Long-Term Fairness in Sequential Multi-Agent Selection with Positive Reinforcement
Abstract
While much of the rapidly growing literature on fair decision-making focuses on metrics for one-shot decisions, recent work has raised the intriguing possibility of designing sequential decision-making to positively impact long-term social fairness. In selection processes such as college admissions or hiring, biasing slightly towards applicants from under-represented groups is hypothesized to provide positive feedback that increases the pool of under-represented applicants in future selection rounds, thus enhancing fairness in the long term. In this paper, we examine this hypothesis and its consequences in a setting in which multiple agents are selecting from a common pool of applicants. We propose the Multi-agent Fair-Greedy policy, that balances greedy score maximization and fairness. Under this policy, we prove that the resource pool and the admissions converge to a long-term fairness target set by the agents when the score distributions across the groups in the population are identical. We provide empirical evidence of existence of equilibria under non-identical score distributions through synthetic and adapted real-world datasets. We then sound a cautionary note for more complex applicant pool evolution models, under which uncoordinated behavior by the agents can cause negative reinforcement, leading to a reduction in the fraction of under-represented applicants. Our results indicate that, while positive reinforcement is a promising mechanism for long-term fairness, policies must be designed carefully to be robust to variations in the evolution model, with a number of open issues that remain to be explored by algorithm designers, social scientists, and policymakers.
1 Introduction
With the increasing use of machine learning models for decision-making systems with significant societal impact, such as recruitment Li et al., (2021), criminal justice Dressel and Farid, (2018), and credit lending Berkovec et al., (2018), there is also growing concern that such models may inherit existing bias in data, perpetuating and potentially exacerbating discrimination against certain groups in the population. This has prompted a growing body of research focused on developing fair and unbiased models, with much of the early literature focused on imposing notions of statistical fairness, such as equal selection rates or equal true positive rates, in static frameworks through pre-processing Zemel et al., (2013); Gordaliza et al., (2019); Kamiran and Calders, (2012), in-processing Zhang et al., (2018); Zafar et al., (2017), or post-processing Hardt et al., (2016) mechanisms.
Going beyond concepts of one-shot fairness and unbiasedness, there is also increasing interest in the long-term impacts of automated decisions under various dynamical models. For example, the potentially adverse consequences of myopic fairness are pointed out in Liu et al., (2018): unanticipated feedback dynamics due to the decisions made may change population statistics in an undesirable manner. For example, credit lending decisions which equalize true positive rates across groups to satisfy statistical fairness might lead to loans being offered to less creditworthy applicants from a disadvantaged group. Lower repayment rates from this group may then end up further decreasing its creditworthiness. On the other hand, feedback dynamics could also be used to shape population statistics in a desired direction. We take a step in this direction by hypothesizing that biasing slightly in favor of an underrepresented group in a selection problem (e.g., hiring or college admissions) provides positive reinforcement, increasing the proportion of applicants from that group in future selection rounds.
While most prior works on exploring such dynamics consider sequential decision-making by a single agent, we take a first step towards exploring the dynamics and long-term impact of multiple decision-making agents competing for a common pool of resources. We consider a selection problem, where we wish to use positive feedback to increase the proportion of underrepresented applicants in the presence of multiple agents (e.g, universities or companies) selecting from among a common pool of applicants. In order to focus attention on feedback dynamics, we consider a simplified model in which the agents are strictly rank ordered in terms of desirability from the applicants’ point of view. For this model, we provide a mathematical framework for studying whether some level of cooperation between the agents helps promote long-term fairness, and whether the concept of positive reinforcement is robust to variations in the evolution model. We propose the evolution model of positive reinforcement where if a higher proportion of applicants from a specific group is selected, it will lead to an increase in the proportion of applicants from that group in subsequent rounds. We study variants of this basic model of reinforcement, a particularly interesting one being the notion of role model reinforcement. Here only a certain fraction of the admitted applicants (as opposed to all admitted applicants) are in a position to influence applicant proportions in the future, by virtue of being role models. The idea that role models in society, to which a group can relate, could positively influence more aspirants to enter a field is supported by several works in social sciences and economics Morgenroth et al., (2015); Bettinger and Long, (2005).
Contributions
The contributions of this work are summarized as follows:
-
•
We propose the Multi-agent Fair-Greedy (MFG) policy, in which agents operate in a decentralized fashion, maximizing a greedy utility (based on the scores of selected applicants) while minimizing the disparity from a fixed long-term fairness target (based on the deviation of the selected proportion of minority applicants from a target proportion deemed to be socially fair). We characterize optimal actions under this policy and theoretically demonstrate the convergence of the overall applicant pool and the admission proportions to the desired long-term fairness target under the pure positive reinforcement model for the evolution of the composition of the applicant pool.
-
•
Different population dynamics are studied empirically to evaluate the impact of variations in population behavior. We find that while the decentralized MFG policy attains long-term fairness under pure positive reinforcement, if the population dynamics follow a simple variant, termed the role model reinforcement, uncoordinated behavior by agents can result in an overall negative feedback, leading to a steady decrease in the number of underrepresented applicants in the pool. We propose a centralized version of the MFG policy which can restore positive feedback.
-
•
We illustrate our mathematical framework through comprehensive experimental results based on synthetic and semi-synthetic datasets, highlighting variations in system behavior under different evolution models, and under decentralized and centralized MFG policies. These results show that positive reinforcement indeed has potential for promoting long-term fairness even with multiple agents, but that policy design must be carefully considered in order to be robust to changes in the evolution model.
2 Related Work
There is a rich and rapidly growing literature on fair strategies that mitigate bias in one-shot algorithmic decision making, including pre-processing the labels or data and reweighting costs based on groups Kamiran and Calders, (2012), reducing mutual information between sensitive attributes and predictions Cho et al., (2020); Kamishima et al., (2012), adversarial de-biasing Zhang et al., (2018), addition of constraints that satisfy fairness criteria Zafar et al., (2017), learning representations that obfuscate group information Zemel et al., (2013), and other information theoretic methods Calmon et al., (2017); Ghassami et al., (2018); Kenfack et al., (2023); Kairouz et al., (2022); Shen et al., (2023). However, recent research has introduced an intriguing possibility: the design of sequential decision-making strategies that can have a positive long-term impact on social fairness and a study of their consequence on the population.
The effects of fairness-aware decisions on underlying population statistics were first studied in Liu et al., (2018) for two-stage models: in the first stage, the algorithmic decisions are designed such that fairness constraints such as statistical parity or equal opportunity are satisfied, while the second stage examines the impact of these fairness interventions on the groups. Each sample is associated with a score corresponding to the probability of a positive outcome, sampled from group-specific distributions. The policy-maker or institution chooses selection policies to maximize utility subject to statistical fairness. The measure of interest in Liu et al., (2018) is the expected change in the mean of the score distributions for the two groups as a result of one step of feedback. It was found that imposing equal selection rates or true positives could lead to either improvement or cause harm, particularly to the minority group, depending on certain regimes. The results of Liu et al., (2018) highlight the importance of going beyond static notions of fairness in algorithm/policy design.
Several works propose notions of statistical fairness focused on improving feature distributions among groups. For example, Heidari et al., (2019) presents a fairness notion that equalizes the maximum change in reward for groups with the same effort budget for improving their features. The authors examine how fairness interventions impact evenness, centralization, and clustering in the groups through their efforts, affecting score distributions. In another example, Guldogan et al., (2023) proposes to equalize the proportion of unqualified candidates from different groups that can be qualified with a limited effort for improving their features. The authors investigate how statistical fairness notions change feature distributions among groups in the long term through modeling feature evolution.
Formal investigation of temporal effects of decision feedback and their equilibrium is typically performed in reinforcement learning Jabbari et al., (2017); Wen et al., (2021); Heidari and Krause, (2018); Yin et al., (2023) or bandit settings Joseph et al., (2018); Chen et al., (2020); Gillen et al., (2018); Patil et al., (2020); Ghalme et al., (2021). The environment is described through a Markov Decision Process (MDP) framework where at each time, the decision-maker in a particular state takes an action and receives a reward. State transitions are governed by update models, and fairness constraints are included within reward definitions.
The long-term effects of fair decisions on the qualification rate of the group, which is defined as the probability of an individual from a particular group being qualified, is investigated in Zhang et al., (2020) under a partially observable MDP setting. The group proportions over time are fixed, but the decisions affect the feature distributions which in turn change their true qualification state, which is modeled as a hidden state. Decisions are performed on the features to maximize myopic instantaneous utility, subject to statistical fairness constraints. Threshold-based policies and their equilibrium are studied under two regimes: “lack of motivation,” where the probability of remaining qualified on receiving a positive decision is less than that on being rejected, and “leg-up,” which is the opposite, where an accepted individual becomes inspired to become more qualified. Studies such as Mouzannar et al., (2019); Williams and Kolter, (2019) also examine the effects of fair policies on the distributions of the features. In particular, Mouzannar et al., (2019) studies how the qualification profiles of groups are influenced by a policy that imposes demographic parity (equal selection rates) across two groups of the population. They assume that social equity is achieved through equalized qualification profiles in equilibrium. The dynamic model in Williams and Kolter, (2019) is motivated by credit lending. The authors model the distributions of loan repayment likelihood (payback probabilities) by group, and examine the dynamics governed by the hypothesis that granting loans leads to upward mobility for the population if they are repaid. They study the impact of fair decisions on loan repayment likelihood and the negative effects of unequal misestimation of payback probabilities across groups, even if the decisions are fair. In contrast to studying the effects on group qualification, it is also imperative to understand how group representation could vary over time. It was first shown in Hashimoto et al., (2018) that empirical risk minimization can exacerbate the disparity in group representation. In the context of long-term fairness, Zhang et al., (2019) study how algorithmic decisions which are constrained by statistical fairness could degrade the representation of a minority group, and eventually cause the loss of minority representation in the system.
Our prior work: The work reported here builds upon preliminary results shown in our conference paper Puranik et al., (2022), where we first introduce the problem of selecting applicants from a pool under the setting of a single institution. We introduce the positive reinforcement model for evolution of the applicant pool, which is similar in spirit to the “leg-up” model in Zhang et al., (2020), except that it applies at the level of a population rather than an individual: selection of a larger proportion of applicants from a specific group feeds back into society and leads to an increase in the proportion of applicants from that group in future rounds. The score of an applicant, drawn from a group-specific distribution, is taken to represent the level of qualification of that individual. The Fair-Greedy policy, proposed in a single institution setting, greedily balances the sum of the scores of selected applicants against a fairness measure which increases with the deviation of the selected proportion of applicants from the under-represented group from a specified long-term target proportion. Theoretical results for identical score distributions across groups, and empirical results for other models, show convergence to a long-term fairness target set by the decision-maker. While the preliminary results in Puranik et al., (2022) show long-term fairness through positive feedback under a single institution, in this journal paper, we extend the promise of positive reinforcement to multiple-agents, consider variations in the evolution model, and find that careful design of feedback mechanism is required.
All of the preceding works on long-term fairness focus on settings with a single decision-maker accessing a pool of samples from the population. However, in real-world selection processes such as college admissions or hiring, there are often multiple agents or institutions competing for a common pool of applicants. The composition of the applicant pool can therefore be affected by the collective decisions of these agents. To the best of our knowledge, ours is the first work to study the long-term evolution of fairness in such a multi-agent setting. While two-sided matching problems, where multiple agents and resources are to be matched to each other, are well studied in resource allocation problems and game theoretic settings Dai and Jordan, (2021); Cho et al., (2022), the notion of long-term fairness in such settings is yet to be examined, and the definitions of fairness considered are quite distinct from those in fairness literature. Since our focus is on dynamical evolution, we sidestep the problem of matching between institutions (agents) and applicants (resources) by assuming that each applicant has the same fixed preference among the institutions.
3 Modeling Multi-Agent Decision-Making
Consider the problem of agents, or institutions, selecting from a common pool of resources, or applicants. The applicant pool is composed of applicants from two groups , based on a sensitive attribute. Without loss of generality, we usually refer to as the minority group and as the majority group. We denote the number of applicants in round , belonging to group by , and the total number of applicants as . Every applicant is associated with a score which is sampled from a group-dependent distribution .
In many applications, the institutions have a growth in the program size, which is typically proportional to the population. For instance, the University of California system intends to serve top one-eighth of California’s high school graduating class population UCOP, (2024). Motivated by this line of thought, we consider that every institution fixes the total number of applicants it can admit, through the capacity for institution , set as a fraction of applicants it admits, out of the total number of applicants in the pool in that round. Thus we have .
Each institution has to determine how to fill its admission slots, particularly by deciding how many minority and majority applicants are to be admitted, while satisfying two-fold objectives: (i) to accept applicants with the largest scores (ii) to achieve a long-term fairness target (denoted by ) in the admission of applicants, which measures the proportion of admitted applicants belonging to the minority group, . The goal of the institutions is to move towards the long-term fairness target, while admitting applicants with the highest scores. We denote the number of applicants admitted by institution as , out of which belong to group . Thus, we have , and the institutions hope to make decisions such that approaches in equilibrium for all .
We assume that the institutions are ranked, and that every applicant prefers institutions in the same order. Without loss of generality, we assume that the institutions are indexed by rank order, with corresponding to the highest-ranked institution. Since the preference order is fixed, the matching of applicants to institutions simplifies to institutions picking from the application pool sequentially, in their ranked order. The decision variable at each institution in each round is the fraction of admitted applicants from each group (selecting from the highest scoring applicants in each group, chosen from among the pool that remains after higher-ranked institutions have made their selections). We, therefore, have an effectively sequential selection process in each round, where the selections are started by the highest-ranked institution and completed by the lowest-ranked institution.
The problem is formulated as a Markov Decision Process (MDP). The state is the fraction of applicants from group in the applicant pool. Thus, at round we have . An institution is associated with its respective action , which is the fraction of applicants admitted from group among the total number of applicants the institution admits. Thus, . The actions or the decision variables of each of the institutions are to be determined based on optimizing their respective fairness-aware utilities, defined below.
First, a set of applicants in round are associated with a set of scores , where each , ], is sampled independently from . Additionally, denotes the top score out of applicants from group . We define the score-based reward for an institution with rank as the expectation of the sum of scores of the applicants admitted by the institution normalized by the number of total applicants it admits. Note that for an institution , this depends upon the actions of the preceding -ranked institutions, as each institution selects sequentially from the remnant pool of applicants. For , we define as the number of applicants from group that have already been selected by higher ranked institutions , with . Thus, we have the score-based reward:
| (1) |
with the group-specific offsets given by
| (2) |
Each institution is associated with its fairness loss, which is the squared difference between the proportion of group out of the total admitted, and the long-term fairness target , given by The considered fairness loss is a simple measure of disparity from the long-term fairness target, and penalizes the bias against both groups on the long run.
The “multi-agent fairness aware” utility of each institution is the sum of its score-based reward and fairness loss, expressed as
| (3) |
where is a parameter that governs balancing fairness objective with score-based reward.
Thus each institution aims to maximize its score-based reward by admitting applicants with the highest scores, while minimizing its disparity from the long-term fairness target.
Multi-agent Fair-Greedy Policy
We propose the Multi-agent Fair-Greedy (MFG) policy, which is a set of policies , where each institution optimizes its own multi-agent fairness aware utility as follows:
| (4) |
where is the set of feasible actions for institution in round , which depends on the actions of higher ranked institutions and the state . After higher ranked institutions have made their selections, the feasible action space for institution is determined by the remaining capacity of the institution and the remaining applicants in the pool, and can be written as . For each institution, optimization of the instantaneous multi-agent fairness aware utility is equivalent to finding group-specific set of thresholds on the score distributions. In our rank-ordered model for institutions, each institution admits applicants whose scores exceed its threshold, choosing from the pool remaining after higher-ranked institutions have made their selections. However, we reiterate that the state represents the original minority group proportion in the pool at round .
Resource pool evolution
A key ingredient of our formulation is modeling the manner in which the collective decisions of the institutions affect the pool of resources seen in the subsequent rounds of the problem. This is a complex relationship requiring data collected from carefully designed long-term experiments. While such data is not yet available, we can develop valuable insights by exploring different models for how the applicant pool might be shaped by institutional policies.
We assume that the state is a random variable with mean and bounded variance. We model the number of applicants from group and as being sampled from Poisson distributions, with and , where is the expected number of applicants in the pool. The total number of applicants in round is given by .111When both and are equal to zero, the round is completed without any admissions. The choice of the Poisson distribution is for the sake of simplicity, and the outcomes of our analysis remain independent of this particular choice of distribution. We consider different models for the evolution of in this paper, focusing first on the model of pure positive reinforcement. In this model, a higher proportion of admission of a particular group in comparison to its application proportion, motivates more applicants from the group to participate in future selection rounds. Here the evolution follows:
| (5) |
where is the projection onto the set (or, simply clipping the mean parameter) where is a small positive number to avoid the mean parameter from reaching the boundary of the set and it implies that the any group cannot be completely eliminated from the pool. Here, is a step size parameter and represents the weighted actions of all the institutions.
In particular, under the MFG policy, depends upon on the policies of all the institutions weighted by their capacities, which is also equivalent to the proportion of minority group among all the admitted applicants, defined as:
| (6) |
Thus, the collective decisions of all institutions, in particular their admission of applicants from a particular group, promote more such applicants to participate in the process, and shape the evolution dynamics.
In the remainder of this section, we characterize the MFG policy in a decentralized setting, under the pure positive reinforcement model. We show that the optimal policy for each institution depends on actions that optimize the score-based reward alone, and the fairness loss alone. We therefore first derive the reward-optimal and fairness-optimal actions for each institution, and then characterize the MFG policy in terms of these actions. We then show that, for pure positive reinforcement and identical score distributions , the applicant pool (state) and the admission proportions (actions) for all institutions converge to the long-term fairness target. We use the following assumptions in our convergence analysis:
Assumption 1.
The expected number of applicants in the pool is large enough that the empirical distribution of scores can be replaced by statistical distributions using the law of large numbers.
This assumption is required for the asymptotic analysis of the applicant pool and admission proportions. It is also used to derive the reward-optimal actions for the institutions.
Assumption 2.
The score distributions are identical across groups.
This assumption implies that the only difference in the groups is the proportion of applicants from each group in the pool at each round. We relax this assumption in Section 5.1 and provide empirical evidence for the existence of equilibria of the applicant pool proportion and the admission proportions.
Fairness-optimal action
Each institution can minimize its fairness loss by setting its action to be equal to the long-term fairness target:
| (7) |
where is the projection of onto the feasible action space .
The next theorem characterizes the reward-optimal actions for the institutions.
Theorem 1.
The detailed proof of this theorem can be found in Appendix A.
Remark.
Under the asymptotic regime of Assumption 1 (i.e., assuming that empirical distributions of applicant scores can be replaced by statistical distributions), the proof of Theorem 1 can rely on the following simplification. For institution , the selection of applicants with top scores is equivalent to thresholding the group’s score, and admitting applicants with scores within the group-specific lower and upper thresholds, denoted by and respectively. The upper threshold equals the lower threshold of institution for group . In Lemma 2 we show that for reward optimality for any institution , its group-specific lower thresholds should be equal; , if possible. While this holds even if the group-specific score distributions are different, we can derive closed-form expressions for reward-optimal actions as in Theorem 1 when the distributions are identical across groups.
Remark.
The optimal policy of institution that maximizes its multi-agent fairness aware utility can be expressed as a convex combination of its pre-projected optimal score-based reward action and optimal fair-only actions, as , where (please refer to Appendix B for details). The closed-form expression for is not available in general, but it can be numerically computed due to the concavity of the fairness-aware utility function. It can be shown that the reward-optimal action can be expressed as:
| (9) |
Thus, when the hyperparameter , if , for we have , and vice-versa. Note that, for a special case where there is a single institution, lies between the state and long-term fairness target . But that is not necessarily the case for for , when there are multiple institutions.
In the following lemma, we characterize the weighted policy of the institutions, that ultimately governs the pool evolution (5).
Lemma 1.
Please refer to Appendix B for proof.
We utilize this result to prove the convergence of the applicant pool and admission proportions to the long-term fairness target. In the following theorem, we first show that the target proportion is a unique fixed-point of the pool evolution update. We then show that the weighted policy lies between the applicant and target proportions, as a result of which the mean state parameter and the state converge to the target. Although our analysis is for identical group-wise score distributions, we later provide empirical evidence of equilibrium in state and actions of all institutions when the score distributions are different across groups.
Theorem 2.
Under Assumptions 1, 2 and , the weighted MFG policy is such that if , or if . Further, is a unique fixed-point of the weighted policy . In addition, the applicant pool proportion converges to the long-term fairness target , if the step size parameter is decaying with time and satisfies the assumptions that and . Further, the admission proportions of all institutions approach the long-term fairness target at equilibrium.
The proof of this theorem can be found in Appendix B.
Remark.
For identical group-wise distributions as considered in Theorem 2, the convergence to the target holds irrespective of the value of the hyperparameter weighing fairness in the utility function, as long as it is positive (). For non-identical score distributions across groups, we provide empirical evidence for the existence of equilibria of the applicant pool proportion and the admission proportions in Section 5.1. However, the actual value of is now found to be important in determining how close to the fairness target we get.
What happens if we ignore fairness?
In the scenario of identical score distributions, if each institution completely disregards the fairness objective and optimizes only its score-based reward, as seen from (9) where , it follows that for all . Consequently, the mean parameter would not experience any drift, and the composition of the applicant pool would remain unchanged. While each institution greedily acquires the best applicants by sacrificing diversity, there is no hope of influencing the participation of the underrepresented. However, biasing slightly in favor of the underrepresented group by introducing the fairness objective could lead to both and converging to the long-term fairness target.
4 Variations on the Pool Evolution Model
Achieving long-term fairness relies on how the applicant pool evolves with institutional decisions over time. In this section, we introduce variations of the pure positive reinforcement model, and examine how the MFG policy fares under these new variants of the evolution model termed (i) order-based (ii) weighted (iii) role-model reinforcement. The bulk of our discussion in this section focuses on the motivation and study of role-model reinforcement and pitfalls under it, while we first briefly discuss the other two below:
Order-based positive reinforcement
This simple variant allows control over the strength of positive reinforcement by raising the feedback in pure positive reinforcement to a power :
| (11) |
Pure positive reinforcement is a special case of the above model for . The feedback is amplified for and is attenuated for , since .
Weighted positive reinforcement
The second simple variation allows custom weights on the institutions’ policies
| (12) |
with pool evolution
| (13) |
Here reduces back to pure positive reinforcement, which gives greater influence to an agent with higher capacity. The more general models (12)-(13) here allow us more flexibility in assigning influence. For example, we can give equal influence to all institutions by setting .
Role model reinforcement
Thus far, we have assumed that all selected applicants in an institution have equal ability to influence the reinforcement. However, applicants who do well post-selection in a given institution, who we term role models, could influence future applicant pools significantly more than other admitted applicants in the institution. The motivation for this model stems from the fact that in practice, success in an institution depends not just on qualifications at the time of admission, but on support mechanisms within the institution to aid in continued growth and success of the admitted applicants, as well as on circumstances that may be difficult to characterize. However, to develop analytical insight into what happens when positive reinforcement occurs due to the applicants who do well post-selection, we consider a score-based criterion for identifying these role models: among all applicants (from both groups) admitted to institution , the role models are composed of a fraction of applicants with the highest scores. From among this group, the fraction of minority (group ) applicants, denoted by , drive the pool evolution. We now develop the notation required to define this model precisely.
Let denote the set of scores of all applicants admitted by the institution at time ,
| (14) |
The role models for each institution are selected as top proportion of the admissions with the highest scores, Then, let denote the fraction of the minority group in the role models set for the institution at round . It can be written as:
| (15) |
Then, the pool evolution model depends on the fraction of the applicants from the minority group among the role models, , instead of the fraction of the applicants from the minority in the admissions, . The weighted role model parameter is defined as
| (16) |
If a group has a higher proportion of role models in comparison to its application proportion, it will provide positive reinforcement. The pool update is then governed by:
| (17) |
For , role model reinforcement reduces back to pure positive reinforcement. Setting implies that minority applicants whose scores are above the median score for admitted applicants in their institution are role models driving pool evolution.
While we showed that convergence to long-term fairness target is assured under pure positive reinforcement, we shall now see that it is not the case, under this variant evolution model. First, let us focus first on a special case when . Under a limiting case of role-model reinforcement when , convergence to long-term fairness is guaranteed. In the other extreme case, when the bar for role models is extremely high, i.e., (small), . Thus, although the MFG policy biases in favor of minority group, there could be no drift in the mean state parameter, leading to a stagnation in the composition of the applicant pool. However, when there are multiple institutions involved, this could lead to explicit negative feedback, causing the proportion of minority in the applicant pool to steadily reduce. We now show in Proposition 1 below that role model reinforcement can lead to negative feedback under the MFG policy, specifically when there are multiple institutions(). Assuming identical group-wise score distributions, we show that if the long-term fairness target is higher than the initial proportion of the minority group, the first institution will admit more minority applicants than their application proportion. This results in the subsequent institutions having a higher proportion of top admissions from the majority group, leading to a lower proportion of minority group role models. This can eventually cause the minority group to be removed from the applicant pool, as formally demonstrated next, and empirically supported by experiments in Section 5.1. Furthermore, we empirically demonstrate that coordinated behavior by the agents could help in alleviating this negative feedback.
Proposition 1.
Please see Appendix C for proof.
Remark.
The evolution of the applicant pool under role model reinforcement is such that only admitted applicants from group with scores larger than a group-independent threshold , will contribute to reinforcing the pool. The threshold increases as we reduce the role model parameter , raising the bar for being a role model. Let and denote the lower and upper thresholds of the MFG policy for group and institution . The key idea behind the proof is that when the initial mean parameter is small, there exists a small enough such that for institution , we have . Using this, we show that the role model proportions are such that for and . Hence, the mean parameter obtains a negative drift, and the proportion of the minority group in the applicant pool approaches zero.
In order to mitigate the effects of such negative feedback, we define a centralized version of the MFG policy in the next section.
4.1 Centralized Multi-agent Fair-Greedy Policy
The selection process under the original MFG policy, in which the institutions do not cooperate, is sequential based on the ranking order of the institutions. We now consider decision-making by a central coordinator which knows the utility of each institution, and maximizes the sum utility across institutions:
| (18) |
Thus, the Centralized Multi-agent Fair-Greedy (CMFG) policy is defined as a set of policies maximizing the total utility over the space of joint actions as:
| (19) |
The main difference between the MFG and CMFG policies lies in the way that institutions work together. Intuitively, we can view the set of policies as the joint imposition of group-dependent thresholds corresponding to all institutions simultaneously in order to maximize the total utility, as opposed to the earlier decentralized version, where a higher ranked institution imposes its thresholds without consideration of downstream effects on the utilities of lower-ranked institutions. Thus, in CMFG policy, institutions collaborate with each other to maximize their total utility. This allows a central coordinator to distribute the cost of fairness among all institutions, potentially leading to a selection policy that is different from sequential decentralized selection. In particular, the effects of the negative feedback loop observed with the sequential selection under role model reinforcement can be mitigated, as shown in the experimental results in Section 5.1.
In summary, the discussion of the role model reinforcement variant model serves the following objectives within the context of this study. Firstly, it allows us to simulate a realistic and plausible scenario wherein only a subset of admitted applicants possesses the capacity to exert influence on future participation dynamics. To illustrate this concept, we designate top applicants from each institution as role models, albeit with an acknowledgment of the inherent complexity of truly characterizing successful applicants in real-world situations. This abstraction enables us to underscore the notion that a simplistic strategy of biasing in favor of minority applicants alone does not suffice as a comprehensive solution for fostering future participation. Instead, it underscores the critical importance of institutional support for the admitted applicants to facilitate their growth and eventual success. The effectiveness of this support hinges upon the mechanisms and extent of backing provided by each institution. We show that as a growing number of admitted applicants receive the necessary support to attain a level of success that qualifies them as symbolic role models, the potential for positive reinforcement substantially increases. The precise means by which institutions implement and coordinate these support mechanisms constitutes an open question of paramount significance, particularly for policymakers tasked with shaping equitable participation.
5 Experimental Evaluation
We empirically evaluate the proposed MFG policy under different models for the evolution of the applicant pool. We begin with experiments on synthetic data, where the scores are sampled from group-specific Gaussian distributions, followed by learning the score distributions from real-world datasets. The MFG and centralized MFG policies are computed numerically and the optimal policies are obtained using the grid search over the space of policies. The number of applicants is kept finite in the experiments. The code for our experiments is available in a repository. 222https://github.com/guldoganozgur/long_term_fairness_pos_reinf
5.1 Multi-agent framework evaluated on synthetic data
Identical score distributions
We first consider the case when the score distributions across the two groups in the population are the same. The parameter setting employed for these experiments is listed next. The long-term fairness target is set at . The number of institutions is with capacities , and , resulting in a total capacity of . The score distributions are Gaussian, with means and variances . The initial mean parameter is , giving the minority group lower representation in the resource pool. The range of the mean parameter is , and the mean parameter is projected to the range at each iteration. The state is defined as , where follows a Poisson distribution with parameter , follows a Poisson distribution with parameter , and . For computational efficiency, once the state is computed, the total number of applicants is fixed to , and the number of applicants from each group is adjusted according to the state and then rounded to the nearest integer for numerical convenience. Other parameters include and the step-size is fixed as . All the plots are averaged over instances of the problem.
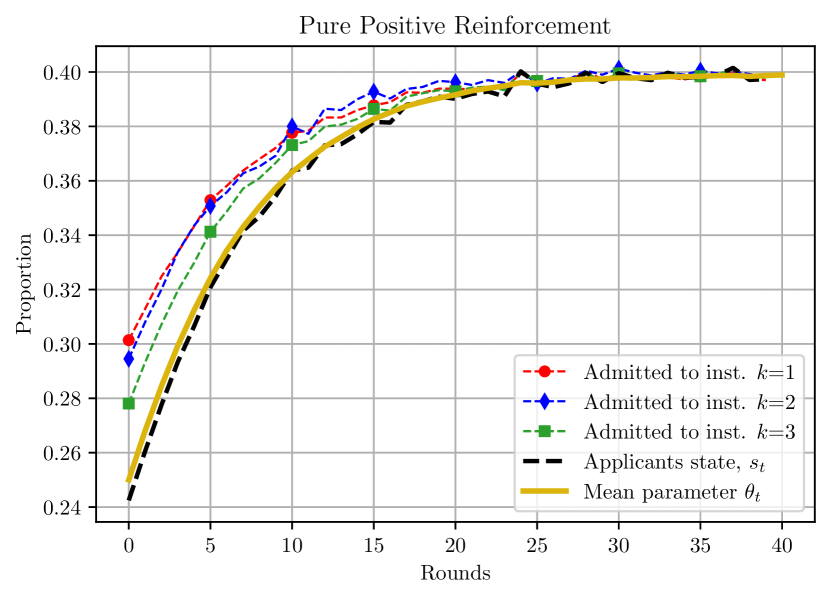


We demonstrate the evolution of the applicant and admission proportions, and the mean parameter, for the MFG policy under different reinforcement models. In Figure 1(a), we can observe that under the pure positive reinforcement model, for each institution, the admission proportion is larger than the applicant proportion (state), and hence the weighted MFG policy being larger than the applicant proportion results in the positive reinforcement of the applicant pool (observed through the evolution of mean parameter ) and long-term fairness in admissions as well. Next, we focus on the robustness of the MFG policy under different evolution models. The order-based reinforcement in Figure 1(b) uses , and shows that faster convergence can be achieved in comparison to the pure positive reinforcement model. The weighted positive reinforcement model in Figure 1(c) uses identical weights for all institutions, showcasing the pool evolution when equal importance is assigned to every institution. In both these cases, for the setting considered, the MFG policy leads to the achievement of long-term fairness.
Further, we show the evolution of the mean applicant pool parameter under pure positive reinforcement model and the MFG policy for different weights, , allotted to fairness loss in Figure 2, where we observe that the mean parameter achieves the same long-term fairness target in equilibrium, independent of the hyperparameter , under identical score distributions, and long as . However, the rate of convergence depends on .




.
Next, we gain valuable insights into the operational dynamics of the MFG policy. Our objective is to comprehend the trade-offs made, in terms of scores of admitted applicants of the majority and minority groups, to foster fairness. Figure 3(a) depicts the percentile at which the admitted applicant with the lowest score is positioned, for both the groups and all institutions, when across all participating institutions. Next, in Figure 3(b), we extend our examination to a scenario in which the values are decremented across institutions as , signifying that lower-ranked institutions temporarily de-prioritize diversity to minimize a significant decline in the quality of admitted applicants. Consequently, this approach illustrates how a judicious delay in the pursuit of immediate fairness objectives by lower-ranked institutions can assist in averting a large drop in their admission standards. However, this strategy of decreasing impacts the overall convergence rate (see Fig. 3(c)), as all institutions experience a deferment in the applicant pool reaching the long-term fairness objective. This serves as an example of the delicate balance that institutions must navigate between the convergence to fairness targets and maximization of short-term rewards. Nonetheless, the precise strategies and mechanisms to be adopted by individual institutions in achieving this balance remains open.




Potential for negative feedback
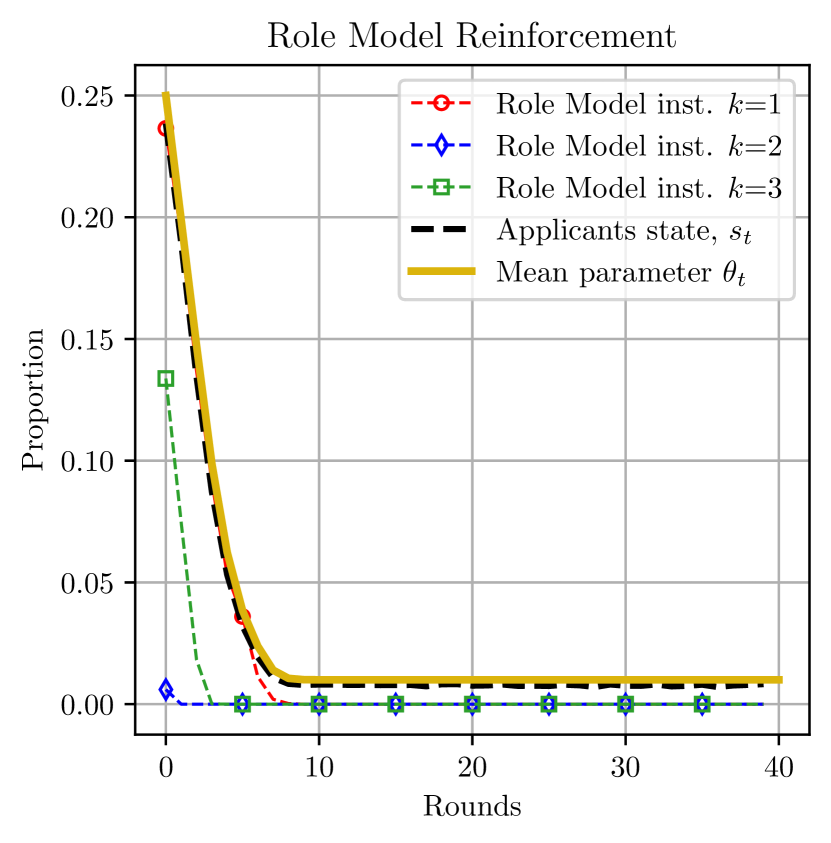
The evolution dynamics of role model reinforcement, under the MFG policy is examined here. We consider a scenario where role model reinforcement is applied with a parameter of , i.e., the admissions with scores above the median score in the respective institution are considered role models for the resource pool evolution. As seen in Figure 4(a), the MFG policy creates a negative feedback loop, causing a significant decrease of the minority group in the applicant pool over time. This is because the role model proportions are such that the weighted role model policy is consistently smaller than the state. In particular, as seen in Figure 4(b), the second and the third institutions see a very small fraction of role models among the minority group, since the first institution admits the top minority applicants. These effects could potentially be alleviated by considering a centralized policy, such as the CMFG policy, whose evolution for the admitted applicants and the proportion of the role models under this setting are shown in Figure 4(c) and 4(d). Although the initial dynamics between the institutions under CMFG policy are not desirable in the real-world and not well understood, it shows a potential of ultimately attaining an equilibrium close to the long-term fairness target. We also remark that the adverse effects under role model reinforcement in conjunction with the MFG policy could be avoided by increasing the parameter, which essentially means that the institutions must design intervention mechanisms or remedies to support a large fraction of the admissions to eventually be successful in society, and influence others by being true role models.
For completeness, we show the evolution of applicant and admission proportions under the CMFG policy under pure positive reinforcement, order-based and weighted positive reinforcement models in Appendix D.1.
Distinct score distributions



We now examine the scenario where the score distributions for the groups are distinct. We assume that the minority group has a slightly lower mean and higher variance than the majority group ( and ). The other parameters remain the same as in the first scenario, with a long-term fairness target of , capacities , and , an initial mean parameter , and fixed step size .
Figure 5(a) shows the evolution of the mean parameter under different weights, , for fairness loss, under non-identical distributions. We observe that by altering , the equilibrium point can be varied. Thus, a higher value of is required to achieve the long-term fairness goal. We then show in Figures 5(b) and 5(c), the evolution of the applicant pool, admission proportions, and their convergence under the pure positive reinforcement model, under MFG and CMFG policies respectively, with . They both converge to similar equilibrium although the admission decisions in initial rounds are quite distinct. We observe a behavior of negative feedback under the role-model reinforcement model under distinct score distributions as well. The results showing negative feedback and the alleviation of this effect through the CMFG policy are deferred to Appendix D.2. In the next section, we will examine cases where the score distributions are significantly different, obtained from a real-world dataset.
5.2 Multi-agent framework evaluated on semi-synthetic dataset



In this section, we report on experiments on the law school bar study dataset Wightman, (1998). The dataset is used to construct the initial setup of the experiments as defined in the previous section, therefore we refer it to as a semi-synthetic dataset. This dataset contains information collected by the Law School Admission Council from law schools in the US, including information on whether an applicant passed the bar exam based on features such as LSAT scores, undergraduate GPA, law school GPA, race, gender, family income, age, and others. We take race as the protected attribute and simplify it to a binary classification problem by grouping all races except ”white” into the ”non-white” category, serving as the minority group (group ) with only representation in the dataset. The dataset used in our experiments contains around 1800 instances and we followed the same pre-processing steps at Kearns et al., (2018). Next, we follow the procedure outlined in Puranik et al., (2022) to obtain the score distributions for each group. After pre-processing the data, we fit a logistic regression model to approximate the score distributions as Gaussians. This gives us the means and , and the variances and , as seen in Figure 6(a). The long-term fairness target is set to , with three institutions having capacities of , and . The step size, , is fixed at 0.5. Our first examination is of the pure positive reinforcement model. Figures 6(b) and 6(c) depict the mean parameter, at equilibrium for the MFG and CMFG policies, respectively, with varying fairness loss coefficients, . A higher value of is needed to achieve the long-term fairness goal for both policies, with the CMFG showing a slightly better equilibrium point at a smaller value of (for instance, ). We defer the evaluation under role-model reinforcement model to Appendix D.3.
Our experiments with distinct distributions illustrate that the principles of reinforcement and the policies developed in this paper hold even when the score distributions are non-identical.
6 Conclusion
This paper studies the evolution of long-term fairness in a selection setting with multiple decision-makers choosing from a common pool. We have shown that the Multi-agent Fair-Greedy (MFG) policy does succeed in achieving long-term fairness targets under the model of pure positive reinforcement. However, when we set a higher bar for successful influence via the role-model reinforcement model, the minority group may actually experience negative feedback under MFG policy, and ultimately exit the selection process. Centralized coordination among the institutions could potentially alleviate this problem, raising the question of whether we can design mechanisms for competing institutions to collaborate (without laying themselves open to charges of collusion) in order to advance long-term fairness in society at large.
We hope that this work, despite the simplicity of the models considered, stimulates continuing discussion on the long-term societal impact of automated decision-making in a multi-agent setting, and how we can shape it. The sensitivity of our simple system to the model for evolution motivates a concerted effort to launch real-world experiments and data collection in which algorithm designers collaborate closely with social scientists and policymakers. An important complementary effort is to pursue analytical insights for more complex models that capture different aspects of the real world. For example, while our current concept of role model is based on the relative score upon admission, qualifications upon admission are often not a predictor of ultimate success; support mechanisms provided by the institution may be more important. Can we derive insights from a plausible model for such support mechanisms? Similarly, is there a qualitative difference in our conclusions if we relax the simplifying assumption of strict institutional rankings determining preferences for all applicants?
References
- Berkovec et al., (2018) Berkovec, J. A., Canner, G. B., Gabriel, S. A., and Hannan, T. H. (2018). Mortgage discrimination and fha loan performance. In Mortgage Lending, Racial Discrimination, and Federal Policy, pages 289–305. Routledge.
- Bettinger and Long, (2005) Bettinger, E. P. and Long, B. T. (2005). Do faculty serve as role models? the impact of instructor gender on female students. American Economic Review, 95(2):152–157.
- Calmon et al., (2017) Calmon, F., Wei, D., Vinzamuri, B., Natesan Ramamurthy, K., and Varshney, K. R. (2017). Optimized pre-processing for discrimination prevention. Advances in neural information processing systems, 30.
- Chen et al., (2020) Chen, Y., Cuellar, A., Luo, H., Modi, J., Nemlekar, H., and Nikolaidis, S. (2020). Fair contextual multi-armed bandits: Theory and experiments. In Conference on Uncertainty in Artificial Intelligence, pages 181–190. PMLR.
- Cho et al., (2020) Cho, J., Hwang, G., and Suh, C. (2020). A fair classifier using mutual information. In 2020 IEEE International Symposium on Information Theory (ISIT), pages 2521–2526.
- Cho et al., (2022) Cho, S.-H., Todo, T., and Yokoo, M. (2022). Two-sided matching over social networks. In 31st International Joint Conference on Artificial Intelligence, IJCAI 2022, pages 186–193. International Joint Conferences on Artificial Intelligence.
- Dai and Jordan, (2021) Dai, X. and Jordan, M. (2021). Learning in multi-stage decentralized matching markets. Advances in Neural Information Processing Systems, 34:12798–12809.
- Dressel and Farid, (2018) Dressel, J. and Farid, H. (2018). The accuracy, fairness, and limits of predicting recidivism. Science advances, 4(1):eaao5580.
- Ghalme et al., (2021) Ghalme, G., Nair, V., Patil, V., and Zhou, Y. (2021). Long-term resource allocation fairness in average markov decision process (amdp) environment. arXiv preprint arXiv:2102.07120.
- Ghassami et al., (2018) Ghassami, A., Khodadadian, S., and Kiyavash, N. (2018). Fairness in supervised learning: An information theoretic approach. In 2018 IEEE international symposium on information theory (ISIT), pages 176–180. IEEE.
- Gillen et al., (2018) Gillen, S., Jung, C., Kearns, M., and Roth, A. (2018). Online learning with an unknown fairness metric. Advances in neural information processing systems, 31.
- Gordaliza et al., (2019) Gordaliza, P., Del Barrio, E., Fabrice, G., and Loubes, J.-M. (2019). Obtaining fairness using optimal transport theory. In International Conference on Machine Learning, pages 2357–2365. PMLR.
- Guldogan et al., (2023) Guldogan, O., Zeng, Y., yong Sohn, J., Pedarsani, R., and Lee, K. (2023). Equal improvability: A new fairness notion considering the long-term impact. In International Conference on Learning Representations.
- Hardt et al., (2016) Hardt, M., Price, E., and Srebro, N. (2016). Equality of opportunity in supervised learning. Advances in neural information processing systems, 29.
- Hashimoto et al., (2018) Hashimoto, T., Srivastava, M., Namkoong, H., and Liang, P. (2018). Fairness without demographics in repeated loss minimization. In International Conference on Machine Learning, pages 1929–1938. PMLR.
- Heidari and Krause, (2018) Heidari, H. and Krause, A. (2018). Preventing disparate treatment in sequential decision making. In IJCAI, pages 2248–2254.
- Heidari et al., (2019) Heidari, H., Nanda, V., and Gummadi, K. (2019). On the long-term impact of algorithmic decision policies: Effort unfairness and feature segregation through social learning. In International Conference on Machine Learning, pages 2692–2701. PMLR.
- Jabbari et al., (2017) Jabbari, S., Joseph, M., Kearns, M., Morgenstern, J., and Roth, A. (2017). Fairness in reinforcement learning. In International conference on machine learning, pages 1617–1626. PMLR.
- Joseph et al., (2018) Joseph, M., Kearns, M., Morgenstern, J., Neel, S., and Roth, A. (2018). Meritocratic fairness for infinite and contextual bandits. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pages 158–163.
- Kairouz et al., (2022) Kairouz, P., Liao, J., Huang, C., Vyas, M., Welfert, M., and Sankar, L. (2022). Generating fair universal representations using adversarial models. IEEE Transactions on Information Forensics and Security, 17:1970–1985.
- Kamiran and Calders, (2012) Kamiran, F. and Calders, T. (2012). Data preprocessing techniques for classification without discrimination. Knowledge and information systems, 33(1):1–33.
- Kamishima et al., (2012) Kamishima, T., Akaho, S., Asoh, H., and Sakuma, J. (2012). Fairness-aware classifier with prejudice remover regularizer. In Joint European conference on machine learning and knowledge discovery in databases, pages 35–50. Springer.
- Kearns et al., (2018) Kearns, M., Neel, S., Roth, A., and Wu, Z. S. (2018). Preventing fairness gerrymandering: Auditing and learning for subgroup fairness. In International conference on machine learning, pages 2564–2572. PMLR.
- Kenfack et al., (2023) Kenfack, P. J., Rivera, A. R., Khan, A. M., and Mazzara, M. (2023). Learning fair representations through uniformly distributed sensitive attributes. In 2023 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 58–67.
- Li et al., (2021) Li, L., Lassiter, T., Oh, J., and Lee, M. K. (2021). Algorithmic hiring in practice: Recruiter and hr professional’s perspectives on ai use in hiring. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’21, page 166–176, New York, NY, USA. Association for Computing Machinery.
- Liu et al., (2018) Liu, L. T., Dean, S., Rolf, E., Simchowitz, M., and Hardt, M. (2018). Delayed impact of fair machine learning. In International Conference on Machine Learning, pages 3150–3158. PMLR.
- Morgenroth et al., (2015) Morgenroth, T., Ryan, M. K., and Peters, K. (2015). The motivational theory of role modeling: How role models influence role aspirants’ goals. Review of general psychology, 19(4):465–483.
- Mouzannar et al., (2019) Mouzannar, H., Ohannessian, M. I., and Srebro, N. (2019). From fair decision making to social equality. In Proceedings of the Conference on Fairness, Accountability, and Transparency, pages 359–368.
- Patil et al., (2020) Patil, V., Ghalme, G., Nair, V., and Narahari, Y. (2020). Achieving fairness in the stochastic multi-armed bandit problem. In AAAI, pages 5379–5386.
- Puranik et al., (2022) Puranik, B., Madhow, U., and Pedarsani, R. (2022). A dynamic decision-making framework promoting long-term fairness. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’22, page 547–556, New York, NY, USA. Association for Computing Machinery.
- Shen et al., (2023) Shen, X., Wong, Y., and Kankanhalli, M. (2023). Fair representation: Guaranteeing approximate multiple group fairness for unknown tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):525–538.
- UCOP, (2024) UCOP (2024). California master plan for higher education. https://web.archive.org/web/20240318074731/https://www.ucop.edu/institutional-research-academic-planning/content-analysis/academic-planning/california-master-plan.html. [Accessed:March 2024].
- Wen et al., (2021) Wen, M., Bastani, O., and Topcu, U. (2021). Algorithms for fairness in sequential decision making. In International Conference on Artificial Intelligence and Statistics, pages 1144–1152. PMLR.
- Wightman, (1998) Wightman, L. F. (1998). Lsac national longitudinal bar passage study. lsac research report series.
- Williams and Kolter, (2019) Williams, J. and Kolter, J. Z. (2019). Dynamic modeling and equilibria in fair decision making. arXiv preprint arXiv:1911.06837.
- Yin et al., (2023) Yin, T., Raab, R., Liu, M., and Liu, Y. (2023). Long-term fairness with unknown dynamics.
- Zafar et al., (2017) Zafar, M. B., Valera, I., Gomez Rodriguez, M., and Gummadi, K. P. (2017). Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment. In Proceedings of the 26th international conference on world wide web, pages 1171–1180.
- Zemel et al., (2013) Zemel, R., Wu, Y., Swersky, K., Pitassi, T., and Dwork, C. (2013). Learning fair representations. In International conference on machine learning, pages 325–333. PMLR.
- Zhang et al., (2018) Zhang, B. H., Lemoine, B., and Mitchell, M. (2018). Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pages 335–340.
- Zhang et al., (2019) Zhang, X., Khaliligarekani, M., Tekin, C., and Liu, M. (2019). Group retention when using machine learning in sequential decision making: the interplay between user dynamics and fairness. Advances in Neural Information Processing Systems, 32.
- Zhang et al., (2020) Zhang, X., Tu, R., Liu, Y., Liu, M., Kjellstrom, H., Zhang, K., and Zhang, C. (2020). How do fair decisions fare in long-term qualification? Advances in Neural Information Processing Systems, 33:18457–18469.
Appendices
Appendix A Optimizing the score-based reward under MFG policy
We provide below a detailed proof of Theorem 1 for the optimal action that maximizes the score-based reward of each institution.
Proof.
Assuming the score distributions’ CDF is denoted by . By the Lemma 2, the score-based reward function of the institution is concave and it is maximized when the absolute difference between the lower thresholds of both groups is minimized, . This is equivalent to the following minimization;
| (20) |
where and . Due to the monotonicity of the inverse CDF, the optimal action that maximizes the score-based reward is equivalent to minimizing the following:
| (21) |
This can be simplified to the following:
| (22) |
The argument of the minimum can be multiplied by to simplify the expression as follows:
| (23) |
The terms with the action and the terms without the action can be grouped as follows:
| (24) |
Therefore, the optimal action that maximizes the score-based reward is as stated in the theorem. It can also be seen from the Lemma 2 that the score-based reward function of the institution is maximized when the lower thresholds of both groups are equal, This is satisfied when . ∎
A.1 Technical Lemmas
In this section, we show that the score-based reward function of each institution is concave and has a unique action that maximizes its reward.
Lemma 2.
Under Assumption 1, the score-based reward function, , is concave and it is maximized when the absolute difference between the lower thresholds of both groups is minimized, . This is equivalent to the following minimizing;
| (25) |
where and and for , the action that maximizes the score-based reward is equivalent to minimizing .
Proof.
Dropping the superscript in the notation of the action for brevity, the score-based reward of the institution is:
| (26) |
The number of admitted applicants is approximated as , as we are considering that the number of applicants is large. Under this regime, the collection of scores is in accordance with their respective group-specific score distributions . Following the idea in Puranik et al., (2022), the average scores of selected applicants from each group can be represented by the following conditional expectations:
| (27) |
| (28) |
Then, the score-based reward function of the institution can be written as follows:
| (29) |
We denote the cumulative distribution function (CDF) of the score-distributions by and . The tail of the distributions beyond the upper thresholds represents the proportion of the applicants from the particular group who have been already admitted by the better-ranked institutions.
| (30) | ||||
| (31) |
Moreover, the area between the lower and upper thresholds in the distributions signifies the proportion of applicants admitted by the specific group from the total number of applicants belonging to that group at the institution. Thus, we have:
| (32) |
Then using the upper thresholds, we can write the lower thresholds as follows:
| (33) |
Then, we can write the lower thresholds as follows:
| (34) |
We can write the score reward function of the institution as follows:
| (35) |
We can move the common denominator out of the integral since it is a constant:
| (36) |
Then, the denominator can be written in terms of the CDF as follows:
| (37) |
Using the equations (32), we can write the score-based reward function of the institution as follows:
| (38) |
The upper thresholds are not dependent on the current institution’s action. Then, we can use the definitions of lower thresholds from equations (34) to write the score-based reward function of the institution as follows:
| (39) |
Using the fundamental theorem of calculus, we can write the derivative of the score-based reward function of the institution as follows:
| (40) |
Then, we can write the second derivative as follows:
| (41) |
Since the PDF functions are non-negative, , and , the second derivative is non-positive. This means the score-based reward function of the institution is concave.
The score-based reward function of the institution is concave and its first derivative is monotone and defined on the interval . Then, the score-based reward function of the institution is maximized when the absolute difference between the lower thresholds of both groups is minimized, . This is equivalent to the following minimization:
| (42) |
where and . For , the action that maximizes the score-based reward is equivalent to minimizing . ∎
Appendix B Proof details for applicant pool convergence under MFG policy
We first provide a proof of Lemma 1 below.
Proof.
Firstly, we observe that the optimal policy of institution can be expressed as a convex combination of its optimal score-based reward action and optimal fair-only action as , where . This follows from the fact that the fairness-aware utility function is a concave function of the action, and the score-based reward function and the fairness loss functions are monotone. Then, we claim that the optimal policy of institution can be expressed as a convex combination of its pre-projection optimal score-based reward action and pre-projection optimal fairness-aware action (before being projected to the feasible action space ), as , where .
Let and , which represent the pre-projected optimal actions. If both and , then the claim is straight-forward. Similarly, if only one of them is not in the feasible action space, then the claim is straightforward. The only case that needs to be considered is when both pre-projected optimal actions are not in the feasible action space. If one of them lies on the left of the feasible action interval and the other lies on the right of the feasible action interval, then the claim is straightforward. We will show that pre-projected optimal actions cannot simultaneously lie on the left/right of the feasible action interval. The first case is when both pre-projected optimal actions are on the left of the feasible action interval. Suppose that and . If the maximum is equal to 0, then there is a contradiction since . Similarly, if the maximum is equal to , then there is a contradiction since , due to the condition that . Thus, pre-projected optimal actions cannot lie on the left of the feasible action interval at the same time. The second case is when both pre-projected optimal actions are on the right of the feasible action interval. Suppose that and . If the minimum is equal to 1, then there is a contradiction since . Similarly, if the minimum is equal to , then there is a contradiction since , due to the condition that . Thus, the pre-projected optimal actions cannot lie on the right of the feasible action interval at the same time. Therefore, our claim holds.
By utilizing this relation, equation (8) can be expressed as the following by iteratively writing expressions for the optimal score-based reward action in the increasing order of the institutions:
| (43) |
We use the above expression and now prove the lemma. The optimal action of the institution can be expressed as follows:
| (44) |
We can compute the weighted action as follows;
| (45) |
We can add and subtract ;
| (46) |
We can add and subtract ;
| (47) |
It can be grouped as follows:
| (48) |
It can be seen that the second and third terms are telescoping, and the summation of the weighted actions of all institutions can be written as follows:
| (49) |
After dividing by the total capacity, we obtain the desired expression. ∎
We will now utilize the result of the above lemma in showing the proof of Theorem 2, where we state that the applicant pool proportion, and the admission proportions of the institutions converge to the long-term fairness target set by the agents, under the MFG policy with pure positive reinforcement model.
Proof.
Suppose that the state of the MDP equals the fairness target . It follows that the top institution maximizes its utility by selecting proportion of group among all its admitted applicants , as its optimal score-based reward action itself is . Further, by equation (8), which implies that . It can be seen that , due to which the weighted average , i.e., it is a fixed-point of the weighted policy. We will show the uniqueness of the fixed point by showing . Assume that . Then, the optimal score-based reward action of the top institution is , since the top institution maximizes its score-based reward when it sets same threshold for both groups. The optimal fair-only action is . Since the MFG policy for the top institution will accept more from the minority group than the applicant proportion due to the structure of the weighted MFG policy. Then, and . The score-based reward of the second institution is maximized when it sets the same threshold for both groups, this implies that because the first institution admitted more from the minority group than the applicant proportion. The optimal fair-only action is . Then, and . The same argument can be made for the subsequent institutions, since the optimal score-based reward action of the institution is because the previous institutions admitted more from the minority group than the applicant proportion. The optimal fair-only action is . Then, and . The same argument can be used when .
Next, since from the update for pure positive reinforcement (5), it follows that the mean parameter drifts towards the fairness target , irrespective of the state, due to the structure of the weighted MFG policy. In addition, since is a unique fixed-point, as the step size is decaying with time, it can be shown that the mean parameter converges to the fairness target. Let . Fix an . Then, we need to show that there exists some such that for all ,
| (50) | ||||
| (51) |
where is a positive constant. Moreover and . If the above conditions are satisfied, then eventually for some , we have . But due to equations (50) and (51), we have for all . Since is arbitrary, we have as .
| (52) | ||||
| (53) |
Since , if , then for some .
When , first we will account for the stochasticity of . We have . Denoting , using equation (52), we have
where is a zero-mean random variable. Also , which is bounded. Therefore, is a martingale and is also bounded. This implies by the martingale convergence theorem that converges to a finite random variable. Therefore, we have . Since, is bounded, the effect of the noise is negligible. Therefore we have
We want to show that
| (54) |
for some . If this holds, we have
| (55) |
Let us denote . Since, , there exists such that for all . Moreover, due to assumptions on the step size, we have .
What remains to show is equation (54). In the regime where the number of applicants is large, we can see that the state is equal to its mean with probability approaching through Chebyshev inequality. When , since is equal to its mean , we need to consider only cases (i) and (ii) . Under both cases, we have due to the structure of the weighted MFG policy when the score distributions are identical. ∎
Appendix C Negative feedback in role model reinforcement
Here, we provide a proof for Proposition 1, and show that MFG policy can cause negative feedback under role model reinforcement and drive the under-represented group out of the system.
Proof.
We assume that the MFG policy assigns non-zero weight to the long-term fairness objective, i.e., . Since we are interested in the regime where the number of applicants is large, we assume that the histograms of the scores of applicants approach the distribution. Without loss of generality, we denote group to be the under-represented group, and assume that the initial state is less than the fairness target, . However, the same procedure applies when group has a higher proportion than the long-term fairness target. We will also assume that the initial mean parameter is small.
We recall that for the top institution, the action maximizing its score-based reward , the current state, by Theorem 1 and the action minimizing its fairness loss , the long-term fairness target. We also know the MFG policy for the top institution will be the convex combination . Then, because by our assumption. Viewing the first institution’s MFG policy as applying group-dependent lower and upper thresholds on the score distributions as in the proof of Theorem 1, and admitting all applicants between the group-specific thresholds, we can infer that the lower threshold for group 0 (denoted by ) is strictly less than the lower threshold for group 1 (denoted by ), due to the fact that admits more from the minority group than the applicant proportion. Implicitly, the upper thresholds for the first institution are infinity. Thus we have:
| (56) |
Note that these thresholds are different from the thresholds optimizing only for the score-based rewards, which have also been described by the same notation in the proof of Theorem 1.
Let us assume that the fraction of the role models . The evolution of the applicant pool is such that only those admitted applicants with scores larger than a certain threshold determined by parameter will contribute to reinforcing the pool. Let us denote this threshold for institution as . As the parameter decreases, the threshold increases. It follows that there exists small enough, such that the role model threshold for the first institution is . We remark that the role model threshold is independent of the group membership.
Now, note that is equivalent to the ratio of the number of group applicants with scores higher than , to the number of applicants with scores larger than . Thus we can write an expression for in terms of the CDF of the score distribution, denoted by , as
| (57) |
For the subsequent institutions, it is known from (43) that for all , if , the action optimizing the score-based reward is . Therefore, the policy for the institution () is
| (58) |
since we have . Note that for the MFG policies of the institutions, the lower threshold of institution will be equal to the upper threshold of institution , as it would admit all applicants with scores in between the lower and upper thresholds.
If the institutions with were optimizing only the score-based reward their lower thresholds would be equal across the groups, as argued in the equation (42). But here, since the MFG policy admits a higher proportion from group , i.e., (58), the thresholds are such that the lower threshold of group 0 is always less than the lower threshold of group 1,
| (59) |
Furthermore, if is small enough, the role model thresholds for all subsequent institutions are large enough to satisfy Then, we can express the proportion of the role models from group 0 for the institution as
| (60) |
Using , we can upper bound as
| (61) | |||
| (62) |
for all and .
Under the role model reinforcement, group ’s applicant proportion receives a positive drift only if the weighted parameter in equation (16) is larger than . Due to (57) and (62), the weighted proportion of the role models is
| (63) |
Hence, the pool update parameter . If the initial mean parameter is small enough, i.e., group is heavily under-represented in the initial pool, with a large probability the future state . Hence we can approximately see that the mean parameter of the proportion of minority group in the applicant pool decreases to zero. Therefore, we show that MFG policy can cause a negative feedback loop under role model reinforcement if the role model proportion is small enough, driving the under-represented group out of the system. ∎
Appendix D Additional experimental results
D.1 Identical score distributions



We show the evolution of applicant and admission proportions of the CMFG policy under the pure positive reinforcement model, order-based and weighted positive reinforcement models in Figures 7(a), 7(b) and 7(c). The parameter settings are exactly the same as in Section 5.1 for the case when the score distributions are identical. In these figures, we can observe that an institution’s admission proportion is larger than the applicant proportion, and since the weighted average of the admission proportion governs the evolution, the pool gets positive feedback and approaches the fairness target.
D.2 Distinct score distributions
Here, we consider the role model reinforcement with , under distinct score distributions, with all other parameters as described in Section 5.1. As seen in Figure 8(a), the MFG policy again leads to a negative feedback loop with the distinct score distributions, resulting in the reduction of the minority group in the applicants pool. As seen in Figure 8(b), the second and the third institutions have a very small fraction of role models as a result of the first institution admitting the top minority applicants. However, the CMFG policy could alleviate this, resulting in an equilibrium point lower than the initial mean parameter as shown in Figure 8(c). In Figure 8(d), it is evident that all institutions feature role models from the minority group, leading to an equilibrium point within the applicant pool.



D.3 Semi-synthetic dataset


We consider the role-model reinforcement with , where the top of the admitted applicants are considered role models for the resource pool. Figures 9(a) and 9(b) show the mean parameter at equilibrium for the MFG and CMFG policies, respectively, with varying values of . Both policies perform similarly on the law school dataset, possibly due to a larger difference between the score distributions of the groups.