Logic Embeddings for Complex Query Answering
Abstract
Answering logical queries over incomplete knowledge bases is challenging because: 1) it calls for implicit link prediction, and 2) brute force answering of existential first-order logic queries is exponential in the number of existential variables. Recent work of query embeddings provides fast querying, but most approaches model set logic with closed regions, so lack negation. Query embeddings that do support negation use densities that suffer drawbacks: 1) only improvise logic, 2) use expensive distributions, and 3) poorly model answer uncertainty. In this paper, we propose Logic Embeddings, a new approach to embedding complex queries that uses Skolemisation to eliminate existential variables for efficient querying. It supports negation, but improves on density approaches: 1) integrates well-studied t-norm logic and directly evaluates satisfiability, 2) simplifies modeling with truth values, and 3) models uncertainty with truth bounds. Logic Embeddings are competitively fast and accurate in query answering over large, incomplete knowledge graphs, outperform on negation queries, and in particular, provide improved modeling of answer uncertainty as evidenced by a superior correlation between answer set size and embedding entropy.
1 Introduction
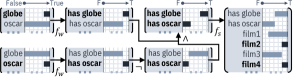
Reasoning over knowledge bases is fundamental to Artificial Intelligence, but still challenging since most knowledge graphs (KGs) such as DBpedia (Bizer et al., 2009), Freebase (Bollacker et al., 2008), and NELL (Carlson et al., 2010) are often large and incomplete. Answering complex queries is an important use of KGs, but missing facts makes queries unanswerable under normal inference. Figure 1 shows an example of handling a logic query representing the natural language question “Which films star Golden Globe winners that have not also won an Oscar?”. Answering this query involves multiple steps of KG traversal and existential first-order logic (FOL) operations, each producing intermediate entities. We consider queries involving missing facts, which means there is uncertainty about these intermediates that complicates the task. Two main approaches to answering such multi-hop queries involving missing facts are (i) sequential path search and (ii) query embeddings. Sequential path search grows exponentially in the number of hops, and requires approaches like reinforcement learning (Das et al., 2017) or beam search (Arakelyan et al., 2020) that have to explicitly track intermediate entities. Query embeddings prefer composition over search, for fast (sublinear) inference and tractable scaling to more complex queries. While relation functions have to learn knowledge, composition can otherwise use inductive bias to model logic operators directly to alleviate learning difficulty.
Query embeddings need to (a) predict missing knowledge, (b) model logic operations, and (c) model answer uncertainty. Query2Box models conjunction as intersection of boxes, but is unable to model negation as the complement of a closed region is not closed (Ren et al., 2020). Beta embeddings of (Ren & Leskovec, 2020) model conjunction as weighted interpolation of Beta distributions and negation as inversion of density, but improvise logic and depend on neural versions of logic conjunction for better accuracy.
(Hamilton et al., 2018) models entities as points so are unable to naturally express uncertainty, while Query2Box uses poorly differentiable geometric shapes unsuited to uncertainty calculations. Beta embeddings naturally model uncertainty with densities and do support complex query embedding, although its densities have no closed form and entropy calculations are expensive.
Beta embeddings (Ren & Leskovec, 2020) are the first query embedding that supports negation and models uncertainty, however it (1) abruptly converts first-order logic to set logic, (2) only improvises set logic with densities, (3) requires expensive Beta distribution (no closed form), and (4) dissimilarity uses divergence that needs integration.

We present our logic embeddings to address these issues with (1) formulation of set logic in terms of first-order logic, (2) use of well-studied logic, (3) simple representation with truth bounds, and (4) fast, symmetric dissimilarity measure.
Logic embeddings are a compositional query embedding with inductive bias of real-valued logic, for answering (with uncertainty) existential () FOL multi-hop logical queries over incomplete KGs. It represents entity subsets with arrays of truth bounds on latent propositions that describe and compress their features and relations. This allows us to directly use real-valued logic to filter and identify answers. Truth bounds from (Riegel et al., 2020) express uncertainty about truths, stating it can be a value range (e.g. unknown ). Sum of bound widths model uncertainty, which correlates to answer size. Now intersection is simply conjunction () of bounds to retain only shared propositions, union is disjunction () to retain all propositions, and complement is negation () of bounds to find subsets with opposing propositions.
The novelty of logic embeddings is that it (a) performs set logic with real-valued logic, (b) characterizes subsets with truth bounds, and (c) correlates bounds with uncertainty. Its benefits are (a) improved accuracy with well-studied t-norms, (b) faster, simplified calculations, and (c) improved prediction of answer size.

Our contributions of logic embeddings make several advances to address issues of poor logic and uncertainty modeling, and computational expense of current methods:
1. Direct logic. Defines Skolem set logic via maximal Skolemisation of first-order logic to embed queries, where proximity of logic embeddings directly evaluates logic satisfiability of first-order logic queries.
2. Improved logic. Performs set intersection as logic conjunction over latent propositions with t-norms, often used for intersection of fuzzy sets. (Mostert & Shields, 1957) decomposition provide weak, strong, and nilpotent conjunctions, which show higher accuracy than idempotent conjunction via density interpolation of (Ren & Leskovec, 2020).
3. Direct uncertainty. Truth bounds naturally model uncertainty and have fast entropy calculation. Both entropy and bounds width show superior correlation to answer size.
4. Improved measure. Measures dissimilarity with simple -norm, which improves training speed and accuracy.
Our contributions also include (i) introduction of Skolem set logic in Section 2 to enable lifted inference, (ii) definition of logic embeddings in Section 3 to enable logic query composition, (iii) implementation details of method in Section 4, and (iv) detailed evaluation in Section 5 and new cardinality prediction experiment showing benefit of truth bounds.
2 Querying with Skolem set logic
We define an existential first-order language whose signature contains a set of functional symbols and a set of predicate symbols . The alphabet of includes the logic symbols of conjunction (), disjunction (), negation (), and existential quantification (). The semantics of interprets the domain of discourse as a family of subsets , where denotes the power set of a set of entities . This allows for lifted inference where variables and terms map to entity subsets, which are single elements in the discourse.
Sentences of express relational knowledge, e.g. a binary predicate relates two unordered subsets via function that evaluates to a real truth value. However, the underlying knowledge is predicated under a different signature on domain of discourse , relating entities via . Subsets are related via , with the union over all underlying propositions for each entity (see Figure 5).
Existential quantification in results in sentences that are always true in the underlying interpretation111Universal quantification is not supported as interpretation in the underlying knowledge is contradictory, since useful relations cannot all be true for both empty and non-empty subsets. , because the nullset is present in . We introduce maximal quantification via a modified Skolem function to make useful.


Definition 1 (Maximal Skolem function). A maximal Skolem function assigns the maximal subset to an existentially quantified variable so that (equisatisfiable). The function receives input element and outputs the related subset over with the largest cardinality, so that .
Formulae in such as can thus convert to sentences by quantification over free variables, and the largest satisfying assignment to target variable obtained via maximal Skolemisation then subsumes all valid groundings in the underlying interpretation over . “Relation following” of (Cohen et al., 2020) is similar where . Normal Skolem functions are different as they only map to single entities.
Skolem set logic. This is set logic that involves Skolem functions that substitute related subsets. We introduce notation for maximal Skolemisation of sentences in that represents set logic on Skolem terms in their underlying interpretation over . Evaluation in of conjunction , disjunction , and negation correspond to intersection, union, and complement in Skolem set logic, respectively.222Skolem set logic reuses operators to signify that it performs direct real-valued logic on truth vectors of its terms. Skolem set logic usages are noted to avoid confusion with FOL.
| First-order logic | Skolem set logic | |
|---|---|---|
| 1p | ||
| 2p | ||
| 3p | ||
| 2i | ||
| 3i | ||
| pi | ||
| ip | ||
| 2in | ||
| 3in | ||
| pin | ||
| pni | ||
| inp | ||
| 2u | ||
| up |
Sentence forms and their Skolem set logic representations (, extends trivially to more inputs) for target variable , given anchor elements , (assigned subsets) and relation predicates () include these conversion rules:
-
•
Relation: gives .
-
•
Negation: gives .
-
•
Conjunction: gives .
-
•
Disjunction: gives .
-
•
Multi-hop: has chain-like relations that give .
Query formulae. We consider query formulae defined over with anchor entities , a single free target variable , and bound variables . Query answering assigns the subset of entities to that satisfy
| (1) |
We recast formulae into by converting anchor entities to singleton subsets, we then quantify to maximally Skolemise the sentence and derive its Skolem set logic term for given the anchor entities.
The dependency graph of formula (1) consists of vertices and a directed edge for each vertex pair related inside the formula, e.g. via . Queries are valid when the dependency graph is a single-sink acyclic graph with anchor entities as source nodes (Hamilton et al., 2018), and an equivalent to the original formula can then be recovered from Skolem set logic.
3 Logic Embeddings
Our approach for positive inference on queries of form (1) require only Skolem set logic, but should also support:
-
1.
Lifted inference: Inference over subsets of entities, needing fewer actions than with single-entity inference;
-
2.
Knowledge integration: Underlying single-entity knowledge over integrates over subsets from ;
-
3.
Generalization: Use of subset similarities to predict absent knowledge with an uncertainty measure.
The powerset over entities from a typical KB is extremely large, so discrete approaches to achieve above with non-uniform subset representations are likely intractable.
Set embeddings. We consider set embeddings that map to a continuous space , so these images of subsets approximately preserve their relationships from (Sun & Nielsen, 2019). It has metric properties such as the volume of subsets, not usually considered by graph embeddings. Set embeddings have the following properties:
-
•
Uniform: Enables standard parameterization, simplifies memory structures and related computation;
-
•
Continuous: Differentiable, enables optimization;
-
•
Permutation-invariant: Subset elements unordered;
-
•
Uncertainty: Subset size corresponds to entropy;
-
•
Proximity: Relatively preserves subset dissimilarities.
Definition 2 (Logic embeddings). Logic embeddings are set embeddings that characterize subsets with latent propositions, and perform set logic on subsets via logic directly over their latent propositions.
Logic embeddings inherit the aforementioned properties and benefits of set embeddings, but are also:
-
•
Logical: Logic over truth values in embeddings performs set logic, and proximity correlates with satisfiability;
-
•
Contextual: Latent propositions integrate select knowledge depending on the subset;
-
•
Open-world: Accepts and integrates unknown or partially known knowledge and inferences.
Logic embeddings also share query embedding advantages of efficient answering, generalization, and full logic support:
-
•
Fast querying: Obtains answers closest to query embedding in sublinear time, unlike subgraph matching with exponential time in query size (Dalvi & Suciu, 2007).
-
•
General querying: Generalizes to unseen query forms.
-
•
Implicit prediction: Implicitly imputes missing relations, and avoids exhaustive link prediction (De Raedt, 2008) subgraph matching requires and scales poorly on.
-
•
Natural modeling: Supports intuitive set intersection, unlike point embeddings (Hamilton et al., 2018).
-
•
Uncertainty: Models answer size with embedding entropy (Ren & Leskovec, 2020) or truth bounds (ours).
-
•
Fundamental support: Handles negation (and disjunction via De Morgan’s law), unlike box embeddings where complements are not closed regions (and union resorts to disjunctive normal form) (Ren et al., 2020).
Latent propositions. A logic embedding keeps truth values with associate distribution on latent propositions of features and properties that characterize and distinguish subset . Subset entities may share a similar relation to a particular subset , where latent propositions can integrate such identifying relations. Logic embeddings need to be contextual given the limited embedding capacity, as only some relations may be relevant to define a particular subset.
Uncertainty. We represent volume in embedding space with lower and upper bounds on truth values, to express uncertainty and allow correlation of embedding entropy of a subset with its cardinality. We use truth bounds of (Riegel et al., 2020) that admit the open-world assumption and have probabilistic semantics to interpret known (), unknown () and contradictory states (, not considered here).
The logic embedding for is an -tuple of lower and upper bound pairs () that represents an -tuple of uniform distributions , which omits contradiction . The chain rule for differential entropy of the embedding distribution applies and gives an upper-bound in terms of components , where
Condition 1 (Uncertainty axiom). Set embeddings should (approx.) satisfy : entropy is a monotonically increasing function of , where is a uniform distribution over elements of (Sun & Nielsen, 2019).
We measure adherence to the uncertainty axiom with correlation between subset size and entropy upper-bound or total truth interval width , and by predicting from .
Proximity. Subsets with high overlap should embed close by, whereas little to no overlap should result in relatively distant embeddings. We now review the proximity axiom.
Condition 2 (Proximity axiom). : should positively correlate with , given information divergence (Sun & Nielsen, 2019).
Relative entropy is an important divergence where the family of -divergences typically include or terms over finite support . Uniform distributions in logic embeddings may not cover a support, and may result in undefined divergence. Therefore, we measure dissimilarity between logic embeddings of subsets with the expected mean of -norms of truth bounds, where
| (2) |
Condition 3 (Satisfiability axiom). Substitution instance of first-order logic formula has satisfiability , where target variable has answer .
Query is true for answer , since , but candidate satisfiability can reduce to minimum 0 (false), depending on the dissimilarity between and .
Set logic. Conjunction and disjunction of latent propositions of subsets perform their intersection and union, respectively, unlike information-geometric set embeddings that interpolate distributions. De Morgan’s law replaces disjunction with conjunction and negations . Involute negation of describes complement333Truth bounds can share intervals with their negations, therefore complements can share latent propositions, which supports the diverse partitioning that complex queries require. . We use continuous t-norm to perform generalized conjunction for real-valued logic, and calculate as
| (3) |
(Mostert & Shields, 1957) decompose any continuous t-norm into Archimedean t-norms, namely minimum/Gödel , product , and Łukasiewicz , which we evaluate separately to consider all prime aspects.
Contextual. Limited capacity requires intersection to reintegrate latent propositions contextually via a weighted t-norm: 1) continuous function444We use non-monotonic smoothmin () for weighted minimum t-norm and set when . of weights and truths ; 2) behaves equal to unweighted case if weights are 1; and 3) removes input , and weights are in .
| (4) | ||||
| (5) | ||||
| (6) |
Weight for , the truth bounds in input , depends on bounds of all conjunction inputs via attention, starting with function as
| (7) |
Softargmax over all the conjunction inputs yields a score which normalizes after to ensure max weight 1.
4 Implementation
Query embedding. We calculate a logic embedding for a single-sink acyclic query with Skolem set logic over anchor entities. We keep vectors for relation embeddings, and for logic embeddings of all entities, where . To measure the “cost” of modeling uncertainty by tracking bounds we also test point truth embeddings (), where .
We parameterize our Skolem function with , , and to relate to , where activates sigmoid.
Set logic has attention that uses with parameter matrices and .
Cardinality prediction. We predict5551:1 train:test, , 250 epochs, Adam opt. (). the cardinality of subset from the entropy vector of its logic embedding with scaled by , where , , and .
Query answering. Our objective is to embed a query relatively close to its answers and far from negative samples . We train model parameters666Hyperparameters include , , , random negative samples, batch size, k epochs, Adam optimizer (). Pytorch on 1x NVIDIA Tesla V100. of 1) entity logic embeddings, 2) relation embeddings, 3) Skolem function, and 4) t-norm attention, to minimize query answering loss
| (8) |
5 Experiments
We primarily compare against Beta embeddings (BetaE (Ren & Leskovec, 2020)) that also support arbitrary FOL queries and negation, where our logic embeddings (LogicE with Łukasiewicz t-norm) show improved 1) generalization, 2) reasoning, 3) uncertainty modeling, and 4) training speed.
Datasets. We use two complex logical query datasets from: q2b with 9 query structures (Ren et al., 2020), and BetaE that adds 5 for negation (Ren & Leskovec, 2020). They generate random queries separately over three standard KGs with official train/valid/test splits, namely FB15k (Bordes et al., 2013), FB15k-237 (Toutanova & Chen, 2015), NELL995 (Xiong et al., 2017). Table 1 shows the first-order logic and Skolem set logic forms of the 14 query templates.
We separately follow the evaluation procedures of above q2b and BetaE datasets.777https://github.com/francoisluus/KGReasoning Training omits ip/pi/2u/up (Table 1) to test handling of unseen query forms. Negation is challenging with 10x less queries than conjunctive ones.888Please see appendix for statistics of datasets.
Generalization. Queries have at least one link prediction task to test generalization, where withheld data contain goal answers. We measure Hits@k and mean reciprocal rank (MRR) of these non-trivial answers that do not appear in train/valid data. Table 4 tests both disjunctive normal form (DNF) and De Morgan’s form (DM) for unions (2u/up), but we only report DNF elsewhere as it outperforms DM.
LogicE with bounds generalizes better than BetaE, q2b, and gqe (Hamilton et al., 2018) on almost all query forms in Table 4, and further improves with point truths.999Please see appendix for full results on FB15k and NELL. LogicE also answers negation queries more accurately than BetaE for most query forms in Table 2. CQD-Beam does not handle negation nor uncertainty and is expensive as it grounds candidate entities explicitly, yet LogicE generalizes better and more efficiently in Table 5(a) on FB15k-237 and NELL.
| FB15k-237 | FB15k | NELL | ||||||
|---|---|---|---|---|---|---|---|---|
| Model | 2in | 3in | inp | pin | pni | avg | avg | avg |
| LogicE | 4.9 | 8.2 | 7.7 | 3.6 | 3.5 | 5.6 | 12.5 | 6.2 |
| bounds | 4.9 | 8.0 | 7.3 | 3.6 | 3.5 | 5.5 | 11.7 | 6.3 |
| BetaE | 5.1 | 7.9 | 7.4 | 3.6 | 3.4 | 5.4 | 11.8 | 5.9 |
Reasoning. Logical entailment on queries without missing links tests how faithful deductive reasoning is. We thus train on all splits and measure entailment accuracy in Table 5(b). LogicE on average reasons more faithfully than BetaE, q2b, and gqe baselines on all datasets.
EmQL is a query embedding that specifically optimises faithful reasoning (Sun et al., 2020), and thus outperforms all other methods in Table 5(b). However, EmQL without its sketch method has worse faithfulness than LogicE with point truths for FB15k and NELL, also EmQL does not support negation nor models uncertainty like LogicE.
Compare logics. LogicE can intersect via minimum, product, or Łukasiewicz t-norms, which perform similarly (1%) in Table 3, while all outperform BetaE. Łukasiewicz provides superior uncertainty modeling, so is the default choice for LogicE. Attention via weighted t-norm improves LogicE accuracy (+9.6%), where one hypothesis is better use of limited embedding capacity through learning weighted combinations of latent propositions.
| Model | FB15k-237 | NELL995 | |||||||
| i | n | p | all | i | n | p | all | avg | |
| No bounds with attention (LogicE) | |||||||||
| luk | 14.4 | 5.0 | 13.2 | 15.8 | 18.8 | 6.5 | 19.5 | 21.5 | 18.7 |
| min | 14.4 | 5.0 | 13.2 | 15.7 | 18.6 | 6.6 | 19.4 | 21.5 | 18.6 |
| prod | 14.4 | 5.0 | 13.3 | 15.8 | 18.7 | 6.6 | 19.4 | 21.5 | 18.7 |
| Bounds with attention ( bounds) | |||||||||
| luk | 13.9 | 5.0 | 12.9 | 15.3 | 18.7 | 6.5 | 19.0 | 21.3 | 18.3 |
| min | 13.9 | 5.0 | 12.7 | 15.2 | 18.5 | 6.6 | 19.0 | 21.3 | 18.2 |
| prod | 14.0 | 5.0 | 13.0 | 15.4 | 18.6 | 6.7 | 19.1 | 21.3 | 18.4 |
| BetaE | 13.7 | 4.8 | 12.6 | 15.0 | 17.5 | 6.1 | 17.0 | 19.6 | 17.3 |
| Bounds with no attention | |||||||||
| luk | 12.7 | 5.1 | 11.7 | 14.1 | 16.1 | 6.8 | 16.7 | 18.9 | 16.5 |
| min | 13.0 | 5.4 | 11.8 | 14.4 | 16.4 | 7.1 | 16.8 | 19.1 | 16.8 |
| prod | 12.9 | 5.3 | 11.9 | 14.3 | 16.5 | 7.1 | 17.0 | 19.2 | 16.8 |
| BetaE | 11.6 | 5.0 | 11.7 | 13.3 | 15.4 | 5.7 | 14.8 | 17.5 | 15.4 |
However, BetaE improves by avg. +12.3% with a similar attention mechanism so has greater dependence on it, possibly because it devises intersection as interpolation of densities, whereas LogicE uses established real-valued logic via t-norms. In particular, the BetaE intersect is idempotent while LogicE offers weak and strong conjunctions of which Łukasiewicz offers nilpotency.
| Generalization on FB15k-237 | FB15k | NELL | ||||||||||||
| Model | 1p | 2p | 3p | 2i | 3i | pi | ip | 2u | up | avg | avg | avg | ||
| DNF | DM | DNF | DM | |||||||||||
| LogicE | 41.3 | 11.8 | 10.4 | 31.4 | 43.9 | 23.8 | 14.0 | 13.4 | 13.1 | 10.2 | 9.8 | 22.3 | 44.1 | 28.6 |
| bounds | 40.5 | 11.4 | 10.1 | 29.8 | 42.2 | 22.4 | 13.4 | 13.0 | 12.9 | 9.8 | 9.6 | 21.4 | 40.8 | 28.0 |
| BetaE | 39.0 | 10.9 | 10.0 | 28.8 | 42.5 | 22.4 | 12.6 | 12.4 | 11.1 | 9.7 | 9.9 | 20.9 | 41.6 | 24.6 |
| q2b | 40.6 | 9.4 | 6.8 | 29.5 | 42.3 | 21.2 | 12.6 | 11.3 | - | 7.6 | - | 20.1 | 38.0 | 22.9 |
| gqe | 35.0 | 7.2 | 5.3 | 23.3 | 34.6 | 16.5 | 10.7 | 8.2 | - | 5.7 | - | 16.3 | 28.0 | 18.6 |
| (a) Generalization on FB15k-237 (q2b datasets) | FB15k | NELL | ||||||||||
| Model | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up | avg | avg | avg |
| LogicE | 46.1 | 28.6 | 24.8 | 34.8 | 46.5 | 12.0 | 23.7 | 27.7 | 21.1 | 29.5 | 54.9 | 39.3 |
| bounds | 45.0 | 26.6 | 23.0 | 32.0 | 44.1 | 11.1 | 22.1 | 25.5 | 20.4 | 27.7 | 50.3 | 38.6 |
| EmQL | 37.7 | 34.9 | 34.3 | 44.3 | 49.4 | 40.8 | 42.3 | 8.7 | 28.2 | 35.8 | 49.5 | 46.8 |
| CQD-Beam | 51.2 | 28.8 | 22.1 | 35.2 | 45.7 | 12.9 | 24.9 | 28.4 | 12.1 | 29.0 | 68.0 | 37.5 |
| BetaE | 43.1 | 25.3 | 22.3 | 31.3 | 44.6 | 10.2 | 22.3 | 26.6 | 18.0 | 27.1 | 51.4 | 33.8 |
| q2b | 46.7 | 24.0 | 18.6 | 32.4 | 45.3 | 10.8 | 20.5 | 23.9 | 19.3 | 26.8 | 48.4 | 30.6 |
| gqe | 40.5 | 21.3 | 15.5 | 29.8 | 41.1 | 8.5 | 18.2 | 16.9 | 16.3 | 23.1 | 38.7 | 24.8 |
| (b) Entailment on FB15k-237 (q2b datasets) | FB15k | NELL | ||||||||||
| LogicE | 81.5 | 54.2 | 46.0 | 58.1 | 67.1 | 28.5 | 44.0 | 66.6 | 40.8 | 54.1 | 65.5 | 85.3 |
| bounds | 73.7 | 46.4 | 38.9 | 49.8 | 61.5 | 22.0 | 37.2 | 54.6 | 35.1 | 46.6 | 58.4 | 80.1 |
| EmQL | 100.0 | 99.5 | 94.7 | 92.2 | 88.8 | 91.5 | 93.0 | 94.7 | 93.7 | 94.2 | 91.4 | 98.8 |
| sketch | 89.3 | 55.7 | 39.9 | 62.9 | 63.9 | 51.9 | 54.7 | 53.8 | 44.7 | 57.4 | 55.5 | 82.5 |
| BetaE | 77.9 | 52.6 | 44.5 | 59.0 | 67.8 | 23.5 | 42.2 | 63.7 | 35.1 | 51.8 | 60.6 | 80.2 |
| q2b | 58.5 | 34.3 | 28.1 | 44.7 | 62.1 | 11.7 | 23.9 | 40.5 | 22.0 | 36.2 | 43.7 | 51.1 |
| gqe | 56.4 | 30.1 | 24.5 | 35.9 | 51.2 | 13.0 | 25.1 | 25.8 | 22.0 | 31.6 | 43.7 | 49.8 |
| Spearman’s rank correlation on FB15k-237 | FB15k | NELL | |||||||||||||
| Model | 1p | 2p | 3p | 2i | 3i | pi | ip | 2in | 3in | inp | pin | pni | avg | avg | avg |
| Entropy | 0.65 | 0.67 | 0.72 | 0.61 | 0.51 | 0.57 | 0.60 | 0.69 | 0.54 | 0.62 | 0.61 | 0.67 | 0.62 | 0.58 | 0.61 |
| Interval | 0.61 | 0.58 | 0.58 | 0.64 | 0.64 | 0.54 | 0.49 | 0.58 | 0.50 | 0.41 | 0.49 | 0.60 | 0.56 | 0.51 | 0.53 |
| BetaE | 0.40 | 0.50 | 0.57 | 0.60 | 0.52 | 0.54 | 0.44 | 0.69 | 0.58 | 0.51 | 0.47 | 0.67 | 0.54 | 0.49 | 0.55 |
| q2b | 0.18 | 0.23 | 0.27 | 0.35 | 0.44 | 0.36 | 0.20 | - | - | - | - | - | - | - | - |
| Pearson correlation coef. on FB15k-237 | FB15k | NELL | |||||||||||||
| Entropy | 0.33 | 0.53 | 0.61 | 0.45 | 0.37 | 0.37 | 0.47 | 0.58 | 0.44 | 0.52 | 0.49 | 0.57 | 0.48 | 0.46 | 0.52 |
| BetaE | 0.23 | 0.37 | 0.45 | 0.36 | 0.31 | 0.32 | 0.33 | 0.46 | 0.41 | 0.39 | 0.36 | 0.48 | 0.37 | 0.36 | 0.4 |
| q2b | 0.02 | 0.19 | 0.26 | 0.37 | 0.49 | 0.34 | 0.20 | - | - | - | - | - | - | - | - |
| Answer size prediction error on FB15k-237 | FB15k | NELL | |||||||||||||
| Model | 1p | 2p | 3p | 2i | 3i | pi | ip | 2in | 3in | inp | pin | pni | avg | avg | avg |
| LogicE | 78 | 83 | 86 | 82 | 94 | 89 | 86 | 81 | 79 | 81 | 81 | 81 | 83 | 87 | 80 |
| BetaE | 111 | 96 | 97 | 97 | 97 | 95 | 97 | 97 | 95 | 97 | 97 | 98 | 98 | 95 | 95 |
| q2b | 191 | 101 | 100 | 310 | 780 | 263 | 103 | - | - | - | - | - | - | - | - |
Uncertainty modeling. Correlation between differential entropy (upper-bound) and answer size (uncertainty, number of entities) is significantly higher in LogicE than BetaE using both Spearman’s rank correlation and Pearson’s correlation coefficient in Table 6. Both significantly outperform uncertainty of q2b with box size.
Total truth interval width of LogicE correlates better to answer size in most cases than BetaE, and offers direct use of the probabilistic semantics of truth bounds to simplify uncertainty modeling. Note that minimizing query answering loss in Eq. (8) does not directly optimize answer cardinality, so LogicE naturally models uncertainty only as by-product of learning to answer.
Cardinality prediction. Above evaluation aggregates entropy, but element-wise entropies contain more information that we use for explicit answer size prediction. We train a regression classifier to map provided uncertainties to answer size , and measure mean absolute error of size prediction .
Table 7 shows reduced cardinality prediction error of 83% with LogicE, compared to avg. 96% with BetaE, indicating more informative uncertainties with LogicE. However, these errors are still quite large, possibly because the main training objective does not directly optimize uncertainties for cardinality prediction.
Training speed. BetaE uses the Beta distribution with no closed form that requires integration to compute entropy and dissimilarity. In contrast, LogicE uses simple truth bounds with fast entropy and dissimilarity calculations. Figure 6 shows that LogicE with any t-norm trains 2-3x faster than BetaE, with the exact same compute resources, optimizer and learning rate. The LogicE training curve also appears smooth and monotonic, compared to disrupted learning progress with BetaE.



6 Related work
In addition to the overview of query embeddings in the Introduction, we also relate our work to 1) tensorized logic, 2) querying with t-norms, and 3) lifted inference.101010Please see appendix for an extended related work section.
Tensorized logic. Distributed representations like embeddings can enable generalization and efficient inference that symbolic logic lacks. Logic tensors of (Grefenstette, 2013) express truths as specific tensors and map entities to one-hot vectors with full-rank matrices, but only memorize facts. Matrix factorization reduces one-hot vectors to low dimensions to enable generalization and efficiency while optimizing logic constraints, but can scale exponentially in the number of query variables (Rocktäschel et al., 2015).
Logic Tensor Networks learn a real vector per entity and even Skolem functions that map to entity features, but has weak inductive bias as it needs to learn predicates to perform logic (Serafini & Garcez, 2016). In contrast, logic embeddings support uncertainty and only has to learn Skolem functions to express knowledge and generalize, with direct logic on latent truths and logic satisfiability via distance.
Querying with t-norms. Triangular norms allow for differentiable composition of scores, often in the context of expensive search. (Guo et al., 2016) jointly embed KGs and logic rules via t-norm of scores, but only for simple rules. (Arakelyan et al., 2020) combine scores from a pretrained link predictor via t-norms repeatedly to search for an answer while tracking intermediaries, whereas logic embeddings perform vectorized t-norm to directly embed answers.
Lifted inference. Many probabilistic inference algorithms accept first-order specifications, but perform inference on a mostly propositional level by instantiating first-order constructs (Friedman et al., 1999; Richardson & Domingos, 2006). In contrast, lifted inference operates directly on first-order representations, manipulating not only individuals but also groups of individuals, which has the potential to significantly speed up inference (de Salvo Braz et al., 2007). We need to reason about entities we know about, as well as those we know exist but with unknown properties. Logic embeddings perform a type of lifted inference as it does not have to ground out the theory or reason separately for each entity, but can perform logic inference directly on subsets.
7 Conclusion
Embedding complex logic queries close to answers is efficient but presents several difficulties in set theoretic modeling of uncertainty and full existential FOL, where Euclidean geometry and probability density approaches suffer deficiency and computational expense. Our logic embeddings overcome these difficulties by converting set logic into direct real-valued logic. We execute FOL queries logically, and not through Venn diagram models like other embeddings, yet we achieve efficiency of lifted inference over subsets.
Main limitations include the need for more training data than search-based methods, although we have strong inductive bias of t-norm logic to reduce sample size dependence. Future work will consider negation attending to applied relations of its input to benefit from context like the t-norms.
References
- Arakelyan et al. (2020) Arakelyan, E., Daza, D., Minervini, P., and Cochez, M. Complex query answering with neural link predictors. arXiv preprint arXiv:2011.03459, 2020.
- Bizer et al. (2009) Bizer, C., Lehmann, J., Kobilarov, G., Auer, S., Becker, C., Cyganiak, R., and Hellmann, S. Dbpedia-a crystallization point for the web of data. Journal of web semantics, 7(3):154–165, 2009.
- Bollacker et al. (2008) Bollacker, K., Evans, C., Paritosh, P., Sturge, T., and Taylor, J. Freebase: a collaboratively created graph database for structuring human knowledge. In ACM SIGMOD international conference on Management of data (SIGMOD). ACM, 2008.
- Bordes et al. (2013) Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., and Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems (NeurIPS), 2013.
- Carlson et al. (2010) Carlson, A., Betteridge, J., Kisiel, B., Settles, B., Hruschka, E. R., and Mitchell, T. M. Toward an architecture for never-ending language learning. In AAAI Conference on Artificial Intelligence (AAAI), 2010.
- Chang & Lee (2014) Chang, C.-L. and Lee, R. C.-T. Symbolic logic and mechanical theorem proving. Academic press, 2014.
- Cohen et al. (2020) Cohen, W. W., Sun, H., Hofer, R. A., and Siegler, M. Scalable neural methods for reasoning with a symbolic knowledge base. arXiv preprint arXiv:2002.06115, 2020.
- Dalvi & Suciu (2007) Dalvi, N. and Suciu, D. Efficient query evaluation on probabilistic databases. VLDB, 2007.
- Das et al. (2017) Das, R., Dhuliawala, S., Zaheer, M., Vilnis, L., Durugkar, I., Krishnamurthy, A., Smola, A., and McCallum, A. Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning. arXiv preprint arXiv:1711.05851, 2017.
- De Raedt (2008) De Raedt, L. Logical and relational learning. Springer Science & Business Media, 2008.
- de Salvo Braz et al. (2007) de Salvo Braz, R., Amir, E., and Roth, D. Lifted first-order probabilistic inference. Statistical relational learning, pp. 433, 2007.
- Friedman et al. (1999) Friedman, N., Getoor, L., Koller, D., and Pfeffer, A. Learning probabilistic relational models. In IJCAI, volume 99, pp. 1300–1309, 1999.
- Grefenstette (2013) Grefenstette, E. Towards a formal distributional semantics: Simulating logical calculi with tensors. arXiv preprint arXiv:1304.5823, 2013.
- Guo et al. (2016) Guo, S., Wang, Q., Wang, L., Wang, B., and Guo, L. Jointly embedding knowledge graphs and logical rules. In Empirical Methods in Natural Language Processing (EMNLP), 2016.
- Guu et al. (2015) Guu, K., Miller, J., and Liang, P. Traversing knowledge graphs in vector space. In Empirical Methods in Natural Language Processing (EMNLP), 2015.
- Hamilton et al. (2018) Hamilton, W., Bajaj, P., Zitnik, M., Jurafsky, D., and Leskovec, J. Embedding logical queries on knowledge graphs. In Advances in Neural Information Processing Systems (NeurIPS), 2018.
- Hong et al. (2018) Hong, S., Park, N., Chakraborty, T., Kang, H., and Kwon, S. Page: Answering graph pattern queries via knowledge graph embedding. In International Conference on Big Data, pp. 87–99. Springer, 2018.
- Lou et al. (2020) Lou, Z., You, J., Wen, C., Canedo, A., Leskovec, J., et al. Neural subgraph matching. arXiv preprint arXiv:2007.03092, 2020.
- Mostert & Shields (1957) Mostert, P. S. and Shields, A. L. On the structure of semigroups on a compact manifold with boundary. Annals of Mathematics, pp. 117–143, 1957.
- Poole (2003) Poole, D. First-order probabilistic inference. In IJCAI, volume 3, pp. 985–991, 2003.
- Ren & Leskovec (2020) Ren, H. and Leskovec, J. Beta embeddings for multi-hop logical reasoning in knowledge graphs. Advances in Neural Information Processing Systems, 33, 2020.
- Ren et al. (2020) Ren, H., Hu, W., and Leskovec, J. Query2box: Reasoning over knowledge graphs in vector space using box embeddings. In International Conference on Learning Representations (ICLR), 2020.
- Richardson & Domingos (2006) Richardson, M. and Domingos, P. Markov logic networks. Machine learning, 62(1-2):107–136, 2006.
- Riegel et al. (2020) Riegel, R., Gray, A., Luus, F., Khan, N., Makondo, N., Akhalwaya, I. Y., Qian, H., Fagin, R., Barahona, F., Sharma, U., et al. Logical neural networks. arXiv preprint arXiv:2006.13155, 2020.
- Rocktäschel et al. (2015) Rocktäschel, T., Singh, S., and Riedel, S. Injecting logical background knowledge into embeddings for relation extraction. In Proceedings of the 2015 conference of the north American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1119–1129, 2015.
- Serafini & Garcez (2016) Serafini, L. and Garcez, A. d. Logic tensor networks: Deep learning and logical reasoning from data and knowledge. arXiv preprint arXiv:1606.04422, 2016.
- Sun et al. (2020) Sun, H., Arnold, A. O., Bedrax-Weiss, T., Pereira, F., and Cohen, W. W. Faithful embeddings for knowledge base queries. Advances in Neural Information Processing Systems, 33, 2020.
- Sun & Nielsen (2019) Sun, K. and Nielsen, F. Information-geometric set embeddings (igse): From sets to probability distributions. arXiv preprint arXiv:1911.12463, 2019.
- Sun et al. (2019) Sun, Z., Deng, Z.-H., Nie, J.-Y., and Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. In International Conference on Learning Representations (ICLR), 2019.
- Toutanova & Chen (2015) Toutanova, K. and Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality, 2015.
- Xiong et al. (2017) Xiong, W., Hoang, T., and Wang, W. Y. Deeppath: A reinforcement learning method for knowledge graph reasoning. In Empirical Methods in Natural Language Processing (EMNLP), 2017.
Appendix A Extended Related Work
Link prediction. Reasoning over knowledge bases is fundamental to Artificial Intelligence, but still challenging since most knowledge graphs (KGs) such as DBpedia (Bizer et al., 2009), Freebase (Bollacker et al., 2008), and NELL (Carlson et al., 2010) are often large and incomplete. Answering complex queries is an important use of KGs, but missing facts makes queries unanswerable under normal inference. KG embeddings are popular for predicting facts, learning entities as vectors and relations between them as functions in vector space, like translation (Bordes et al., 2013) or rotation (Sun et al., 2019).
Link prediction uncovers similar behavior of entities, and semantic similarity between relations (e.g. birthplace predicts nationality). Path queries involve multi-hop reasoning (e.g. country of birthcity of person), where compositional learning embeds queries close to answer entities with fast (sublinear) neighbor search (Guu et al., 2015). In contrast, sequential path search grows exponentially in the number of hops, and requires approaches like reinforcement learning (Das et al., 2017) or beam search (Arakelyan et al., 2020) that have to explicitly track intermediate entities.
Path-based methods. A simple approach to complex query answering represents first-order logical queries as a directed graph corresponding to the reasoning path to be followed. Such path-based methods are characterized by carrying out a sub-graph matching strategy in their pursuit for solving complex queries. However, they fail to deal with queries with missing relations and cannot scale to large KGs as the complexity of sub-graph matching grows exponentially in the query size. Several works aim at addressing the former by imputing missing relations (Guu et al., 2015; Hong et al., 2018), leading into a denser KG with high computational demand.
Query embeddings. Recent approaches aim to address the two issues by learning embeddings of the query such that entities that answer the query are close to the embeddings of the query and answers can be found by fast nearest neighbor searches. Such approaches implicitly impute missing relations and also lead to faster querying compared to subgraph matching. Here, logical queries as well as KG entities are embedded into a lower-dimensional vector space as geometric shapes such as points (Hamilton et al., 2018), boxes (Ren et al., 2020) and distributions with bounded support (Ren & Leskovec, 2020).
Compared to point-based embeddings, boxes and distributions naturally model sets of entities they enclose, with set operations on those sets corresponding to logical operations (e.g., set intersection corresponds to the conjunction operator), and thus iteratively executing set operations results in logical reasoning. Furthermore, box and distribution-based embeddings allow handling the uncertainty over the queries.
Majority of early embedding based approaches are limited to a subset of first-order logic consisting of existential quantification and conjunctions, with a few recent papers supporting the so-called existential positive first-order (EPFO) queries (Ren et al., 2020; Arakelyan et al., 2020) that additionally include disjunctions. The work by (Ren & Leskovec, 2020) is the first to handle the full set of first-order logic including negation.
Recent path-based approaches utilize knowledge graph embeddings to learn to tractably traverse the graph in the embedding space (Lou et al., 2020) or using pre-trained black boxes for link prediction (Arakelyan et al., 2020). Neural Subgraph Matching (Lou et al., 2020) uses order embeddings to embed the query and KG graphs into a lower-dimensional space, and efficiently performs subgraph matching directly in the embedding space. This has the potential to impute missing relations and has been shown to be orders of magnitude faster than standard sub-graph matching approaches on subgraph matching benchmarks. However, it has not been applied to complex query answering problems. (Arakelyan et al., 2020) use a pre-trained, black-box, neural link predictor to reduce sample complexity and scale to larger KGs, and was shown to be effective on EPFO queries, but does not support the full set of first-order logic queries.
Lifted inference. Many probabilistic inference algorithms accept first-order specifications, but perform inference on a mostly propositional level by instantiating first-order constructs (Friedman et al., 1999; Richardson & Domingos, 2006). In contrast, lifted inference operates directly on first-order representations, manipulating not only individuals but also groups of individuals, which has the potential to significantly speed up inference (de Salvo Braz et al., 2007).
Variable elimination of non-observed non-query variables is the basis of several lifted inference algorithms (Poole, 2003; de Salvo Braz et al., 2007), and strongly resembles the lifting lemma which simulates ground resolution because it is complete and then lifts the resolution proof to the first-order world (Chang & Lee, 2014).
Theorem proving produces a potentially unbounded number of resolutions on grounded representations by performing unification and resolution on clauses with free variables, operating directly on the first-order representation. However, reasoning over incomplete knowledge requires generalization where particular facts about some individuals could apply with uncertainty to a similar group, thus predicting missing facts.
We need to reason about entities we know about, as well as entities we know exist but which have unknown properties. Logic embeddings perform a type of lifted inference as it does not have to ground out the theory or reason separately for each entity, but can perform logic inference directly with compact representations of smooth sets of entities.
Appendix B Query forms
Table 9 gives logic query forms from (Ren & Leskovec, 2020) with corresponding Skolem normal form and Skolem set logic. Note that Skolem normal form uses conventional set logic symbols inside predicates, to avoid confusion with logic symbols composing predicates. Subsequent Skolem set logic resumes use of logic symbols, as the actual operations are logical over vectors of truth values.
Appendix C Dataset statistics
Appendix D Additional Results
Table 8 compares test MRR results for LogicE and BetaE on different datasets. Table 13 compares test MRR results for queries without negation. Table 14 provides full details of Spearman’s rank correlation for all three KGs. Table 15 gives full numbers on Pearson’s correlation coefficient for all three KGs. Table 16 gives answer size prediction mean absolute error for all three KGs. Table 17 provides generalization and entailment scores for all three KGs.
| Dataset | Model | 2in | 3in | inp | pin | pni | avg |
|---|---|---|---|---|---|---|---|
| FB15k | LogicE | 15.1 | 14.2 | 12.5 | 7.1 | 13.4 | 12.5 |
| bounds | 14.0 | 13.4 | 11.9 | 6.6 | 12.4 | 11.7 | |
| BetaE | 14.3 | 14.7 | 11.5 | 6.5 | 12.4 | 11.8 | |
| FB15k-237 | LogicE | 4.9 | 8.2 | 7.7 | 3.6 | 3.5 | 5.6 |
| bounds | 4.9 | 8.0 | 7.3 | 3.6 | 3.5 | 5.5 | |
| BetaE | 5.1 | 7.9 | 7.4 | 3.6 | 3.4 | 5.4 | |
| NELL995 | LogicE | 5.3 | 7.5 | 11.1 | 3.3 | 3.8 | 6.2 |
| bounds | 5.3 | 7.8 | 11.1 | 3.3 | 3.8 | 6.3 | |
| BetaE | 5.1 | 7.8 | 10.0 | 3.1 | 3.5 | 5.9 |
| First-order logic | Skolem normal form | Skolem set logic | |
| 1p | |||
| 2p | |||
| 3p | |||
| 2i | |||
| 3i | |||
| pi | |||
| ip | |||
| 2in | |||
| 3in | |||
| pin | |||
| pni | |||
| inp | |||
| 2u | |||
| up | |||
| Dataset | Relations | Entities | Training Edges | Validation Edges | Test Edges | Total Edges |
|---|---|---|---|---|---|---|
| FB15k | 1,345 | 14,951 | 483,142 | 50,000 | 59,071 | 592,213 |
| FB15k-237 | 237 | 14,505 | 272,115 | 17,526 | 20,438 | 310,079 |
| NELL995 | 200 | 63,361 | 114,213 | 14,324 | 14,267 | 142,804 |
| Training | Validation | Test | ||||
|---|---|---|---|---|---|---|
| Dataset | 1p | others | 1p | others | 1p | others |
| FB15k | 273,710 | 273,710 | 59,097 | 8,000 | 67,016 | 8,000 |
| FB15k-237 | 149,689 | 149,689 | 20,101 | 5,000 | 22,812 | 5,000 |
| NELL995 | 107,982 | 107,982 | 16,927 | 4,000 | 17,034 | 4,000 |
| Training | Validation | Test | ||||
|---|---|---|---|---|---|---|
| Dataset | 1p/2p/3p/2i/3i | 2in/3in/inp/pin/pni | 1p | others | 1p | others |
| FB15k | 273,710 | 27,371 | 59,097 | 8,000 | 67,016 | 8,000 |
| FB15k-237 | 149,689 | 14,968 | 20,101 | 5,000 | 22,812 | 5,000 |
| NELL995 | 107,982 | 10,798 | 16,927 | 4,000 | 17,034 | 4,000 |
| Dataset | Model | 1p | 2p | 3p | 2i | 3i | pi | ip | 2u | up | avg | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DNF | DM | DNF | DM | ||||||||||
| FB15k | LogicE | 72.3 | 29.8 | 26.2 | 56.1 | 66.3 | 42.7 | 32.6 | 43.4 | 37.1 | 27.5 | 26.7 | 44.1 |
| bounds | 67.8 | 27.1 | 24.6 | 51.4 | 61.3 | 41.3 | 30.1 | 38.1 | 33.7 | 25.1 | 23.8 | 40.8 | |
| BetaE | 65.1 | 25.7 | 24.7 | 55.8 | 66.5 | 43.9 | 28.1 | 40.1 | 25.0 | 25.2 | 25.4 | 41.6 | |
| q2b | 68.0 | 21.0 | 14.2 | 55.1 | 66.5 | 39.4 | 26.1 | 35.1 | - | 16.7 | - | 38.0 | |
| gqe | 54.6 | 15.3 | 10.8 | 39.7 | 51.4 | 27.6 | 19.1 | 22.1 | - | 11.6 | - | 28.0 | |
| FB15k-237 | LogicE | 41.3 | 11.8 | 10.4 | 31.4 | 43.9 | 23.8 | 14.0 | 13.4 | 13.1 | 10.2 | 9.8 | 22.3 |
| bounds | 40.5 | 11.4 | 10.1 | 29.8 | 42.2 | 22.4 | 13.4 | 13.0 | 12.9 | 9.8 | 9.6 | 21.4 | |
| BetaE | 39.0 | 10.9 | 10.0 | 28.8 | 42.5 | 22.4 | 12.6 | 12.4 | 11.1 | 9.7 | 9.9 | 20.9 | |
| q2b | 40.6 | 9.4 | 6.8 | 29.5 | 42.3 | 21.2 | 12.6 | 11.3 | - | 7.6 | - | 20.1 | |
| gqe | 35.0 | 7.2 | 5.3 | 23.3 | 34.6 | 16.5 | 10.7 | 8.2 | - | 5.7 | - | 16.3 | |
| NELL995 | LogicE | 58.3 | 17.7 | 15.4 | 40.5 | 50.4 | 27.3 | 19.2 | 15.9 | 14.4 | 12.7 | 11.8 | 28.6 |
| bounds | 57.6 | 16.9 | 14.6 | 40.8 | 50.2 | 26.5 | 18.0 | 15.3 | 13.5 | 12.0 | 11.3 | 28.0 | |
| BetaE | 53.0 | 13.0 | 11.4 | 37.6 | 47.5 | 24.1 | 14.3 | 12.2 | 11.0 | 8.5 | 8.6 | 24.6 | |
| q2b | 42.2 | 14.0 | 11.2 | 33.3 | 44.5 | 22.4 | 16.8 | 11.3 | - | 10.3 | - | 22.9 | |
| gqe | 32.8 | 11.9 | 9.6 | 27.5 | 35.2 | 18.4 | 14.4 | 8.5 | - | 8.8 | - | 18.6 | |
| Dataset | Model | 1p | 2p | 3p | 2i | 3i | pi | ip | 2in | 3in | inp | pin | pni | avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | LogicE entropy | 0.50 | 0.65 | 0.70 | 0.52 | 0.33 | 0.56 | 0.58 | 0.71 | 0.55 | 0.58 | 0.62 | 0.70 | 0.58 |
| LogicE bounds | 0.44 | 0.51 | 0.50 | 0.60 | 0.52 | 0.58 | 0.48 | 0.56 | 0.53 | 0.33 | 0.43 | 0.59 | 0.51 | |
| BetaE | 0.37 | 0.48 | 0.47 | 0.57 | 0.40 | 0.52 | 0.42 | 0.62 | 0.55 | 0.46 | 0.47 | 0.61 | 0.49 | |
| q2b | 0.30 | 0.22 | 0.26 | 0.33 | 0.27 | 0.30 | 0.14 | - | - | - | - | - | - | |
| FB15k-237 | LogicE entropy | 0.65 | 0.67 | 0.72 | 0.61 | 0.51 | 0.57 | 0.60 | 0.69 | 0.54 | 0.62 | 0.61 | 0.67 | 0.62 |
| LogicE bounds | 0.61 | 0.58 | 0.58 | 0.64 | 0.64 | 0.54 | 0.49 | 0.58 | 0.50 | 0.41 | 0.49 | 0.60 | 0.56 | |
| BetaE | 0.40 | 0.50 | 0.57 | 0.60 | 0.52 | 0.54 | 0.44 | 0.69 | 0.58 | 0.51 | 0.47 | 0.67 | 0.54 | |
| q2b | 0.18 | 0.23 | 0.27 | 0.35 | 0.44 | 0.36 | 0.20 | - | - | - | - | - | - | |
| NELL995 | LogicE entropy | 0.67 | 0.64 | 0.60 | 0.63 | 0.64 | 0.55 | 0.58 | 0.70 | 0.59 | 0.49 | 0.55 | 0.70 | 0.61 |
| LogicE bounds | 0.51 | 0.56 | 0.48 | 0.68 | 0.67 | 0.62 | 0.40 | 0.56 | 0.61 | 0.30 | 0.34 | 0.58 | 0.53 | |
| BetaE | 0.42 | 0.55 | 0.56 | 0.59 | 0.61 | 0.60 | 0.54 | 0.71 | 0.60 | 0.35 | 0.45 | 0.64 | 0.55 | |
| q2b | 0.15 | 0.29 | 0.31 | 0.38 | 0.41 | 0.36 | 0.35 | - | - | - | - | - | - |
| Dataset | Model | 1p | 2p | 3p | 2i | 3i | pi | ip | 2in | 3in | inp | pin | pni | avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | LogicE | 0.28 | 0.50 | 0.56 | 0.47 | 0.34 | 0.38 | 0.43 | 0.56 | 0.46 | 0.45 | 0.48 | 0.56 | 0.46 |
| BetaE | 0.22 | 0.36 | 0.38 | 0.39 | 0.30 | 0.31 | 0.31 | 0.44 | 0.41 | 0.34 | 0.36 | 0.44 | 0.36 | |
| q2b | 0.08 | 0.22 | 0.26 | 0.29 | 0.23 | 0.25 | 0.13 | - | - | - | - | - | - | |
| FB15k-237 | LogicE | 0.33 | 0.53 | 0.61 | 0.45 | 0.37 | 0.37 | 0.47 | 0.58 | 0.44 | 0.52 | 0.49 | 0.57 | 0.48 |
| BetaE | 0.23 | 0.37 | 0.45 | 0.36 | 0.31 | 0.32 | 0.33 | 0.46 | 0.41 | 0.39 | 0.36 | 0.48 | 0.37 | |
| q2b | 0.02 | 0.19 | 0.26 | 0.37 | 0.49 | 0.34 | 0.20 | - | - | - | - | - | - | |
| NELL995 | LogicE | 0.43 | 0.53 | 0.53 | 0.53 | 0.49 | 0.46 | 0.45 | 0.66 | 0.54 | 0.46 | 0.55 | 0.63 | 0.52 |
| BetaE | 0.24 | 0.40 | 0.43 | 0.40 | 0.39 | 0.40 | 0.40 | 0.52 | 0.51 | 0.26 | 0.35 | 0.46 | 0.40 | |
| q2b | 0.07 | 0.21 | 0.31 | 0.36 | 0.29 | 0.24 | 0.34 | - | - | - | - | - | - |
| Dataset | Model | 1p | 2p | 3p | 2i | 3i | pi | ip | 2in | 3in | inp | pin | pni | avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | LogicE | 78 | 86 | 91 | 88 | 93 | 96 | 95 | 85 | 83 | 82 | 86 | 84 | 87 |
| BetaE | 105 | 95 | 96 | 92 | 94 | 92 | 94 | 95 | 92 | 95 | 95 | 96 | 95 | |
| q2b | 264 | 113 | 100 | 444 | 730 | 386 | 125 | - | - | - | - | - | - | |
| FB15k-237 | LogicE | 78 | 83 | 86 | 82 | 94 | 89 | 86 | 81 | 79 | 81 | 81 | 81 | 83 |
| BetaE | 111 | 96 | 97 | 97 | 97 | 95 | 97 | 97 | 95 | 97 | 97 | 98 | 98 | |
| q2b | 191 | 101 | 100 | 310 | 780 | 263 | 103 | - | - | - | - | - | - | |
| NELL995 | LogicE | 59 | 82 | 85 | 83 | 83 | 90 | 83 | 76 | 92 | 77 | 78 | 77 | 80 |
| BetaE | 97 | 96 | 95 | 94 | 100 | 97 | 95 | 95 | 90 | 96 | 94 | 96 | 95 | |
| q2b | 254 | 100 | 100 | 1 371 | 2 638 | 539 | 109 | - | - | - | - | - | - |
| Generalization | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up | avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | LogicE | 81.0 | 51.9 | 46.3 | 62.5 | 73.2 | 28.4 | 47.8 | 65.3 | 37.6 | 54.9 |
| bounds | 76.4 | 47.9 | 43.3 | 56.6 | 67.1 | 25.0 | 42.6 | 57.9 | 35.9 | 50.3 | |
| EmQL | 42.4 | 50.2 | 45.9 | 63.7 | 70.0 | 60.7 | 61.4 | 9.0 | 42.6 | 49.5 | |
| BetaE | 75.8 | 46.0 | 41.8 | 62.5 | 74.3 | 24.3 | 48.0 | 60.2 | 29.2 | 51.4 | |
| q2b | 78.6 | 41.3 | 30.3 | 59.3 | 71.2 | 21.1 | 39.7 | 60.8 | 33.0 | 48.4 | |
| gqe | 63.6 | 34.6 | 25.0 | 51.5 | 62.4 | 15.1 | 31.0 | 37.6 | 27.3 | 38.7 | |
| FB15k-237 | LogicE | 46.1 | 28.6 | 24.8 | 34.8 | 46.5 | 12.0 | 23.7 | 27.7 | 21.1 | 29.5 |
| bounds | 45.0 | 26.6 | 23.0 | 32.0 | 44.1 | 11.1 | 22.1 | 25.5 | 20.4 | 27.7 | |
| EmQL | 37.7 | 34.9 | 34.3 | 44.3 | 49.4 | 40.8 | 42.3 | 8.7 | 28.2 | 35.8 | |
| BetaE | 43.1 | 25.3 | 22.3 | 31.3 | 44.6 | 10.2 | 22.3 | 26.6 | 18.0 | 27.1 | |
| q2b | 46.7 | 24.0 | 18.6 | 32.4 | 45.3 | 10.8 | 20.5 | 23.9 | 19.3 | 26.8 | |
| gqe | 40.5 | 21.3 | 15.5 | 29.8 | 41.1 | 8.5 | 18.2 | 16.9 | 16.3 | 23.1 | |
| NELL995 | LogicE | 64.5 | 36.4 | 36.6 | 41.4 | 54.6 | 14.9 | 26.0 | 51.4 | 27.9 | 39.3 |
| bounds | 63.9 | 35.1 | 35.5 | 40.7 | 54.4 | 14.2 | 25.2 | 50.3 | 27.6 | 38.6 | |
| EmQL | 41.5 | 40.4 | 38.6 | 62.9 | 74.5 | 49.8 | 64.8 | 12.6 | 35.8 | 46.8 | |
| BetaE | 58.7 | 29.6 | 30.7 | 36.1 | 50.0 | 11.0 | 22.9 | 44.1 | 21.1 | 33.8 | |
| q2b | 55.5 | 26.6 | 23.3 | 34.3 | 48.0 | 13.2 | 21.2 | 36.9 | 16.3 | 30.6 | |
| gqe | 41.8 | 23.1 | 20.5 | 31.8 | 45.4 | 8.1 | 18.8 | 20.0 | 13.9 | 24.8 | |
| Entailment | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up | avg | |
| FB15k | LogicE | 88.4 | 64.0 | 57.9 | 70.8 | 80.6 | 41.0 | 59.0 | 76.6 | 51.0 | 65.5 |
| bounds | 82.9 | 57.3 | 51.9 | 62.5 | 73.0 | 34.1 | 51.5 | 67.2 | 45.5 | 58.4 | |
| EmQL | 98.5 | 96.3 | 91.1 | 91.4 | 88.1 | 87.8 | 89.2 | 88.7 | 91.3 | 91.4 | |
| sketch | 85.1 | 50.8 | 42.4 | 64.4 | 66.1 | 50.4 | 53.8 | 43.2 | 42.7 | 55.5 | |
| BetaE | 83.2 | 57.3 | 51.0 | 71.1 | 81.4 | 32.7 | 56.9 | 70.4 | 41.0 | 60.6 | |
| q2b | 68.0 | 39.4 | 32.7 | 48.5 | 65.3 | 16.2 | 32.9 | 61.4 | 28.9 | 43.7 | |
| gqe | 73.8 | 40.5 | 32.1 | 49.8 | 64.7 | 18.9 | 36.1 | 47.2 | 30.4 | 43.7 | |
| FB15k-237 | LogicE | 81.5 | 54.2 | 46.0 | 58.1 | 67.1 | 28.5 | 44.0 | 66.6 | 40.8 | 54.1 |
| bounds | 73.7 | 46.4 | 38.9 | 49.8 | 61.5 | 22.0 | 37.2 | 54.6 | 35.1 | 46.6 | |
| EmQL | 100.0 | 99.5 | 94.7 | 92.2 | 88.8 | 91.5 | 93.0 | 94.7 | 93.7 | 94.2 | |
| sketch | 89.3 | 55.7 | 39.9 | 62.9 | 63.9 | 51.9 | 54.7 | 53.8 | 44.7 | 57.4 | |
| BetaE | 77.9 | 52.6 | 44.5 | 59.0 | 67.8 | 23.5 | 42.2 | 63.7 | 35.1 | 51.8 | |
| q2b | 58.5 | 34.3 | 28.1 | 44.7 | 62.1 | 11.7 | 23.9 | 40.5 | 22.0 | 36.2 | |
| gqe | 56.4 | 30.1 | 24.5 | 35.9 | 51.2 | 13.0 | 25.1 | 25.8 | 22.0 | 31.6 | |
| NELL995 | LogicE | 96.2 | 90.7 | 84.1 | 84.1 | 89.5 | 65.2 | 76.0 | 94.7 | 87.1 | 85.3 |
| bounds | 94.1 | 86.0 | 78.7 | 80.4 | 87.1 | 53.6 | 68.5 | 90.9 | 81.2 | 80.1 | |
| EmQL | 99.0 | 99.0 | 97.1 | 99.7 | 99.6 | 98.7 | 98.9 | 98.8 | 98.5 | 98.8 | |
| sketch | 94.5 | 77.4 | 52.9 | 97.4 | 97.5 | 88.1 | 90.8 | 70.4 | 73.5 | 82.5 | |
| BetaE | 94.3 | 88.2 | 76.2 | 84.0 | 90.2 | 46.6 | 68.8 | 92.5 | 81.4 | 80.2 | |
| q2b | 83.9 | 57.7 | 47.8 | 49.9 | 66.3 | 19.9 | 29.6 | 73.7 | 31.0 | 51.1 | |
| gqe | 72.8 | 58.0 | 55.2 | 45.9 | 57.3 | 24.8 | 34.2 | 59.0 | 40.7 | 49.8 | |