Long-Term Fairness with Unknown Dynamics
Abstract
While machine learning can myopically reinforce social inequalities, it may also be used to dynamically seek equitable outcomes. In this paper, we formalize long-term fairness in the context of online reinforcement learning. This formulation can accommodate dynamical control objectives, such as driving equity inherent in the state of a population, that cannot be incorporated into static formulations of fairness. We demonstrate that this framing allows an algorithm to adapt to unknown dynamics by sacrificing short-term incentives to drive a classifier-population system towards more desirable equilibria. For the proposed setting, we develop an algorithm that adapts recent work in online learning. We prove that this algorithm achieves simultaneous probabilistic bounds on cumulative loss and cumulative violations of fairness (as statistical regularities between demographic groups). We compare our proposed algorithm to the repeated retraining of myopic classifiers, as a baseline, and to a deep reinforcement learning algorithm that lacks safety guarantees. Our experiments model human populations according to evolutionary game theory and integrate real-world datasets.
1 Introduction
As machine learning (ML) algorithms are deployed for tasks with real-world social consequences (e.g., school admissions, loan approval, medical interventions, etc.), the possibility exists for runaway social inequalities (Crawford and Calo, 2016; Chaney et al., 2018; Fuster et al., 2018; Ensign et al., 2018). While “fairness” has become a salient ethical concern in contemporary research, the closed-loop dynamics of real-world systems comprising ML policies and populations that mutually adapt to each other (Fig. 5 in the supplementary material) remain poorly understood.
In this paper, our primary contribution is to consider the problem of long-term fairness, or algorithmic fairness in the context of a dynamically responsive population, as a reinforcement learning (RL) problem subject to constraint. In our formulation, the central learning task is to develop a policy that minimizes cumulative loss (e.g., financial risk, negative educational outcomes, misdiagnoses, etc.) incurred by an ML agent interacting with a human population up to a finite time horizon, subject to constraints on cumulative “violations of fairness”, which we refer to in a single time step as disparity and cumulatively as distortion.
Our central hypothesis is that an RL formulation of long-term fairness may allow an agent to learn to sacrifice short-term utility in order to drive the system towards more desirable equilibria. The core practical difficulties posed by our general problem formulation, however, are the potentially unknown dynamics of the system under control, which must be determined by the RL agent online (i.e., during actual deployment), and the general non-convexity of the losses or constraints considered. Additionally, we address continuous state and action spaces, in general, which preclude familiar methods with performance guarantees in discrete settings.
Our secondary contributions are 1) to show that long-term fairness can be solved within asymptotic, probabalistic bounds under certain dynamical assumptions and 2) to demonstrate that the problem of long-term fairness can also be addressed more flexibly. For theoretical guarantees, we develop L-UCBFair, an online RL method, and prove sublinear bounds on regret (suboptimiality of cumulative loss) and distortion (suboptimality of cumulative disparity) with high probability (Section 3.1). To demonstrate practical solutions without limiting assumptions, we apply R-TD3, an adaptation of a well-known deep reinforcement learning method (viz., TD3) to a Lagrangian relaxation of the central problem with time-dependent regularization. We compare L-UCBFair and R-TD3 to a baseline, myopic policy in interaction with simulated populations initialized with synthetic or real-world data and updated according to evolutionary game theory (Section 4).
This paper considers fairness in terms of statistical regularities across (ideally) socioculturally meaningful groups. Acknowledging that internal conflict exists between different statistical measures of fairness, we show that an RL approach to long-term fairness can mitigate trade-offs between fairness defined on the statistics of immediate policy decision outcomes (Chen et al., 2022), (e.g., acceptance rate disparities (Dwork et al., 2012; Zemel et al., 2013; Feldman et al., 2015)) and underlying distributional parameters (e.g., qualification rate (Raab and Liu, 2021; Zhang et al., 2020)).
1.1 Related Work
Our effort to formalize long-term fairness as a reinforcement learning problem bridges recent work on “fairness in machine learning”, which has developed in response to the proliferation of data-driven methods in society, and “safe reinforcement learning”, which seeks theoretical safety guarantees in the control of dynamical systems.
Dynamics of Fairness in Machine Learning We distinguish long-term fairness from the dynamics of fair allocation problems Joseph et al. (2016); Jabbari et al. (2017); Tang et al. (2021); Liu et al. (2017) and emphasize side-effects of algorithmic decisions affecting future decision problems. By formalizing long-term fairness in terms of cumulative losses and disparities, we iterate on a developing research trend that accounts for the dynamical response of a human population to deployed algorithmic prediction: both as a singular reaction Liu et al. (2018); Hu et al. (2019); Perdomo et al. (2020) or as a sequence of mutual updates to the population and the algorithm Coate and Loury (1993); D’Amour et al. (2020); Zhang et al. (2020); Heidari et al. (2019); Wen et al. (2019); Liu et al. (2020); Hu and Chen (2018); Mouzannar et al. (2019); Williams and Kolter (2019); Raab and Liu (2021). In particular, Perdomo et al. (2020) introduces the concept of “performative prediction”, analyzing the fixed-points of interactions between a population and an algorithmic classifier, but with state treated as a pure function of a classifier’s actions. For more realistic dynamics, Mouzannar et al. (2019) and Raab and Liu (2021) model updates to qualification rates that depend on both previous state and the classifier’s actions, but only treat myopic classifiers that optimize immediate utility (subject to fairness constraints) rather than learning to anticipate dynamical population responses. Wen et al. (2019) adopted reinforcement learning to achieve long-term fairness. However, they explore a setting that is restricted to discrete state and action spaces. In particular, this recommends a tabular explore-then-commit approach to reinforcement learning that does not generalize to continuous spaces and thus cannot be directly used in our setting. In addition, we provide separate and tighter bounds for both utility and disparity.
Safe Reinforcement Learning L-UCBFair furthers recent efforts in safe RL. While “model-based” approaches, in which the algorithm learns an explicit dynamical model of the environment, constitute one thread of prior work Efroni et al. (2020); Singh et al. (2020); Brantley et al. (2020); Zheng and Ratliff (2020); Kalagarla et al. (2021); Liu et al. (2021); Ding et al. (2021), such algorithms are typified by significant time and space complexity. Among “model-free” algorithms, the unknown dynamics of our setting preclude the use of a simulator that can generate arbitrary state-action pairs Xu et al. (2021); Ding et al. (2020); Bai et al. (2022). While Wei et al. (2022) introduce a model-free and simulator-free algorithm, the tabular setting considered is only applicable to discrete state and action spaces. To tackle continuous state space, Ding et al. (2021); Ghosh et al. (2022) consider linear dynamics: Ding et al. (2021) develop a primal-dual algorithm with safe exploration, and Ghosh et al. (2022) use a softmax policy design. Both algorithms are based on the work of Jin et al. (2020), which proposed a least squares value iteration method, using an Upper Confidence Bound (UCB) Auer et al. (2002) to estimate a state-action “” function. To our knowledge, L-UCBFair is the first model-free, simulator-free RL algorithm that provides theoretical safety guarantees for both discrete and continuous state and action spaces. Moreover, L-UCBFair achieves bounds on regret and distortion as tight as any algorithm thus far with discrete action space Ghosh et al. (2022).
2 Problem Formulation
A binary classification task is an initial motivating example for our formulation of long-term fairness, though the formal problem we propose is more widely applicable. To this initial task, we introduce “fairness” constraints, then population dynamics, and then cumulative loss and “disparity”, before formalizing the problem of optimizing cumulative loss subject to constraints on cumulative disparity.
We provide notation for the binary classification task: a random individual, sampled i.i.d. from a population, has features , a label , and a demographic group (where for ). Denote the joint distribution of these variables in the population as . The task is to predict (as ) from and . Specifically, the task is to choose a classifier , such that , that minimizes some bounded loss over . This basic classification task is
Typically, corresponds to the expectation value of a loss function (such as zero-one-loss) defined for individuals drawn from . We consider this example, but, in general, allow arbitrary, (unit-interval) bounded loss functions :
The standard “fair” classification task (without a dynamically responsive population) is to constrain classifier such that the disparity induced on distribution by is bounded by some value :
A standard example of disparity is the expected divergence of group acceptance rates . e.g., when ,
In this example, measures the violation of “demographic parity”: the condition under which a classifier achieves group-independent positive classification rates Dwork et al. (2012). In this paper, we also consider measures of fairness based on inherent population statistics (e.g., parity of group qualification rates ), which must be driven dynamically Raab and Liu (2021); Zhang et al. (2020). Such notions of disparity are well-suited to an RL formulation of long-term fairness.
State, Action, and Policy
Considering the semantics of iterated classification tasks, we identify the distribution of individuals in the population as a state and the classifier as an action. While state space is arbitrary, we assume that action space admits a Euclidean metric, under which it is closed (i.e., is isomorphic to ). At a given time , is sampled stochastically according to the current policy : We assume is fully observable at time . In practice, must be approximated from finitely many empirical samples, though this caveat introduces well-understood errors that vanish in the limit of infinitely many samples.
Dynamics
In contrast to a “one-shot” fair classification task, we assume that a population may react to classification, inducing the distribution to change. Importantly, such “distribution shift” is a well-known, real-world phenomenon that can increase realized loss and disparity when deployed classification policies are fixed Chen et al. (2022). For classification policies that free to change in response to a mutating distribution , subsequent classification tasks depend on the (stochastic) predictions made in previous tasks. In our formulation, we assume the existence of dynamical kernel that maps a state and action at time to a distribution over possible states at time :
| (1) |
We stipulate that may be initially unknown, but it does not explicitly depend on time and may be reasonably approximated “online”. While real-world dynamics may depend on information other than the current distribution (e.g., exogenous parameters, history, or additional variables of state), we identify with the current distribution for simplicity in our treatment of long-term fairness.
Reward and Utility
Because standard RL literature motivates maximizing reward rather than minimizing loss, let us define the instantaneous reward and a separate, instantaneous “utility” for an RL agent as
| (2) | ||||
| (3) |
where and do not explicitly depend on time .
Value and Quality Functions
Learnable dynamics inspire us to optimize anticipated cumulative reward, given constraints on anticipated cumulative utility. Let represent either reward or utility . We use the letter (for “value”) to denote the future expected accumulation of over steps (without time-discounting) starting from state , using policy . Likewise, we denote the “quality” of an action in state with the letter . For ,
| (4) | ||||
| (5) |
By the boundedness of , and belong to the interval .
“Long-term fairness” via reinforcement learning
The central problem explored in this paper is
| (6) |
We emphasize that this construction of long-term fairness considers a finite time horizon of steps and denote the optimal value of as .
Assumption 2.1 (Slater’s Condition).
i.e., “strict primal feasibility”: , , such that .
The Online Setting
Given initially unknown dynamics, we formulate long-term fairness for the “online” setting, in which learning is only possible through actual “live” deployment of policy, rather than through simulation. As it is not possible to unconditionally guarantee constraint satisfaction in Eq. 6 over a finite number of episodes, we instead measure two types of regret: one that measures the suboptimality of a policy with respect to cumulative incurred loss, which we will continue to call “regret”, and one that measures the suboptimality of a policy with respect to cumulative induced disparity, which we will call “distortion”. Note that we define regret and distortion in Eq. 7 by marginalizing over the stochasticity of state transitions and the sampling of actions:
| (7) | |||
3 Algorithms and Analysis
We show that it is possible to provide guarantees for long-term fairness in the online setting. Specifically, we develop an algorithm, L-UCBFair, and prove that it provides probabilistic, sublinear bounds for regret and distortion under a linear MDP assumption (3.2) and properly chosen parameters (Section A.1, in the supplementary material). L-UCBFair is the first model-free algorithm to provide such guarantees in the online setting with continuous state and action spaces.
3.1 L-UCBFair
Episodic MDP
L-UCBFair inherits from a family of algorithms that treat an episodic Markov decision process (MDP) Jin et al. (2020). Therefore, we first map the long-term fairness problem to the episodic MDP setting, which we denote as . The algorithm runs for episodes, each consisting of time steps. At the beginning of each episode, which we index with , the agent commits to a sequence of policies for the next steps. At each step within an episode, an action is sampled according to policy , then the state is sampled according to the transition kernel . and are the loss and disparity functions. is sampled arbitrarily with each episode.
Episodic Regret
Because L-UCBFair predetermines its policy for an entire episode, we amend our definition of regret and distortion for the all time steps by breaking it into a sum over episodes of length .
| (8) | |||
The Lagrangian
Consider the Lagrangian function associated with Eq. 6, with dual variable :
| (9) |
L-UCBFair approximately solves the primal problem , which is non-trivial, since the objective function is seldom concave in practical parameterizations of . Let to denote the optimal value of .
Lemma 3.1 (Boundedness of ).
For and satisfying Slater’s Condition (2.1),
Lemma 3.1, defines as an upper bound for the optimal dual variable . is an input to L-UCBFair.
Assumption 3.2 (Linear MDP).
is a linear MDP with feature map : For any , there exist signed measures over , such that, for any ,
In addition, there exist vectors , such that, for any ,
3.1.1 Explicit Construction
L-UCBFair, or “LSVI-UCB for Fairness ” (Algorithm 1) is based on an optimistic modification of a Least-Squares Value Iteration, where optimism is realized by an Upper-Confidence Bound, as in LSVI-UCB Jin et al. (2020). For each -step episode , L-UCBFair maintains estimates for and a time-indexed policy . In each episode , L-UCBFair updates , interacts with the environment, and updates the dual variable (constant in ).
LSVI-UCB Jin et al. (2020)
The estimation of is challenging. Consider the Bellman equation:
It is impossible to iterate over all pairs, since and are continuous. Instead, LSVI parameterizes by the linear form , which is supported by Jin et al. (2020). As an additional complication, is unknown is estimated by LSVI from empirical samples. Combining these techniques, the Bellman equation can be replaced by a least squares problem.
In addition, a “bonus term” is added to the estimate of Q to encourage exploration.
Adaptive Search Policy Compared to the works of Ding et al. (2021) and Ghosh et al. (2022), the major challenge we face for long-term fairness is a continuous action space , which renders the independent computation of for each action impossible. To handle this issue, we propose an adaptive search policy: Instead of drawing an action directly from a distribution over continuous values, represents a distribution over finitely many, finite regions of . After sampling a region from a Softmax scheme, the agent draws action uniformly at random from it.
Definition 3.3.
Given a set of distinct actions , where is a closed set in Euclidean space, define as the subset of actions closer to than to , i.e., the Voronoi region corresponding to locus , with tie-breaking imposed by the order of indices . Also define the locus function .
Lemma 3.4.
The Voronoi partitioning described above satisfies and .
Theorem 3.5.
If the number of distinct loci or regions partitioning is sufficiently large, there exists a set of loci such that .
In addition to defining a Voronoi partitioning of the action space for the adaptive search policy of L-UCBFair, we make the following assumption:
Assumption 3.6.
There exists , such that
This assumption is used to bound the distance of estimated action-value function and value function, thus bound adaptive search policy and the optimal policy.
Dual Update For L-UCBFair, the update method for the dual variable in Eq. 9 is also essential. Since and are unknown, we use and to estimate them. is iteratively updated by minimizing Eq. 9 with step-size , and is an upper bound for . A similar method is also used in Ding et al. (2021); Ghosh et al. (2022).
3.1.2 Analysis
We next bound the regret and distortion, defined in Eq. 8, realizable by L-UCBFair. We then compare L-UCBFair with existing algorithms for discrete action spaces and discuss the importance of the number of regions and the distance .
Theorem 3.7 (Boundedness).
With probability , there exists a constant such that L-UCBFair achieves
| (10) | ||||
| (11) |
when selecting parameter values , , and .
For a detailed proof of Theorem 3.7, refer to Section A.1. Theorem 3.7 indicates that L-UCBFair reaches bounds for both regret and distortion with high probability. Compared to the algorithms introduced by Ding et al. (2021); Ghosh et al. (2022), which work with discrete action space, L-UCBFair guarantees the same asymptotic bounds on regret and distortion.
3.2 R-TD3
Because assumptions made in Section 3.1 (e.g., the linear MDP assumption) are often violated in the real world, we also consider more flexible and arguably powerful deep reinforcement learning methods. Concretely, we utilize “Twin-Delayed Deep Deterministic Policy Gradient” (TD3) Fujimoto et al. (2018) with the implementation and default parameters provided by the open-source package “Stable Baselines 3” Raffin et al. (2021) on a (Lagrangian) relaxation of the long-term fairness problem. We term this specific algorithm for long-term fairness R-TD3.
In general, methods such as TD3 lack provable safety guarantees, however they may still confirm our hypothesis that agents trained via RL can learn to sacrifice short-term utility in order to drive dynamics towards preferable long-term states and expliictly incorporate dynamical control objectives provided as functions of state.
To treat the long-term fairness problem (Eq. 6) using unconstrained optimization techniques (i.e., methods like TD3), we consider a time-dependent Lagrangian relaxation of Eq. 6. We train R-TD3 to optimize
| (12) |
where , , and .
Strictly applied, myopic fairness constraints can lead to undesirable dynamics and equilibria Raab and Liu (2021). Relaxing these constraints (hard soft) for the near future while emphasizing them long-term, we hope to develop classifiers that learn to transition to more favorable equilibria.
3.3 Greedy Baseline
In our experiments, we compare L-UCBFair and R-TD3 to a “Greedy Baseline” agent as a proxy for a myopic status quo in which policy is repeatedly determined by optimizing for immediate utility, without regard for the population dynamics induced by algorithmic actions. Our chosen algorithm for the greedy baseline is simply gradient descent in , defined as loss regularized by disparity, performed anew with each time step with fixed parameter .
| (13) |
While such an algorithm does not guarantee constraint satisfaction, it is nonetheless “constraint aware” in precisely the same way as a firm that (probabilistically) incurs penalties for violating constraints.
4 Simulated Environments
We describe our experiments with the algorithms we have detailed for long-term fairness as an RL problem: We consider a series of binary ( classification tasks on a population of two groups modeled according to evolutionary game theory (using replicator dynamics). We consider two families of distributions of real-valued features for the population: One that is purely synthetic, for which , independent of group , and one that is based on a logistic regression to real-world data. Both families of distributions are parameterized by the joint distribution . RL agents are trained on episodes of length initialized with randomly sampled states.
4.1 Setting
The following assumptions simplify our hypothesis space for classifiers in order to better handle continuous state space. These assumptions appeared in Raab and Liu (2021).
Assumption 4.1 (Well-behaved feature).
For purely synthetic data, we require to be a “well-behaved” real-valued feature or “score” within each group. That is,
As an intuitive example of 4.1, if represents qualification for a fixed loan and represents credit-score, we require higher credit scores to strongly imply higher likelihood that an individual is qualified for the loan.
Theorem 4.2 (Threshold Bayes-optimality).
For each group , when 4.1 is satisfied, the Bayes-optimal, deterministic binary classifier is a threshold policy
where is the feature threshold for group .
As a result of Theorem 4.2, we consider our action space to be the space of group-specific thresholds, and denote an individual action as the vector .
4.2 Replicator Dynamics
Our use of replicator dynamics closely mirrors that of Raab and Liu (2021) as an “equitable” model of a population, in which individuals my be modeled identically, independently of group membership, yet persistent outcome disparities may nonetheless emerge from disparate initial conditions between groups. In particular, we parameterize the evolving distribution , assuming constant group sizes, in terms of “qualification rates” and update these qualification rates according to the discrete-time replicator dynamics:
In this model, the fitness of label in group may be interpreted as the “average utility to the individual” in group of possessing label , and thus relative replication rate of label in group , as agents update their labels by mimicking the successful strategies of in-group peers. Also following Raab and Liu (2021), we model in terms of acceptance and rejection rates with a group-independent utility matrix :
We choose the matrix to eliminate dominant strategies (i.e., agents prefer one label over another, independent of classification), assert that agents always prefer acceptance over rejection, and to imply that the costs of qualification are greater than the costs of non-qualification among accepted individuals. While other parameterizations of are valid, this choice of parameters guarantees internal equilibrium of the replicator dynamics for a Bayes-optimal classifier and “well-behaved” scalar-valued feature , such that is monotonically increasing in Raab and Liu (2021).
4.3 Data Synthesis and Processing
In addition to a synthetic distribution, for which we assume , independent of , for all time, we also consider real-world distributions in simulating and comparing algorithms for “long-term fairness”. In both cases, as mentioned above, we wish to parameterize distributions in terms of qualification rates . As we perform binary classification on discrete groups and scalar-valued features, in addition to parameterizing a distribution in terms of , we desire a scalar-valued feature for each example, rather than the multi-dimensional features common to real-world data. Our solution to parameterize a distribution of groups and scalar features is to use an additional learning step for “preprocessing”: Given a static dataset from which is drawn i.i.d., (e.g., the “Adult Data Set” Dua and Graff (2017)), at each time-step, we train a stochastic binary classifier , such that with a loss that re-weights examples by label value, in order to simulate the desired : , where , is zero-one loss, and, in our experiments, we choose according to logistic regression. We interpret as a new, scalar feature value mapped from from higher-dimensional features as the output of a learned “preprocessing” function , 4.1 is as hard to satisfy in general as solving the Bayes-optimal binary classification task over higher-dimensional features. Nonetheless, we expect 4.1 to be approximately satisfied by such a “preprocessing” pipeline.
4.4 Linearity of Dynamics
L-UCBFair relies on 3.2, which asserts the existence of some Hilbert space in which the state dynamics are linear. Such linearity for real-world (continuous time) dynamics holds only in infinite-dimensional Hilbert space Brunton et al. (2021) and is not computationally tractable. In addition, the “feature map” that maps state-action pairs to the aforementioned Hilbert space must be learned by the policy maker. In experiment, we use a neural network to estimate a feature map which approximately satisfies the linear MDP assumption. We defer details to Section C.1.
5 Experimental Results
Do RL agents learn to seek favorable equilibria against short-term utility? Is a Lagrangian relaxation of long-term fairness sufficient to encourage this behavior? We give positive demonstrations for both questions.
5.1 Losses and Disparities Considered
Our experiments consider losses which combine true-positive and true-negative rates, where, for ,
| (14) |
where and . For disparity , we consider demographic parity (DP) Dwork et al. (2012), equal opportunity (EOp) Hardt et al. (2016), and qualification rate (QR):
| Func. | Form | |
|---|---|---|
| DP | ||
| QR | ||
| EOp | ||
| EO |
QR does not matter to myopic fair classification, which does not consider mutable population state.



5.2 Results
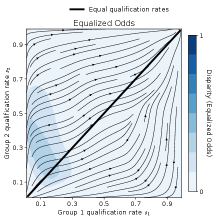
Our experiments show that algorithms trained with an RL formulation of long-term fairness can drive a reactive population toward states with higher utility and fairness, even when short-term utility is misaligned with desirable dynamics. Our central hypothesis, that long-term fairness via RL may induce an algorithm to sacrifice short-term utility for better long-term outcomes, is concretely demonstrated by Fig. 1, in which a greedy classifier and L-UCBFair, maximizing true positive rate tp (Section 5.1) subject to demographic parity DP (Section 5.1), drive a population to universal non-qualification ( and universal qualification (, respectively. Each phase plot shows the dynamics of qualification rates , which parameterize the population state and define the axes, with streamlines; color depicts averaged disparity incurred by in state .


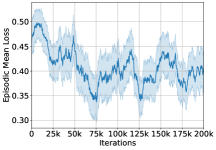
While both algorithms achieve no or little violation of demographic parity, the myopic algorithm eventually precludes future true-positive classifications (arrows in Fig. 1 approach a low qualification state), while L-UCBFair maintains stochastic thresholds at equilibrium (mean [0.49, 0.38], by group) with a non-trivial fraction of true-positives. The episodic mean loss and disparity training curves for L-UCBFair are depicted in Fig. 3.
We show that RL algorithms that are not limited by the same restrictive assumptions as L-UCBFair are applicable to long-term fairness. In Fig. 2, R-TD3 achieves similar qualitative behavior (i.e., driving near-universal qualification at the expense of short-term utility) when optimizing a loss subject to scheduled disparity regularization. This figure also highlights the lack of guarantees of R-TD3 in incurring prominent violations of the fairness constraint and failing to convincingly asymptote to the global optimum.





Finally, we demonstrate the capability of RL to utilize notions of fairness that are impossible to treat in the myopic setting, viz. qualification rate parity, in Fig. 4. In this example, while both RL agents achieve qualification rate parity, we note that L-UCBFair fails to realize the optimal equilibrium discovered by R-TD3.
Concluding remarks
We have demonstrated that desirable social outcomes that are in conflict with myopic optimization may be realized as solutions to long-term fairness formalized through the lens of reinforcement learning. Moreover, we have shown that this problem both admits solutions with theoretical guarantees and can be relaxed to accommodate a wider class of recent advances in RL. We hope our contributions spur interest in long-term mechanisms and incentive structures for machine learning to be a driver of positive social change.
Acknowledgement
This work is partially supported by the National Science Foundation (NSF) under grants IIS-2143895 and IIS-2040800, and CCF-2023495.
References
- Auer et al. (2002) Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47(2):235–256, 2002.
- Bai et al. (2022) Qinbo Bai, Amrit Singh Bedi, Mridul Agarwal, Alec Koppel, and Vaneet Aggarwal. Achieving zero constraint violation for constrained reinforcement learning via primal-dual approach. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 3682–3689, 2022.
- Brantley et al. (2020) Kianté Brantley, Miro Dudik, Thodoris Lykouris, Sobhan Miryoosefi, Max Simchowitz, Aleksandrs Slivkins, and Wen Sun. Constrained episodic reinforcement learning in concave-convex and knapsack settings. Advances in Neural Information Processing Systems, 33:16315–16326, 2020.
- Brunton et al. (2021) Steven L Brunton, Marko Budišić, Eurika Kaiser, and J Nathan Kutz. Modern koopman theory for dynamical systems. arXiv preprint arXiv:2102.12086, 2021.
- Chaney et al. (2018) Allison JB Chaney, Brandon M Stewart, and Barbara E Engelhardt. How algorithmic confounding in recommendation systems increases homogeneity and decreases utility. In Proceedings of the 12th ACM Conference on Recommender Systems, pages 224–232. ACM, 2018.
- Chen et al. (2022) Yatong Chen, Reilly Raab, Jialu Wang, and Yang Liu. Fairness transferability subject to bounded distribution shift. arXiv preprint arXiv:2206.00129, 2022.
- Coate and Loury (1993) Stephen Coate and Glenn C Loury. Will affirmative-action policies eliminate negative stereotypes? The American Economic Review, pages 1220–1240, 1993.
- Crawford and Calo (2016) Kate Crawford and Ryan Calo. There is a blind spot in AI research. Nature News, 538(7625):311, 2016.
- D’Amour et al. (2020) Alexander D’Amour, Hansa Srinivasan, James Atwood, Pallavi Baljekar, D Sculley, and Yoni Halpern. Fairness is not static: Deeper understanding of long term fairness via simulation studies. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pages 525–534, 2020.
- Ding et al. (2020) Dongsheng Ding, Kaiqing Zhang, Tamer Basar, and Mihailo Jovanovic. Natural policy gradient primal-dual method for constrained markov decision processes. Advances in Neural Information Processing Systems, 33:8378–8390, 2020.
- Ding et al. (2021) Dongsheng Ding, Xiaohan Wei, Zhuoran Yang, Zhaoran Wang, and Mihailo Jovanovic. Provably efficient safe exploration via primal-dual policy optimization. In International Conference on Artificial Intelligence and Statistics, pages 3304–3312. PMLR, 2021.
- Dua and Graff (2017) Dheeru Dua and Casey Graff. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Dwork et al. (2012) Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. In Proceedings of the 3rd innovations in theoretical computer science conference, pages 214–226, 2012.
- Efroni et al. (2020) Yonathan Efroni, Shie Mannor, and Matteo Pirotta. Exploration-exploitation in constrained mdps. arXiv preprint arXiv:2003.02189, 2020.
- Ensign et al. (2018) Danielle Ensign, Sorelle A Friedler, Scott Neville, Carlos Scheidegger, and Suresh Venkatasubramanian. Runaway feedback loops in predictive policing. In Conference of Fairness, Accountability, and Transparency, 2018.
- Epasto et al. (2020) Alessandro Epasto, Mohammad Mahdian, Vahab Mirrokni, and Emmanouil Zampetakis. Optimal approximation-smoothness tradeoffs for soft-max functions. Advances in Neural Information Processing Systems, 33:2651–2660, 2020.
- Feldman et al. (2015) Michael Feldman, Sorelle A Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian. Certifying and removing disparate impact. In proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, pages 259–268, 2015.
- Fujimoto et al. (2018) Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In International conference on machine learning, pages 1587–1596. PMLR, 2018.
- Fuster et al. (2018) Andreas Fuster, Paul Goldsmith-Pinkham, Tarun Ramadorai, and Ansgar Walther. Predictably unequal? The effects of machine learning on credit markets. The Effects of Machine Learning on Credit Markets, 2018.
- Ghosh et al. (2022) Arnob Ghosh, Xingyu Zhou, and Ness Shroff. Provably efficient model-free constrained rl with linear function approximation. arXiv preprint arXiv:2206.11889, 2022.
- Hardt et al. (2016) Moritz Hardt, Eric Price, and Nathan Srebro. Equality of opportunity in supervised learning, 2016.
- Heidari et al. (2019) Hoda Heidari, Vedant Nanda, and Krishna P. Gummadi. On the long-term impact of algorithmic decision policies: Effort unfairness and feature segregation through social learning. the International Conference on Machine Learning (ICML), 2019.
- Hu and Chen (2018) Lily Hu and Yiling Chen. A short-term intervention for long-term fairness in the labor market. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, pages 1389–1398. International World Wide Web Conferences Steering Committee, 2018.
- Hu et al. (2019) Lily Hu, Nicole Immorlica, and Jennifer Wortman Vaughan. The disparate effects of strategic manipulation. In Proceedings of the Conference on Fairness, Accountability, and Transparency, pages 259–268, 2019.
- Jabbari et al. (2017) Shahin Jabbari, Matthew Joseph, Michael Kearns, Jamie Morgenstern, and Aaron Roth. Fairness in reinforcement learning. In International conference on machine learning, pages 1617–1626. PMLR, 2017.
- Jin et al. (2020) Chi Jin, Zhuoran Yang, Zhaoran Wang, and Michael I Jordan. Provably efficient reinforcement learning with linear function approximation. In Conference on Learning Theory, pages 2137–2143. PMLR, 2020.
- Joseph et al. (2016) Matthew Joseph, Michael Kearns, Jamie H Morgenstern, and Aaron Roth. Fairness in learning: Classic and contextual bandits. Advances in neural information processing systems, 29, 2016.
- Kalagarla et al. (2021) Krishna C Kalagarla, Rahul Jain, and Pierluigi Nuzzo. A sample-efficient algorithm for episodic finite-horizon mdp with constraints. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 8030–8037, 2021.
- Liu et al. (2018) Lydia T Liu, Sarah Dean, Esther Rolf, Max Simchowitz, and Moritz Hardt. Delayed impact of fair machine learning. In International Conference on Machine Learning, pages 3150–3158. PMLR, 2018.
- Liu et al. (2020) Lydia T Liu, Ashia Wilson, Nika Haghtalab, Adam Tauman Kalai, Christian Borgs, and Jennifer Chayes. The disparate equilibria of algorithmic decision making when individuals invest rationally. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pages 381–391, 2020.
- Liu et al. (2021) Tao Liu, Ruida Zhou, Dileep Kalathil, Panganamala Kumar, and Chao Tian. Learning policies with zero or bounded constraint violation for constrained mdps. Advances in Neural Information Processing Systems, 34:17183–17193, 2021.
- Liu et al. (2017) Yang Liu, Goran Radanovic, Christos Dimitrakakis, Debmalya Mandal, and David C Parkes. Calibrated fairness in bandits. arXiv preprint arXiv:1707.01875, 2017.
- Mouzannar et al. (2019) Hussein Mouzannar, Mesrob I Ohannessian, and Nathan Srebro. From fair decision making to social equality. In Proceedings of the Conference on Fairness, Accountability, and Transparency, pages 359–368. ACM, 2019.
- Pan et al. (2019) Ling Pan, Qingpeng Cai, Qi Meng, Wei Chen, Longbo Huang, and Tie-Yan Liu. Reinforcement learning with dynamic boltzmann softmax updates. arXiv preprint arXiv:1903.05926, 2019.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019.
- Perdomo et al. (2020) Juan Perdomo, Tijana Zrnic, Celestine Mendler-Dünner, and Moritz Hardt. Performative prediction. In International Conference on Machine Learning, pages 7599–7609. PMLR, 2020.
- Raab and Liu (2021) Reilly Raab and Yang Liu. Unintended selection: Persistent qualification rate disparities and interventions. Advances in Neural Information Processing Systems, 34:26053–26065, 2021.
- Raffin et al. (2021) Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research, 22(268):1–8, 2021.
- Singh et al. (2020) Rahul Singh, Abhishek Gupta, and Ness B Shroff. Learning in markov decision processes under constraints. arXiv preprint arXiv:2002.12435, 2020.
- Tang et al. (2021) Wei Tang, Chien-Ju Ho, and Yang Liu. Bandit learning with delayed impact of actions. Advances in Neural Information Processing Systems, 34:26804–26817, 2021.
- Wei et al. (2022) Honghao Wei, Xin Liu, and Lei Ying. Triple-q: A model-free algorithm for constrained reinforcement learning with sublinear regret and zero constraint violation. In International Conference on Artificial Intelligence and Statistics, pages 3274–3307. PMLR, 2022.
- Wen et al. (2019) Min Wen, Osbert Bastani, and Ufuk Topcu. Fairness with dynamics. arXiv preprint arXiv:1901.08568, 2019.
- Williams and Kolter (2019) Joshua Williams and J Zico Kolter. Dynamic modeling and equilibria in fair decision making. arXiv preprint arXiv:1911.06837, 2019.
- Xu et al. (2021) Tengyu Xu, Yingbin Liang, and Guanghui Lan. Crpo: A new approach for safe reinforcement learning with convergence guarantee. In International Conference on Machine Learning, pages 11480–11491. PMLR, 2021.
- Zemel et al. (2013) Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi, and Cynthia Dwork. Learning fair representations. In International conference on machine learning, pages 325–333. PMLR, 2013.
- Zhang et al. (2020) Xueru Zhang, Ruibo Tu, Yang Liu, Mingyan Liu, Hedvig Kjellström, Kun Zhang, and Cheng Zhang. How do fair decisions fare in long-term qualification? arXiv preprint arXiv:2010.11300, 2020.
- Zheng and Ratliff (2020) Liyuan Zheng and Lillian Ratliff. Constrained upper confidence reinforcement learning. In Learning for Dynamics and Control, pages 620–629. PMLR, 2020.
Appendix A Proof
Without loss of generality, we assume for all , and for all .
A.1 Proof of Theorem 3.7
See 3.7 Outline The outline of this proof simulates the proof in Ghosh et al. (2022). For brevity, denote . Then
| (15) | |||
| (16) | |||
| (17) |
Similar to Efroni et al. (2020), we establish
is easily bounded if . The major task remains bound and .
Bound and . We have following two lemmas.
Lemma A.1 (Boundedness of ).
With probability , we have . Specifically, if and , we have with probability .
Lemma A.2 (Boundedness of ).
Ghosh et al. (2022) With probability , where .
Lemma A.2 follows the same logic in Ghosh et al. (2022), and we delay the proof of Lemma A.1 to Section LABEL:sec:t1t2. Now we are ready to proof Theorem 3.7.
Proof.
For any , with prob. ,
| (19) |
Taking , there exist constant ,
Taking ,
Following the idea of Efroni et al. (2020), there exists a policy such that . By the occupancy measure, and are linear in occupancy measure induced by . Thus, the average of occupancy measure also produces an occupancy measure which induces policy and , and . We take when , otherwise . Hence, we have
| (20) |
Since , and using the result of Lemma A.11, we have
A.2 Prepare for Lemma A.1
In order to bound and , we introduce the following lemma.
Lemma A.3.
There exists a constant such that for any fixed , with probability at least , the following event holds
for , where for some constant .
We delay the proof of Lemma A.3 to Section A.4.
Lemma A.3 shows the bound of estimated value function and value function corresponding in a given policy at k. We now introcuce the following lemma appeared in Ghosh et al. (2022). This lemma bounds the difference between the value function without bonus in L-UCBFair and the true value function of any policy . This is bounded using their expected difference at next step, plus a error term.
Lemma A.4.
We also introduce the following lemma. This lemma bound the value function by taking L-UCBFair policy and greedy policy.
Lemma A.6.
Define the value function corresponding to greedy policy, we have
| (21) |
Proof.
Define the solution of greedy policy,
| (22) | ||||
| (23) | ||||
| (24) | ||||
| (25) | ||||
| (26) | ||||
| (27) | ||||
| (28) |
The first inequality follows from Lemma A.10 and the second inequality holds because of Proposition 1 in Pan et al. (2019).
A.3 Proof of Lemma A.1
Now we’re ready to proof Lemma A.1.
Proof.
This proof simulates Lemma 3 in Ghosh et al. (2022).
We use induction to proof this lemma. At step , we have by definition. Under the event in Lemma A.9 and using Lemma A.4, we have for ,
Thus .
From the definition of ,
for any policy . Thus, it also holds for , the optimal policy. Using Lemma A.6 we can get
Now, suppose that it is true till the step and consider the step . Since, it is true till step , thus, for any policy ,
From (27) in Lemma 10 and the above result, we have for any
Hence,
Now, again from Lemma 11, we have . Thus,
Now, since it is true for any policy , it will be true for . From the definition of , we have
Hence, the result follows by summing over and considering .
A.4 Proof of Lemma A.3
We first define some useful sets. Let be the set of Q functions, where . Since the minimum eigen value of is no smaller than one so the Frobenius norm of is bounded.
Let be the set of Q functions, where . Define
the set of policies.
It’s easy to verify .
Then we introduce the proof of Lemma A.3. To proof Lemma A.3, we need the -covering number for the set of value functions(Lemma A.9Ghosh et al. (2022)). To achieve this, we need to show if two functions and the dual variable are close, then the bound of policy and value function can be derived(Lemma A.7, Lemma A.8). Though the proof of Lemma A.7 and Lemma A.8 are different from Ghosh et al. (2022), we show the results remain the same, thus Lemma A.9 still holds. We’ll only introduce Lemma A.9 and omit the proof.
We now proof Lemma A.7.
Lemma A.7.
Let be the policy of L-UCBFair corresponding to , i.e.,
| (29) |
and
| (30) |
if and , then .
Proof.
| (31) | ||||
| (32) |
The last inequaity holds because of Theorem 4.4 in Epasto et al. (2020). Using Corollary A.13, we have
| (33) |
Now since we have Lemma A.7, we can further bound the value functions.
Lemma A.8.
If , where , then there exists such that
Proof.
For any ,
Using Lemmas above, we can have the same result presented in Lemma 13 of Ghosh et al. (2022) as following.
Lemma A.9.
Ghosh et al. (2022) There exists a parameterized by such that dist where
Let be the -covering number for the set , then,
where
Lemma A.10.
.
Proof.
| (34) | ||||
| (35) | ||||
| (36) |
From Lemma A.12 and 3.6 we get the result.
A.5 Preliminary Results
Lemma A.11.
Lemma A.12.
Jin et al. (2020) For any , the weight satisfies
Corollary A.13.
If , and , then, .
Appendix B Additional Figures


Appendix C Experiment
C.1 Experiment Details
Device and Packages. We run all the experiment on a single 1080Ti GPU. We implement the R-TD3 agent using StableBaseline3Raffin et al. (2021). The neural network is implemented using PytorchPaszke et al. (2019).
Neural Network to learn . We use a multi-layer perceptron to learn . Specifically, we sample 100000 data points using a random policy, storing , , and . The inputs of the network are state and action, passing through fully connected (fc) layers with size 256, 128, 64, 64. ReLU is used as activation function between fc layers, while a SoftMax layer is applied after the last fc layer. We treat the outcome of this network as . To learn , we apply two separated fc layers (without bias) with size 1 to and treat the outputs as predicted and predicted . A combination of MSE losses of and are adopted. We use Adam as the optimizer. Weight decay is set to 1e-4 and learning rate is set to 1e-3, while batch size is 128.
Note that, is linear regarding and , but the linearity of transition kernel cannot be captured using such a schema. Therefore, equivalently we made an assumption that there always exists measure such that for given , the linearity of transition kernel holds. It’s a stronger assumption than Assumption 3.2.











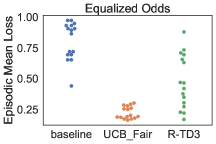











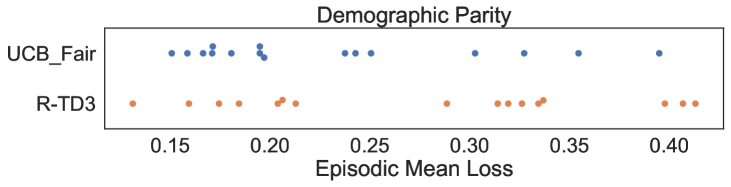
C.2 zero one accuracy with more weights on true positive


















C.3 Training Curves: L-UCBFair
C.3.1










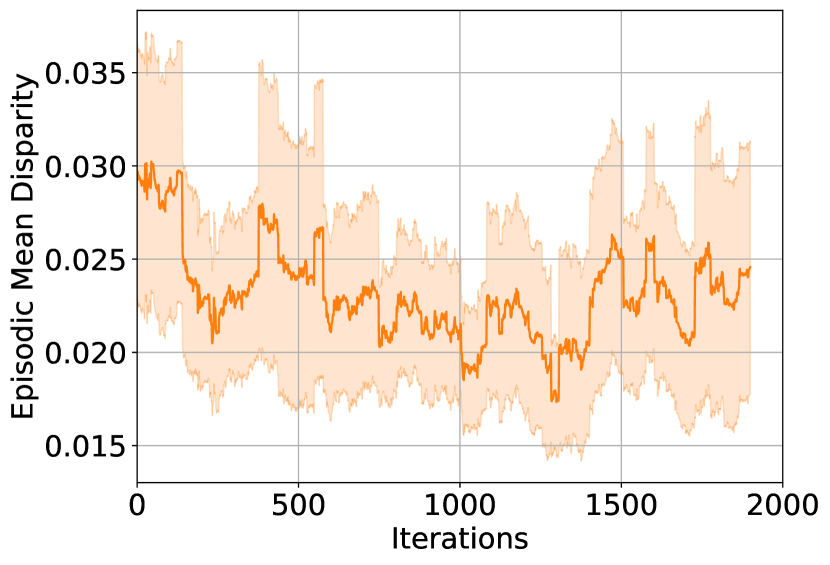

C.4 Training Curves: R-TD3











C.5 Reduction of Utility
