Low-Resource Task-Oriented Semantic Parsing
via Intrinsic Modeling
Abstract
Task-oriented semantic parsing models typically have high resource requirements: to support new ontologies (i.e., intents and slots), practitioners crowdsource thousands of samples for supervised fine-tuning. Partly, this is due to the structure of de facto copy-generate parsers; these models treat ontology labels as discrete entities, relying on parallel data to extrinsically derive their meaning. In our work, we instead exploit what we intrinsically know about ontology labels; for example, the fact that SL:TIME_ZONE has the categorical type “slot” and language-based span “time zone”. Using this motivation, we build our approach with offline and online stages. During preprocessing, for each ontology label, we extract its intrinsic properties into a component, and insert each component into an inventory as a cache of sorts. During training, we fine-tune a seq2seq, pre-trained transformer to map utterances and inventories to frames, parse trees comprised of utterance and ontology tokens. Our formulation encourages the model to consider ontology labels as a union of its intrinsic properties, therefore substantially bootstrapping learning in low-resource settings. Experiments show our model is highly sample efficient: using a low-resource benchmark derived from TOPv2 Chen et al. (2020), our inventory parser outperforms a copy-generate parser by +15 EM absolute (44% relative) when fine-tuning on 10 samples from an unseen domain.
1 Introduction
Task-oriented conversational assistants face an increasing demand to support a wide range of domains (e.g., reminders, messaging, weather) as a result of their emerging popularity Chen et al. (2020); Ghoshal et al. (2020). For practitioners, enabling these capabilities first requires training semantic parsers which map utterances to frames executable by assistants Gupta et al. (2018); Einolghozati et al. (2018); Pasupat et al. (2019); Aghajanyan et al. (2020); Li et al. (2020); Chen et al. (2020); Ghoshal et al. (2020). However, current methodology typically requires crowdsourcing thousands of samples for each domain, which can be both time-consuming and cost-ineffective at scale Wang et al. (2015); Jia and Liang (2016); Herzig and Berant (2019); Chen et al. (2020). One step towards reducing these data requirements is improving the sample efficiency of current, de facto copy-generate parsers. However, even when leveraging pre-trained transformers, these models are often ill-equipped to handle low-resource settings, as they fundamentally lack inductive bias and cross-domain reusability.
In this work, we explore a task-oriented semantic parsing model which leverages the intrinsic properties of an ontology to improve generalization. To illustrate, consider the ontology label SL:TIME_ZONE : a slot representing the time zone in a user’s query. Copy-generate models typically treat this label as a discrete entity, relying on parallel data to extrinsically learn its semantics. In contrast, our model exploits what we intrinsically know about this label, such as its categorical type (e.g., “slot”) and language-based span (e.g., “time zone”). Guided by this principle, we extract the properties of each label in a domain’s ontology, building a component with these properties and inserting each component into an inventory. By processing this domain-specific inventory through strong language models, we effectively synthesize an inductive bias useful in low-resource settings.
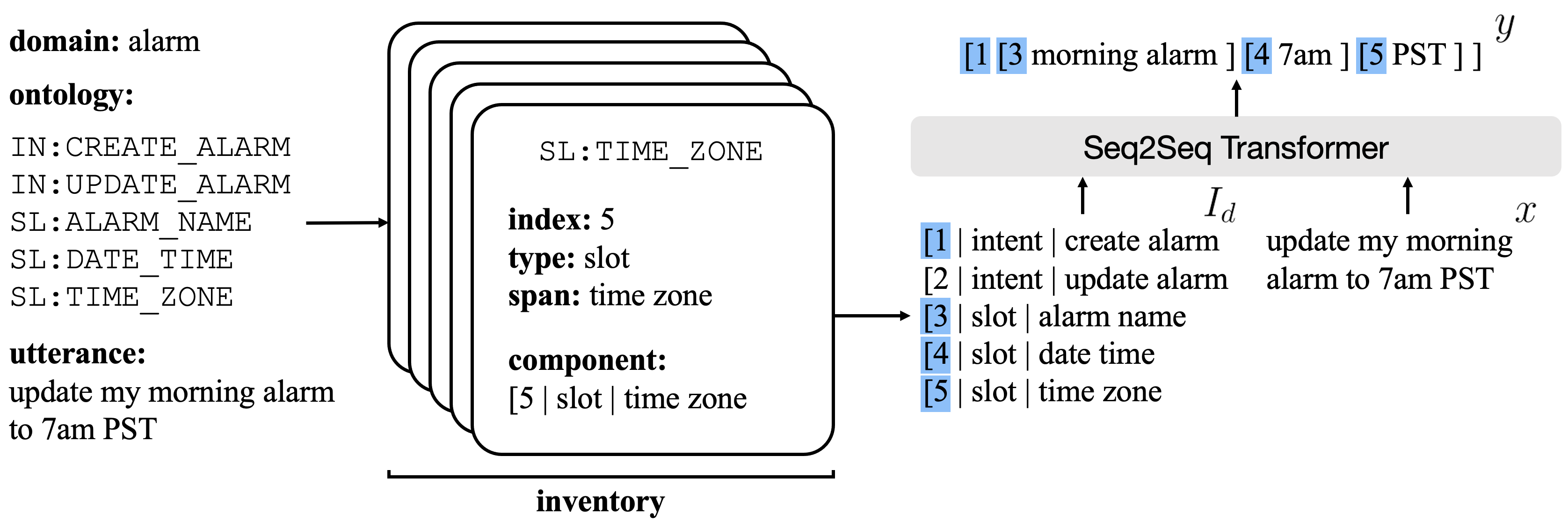
Concretely, we build our model on top of seq2seq, pre-trained transformer, namely BART Lewis et al. (2020), and fine-tune it to map utterances to frames, as depicted in Figure 1. Our model operates in two stages: (1) the encoder inputs a domain-specific utterance and inventory and (2) the decoder outputs a frame composed of utterance and ontology tokens. Here, instead of performing vocabulary augmentation, the standard way of “generating” ontology tokens in copy-generate parsers, we treat ontology tokens as pointers to inventory components. This is particularly useful in low-resource settings; our model is encouraged to represent ontology tokens as a union of its intrinsic properties, and as a result, does not require many labeled examples to achieve strong performance.
We view sample efficiency as one of the advantages of our approach. As such, we develop a comprehensive low-resource benchmark derived from TOPv2 Chen et al. (2020), a task-oriented semantic parsing dataset spanning 8 domains. Using a leave-one-out setup on each domain, models are fine-tuned on a high-resource, source dataset (other domains; 100K+ samples), then fine-tuned and evaluated on a low-resource, target dataset (this domain; 10-250 samples). We also randomly sample target subsets to make the transfer task more difficult. In aggregate, our benchmark provides 32 experiments, each varying in domain and number of target samples.
Both coarse-grained and fine-grained experiments show our approach outperforms baselines by a wide margin. Overall, when averaging across all domains, our inventory model outperforms a copy-generate model by +15 EM absolute (44% relative) in the most challenging setting, where only 10 target samples are provided. Notably, our base inventory model (139M parameters) also outperforms a large copy-generate model (406M parameters) in most settings, suggesting usability in resource-constrained environments. We also show systematic improvements on a per-domain basis, even for challenging domains with high compositionality and ontology size, such as reminders and navigation. Finally, through error analysis, we show our model’s predicted frames are largely precise and linguistically consistent; even when inaccurate, our frames not require substantial modifications to achieve gold quality.
2 Background and Motivation
Task-oriented semantic parsers typically cast parsing as transduction, utilizing seq2seq transformers to map utterances to frames comprised of intents and slots Aghajanyan et al. (2020); Li et al. (2020); Chen et al. (2020); Ghoshal et al. (2020). Because frames are a composition of utterance and ontology tokens, these models are often equipped with copy-generate mechanisms; at each timestep, the decoder either copies from the utterance or generates from the ontology See et al. (2017); Aghajanyan et al. (2020); Chen et al. (2020); Ghoshal et al. (2020). These parsers are empirically effective in high-resource settings, achieving state-of-the-art performance on numerous benchmarks Aghajanyan et al. (2020), but typically lack inductive bias in low-resource settings.
To illustrate, consider a hypothetical domain adaptation scenario where a copy-generate parser adapts to the weather domain. In standard methodology, a practitioner augments the decoder’s vocabulary with weather ontology labels, then fine-tunes the parser on weather samples. This subsequently trains the copy-generate mechanism to generate these labels as deemed appropriate. But, the efficacy of this process scales with the amount of training data as these ontology labels (though, more specifically, their embeddings) iteratively derive extrinsic meaning. Put another way, before training, there exists no correspondence between an ontology label (e.g., SL:LOCATION) and an utterance span (e.g., “Menlo Park”). Such an alignment is only established once the model has seen enough parallel data where the two co-occur.
In contrast, we focus on reducing data requirements by exploiting the intrinsic properties of ontology labels. These labels typically have several core elements, such as their label types and spans. For example, by teasing apart SL:LOCATION, we can see it is composed of the type “slot” and span “location”. These properties, when pieced together and encoded by strong language models, provide an accurate representation of what the ontology label is. While these properties are learned empirically with sufficient training data, as we see with the copy-generate parser, our goal is to train high-quality parsers with as little data as possible by explicitly supplying this information. Therefore, a central question of our work is whether we can build a parser which leverages the intrinsic nature of an ontology space while retaining the flexibility of seq2seq modeling; we detail our approach in the next section.
3 Semantic Parsing via Label Inventories
| Components | |||
|---|---|---|---|
| Ontology Label | Index | Type | Span |
| IN:CREATE_ALARM | 1 | intent | create alarm |
| IN:UPDATE_ALARM | 2 | intent | update alarm |
| SL:ALARM_NAME | 3 | slot | alarm name |
| SL:DATE_TIME | 4 | slot | date time |
| SL:TIME_ZONE | 5 | slot | time zone |
Illustrated in Figure 1, we develop a seq2seq parser which uses inventories—that is, tables enumerating the intrinsic properties of ontology labels—to map utterances to frames. Inventories are domain-specific, and each component carries the intrinsic properties of a single label in the domain’s ontology. On the source-side, a pre-trained encoder consumes both an utterance and inventory (corresponding to the utterance’s domain). Then, on the target-side, a pre-trained decoder mimics a copy-generate mechanism by either selecting from the utterance or ontology. Instead of selecting ontology labels from an augmented vocabulary, as in copy-generate methods, our decoder naturally references these labels in the source-side inventory through self-attention. The sequence ultimately decoded during generation represents the frame.
As alluded to earlier, we focus on two intrinsic properties of ontology labels: types and spans. The type is particularly useful for enforcing syntactic structure; for example, the rule “slots cannot be nested in other slots” Gupta et al. (2018) is challenging to meet unless a model can delineate between intents and slots. Furthermore, the span is effectively a natural language description, which provides a general overview of what the label aligns to. Though inventory components can incorporate other intrinsic properties, types and spans do not require manual curation and can be automatically sourced from existing annotations.
Despite the reformulation of the semantic parsing task with inventories, our approach inherits the flexibility and simplicity of copy-generate models Aghajanyan et al. (2020); Li et al. (2020); Chen et al. (2020); Ghoshal et al. (2020); we also treat parsing as transduction, leverage pre-trained modules, and fine-tune with log loss. However, a key difference is our parser is entirely text-to-text and does not require extra parameters, which we show promotes reusability in low-resource settings. In the following sub-sections, we elaborate on our approach in more detail and comment on several design decisions.
3.1 Inventories
Task-oriented semantic parsing datasets typically have samples of the form Gupta et al. (2018); Li et al. (2020); Chen et al. (2020); that is, a domain , utterance , and frame . There exist many domains , where each domain defines an ontology , or list of intents and slots. For a given domain , we define its inventory as a table where each component is a tuple storing the intrinsic properties of a corresponding label .
Specifically, these components consist of: (1) an index representing the label’s position in the (sorted) ontology; (2) a type denoting whether the label is an intent or slot; and (3) a span representing an ontology description, formally represented as a string from a vocabulary . The index is a unique referent to each component and is largely used as an optimization trick during generation; we elaborate on this in the next section. In Table 1, we show an example inventory for the alarm domain.
3.2 Seq2Seq Model
Our model is built on top of a pre-trained, seq2seq transformer architecture Vaswani et al. (2017) with vocabulary .
Encoder.
The input to the model is a concatenation of an utterance and its domain ’s inventory .
Following recent work in tabular understanding Yin et al. (2020), we encode our tabular inventory as a linearized string . As shown in Figure 1, for each component, the index is preceded by [ and the remaining elements are demarcated by |. Because our tabular structure is not significantly complex, we elect not to use explicit row and column segment embeddings.
Decoder.
The output from the model is a frame , where at timestep , the decoder either selects an utterance token () or ontology token ().
Here, we use each component’s index in place of typical ontology tokens. Similar to when a copy-generate parser generates a token from an ontology, our inventory parser generates an index corresponding to an entry. A key advantage is these indices, numerical values by nature, are already present in most transformer vocabularies and therefore do not require special augmentation. We primarily use this format to minimize the target sequence length; instead of requiring the decoder to generate a label’s intrinsic properties as a means of “selecting” it, which typically requires several decoding steps, we use the label’s index as a proxy. Implicitly, this manifests in a pooling effect during training, where the index acts as a snapshot over the corresponding component.
Furthermore, because our gold frames do not originally come with index pointers, we modify these frames to ensure compatibility with our approach. Implementation-wise, we maintain a dictionary of indices to ontology labels, which ensures this mapping is injective.
Optimization.
Finally, we fine-tune our seq2seq model by minimizing the log loss of the gold frame token at each timestep, conditioning on the utterance, inventory, and previous timesteps:
4 Low-Resource Semantic Parsing Benchmark
| Domains | Source | Target (SPIS) | |||
|---|---|---|---|---|---|
| 1 | 2 | 5 | 10 | ||
| Alarm | 104,167 | 13 | 25 | 56 | 107 |
| Event | 115,427 | 22 | 33 | 81 | 139 |
| Messaging | 114,579 | 23 | 44 | 89 | 158 |
| Music | 113,034 | 19 | 41 | 92 | 187 |
| Navigation | 103,599 | 33 | 63 | 141 | 273 |
| Reminder | 106,757 | 34 | 59 | 130 | 226 |
| Timer | 113,073 | 13 | 27 | 62 | 125 |
| Weather | 101,543 | 10 | 22 | 47 | 84 |
In this section, we describe our low-resource benchmark used to assess the sample efficiency of our model. The benchmark is derived from TOPv2 Chen et al. (2020), a task-oriented semantic parsing dataset covering 8 domains: alarm, event, messaging, music, navigation, reminder, timer, and weather. TOPv2 samples have a combination of both linear and nested frames, uniquely reflecting the data distribution our parsers are likely to encounter in practice.
TOPv2-DA Benchmark.
To build our benchmark, nicknamed TOPv2-DA111TOPv2 Domain Adaptation (DA), we adopt a paradigm of source and target dataset fine-tuning, where a model is initially fine-tuned on a high-resource, source dataset (consisting of multiple domains), and is then fine-tuned on a low-resource, target dataset (consisting of one domain). This process describes one such transfer scenario; within this scenario, we can assess a model’s few-shot capabilities incrementally by fine-tuning it on multiple subsets, each randomly sampled from the target dataset.
Table 2 provides a quantitative overview of our benchmark. We typically have 100K+ samples for source fine-tuning, but only about 10-250 samples for target fine-tuning, depending on the subset used. In aggregate, our benchmark provides 32 experiments (8 scenarios 4 subsets), offering a rigorous evaluation of sample efficiency.
Creating Experiments.
We use a leave-one-out algorithm to create source and target datasets. Given domains , we create scenarios where the th scenario uses domains as the source dataset and domain as the target dataset. For each target dataset, we also create subsets using a random sampling algorithm, each with an increasing number of samples.
For our random sampling algorithm, we use samples per intent slot (SPIS), shown abovex, which ensures at least ontology labels (i.e., intents and slots) appear in the resulting subset Chen et al. (2020). Unlike a traditional algorithm which selects samples exactly, SPIS guarantees coverage over the entire ontology, but as a result, the number of samples per subset is typically much greater than Chen et al. (2020). Therefore, we use conservative values of ; for each scenario, we sample target subsets of 1, 2, 5, and 10 SPIS. Our most extreme setting of 1 SPIS is still 10 smaller than the equivalent setting in prior work Chen et al. (2020); Ghoshal et al. (2020).
5 Experimental Setup
We seek to answer three questions in our experiments: (1) How sample efficient is our model when benchmarked on TOPv2-DA? (2) Does our model perform well on average or does it selectively work on particular domains? (3) How do the intrinsic components of an inventory component (e.g., types and spans) contribute to performance?
Systems for Comparison.
We chiefly experiment with CopyGen and Inventory, a classical copy-generate parser and our proposed inventory parser, as discussed in Sections 2 and 3, respectively. Though both models are built on top of off-the-shelf, seq2seq transformers, the copy-generate parser requires special tweaking; to prepare its “generate” component, we augment the decoder vocabulary with dataset-specific ontology tokens and initialize their embeddings randomly, as is standard practice Aghajanyan et al. (2020); Chen et al. (2020); Li et al. (2020). In addition, both models are initialized with pre-trained weights. We use BART Lewis et al. (2020), a seq2seq transformer pre-trained with a denoising objective for generation tasks. Specifically, we we use the BART (139M parameters; 12L, 768H, 16A) and BART (406M parameters; 24L, 1024H, 16A) checkpoints.
We benchmark the sample efficiency of these models on TOPv2-DA. Following the methodology outlined in Section 4, for each scenario and subset experiment, each model undergoes two rounds of fine-tuning: it is initially fine-tuned on a high-resource, source dataset, then fine-tuned again on a low-resource, target dataset using the splits in Table 2. The resulting model is then evaluated on the target domain’s TOPv2 test set; note that this set is not subsampled for accurate evaluation. We report the exact match (EM) between the predicted and gold frame. To account for variance, we average EM across three runs, each with a different seed.
Hyperparameters.
We use BART checkpoints from fairseq Ott et al. (2019) and elect to use most hyperparameters out-of-the-box. However, during initial experimentation, we find the batch size, learning rate, and dropout settings to heavily impact performance, especially for target fine-tuning. For source fine-tuning, our models use a batch size of 16, dropout in [0, 0.5], and learning rate in [1e-5, 3e-5]. Each model is fine-tuned on a single 32GB GPU given the size of the source datasets. For target fine-tuning, our models use a batch size in [1, 2, 4, 8], dropout in [0, 0.5], and learning rate in [1e-6, 3e-5]. Each model is fine-tuned on a single 16GB GPU. Finally, across both source and target fine-tuning, we optimize models with Adam Kingma and Ba (2015).
| SPIS | ||||
|---|---|---|---|---|
| 1 | 2 | 5 | 10 | |
| CopyGen | 27.93 | 39.12 | 46.23 | 52.51 |
| CopyGen | 35.51 | 44.40 | 51.32 | 56.09 |
| Inventory | 38.93 | 48.98 | 57.51 | 63.19 |
| Inventory | 51.34 | 57.63 | 63.06 | 68.76 |
| Base Model (SPIS) | Large Model (SPIS) | |||||||
| 1 | 2 | 5 | 10 | 1 | 2 | 5 | 10 | |
| Domain: Alarm | ||||||||
| CopyGen | 20.41 | 38.90 | 45.50 | 52.01 | 36.91 | 43.70 | 45.73 | 53.89 |
| Inventory | 62.13 | 65.26 | 71.81 | 75.27 | 67.25 | 72.11 | 71.82 | 78.15 |
| Domain: Event | ||||||||
| CopyGen | 31.85 | 38.85 | 38.31 | 41.78 | 32.37 | 34.59 | 38.48 | 43.93 |
| Inventory | 46.57 | 54.31 | 58.87 | 68.42 | 64.77 | 55.84 | 67.70 | 71.21 |
| Domain: Messaging | ||||||||
| CopyGen | 38.12 | 49.79 | 52.79 | 58.90 | 46.57 | 58.42 | 56.54 | 63.10 |
| Inventory | 46.54 | 57.43 | 63.72 | 70.14 | 60.36 | 66.68 | 74.69 | 78.04 |
| Domain: Music | ||||||||
| CopyGen | 25.58 | 33.28 | 48.75 | 55.16 | 23.84 | 36.84 | 56.17 | 59.18 |
| Inventory | 23.00 | 39.65 | 53.59 | 52.18 | 38.68 | 52.75 | 58.23 | 59.73 |
| Domain: Navigation | ||||||||
| CopyGen | 19.96 | 30.11 | 43.38 | 45.26 | 24.31 | 36.28 | 48.71 | 56.14 |
| Inventory | 21.16 | 29.08 | 42.59 | 53.97 | 28.74 | 47.47 | 49.98 | 64.08 |
| Domain: Reminder | ||||||||
| CopyGen | 23.66 | 23.30 | 36.37 | 41.66 | 31.74 | 31.82 | 41.57 | 42.62 |
| Inventory | 28.58 | 38.21 | 48.88 | 52.04 | 40.72 | 41.95 | 53.57 | 58.24 |
| Domain: Timer | ||||||||
| CopyGen | 16.62 | 40.80 | 54.79 | 63.26 | 32.64 | 59.94 | 59.80 | 66.27 |
| Inventory | 28.92 | 53.58 | 55.54 | 66.82 | 48.45 | 61.70 | 63.74 | 68.44 |
| Domain: Weather | ||||||||
| CopyGen | 47.24 | 57.97 | 49.94 | 62.07 | 53.08 | 53.60 | 63.56 | 63.58 |
| Inventory | 54.53 | 54.31 | 65.09 | 66.66 | 61.77 | 62.52 | 64.73 | 72.14 |
6 Results and Discussion
6.1 TOPv2-DA Experiments



| Model | Utterance / Frame |
|---|---|
| I need you to send a video message now | |
| Index | [IN:SEND_MESSAGE ] |
| + Type, Span | [IN:SEND_MESSAGE + [SL:TYPE_CONTENT video ] ] |
| Did I get any messages Tuesday on Twitter | |
| Index | [IN:GET_MESSAGE - [SL:RECIPIENT i ] [SL:ORDINAL Tuesday ] - [SL:TAG_MESSAGE Twitter ] ] |
| + Type, Span | [IN:GET_MESSAGE + [SL:DATE_TIME Tuesday ] + [SL:RESOURCE Twitter ] ] |
| Message Lacey and let her know I will be at the Boxer Rescue Fundraiser Saturday around 8 | |
| Index | [IN:SEND_MESSAGE [SL:RECIPIENT Lacey ] [SL:CONTENT_EXACT I will be at the Boxer Rescue Fundraiser - ] [SL:GROUP Saturday around 8 ] ] |
| + Type, Span | [IN:SEND_MESSAGE [SL:RECIPIENT Lacey ] [SL:CONTENT_EXACT I will be at the Boxer Rescue Fundraiser Saturday around 8 ] ] |
| SPIS | ||||
|---|---|---|---|---|
| Component | 1 | 2 | 5 | 10 |
| Index | 36.78 | 44.13 | 60.63 | 61.90 |
| + Type | 46.54 | 49.67 | 65.21 | 69.98 |
| + Span | 60.36 | 66.68 | 74.69 | 78.04 |
Table 3 presents the EM of CopyGen and Inventory on TOPv2-DA averaged across 8 domains. We also present more fine-grained results in Table 4, breaking down EM by domain. From these tables, we draw the following conclusions:
Inventory consistently outperforms CopyGen in 1, 2, 5, and 10 SPIS settings.
On average, Inventory shows improvements across the board, improving upon CopyGen by at least +10 EM on each SPIS subset. Compared to CopyGen, Inventory is especially strong at 1 SPIS, demonstrating gains of +11 and +15 EM across the base and large variants, respectively. Furthermore, we see Inventory outperforms CopyGen, indicating our model’s performance can be attributed to more than just the pre-trained weights and, as a result, carries more utility in compute-constrained environments.
However, provided that these constraints are not a concern, Inventory makes better use of larger representations. Figure 2 illustrates this by plotting the EM between the base and large variants of both models. The delta is especially pronounced at 1 SPIS, where Inventory Inventory yields +12 EM but CopyGen CopyGen only yields +7 EM. Unlike CopyGen which requires fine-tuning extra parameters in a target domain, Inventory seamlessly integrates stronger representations without modification to the underlying architecture. This is an advantage: we expect our model to iteratively improve in quality with the advent of new pre-trained transformers.
Inventory also yields strong results when inspecting each domain separately.
TOPv2 domains typically have a wide range of characteristics, such as their compositionality or ontology size, so one factor we can investigate is how our model performs on a per-domain basis. Specifically, is our model generalizing across the board or overfitting to particular settings? Using the per-domain, large model, 1 SPIS results in Table 4, we analyze EM versus % compositionality (fraction of nested frames) and # ontology labels (count of intent and slots). Figure 3 plots these relationships. A key trend we notice is Inventory improves EM in general, though better performance is skewed towards domains with 20% compositionality and 20-30 ontology labels. This can be partially explained by the fact that domains with these characteristics are more empirically dominant in TOPv2, as shown by the proximity of the dots to the vertical bars. Domains like reminder and navigation are more challenging given the size of their ontology space, but Inventory still outperforms CopyGen by a reasonable margin.
| Model | Utterance / Frame |
|---|---|
| Domain: Alarm | |
| Delete my 6pm alarm | |
| Inventory | [IN:DELETE_ALARM [SL:DATE_TIME 6pm ] ] |
| Oracle | [IN:DELETE_ALARM + [SL:ALARM_NAME [IN:GET_TIME [SL:DATE_TIME 6pm ] + ] ] ] |
| Domain: Event | |
| Fun activities in Letchworth next summer | |
| Inventory | [IN:GET_EVENT [SL:CATEGORY_EVENT - fun activities ] [SL:LOCATION Letchworth ] [SL:DATE_TIME next summer ] ] |
| Oracle | [IN:GET_EVENT [SL:CATEGORY_EVENT activities ] [SL:LOCATION Letchworth ] [SL:DATE_TIME next summer ] ] |
| Domain: Messaging | |
| Message Candy to send me details for her baby shower | |
| Inventory | [IN:SEND_MESSAGE - [SL:SENDER Candy ] [SL:CONTENT_EXACT details for her baby shower ] ] |
| Oracle | [IN:SEND_MESSAGE + [SL:RECIPIENT Candy ] [SL:CONTENT_EXACT + send me details for her baby shower ] ] |
| Domain: Navigation | |
| What is the distance between Myanmar and Thailand | |
| Inventory | [IN:GET_DISTANCE - [SL:UNIT_DISTANCE Myanmar ] - [SL:UNIT_DISTANCE Thailand ] ] |
| Oracle | [IN:GET_DISTANCE + [SL:SOURCE Myanmar ] + [SL:DESTINATION Thailand ] ] |
| Domain: Reminder | |
| Remind me that I have lunch plans with Derek in two days at 1pm | |
| Inventory | [IN:CREATE_REMINDER [SL:PERSON_REMINDED me ] [SL:TODO I have lunch plans ] [SL:ATTENDEE_EVENT Derek ] [SL:DATE_TIME in two days ] [SL:DATE_TIME at 1pm ] ] |
| Oracle | [IN:CREATE_REMINDER [SL:PERSON_REMINDED me ] [SL:TODO + [IN:GET_TODO [SL:TODO lunch plans ] [SL:ATTENDEE Derek ] + ] ] [SL:DATE_TIME + in two days at 1pm ] ] |
| Domain: Timer | |
| Stop the timer | |
| Inventory | - [IN:DELETE_TIMER [SL:METHOD_TIMER timer ] ] |
| Oracle | + [IN:PAUSE_TIMER [SL:METHOD_TIMER timer ] ] |
| Domain: Weather | |
| What is the pollen count for today in Florida | |
| Inventory | - [IN:GET_WEATHER [SL:WEATHER_ATTRIBUTE pollen ] [SL:DATE_TIME for today ] [SL:LOCATION Florida ] ] |
| Oracle | + [IN:UNSUPPORTED_WEATHER [SL:WEATHER_ATTRIBUTE pollen + count ] [SL:DATE_TIME for today ] [SL:LOCATION Florida ] ] |
6.2 Inventory Ablation
Moving beyond benchmark performance, we now turn towards better understanding the driving factors behind our model’s performance. From Section 3.1, recall each inventory component consists of an index, type, and span. The index is merely a unique identifier, while the type and span represent intrinsic properties of a label. Therefore, the goal of our ablation is to quantify the impact adding types and spans to inventories. Because conducting ablation experiments on each domain is cost-prohibitive, we use the messaging domain as a case study given its samples strike a balance between compositionality and ontology size.
We experiment with three Inventory models, where each model iteratively adds an element to its inventory components: (1) index only, (2) index and type, (3) index, type, and span. The results are shown in Table 6. Here, we see that while an index model performs poorly, adding types and spans improve performance across all subsets. At 1 SPIS, in particular, an index model improves by roughly +10 and +20 EM when types and spans are added, respectively. These results suggest that these intrinsic properties provide a useful inductive bias in the absence of copious training data.
In Table 5, we contrast the predictions of the index only (1) and index + type + span (3) models more closely, specifically looking at 1 SPIS cases where the frame goes from being incorrect to correct. We see a couple of cases where knowing about a label’s intrinsic properties might help make the correct assessment during frame generation. The second example shows a scenario where our model labels “tuesday” as SL:DATE_TIME rather than SL:ORDINAL. This distinction is more or less obvious when contrasting the phrases “date time” and “ordinal”, where the latter typically maps to numbers. In the third example, a more tricky scenario, our model correctly labels the entire subordinate clause as an exact content slot. While partitioning this clause and assigning slots to its constituents may yield a plausible frame, in this instance, there is not much correspondence between SL:GROUP and “saturday around 8”.
7 Error Analysis
Thus far, we have demonstrated the efficacy of inventory parsers, but we have not yet conducted a thorough investigation of their errors. Though models may not achieve perfect EM in low-resource settings, they should ideally fail gracefully, making mistakes which roughly align with intuition. In this section, we assess this by combing through our model’s cross-domain errors. Using Inventory models fine-tuned in each domain’s 1 SPIS setting, we first manually inspect 100 randomly sampled errors to build an understanding of the error distribution. Then, for each domain, we select one representative error, and present the predicted and gold frame in Table 7.
In most cases, the edit distance between the predicted and gold frames is quite low, indicating the frames our models produce are fundamentally good and do not require substantial modification. We do not see evidence of erratic behavior caused by autoregressive modeling, such as syntactically invalid frames or extraneous subword tokens in the output sequence. Instead, most errors are relatively benign; we can potentially resolve them with rule-based transformations or data augmentation, though these are outside the scope of our work. Below, we comment on specific observations:
Frame slots are largely correct and respect linguistic properties.
One factor we investigate is if our model copies over utterance spans correctly, which correspond to arguments in an API call. These spans typically lie on well-defined constituent boundaries (e.g., prepositional phrases), so we inspect the degree to which this is respected. Encouragingly, the vast majority of spans our model copies over are correct, and the cases which are incorrect consist of adding or dropping modifiers. For example, in the event example, our model adds the adjective “fun”, and in the weather example, our model drops the noun “count”. These cases are relatively insignificant; they are typically a result of annotation inconsistency and do not carry much weight in practice. However, a more serious error we see is failing to copy over larger spans. For example, in the reminder example, SL:DATE_TIME corresponds to both “in two days” and “at 1pm”, but our model only copies over the latter.
Predicting compositional structures is challenging in low-resource settings.
Our model also struggles with compositionality in low-resource settings. In both the alarm and reminder examples, our model does not correctly create nested structures, which reflect how slots ought to be handled during execution. Specifically, in the alarm example, because “6pm” is both a name and date/time, the gold frame suggests resolving the alarm in question before deleting it. Similarly, in the reminder example, we must first retrieve the “lunch plans” todo before including it as a component in the remainder of the frame. Both of these cases are tricky as they target prescriptive rather than descriptive behavior. Parsers often learn this type of compositionality in a data-driven fashion, but it remains an open question how to encourage this behavior given minimal supervision.
Ontology labels referring to “concepts” are also difficult.
Another trend we notice is our model predicts concept-based ontology labels with low precision. These labels require understanding a deeper concept which is not immediately clear from the surface description. A prominent example of this is the ontology label IN:UNSUPPORTED_WEATHER used to tag unsupported weather intents. To use this label, a parser must understand the distinction between in-domain and out-of-domain intents, which is difficult to ascertain from inventories alone. Other examples of this phenomenon manifest in the messaging and navigation domain with the slot pairs (SL:SENDER, SL:RECIPIENT) and (SL:SOURCE, SL:DESTINATION), respectively. While these slots are easier to comprehend given their intrinsic properties, a parser must leverage contextual signals and jointly reason over their spans to predict them.
8 Related Work
Prior work improving the generalization of task-oriented semantic parsers can be categorized into two groups: (1) contextual model architectures and (2) fine-tuning and optimization. We compare and contrast our work along these two axes below.
Contextual Model Architectures.
Bapna et al. (2017); Lee and Jha (2018); Shah et al. (2019) propose BiLSTMs which process both utterance and slot description embeddings, and optionally, entire examples, to generalize to unseen domains. Similar to our work, slot descriptions help contextualize what their respective labels align to. These descriptions can either be manually curated or automatically sourced. Our work has three key differences: (1) Inventories are more generalizable, specifying a format which encompasses multiple intrinsic properties of ontology labels, namely their types and spans. In contrast, prior work largely focuses on spans, and that too, only for slot labels. (2) Our model is interpretable: the decoder explicitly aligns inventory components and utterance spans during generation, which can aid debugging. However, slot description embeddings are used in an opaque manner; the mechanism through which BiLSTMs use them to tag slots is largely hidden. (3) We leverage a seq2seq framework which integrates inventories without modification to the underlying encoder and decoder. In contrast, prior work typically builds task-specific architectures consisting of a range of trainable components, which can complicate training.
Fine-tuning and Optimization.
Recently, low-resource semantic parsing has seen a methodological shift with the advent of pre-trained transformers. Instead of developing new architectures, as discussed above, one thrust of research tackles domain adaptation via robust optimization. These methods are typically divided between source and target domain fine-tuning. Chen et al. (2020) use Reptile Nichol et al. (2018), a meta-learning algorithm which explicitly optimizes for generalization during source fine-tuning. Similarly, Ghoshal et al. (2020) develop LORAS, a low-rank adaptive label smoothing algorithm which navigates structured output spaces, therefore improving target fine-tuning. Our work is largely orthogonal; we focus on redefining the inputs and outputs of a transformer-based parser, but do not subscribe to specific fine-tuning or optimization practices. Our experiments use MLE and Adam for simplicity, though future work can considering improving our source and target fine-tuning steps with better algorithms. However, one important caveat is both Reptile and LORAS rely on strong representations (i.e., BART) for maximum efficiency, and typically show marginal returns with weaker representations (i.e., BART). In contrast, even when using standard practices, both the base and large variants of our model perform well, indicating our approach is more broadly applicable.
9 Conclusion
In this work, we present a seq2seq-based, task-oriented semantic parser based on inventories, tabular structures which capture the intrinsic properties of an ontology space, such as label types (e.g., “slot”) and spans (e.g., “time zone”). Our approach is both simple and flexible: we leverage out-of-the-box, pre-trained transformers with no modification to the underlying architecture. We chiefly perform evaluations on TOPv2-DA, a benchmark consisting of 32 low-resource experiments across 8 domains. Experiments show our inventory parser outperforms classical copy-generate parsers by a wide margin and ablations illustrate the importance of types and spans. Finally, we conclude with an error analysis, providing insight on the types of errors practitioners can expect when using our model in low-resource settings.
References
- Aghajanyan et al. (2020) Armen Aghajanyan, Jean Maillard, Akshat Shrivastava, Keith Diedrick, Michael Haeger, Haoran Li, Yashar Mehdad, Veselin Stoyanov, Anuj Kumar, Mike Lewis, and Sonal Gupta. 2020. Conversational Semantic Parsing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Bapna et al. (2017) Ankur Bapna, Gokhan Tür, Dilek Hakkani-Tür, and Larry Heck. 2017. Towards Zero-Shot Frame Semantic Parsing for Domain Scaling. In Proceedings of INTERSPEECH.
- Chen et al. (2020) Xilun Chen, Ashish Ghoshal, Yashar Mehdad, Luke Zettlemoyer, and Sonal Gupta. 2020. Low-Resource Domain Adaptation for Compositional Task-Oriented Semantic Parsing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Einolghozati et al. (2018) Arash Einolghozati, Panupong Pasupat, Sonal Gupta, Rushin Shah, Mrinal Mohit, Mike Lewis, and Luke Zettlemoyer. 2018. Improving Semantic Parsing for Task-Oriented Dialog. In Proceedings of the Conversational AI Workshop.
- Ghoshal et al. (2020) Asish Ghoshal, Xilun Chen, Sonal Gupta, Luke Zettlemoyer, and Yashar Mehdad. 2020. Learning Better Structured Representations using Low-Rank Adaptive Label Smoothing. In Proceedings of the International Conference on Learning Representations (ICLR).
- Gupta et al. (2018) Sonal Gupta, Rushin Shah, Mrinal Mohit, Anuj Kumar, and Mike Lewis. 2018. Semantic Parsing for Task Oriented Dialog using Hierarchical Representations. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Herzig and Berant (2019) Jonathan Herzig and Jonathan Berant. 2019. Don’t Paraphrase, Detect! Rapid and Effective Data Collectionf or Semantic Parsing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).
- Jia and Liang (2016) Robin Jia and Percy Liang. 2016. Data Recombination for Neural Semantic Parsing. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference for Learning Representations (ICLR).
- Lee and Jha (2018) Sungjin Lee and Rahul Jha. 2018. Zero-Shot Adaptive Transfer for Conversational Language Understanding. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI).
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).
- Li et al. (2020) Haoran Li, Abhinav Arora, Shuohui Chen, Anchit Gupta, Sonal Gupta, and Yashar Mehdad. 2020. MTOP: A Comprehensive Multilingual Task-Oriented Semantic Parsing Benchmark. arXiv preprint arXiv:2008.09335.
- Nichol et al. (2018) Alex Nichol, Joshua Achiam, and John Schulman. 2018. On First-Order Meta-Learning Algorithms. arXiv preprint arXiv:1803.02999.
- Ott et al. (2019) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. 2019. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. arXiv preprint arXiv:1904.01038.
- Pasupat et al. (2019) Panupong Pasupat, Sonal Gupta, Karishma Mandyam, Rushin Shah, Michael Lewis, and Luke Zettlemoyer. 2019. Span-based Hierarchical Semantic Parsing for Task-Oriented Dialog. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).
- See et al. (2017) Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get to the Point: Summarization with Pointer-Generator Networks. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).
- Shah et al. (2019) Darsh Shah, Raghav Gupta, Amir Fayazi, and Dilek Hakkani-Tur. 2019. Robust Zero-Shot Cross-Domain Slot Filling with Example Values. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NeurIPS).
- Wang et al. (2015) Yushi Wang, Jonathan Berant, and Percy Liang. 2015. Building a Semantic Parser Overnight. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).
- Yin et al. (2020) Pengcheng Yin, Graham Neubig, Wen tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).