Location Information Assisted Beamforming Design for Reconfigurable Intelligent Surface Aided Communication Systems
Abstract
In reconfigurable intelligent surface (RIS) aided millimeter-wave (mmWave) communication systems, in order to overcome the limitation of the conventional channel state information (CSI) acquisition techniques, this paper proposes a location information assisted beamforming design without the requirement of the conventional channel training process. First, we establish the geometrical relation between the channel model and the user location, based on which we derive an approximate CSI error bound based on the user location error by means of Taylor approximation, triangle and power mean inequalities, and semidefinite relaxation (SDR). Second, for combating the uncertainty of the location error, we formulate a worst-case robust beamforming optimization problem. To solve the problem efficiently, we develop a novel iterative algorithm by utilizing various optimization tools such as Lagrange multiplier, matrix inversion lemma, SDR, as well as branch-and-bound (BnB). Additionally, we provide sufficient conditions for the SDR to output rank-one solutions, and modify the BnB algorithm to acquire the phase shift solution under an arbitrary constraint of possible phase shift values. Finally, we analyse the algorithm convergence and complexity, and carry out simulations to validate the theoretical derivation of the CSI error bound and the robustness of the proposed algorithm. Compared with the existing non-robust approach and the robust beamforming techniques based on S-procedure and penalty convex-concave procedure (CCP), our method can converge more quickly and achieve better performance in terms of the worst-case signal-to-noise ratio (SNR) at the receiver.
I Introduction
For decades, the rapid development of telecommunication technologies has been concomitant with a surge of mobile data traffic along with a sharp increase in the number of mobile terminals, which sparks off a burning issue of spectrum scarcity. To deal with this issue, several key enabling techniques, such as millimeter-wave (mmWave), massive multiple-input-multiple-output (MIMO) and ultra-dense network (UDN), have been incorporated into the fifth-generation (5G) wireless communication network [1]. Although these techniques are validated to be advantageous in terms of improving the spectral efficiency and providing reliable connectivity, they are still unable to adequately address the problems of high energy consumption (EC) and high hardware/deployment cost (HDC). These problems will become even more serious in the future sixth-generation (6G) wireless communication network.
Recently, the urgent demand for coping with the problems of high EC and HDC in 5G/6G, has promoted the emergence and development of a new concept, termed reconfigurable intelligent surface (RIS), which aims to make the wireless communication environment smarter and more controllable for combating the undesirable propagation conditions [2, 21]. An RIS is generally an artificial metasurface consisting of a large quantity of near-passive reflecting units, each of which is independently controlled in a software-defined manner to adjust the physical properties, such as phase shifts, of the impinging electromagnetic waves, so as to reflect the waves to a desired receiver [4, 5, 6, 7]. As the RIS can generally be fabricated with low-cost simple electronic components (e.g. varactor diodes [8] and positive intrinsic-negative (PIN) diodes [9]) and does not need power-consuming radio-frequency (RF) chains to perform active signal retransmission, it has attracted considerable attention and has been envisioned as one of the most promising candidate technologies in 5G/6G [10].
Summarized from the existing researches, the RIS is mostly employed to assist the wireless communication or user localization when the line-of-sight (LoS) link is weak or even unavailable, and to improve the system performance including (but not limited to) channel capacity [11], physical-layer security [12], outage probability [13], robustness [14], spectral/energy efficiency [15, 16, 17], achievable data rate[18, 19, 20], potential positioning accuracy [21, 22], etc., under either perfect [11, 12, 13, 14, 15, 16, 21, 22, 19, 20] or non-ideal hardware conditions [17, 18]. To achieve these goals, the phase shift design/optimization, also known as passive beamforming, needs to be performed at the RIS. This implies that the RIS controller should first acquire adequate instantaneous channel state information (CSI) from the base station (BS). Although the instantaneous CSI can generally be obtained by various channel estimation techniques developed for the RIS-aided wireless communication [23, 24, 25], several problems still exist during this procedure. First, when the number of the RIS reflecting units is large, conventional CSI estimation techniques require a huge overhead for channel training. Second, when the BS acquires the CSI, the CSI needs to be delivered to the RIS controller via an additional link, which incurs an extra communication overhead [26]. Third, since the CSI is generally time-variant in real applications, the update of passive beamforming may become hysteretic due to training and/or communication delay, which seriously compromises the potential gain achieved by the use of RIS.
In view of the aforementioned issues, a novel RIS-aided communication scheme based on user location information has been proposed recently [26]. Specifically, in practice, the positions of the BS and RIS are generally fixed and known after their deployments, while the position of a user can be easily acquired in many ways. For instance, the user position is available when 1) the RIS is designed to support the user positioning, or 2) the user is covered by the external global positioning system (GPS) or ultra-wide band (UWB) signals in the outdoor or indoor environments. The first case has been addressed by several prior works [27, 28, 29, 30], where the RIS was leveraged to localize the user by means of the maximum likelihood estimation (MLE), the machine learning, as well as the codebook design, and the phase shift configurations and the Cramér-Rao Lower Bound of the potential localization errors were also investigated. The second case is relatively straightforward in the presence of the cooperation of the existing localization system and the RIS-aided communication system [26]. Once the user position is obtained, according to the spatial geometric relations between the coordinates of the BS, the RIS, the user, and the array responses at each terminal side, the channel matrices or vectors can be directly reconstructed without the channel training process. The reconstructed channels are further dedicated to the subsequent transmit or passive beamforming design/optimization. Therefore, utilizing the location information to acquire the CSI can overcome the drawbacks of the conventional CSI estimation described in the previous paragraph.
However, the user position from the localization systems is generally inaccurate. Due to the unavoidable localization error caused by inherent accuracy limitation or hardware imperfection of the localization devices, the reconstructed channels suffer from CSI uncertainty. In such a situation, in order to maintain a good system performance, the transmit or passive beamforming should be designed to be robust to the CSI uncertainty. Up to now, there have already been several important prior works which studied the robust beamforming in the RIS-aided communication systems. For instance, G. Zhou, et al. [31, 32], considered both the bounded CSI error and the statistical CSI error, and designed robust transmit and passive beamforming optimization algorithms based on S-procedure and penalty convex-concave procedure (CCP); J. Zhang, et al. [33], and M. Zhao, et al. [34], focused on minimizing the average mean squared error (MSE) of the data symbols, or minimizing the transmit power with outage probability constraints, in consideration of the statistical CSI error. However, these works did not investigate the CSI error arising from the user location uncertainty, and might suffer from slow convergence when the number of transmit antennas or reflecting elements became large. To the best of our knowledge, how to achieve an efficient robust transmit and passive beamforming optimization approach based on the location information has not been explored yet, which motivates our research herein. Although in our previous conference paper [14], we addressed this remaining issue by relating the CSI error bound to the user location error bound and designing a non-iterative worst-case robust beamforming optimization scheme based on the saddle point theory, the proposed design in [14] was only suitable for a special far-field communication scenario, where the investigated BS-RIS channel was characterized by a deterministic rank-one LoS model. Instead, in this work, we propose a novel iterative worst-case robust beamforming optimization approach for the RIS-aided location information assisted wireless communication system, which applies to a more general communication scenario in the presence of Rician fading. In such a case, compared to [14], both the derivation of the CSI error bound and the optimization process of the transmit and passive beamforming are essentially different and more challenging.
The contributions of this paper are summarized as follows.
-
•
Derivation of the CSI error bound: First, we consider a three-dimensional (3D) RIS-aided mmWave communication system, where the locations of the BS, the RIS and the user are adopted to acquire the CSI of the BS-RIS-user link. Under the assumption that the user location error is restricted in a spherical region [26], we combine the Taylor expansion, the triangle inequality, the power mean inequality, and the semidefinite relaxation (SDR) to derive an approximate CSI error bound according to the user location error bound. This new bound has not been obtained by the previous studies to the best of our knowledge, but is essential to our subsequent robust transmit and passive beamforming design. The CSI error bound is empirically verified to be tight when the user location uncertainty is moderate, or when the user is far away from the RIS.
-
•
Robust transmit and passive beamforming: After the CSI error bound is derived, a worst-case robust transmit and passive beamforming optimization problem is formulated. Since the original problem is non-convex and difficult to be solved efficiently, a novel iterative optimization approach is proposed to acquire a suboptimal solution. Specifically, the inner minimization is first conducted by introducing a Lagrange multiplier, and the outer maximization is then iteratively accomplished to obtain the optimal solutions of the Lagrange dual variable and the phase-shift matrix. Owing to the constant-modulus property of the reflectors, the outer maximization problem is decomposed into a feasibility-check problem and a constrained QCQP problem with the aid of the matrix inversion lemma, where the QCQP problem is solved by the SDR when the phase shift arguments belong to , or by the branch-and-bound (BnB) algorithm when the phase shift arguments are arbitrarily constrained. Regarding the SDR for the RIS phase shift optimization, our work makes the first attempt to rigorously show that the SDR yields rank-one solutions when certain regularity condition holds.
-
•
Algorithm design and performance evaluation: Based on the proposed optimization approach, the overall algorithm is finally built, and its convergence behaviour and computational complexity are analysed. Afterwards, the theoretical derivation of the CSI error bound is verified, and the performance of the developed algorithm is evaluated numerically. Compared with the conventional non-robust approach, the proposed algorithm shows strong robustness against the CSI uncertainty. Compared with the existing worst-case robust beamforming methods based on S-procedure and penalty CCP, our proposed approach can perform better and converge more quickly in terms of the worst-case signal-to-noise ratio (SNR) at the receiver. Besides, our proposed algorithm with BnB has the advantages of being able to provide near-optimal solutions and deal with arbitrary phase shift argument sets.
The rest of this paper is organized as follows. Section II describes the system model and the problem formulation for the robust transmit and passive beamforming optimization. Section III derives the CSI error bound based on the user location error bound. Section IV proposes an iterative optimization approach to acquire the solutions of the transmit beamforming vector and the reflective phase-shift matrix. Section V carries out the simulations and comparisons to evaluate the algorithm performance. Section VI draws the final conclusions and prospects.
Notations: and represent the -th and -th element in vector and matrix . , and denote the transpose, conjugate and conjugate transpose of . means that is an sized complex-value matrix. symbolizes the -norm. , and denote the expectation, trace and argument, respectively. represents a diagonal matrix whose diagonal elements are . and denote the real part and the imaginary part of , respectively. is an sized identity matrix.
II System Model and Problem Formulation

In this paper, an RIS-aided mmWave communication system in a 3D propagation environment, as shown in Fig. 1, is investigated. The system is composed of a BS with a uniform linear array (ULA) consisting of antennas, an RIS with a uniform square planar array (USPA) consisting of reflecting elements with being the number of rows or columns of the USPA, a user equipment (UE) with one antenna, and an RIS controller. The UE is assumed moving slowly or nearly static. The antenna spacing of the BS is , while the element spacing of the RIS is . To guarantee a good communication performance, the RIS is deployed near the BS. For convenience of system description, a 3D Cartesian coordinate system, as shown in the top-left corner of Fig. 1, is established to specify the positions of the BS, the RIS and the UE. With the aid of coordinate indication, the position of the UE is represented by . Assume that the ULA on the BS and the USPA on the RIS are deployed parallel to the -axis and the -- plane, respectively. Then, let denote the coordinates of the left-end BS antenna, and denote the coordinates of the reflecting element in the bottom-left corner of the RIS. Hence, the positions of the -th antenna on the BS, for , and the -th reflecting element on the RIS, for and , are represented by
| (1) |
| (2) |
where and .
Based on this system setup, the remainder of this section will illustrate the channel and received signal models, CSI error model, and problem formulation.
II-A Channel and Received Signal Models
In the considered communication system, an obstruction, e.g. an edifice or building, exists on the direct path between the BS and the UE, whereas no object blocks the LoS links between the BS/RIS and the RIS/UE. In this situation, the baseband equivalent BS-UE channel, denoted by , is characterized by the Rayleigh fading model, whose elements follow zero mean complex Gaussian distributions [35]. The baseband equivalent BS-RIS and RIS-UE channels, denoted respectively by and , are modelled as [16]
| (3) |
| (4) |
where represents the Rician factor; and are the non-LoS Rayleigh fading components [35]; and are the LoS components given by (5) and (6) on the top of the next page [36],
| (5) |
| (6) |
where is the signal wavelength; and , for , and , are expressed as
| (7) |
| (8) |
and are, respectively, the large-scale path loss coefficients from the -th BS antenna to the -th RIS element and from the -th RIS element to the UE, given by [16]
| (9) |
| (10) |
where is the reference distance; denotes the path loss at the reference distance of m; represents the path loss exponent; and are given by
Based on the above channel models, the signal received by the UE is modelled as
| (11) |
where is a binary variable representing the eventuality of the BS-UE channel, and in this paper, we consider the existence of with ; denotes the total transmit power; represents the transmit symbol which satisfies ; denotes the receiver noise; is the unit-norm transmit beamforming vector; is the phase-shift matrix of the RIS, given by , where and denote the amplitude and phase shift argument of the -th reflecting element, respectively. As the RIS is a near-passive reflecting apparatus, we assume that the reflection amplitudes satisfy [18] without loss of generality, where . The phase shift arguments belong to a set , where can be one of the following categories:
1) : the simplest and most universal argument set.
2) : a general argument set restricted within an arbitrary interval, where and are real values satisfying .
3) : a discrete argument set with phase shift levels, where [17].
II-B CSI Error Model
Considering that the locations of BS and RIS are stationary, the channel condition between BS and RIS hardly changes over time. Moreover, because the RIS is close to the BS and the mmWave channel has limited scattering, the LoS component in the BS-RIS channel is dominant whereas the non-LoS component is substantially weak, resulting in [37, 18]. Therefore, by assuming that the exact locations of each antenna on the BS and each reflecting element on the RIS are fixed and known after their deployments, can be perfectly obtained by (5), (7) and (9). The UE is considered within the coverage areas of the external localization systems, e.g. the GPS or UWB, which can provide the UE location for the RIS-aided communication system to acquire (reconstruct) based on (6), (8) and (10).111It is remarkable that the UE may occasionally appear in the blind zone of the existing localization systems, where the UE location is hardly available. Under this circumstance, conventional cascaded channel estimation techniques, which have been widely investigated in, e.g. [23, 24, 25], are responsible for CSI acquisition. The acquired RIS-UE channel, denoted by herein, contains an unavoidable error caused primarily by two factors:
•User location error: In view of the inherent hardware imperfection, limited precision of measurements or some other unfavorable aspects, the user location obtained, e.g. from GPS or UWB, denoted by , is generally inaccurate. By referring to [26], satisfies , where is the user location error, bounded by , where is a known small positive constant depending on the localization accuracy [26].
•Non-LoS component: The non-LoS Rayleigh fading component may not be neglected when the UE stands far away from the RIS. Although is random, its -norm within a certain communication duration can be determined by the existing channel norm feedback techniques based on pilot data sequence [38, 39] or on channel correlation matrix [40]. When the UE moves slowly, the -norm of can be regarded approximately as a fixed term in a short period, since the variation of channel condition between RIS and UE is slow. Thus, we can assume that is known and given by . Similarly, we can also assume that is known and given by for the same reason, although is stochastic and cannot be reconstructed by either. These values are conducive to facilitating the subsequent derivation of the CSI error bound and the beamforming optimization process.
Therefore, when is used to acquire (reconstruct) the LoS part of the RIS-UE channel, the overall CSI error between the actual and reconstructed channels can be expressed as
| (12) |
where denotes the LoS part of the RIS-UE channel acquired by , which can be calculated via
| (13) |
where is expressed as , and is computed by (10) using
From (12), it is observed that , representing the CSI error of the LoS component depending on , is given by
| (14) |
while , standing for the CSI error caused by the non-LoS component, is given by
| (15) |
II-C Problem Formulation
For the aforementioned system model, the worst-case robust beamforming optimization problem is formulated as
| (16a) | ||||
| (16b) | ||||
| (16c) | ||||
| (16d) | ||||
| (16e) | ||||
| (16f) | ||||
where the constant terms of and are omitted for conciseness, without changing the optimization results. Constraint (16b) comes from the unit-norm transmit beamforming vector. Constraint (16c) means that the overall CSI error is bounded in a spherical uncertainty region. Constraint (16d) comes from , which is fixed and known as illustrated in Section II-B. Constraint (16e) comes from the constant-modulus phase shifts of the RIS. Constraint (16f) represents the phase shift argument constraint.
III Derivation of the CSI Error Bound
This section is dedicated to the derivation of the overall CSI error bound in (16c) according to and . 222 The paper is dedicated to a single-user communication scenario. Potential extension of the derivation process in this section to a multi-user case is feasible, since the location information based CSI acquisition and the derivation of the CSI error bound can be performed independently for each single user. First, when retrospecting (12), we have (17) on the top of the next page,
| (17) |
where denotes the upper bound of , which is unknown and should be derived according to .
III-A Derivation of
Here we begin the derivation of from , which can be expanded into
| (18) |
where is a function of , expressed as (19) on the top of the next page,
| (19) |
with being detailed as
where is independent of ; derivation uses the property that for a fixed real-valued vector and a variable , can be well approximated by its first-order approximation of .
It is remarkable that when and are given, deriving is equivalent to deriving the maximum of under the constraint of , which however, is a challenging task, as appears in both the cosine function and the -norm. In view of this issue, we will further transform into a simpler form by means of approximation.
Nevertheless, the approximation of may lead to an inaccurate , implying that the theoretically derived will be either higher or lower than the practical . Both of the two outcomes will influence the optimal solution of problem (16) to some extent. Fortunately, if the theoretically derived is higher than the practical , the worst-case CSI experienced during the optimization process will become even worse than the practical worst-case CSI, hence resulting in a more robust solution for problem (16). Consequently, in order to preserve the robustness of the transmit and passive beamforming, we need to derive an approximate upper bound of the maximum of under . The result is provided in the following Lemma 1.
Lemma 1.
When , the approximate upper bound of the maximum of , denoted by , can be derived as
| (20) |
from the solution of the following convex problem:
| (21a) | ||||
| (21b) | ||||
where and are expressed as
| (22) |
| (23) |
in which , and are given by
| (24) |
| (25) |
| (26) |
Proof.
The proof is given in Appendix A. ∎
III-B Determination of
After deriving , based on (17), we consequently obtain
| (28) |
which completes the derivation of the CSI error bound.
IV Robust Transmit and Passive Beamforming
Since has been derived and the constraint of (16c) has been determined, we are now ready to solve problem (16), by proposing a robust beamforming optimization approach using the CSI acquired completely from the location information.
According to (16a) and (16b), the optimal transmit beamforming vector, denoted by , is readily formed by
| (29) |
Note that in (29), , and are currently all undetermined variables. Hence, in order to settle , the optimal as well as the worst-case and should be determined first. By substituting (29) into (16a) and (16b), problem (16) is recast as
| (30a) | ||||
| (30b) | ||||
| (30c) | ||||
| (30d) | ||||
| (30e) | ||||
which is a max-min problem with respect to , and . Note that in accordance with the triangle inequality, the objective function in (30a) satisfies
| (31) |
where the equality holds when
| (32) |
with representing the worst-case of (31). Then, the objective of problem (30) is equivalent to or . As a result, problem (30) is transformed into
| (33a) | ||||
| (33b) | ||||
| (33c) | ||||
| (33d) | ||||
which is now a max-min problem with respect to and .
To solve a max-min problem, existing methods such as S-procedure [41] or saddle point theory [42] based techniques, can be applied to eliminate the disturbance caused by the nondeterminacy of the CSI error, or to find the worst-case CSI from an equivalent min-max problem. However, in view of 1) the existence of the constant-modulus constraint in (33c) and the argument constraint in (33d), and 2) the difficulty in determining the closed-form optimal , using these conventional methods to solve problem (33) is a hard nut to crack. Therefore, in this section, we develop an iterative optimization approach to solve problem (33), and design the overall optimization algorithm.
IV-A Proposed Iterative Optimization Approach
This subsection focuses on finding the solution of problem (33), by firstly solving the inner minimization problem and then solving the outer maximization problem. In particular, unlike the existing iterative algorithms in e.g. [31] or [32] which provide approximate solutions of the subproblems in each iteration, here we propose a novel alternating optimization process through the instrumentality of Lagrange multiplier and matrix inverse lemma. In this process, the optimal solutions of the Lagrange dual variable in the inner minimization and the RIS phase shifts in the outer maximization are alternatively obtained, via the bisection search and the SDR/BnB, respectively. Results will finally demonstrate that the proposed approach can outperform the ones in [31] or [32], in terms of both the eventual optimization result and the overall convergence rate.
1) Solve the Inner Minimization Problem:
To solve problem (33), let us first consider the following inner minimization problem when treating as a fixed term:
| (34a) | ||||
| (34b) | ||||
Here, we can rewrite constraint (34b) as
| (35) |
so that problem (34) is a standard QCQP problem with respect to . To acquire the optimal solution of (e.g. the worst-case ), we construct the Lagrange function:
| (36) |
where is the Lagrange dual variable.
The optimal solutions of and should satisfy the Karush-Kuhn-Tucker (KKT) conditions, listed as
| (37a) | ||||
| (37b) | ||||
| (37c) | ||||
| (37d) | ||||
By calculating , we obtain
| (38) |
from which we derive the closed-form worst-case with respect to and , denoted by , as
| (39) |
According to (37d), the optimal solutions of and should either satisfy or . If , in (39) degenerates into , which makes the objective function in (34a) reduce to zero. In this case, the optimization process fails to find the optimal . Therefore, the optimization process is feasible only if and .
| (40) |
| (41) |
It is noted that if (40) is satisfied, (41) is the lower bound of for any , and the minimum objective value of the inner minimization problem is achieved. Therefore, based on (40) and (41), problem (33) is transformed into
| (42a) | ||||
| (42b) | ||||
| (42c) | ||||
| (42d) | ||||
2) Solve the Outer Maximization Problem (42):
Subsequently, we focus on solving problem (42). It is remarkable that problem (42) is a complicated non-convex problem containing the inverse of , which makes problem (42) difficult to be solved efficiently. To deal with , one feasible choice is to define a new variable as , and optimize and iteratively until the optimization process converges [47]. However, this choice has one major drawback, i.e. additional iterations are included in the optimization process, leading to an increase of the overall computational complexity. In view of this defect, we focus on pursuing another effective way to simplify the objective function and the constraints by adopting matrix inversion lemma in the following Proposition 1.
Proposition 1.
Proof.
The proof is given in Appendix B. ∎
Problem (43) is still non-convex and difficult to be solved directly, due to the coupling of and . In order to decouple the two variables and solve (43) efficiently, here we propose a relaxed alternating optimization process (RAOP) to optimize and iteratively. In specific, with a given , we find the optimal by solving the following problem:
| (44a) | ||||
| (44b) | ||||
which can be solved by the well-known bisection search [48]. After the solution of is obtained, we optimize by solving the following relaxed problem:
| (45a) | ||||
| (45b) | ||||
| (45c) | ||||
| (45d) | ||||
The above procedure repeats until some convergence criteria (e.g. the difference between the objective values of two adjacent iterations becomes smaller than a threshold) are met. In (45), the constraint of is relaxed into , in order to guarantee the convergence of the alternating optimization, by ensuring that the objective value of is monotonically increasing during the iteration process (For more details, please refer to the convergence analysis in Section IV-C). The relaxation will become tight when the alternating optimization converges, owing to the equality of (44b).
Problem (45) can be solved by various existing techniques. Here, we briefly introduce two state-of-the-art algorithms for solving problem (45), which are semidefinite relaxation (SDR) algorithm and branch-and-bound (BnB) algorithm. 333 Problem (45) is a non-convex constant-modulus and argument constrained QCQP problem, which is NP-hard in general. To solve such a problem, this paper introduces SDR since it has been validated to be a powerful, computationally efficient technique that can transform non-convex objectives/constraints into convex trace forms, and can provide accurate or sometimes near-optimal solutions [43]. It is noted that the SDR simply drops the argument constraint, so that it only performs well when . Therefore, this paper also introduces the recently developed BnB to handle other argument sets and solve problem (45) globally [45]. In specific, the BnB is slightly modified to deal with our problem.
1) SDR algorithm: When , problem (45) can be solved by the SDR algorithm, which has been widely utilized in wireless communication and signal processing fields to transform non-convex problems into semidefinite programming (SDP) problems. Considering problem (45) as an example, the main idea of the SDR is to introduce a new variable , and transform problem (45) by dropping the rank-one constraint into
| (46a) | ||||
| (46b) | ||||
| (46c) | ||||
where the matrix satisfies
| (47) |
Problem (46) can be solved by existing methods such as interior-point method. To address the omitted rank-one constraint after solving problem (46) and obtaining the solution of , denoted by , one can perform eigenvalue decomposition for to acquire the optimal if is rank-one [43], or use some convex relaxation techniques for phase-only beamforming, e.g., the SDP concave-convex procedure [44], to iteratively acquire an approximate rank-one solution if the SDR for problem (46) is not intrinsically guaranteed to be tight. Fortunately, it can be proved that the SDR for problem (46) is sometimes tight. For instance, regarding problem (46), here we theoretically derive two specific conditions making hold in the following Proposition 2:
Proposition 2.
holds if the conditions below are concurrently satisfied:
Condition 1: is rank-one, and each element in its eigenvector is non-zero.
Condition 2: The solution satisfies .
Proof.
The proof is given in Appendix C. ∎
Remark 1.
For Condition 1 in Proposition 2, according to (71) and (72), if , we obtain . Since the elements in are non-zero, the elements in the eigenvector of are non-zero as well according to (87) in Appendix D. Therefore, Condition 1 can hold when , i.e. is a far-field LoS channel [14]. For Condition 2 in Proposition 2, let and denote the solutions of in the -th iteration and the -th iteration, respectively (similar definitions are given for and ). If the iteration process is not terminated in the -th iteration, we have and according to the structures in (71) and (74). Moreover, because holds in accordance with problem (44), we obtain . Finally, because should be in the feasible region of (46b), we obtain . Therefore, Condition 2 can hold if the iteration process is not terminated.
Although can possibly hold in some cases, a non-zero gap between and the true optimal generally exists when . In addition, if is an arbitrary argument set of instead of , the SDR fails to solve problem (45). Forasmuch as these drawbacks of SDR, the BnB has been proposed, with the details stated below.
2) BnB algorithm: The BnB algorithm was proposed in [45, 46] to find the global optimal solution of complex quadratic programming problems, by branching on the argument sets. Compared with the SDR, the BnB has two major advantages. First, the BnB can deal with arbitrary argument sets of with , such as , , or discrete argument values, whereas the SDR is only able to handle . Second, the solution of BnB can be very close to the true optimum after sufficient times of iterations.
Since the BnB requires , when dealing with in which , we first divide into two subsets of and , where and 444For example, if , we divide into and , with , and .. For each subset, we construct a convex envelope, denoted by , where ; and satisfy and for subset , or satisfy and for subset . For more visual details, one can refer to [Fig. 1, 45] which depicts the convex envelope. Then, based on , we reformulate problem (45) as
| (48a) | ||||
| (48b) | ||||
| (48c) | ||||
| (48d) | ||||
which is convex. Afterwards, considering problem (48), we adopt [Algorithm 1, 45] to find the optimal solutions for the two subsets of and separately, which are represented by and . The main idea of [Algorithm 1, 45] is to continuously execute the following procedure:
1) Cut or into smaller sets and solve problem (48).
2) Use the rounding operation to acquire a projection of the solution of on the feasible domain of .
The procedure stops when the gap between the objective values with respect to the projection and the solution of problem (48) is smaller than a predetermined error tolerance . After obtaining and , we substitute them into (45a) to calculate the objective values. Then, from and , we choose the one corresponding to the higher objective value as the final solution. The flowchart of the modified BnB in our algorithm is described in Fig. 2, which shows the above process.
Moreover, when dealing with the discrete phase shift argument sets, the BnB algorithm in [45] can be readily adopted by constructing a polyhedral convex hull. One can refer to [45] for more details.

Based on the analysis in this subsection, the overall robust beamforming optimization algorithm is designed as follows.
IV-B Overall Algorithm Design
Our robust beamforming optimization algorithm is designed as Algorithm 1, which can be summarized as 4 steps.
-
•
Step 1: Input parameters: the parameters including locations, number of antennas and reflecting elements, etc., are input to the algorithm.
-
•
Step 2: Compute CSI error bound: the CSI error bound is calculated using (28).
-
•
Step 3: Robust beamforming optimization: first, the phase-shift matrix, total iteration times, iteration index, terminating condition and objective value are initialized. Then, problem (44) and problem (45) are iteratively solved by bisection method and SDR/BnB to optimize and , until the optimization procedure converges.
-
•
Step 4: Output solutions: the optimal Lagrange dual variable, worst-case CSI error, worst-case BS-UE channel, and optimal transmit and passive beamforming are obtained and output.
IV-C Convergence Analysis
Since Algorithm 1 includes an iteration procedure, it is necessary to investigate its convergence behaviour. To facilitate the analysis, we first prove the following property:
Proposition 3.
With a given , if grows, the value of increases, whereas the value of decreases.
Proof.
The proof is given in Appendix D. ∎
Based on Proposition 3, we are now ready to prove the convergence of Algorithm 1.
Proposition 4.
The proposed Algorithm 1 is convergent.
Proof.
Let () and () be the solutions of and in the -th (-th) iteration, respectively. To prove the algorithm convergence, we need to prove that
| (49) |
strictly holds for .
First, when is given, we can readily obtain
| (50) |
owing to the maximization of the objective function in problem (45). Afterwards, when is given, we need to compare and .
Since is the solution of problem (45) with a given , according to (45b), we have
| (51) |
Subsequently, by solving problem (44), we obtain with a given , such that
| (52) |
Thus, based on (51) and (52), we have
| (53) |
Combining (53) with Proposition 3, we obtain , resulting in . Consequently, we obtain
| (54) |
implying that the solution of Algorithm 1 in the -th iteration is better than that in the -th iteration. In addition, the objective value of is upper-bounded owing to the constraint of for . Therefore, we prove that Algorithm 1 is convergent. ∎
IV-D Computational Complexity Analysis
Here we analyse the approximate computational complexity of Algorithm 1 through the comparisons with the following benchmarks:
-
1)
Benchmark 1 (B1): the non-robust approach in [26], which directly uses the estimated CSI depending on angle-of-departure/arrival (AOD/AOA) to design the beams, without considering the CSI errors.
- 2)
| Algorithms | Approximate complexities per iteration | Overall complexities |
|---|---|---|
| Proposed algorithm with SDR | ||
| Proposed algorithm with BnB | ||
| Robust beamforming in [31] or [32] (B2) | ||
| Non-robust beamforming in [26] (B1) |
Table I lists the approximate computational complexities of our algorithm and B1, B2, where
-
1)
is the complexity of the bisection search, which is used to find the optimal from (40), where denotes the length of the search interval.
- 2)
-
3)
is the complexity of BnB, which is used to solve problem (43), where is specified in [Lemma 4, 45].
-
4)
and are the complexities of the transmit beamforming optimization and passive beamforming optimization of B2.
-
5)
and stand for the total iteration times required for the convergence of Algorithm 1 and B2.
Table I indicates that: 1) B1 requires only one time of SDR optimization. It is the simplest approach but may suffer from serious performance degradation in the presence of CSI errors. 2) In each iteration, B2 is more computationally complex than the proposed algorithm with SDR, whereas their overall complexities depend on the total iteration times for convergence, which will be numerically investigated in Section V-C. 3) Although the proposed algorithm with BnB is also computationally complicated in one iteration, it has the advantages of providing near-optimal solutions and dealing with arbitrary phase shift argument sets. These advantages will be justified in Section V-C as well.
V Simulation Results
In this section, the system parameters are configured and the performance metric is defined. Then, the CSI error bound, derived in Section III, is numerically investigated. Finally, the performance of Algorithm 1 is evaluated and compared with those of B1 and B2, in terms of the worst-case SNR at the UE and the algorithm efficiency.
V-A System Parameters and Performance Metric
V-A1 System Parameters
In the simulations, the system parameters are set as follows. , and are set as , and in meters. The antenna/element spacing is cm. The number of transmit antennas is . The total transmit power is dBm. The noise power at the receiver side is dBm. The carrier frequency is GHz. The speed of light is m/s. The signal wavelength is calculated by . The reflection amplitude is . For the large-scale path loss, we set dB, m, and [35, 37]. The Rician factor is . The -norm of and are set as and , respectively. When performing Algorithm 1, we set , and configure the error tolerance of BnB and the maximum of total iteration times of BnB to be and , respectively. In addition, the user location error bound and the number of reflecting elements (or ) will vary for diverse observations.
V-A2 Performance Metric
For evaluating the performance of the proposed algorithm, the worst-case SNR at the UE with respect to the optimized transmit and passive beamforming is considered as a performance metric:
| (55) |
which is a function of and , where is the worst-case channel from RIS to UE. In the simulation results, is presented as original ratio value instead of decibel (dB).
V-B CSI Error Bound
Based on the system setup, we first numerically verify the theoretical derivation of the CSI error bound in Section III. Specifically, we compare the following two results to examine the tightness of the CSI error bound:
1) , which is theoretically derived from (28).
2) The actual CSI error bound, which is obtained by finding the maximum of from computations of , where each computation corresponds to one channel realization of with a random in the spherical uncertainty region of .

Fig. 3 depicts the CSI error bounds with respect to and . It indicates that first, the overall theoretical results fit well with the actual ones, implying that the derivation of the CSI error bound is correct. Second, the CSI error bounds increase as or grows, illustrating that more reflecting elements or higher level of user location uncertainty will lead to graver CSI error. Third, the red dashed curves are always below the blue solid curves, manifesting that the theoretical results are upper bounds of the corresponding actual results, which become tight when the level of the user location uncertainty is moderate.



Fig. 4 displays the CSI error bounds with respect to user coordinates, with m and different . It demonstrates that when the distance between the RIS and the UE increases while the user location error bound is fixed, the theoretical CSI error bounds descend and become tighter.
V-C Algorithm Performance Evaluation
Subsequently, we investigate the performance of the proposed algorithm through the comparisons with B1 and B2, in terms of both the worst-case SNR and the algorithm efficiency. As B1 and B2 can only apply to the phase shift argument set of , here we first compare the performances under the condition of , and then justify the advantages of our algorithm with BnB in the cases of other .
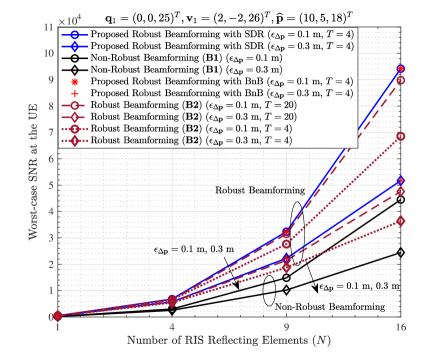

Fig. 5 and Fig. 6 show the worst-case SNRs at the UE with respect to and when . Results reveal that: 1) the worst-case SNRs at the UE are strongly influenced by the number of the RIS reflecting elements and the level of the CSI uncertainty. 2) The proposed approach significantly outperforms the non-robust approach, i.e. B1, thus validating the robustness of our algorithm. 3) The proposed algorithm is superior to B2 in terms of the worst-case SNR performance, when the number of the iterations is small ( in specific, as shown in the figures). However, it can also be seen that if is large enough, the worst-case SNRs of B2 are close to those of the proposed algorithm. Thereupon, we will evaluate the performance from the perspective of the convergence rate as well, in order to show a more comprehensive comparison.

Fig. 7 depicts the convergence behaviour of the proposed algorithm at . In Fig. 7, each simulation curve is obtained by averaging on five Monte Carlo trials with randomly initialized RIS phase shifts. It is demonstrated that the proposed algorithm with SDR/BnB is convergent, verifying the theoretical analysis in Proposition 3 and 4. Furthermore, it also indicates that the proposed algorithm can possibly converge to the optimum after around 4 iterations. This could be a potential key advantage facilitating the practical application of the proposed design.

Fig. 8 compares the convergence rates of the proposed algorithm and B2 when , showing that the proposed algorithm converges after around iterations, while B2 converges after around iterations. This demonstrates that our algorithm can outperform B2 in terms of the convergence rate, illustrating meanwhile that our proposed design would be more advantageous in terms of the algorithm efficiency.

Finally, in order to justify that the proposed algorithm with BnB possesses the advantage of handling arbitrary phase shift argument sets, we take as an example, and investigate the performances of B2 and the proposed algorithm with BnB in the cases of and . Since the solutions of B2 intrinsically belong to , we perform the rounding operations for to map the arguments into and after running B2. Specifically, under the argument constraint of , we perform
| (56) |
and under the argument constraint of , we perform
| (57) |
Fig. 9 depicts the worst-case SNRs at the UE with the two phase shift argument sets, demonstrating that when , the BnB can still maintain good SNR performance, whereas B2 performs worse as B2 only applies to the phase shift argument constraint of .
VI Conclusions and Prospects
In this paper, when adopting the user location to acquire the CSI in the RIS-aided wireless communication system, we theoretically derived an approximate CSI error bound in the presence of user location uncertainty, with the aid of Taylor approximation, triangle and power mean inequalities, and SDR method. Then, in order to resist the impact of location error on the beamforming design, we formulated a worst-case robust beamforming optimization problem to jointly optimize the transmit and passive beamforming. To solve this non-convex problem efficiently, we proposed an iterative optimization approach based on Lagrange multiplier and matrix inverse lemma, and evaluated its performance in terms of the worst-case SNR at the UE, convergence behaviour, and algorithm efficiency. Results verified the theoretical derivation of the CSI error bound, and validated the robustness of the proposed approach. Compared with the existing S-procedure and penalty CCP based robust beamforming techniques, our algorithm could perform better and converge more quickly to the optimum. Consequently, the proposed design in this work would be promising in contributing to the development of location information assisted RIS-aided communications.
Finally, a brief discussion on the potential applicability and extensibility of the proposed beamforming design is presented, from the following two aspects:
1) UE mobility: If the UE is moving, the system performance could be maintained only when the actual UE location is still within the uncertainty region of before the transmit/passive beamforming is updated. Nevertheless, the high-speed mobility of the UE may generally not be neglected in several cases, e.g. when the UE is inside a moving vehicle on the high-way. If the UE location changes significantly within a short period, the location information assisted beamforming optimization may provide a hysteretic result, which degrades the current system performance to some extent. Hence, it is worth developing a high-efficiency and low-latency approach to combat the potential negative effect caused by the high-speed UE movement in the future. 2) RIS calibration: This work considers the constant-modulus reflection model, implying that the inherent element responses of the RIS reflectors are approximately invariant and same toward arbitrary incident/reflective directions, which however, may not exactly be the case in practice. As such, the mismatch between the reconstructed and the actual RIS-UE channels may generally be non-negligible, on account of the differences of the RIS element responses toward distinct UE locations. To compensate for such a mismatch, developing an efficient RIS calibration procedure deserves further effort.
Appendix A Proof of Lemma 1
In Appendix A, we prove the results in Lemma 1. Since the cosine term in (19) is the dominant factor that makes the derivation for the maximum of become challenging, we first apply the fourth-order Taylor expansion of at to approximate , and obtain
| (58) |
Substituting (58) into (19), after some manipulations, we have
| (59) |
where and are expressed as (60) and (61) on the top of the next page.
| (60) |
| (61) |
Note that because , we have , yielding . Therefore, by utilizing the triangle inequality of , we have because is positive, and obtain an upper bound of , denoted by , as
| (62) |
where is specified in (63) on the top of the next page, which is an upper bound of .
| (63) |
Subsequently, as it is still difficult to derive the maximum of under the constraint of , we focus on finding an approximation of . As the value of is generally around 2 in the sparse geometry channel model [37], the second-order Taylor approximation for can be sufficiently accurate. Therefore, by using the second-order Taylor expansion:
at to approximate , and after a few manipulations, we have
| (64) |
where is given by (23) in Lemma 1, while is expressed as (65) on the top of the next page.
| (65) |
In (65), because a quadratic function with respect to appears as its square form inside the summation operator in , we use the power mean inequality, i.e. for to derive an upper bound of , denoted by , and obtain (66) on the top of the next page,
| (66) |
where is detailed in (22) in Lemma 1. Thus, is upper bounded by
| (67) |
Consequently, we have , indicating that is an approximate upper bound of . In order to acquire the maximum of under the constraint of , we can formulate the following maximization problem:
| (68a) | ||||
| (68b) | ||||
By defining and using SDR, problem (68) can be further transformed by dropping the rank-one constraint into problem (21) in Lemma 1. Problem (21) is convex, because: 1) the is linear, while the is concave, making the objective function in (21a) concave with respect to ; 2) the constraint (21b) is convex. Hence, it can be solved by CVX, after which the maximum of under can be derived. Because is an approximate upper bound of , the maximum of is also an approximate upper bound of the maximum of , which completes the proof.
Appendix B Proof of Proposition 1
In Appendix B, we prove that problem (42) can be transformed into problem (43). Here, the existence of is the primary factor that makes problem (42) tough to compute. Fortunately, as is invertible, can be further expanded with the aided of the matrix inversion lemma. Although the matrix inversion lemma generally leads to an expansion in a more complicated form, it is remarkable that in problem (42), we have , which can potentially make the expansion become rather simple.
According to the matrix inversion lemma, we have
if is invertible. Hence, let , and . Then, we obtain (69) on the top of the next page.
| (69) |
Eq. (69) indicates that can be expanded into an expression, in which is not included in the inverse operator. Subsequently, using (69), we further simplify and in problem (42). First, we simplify . By substituting (69) into (41), we obtain (70) on the top of the next page,
| (70) |
where the derivation (A1) uses the properties of and , and is expressed as
| (71) |
with given by
| (72) |
Then, we simplify . Substituting (69) into (40), we obtain (73) on the top of the next page,
| (73) |
where is expressed as
| (74) |
with given by
| (75) |
Appendix C Proof of Proposition 2
Here, we prove that we can obtain under the conditions of: 1) is rank-one, and each element in its eigenvector is non-zero; 2) satisfies .
First, the Lagrange function of problem (46) is
| (76) |
where , to , and are the Lagrange multipliers of the constraint (46b), constraint (46c), and constraint , respectively.
Then, based on the KKT conditions, the optimal solution should simultaneously satisfy
| (77) |
| (78) |
| (79) |
According to (77), we have
| (80) |
If , we obtain according to the complementary slacking constraint (79). Then, we can simplify (80) into
| (81) |
Note that because and , there should be , hinting that for . Then, we use to transform (81) into
| (82) |
yielding
| (83) |
If and each element in the eigenvector of is non-zero, we can decompose into , where is the eigenvalue of , and is the corresponding eigenvector with for . Therefore, (83) can be recast as
| (84) |
From (84), one can prove that is a full-rank diagonal matrix. This is because that if is not full-rank, there will be at least one such that has at least one row of zeros. Then, will have at least one row of zeros as well. However, since cannot be an all-zero vector, there should exist at least one generating a row of zeros in , which contradicts the prerequisite of for . Therefore, should be full-rank.
Finally, according to the manipulation rules of rank, we have
Since must hold, we have , which completes the proof of Proposition 2.
Appendix D Proof of Proposition 3
We begin this proof by calculating the derivatives of and with respect to , i.e. calculating
| (85) |
| (86) |
To derive , we first perform eigenvalue decomposition for and obtain , where is a unitary matrix and is the diagonal eigenvalue matrix. satisfies since is positive semidefinite.
Then, based on (71), (72), and after a few manipulations, can be recast as
| (87) |
where with respect to is given by
| (88) |
It is indicated in (88) that is a diagonal matrix, whose -th diagonal element is given by
| (89) |
We calculate the derivative of each with respect to , and obtain
Because and , we have , resulting in . This implies that
As a result, we obtain that
| (90) |
strictly holds for .
References
- [1] M. Agiwal, A. Roy and N. Saxena, ”Next generation 5G wireless networks: A comprehensive survey,” IEEE Communications Surveys & Tutorials, vol. 18, no. 3, pp. 1617-1655, Third Quarter 2016.
- [2] C. Liaskos, et al., ”A new wireless communication paradigm through software-controlled metasurfaces,” IEEE Communications Magazine, vol. 56, no. 9, pp. 162-169, Sept. 2018.
- [3] S. Hu, F. Rusek and O. Edfors, ”Beyond massive MIMO: The potential of data transmission with large intelligent surfaces,” IEEE Transactions on Signal Processing, vol. 66, no. 10, pp. 2746-2758, May. 2018.
- [4] M. D. Renzo, et al., ”Smart radio environments empowered by reconfigurable intelligent surfaces: How it works, state of research, and the road ahead,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 11, pp. 2450-2525, Nov. 2020.
- [5] S. Gong, et al., ”Toward smart wireless communications via intelligent reflecting surfaces: A contemporary survey,” IEEE Communications Surveys & Tutorials, vol. 22, no. 4, pp. 2283-2314, Fourth Quarter 2020.
- [6] Q. Wu and R. Zhang, ”Towards smart and reconfigurable environment: Intelligent reflecting surface aided wireless network,” IEEE Communications Magazine, vol. 58, no. 1, pp. 106-112, Jan. 2020.
- [7] C. Huang, et al., ”Holographic MIMO surfaces for 6G wireless networks: Opportunities, challenges, and trends,” IEEE Wireless Communications, vol. 27, no. 5, pp. 118-125, Oct. 2020.
- [8] J. Y. Lau and S. V. Hum, ”Reconfigurable transmitarray design approaches for beamforming applications,” IEEE Transactions on Antennas and Propagation, vol. 60, no. 12, pp. 5679-5689, Dec. 2012.
- [9] L. Dai, et al., ”Reconfigurable intelligent surface-based wireless communications: Antenna design, prototyping, and experimental results,” IEEE Access, vol. 8, pp. 45913-45923, Mar. 2020.
- [10] N. Rajatheva, et al., ”White paper on broadband connectivity in 6G,” 6G Research Visions, no. 10, University of Oulu, Jun. 2020.
- [11] E. Björnson, Ö. Özdogan, and E. G. Larsson, ”Intelligent reflecting surface versus decode-and-forward: How large surfaces are needed to beat relaying?” IEEE Wireless Communications Letters, vol. 9, no. 2, pp. 244-248, Feb. 2020.
- [12] M. Cui, G. Zhang and R. Zhang, ”Secure wireless communication via intelligent reflecting surface,” IEEE Wireless Communications Letters, vol. 8, no. 5, pp. 1410-1414, Oct. 2019.
- [13] C. Guo, Y. Cui, F. Yang and L. Ding, ”Outage probability analysis and minimization in intelligent reflecting surface-assisted MISO systems,” IEEE Communications Letters, vol. 24, no. 7, pp. 1563-1567, Jul. 2020.
- [14] Z. Xing, R. Wang, X. Yuan and J. Wu, ”Location-aware beamforming design for reconfigurable intelligent surface aided communication system,” in Proc. IEEE/CIC International Conference on Communications in China, Xiamen, China, Jul. 2021, pp. 1-6.
- [15] C. Huang, et al., ”Reconfigurable intelligent surfaces for energy efficiency in wireless communication,” IEEE Transactions on Wireless Communications, vol. 18, no. 8, pp. 4157-4170, Aug. 2019.
- [16] Q. Wu and R. Zhang, ”Intelligent reflecting surface enhanced wireless network via joint active and passive beamforming,” IEEE Transactions on Wireless Communications, vol. 18, no. 11, pp. 5394-5409, Nov. 2019.
- [17] Q. Wu and R. Zhang, ”Beamforming optimization for wireless network aided by intelligent reflecting surface with discrete phase shifts,” IEEE Transactions on Communications, vol. 68, no. 3, pp. 1838-1851, Mar. 2020.
- [18] Z. Xing, R. Wang, J. Wu and E. Liu, ”Achievable rate analysis and phase shift optimization on intelligent reflecting surface with hardware impairments,” IEEE Transactions on Wireless Communications, Mar. 2021, DOI: 10.1109/TWC.2021.3068225.
- [19] C. Huang, A. Zappone, M. Debbah and C. Yuen, ”Achievable rate maximization by passive intelligent mirrors,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, Apr. 2018, pp. 3714-3718.
- [20] X. Hu, et al., ”Programmable metasurface-based multicast systems: Design and analysis,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 8, pp. 1763-1776, Aug. 2020.
- [21] S. Hu, F. Rusek and O. Edfors, ”Beyond massive MIMO: The potential of positioning with large intelligent surfaces,” IEEE Transactions on Signal Processing, vol. 66, no. 7, pp. 1761-1774, Apr. 2018.
- [22] J. He, et al., ”Large intelligent surface for positioning in millimeter wave MIMO systems,” in Proc. IEEE 91st Vehicular Technology Conference, Antwerp, Belgium, May 2020, pp. 1-5.
- [23] B. Zheng and R. Zhang, ”Intelligent reflecting surface-enhanced OFDM: Channel estimation and reflection optimization,” IEEE Wireless Communications Letters, vol. 9, no. 4, pp. 518-522, Apr. 2020.
- [24] L. Wei, et al., ”Channel estimation for RIS-empowered multi-user MISO wireless communications,” IEEE Transactions on Communications, Mar. 2021, DOI: 10.1109/TCOMM.2021.3063236.
- [25] Z.-Q. He and X. Yuan, ”Cascaded channel estimation for large intelligent metasurface assisted massive MIMO,” IEEE Wireless Communications Letters, vol. 9, no. 2, pp. 210-214, Feb. 2020.
- [26] X. Hu, C. Zhong, Y. Zhang, X. Chen and Z. Zhang, ”Location information aided multiple intelligent reflecting surface systems,” IEEE Transactions on Communications, vol. 68, no. 12, pp. 7948-7962, Dec. 2020.
- [27] A. Elzanaty, A. Guerra, F. Guidi and M.-S. Alouini, ”Reconfigurable intelligent surfaces for localization: Position and orientation error bounds,” IEEE Transactions on Signal Processing, vol. 69, pp. 5386-5402, Oct. 2021.
- [28] H. Wymeersch, J. He, B. Denis, A. Clemente and M. Juntti, ”Radio localization and mapping with reconfigurable intelligent surfaces: Challenges, opportunities, and research directions,” IEEE Vehicular Technology Magazine, vol. 15, no. 4, pp. 52-61, Dec. 2020.
- [29] C. L. Nguyen, O. Georgiou and G. Gradoni, ”Reconfigurable intelligent surfaces and machine learning for wireless fingerprinting localization,” arXiv preprint, arXiv:2010.03251, Oct. 2020.
- [30] A. Fascista, A. Coluccia, H. Wymeersch and G. S.-Granados, ”RIS-aided joint localization and synchronization with a single-antenna mmWave receiver,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, Jun. 2021, pp. 4455-4459.
- [31] G. Zhou, C. Pan, H. Ren, K. Wang and A. Nallanathan, ”A framework of robust transmission design for IRS-aided MISO communications with imperfect cascaded channels,” IEEE Transactions on Signal Processing, vol. 68, pp. 5092-5106, Aug. 2020.
- [32] G. Zhou, et al., ”Robust beamforming design for intelligent reflecting surface aided MISO communication systems,” IEEE Wireless Communications Letters, vol. 9, no. 10, pp. 1658-1662, Oct. 2020.
- [33] J. Zhang, Y. Zhang, C. Zhong and Z. Zhang, ”Robust design for intelligent reflecting surfaces assisted MISO systems,” IEEE Communications Letters, vol. 24, no. 10, pp. 2353-2357, Oct. 2020.
- [34] M. Zhao, A. Liu and R. Zhang, ”Outage-constrained robust beamforming for intelligent reflecting surface aided wireless communication,” IEEE Transactions on Signal Processing, vol. 69, pp. 1301-1316, Feb. 2021.
- [35] C. Pan, et al., ”Intelligent reflecting surface aided MIMO broadcasting for simultaneous wireless information and power transfer,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 8, pp. 1719-1734, Aug. 2020.
- [36] Z. A. Shaban, et al., ”Near-field localization with a reconfigurable intelligent surface acting as lens,” arXiv:2010.05617v1, Oct. 2020.
- [37] K. Zhi, C. Pan, H. Ren and K. Wang, ”Uplink achievable rate of intelligent reflecting surface-aided millimeter-wave communications with low-resolution ADC and phase noise,” IEEE Wireless Communications Letters, vol. 10, no. 3, pp. 654-658, Mar. 2021.
- [38] D. Hammarwall, M. Bengtsson and B. Ottersten, ”Acquiring partial CSI for spatially selective transmission by instantaneous channel norm feedback,” IEEE Transactions on Signal Processing, vol. 56, no. 3, pp. 1188-1204, Mar. 2008.
- [39] E. Björnson and B. Ottersten, ”Exploiting long-term statistics in spatially correlated multi-user MIMO systems with quantized channel norm feedback,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, Apr. 2008, pp. 3117-3120.
- [40] E. Björnson, D. Hammarwall and B. Ottersten, ”Exploiting quantized channel norm feedback through conditional statistics in arbitrarily correlated MIMO systems,” IEEE Transactions on Signal Processing, vol. 57, no. 10, pp. 4027-4041, Oct. 2009.
- [41] J. Wang and D. P. Palomar, ”Worst-case robust MIMO transmission with imperfect channel knowledge,” IEEE Transactions on Signal Processing, vol. 57, no. 8, pp. 3086-3100, Aug. 2009.
- [42] H. Shen, W. Xu, J. Wang and C. Zhao, ”A worst-case robust beamforming design for multi-antenna AF relaying,” IEEE Communications Letters, vol. 17, no. 4, pp. 713-716, Apr. 2013.
- [43] Z.-Q. Luo, et al., ”Semidefinite relaxation of quadratic optimization problems,” IEEE Signal Processing Magazine, vol. 27, no. 3, pp. 20-34, May. 2010.
- [44] M. Á. Vázquez, L. Blanco and A. I. Pérez-Neira, ”Spectrum sharing backhaul satellite-terrestrial systems via analog beamforming,” IEEE Journal of Selected Topics in Signal Processing, vol. 12, no. 2, pp. 270-281, May 2018.
- [45] C. Lu, Z. Deng, W.-Q. Zhang and S.-C. Fang, ”Argument division based branch-and-bound algorithm for unit-modulus constrained complex quadratic programming,” Journal of Global Optimization, vol. 70, pp. 171-187, Aug. 2017.
- [46] C. Lu and Y.-F. Liu, ”An efficient global algorithm for single-group multicast beamforming,” IEEE Transactions on Signal Processing, vol. 65, no. 14, pp. 3761-3774, Jul. 2017.
- [47] R. Wang, M. Tao and Y. Huang, ”Linear precoding designs for amplify-and-forward multiuser two-way relay systems,” IEEE Transactions on Wireless Communications, vol. 11, no. 12, pp. 4457-4469, Dec. 2012.
- [48] A. Kaw, J. Paul and M. Keteltas, ”Bisection method of solving a nonlinear equation,” [Online]. Available: https://resources.saylor.org/ wwwresources/archived/site/wp-content/uploads/2011/11/ME205-3.1-TEXT.pdf, pp. 1-12, Nov. 2011.