regularization for ensemble Kalman inversion
Abstract
Ensemble Kalman inversion (EKI) is a derivative-free optimization method that lies between the deterministic and the probabilistic approaches for inverse problems. EKI iterates the Kalman update of ensemble-based Kalman filters, whose ensemble converges to a minimizer of an objective function. EKI regularizes ill-posed problems by restricting the ensemble to the linear span of the initial ensemble, or by iterating regularization with early stopping. Another regularization approach for EKI, Tikhonov EKI, penalizes the objective function using the penalty term, preventing overfitting in the standard EKI. This paper proposes a strategy to implement regularization for EKI to recover sparse structures in the solution. The strategy transforms a problem into a problem, which is then solved by Tikhonov EKI. The transformation is explicit, and thus the proposed approach has a computational cost comparable to Tikhonov EKI. We validate the proposed approach’s effectiveness and robustness through a suite of numerical experiments, including compressive sensing and subsurface flow inverse problems.
1 Introduction
A wide range of problems in science and engineering are formulated as inverse problems. Inverse problems aim to estimate a quantity of interest from noisy, imperfect observation or measurement data, such as state variables or a set of parameters that constitute a forward model. Examples include deblurring and denoising in image processing [13], recovery of permeability in subsurface flow using pressure fields [21], and training a neural network in machine learning [14, 18] to name a few. In this paper, we consider the inverse problem of finding from measurement data where and are related as follows
| (1) |
Here is a forward model that can be nonlinear and computationally expensive to solve, for example, solving a PDE problem. The last term is a measurement error. The measurement error is unknown in general, but we assume that it is drawn from a known probability distribution, a Gaussian distribution with mean zero and a known covariance . By assuming that the forward model and the observation covariance are known, the unknown variable is estimated by solving an optimization problem
| (2) |
where is the norm induced from the inner product using the inverse of the covariance matrix , that is for the standard inner product in .
Ensemble Kalman inversion (EKI), pioneered in the oil industry [21] and mathematically formulated in an application-neutral setting in [16], is a derivative-free method that lies between the deterministic and the probabilistic approaches for inverse problems. EKI’s key feature is an iterative application of the Kalman update of the ensemble-based Kalman filters [1, 11]. Ensemble-based Kalman filters are well known for their success in numerical weather prediction, stringent inverse problems involving high-dimensional systems. EKI iterates the ensemble-based Kalman update in which the ensemble mean converges to the solution of the optimization problem eq. 2. EKI can be thought of as a least-squares method in which the derivatives are approximated from an empirical correlation of an ensemble [5], not from a variational approach. Thus, EKI is highly parallelizable without calculating the derivatives related to the forward or the adjoint problem used in the gradient-based methods.
Inverse problems are often ill-posed, which suffer from non-uniqueness of the solution and lack stability. Also, in the context of regression, the solution can show overfitting. A common strategy to overcome ill-posed problems is regularizing the solution of the optimization problem [3]. That is, a special structure of the solution from prior information, such as sparsity, is imposed to address ill-posedness. The standard EKI [16] implements regularization by restricting the ensemble to the linear span of the initial ensemble reflecting prior information. The ensemble-based Kalman update is known for that the ensemble remains in the linear span of the initial ensemble [19, 16]. Thus, the EKI ensemble always stays in the linear span of the initial ensemble, which regularizes the solution. Although this approach shows robust results in certain applications, numerical evidence demonstrates that overfitting may still occur [16]. As an effort to address the overfitting of the standard EKI, an iterative regularization method has been proposed in [17], which approximates the regularizing Levenberg-Marquardt scheme [15]. As another regularization approach using a penalty term to the objective function, a recent work called Tikhonov EKI (TEKI) [8] implements the Tikhonov regularization (which imposes a penalty term to the objective function) using an augmented measurement model that adds artificial measurements to the original measurement. TEKI’s implementation is a straightforward modification of the standard EKI method with a marginal increase in the computational cost.
The regularization methods for EKI mentioned above address several issues of ill-posed problems, including overfitting. However, it is still an open problem to implement other types of regularizers, such as or total variation (TV) regularization. This paper aims to implement , regularization to recover sparse structures in the solution of inverse problems. In other words, we propose a highly-parallelizable derivative-free method that solves the following regularized optimization problem
| (3) |
where is the norm of u, i.e., , and is a regularization coefficient. The proposed method’s key idea is a transformation of variables that converts the regularization problem to the Tikhonov regularization problem. Therefore, a local minimizer of the original problem can be found by a local minimizer of the problem that is solved using the idea of Tikhonov EKI. As this transformation is explicit and easy to calculate, the proposed method’s overall computational complexity remains comparable to the complexity of Tikhonov EKI. In general, a transformed optimization problem can lead to additional difficulties, such as change of convexity, increased nonlinearity, additional/missing local minima of the original problem, etc. [12]. We show that the transformation does not add or remove local minimizers in the transformed formulation. A work imposing sparsity in EKI has been reported recently [25]. The idea of this work is to use thresholding and a constraint to impose sparsity in the inverse problem solution. The constraint is further relaxed by splitting the solution into positive and negative parts. The split converts the problem to a quadratic problem, while it still has a non-negativity constraint. On the other hand, our method does not require additional constraints by reformulating the optimization problem and works as a solver for the regularized optimization problem eq. 3.
This paper is structured as follows. Section 2 reviews the standard EKI and Tikhonov EKI. In section 3, we describe a transformation that converts the regularization problem eq. 3, , to the Tikhonov (that is, ) regularization problem, and provide the complete description of the regularized EKI algorithm. We also discuss implementation and computation issues. Section 4 is devoted to the validation of the effectiveness and robustness of regularized EKI through a suite of numerical tests. The tests include a scalar toy problem with an analytic solution, a compressive sensing problem to benchmark with a convex minimization method, and a PDE-constrained nonlinear inverse problem from subsurface flow. We conclude this paper in section 5, discussing the proposed method’s limitations and future work.
2 Ensemble Kalman inversion
The regularized EKI uses a change of variables to transform a problem into a problem, which is then solved by the standard EKI using an augmented measurement model. This section reviews the standard EKI and the application of the augmented measurement model in Tikhonov EKI to implement regularization. The review is intended to be concise, delivering the minimal ideas for the regularized EKI. Detailed descriptions of the standard EKI and the Tikhonov EKI methods can be found in [16] and [8], respectively.
2.1 Standard ensemble Kalman inversion
EKI incorporates an artificial dynamics, which corresponds to the application of the forward model to each ensemble member. This application moves each ensemble member to the measurement space, which is then updated using the ensemble Kalman update formula. The ensemble updated by EKI stays in the linear span of the initial ensemble [16, 19]. Therefore, by choosing an initial ensemble appropriately for prior information, EKI is regularized as the ensemble is restricted to the linear span of the initial ensemble. Under a continuous-time limit, when the operator is linear, it is proved in [24] that EKI estimate converges to the solution of the following optimization problem
| (4) |
In this paper, we consider the discrete-time EKI in [16], which is described below.
Algorithm: standard EKI
Assumption: an initial ensemble of size , from prior information, is given.
For
-
1.
Prediction step using the artificial dynamics:
-
(a)
Apply the forward model to each ensemble member
(5) -
(b)
From the set of the predictions , calculate the mean and covariances
(6) (7) where is the mean of , i.e., .
-
(a)
-
2.
Analysis step:
-
(a)
Update each ensemble member using the Kalman update
(8) where is a perturbed measurement using Gaussian noise with mean zero and covariance .
-
(b)
Compute the mean of the ensemble as an estimate for the solution
(9)
-
(a)
2.2 Tikhonov ensemble Kalman inversion
EKI is regularized through the initial ensemble reflecting prior information. However, there are several numerical evidence showing that EKI regularized only through an ensemble may have overfitting [16]. Among other approaches to regularize EKI, Tikhonov EKI [8] uses the idea of an augmented measurement to implement regularization, which is a simple modification of the standard EKI. For the original measurement , the augmented measurement model extends by adding the zero vector in , which yields an augmented measurement vector
| (10) |
The forward model is also augmented to account for the augmented measurement vector, which adds the identity measurement
| (11) |
Using the augmented measurement vector and the model, Tikhonov EKI has the following inverse problem of estimating from
| (12) |
Here is a -dimensional measurement error for the augmented measurement model, which is Gaussian with mean zero and covariance
| (13) |
for the identity matrix .
The mechanism enabling the regularization in Tikhonov EKI is the incorporation of the penalty term as a part of the augmented measurement model. From the orthogonality between different components in , we have
| (14) |
Therefore, the standard EKI algorithm applied to the augmented measurement minimizes , which equivalently minimizes the regularized problem.
3 -regularization for EKI
This section describes a transformation that converts a regularization problem to a regularization problem. -regularized EKI (EKI), which we completely describe in section 3.2, utilizes this transformation and solves the transformed regularization problem using the idea of Tikhonov EKI [8], the augmented measurement model.
3.1 Transformation of regularization into regularization
For , we define a function given by
| (15) |
Here is the sign function of , which has 1 for , 0 for , and -1 for . It is straightforward to check that is bijective and has an inverse defined as
| (16) |
For in , we define a nonlinear map , which applies to each component of ,
| (17) |
As has an inverse, the map also has an inverse, say
| (18) |
For , it can be checked that for each ,
and thus we have the following norm relation
| (19) |
This relation shows that the map converts the -regularized optimization problem in eq. 3 to a regularized problem in ,
| (20) |
where is the pullback of by
| (21) |
A transformation between and regularization terms has already been used to solve an inverse problem in the Bayesian framework [26]. In the context of the randomize-then-optimize framework [2], the method in [26] draws a sample from a Gaussian distribution, which is then transformed to a Laplace distribution. As this method needs to match the corresponding densities of the variables (the original and the transformed variables) as random variables, the transformation involves calculations related to cumulative distribution functions. For the scalar case, , the transformation from to , denoted as , is given by
| (22) |
where is the cumulative distribution function of the standard Gaussian distribution. fig. 1 shows the two transformations eq. 16 and eq. 22; the former is based on the norm relation eq. 19 and the latter is based on matching densities as random variables.

We note that the transformation has a region around 0 flatter than the transformation , but diverts quickly as moves further away from . From this comparison, we expect that the flattened region of plays another role in imposing sparsity by trapping the ensemble to the flattened area.
In general, a reformulation of an optimization problem using a transformation has the following potential issues [12]: i) the degree of nonlinearity may be significantly increased, ii) the desired minimum may be inadvertently excluded, or iii) an additional local minimum can be included. In [9], for a non-convex problem, it is shown that TEKI converges to an approximate local minimum if the gradient and Hessian of the objective function are bounded. It is straightforward to check that the transformed objective function has bounded gradient and Hessian if regardless of the convexity of the problem. Therefore, if we can show that the original and the transformed problems have the same number of local minima, then it is guaranteed to find a local minimum of the original problem by finding a local minimum of the transformed problem using TEKI. We want to note the importance of the sign function in defining and . The sign function is not necessary to satisfy the norm relation eq. 19, but it is essential to make the transformation and its inverse bijective. Without being bijective, the transformed problem can have more or less local minima than the original problem.
The following theorem shows that the transformation does not add or remove local minima.
Theorem 1.
For an objective function , if is a local minimizer of , is also a local minimizer of . Similarly, if is a local minimizer of , then is also a local minimizer of .
Proof.
From the definition eq. 17 and eq. 18, and are continuous and bijective. Thus for , both and map a neighborhood of to neighborhoods of and , respectively. As is a local minimizer, there exists a neighborhood of such that
| (23) |
Let and that is a neighborhood of . For any , and thus we have
| (24) |
which shows that is a local minimizer of . The other direction is proved similarly by changing the roles of and and of and . ∎
3.2 Algorithm
-regularized EKI (EKI) solves the transformed regularization problem using the standard EKI with the augmented measurement model. For the current study’s completeness to implement EKI, this subsection describes the complete EKI algorithm and discuss issues related to implementation. Note that the Tikhonov EKI (TEKI) part in EKI is slightly modified to reflect the setting assumed in this paper. The general TEKI algorithm and its variants can be found in [8].
We assume that the forward model and the measurement error covariance are known, and measurement is given (and thus is also given). We also fix the regularization coefficient and . Under this assumption, EKI uses the following iterative procedure to update the ensemble until the ensemble mean converges.
Algorithm: -regularized EKI
Assumption: an initial ensemble of size , , is given.
For
-
1.
Prediction step using the forward model:
-
(a)
Apply the augmented forward model to each ensemble member
(26) -
(b)
From the set of the predictions , calculate the mean and covariances
(27) (28) where is the ensemble mean of , i.e., .
-
(a)
-
2.
Analysis step:
-
(a)
Update each ensemble member using the Kalman update
(29) where is a perturbed measurement using Gaussian noise with mean zero and covariance .
-
(b)
For the ensemble mean , the EKI estimate, , for the minimizer of the regularization is given by
(30)
-
(a)
Remark 2.
In EKI and TEKI, the covariance of can be set to zero so that all ensemble member uses the same measurement without perturbations. In our study, we focus on the perturbed measurement using the covariance matrix .
Remark 3.
The above algorithm is equivalent to TEKI, except that the forward model is replaced with the pullback of by the transformation . In comparison with TEKI, the additional computational cost for EKI is to calculate the Transformation . In comparison with the standard EKI, the additional cost of EKI, in addition to the cost related to the transformation, is the matrix inversion in the augmented measurement space instead of a matrix inversion in the original measurement space . As the covariance matrices are symmetric positive definite, the matrix inversion can be done efficiently.
Remark 4.
In EKI, it is also possible to consider estimating by transforming each ensemble member and take average of the transformed members, that is,
| (31) |
instead of eq. 30. If the ensemble spread is large, these two approaches will make a difference. In our numerical tests in the next section, we do not incorporate covariance inflation. Thus the ensemble spread becomes relatively small when the estimate converges, and thus eq. 30 and eq. 31 are not significantly different. In this study, we use eq. 30 to measure the performance of EKI.
In recovering sparsity using the penalty term, if the penalty term’s convexity is not necessary, it is preferred to use a small as a smaller imposes stronger sparsity. The transformation in EKI works for any positive , but the transformation can lead to an overflow for a small ; the function depends on an exponent that becomes large for a small . Therefore, there is a limit for the smallest . In our numerical experiments in the next section, the smallest is 0.7 in the compressive sensing test.
There is a variant of EKI worth further consideration. In [24], a continuous-time limit of EKI has been proposed, which rescales using so that the matrix inversion is approximated by as a limit of . In many applications, the measurement error covariance is assumed to be diagonal. That is, the measurement error corresponding to different components are uncorrelated. Thus the inversion becomes a cheap calculation in the continuous-time limit. The continuous-time limit is then discretized in time using an explicit time integration method with a finite time step. The latter is called ‘learning rate’ in the machine learning community, and it is known that an adaptive time-stepping to solve an optimization often shows improved results [10, 22]. The current study focuses on the discrete-time update described in eq. 8 and we leave adaptive time-stepping for future work.
4 Numerical tests
We apply -regularized EKI (EKI) to a suite of inverse problems to check its performance in regularizing EKI and recovering sparse structures of solutions. The tests include: i) a scalar toy model where an analytic solution is available, ii) a compressive sensing problem to recover a sparse signal from random measurements of the signal, iii) an inverse problem in subsurface flow; estimation of permeability from measurements of hydraulic pressure field whose forward model is described by a 2D elliptic partial differential equation [7, 21]. In all tests, we run EKI for various values of , and compare with the result of Tikhonov EKI. We analyze the results to check how effectively EKI implements regularization and recover sparse solutions. When available, we also compare EKI with a convex minimization method. As quantitative measures for the estimation performance, we calculate the error of the EKI estimates and the data misfit .
Several parameters are to be determined in EKI to achieve robust estimation results, the regularization coefficient , ensemble size, and its initialization. The regularization coefficient can be selected, for example, using cross-validation. As the coefficient can significantly affect the performance, we find the coefficient by hand-tuning so that EKI achieves the best result for a given . Ensemble initialization plays a role in regularizing EKI, restricting the estimate to the linear span of the initial ensemble. In our experiments, instead of tuning the initial ensemble for improved results, we initialize the ensemble using a Gaussian distribution with mean zero and a constant diagonal covariance matrix (the variance will be specified later for each test). As this initialization does not utilize any prior information, a sparse structure in the solution, we regularize the solution mainly through the penalty term. For each test, we run 100 trials of EKI through 100 realizations of the initial ensemble distribution and use the estimate averaged over the trials along with its standard deviation to measure the performance difference.
Regarding the ensemble size, for the scalar toy and the compressive sensing problems, we test ensemble sizes larger than the dimension of , the unknown variable of interest. The purpose of a large ensemble size is to minimize the sampling error while we focus on the regularization effect of EKI. To show the applicability of EKI for high-dimensional problems, we also test a small ensemble size using the idea of multiple batches used in [23]. The multiple batch approach runs several batches where small magnitude components are removed after each batch. After removing small magnitude components from the previous batch, the ensemble is used for the next batch. The multiple batch approach enables a small ensemble size, 50 ensemble members, for the compressive sensing and the 2D elliptic inversion problems where the dimensions of are 200 and 400, respectively.
In ensemble-based Kalman filters, covariance inflation is an essential tool to stabilize and improve the performance of the filters. In a connection with the inflation, an adaptive time-stepping has been investigated to improve the performance of EKI. Although the adaptive time-stepping can be incorporated in EKI for performance improvements, we use the discrete version EKI described in section 3.2 focusing on the effect of different types of regularization on inversion. We will report a thorough investigation along the line of adaptive time-stepping in another place.
4.1 A scalar toy problem
The first numerical test is a scalar problem for with an analytic solution. As this is a scalar problem, there is no effect of regularization from ensemble initialization, and we can see the effect from the penalty term. The scalar optimization problem we consider here is the minimization of an objective function
| (32) |
This setup is equivalent to solving the optimization problem eq. 3 using regularization with , where , , and is Gaussian with mean zero and variance 1. Using the transformation defined in eq. 15, EKI minimizes a transformed objective function
| (33) |
which is an regularization of .
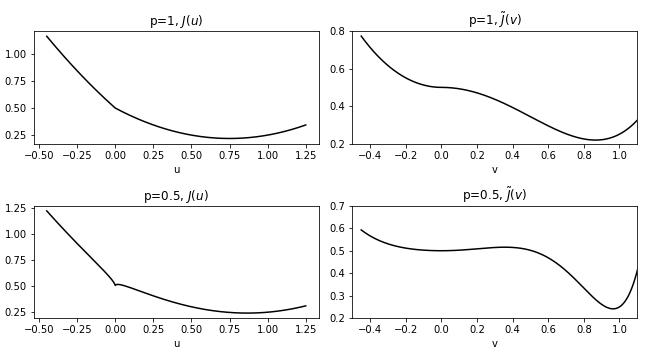
For , the first row of fig. 2 shows the objective functions of eq. 32 and the transformed eq. 33 formulations. Each objective function has a unique global minimum without other local minima. The minimizers are and for and , respectively. We can check that the transformation does not add/remove local minimizers, but the convexity of the objective function changes. The transformed objective function has an inflection point at , which is also a stationary point. Note that the original function has no other stationary points than the global minimizer.
When , a potential issue of the transformation can be seen explicitly. The original objective and the transformed objective functions are shown in the second row of fig. 2. Due to the regularization term with , the objective functions are non-convex and have a local minimizer at in addition to the global minimizers. In the transformed formulation (bottom right of fig. 2), the objective function flattens around , which shows a potential issue of trapping ensemble members around . Numerical experiments show that if the ensemble is initialized with a small variance, the ensemble is trapped around . On the other hand, if the ensemble is initialized with a sufficiently large variance (so that some of the ensemble members are initialized out of the well around ), EKI shows convergence to the true minimizer, (or ) even when it is initialized around .

We use 100 different realizations for the ensemble initialization and each trial uses 50 ensemble members. The estimates at each iteration, which is averaged over different trials, are shown in fig. 3. For (first row) and (second row), the left and right columns show the results when the ensemble is initialized with mean 1 and 0, respectively. When and initialized around , the ensemble estimate quickly converges to the true value as the objective function is convex, and the initial guess is close to the true value. When , as the objective function is non-convex due to the regularization term, the convergence is slower than the case. When the ensemble is initialized around 0 for , a local minimizer, the ensemble needs to be initialized with a large variance. Using variance 1, which is 10 times larger than 0.1, the variance for the ensemble initialization around 1, EKI converges to the true value. The performance difference between different trials is marginal. The standard deviations of the estimate after 50 iterations are ( initialized with 1), ( initialized with 0), ( initialized with 1), and ( initialized with 0). As a reference, the estimate using the transformation eq. 22 based on matching the densities of random variables converges to 0.71.
4.2 Compressive sensing
The second test is a compressive sensing problem. The true signal is a vector in , which is sparse with only four randomly selected non-zero components (their magnitudes are also randomly chosen from the standard normal distribution.) The forward model is a random Gaussian matrix of size , which yields a measurement vector in . The measurement is obtained by applying the forward model to the true signal polluted by Gaussian noise with mean zero and variance . As the forward model is linear, several robust methods can solve the sparse recovery problem, including the convex minimization method [4]. This test aims to compare the performance of EKI for various values, rather than to advocate the use of EKI over other standard methods. As the forward model is linear and cheap to calculate, the standard methods are preferred over EKI for this test.
We first use a large ensemble size, 2000 ensemble members, to run EKI. The ensemble is initialized by drawing samples from a Gaussian distribution with mean zero and a diagonal covariance (which yields variance 0.1 for each component). For and , the tuned regularization coefficients, , are 100 and 300. When , which corresponds to TEKI, the best result can be obtained using ranging from 10 to 200; we use the result of to compare with the other cases. For , we also compare the result of the convex minimization method using the KKT solver in the Python library CVXOPT [20].

.
Figure 4 shows the EKI estimates after 20 iterations averaged over 100 trials for (top left), (top right), and (bottom left), along with the estimate by the convex optimization (bottom right). As it is well known in compressive sensing, regularization fails to capture the true signal’s sparse structure. As decreases to 1, EKI develops sparsity in the estimate, comparable to the estimate of the convex minimization method. The slightly weak magnitudes of the three most significant components by EKI improve as decreases to . When , EKI captures the correct magnitudes at the cost of losing the smallest magnitude component. We note that the smallest magnitude component is difficult to capture; the magnitude is comparable to the measurement error .
| Method | error | data misfit |
|---|---|---|
| , ens size 2000 | 14.0802 | 0.0515 |
| , ens size 2000 | 0.7848 | 0.8018 |
| , ens size 2000 | 0.2773 | 1.2737 |
| , ens size 50 | 1.6408 | 1.4095 |
| , ens size 50 | 0.6027 | 1.8958 |
| convex minimization | 0.5623 | 0.9030 |

Another cost of using to impose stronger sparsity than is a slow convergence rate ofEKI. The time series of the estimation error and the data misfit of EKI averaged over 100 trials are shown in fig. 5 alongside those of the convex optimization method. The results show that converges slower than (see Table table 1 for the numerical values of the error and the misfit). Although there is a slowdown in convergence, it is worth noting that EKI with converges in a reasonably short time, 15 iterations, to achieve the best result. EKI with converges fast with the smallest data misfit. However, the regularization is not strong enough to impose sparsity in the estimate and yields the largest estimation error, which is 20 times larger than the case of . Note that the convex optimization method has the fastest convergence rate; it converges within three iterations and captures the four nonzero components with slightly smaller magnitudes than for the three most significant components.

The ensemble size 2000 is larger than the dimension of the unknown vector , 200. A large ensemble size can be impractical for a high-dimensional unknown vector. To see the applicability of EKI using a small ensemble size, we use 50 ensemble members and two batches following the multiple batch approach [23]. The first batch runs 10 iterations, and all components whose magnitudes are less than 0.1 (the square root of the observation variance) are removed. The problem’s size the second batch solves ranges from 30-45 (depending on a realization of the initial ensemble), which is then solved for another 10 iterations. The estimates using 50 ensemble members for and after two batch runs (i.e., 20 iterations) are shown in fig. 6. Compared with the large ensemble size case, the small ensemble size run also captures the most significant components at the cost of fluctuating components larger than the large ensemble size test. We note that the estimates are averaged over 100 trials, and thus there are components whose magnitudes are less than the threshold value 0.1 used in the multiple batch run.

As a measure to check the performance difference for different trials, fig. 7 shows the standard deviations of EKI estimates for and after 20 iterations. The first row shows the results using 2000 ensemble members, while the second row shows the ones using 50 ensemble members. The standard deviations of the large ensemble size are smaller than those of the small ensemble size case as the large ensemble size has a smaller sampling error. In all cases, the standard deviations are smaller than 6% of the magnitude of the most significant components. In terms of , the standard deviations of are smaller than those of .
4.3 2D elliptic problem
Next, we consider an inverse problem where the forward model is given by an elliptic partial differential equation. The model is related to subsurface flow described by Darcy flow in the two-dimensional unit square
| (34) |
The scalar field is the permeability, and another field is the piezometric head or the pressure field of the flow. For a known source term , the inverse problem estimates the permeability from measurements of the pressure field . This model is a standard model for an inverse problem in oil reservoir simulations and has been actively used to measure EKI’s performance and its variants, including TEKI [16, 8].
We follow the same setting used in TEKI [8] for the boundary conditions and the source term. The boundary conditions consist of Dirichlet and Neumann boundary conditions
and the source term is piecewise constant
A physical motivation of the above configuration can be found in [7]. We use regularly spaced points in to measure the pressure field with a small measurement error variance . For a given , the forward model is solved by a FEM method using the second-order polynomial basis on a uniform mesh.
In addition to the standard setup, we impose a sparse structure in the permeability. We assume that the log permeability, , can be represented by 400 components in the cosine basis
| (35) |
where only six of are nonzero. That is, we assume that the discrete cosine transform of is sparse with only 6 nonzero components out of 400 components. Thus, the problem we consider here can be formulated as an inverse problem to recover (which has only six nonzero components) from a measurement , the measurement of at regularly spaced points. In terms of sparsity reconstruction, the current setup is similar to the previous compressive sensing problem, but the main difference lies in the forward model. In this test, the forward model is nonlinear and computationally expensive to solve, where the forward model in the compressive sensing test was linear using a random measurement matrix.
For this test, we run EKI using only a small ensemble size due to the high computational cost of running the forward model. As in the previous test, we use the multiple batch approach. First, the EKI ensemble of size 50 is initialized around zero with Gaussian perturbations of variance 0.1. After the first five iterations, all components whose magnitudes less than are removed at each iteration. The threshold value is slightly smaller than the smallest magnitude component of the true signal. Over 100 different trials, the average number of nonzero components after 30 iterations is 18 that is smaller than the ensemble size.




The true value of used in this test and its corresponding log permeability, , are shown in the first row of fig. 8 ( is represented as a one-dimensional vector by concatenating the row vectors of ). The EKI estimates for , and are shown in the second to the fourth rows of fig. 8. Here was the smallest value we can use for EKI due to the numerical overflow in the exponentiation of . A smaller can be used with a smaller variance for ensemble initialization, but the gain is marginal. The results of EKI are similar to the compressive sensing case. has the best performance recovering the four most significant components of . has slightly weak magnitudes missing the correct magnitudes of the two most significant components (corresponding to one-dimensional indices 141 and 364). Both cases converge within 20 iterations to yield the best result (see fig. 9 and Table table 2 for the time series and numerical values of the error and data misfit). When , EKI performs the worst; it has the largest error and data misfit. We note that uses the result after running 50 iterations at which the estimate converges.


The performance difference between different trials is not significant. The standard deviations of the EKI estimates using 100 trials are shown in fig. 10. The standard deviations for nonzero components are larger than the other components, but the largest standard deviation is less than 3% of the magnitude of the true signal. As in the compressive sensing test, the deviations are slightly smaller for than .
| error | data misfit | |
|---|---|---|
| 2 | 21.3389 | 4.1227 |
| 1 | 0.1553 | 0.5707 |
| 0.8 | 0.0719 | 0.5682 |
5 Discussions and conclusions
We have proposed a strategy to implement , regularization in ensemble Kalman inversion (EKI) to recover sparse structures in the solution of an inverse problem. The -regularized ensemble Kalman inversion (EKI) proposed here uses a transformation to convert the regularization to the regularization, which is then solved by the standard EKI with an augmented measurement model used in Tikhonov EKI. We showed a one-to-one correspondence between the local minima of the original and the transformed formulations. Thus a local minimum of the original problem can be obtained by finding a local minimum of the transformed problem. As other iterative methods for non-convex problems, initialization plays a vital role in the proposed method’s performance. The effectiveness and robustness of regularized EKI are validated through a suite of numerical tests, showing robust results in recovering sparse solutions using .
In implementing regularization for EKI, there is a limit for due to an overflow. One possible workaround is to use a nonlinear augmented measurement model related to the transformation , not the transformation . The nonlinear measurement model is general to incorporate the regularization term directly instead of using the transformed problem. However, this approach lacks a mathematical framework to prevent the inadvertent addition of local minima. This approach is under investigation and will be reported in another place.
For successful applications of EKI for high-dimensional inverse problems, it is essential to maintain a small ensemble size for efficiency. In the current study, we considered the multiple batch approach. The approach removes non-significant components after each batch, and thus the problem size (i.e., the dimension of the unknown signal) decreases over different batch runs. This approach enabled EKI to use only 50 ensemble members to solve 200 and 400-dimensional inverse problems. Other techniques, such as variance inflation and localization, improve the performance of the standard EKI using a small ensemble size [24]. It would be natural to investigate if these techniques can be extended to EKI to decrease the sampling error of EKI.
In the current study, we have left several variants of EKI for future work. Weighted has been shown to recover sparse solutions using fewer measurements than the standard [6]. It is straightforward to implement weighted (and further weighted for ) in EKI by replacing the identity matrix in eq. 13 with another type of covariance matrix corresponding to the desired weights. We plan to study several weighting strategies to improve the performance ofEKI. As another variant ofEKI, we plan to investigate the adaptive time-stepping under the continuous limit. The time step for solving the continuous limit equation, which is called ‘learning rate’ in the machine learning community, is known to affect an optimization solver [10]. The standard ensemble Kaman inversion has been applied to machine learning tasks, such as discovering the vector fields defining a differential equation, using time series data [18] and sparse learning using thresholding [25]. We plan to investigate the effect of an adaptive time-stepping for performance improvements and compare with the sparsity EKI method using thresholding in dimension reduction in machine learning.
References
- [1] J. L. Anderson, An ensemble adjustment kalman filter for data assimilation, Monthly Weather Review, 129 (2001), pp. 2884–2903.
- [2] J. M. Bardsley, A. Solonen, H. Haario, and M. Laine, Randomize-then-optimize: A method for sampling from posterior distributions in nonlinear inverse problems, SIAM Journal on Scientific Computing, 36 (2014), pp. A1895–A1910.
- [3] M. Benning and M. Burger, Modern regularization methods for inverse problems, Acta Numerica, 27 (2018), p. 1–111.
- [4] S. Boyd and L. Vandenberghe, Convex Optimization, Cambridge University Press, USA, 2004.
- [5] A. C. Reynolds, M. Zafari, and G. Li, Iterative forms of the ensemble kalman filter, (2006).
- [6] E. J. Candès, M. B. Wakin, and S. P. Boyd, Enhancing sparsity by reweighted minimization, Journal of Fourier Analysis and Applications, 14 (2008), pp. 877–905.
- [7] J. Carrera and S. P. Neuman, Estimation of aquifer parameters under transient and steady state conditions: 3. application to synthetic and field data, Water Resources Research, 22 (1986), pp. 228–242.
- [8] N. K. Chada, A. M. Stuart, and X. T. Tong, Tikhonov regularization within ensemble kalman inversion, SIAM Journal on Numerical Analysis, 58 (2020), pp. 1263–1294.
- [9] N. K. Chada and X. T. Tong, Convergence acceleration of ensemble kalman inversion in nonlinear settings, (2019). arXiv:1911.02424.
- [10] J. Duchi, E. Hazan, and Y. Singer, Adaptive subgradient methods for online learning and stochastic optimization, J. Mach. Learn. Res., 12 (2011), p. 2121–2159.
- [11] G. Evensen, Data Assimilation: The Ensemble Kalman Filter, Springer, London, 2009.
- [12] R. Fletcher, Practical methods of optimization, John Wiley, New York, 2nd ed., 1987.
- [13] S. Foucart and H. Rauhut, A Mathematical Introduction to Compressive Sensing, Birkhäuser Basel, 2013.
- [14] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning, The MIT Press, 2016.
- [15] M. Hanke, A regularizing levenberg - marquardt scheme, with applications to inverse groundwater filtration problems, Inverse Problems, 13 (1997), pp. 79–95.
- [16] M. Iglesias, K. J. H. Law, and A. Stuart, Ensemble kalman methods for inverse problems, Inverse Problems, 29 (2013), p. 045001.
- [17] M. A. Iglesias, A regularizing iterative ensemble kalman method for PDE-constrained inverse problems, Inverse Problems, 32 (2016), p. 025002.
- [18] N. B. Kovachki and A. M. Stuart, Ensemble kalman inversion: a derivative-free technique for machine learning tasks, Inverse Problems, 35 (2019), p. 095005.
- [19] A. C. Li, Gaoming; Reynolds, An iterative ensemble kalman filter for data assimilation, (2007).
- [20] L. V. M.S. Andersen, J. Dahl, Cvxopt: A python package for convex optimization. cvxopt.org.
- [21] D. Oliver, A. C. Reynolds, and N. Liu, Inverse Theory for Petroleum Reservoir Characterization and History Matching, Cambridge University Press, Cambridge, UK, 1st ed., 2008.
- [22] B. T. Polyak and A. B. Juditsky, Acceleration of stochastic approximation by averaging, SIAM Journal on Control and Optimization, 30 (1992), pp. 838–855.
- [23] H. Schaeffer, Learning partial differential equations via data discovery and sparse optimization, Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 473 (2017), p. 20160446.
- [24] C. Schillings and A. M. Stuart, Analysis of the ensemble kalman filter for inverse problems, SIAM Journal on Numerical Analysis, 55 (2017), pp. 1264–1290.
- [25] T. Schneider, A. M. Stuart, and J.-L. Wu, Imposing sparsity within ensemble kalman inversion, (2020). arXiv:2007.06175.
- [26] Z. Wang, J. M. Bardsley, A. Solonen, T. Cui, and Y. M. Marzouk, Bayesian inverse problems with $l_1$ priors: A randomize-then-optimize approach, SIAM Journal on Scientific Computing, 39 (2017), pp. S140–S166.