Lookahead Pathology in Monte-Carlo Tree Search
Abstract
Monte-Carlo Tree Search (MCTS) is a search paradigm that first found prominence with its success in the domain of computer Go. Early theoretical work established the soundness and convergence bounds for Upper Confidence bounds applied to Trees (UCT), the most popular instantiation of MCTS; however, there remain notable gaps in our understanding of how UCT behaves in practice. In this work, we address one such gap by considering the question of whether UCT can exhibit lookahead pathology in adversarial settings — a paradoxical phenomenon first observed in Minimax search where greater search effort leads to worse decision-making. We introduce a novel family of synthetic games that offer rich modeling possibilities while remaining amenable to mathematical analysis. Our theoretical and experimental results suggest that UCT is indeed susceptible to pathological behavior in a range of games drawn from this family.
1 Introduction
Monte-Carlo Tree Search (MCTS) is an online planning framework that originally found widespread use in game-playing applications (Coulom 2007; Finnsson and Björnsson 2008; Arneson, Hayward, and Henderson 2010), culminating in the spectacular success of AlphaGo (Silver et al. 2016, 2017). MCTS-based approaches have since been successfully adapted to a broad range of other domains, including combinatorial search and optimization (Sabharwal, Samulowitz, and Reddy 2012; Goffinet and Ramanujan 2016), malware analysis (Sartea and Farinelli 2017), knowledge extraction (Liu et al. 2020), and molecule synthesis (Kajita, Kinjo, and Nishi 2020).
Despite these high-profile successes, however, there are still aspects of the algorithm that remain poorly understood. Early theoretical work by \oldciteauthormcts (2006) introduced the Upper Confidence bounds applied to Trees (UCT) algorithm, now the most widely used variant of MCTS. Their work established that in the limit, UCT correctly identified the optimal action in sequential decision-making tasks, with the regret associated with choosing sub-optimal actions increasing at a logarithmic rate (Kocsis and Szepesvári 2006). \oldciteauthorcoquelin_munos (2007), however, showed that in the worst-case scenario, UCT’s convergence could take time super-exponential in the depth of the tree. More recent work by \oldciteauthornew_mcts (2020) proposes a “corrected” UCT with better convergence properties.
In parallel, there has been a line of experimental work that has attempted to understand the reasons for UCT’s success in practice and characterize the conditions under which it may fail. One such effort considered the impact of shallow traps — highly tactical positions in games like Chess that can be established as wins for the opponent with a relatively short proof tree — and argued that UCT tended to misevaluate such positions (Ramanujan, Sabharwal, and Selman 2010a; Ramanujan and Selman 2011). \oldciteauthorgiga (2011) considered the performance of UCT in a set of artificial games and pinpointed optimistic moves, a notion similar to shallow traps, as a potential Achilles heel. \oldciteauthorJames_Konidaris_Rosman (2017) studied the role of random playouts, a key step in the inner loop of the UCT algorithm, and concluded that the smoothness of the payoffs in the application domain determined the effectiveness of playouts. Our work adds to this body of empirical research, but is concerned with a question that has thus far not been investigated in the literature: can UCT behave pathologically?
The phenomenon of lookahead pathology was first discovered and analyzed in the 1980s in the context of planning in two-player adversarial domains (Beal 1980; Nau 1982; Pearl 1983). Researchers found that in a family of synthetic board-splitting games, deeper Minimax searches counter-intuitively led to worse decision-making. In this paper, we present a novel family of abstract, two-player, perfect information games, inspired by the properties of real games such as Chess, in which UCT-style planning displays lookahead pathology under a wide range of conditions.
2 Background
Monte-Carlo Tree Search
Consider a planning instance where an agent needs to determine the best action to take in a given state. An MCTS algorithm aims to solve this problem by iterating over the following steps to build a search tree.
-
•
Selection: Starting from the root node, we descend the tree by choosing an action at each level according to some policy . UCT uses UCB1 (Auer, Cesa-Bianchi, and Fischer 2002), an algorithm that optimally balances exploration and exploitation in the multi-armed bandit problem, as the selection policy. Specifically, at each state , UCT selects the action that maximizes the following upper confidence bound:
Here, is the transition function that returns the state that is reached from taking action in state , is the current estimated utility of state , and is the visit count of state . The constant is a tunable exploration parameter. In adversarial settings, the negamax transformation is applied to the UCB1 formula, to ensure that utilities are alternatingly maximized and minimized at successive levels of the search tree.
-
•
Evaluation: The recursive descent of the search tree using ends when a node that is previously unvisited, or that corresponds to a terminal state (i.e., one from which no further actions are possible), is reached. If is non-terminal, then an estimate of its utility is calculated. This calculation may take the form of random playouts (i.e., the average outcome of pseudorandom completions of the game starting from ), handcrafted heuristics, or the prediction of a learned estimator like a neural network. For terminal nodes, the true utility of the state is used as instead. The node is then added to the search tree, so that the size of the search tree grows by one after each iteration.
-
•
Backpropagation: Finally, the reward is used to update the visit counts and the utility estimates of each state that was encountered on the current iteration as follows:
This update assigns to each state the average reward accumulated from every episode that passed through it.
We repeat the above steps until the designated computational budget is met; at that point, the agent selects the action to execute at the root node .
Lookahead Pathology
Searching deeper is generally believed to be more beneficial in planning domains. Indeed, advances in hardware that permitted machines to tractably build deeper Minimax search trees for Chess were a key reason behind the success of Deep Blue (Campbell, Hoane, and Hsu 2002). However, there are settings in which this property is violated, such as the artificial P-games investigated by several researchers in the 1980s (Beal 1980; Nau 1982; Pearl 1983) and which we describe in the following section. Over the years, many have attempted to explain the causes of pathology and why it is not encountered in real games like Chess. \oldciteauthorpath_survey (2010) reconciled these different proposals and offered a unified explanation that focused on three factors: the branching factor of the game, the degree to which the game demonstrates local similarity (a measure of the correlation in the utilities of nearby states in the game tree), and the granularity of the heuristic function used (the number of distinct values that the heuristic takes on). They concluded that pathology was most pronounced in games with a high branching factor, low local similarity and low heuristic granularity (Nau et al. 2010). They also found that while it was not a widespread issue in real games, certain sub-games of Chess and variations of Kalah could exhibit pathology. Finally, it is also worth noting that pathology has been observed in single-agent domains (Bulitko et al. 2003; Bulitko and Lustrek 2006), but our focus in this paper remains on the two-player setting where the phenomenon has been most extensively studied.
Synthetic Game Tree Models


There is a long tradition of using abstract, artificial games to empirically understand the behavior of search algorithms. The P-game model is a notable example, that constructs a game tree in a bottom-up fashion (Pearl 1980). To create a P-game instance, the values of the leaves of the tree are carefully set to win/loss values (Pearl 1980), though variants using real numbers instead have also been studied (Luštrek, Gams, and Bratko 2005). The properties of the tree arise organically from the distribution used to set the leaf node values. P-games were the subject of much interest in the 1980s, as the phenomenon of lookahead pathology was first discovered in the course of analyzing the behavior of Minimax search in this setting (Beal 1980; Nau 1982). While the model’s relative simplicity allows for rigorous mathematical analysis, P-games also suffer from a couple of drawbacks. Firstly, computing the value of the game and the minimax value of the internal nodes requires search, and that all the leaf nodes of the tree be retained in memory, which restricts the size of the games that may be studied in practice. Secondly, the construction procedure only models a narrow class of games, namely, ones where the values of leaf nodes are independent of each other.
Other researchers have proposed top-down models, where each internal node of the tree maintains some state information that is incrementally updated and passed down the tree. The value of a leaf node is then determined by a function of the path that was taken to reach it. For example, in the models studied by \oldciteauthornau83:probbackup (1983) and \oldciteauthorsk98 (1998), values are assigned to the edges in the game tree and the utility of a leaf node is determined by the sum of the edge values on the path from the root node to the leaf. These models were used to demonstrate that correlations among sibling nodes were sufficient to eliminate lookahead pathology in Minimax. More recently, \oldciteauthorsocs11 (2011) used a similar top-down construction to evaluate the effectiveness of a distributed UCT implementation. However, search is still required to determine the true value of internal nodes in these models, thereby only allowing for the study of small games. \oldciteauthorpvtrees (2009) proposed prefix value trees that extend the model of \oldciteauthorsk98 by observing that the minimax value of nodes along a principal variation can never worsen for the player on move. Setting the values of nodes while obeying this constraint during top-down tree construction obviates the need for search, which allowed them to generate arbitrarily large games.
Finally, synthetic game tree models have also been used to study the behavior of MCTS algorithms like UCT. For example, \oldciteauthorgiga (2011) used variations of Chess to identify the features of the search space that informed the success and failure of UCT. \oldciteauthorRSS_critical_moves (2010b) studied P-games augmented with “critical moves” — specific actions that an agent must get right at important junctures in the game to ensure victory. We refine this latter idea and incorporate it into a top-down model, which we present in the following section.
3 Critical Win-Loss Games
Our goal in this paper is to determine some sufficient conditions under which UCT exhibits lookahead pathology. To conduct this study, we seek a class of games that satisfy several properties. Firstly, we desire a model that permits us to construct arbitrarily large games to more thoroughly study the impact of tree depth on UCT’s performance. We note that most of the game tree models discussed in Section 2 do not meet this requirement. The one exception is the prefix value tree model of \oldciteauthorpvtrees that, however, fails a different test: the ability to construct games with parameterizable difficulty. Specifically, we find that prefix value games are too “easy” as evidenced by the fact that a naïve planning algorithm that combines minimal lookahead with purely random playouts achieves perfect decision-making accuracy in this setting (see Appendix A). In this section, we describe critical win-loss games, a new generative model of extensive-form games, that addresses both these shortcomings of existing models.
Game Tree Model



Our model generates game trees in a top-down fashion, assigning each node a true utility of either or . In principle, every state in real games like Chess or Go can be labeled in a similar fashion (ignoring the possibility of draws) with their true game-theoretic values. Thus, we do not lose any modeling capacity by limiting ourselves to just win-loss values. The true minimax value of a state imposes constraints on the values of its children as noted by \oldciteauthorpvtrees (2009) — in our setting, this leads to two kinds of internal tree nodes. A forced node is one with value () at a maximizing (minimizing) level. All the children of such a node are constrained to also be (). A choice node, on the other hand, is one with value () at a maximizing (minimizing) level. At least one child of such a node must have the same minimax value as its parent. Figure 1 presents examples of these concepts.
All the variation that is observed in the structures of different game trees is completely determined by what happens at choice nodes. As noted earlier, one child of a choice node must share the minimax value of its parent; the values of the remaining children are unconstrained. We introduce a parameter called the critical rate () that determines the values of these unconstrained children. We now describe our procedure for growing a critical win-loss tree rooted at a node with minimax value :
-
•
Let denote the children of .
-
•
If is a forced node, then we set , and continue recursively growing each subtree.
-
•
If is a choice node, then we pick an uniformly at random and set , designating to be the child that corresponds to the optimal action choice at . For each such that , we set with probability and we set with probability , before recursively continuing to grow each subtree.
We make several observations about the trees grown by this model. Firstly, one can apply the above growth procedure in a lazy manner, so that only those parts of the game tree that are actually reached by the search algorithm need to be explicitly generated. Thus, the size of the games is only limited by the amount of search effort we wish to expend. Secondly, the critical rate parameter serves as a proxy for game difficulty. At one extreme, if , then every child at every choice node has the same value as its parent — in effect, there are no wrong moves for either player, and planning becomes trivial. At the other extreme, if , then every sub-optimal move at every choice node leads to a loss and the game becomes unforgiving. A single blunder at any stage of the game instantly hands the initiative to the opponent. Figure 2 gives examples of game trees generated with different settings of . For the sake of simplicity, we focus on trees with a uniform branching factor in this study.
Critical Rates in Real Games
Before proceeding, we pause to validate our model by measuring the critical rates of positions in Chess (see Appendix E for similar data on Othello). We begin by first sampling a large set of positions that are plies deep into the game. These samples are gathered using two different methods:
-
•
Light playouts: each side selects among the legal moves uniformly at random.
-
•
Heavy playouts: each side runs a 10-ply search using the Stockfish 13 Chess engine (Romstad et al. 2017), which is freely available online under a GNU GPL v3.0 license, and then selects among the top-3 moves uniformly at random.
We approximate for these sampled states using deep Minimax searches. Specifically, we use , where denotes the result of a -ply Stockfish search. To compute the empirical critical rate for a particular choice node , we begin by computing and for all the children of and then calculate:
Admittedly, using the outcome of a deep search as a stand-in for the true game theoretic value of a state is not ideal. However, strong Chess engines are routinely used in this manner as analysis tools by humans, and we thus believe this to be a reasonable approach. Figure 3 presents histograms of data collected for and , using both light and heavy playouts. Each histogram aggregates data over positions.

We note that about – of the positions sampled have values higher than , which is consistent with Chess’s reputation for being a highly tactical game. We also see that the values collected for Chess form a distribution that is non-stationary with respect to game progression, unlike in our proposed game tree model where is fixed to be a constant. Nonetheless, we believe that this simplification in our modeling is reasonable: at deeper plies, the distribution of becomes strikingly bimodal, with most of the mass accumulating in the ranges and . This clustering means that one could partition Chess game tree into two very different kinds of subgames (with high and low ), within each of which the critical rate remains within a narrow range.
Heuristic Design
Before we can run UCT search experiments on critical win-loss games, we need to resolve one more issue: how should UCT estimate the utility of non-terminal nodes? One popular approach to constructing artificial heuristics is the additive noise model — the heuristic estimate for a node is computed as , where is a random variable drawn from a standard distribution, like a Gaussian (Luštrek, Gams, and Bratko 2005; Ramanujan, Sabharwal, and Selman 2011). However, as we will see, static evaluations of positions in real games often follow complex distributions.


To better understand the behavior of heuristic functions in real games, we once again turn to Chess and the Stockfish engine. We sample positions each using light and heavy playouts for . As before, we use as a proxy for for each sampled state . We also compute for each , which we normalize to the range — this is the static evaluation of each without any lookahead. Figure 4 presents histograms of , broken out by . A clearer separation between the orange and blue histograms (i.e., between the evaluations of and nodes) indicates that the heuristic is better at telling apart winning positions from losing ones. Indeed, the ideal heuristic would score every position higher than every position, thus ordering them perfectly. We see in Figure 4 that such clear sorting does not arise in practice in Chess, particularly for positions that are encountered with strong play. Moreover, the valuations assigned to positions do not follow a Gaussian distribution, and attempts to model them as such—for example, like in (Nau et al. 2010)—are perhaps too simplistic. However, these histograms also suggest an empirical method for generating heuristic valuations of nodes — we can treat the histograms as probability density functions and sample from them. For example, to generate a heuristic estimate for a node in our synthetic game, we can draw according to the distribution described by one of the blue histograms in Figure 4. Of course, given the sensitivity of the shape of these histograms to the sampling parameters, it is natural to wonder which histogram should be used. Rather than make an arbitrary choice, we run experiments using a diverse set of such histogram-based heuristics, generated from different choices of , different playout sampling strategies, and different game domains.
Additionally, we note that one can also use random playouts as heuristic evaluations, like in the original formulation of UCT. One advantage of our critical win-loss game tree model is that we can analytically characterize the density of and nodes at a depth from the root node, given a critical rate and branching factor . Specifically, for a tree rooted at a maximizing choice node, the density of nodes at depths and (denoted as and respectively) are given by:
| (1) | ||||
| (2) |
where . We refer the reader to Appendix B for the relevant derivations. Access to these expressions means that we can cheaply simulate random playouts of depth : the outcome of a single playout () corresponds to sampling from the set with probabilities and respectively. For lower variance estimates, we can use the mean of this distribution instead, which would correspond to averaging the outcomes of a large number of playouts (). In our experiments, we explore the efficacy of the heuristics and as well.
4 Results
Theoretical Analysis
We begin with our main theoretical result and provide a sketch of the proof.
Theorem 1.
In a critical win-loss game with , UCT with a search budget of nodes will exhibit lookahead pathology for choices of the exploration parameter , even with access to a perfect heuristic.
The key observation underpinning the result is that the densities of nodes in both the optimal and sub-optimal subtrees rooted at a choice node (given by equations (1) and (2)) begin to approach the same value for large enough depths. This in turn suggests a way to lead UCT astray, namely to force UCT to over-explore so that it builds a search tree in a breadth-first manner. In such a scenario, the converging node densities in the different subtrees, together with the averaging back-up mechanism in the algorithm, leaves UCT unable to tell apart the utilities of its different action choices. Notably, this happens even though we provide perfect node evaluations to UCT (i.e., the true minimax value of each node) — the error arises purely due to the structural properties of the underlying game tree. All that remains to be done is to characterize the conditions under which this behavior can be induced, which is presented in detail in Appendix C. Our experimental results suggest that the bound in Theorem 1 can likely be tightened, since in practice, we often encounter pathology at much lower values for than expected. We further find that the pathology persists even when we relax the assumption that , as described in the following sections.
Experimental Setup
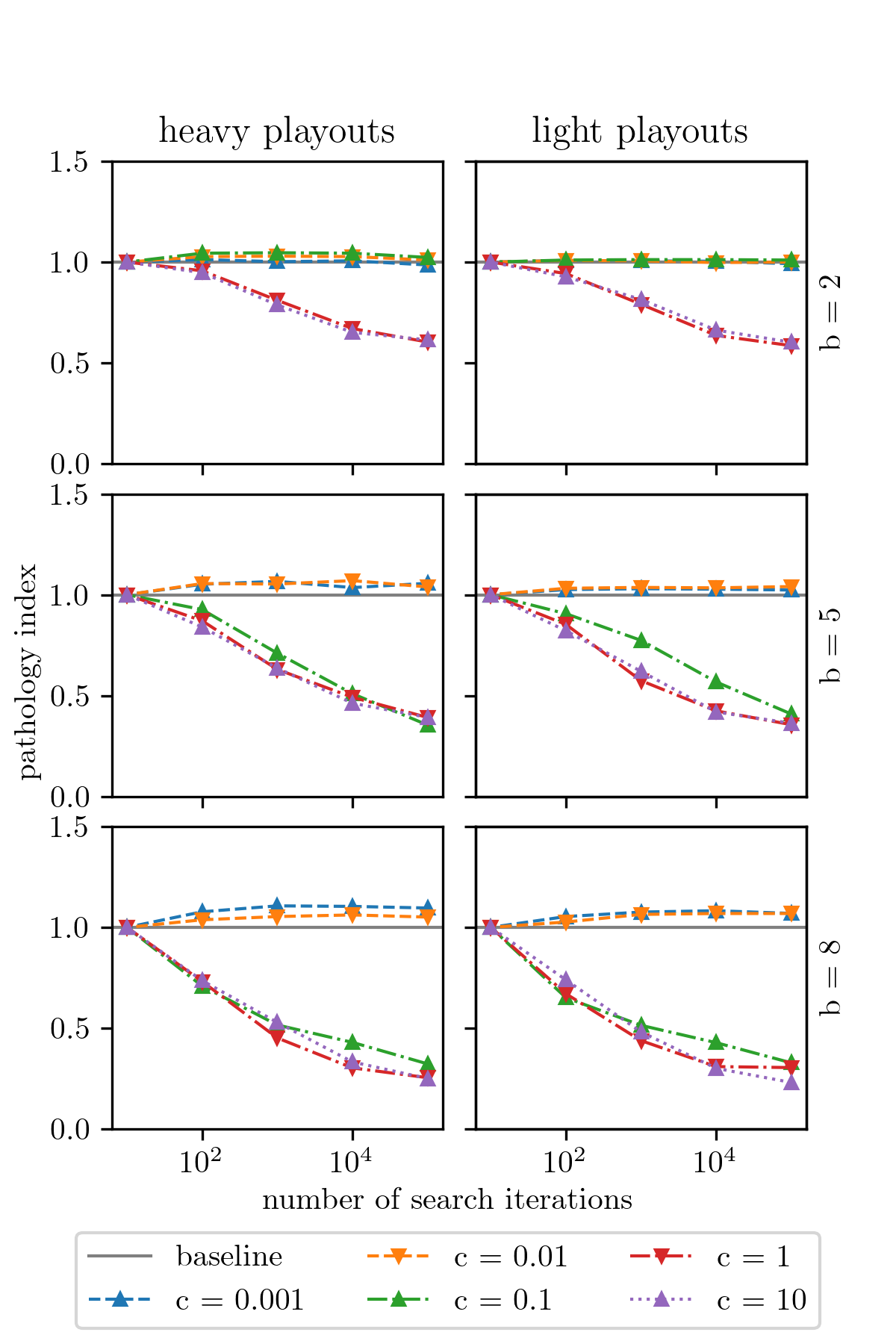
We now describe our experimental methodology for investigating pathology in UCT. Without loss of generality, we focus on games that are rooted at maximizing choice nodes (i.e., root node has a value of ). We set the maximum game tree depth at , which ensures that relatively few terminal nodes are encountered within the search horizon (other depths are explored in Appendix F). We present results from a 4-factor experimental design: 2 choices of critical rate () 3 choices of branching factor () 2 choices of heuristic models 5 choices of the UCT exploration constant (). A larger set of results, exploring a wider range of these parameter settings, is presented in Appendices F–H. For each chosen parameterization, we generate synthetic games using our critical win-loss tree model. We run UCT with different computational budgets on each of these trees, as measured by the number of search iterations (i.e., the size of the UCT search tree). We define the decision accuracy (denoted as ) to be the number of times that UCT chose the correct action at the root node, when run for iterations, averaged across the members of each tree family sharing the same parameter settings. Our primary performance metric is the pathology index defined as:
where . Values of indicate that additional search effort leads to worse outcomes (i.e., pathological behavior), while indicates that search is generally beneficial. We ran our experiments on an internal cluster of Intel Xeon Gold GHz CPUs with G of RAM. We estimate that replicating the full set of results presented in this paper, with jobs running in parallel, would take about three weeks of compute time on a similar system. The code for reproducing our experiments is available at the following URL: https://github.com/npnkhoi/mcts-lp.


Discussion
Figure 5 presents our main results. Our chief finding is that the choice of is the biggest determinant of pathological behavior in UCT. For games generated with , we find that UCT exhibits lookahead pathology regardless of all other parameters — the exploration constant, the branching factor, or how the heuristic is constructed. Appendices F and H confirm the robustness of this result using additional data collected for other game tree depths and for heuristics constructed using data collected from Othello. For smaller values of , the effect is not as strong and other factors begin to play a role. For example, with , pathological behavior is most apparent at higher branching factors and with more uniform exploration strategies (i.e., higher settings of ), consistent with Theorem 1. For , pathology is almost completely absent, regardless of other parameters (see Appendix G).
Poor performance from UCT in a synthetic domain, particularly when it is forced to over-explore, may seem unsurprising at first glance — so we will pause here to address these concerns, clearly elucidate the significance and novelty of these results, and to contextualize them better. Firstly, we note that lookahead pathology is distinct from poor planning performance. Practitioners routinely encounter domains where MCTS-style approaches simply fail to produce good results (for example, see (Ramanujan, Sabharwal, and Selman 2010a; Ramanujan, Sabharwal, and Selman 2010b)), regardless of the size of the computational budget, but our work demonstrates a subtly different phenomenon. Namely, there are situations where UCT will initially make good decisions (when it is allowed to build a tree of size, say, 100 nodes), but that its performance will degrade as it is afforded more “thinking” time (on trees of size 10k nodes). Moreover, we have done so in a two-player setting, where winning strategies for a player need to be robust to any counter-move by the opponent. In practice, this means that there are an exponential number of winning leaf nodes for both players. Thus, demonstrating degenerate behavior using constructions such as those of \oldciteauthorcoquelin_munos (2007), where the optimal leaf node is strategically hidden in the midst of an exponential number of suboptimal nodes, are not possible. In fact, our model is symmetric; we use the same critical rate for both players so that the game is equally (un)forgiving for both players, without stacking the deck against one player or the other. Seeing pathology arise under these conditions is thus more unexpected. We also note that more exploration has been proposed in the past as an antidote to undesirable behavior in UCT (Coquelin and Munos 2007). Our results indicate that over-exploration may create new problems of its own.
For the sake of completeness, we also evaluate the performance of Minimax search with alpha-beta pruning on our critical win-loss games. These results are presented in Appendix J. We find that Minimax is similarly susceptible to lookahead pathology in our setting, particularly in games where . Games with high critical rates correspond to those with a high clustering factor (Sadikov, Bratko, and Kononenko 2005), and thus, low local similarity — in such games, there is a lower degree of correlation among the true utilities of nodes that are near each other in the game tree, which has been identified as a key driver of pathology (Nau et al. 2010). Our results are thus consistent with the findings of \oldciteauthorpath_survey (2010). One point of departure from their findings, however, is that pathology arises in our experiments even though we use a highly granular heuristic. In their work, \oldciteauthorpath_survey (2010) create heuristic estimates for node utilities via an additive Gaussian noise model, whereas ours are derived from binning Stockfish’s evaluation function and treating that as a distribution. This suggests that the manner in which heuristics are modeled may contribute to pathology, in addition to their resolution.
We conclude by considering the performance of UCT on the classical P-games devised by \oldciteauthorpearl80 (1980). As noted in Section 2, the bottom-up nature of a P-game’s construction requires that we keep the entire game tree in memory during our experiments, which limits the size of the games we can study. Our results, presented in Appendix K, indicate that UCT demonstrates few signs of pathology in these games. Inducing pathological behavior in UCT thus appears to require large games with more intricate structural properties — requirements which are satisfied by the critical win-loss games which we have introduced in this work.
Broader Impacts
This paper highlights a counter-intuitive failure mode for MCTS that deserves broader appreciation and recognition from researchers and practitioners. The fact that UCT has the potential to make worse decisions when given additional compute time means that the algorithm needs to be used with greater care. We recommend that users generate scaling plots such as those shown in Figure 5 to better understand whether UCT is well-behaved in their particular application domain, before wider deployment.
5 Conclusions
In this paper, we explored the question of whether MCTS algorithms like UCT could exhibit lookahead pathology — an issue hitherto overlooked in the literature. Due to the shortcomings of existing synthetic game tree models, we introduced our own novel generative model for extensive-form games. We used these critical win-loss games as a vehicle for exploring search pathology in UCT and found it to be particularly pronounced in high critical rate regimes. Important avenues for follow-up work include generalizing the theoretical results presented in this paper to games where and deriving tighter bounds for the exploration parameter , as well as investigating whether such pathologies emerge in real-world domains. It would also be interesting to study whether pathological behavior can be mitigated by choosing alternatives to the UCB1 bandit algorithm in the MCTS loop.
Acknowledgements
The authors would like to thank Michael Blackmon for technical support, Corey Poff, Ashish Sabharwal and Bart Selman for useful discussions, and the anonymous reviewers for their feedback during the peer review process. KPNN’s work was supported by the TPBank STEM Scholarship at Fulbright University Vietnam.
References
- Arneson, Hayward, and Henderson (2010) Arneson, B.; Hayward, R. B.; and Henderson, P. 2010. Monte Carlo Tree Search in Hex. IEEE Transactions on Computational Intelligence and AI in Games, 2(4): 251–258.
- Auer, Cesa-Bianchi, and Fischer (2002) Auer, P.; Cesa-Bianchi, N.; and Fischer, P. 2002. Finite-time Analysis of the Multiarmed Bandit Problem. Machine Learning, 47(2): 235–256.
- Beal (1980) Beal, D. F. 1980. An analysis of Minimax. Advances in Computer Chess 2, 103–109.
- Bulitko et al. (2003) Bulitko, V.; Li, L.; Greiner, R.; and Levner, I. 2003. Lookahead pathologies for single agent search. In Proceedings of the 18th International Joint Conference on Artificial Intelligence, IJCAI’03, 1531–1533. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc.
- Bulitko and Lustrek (2006) Bulitko, V.; and Lustrek, M. 2006. Lookahead Pathology in Real-Time Path-Finding. In Proceedings, The Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference, July 16-20, 2006, Boston, Massachusetts, USA. AAAI Press.
- Campbell, Hoane, and Hsu (2002) Campbell, M.; Hoane, A. J.; and Hsu, F. H. 2002. Deep Blue. Artificial Intelligence, 134(1): 57–83.
- Coquelin and Munos (2007) Coquelin, P.-A.; and Munos, R. 2007. Bandit Algorithms for Tree Search. In Proceedings of the Twenty-Third Conference on Uncertainty in Artificial Intelligence, UAI’07, 67–74. Arlington, Virginia, USA: AUAI Press. ISBN 0974903930.
- Coulom (2007) Coulom, R. 2007. Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search. In Computers and Games, 72–83. Berlin, Heidelberg: Springer Berlin Heidelberg. ISBN 978-3-540-75538-8.
- Finnsson and Björnsson (2008) Finnsson, H.; and Björnsson, Y. 2008. Simulation-Based Approach to General Game Playing. In AAAI ’08, 259–264. AAAI Press. ISBN 9781577353683.
- Finnsson and Björnsson (2011) Finnsson, H.; and Björnsson, Y. 2011. Game-Tree Properties and MCTS Performance. In IJCAI 2011 Workshop on General Intelligence in Game Playing Agents, 23–30.
- Furtak and Buro (2009) Furtak, T.; and Buro, M. 2009. Minimum Proof Graphs and Fastest-Cut-First Search Heuristics. In IJCAI ’09, 492–498. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc.
- Goffinet and Ramanujan (2016) Goffinet, J.; and Ramanujan, R. 2016. Monte-Carlo Tree Search for the Maximum Satisfiability Problem. In Principles and Practice of Constraint Programming, 251–267. Cham: Springer International Publishing. ISBN 978-3-319-44953-1.
- James, Konidaris, and Rosman (2017) James, S.; Konidaris, G.; and Rosman, B. 2017. An Analysis of Monte Carlo Tree Search. Proceedings of the AAAI Conference on Artificial Intelligence, 31(1).
- Kajita, Kinjo, and Nishi (2020) Kajita, S.; Kinjo, T.; and Nishi, T. 2020. Autonomous molecular design by Monte-Carlo tree search and rapid evaluations using molecular dynamics simulations. Communications Physics, 3(1): 77.
- Kocsis and Szepesvári (2006) Kocsis, L.; and Szepesvári, C. 2006. Bandit Based Monte-Carlo Planning. In Proceedings of the 17th European Conference on Machine Learning, ECML’06, 282–293. Berlin, Heidelberg: Springer-Verlag. ISBN 354045375X.
- Liu et al. (2020) Liu, G.; Li, X.; Wang, J.; Sun, M.; and Li, P. 2020. Extracting Knowledge from Web Text with Monte Carlo Tree Search, 2585–2591. New York, NY, USA: Association for Computing Machinery. ISBN 9781450370233.
- Luštrek, Gams, and Bratko (2005) Luštrek, M.; Gams, M.; and Bratko, I. 2005. Why minimax works: an alternative explanation. In IJCAI ’05, 212–217. Edinburgh, Scotland.
- Nau (1982) Nau, D. S. 1982. An investigation of the causes of pathology in games. Artificial Intelligence, 19(3): 257–278.
- Nau (1983) Nau, D. S. 1983. Pathology on Game Trees Revisited, and an Alternative to Minimaxing. Artificial Intelligence, 21(1-2): 221–244.
- Nau et al. (2010) Nau, D. S.; Luštrek, M.; Parker, A.; Bratko, I.; and Gams, M. 2010. When is it better not to look ahead? Artificial Intelligence, 174(16): 1323–1338.
- Pearl (1980) Pearl, J. 1980. Asymptotic Properties of Minimax Trees and Game-Searching Procedures. Artificial Intelligence, 14(2): 113–138.
- Pearl (1983) Pearl, J. 1983. On the nature of pathology in game searching. Artificial Intelligence, 20(4): 427–453.
- Ramanujan, Sabharwal, and Selman (2010a) Ramanujan, R.; Sabharwal, A.; and Selman, B. 2010a. On Adversarial Search Spaces and Sampling-Based Planning. In ICAPS 2010, Toronto, Ontario, Canada, May 12-16, 2010, 242–245. AAAI.
- Ramanujan, Sabharwal, and Selman (2010b) Ramanujan, R.; Sabharwal, A.; and Selman, B. 2010b. Understanding Sampling Style Adversarial Search Methods. In UAI 2010, Catalina Island, CA, USA, July 8-11, 2010, 474–483. AUAI Press.
- Ramanujan, Sabharwal, and Selman (2011) Ramanujan, R.; Sabharwal, A.; and Selman, B. 2011. On the Behavior of UCT in Synthetic Search Spaces. In ICAPS 2011 Workshop on Monte Carlo Tree Search: Theory and Applications, Freiburg, Germany June 12, 2011.
- Ramanujan and Selman (2011) Ramanujan, R.; and Selman, B. 2011. Trade-Offs in Sampling-Based Adversarial Planning. In ICAPS 2011, Freiburg, Germany June 11-16, 2011. AAAI.
- Romstad et al. (2017) Romstad, T.; Costalba, M.; Kiiski, J.; and Linscott, G. 2017. Stockfish: A strong open source chess engine. Open Source available at https://stockfishchess. org/. Retrieved November 29th, 2020.
- Sabharwal, Samulowitz, and Reddy (2012) Sabharwal, A.; Samulowitz, H.; and Reddy, C. 2012. Guiding Combinatorial Optimization with UCT. In CPAIOR 2012, 356–361. Berlin, Heidelberg: Springer-Verlag. ISBN 9783642298271.
- Sadikov, Bratko, and Kononenko (2005) Sadikov, A.; Bratko, I.; and Kononenko, I. 2005. Bias and pathology in minimax search. Theoretical Computer Science, 349(2): 268–281. Advances in Computer Games.
- Sartea and Farinelli (2017) Sartea, R.; and Farinelli, A. 2017. A Monte Carlo Tree Search approach to Active Malware Analysis. In IJCAI-17, 3831–3837.
- Scheucher and Kaindl (1998) Scheucher, A.; and Kaindl, H. 1998. Benefits of using multivalued functions for minimaxing. Artificial Intelligence, 99(2): 187 – 208.
- Shah, Xie, and Xu (2020) Shah, D.; Xie, Q.; and Xu, Z. 2020. Non-Asymptotic Analysis of Monte Carlo Tree Search. In Abstracts of the 2020 SIGMETRICS/Performance Joint International Conference on Measurement and Modeling of Computer Systems, SIGMETRICS ’20, 31–32. New York, NY, USA: Association for Computing Machinery. ISBN 9781450379854.
- Silver et al. (2016) Silver, D.; Huang, A.; Maddison, C. J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; Dieleman, S.; Grewe, D.; Nham, J.; Kalchbrenner, N.; Sutskever, I.; Lillicrap, T.; Leach, M.; Kavukcuoglu, K.; Graepel, T.; and Hassabis, D. 2016. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587): 484–489.
- Silver et al. (2017) Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; Chen, Y.; Lillicrap, T.; Hui, F.; Sifre, L.; van den Driessche, G.; Graepel, T.; and Hassabis, D. 2017. Mastering the game of Go without human knowledge. Nature, 550(7676): 354–359.
- Yoshizoe et al. (2011) Yoshizoe, K.; Kishimoto, A.; Kaneko, T.; Yoshimoto, H.; and Ishikawa, Y. 2011. Scalable distributed Monte-Carlo tree search. In Proceedings of the 4th Annual Symposium on Combinatorial Search, SoCS 2011, 180–187.
Supplementary Material
Appendix A On Planning in Prefix Value Trees
In a prefix value (PV) tree, the values of nodes are drawn from the set of integers, with positive values representing wins for the maximizing player (henceforth, Max) and the rest indicating wins for the minimizing player (Min). For the sake of simplicity, we disallow draws. Let represent the minimax value of a node . We grow the subtree rooted at as follows:
-
•
Let represent the set of children of , corresponding to action choices .
-
•
Pick an uniformly at random — this is designated to be the optimal action choice at .
-
•
Assign . If Max is on move at , then . If Min is on move , then .
Here, is a constant that represents the cost incurred by the player on move for taking a sub-optimal action. The depth of the tree is controlled by the parameter and a uniform branching factor of is assumed.
The PV tree model, is an attractive object of study as despite its relative simplicity, it captures a very rich class of games. However, it has one major drawback: a simple 1-ply lookahead search, using the average outcome of random playout trajectories as a heuristic, achieves very high decision accuracies. We now explore this phenomenon a little deeper.
Without loss of generality, we restrict our attention to trees
where Max is on move at the root node . Moreover, we require that
and that has exactly one optimal child — this ensures
that our search algorithm is faced with a non-trivial decision at
the root node. While we focus on the case where in what
follows, extending our results to higher branching factors is
straightforward. We denote the left and right children of by
and respectively and assume that is the optimal move. Define
to be the sum of the minimax values of the leaf nodes in the
subtree of depth rooted at node .
Proposition 1.
for all .
Proof.
We proceed by induction on . For the base case, by definition. Assume the claim holds for , where is a Max level. Then, . A symmetric argument can be made for the case where is a Min level. ∎
Define to be the average outcome of random playouts performed
from the node . If the subtree rooted at has uniform depth ,
then . An immediate consequence of
Proposition 1 is that , for any depth , i.e., in the limit,
the estimated utility of the optimal move at the root will always
be greater than that of . In other words, the decision accuracy of
a 1-ply lookahead search informed by random playouts approaches with increasing number of playouts, independent of the depth of the tree. It is straightforward to extend this result to the case even when is a random variable, drawn uniformly at random from some set .
Appendix B On the Distribution of Leaf Node Values in Critical Win-Loss Games
In this section, we analyze the density of nodes in critical win-loss game as a function of its depth (), branching factor () and critical rate (). We limit ourselves to the case where is uniform, and .
Without loss of generality, we assume that the root is a maximizing choice node (i.e., has a minimax value of ). Then, the expected number of its children is:
We denote the expected density of these children (among the possible children) by , where:
| (3) |
We note that by a symmetric argument, this expression also captures the density of the children of a minimizing choice node.
Now consider a critical win-loss game instance rooted at a maximizing choice node. Let denote the density at depth in this tree. We will calculate a closed-form expression for . When is even (i.e., Max is on move), we have the following recursive relationship due to equation (3):
Substituting for , we have:
| (4) |
When is odd (i.e., Min is on move), the choice nodes have value . Once again using equation (3), we derive the following recursive equation for nodes:
Substituting for , we have:
| (5) |
From equations (4) and (5), we have:
By induction, we can then derive the following non-recurrent formula for :
where . Simplifying, we have:
If we now allow , we have:
| (6) |
and:
| (7) |
Appendix C Deriving Bounds on Pathological Behavior
Theorem 1.
In a critical win-loss game with , UCT with a search budget of nodes will exhibit lookahead pathology for choices of the exploration parameter , even with access to a perfect heuristic.
Proof.
The proof consists of two parts. First, we argue that with an appropriately chosen value for the exploration constant , UCT will build a balanced search tree in a breadth-first fashion. Then, we show that such a tree building strategy will cause UCT’s decision accuracy to devolve to random guessing with increased search effort. Consider a node with children. Let and denote two of these children such that . Our aim is to find a value for the exploration parameter such that the UCB1 formula will prioritize visiting over , regardless of the difference in their (bounded) utility estimates. This amounts to UCT building a search tree in a breadth-first fashion.
Without loss of generality, assume is a maximizing node. For UCT to visit before on the next iteration, we must have:
Rearranging terms, this is equivalent to the condition:
| (8) |
We will now bound the right-hand side of equation 8 in terms of our search budget . Firstly, since the heuristic estimates of nodes are bounded by , we know that for any node . We can therefore bound the numerator of equation (8) from above as:
| (9) |
Now we turn our attention to the denominator of equation (8). We have:
| by the AM-GM inequality | ||||
Combining this bound with equation (9), we conclude that:
Thus, choosing a value for the exploration constant that is larger than this quantity, as per equation (8), will force UCT to build a search tree in a breadth-first fashion.
We now conclude by arguing why such a node expansion strategy will lead to lookahead pathology. Without loss of generality, consider a game tree rooted at a minimizing choice node (i.e., a minimizing node with minimax value ). Let denote an optimal child of and let denote a sub-optimal child. This means that is a maximizing forced node and is a maximizing choice node. The density of winning nodes from the maximizing perspective at depth from is then given by equation (1). Since is a forced node, we cannot directly use equations (1) or (2). However, we observe that all the children of are minimizing choice nodes, and thus, the density of winning moves from the minimizing perspective at depth from is given by . We can use the negamax transformation to recast this as the density of winning nodes from the maximizing perspective at depth from : this is given by . For large values of , we know from equations (6) and (7) that , or . In other words, the density of leaf nodes at depth in the subtrees rooted at and approach the same value, for sufficiently large . Since the average of the utilities of these leaves at level will dominate the average of all the leaves in the respective subtrees, we conclude that in large enough search trees, UCT’s estimate of will approach its estimate of . In other words, the algorithm will not be able to tell apart optimal and sub-optimal moves as it builds deeper trees, even though we have access to the true minimax value of each node in this setting, leading to the emergence of pathological behavior. ∎
Appendix D Game Engine Settings
We collected our Chess data using the Stockfish 13 engine, with the following configuration:
"Debug Log File": "", "Contempt": "24", "Threads": "1", "Hash": "16", "Clear Hash Ponder": "false", "MultiPV": "1", "Skill Level": "20", "Move Overhead": "10", "Slow Mover": "100", "nodestime": "0", "UCI_Chess960": "false", "UCI_AnalyseMode": "false", "UCI_LimitStrength": "false", "UCI_Elo": "1350", "UCI_ShowWDL": "false", "SyzygyPath": "", "SyzygyProbeDepth": "1", "Syzygy50MoveRule": "true", "SyzygyProbeLimit": "7", "Use NNUE": "false", "EvalFile": "nn-62ef826d1a6d.nnue"
We collected our Othello data using the Edax 4.4 engine111https://github.com/abulmo/edax-reversi with the default settings. Edax is freely available online under a GNU GPL v3.0 license.
Appendix E Critical Rates in Othello

Appendix F Impact of Maximum Tree Depth on Pathology

Appendix G Impact of Low Critical Rate on Pathology


Appendix H Investigating Pathology with Othello-Derived Heuristics
Appendix I Investigating Pathology when Using True Node Utilities

Appendix J Investigating Pathology in Alpha-Beta Search

Appendix K Investigating Pathology in UCT in P-Games

