Looking From the Future: Multi-order Iterations Can Enhance Adversarial Attack Transferability
Abstract
Various methods try to enhance adversarial transferability by improving the generalization from different perspectives. In this paper, we rethink the optimization process and propose a novel sequence optimization concept, which is named Looking From the Future (LFF). LFF makes use of the original optimization process to refine the very first local optimization choice. Adapting the LFF concept to the adversarial attack task, we further propose an LFF attack as well as an MLFF attack with better generalization ability. Furthermore, guiding with the LFF concept, we propose an attack which entends the LFF attack to a multi-order attack, further enhancing the transfer attack ability. All our proposed methods can be directly applied to the iteration-based attack methods. We evaluate our proposed method on ImageNet1k datasets by applying several SOTA adversarial attack methods under four kinds of tasks. Experimental results show that our proposed method can greatly enhance the attack transferability. Ablation experiments are also applied to verify the effectiveness of each component. The source code will be released after this paper is accepted.
Index Terms:
Adversarial attack, Optimization process, XAII Introduction
Deep Neural Networks(DNNs) have shown vulnerability to adversarial examples. By adding human-imperceptible perturbations to the clean input, DNNs will result in misclassification. At the same time, some adversarial examples generated on one network can also have an attack effect on another network. This phenomenon is called adversarial attack transferability. And, some methods are trying to attack a black-box network by generating adversarial examples on a white-box network. This kind of attack behavior is called the transfer attack. For the generated adversarial sample, the more black-box networks it can successfully attack, the stronger the transfer attack capability of the adversarial sample will be. This capability is also called adversarial transferability.
Nowadays, a lot of works try to enhance adversarial transferability with various kinds of approaches. One of the most classic methods is the MI-FGSM[1]. MI-FGSM, utilizing momentum to replace the gradient, inherits the iterative method in I-FGSM[5] to enhance the attack capability of the adversarial examples and enhance adversarial transferability by combining historical gradient information at the same time. This leads to a branch of adversarial attack methods with optimizing gradients themselves. These methods attempt to improve the adversarial transferability of adversarial examples by changing the gradient of the optimization process to avoid falling into local minima. Then another branch of adversarial methods is directly modifying the loss function to change the optimization terminal. Recently, input-transformation methods utilize data augmentation approaches, changing the input, to improve the diversity of the gradients. These methods indeed effectively enhance the adversarial transferability.
However the essential of these methods is solving the optimization problem, i.e. optimization methods. The optimization process of finding the optimal result through iteration can be regarded as a sequence. Then, each search point is a node in this sequence. Once the optimization method and the starting point of the search are determined, the sequence itself is relatively fixed. It can be found that most of the existing adversarial attack methods only generate the next node with information from the current node and previous nodes. This will prevent the optimization process itself from benefiting from information from subsequent nodes. Merely using the current node or previous nodes will make each node update only in the direction of local optimization with limited global information. Since the subsequent nodes belong to the future for the current node, we name the information from the subsequent nodes as future information. Similarly, the information from previous nodes is called historical information. Therefore, refining the optimization process with future information is necessary.
There are a few works that have made preliminary attempts to use this future information. [14] proposed the PI-FGSM method which looks ahead with one step to guide the momentum generation. Although this work somehow utilizes a little future information, i.e. the gradient from the next node, the terminal goal is to rich the local information by sampling around the current node. Another work that somehow utilizes future information is [9]. This work determines the starting state of momentum to optimize gradient consistency by pre-querying the perturbations after N rounds before starting the search. However, the future information is merely utilized once at the very beginning of the optimization. Also, with the search steps going greater, the future information will be diluted. Therefore, the above two works still only use local gradients to update nodes to a certain extent.
In this work, we start by drawing the concept of looking from the future (LFF). LFF rethinks the optimization process and regenerates the first node from the perspective of the optimization result. However, there are two problems for LFF directly applying to generate adversarial examples. The first one is the constraint of perturbation of each node makes the re-optimization result from LFF have worse attack capability. Another one is if the optimization process utilizes the historical information, LFF will repeatedly accumulate historical information, thus falling into local search again. To tackle the above two problems, we modify the LFF concept into the process of the original adversarial attack methods and formally propose the LFF attack. We reintegrate the weights of each piece of information in the optimization process so that no overfitting of local optimization will occur regardless of whether only the current node information or historical information is used. Therefore, the LFF attack can be easily applied to the existing adversarial attack methods, which are based on the iteration optimization process, to enhance the adversarial attack performance. At the same time, to reduce the complexity of the algorithm and further increase the adversarial transferability, we also combined the existing mechanisms to optimize the attack process. Furthermore, we also propose a multi-order LFF attack, under the guidance of the LFF concept, which further enhances the transfer attack performance.
To evaluate our method comprehensively, we evaluate the performance of our proposed method with several state-of-the-art adversarial attack methods on a wide range of high-performance deep neural networks, containing both CNN structure networks and Transformer structure networks. By covering the scenery of single model attacks, attack defensive networks, targetted attacks and ensemble network attacks, the comparison experiment can verify the effectiveness of our proposed method. The ablation experiment is also applied to check the effect of each component and each hyperparameter.
The remainder of this paper is structured as follows. Section II delves into related work on adversarial attack methods. Section III provides an overview of the notations used in adversarial attacks, the concept of looking from the future and the difficulty of applying LFF to the adversarial attack process. In Section IV, we present the LFF attack method and derivation process. The multi-order LFF attack method is also attached. Section V presents the results of our experiments and corresponding analysis. Lastly, in section VI, we offer some concluding remarks and outline potential avenues for future research.
II Related Work
Since [4] proposed the FGSM methods, the adversarial attack, especially the transfer attack, has been greatly improved. A lot of methods improve the adversarial attack based on the FGSM methods which are marked as FGSMs. One of the most classic methods is the I-FGSM[5]. I-FGSM enhances the adversarial attack by iteratively searching the perturbation, while FGSM merely generates the adversarial example with one step. Although I-FGSM can successfully attack the white-box networks, which means a high attack capability, it has a very poor transfer attack performance. Then various branches of methods try to enhance the adversarial transferability based on the I-FGSM.
II-A FGSMs based on gradients
One of the branches is modifying the gradients to obtain generalization adversarial examples. The most representative work is the MI-FGSM[1]. Via introducing momentum into to adversarial examples generation process, gradients from each previous node will be utilized to smooth the search direction for the current node. This will help the optimization process somehow avoid the local minima. NI-FGSM[7] method refined the momentum calculation process to further enhance the adversarial example generalization. VMI-FGSM and VNI-FGSM [12] utilize the variance tuning the momentum to further avoid the local minima. EMI-FGSM[14] sampling the local gradient information around the node from PI-FGSM and ensemble the information to enhance the adversarial transferability. PGN[3] tries to find the local maxima point to directly find the better transfer attack condition. MIG[8] utilizes the integrated gradients in XAI methods to enhance the gradient in MI-FGSM. Some other works inspired by the optimizers refine the gradients or the momentums with the latest optimizer [20, 18, 21].
The above methods mainly focus on refining the gradient itself, while some other methods try to enhance the gradient by modifying the loss function. [6] proposes the Po+Trip loss to enhance the targeted transfer attack inspired by the Poincare distance. [22] thinks that the simple logit loss also has good transfer attack performance. [19] considers the class interaction and proposes the relative Cross Entropy loss by raising the prediction probability of other classes to enhance the adversarial attack generalization.
II-B FGSMs based on data augmentation
Another one of the branches is utilizing data augmentation to enhance the diversity of input, which is also called input transformation. The most representative work is the -FGSM [17], which uses resize and padding operations to enhance input diversity. TI-FGSM [2] utilizes shifting operation with a kernel matrix on the gradients. SI-FGSM [7] applies scale transformation to the input image to gain augmented data. SIA [16] divides the original image into blocks and applies a random image transformation onto each image block to craft a set of diverse images for gradient calculation. BSR [10] furthermore introduces the block shuffle and rotation operations into the input transformation.
The above methods mainly focus on the transformation of the input image itself, which can be called self-transformation. Some other methods try to enhance the input diversity by introducing information from other images. [13] extends the SI-FGSM with the mixup strategy, which is named Admix. This method chooses several other images and mixes them into the original images to enhance the input diversity. [11] improves the mixup strategy with a non-linear way to mask the chosen image into the original image. [15] rethinks the process of the admix and changes the mixing images process to the mixing gradients process.
III Preliminary
III-A Notations
Here we first give out some fundamental notations. is the input data sample, where is the data dimension. is the feature extractor, where is the feature dimension. is the classifier, where is the number of classes. Then is the entire classification network. The output of is called logits. The output of is which is the predicted probability. is also marked as to emphsize the network and input data. The goal of the adversarial attack is to generate an adversarial example that can lead to fail, which is expressed as . Here indicates the truth label of as the specific predicted class index. To express without ambiguity, represents the index classification result for , represents the vector result for and represents the vector result for .
Then the adversarial attack transferability usually can be expressed as follows:
| (1) |
This expression can be understood that for an adversarial example which can successfully attack network , can also successfully attack network .
Then perturbation is generated by the adversarial example generation method which is marked as . Under iteration scope, the perturbation can be decomposed with the sum of the perturbation from each iteration which can be presented as . The constraint for each iteration perturbation can be presented as . In the I-FGSM-based method, usually constantly equals a certain value, e.g. . To make a more clear statement, with no special instructions, with subscript numbers represents the corresponding iteration perturbation, e.g. is the -th round perturbation. And with superscript numbers represents the sum of the corresponding iteration perturbation, e.g. .
III-B Looking from the future (new)
The terminal goal of the adversarial attack is to find an optimal adversarial example that can successfully attack the target model with minor perturbation as much as it can. This task is usually transferred into an optimization task with setting a loss function as the optimization goal, e.g. the optimization goal for the untargeted attack task can be formulated as:
| (2) |
where is the threshold for the perturbation which emphasizes the perturbation constraint. Previous methods try to enhance the adversarial transferability by optimizing the optimal process with various approaches. However, from the goal to look at the optimization process, if there is an optimal point for (2), then the shortest search routine can be determined, e.g. the straight line segment from and in Euclidean space. Then the best first iteration result for the entire optimization task should satisfy:
| (3) |
The solution for this optimization is
| (4) |
where is a linear coefficient to limit satisfying the constraint. However, directly obtaining is a really tough task. Finding the optimization point through iteration is one of the most effective and commonly used methods. These methods continuously approach the optimization target in an iterative manner to obtain an approximation of the optimization result. After a certain round of search, the optimization result can be treated as an approximation point for the optimal point . Then, the shortest search routine from to can be determined. When back to the very first iteration, the best first optimization search result should be
| (5) |
The corresponding solution for this optimization is
| (6) |
From a general scope, for any optimization task, after obtaining the original search routine, the approximation for the best first iteration result can also be obtained with Eq. (6). Then with the same optimization process, the approximation for the best next iteration result () as well as any -th iteration result () can be obtained. Considering that the usually cannot be directly obtained, can also be represented with in this manuscript. We name this process as Looking From the Future (LFF).
III-C LFF in transfer attack
I-FGSM-based attack methods obtain great success in transfer attacks. Intuitively, LFF can be directly used to enhance these kinds of attack methods. However, FGSM-based methods have the mechanism of symbolization of gradients which means perturbations of each iteration all satisfy and at the same time. However, direcly applying Eq. (6) which refers to will cause and . Only when , and . This can only happen on a strictly linear function, while feature space in deep learning networks is usually nonlinear. The in Eq. (6) can apply to satisfy or . However, simply applying LFF on constraint will not work. Keeping will cause which means will have a smaller Euclidean distance compared with . A smaller Euclidean distance will lead to a slower convergence speed, which means it may even need more iterations to reach the optimal points.
Meanwhile, applying LFF on will cause the . When the search routine comes near (the constraint to the final perturbation), a large number of effective updates for those dimensions that already reach will be discarded. This will also make the optimization routine less effective.
Also, considering that greater adversarial transferability related to more generalized examples for each model, when itself gets overfitting to a certain model or repeatedly using history information, LFF will further exacerbate the degree of the overfitting.
IV Methodology
IV-A One Order LFF Attack
Giving an I-FGSM based attacking method and the clean data , the original -th iteration from the attack process is , where and . The gradient corresponding to the is , which means that , where is the symbolization function. is the quantity of the steps looking from the future, i.e. iters steps. Then the straightforward description for the -th perturbation from one order LFF attack is :
| (7) |
where is the updating rate, , and is the future penalty coefficient.
When Eq. (7) is directly applied to the pure I-FGSM method, equals the gradients of the corresponding input. The description is:
| (8) |
where is the gradient of for the loss function . Then Eq. (7) can be rewritten with the following description:
| (9) |
When Eq. (7) is applied to the MI-FGSM method, which is the most widely used method, equals the momentums of the corresponding input. The description is
| (10) | ||||
where and is the momentum decay factor. When Eq.(10) is introduced into Eq.(7), the formulation can be obtained as
| (11) |
The expansion of Eq.(11) (shorten with ) is
| (12) | ||||
Eq.(12) indicates that for a given optimization process, the can be represented as a polynomial refers to the gradient of each optimization point using -norm regularization. The coefficient refers to the -th optimization point can be marked as and the gradient of -th optimization point with -norm regularization can be marked as . Then Eq.(12) can be refined as
| (13) |
where is the inner product, and . Then Eq.(13) can be understood as a superposition of . with a smaller value of is closer to the starting point . The closer the gradient of a point is to , the more local optimization information it contains; the farther the gradient of a point is from , the more generalization information it contains. When coefficients of those with a smaller value of are too great, will tend to which means overfitting. When coefficients of those with a greater value of are too great, will reduce attack capability due to too much generalization. Looking back to , the result of dividing by is
| (14) | ||||
For an attack method without overfitting, it can be assumed that . Then for given and , will be greater when becomes greater. For example, when and , the upper bound of Eq.(14) is
| (15) |
Even if is not great, e.g. , will be which is much greater than . And, this will cause the LFF result to tend to the with a smaller index value. In extreme cases, this situation can be described as:
| (16) |
Then, LLF will degenerate to the original attack method. To avoid this situation, a very simple but effective method can be applied, which is directly applying future penalty coefficient to . Then the -th coefficient equals . To avoid ambiguity in the expression, this new coefficient is marked as . Then the coefficients vector is . The perturbation update process can be described as
| (17) |
At the same time, is just the approximation to the optimal point with steps. Greater refers to greater complexity. Therefore, LFF can set with a certain value that is not too great, which can combine the advantages of LFF and the low calculation complexity with the original iteration process. Especially, when , the LFF attack will be degenerated to the corresponding IFGSM-based method. Naturally, the iteration between each can also be optimized with a similar gradient-based method, e.g. the momentum method. Then a momentum version of the LFF attack, which is named MLFF, can be described as:
| (18) | ||||
where is the momentum decay factor.
IV-B Multi-order LFF () Attack
The sequence of the from the one-order LFF attack can still be enhanced with the LFF mechanism. With the same guidelines, the enhancing process can be iterated to -order LFF, which is named attack. The description for the attack is:
| (19) |
where is the indicator for the order,
| (20) | ||||
and . Especially, when , Eq.(19) will be degenerated to Eq.(17). In the attack, there are multi-iteration processes. Therefore, there are many ways to combine operations that can further optimize the optimization process. Here, only a simple extension for MLFF with applying momentum mechanism for any -th order, where . This method is named . The corresponding formulation is shown as follows:
| (21) | ||||
where is the momentum penalty factor for -th order.
V Experiment
V-A Experiment Settings
Because most SOTA methods are realized on MI-FGSM, we conduct the comparison experiment using the MLLF method with those SOTA methods.
V-A1 Classifcation Networks
We conduct a wide range of classification networks within the Timm which is one of the greatest deep neural network libraries with various pre-trained models. We apply both CNN structure networks and Transformer structure networks. All classification networks include ResNet-50, BiT-50, Inception-v3, Inception-ResNet-v2, ConvNeXT-B, ViT-B, Swin-B, Deit-B. ResNet is one of the most classic deep learning networks. BiT-50 is one of the latest structures for ResNet models, which represents the best performance of the ResNet series. Inception-v3 is the pure inception structure CNNs, and Inception-ResNet is the combination of ResNet and inception structure. ConvNeXT is the most latest CNN structure network which represents the best performance of CNNs. Vision Transformer(ViT) is the typical Transformer structure network for image classification. Swin and Deit are two of the latest Transformer structure models.
V-A2 Dataset
We conduct the ImageNet1k dataset for all experiments. ImageNet1k dataset contains 1000 classes from the ImageNet dataset. All classification networks used in the experiments from Timm are pre-trained with the ImageNet1k dataset. Specifically, we conduct the ILSVRC2012 dataset as the testing dataset. The ILSVRC2012 dataset is one of the most classic datasets for adversarial attacks. The ILSVRC2012 dataset comes from the testing data of the ImageNet1k dataset. It still is widely used for evaluating adversarial attack performance, especially the transfer attack.
V-A3 Baselines
We conduct four attack methods as the baselines for the comparison experiment. They are MI-FGSM, EMI-FGSM, Admix and SIA. MI-FGSM is one of the most classic methods as well as one of the most widely used methods. The other baselines are all realized based on MI-FGSM. EMI-FGSM is one of the most recent gradient-based methods. Admix can typically represent the method with the mixup strategy. SIA is one of the latest self-transformation data augmentation methods. SIA is also one of the methods to achieve the best attack performance.
| Model | Attack | Res50 | BiT50 | IncRes-v2 | ConvneXT-B | ViT-B | Swin-B | Deit-B | Inc-v3 |
|---|---|---|---|---|---|---|---|---|---|
| Inc-v3 | MI | 41.4 | 20.6 | 43.9 | 20.6 | 9.3 | 15.1 | 11.3 | 100.0 |
| MLFF-MI | 47.0 | 23.4 | 55.5 | 24.4 | 9.7 | 16.2 | 12.5 | 100.0 | |
| Inc. | +5.6 | +2.8 | +11.6 | +3.8 | +0.4 | +1.1 | +1.2 | +0.0 | |
| EMI | 71.1 | 43.6 | 81.0 | 42.0 | 16.9 | 33.0 | 22.4 | 100.0 | |
| MLFF-EMI | 76.2 | 49.4 | 85.1 | 48.0 | 21.9 | 37.8 | 26.6 | 100.0 | |
| Inc. | +5.1 | +5.8 | +4.1 | +6.0 | +5.0 | +4.8 | +4.2 | +0.0 | |
| Admix | 80.0 | 52.6 | 86.8 | 45.9 | 23.3 | 39.3 | 30.5 | 100.0 | |
| MLFF-Admix | 82.7 | 53.6 | 87.5 | 46.2 | 23.6 | 39.6 | 30.1 | 100.0 | |
| Inc. | +2.7 | +1.0 | +0.7 | +0.3 | +0.3 | +0.3 | -0.4 | +0.0 | |
| SIA | 91.9 | 72.3 | 95.8 | 62.6 | 32.2 | 54.5 | 36.0 | 100.0 | |
| MLFF-SIA | 95.9 | 81.6 | 99.0 | 74.0 | 40.0 | 63.9 | 43.2 | 100.0 | |
| Inc. | +4.0 | +9.3 | +3.2 | +11.4 | +7.8 | +9.4 | +6.8 | +0.0 | |
| ViT-B | MI | 51.3 | 37.7 | 32.6 | 41.2 | 100.0 | 54.4 | 66.9 | 39.8 |
| MLFF-MI | 53.1 | 37.4 | 32.9 | 38.3 | 100.0 | 52.0 | 68.4 | 42.4 | |
| Inc. | +1.8 | -0.3 | +0.3 | -2.9 | +0.0 | -2.2 | +1.5 | +2.6 | |
| EMI | 71.8 | 62.2 | 55.8 | 66.7 | 100.0 | 77.8 | 89.9 | 62.5 | |
| MLFF-EMI | 76.2 | 69.7 | 60.4 | 70.2 | 100.0 | 82.5 | 94.2 | 67.0 | |
| Inc. | +4.4 | +7.5 | +4.6 | +3.5 | +0.0 | +4.7 | +4.3 | +4.5 | |
| Admix | 68.1 | 61.2 | 51.6 | 63.6 | 99.9 | 76.0 | 87.4 | 58.5 | |
| MLFF-Admix | 72.9 | 64.2 | 53.7 | 64.7 | 100.0 | 79.4 | 91.2 | 61.8 | |
| Inc. | +4.8 | +3.0 | +2.1 | +1.1 | +0.1 | +3.4 | +3.8 | +3.3 | |
| SIA | 82.6 | 80.7 | 71.2 | 82.5 | 99.6 | 87.5 | 89.0 | 75.6 | |
| MLFF-SIA | 91.1 | 90.8 | 83.8 | 91.9 | 100.0 | 94.5 | 96.2 | 86.9 | |
| Inc. | +8.5 | +10.1 | +12.6 | +9.4 | +0.4 | +7.0 | +7.2 | +11.3 |
| Model | Attack | Inc-v3adv | IncRes-v2adv | ConvNeXT-B+FD | Swin-B+FD | ConvNeXT-B+Bit-Red | Swin-B+Bit-Red |
|---|---|---|---|---|---|---|---|
| Inc-v3 | MI | 19.7 | 7.8 | 16.5 | 15.2 | 20.8 | 14.7 |
| MLFF-MI | 23.4 | 8.8 | 16.7 | 16.1 | 23.7 | 16.4 | |
| Inc. | +3.7 | +1.0 | +0.2 | +0.9 | +2.9 | +1.7 | |
| EMI | 38.5 | 15.6 | 27.8 | 25.4 | 42.2 | 33.0 | |
| MLFF-EMI | 43.3 | 19.4 | 31.0 | 28.8 | 46.7 | 37.9 | |
| Inc. | +4.8 | +3.8 | +3.2 | +3.4 | +4.5 | +4.9 | |
| Admix | 55.2 | 27.2 | 36.9 | 33.0 | 45.6 | 39.5 | |
| MLFF-Admix | 55.8 | 26.9 | 37.2 | 34.0 | 46.6 | 40.9 | |
| Inc. | +0.6 | -0.3 | +0.3 | +1.0 | +1.0 | +1.4 | |
| SIA | 54.0 | 28.2 | 39.3 | 38.6 | 61.8 | 53.2 | |
| MLFF-SIA | 68.6 | 35.1 | 42.3 | 42.5 | 73.7 | 65.1 | |
| Inc. | +14.6 | +6.9 | +3.0 | +3.9 | +11.9 | +11.9 |
V-A4 Hyperparameters
Following many previous works, the perturbation constraint is set to , the quantity of the iteration is , the update rate is . For the very basic method MI-FGSM, the momentum decay factor is . The number of gradient collections in EMI-FGSM is with a linear sample and the radius value is . For Admix, the number of scale copies is set to and the number of mix images is set to while the mix ratio is . In SIA, we set the splitting number to and the number of transformed images for gradient calculation is .
In the comparison experiment, to fairly compare the performance of LFF and other methods, is set to , which means a low calculation complexity and only looking from a very near future. Because when is small LFF will tend to I-FGSM even if the attack method applied is the MI-FGSM-based method, the MLFF method is applied to the comparison experiment. The future penalty factor is set to and the momentum decay for the MLFF is .
V-A5 Evaluation metrics
Attack Success Rate (ASR) is applied as the main evaluation metric for the performance of attack methods. ASR can present how many images have been successfully attacked, no matter for the white-box network (surrogate network) or the black-box network (victim networks). In addition, because the LFF attack is applied to the existing attack methods, the increment of the ASR, which is marked as Inc., is also considered to present the increment of the performance compared with the original attack method. The greater ASR and Inc. are, the better.
V-B Comparison Experiments
The comparison experiment is applied within four scopes. Firstly we evaluate baselines and our proposed method under the condition of a single surrogate network with the untargeted attack task. Secondly, we apply the comparison on the defensive networks as well as defense methods applied to pre-trained networks. Thirdly, the targeted attack task is applied. Fourthly, ensemble networks are applied as the surrogate network. The adversarial example from ensemble networks is tested by both original networks and defensive networks as well as defense methods.
| Model | Attack | Res50 | BiT50 | IncRes-v2 | ConvNeXT-B | ViT-B | Swin-B | Deit-B | Inc-v3 |
|---|---|---|---|---|---|---|---|---|---|
| Inc-v3 | MI | 0.3 | 0.4 | 0.5 | 0.4 | 0.0 | 0.1 | 0.1 | 100.0 |
| MLFF-MI | 0.6 | 0.4 | 0.9 | 0.2 | 0.1 | 0.0 | 0.1 | 100.0 | |
| Inc. | +0.3 | +0.0 | +0.4 | -0.2 | +0.1 | -0.1 | +0.0 | +0.0 | |
| EMI | 2.7 | 1.2 | 5.9 | 1.4 | 0.1 | 0.7 | 0.2 | 97.4 | |
| MLFF-EMI | 5.0 | 2.0 | 12.1 | 2.0 | 0.4 | 1.1 | 1.0 | 100.0 | |
| Inc. | +2.3 | +0.8 | +6.2 | +0.6 | +0.3 | +0.4 | +0.8 | +2.6 | |
| Admix | 2.9 | 0.7 | 5.1 | 1.2 | 0.4 | 0.5 | 0.3 | 98.7 | |
| MLFF-Admix | 4.1 | 1.7 | 8.7 | 1.7 | 0.5 | 0.8 | 0.5 | 99.8 | |
| Inc. | +1.2 | +1.08 | +3.6 | +0.5 | +0.1 | +0.3 | +0.2 | +1.1 | |
| SIA | 7.0 | 3.8 | 15.9 | 3.9 | 1.0 | 2.6 | 1.2 | 74.5 | |
| MLFF-SIA | 26.7 | 13.7 | 49.3 | 13.2 | 2.3 | 6.8 | 3.5 | 97.0 | |
| Inc. | +19.7 | +9.9 | +33.4 | +8.3 | +1.3 | +4.2 | +2.3 | +22.5 |
| Model | Attack | Res50 | BiT50 | IncRes-v2 | ConvNeXT-B | ViT-B | Swin-B | Deit-B | Inc-v3 |
|---|---|---|---|---|---|---|---|---|---|
| Em | MI | 100.0 | 68.9 | 72.4 | 70.4 | 98.5 | 71.0 | 98.9 | 99.7 |
| MLFF-MI | 100.0 | 75.4 | 79.5 | 73.7 | 100.0 | 73.8 | 99.8 | 100.0 | |
| Inc. | +0.0 | +6.5 | +7.1 | +3.3 | +1.5 | +2.8 | +0.9 | +0.3 | |
| EMI | 100.0 | 92.1 | 94.7 | 89.5 | 99.6 | 90.5 | 99.6 | 100.0 | |
| MLFF-EMI | 100.0 | 95.2 | 96.5 | 92.8 | 100.0 | 93.3 | 100.0 | 100.0 | |
| Inc. | +0.0 | +3.1 | +1.8 | +3.3 | +0.4 | +2.8 | +0.4 | +0.0 | |
| Admix | 100.0 | 93.8 | 96.8 | 88.7 | 97.6 | 90.2 | 97.7 | 100.0 | |
| MLFF-Admix | 100.0 | 96.2 | 98.7 | 93.1 | 99.7 | 93.8 | 99.8 | 100.0 | |
| Inc. | +0.0 | +2.4 | +1.9 | +4.4 | +2.1 | +3.6 | +2.1 | +0.0 | |
| SIA | 100.0 | 98.1 | 98.8 | 97.3 | 98.9 | 97.3 | 99.4 | 99.8 | |
| MLFF-SIA | 100.0 | 99.8 | 99.9 | 99.6 | 99.8 | 99.4 | 99.8 | 100.0 | |
| Inc. | +0.0 | +1.7 | +1.1 | +2.3 | +0.9 | +2.1 | +0.4 | +0.2 |
| Model | Attack | Inc-v3adv | IncRes-v2adv | ConvNeXT-B+FD | Swin-B+FD | ConvNeXT-B+Bit-Red | Swin-B+Bit-Red |
|---|---|---|---|---|---|---|---|
| Em | MI | 37.4 | 25.0 | 45.6 | 52.1 | 69.5 | 70.5 |
| MLFF-MI | 40.1 | 22.5 | 47.3 | 53.3 | 73.8 | 73.7 | |
| Inc. | +2.7 | +2.5 | +1.7 | +1.2 | +4.3 | +3.2 | |
| EMI | 69.0 | 48.2 | 73.3 | 76.6 | 89.3 | 90.2 | |
| MLFF-EMI | 76.0 | 55.3 | 78.7 | 80.1 | 92.5 | 93.2 | |
| Inc. | +7.0 | +7.1 | +5.4 | +3.5 | +3.2 | +3.0 | |
| Admix | 80.6 | 64.0 | 77.6 | 79.9 | 89.1 | 89.8 | |
| MLFF-Admix | 85.1 | 69.0 | 82.2 | 84.4 | 93.5 | 94.1 | |
| Inc. | 4.5 | +5.0 | +4.6 | +4.5 | +4.4 | +4.3 | |
| SIA | 86.4 | 72.3 | 85.3 | 86.7 | 97.4 | 97.3 | |
| MLFF-SIA | 94.0 | 84.0 | 91.5 | 93.4 | 99.6 | 99.4 | |
| Inc. | +7.6 | +11.7 | +6.2 | +6.7 | +2.2 | +2.1 |

V-B1 Untargeted attack with single surrogate network
In this comparison experiment, Inception-v3 and Vit-B are chosen to be the surrogate networks individually. Inception-v3 represents the adversarial examples from the CNN structure, while ViT represents the adversarial examples from the Transformer structure. All other networks are applied as the victim networks. The experimental results are shown in Table I.
Overall, the MLFF method can greatly improve the performance of all baselines. No matter whether the surrogate network is the CNN structure or the Transformer structure, the ASRs for the victim networks almost have increased. Especially, some of Inc. are over . From the details, there are three conditions the Inc. is the negative value. One occurs by applying Admix as the baseline with generating adversarial examples from Inception-v3 and testing for the Deit-B networks. However, when observing the Inc. for the MLFF Admix, it can be noted that MLFF seems to have not very great performance improvement on Admix. This might refer to the randomness in Admix. For each iteration, Admix randomly chooses images to mix up. Therefore, the process of the optimization itself is not fixed. Especially when this randomness is great, the randomness of the original sequence obtained in the LFF mechanism will be very great, thereby reducing the optimization effect. The performance of the MLFF-Admix in ViT-B can also verify this phenomenon. Another two occur by applying MI-FGSM as the baseline with generating adversarial examples from ViT-B and testing for ConvNeXT-B and Swin-B. This may be due to the small value of we set. The small will cause the MLFF to tend to the original attack, i.e. the MI-FGSM itself. At the same time, when the attack method tramps into the overfitting, MLFF will accelerate the overfitting. This all might be the reason that there are conditions that MLFF has negative Inc. values. It should also be noted that MLFF has very great Inc. values for both EMI and SIA methods. Although SIA itself has performed relatively well on ASR, MLFF-SIA can further enhance the adversarial transferability with a larger degree of improvement.
V-B2 Untargeted attack with defensive models
In this comparison experiment, two adversarial training networks are applied, i.e. Adversarial Inception-v3 and Ensemble Adversarial Inception-ResNet-v2. Two defensive methods FD and Bit-Red are applied to the ConvNext and Swin individually. The surrogate network is the Inception-v3 network. The experimental results are shown in Table II.
The experimental results are still corresponding to the previous experimental results. The increment to MI-FGSM and Admix method are relatively small, while the increment to EMI and SIA are very great.
V-B3 Targeted attack
In this comparison experiment, the targeted label for the attack is randomly chosen without repeating. The loss function for the targeted attack is the Cross-Entropy loss. The surrogate model is the Inception-v3 network. The experimental results are shown in Table III.
V-B4 Untargeted attack with ensemble networks
In this comparison experiment, the ensembled network is treated as the surrogate network for adversarial example generation. The ensembled network contains four networks, i.e. ResNet50, Inception-v3, ViT-B and Deit-B. This ensemble network contains both CNN structure networks and Transformer structure networks. The attack success rates for the original networks are placed in Table IV. The attack success rates for the defensive networks as well as defense methods are placed in Table V.
V-C Ablation Experiment
The ablation experiment is applied within 2 scopes. Firstly, we verify the effectiveness of the LFF as well as the MLFF with different . Then, we verify the influence of the future penalty factor .
V-C1 Influence of the looking from the future steps
In this ablation experiment, the quantity of the looking from the future is changed to verify the mechanism of the LLF. With greater , LFF attack as well as MLFF attack will have better attack performance. With smaller , the LFF attack will have very poor attack performance but the MLFF attack will keep a relatively stable performance. We apply the LFF attack and the MLFF attack to MI-FGSM and I-FGSM respectively. The experimental results are shown in the Fig. 1.
Overall, the experimental results can sufficiently verify the effect of the . The greater value of is, LFF attack as well as MLFF attack performances better. This tendency is especially obvious when the baseline is the MI-FGSM. However, this tendency seems to be weak for the MLFF-I attack. We speculate that this phenomenon is caused by the I-FGSM. Because I-FGSM easily falls into the local minima, which means low adversarial transferability, MLFF can only help I-FGSM quickly approach this local optimal point, although MLFF-I has a relatively good performance compared with the MI-FGSM.
V-C2 Influence of the future penalty factor
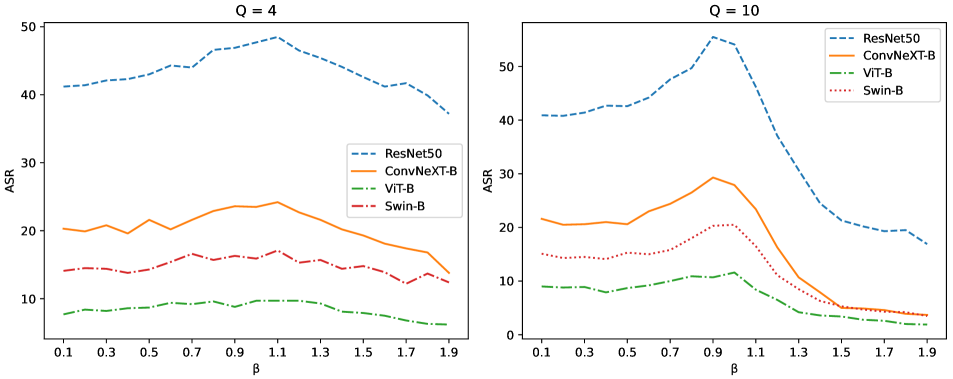
In this ablation experiment, the future penalty factor is changed. With greater , the LFF attack will contain more future information to generalize the perturbation. When is too great, the attack performance will drop due to losing attack capability. With smaller , the LFF attack will contain more local attack information. When is too small, the attack performance will degenerate to the original attack. Hence we apply from to with intervel under the condition of and respectively. Because is relatively small, the MLFF method is applied. The baseline is the MI-FGSM method. The experimental results are shown in the Fig. 2.
Overall, it can be noted that the trend in both subfigures is that ASR gradually increases with the increment of value. After reaching the peak, ASR gradually decreases as the value decreases. This phenomenon verifies the guess about the effect of the , i.e. the effect of the gradients in Eq. (17). A closer look at the horizontal coordinates of the peaks of the two graphs reveals that the optimal value of is different when facing different . When becomes greater, the best seems to become smaller. When comparing the two subfigures horizontally, it can be found that the average performance is significantly better when the is greater than when the is smaller.
VI Conclusion and Discussion
In this paper, we propose a novel concept which is named Looking From the Future. We extend the LFF concept into the adversarial attack task and propose the LFF attack as well as the MLFF attack while eliminating the disadvantages of focusing the local information and overfitting. Furthermore, we extend the LFF attack to the multi-order LFF attack, which is named . Comparison experiments on four tasks as well as ablation experiments have conducted the performance of our proposed method. Experimental results clearly show that the LFF attack can greatly increase existing adversarial attack methods.
References
- [1] Y. Dong, F. Liao, T. Pang, H. Su, J. Zhu, X. Hu, and J. Li. Boosting adversarial attacks with momentum. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 9185–9193, 2018.
- [2] Y. Dong, T. Pang, H. Su, and J. Zhu. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4312–4321, 2019.
- [3] Z. Ge, H. Liu, W. Xiaosen, F. Shang, and Y. Liu. Boosting adversarial transferability by achieving flat local maxima. Advances in Neural Information Processing Systems, 36:70141–70161, 2023.
- [4] I. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- [5] A. Kurakin, I. J. Goodfellow, and S. Bengio. Adversarial examples in the physical world. In Artificial intelligence safety and security, pages 99–112. Chapman and Hall/CRC, 2018.
- [6] M. Li, C. Deng, T. Li, J. Yan, X. Gao, and H. Huang. Towards transferable targeted attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [7] J. Lin, C. Song, K. He, L. Wang, and J. E. Hopcroft. Nesterov accelerated gradient and scale invariance for adversarial attacks. arXiv preprint arXiv:1908.06281, 2019.
- [8] W. Ma, Y. Li, X. Jia, and W. Xu. Transferable adversarial attack for both vision transformers and convolutional networks via momentum integrated gradients. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4630–4639, 2023.
- [9] J. Wang, Z. Chen, K. Jiang, D. Yang, L. Hong, P. Guo, H. Guo, and W. Zhang. Boosting the transferability of adversarial attacks with global momentum initialization. arXiv preprint arXiv:2211.11236, 2022.
- [10] K. Wang, X. He, W. Wang, and X. Wang. Boosting adversarial transferability by block shuffle and rotation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24336–24346, 2024.
- [11] T. Wang, Z. Ying, Q. Li, et al. Boost adversarial transferability by uniform scale and mix mask method. arXiv preprint arXiv:2311.12051, 2023.
- [12] X. Wang and K. He. Enhancing the transferability of adversarial attacks through variance tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1924–1933, 2021.
- [13] X. Wang, X. He, J. Wang, and K. He. Admix: Enhancing the transferability of adversarial attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16158–16167, 2021.
- [14] X. Wang, J. Lin, H. Hu, J. Wang, and K. He. Boosting adversarial transferability through enhanced momentum. arXiv preprint arXiv:2103.10609, 2021.
- [15] X. Wang and Z. Yin. Rethinking mixup for improving the adversarial transferability. arXiv preprint arXiv:2311.17087, 2023.
- [16] X. Wang, Z. Zhang, and J. Zhang. Structure invariant transformation for better adversarial transferability. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4607–4619, 2023.
- [17] C. Xie, Z. Zhang, Y. Zhou, S. Bai, J. Wang, Z. Ren, and A. L. Yuille. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2730–2739, 2019.
- [18] B. Yang, H. Zhang, Z. Li, Y. Zhang, K. Xu, and J. Wang. Adversarial example generation with adabelief optimizer and crop invariance. Applied Intelligence, 53(2):2332–2347, 2023.
- [19] C. Zhang, P. Benz, A. Karjauv, J. W. Cho, K. Zhang, and I. S. Kweon. Investigating top-k white-box and transferable black-box attack. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15085–15094, 2022.
- [20] J. Zhang, W. Qian, R. Nie, J. Cao, and D. Xu. Generate adversarial examples by adaptive moment iterative fast gradient sign method. Applied Intelligence, 53(1):1101–1114, 2023.
- [21] Q. Zhang, Y. Zhang, Y. Shao, M. Liu, J. Li, J. Yuan, and R. Wang. Boosting adversarial attacks with nadam optimizer. Electronics, 12(6):1464, 2023.
- [22] Z. Zhao, Z. Liu, and M. Larson. On success and simplicity: A second look at transferable targeted attacks. Advances in Neural Information Processing Systems, 34:6115–6128, 2021.