Lorenz map, inequality ordering and curves based on multidimensional rearrangements
Abstract.
We propose a multivariate extension of the Lorenz curve based on multivariate rearrangements of optimal transport theory. We define a vector Lorenz map as the integral of the vector quantile map associated with a multivariate resource allocation. Each component of the Lorenz map is the cumulative share of each resource, as in the traditional univariate case. The pointwise ordering of such Lorenz maps defines a new multivariate majorization order, which is equivalent to preference by any social planner with inequality averse multivariate rank dependent social evaluation functional. We define a family of multi-attribute Gini index and complete ordering based on the Lorenz map.
We propose the level sets of an Inverse Lorenz Function as a practical tool to visualize and compare inequality in two dimensions, and apply it to income-wealth inequality in the United States between 1989 and 2022.
Keywords: Multidimensional inequality, Lorenz curve, Gini index, vector quantiles, optimal transport, majorization
JEL codes: D63
Introduction
The Lorenz curve, first proposed in Lorenz (1905), is a compelling visual and simple quantification tool for the analysis of dispersion in univariate distributions. It allows easy visualization of dispersion from the curvature of a convex curve and its distance from the diagonal. The diagonal itself is the Lorenz curve of a degenerate distribution– an egalitarian allocation where all individuals have the same amount of resource. It also enables quick computations, reading off the curve, as it were, of the share of a resource held by the top or bottom of the allocation distribution for that resource. These features of the Lorenz curve account for much of its enduring appeal among practitioners, policy analysts and policy makers. This appeal is further enhanced by the relation between majorization and the pointwise ordering of Lorenz curves, which provides a way to visualize inequality comparisons between populations and within a given population between time periods. Comprehensive accounts are given in Marshall et al. (2011) and Arnold and Sarabia (2018).
The appealing properties of the Lorenz curve are well captured by the formulation given in Gastwirth (1971). In that formulation, the Lorenz curve is the graph of the Lorenz map, and the latter is the cumulative share of individuals below a given rank in the distribution, i.e., the normalized integral of the quantile function. The relation to majorization and the convex order follows immediately, as shown in section C of Marshall et al. (2011). As pointed out by Arnold (2008), this makes the Lorenz ordering an uncontroversial partial inequality ordering of univariate distributions, and most open questions concern the higher dimensional case.
Dispersion in multivariate distributions is not adequately described by the Lorenz curve of each marginal, and a genuinely multidimensional approach is needed. Even for utilitarian welfare inequality, Atkinson and Bourguignon (1982) motivate the need for the multidimensional approach initiated by Fisher (1956). More generally, the literature on multidimensional inequality of outcomes and its measurement is vast, as evidenced by many recent surveys, see for instance Decancq and Lugo (2012), Aaberge and Brandolini (2014), Andreoli and Zoli (2020). We only discuss it insofar as it relates to the Lorenz curve.
Multivariate extensions have been proposed for the Lorenz curve, most notably Taguchi (1972a, 1972b), Arnold (1983), and Koshevoy and Mosler (1996, 1999)111More recently, subsequent to our work, Hallin and Mordant (2022) also adopt a multivariate rearrangement approach to the definition of multi-attribute Lorenz curves. They adopt a center-outward approach (see Hallin et al. (2021)), which is better suited to define notions of middle class.. They are reviewed in Marshall et al. (2011) and Sarabia and Jorda (2014) and discussed in more details in section 1.4.1, where we compare them to our proposal. We contribute to this literature with a vector version of the Gastwirth (1971) formulation of the Lorenz curve. We provide an implementable criterion to measure and compare inequality in multivariate distributions, which emulates the features of the Lorenz curve that most contributed to its success.
The traditional Gastwirth (1971) formulation of the Lorenz curve is an integrated quantile over the lowest ranked individuals. To simplify the argument in the univariate case, model the population as a continuum on and suppose the distribution of incomes in the population is continuous. Then the Gastwirth (1971) formulation can be thought of involving two stages. Take an income allocation , which is a random variable on with cumulative distribution function . First, reorder individuals in the population so that they are ranked in increasing incomes. Then compute the cumulative share of lowest ranked individuals by integrating from to and dividing by the mean. The first step involves the probability integral transform , which should be thought of in this context as a cardinal to ordinal transformation, since is uniform on , so cardinal information is purged, but is increasing, so ordinal information is preserved. Our proposal is based on a multivariate version of the cardinal to ordinal transformation involved in the first stage. The latter is the unique map that transforms a dimensional allocation into a uniform one on , and is cyclically monotone222Existence and uniqueness are shown in McCann (1995). See section 1.1 for details and definitions. and hence preserves ordinal information. This motivates our definition of the vector Lorenz map as the cumulative integral of the multivariate quantile of Chernozhukov et al. (2017).
The vector Lorenz map we propose, therefore, is the vector of shares of each resource held by individuals below a given rank. The associated Lorenz inequality dominance criterion deems a multivariate allocation more equal if this share of resources is larger for each rank. Hence, our proposal shares the interpretation of the traditional Lorenz curve and Lorenz dominance. It also shares the desirable properties of the Lorenz curve and dominance ordering. Like the Lorenz zonoid of Koshevoy and Mosler (1996, 1999), it characterizes the distribution of an allocation (see section 1.4.1 for a definition and discussion). Unlike the Lorenz zonoid, the vector Lorenz map we propose can be efficiently computed as an unconstrained convex optimization problem and connected to recent developments in computational optimal transport theory333An account of recent advances is given in Peyré and Cuturi (2018).. Hence, the Lorenz dominance order we propose is an implementable inequality dominance criterion. Using recent advances on the asymptotic properties of multivariate quantiles, surveyed in Hallin (2022), our Lorenz dominance criterion can be the basis for inequality dominance testing that accounts for sampling uncertainty. This contrasts our proposal with the growing literature on multivariate inequality dominance criteria proposed for finite populations. See for instance Gravel and Moyes (2012), Banerjee (2016), Faure and Gravel (2021) and references within.
Other implementable inequality dominance criteria are proposed in the literature, in Koshevoy (1995), Koshevoy and Mosler (1996), Koshevoy and Mosler (2007) and Banerjee (2016) and other references surveyed in Arnold and Sarabia (2018). However, they do not provide an equivalence between the Lorenz dominance criterion and a class of compatible social evaluation functionals. An exception is Gravel and Moyes (2012) and Faure and Gravel (2021) who give a comprehensive treatment of the special case of a finite population with a single cardinal transferable attribute combined with an ordinal non transferable one. We characterize the class of social evaluation functionals that are inequality averse in the sense that they are increasing in the Lorenz dominance order. We build on the multivariate extension of the Quiggin (1992)-Yaari (1987) rank dependent decision theory in Galichon and Henry (2012) to show that, as in Weymark (1981) for the univariate case, social evaluation functionals are inequality averse if and only if they are rank dependent social evaluation functionals with attribute specific weights decreasing in ranks. We also characterize the class of transfers that increase inequality according to the Lorenz dominance criterion as rank preserving transfers of any attribute from a lower to a higher ranked individual. A special case of such transfers, which we call monotone regressive transfers weakly increase marginal inequality and dependence between attributes.
To visualize Lorenz dominance, we define an Inverse Lorenz Function at a given vector of resource shares as the fraction of the population that cumulatively holds those shares. It is characterized by the cumulative distribution function of the image of a uniform random vector by the Lorenz map. Hence, it is a cumulative distribution function by construction, like the univariate inverse Lorenz curve. In two dimensions, the -level sets of this cumulative distribution function, which we call -Lorenz curves, are non crossing downward sloping curves that shift to the south-west when inequality increases, as defined by the Lorenz ordering. For the cases, where allocations are not ranked in the Lorenz inequality dominance ordering, we propose a family of multivariate S-Gini coefficients based on our vector Lorenz map, with the flexibility to entertain different tastes for inequality in different dimensions. Finally, we propose an illustration to the analysis of income-wealth inequality in the United States between 1989 and 2022.
Plan of the paper
In the first section, we define the Lorenz map, explain its computation, detail its properties and how it compares with alternative proposals. In section 2, we introduce the Lorenz dominance ordering, its characterization in terms of classes of social evaluation functionals and in terms of transfers compatible with it. Section 3 illustrates the implementation of our proposed tools, and the final section concludes.
1. Vector Lorenz Map
1.1. Definition of the Lorenz map
The Lorenz curve was originally proposed in Lorenz (1905) to provide a graphical representation of inequality of distribution of a single resource. Let be a random variable on with cumulative distribution function , which represents the allocation of a resource in a population. The population is modeled as the continuum .
The Lorenz curve is traditionally defined as the set of points in , parameterized by , with coordinates
| (1.1) |
where is the expectation of . See for instance page 149 of Arnold and Sarabia (2018). Gastwirth (1971) points out that the Lorenz curve is given by the graph of the map on
| (1.3) |
where is the traditional quantile function. Formulation (1.3) provides a closed form expression and simple interpretation: For each proportion , the Lorenz map gives the cumulative share of the resource held by the poorest proportion of the population. This relies on the well known fact that the quantile function is the only increasing function such that for any uniformly distributed random variable on , is distributed identically to . Hence, integrating from to and normalizing produces the cumulative share held by the individuals ranked below .
Conversely, when admits a density, the probability integral transform produces a uniformly distributed random variable on , which preserves the ranks of individuals in the population. This holds because is an increasing map. Hence, the probability integral transform removes cardinal information (by producing a uniformly distributed outcome), while preserving ordinal information (by keeping the rank order of individuals in the population). The probability integral transform is the rank associated with allocation .
If is not continuous, then is no longer uniformly distributed (positive masses of individuals have identical ranks). However, it is still the case that for any uniformly distributed random variable on , is distributed identically to . Hence, the closed form solution for the Lorenz map (1.3) still holds with the same interpretation: Integrating from to and normalizing still produces the cumulative share held by the individuals ranked below .
Consider now an allocation of resources in the population. To analyze inequality in allocation , we can first look at inequality in each marginal allocation , using the univariate Lorenz curves . However, this strategy disregards the effect of dependence. The latter is relevant to inequality, as can be trivially illustrated by the fact that for given wealth and income marginal allocations, the comonotonic allocation (the wealthier individuals have higher income) is more unequal than the admittedly unrealistic counter-monotonic allocation (the wealthier individuals have lower income).
To take dependence into account, we propose to emulate the Gastwirth (1971) formulation by measuring cumulative shares of each resource for all individuals, below a certain rank. Conceptually, this is achieved in two steps. First, we find a transformation that removes cardinal information while preserving individual’s ranking in the population, i.e., a cardinal to ordinal transformation. Then we integrate the shares of individuals with lowest rank. The difficulty here, of course, is the absence of a canonical order in to define the rank.
As noted in Faugeras and Rüschendorf (2017), by Borel’s Isomorphism Theorem444See for instance section 13.1 page 487 of Dudley (2002)., there exist measurable bijective maps such that for any uniformly distributed random variable on , is distributed identically to . However, such maps are unsuitable cardinal to ordinal transformations for two main reasons. First, there is no known explicit construction, hence no way to compute them. Second, even if we could compute such a map, its choice would imply an implicit ad hoc aggregation of the different resources in allocation in order to arrive at a scalar ranking of individuals in the population.
In order to avoid an implicit ad hoc aggregation of the different resources in , the cardinal to ordinal transformation must be between and . Hence, we model the population as a continuum on and individual ranks are points in . The multivariate quantile transform, and its inverse (the cardinal to ordinal transform, or rank transform), must satisfy the same requirements as in the univariate case: It must map the uniform distribution (no cardinal information) to the distribution of the allocation, and it must be monotonic (so as to preserve ordinal information). The monotonicity of the quantile in the univariate case ensures that the cardinal to ordinal transformation does indeed preserve the rankings of individuals in the population.
To construct an analogue of the Gastwirth (1971) Lorenz curve formulation, we therefore need the cardinal to ordinal transformation to satisfy a form of multivariate monotonicity. The classical notion of monotonicity in , also known as -monotonicity of a map , requires
for any pair of vectors . It can be interpreted as monotonicity on average. For uniqueness of the cardinal to ordinal transformation, we need the stronger version of monotonicity, called cyclical monotonicity, which characterizes the gradients of convex functions and was introduced by Rockafellar (1966). Cyclical monotonicity requires
for any , and any collection of vectors , setting . Cyclical monotonicity also characterizes maps that minimize distortion in the sense that in case the allocation has continuous distribution with finite variance, minimizes among all the maps such that is uniformly distributed on .
The following definition summarizes the properties needed for a cardinal to ordinal transformation as a first step in the Lorenz map construction.
Definition 1 (Vector quantile).
A vector quantile associated with random vector on is a map with the following properties.
-
(1)
For any uniformly distributed random variable on , is distributed identically to .
-
(2)
If the distribution of is absolutely continuous, is invertible and is uniformly distributed on .
-
(3)
The map is cyclically monotone.
-
(4)
When , is the traditional quantile function (This is automatically satisfied when (1) and (3) hold).
As shown in McCann (1995), there exists a transformation that conforms with definition 1 and it is unique in the sense that two such transformations are equal almost everywhere. It is proposed as a vector quantile notion in Chernozhukov et al. (2017), and we will refer to it as the vector quantile associated with .
Once we model the population as a continuum on , interpret each point on as a rank, and define the vector quantile as a multidimensional rearrangement of the allocation in rank order, we simply integrate the quantile over the lowest ranks to define a multivariate version of the Gastwirth (1971) formulation of the Lorenz curve.
Definition 2 (Lorenz map).
Let be a uniformly distributed random vector on , and let be an allocation, i.e., a random vector on with finite mean . Call the normalized version of , i.e.,
and let be the vector quantile of . The Lorenz map of allocation is the vector-valued function defined for each by
| (1.4) |
The transformation of into its normalized version prior to integrating the vector quantile is required to remove dependence of the Lorenz map of definition 2 on units of measurements. Different resources, such as earnings and health, may not be measured with the same units of measurement. The transformation into makes the allocation unit free. Hence the Lorenz map satisfies ratio-scale invariance (i.e., invariance to rescaling of the different attributes, or change of units of measurement). Section 1.3 discusses an alternative unnormalized version of the definition in the spirit of Shorrocks (1983).
When has absolutely continuous distribution , its quantile function is -almost everywhere invertible (see for instance theorem 2.1 in Chernozhukov et al. (2017)). In that case, the transformation is the vector analogue of the probability integral transform discussed above. The random vector is uniformly distributed on , and is the vector rank of the individual with endowment , in the terminology of Chernozhukov et al. (2017). The Lorenz map of definition 2 can then be rewritten as:
| (1.5) |
This clarifies the interpretation of as the cumulative share of all individuals with vector rank below in the partial order of .
In the scalar case discussed above, inverting the Lorenz curve defined in (1.3) yields the inverse Lorenz curve
| (1.7) |
where the probability is taken with respect to a uniformly distributed random variable on . The scalar inverse Lorenz curve at is therefore shown in (1.7) to be equal to the maximum proportion of the population with cumulative share of the resource equal to . In the vector case, the analogue of the right-hand side of (1.7) can still be used to define an Inverse Lorenz Function.
Definition 3 (Inverse Lorenz Function).
The Inverse Lorenz Function (ILF) of a random vector is the function defined for each by where , inequality is understood component-wise, and the probability is taken with respect to the uniform random vector on .
The expression above is no longer the mathematical inverse of the Lorenz map , but it can still be interpreted as the share of the population with cumulative shares of all resources equal to a predetermined proportion .
1.2. Computation and examples
1.2.1. Computation
We now give a step-by-step method to compute the Lorenz map of a discrete distribution, which may be the allocation in a finite population, or the empirical distribution of a (possibly weighted) sample from an underlying (possibly mixed discrete-continuous) distribution. The full algorithm and a step-by-step guide to implementation in R are given in appendix A.
Let be a random vector in with discrete distribution. The probability mass function of the distribution of is given by , where are vectors in and are positive scalar weights summing to .
-
(1)
First, normalize the allocation vector and form , where is the -th coordinate of and is the mean of , for each . The issue of normalization is discussed in section 1.3.
-
(2)
Then compute the vector quantile of . According to definition 1 (requirements (2) and (4)), the vector quantile must satisfy the following requirements:
-
(a)
For any uniformly distributed random variable on , is distributed identically to . Hence:
-
(i)
For all , ;
-
(ii)
For all
(1.8) has measure .
-
(i)
-
(b)
The map is cyclically monotone. Hence, by Rockafellar (1966), there is a convex function such that is almost everywhere equal to the gradient of .
Since takes a finite number of values and is constant and equal to on each , the computation of is equivalent to the computation of the partition of in regions . As is the gradient of the convex function and is constant on each of the , is affine on each of the , and each is a convex polytope in . Aurenhammer et al. (1998) show
where solves the convex optimization program
(1.9) -
(a)
-
(3)
Once we have computed the vector quantile map , the Lorenz map at is obtained straightforwardly as the integral of the piece-wise constant map over :
(1.12) where the term in is the ordinary area of the convex polytope formed by the intersection of the cell and the rectangle .
-
(4)
Finally, can be used to generate a pseudo sample , where is a uniformly distributed random sample or any pseudo-random (a.k.a. minimum discrepancy) sequence that approximates the uniform distribution on . The Inverse Lorenz Function can then be approximated with the empirical distribution of this pseudo-sample:
(1.13)
1.2.2. Examples
To illustrate the definition and the computation of the Lorenz map, we now explore examples of specific allocations and compute the corresponding Lorenz maps. First, we illustrate the computation of the Lorenz map for a discrete allocation.
Example 1 (Discrete allocations).
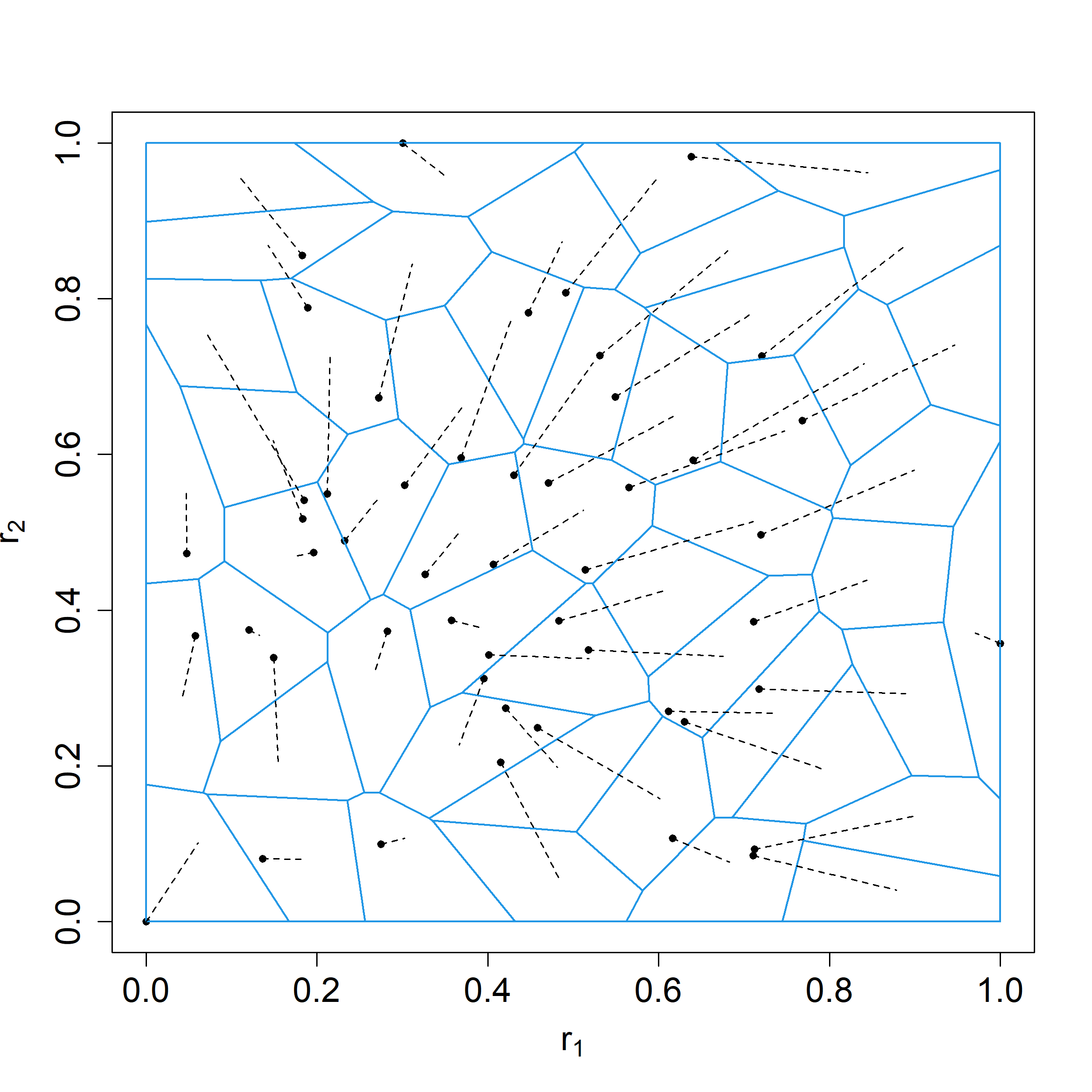
Let be the allocation with probability mass function . We select the support points as the realizations of i.i.d. draws from the bivariate standard normal distribution. The vector quantile of the normalized allocation is characterized by its value on the convex polygon , such that form the partition of shown on the left panel of figure 1. As shown on the right panel of figure 1, the Lorenz map at is equal to the sum of the ’s times the area of intersected with .
Next, we consider the special case, where all individuals are endowed with the same quantity of resources.
Example 2 (Identical allocations).
Let be the constant allocation . Then for all , so that is a -vector with identical entries . The image of is the diagonal in . The Inverse Lorenz Function of is when . For and , and letting , the Inverse Lorenz Function of is
We also check that our definition is compatible with scalar definitions when all resources are independently distributed.
Example 3 (Independent Resources).
Let the components of be independent with marginal Lorenz curves , respectively. Then, the th component of the Lorenz map is . This expression of the Lorenz map has the following interpretation. Consider the first component . The share of resource held by people with multivariate rank in is the marginal share, equal to the marginal Lorenz curve. Since the resources are independent, this share is uniformly distributed along the other dimensions, so that people with ranks in command a share . The other components are interpreted analogously. When and , the Lorenz map takes values . That is, the image of under is the marginal Lorenz curve of the second resource (and symmetrically when ).
The Inverse Lorenz Function of allocation with independent components is
where is the univariate inverse Lorenz curve of .
Next, we derive the Lorenz map in the case of allocations with the same components, i.e., almost surely. We stick to for notational simplicity.
Example 4 (Comonotonic Resources).
Consider bivariate comonotonic allocations. Let the components and of the allocation be almost surely equal. Then, and have identical distributions. Since the distribution of concentrates on the line , the vector quantile depends on only through (it is an index cost in the terminology of Chiappori et al. (2017)). More precisely, it is , where is the optimal transport map from to the distribution of , where has density on given by . Each component of the Lorenz curve is then given by
In case and are uniformly distributed on , the optimal transport map for is given by , so that . We then have,
when , and
when . The image of this Lorenz map is once again the diagonal in .
Letting , the Inverse Lorenz Function of allocation with almost surely, is
where is the -th component, , of , and is the distribution function of .
1.3. Relative scale and normalization
Let be the original allocation. Normalizing into as in definition 2 by dividing each component by its mean, removes any sensitivity to (changes in) units of measurements. It is a standard approach to achieve ratio-scale invariance. See for instance Banerjee (2010, 2016). However, by construction, it comes with the disadvantage of removing scale effects. In the univariate case, Shorrocks (1983) proposes to eschew normalization in order to take scale effects into account in the measurement of inequality.
When units of measurement are not a concern, an alternative definition without the feature described above is defined as
where is the vector quantile of the original allocation (not the normalized one). This alternative version also allows the weighting of different resources according to a priori importance to overall inequality. Call the suitably rescaled version of the initial allocation . Define the sequence of weights in such a way that as . In this way, resources are ordered in decreasing importance to inequality, and we can entertain the extreme lexicographic case, where .
It follows from Carlier et al. (2010) that, when has an absolutely continuous distribution, as tends to , the alternative Lorenz map tends to the map
where is the inverse of the Knothe-Rosenblatt transform of the original allocation proposed by Rosenblatt (1952) and Knothe (1957), and defined as follows
The Knothe-Rosenblatt quantile map is the only multivariate quantile map from the uniform on to proposed in the literature other than optimal transport based vector quantiles as in definition 1. The result above shows that the Knothe-Rosenblatt quantile is not a good alternative to vector quantiles of definition 1 to base an integrated quantile definition for the Lorenz map, since it relies on an a priori lexicographic ordering of the different resources in the allocation.
1.4. Properties and comparisons with other multivariate Lorenz concepts
In this section, we detail previous proposals for multivariate extensions of the Lorenz curve and list the properties that distinguish our proposal from the former.
1.4.1. Alternative multivariate Lorenz proposals
Until now, the development of multivariate extensions of the Lorenz curve was hampered by the lack of simple multivariate analogues of ranks and quantiles. Early proposals for bivariate extensions of the Lorenz curve in Taguchi (1972a,1972b) and Arnold (1983,2012) are based on a direct ad-hoc extension of the traditional formula given in (1.1). Let be the CDF of a bivariate allocation with density and mean . Taguchi (1972a,1972b) proposes the bivariate Lorenz surface defined implicitly by
| (1.15) |
In order to treat both dimensions of the allocation symmetrically, Arnold (1983,2012) proposes the alternative Lorenz surface parameterized by as the set of points
| (1.16) |
where and are the marginal CDFs associated with , and is the expectation of the product . A closed form solution, given in Sarabia and Jorda (2014), makes the Lorenz surface (1.16) amenable to parameterization and statistical analysis. However, it does not share the interpretation or any of the properties of the univariate Lorenz curve.
A more successful proposal in that respect, is the Lorenz zonoid of Koshevoy and Mosler (1996). Again, take (1.1) in the univariate case as the point of departure. It associates a fraction of the population to the share of the resource collectively held by the poorest fraction of the population. Koshevoy and Mosler (1996) eschew the need to order the population by associating with a fraction of the population the share of resources held by any group of individuals making up a fraction of the population, poor, rich, or mixed. The lower bound is the share held by the poorest individuals (the traditional Lorenz curve), and the upper bound is the share held by the richest individuals (a reverse Lorenz curve). The Lorenz zonoid is defined in Koshevoy and Mosler (1996) as the collection of all such shares for each fraction of the population. It is a convex region in bounded below by the Lorenz curve and above by the reverse Lorenz curve. More precisely, the Lorenz zonoid is defined as the set of points
where the function ranges over the set of measurable functions from to . The lower (resp. upper) bound is obtained with the collection of functions (resp. ), .
Since the definition of the Lorenz zonoid does not rely on ranks or quantiles, the extension to higher dimensions is straightforward. Let now be the set of measurable functions from to and be a multivariate allocation with CDF and mean . The Lorenz zonoid of Koshevoy and Mosler (1996) is defined as the set of points
The Lorenz zonoid is an American football-shaped region in with poles at points and . The Lorenz surface of Taguchi (1972a,1972b) is a subset of the Lorenz zonoid, obtained when is restricted to the set of functions , all . A function defines a point in the zonoid. The interpretation is simple in the case of indicator functions. The latter pick out specific groups of individuals in the population and the corresponding point in the zonoid has first coordinate equal to the fraction of the population involved. The other coordinates are the shares of each of the resources held by this group of individuals.
Definition 4.1 of Banerjee (2016) proposes a multivariate inequality ordering in the finite population case. The analogue multivariate Lorenz map in the general case of a (possibly mixed discrete continuous) vector allocation with normalized version can be defined555We thank Xiaoxia Shi for bringing this to our attention. for all by
where, for each , and is the quantile function associated with the random variable . If the latter were replaced by , the Lorenz map would be the vector of marginal Lorenz curves. Mixing with the average across allocation introduces sensitivity to dependence between the marginal allocations. Note however, that is not a valid vector quantile for , since is not distributed like when is uniform on . As a result, is not a vector of resource shares, as is the case for the univariate Lorenz curve.
1.4.2. Properties of the Lorenz map and Inverse Lorenz Function
The proposed multivariate extensions of the Lorenz curve in both Taguchi (1972a,1972b) and Koshevoy and Mosler (1996) relate population proportions to a vector of resource shares. Our proposal differs substantially from these in that it directly relates a specific subset of the population, namely individuals with multivariate rank below to their share of both resources. Beyond this major conceptual difference, we now investigate properties of our multivariate extension of the Lorenz curve that make it a valuable contribution.
-
(1)
Interpretation. Unlike other multivariate proposals, the Lorenz map shares the interpretation of the traditional Lorenz curve as the cumulative share of resources held by the lowest ranked individuals.
-
(2)
Computation. As shown in section 1.2, the Lorenz map can be efficiently computed via convex programming. As an integrated vector quantile, it relies on the growing literature on computational geometry and computational optimal transport, where algorithms and implementations abound and are tested in a variety of applied fields. This is in sharp contrast with the Lorenz zonoid proposed by Koshevoy and Mosler (1996) which is notoriously difficult to compute.
-
(3)
Statistical inference. As an integrated quantile, the Lorenz map is amenable to statistical inference. The convergence of sample analogues of vector quantiles to their theoretical counterpart was shown in Chernozhukov et al. (2017) and Figalli (2018). Vector ranks are distribution free and can be used in rank based statistical procedures that emulate scalar rank-based inference, as shown in Deb and Sen (2023), Ghosal and Sen (2022) and Shi et al. (2022). See the survey in Hallin (2022) and references within.
-
(4)
Uniqueness. The Lorenz map characterizes the distribution of the allocation it is associated with. This property is shared with the Lorenz zonoid of Koshevoy and Mosler (1996), but not the other alternative proposals in the literature.
Proposition 1.
The Lorenz map characterizes the distribution of in the sense that and are identically distributed if and only if .
-
(5)
Lorenz curve as a CDF. The Lorenz map is a map from to . Hence, unlike the traditional scalar Lorenz curve, it cannot be a CDF. However, the Inverse Lorenz Function is the cumulative distribution function of a random vector on by construction. This property is not shared by the alternative proposals in the literature.
-
(6)
Decomposition under independent attributes. As shown in example 3, the Lorenz map reduces to a simple function of the marginal Lorenz curves in case marginal attribute allocations are independent. This feature is shared with the multivariate Lorenz proposal in Arnold (1983,2012) but not the alternative proposals.
-
(7)
Dominance of egalitarian allocations. In the univariate case, the Lorenz curve of the identical allocation almost surely, is , which is sometimes called the egalitarian line. The Lorenz curve of any other allocation is below the egalitarian line, i.e., , for all . For , the identical allocation of example 2 is a direct extension of the univariate notion of egalitarian. We show here that the Lorenz map and Inverse Lorenz Function of the identical allocation provide similar bounds in the multi-attribute case. For this, we require allocations with components that display a form of positive association defined in assumption 1.
Assumption 1.
The vector quantile of is such that, for each , is monotonically increasing in each of the , , where the vector is uniform on .
This assumption imposes a type of positive dependence between the components of through their ranks. More precisely, assumption 1 imposes a form of positive regression dependence, as in Lehmann (1966), between one resource and the others’ ranks. For allocations satisfying assumption 1, we show that Lorenz map and Inverse Lorenz Function of the identical allocation serve as upper and lower bounds, respectively.
Proposition 2.
We argue in appendix C.2 that defining egalitarianism solely by identical allocations is too restrictive in the case of multiple resources. In case , we show that a much larger class of allocations have Lorenz maps dominated by an egalitarian allocation from definition 9, which includes the identical allocation.
2. Multi-attribute inequality comparisons
We can use the vector Lorenz map of an allocation introduced in section 1.1 as a tool to compare inequality of different allocations. We base an inequality dominance criterion to compare different allocations on the dominance of Lorenz maps. We develop a visualization tool for inequality dominance, and an inequality index for the cases, where the allocations are not Lorenz ordered.
2.1. Lorenz dominance
Consider two allocations and , with respective Lorenz maps and . If for some vector rank , the same proportion of the population with vector ranks below commands a larger share of all resources in allocation than in allocation . If this is true for any vector rank in , then, we say that allocation is more unequal than allocation .
Definition 4.
An allocation is said to be more unequal in the Lorenz order than an allocation if for all . We denote this .666As a partial ordering based on cumulative sums of vector quantiles, the relation is a multivariate extension of the concept of majorization of Hardy et al. (1934). It is different from existing multivariate notions of majorization reviewed in Marshall et al. (2011) and Arnold and Sarabia (2018), in that it relies on a multivariate reordering of the random vector allocation.
The Lorenz partial order of definition 4 is an implementable dominance criterion: The Lorenz maps can be computed and compared. The relation is equivalent to stochastic dominance of the random vector , with , over (see Section 3.8 of Müller and Stoyan (2002)). Hence, dominance tests can be derived on the basis of sample analogues of the Lorenz maps to emulate the large literature on inference techniques to compare inequality of distributions of a single attribute. See Davidson and Duclos (2000) and references within.
Following the literature on the measurement of inequality, we assess the value of this implementable dominance criterion for inequality comparisons in two ways. First, we analyze the class of social evaluation functionals that are compatible with the Lorenz order, and show that they are rank-dependent social evaluation functionals, with weights decreasing in rank. Second, we identify the class of transfers that increase inequality as defined by this Lorenz criterion.
2.1.1. Rank-dependent social evaluation functionals
The first way to gain insight into the relevance of our multivariate Lorenz dominance criterion is to characterize the set of social evaluation functionals that are compatible with it. A social evaluation functional is a map from an allocation , i.e., a random vector in , to , which orders allocations in their social desirability. A social evaluation functional is compatible with the dominance criterion if . Compatibility with Lorenz dominance is a form of inequality aversion of the social evaluation functional, since more equal allocations are deemed socially more desirable.
By construction, a social evaluation functional that is compatible with the Lorenz dominance order must satisfy anonymity and ratio-scale invariance. Anonymity, also called law-invariance or symmetry in the literature, refers to the fact that whenever and are identically distributed. The identity of individuals does not matter in the social evaluation, so that a permutation of individuals in the population leaves unchanged. Ratio-scale invariance refers to the fact that for any positive vector . Hence, the social evaluation is not affected by a change in units of measurement.
Next, and more substantively, all social evaluation functionals that are compatible with the Lorenz dominance criterion are rank-dependent social evaluation functionals. Individuals are weighted in the social evaluation according to their rank in the distribution. To define and formalize this statement, start with the case of a single attribute. Weymark (1981) shows that social evaluations that satisfy the comonotonic independence property defined below take the form of weighted sums of quantiles.
Property CI (Comonotonic Independence). A social evaluation functional is said to satisfy comonotonic independence if, whenever , and are comonotonic allocations, and , then, for all , .
In the univariate case, two allocations are called comonotonic if one is a positive increasing function of the other. In other words, individuals are ranked identically in both allocations. Comonotonic independence means that the comparison of two allocations with a common component only depends on the comparison between the two variable components, as long as rankings stay unchanged. As an illustration, when assessing the effect on household income distributions of a policy that only affects women, under perfect assortative matching, one need only look at the change in the distribution of women’s income.
The same property of comonotonic independence can be entertained in the multi-attribute case, with the same interpretation. Two allocations are comonotonic if individuals are ranked identically in both allocations. Now, in case of random vectors and , comonotonicity is defined in the same way by the fact that and have the same vector ranks. Definition 5 below follows Galichon and Henry (2012) and Ekeland et al. (2012), where it is called -comonotonicity777See Puccetti and Scarsini (2010) for a discussion of this and other multivariate comonotonicity concepts. of .
Definition 5 (Vector comonotonicity).
With this definition of comonotonicity (which coincides with the usual definition in the single attribute case), comonotonic independence of a social evaluation functional is still defined as property CI. If individuals are ranked identically in allocations and , and is socially less desirable than , then, adding to both and a third common allocation cannot reverse the ordering, if ranks individuals as and do.
As in Weymark (1981) for the single attribute case, Galichon and Henry (2012) show that comonotonic additive social evaluation functionals are rank dependent, i.e., of the form
| (2.1) |
for some function . To each vector rank , associates the attribute-specific weights of ranked individual in the social evaluation. We show that social evaluation functionals are only compatible with the Lorenz dominance order if they satisfy comonotonic additivity, hence if they are rank-dependent social evaluation functionals. There remains to determine which functions make social evaluation functional compatible with the Lorenz dominance criterion. As we discuss below, they are characterized by inequality aversion.
Inequality aversion of a rank dependent social evaluation functional implies a weighting scheme that gives more weight to lower ranked individuals. In the scalar case analyzed in Weymark (1981), an inequality averse rank dependent social evaluation functional is characterized by decreasing weights as ranks increase. We show a similar result in the multivariate case. Social evaluation functionals that are compatible with the Lorenz order of definition 4 are rank dependent social evaluation functionals with rank-specific weights of the form
| (2.2) |
where is a non negative measure on , all .
Proposition 3.
A social evaluation functional is compatible with the Lorenz dominance order of definition 4 if and only if it is of the form
| (2.3) |
A special case of weighting scheme satisfying proposition 3 is the case all , where all individuals below rank receive weight and all individuals above rank receive weight . More generally, individuals can be given different weights for different resource dimensions, but as non negative mixtures of the indicators , the weights are always decreasing in ranks.
2.1.2. Increasing marginal inequality and increasing correlation
The second way we evaluate our Lorenz dominance criterion is by identifying transfers of resources between individuals that increase inequality according to this criterion. Since inequality is a cardinal aspect of the distribution, we consider a class of transfers that preserves the multivariate ranks. The transfers we consider are functions . If the -th component of transfer is positive (resp. negative), it is added to (subtracted from) the endowment in resource of individual with rank .
Definition 6.
A rank preserving transfer from allocation to allocation is a transfer such that pre-transfer and post-transfer allocations are comonotonic (individuals preserve the same rank). Equivalently, it is a function such that for all , where is the vector quantile of definition 1 associated with the distribution of , and is the component-wise demeaned version of .
First we show that the transfers that increase inequality according to the Lorenz criterion are the arbitrary combinations of rank preserving transfers of a non negative quantity of one of the resources from an individual with rank to an individual with rank .
Proposition 4.
An allocation is more unequal than , i.e., , if and only if an allocation with the same distribution as can be obtained from via an arbitrary sequence of rank preserving transfers such that for all ,
| (2.4) |
The inequality in (2.4) expresses the fact that mass is transferred from lower ranked to higher ranked individuals.
A desirable feature of the Lorenz inequality ordering of definition 4 is its ability to rank two allocations and , when the latter is obtained from the former through a transfer that increases inequality of the marginals or that increases the degree of positive dependence between the marginals. We formalize this feature with a specific type of multivariate transfer we call Monotone Regressive Transfers. We specialize the discussion to bivariate allocations to avoid wading into concepts of increasing multivariate dependence when .
Definition 7 (Monotone Regressive Transfer, MRT).
A transfer is a monotone regressive transfer if is rank preserving and has non-negative Jacobian (i.e., the Jacobian’s entries are all non negative).
In the univariate case, a monotone regressive transfer reduces to a monotone mean preserving spread (Quiggin (1992)), also called Bickel-Lehmann increase in dispersion (Bickel and Lehmann (1976)). In the multivariate case888A related extension in the theory of multivariate risks was proposed in Charpentier et al. (2016)., monotone regressive transfers weakly increase both marginal inequality and positive dependence. The former happens because each component of the transfer has non negative own derivative, hence is increasing in each component of the rank. The latter happens because the transfer has non negative cross derivative, hence increases the degree of positive dependence between the two resources.
Proposition 5 (Monotonicity in MRT).
If an allocation is obtained from an allocation through a monotone regressive transfer, then , i.e., is more unequal than as defined by the Lorenz dominance partial order of definition 4.
Proposition 5 shows that the multivariate Lorenz dominance order of definition 4 therefore ranks an allocation as more unequal if the marginal resource allocations are weakly more unequal and if the marginal resource allocations are weakly more positively dependent. This is in contrast with the Lorenz dominance order based on inclusion of Lorenz zonoids proposed in Koshevoy and Mosler (1996). Indeed, by Proposition 8 in Koshevoy and Mosler (2007), if two allocations have identical marginals, and dominates in the Lorenz dominance order based on Lorenz zonoid inclusion, then and are identically distributed.
The Lorenz dominance ordering of definition 4 does not satisfy the uniform majorization principle proposed by Kolm (1977). In case of discrete populations, the uniform majorization principle stipulates that inequality should be reduced through multiplication by a doubly stochastic matrix different from a permutation. However, as Dardanoni (1993) points out, such transformations can increase correlation and therefore increase inequality in an egregious way. See the discussion in Farina and Savaglio (2006). We show that a similar issue arises with the continuous version of the uniform majorization principle. The latter requires an inequality dominance order to be monotonic with respect to the concave order. From theorem 4 of Galichon and Henry (2012), we deduce that a social evaluation functional that satisfies uniform majorization and comonotonic independence must be equal to
| (2.5) |
up to an affine transformation. We show in appendix C.3 that in the case of bivariate allocation , is minimized when the two components and of allocation are independent, which runs against the intuition that increased dependence can increase inequality999Note that we are considering inequality over outcomes, not welfare inequality. Hence, the point made in Atkinson and Bourguignon (1982), that increased correlation may decrease utilitarian welfare inequality when resources are complements, doesn’t apply here..
2.2. Visualization of Lorenz dominance
Failures of Lorenz dominance can be visualized with the Inverse Lorenz Function. Consider two allocations and , with respective Inverse Lorenz Functions and . If for some vector of shares , a larger proportion of the population commands the same share of resources in allocation than in allocation . Lorenz dominance of allocation over allocation (in the sense of definition 4) implies that the relation holds for each resource share vector (see proposition 9 in the appendix).
In case of bivariate allocations, the latter can be easily visualized on through the relative positions of the level sets of the Inverse Lorenz Function, which we call -Lorenz curves, denoted
The -Lorenz curves provide a visualization of Lorenz dominance. We can compare the inequality of different allocations based on the shape and relative positions of their respective -Lorenz curves. Suppose is less unequal in the Lorenz dominance order than . Then, by proposition 9 in appendix E, for any , . So with . This can be visualized as a shift to the north-east of the -Lorenz curves of the more unequal allocation to the -Lorenz curves of the less unequal allocation .
Figure 2 and 3 display -Lorenz curves of the multivariate lognormal allocation defined by
| (2.6) |
where is the normal distribution, control the dispersion of the respective marginals and controls the degree of dependence.
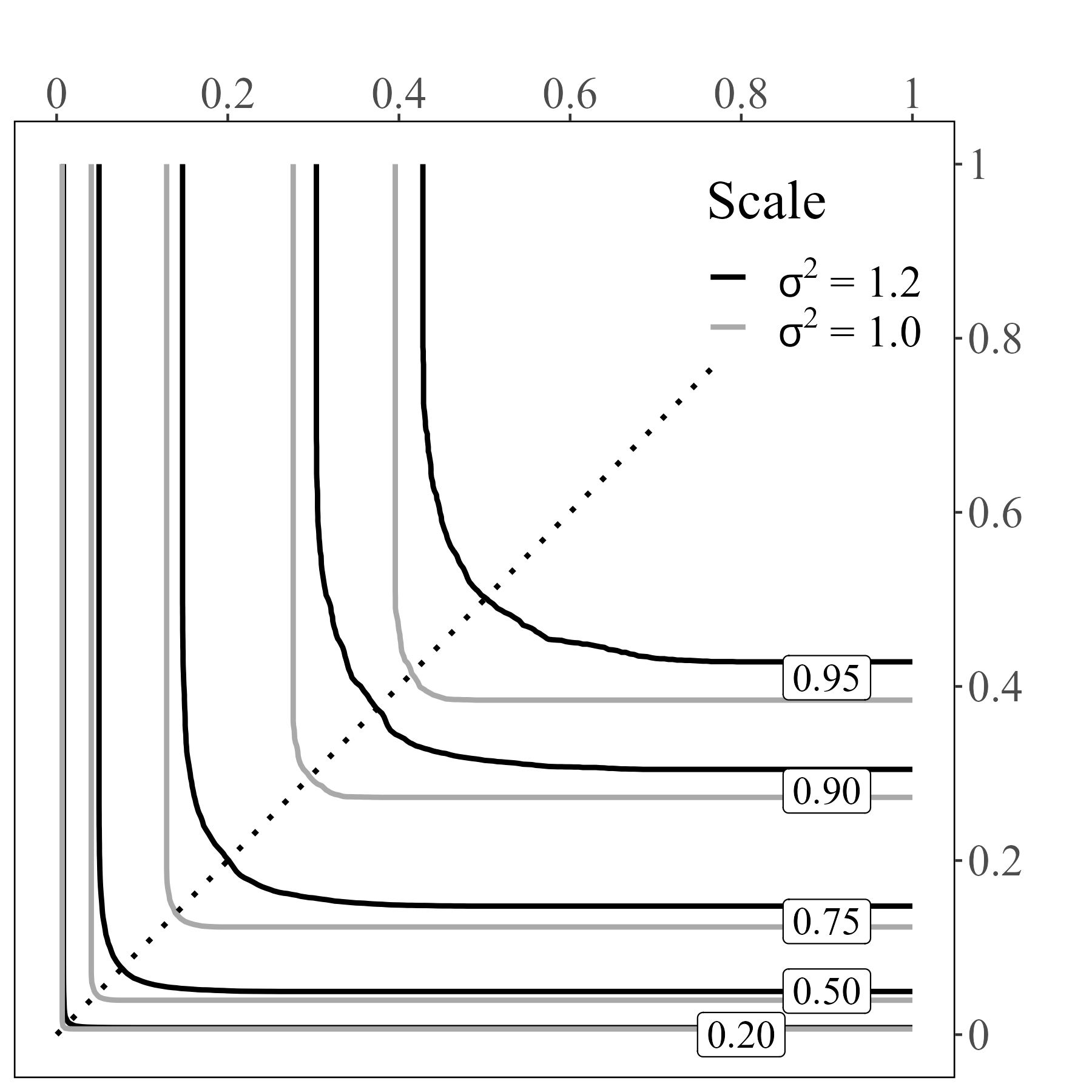
In figure 2, we revisit the three special cases of identical allocations, independent attributes and comonotonic attributes. We also add the counter-monotonic case, where individuals are ranked in opposite order for the two resources, as well as intermediate dependence cases. Figure 2 shows the -Lorenz curve (with ) of the identical allocation compared to multivariate lognormal allocations with variances and correlation coefficients (counter-monotonic), , (independent), , and (comonotonic).
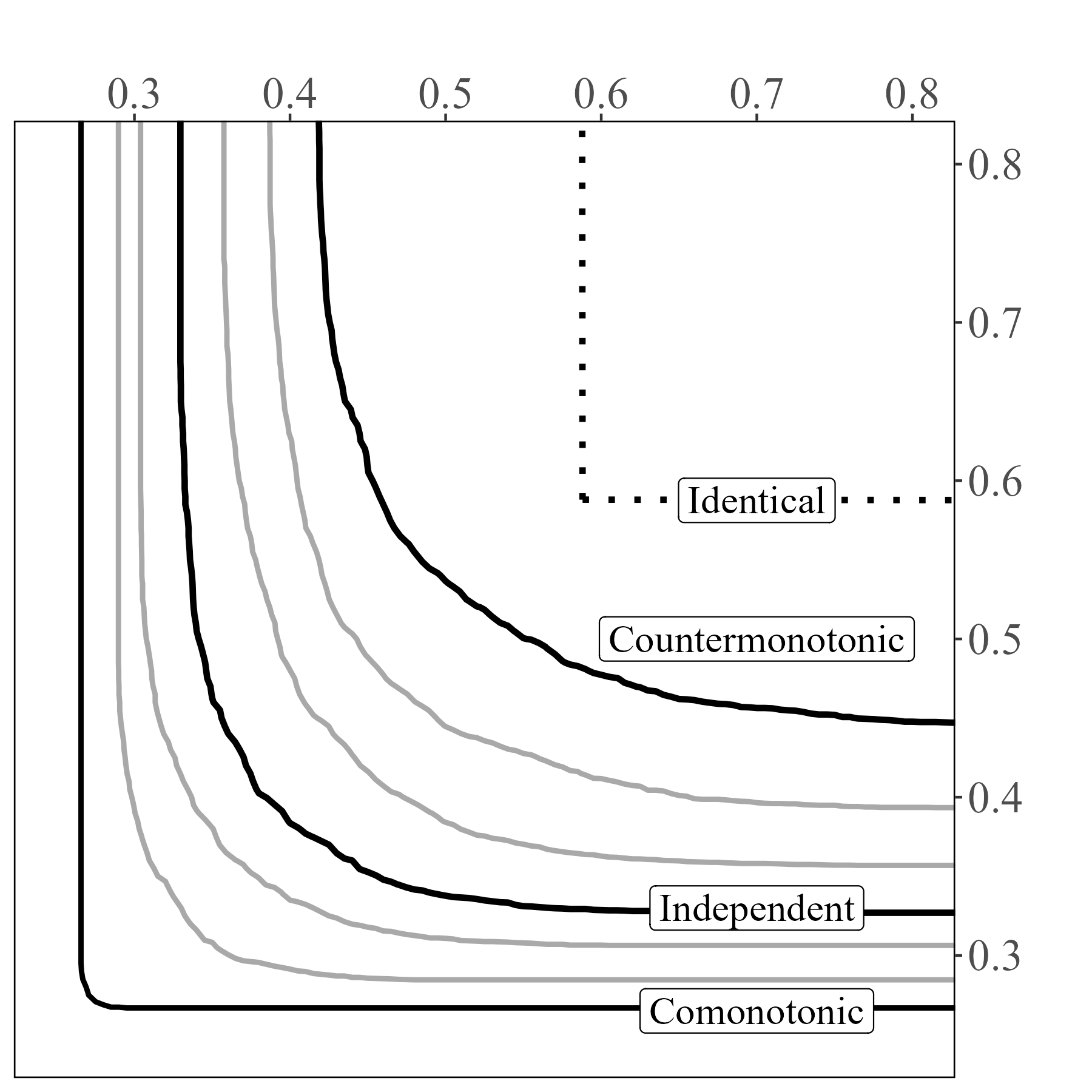
Visually, inequality can be assessed by the departure of -Lorenz curves from those of the identical allocation. This visual comparison is facilitated by the fact that they are shaped like indifference curves. In addition, correlation information is preserved through the curvature of the -Lorenz curves, which decreases when positive dependence increases.
Proposition 6.
(1) The -Lorenz curves are the level curves of a bivariate cdf, hence they are downward sloping, non decreasing in and they do not cross. In addition, (2) The -Lorenz curves are convex if
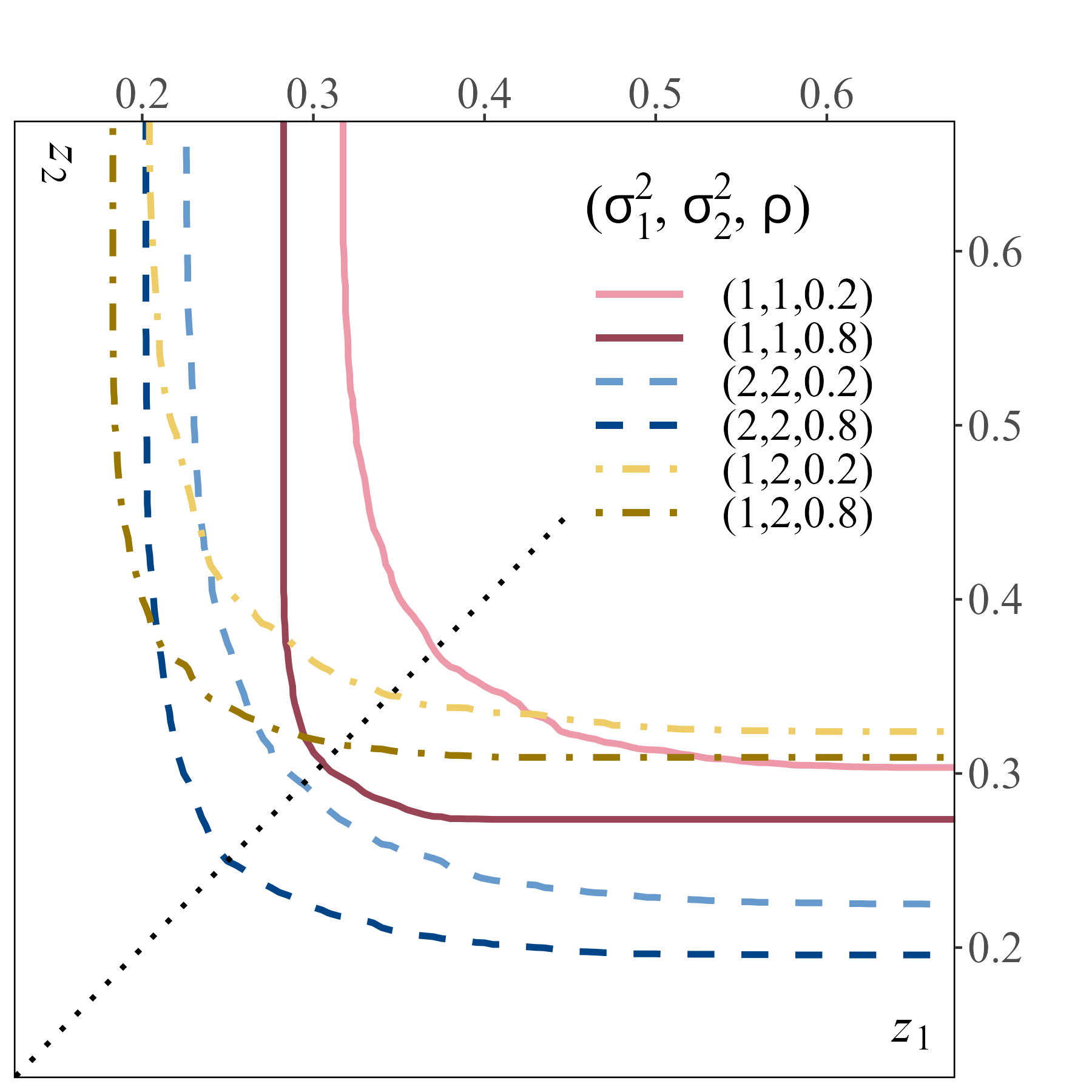
Figure 3 compares -Lorenz curves of different allocations that are multivariate lognormally distributed as in (2.6), for . The parameters and take values or , whereas takes values or . In case of marginals with different , the asymmetry is reflected in the -Lorenz curves. Moreover, other things equal, inequality increases with , which measures inequality in the marginals, and with , which measures correlation.
Finally, figure 4 shows an example of two multivariate lognormally distributed allocations and such that the marginals of are more unequal than those of , but is more unequal overall due to positive dependence of its marginals. Specifically, the marginals of are independent and have the same scale parameter , while has marginals with correlation parameter and scale each. This shows that the Lorenz inequality dominance ordering does not imply dominance of the marginals, and how it can instead incorporate trade-offs between marginal inequality and positive dependence.
2.3. Multivariate Gini inequality index
The Lorenz dominance ordering is a partial ordering of multivariate distributions. In many cases, -Lorenz curves may cross. For a complete inequality ordering, we also propose an extension of the classical Gini index to compare inequality in multi-attribute allocations. Gajdos and Weymark (2005) propose a multivariate Gini coefficient based on aggregation across individuals first, then across dimensions, which removes the effect of dependence across attributes. Decancq and Lugo (2012) propose to aggregate across dimensions first, then across individuals, in order to keep track of correlation. From the volume of the Lorenz zonoid, a multidimensional Gini coefficient can be derived naturally as in Koshevoy and Mosler (1997). An alternative strategy is followed by Arnold (1983), Koshevoy and Mosler (1997), who extend the definition based on the sum of all distances between pairs of individuals.101010Other multivariate Gini indices based on multivariate Lorenz curve proposals include Banerjee (2010), Grothe et al. (2022), and Sarabia and Jorda (2020).
The univariate Gini index can be interpreted as the average deviation from the egalitarian allocation, the univariate version of our identical allocation. We emulate this interpretation and define a multivariate Gini based on an average deviation from the Lorenz map . The deviation measure we propose is
| (2.7) |
where is the -th component of the Lorenz map , with . After normalization, (2.7) becomes
| (2.8) |
which yields the following definition.
Definition 8 (Gini Index).
(2.8) defines the multivariate Gini index of allocation .
The traditional Gini index of a univariate allocation can also be characterized as a weighted sum of outcomes, where the weights are increasing linearly in the rank of the individual in the population. Hence, the negative of the Gini, seen as a social evaluation functional displays inequality aversion by giving more weight to the outcomes of lower ranked individuals than to those of higher ranked ones.
The same interpretation is valid for our multivariate Gini. Specifically,
| (2.9) | |||||
is an inequality averse social evaluation functional of the form (2.3) with uniform measures on in (2.2). So evaluates the social desirability of an allocation with a weighted sum of individual endowments, where the weights are component-wise decreasing in the individual’s rank .
The Gini index correspondingly takes the form with as in (2.9). For instance, in the case of bivariate allocations, (2.8) takes the form
| (2.10) |
In expression (2.10), and are the components of , so that is the sum of the two normalized resource allocations of the individual in the population with vector rank . Hence, the Gini index is indeed a weighted sum of outcomes, with weights increasing with the vector ranks . It is a genuinely multivariate extension in that the weighting scheme, hence the social evaluation of inequality, depends on multivariate ranks of individuals.
- Examples 1 continued
-
Examples 3 and 4 continued
We compare Gini indices in the independent case with the perfect comonotonicity case, where and have the same marginal distributions (uniform on ). We verify (analytically for and numerically using Wolfram for ) that is smaller in the comonotonic case, than in the independent case. Hence the Gini index (and the measure of inequality) is larger in the comonotonic case.
Example 5 (Countermonotone Resources).
If we have a.s., then for almost all , and we obtain , so that, in particular, the Gini index in the countermonotone case is the same as in the case of the identical allocation, i.e., equal to , and both are smaller than the Gini of the allocation with independent resources. This is consistent with the fact that these allocations are considered egalitarian according to definition 9 in appendix C.2.
The Gini index of definition 8 is in under assumption 1. It equals for the identical allocation. It tends to , when the Lorenz map tends to (extreme inequality). The Gini index of an allocation with independent components reduces to the average of classical scalar Ginis of both components. Like the classical scalar Gini index, it preserves the Lorenz inequality ordering, in the sense that higher inequality according to implies a larger value of the Gini index. In other words, implies , so that the negative of the Gini is a compatible social evaluation functional. Hence it inherits the properties of anonymity, scale invariance and comonotonic independence.
Multivariate S-Gini
The multivariate Gini in expression (2.8) is the suitably normalized negative of an inequality averse social evaluation functional of the form (2.3) with uniform measures on in (2.2). It can be extended to reflect varying concern for inequality in different attributes. To achieve this, a multivariate Gini coefficient can be defined as , where is a normalizing constant and is a social evaluation functional that reflects different degrees of inequality aversion in different attributes.
In the univariate case, to reflect varying degrees of inequality aversion, Donaldson and Weymark (1980) propose a single parameter family of Gini coefficients, called S-Gini, defined by
where is the traditional Lorenz curve, and ranges from , corresponding to indifference to inequality, to the Rawlesian extreme at the limit , where only the poorest individual matters111111We were unable to locate a precise statement of this in the literature, so we include it in proposition 10 in the appendix with a proof for completeness..
The S-Gini family of Donaldson and Weymark (1980) can be extended to the assessment of multivariate inequality within our framework. Let be a -dimensional parameter, where , reflects the concern for inequality in attribute . We define the family of multivariate S-Gini coefficients of inequality of an allocation with Lorenz map as
where is a normalizing constant, and is the social evaluation functional
The normalizing constant is chosen such that the multivariate S-Gini lies in and is zero in case of the identical allocation. There remains to verify that the social evaluation functional is indeed of the form (2.3), and hence compatible with the Lorenz order. Indeed, we have
with , for each . The multivariate S-Gini thereby incorporates varying degrees of inequality aversion for different attributes. We recover the S-Gini of Donaldson and Weymark (1980) when , and the multivariate Gini of section 2.3 when , for all , as desired. We also recover Rawelsian limits as tends to zero as formalized in proposition 11 in the appendix.
3. Empirical Illustration
In this section, we apply our methodology to the analysis of income-wealth inequality in the United States between 1989 and 2022, based on the public version of the triennial Survey of Consumer Finances (SCF). Wealth refers to all assets, financial and otherwise. Details of the sampling technique and a discussion of specific features and issues with the data set are given in appendix B. A guide for practical implementation of the computational procedure outlined in section 1.2 is given in appendix A. We refer to inequality displayed by our measure as overall inequality, while specific marginal inequality is described as wealth or income inequality.
3.1. Income-wealth -Lorenz curves
Figure 5 shows the -Lorenz curves for for the years 1989, 2007, 2010, and 2022. There is a general worsening of overall inequality over 3 decades since the curves shift away from the north-east corner. The tight curvature also reflects the positive correlation of income and wealth as in figure 2. Using figure 3 as reference, the skew towards the wealth axis indicates inequality from the wealth marginal is dominant at these -levels, as expected.

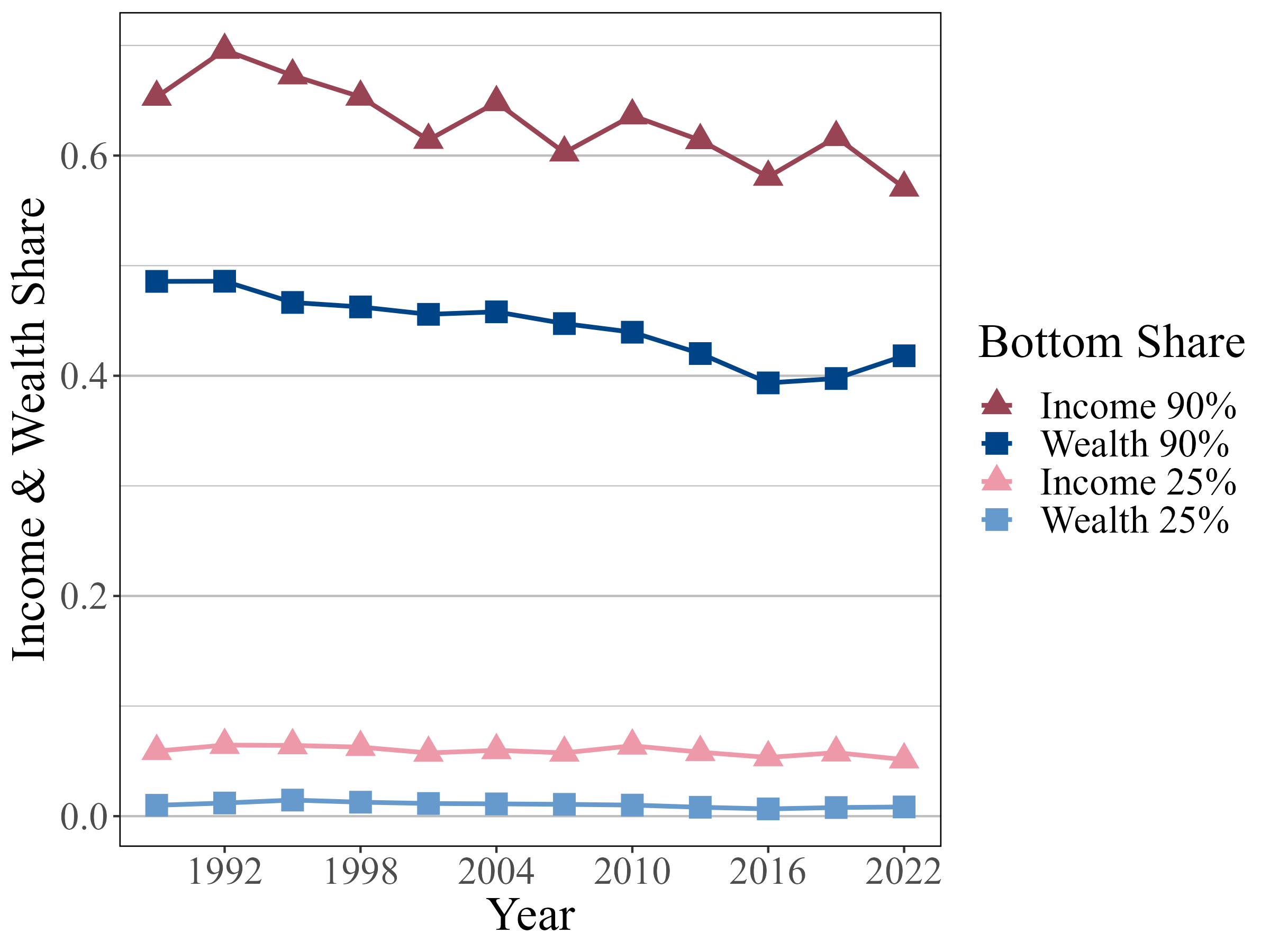
3.2. Resource shares
Figure 6 shows resource shares of the fraction of the the population below rank as well as the fraction121212The fraction of the population is exactly . of the population below rank . The shares in both resources of the bottom have been steadily declining and the shares of wealth are lower than the shares of income. Between 2007 and 2010, we see income shares increasing relatively more than the decrease in wealth shares. Wealth and income shares both fell from 2010 to 2022, explaining the shift in the curves from figure 5. As for the bottom , changes over time are minor compared to those of the bottom .
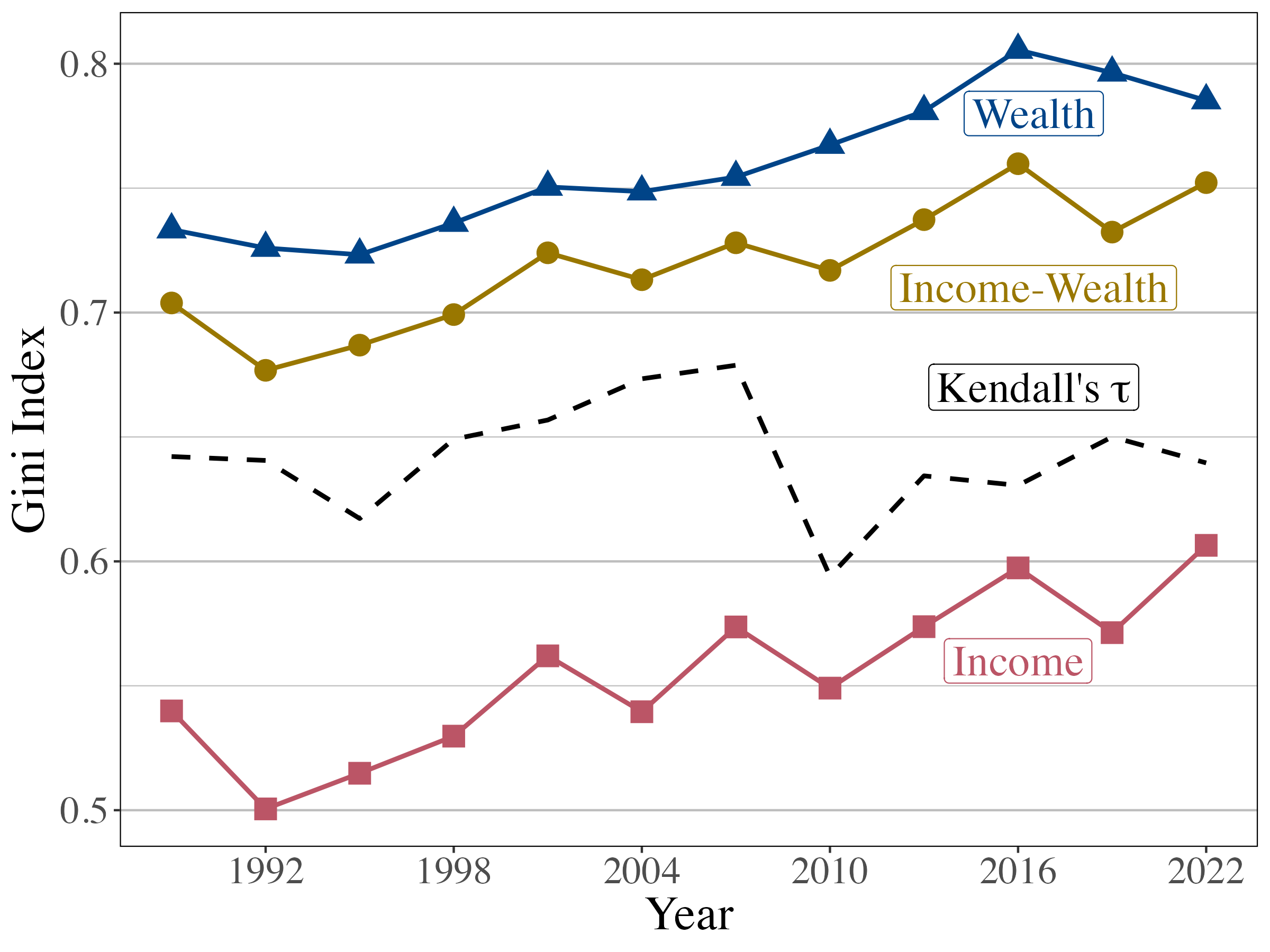
3.3. Gini indices
Figure 7 displays the marginal Gini indices for income and for wealth, the multivariate Gini index based on (2.8), as well as Kendall’s for the dependence between income and wealth over time. The multivariate Gini shows a steady increase in overall inequality. If the resources were independent, the multivariate Gini would be the average of the marginal Ginis. In the present case, the multivariate Gini reveals a positive association between resources since it is higher than the average of the marginal Gini indices. The multivariate Gini shows reduced overall inequality between and . The decreased correlation and income inequality may have been sufficient to offset the rise in wealth inequality.
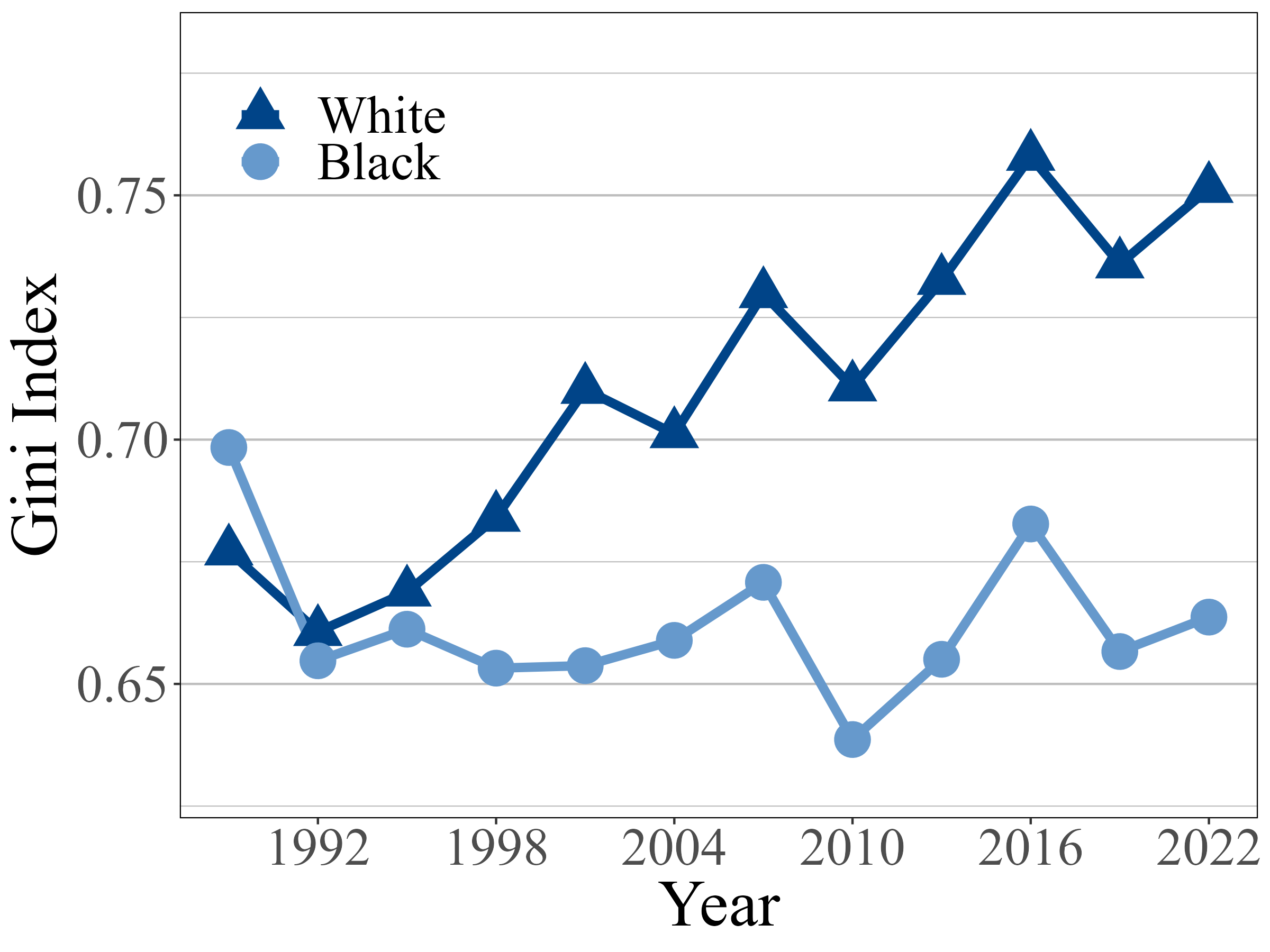
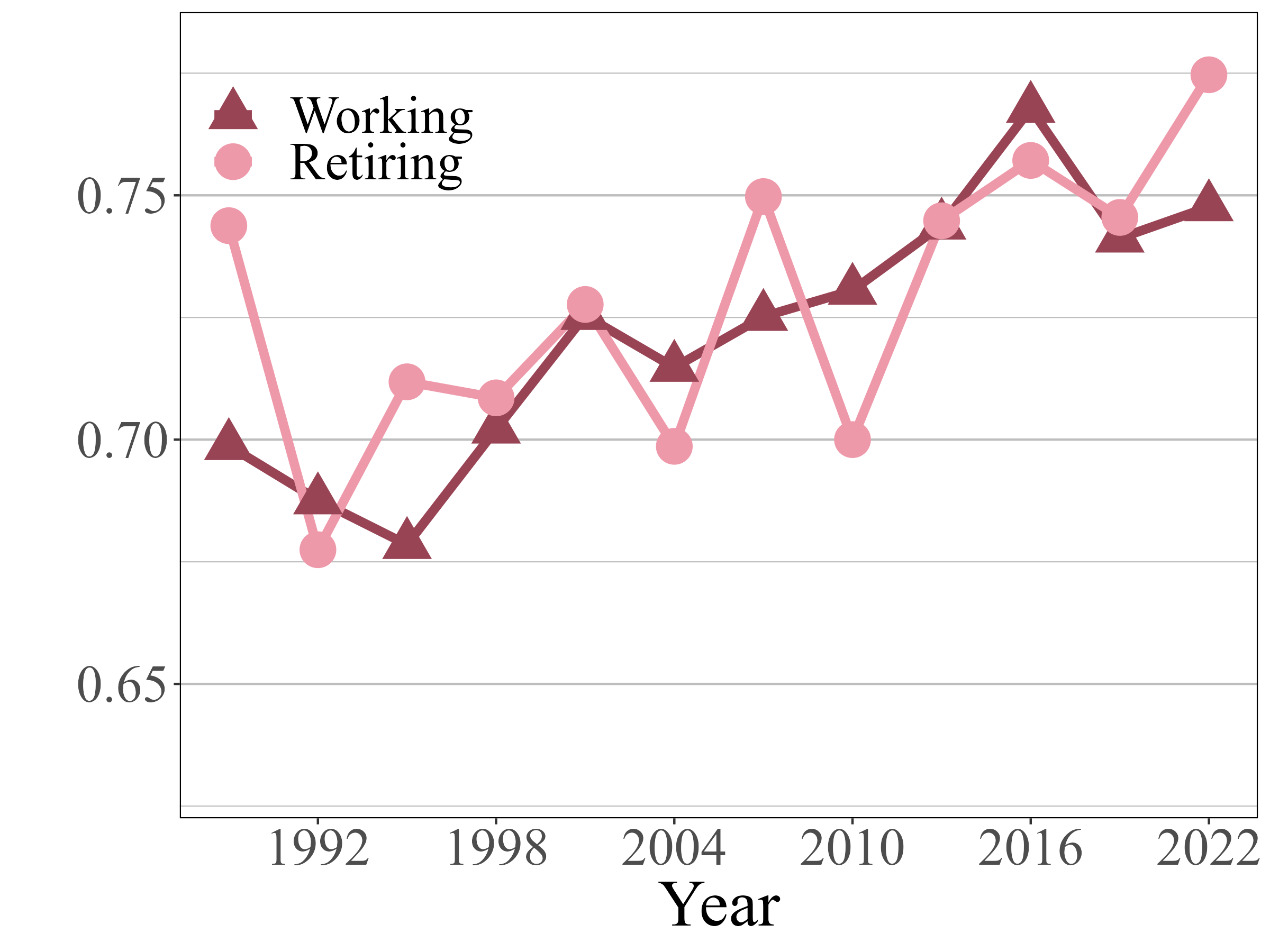
Inequality analysis across groups can reveal further insights. Figure 8 shows Gini indices among White and Black respondents as well as among the working age (64 years and below) and retiring age populations (65 years and above). While overall inequality has worsened among White respondents, the inequality among Black respondents has remained steady. When comparing inequality across age groups, they both exhibit a steady increase in overall inequality, however the multivariate Gini among the retiring age group inherits the variability in the income marginal.
Concluding remarks
In this paper, we propose a new multivariate extension of the Lorenz curve. We propose to emulate the Gastwirth (1971) formulation of the Lorenz curve and define a Lorenz map by integrating vector quantiles of Chernozhukov et al. (2017). The value of the Lorenz map is a vector of shares of each resource held by the poorer section of the population, as in the scalar case. Dominance of Lorenz maps defines a multi-attribute inequality dominance partial ordering. This Lorenz ordering is, like its scalar counterpart, an implementable criterion to compare inequality in allocations. It is, also like its scalar counterpart, equivalent to preference by any inequality averse rank dependent social evaluation functional. We propose an Inverse Lorenz Function and its level sets as a multivariate inequality visual comparison tool, and apply it to income and wealth in the United States between and .
Multi-attribute inequality can vary substantially across population groups, as shown in Maasoumi and Racine (2016) within the information theoretic framework of Maasoumi (1986). There is a tension between heterogeneity across covariates and the anonymity axiom, according to which inequality measurement should not depend on individual’s identities, but only on the distribution of resource allocations. As Kolm (1977) pointed out, this tension is alleviated in part by including more variables in the allocation. This reinforces the motivation for a multidimensional approach to inequality measurement. As for the other potential sources of individual heterogeneity that matters to the social planner, anonymity can be restored by measuring inequality in each subgroup. We illustrate this in figure 8. Beyond this, the conditional approach of Maasoumi and Racine (2016) could also be extended to our framework with the use of conditional vector quantiles in Carlier et al. (2016).
Finally, we argue that a formal test of multi-attribute inequality dominance can be based on our Lorenz map, in analogy to dominance testing based on the traditional Lorenz curve in Davidson and Duclos (2000) and references within. The statistical theory for such a test relies on multivariate stochastic dominance testing and the regularity of optimal transport maps, and is left for future research.
Appendix A User’s implementation guide
In this section, we will point to specific computational routines the reader may use to accomplish each step in section 1.2. All of the figures in this paper were generated via implementations in the R language, however these implementations are standard and can be found in other languages and packages. Algorithm 1 is therefore intended to guide the reader across the key steps of the implementation. We specialize to the case of and leave for the online supplement.
For the vector quantile, the transport package for R provides various implementations to solve (1.9) that are found in the function semidiscrete. Both the standard descent approach of Aurenhammer et al. (1998) and, our preferred, multiscale initialization and L-BGFS approach of Mérigot (2011) are supported methods. Alternatively and for all of our calculations, we used the Rgeogram package that is a wrapper of the C++ Geogram library implementation of Mérigot (2011). Both packages provide the optimal weight vector required for the next steps.
The Lorenz map requires solving for the convex cells defined in (1.10). The optimal from the vector quantile calculation can be used as an input for the power_diagram function in the transport package. It will provide as output the vertices of the convex cells. With a desired rank , the next step is to find the area of the intersection of the convex cells with the rectangle . The sf package provides these tools: first, the function st_polygon transforms the vertices of the cells and rectangle into a “polygon” object that can be then read into st_intersection and st_area, which calculate the intersection and the area, respectively. These two functions can be used to calculate in (1.12) for all .
The Inverse Lorenz Function is calculated as an empirical distribution function. To facilitate drawing -Lorenz curves, it is recommended to form a uniform grid of values and calculate the ecdf at each value, e.g., . Each pair should correspond to a row and column in a matrix of ecdf values. Then, pass this matrix as input into any function that plots contours of three-dimensional surfaces such as the base R function contour or geom_contour as part of the ggplot2 package. Finally, with a sample of Lorenz map values, one can compute the Gini index (2.8) by plug-in.
Appendix B Specific features and issues with the data source
We review some known issues with the data set that impact our analysis. See Hanna et al. (2018) for a more in-depth account.
Sampling strategy
The over sampling of high income and wealthy households is achieved by applying two distinct sampling techniques. The first sample is the core representative sample selected by a standard multi-stage area-probability design. The second is the high income supplement from statistical records derived from tax data by the Statistics of Income (SOI) division of the U.S. Internal Revenue Service. The stages sample disproportionately– usually one-third of the final sample is from the high income supplement. Sampling in this way retains characteristic information of the population while also addressing the known selection biases of the wealthy not responding to surveys. In order to represent the population with this sample, weights must be constructed for each unit of observation. For more details on the construction of weights and their implications on the distribution of wealth, see Kennickell and Woodburn (1999).
Unit of observation and timing of interviews
The observations in this data set are not households, but rather a subset called the primary economic unit (PEU) that may be individuals or couples and their financial dependents. For example in the 2016 data set 13% of PEUs were in a household that contained one or more members not in their PEU. Additionally, the respondent is not necessarily the head of the household, so special care must be taken if analyzing attitudes in relation to some demographic characteristics such as age. The interviews start in May of the survey year, after most income taxes are filed and usually finish by the end of the calendar year, see Kennickell (2017b) for challenges at the end of the interview period. Questions also may change over time so it is important to review the codebook each year when making comparisons across time.
Multiple Imputation
During interviews, respondents may omit answers or provide a range of values for which their response belongs. This missing data impacts analysis and so the SCF contains 5 imputed values for each PEU, creating a sample 5 times larger than the actual number of respondents and forms 5 data sets called implicates. Imputation is done by the Federal Reserve Imputation Technique Zeta model (FRITZ), details can be found in Kennickell (2017a) based upon the ideas of Little and Rubin (2019). Multiple imputation for missing data provide multiple probable values. Each of these form a data set from which sample statistics can be found. The technique of Repeated Imputation Inference (RII) is applied in our analysis. For each implicate , the empirical Inverse Lorenz Function is calculated using the appropriate quantile map estimator taking into account sample weights. Then the repeated-imputation estimate of is
Calculation of the Gini index follows a similar procedure. Accounting for the multiple imputation in the calculation of standard errors is an important issue, but is not revelant to our visualization technique. For more information on multiple imputation and inference with imputed values, see Rubin (1996).
Definition of Wealth
In the literature, there is no consensus on what factors should be included in wealth measurement. Wolff (2021) defines wealth as marketable weath, which is the sum of marketable or fungible assets less the current value of all debts. Bricker et al. (2017) define wealth as net worth including those assets which are not readily transformed into consumption: properties, vehicles, etc. In our analysis we consider all assets, including financial, as our wealth variable.
Appendix C Additional details and results
C.1. Vector ranks and quantiles
Proposition 7 below, a seminal result in the theory of measure transportation (see Villani (2003, 2009)), states essential uniqueness of the gradient of a convex function (hence cyclically monotone map) that pushes the uniform distribution on into the distribution of an allocation .
Following Villani (2003), we let denote the image measure (or push-forward) of a measure by a measurable map . Explicitly, for any Borel set , . The symbol denotes the gradient, and the Jacobian. The convex conjugate of a convex lower semicontinuous function is denoted .
Proposition 7 (McCann 1995).
Let and be two distributions on . () If is absolutely continuous with respect to the Lebesgue measure on , with support contained in a convex set , the following statements hold: there exists a convex function such that . The function exists and is unique, -almost everywhere. () If, in addition, is absolutely continuous on with support contained in a convex set , the following holds: there exists a convex function such that . The function exists, is unique and equal to , -almost everywhere.
Proposition 7 is an extension of Brenier (1991) (see also Rachev and Rüschendorf (1990)). It removes the finite variance requirement, which is undesirable in our context. Proposition 7 is the basis for the definition of vector quantiles and ranks in Chernozhukov et al. (2017). In our context, it is applied with uniform reference measure.131313This vector quantile notion was introduced in Galichon and Henry (2012) and Ekeland et al. (2012) and called -quantile.
In case , gradients of convex functions are nondecreasing functions, hence vector quantiles and ranks reduce to classical quantile and cumulative distribution functions. As the notation indicates, the function of proposition 7 is the convex conjugate of . In case of absolutely continuous distributions on with finite variance, the vector rank function solves a quadratic optimal transport problem, i.e., vector rank minimizes, among all functions such that is uniform on , the quantity , where .
C.2. Egalitarian multi-attribute allocations
C.2.1. Identical allocations: additional details
In this section, we consider bivariate allocations only. A sufficient condition for assumption 1 is supermodularity of the potential function of allocation , as shown in lemma 1 below. We also show in lemma 1, that supermodularity of the potential function also implies positive quadrant dependence of the two components and of , i.e., , for all , see Lehmann (1966).
Lemma 1 (Supermodular potential).
Suppose has a supermodular potential function, i.e.,
Then, assumption 1 holds, and and are positive quadrant dependent.
For allocations satisfying assumption 1, we show that Lorenz map and Inverse Lorenz Function of the identical allocation serve as upper and lower bounds, respectively. Without assumption 1, some allocations may have a Lorenz map that is component-wise larger than the Lorenz map of the identical allocation for some ranks. To illustrate the point, consider the potential . It corresponds to an allocation , whose distribution is supported on the line . Calculating the Lorenz map, we obtain
Notice, in particular, that in the region where . If the implicit relative price of resource is , allocation is an egalitarian allocation, since all individuals have equal budgets. However, this allocation does not satisfy assumption 1 and its Lorenz map is not dominated by as we have shown. This apparent departure from properties of the scalar Lorenz curve is due to the fact that an allocation with a.s. can also be considered egalitarian, as we discuss in the following section.
C.2.2. Egalitarian allocations
The identical allocation with Lorenz map is a very special instance of egalitarian allocation. We extend this narrow notion of egalitarian allocation to include income egalitarianism, in the terminology of Kolm (1977). In the special case where the two resources are transferable with relative price of the second resource, an allocation is deemed egalitarian if all agents have the same budget endowment, i.e., if (where the constant value is derived from the normalization ). In the general case of non (or imperfectly) transferable resources, we call egalitarian the allocations with equalized shadow budgets.
Definition 9 (Egalitarian allocation).
An allocation such that a.s., for some , is called egalitarian.
Another way to interpret egalitarianism of such an allocation, beyond shadow budget equality, is through the perfect compensation of inequality in the marginal resource allocations by perfect negative correlation between resource allocations. The vector quantile and Lorenz map of egalitarian allocations can be characterized in the following way.
Proposition 8.
Let be a random vector with distribution . An egalitarian allocation such that , admits potential for some convex function such that and allocation is equal in distribution to ; The Lorenz map is given by
If, in addition, denotes the quantile function of , then
where is the cdf of the random variable ; see lemma 2 below for an explicit expression for .
Lemma 2 (Explicit formula for ).
The cumulative distribution function of with is given by the following.
We see in proposition 8 that the distribution of the egalitarian allocation is entirely determined by the convex function , which is itself determined by the distribution of one of the marginals of . This follows from the deterministic linear relationship between the two resource allocations. The perfect negative correlation compensates any inequality in the marginal allocations.
With this definition of egalitarian allocations, we show that a large class of allocations are dominated in the Lorenz order by egalitarian allocations, and that egalitarian allocations are maximal in the Lorenz order of definition 4.
Assumption 2.
For some , the potential of allocation satisfies for all :
Before stating the main result of this section, which is an extension of property (7) in section 1.4.2, we discuss sufficient conditions for assumption 2 and examples of classes of allocations that satisfy assumption 2. The following lemma provides sets of sufficient conditions based on a suitable choice of .
Lemma 3 (Sufficient condition for assumption 2).
An allocation with potential satisfies assumption 2 if any of the following conditions hold.
-
The potential is supermodular.
-
The potential satisfies:
(C.4) -
The function
is positive and constant equal to over and, for all , the Hessian of is constant over .
The first sufficient condition in lemma 3, i.e., supermodularity of the potential , imposes a form of positive dependence between the two resources, which implies assumption 2 (and 1). However, assumption 2 also accommodates allocations that do not exhibit positive dependence. For instance, the mixture of an egalitarian allocation with a positively dependent one satisfies assumption 2.
Example 6.
An allocation with potential , with convex, and ultramodular, satisfies assumption 2. It mixes a perfectly negatively correlated allocation with a positively dependent one.
Aspecial case of condition (2) in lemma 3 is the case, where is a quadratic function, hence has a constant Hessian. Indeed, in that case, convexity of immediately yields (C.4).
Example 7.
All allocations with quadratic potential with , i.e., allocations of the form , with , satisfy assumption 2.
Sufficient condition (2) in lemma 3 can also be used to show that allocations where the two marginal resource allocations are independent also satisfy assumption 2. More generally, a large class of allocations defined as deviations from independence satisfy assumption 2 as formalized in the following example.
Example 8.
An allocation with potential satisfies assumption 2 if , , and with . The case is the case of independent marginal allocations.
Assumption 2 is not satisfied, however, in case and are perfectly negatively dependent, i.e., with increasing , when is nonlinear.
Under assumption 2, we can complement property (7) in section 1.4.2 and emulate the traditional property of Lorenz curves, which are maximal at perfect equality. Here we show that egalitarian allocations dominate all allocations that satisfy assumption 2, and are themselves undominated thereby forming a class of distributions that are maximal under the Lorenz order.
-
Property (7) continued
[Lorenz map maximal at egalitarian allocations] For any allocation satisfying assumption 2, there is an egalitarian allocation such that , i.e., for all . In addition, if two egalitarian allocations are ranked in the Lorenz order, then they are equal.
C.2.3. Proofs for section C.2
Proof of lemma 1.
Let . Let , . Then is distributed identically to . Since is monotonically increasing in , we have . Hence
Under the stated assumption, is increasing in and . Since , we have
where denotes the cumulative distribution function of conditional on . Now is increasing in , since
Similarly is increasing in . We conclude that , see e.g. Joe (1997). ∎
Proof of proposition 8.
The potential of an egalitarian allocation satisfies . Solutions are of the form
Convexity of implies convexity of . The normalization
implies
The latter, in turn, implies
Call the cdf of , where . Call the cdf of , which is the first marginal of allocation . Then
Now
Hence
as desired. ∎
Proof of lemma 3.
A sufficient condition for assumption 2 is
If we choose the optimal value of , i.e.,
we get the sufficient inequality
as desired. ∎
Proof of example 2.
Let , with convex and twice continuously differentiable, and ultramodular. We have, for
Also,
Therefore
∎
Proof of “property (7) continued” in C.2.2.
Define
Under assumption 2,
Hence is an ultramodular function. Applying the proof of property (7) in section 1.4.2, we find that for all ,
Hence
where as desired.
We now show that egalitarian allocations do not dominate each other. Suppose an egalitarian allocation with potential dominates an allocation with potential . Then
Hence, for all ,
so that both allocations have the same Lorenz map, hence are equally distributed. ∎
C.3. Uniform Majorization
In this section, we show the undesirable feature of uniform majorization detailed in section 2.1.2. Galichon and Henry (2012) show that the only rank dependent social evaluation functional (up to an affine transformation) that satisfies the uniform majorization principle of Kolm (1977) is given in (2.5). We now show that it is unsuitable as a tool to measure multivariate inequality with the following two observations about bivariate allocations . First, the following expression shows that only depends on , hence, on very specific features of the dependence between the two components and of allocation .
| (C.10) |
Second, and more troubling still, for any given fixed marginals for and , is minimized when and are independent. Indeed, we show below that is always larger than minus the average of univariate Gini coefficients, which is its value when the marginals are independent.
| (C.11) |
where and denote the classical scalar Gini index of components and respectively.
Proof of (C.10).
Let be uniformly distributed on . Note that
Now,
where the last equality follows from interchangeability of the order of integration and is the first component of the Lorenz map. Note that
and
Therefore
Similarly, we have , as desired. ∎
Proof of (C.11).
The inequality follows from and . We now prove the latter. Letting be the vector quantile function of , note that since pushes uniform measure on forward to law, we can write
where is the quantile of the random variable . Note that the area of the domain of integration must be . On the other hand,
is an integral of the same function over a region with the same area. Writing , we have , where and and the union is disjoint. Similarly, where . Note that the areas of and must be the same, , and throughout while throughout . We have
Note that this inequality holds for any dependence structure between and . ∎
Appendix D Inequality Dominance based on the Inverse Lorenz Function
We can also define an increasing inequality order based on the Inverse Lorenz Functions. Consider two allocations and , with respective Inverse Lorenz Functions and . If for some vector of shares , a larger proportion of the population commands the same share of resources in allocation than in allocation . If this is true for any vector of resource shares in , then, we say that allocation is more unequal than allocation .
Definition 10.
An allocation is said to be more unequal in the weak Lorenz order than an allocation if for all . We denote this .
The relation is equivalent to lower orthant dominance of the random vector , with , over (see Section 3.8 of Müller and Stoyan (2002)). In the scalar case, the orderings of definitions 4 and 10 both coincide with the traditional Lorenz ordering. In higher dimensions, however, the equivalence may not hold141414We have not been able to either prove the equivalence or find a counterexample.. Nonetheless, as the name indicates, the weak Lorenz inequality order of definition 10 is weaker than the Lorenz order of definition 4, as we show in proposition 9.
Proposition 9.
Appendix E Proofs of the main results
Recall that in the proofs, we shall use the notation for the vector quantile of a random vector and call convex function the transport potential associated with the distribution of . See section C.1 for details. In this section, we omit the subscript of for notational compactness.
Proof of proposition 1.
In case , the off diagonal elements of the Jacobian of are and . From the latter, by differentiation, we can recover . The result then follows from the fact that characterizes , see for instance Chernozhukov et al. (2017). The result extends straightforwardly to . ∎
Proof of proposition 2.
We only need to show the result for one component of the Lorenz map and the others follow with similar reasoning. We have for the first component
Now define . Then
is monotone increasing in , since it is the integral of the functions , which are monotonically increasing by assumption. Therefore, is convex and so . Note that as an integral over a degenerate interval, so . A very similar argument yields , so that , and, iterating in this way, we eventually obtain,
We then conclude
The integral is , as the expected value of the normalized , and so we obtain the desired result. ∎
Proof of proposition 3.
We need to show that a social evaluation functional of the form (2.1) satisfies
if and only if is of the form (2.2). To show this, we note that
So sufficiency holds for all non-negative measures. Necessity follows by taking one of the measures as a degenerate measure and the other measures as trivial measures. ∎
Proof of proposition 4.
It suffices to see that if and only if
∎
Proof of proposition 5.
Suppose is obtained from through an MRT, so that there is a supermodular and component-wise convex function , such that holds for all . We want to show , i.e., . Consider the first component:
by convexity.
Now, note that supermodularity implies the function is convex with respect to , and it is clearly when . Therefore,
Similarly,
Continuing iteratively in this way, we eventually obtain:
Similar reasoning applies to the other components, and the result follows. ∎
Proof of proposition 6.
(1) Let . Since is a cdf, hence non decreasing in both arguments, then is non increasing in and non decreasing in . (2) See Claim 1 in Brock and Thomson (1966). ∎
Proposition 10.
(Rawlesian limits of social welfare functions) For a random variable in , define, as in Section 2.3, the social welfare function:
Then .
Proof of proposition 10.
Integrating by parts implies
for any positive integer . As the quantile is increasing, we then have
where the function tends to as .
Similarly, we have
where tends to as . We therefore have
As this holds for every integer , and , the result follows. ∎
The following is a multivariate extension:
Proposition 11.
Let be a dimensional random variable and its multivariate quantile. Consider the th term in the sum defining the multivariate S-Gini in Section 2.3:
Then
where .
Note that the expression is a measure of inequality among agents with lowest rank in the th component, with weighting functions in the other rank variables as in the standard Gini index.
Proof.
The proof is similar to the argument above. Without loss of generality, we assume . Integrating by parts, we have, for any positive integer :
Using monotonicity of in the first argument, we then have:
| (E.1) |
where converges monotonically to as .
Therefore, using the monotone convergence theorem, we have
As this holds for all , and is monotone in the first argument, we can take the limit as and apply the monotone convergence theorem again to obtain
A very similar argument to the one used to derive (E) then implies:
where converges monotonically to as . Proceeding as above gives
which implies the desired conclusion. ∎
References
- Aaberge and Brandolini [2014] R. Aaberge and A. Brandolini. Multidimensional poverty and inequality. Discussion Papers, No. 792, Statistics Norway, Research Department, Oslo, 2014.
- Andreoli and Zoli [2020] F. Andreoli and C. Zoli. From unidimensional to multidimensional inequality: a review. Metron, 78:5–42, 2020.
- Arnold [2008] B. Arnold. The Lorenz curve: Evergreen after 110 years. In Advances on Income Inequality and Concentration Measures. Routledge, 2008.
- Arnold [1983] B. C. Arnold. Pareto Distributions. International Co-operative Publishing House, 1983.
- Arnold [2012] B. C. Arnold. Majorization and the Lorenz order: A brief introduction. Springer Science & Business Media, 2012.
- Arnold and Sarabia [2018] B. C. Arnold and J. M. Sarabia. Majorization and the Lorenz order with Applications in Applied Mathematics and Economics. Springer, 2018.
- Atkinson and Bourguignon [1982] A. Atkinson and F. Bourguignon. The comparison of multi-dimensioned distributions of economic status. Review of Economic Studies, 49:183–201, 1982.
- Aurenhammer et al. [1998] F. Aurenhammer, F. Hoffmann, and B. Aronov. Minkowski-type theorems and least-squares clustering. Algorithmica, 20:61–76, 1998.
- Banerjee [2010] A. Banerjee. Multidimensional Gini index. Mathematical Social Sciences, 60:87–93, 2010.
- Banerjee [2016] A. Banerjee. Multidimensional Lorenz dominance: A definition and an example. Keio Economic Studies, 52:65–80, 2016.
- Bickel and Lehmann [1976] P. Bickel and E. Lehmann. Descriptive statistics for nonparametric models, iii. dispersion. Annals of Statistics, 4:1139–1158, 1976.
- Brenier [1991] Y. Brenier. Polar factorization and monotone rearrangement of vector‐valued functions. Communications on Pure and Applied Mathematics, 4:375–417, 1991.
- Bricker et al. [2017] J. Bricker, L. J. Dettling, A. Henriques, J. W. Hsu, L. Jacobs, K. B. Moore, S. Pack, J. Sabelhaus, J. Thompson, and R. A. Windle. Changes in US family finances from 2013 to 2016: Evidence from the survey of consumer finances. Fed. Res. Bull., 103:1, 2017.
- Brock and Thomson [1966] W. Brock and R. Thomson. Convex solutions of implicit relations. Mathematics Magazine, 39:208–111, 1966.
- Carlier et al. [2010] G. Carlier, A. Galichon, and F. Santambrogio. From Knothe’s transport to Brenier’s map and a continuation method for optimal transport. SIAM Journal on Mathematical Analysis, 41:2554–2576, 2010.
- Carlier et al. [2016] G. Carlier, V. Chernozhukov, and A. Galichon. Vector quantile regression: An optimal transport approach. Annals of Statistics, 44:1165–1192, 2016.
- Charpentier et al. [2016] A. Charpentier, A. Galichon, and M. Henry. Local utility and multivariate risk aversion. Mathematics of Operations Research, 41:266–276, 2016.
- Chernozhukov et al. [2017] V. Chernozhukov, A. Galichon, M. Hallin, and M. Henry. Monge-Kantorovich depth, quantiles, ranks and signs. Annals of Statistics, 45:223–256, 2017.
- Chiappori et al. [2017] P.-A. Chiappori, R. McCann, and B. Pass. Multi to one-dimensional transport. Communications on Pure and Applied Mathematics, 70:2405–2444, 2017.
- Dardanoni [1993] V. Dardanoni. Measuring social mobility. Journal of Economic Theory, 61:372–394, 1993.
- Davidson and Duclos [2000] R. Davidson and J.-Y. Duclos. Statistical inference for stochastic dominance and for the measurement of poverty and inequality. Econometrica, 68:1435–1464, 2000.
- Deb and Sen [2023] N. Deb and B. Sen. Multivariate rank-based distribution-free nonparametric testing using measure transportation. Journal of the American Statistical Association, 118:192–207, 2023.
- Decancq and Lugo [2012] K. Decancq and M. Lugo. Inequality of wellbeing: A multidimensional approach. Economica, 79:721–746, 2012.
- Donaldson and Weymark [1980] D. Donaldson and J. Weymark. Single parameter generalizations of Gini indices of inequality. Journal of Economic Theory, 22:67–86, 1980.
- Dudley [2002] R. Dudley. Real Analysis and Probability. Cambridge University Press, 2002.
- Ekeland et al. [2012] I. Ekeland, A. Galichon, and M. Henry. Comonotone measures of multivariate risks. Mathematical Finance, 22:109–132, 2012.
- Farina and Savaglio [2006] F. Farina and E. Savaglio, editors. Three approaches to the analysis of multidimensional inequality, chapter 10. Routledge, 2006.
- Faugeras and Rüschendorf [2017] O. Faugeras and Rüschendorf. Markov morphisms: A combined copula and mass transportation approach to multivariate quantiles. Mathematica Applicanda, 45:3–45, 2017.
- Faure and Gravel [2021] M. Faure and N. Gravel. Reducing inequalities among unequals. International Economic Review, 62:357–404, 2021.
- Figalli [2018] A. Figalli. On the continuity of center-outward distribution and quantile functions. Nonlinear Analysis, 177:413–429, 2018.
- Fisher [1956] F. Fisher. Income distribution, value judgments and welfare. Quarterly Journal of Economics, 70:380–424, 1956.
- Gajdos and Weymark [2005] T. Gajdos and J. Weymark. Multidimensional generalized Gini indices. Economic Theory, 26:471–496, 2005.
- Galichon and Henry [2012] A. Galichon and M. Henry. Dual theory of choice under multivariate risks. Journal of Economic Theory, 147:1501–1516, 2012.
- Gastwirth [1971] J. L. Gastwirth. A general definition of the Lorenz curve. Econometrica, 39:1037–1039, 1971.
- Ghosal and Sen [2022] P. Ghosal and B. Sen. Multivariate ranks and quantiles using optimal transport: Consistency, rates, and nonparametric testing. Annals of Statistics, 2022.
- Gravel and Moyes [2012] N. Gravel and P. Moyes. Ethically robust comparisons of bi-dimensionnal distributions with an ordinal attribute. Journal of Economic Theory, 147:1384–1426, 2012.
- Grothe et al. [2022] O. Grothe, F. Kächele, and F. Schmid. A multivariate extension of the Lorenz curve based on copulas and a related multivariate gini coefficient. Journal of Economic Inequality, 20:727–748, 2022.
- Hallin [2022] M. Hallin. Measure transportation and statistical decision theory. Annual Review of Statistics and Its Application, 9:410–424, 2022.
- Hallin and Mordant [2022] M. Hallin and G. Mordant. Center-outward multiple-output Lorenz curves and Gini indices a measure transportation approach. Unpublished manuscript, 2022.
- Hallin et al. [2021] M. Hallin, E. del Barrio, J. Cuesta-Albertos, and C. Matrán. Distribution and quantile functions, ranks and signs in dimension d: A measure transportation approach. Annals of Statistics, 49:1139–1165, 2021.
- Hanna et al. [2018] S. D. Hanna, K. T. Kim, and S. Lindamood. Behind the numbers: Understanding the survey of consumer finances. Journal of Financial Counseling and Planning, 29:410–418, 2018.
- Hardy et al. [1934] G. Hardy, J. Littlewood, and G. Pólya. Inequalities. Cambridge University Press, 1934.
- Joe [1997] H. Joe. Multivariate Models and Multivariate Dependence Concepts. Chapman and Hall, 1997.
- Kennickell [2017a] A. Kennickell. Multiple imputation in the survey of consumer finances. Statistical Journal of the IAOS, 33:143–151, 2017a.
- Kennickell [2017b] A. B. Kennickell. The bitter end? The close of the 2007 SCF field period. Statistical Journal of the IAOS, 33:93–99, 2017b.
- Kennickell and Woodburn [1999] A. B. Kennickell and R. L. Woodburn. Consistent weight design for the 1989, 1992 and 1995 SCFs, and the distribution of wealth. Review of Income and Wealth, 45:193–215, 1999.
- Knothe [1957] H. Knothe. Contributions to the theory of convex bodies. Michigan Mathematical Journal, 4:39–52, 1957.
- Kolm [1977] S.-C. Kolm. Multidimensional egalitarianisms. The Quarterly Journal of Economics, 91:1–13, 1977.
- Koshevoy [1995] G. Koshevoy. Multivariate Lorenz majorization. Social Choice and Welfare, 12:93–102, 1995.
- Koshevoy and Mosler [1996] G. Koshevoy and K. Mosler. The Lorenz zonoid of a multivariate distribution. Journal of the American Statistical Association, 91:873–882, 1996.
- Koshevoy and Mosler [1997] G. Koshevoy and K. Mosler. Multivariate Gini indices. Journal of Multivariate Analysis, 60:252–276, 1997.
- Koshevoy and Mosler [1999] G. Koshevoy and K. Mosler. Price majorization and the inverse Lorenz function. Discussion Papers in Statistics and Econometrics 3/99, University of Cologne, 1999.
- Koshevoy and Mosler [2007] G. Koshevoy and K. Mosler. Multivariate Lorenz dominance based on zonoids. AStA, 91:57–76, 2007.
- Lehmann [1966] E. L. Lehmann. Some concepts of dependence. The Annals of Mathematical Statistics, 37:1137–1153, 1966.
- Little and Rubin [2019] R. J. Little and D. B. Rubin. Statistical analysis with missing data, volume 793. John Wiley & Sons, 2019.
- Lorenz [1905] M. Lorenz. Methods of measuring the concentration of wealth. Publication of the American Statistical Association, 9:209–219, 1905.
- Maasoumi [1986] E. Maasoumi. The measurement and decomposition of multi-dimensional inequality. Econometrica, 54:991–997, 1986.
- Maasoumi and Racine [2016] E. Maasoumi and J. Racine. A solution to aggregation and an application to multidimensional ‘well-being’ frontiers. Journal of Econometrics, 191:374–383, 2016.
- Marshall et al. [2011] A. W. Marshall, I. Olkin, and B. C. Arnold. Inequalities: Theory of Majorization and Its Applications. Springer, 2nd edition, 2011.
- McCann [1995] R. J. McCann. Existence and uniqueness of monotone measure-preserving maps. Duke Mathematical Journal, 80:309–323, 1995.
- Mérigot [2011] Q. Mérigot. A multiscale approach to optimal transport. Computer Graphics Forum, 30:1583–1592, 2011.
- Müller and Stoyan [2002] A. Müller and D. Stoyan. Comparison Methods for Stochastic Models and Risks. Wiley, 2002.
- Peyré and Cuturi [2018] G. Peyré and M. Cuturi. Computational Optimal Transport. ArXiv:1803.00567, 2018.
- Puccetti and Scarsini [2010] G. Puccetti and M. Scarsini. Multivariate comonotonicity. Journal of Multivariate Analysis, 101:291–304, 2010.
- Quiggin [1992] J. Quiggin. Increasing risk: Another definition. In A. Chikan, editor, Progress in Decision, Utility and Risk Theory, pages 239–248. Kluwer: Dordrecht, 1992.
- Rachev and Rüschendorf [1990] S. Rachev and L. Rüschendorf. A characterization of random variables with minimal L2 distance. Journal of Multivariate Analysis, 32:48–54, 1990.
- Rockafellar [1966] R. T. Rockafellar. Characterization of the subdifferentials of convex functions. Pacific Journal of Mathematics, 17:497–510, 1966.
- Rosenblatt [1952] M. Rosenblatt. Remarks on a multivariate transformation. Annals of Mathematical Statistics, 23:470–472, 1952.
- Rubin [1996] D. B. Rubin. Multiple imputation after 18+ years. Journal of the American Statistical Association, 91:473–489, 1996.
- Sarabia and Jorda [2014] J.-M. Sarabia and V. Jorda. Bivariate Lorenz curves: a review of recent proposals. In XXII Jornadas de ASEPUMA, 2014.
- Sarabia and Jorda [2020] J.-M. Sarabia and V. Jorda. Lorenz surfaces based on the Sarmanov–Lee distribution with applications to multidimensional inequality in well-being. Mathematics, 8:1–17, 2020.
- Shaked and Shanthikumar [2007] M. Shaked and J. G. Shanthikumar. Stochastic Orders. Springer, 2007.
- Shi et al. [2022] H. Shi, M. Drton, and F. Han. Distribution-free consistent independence tests via center-outward ranks and signs. Journal of the American Statistical Association, 117:395–410, 2022.
- Shorrocks [1983] A. F. Shorrocks. Ranking income distributions. Economica, 197:3–17, 1983.
- Taguchi [1972a] T. Taguchi. On the two-dimensional concentration surface and extensions of concentration coefficient and Pareto distribution to the two-dimensional case-i. Annals of the Institute of Statistical Mathematics, 24:355–382, 1972a.
- Taguchi [1972b] T. Taguchi. On the two-dimensional concentration surface and extensions of concentration coefficient and Pareto distribution to the two-dimensional case-ii. Annals of the Institute of Statistical Mathematics, 24:599–619, 1972b.
- Villani [2003] C. Villani. Topics in Optimal Tranportation. American Mathematical Society, 2003.
- Villani [2009] C. Villani. Optimal Transport: Old and New. Springer, 2009.
- Weymark [1981] J. Weymark. Generalized Gini inequality indices. Mathematical Social Sciences, 1:409–430, 1981.
- Wolff [2021] E. N. Wolff. Household wealth trends in the United States, 1962 to 2019: Median wealth rebounds… but not enough. Working paper, National Bureau of Economic Research, 2021.
- Yaari [1987] M. E. Yaari. The dual theory of choice under risk. Econometrica, 55:95–115, 1987.