Low-overhead distribution strategy for simulation and optimization of large-area metasurfaces
Fast and accurate electromagnetic simulation of large-area metasurfaces remains a major obstacle in automating their design. In this paper, we propose a metasurface simulation distribution strategy which achieves a linear reduction in the simulation time with the number of compute nodes. Combining this distribution strategy with a GPU-based implementation of the Transition-matrix method, we perform accurate simulations and adjoint sensitivity analysis of large-area metasurfaces. We demonstrate ability to perform a distributed simulation of large-area metasurfaces (over ), while accurately accounting for scatterer-scatterer interactions significantly beyond the locally periodic approximation.
Being able to achieve full phase control of optical fields is a central challenge in optical engineering, with diverse applications in imaging, sensing, augmented, and virtual reality systems lee2019prospects ; berkovic2012optical . The past decades have seen a rapid development of metasurface-based optical elements that exploit collective scattering properties of subwavelength structures for phase-shaping the incoming fields and are significantly more compact and integrable when compared to the conventional refractive optical elements chen2020flat ; zhou2020flat ; colburn2018metasurface ; horie2016wide ; kwon2020single ; lee2018metasurface ; li2021inverse . The most commonly adopted metasurface-design strategy proceeds in two steps — first, a library of periodic meta-atoms with varying transmission amplitudes and phases is generated by varying a few geometric parameters specifying the meta-atom. Next, an aperiodic meta-surface is generated by laying out the periodic meta-atoms corresponding to the target spatially-varying phase profile mcclung2020will ; arbabi2020increasing ; pestourie2020active ; zhan2016low ; aieta2012aberration ; arbabi2016multiwavelength ; devlin2016broadband ; fan2018silicon . This approach suffers from two major limitations — first, the resulting metasurface should be almost periodic, and thus this strategy cannot be used for reliably designing rapidly varying phase-profiles. Second, generating the metasurface library becomes increasingly difficult for multi-functional design problems. For instance, while it is usually not difficult to generate a library for designing a simple phase-mask operating at a few operating modes shi2018single ; arbabi2016multiwavelength ; khorasaninejad2016polarization , it becomes increasingly difficult to scale up the number of modes since the same metasurface is required to simultaneously satisfy multiple design conditions corresponding to the different input modes.
Fully automating design of metasurfaces can provide a potential solution to this problem. Gradient based optimization has been successful in designing integrated optical elements that are more compact, robust and high performing than their classical counterparts Molesky:2018:NP ; yang2020inverse ; wang2011robust ; hughes2018adjoint ; sapra2020chip ; dory2019inverse ; piggott2015inverse ; su2020nanophotonic . A key ingredient in these approaches is the ability to rapidly simulate the full electromagnetic structure. This presents a challenge for metasurface designs, since practical metasurfaces could be approximately - in the linear dimension, making it impractical to use general-purpose electromagnetic solvers such as Finite-Difference Time-Domain (FDTD) taflove2000computational , Finite-Difference Frequency-Domain (FDFD) rumpf2012simple , or Finite Element Method (FEM) reddy2019introduction . Inverse-design approaches that use discrete general-purpose electromagnetic solvers to simulate and design the full surface are limited to small design areas or a small number of optimization iterationscamayd2020multifunctional ; mansouree2020multifunctional , or restrict the parameter space through a specific symmetry that allows for fast simulations christiansen2020fullwave ; lin2021computational ; chung2020high . Consequently, nearly all the current methods for inverse-designing large-scale 3D metasurfaces rely on approximate electromagnetic simulations of the metasurface locally using either periodic or radiation boundary conditions li2021inverse ; lin2019topology ; pestourie2018inverse ; chung2020tunable ; sell2017periodic ; phan2019high ; lin2019overlapping ; sell2017large ; bayati2021inverse ; zhelyeznyakov2021deep ; jiang2019global ; jiang2019free ; byrnes2016designing , which do not accurately account for interactions between different meta-atoms. These approaches are thus fundamentally limited to designing metasurfaces with slow phase variations due to the implicit local approximation. A coupled-mode formalism can also be applied for metasurface simulation and optimization doi:10.1021/acsphotonics.1c00100 but this approach is not guaranteed to yield exact fields, particularly for metasurfaces with multiple low quality-factor modes.
In this paper, we propose and demonstrate a numerically accurate simulation strategy that can be used to design and analyze large-area metasurfaces. Our strategy relies on a distribution of the simulation method where the simulation time scales linearly with the compute resources. This is achieved by a Nyquist-sampling decomposition of the fields incident on the metasurface, similar to that used recently to characterize the discrete impulse response of aperiodic metasurfaces torfeh2020modeling . Our distribution strategy, by ensuring minimal communication between compute nodes, allows for a linear reduction in the simulation time with the number of compute nodes, indicating that arbitrarily large metasurfaces can be simulated in reasonable time with sufficiently large number of compute nodes. On each compute node, we implement a GPU-based transition-matrix (T-matrix) simulationzhan2019controlling ; zhan2018inverse ; zhelyeznyakov2020design . Though there are GPU-optimized FDTD implementations that allow fast simulation of unit-cells up to 100 100 hughestiny3d , these approaches do not currently provide a low-overhead means of parallel simulation distribution. We demonstrate numerically accurate simulations of metasurfaces of size 1mm 1 mm at a wavelength of m (about ) on a cluster of 48 GPU nodes. Finally, we demonstrate the ability to efficiently compute the gradients with respect to both the geometry and the positions of the meta-atoms, thus enabling the application of optimization-based design to large-scale metasurfaces.
Low-Overhead Multi-GPU Simulation Strategy.
To simulate millimeter-scale metasurfaces, it is essential to parallelize the simulation method across multiple compute nodes. In order to be scalable, however, this parallelization scheme should introduce only a modest communication overhead in the simulation as this communication overhead can potentially offset any time savings achieved due to the parallelization (tang2020parallelized ; hermann2010multi ; dziekonski2017communication ).
For metasurface simulations, however, by utilizing the property that the incident fields generated by far-field sources will be within the light-cone in the space, a parallelization strategy can be devised that requires minimal communication between the compute nodes. The fundamental principle behind this parallelization is to represent the bandlimited incident field by its samples using the Nyquist sampling theorem landau1967sampling . More precisely, consider an incident field propagating along the direction — the transverse polarization of this field, at any can be expressed as
where with being the wavelength in the background medium, and is a jinc function goodman2005introduction centered at . Each term in the Nyquist decomposition can be considered to be an independent source, which falls off to zero with distance (Fig. 1a), and the response of a metasurface to these individual sources can be obtained by considering only a spatially-truncated portion of the metasurface in the simulation. This is numerically demonstrated in Fig. 1b, in which we consider the scattered power obtained on exciting a metasurface with a single jinc source as a function of the size of the metasurface included in the simulation. As the size of the metasurface is increased, the scattered power converges, indicating that a local simulation is sufficient to capture the metasurface response. The size of the metasurface to achieve a particular accuracy in the simulation is governed by diffraction of the jinc source by the time it reaches the metasurface.
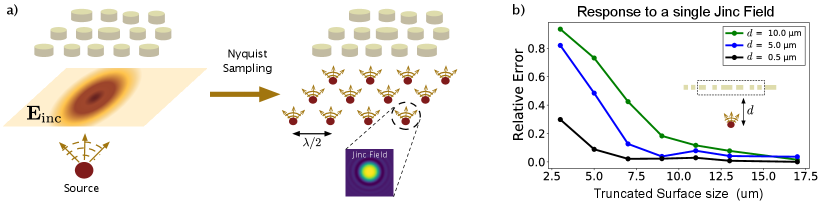
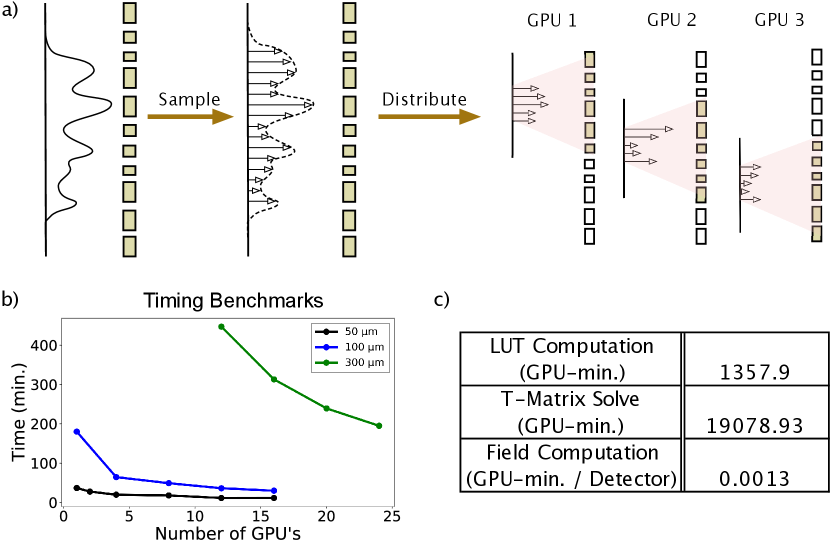
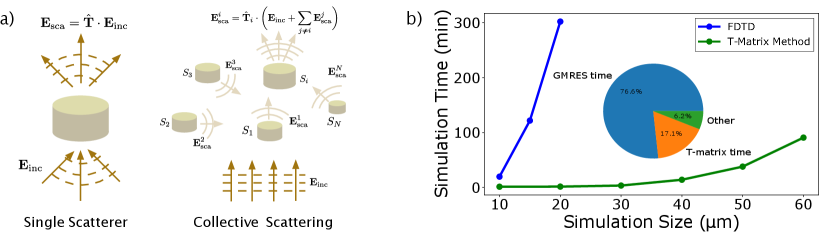
To parallelize the simulation, we can then divide up the jinc sources that compose the incident electric fields into smaller groups, and simulate the local response of the metasurface for each source group by performing an independent solve on a single compute node (Fig. 2a). This parallelization strategy only requires communication between the compute nodes at the start and end of the simulation — once to distribute the simulation data corresponding to the local subregions, and then to consolidate the electric field data computed per subregion. On each compute node, we implement a GPU-parallelized transition-matrix (T-matrix) electromagnetic solver egel2017extending ; doicu2006light (See appendix I for details of the T-matrix method and our implementation of it). In order to accurately account for the diffraction of the jinc source while computing the local response of the metasurface, we include a padding region around the group of sources for each compute node. While in principle, we should ensure that the performance metric being analyzed (e.g. metasurface efficiency) converges with respect to the padding, in practice and for typical metasurfaces, the thickness of padding required for accurate simulations can be estimated simply by studying the response of a local patch of the metasurface to one source similar to that done in Fig. 1b. After having performed all the simulations, the electric fields obtained can be added together to compute the total electric field. Furthermore, because each compute node performs roughly the same amount of compute, the total simulation time scales as (Fig. 2b). Details of our jinc source computation for the T-matrix method single-node simulation can be found in Appendix II.
Thus, given a sufficiently large number of compute nodes, we expect the simulation strategy to be able to handle large problems - on a compute cluster with 48 V100 GPU nodes, we were able to simulate metasurfaces of size about in about 10 hours. This total time is broken down into the compute times for the key simulation parts in Fig. 2c.
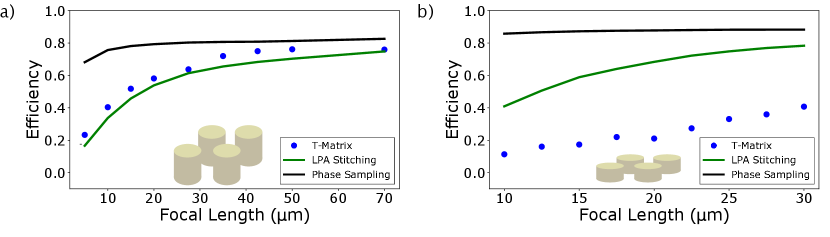
Comparison with locally-periodic approximation. Approximate simulations of large-area metasurfaces often rely on the locally-periodic approximation (LPA) arbabi2015subwavelength ; khorasaninejad2016polarization ; pestourie2018inverse , wherein the local electromagnetic response of the metasurface is approximated with that of a periodic metasurface. To demonstrate that the full metasurface simulation approach captures meta-atom interactions beyond LPA, we compare the T-matrix simulation method with two commonly-used LPA approaches in Fig. 3. First is a simple transmission mask approximation, wherein we assume that the metasurface imparts a smooth position-dependent amplitude and phase to the incident field as determined by the periodic simulationarbabi2015subwavelength , and ignore the variation of the fields within a single unit cell. Second, we consider a more exact field stitching method li2021inverse , wherein the fields near the metasurface within each unit cell is approximated with the fields from the periodic simulation and then propagated. For high aspect ratio scatterers, we find that while the transmission mask method significantly deviates from the T-matrix method, the field stitching method does not. However, for small aspect-ratio scatterers, which are expected to have larger inter meta-atom interactions, both the LPA approximations significantly deviate from the T-matrix method gigli2020fundamental . These results are a strong indication of the ability of the T-matrix method to capture meta-atom interactions and accurately simulate the metasurface response.
Distributed optimization-based design.
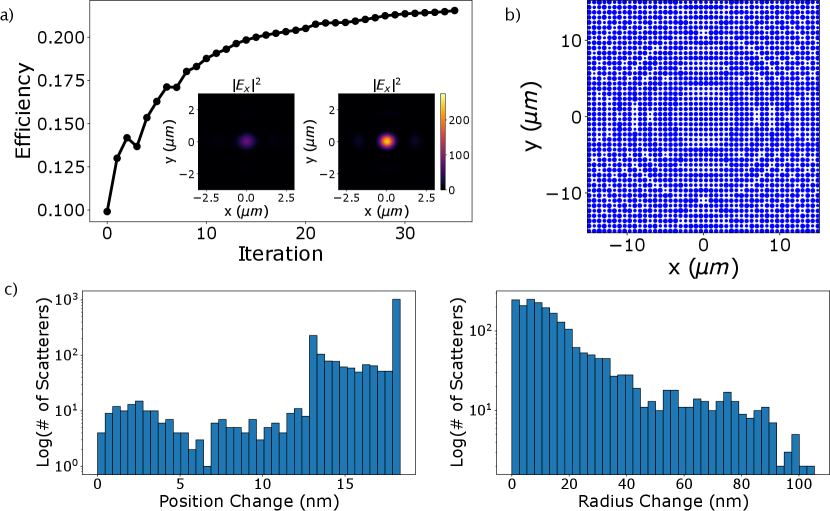
An essential ingredient for optimization-based design of metasurfaces is an efficient evaluation of the gradient of the figure of merit with respect to the design parameters. A particularly useful method to evaluate gradients is based on adjoint-sensitivity analysis lalau2013adjoint ; piggott2017fabrication which analytically differentiates through Maxwell’s equations and computes the gradients with respect to all the design parameters with a cost proportional to only two electromagnetic simulations. The distributed T-matrix simulation method is also amenable to distributed adjoint sensitivity analysis and can allow for scalable evaluation of the gradient of a performance metric defined on the electric fields scattered from the metasurface with respect to both the meta-atom shape and positions (see Appendix IV for details). Fig. 4 demonstrates a distributed gradient-based optimization with respect to the positions and radii of the cylindrical meta-atoms of a cost function evaluating the amount of power within a spot at the focal plane for a 30 m 30 m metalens with focal-length 20 m initially designed with the same scatterer library used in Fig. 3(b). The distributed optimization was performed on 9 T4 GPUs with the metalens divided into 9 subregions (subregion size of 10 m 10 m, and padding size of 6 m). The forward simulations performed took an average of about 120 GPU-min and the gradient computations with respect to radius and position took an average of 150 GPU-min). The metalens has a very high NA of 0.996 and the optimization improves the efficiency of the metalens by about 2 , giving a final efficiency of about . Although thin low-aspect ratio metasurfaces (Huygens metasurfaces) are of interest because they are more amenable to large-scale fabrication, they have not found widespread adoption due to their very limited efficiencies and angular responses gigli2020fundamental . Our ability to accurately model the scatterer-scatterer effects in our metasurface inverse-design may allow discovery of more practical Huygens metasurfaces ollanik2018high ; cai2020inverse . Combining this multi-GPU gradient computation with the multi-GPU forward simulation, we have opened the door to gradient-based optimization over the many degrees of freedom afforded by arbitrarily large metasurfaces. In particular, our method allows optimizing both the shape and position of the scatterers composing the large-area metasurface — optimizing the scatterer positions is very difficult for any inverse-design approach that relies on a periodicity assumption.
Conclusion.
We have demonstrated a scalable distribution method to accurately simulate arbitrarily large-area metasurfaces. Our method uses the Nyquist sampling theorem to allow parallel distribution of compute across multiple GPU nodes, on which a T-matrix method formulation is used to efficiently simulate the subregion. We show a roughly scaling of the total simulation time and demonstrate that our method accurately accounts for all scatterer interactions. Finally, we demonstrate our ability to apply our distribution method to the computation of the gradient with respect to all design parameters. Our simulation distribution method provides a solution to the long-standing problem of simulating large-area metasurfaces and opens the door to gradient-based optimization of the full metasurface, taking advantage of all the design degrees of freedom.
Data availability The data that support the plots within this paper and other findings of this study are available from the corresponding author upon reasonable request.
Competing interests
The authors declare that there are no competing interests.
Author Contributions
R.T. and L.S. conceived the idea. J.S., R.T., and L.S. designed and implemented the software. J.S., R.T., L.S., D.A-S., and H.K. ran benchmarks and conducted numerical experiments. J.V., S.H., and S.F. supervised the project. All authors assisted with data analysis and manuscript preparation.
Acknowledgements This work was supported by the Samsung GRO program. J.S acknowledges support from the National Science Foundation Graduate Research Fellowship (grant no. DGE-1656518) and Cisco Systems Stanford Graduate Fellowship (SGF). R.T acknowledges support from Max Planck Harvard research center for Quantum Optics (MPHQ) fellowship, and Sarah and Kailath Stanford Graduate Fellowship (SGF).
References
- (1) Lee, Y.-H., Zhan, T. & Wu, S.-T. Prospects and challenges in augmented reality displays. Virtual Real. Intell. Hardw. 1, 10–20 (2019).
- (2) Berkovic, G. & Shafir, E. Optical methods for distance and displacement measurements. Advances in Optics and Photonics 4, 441–471 (2012).
- (3) Chen, W. T., Zhu, A. Y. & Capasso, F. Flat optics with dispersion-engineered metasurfaces. Nature Reviews Materials 5, 604–620 (2020).
- (4) Zhou, Y., Zheng, H., Kravchenko, I. I. & Valentine, J. Flat optics for image differentiation. Nature Photonics 14, 316–323 (2020).
- (5) Colburn, S., Zhan, A. & Majumdar, A. Metasurface optics for full-color computational imaging. Science advances 4, eaar2114 (2018).
- (6) Horie, Y., Arbabi, A., Arbabi, E., Kamali, S. M. & Faraon, A. Wide bandwidth and high resolution planar filter array based on dbr-metasurface-dbr structures. Optics express 24, 11677–11682 (2016).
- (7) Kwon, H., Arbabi, E., Kamali, S. M., Faraji-Dana, M. & Faraon, A. Single-shot quantitative phase gradient microscopy using a system of multifunctional metasurfaces. Nature Photonics 14, 109–114 (2020).
- (8) Lee, G.-Y. et al. Metasurface eyepiece for augmented reality. Nature communications 9, 1–10 (2018).
- (9) Li, Z. et al. Inverse design enables large-scale high-performance meta-optics reshaping virtual reality. arXiv preprint arXiv:2104.09702 (2021).
- (10) McClung, A., Mansouree, M. & Arbabi, A. At-will chromatic dispersion by prescribing light trajectories with cascaded metasurfaces. Light: Science & Applications 9, 1–9 (2020).
- (11) Arbabi, A. et al. Increasing efficiency of high numerical aperture metasurfaces using the grating averaging technique. Scientific reports 10, 1–10 (2020).
- (12) Pestourie, R., Mroueh, Y., Nguyen, T. V., Das, P. & Johnson, S. G. Active learning of deep surrogates for pdes: Application to metasurface design. npj Computational Materials 6, 1–7 (2020).
- (13) Zhan, A. et al. Low-contrast dielectric metasurface optics. ACS Photonics 3, 209–214 (2016).
- (14) Aieta, F. et al. Aberration-free ultrathin flat lenses and axicons at telecom wavelengths based on plasmonic metasurfaces. Nano letters 12, 4932–4936 (2012).
- (15) Arbabi, E., Arbabi, A., Kamali, S. M., Horie, Y. & Faraon, A. Multiwavelength polarization-insensitive lenses based on dielectric metasurfaces with meta-molecules. Optica 3, 628–633 (2016).
- (16) Devlin, R. C., Khorasaninejad, M., Chen, W. T., Oh, J. & Capasso, F. Broadband high-efficiency dielectric metasurfaces for the visible spectrum. Proceedings of the National Academy of Sciences 113, 10473–10478 (2016).
- (17) Fan, Z.-B. et al. Silicon nitride metalenses for close-to-one numerical aperture and wide-angle visible imaging. Physical Review Applied 10, 014005 (2018).
- (18) Shi, Z. et al. Single-layer metasurface with controllable multiwavelength functions. Nano letters 18, 2420–2427 (2018).
- (19) Khorasaninejad, M. et al. Polarization-insensitive metalenses at visible wavelengths. Nano letters 16, 7229–7234 (2016).
- (20) Molesky, S., Piggott, A. Y., Weiliang, J., Vučković, J. & Rodriguez, A. W. Inverse design in nanophotonics. Nature Photonics 9, 659 (2018).
- (21) Yang, K. Y. et al. Inverse-designed non-reciprocal pulse router for chip-based lidar. Nature Photonics 14, 369–374 (2020).
- (22) Wang, F., Jensen, J. S. & Sigmund, O. Robust topology optimization of photonic crystal waveguides with tailored dispersion properties. JOSA B 28, 387–397 (2011).
- (23) Hughes, T. W., Minkov, M., Williamson, I. A. & Fan, S. Adjoint method and inverse design for nonlinear nanophotonic devices. ACS Photonics 5, 4781–4787 (2018).
- (24) Sapra, N. V. et al. On-chip integrated laser-driven particle accelerator. Science 367, 79–83 (2020).
- (25) Dory, C. et al. Inverse-designed diamond photonics. Nature communications 10, 1–7 (2019).
- (26) Piggott, A. Y. et al. Inverse design and demonstration of a compact and broadband on-chip wavelength demultiplexer. Nature Photonics 9, 374–377 (2015).
- (27) Su, L. et al. Nanophotonic inverse design with spins: Software architecture and practical considerations. Applied Physics Reviews 7, 011407 (2020).
- (28) Taflove, A. & Hagness, S. C. Computational electrodynamics, vol. 28 (Artech house publishers Norwood, MA, 2000).
- (29) Rumpf, R. C. Simple implementation of arbitrarily shaped total-field/scattered-field regions in finite-difference frequency-domain. Progress In Electromagnetics Research 36, 221–248 (2012).
- (30) Reddy, J. N. Introduction to the finite element method (McGraw-Hill Education, 2019).
- (31) Camayd-Muñoz, P., Ballew, C., Roberts, G. & Faraon, A. Multifunctional volumetric meta-optics for color and polarization image sensors. Optica 7, 280–283 (2020).
- (32) Mansouree, M. et al. Multifunctional 2.5 d metastructures enabled by adjoint optimization. Optica 7, 77–84 (2020).
- (33) Christiansen, R. E. et al. Fullwave maxwell inverse design of axisymmetric, tunable, and multi-scale multi-wavelength metalenses. Optics Express 28, 33854–33868 (2020).
- (34) Lin, Z., Roques-Carmes, C., Christiansen, R. E., Soljačić, M. & Johnson, S. G. Computational inverse design for ultra-compact single-piece metalenses free of chromatic and angular aberration. Applied Physics Letters 118, 041104 (2021).
- (35) Chung, H. & Miller, O. D. High-na achromatic metalenses by inverse design. Optics express 28, 6945–6965 (2020).
- (36) Lin, Z., Liu, V., Pestourie, R. & Johnson, S. G. Topology optimization of freeform large-area metasurfaces. Optics express 27, 15765–15775 (2019).
- (37) Pestourie, R. et al. Inverse design of large-area metasurfaces. Optics express 26, 33732–33747 (2018).
- (38) Chung, H. & Miller, O. D. Tunable metasurface inverse design for 80% switching efficiencies and 144 angular deflection. ACS Photonics 7, 2236–2243 (2020).
- (39) Sell, D., Yang, J., Doshay, S. & Fan, J. A. Periodic dielectric metasurfaces with high-efficiency, multiwavelength functionalities. Advanced Optical Materials 5, 1700645 (2017).
- (40) Phan, T. et al. High-efficiency, large-area, topology-optimized metasurfaces. Light: Science & Applications 8, 1–9 (2019).
- (41) Lin, Z. & Johnson, S. G. Overlapping domains for topology optimization of large-area metasurfaces. Optics express 27, 32445–32453 (2019).
- (42) Sell, D., Yang, J., Doshay, S., Yang, R. & Fan, J. A. Large-angle, multifunctional metagratings based on freeform multimode geometries. Nano letters 17, 3752–3757 (2017).
- (43) Bayati, E. et al. Inverse designed extended depth of focus meta-optics for broadband imaging in the visible. arXiv preprint arXiv:2105.00160 (2021).
- (44) Zhelyeznyakov, M. V., Brunton, S. & Majumdar, A. Deep learning to accelerate scatterer-to-field mapping for inverse design of dielectric metasurfaces. ACS Photonics 8, 481–488 (2021).
- (45) Jiang, J. & Fan, J. A. Global optimization of dielectric metasurfaces using a physics-driven neural network. Nano letters 19, 5366–5372 (2019).
- (46) Jiang, J. et al. Free-form diffractive metagrating design based on generative adversarial networks. ACS nano 13, 8872–8878 (2019).
- (47) Byrnes, S. J., Lenef, A., Aieta, F. & Capasso, F. Designing large, high-efficiency, high-numerical-aperture, transmissive meta-lenses for visible light. Optics express 24, 5110–5124 (2016).
- (48) Zhou, M. et al. Inverse design of metasurfaces based on coupled-mode theory and adjoint optimization. ACS Photonics 0, null (0). URL https://doi.org/10.1021/acsphotonics.1c00100. eprint https://doi.org/10.1021/acsphotonics.1c00100.
- (49) Torfeh, M. & Arbabi, A. Modeling metasurfaces using discrete-space impulse response technique. ACS Photonics 7, 941–950 (2020).
- (50) Zhan, A. et al. Controlling three-dimensional optical fields via inverse mie scattering. Science advances 5, eaax4769 (2019).
- (51) Zhan, A., Fryett, T. K., Colburn, S. & Majumdar, A. Inverse design of optical elements based on arrays of dielectric spheres. Applied optics 57, 1437–1446 (2018).
- (52) Zhelyeznyakov, M. V., Zhan, A. & Majumdar, A. Design and optimization of ellipsoid scatterer-based metasurfaces via the inverse t-matrix method. OSA Continuum 3, 89–103 (2020).
- (53) Hughes, T. W., Minkov, M., Liu, V., Yu, Z. & Fan, S. Full wave simulation and optimization of large area metalens. OSA Optical Design and Fabrication Congress 2021 (2021).
- (54) Tang, J., Zheng, Y., Yang, C., Wang, W. & Luo, Y. Parallelized implementation of the finite particle method for explicit dynamics in gpu. Computer Modeling in Engineering & Sciences 122, 5–31 (2020).
- (55) Hermann, E., Raffin, B., Faure, F., Gautier, T. & Allard, J. Multi-gpu and multi-cpu parallelization for interactive physics simulations. In European Conference on Parallel Processing, 235–246 (Springer, 2010).
- (56) Dziekonski, A., Sypek, P., Lamecki, A. & Mrozowski, M. Communication and load balancing optimization for finite element electromagnetic simulations using multi-gpu workstation. IEEE Transactions on Microwave Theory and Techniques 65, 2661–2671 (2017).
- (57) Landau, H. Sampling, data transmission, and the nyquist rate. Proceedings of the IEEE 55, 1701–1706 (1967).
- (58) Goodman, J. W. Introduction to fourier optics, roberts & co. Publishers, Englewood, Colorado (2005).
- (59) Egel, A. et al. Extending the applicability of the t-matrix method to light scattering by flat particles on a substrate via truncation of sommerfeld integrals. Journal of Quantitative Spectroscopy and Radiative Transfer 202, 279–285 (2017).
- (60) Doicu, A., Wriedt, T. & Eremin, Y. A. Light scattering by systems of particles: null-field method with discrete sources: theory and programs, vol. 124 (Springer, 2006).
- (61) Arbabi, A., Horie, Y., Ball, A. J., Bagheri, M. & Faraon, A. Subwavelength-thick lenses with high numerical apertures and large efficiency based on high-contrast transmitarrays. Nature communications 6, 1–6 (2015).
- (62) Gigli, C. et al. Fundamental limitations of huygens’ metasurfaces for optical beam shaping. arXiv e-prints arXiv–2011 (2020).
- (63) Lalau-Keraly, C. M., Bhargava, S., Miller, O. D. & Yablonovitch, E. Adjoint shape optimization applied to electromagnetic design. Optics express 21, 21693–21701 (2013).
- (64) Piggott, A. Y., Petykiewicz, J., Su, L. & Vučković, J. Fabrication-constrained nanophotonic inverse design. Scientific reports 7, 1–7 (2017).
- (65) Ollanik, A. J., Smith, J. A., Belue, M. J. & Escarra, M. D. High-efficiency all-dielectric huygens metasurfaces from the ultraviolet to the infrared. ACS photonics 5, 1351–1358 (2018).
- (66) Cai, H. et al. Inverse design of metasurfaces with non-local interactions. npj Computational Materials 6, 1–8 (2020).
- (67) Solutions, F. Lumerical solutions. Inc., http://www. lumerical. com (2003).
- (68) Markkanen, J. & Yuffa, A. J. Fast superposition t-matrix solution for clusters with arbitrarily-shaped constituent particles. Journal of Quantitative Spectroscopy and Radiative Transfer 189, 181–188 (2017).
Supplementary Information to
Low-overhead distribution strategy for simulation and optimization of large-area metasurfaces
Jinhie Skarda1,∗, Rahul Trivedi1,2,∗,†, Logan Su1,∗, Diego Ahmad-Stein1, Hyounghan Kwon1,
Seunghoon Han3, Shanhui Fan1, and Jelena Vuc̆ković1,†
1E. L. Ginzton Laboratory, Stanford University, Stanford, CA 94305, USA.
2Max-Planck-Institut für Quantenoptik, Hans-Kopfermann-Str. 1, 85748 Garching, Germany.
3Samsung Advanced Institute of Technology, Samsung Electronics, Suwon-si, Gyeonggi-do 443-803, Republic of Korea
*These authors contributed equally to this work.
†Corresponding authors: [email protected],[email protected]
Appendix I T-Matrix Simulation Method
The key idea behind the T-matrix method is illustrated in Fig. S1(a) — the scattering properties of each meta-atom is captured by its T-matrix, which is a mathematical representation of the linear transformation mapping the incident field on the meta-atom to the scattered field. In principle, any basis for the incident or scattered fields can be used to represent this T-matrix. However, since the meta-atom sizes are of the order of a wavelength, choosing the spherical or spheroidal basis functionsdoicu2006light provides a computationally economical description of the T-matrix (i.e. only a modest number of basis functions are needed to capture the scattering properties of individual meta-atoms).
After computing the T-matrix for each meta-atom, a coupled system of equations can then be setup to account for interactions between different meta-atoms by treating the fields scattered from one meta-atom as being incident on the other meta-atoms. The coupling coefficients in such a system of equations are provided by the translation theorems for the chosen basis functions doicu2006light , which allow an expansion for basis functions centered at one meta-atom on the basis functions centered at a different meta-atom. These coupled systems of equations are then solved to obtain a representation of the total scattered field on the chosen basis functions, which can then be used to compute the electric fields in position space and allow for an evaluation of any relevant metasurface performance metric.
To obtain a more computationally-efficient implementation of the T-matrix method, we implement several optimizations often used in the field of computational engineering. First, we use an iterative algorithm (GMRES) to solve the system of equations resulting from the T-matrix formalism — a major advantage of using iterative algorithms is that they only require matrix-vector products which we program in a fully parallelized manner on GPUs. Furthermore, the computation of the T-matrix of the individual meta-atoms as well as of the coupling coefficients requires computing special functions which can be time consuming. In our implementation, we precompute lookup tables for these special functions before the start of the T-matrix simulation which significantly cuts down the run-time of the full simulation.
Fig.S1b shows a comparison of the simulation time of our implementation when compared to commercially available FDTD solvers solutions2003lumerical . We note that this is not a strictly rigorous benchmark, as the parallelization settings are not exactly the same between our software and Lumerical – the purpose of this comparison is only to roughly put our simulation times in context of a simulation tool the reader is likely familiar with. Our software is able to simulate a large metasurface in 1-1.5 hours on a single GPU core (Nvidia V100). As seen in the inset in Fig. S1b, the bulk of the simulation time is spent in the linear system solve.
In the following subsections, we further describe the details of the T-matrix simulation method that we use on each compute node, and provide definitions of various objects used while setting up the simulations (e.g. vector spherical wave functions, transition matrices, translation theorems etc.). The focus is not derive the simulation method, but to present the equations that are ultimately implemented — the interested reader can refer to Doicu for a rigorous derivation of the simulation method.
I.1 Vector spherical wavefunctions
In this subsection, we provide definitions and some properties of the vector spherical wavefunctions. These wavefunctions serve as a basis functions to compactly represent the fields incident on and scattered from subwavelength scatterers, and are an important component of the transition matrix method. The definitions given here closely follow appendix B of Doicu .
The vector spherical wavefunctions are solutions of the frequency-domain Maxwell’s equations in homogenous media. Consider a medium with wavenumber — the electric field in source-free regions then satisfies:
| (1) |
along with the transversality condition and the transversality condition .
To construct the vector spherical wave functions, we begin by considering the solutions of the scalar helmholtz equation, which is the scalar counterpart of Eq. 1:
| (2) |
It can be shown, with a straightforward application of the separation of variables method, that the spherical wavefunctions and defined below are solutions of the scalar helmholtz equation:
| (3a) | |||
| (3b) | |||
where , , are the spherical coordinates of the point x, is the spherical hankel function of the first kind, is the spherical bessel function and is the normalized associated legendre polynomial. Note that each solution of the scalar wave function is indexed by two numbers — the orbital index and the magnetic index . indicates whether the wavefunction is well behaved at the origin — evaluates to 0 at the origin while diverges at the origin. Additionally, captures spherical waves radiating to infinity, while captures spherical standing waves (equal superpositions of outgoing and incoming waves) — this can be best appreciated by considering the asymptotic forms of these wavefunctions at large radial coordinates ():
| (4) | ||||
| (5) |
For each scalar wave function, we can construct two vector spherical wave functions (corresponding to two independent polarizations) which satisfy Eq. 1 along with the transversality condition . We denote the vector spherical wave functions by and (where is the polarization index) — these are then defined by:
| (6a) | |||
| (6b) | |||
where , and . The vector spherical harmonics form a basis for the solutions of the vector helmholtz equation (Eq. 1), and an orthogonality condition can be constructed for them on the surface of (an arbitrarily chosen) sphere as delineated in Doicu .
I.2 Transition matrix
Consider a scatterer with permittivity embedded in a medium of permittivity — we denote by the volume of the scatterer, the surface of the scatterer and by the surface of a sphere enclosing the scatterer. Note that can be chosen arbitrarily as long as it completely encloses the scatterer — for performing practical computations, it is customary to choose as the smallest sphere that can enclose the scatterer. Throughout this section, we assume that the center of is at the origin of the coordinate system.
Consider exciting the scatterer with an incident electric field that is a superposition of regular vector spherical wavefunctions , where :
| (7) |
This incident field interacts with the scatterer, resulting in a scattered field radiating away from the scatterer. Outside the sphere , the scattered field can be expressed as a superposition of vector spherical wavefunctions :
| (8) |
Note that the scattered fields can be entirely captured without including the contribution of regular vector spherical wave functions — this is a consequence of the fact that the scattered field is expected to propagate radially outward from the scatterer, and the regular vector spherical harmonics have a radially inward propagating component (Eq. 4). Moreover, the linearity of Maxwell’s equations implies that the coefficients must be related to via a linear transformation:
| (9) |
In practice, the expansions of the incident and scattered fields Eqs. 7 and 8 are typically truncated to a finite number of terms by ignoring contributions of basis functions with [this corresponds to using basis functions]. In this case, all the coefficients () can be collected into a vector a (s), and Eq. 9 can be expressed as a matrix equation . We will refer to T as the transition matrix of the scatterer.
There are a number of approaches to compute the transition matrix elements — we implement the approach based on the null field method Doicu . The null field method uses the surface integral equations to individually relate the incident and scattered fields to the fields on the scatterer surface, expand all the surface fields on the vector spherical harmonic basis, and then compute the relationship between the incident and scattered fields by eliminating the surface fields from the resulting equations. Final computation of the transition matrix method involves computing two matrices P and Q whose elements are given by the following integrals:
| (10a) | |||
| (10b) | |||
where is the wavenumber in the scatterer material, is the wavenumber in the background medium in which the scatterers are embedded, and the transition matrix T is given by:
| (11) |
We use a numerical discretization of 0.0025 microns for evaluating these surface integrals to compute the T-matrix.
Finally, we note that the transition matrix becomes an increasingly accurate description of the scatterer on increasing . However, for subwavelength scatterers, a small usually suffices to accurately describe the scattering properties of the scatterer. This is a key advantage of using the transition matrix method for simulating a collection of small scatterers, since the scattered fields from each scatterer can be described with a very small number of unknowns when expanded on the vector spherical wavefunctions. For all results in this paper, we have used .
I.3 Simulating collective scattering
Finally, we describe how to simulate an ensemble of scatterers when their individual transition matrices are known. Consider scatterers with transition matrices located at . We assume that the enclosing spheres ( defined in section I.2) of the scatterers do not intersect each other. This system of scatterers is excited with an incident field which can be expanded into regular vector spherical wavefunctions centered at each of the scatterers:
| (12) |
where and is the wavenumber of the background medium. Note that the coefficients for different are not independent of each other — in particular, given these coefficients for one choice of , the coefficients for all other can be constructed via an application of the translation theorem for vector spherical wavefunctions Doicu . Typically, the incident field is known analytically (e.g. plane wave field), and hence these coefficients can be analytically determined for an arbitrary .
We express the scattered field as a superposition of vector spherical harmonics radiated from each scatterer:
| (13) |
where it is assumed that x lies outside the enclosing spheres of all scatterers. Consider now the scatterer — the total incident field at this scatterer, is given by the sum of as well as fields radiated by the neighbouring scatterers:
| (14) |
This field can be expressed entirely as a superposition of the regular vector spherical wavefunctions centered at by the application of the translation theorem for the vector spherical wavefunctions. The translation theorem relates vector spherical wavefunctions defined with respect to two different origins to each other Doicu ; Egel — more explicitly:
| (15) |
where
| (16) |
and with as the spherical coordinates of the vector x:
| (17a) | |||
| (17b) | |||
where:
| (18a) | ||||
| (18b) | ||||
with
| (19) |
is the Wigner-3j symbol Luscombe . With this addition theorem, can be rewritten as:
| (20) |
where
| (21) |
Finally, the coefficients can be related to the coefficients via the transition matrix of the scatterer: , where and are column vectors of the coefficients and . Denoting by as the matrix of the translation coefficients with the unprimed indices corresponding to different rows and the primed indices corresponding to different columns, this equation can be compactly written as:
| (22) |
Such an equation can be written for each scatterer — all of these equations collected together provide a completely determined system of linear equations that can be solved to obtain the scattering coefficients . The system of equations can be written in a matrix form:
| (23) |
The matrix in the above system of equations is referred to as the ‘maxwell operator‘, since it is equivalent to expressing the frequency domain maxwell’s equations on the vector spherical wavefunction basis. To summarize, the problem of solving the Maxwell’s equations has been reduced to the problem of solving the linear system in Eq. 23. Once this system of equations is solved to obtain , the electric fields at the desired points can be computed using Eq. 13, which can be concisely expressed as:
| (24) |
where is a column vector of the vector spherical harmonics at position x.
From a numerical perspective, the linear systems Eq. 23 is severely ill conditioned due to the transition matrices being close to singular for small scatterers. This issue can be mitigated using the following block diagonal preconditioner M:
| (25) |
Instead of solving , we solve (a system of equations similar to those found in markkanen2017fast ). Validation simulations for our T-matrix simulation method implementation are shown in Fig. S2 — we see good agreement between the T-matrix method, FDTD, and FDFD simulations.
I.4 Hardware acceleration on GPUs
Accelerating the solution of the resulting system of linear equations using hardware accelerators such as GPUs has been an immensely successful approach in scaling up partial differential equation solvers. In this section, we describe a simple approach to implement the transition matrix simulation on GPUs — in particular, there are two issues that we address using common approaches from the field of computational engineering:
-
1.
Speeding up matrix solve: The matrix solve using GMRES relies on the ability to perform matrix vector products (i.e. if we are solving using GMRES, we need to be able to compute the product of the matrix A with an arbitrary vector x). For a dense matrix, this computation is an operation, and consequently speeding up this operation is a key component of scaling up the simulator to larger systems.
-
2.
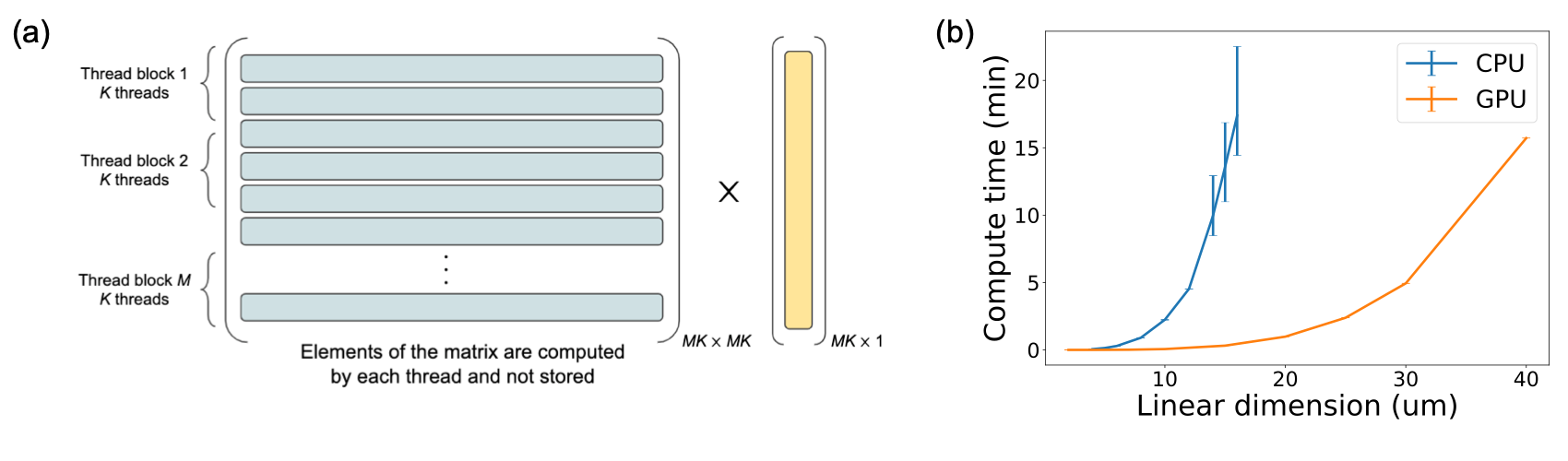
Memory obstacle in precomputing the full matrix: The implementation described in the previous section constructs the full maxwell operator explicitly as a matrix, and then performs the matrix vector products. While this might work for small scale simulations (m in linear dimension for subwavelength silicon scatterers while using a machine with GM RAM), for larger simulations the matrix would become too large to store in memory. So as to obviate this issue, we would like to be able to perform matrix-vector products without explicitly constructing the matrix.
Implementation of the GPU accelerated solver: To this end, we implement the matrix vector product with the maxwell operator as a GPU operation (Fig. S3a). The matrix elements are computed while performing the matrix-vector product and discarded once the computation involving those elements have been performed. While computing the element of the matrix-vector product, the inner product of the row of the matrix with the vector needs to be computed — in our implementation, we assign one GPU thread to handle one such inner product so as to parallelize the matrix-vector product operation. This matrix-vector product operation can then be used along with GMRES to fully solve the system of equations — we implement the operations in GMRES other than the matrix-vector product operation using nvidia’s CUBLAS library cublas . Fig. S3b shows a comparison between the matrix solve time between a CPU implementation of the solution of Eq. 23 and a GPU implementation of the solution of Eq. 23. Both the implementations use lookup tables and interpolation — note that in the CPU solve time, we include the time taken for constructing the maxwell operator and then solving Eq. 23 using GMRES. We observe a speedup on using the GPU implementation over the CPU implementation.
Appendix II Computation of Jinc Sources
While the single-GPU implementation of the T-matrix method outlined in Section I.4 is efficient for metasurfaces with linear dimension up to , it is not scalable to millimeter scale metasurface simulations as can be seen by an extrapolation of the timing benchmark shown in Fig. S3b. In this section, we describe an approach to perform the metasurface simulation over multiple GPUs with very little communication overhead, thereby allowing us to scale the T-matrix method to large-scale metasurface simulations.
The fundamental principle behind the parallelization scheme that we implement is the Nyquist sampling theorem. Consider an incident field propagating along the axis and described by its transverse components as a function of transverse coordinate at , is incident on a metasurface located at . If the incident field is produced by a source that is either far from the metasurface or paraxial, it will be spatially bandlimited to a light-cone. Consequently, at , it can be completely described by its samples where and :
| (26) |
where is the spherical bessel function of order 1 and . Thus with every sample, one can associate an incident field, labelled as ‘jinc source’, with amplitude proportional to the sampled electric field. It can easily be seen that the jinc source is of limited spatial extent, and consequently simulating the response of the metasurface to an individual jinc source only requires performing a simulation of a small part of the metasurface near its center. Consequently, we can divide up the jinc sources that compose the incident electric fields into small groups, and simulate the response of the metasurface locally for each group by performing an independent solve on single GPU. After having performed all the simulations, they can be added together again to compute the total electric field.
We note that, although we have made the assumption that the incident field is propagating at normal incidence, this Nyquist sampling technique also works for oblique incidence. Keeping the same sampling plane as for normal incidence, the Nyquist sampling rate will increase because the maximum magnitude of the in-plane k-vector increases. As long as the angle of incidence is close to normal, this sampling strategy should have performance comparable to the normal-incidence case.
II.1 Implementing jinc source in the vector spherical harmonic basis
In order to implement the Nyquist-sampling-based-parellelization scheme described above, it is necessary to be able to simulate the response of the metasurface to a collection of jinc sources using the T-matrix method. This requires the ability to expand the jinc sources on the vector spherical wavefunctions (Eq. 23). In this section, we mathematically develop such an expansion.
Consider a jinc source at propagating in the direction and centered at in the transverse plane. The transverse electric field at is given by:
| (27) |
where is the first order spherical bessel function and is the transverse polarization of the jinc field. Alternatively, in the fourier representation,
| (28) |
Propagating each plane-wave component, we obtain:
| (29) |
where and
| (30) |
Changing the integration variable to ( and ) where and therefore , and . Moreover, each plane wave can be expanded into a sum of vector spherical harmonic wavefunctions Doicu :
| (31) |
where
| (32a) | |||
| (32b) | |||
where and are vector spherical harmonics with orbital index and azimuthal index . Therefore,
| (33) |
where are given by:
| (34) |
In the remainder of this section, we will evaluate the integral over analytically, and the resulting expression can then be numerically integrated over . To do so, it will be convenient to define a function by:
| (35) |
can be evaluated analytically: making a change of variables to , we obtain:
| (36) |
wherein we have used the identity:
| (37) |
Additionally, note that and . Therefore:
| (38a) | |||
| (38b) | |||
Finally, let , and therefore .
- 1.
- 2.
It can be noted that the numerical integration over can be accelerated by using lookup tables for the various special functions involved in the computation. Furthermore, we also parallelize the computation of the jinc sources on GPU to accelerate it with one thread being assigned to compute for a single choice of with respect to a chosen scatterer.
Finally, we remark that since the jinc sources are spatially limited, we only need to simulate the metasurface locally to compute its response to the jinc source. In order to estimate how local this simulation needs to be, a padding study like the one in Fig. 1(b) should be performed.
Appendix III Scatterer Libraries for Metalens Designs
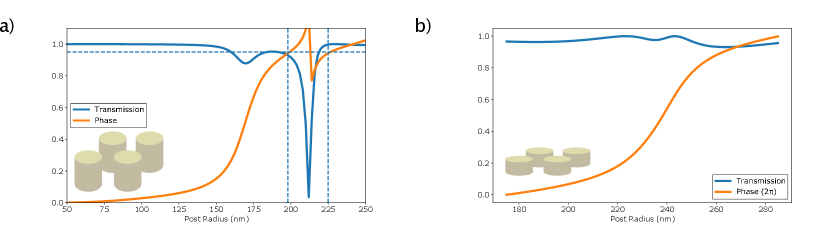
The transmission and phase response for the scatterer library used for the metalens designs simulated and analyzed in Fig. 1, 3(a), and 4 is shown below in Fig.S4 (a). The transmission and phase response for the scatterer library used for the metalens designs simulated and analyzed in Fig. 3(b) is shown below in Fig.S4 (b).
Appendix IV Adjoint Computation
In this section, we describe the computation of the gradient of the metasurface performance with respect to the position and geometry of the meta-atoms. An efficient implementation of the gradient computation would allow us to use gradient-based optimization algorithms to optimize the performance of metasurfaces much like that done with inverse-design of silicon photonics devices.
Suppose that we have scatterers located at . Moreover, the geometry of the scatterers are dependent on parameters (e.g. these parameters can be the radii of the cylindrical meta-atoms, or the lengths and breadths rectangular meta-atoms). Consider a performance metric which takes the following form:
| (43) |
where is a function mapping a complex number to a real number, is the detector volume and is a vector function of space that has information of the ‘desired’ field profile. As a concrete example of such a performance metric, consider attempting to design a lens using meta-atoms located at that focuses an incident plane-wave polarized along within a Gaussian spot of width at . In this case, we could choose and so as to obtain a performance metric that measures how much of the transmitted field is within a gaussian beam mode of the specified width at the focus of the metasurface. More complicated performance metrics can be created by combining those of the form of Eq. 43 based on the specific design problem being solved.
Consider now the computation of derivative of with respect to the coordinates of the scatterer: where with . From Eq. 43, it immediately follows that:
| (44) |
From Eq. 24, it immediately follows that:
| (45) |
where
| (46) |
To compute , we differentiate Eq. 23 with respect to :
| (47) |
from which we obtain:
| (48) |
Following a similar procedure, it is possible to compute the partial derivative of with respect to the geometric parameter to obtain:
| (49) |
where
| (50) |
From Eqs. 48 and 50, we make the following observations about the gradient computation:
-
(a)
It seems that computing the gradient requires computation of — this would be a prohibitively expensive simulation that would render the gradient computation impractical. Note however, in the gradient computation, we only require the computation of and not the full inverse . This is equivalent to solving the following system of equations:
(51) This is labelled as the adjoint simulation, and it needs to be performed once at each step of the optimization (importantly, note that this simulation does not depend on the variable with respect to which the gradient is being computed).
-
(b)
To compute the gradients, we also need to compute and . Since the explicit dependence of on the scatterer coordinates is known (i.e. Eq. 23), can be computed analytically. Computing is equivalent to computing (note that the off-diagonal elements do not depend on the scatterer geometry, only on their locations). Since in our implementation, we are setting up a lookup table for the transition matrices and interpolating between then, this derivative can be numerically approximated using the same lookup table.
References
- (1) Doicu, A., Wriedt, T., & Eremin, Y. A. (2006). Light scattering by systems of particles: null-field method with discrete sources: theory and programs (Vol. 124). Springer.
- (2) Egel, A., Pattelli, L., Mazzamuto, G., Wiersma, D. S., & Lemmer, U. (2017). CELES: CUDA-accelerated simulation of electromagnetic scattering by large ensembles of spheres. Journal of Quantitative Spectroscopy and Radiative Transfer, 199, 103-110.
- (3) Luscombe, J. H., & Luban, M. (1998). Simplified recursive algorithm for wigner 3 j and 6 j symbols. Physical Review E, 57(6), 7274.
- (4) Cublas library (2008), NVIDIA Corporation, Santa Clara, California.
- (5) Arbabi, A., Horie, Y., Ball, A. J., Bagheri, M., & Faraon, A. (2015). Subwavelength-thick lenses with high numerical apertures and large efficiency based on high-contrast transmitarrays. Nature communications, 6(1), 1-6.
- (6) Gigli, C., Li, Q., Chavel, P., Leo, G., Brongersma, M. L., & Lalanne, P. (2020). Fundamental limitations of Huygens’ metasurfaces for optical beam shaping. Laser & Photonics Reviews, 2000448.