Low-Resource Multi-Granularity Academic Function Recognition Based on Multiple Prompt Knowledge
Abstract.
[Purpose] Fine-tuning pre-trained language models (PLMs), e.g., SciBERT, generally requires large numbers of annotated data to achieve state-of-the-art performance on a range of NLP tasks in the scientific domain. However, obtaining the fine-tune data for scientific NLP tasks is still challenging and expensive. Inspired by recent advancements in prompt learning, in this paper, we propose the Mix Prompt Tuning (MPT), which is a semi-supervised method to alleviate the dependence on annotated data and improve the performance of multi-granularity academic function recognition tasks with a small number of labeled examples. [Method] Specifically, the proposed method provides multi-perspective representations by combining manual prompt templates with automatically learned continuous prompt templates to help the given academic function recognition task take full advantage of knowledge in PLMs. Based on these prompt templates and the fine-tuned PLM, a large number of pseudo labels are assigned to the unlabeled examples. Finally, we fine-tune the PLM using the pseudo training set. We evaluate our method on three academic function recognition tasks of different granularity including the citation function, the abstract sentence function, and the keyword function, with datasets from the computer science domain and the biomedical domain.
[Findings] Extensive experiments demonstrate the effectiveness of our method and statistically significant improvements against strong baselines. In particular, it achieves an average increase of 5% in Macro-F1 score compared with fine-tuning, and 6% in Macro-F1 score compared with other semi-supervised methods under low-resource settings.
[Originality/value] In addition, MPT is a general method that can be easily applied to other low-resource scientific classification tasks.111This article has been accepted by The Electronic Library and the full article is now available on Emerald Insight.
1. Introduction
With the exponential expansion of the research community and the volume of scientific publications, it becomes harder and harder to acquire knowledge timely and accurately from scientific literature. In responding to the growing problem of information overload, research and development of efficient strategies (Beltagy et al., 2019; Lu et al., 2018) and intelligent tools (Lahav et al., 2021; Yin et al., 2021) to accelerate scientific breakthroughs have attracted increasing attention from industry and academia. Behind these strategies and tools, there are various fundamental scientific NLP tasks and datasets support. Identifying the multi-granularity function of a keyword (Lu et al., 2020), a sentence (Jin and Szolovits, 2018), or a citation (Cohan et al., 2019) in the scientific paper is critical for downstream tasks, such as impact prediction (Huang et al., 2022; Qin and Zhang, 2022; Zhou and Zhang, 2020), novelty measurement (Luo et al., 2022) and emerging topic prediction (Liang et al., 2021; Huo et al., 2022).

Deep neural networks are adopted to achieve great progress in these scientific NLP tasks, but training such models requires a large mount of annotated data. In the past few years, pre-trained language models (PLMs), such as GPT (Radford et al., 2018) and BERT (Devlin et al., 2019), self-supervised trained on large-scale corpora have emerged as a powerful instrument for language understanding. It is because that PLMs can capture different levels of syntactic (Hewitt and Manning, 2019), linguistic (Jawahar et al., 2019), and semantic (Yenicelik et al., 2020) from Large-scale corpus. As a result, PLM fine-tuning has shown awesome performance on almost all important NLP tasks and becomes a common way of the NLP community instead of training models from scratch (Qiu et al., 2020). Especially in scientific domain, fine-tuning these PLMs, e.g., SciBERT (Beltagy et al., 2019) and BioBERT(Lee et al., 2020), with additional task-specific data achieves new state-of-the-art (SOTA) performances. However, obtaining the fine-tune data for scientific NLP task is still challenging and expensive. It is common in real-world scenarios that there is no annotated fine-tuning data or only a small number of annotated examples. Thus, it is necessary to explore method suitable for low-resource or few-shot scientific NLP tasks.
To address this problem, recently, scholars (Petroni et al., 2019; Radford et al., 2019; Brown et al., 2020) propose to bridge the gap of objective forms in pre-training and fine-tuning, and make full use of PLMs by reformulating tasks as fill-in-the-blanks problems, i.e., prompt learning. In this way, downstream tasks look more like those solved tasks during the original language model (LM) or mask LM training with the help of a prompt (Liu et al., 2021a). For instance, as Figure 1 shown, when recognizing the function of a sentence from a paper, “To assess the effects of a patient oriented decision aid for prioritising treatment goals in diabetes compared with usual care on patient empowerment and treatment decisions”, referring to task descriptions, we could continue with a prompt “This sentence describes the [MASK] of the paper.”, and use the pre-trained mask LM to fill the [MASK] blank with a function word, e.g., “objectives”. A series of research works based on manual prompts have achieved promising performance on few-shot sentiment classification (Schick et al., 2020), fake news detection (Jiang et al., 2022), and natural language inference (Han et al., 2021b). To ease the manual effort of suitable prompt design, some works propose to search prompt based gradient search (Shin et al., 2020; Liu et al., 2021b; Hambardzumyan et al., 2021). Furthermore, Schick and Schütze (2021) introduce a semi-supervised framework utilizing natural language prompt to annotate unlabeled data. Their method substantially outperforms unsupervised, supervised, and strong semi-supervised baselines, e.g., UDA (Xie et al., 2020) and MixText (Chen et al., 2020b). However, scientific NLP tasks, such as keyword function recognition and citation function recognition, in low-resource settings are under-explored. Moreover, it could take more effort to find the most appropriate prompt to allow the PLM to solve the scientific NLP tasks than general NLP tasks.
In this paper, we propose a semi-supervised method, named Mix Prompt Tuning (MPT), to alleviate the dependence on annotated data and improve the performance of scientific NLP tasks in low-resource settings. In addition to be able to combine the expert knowledge to design the most appropriate manual prompt template of academic function, our proposed method also adopts automatically learned soft and manually designed hard prompt templates. The hard templates are manually crafted and make use of the expert knowledge to help us understand what the task is about. The soft templates are meaningless to humans but could be informative to the PLM. These prompt templates provide multi-perspective representations to help the given academic function recognition task take full advantage of knowledge in the PLM. Following the semi-supervised training procedure of iterative pattern-exploiting training (iPET) (Schick and Schütze, 2021), based on various templates, we first fine-tune a separate PLM for each template on a small training set. Second, fine-tuned models are randomly sampled to assign pseudo soft labels to a certain number of unlabeled data. By this means, the original training dataset can be enlarged to train new generation of fine-tuned models. This step is repeated for several times to make all models learn from each other. Finally, the ultimate enlarged dataset with pseudo labels annotated by the last generation models is used to train a standard classifier in knowledge distillation manner. Evaluation is conducted with the standard classifier on the corresponding test set. Our proposed MPT, utilizing multiple prompt templates to annotate unlabeled data, is similar to iPET (Schick and Schütze, 2021). Differently, compared with this method that only adopts the manual prompt, we combine the manual prompt with automatically learned continuous prompt, which can provide multi-perspective representations and take full advantage of knowledge in the PLM and unlabeled data.
To the best of our knowledge, this is the first study to introduce prompt learning with mixing multiple types of prompt templates for scientific classification tasks in a more practical scenario, i.e., low-resource or few-shot settings. We conduct extensive experiments on a suite of different granularity academic function recognition tasks, including word function recognition, structure function recognition, and citation function recognition, to demonstrate the effectiveness of our method and statistically significant improvements against strong unsupervised, supervised, and semi-supervised baselines.
To summarize, our contributions are mainly as follows:
-
(1)
We propose a semi-supervised solution to alleviate the dependence on annotated data and improve the performance of scientific classification tasks in low-resource settings.
-
(2)
We combine the manual prompt with automatically learned continuous prompt to provide multi-perspective representations and take full advantage of knowledge in the PLM.
-
(3)
We perform extensive experiments on a suite of different granularity academic function recognition tasks to demonstrate the effectiveness of our method and statistically significant improvements against strong baselines.
This article is organized as follows: the related work presents an brief literature review; the method section describes the semi-supervised hybrid prompt learning method for academic function recognition; the experiments section describes the tasks, datasets, experimental settings; the results and analysis section provide insight of the experimental results; the conclusion section concludes this work and points out the direction of future work.
2. Related work
2.1. Academic function recognition
In this paper, we mainly focus on three levels of academic function recognition tasks, which are the citation function recognition, the sentence function recognition and the keyword function recognition.
Citation function: Numerous previous studies have introduced citation classification schemes (Teufel et al., 2006; Jurgens et al., 2016; Cohan et al., 2019; Pride and Knoth, 2020) as a way to identify the meaning or purpose of a specific citation. Note that for terminological consistency, we refer to the “citation classification” and the “citation intent classification” as the “citation function recognition”. Jurgens et al. (2016) and Cohan et al. (2019) adopt ML based and DL based methods to recognition the citation function, respectively. Furthermore, Yu et al. (2020) propose a interactive hierarchical attention model with aggregating the heterogeneous contexts to recognize the intention of citing behaviors and retweeting behaviors. Similarly, Beltagy et al. (2019) also fine-tune the SciBERT to recognize the citation function achieve SOTA performance.
Structure function: Structure function recognition tasks for scientific publications mainly concentrate on the abstract sentence function recognition and body sentence structural function recognition. For abstract sentence function, previous studies are mainly based on machine learning (ML) methods (Ruch et al., 2007; Hassanzadeh et al., 2014; Liu et al., 2013) and deep learning (DL) methods (Lui, 2012; Dernoncourt et al., 2016). Recently, SciBERT (Beltagy et al., 2019) is also adopted to directly classify the sentence function and achieve competitive performance. In terms of body sentence structural function recognition, there are also a series of works based on ML (Huang et al., 2016a, b; Lu et al., 2018) and DL (Qin and Zhang, 2020; Wang et al., 2020) based methods. Moreover, scholars also consider the context semantics and structural relation of surrounding sentences (Jin and Szolovits, 2018; Wang et al., 2019) to boost the sentence function recognition performance.
Keyword function: Kondo et al. (2009) were first to conduct research on automatic recognition of lexical semantic functions. They utilize conditional random filed (CRF) to divide the words in the academic title into four labels of “domain”, “problem”, “method”, and “others”. Nanba et al. (2010) adopt support vector machine (SVM) to recognize the “technology” and “effect” word in academic and patent literature. Cheng et al. (2021) use recurrent neural network (RNN) based sequence-to-sequence model to obtain the problem and method words in academic texts. Lu et al. (2020) and Zhang et al. (2021) utilize BERT-based model to classify the problem and method semantic function carried by the keywords in academic literature.
However, above mentioned ML, DL, and even PLMs based methods require a large number of annotated data to achieve competitive performance.
2.2. Low-Resource text classification
Since obtaining the training datasets for these tasks are challenging and expensive, it is important to develop systems that perform decent in low-resource settings, where few labeled examples are available. Intuitively, we can adopt NLP techniques to increase the amount of training data, i.e., data augmentation, including synonym replacement, random insertion, random swap, random deletion (Wei and Zou, 2019), paraphrasing formulation, and back translation (Chen et al., 2020a, b; Xie et al., 2020). Another typical way, widely adopted in computer vision and general NLP tasks, is to design meta-learning paradigm that can learn and adapt to new environments rapidly with a few training examples (Bao et al., 2019; Yao et al., 2021; Sun et al., 2021; Zhang et al., 2022a). These methods usually train a meta-learner that extracts knowledge from various related sub-tasks during meta-training and leverages the knowledge to learn new tasks during meta-testing quickly. Considering that the function of academic publication is already relatively well-defined, there is no need to identify new function category. In this paper, we mainly adopt the data augmentation based methods as target baselines.
2.3. Prompt learning
Fine-tuning the PLMs is a conventional approach to leverage the rich knowledge during pre-training and has achieved satisfying results on supervised tasks (Devlin et al., 2019; Han et al., 2021a). However, tuning the extra classifier requires adequate training examples to achieve decent performance, it is still challenging to apply fine-tuning in low-resource settings, including few-shot and zero-shot learning scenarios (Brown et al., 2020; Yin et al., 2019). Recently, a series of studies (Petroni et al., 2019; Schick and Schütze, 2021; Liu et al., 2021b; Jiang et al., 2022) using prompts to bridge the gap of objective forms in pre-training and fine-tuning and make full use of PLMs. Manual prompts have achieved promising performance in low-resource sentiment classification and natural language inference (Schick et al., 2020; Han et al., 2021b). A typical prompt consists of two parts: a template and a set of label words, i.e., verbalizer. Zhou et al. (2022) propose a data augmentation method that combines prompting method with generating label-flipped data. To ease the manual effort of suitable prompt design, automatic prompt search has been extensively explored. Shin et al. (2020) explore gradient-guided search to generate both templates and label words. Gao et al. (2021) utilize sequence-to-sequence models to generate prompt candidates. These auto-generated hard prompts cannot achieve competitive performance compared with manual prompts (Han et al., 2021b). Thus, a series of research works on soft prompts have been proposed, which directly use learnable continuous embeddings as prompt templates and work well on those large-scale PLMs (Li and Liang, 2021; Qin and Eisner, 2021; Lester et al., 2021). Since the function of academic literature is relatively well-defined and does not require diversification, verbalizer mining methods (Hu et al., 2021; Schick et al., 2020; Cui et al., 2022) are not considered in this paper. We manual adopt the function labels and their related words as the verbalizer of prompts. This process does not require much human effort. Moreover, we propose to combine the manual prompt with automatically learned continuous prompt which provides multi-perspective representations and takes full advantage of knowledge in the PLM.
3. Task formulation and Datasets
3.1. Task formulation
Our research objective is to use the text data of a scientific publication to recognize multi-granularity academic functions, e.g., the academic function of a citation, a abstract sentence, or a keyword. Formally, an academic function recognition training dataset can be denoted as , where is the instance set and is the academic function label set. Each instance consists of several tokens along with a class label . The common approach is to train a model on the dataset . Whereas in real-world scenarios, annotated data for scientific NLP tasks are usually scarce. For instance, each class has only a few dozen or even about 10 labeled instances. Suppose there is a set of unlabeled instances , is typically much larger than the number of training instances . In this study, we explore an effective method to recognize multi-granularity academic function in low-resource settings.
3.2. Tasks and Corresponding Datasets
To illustrate the effectiveness of MPT, we conduct extensive experiments on the following academic function recognition tasks of different granularities: (1) Citation Function Recognition; (2) Abstract Sentence Function Recognition; (3) Keyword Function Recognition.
Citation Function Recognition. We carry out our experiment on a citation function recognition dataset, the SciCite (Cohan et al., 2019), which is more than five times larger and covers multiple scientific domains compared with the ACL-ARC (Jurgens et al., 2016) dataset. Specifically, there are 11,020 instances in the dataset extracted from 6,627 papers in the Computer Science domain and Medicine. Since they utilize a concise annotation scheme, only three types of function labels, i.e., “Background”, “Method”, and “Result comparison”, are assigned.
Structure Function Recognition. We evaluate our method on the medical scientific abstracts benchmark dataset PubMed RCT 20k (Dernoncourt and Lee, 2017) for abstract sentence function recognition, where each sentence of the abstract is annotated with one label associated with the rhetorical structural (“Background”, “Objective”, “Method”, “Result”, and “Conclusion”).
Keyword Function Recognition. We conduct experiments of keyword function recognition task on PMO-kw dataset, which is a Chinese dataset proposed by Zhang et al. (2021) in computer science domain. PMO-kw contains 310,214 keywords extracted from 100,025 papers. Each keyword is annotated with one label associated with the domain-independent keyword semantic functions (“Problem”, “Method”, and “Others”).
| Dataset | Language | Target | Domain | #Test | |
| SciCite | English | Citation Function | CS&MED | 3 | 1,861 |
| RCT-20k | English | Structure Function | MED | 5 | 30,135 |
| PMO-kw | Chinese | Keyword Function | CS | 3 | 800 |
A summary of statistics of these tasks and datasets are shown in Table 1.
4. Methodology
4.1. Preliminaries
Before introducing our proposed Mix Prompt Tuning, we first give some essential preliminaries about prompt tuning for academic function recognition tasks.
Fine-tuning. Let be a language model (PLM) pre-trained on large scale corpora. Previous works adopting the PLM to recognize the academic function mainly utilized the further pre-training and fine-tuning paradigms. Gururangan et al. (2020) find that the PLM could perform better by applying the self-supervised pre-training on the target domain corpus. For the fine-tuning paradigm, the instance is firstly converted to the sequence [CLS] [SEP] by adding special tokens, [CLS] and [SEP], into it. Then is used to encode the converted sequence into contextualized vectors . The mainstream methods all adopt the contextualized hidden state vector of as the representation of the whole input sequence. Then a dense layer with learnable parameters and is utilized to estimate the probability distribution of the instance with a softmax function:
| (1) |
, where . The parameters of , , and are tuned to minimize the loss .
Prompt-tuning. As mentioned above, fine-tuning requires learning extra classifiers on top of the PLM under different classification objectives, which needs more annotated data and makes the model hard to generalize well. Recently, a series of works (Radford et al., 2019; Petroni et al., 2019; Brown et al., 2020) in general text classification tasks use prompt learning to bridge the gap between pre-training and downstream tasks, which make full use of PLMs by reformulating tasks as cloze-style objectives.
Formally, a prompt consists of a template , label words , and a verbalizer . For each instance , the template is leveraged to map to the prompt input , which is named as template wrapping. The template defines the location and number of added additional tokens. Taking the abstract sentence function recognition task as an example, we set the template “ This sentence describes the [MASK] of the paper.”, and map to “ This sentence describes the [MASK] of the paper.”. At least one [MASK] is inserted into for the PLM to fill the label words, while keeping the original tokens of .
After the template wrapping, we can obtain the hidden vector of the [MASK] from by encoding . Then we can utilize to produce a probability distribution that reflects which tokens of are suitable for replacing the [MASK] token:
| (2) |
where is the embedding of the token in .

In prompt learning, there is a verbalizer as an injective mapping function that maps task labels to label words . For instance, we set and . According to whether predicts “literature” or “uses”, we can know the function of the instance is “background” or “method”. Note that for academic function recognition tasks, there may be a set of label token that correspond to a particular label . For instance, “tool”, “approach”, and “method” all indicate the “method” function in the citation function recognition task. Thus, the probability distribution of the [MASK] over can obtained by . The parameters of are tuned to minimize the loss :
| (3) |
4.2. Mix Prompt Tuning (MPT)
So far, we have shown how to reformulate an academic function recognition task as a language modeling task using prompts. Here, we propose the Mix Prompt Tuning (MPT) base on iPET (Schick and Schütze, 2021) framework. The proposed semi-supervised method can not only combine the expert knowledge to design the appropriate manual prompt templates of academic function, but also adopt automatically learned soft continuous prompt and manually designed hard prompt templates. In this way, manually designed templates can improve the performance lower bound and maintain the performance stability. Moreover, automatically learned soft continuous prompt might elicit more knowledge using “model’s language” to improve the performance upper bound. As for the verbalizer , since each class in an academic function recognition task is clearly defined, in this paper, we utilize the same one verbalizer for all of the templates in one task.
Suppose we have a set of unlabeled instances , which is typically larger than the instance number of training set . First, we define a set of templates, which contains learnable soft continuous prompt templates, i.e., Prompt 3 and Prompt 4 in Figure 2, and manual designed fixed hard prompt templates, i.e., Prompt 1 and Prompt 2 in Figure 2. Then we fine-tune the PLM based on one prompt template and the fixed verbalizer in the prompt tuning manner. With the original training instances and the unlabeled instances , multiple PLMs tuned on prompt set can produce pseudo labeled training set by:
| (4) |
where and denotes the weight of template . The pseudo labeled training set is finally utilized to train a classifier.
Since there is high probability that PLMs tuned on some prompt templates perform worse than PLMs tuned on other prompt templates, to force them learn from each other, we further train several generations of models using unlabeled dataset and knowledge distillation strategy. Specifically, we formally denote the first generation PLMs tuned on as , where is tuned with template and verbalizer . After generations training, we can get models , where and is trained with on training dataset . Note that we need to keep the proportion of classes in the dataset constant to avoid learning a biased distribution with iteration. Thus, we expand the size of the labeled dataset by a constant factor , i.e., , where denotes the count of instances with label in generation using template set .
To obtain the training dataset , we randomly sample models from previous generation tuned PLMs except , where . With the subset models , the unlabeled data can be annotated by formula 4 to construct a labeled dataset :
| (5) |
Inspired by the findings (Guo et al., 2017) that instances predicted with high confidence are typically more likely to be classified correctly. As a result, we sample the instances with high probability score of the labels to avoid training next generation model on mislabeled data and improve the performance lower bound. Formally, for class , is constructed by choosing the top scores of label instances from . , the training dataset is composed of the initial training set and even sampled pseudo labeled training set , i.e., . The final enlarged dataset , annotated by the last generation models , is adopted to train a classifier.
As may not contain enough instances for a class under the extremely unbalanced label distribution, we obtain all by choosing the highest instances.
4.3. Designing Template and Verbalizer
| Task | Prompt Template | Verbalizer |
| All | = . ¡Soft¿ ¡Soft¿ [MASK] | - |
| = . ¡Soft¿ ¡Soft¿ ¡Soft¿ [MASK] | ||
| Citation Function | = ¡Task Description¿ . Citation Function: [MASK] | Background: [background, literature] Method: [method, approach] Result: [result] |
| = ¡Task Description¿ . The function of this citation is [MASK] | ||
| = . The function of this citation is [MASK] | ||
| = . Citation Function: [MASK] | ||
| Structure Function | = ¡Task Description¿ . Structure Function: [MASK] | Background: [background] Objective: [objective] Methods: [methods] Results: [results] Conclusions: [conclusions] |
| = ¡Task Description¿ . The structure function of this sentence is [MASK] | ||
| = . The Structure function of this sentence is [MASK] | ||
| = . Structure Function: [MASK] | ||
| Keyword Function | = ¡MASK¿ is the function of in ¡Abstract¿. ¡Title¿. ¡Task Description¿ | Method: [method, algorithm, technology] Problem: [problem, target, orientation] Others: [data, metric, tool] |
| = Keyword function: ¡MASK¿. in ¡Abstract¿. ¡Title¿. ¡Task Description¿ | ||
| = ¡MASK¿ is the function of in ¡Abstract¿. | ||
| = Keyword function: ¡MASK¿. in ¡Abstract¿. |
We now describe the templates and verbalizers adopted for each task. For all tasks, we add two or three soft learnable continuous tokens between the instance content and the [MASK] as soft prompt templates. Moreover, we manually design four hard templates for each task by combing the domain knowledge. Two of these manually designed hard templates are added with the task description. Specifically, for citation function recognition, we adopt “Citation function identifies the meaning or purpose behind a particular citation.” (Pride and Knoth, 2020) as the description and add it at the beginning of and . For structure function recognition, we adopt “An abstract is divided into semantic headings such as background, objective, method, result, and conclusion.” (Dernoncourt et al., 2016). For keyword function recognition, we adopt “The functions carried by the keywords in the literature are problem, method and others (in Chinese).” (Lu et al., 2020). Since each class in an academic function recognition is clearly defined and does not require diversification, we construct the verbalizer of labels with respect to a class according to the class definition or description that reflect the expert knowledge. This process does not require much human effort. More details of prompt templates and verbalizers for all tasks are shown in Table 2.
5. Experiments
Scientific NLP tasks are considered difficult not only because of the task itself, but also because of data scarcity. For many scientific NLP tasks, since task-specific annotations are difficult to obtain, we only have access to a limited amount of annotated data. Therefore, following previous low-resource work in other domains (Xie et al., 2020; Chen et al., 2020b; Schick and Schütze, 2021), we used only 4 to 128 samples per class to construct low-resource scenarios to further increase the difficulty and align with real-world practical situations.
5.1. Baselines
To test the effectiveness of our method, we compare it with several types of recent models:
Supervised baselines. We compare several fine-tuning and prompt-tuning baselines in supervised manner, which have been proved the effectiveness on general text classification tasks in low-resource setting.
Fine-tuning. As PLMs have achieved promising results on various NLP tasks, a lot of efforts have been devoted to fine-tuning PLMs for text classification as well. In this paper, we select (1) BERT (Devlin et al., 2019), (2) RoBERTa (Liu et al., 2019), and (3) SciBERT (Beltagy et al., 2019) as the representative fine-tuning baselines. For fair comparison, we choose the base version of these models, e.g., BERT-base-uncased.
Prompt-tuning. We apply the regular prompt-tuning paradigm (described in subsection 4.1) with the hard and soft prompt templates (shown in Table 2) to form the (4) PT-hard and (5) PT-soft models, respectively. Since there are multiple templates, we tune the PLM with different prompt templates and report the best performance.
Semi-supervised and data augmentation baselines. Semi-supervised learning has been widely used in different NLP tasks combining with massive amount of unlabeled data to improve the model performance, as unlabeled data is often plentiful compared to labeled data. In this paper, we adopt five classic or previous SOTA methods for semi-supervised learning in NLP that rely on data augmentation: (6) Unsupervised Data Augmentation (UDA) (Xie et al., 2020) connects data augmentation with semi-supervised learning and outperforms previous SOTA. It employs back translation and TF-IDF to generate diverse and realistic noise and enforces the model to be consistent with respect to these noise. (7) TMix (Chen et al., 2020b) proposes to create virtual training samples by apply linear interpolations within hidden space, produced by PLMs, as a data augmentation method for text. (8) MixText (Chen et al., 2020b) leverages TMix both on labeled and unlabeled data for semi-supervised learning. The authors propose the label guessing method to generate labels for the unlabeled data in the training process. (9) PET (Schick and Schütze, 2021) is a semi-supervised training procedure that reformulates input examples as cloze-style phrases by prompt templates and verbalizers to help leverage the knowledge contained in PLMs. Along with PLMs, these well-designed templates are used to assign soft labels to unlabeled examples. A standard classifier is trained based on the original labeled data and soft labeled data. (10) iPET (Schick and Schütze, 2021) is the iterative variant of PET. It trains several generations of models using PET manner on datasets of increasing size so that classifiers can learn from each other. We adjust the open-sourced implementations of UDA 222https://github.com/SanghunYun/UDA_pytorch, TMix, MixText333https://github.com/GT-SALT/MixText, PET, and iPET444https://github.com/timoschick/pet to conduct academic function recognition tasks on corresponding datasets.
5.2. Experimental Settings
Since label distributions of academic function recognition datasets are imbalanced, we conduct comparative experiments on balanced and imbalanced label distributions under the low-resource setting. Previous baselines, such as MixText and PET, only conduct the experiments on balanced sampled training set. Moreover, taking the unlabeled dataset of MixText as an example, it is unrealistic and impractical that the unlabeled dataset is carefully selected and balanced sampled. Thus, to conduct the experiments on balanced label distribution, we randomly sample instances in each class from the training set and test the model on the entire test set. Whereas, for the experiments on imbalanced label distribution, i.e., original label distribution, we randomly sample the same number of training instances () with the experiments on balanced label distribution by keeping the original label distribution. For all datasets, we use the macro F1 score and the Accuracy.
All our models and baselines are implemented with PyTorch framework (Paszke et al., 2019) and Huggingface transformers (Wolf et al., 2020). All of the models related to prompt learning are also implemented with the Open-Prompt toolkit (Ding et al., 2021). We fine-tune the PLMs with the AdamW optimizer (Loshchilov and Hutter, 2018). Previous study (Gao et al., 2021) find that, with a large validation set, a model could learn more knowledge and hyperparameters could also be optimized. Different from the experimental settings of Xie et al. (2020) and Chen et al. (2020b) that adopt large validation sets to optimize the hyperparameters, to keep the initial goal of learning from limited data, we assume that there is no access to a large validation set and the size of validation set is the same as training set. For citation function recognition task and structure function recognition task, we use SciBERT (Beltagy et al., 2019) as our PLM backbone. Whereas for keyword function recognition task, since there is only Chinese dataset, we use bert-base-multilingual-cased555https://huggingface.co/bert-base-multilingual-cased as our PLM backbone. We use a learning rate of , a batch size of 16, a maximum sequence length of 128 for citation function recognition and structure function recognition, and a maximum sequence length of 256 for keyword function recognition. Same with the PET framework, we set and . For the comparative experiment of semi-supervised methods, the number of unlabeled instances is selected from . We tune the entire model for 6 epochs under 3 different random seeds and report the best test performance.
5.3. Main Results
In this subsection, we introduce the specific comparative results and provide possible insights of our proposed MPT under two settings, i.e., balanced sample instances (-shot) in each class and randomly sample instances from the original training set.
5.3.1. Balanced sample few-shot
Few-shot supervised methods. The experimental results of comparisons with supervised base model under balanced label distribution are shown in Table 3. We can observe that:
| # Balanced | Method | RCT-20k | SciCite | PMO-kw | |||
| Accuracy | Macro F1 | Accuracy | Macro F1 | Accuracy | Macro F1 | ||
| 4 | BERT | 39.10 | 31.62 | 23.05 | 18.88 | 25.38 | 9.97 |
| RoBERTa | 31.34 | 23.68 | 43.20 | 36.04 | 38.13 | 28.74 | |
| SciBERT | 66.12 | 58.96 | 51.37 | 51.03 | 35.13 | 33.81 | |
| PT-soft | 38.95 | 31.95 | 33.96 | 27.16 | 33.50 | 28.68 | |
| PT-hard | 35.03 | 30.97 | 45.73 | 29.68 | 30.00 | 19.10 | |
| MPT | 78.82 | 73.34 | 82.91 | 78.69 | 46.37 | 46.32 | |
| 8 | BERT | 57.60 | 51.63 | 46.96 | 41.41 | 44.00 | 26.15 |
| RoBERTa | 32.83 | 24.21 | 41.05 | 35.17 | 39.00 | 33.87 | |
| SciBERT | 69.76 | 63.12 | 63.30 | 62.34 | 38.63 | 38.18 | |
| PT-soft | 57.36 | 49.39 | 36.33 | 28.39 | 50.13 | 50.11 | |
| PT-hard | 54.32 | 48.64 | 60.25 | 50.02 | 39.88 | 30.60 | |
| MPT | 81.19 | 75.76 | 83.93 | 82.40 | 55.50 | 55.11 | |
| 16 | BERT | 61.39 | 56.16 | 64.32 | 56.82 | 30.00 | 28.14 |
| RoBERTa | 42.96 | 39.95 | 41.00 | 39.50 | 35.75 | 33.96 | |
| SciBERT | 66.30 | 60.40 | 75.50 | 74.02 | 34.50 | 31.49 | |
| PT-soft | 70.31 | 63.03 | 82.43 | 80.50 | 64.75 | 64.73 | |
| PT-hard | 69.79 | 63.27 | 70.67 | 62.81 | 48.63 | 45.97 | |
| MPT | 82.17 | 76.48 | 86.57 | 84.32 | 71.25 | 71.08 | |
| 32 | BERT | 68.67 | 62.59 | 77.43 | 74.81 | 47.00 | 46.96 |
| RoBERTa | 61.08 | 52.58 | 76.25 | 73.53 | 39.50 | 37.00 | |
| SciBERT | 74.81 | 68.06 | 81.03 | 79.65 | 51.63 | 51.04 | |
| PT-soft | 75.22 | 69.24 | 85.65 | 84.14 | 73.75 | 72.70 | |
| PT-hard | 72.43 | 66.57 | 76.21 | 69.12 | 68.63 | 68.52 | |
| MPT | 81.94 | 76.23 | 83.02 | 81.27 | 78.25 | 78.35 | |
| 64 | BERT | 73.59 | 67.94 | 79.21 | 76.77 | 72.50 | 71.70 |
| RoBERTa | 72.58 | 66.08 | 78.02 | 76.06 | 47.38 | 45.62 | |
| SciBERT | 77.57 | 70.03 | 84.42 | 82.87 | 83.63 | 83.31 | |
| PT-soft | 75.97 | 70.58 | 86.51 | 84.86 | 83.63 | 83.69 | |
| PT-hard | 79.76 | 73.54 | 78.95 | 71.82 | 82.50 | 82.44 | |
| MPT | 83.34 | 77.45 | 84.52 | 82.55 | 85.37 | 85.34 | |
| 128 | BERT | 76.91 | 70.73 | 83.24 | 81.16 | 82.00 | 81.46 |
| RoBERTa | 73.59 | 67.54 | 82.27 | 80.16 | 82.63 | 82.54 | |
| SciBERT | 80.84 | 75.00 | 84.58 | 82.98 | 86.63 | 86.44 | |
| PT-soft | 79.72 | 73.34 | 86.57 | 85.20 | 90.13 | 89.82 | |
| PT-hard | 79.63 | 73.81 | 81.00 | 75.20 | 87.88 | 87.55 | |
| MPT | 82.44 | 76.49 | 84.58 | 82.99 | 90.25 | 90.01 | |
(1) Domain pre-trained model, i.e., SciBERT, achieves better overall performance than other models pre-trained on non-scientific-corpus, even though these non-scientific-corpus are much larger than the pre-trained corpus of SciBERT (approximately 13GB of SciBERT vs. 160GB of RoBERTa). It indicates that the performance gains are from scientific-domain data, which may also contribute to the performance improvement of prompt-learning based method. We will further discuss it in the following Section 6.
| # Balanced | Method | RCT-20k | SciCite | PMO-kw | |||
| Accuracy | Macro F1 | Accuracy | Macro F1 | Accuracy | Macro F1 | ||
| 4 | TMix | 37.35 | 34.32 | 36.38 | 34.89 | 36.50 | 35.69 |
| UDA | 57.89 | 47.88 | 54.55 | 52.38 | 27.27 | 14.29 | |
| MixText | 36.86 | 35.72 | 39.66 | 36.77 | 36.88 | 35.85 | |
| PET | 74.18 | 68.51 | 42.34 | 42.02 | 38.63 | 38.48 | |
| iPET | 78.87 | 72.73 | 62.76 | 62.00 | 46.38 | 46.45 | |
| MPT | 78.82 | 73.34 | 82.91 | 78.69 | 46.37 | 46.32 | |
| 8 | TMix | 44.74 | 39.28 | 44.49 | 42.50 | 38.38 | 34.36 |
| UDA | 69.23 | 69.88 | 78.26 | 78.24 | 39.13 | 31.28 | |
| MixText | 51.71 | 47.70 | 54.43 | 45.06 | 39.50 | 35.71 | |
| PET | 79.56 | 73.79 | 53.73 | 54.68 | 47.63 | 47.79 | |
| iPET | 79.80 | 74.00 | 68.51 | 67.01 | 46.75 | 46.80 | |
| MPT | 81.19 | 75.76 | 83.93 | 82.40 | 55.50 | 55.11 | |
| 16 | TMix | 55.47 | 49.94 | 59.81 | 52.26 | 41.38 | 33.42 |
| UDA | 77.22 | 77.49 | 74.47 | 72.78 | 29.79 | 27.78 | |
| MixText | 55.80 | 50.05 | 69.59 | 64.90 | 43.13 | 34.83 | |
| PET | 80.32 | 74.63 | 72.17 | 70.81 | 48.50 | 48.09 | |
| iPET | 77.58 | 71.86 | 76.09 | 74.50 | 46.25 | 46.17 | |
| MPT | 82.17 | 76.48 | 86.57 | 84.32 | 71.25 | 71.08 | |
| 32 | TMix | 58.01 | 52.89 | 71.57 | 68.05 | 40.50 | 37.78 |
| UDA | 77.99 | 77.67 | 74.74 | 74.76 | 32.63 | 32.22 | |
| MixText | 64.83 | 60.91 | 77.86 | 75.68 | 38.13 | 36.44 | |
| PET | 80.15 | 74.00 | 76.30 | 74.94 | 57.00 | 56.52 | |
| iPET | 78.22 | 71.92 | 78.24 | 76.71 | 53.38 | 52.94 | |
| MPT | 81.94 | 76.23 | 83.02 | 81.27 | 78.25 | 78.35 | |
| 64 | TMix | 76.72 | 69.67 | 74.85 | 72.25 | 40.38 | 36.72 |
| UDA | 77.43 | 77.45 | 81.15 | 80.92 | 37.70 | 37.70 | |
| MixText | 77.83 | 71.59 | 80.44 | 77.77 | 42.00 | 39.47 | |
| PET | 81.75 | 75.55 | 79.80 | 78.16 | 66.13 | 65.91 | |
| iPET | 80.92 | 74.37 | 80.06 | 78.40 | 63.00 | 62.65 | |
| MPT | 83.34 | 77.45 | 84.52 | 82.55 | 85.37 | 85.34 | |
| 128 | TMix | 78.00 | 71.69 | 80.71 | 78.90 | 52.38 | 51.97 |
| UDA | 75.59 | 75.53 | 79.63 | 79.22 | 41.78 | 41.45 | |
| MixText | 77.28 | 71.89 | 83.13 | 81.03 | 50.25 | 50.34 | |
| PET | 81.99 | 75.82 | 81.52 | 79.64 | 65.63 | 65.52 | |
| iPET | 81.72 | 75.53 | 82.70 | 80.94 | 64.63 | 64.57 | |
| MPT | 82.44 | 76.49 | 84.58 | 82.99 | 90.25 | 90.01 | |
(2) As the labeled data increases, prompt-tuning based methods gradually perform better than fine-tuning based methods. Moreover, prompt-tuning based methods also show greater performance gains than fine-tuning based methods. For instance, PT-soft performs better than other PLM based fine-tuning models when on RCT-20k, SciCite, and PMO-kw. This indicates that prompt-tuning based method can effectively stimulate the ability of the PLM and make full use of the scientific knowledge containing in pre-train corpus.
(3) The proposed method performs much better than the fully supervised baselines. Besides the contribution of SciBERT or multilingual backbone, MPT makes full use of the additional unlabeled data with the help of interactive learning from multiple PLMs and pre-train scientific knowledge stimulated by the prompt templates.
(4) With the sampling number increases, all of the recognition performance gradually improves. Moreover, MPT performs significantly higher than the baseline models in most of settings and datasets. For instance, for the PMO-kw dataset, MPT achieves 46.32% Macro F1 score when , which is significantly better than most of baselines. When increases to 32, PT-soft achieves 72.7%. The performance is nearly doubled, but it still cannot surpass MPT, which achieves a significantly better performance of 78.35%.
Few-shot semi-supervised methods. We also demonstrate the comparative experimental results of with semi-supervised baselines under balanced label distribution (few-shot setting) are shown in Table 4. We can observe that:
(1) Overall, semi-supervised methods perform better than fine-tuning based methods. It is because semi-supervised methods utilize back-translation or prompt-tuning to introduce more knowledge into the training phase. Back-translation is a data augmentation method that generates different instances integrated with language diversity and model knowledge. Back-translation based methods shows the superiority under extreme few training instances. However, with the sampling number increases, fine-tuning based methods performs better than back-translation based methods gradually. By analyzing the translation instances, it is found that there are many samples with poor translation quality, which introduces noise and affect the model performance as the number increases.
(2) Prompt-based semi-supervised methods performs better than other semi-supervised methods. In general, PET, iPET, and our proposed MPT performs better than other back-translation based semi-supervised methods in all -shot settings. The performance of back-translation based methods are highly relevant to the translation quality. Compared with prompt-tuning based methods, back-translation based methods cannot stimulate the knowledge of language models directly and effectively.
(3) MPT shows the superiority over other baseline methods under low-resource settings on three datasets. With the same contribution of SciBERT or multilingual BERT, it demonstrates the effectiveness of MPT, which make full use of soft and hard prompt templates to obtain pseudo labels from unlabeled data and force multiple PLMs learn from each other interactively.
5.3.2. Randomly sample instances
Since previous comparative experiments are under few-shot settings that balanced sample instances from the original training set, we also conduct extensive experiments to evaluate the performance of different methods with the original class distribution. Overall, there is some degree of improvement or degradation in the performance of different models. For instance, for the SciCite dataset, MPT trained with few-shot settings performs better than the MPT trained with random samples when data resources are extremely scarce. However, with the growth of data volume, MPT trained with random samples shows a better performance upper boundary, compared to MPT trained with few-shot settings. It is because that models have more opportunity to see the samples of scarce categories in the balanced label distribution of few-shot setting. In the case where the amount of data is not extremely scarce, the consistency between the training distribution and the original distribution will largely affect the performance upper bound. Despite this, Table 5 and Table 6 show that MPT substantially outperforms most of the baselines across all tasks for different training sizes.
| # Examples | Method | RCT-20k | SciCite | PMO-kw | |||
| Accuracy | Macro F1 | Accuracy | Macro F1 | Accuracy | Macro F1 | ||
| —D—=4* | BERT | 45.01 | 29.63 | 54.00 | 37.58 | 30.63 | 17.54 |
| RoBERTa | 32.84 | 9.89 | 13.92 | 8.15 | 40.00 | 27.77 | |
| SciBERT | 58.37 | 39.04 | 67.28 | 50.87 | 41.25 | 28.80 | |
| PT-soft | 48.01 | 36.30 | 60.18 | 39.87 | 27.25 | 24.28 | |
| PT-hard | 34.94 | 17.03 | 52.82 | 25.89 | 42.38 | 31.39 | |
| MPT | 69.97 | 50.78 | 64.59 | 42.74 | 45.00 | 42.11 | |
| —D—=8* | BERT | 57.82 | 38.65 | 42.83 | 33.61 | 33.88 | 29.28 |
| RoBERTa | 33.02 | 17.80 | 36.49 | 28.90 | 35.88 | 29.66 | |
| SciBERT | 68.07 | 50.81 | 64.97 | 51.62 | 34.88 | 30.88 | |
| PT-soft | 53.43 | 40.56 | 59.81 | 40.69 | 46.25 | 38.39 | |
| PT-hard | 73.37 | 66.29 | 53.04 | 25.79 | 45.63 | 33.38 | |
| MPT | 76.41 | 64.44 | 77.32 | 55.77 | 58.87 | 57.45 | |
| —D—=16* | BERT | 64.56 | 56.04 | 53.57 | 36.19 | 27.50 | 17.47 |
| RoBERTa | 51.95 | 36.01 | 48.25 | 37.83 | 39.38 | 34.62 | |
| SciBERT | 72.96 | 60.79 | 78.13 | 73.61 | 32.38 | 30.83 | |
| PT-soft | 67.43 | 60.29 | 78.67 | 75.34 | 65.75 | 64.31 | |
| PT-hard | 71.91 | 64.21 | 83.34 | 79.13 | 50.13 | 45.31 | |
| MPT | 82.43 | 75.32 | 84.09 | 78.91 | 68.37 | 66.50 | |
| —D—=32* | BERT | 70.46 | 59.87 | 70.50 | 56.45 | 41.00 | 34.05 |
| RoBERTa | 70.51 | 61.85 | 50.94 | 30.90 | 38.38 | 32.35 | |
| SciBERT | 80.95 | 72.86 | 80.12 | 75.03 | 59.63 | 57.34 | |
| PT-soft | 75.07 | 68.51 | 82.27 | 78.42 | 75.88 | 73.76 | |
| PT-hard | 76.30 | 70.23 | 85.22 | 83.05 | 74.38 | 71.93 | |
| MPT | 82.89 | 74.73 | 87.91 | 86.55 | 73.00 | 72.78 | |
| —D—=64* | BERT | 75.50 | 66.22 | 80.06 | 76.51 | 58.00 | 56.17 |
| RoBERTa | 76.32 | 69.63 | 83.72 | 81.85 | 39.13 | 38.76 | |
| SciBERT | 81.27 | 73.81 | 86.19 | 84.75 | 66.13 | 66.18 | |
| PT-soft | 79.69 | 73.04 | 84.26 | 82.55 | 81.38 | 80.96 | |
| PT-hard | 77.79 | 70.56 | 85.65 | 84.24 | 84.50 | 84.39 | |
| MPT | 83.71 | 75.43 | 88.18 | 86.90 | 85.62 | 85.56 | |
| —D—=128* | BERT | 77.58 | 69.84 | 83.40 | 80.62 | 78.00 | 77.15 |
| RoBERTa | 78.30 | 71.37 | 83.61 | 81.10 | 77.63 | 77.29 | |
| SciBERT | 82.54 | 75.71 | 83.02 | 80.73 | 84.25 | 84.03 | |
| PT-soft | 81.46 | 81.53 | 85.28 | 83.25 | 88.50 | 88.28 | |
| PT-hard | 80.02 | 73.57 | 86.14 | 84.90 | 88.75 | 88.48 | |
| MPT | 83.79 | 77.89 | 88.93 | 87.82 | 90.38 | 90.40 | |
| # Examples | Method | RCT-20k | SciCite | PMO-kw | |||
| Accuracy | Macro F1 | Accuracy | Macro F1 | Accuracy | Macro F1 | ||
| —D—=4* | TMix | 20.31 | 14.40 | 36.43 | 31.78 | 35.13 | 34.39 |
| UDA | 32.37 | 27.51 | 52.09 | 45.36 | 36.36 | 17.78 | |
| MixText | 16.42 | 12.25 | 39.23 | 32.07 | 40.25 | 30.34 | |
| PET | 63.68 | 41.42 | 61.58 | 38.72 | 45.75 | 23.78 | |
| iPET | 59.23 | 38.78 | 61.15 | 41.78 | 42.13 | 37.79 | |
| MPT | 73.14 | 55.04 | 64.59 | 42.74 | 45.00 | 42.11 | |
| —D—=8* | TMix | 25.79 | 13.96 | 39.01 | 34.91 | 36.13 | 34.83 |
| UDA | 58.08 | 55.88 | 61.58 | 57.97 | 34.78 | 32.11 | |
| MixText | 21.95 | 14.97 | 47.45 | 35.82 | 35.50 | 32.05 | |
| PET | 70.46 | 49.74 | 56.74 | 30.26 | 46.75 | 43.13 | |
| iPET | 79.85 | 71.65 | 66.09 | 50.27 | 53.88 | 53.97 | |
| MPT | 77.92 | 68.68 | 77.32 | 55.77 | 58.87 | 57.45 | |
| —D—=16* | TMix | 35.97 | 17.16 | 45.46 | 34.74 | 41.00 | 35.83 |
| UDA | 65.93 | 65.10 | 70.27 | 69.93 | 40.43 | 36.57 | |
| MixText | 19.86 | 14.26 | 51.59 | 38.53 | 36.63 | 35.94 | |
| PET | 81.98 | 74.69 | 71.31 | 51.11 | 50.13 | 48.13 | |
| iPET | 81.23 | 74.15 | 77.27 | 63.79 | 54.63 | 54.24 | |
| MPT | 82.43 | 75.32 | 84.09 | 78.91 | 68.37 | 66.50 | |
| —D—=32* | TMix | 35.65 | 17.28 | 50.83 | 38.72 | 38.50 | 34.24 |
| UDA | 70.19 | 69.80 | 74.24 | 73.89 | 35.79 | 32.37 | |
| MixText | 26.38 | 20.34 | 53.63 | 40.25 | 37.88 | 35.52 | |
| PET | 83.52 | 76.91 | 82.05 | 76.53 | 57.50 | 56.87 | |
| iPET | 82.80 | 76.03 | 85.44 | 83.03 | 57.88 | 57.22 | |
| MPT | 82.89 | 74.73 | 87.91 | 86.55 | 73.00 | 72.78 | |
| —D—=64* | TMix | 26.99 | 23.03 | 47.18 | 39.01 | 41.88 | 34.68 |
| UDA | 73.98 | 74.39 | 76.36 | 76.30 | 38.74 | 34.23 | |
| MixText | 32.57 | 22.66 | 52.12 | 45.45 | 39.38 | 35.09 | |
| PET | 83.44 | 76.55 | 87.64 | 86.25 | 60.38 | 59.89 | |
| iPET | 82.69 | 75.88 | 88.66 | 87.53 | 61.75 | 61.49 | |
| MPT | 83.71 | 75.43 | 88.18 | 86.90 | 85.62 | 85.56 | |
| —D—=128* | TMix | 35.41 | 16.72 | 51.10 | 32.90 | 42.88 | 34.85 |
| UDA | 76.37 | 76.75 | 80.76 | 80.69 | 44.65 | 20.58 | |
| MixText | 27.67 | 19.13 | 52.28 | 39.63 | 41.38 | 36.22 | |
| PET | 83.53 | 77.25 | 88.34 | 87.32 | 65.63 | 65.69 | |
| iPET | 83.18 | 76.99 | 88.23 | 87.28 | 66.63 | 66.67 | |
| MPT | 83.79 | 77.89 | 88.93 | 87.82 | 90.38 | 90.40 | |
6. Analysis and discussion
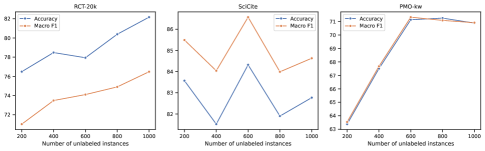
Since we focus on SciBERT based MPT using 600 or 1000 unlabeled instances in the main experiments, we further conduct experiments to better understand the effect of different amount of unlabeled instances, different backbone PLMs, and in-domain pre-train.
6.1. Effect of different number of unlabeled instances
We also conduct experiments, which are shown in Figure 3, to test our model performances with 16 instances per class and different amount of unlabeled data (from 200 to 1000) on Rct-20k, SciCite, and PMO-kw datasets. We can observe that, although for different datasets, models vary in the choice of optimal unlabeled instance size. Overall, with more unlabeled data, the overall performance of MPT becomes much higher. It validates the effectiveness of our proposed MPT in making full use of unlabeled data.
6.2. Can MPT applied to other PLMs?

In this paper, we focus on adopting SciBERT as the backbone of MPT in the main experiments. Can we further extend MPT to other PLMs like BERT and RoBERTa with different pre-train corpus and strategy? To achieve this, we replace the SciBERT or Multilingual BERT in MPT into BERT and RoBERTa. Meanwhile, we keep the same prompt templates and verbalizers with the SciBERT based MPT. As shown in Figure 4, it depicts that MPT performs significantly better than fine-tuning when data is extremely scarce. As the volume of data grows, BERT fine-tuning shows comparative performance with BERT based MPT. Moreover, part of the performance improvement of RoBERT or SciBERT based MPT over BERT based MPT may be due to the contribution of pre-train knowledge. We will further discuss it in the next subsection.
6.3. Effect of in-domain pre-training

Compared to supervised baselines, our proposed MPT and other semi-supervised baselines utilize SciBERT or multilingual BERT. As a result, part of the performance improvement might come from the additional in-domain pre-train corpus. Thus, we compare BERT and SciBERT/Multilingual-BERT based MPT with BERT and SciBERT fine-tuning to test the effect of in-domain pre-training. SciBERT utilizes the same structure as BERT but is pre-trained on scientific domain data, as in-domain pre-train is a common way to improve the model performance (Gururangan et al., 2020; Sung et al., 2019). As shown in Figure 5 shows results of fine-tuning and MPT both using BERT and SciBERT. We can observe that, compared with BERT based MPT, although SciBERT fine-tuning achieves significant better performance when data is extremely scarce and comparative performance with the volume of data grows, it still performs worse than MPT. This observation indicates that MPT not only makes full use of the unlabeled data but also stimulates the pre-train knowledge effectively.
6.4. Comparison with Large Language Models
| Method | RCT-20k | SciCite |
| MPT | 73.34 | 78.69 |
| GPT-4 | 72.74 | 43.99 |
| ERNIE-bot | 67.08 | 43.64 |
| ChatGLM2 | 58.43 | 35.77 |
| GPT-3.5-turbo | 64.19 | 26.34 |
The rapid development of large language models (LLMs), exemplified by ChatGPT, has attracted extensive attention. These massively PLMs, which undergo instruction fine-tuning and align with human intent, have demonstrated excellent performance not only in generative tasks, such as question answering and machine translation, but also in diverse tasks, such as information extraction, text classification, and reasoning when guided by prompts. Therefore, we further compared the 4-shot performance of our proposed MPT with the best 3 to 5 shot best performance of mainstream LLMs, e.g., GPT-4, GPT-3.5-turbo, ERNIE-bot, and ChatGLM2, in the few-shot scenario. Consistent with previous works (Zhang et al., 2022b; Dong et al., 2022; Xu and Zhang, 2024; Liu et al., 2024), we evaluate the performance in an In-Context Learning manner. As shown in Table 7, MPT significantly outperforms these models.
6.5. Connection and comparison with existing work
Our proposed MPT can achieve superior performance for citation function recognition, structure function recognition, and keyword function recognition in different low-resource settings. Previous methods on academic function recognition tasks can mainly be summarized in three categories: (1) a machine learning method based on hand-crafted features (Jurgens et al., 2016; Lu et al., 2018; Nanba et al., 2010); (2) a deep learning model trained from scratch (Cohan et al., 2019; Qin and Zhang, 2020; Wang et al., 2020; Cheng et al., 2021); (3) a PLM fine-tuning method (Beltagy et al., 2019; Huang et al., 2022; Lu et al., 2020; Zhang et al., 2021). Those methods require a large number of annotated data to achieve competitive performance. Our proposed method is based on prompt learning, which is a new paradigm of utilizing PLMs (Liu et al., 2021a) and has great potential in low-resource scenarios. It utilize prompts to bridge the gap of objective forms in pre-training and fine-tuning, which leads to more effective utilization of pre-train knowledge than the standard fine-tuning. Moreover, we introduce prompt learning with mixing multiple types of prompt templates. Whereas previous s studies in other domain tasks are solely based on manual hard templates or automatically learned soft templates. Our comparative experiment results between fine-tuning and prompt learning in Section 5.3 further validate its effectiveness for low-resource academic function recognition tasks.
Our proposed MPT is a semi-supervised method that utilizes multiple prompt templates to annotate unlabeled data. The semi-supervised framework is similar to iPET (Schick and Schütze, 2021), one of the strong semi-supervised baselines. Differently, compared with this method that only adopts the manual prompt, we combine the manual prompt with automatically learned continuous prompt, which can provide multi-perspective representations and take full advantage of knowledge in the PLM and unlabeled data.
Moreover, existing works lack attention to scientific classification tasks in low-resource settings. Since obtaining the annotated data for scientific NLP tasks is still challenging and expensive, it is common in real-world scenarios that there is usually no annotated data or only a small number of annotated instances. To alleviate the dependence on annotated data for scientific classification tasks, we propose the MPT, which combines multiple prompts with a semi-supervised framework. Extensive experiments on a series of academic function recognition tasks at different granularities prove the feasibility of MPT.
6.6. Implications for research
This study has the following implications. First, in the practical scientific NLP scenario, there is a contradiction between the massive unlabeled scientific publications and the scarcity of annotated data. To this end, we propose MPT, a semi-supervised and prompt learning based solution coping with practical low-resource academic function recognition scenarios. Second, the prompt learning paradigm is promising for low-resource scientific NLP tasks. Moreover, MPT is a semi-supervised solution and fuses the manual prompt with automatically learned continuous prompt. It provides multi-perspective representations and takes full advantage of knowledge in the PLM and unlabeled data resources. Third, our proposed MPT has the ability to perform multi-granularity academic function recognition. Moreover, the MPT presented in this study is a general approach that can be easily deployed in other scientific NLP tasks with minor adjustment to the prompt templates and verbalizer. Finally, MPT is a method for low-resource scenario which can be considered a type of Green AI approach, as they aim to develop and use models in a way that is more resource-efficient. By using the method, it is possible to build and train models with less data and compute power, which can reduce the environmental impact of the AI system.
7. Conclusion
In this paper, we propose several prompts and introduce prompt learning method for different granularity academic function recognition tasks. Then we present Mix Prompt Tuning (MPT), a semi-supervised solution that combines the manual prompt with automatically learned continuous prompt for different granularity academic function recognition tasks in practical scenario. Extensive experiments demonstrate that our proposed method outperforms other fine-tuning, prompt-tuning , or semi-supervised baselines.
There are several important directions for future work: (1) inject latent knowledge contained in knowledge graph and citation graph into prompt construction and tuning to increase the interpretability and further alleviate the dependence on the manual prompt. (2) make full use of prompt to exploit pre-trained language models for better scientific fact prediction. (3) investigate the transferability of prompt tuning across different scientific tasks and models.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (72234005 and 72174157).
References
- (1)
- Bao et al. (2019) Yujia Bao, Menghua Wu, Shiyu Chang, and Regina Barzilay. 2019. Few-shot Text Classification with Distributional Signatures. In International Conference on Learning Representations.
- Beltagy et al. (2019) Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A pretrained language model for scientific text. arXiv preprint arXiv:1903.10676 (2019).
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Chen et al. (2020a) Jiaao Chen, Yuwei Wu, and Diyi Yang. 2020a. Semi-supervised models via data augmentationfor classifying interactive affective responses. arXiv preprint arXiv:2004.10972 (2020).
- Chen et al. (2020b) Jiaao Chen, Zichao Yang, and Diyi Yang. 2020b. MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2147–2157.
- Cheng et al. (2021) Qikai Cheng, Pengcheng Li, Guobiao Zhang, and Wei Lu. 2021. Recognition of Lexical Functions in Academic Texts: Problem Method Extraction Based on Title Generation Strategy and Attention Mechanism. Journal of the China Society for Scientific and Technical Information 40, 1, Article 43 (2021), 9 pages.
- Cohan et al. (2019) Arman Cohan, Waleed Ammar, Madeleine Van Zuylen, and Field Cady. 2019. Structural scaffolds for citation intent classification in scientific publications. arXiv preprint arXiv:1904.01608 (2019).
- Cui et al. (2022) Ganqu Cui, Shengding Hu, Ning Ding, Longtao Huang, and Zhiyuan Liu. 2022. Prototypical Verbalizer for Prompt-based Few-shot Tuning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7014–7024.
- Dernoncourt and Lee (2017) Franck Dernoncourt and Ji Young Lee. 2017. PubMed 200k RCT: a Dataset for Sequential Sentence Classification in Medical Abstracts. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 308–313.
- Dernoncourt et al. (2016) Franck Dernoncourt, Ji Young Lee, and Peter Szolovits. 2016. Neural networks for joint sentence classification in medical paper abstracts. arXiv preprint arXiv:1612.05251 (2016).
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT. 4171–4186.
- Ding et al. (2021) Ning Ding, Shengding Hu, Weilin Zhao, Yulin Chen, Zhiyuan Liu, Hai-Tao Zheng, and Maosong Sun. 2021. Openprompt: An open-source framework for prompt-learning. arXiv preprint arXiv:2111.01998 (2021).
- Dong et al. (2022) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022. A survey on in-context learning. arXiv preprint arXiv:2301.00234 (2022).
- Gao et al. (2021) Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 3816–3830.
- Guo et al. (2017) Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On calibration of modern neural networks. In International Conference on Machine Learning. PMLR, 1321–1330.
- Gururangan et al. (2020) Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. 2020. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 8342–8360.
- Hambardzumyan et al. (2021) Karen Hambardzumyan, Hrant Khachatrian, and Jonathan May. 2021. WARP: Word-level Adversarial ReProgramming. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 4921–4933.
- Han et al. (2021a) Xu Han, Zhengyan Zhang, Ning Ding, Yuxian Gu, Xiao Liu, Yuqi Huo, Jiezhong Qiu, Yuan Yao, Ao Zhang, Liang Zhang, et al. 2021a. Pre-trained models: Past, present and future. AI Open 2 (2021), 225–250.
- Han et al. (2021b) Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. 2021b. Ptr: Prompt tuning with rules for text classification. arXiv preprint arXiv:2105.11259 (2021).
- Hassanzadeh et al. (2014) Hamed Hassanzadeh, Tudor Groza, and Jane Hunter. 2014. Identifying scientific artefacts in biomedical literature: The evidence based medicine use case. Journal of biomedical informatics 49 (2014), 159–170.
- Hewitt and Manning (2019) John Hewitt and Christopher D Manning. 2019. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 4129–4138.
- Hu et al. (2021) Shengding Hu, Ning Ding, Huadong Wang, Zhiyuan Liu, Juanzi Li, and Maosong Sun. 2021. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv preprint arXiv:2108.02035 (2021).
- Huang et al. (2022) Shengzhi Huang, Jiajia Qian, Yong Huang, Wei Lu, Yi Bu, Jinqing Yang, and Qikai Cheng. 2022. Disclosing the relationship between citation structure and future impact of a publication. Journal of the Association for Information Science and Technology 73, 7 (2022), 1025–1042.
- Huang et al. (2016a) Yong Huang, Wei Lu, and Qikai Cheng. 2016a. The Structure Function Recognition of Academic Text——Chapter Content Based Recognition. Journal of the China Society for Scientific and Technical Information 35, 03 (2016), 293–300.
- Huang et al. (2016b) Yong Huang, Wei Lu, Qikai Cheng, and Sisi Gui. 2016b. The Structure Function Recognition of Academic Text——Paragraph-based Recognition. Journal of the China Society for Scientific and Technical Information 35, 05 (2016), 530–538.
- Huo et al. (2022) Chaoguang Huo, Shutian Ma, and Xiaozhong Liu. 2022. Hotness prediction of scientific topics based on a bibliographic knowledge graph. Information Processing & Management 59, 4 (2022), 102980.
- Jawahar et al. (2019) Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. 2019. What Does BERT Learn about the Structure of Language?. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 3651–3657.
- Jiang et al. (2022) Gongyao Jiang, Shuang Liu, Yu Zhao, Yueheng Sun, and Meishan Zhang. 2022. Fake news detection via knowledgeable prompt learning. Information Processing & Management 59, 5 (2022), 103029.
- Jin and Szolovits (2018) Di Jin and Peter Szolovits. 2018. Hierarchical neural networks for sequential sentence classification in medical scientific abstracts. arXiv preprint arXiv:1808.06161 (2018).
- Jurgens et al. (2016) David Jurgens, Srijan Kumar, Raine Hoover, Dan McFarland, and Dan Jurafsky. 2016. Citation classification for behavioral analysis of a scientific field. arXiv preprint arXiv:1609.00435 (2016).
- Kondo et al. (2009) Tomoki Kondo, Hidetsugu Nanba, Toshiyuki Takezawa, and Manabu Okumura. 2009. Technical trend analysis by analyzing research papers’ titles. In Language and Technology Conference. Springer, 512–521.
- Lahav et al. (2021) Dan Lahav, Jon Saad Falcon, Bailey Kuehl, Sophie Johnson, Sravanthi Parasa, Noam Shomron, Duen Horng Chau, Diyi Yang, Eric Horvitz, Daniel S Weld, et al. 2021. A Search Engine for Discovery of Scientific Challenges and Directions. arXiv preprint arXiv:2108.13751 (2021).
- Lee et al. (2020) Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 4 (2020), 1234–1240.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 3045–3059.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 4582–4597.
- Liang et al. (2021) Zhentao Liang, Jin Mao, Kun Lu, Zhichao Ba, and Gang Li. 2021. Combining deep neural network and bibliometric indicator for emerging research topic prediction. Information Processing & Management 58, 5 (2021), 102611.
- Liu et al. (2021a) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021a. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv preprint arXiv:2107.13586 (2021).
- Liu et al. (2021b) Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021b. GPT understands, too. arXiv preprint arXiv:2103.10385 (2021).
- Liu et al. (2024) Yinpeng Liu, Jiawei Liu, Xiang Shi, Qikai Cheng, and Wei Lu. 2024. Let’s Learn Step by Step: Enhancing In-Context Learning Ability with Curriculum Learning. arXiv preprint arXiv:2402.10738 (2024).
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
- Liu et al. (2013) Yuanchao Liu, Feng Wu, Ming Liu, and Bingquan Liu. 2013. Abstract sentence classification for scientific papers based on transductive SVM. Computer and Information Science 6, 4 (2013), 125.
- Loshchilov and Hutter (2018) Ilya Loshchilov and Frank Hutter. 2018. Decoupled Weight Decay Regularization. In International Conference on Learning Representations.
- Lu et al. (2018) Wei Lu, Yong Huang, Yi Bu, and Qikai Cheng. 2018. Functional structure identification of scientific documents in computer science. Scientometrics 115, 1 (2018), 463–486.
- Lu et al. (2020) Wei Lu, Pengcheng Li, Guobiao Zhang, and Qikai Cheng. 2020. Recognition of Lexical Functions in Academic Texts: Automatic Classification of Keywords Based on BERT Vectorization. Journal of the China Society for Scientific and Technical Information 39, 12 (2020), 1320–1329.
- Lui (2012) Marco Lui. 2012. Feature stacking for sentence classification in evidence-based medicine. In Proceedings of the Australasian Language Technology Association Workshop 2012. 134–138.
- Luo et al. (2022) Zhuoran Luo, Wei Lu, Jiangen He, and Yuqi Wang. 2022. Combination of research questions and methods: A new measurement of scientific novelty. Journal of Informetrics 16, 2 (2022), 101282.
- Nanba et al. (2010) Hidetsugu Nanba, Tomoki Kondo, and Toshiyuki Takezawa. 2010. Automatic creation of a technical trend map from research papers and patents. In Proceedings of the 3rd international workshop on Patent information retrieval. 11–16.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019).
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language Models as Knowledge Bases?. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2463–2473.
- Pride and Knoth (2020) David Pride and Petr Knoth. 2020. An authoritative approach to citation classification. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020. 337–340.
- Qin and Zhang (2020) Chenglei Qin and Chengzhi Zhang. 2020. Using Hierarchical Attention Network Model to Recognize Structure Functions of Academic Articles. Data Analysis and Knowledge Discovery (2020), 1.
- Qin and Zhang (2022) Chenglei Qin and Chengzhi Zhang. 2022. Which structure of academic articles do referees pay more attention to?: perspective of peer review and full-text of academic articles. Aslib Journal of Information Management ahead-of-print (2022).
- Qin and Eisner (2021) Guanghui Qin and Jason Eisner. 2021. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 5203–5212.
- Qiu et al. (2020) Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. 2020. Pre-trained models for natural language processing: A survey. Science China Technological Sciences 63, 10 (2020), 1872–1897.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training. (2018).
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Ruch et al. (2007) Patrick Ruch, Celia Boyer, Christine Chichester, Imad Tbahriti, Antoine Geissbühler, Paul Fabry, Julien Gobeill, Violaine Pillet, Dietrich Rebholz-Schuhmann, Christian Lovis, et al. 2007. Using argumentation to extract key sentences from biomedical abstracts. International journal of medical informatics 76, 2-3 (2007), 195–200.
- Schick et al. (2020) Timo Schick, Helmut Schmid, and Hinrich Schütze. 2020. Automatically identifying words that can serve as labels for few-shot text classification. arXiv preprint arXiv:2010.13641 (2020).
- Schick and Schütze (2021) Timo Schick and Hinrich Schütze. 2021. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 255–269.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 4222–4235.
- Sun et al. (2021) Pengfei Sun, Yawen Ouyang, Wenming Zhang, and Xin-yu Dai. 2021. MEDA: Meta-Learning with Data Augmentation for Few-Shot Text Classification. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Zhi-Hua Zhou (Ed.). International Joint Conferences on Artificial Intelligence Organization, 3929–3935.
- Sung et al. (2019) Chul Sung, Tejas Dhamecha, Swarnadeep Saha, Tengfei Ma, Vinay Reddy, and Rishi Arora. 2019. Pre-training BERT on domain resources for short answer grading. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 6071–6075.
- Teufel et al. (2006) Simone Teufel, Advaith Siddharthan, and Dan Tidhar. 2006. Automatic classification of citation function. In Proceedings of the 2006 conference on empirical methods in natural language processing. 103–110.
- Wang et al. (2019) Jiamin Wang, Wei Lu, Jiawei Liu, and Qikai Cheng. 2019. Research on structure function recognition of academic text based on multi-level fusion. Library and Information Service 63, 13 (2019), 95.
- Wang et al. (2020) Qian Wang, Jin Zeng, Jiawei Liu, and Yue Qi. 2020. Structure Function Recognition of Academic Text Paragraph Based on Deep Learning. Information Science (In Chinese) 38, 03 (2020), 64–69.
- Wei and Zou (2019) Jason Wei and Kai Zou. 2019. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 6382–6388.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations. 38–45.
- Xie et al. (2020) Qizhe Xie, Zihang Dai, Eduard Hovy, Thang Luong, and Quoc Le. 2020. Unsupervised data augmentation for consistency training. Advances in Neural Information Processing Systems 33 (2020), 6256–6268.
- Xu and Zhang (2024) Shangqing Xu and Chao Zhang. 2024. Misconfidence-based demonstration selection for llm in-context learning. arXiv preprint arXiv:2401.06301 (2024).
- Yao et al. (2021) Huaxiu Yao, Ying-xin Wu, Maruan Al-Shedivat, and Eric Xing. 2021. Knowledge-Aware Meta-learning for Low-Resource Text Classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 1814–1821.
- Yenicelik et al. (2020) David Yenicelik, Florian Schmidt, and Yannic Kilcher. 2020. How does BERT capture semantics? A closer look at polysemous words. In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. 156–162.
- Yin et al. (2021) Da Yin, Weng Lam Tam, Ming Ding, and Jie Tang. 2021. MRT: Tracing the Evolution of Scientific Publications. IEEE Transactions on Knowledge and Data Engineering (2021).
- Yin et al. (2019) Wenpeng Yin, Jamaal Hay, and Dan Roth. 2019. Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3914–3923.
- Yu et al. (2020) Wenhao Yu, Mengxia Yu, Tong Zhao, and Meng Jiang. 2020. Identifying referential intention with heterogeneous contexts. In Proceedings of The Web Conference 2020. 962–972.
- Zhang et al. (2021) Guobiao Zhang, Pengcheng Li, Wei Lu, and Qikai Cheng. 2021. Research on Keyword Semantic Function Recognition Based on Multi-feature Fusion. Library and Information Service 65, 9 (2021), 89.
- Zhang et al. (2022a) Xin Zhang, Fei Cai, Xuejun Hu, Jianming Zheng, and Honghui Chen. 2022a. A Contrastive learning-based Task Adaptation model for few-shot intent recognition. Information Processing & Management 59, 3 (2022), 102863.
- Zhang et al. (2022b) Yiming Zhang, Shi Feng, and Chenhao Tan. 2022b. Active example selection for in-context learning. arXiv preprint arXiv:2211.04486 (2022).
- Zhou et al. (2022) Jing Zhou, Yanan Zheng, Jie Tang, Li Jian, and Zhilin Yang. 2022. FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8646–8665.
- Zhou and Zhang (2020) Qingqing Zhou and Chengzhi Zhang. 2020. Evaluating wider impacts of books via fine-grained mining on citation literatures. Scientometrics 125, 3 (2020), 1923–1948.