 to maintain the dimensionality of the input data (Cohen & Cohen, 1975). The prediction with missing values replaced by a dummy value is straightforward for a random forest model compared to other algorithms (e.g., neural networks). We choose an extreme dummy value that significantly differs from the actual photometric measurements in the input feature space. The random forest model recognizes these dummy values as less informative and makes predictions without relying on them.
Construction of our random forest model requires the determination of three hyperparameters: the number of features used for partitioning, the depth of the decision trees, and the number of bootstrapped sub-training sets. For the number of features used for partitioning, we use the square root of the number of all features because it generally yields the best performance in the regression based on a random forest (James et al., 2021). For our random forest model, the number of features used for partitioning is .
We determine the depth of the decision trees and the number of bootstrapped sub-training sets based on the performance of the photometric redshift estimation for 4421 NEPW sources with spectroscopic redshifts at . We randomly select 10 percent (i.e., 442 sources) of the sources with spectroscopic redshifts as a test set and 90 percent of them as a training set. We predict the output photometric redshifts for the sources in the test set based on our random forest model trained with the training set. We compute the root mean square (RMS) errors between the predicted and spectroscopically measured redshifts. We repeat this test 100 times.
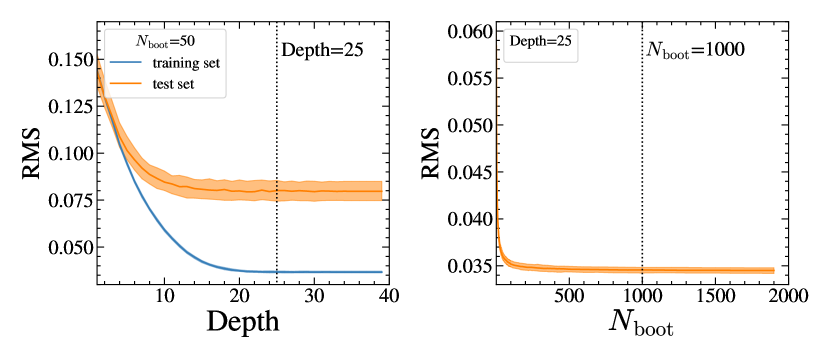
Figure 3 shows the RMS of the predicted (i.e., photometric) redshift measurements as a function of the hyperparameters. The left panel of Figure 3 displays the RMS of the training and test sets as a function of the depth of the decision trees. We fix the number of bootstrapped sub-training sets as 1000 here. As the depth of the tree increases, the RMS of the training and test set decreases. The RMS converges after the depth of 25 for both the training and test set. Thus, we choose 25 as the depth of the decision trees for our random forest model.
The right panel of Figure 3 shows the RMS of the test set as a function of the number of bootstrapped sub-training sets (). For this test, we fix the depth of the decision trees as 25. The RMS decreases rapidly as the number of bootstrapped sub-training sets increases and converges after . Thus, we choose 1000 as the number of bootstrapped sub-training sets for our random forest model.
3.3 Comparison with spectroscopic redshifts and photometric redshifts derived from SED fitting
We evaluate the performance of our random forest photometric redshifts () based on the comparison with spectroscopic redshifts (). For this test, we use 4421 sources with spectroscopic redshifts for training and testing our random forest model. We randomly select 442 sources () with as a test set (Section 3.2). We train our random forest model with the remaining. We repeat the test 100 times for different test sets.
We quantify the accuracy of of the test set with three different accuracy metrics. The first metric is the dispersion of the redshift difference (). Here, the dispersion of the redshift difference corresponds to , where and MAD is the median absolute deviation (e.g., Ho et al., 2021). The second metric is the fraction of catastrophic outliers (); the sources with are classified as outliers. The third metric is the bias (), indicating the mean of the normalized difference between photometric and spectroscopic redshifts.
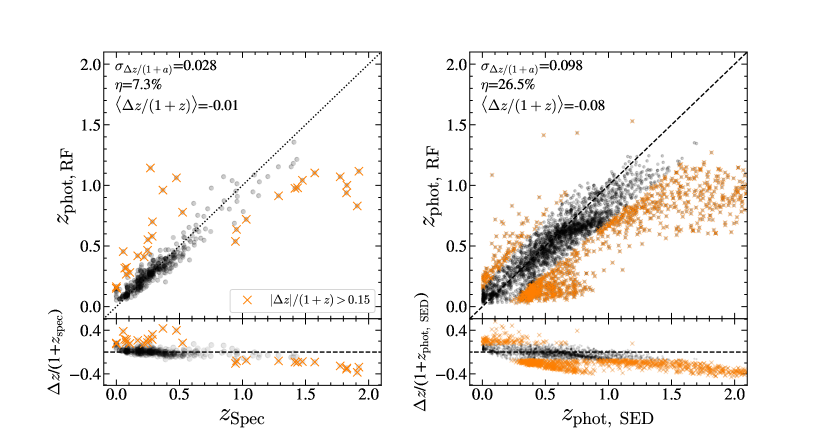
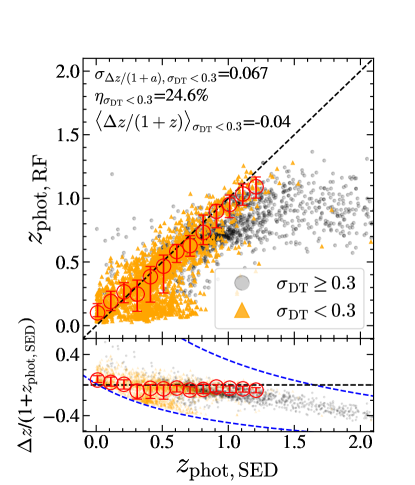
The left panel of Figure 4 compares and derived from one example test set. We quote the median of the three accuracy metrics in Figure 4. The photometric redshifts generally agree with the spectroscopic redshifts with a very small offset (bias ), except for 30 outliers (orange crosses, %). Our random forest model estimates photometric redshifts with smaller redshift difference dispersion and lower catastrophic outlier rates than those from SED fitting ( and =8.9%, Ho et al., 2021).
We also compare the and the photometric redshift measurements based on the SED fitting (, Ho et al., 2021). For this test, we train our random forest model using all sources with spectroscopic redshifts. The right panel of Figure 4 compares and . The accuracy metrics are also computed based on the comparison between and . The photometric redshifts based on two different techniques are generally consistent with each other at . The accuracy metrics indicate that percent of is consistent with with a typical dispersion of at . tend to be smaller than at . We explore the reliability of and at in Section 3.4.
3.4 Reliability and uncertainty of photometric redshift estimation
The random forest returns only a single prediction value unlike many algorithms providing measurement uncertainties in their predictions (e.g., D’Isanto & Polsterer, 2018; Eriksen et al., 2019; Soo et al., 2021). To estimate the reliability and uncertainty of the , we use the variance of the predictions from the decision trees in our random forest model. Because the random forest model makes predictions based on the combination of multiple decision trees, we expect the variance of the predictions from the decision trees to be related to the confidence of the photometric redshift measurement.
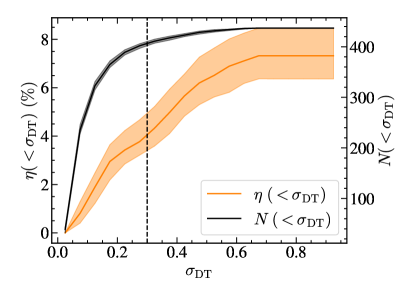
We analyze a cumulative fraction of catastrophic outliers (i.e., ) from 100 randomly selected test sets (hereafter the uncertainty test sample) as a function of the standard deviation of the predictions from decision trees (). Our random forest model has 1000 decision trees. For a single test set, each decision tree yields its own prediction for the photometric redshift. Thus, indicates the standard deviation of 1000 predictions for the photometric redshift.
Figure 5 shows the cumulative fraction of the catastrophic outliers and the cumulative number of photometric measurements as a function of . The outlier fraction increases with . For , 98 percent of the uncertainty test set is included and the fraction of catastrophic outliers remains below five percent. We thus conclude as a criterion to determine the reliability of our photometric redshift measurement.
Figure 6 shows the comparison between and for the two groups separated at . In general, with are consistent with . The objects with inconsistent and have larger than 0.3. At , there is a group of objects where are significantly lower than (). For these objects, are consistent with unlike , indicating that more reliable.
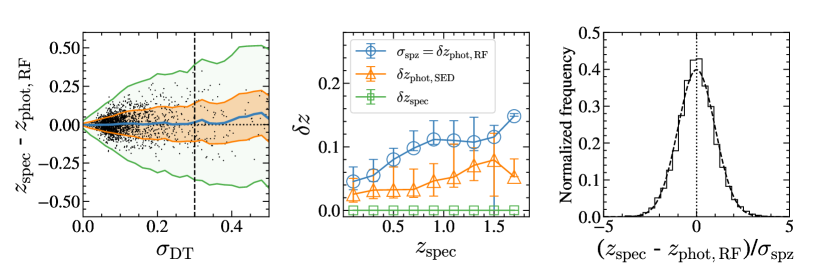
We also devise a method to derive the uncertainties of using . We examine the difference between and as a function of for the uncertainty test sample (the left panel of Figure 7). The blue solid line displays the mean redshift offset. The mean difference remains close to zero as long as there is enough data in the bin (i.e., ), indicating no systematic between spectroscopic and photometric redshifts. The orange and green shaded regions mark the and boundaries. This trend indicates that the range of the and offset increases as a function of . We define the of the as a function of as , corresponding to uncertainty at given . The middle panel of Figure 7 displays the distributions of , the uncertainties of (), and the uncertainties of () as a function of . The tend to be larger than for given and increase as increase. We note that the definitions of and are different, thus comparing them is not straightforward. We discuss the performance of in comparison with that of in Section 4.3.
To justify the use of as the measurement uncertainty, we analyze the distribution of the normalized by the for the uncertainty test sample. The distribution of measurements divided by their uncertainties follows the normal distribution: . Here, indicates the uncertainty of . Because the uncertainties of the spectroscopic redshifts are much smaller than those of the photometric redshifts, we expect if . The right panel of Figure 7 shows the distribution of the normalized differences between the spectroscopic and photometric redshifts. The distribution follows a normal distribution. Therefore, we include for each source as the measurement uncertainty for the photometric redshift estimates.
3.5 A photometric redshift catalog of the NEPW field
| Parameter | Value | |
|---|---|---|
| Survey Area aaThe survey area (deg2) | 5.6 | |
| NbbThe number of sources included in the catalog | 77755 | |
| NccThe number of sources with | 52167 | |
| NddThe number of all spectroscopic redshifts available in the catalog | 4467 |
| NEPW_ID aaID listed in the AKARI NEPW catalog of Kim et al. (2021b). | R.A. | Decl. | r | specz | specz_err bbThe uncertainties of spectroscopic redshifts and the -values from RVSNUpy. We list dummy values (-9.999 or -9.99) for those objects without RVSNUpy redshifts. | specz source ccSources of spectroscopic redshifts: 1 from the previous studies (see Kim et al. 2021b for details), 2 from this study, and 9 indicates unavailability. | -value bbThe uncertainties of spectroscopic redshifts and the -values from RVSNUpy. We list dummy values (-9.999 or -9.99) for those objects without RVSNUpy redshifts. | photz_RF | photz_err ddThe uncertainties of the photometric redshifts. | |
|---|---|---|---|---|---|---|---|---|---|---|
| (deg) | (deg) | (mag) | ||||||||
| 119624 | 268.6480 | 67.2392 | 23.328 | -9.999 | -9.999 | 9 | -9.99 | 0.6653 | 0.1412 | 0.41 |
| 119626 | 268.5046 | 67.2395 | 20.937 | -9.999 | -9.999 | 9 | -9.99 | 0.4170 | 0.0802 | 0.14 |
| 119627 | 268.3835 | 67.2417 | 22.266 | -9.999 | -9.999 | 9 | -9.99 | 0.5352 | 0.1039 | 0.23 |
| 119630 | 268.3894 | 67.2466 | 19.283 | -9.999 | -9.999 | 9 | -9.99 | 0.0501 | 0.0684 | 0.10 |
| 119631 | 268.3978 | 67.2442 | 24.597 | -9.999 | -9.999 | 9 | -9.99 | 0.9397 | 0.1524 | 0.43 |
| 119633 | 268.7164 | 67.2457 | 23.272 | -9.999 | -9.999 | 9 | -9.99 | 0.6902 | 0.1343 | 0.40 |
| 119634 | 268.7115 | 67.2433 | 23.319 | -9.999 | -9.999 | 9 | -9.99 | 0.6557 | 0.1343 | 0.39 |
| 119635 | 268.4547 | 67.2798 | 16.688 | 0.0900 | -9.999 | 1 | -9.99 | 0.0858 | 0.0081 | 0.01 |
| 119637 | 268.4605 | 67.2593 | 18.261 | -9.999 | -9.999 | 9 | -9.99 | 0.0640 | 0.0327 | 0.05 |
| 119638 | 268.4791 | 67.2695 | 20.168 | -9.999 | -9.999 | 9 | -9.99 | 0.1038 | 0.0941 | 0.17 |
| 119639 | 268.4817 | 67.2489 | 20.722 | -9.999 | -9.999 | 9 | -9.99 | 0.1386 | 0.0941 | 0.18 |
| 119640 | 268.4627 | 67.2655 | 19.833 | 0.3234 | 0.0001 | 2 | 9.40 | 0.3057 | 0.0327 | 0.06 |
| 119641 | 268.4778 | 67.2674 | 21.167 | -9.999 | -9.999 | 9 | -9.99 | 0.4055 | 0.0941 | 0.18 |
| 119642 | 268.4684 | 67.2722 | 20.870 | -9.999 | -9.999 | 9 | -9.99 | 0.3616 | 0.0979 | 0.19 |
| 119643 | 268.4848 | 67.2570 | 21.402 | -9.999 | -9.999 | 9 | -9.99 | 0.5406 | 0.1156 | 0.26 |
| 119646 | 268.4622 | 67.2636 | 21.826 | -9.999 | -9.999 | 9 | -9.99 | 0.5284 | 0.0941 | 0.17 |
We finally construct the value-added NEPW band-merged catalog, including and their uncertainties. The catalog includes 77755 sources with Subaru/HSC photometry because we use the colors from HSC photometry. Table 2 summarizes the key characters of our value-added NEPW catalog. Table 3 lists the individual objects in our value-added NEPW catalog.
4 Discussion
4.1 Significance of input features on the photometric redshift measurements
We investigate which photometric information in the input feature contributes significantly to the measurements. The ‘permutation importance’ is a widely used parameter to test the impact of certain input features in the machine learning prediction (Pedregosa et al., 2011). The permutation importance is defined as:
| (2) |
where is the RMS of the prediction based on all features, and is the RMS of the prediction based on the data sets with the randomly shuffled -th feature.
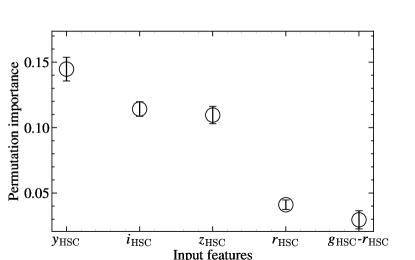
Figure 8 shows the result of the permutation importance computation for our 56 input features. There are five features with permutation importance larger than 0.03; . Not surprisingly, all top five features are from HSC photometry because all photometric sources we measured have the HSC photometry. Because photometry from other observational data is incomplete for our input sources, the contribution of other band photometry is less significant in the determination of .
4.2 High fraction of catastrophic outliers for AGNs
While analyzing the result from the test set, we note that the catastrophic outlier rate is particularly high for AGNs () compared to that for galaxies ( %). The high fraction of catastrophic outlier rate of AGNs originates from the lack of AGN samples in the training set; there are only 233 () confirmed AGNs in our training set. Furthermore, the shapes of AGN SEDs are highly variable depending on the sources. Thus, estimating the significantly suffers from the small size of the sample and high variability. Although the total AGN fraction in the NEPW catalog is low (234 AGAN candidates based on X-ray observations Krumpe et al., 2015), the estimates for AGN candidates in the NEPW catalog require special caution.
4.3 Prediction accuracy depending on the input features
Our test with permutation importance indicates that the contribution of each input feature to the prediction can vary significantly. In other words, the inclusion/exclusion of certain parameters can affect the estimation of . Furthermore, we include the dummy values when some band photometry is not available. The impact of the choice of dummy values in the needs to be investigated to test the reliability of .
Here, we examine the accuracy of measurement depending on the input features. We test the effect of the inclusion of magnitude uncertainties as input features. We also investigate the effect of dummy values we included to replace the missing photometry. The usage of color information in is also examined. For this test, we generate the following datasets with various input features (summarized in Table 4):
| Set | magnitude uncertainty | missing photometry | included HSC photometry |
|---|---|---|---|
| included | replaced with 1000 | mag., mag. uncertainties, and colors | |
| excluded | replaced with 1000 | mag., mag. uncertainties, and colors | |
| excluded, reflected in mag. | replaced with 1000 | mag., mag. uncertainties, and colors | |
| included | replaced with -1000 | mag., mag. uncertainties, and colors | |
| included | replaced with -100 | mag., mag. uncertainties, and colors | |
| included | replaced with 100 | mag., mag. uncertainties, and colors | |
| included | interpolated by adjacent photometry | mag., mag. uncertainties, and colors | |
| included | replaced with 1000 | mag. uncertainties, colors, and -mag. | |
| included | replaced with 1000 | mag. and mag. uncertainties |
-
•
is a fiducial input dataset including 26 magnitudes and their uncertainties, and four HSC colors (see Section 3.2).
-
•
is similar to Setfiducial, but without magnitude uncertainties.
-
•
is similar to Set, but lists reconstructed magnitudes. Here, the reconstructed magnitudes indicate the sum of source magnitudes and their tentative magnitude uncertainties randomly extracted from the Gaussian distribution with the standard deviation corresponding to the photometric magnitude uncertainty.
-
•
is the same as Setfiducial, but the dummy value for missing photometry is -1000.
-
•
is the same as Setfiducial, but the dummy value for missing photometry is -100.
-
•
is the same as Setfiducial, but the dummy value for missing photometry is 100.
-
•
is similar to Setfiducial, but the missing photometry is replaced with the values derived from interpolation (or extrapolation) of nearby band photometry, rather than using dummy values.
-
•
contains 22 band photometry (and their uncertainties) except for HSC -band photometry. The excluded HSC bands are replaced with HSC colors (i.e., g-r, r-i, i-z, z-Y).
-
•
is similar to , but excludes Subaru/HSC colors (i.e., g-r, r-i, i-z, z-Y) from the input features.
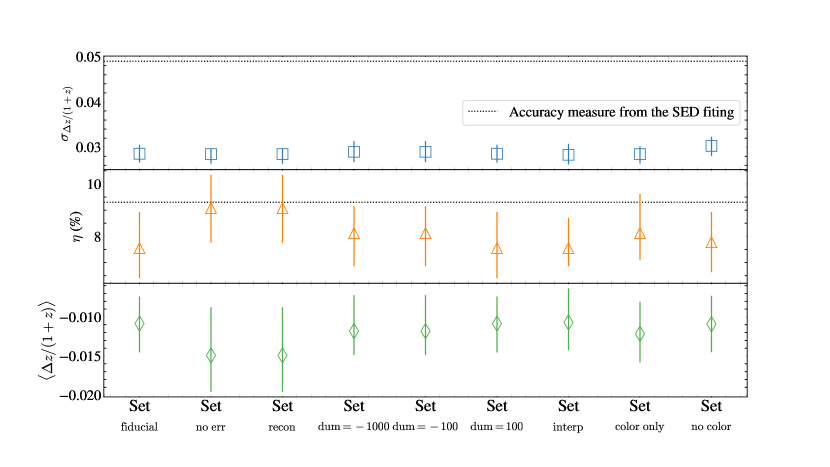
Figure 9 summarizes the accuracy metrics for with respect to derived from nine different input datasets based on the 100 randomly selected training sets. The top panel shows the redshift difference dispersions (i.e., ) of the nine datasets. The dispersions change little depending on the input datasets. Similarly, the catastrophic outlier fractions and the biases for the different input datasets are consistent with each other. Interestingly, the accuracy metrics (i.e., , , and ) for for all nine input datasets are lower than those for , suggesting the better performance of estimations.
4.4 Systematics at
We note that the are slightly lower than by across all input datasets. This redshift offset results from the high redshift () targets. Discrepancies between and begin to appear at at (Figure 4). The primary reason for the low accuracy of at is the scarcity of training data at the redshift range. Because the random forest is only able to interpolate, the random forest precision is constrained by 1) the minimum and maximum redshifts and 2) the number density of redshifts in the training set. In our case, the training set only includes the objects with , and 8% of them are at (see also Figure 2).
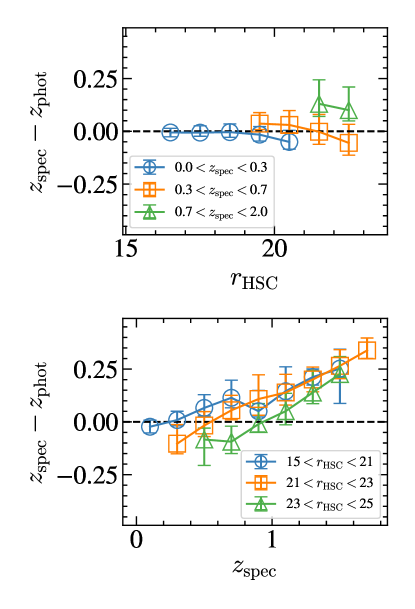
In the top panel of Figure 10, we show the redshift difference as a function of HSC -band magnitude for three redshift subsamples: , , and . The redshift difference is more significant for the higher-redshift subsample, likely due to the smaller size of the training set for faint, high-redshift galaxies. Similarly, in the bottom panel of Figure 10, we display the redshift difference as a function of redshift for three HSC -band magnitude subsamples. The redshift offset increases at higher redshift, reflecting the relative scarcity of high- objects in the training set.
4.5 The accuracy of the photometric redshifts and the effect of incorrect photometry on the photometric redshift estimation
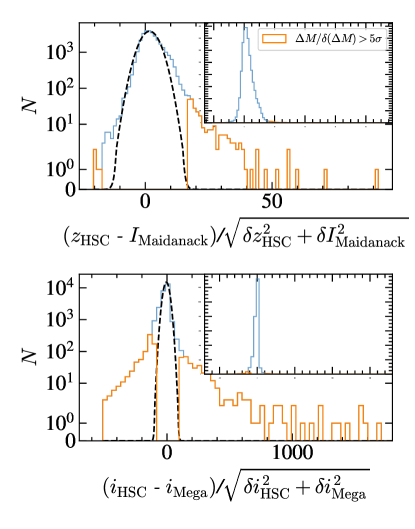
Our photometric data are compiled from various photometric catalogs (Kim et al., 2021b) obtained from multi-wavelength observations. In some regions within the NEPW field, there are photometric data from bands with similar wavelength ranges. For example, the Subaru/HSC z-band with Å partially overlaps with the Maidanak/SNUCAM I-band ( Å). The Subaru/HSC i-band with Å also overlaps with the CFHT/MegaCam i-band ( Å). Ho et al. (2021) showed that objects in the NEPW catalog have magnitude differences larger than of the quadratic sum of the magnitude uncertainties in the two bands. The magnitude discrepancy is mainly due to the deblending of bright sources or sources with structures observed with instruments with different resolutions. The deep, high-resolution HSC images generally enable the identification of fainter sources or segments of bright sources. To avoid over-deblending in Subaru/HSC data, Ho et al. (2021) used only CFHT/MegaCAM or Maidanak/SNUCAM magnitudes for the SED fitting for the sources with large magnitude discrepancies.
Figure 11 shows the differences between HSC z-band and Maidanak I-band magnitudes normalized by their uncertainties: - / for the sources with overlapped photometry. The dashed line shows the best-fit Gaussian to the distribution. There are 262 sources with the normalized magnitude differences larger than (the orange histogram in Figure 11). Hereafter, we refer to these objects as ‘problematic’ HSC photometry, because over-deblending in HSC photometry is the main cause. Similarly, there are 1131 sources identified as problematic due to magnitude differences greater than between HSC -band and MegaCam -band.
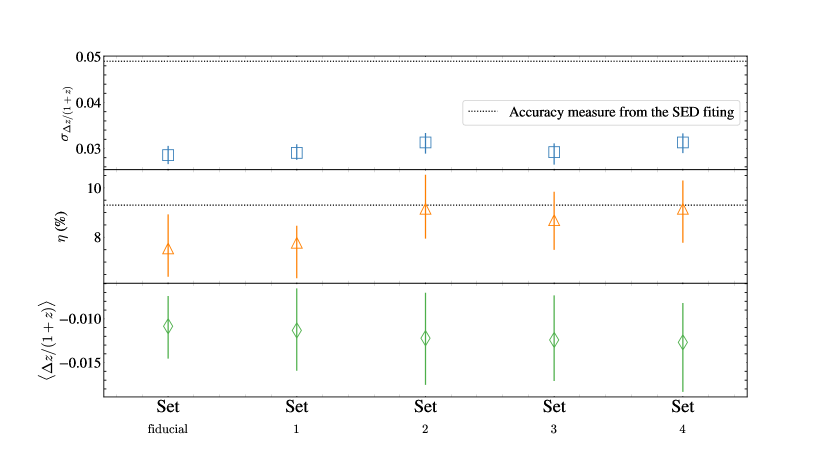
We test the impact of the magnitude discrepancy in the overlapped-band photometry on the measurements. We prepare four input datasets that handle the problematic HSC photometry differently:
-
1.
Setfiducial is the input dataset including all magnitudes and their uncertainties from 26-bands (See Sections 3.2).
-
2.
Set 1 is the dataset including all magnitudes and their uncertainties from 26-bands. The dummy value of 1000 is used for the problematic HSC photometry.
-
3.
Set 2 is identical to Set 1, but we additionally replace the other band photometry with S/N with the dummy value.
-
4.
Set 3 is similar to Set 1, but we also replace both Maidanak and MegaCam band magnitude and their uncertainties with the dummy value.
-
5.
Set 4 is identical to Set 3, but we additionally replace the other band photometry with S/N with the dummy value.
We estimate based on the four different input datasets and the Setfiducial. Figure 12 displays the three accuracy metrics (, , ) derived from the different input datasets with respect to . Horizontal lines show the accuracy metrics for (Ho et al., 2021). The three accuracy metrics of derived from five different datasets are all consistent with each other. In particular, the differences between Setfiducial and other Sets are negligible. In other words, exclusion (or inclusion) of problematic HSC photometry has little effect on the measurements. The test assures that derived from Setfiducial, which we provided in the value-added catalog, are robust.
5 Conclusions
We derive photometric redshift of the sources in the NEPW field based on the extended multi-band photometry covering optical to infrared. We conduct our own MMT/Hectospec redshift survey to increase the number of spectroscopic redshifts. We then construct the random forest machine learning model to estimate the photometric redshifts trained with the spectroscopic sample based on spectroscopic redshifts we compile from literature and from our survey. We present the value-added NEPW catalog, including photometric redshifts () for 77775 sources.
-
•
We obtain 2572 spectroscopic redshifts from our own MMT/Hectospec redshift survey for the NEPW field. We develop RVSNUpy (T. Kim et al. in preparation), a redshift measuring package based on a cross-correlation technique, to derive the spectroscopic redshifts from Hectospec spectra. Combined with the spectroscopic redshifts from the literature, we build the extended catalog, including 4421 spectroscopic redshifts at .
-
•
We construct the random forest model to estimate photometric redshifts for the NEPW sources. We train the model based on the NEPW sample with 26-band photometry ranging with the spectroscopic redshifts. The random forest model successfully measures photometric redshifts for 77755 sources within the NEPW field with a homogenous HSC photometry.
-
•
We also devise a method to evaluate the uncertainty of random forest photometric redshift measurements. We found that there is a correlation between the of photometric and spectroscopic redshift difference (i.e., ) as a function of , the of the photometric redshift estimations from multiple decision trees for each object. We thus estimate the uncertainty of photometric redshift measurement for each object based on the and the relation between and .
-
•
We evaluate the quality of by comparing it to and photometric redshifts derived from the SED fitting. The fraction of catastrophic outliers with for our random forest measurements is comparable to that for the SED fitting measurements. However, show a smaller scatter relative to than , indicating that are generally closer to with smaller uncertainties.
-
•
We carefully examine measurements based on the various input datasets to understand the impact of the inclusion of certain photometric bands and dummy values for missing photometry. Our test results assure that measurements are robust regardless of the change in a number of input features. The missing photometry also has little impact on the estimations.
-
•
Finally, we present the value-added catalog for the NEPW band-merged catalog. We list the new spectroscopic redshifts from our Hectospec survey. In addition, we provide we derive for 77755 sources based on our random forest machine learning model.
Acknowledgements
We thank the referee for the careful and insightful review of our manuscript. This work was supported by K-GMT Science Program (PID: UAO-G209-20B, UAO-G181-21B, UAO-G178-22A, SP ID: MMT-2020A-002, MMT-2020B-002, MMT-2021A-002, MMT-2021B-002) funded through Korean GMT Project operated by Korea Astronomy and Space Science Institute (KASI). N.H. and B.-G. P. acknowledge the support by the Korea Astronomy and Space Science Institute (KASI) grant funded by the Korean government (MSIT; No. 2023-1-860-02, International Optical Observatory Project). HSH acknowledges the support by Samsung Electronic Co., Ltd. (Project Number IO220811-01945-01), the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT), NRF-2021R1A2C1094577, and Hyunsong Educational & Cultural Foundation. HS acknowledges the support by the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (2022M3K3A1093827). SH acknowledges the support of The Australian Research Council Centre of Excellence for Gravitational Wave Discovery (OzGrav) and the Australian Research Council Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D), through project number CE17010000 and CE170100013, respectively. JS acknowledges the support by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (RS-2023-00210597). This work is based on observations with AKARI, a JAXA project with the participation of ESA, universities, and companies in Japan, Korea, and the UK.
References
- Ahumada et al. (2020) Ahumada, R., Allende Prieto, C., Almeida, A., et al. 2020, ApJS, 249, 3, doi: 10.3847/1538-4365/ab929e
- Almeida et al. (2023) Almeida, A., Anderson, S. F., Argudo-Fernández, M., et al. 2023, ApJS, 267, 44, doi: 10.3847/1538-4365/acda98
- Arnouts et al. (1999) Arnouts, S., Cristiani, S., Moscardini, L., et al. 1999, MNRAS, 310, 540, doi: 10.1046/j.1365-8711.1999.02978.x
- Barrufet et al. (2020) Barrufet, L., Pearson, C., Serjeant, S., et al. 2020, A&A, 641, A129, doi: 10.1051/0004-6361/202037838
- Baum (1957) Baum, W. A. 1957, AJ, 62, 6, doi: 10.1086/107433
- Benítez (2000) Benítez, N. 2000, ApJ, 536, 571, doi: 10.1086/308947
- Bolzonella et al. (2000) Bolzonella, M., Miralles, J. M., & Pelló, R. 2000, A&A, 363, 476, doi: 10.48550/arXiv.astro-ph/0003380
- Breiman (2001) Breiman, L. 2001, Machine Learning, 45, 5, doi: 10.1023/A:1010933404324
- Cavuoti et al. (2012) Cavuoti, S., Brescia, M., Longo, G., & Mercurio, A. 2012, A&A, 546, A13, doi: 10.1051/0004-6361/201219755
- Chen et al. (2021) Chen, B. H., Goto, T., Kim, S. J., et al. 2021, MNRAS, 501, 3951, doi: 10.1093/mnras/staa3865
- Chiang et al. (2019) Chiang, C.-Y., Goto, T., Hashimoto, T., et al. 2019, PASJ, 71, 31, doi: 10.1093/pasj/psz012
- Cohen & Cohen (1975) Cohen, J., & Cohen, P. 1975, Applied multiple regression/correlation analysis for the behavioral sciences. (Lawrence Erlbaum)
- Davis & Peebles (1983) Davis, M., & Peebles, P. J. E. 1983, ApJ, 267, 465, doi: 10.1086/160884
- DESI Collaboration et al. (2024) DESI Collaboration, Adame, A. G., Aguilar, J., et al. 2024, AJ, 168, 58, doi: 10.3847/1538-3881/ad3217
- Díaz Tello et al. (2017) Díaz Tello, J., Miyaji, T., Ishigaki, T., et al. 2017, A&A, 604, A14, doi: 10.1051/0004-6361/201730611
- D’Isanto & Polsterer (2018) D’Isanto, A., & Polsterer, K. L. 2018, A&A, 609, A111, doi: 10.1051/0004-6361/201731326
- Doré et al. (2016) Doré, O., Werner, M. W., Ashby, M., et al. 2016, arXiv e-prints, arXiv:1606.07039, doi: 10.48550/arXiv.1606.07039
- Doré et al. (2018) Doré, O., Werner, M. W., Ashby, M. L. N., et al. 2018, arXiv e-prints, arXiv:1805.05489, doi: 10.48550/arXiv.1805.05489
- Eriksen et al. (2019) Eriksen, M., Alarcon, A., Gaztanaga, E., et al. 2019, MNRAS, 484, 4200, doi: 10.1093/mnras/stz204
- Fabricant et al. (2005) Fabricant, D., Fata, R., Roll, J., et al. 2005, PASP, 117, 1411, doi: 10.1086/497385
- Goto et al. (2017) Goto, T., Toba, Y., Utsumi, Y., et al. 2017, Publication of Korean Astronomical Society, 32, 225, doi: 10.5303/PKAS.2017.32.1.225
- Goto et al. (2019) Goto, T., Oi, N., Utsumi, Y., et al. 2019, PASJ, 71, 30, doi: 10.1093/pasj/psz009
- Henghes et al. (2022) Henghes, B., Thiyagalingam, J., Pettitt, C., Hey, T., & Lahav, O. 2022, MNRAS, 512, 1696, doi: 10.1093/mnras/stac480
- Ho et al. (2021) Ho, S. C. C., Goto, T., Oi, N., et al. 2021, MNRAS, 502, 140, doi: 10.1093/mnras/staa3549
- Hopfield (1982) Hopfield, J. J. 1982, Proceedings of the National Academy of Science, 79, 2554, doi: 10.1073/pnas.79.8.2554
- Huang et al. (2020) Huang, T.-C., Matsuhara, H., Goto, T., et al. 2020, MNRAS, 498, 609, doi: 10.1093/mnras/staa2459
- Huang et al. (2021) —. 2021, MNRAS, 506, 6063, doi: 10.1093/mnras/stab2128
- Hwang et al. (2007) Hwang, N., Lee, M. G., Lee, H. M., et al. 2007, ApJS, 172, 583, doi: 10.1086/519216
- Ilbert et al. (2006a) Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006a, A&A, 457, 841, doi: 10.1051/0004-6361:20065138
- Ilbert et al. (2006b) —. 2006b, A&A, 457, 841, doi: 10.1051/0004-6361:20065138
- James et al. (2021) James, G., Witten, D., Hastie, T., & Tibshirani, R. 2021, An introduction to Statistical Learning, 2nd edn. (NY: Springer New York), doi: 10.1007/978-1-0716-1418-1
- Jansen & Windhorst (2018) Jansen, R. A., & Windhorst, R. A. 2018, PASP, 130, 124001, doi: 10.1088/1538-3873/aae476
- Jarrett et al. (2011) Jarrett, T. H., Cohen, M., Masci, F., et al. 2011, ApJ, 735, 112, doi: 10.1088/0004-637X/735/2/112
- Jeon et al. (2010) Jeon, Y., Im, M., Ibrahimov, M., et al. 2010, ApJS, 190, 166, doi: 10.1088/0067-0049/190/1/166
- Jeon et al. (2014) Jeon, Y., Im, M., Kang, E., Lee, H. M., & Matsuhara, H. 2014, ApJS, 214, 20, doi: 10.1088/0067-0049/214/2/20
- Kim et al. (2021a) Kim, E., Hwang, H. S., Jeong, W.-S., et al. 2021a, MNRAS, 507, 3113, doi: 10.1093/mnras/stab2090
- Kim et al. (2018) Kim, H. K., Malkan, M. A., Oi, N., et al. 2018, in The Cosmic Wheel and the Legacy of the AKARI Archive: From Galaxies and Stars to Planets and Life, ed. T. Ootsubo, I. Yamamura, K. Murata, & T. Onaka
- Kim et al. (2012) Kim, S. J., Lee, H. M., Matsuhara, H., et al. 2012, A&A, 548, A29, doi: 10.1051/0004-6361/201219105
- Kim et al. (2019) Kim, S. J., Jeong, W.-S., Goto, T., et al. 2019, PASJ, 71, 11, doi: 10.1093/pasj/psy121
- Kim et al. (2021b) Kim, S. J., Oi, N., Goto, T., et al. 2021b, MNRAS, 500, 4078, doi: 10.1093/mnras/staa3359
- Krumpe et al. (2015) Krumpe, M., Miyaji, T., Brunner, H., et al. 2015, MNRAS, 446, 911, doi: 10.1093/mnras/stu2010
- Kurtz & Mink (1998) Kurtz, M. J., & Mink, D. J. 1998, PASP, 110, 934, doi: 10.1086/316207
- Laigle et al. (2016) Laigle, C., McCracken, H. J., Ilbert, O., et al. 2016, ApJS, 224, 24, doi: 10.3847/0067-0049/224/2/24
- Lee et al. (2009) Lee, H. M., Kim, S. J., Im, M., et al. 2009, PASJ, 61, 375, doi: 10.1093/pasj/61.2.375
- Lee & Shin (2021) Lee, J., & Shin, M.-S. 2021, AJ, 162, 297, doi: 10.3847/1538-3881/ac2e96
- Leistedt & Hogg (2017) Leistedt, B., & Hogg, D. W. 2017, ApJ, 838, 5, doi: 10.3847/1538-4357/aa6332
- Luo et al. (2024) Luo, Z., Li, Y., Lu, J., et al. 2024, MNRAS, doi: 10.1093/mnras/stae2446
- Matsuhara et al. (2006) Matsuhara, H., Wada, T., Matsuura, S., et al. 2006, PASJ, 58, 673, doi: 10.1093/pasj/58.4.673
- Miyaji et al. (2024) Miyaji, T., Bravo-Navarro, B. A., Díaz Tello, J., et al. 2024, A&A, 689, A83, doi: 10.1051/0004-6361/202450453
- Murakami et al. (2007) Murakami, H., Baba, H., Barthel, P., et al. 2007, PASJ, 59, S369, doi: 10.1093/pasj/59.sp2.S369
- Nayyeri et al. (2018) Nayyeri, H., Ghotbi, N., Cooray, A., et al. 2018, ApJS, 234, 38, doi: 10.3847/1538-4365/aaa07e
- Ohyama et al. (2018) Ohyama, Y., Wada, T., Matsuhara, H., et al. 2018, A&A, 618, A101, doi: 10.1051/0004-6361/201731470
- Oi et al. (2017) Oi, N., Goto, T., Malkan, M., Pearson, C., & Matsuhara, H. 2017, Publications of the Astronomical Society of Japan, 69, doi: 10.1093/pasj/psx053
- Oi et al. (2014) Oi, N., Matsuhara, H., Murata, K., et al. 2014, A&A, 566, A60, doi: 10.1051/0004-6361/201322561
- Oi et al. (2021) Oi, N., Goto, T., Matsuhara, H., et al. 2021, MNRAS, 500, 5024, doi: 10.1093/mnras/staa3080
- Pasquet et al. (2019) Pasquet, J., Bertin, E., Treyer, M., Arnouts, S., & Fouchez, D. 2019, A&A, 621, A26, doi: 10.1051/0004-6361/201833617
- Pedregosa et al. (2011) Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, Journal of Machine Learning Research, 12, 2825
- Poliszczuk et al. (2021) Poliszczuk, A., Pollo, A., Małek, K., et al. 2021, A&A, 651, A108, doi: 10.1051/0004-6361/202040219
- Puschell et al. (1982) Puschell, J. J., Owen, F. N., & Laing, R. A. 1982, ApJ, 257, L57, doi: 10.1086/183808
- Rasmussen & Williams (2006) Rasmussen, C. E., & Williams, C. K. I. 2006, Gaussian Processes for Machine Learning
- Salvato et al. (2019) Salvato, M., Ilbert, O., & Hoyle, B. 2019, Nature Astronomy, 3, 212, doi: 10.1038/s41550-018-0478-0
- Santos et al. (2021) Santos, D. J. D., Goto, T., Kim, S. J., et al. 2021, MNRAS, 507, 3070, doi: 10.1093/mnras/stab2352
- Schuldt et al. (2021) Schuldt, S., Suyu, S. H., Cañameras, R., et al. 2021, A&A, 651, A55, doi: 10.1051/0004-6361/202039945
- Shim et al. (2013) Shim, H., Im, M., Ko, J., et al. 2013, ApJS, 207, 37, doi: 10.1088/0067-0049/207/2/37
- Shim et al. (2023) Shim, H., Hwang, H. S., Jeong, W.-S., et al. 2023, AJ, 165, 31, doi: 10.3847/1538-3881/aca09c
- Shogaki et al. (2018) Shogaki, A., Matsuura, S., Oi, N., et al. 2018, in The Cosmic Wheel and the Legacy of the AKARI Archive: From Galaxies and Stars to Planets and Life, ed. T. Ootsubo, I. Yamamura, K. Murata, & T. Onaka
- Sohn et al. (2023) Sohn, J., Geller, M. J., Hwang, H. S., et al. 2023, ApJ, 945, 94, doi: 10.3847/1538-4357/acb925
- Soo et al. (2021) Soo, J. Y. H., Joachimi, B., Eriksen, M., et al. 2021, MNRAS, 503, 4118, doi: 10.1093/mnras/stab711
- Strauss & Willick (1995) Strauss, M. A., & Willick, J. A. 1995, Phys. Rep., 261, 271, doi: 10.1016/0370-1573(95)00013-7
- Takagi et al. (2010) Takagi, T., Ohyama, Y., Goto, T., et al. 2010, A&A, 514, A5, doi: 10.1051/0004-6361/200913466
- Tanaka (2015) Tanaka, M. 2015, ApJ, 801, 20, doi: 10.1088/0004-637X/801/1/20
- Toba et al. (2020) Toba, Y., Goto, T., Oi, N., et al. 2020, ApJ, 899, 35, doi: 10.3847/1538-4357/ab9cb7
- Tonry & Davis (1979) Tonry, J., & Davis, M. 1979, AJ, 84, 1511, doi: 10.1086/112569
- Vanderplas et al. (2012) Vanderplas, J., Connolly, A., Ivezić, Ž., & Gray, A. 2012, in Conference on Intelligent Data Understanding (CIDU), 47 –54, doi: 10.1109/CIDU.2012.6382200
- Wang et al. (2020) Wang, T.-W., Goto, T., Kim, S. J., et al. 2020, MNRAS, 499, 4068, doi: 10.1093/mnras/staa2988
- Werner et al. (2004) Werner, M., Roellig, T. L., Low, F. J., et al. 2004, in American Astronomical Society Meeting Abstracts, Vol. 204, American Astronomical Society Meeting Abstracts #204, 33.01
- Wright et al. (2010) Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868, doi: 10.1088/0004-6256/140/6/1868