Long-Tail Prediction Uncertainty Aware Trajectory Planning for Self-driving Vehicles
Abstract
A typical trajectory planner of autonomous driving commonly relies on predicting the future behavior of surrounding obstacles. Recently, deep learning technology has been widely adopted to design prediction models due to their impressive performance. However, such models may fail in the “long-tail” driving cases where the training data is sparse or unavailable, leading to planner failures. To this end, this work proposes a trajectory planner to consider the prediction model uncertainty arising from insufficient data for safer performance. Firstly, an ensemble network structure estimates the prediction model’s uncertainty due to insufficient training data. Then a trajectory planner is designed to consider the worst-case arising from prediction uncertainty. The results show that the proposed method can improve the safety of trajectory planning under the prediction uncertainty caused by insufficient data. At the same time, with sufficient data, the framework will not lead to overly conservative results. This technology helps to improve the safety and reliability of autonomous vehicles under the long-tail data distribution of the real world.
Index Terms:
Autonomous vehicle, Trajectory planning, Prediction uncertainty, Long-tailI Introduction
Self-driving technology is believed to improve traffic efficiency and safety in the future [1]. A typical self-driving system can be divided into several modules: perception, planning, control. Among them, the task of the trajectory planner is to compute a feasible trajectory for self-driving vehicles (SDVs) using the estimated status of surrounding objects (provided by the perception module). Then the control module will drive the SDV following the output trajectory.
A trajectory planner commonly relies on the future prediction of surrounding objects in finding the optimal trajectory [2] [3]. Such prediction task is typically accomplished by a deep learning-based model trained with collected real-world driving data [4]. However, the real-world scenarios are usually “long-tail” distributed [5], leading to low model performance in the data-sparse cases [6] [7]. It is because the model “lacks knowledge” about the environment due to insufficient data, also described as high model uncertainty [8] [9]. As a result, the downstream trajectory planner may make risky decisions in “long-tail” cases.
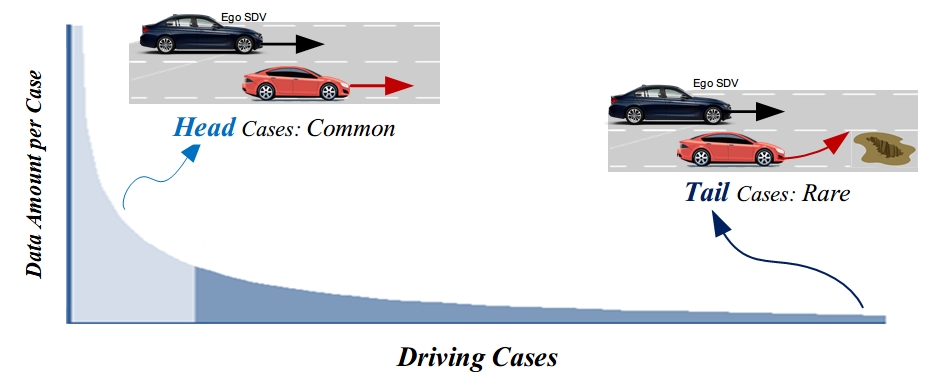
A straightforward solution to alleviate the problem is to collect more data on “long-tail” cases for performance improvement [10]. However, it would be too costly as re-encountering a rare driving case can require billions of kilometers of natural driving [11]. Furthermore, the prediction model and planner will operate under a known risk of failure until sufficient data is collected. Other existing methods like data re-balancing and data-augmentation [5] are proved effective but still cannot guarantee model performance in “long-tail” cases.
To this end, we aim to design a planner to work safely under prediction model uncertainty caused by insufficient training data. Related works to improve planning performance on prediction uncertainty can be divided into three methods: 1) Fixed uncertainty bound, 2) Prediction results correction, and 3) Probabilistic prediction results.
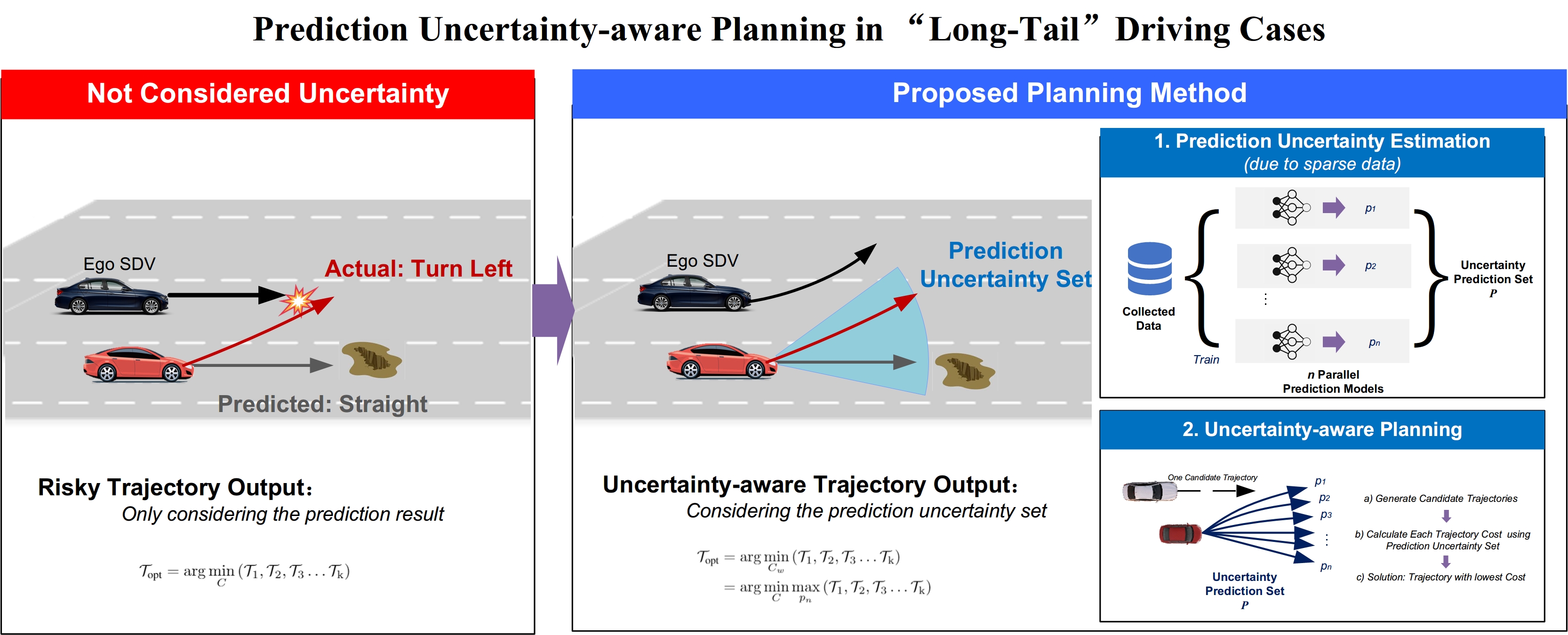
The fixed uncertainty bound method enlarges surrounding objects’ bounding boxes to avoid potential prediction uncertainty. For example, the space occupied by obstacles gets larger when the prediction time is longer [12]. Furthermore, errors from sensors and localization are taken into account to help determine the extent of enlargement [13] [14]. The reachable-set planners avoid all possible future of surrounding objects for safety [15]. However, those methods usually rely on a fixed parameter that works in all driving cases. As a result, the AV might be over-conservative even with good prediction results and still risky when the prediction result exceeds the error bound.
The prediction result correction methods incorporate some physical/rule-based models to restrict the prediction results. For example, physics model of vehicle or pedestrian [16]. The driver intention is also considered for modification [17] [18]. This prior knowledge helps to improve the accuracy of the prediction results overall, but the uncertainty caused by the insufficient data in the “long-tail” cases is still a problem.
The probabilistic prediction methods model and consider prediction uncertainty for safer planning performance. The planner takes into account the probabilistic prediction results for safer performance [19] [13]. Such probabilistic results can be obtained from pre-modeled distribution [20], probabilistic learning-based models [16], etc. These methods achieve safer performance by considering the prediction’s uncertainty. However, the probabilities output by learning-based models are also learned from a “long-tail” distributed dataset. Thus the wrong prediction probability may still happen in data-sparse cases and cause planning failures.
Unlike the previous methods, this work proposed a planning framework to consider prediction uncertainty arising from the “long-tail” data distribution. Such uncertainty is related to data amount and varies in different driving cases. Thus, the pre-design models/rules are challenging to handle. This work will estimate the prediction uncertainty using collected training data and design a planning framework to account for the estimated uncertainty for safer performance.
The contributions include:
1) A method to estimate prediction model uncertainty due to insufficient training data in different driving cases from collected training data.
2) A planning framework considers the estimated prediction uncertainty for safer performance.
The rest of the paper is structured as follows: Section II introduces the preliminaries and problem definition. Section III presents the proposed planning method. Section IV evaluates the algorithm’s performance, and Section V summarizes the work with a brief discussion of future work.
II Preliminaries and Problem Definitions
We first define some basic notions. In this work, a snapshot at time of the environment’s status is defined as a state . Each state is defined including status of ego SDV and surrounding vehicles .
| (1) |
The current state of an agent with its histories for the previous timesteps is denoted as . A “driving case” is defined as:
| (2) |
Similarly, the distribution over all surrounding agents’ future states for the next timesteps is defined as:
| (3) |
This work aims to solve the following problem: an SDV should plan a safe trajectory under prediction uncertainty caused by “long-tail” training data distribution. A typical planning process in a driving case can be described as:
| (4) |
where denotes the generated trajectory. The trajectory planner is driving the SDV using the prediction results as well as the ego SDV information . The prediction results is estimated from a prediction model that takes as input.
| (5) |
In this work, the prediction model is a deep learning-based model with parameters learned from collected driving data .
The “long-tail” challenge of the described planning process is that the trained model might be far from optimal in the data-sparse driving cases, leading to a large error of then sub-optimal or risky .
This work will first estimate the model uncertainty to know “how bad the performance of is in the current driving case ”. Then we will design a trajectory planner to consider the estimated uncertainty for more safety performance:
| (6) |
In addition, the specific implementation and type of the prediction model will not be restricted in this work, for example, LSTM [21], Graph neural network [22]. Moreover, this work will not improve the accuracy of the prediction model. We also assume that a control module uses PID or preview control to track the desired trajectory with an acceptable bounded tracking error [23].
III Methods
III-A Framework
The framework of the proposed prediction-uncertainty-aware planner is shown in Fig. 2. The algorithm includes two main parts: 1) an uncertainty estimator for prediction model outputs in different driving cases. 2) a planning framework designed to account for the uncertainty for safer performance.
III-B Prediction Model Uncertainty Estimation
This section describes the method of prediction uncertainty estimation for deep learning-based models trained on a “long-tail” distributed dataset. Commonly, a prediction model is trained to give a maximum likelihood estimate of ground truth [16] [22]. However, the training dataset has a “long-tail” of rare driving cases in our problem setting. It means that the data amount of these specific driving cases is low. From a deep learning perspective, the prediction model will be considered to have high epistemic uncertainty under such inputs [8]. Furthermore, previous works have also shown that a deep learning-based model has a higher prediction error in these “long-tail” cases (compared to the cases with more data) [6].
To quantify such uncertainty in “long-tail” driving cases, we design an ensemble network structure to give a distribution over the estimated prediction results , as shown in Fig. 2 . The ensemble method efficiently captures the uncertainty of deep learning models without modifications to the original network structure [24]. Here, we assume a learning-based prediction model exists. Then the ensemble network will contain prediction models in parallel, each of which has the same structure with . To train the ensemble network, each prediction network contained will be initialized randomly. Then, we can obtain a set of prediction models that indicate the uncertainty arising from “long-tail” data distribution. The prediction model is defined as a prediction model uncertainty set:
| (7) |
We adopt a GNN-based prediction model as in this work. Such type of model is widely used because of its state-of-art performance. The chosen model has a similar structure with [16]. More specific, the model takes historically observed states (e.g., position, velocity) of surrounding obstacles as input. It contains a self-attention layer to capture the interaction between agents. Then a decoder outputs each object’s future probability distribution trajectory. Note that the chosen GNN-based prediction model is only an example. The proposed uncertainty estimation and planning method is not limited to a specific model structure. Other learning-based prediction models are also working but were not explored in this work.
III-C Prediction Model Uncertainty-aware Trajectory Planner
In this section, a planning framework that accounts for the estimated prediction model uncertainty is designed. The idea is to consider the worst-case of given prediction uncertainty set instead of a single prediction model result.
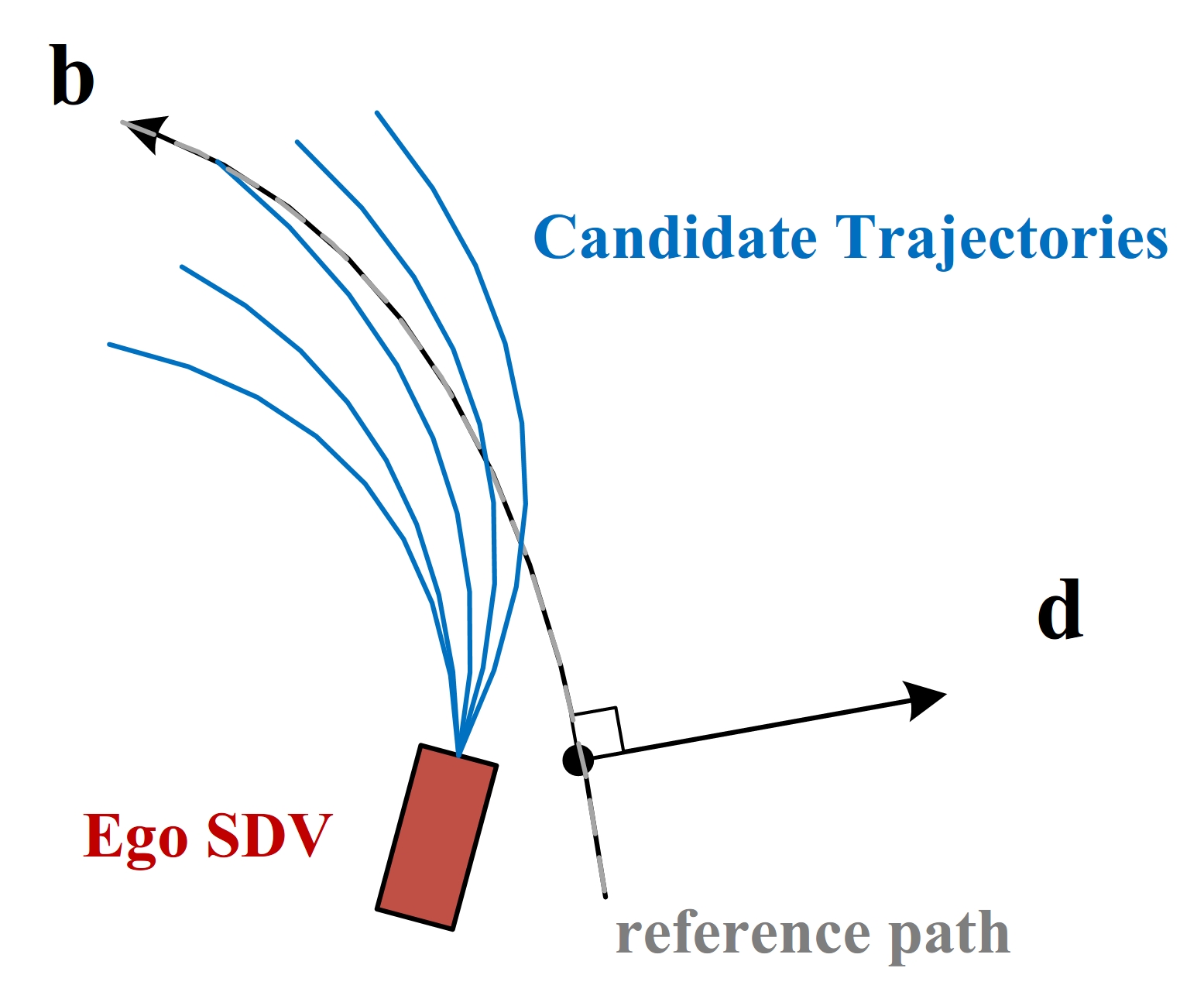
The proposed planner is based on lattice planner [25]. The lattice planner works on Frenét frame built on each lane/reference path, as shown in Fig. 3. The idea of lattice planner is first to sample a group of candidate trajectories, then choose the optimal solution using a pre-defined cost function . In this work, we keep the candidate trajectory generation part and redesign the second part to account for prediction uncertainty for safer performance.
In first step, the planner will first sample a certain number of trajectory end states . Those end states vary in lateral and longitudinal distances under the Frenét frame. Then a candidate trajectory will be generated using a quintic polynomial with ego vehicle state as start and as the end state, as shown in Fig. 3. In [25], the authors proved that such a quintic polynomial is the optimal solution to the minimization problem of the cost function:
| (8) |
where denotes the time integral of the square of jerk, denotes the expected time consume from start state to end state, denotes the lateral offset of end state , and are arbitrary functions and . As a result, polynomials for different end states are grouped as candidate trajectories .
In the original lattice planner, the final solution is obtained by choosing the trajectory with the lowest cost as well as passing the collision checking:
| (9) |
| (10) |
| (11) |
The safety performance is guaranteed by collision checking (Eq. 11), which uses the prediction model results directly. The candidate trajectory and the prediction results of surrounding objects are checked sequentially in time to see if they will collide in the future. As mentioned above, the prediction results might be wrong in “long-tail” driving cases. Thus the chosen trajectory (that passed the collision checking) might lead to accidents.
To account for the prediction model uncertainty for safer performance, we redesign the method of choosing the optimal solution from candidate trajectories:
| (12) | ||||
| (13) | ||||
The idea of Eq. 12 is to consider the worst-case in the prediction uncertainty set (described in Eq. 7). More specific, general practice for trajectory planners is to directly use prediction results as Eq. 9. This work further considers the uncertainty arising from insufficient training data in “long-tail” cases. The “max” in Eq. LABEL:equ:cost3 considers the worst-case in the estimated prediction uncertainty. It is easy to find that when , our method is equal to the original lattice planner (Eq. 9).
In this way, the safe performance of the trajectory planner can be improved and not lead to unnecessarily over-conservative behaviors because 1) When the AV is driving in “long-tail” cases with high prediction uncertainty, directly using the (maybe significantly wrong) prediction results might lead to a collision. Our method considers the prediction model uncertainty through the prediction model set. The variance of is expected to be high in these cases and more likely to cover the true value than a single estimation ( as the original planner). Thus the planner considered “worst-case” more likely to consider the risk brought by the true value and output a safe trajectory conservatively. 2) When the AV is driving in driving cases with enough training data, the uncertainty of the prediction model is expected to be low, reflected in closed outputs of . In this case, the “worst-case” estimated from prediction results is similar to one single model (baseline). Thus, the proposed planner would not lead to over-conservative trajectories because it works similar to Eq. 9.
The proposed method is based on but not limited to the lattice planer. The idea of considering the “worst-case” from the estimated prediction uncertainty set can be applied to other planners that optimize a specific cost function using the prediction results. The way to apply the “worst-case” idea is straightforward as from Eq. 10 to Eq. 12.
IV Experiment
IV-A Environment Setting
To train and verify the algorithm, we set up an unprotected left-turn scenario in the CARLA simulator [26], as shown in Fig. 4.
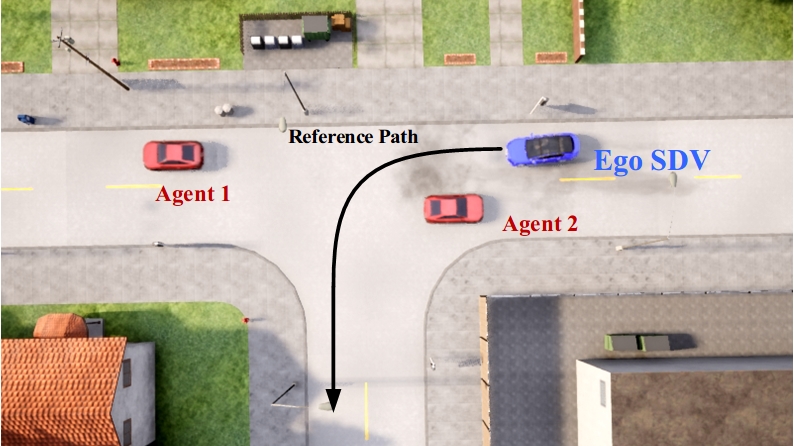
The goal of the test SDV is to complete the left-turn task safely considering the surrounding vehicles. The surrounding vehicles going through the intersection will drive without considering traffic lights. Those vehicles are randomly generated with random driving intentions and born positions to create natural and diverse test cases. The simulator provides the dynamics and automatic driving rules.
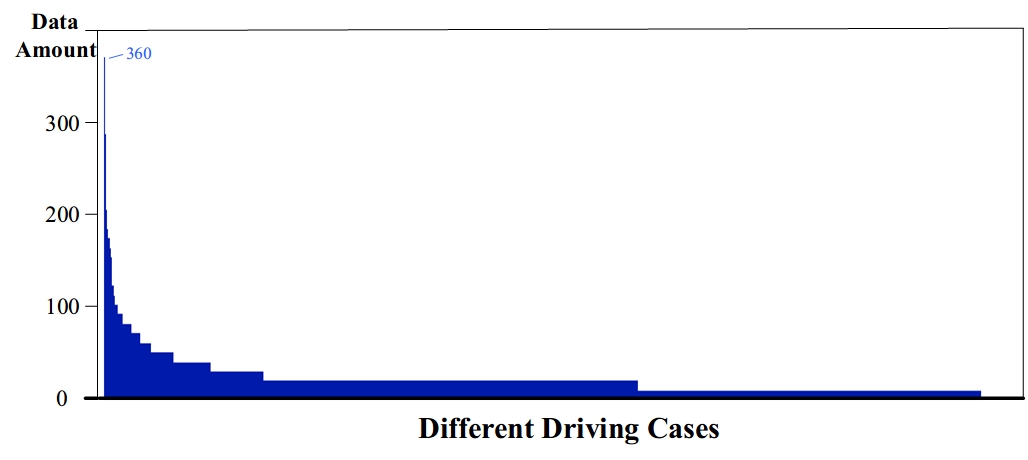
Under this setting, we count the distribution of the generated test samples. In the left-turn scenario, the distribution of driving cases we collected is similar to reality and has a “long-tail”, as shown in Fig. 5. The collected data will be used for training the prediction model.
IV-B Evaluation Metrics
We use the following metrics to evaluate the performance of our system:
IV-B1 Prediction Error Decrease Rate
This metric measures how much the prediction model uncertainty set results are likely to cover the ground truth. We use two popular metrics in the agent prediction area:
a. Average Displacement Error (ADE): Mean distance between the ground truth and predicted trajectories.
b. Final Displacement Error (FDE): distance between the predicted final position and the ground truth final position at the prediction horizon .
The decrease rate of ADE (FDE) is defined as to quantify how much the ensemble prediction models help to decrease the prediction error by covering the ground truth. In our experiment, we will calculated the minimum ADE (FDE) value of all prediction models in the prediction model uncertainty set:
| (14) |
| (15) |
IV-B2 Safety of Planning Results
The safety of planning results (under different driving cases) is evaluated as:
| (16) |
where denotes the safe planning times (that not lead to collision), denotes the total planning times.
IV-B3 Efficiency of Planning Results
The driving efficiency is quantified by two average metrics for planning results of a driving case.
| (17) |
where denotes how much time the SDV encounters the driving cases in test, denote the average expected velocity of a planned trajectory.
| Number of Prediction Models | (baseline) | |||
|---|---|---|---|---|
| Average planning success rate (%) | 98.09 | 99.23 | 99.61 | 99.65 |
| Average planning velocity (m/s) | 6.89 | 6.66 | 5.91 | 5.63 |
| Average planning velocity (normal cases) (m/s) | 6.38 | 6.35 | 6.33 | 6.27 |
| Prediction Error Decrease Rate (%) | 0 | 0.29 | 15.01 | 23.58 |
| Prediction Error Decrease Rate (%) | 0 | 2.22 | 15.65 | 23.88 |
| Parameters | Symbol | Value |
|---|---|---|
| Cost weights of comfort | 0.1 | |
| Cost weights of efficiency | 0.1 | |
| Cost weights of offset | 1.0 | |
| Planning time step | 0.1s | |
| Sample number | 10 |
IV-C Baseline
The baseline used for comparison is the lattice planner [25]. In fact, the proposed planner is equal to the baseline when the number of prediction models in the ensemble network structure is set to 1. In this case, there is only one prediction model in the ensemble structure, and the worst-case consideration (Eq. LABEL:equ:cost3) is equal to baseline (Eq. 9).
IV-D Algorithm Parameters and Training
IV-E Computational Performance
We implemented our planner on a computer with Intel Xeon(R) E5-2620 CPU, 128Gb RAM, and GeForce GTX 1080 Ti. The planner runs at 10Hz when the number of the prediction model is ten (). Theoretically, the computational cost of the proposed method is times of the baseline. Though not explored in this work, the models can be designed to work in parallel for acceleration in the future. The parallel design will not affect the planning performance. More specific, the models make predictions and calculate cost (in Eq. 8) in parallel. In this way, the proposed method can work with potential larger numbers and not reduce real-time planning performance too much (compared to baseline).
IV-F Results
IV-F1 Quantitative results
We test the proposed uncertainty-aware planner and baseline. The quantitative results are shown in Table. I. Different value of (number of prediction models in ensemble model structure) is obtained and tested. Note that the proposed uncertainty-aware planner is equal to baseline when equals 1.
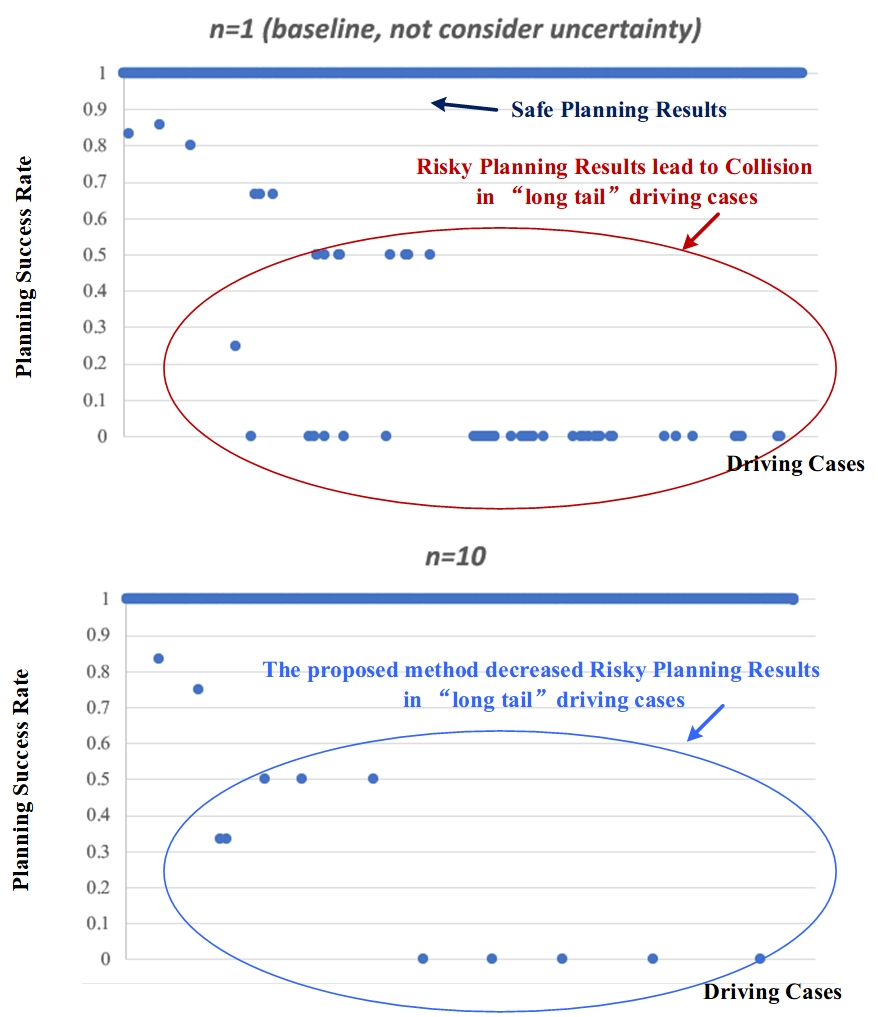
The results show that the proposed planner can improve safety performance. The planning success rate in different driving cases increases from 98.09% to 99.65%. Fig. 6 compares the planning safety metrics of proposed method () and baseline in different driving cases. The driving cases in Fig. 6 are arranged in the same order as Fig. 5, which means that the right-hand side is the data-sparse “long-tail” cases. The figure shows that the baseline planner not considering prediction uncertainty leads to numerous collisions (leading to a low planning success rate) in “long-tail” driving cases. The proposed uncertainty-aware planner significantly reduces the number of risky planning results in “long-tail” driving cases.
Different values of also affect the performance of the proposed uncertainty-aware planner. The larger is, the higher the planning success rate is. It is because increases come with a more accurate estimation of prediction uncertainty arising from “long-tail” data sparsity, leading to safer planning results. It can be seen that just considering one more prediction uncertainty sampling () can significantly improve planning safety. When , the improvement gradually decreases with further increasing value.
The cost of accounting for prediction uncertainty is reducing the driving efficiency. The average planning velocity will be lower with larger . That is because a larger means more accurate uncertainty estimates and more coverage of environmental space (in the future), which leads to more conservative decision outputs.
Besides, the efficiency of the proposed planner will not be affected too much in typical driving cases. We define the top 10% of all cases with the largest amount of data as ”non-long-tail cases.” The planning efficiency of the proposed method in these cases (6.27 m/s for ) is close to baseline (6.38 m/s), as shown in Table. I. Thus, the proposed planner would not lead to overly conservative results in “non-long tail” driving cases.
It also can be seen in Table. I that the prediction error can be decreased with a prediction uncertainty set. A larger leads to a higher prediction error decrease rate. This is because the outputs from the uncertainty prediction set can be seen as samples from the probability distribution of true value. More samples mean a higher probability of including (or approaching) the truth value. Thus the minimum error in the prediction uncertainty set will be lower (with higher ). Furthermore, the proposed planner considers the worst-case from the entire prediction uncertainty set. So when the set is more likely to include the true value, the planner will likely plan a safe trajectory that considers the true value.
IV-F2 Typical Cases
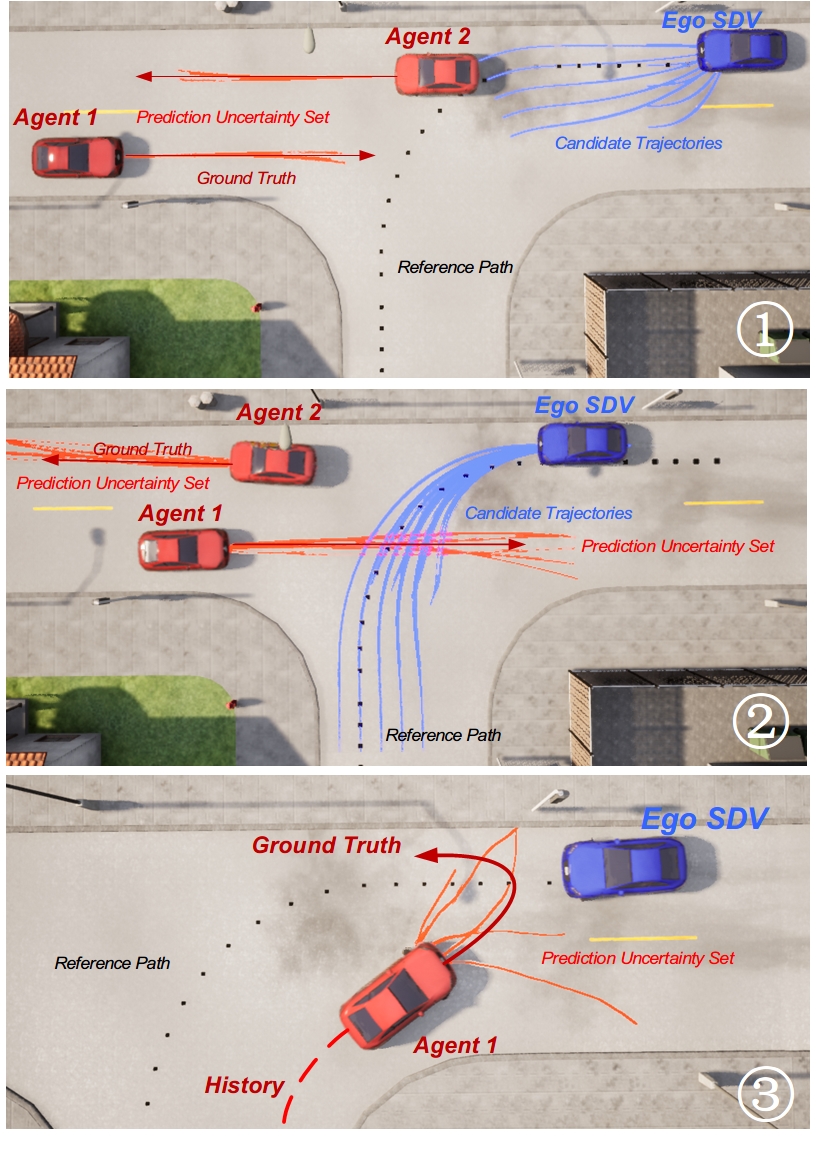
This section will introduce two example cases to explain how the proposed planner work in “long tail” and “non-long-tail” driving cases. The example is shown in Fig. 7. In the figures, the blue curves denotes candidate trajectories of ego SDV , the light red curves are the prediction results from the prediction model uncertainty set , the deep red curves are the ground truth of agents’ future trajectories.
The upper two figures show how the proposed methods behave in “non-long-tail” cases where the training data is sufficient. In the two cases, the environmental agents drive to follow a straight line. The outputs of the prediction uncertainty set are closed around the ground truth. More specific, the output of a single prediction model result (, baseline) and results from our proposed prediction uncertainty set are similar with both low errors. Thus, the planning results of the baseline planner (using a single prediction result) and proposed uncertainty-aware planner are similar and both safe. In this case, the proposed planner does not decrease the planning efficiency.
The figure below shows how the proposed method improves planning safety in “long-tail” driving cases. In this case, the environmental agent makes an unexpected left turn after completing a regular right turn at an intersection. With few training data, a single prediction model (even with probabilistic output) may have high prediction error (for example, predict the vehicle to keep turning right with different speeds), leading to a collision of baseline planner. Here, the prediction uncertainty set gives diverse prediction results, samples from the possible ground truth distribution. As seen from the figure, the results from prediction uncertainty are set to cover most of the ground truth future. Therefore, the uncertainty-aware planner can avoid the potential future of the agent and achieve safe performance.
V Conclusion
In this paper, we proposed a trajectory planning method to consider the prediction model uncertainty arising from the “long-tail” distribution of the training dataset. The deep learning-based prediction model may have a high error in data-sparse “long-tail” driving cases. We defined a notion of prediction model uncertainty to quantify the potential high errors. The model uncertainty is estimated by an ensemble network structure. This network contains several parallel prediction models to output a prediction uncertainty set. We also designed an uncertainty-aware planning method, which considers the worst-case arising from the set for safer performance.
The experiment results show that the proposed planner can significantly improve the safety of SDV in “long-tail” driving cases where the data is sparse. At the same time, the proposed planner will not lead to overly conservative results in “non-long-tail” driving cases where data is sufficient. Besides, the technology can make the SDV more reliable in real-world “long-tail” driving cases.
In the future, other methods of estimating deep learning model uncertainty can be employed for better planning performance.
ACKNOWLEDGMENT
This work is supported by the National Natural Science Foundation of China (NSFC) (U1864203, 52102460) and China Postdoctoral Science Foundation (2021M701883) It is also funded by the Tsinghua University-Toyota Joint Center.
References
- [1] D. Yang, K. Jiang, D. Zhao, C. Yu, Z. Cao, S. Xie, Z. Xiao, X. Jiao, S. Wang, and K. Zhang, “Intelligent and connected vehicles: Current status and future perspectives,” Science China Technological Sciences, vol. 61, no. 10, pp. 1446–1471, 2018.
- [2] W. Schwarting, J. Alonso-Mora, and D. Rus, “Planning and decision-making for autonomous vehicles,” Annual Review of Control, Robotics, and Autonomous Systems, 2018.
- [3] W. Zhou, K. Jiang, Z. Cao, N. Deng, and D. Yang, “Integrating deep reinforcement learning with optimal trajectory planner for automated driving,” in 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2020, pp. 1–8.
- [4] S. Mozaffari, O. Y. Al-Jarrah, M. Dianati, P. Jennings, and A. Mouzakitis, “Deep learning-based vehicle behavior prediction for autonomous driving applications: A review,” IEEE Transactions on Intelligent Transportation Systems, 2020.
- [5] Y. Zhang, B. Kang, B. Hooi, S. Yan, and J. Feng, “Deep long-tailed learning: A survey,” arXiv preprint arXiv:2110.04596, 2021.
- [6] Y. Yang, K. Zha, Y.-C. Chen, H. Wang, and D. Katabi, “Delving into deep imbalanced regression,” arXiv preprint arXiv:2102.09554, 2021.
- [7] O. Makansi, Ö. Cicek, Y. Marrakchi, and T. Brox, “On exposing the challenging long tail in future prediction of traffic actors,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 147–13 157.
- [8] E. Hüllermeier and W. Waegeman, “Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods,” Machine Learning, vol. 110, no. 3, pp. 457–506, 2021.
- [9] Z. Cao, S. Xu, H. Peng, D. Yang, and R. Zidek, “Confidence-aware reinforcement learning for self-driving cars,” IEEE Transactions on Intelligent Transportation Systems, 2021.
- [10] Z. Cao, S. Xu, X. Jiao, H. Peng, and D. Yang, “Trustworthy safety improvement for autonomous driving using reinforcement learning,” Transportation research part C: emerging technologies, vol. 138, p. 103656, 2022.
- [11] W. Wachenfeld and H. Winner, “The release of autonomous vehicles,” in Autonomous driving. Springer, 2016, pp. 425–449.
- [12] W. Xu, J. Pan, J. Wei, and J. M. Dolan, “Motion planning under uncertainty for on-road autonomous driving,” in 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 2507–2512.
- [13] S. Khaitan, Q. Lin, and J. M. Dolan, “Safe planning and control under uncertainty for self-driving,” IEEE Transactions on Vehicular Technology, vol. 70, no. 10, pp. 9826–9837, 2021.
- [14] Z. Cao, J. Liu, W. Zhou, X. Jiao, and D. Yang, “Lidar-based object detection failure tolerated autonomous driving planning system,” in 2021 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2021, pp. 122–128.
- [15] M. Althoff, G. Frehse, and A. Girard, “Set propagation techniques for reachability analysis,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 4, pp. 369–395, 2021.
- [16] T. Salzmann, B. Ivanovic, P. Chakravarty, and M. Pavone, “Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data,” in European Conference on Computer Vision. Springer, 2020, pp. 683–700.
- [17] H. Zhao, J. Gao, T. Lan, C. Sun, B. Sapp, B. Varadarajan, Y. Shen, Y. Shen, Y. Chai, C. Schmid et al., “Tnt: Target-driven trajectory prediction,” arXiv preprint arXiv:2008.08294, 2020.
- [18] B. Mersch, T. Höllen, K. Zhao, C. Stachniss, and R. Roscher, “Maneuver-based trajectory prediction for self-driving cars using spatio-temporal convolutional networks,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 4888–4895.
- [19] C. Hubmann, J. Schulz, M. Becker, D. Althoff, and C. Stiller, “Automated driving in uncertain environments: Planning with interaction and uncertain maneuver prediction,” IEEE transactions on intelligent vehicles, vol. 3, no. 1, pp. 5–17, 2018.
- [20] Y. Chai, B. Sapp, M. Bansal, and D. Anguelov, “Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction,” arXiv preprint arXiv:1910.05449, 2019.
- [21] L. Hou, L. Xin, S. E. Li, B. Cheng, and W. Wang, “Interactive trajectory prediction of surrounding road users for autonomous driving using structural-lstm network,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 11, pp. 4615–4625, 2019.
- [22] J. Gao, C. Sun, H. Zhao, Y. Shen, D. Anguelov, C. Li, and C. Schmid, “Vectornet: Encoding hd maps and agent dynamics from vectorized representation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 525–11 533.
- [23] S. Xu, R. Zidek, Z. Cao, P. Lu, X. Wang, B. Li, and H. Peng, “System and experiments of model-driven motion planning and control for autonomous vehicles,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2021.
- [24] M. Ganaie, M. Hu et al., “Ensemble deep learning: A review,” arXiv preprint arXiv:2104.02395, 2021.
- [25] M. Werling, J. Ziegler, S. Kammel, and S. Thrun, “Optimal trajectory generation for dynamic street scenarios in a frenet frame,” in 2010 IEEE International Conference on Robotics and Automation. IEEE, 2010, pp. 987–993.
- [26] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “Carla: An open urban driving simulator,” arXiv preprint arXiv:1711.03938, 2017.