Locally Differentially Private Analysis of Graph Statistics
Abstract
Differentially private analysis of graphs is widely used for releasing statistics from sensitive graphs while still preserving user privacy. Most existing algorithms however are in a centralized privacy model, where a trusted data curator holds the entire graph. As this model raises a number of privacy and security issues – such as, the trustworthiness of the curator and the possibility of data breaches, it is desirable to consider algorithms in a more decentralized local model where no server holds the entire graph.
In this work, we consider a local model, and present algorithms for counting subgraphs – a fundamental task for analyzing the connection patterns in a graph – with LDP (Local Differential Privacy). For triangle counts, we present algorithms that use one and two rounds of interaction, and show that an additional round can significantly improve the utility. For -star counts, we present an algorithm that achieves an order optimal estimation error in the non-interactive local model. We provide new lower-bounds on the estimation error for general graph statistics including triangle counts and -star counts. Finally, we perform extensive experiments on two real datasets, and show that it is indeed possible to accurately estimate subgraph counts in the local differential privacy model.
1 Introduction
Analysis of network statistics is a useful tool for finding meaningful patterns in graph data, such as social, e-mail, citation and epidemiological networks. For example, the average degree (i.e., number of edges connected to a node) in a social graph can reveal the average connectivity. Subgraph counts (e.g., the number of triangles, stars, or cliques) can be used to measure centrality properties such as the clustering coefficient, which represents the probability that two friends of an individual will also be friends of one another [41]. However, the vast majority of graph analytics is carried out on sensitive data, which could be leaked through the results of graph analysis. Thus, there is a need to develop solutions that can analyze these graph properties while still preserving the privacy of individuals in the network.
The standard way to analyze graphs with privacy is through differentially private graph analysis [49, 23, 22]. Differential privacy provides individual privacy against adversaries with arbitrary background knowledge, and has currently emerged as the gold standard for private analytics. However, a vast majority of differentially private graph analysis algorithms are in the centralized (or global) model [13, 15, 16, 27, 33, 35, 42, 48, 49, 52, 59, 58], where a single trusted data curator holds the entire graph and releases sanitized versions of the statistics. By assuming a trusted party that can access the entire graph, it is possible to release accurate graph statistics (e.g., subgraph counts [33, 35, 52], degree distribution [16, 27, 48], spectra [59]) and synthetic graphs [15, 58].
In many applications however, a single trusted curator may not be practicable due to security or logistical reasons. A centralized data holder is amenable to security issues such as data breaches and leaks – a growing threat in recent years [38, 51]. Additionally, decentralized social networks [43, 50] (e.g., Diaspora [5]) have no central server that contains an entire social graph, and use instead many servers all over the world, each containing the data of users who have chosen to register there. Finally, a centralized solution is also not applicable to fully decentralized applications, where the server does not automatically hold information connecting users. An example of this is a mobile application that asks each user how many of her friends she has seen today, and sends noisy counts to a central server. In this application, the server does not hold any individual edge, but can still aggregate the responses to determine the average mobility in an area.
The standard privacy solution that does not assume a trusted third party is LDP (Local Differential Privacy) [20, 34]. This is a special case of DP (Differential Privacy) in the local model, where each user obfuscates her personal data by herself and sends the obfuscated data to a (possibly malicious) data collector. Since the data collector does not hold the original personal data, it does not suffer from data leakage issues. Therefore, LDP has recently attracted attention from both academia [8, 11, 10, 24, 31, 32, 39, 45, 57, 62] as well as industry [56, 17, 55]. However, the use of LDP has mostly been in the context of tabular data where each row corresponds to an individual, and little attention has been paid to LDP for more complex data such as graphs (see Section 2 for details).

In this paper, we consider LDP for graph data, and provide algorithms and theoretical performance guarantees for calculating graph statistics in this model. In particular, we focus on counting triangles and -stars – the most basic and useful subgraphs. A triangle is a set of three nodes with three edges (we exclude automorphisms; i.e., #closed triplets #triangles). A -star consists of a central node connected to other nodes. Figure 1 shows an example of triangles and -stars. Counting them is a fundamental task of analyzing the connection patterns in a graph, as the clustering coefficient can be calculated from triangle and -star counts as: (in Figure 1, ).
When we look to protect privacy of relationship information modeled by edges in a graph, we need to pay attention to the fact that some relationship information could be leaked from subgraph counts. For example, suppose that user (node) in Figure 1 knows all edges connected to and all edges between as background knowledge, and that wants to know who are friends with . Then “#2-stars = 20” reveals the fact that has three friends, and “#triangles = 5” reveals the fact that the three friends of are , , and . Moreover, a central server that holds all friendship information (i.e., all edges) may face data breaches, as explained above. Therefore, a private algorithm for counting subgraphs in the local model is highly beneficial to individual privacy.
The main challenge in counting subgraphs in the local model is that existing techniques and their analysis do not directly apply. The existing work on LDP for tabular data assumes that each person’s data is independently and identically drawn from an underlying distribution. In graphs, this is no longer the case; e.g., each triangle is not independent, because multiple triangles can involve the same edge; each -star is not independent for the same reason. Moreover, complex inter-dependencies involving multiple people are possible in graphs. For example, each user cannot count triangles involving herself, because she cannot see edges between other users; e.g., user cannot see an edge between and in Figure 1.
We show that although these complex dependency among users introduces challenges, it also presents opportunities. Specifically, this kind of interdependency also implies that extra interaction between users and a data collector may be helpful depending on the prior responses. In this work, we investigate this issue and provide algorithms for accurately calculating subgraph counts under LDP.
Our contributions. In this paper, we provide algorithms and corresponding performance guarantees for counting triangles and -stars in graphs under edge Local Differential Privacy. Specifically, our contributions are as follows:
-
•
For triangles, we present two algorithms. The first is based on Warner’s RR (Randomized Response) [60] and empirical estimation [31, 39, 57]. We then present a more sophisticated algorithm that uses an additional round of interaction between users and data collector. We provide upper-bounds on the estimation error for each algorithm, and show that the latter can significantly reduce the estimation error.
-
•
For -stars, we present a simple algorithm using the Laplacian mechanism. We analyze the upper-bound on the estimation error for this algorithm, and show that it is order optimal in terms of the number of users among all LDP mechanisms that do not use additional interaction.
-
•
We provide lower-bounds on the estimation error for general graph functions including triangle counts and -star counts in the local model. These are stronger than known upper bounds in the centralized model, and illustrate the limitations of the local model over the central.
-
•
Finally, we evaluate our algorithms on two real datasets, and show that it is indeed possible to accurately estimate subgraph counts in the local model. In particular, we show that the interactive algorithm for triangle counts and the Laplacian algorithm for the -stars provide small estimation errors when the number of users is large.
We implemented our algorithms with C/C++, and published them as open-source software [1].
2 Related Work
Graph DP. DP on graphs has been widely studied, with most prior work being in the centralized model [13, 15, 16, 27, 33, 35, 42, 48, 49, 52, 59, 58]. In this model, a number of algorithms have been proposed for releasing subgraph counts [33, 35, 52], degree distributions [16, 27, 48], eigenvalues and eigenvectors [59], and synthetic graphs [15, 58].
There has also been a handful of work on graph algorithms in the local DP model [46, 53, 63, 64, 65]. For example, Qin et al. [46] propose an algorithm for generating synthetic graphs. Zhang et al. [65] propose an algorithm for software usage analysis under LDP, where a node represents a software component (e.g., function in a code) and an edge represents a control-flow between components. Neither of these works focus on subgraph counts.
Sun et al. [53] propose an algorithm for counting subgraphs in the local model under the assumption that each user allows her friends to see all her connections. However, this assumption does not hold in many practical scenarios; e.g., a Facebook user can change her setting so that friends cannot see her connections. Therefore, we assume that each user knows only her friends rather than all of her friends’ friends. The algorithms in [53] cannot be applied to this setting.
Ye et al. [63] propose a one-round algorithm for estimating graph metrics including the clustering coefficient. Here they apply Warner’s RR (Randomized Response) to an adjacency matrix. However, it introduces a very large bias for triangle counts. In [64], they propose a method for reducing the bias in the estimate of triangle counts. However, the method in [64] introduces some approximation, and it is unclear whether their estimate is unbiased. In this paper, we propose a one-round algorithm for triangles that uses empirical estimation as a post-processing step, and prove that our estimate is unbiased. We also show in Appendix A that our one-round algorithm significantly outperforms the one-round algorithm in [63]. Moreover, we show in Section 5 that our two-rounds algorithm significantly outperforms our one-round algorithm.
LDP. Apart from graphs, a number of works have looked at analyzing statistics (e.g., discrete distribution estimation[8, 24, 31, 32, 39, 57, 62], heavy hitters [11, 10, 45]) under LDP.
However, they use LDP in the context of tabular data, and do not consider the kind of complex interdependency in graph data (as described in Section 1). For example, the RR with empirical estimation is optimal in the low privacy regimes for estimating a distribution for tabular data [31, 32]. We apply the RR and empirical estimation to counting triangles, and show that it is suboptimal and significantly outperformed by a more sophisticated two-rounds algorithm.
Upper/lower-bounds. Finally, we note that existing work on upper-bounds and lower-bounds cannot be directly applied to our setting. For example, there are upper-bounds [8, 31, 32, 62, 29, 28] and lower-bounds [7, 21, 19, 29, 18, 28, 30] on the estimation error (or sample complexity) in distribution estimation of tabular data. However, they assume that each original data value is independently sampled from an underlying distribution. They cannot be directly applied to our graph setting, because each triangle and each -star involve multiple edges and are not independent (as described in Section 1). Rashtchian et al. [47] provide lower-bounds on communication complexity (i.e., number of queries) of vector-matrix-vector queries for estimating subgraph counts. However, their lower-bounds are not on the estimation error, and cannot be applied to our problem.
3 Preliminaries
3.1 Graphs and Differential Privacy
Graphs. Let , , , and be the sets of natural numbers, non-negative integers, real numbers, and non-negative real numbers, respectively. For , let .
We consider an undirected graph , where is a set of nodes (i.e., users) and is a set of edges. Let be the number of users in , and let the -th user; i.e., . An edge represents a relationship between users and . The number of edges connected to a single node is called the degree of the node. Let be the maximum degree (i.e., maximum number of edges connected to a node) in graph . Let be the set of possible graphs on users. A graph can be represented as a symmetric adjacency matrix , where if and otherwise.
Types of DP. DP (Differential Privacy) [23, 22] is known as a gold standard for data privacy. According to the underlying architecture, DP can be divided into two types: centralized DP and LDP (Local DP). Centralized DP assumes the centralized model, where a “trusted” data collector collects the original personal data from all users and obfuscates a query (e.g., counting query, histogram query) on the set of personal data. LDP assumes the local model, where each user does not trust even the data collector. In this model, each user obfuscates a query on her personal data by herself and sends the obfuscated data to the data collector.
If the data are represented as a graph, we can consider two types of DP: edge DP and node DP [27, 49]. Edge DP considers two neighboring graphs that differ in one edge. In contrast, node DP considers two neighboring graphs in which is obtained from by adding or removing one node along with its adjacent edges.
Although Zhang et al. [65] consider node DP in the local model where each node represents a software component, we consider a totally different problem where each node represents a user. In the latter case, node DP requires us to hide the existence of each user along with her all edges. However, many applications in the local model send the identity of each user to a server. For example, we can consider a mobile application that sends to a server how many friends a user met today along with her user ID. In this case, the user may not mind sending her user ID, but may want to hide her edge information (i.e., who she met today). Although we cannot use node DP in such applications, we can use edge DP to deny the presence/absence of each edge (friend). Thus we focus on edge DP in the same way as [46, 53, 63, 64].
Below we explain edge DP in the centralized model.
Centralized DP. We call edge DP in the centralized model edge centralized DP. Formally, it is defined as follows:
Definition 1 (-edge centralized DP).
Let . A randomized algorithm with domain provides -edge centralized DP if for any two neighboring graphs that differ in one edge and any ,
| (1) |
Edge centralized DP guarantees that an adversary who has observed the output of cannot determine whether it is come from or with a certain degree of confidence. The parameter is called the privacy budget. If is close to zero, then and are almost equally likely, which means that an edge in is strongly protected.
We also note that edge DP can be used to protect edges by using the notion of group privacy [23]. Specifically, if provides -edge centralized DP, then for any two graphs that differ in edges and any , we obtain: ; i.e., edges are protected with privacy budget .
3.2 Local Differential Privacy
LDP (Local Differential Privacy) [34, 20] is a privacy metric to protect personal data of each user in the local model. LDP has been originally introduced to protect each user’s data record that is independent from the other records. However, in a graph, each edge is connected to two users. Thus, when we define edge DP in the local model, we should consider what we want to protect. In this paper, we consider two definitions of edge DP in the local model: edge LDP in [46] and relationship DP introduced in this paper. Below, we will explain these two definitions in detail.
Edge LDP. Qin et al. [46] defined edge LDP based on a user’s neighbor list. Specifically, let be a neighbor list of user . Note that is the -th row of the adjacency matrix of graph . In other words, graph can be represented as neighbor lists .
Then edge LDP is defined as follows:
Definition 2 (-edge LDP [46]).
Let . For any , let with domain be a randomized algorithm of user . provides -edge LDP if for any two neighbor lists that differ in one bit and any ,
| (2) |
Edge LDP in Definition 2 protects a single bit in a neighbor list with privacy budget . As with edge centralized DP, edge LDP can also be used to protect bits in a neighbor list by using group privacy; i.e., bits in a neighbor list are protected with privacy budget .
RR (Randomized Response). As a simple example of a randomized algorithm providing -edge LDP, we explain Warner’s RR (Randomized Response) [60] applied to a neighbor list, which is called the randomized neighbor list in [46].
Given a neighbor list , this algorithm outputs a noisy neighbor lists by flipping each bit in with probability ; i.e., for each , with probability and with probability . Since and in (2) differ by for and that differ in one bit, this algorithm provides -edge LDP.
Relationship DP. In graphs such as social networks, it is usually the case that two users share knowledge of the presence of an edge between them. To hide their mutual edge, we must consider that both user’s outputs can leak information. We introduce a DP definition called relationship DP that hides one entire edge in graph during the whole process:
Definition 3 (-relationship DP).
Let . A tuple of randomized algorithms , each of which is with domain , provides -relationship DP if for any two neighboring graphs that differ in one edge and any ,
| (3) |
where (resp. ) is the -th row of the adjacency matrix of graph (resp. ).
Relationship DP is the same as decentralized DP in [53] except that the former (resp. latter) assumes that each user knows only her friends (resp. all of her friends’ friends).
Edge LDP assumes that user ’s edge connected to user and user ’s edge connected to user are different secrets, with user knowing the former and user knowing the latter. Relationship DP assumes that the two secrets are the same.
Note that the threat model of relationship DP is different from that of LDP – some amount of trust must be given to the other users in relationship DP. Specifically, user must trust user to not leak information about their shared edge. If users decide not to follow their protocols, then up to edges incident to user may be compromised. This trust model is stronger than LDP, which assumes nothing about what other users do, but is much weaker than centralized DP in which all edges are in the hands of the central party.
Other than the differing threat models, relationship DP and edge LDP are quite closely related:
Proposition 1.
If randomized algorithms provide -edge LDP, then provides -relationship DP.
Proof.
Proposition 1 states that when we want to protect one edge as a whole, the privacy budget is at most doubled. Note, however, that some randomized algorithms do not have this doubling issue. For example, we can apply the RR to the -th neighbor list so that outputs noisy bits for only users with smaller user IDs; i.e., for each , with probability and with probability . In other words, we can extend the RR for a neighbor list so that outputs only the lower triangular part of the noisy adjacency matrix. Then all of provide -edge LDP. In addition, the existence of edge affects only one element in the lower triangular part of . Thus, provides -relationship DP (not ).
Our proposed algorithm in Section 4.3 also has this property; i.e., it provides both -edge LDP and -relationship DP.
3.3 Global Sensitivity
In this paper, we use the notion of global sensitivity [23] to provide edge centralized DP or edge LDP.
Let be the set of possible input data of a randomized algorithm. In edge centralized DP, . In edge LDP, . Let be a function that takes data as input and outputs some statistics about the data. The most basic method for providing DP is to add the Laplacian noise proportional to the global sensitivity [23].
Definition 4 (Global sensitivity).
The global sensitivity of a function is given by:
where represents that and are neighbors; i.e., they differ in one edge in edge centralized DP, and differ in one bit in edge LDP.
In graphs, the global sensitivity can be very large. For example, adding one edge may result in the increase of triangle (resp. -star) counts by (resp. ).
One way to significantly reduce the global sensitivity is to use graph projection [16, 35, 48], which removes some neighbors from a neighbor list so that the maximum degree is upper-bounded by a predetermined value . By using the graph projection with , we can enforce small global sensitivity; e.g., the global sensitivity of triangle (resp. -star) counts is at most (resp. ) after the projection.
Ideally, we would like to set to avoid removing neighbors from a neighbor list (i.e., to avoid the loss of utility). However, the maximum degree can leak some information about the original graph . In this paper, we address this issue by privately estimating with edge LDP and then using the private estimate of as . This technique is also known as adaptive clipping in differentially private stochastic gradient descent (SGD) [44, 54].
3.4 Graph Statistics and Utility Metrics
Graph statistics. We consider a graph function that takes a graph as input and outputs some graph statistics. Specifically, let be a graph function that outputs the number of triangles in . For , let be a graph function that outputs the number of -stars in . For example, if a graph is as shown in Figure 1, then , , and . The clustering coefficient can also be calculated from and as: .
Symbol Description Number of users. Graph with nodes (users) and edges . -th user in . Maximum degree of . Upper-bound on (used for projection). Set of possible graphs on users. Adjacency matrix. -th row of (i.e., neighbor list of ). Randomized algorithm on . Number of triangles in . Number of -stars in .
Table 1 shows the basic notations used in this paper.
Utility metrics. We use the loss (i.e., squared error) [31, 57, 39] and the relative error [12, 14, 61] as utility metrics.
Specifically, let be an estimate of graph statistics . Here can be instantiated by or ; i.e., and are the estimates of and , respectively. Let be the loss function, which maps the estimate and the true value to the loss; i.e., . Note that when we use a randomized algorithm providing edge LDP (or edge centralized DP), depends on the randomness in the algorithm. In our theoretical analysis, we analyze the expectation of the loss over the randomness, as with [31, 57, 39].
4 Algorithms
In the local model, there are several ways to model how the data collector interacts with the users [20, 30, 46]. The simplest model would be to assume that the data collector sends a query to each user once, and then each user independently sends an answer to the data collector. In this model, there is one-round interaction between each user and the data collector. We call this the one-round LDP model. For example, the RR for a neighbor list in Section 3.2 assumes this model.
However, in certain cases it may be possible for the data collector to send a query to each user multiple times. This could allow for more powerful queries that result in more accurate subgraph counts [53] or more accurate synthetic graphs [46]. We call this the multiple-rounds LDP model.
In Sections 4.1 and 4.2, we consider the problems of computing and for a graph in the one-round LDP model. Our algorithms and bounds highlight limitations of the one-round LDP model. Compared to the centralized graph DP model, the one-round LDP model cannot compute as accurately. Furthermore, the algorithm for does not perform well. In Section 4.3, we propose a more sophisticated algorithm for computing in the two-rounds LDP model, and show that it provides much smaller expected loss than the algorithm in the one-round LDP model. In Section 4.4, we show a general result about lower bounds on the expected loss of graph statistics in LDP. The proofs of all statements in Section 4 are given in Appendix D.
4.1 One-Round Algorithms for -Stars
Algorithm. We begin with the problem of computing in the one-round LDP model. For this model, we introduce a simple algorithm using the Laplacian mechanism, and prove that this algorithm can achieve order optimal expected loss among all one-round LDP algorithms.
Algorithm 1 shows the one-round algorithm for -stars. It takes as input a graph (represented as neighbor lists ), the privacy budget , and a non-negative integer .
The parameter plays a role as an upper-bound on the maximum degree of . Specifically, let be the degree of user ; i.e., the number of “”s in her neighbor list . In line 3, user uses a function (denoted by GraphProjection) that performs graph projection [16, 35, 48] for as follows. If exceeds , it randomly selects neighbors out of neighbors; otherwise, it uses as it is. This guarantees that each user’s degree never exceeds ; i.e., after line 4.
After the graph projection, user counts the number of -stars of which she is a center (line 5), and adds the Laplacian noise to (line 6). Here, since adding one edge results in the increase of at most -stars, the sensitivity of -star counts for user is at most (after graph projection). Therefore, we add to , where and for is a random variable that represents the Laplacian noise with mean and scale . The final answer of Algorithm 1 is simply the sum of all the noisy -star counts. We denote this algorithm by LocalLapk⋆.
The value of greatly affects the utility. If is too large, a large amount of the Laplacian noise would be added. If is too small, a great number of neighbors would be reduced by graph projection. When we have some prior knowledge about the maximum degree , we can set to an appropriate value. For example, the maximum number of connections allowed on Facebook is [3]. In this case, we can set , and then graph projection does nothing. Given that the number of Facebook monthly active users is over billion [6], is much smaller than . For another example, if we know that the degree is smaller than for most users, then we can set and perform graph projection for users whose degrees exceed .
In some applications, the data collector may not have such prior knowledge about . In this case, we can privately estimate by allowing an additional round between each user and the data collector, and use the private estimate of as . We describe how to privately estimate with edge LDP at the end of Section 4.1.
Theoretical properties. LocalLapk⋆ has the following guarantees:
Theorem 1.
LocalLapk⋆ provides -edge LDP.
Theorem 2.
Let be the output of LocalLapk⋆. Then, for all , and such that the maximum degree of is at most , .
The factor of in the expected loss of LocalLapk⋆ comes from the fact that we are adding the Laplacian noise times. In the centralized model, this factor of is not there, because the central data collector sees all -stars; i.e., the data collector knows . The sensitivity of is at most (after graph projection) under edge centralized DP. Therefore, we can consider an algorithm that simply adds the Laplacian noise to , and outputs . We denote this algorithm by CentralLapk⋆. Since the bias of the Laplacian noise is , CentralLapk⋆ attains the expected loss ( variance) of .
It seems impossible to avoid this factor of in the one-round LDP model, as the data collector will be dealing with independent answers to queries. Indeed, this is the case—we prove that the expected error of LocalLapk⋆ is order optimal among all one-round LDP algorithms, and the one-round LDP model cannot improve the factor of .
Corollary 1.
Let be any one-round LDP algorithm that computes satisfying -edge LDP. Then, for all and such that is even, there exists a set of graphs on nodes such that the maximum degree of each is at most , and .
This is a corollary of a more general result of Section 4.4. Thus, any algorithm computing -stars cannot avoid the factor of in its loss. -stars is an example where the non-interactive graph LDP model is strictly weaker than the centralized DP model.
Nevertheless, we note that LocalLapk⋆ can accurately calculate for a large number of users . Specifically, the relative error decreases with increase in because LocalLapk⋆ has a factor of (not ) in the expected error, i.e., and (when we ignore and ). In our experiments, we show that the relative error of LocalLapk⋆ is small when is large.
Private calculation of . By allowing an additional round between each user and the data collector, we can privately estimate and use the private estimate of as . Specifically, we divide the privacy budget into and ; i.e., . We first estimate with -edge LDP and then run LocalLapk⋆ with the remaining privacy budget . Note that LocalLapk⋆ with the private calculation of results in a two-rounds LDP algorithm.
We consider the following simple algorithm. At the first round, each user adds the Laplacian noise to her degree . Let be the noisy degree of ; i.e., . Then user sends to the data collector. Let be the maximum value of the noisy degree; i.e., . We call the noisy max degree. The data collector calculates the noisy max degree as an estimate of , and sends back to all users. At the second round, we run LocalLapk⋆ with input , , and .
At the first round, the calculation of provides -edge LDP because each user’s degree has the sensitivity under edge LDP. At the second round, Theorem 1 guarantees that LocalLapk⋆ provides -edge LDP. Then by the composition theorem [23], this two-rounds algorithm provides -edge LDP in total ().
In our experiments, we show that this algorithm provides the utility close to LocalLapk⋆ with the true max degree .
4.2 One-Round Algorithms for Triangles.
Algorithm. Now, we focus our attention on the more challenging query. This query is more challenging in the graph LDP model because no user is aware of any triangle; i.e., user is not aware of any triangle formed by , because cannot see any edge in graph .
One way to count with edge LDP is to apply the RR (Randomized Response) to a neighbor list. For example, user applies the RR to (which corresponds to users with smaller user IDs) in her neighbor list ; i.e., we apply the RR to the lower triangular part of adjacency matrix , as described in Section 3.2. Then the data collector constructs a noisy graph from the lower triangular part of the noisy adjacency matrix, and estimates the number of triangles from . However, simply counting the triangles in can introduce a significant bias because is denser than especially when is small.
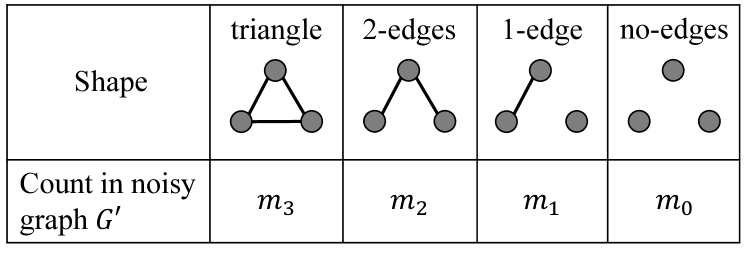
Through clever post-processing known as empirical estimation [31, 39, 57], we are able to obtain an unbiased estimate of from . Specifically, a subgraph with three nodes can be divided into four types depending on the number of edges. Three nodes with three edges form a triangle. We refer to three nodes with two edges, one edge, and no edges as 2-edges, 1-edge, and no-edges, respectively. Figure 2 shows their shapes. can be expressed using , , , and as follows:
Proposition 2.
Let be a noisy graph generated by applying the RR to the lower triangular part of . Let be respectively the number of triangles, 2-edges, 1-edge, and no-edges in . Then
| (4) |
Therefore, the data collector can count , , , and from , and calculate an unbiased estimate of by (4). In Appendix A, we show that the loss is significantly reduced by this empirical estimation.
Algorithm 2 shows this algorithm. In line 2, user applies the RR with privacy budget (denoted by ) to in her neighbor list , and outputs . In other words, we apply the RR to the lower triangular part of and there is no overlap between edges sent by users. In line 5, the data collector uses a function (denoted by UndirectedGraph) that converts the bits of into an undirected graph by adding edge with to if and only if the -th bit of is . Note that is biased, as explained above. In line 6, the data collector uses a function (denoted by Count) that calculates , , , and from . Finally, the data collector outputs the expression inside the expectation on the left-hand side of (4), which is an unbiased estimator for by Proposition 2. We denote this algorithm by LocalRR△.
Theoretical properties. LocalRR△ provides the following guarantee.
Theorem 3.
LocalRR△ provides -edge LDP and -relationship DP.
LocalRR△ does not have the doubling issue (i.e., it provides not but -relationship DP), because we apply the RR to the lower triangular part of , as explained in Section 3.2.
Unlike the RR and empirical estimation for tabular data [31], the expected loss of LocalRR△ is complicated. To simplify the utility analysis, we assume that is generated from the Erdös-Rényi graph distribution with edge existence probability ; i.e., each edge in with nodes is independently generated with probability .
Theorem 4.
Let be the Erdös-Rényi graph distribution with edge existence probability . Let and . Let be the output of LocalRR△. If , then for all , .
Note that we assume the Erdös-Rényi model only for the utility analysis of LocalRR△, and do not assume this model for the other algorithms. The upper-bound of LocalRR△ in Theorem 4 is less ideal than the upper-bounds of the other algorithms in that it does not consider all possible graphs . Nevertheless, we also show that the loss of LocalRR△ is roughly consistent with Theorem 4 in our experiments using two real datasets (Section 5) and the Barabási-Albert graphs [9], which have power-law degree distribution (Appendix B).
The parameters and are edge existence probabilities in the original graph and noisy graph , respectively. Although is very small in a sparse graph, can be large for small . For example, if and , then .
Theorem 4 states that for large , the loss of LocalRR△ () is much larger than the loss of LocalRR (). This follows from the fact that user is not aware of any triangle formed by , as explained above.
In contrast, counting in the centralized model is much easier because the data collector sees all triangles in ; i.e., the data collector knows . The sensitivity of is at most (after graph projection). Thus, we can consider a simple algorithm that outputs . We denote this algorithm by CentralLap△. CentralLap△ attains the expected loss ( variance) of .
The large loss of LocalRR△ is caused by the fact that each edge is released independently with some probability of being flipped. In other words, there are three independent random variables that influence any triangle in . The next algorithm, using interaction, reduces this influencing number from three to one by using the fact that a user knows the existence of two edges for any triangle that involves the user.
4.3 Two-Rounds Algorithms for Triangles
Algorithm. Allowing for two-rounds interaction, we are able to compute with a significantly improved loss, albeit with a higher per-user communication overhead. As described in Section 4.2, it is impossible for user to see edge in graph at the first round. However, if the data collector publishes a noisy graph calculated by LocalRR△ at the first round, then user can see a noisy edge in the noisy graph at the second round. Then user can count the number of noisy triangles formed by such that , , and , and send the noisy triangle counts with the Laplacian noise to the data collector in an analogous way to LocalLapk⋆. Since user always knows that two edges and exist in , there is only one noisy edge in any noisy triangle (whereas all edges are noisy in LocalRR△). This is an intuition behind our proposed two-rounds algorithm.
As with the RR in Section 4.2, simply counting the noisy triangles can introduce a bias. Therefore, we calculate an empirical estimate of from the noisy triangle counts. Specifically, the following is the empirical estimate of :
Proposition 3.
Let be a noisy graph generated by applying the RR with privacy budget to the lower triangular part of . Let . Let be the number of triplets such that , , , and . Let be the number of triplets such that , , and . Let . Then
| (5) |
Note that in Proposition 3, we count only triplets with to use only the lower triangular part of . is the number of noisy triangles user can see at the second round. is the number of -stars of which user is a center. Since and can reveal information about an edge in , user adds the Laplacian noise to in (5), and sends it to the data collector. Then the data collector calculates an unbiased estimate of by (5).
Algorithm 3 contains the formal description of this process. It takes as input a graph , the privacy budgets at the first and second rounds, respectively, and a non-negative integer . At the first round, we apply the RR to the lower triangular part of (i.e., there is no overlap between edges sent by users) and use the UndirectedGraph function to obtain a noisy graph by the RR in the same way as Algorithm 2. Note that is biased. We calculate an unbiased estimate of from at the second round.
At the second round, each user calculates by adding the Laplacian noise to in Proposition 3 whose sensitivity is at most (as we will prove in Theorem 5). Finally, we output , which is an unbiased estimate of by Proposition 3. We call this algorithm Local2Rounds△.
Theoretical properties. Local2Rounds△ has the following guarantee.
Theorem 5.
Local2Rounds△ provides -edge LDP and -relationship DP.
As with LocalRR△, Local2Rounds△ does not have the doubling issue; i.e., it provides -relationship DP (not ). This follows from the fact that we use only the lower triangular part of ; i.e., we assume in counting and .
Theorem 6.
Let be the output of Local2Rounds△. Then, for all , , and such that the maximum degree of is at most , .
Theorem 6 means that for triangles, the loss is reduced from to by introducing an additional round.
Private calculation of . As with -stars, we can privately calculate by using the method described in Section 4.1. Furthermore, the private calculation of does not increase the number of rounds; i.e., we can run Local2Rounds△ with the private calculation of in two rounds.
Specifically, let be the privacy budget for the private calculation of . At the first round, each user adds to her degree , and sends the noisy degree () to the data collector, along with the outputs of the RR. The data collector calculates the noisy max degree () as an estimate of , and sends it back to all users. At the second round, we run Local2Rounds△ with input (represented as ), , , and .
At the first round, the calculation of provides -edge LDP. Note that it provides -relationship DP (i.e., it has the doubling issue) because one edge affects both of the degrees and by 1. At the second round, LocalLapk⋆ provides -edge LDP and -relationship DP (Theorem 5). Then by the composition theorem [23], this two-rounds algorithm provides -edge LDP and -relationship DP. Although the total privacy budget is larger for relationship DP, the difference () can be very small. In fact, we set or in our experiments (i.e., the difference is or ), and show that this algorithm provides almost the same utility as Local2Rounds△ with the true max degree .
Time complexity. We also note that Local2Rounds△ has an advantage over LocalRR△ in terms of the time complexity.
Specifically, LocalRR△ is inefficient because the data collector has to count the number of triangles in the noisy graph . Since the noisy graph is dense (especially when is small) and there are subgraphs with three nodes in , the number of triangles is . Then, the time complexity of LocalRR△ is also , which is not practical for a graph with a large number of users . In fact, we implemented LocalRR△ () with C/C++ and measured its running time using one node of a supercomputer (ABCI: AI Bridging Cloud Infrastructure [4]). When , , , and , the running time was , , , and seconds, respectively; i.e., the running time was almost cubic in . We can also estimate the running time for larger . For example, when , LocalRR△ () would require about years .
In contrast, the time complexity of Local2Rounds△ is 111When we evaluate Local2Rounds△ in our experiments, we can apply the RR to only edges that are required at the second round; i.e., in line 8 of Algorithm 3. Then the time complexity of Local2Rounds△ can be reduced to in total. We also confirmed that when , the running time of Local2Rounds△ was seconds on one node of the ABCI. Note, however, that this does not protect individual privacy, because it reveals the fact that users and are friends with to the data collector.. The factor of comes from the fact that the size of the noisy graph is . This also causes a large communication overhead, as explained below.
Communication overhead. In Local2Rounds△, each user need to see the noisy graph of size to count and . This results in a per-user communication overhead of . Although we do not simulate the communication overhead in our experiments that use Local2Rounds△, the overhead might limit its application in very large graphs. An interesting avenue of future work is how to compress the graph size (e.g., via graph projection or random projection) to reduce both the time complexity and the communication overhead.
| Centralized | One-round local | Two-rounds local | ||
|---|---|---|---|---|
| Upper Bound | Lower Bound | Upper Bound | Upper Bound | |
| (when ) | ||||
4.4 Lower Bounds
We show a general lower bound on the loss of private estimators of real-valued functions in the one-round LDP model. Treating as a constant, we have shown that when , the expected loss of LocalLaplacek⋆ is (Theorem 2). However, in the centralized model, we can use the Laplace mechanism with sensitivity to obtain errors of for . Thus, we ask if the factor of is necessary in the one-round LDP model.
We answer this question affirmatively. We show for many types of queries , there is a lower bound on for any private estimator of the form
| (6) |
where satisfy -edge LDP or -relationship DP and is an aggregate function that takes as input and outputs . Here we assume that are independently run, meaning that they are in the one-round setting. For our lower bound, we require that input edges to be “independent” in the sense that adding an edge to an input graph independently change by at least . The specific structure of input graphs we require is as follows:
Definition 5.
[-independent cube for ] Let . For , let be a graph on nodes, and let for integers be a set of edges such that each of is distinct (i.e., perfect matching on the nodes). Suppose that is disjoint from ; i.e., for any . Let . Note that is a set of graphs. We say is an -independent cube for if for all , we have
where satisfies for any .


Such a set of inputs has an “independence” property because, regardless of which edges from has been added before, adding edge always changes by . Figure 3 shows an example of a -independent cube for .
We can also construct a independent cube for a -star function as follows. Assume that is even. It is well known in graph theory that if is even, then for any , there exists a -regular graph where every node has degree [25]. Therefore, there exists a -regular graph of size . Pick an arbitrary perfect matching on the nodes. Now, let such that . Every node in has degree between and . Adding an edge in to will produce at least new -stars. Thus, forms an -independent cube for . Note that the maximum degree of each graph in is at most . Figure 4 shows how to construct an independent cube for a -star function when and .
Using the structure that the -independent cube imposes on , we can prove a lower bound:
Theorem 7.
Let have the form of (6), where are independently run. Let be an -independent cube for . If provides -relationship DP, then we have
A corollary of Theorem 7 is that if satisfy -edge LDP, then they satisfy -relationship DP and thus for edge LDP we have a lower bound of .
Theorem 7, combined with the fact that there exists an -independent cube for a -star function implies Corollary 1. In Appendix C, we also construct an independent cube for and establish a lower bound of for .
The upper and lower bounds on the losses shown in this section appear in Table 2.
5 Experiments
Based on our theoretical results in Section 4, we would like to pose the following questions:
-
•
For triangle counts, how much does the two-rounds interaction help over a single round in practice?
-
•
What is the privacy-utility trade-off of our LDP algorithms (i.e., how beneficial are our LDP algorithms)?
We conducted experiments to answer to these questions.
5.1 Experimental Set-up
We used the following two large-scale datasets:
IMDB. The Internet Movie Database (denoted by IMDB) [2] includes a bipartite graph between actors and movies. We assumed actors as users. From the bipartite graph, we extracted a graph with nodes (actors), where an edge between two actors represents that they have played in the same movie. There are edges in , and the average degree in is .
Orkut. The Orkut online social network dataset (denoted by Orkut) [36] includes a graph with users and edges. The average degree in is . Therefore, Orkut is more sparse than IMDB (whose average degree in is ).
For each dataset, we randomly selected users from the whole graph , and extracted a graph with users. Then we estimated the number of triangles , the number of -stars , and the clustering coefficient () using -edge LDP (or -edge centralized DP) algorithms in Section 4. Specifically, we used the following algorithms:
Algorithms for triangles. For algorithms for estimating , we used the following three algorithms: (1) the RR (Randomized Response) with the empirical estimation method in the local model (i.e., LocalRR△ in Section 4.2), (2) the two-rounds algorithm in the local model (i.e., Local2Rounds△ in Section 4.3), and (3) the Laplacian mechanism in the centralized model (i.e., CentralLap in Section 4.2).
Algorithms for -stars. For algorithms for estimating , we used the following two algorithms: (1) the Laplacian mechanism in the local model (i.e., LocalLap in Section 4.1) and (2) the Laplacian mechanism in the centralized model (i.e., CentralLap in Section 4.1).
For each algorithm, we evaluated the loss and the relative error (as described in Section 3.4), while changing the values of and . To stabilize the performance, we attempted ways to randomly select users from , and averaged the utility value over all the ways to randomly select users. When we changed from to , we set because the variance was large. For other cases, we set .
In Appendix B, we also report experimental results using artificial graphs based on the Barabási-Albert model [9].


5.2 Experimental Results
Relation between and the loss. We first evaluated the loss of the estimates of , , and while changing the number of users . Figures 5 and 6 shows the results (). Here we did not evaluate LocalRR△ when was larger than , because LocalRR△ was inefficient (as described in Section 4.3 “Time complexity”). In Local2Rounds△, we set . As for , we set (i.e., we assumed that is publicly available and did not perform graph projection) because we want to examine how well our theoretical results hold in our experiments. We also evaluate the effectiveness of the private calculation of at the end of Section 5.2.
Figure 5 shows that Local2Rounds△ significantly outperforms LocalRR△. Specifically, the loss of Local2Rounds△ is smaller than that of LocalRR△ by a factor of about . The difference between Local2Rounds△ and LocalRR△ is larger in Orkut. This is because Orkut is more sparse, as described in Section 5.1. For example, when , the maximum degree in was and on average in IMDB and Orkut, respectively. Recall that for a fixed , the expected loss of Local2Rounds△ and LocalRR△ can be expressed as and , respectively. Thus Local2Rounds△ significantly outperforms LocalRR△, especially in sparse graphs.
Figures 5 and 6 show that the loss is roughly consistent with our upper-bounds in terms of . Specifically, LocalRR△, Local2Rounds△, CentralLap△, LocalLapk⋆, and CentralLapk⋆ achieve the expected loss of , , , , and , respectively. Here note that each user’s degree increases roughly in proportion to (though the degree is much smaller than ), as we randomly select users from the whole graph . Assuming that , Figures 5 and 6 are roughly consistent with the upper-bounds. The figures also show the limitations of the local model in terms of the utility when compared to the centralized model.
Relation between and the loss. Next we evaluated the loss when we changed the privacy budget in edge LDP. Figure 7 shows the results for triangles and -stars (). Here we omit the result of -stars because it is similar to that of -stars. In Local2Rounds△, we set .
Figure 7 shows that the loss is roughly consistent with our upper-bounds in terms of . For example, when we decrease from to , the loss increases by a factor of about , , and for both the datasets in LocalRR△, Local2Rounds△, and CentralLap△, respectively. They are roughly consistent with our theoretical results that for small , the expected loss of LocalRR△, Local2Rounds△, and CentralLap△ is 222We used to derive the upper-bound of LocalRR△ for small ., , and , respectively.


Figure 7 also shows that Local2Rounds△ significantly outperforms LocalRR△ especially when is small, which is also consistent with our theoretical results. Conversely, the difference between LocalRR△ and Local2Rounds△ is small when is large. This is because when is large, the RR outputs the true value with high probability. For example, when , the RR outputs the true value with . However, LocalRR△ with such a large value of does not guarantee strong privacy, because it outputs the true value in most cases. Local2Rounds△ significantly outperforms LocalRR△ when we want to estimate or with a strong privacy guarantee; e.g., [37].
Relative error. As the number of users increases, the numbers of triangles and -stars increase. This causes the increase of the loss. Therefore, we also evaluated the relative error, as described in Section 3.4.
Figure 8 shows the relation between and the relative error (we omit the result of -stars because it is similar to that of -stars). In the local model, we used Local2Rounds△ and LocalLap for estimating and , respectively (we did not use Local2RR△, because it is both inaccurate and inefficient). For both algorithms, we set or ( in Local2Rounds△) and . Then we estimated the clustering coefficient as: , where and are the estimates of and , respectively. If the estimate of the clustering coefficient is smaller than (resp. larger than ), we set the estimate to (resp. ) because the clustering coefficient is always between and . In the centralized model, we used CentralLap△ and CentralLap ( or , ) and calculated the clustering coefficient in the same way.
Figure 8 shows that for all cases, the relative error decreases with increase in . This is because both and significantly increase with increase in . Specifically, let the number of triangles that involve user , and be the number of -stars of which user is a center. Then and . Since both and increase with increase in , both and increase at least in proportion to . Thus and . In contrast, Local2Rounds△, LocalLap, CentralLap△, and CentralLap achieve the expected loss of , , , and , respectively (when we ignore and ), all of which are smaller than . Therefore, the relative error decreases with increase in .
This result demonstrates that we can accurately estimate graph statistics for large in the local model. In particular, the relative error is smaller in IMDB because IMDB is denser and includes a larger number of triangles and -stars; i.e., the denominator of the relative error is large. For example, when and , the relative error is and for triangles and -stars, respectively. Note that the clustering coefficient requires because we need to estimate both and . Yet, we can still accurately calculate the clustering coefficient with a moderate privacy budget; e.g., the relative error of the clustering coefficient is when the privacy budget is (i.e., ). If is larger, then would be smaller at the same value of the relative error.

Private calculation of . We have so far assumed that (i.e., is publicly available) in our experiments. We finally evaluate the methods to privately calculate with -edge LDP (described in Sections 4.1 and 4.3).
Specifically, we used Local2Rounds△ and LocalLap for estimating and , respectively, and evaluated the following three methods for setting : (i) ; (ii) ; (iii) , where is the private estimate of (noisy max degree) in Sections 4.1 and 4.3.
We set in IMDB and in Orkut. Regarding the total privacy budget in edge LDP for estimating or , we set or . We used for privately calculating (i.e., ), and the remaining privacy budget as input to Local2Rounds△ or LocalLap. In Local2Rounds△, we set ; i.e., we set or . Then we estimated the clustering coefficient in the same way as Figure 8.
Figure 9 shows the results. Figure 9 shows that the algorithms with (noisy max degree) achieves the relative error close to (sometimes almost the same as) the algorithms with and significantly outperforms the algorithms with . This means that we can privately estimate without a significant loss of utility.
Summary of results. In summary, our experimental results showed that the estimation error of triangle counts is significantly reduced by introducing the interaction between users and a data collector. The results also showed that we can achieve small relative errors (much smaller than 1) for subgraph counts with privacy budget or in edge LDP.
As described in Section 1, non-private subgraph counts may reveal some friendship information, and a central server may face data breaches. Our LDP algorithms are highly beneficial because they enable us to analyze the connection patterns in a graph (i.e., subgraph counts) or to understand how likely two friends of an individual will also be a friend (i.e., clustering coefficient) while strongly protecting individual privacy.
6 Conclusions
We presented a series of algorithms for counting triangles and -stars under LDP. We showed that an additional round can significantly reduce the estimation error in triangles, and the algorithm based on the Laplacian mechanism provides an order optimal error in the non-interactive local model. We also showed lower-bounds for general functions including triangles and -stars. We conducted experiments using two real datasets, and showed that our algorithms achieve small relative errors, especially when the number of users is large.
As future work, we would like to develop algorithms for other subgraph counts such as cliques and -triangles [33].
Acknowledgments
Kamalika Chaudhuri and Jacob Imola would like to thank ONR under N00014-20-1-2334 and UC Lab Fees under LFR 18-548554 for research support. Takao Murakami was supported in part by JSPS KAKENHI JP19H04113.
References
- [1] Tool: LDP graph statistics. https://github.com/LDPGraphStatistics/LDPGraphStatistics.
- [2] 12th Annual Graph Drawing Contest. http://mozart.diei.unipg.it/gdcontest/contest2005/index.html, 2005.
- [3] What to Do When Your Facebook Profile is Maxed Out on Friends. https://authoritypublishing.com/social-media/what-to-do-when-your-facebook-profile-is-maxed-out-on-friends/, 2012.
- [4] AI bridging cloud infrastructure (ABCI). https://abci.ai/, 2020.
- [5] The diaspora* project. https://diasporafoundation.org/, 2020.
- [6] Facebook Reports Third Quarter 2020 Results. https://investor.fb.com/investor-news/press-release-details/2020/Facebook-Reports-Third-Quarter-2020-Results/default.aspx, 2020.
- [7] Jayadev Acharya, Clément L. Canonne, Yuhan Liu, Ziteng Sun, and Himanshu Tyagi. Interactive inference under information constraints. CoRR, 2007.10976, 2020.
- [8] Jayadev Acharya, Ziteng Sun, and Huanyu Zhang. Hadamard response: Estimating distributions privately, efficiently, and with little communication. In Proc. AISTATS’19, pages 1120–1129, 2019.
- [9] Albert-László Barabási. Network Science. Cambridge University Press, 2016.
- [10] Raef Bassily, Kobbi Nissim, Uri Stemmer, and Abhradeep Thakurta. Practical locally private heavy hitters. In Proc. NIPS’17, pages 2285––2293, 2017.
- [11] Raef Bassily and Adam Smith. Local, private, efficient protocols for succinct histograms. In Proc. STOC’15, pages 127–135, 2015.
- [12] Vincent Bindschaedler and Reza Shokri. Synthesizing plausible privacy-preserving location traces. In Proc. S&P’16, pages 546–563, 2016.
- [13] Jeremiah Blocki, Avrim Blum, Anupam Datta, and Or Sheffet. The johnson-lindenstrauss transform itself preserves differential privacy. In Proc. FOCS’12, pages 410–419, 2012.
- [14] Rui Chen, Gergely Acs, and Claude Castelluccia. Differentially private sequential data publication via variable-length n-grams. In Proc. CCS’12, pages 638–649, 2012.
- [15] Xihui Chen, Sjouke Mauw, and Yunior Ramírez-Cruz. Publishing community-preserving attributed social graphs with a differential privacy guarantee. Proceedings on Privacy Enhancing Technologies (PoPETs), (4):131–152, 2020.
- [16] Wei-Yen Day, Ninghui Li, and Min Lyu. Publishing graph degree distribution with node differential privacy. In Proc. SIGMOD’16, pages 123–138, 2016.
- [17] Bolin Ding, Janardhan Kulkarni, and Sergey Yekhanin. Collecting telemetry data privately. In Proc. NIPS’17, pages 3574–3583, 2017.
- [18] John Duchi and Ryan Rogers. Lower Bounds for Locally Private Estimation via Communication Complexity. arXiv:1902.00582 [math, stat], May 2019. arXiv: 1902.00582.
- [19] John Duchi, Martin Wainwright, and Michael Jordan. Minimax Optimal Procedures for Locally Private Estimation. arXiv:1604.02390 [cs, math, stat], November 2017. arXiv: 1604.02390.
- [20] John C. Duchi, Michael I. Jordan, and Martin J. Wainwright. Local privacy and statistical minimax rates. In Proc. FOCS’13, pages 429–438, 2013.
- [21] John C. Duchi, Michael I. Jordan, and Martin J. Wainwright. Local privacy, data processing inequalities, and minimax rates. CoRR, 1302.3203, 2014.
- [22] Cynthia Dwork. Differential privacy. In Proc. ICALP’06, pages 1–12, 2006.
- [23] Cynthia Dwork and Aaron Roth. The Algorithmic Foundations of Differential Privacy. Now Publishers, 2014.
- [24] Giulia Fanti, Vasyl Pihur, and Ulfar Erlingsson. Building a RAPPOR with the unknown: Privacy-preserving learning of associations and data dictionaries. Proceedings on Privacy Enhancing Technologies (PoPETs), 2016(3):1–21, 2016.
- [25] Ghurumuruhan Ganesan. Existence of connected regular and nearly regular graphs. CoRR, 1801.08345, 2018.
- [26] Aric A. Hagberg, Daniel A. Schult, and Pieter J. Swart. Exploring network structure, dynamics, and function using networkx. In Proceedings of the 7th Python in Science Conference (SciPy’08), pages 11–15, 2008.
- [27] Michael Hay, Chao Li, Gerome Miklau, and David Jensen. Accurate estimation of the degree distribution of private networks. In Proc. ICDM’09, pages 169–178, 2009.
- [28] Matthew Joseph, Janardhan Kulkarni, Jieming Mao, and Zhiwei Steven Wu. Locally Private Gaussian Estimation. arXiv:1811.08382 [cs, stat], October 2019. arXiv: 1811.08382.
- [29] Matthew Joseph, Jieming Mao, Seth Neel, and Aaron Roth. The Role of Interactivity in Local Differential Privacy. arXiv:1904.03564 [cs, stat], November 2019. arXiv: 1904.03564.
- [30] Matthew Joseph, Jieming Mao, and Aaron Roth. Exponential separations in local differential privacy. In Proc. SODA’20, pages 515–527, 2020.
- [31] Peter Kairouz, Keith Bonawitz, and Daniel Ramage. Discrete distribution estimation under local privacy. In Proc. ICML’16, pages 2436–2444, 2016.
- [32] Peter Kairouz, Sewoong Oh, and Pramod Viswanath. Extremal mechanisms for local differential privacy. Journal of Machine Learning Research, 17(1):492–542, 2016.
- [33] Vishesh Karwa, Sofya Raskhodnikova, Adam Smith, and Grigory Yaroslavtsev. Private analysis of graph structure. Proceedings of the VLDB Endowment, 4(11):1146–1157, 2011.
- [34] Shiva Prasad Kasiviswanathan, Homin K. Lee, Kobbi Nissim, and Sofya Raskhodnikova. What can we learn privately? In Proc. FOCS’08, pages 531–540, 2008.
- [35] Shiva Prasad Kasiviswanathan, Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. Analyzing graphs with node differential privacy. In Proc. TCC’13, pages 457–476, 2013.
- [36] Jure Leskovec and Andrej Krevl. SNAP Datasets: Stanford large network dataset collection. http://snap.stanford.edu/data, 2014.
- [37] Ninghui Li, Min Lyu, and Dong Su. Differential Privacy: From Theory to Practice. Morgan & Claypool Publishers, 2016.
- [38] Chris Morris. Hackers had a banner year in 2019. https://fortune.com/2020/01/28/2019-data-breach-increases-hackers/, 2020.
- [39] Takao Murakami and Yusuke Kawamoto. Utility-optimized local differential privacy mechanisms for distribution estimation. In Proc. USENIX Security’19, pages 1877–1894, 2019.
- [40] Kevin P. Murphy. Machine Learning: A Probabilistic Perspective. The MIT Press, 2012.
- [41] M. E. J. Newman. Random graphs with clustering. Physical Review Letters, 103(5):058701, 2009.
- [42] Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. Smooth sensitivity and sampling in private data analysis. In Proc. STOC’07, pages 75–84, 2007.
- [43] Thomas Paul, Antonino Famulari, and Thorsten Strufe. A survey on decentralized online social networks. Computer Networks, 75:437–452, 2014.
- [44] Venkatadheeraj Pichapati, Ananda Theertha Suresh, Felix X. Yu, Sashank J. Reddi, and Sanjiv Kumar. AdaCliP: Adaptive clipping for private SGD. CoRR, 1908.07643, 2019.
- [45] Zhan Qin, Yin Yang, Ting Yu, Issa Khalil, Xiaokui Xiao, and Kui Ren. Heavy hitter estimation over set-valued data with local differential privacy. In Proc. CCS’16, pages 192–203, 2016.
- [46] Zhan Qin, Ting Yu, Yin Yang, Issa Khalil, Xiaokui Xiao, and Kui Ren. Generating synthetic decentralized social graphs with local differential privacy. In Proc. CCS’17, pages 425–438, 2017.
- [47] Cyrus Rashtchian, David P. Woodruff, and Hanlin Zhu. Vector-matrix-vector queries for solving linear algebra, statistics, and graph problems. CoRR, 2006.14015, 2020.
- [48] Sofya Raskhodnikova and Adam Smith. Efficient lipschitz extensions for high-dimensional graph statistics and node private degree distributions. CoRR, 1504.07912, 2015.
- [49] Sofya Raskhodnikova and Adam Smith. Differentially Private Analysis of Graphs, pages 543–547. Springer, 2016.
- [50] Andrea De Salve, Paolo Mori, and Laura Ricci. A survey on privacy in decentralized online social networks. Computer Science Review, 27:154–176, 2018.
- [51] Tara Seals. Data breaches increase 40% in 2016. https://www.infosecurity-magazine.com/news/data-breaches-increase-40-in-2016/, 2017.
- [52] Shuang Song, Susan Little, Sanjay Mehta, Staal Vinterboy, and Kamalika Chaudhuri. Differentially private continual release of graph statistics. CoRR, 1809.02575, 2018.
- [53] Haipei Sun, Xiaokui Xiao, Issa Khalil, Yin Yang, Zhan Qui, Hui (Wendy) Wang, and Ting Yu. Analyzing subgraph statistics from extended local views with decentralized differential privacy. In Proc. CCS’19, pages 703–717, 2019.
- [54] Om Thakkar, Galen Andrew, and H. Brendan McMahan. Differentially private learning with adaptive clipping. CoRR, 1905.03871, 2019.
- [55] Abhradeep Guha Thakurta, Andrew H. Vyrros, Umesh S. Vaishampayan, Gaurav Kapoor, Julien Freudiger, Vivek Rangarajan Sridhar, and Doug Davidson. Learning New Words, US Patent 9,594,741, Mar. 14 2017.
- [56] Úlfar Erlingsson, Vasyl Pihur, and Aleksandra Korolova. RAPPOR: Randomized aggregatable privacy-preserving ordinal response. In Proc. CCS’14, pages 1054–1067, 2014.
- [57] Tianhao Wang, Jeremiah Blocki, Ninghui Li, and Somesh Jha. Locally differentially private protocols for frequency estimation. In Proc. USENIX Security’17, pages 729–745, 2017.
- [58] Yue Wang and Xintao Wu. Preserving differential privacy in degree-correlation based graph generation. Transactions on Data Privacy, 6(2), 2013.
- [59] Yue Wang, Xintao Wu, and Leting Wu. Differential privacy preserving spectral graph analysis. In Proc. PAKDD’13, pages 329–340, 2013.
- [60] Stanley L. Warner. Randomized response: A survey technique for eliminating evasive answer bias. Journal of the American Statistical Association, 60(309):63–69, 1965.
- [61] Xiaokui Xiao, Gabriel Bender, Michael Hay, and Johannes Gehrke. ireduct: Differential privacy with reduced relative errors. In Proc. SIGMOD’11, pages 229–240, 2011.
- [62] Min Ye and Alexander Barga. Optimal schemes for discrete distribution estimation under local differential privacy. In Proc. ISIT’17, pages 759––763, 2017.
- [63] Qingqing Ye, Haibo Hu, Man Ho Au, Xiaofeng Meng, and Xiaokui Xiao. Towards locally differentially private generic graph metric estimation. In Proc. ICDE’20, pages 1922–1925, 2020.
- [64] Qingqing Ye, Haibo Hu, Man Ho Au, Xiaofeng Meng, and Xiaokui Xiao. LF-GDPR: A framework for estimating graph metrics with local differential privacy. IEEE Transactions on Knowledge and Data Engineering (Early Access), pages 1–16, 2021.
- [65] Hailong Zhang, Sufian Latif, Raef Bassily, and Atanas Rountev. Differentially-private control-flow node coverage for software usage analysis. In Proc. USENIX Security’20, pages 1021–1038, 2020.
Appendix A Effectiveness of empirical estimation in LocalRR△
In Section 4.2, we presented LocalRR△, which uses the empirical estimation method after the RR. Here we show the effectiveness of empirical estimation by comparing LocalRR△ with the RR without empirical estimation [46, 63].
As the RR without empirical estimation, we applied the RR to the lower triangular part of the adjacency matrix ; i.e., we ran lines 1 to 6 in Algorithm 2. Then we output the number of noisy triangles . We denote this algorithm by RR w/o emp.
Figure 10 shows the loss of LocalRR△ and RR w/o emp when we changed from to or in edge LDP from to . The experimental set-up is the same as Section 5.1. Figure 10 shows that LocalRR△ significantly outperforms RR w/o emp, which means that the loss is significantly reduced by empirical estimation. As shown in Section 5, the loss of LocalRR△ is also significantly reduced by an additional round of interaction.

Appendix B Experiments on Barabási-Albert Graphs
Experimental set-up. In Section 5, we evaluated our algorithms using two real datasets: IMDB and Orkut. We also evaluated our algorithms using artificial graphs that have power-law degree distributions. We used the BA (Barabási-Albert) model [9] to generate such graphs.
In the BA model, an artificial graph (referred to as a BA graph) is grown by adding new nodes one at a time. Each new node is connected to existing nodes with probability proportional to the degree of the existing node. In our experiments, we used NetworkX [26], a Python package for graph analysis, to generate BA graphs.
We generated a BA graph with nodes using NetworkX. For the attachment parameter , we set or . When (resp. ), the average degree of was (resp. ). For each case, we randomly generated users from the whole graph , and extracted a graph with the users. Then we estimated the number of triangles and the number of -stars . For triangles, we evaluated LocalRR△, Local2Rounds△, and CentralLap. For -stars, we evaluated LocalLap and CentralLap. In Local2Rounds△, we set . For , we set .
We evaluated the loss while changing and . We attempted ways to randomly select users from , and averaged the loss over all the ways to randomly select users. As with Section 5, we set and changed from to while fixing . Then we set and changed from to while fixing .
Experimental results. Figure 11 shows the results. Overall, Figure 11 has a similar tendency to Figures 5, 6, and 7. For example, Local2Rounds△ significantly outperforms LocalRR△, especially when the graph is sparse; i.e., . In Local2Rounds△, CentralLap, LocalLap, and CentralLap, the loss increases with increase in . This is because the maximum degree increases with increase in .

Figure 11 also shows that the loss is roughly consistent with our upper-bounds in Section 4. For example, recall that LocalRR△, Local2Rounds△, CentralLap△, LocalLap2⋆, and CentralLap2⋆ achieve the expected loss of , , , , and , respectively. Assuming that , the left panels of Figure 11 are roughly consistent with these upper-bounds. In addition, the right panels of Figure 11 show that when we set and decrease from to , the loss increases by a factor of about , , and in LocalRR△, Local2Rounds△, and CentralLap△, respectively. They are roughly consistent with our upper-bounds – for small , the expected loss of LocalRR△, Local2Rounds△, and CentralLap△ is , , and , respectively.
In summary, for both the two real datasets and the BA graphs, our experimental results showed the following findings: (1) Local2Rounds△ significantly outperforms LocalRR△, especially when the graph is sparse; (2) our experimental results are roughly consistent with our upper-bounds.
Appendix C Construction of an independent cube for
Suppose that is even and is divisible by . Since , it is possible to write for integers such that and . Because and are even, we must have is even. Now, we can write . Thus, we can define a graph on nodes consisting of cliques of even size and one final clique of an even size with all cliques disjoint.
Since consists of even-sized cliques, it contains a perfect matching . Figure 12 shows examples of and , where , , , and . Let such that . Let . Each edge in is part of at least triangles. For each pair of edges in , the triangles of of which they are part are disjoint. Thus, for any edge , removing from a graph in will remove at least triangles. This implies that is an independent cube for .

Appendix D Proof of Statements in Section 4
Here we prove the statements in Section 4. Our proofs will repeatedly use the well-known bias-variance decomposition [40], which we briefly explain below. We denote the variance of the random variable by . If we are producing a private, randomized estimate of the graph function , then the expected loss (over the randomness in the algorithm) can be written as:
| (7) |
The first term is the bias, and the second term is the variance. If the estimate is unbiased (i.e., ), then the expected loss is equal to the variance.
D.1 Proof of Theorem 1
Let be LocalLapk⋆. Let be the number of “1”s in two neighbor lists that differ in one bit. Let and . Below we consider two cases about : when and when .
Case 1: . In this case, both and do not change after graph projection, as . Then we obtain:
where . Therefore,
| (8) | ||||
If , then in (8) can be written as follows:
Since we add to , we obtain:
| (9) |
If , then and (9) holds. Therefore, LocalLapk⋆ provides -edge LDP.
Case 2: . Assume that . In this case, . Therefore, becomes after graph projection. In addition, also becomes after graph projection. Therefore, we obtain after graph projection. Thus .
Assume that . If , then after graph projection. Thus . If , then (9) holds. Therefore, LocalLapk⋆ provides -edge LDP. ∎
D.2 Proof of Theorem 2
Assuming the maximum degree of is at most , the only randomness in the algorithm will be the Laplace noise since graph projection will not occur. Since the Laplacian noise has mean , the estimate is unbiased. Then by the bias-variance decomposition [40], the expected loss is equal to the variance of . The variance of can be written as follows:
Since , we obtain:
∎
D.3 Proof of Proposition 2
Let and be a matrix such that:
| (14) |
Let be respectively the number of triangles, 2-edges, 1-edge, and no-edges in . Then we obtain:
| (15) |
In other words, is a transition matrix from a type of subgraph (i.e., triangle, 2-edges, 1-edge, or no-edge) in to a type of subgraph in .
D.4 Proof of Theorem 3
Since LocalRR△ applies the RR to the lower triangular part of the adjacency matrix , it provides -edge LDP for . Lines 5 to 8 in Algorithm 2 are post-processing of . Thus, by the immunity to post-processing [23], LocalRR△ provides -edge LDP for the output .
In addition, the existence of edge affects only one element in the lower triangular part of . Therefore, LocalRR△ provides -relationship DP.
D.5 Proof of Theorem 4
By Proposition 2, the estimate by LocalRR△ is unbiased. Then by the bias-variance decomposition [40], the expected loss is equal to the variance of . Let , , , and . Then the variance of can be written as follows:
| (19) |
where represents the covariance of and . The covariance can be written as follows:
| (20) |
| (21) |
Below we calculate , , , and by assuming the Erdös-Rényi model for :
Lemma 1.
Let . Let and . Then , , and .
Before going into the proof of Lemma 1, we prove Theorem 4 using Lemma 1. By (21) and Lemma 1, we obtain:
which proves Theorem 4. ∎
We now prove Lemma 1:
Proof of Lemma 1.
Fist we show the variance of and . Then we show the variance of and .
Variance of and . Since each edge in the original graph is independently generated with probability , each edge in the noisy graph is independently generated with probability , where . Thus is the number of triangles in graph .
For , let be a variable that takes if and only if forms a triangle. Then can be written as follows:
| (22) |
in (22) is the probability that both and form a triangle. This event can be divided into the following four types:
-
1.
. There are such terms in (22). For each term, .
-
2.
and have two elements in common. There are such terms in (22). For each term, .
-
3.
and have one element in common. There are such terms in (22). For each term, .
-
4.
and have no common elements. There are such terms in in (22). For each term, .
Moreover, . Therefore, the variance of can be written as follows:
By changing to and counting triangles, we get a random variable with the same distribution as . Thus,
Variance of and . For , let be a variable that takes if and only if forms -edges (i.e., exactly one edge is missing in the three nodes). Then can be written as follows:
| (23) |
in (23) is the probability that both and form -edges. This event can be divided into the following four types:
-
1.
. There are such terms in (23). For each term, .
-
2.
and have two elements in common. There are such terms in (23). For example, consider a term in which , , , and . Both and form 2-edges if:
(a) , ,
(b) , ,
(c) , ,
(d) , , or
(e) , .
Thus, for this term. Similarly, for the other terms. -
3.
and have one element in common. There are such terms in (23). For each term, .
-
4.
and have no common elements. There are such terms in (23). For each term, .
Moreover, . Therefore, the variance of can be written as follows:
By simple calculations,
Thus we obtain:
Similarly, the variance of can be written as follows:
∎
D.6 Proof of Proposition 3
Let and . Let be the number of triplets such that , , and . Let be the number of triplets such that , . Note that and .
Consider a triangle . This triangle is counted () times in expectation in . Consider -edges (i.e., exactly one edge is missing in the three nodes). This is counted () times in expectation in . No other events can change . Therefore, we obtain:
By and , we obtain:
hence
∎
D.7 Proof of Theorem 5
Let be Local2Rounds△. Consider two neighbor lists that differ in one bit. Let (resp. ) be the number of “1”s in (resp. ). Let (resp. ) be neighbor lists obtained by setting all of the -th to the -th elements in (resp. ) to . Let (resp. ) be the number of “1”s in (resp. ). For example, if , , and , then , , , , , and .
Furthermore, let (resp. ) be the number of triplets such that , , , and in (resp. ). Let (resp. ) be the number of triplets such that , , and in (resp. ). Let and . Below we consider two cases about : when and when .
Case 1: . Assume that . In this case, we have either or . If , then , , and , hence . If , then and can be expressed as and , respectively. Then we obtain:
In addition, since we consider an additional constraint “” in counting and , we have . Therefore,
Since we add to , we obtain:
| (24) |
Assume that . In this case, we have either or . If , then . If , then we obtain and . Thus and (24) holds. Therefore, Local2Rounds△ provides -edge LDP at the second round. Since Local2Rounds△ provides -edge LDP at the first round (by Theorem 3), it provides -edge LDP in total by the composition theorem [23].
Case 2: . Assume that . In this case, we obtain after graph projection.
Note that and can differ in zero or two bits after graph projection. For example, consider the case where , , , and . If the permutation is 1,4,6,8,2,7,5,3, then after graph projection. However, if the permutation is 3,1,4,6,8,2,7,5, then and become and , respectively; i.e., they differ in the third and eighth elements.
If , then . If and differ in two bits, and differ in at most two bits (because we set all of the -th to the -th elements in and to ). For example, we can consider the following three cases:
-
•
If and , then .
-
•
If and , then and ; i.e., they differ in one bit.
-
•
If and , then and ; i.e., they differ in two bits.
If , then . If and differ in one bit, then . In this case, we obtain (24) in the same way as Case 1.
We need to be careful when and differ in two bits. In this case, (because after graph projection). Then we obtain . Since the number of -stars that involve a particular user in is , we obtain . Therefore,
and (24) holds. Therefore, if , then Local2Rounds△ provides -edge LDP in total.
Assume that . If , then after graph projection. Thus Local2Rounds△ provides -edge LDP in total in the same as above. If , then we obtain (24) in the same way as Case 1, and therefore Local2Rounds△ provides -edge LDP in total.
In summary, Local2Rounds△ provides -edge LDP in both Case 1 and Case 2. Local2Rounds△ also provides -relationship DP because it uses only the lower triangular part of the adjacency matrix . ∎
D.8 Proof of Theorem 6
When the maximum degree of is at most , no graph projection will occur. By Proposition 3, the estimate by Local2Rounds△ is unbiased.
By bias-variance decomposition (7), the expected loss is equal to . Recall that . can be written as follows:
| (25) | |||
| (26) |
In the last line, we are able to get rid of the ’s because they are deterministic. We are also able to sum the variances of the Lap random variables since they are independent; we are not able to do the same with the sum of the s.
Recall the definition of computed by the first round of Local2Rounds△—the noisy edges released by randomized response. Now,
This gives
Let . Notice that are independent events. Thus, the variance of the above expression is
| (27) |
is the number of ordered 2-paths from to in . Because the degree of user is at most , . There are at most ordered 2-paths in , since there are only nodes to go to once a first is picked. Thus, . Using a Jensen’s inequality style argument, the best way to maximize (27) is to have all be or . At most of the can be , and the rest are zero. Thus,
Plugging this into (26)
∎
D.9 Proof of Theorem 7
Preliminaries.
We begin by defining a Boolean version of the independent cube in Definition 5, which we call the Boolean independent cube. The Boolean independent cube works for functions in the local DP model, where each of users has a single bit and obfuscates the bit to provide -DP. As shown later, there is a one-to-one correspondence between the independent cube in Definition 5 and the Boolean independent cube. Based on this, we show a lower-bound for the Boolean independent cube, and use the lower-bound to prove Theorem 7.
Below we define the Boolean independent cube. For , let be a bit of user . Let . We assume user obfuscates using a randomizer , where satisfies -DP and is a range of . Examples of include Warner’s RR. Furthermore, we assume the one-round setting, where each is independent, and where the estimator for has the form
| (28) |
is an aggregate function that takes as input and outputs .
We will prove a lower bound which uses the following stripped-down form of an independent cube (Definition 5).
Definition 6.
[Boolean -independent cube] Let , and . We say has a Boolean -independent cube if for all we have
where satisfies for any .
The following theorem applies to the Boolean independent cube and will help us establish Theorem 7. We prove this theorem in Section D.10.
Theorem 8.
Let be a function that has a Boolean -independent cube. Let be an estimator having the form of (28), where each provides -DP and is mutually independent. Let be drawn uniformly from . Over the randomness both in selecting and in , .
Proof of Theorem 7 using Theorem 8.
To prove Theorem 7, let be the -independent cube (Definition 5) for given in the statement of Theorem 7. Let be the graph, and be the corresponding symmetric adjacency matrix. Below we sometimes write as a function on neighbor lists (rather than ) because there is a one-to-one correspondence between and . Let be the perfect matching that defines . Let .
The idea is to pair up users that matches to make a new function that has a Boolean -independent cube and new randomizers that satisfy -DP. In other words, we regard a pair of users in as a virtual user (since , there are virtual users in total). Then we apply Theorem 8.
Assume that without loss of generality (we can construct and for arbitrary in the same way). For , define
where is the -th standard basis vector that has in the -th coordinate and elsewhere. In other words, indicates whether the -th edge in should be added to . Thus, has a Boolean -independent cube, and there is a one-to-one correspondence between an -independent cube in Definition 5 and -Boolean independent cube in Definition 6. Figure 13 shows a -Boolean independent cube for corresponding to the -independent cube for in Figure 3.

Now, for , define for by
| (29) |
In other words, is simply the product of the outputs of users , with indicating whether to add the edge in between them.
Assume that each is mutually independent and that provides -relationship DP in Definition 3. Then by (3) and (29), each provides -DP and is mutually independent.
Since there is a one-to-one correspondence between the ()-independent cube and the ()-Boolean independent cube , we also have
where is drawn uniformly from , which proves Theorem 7. ∎
D.10 Proof of Theorem 8
Assume that . For , let and with . We rewrite the quantity of interest as
By the law of total expectation, this quantity is the same as the expected value of the conditional expected value of given :
| (30) |
Let . Then the inner expectation in (30) can be written as follows:
Thus, it suffices to show that . For , we have
Since does not depend on and , can also be expressed as
| (31) |
Since are independently run, we have
Define
Because each satisfies -DP, we have . By (31) and , we have
| (32) |
This means that is distributed according to the independent product of for .
Now, because has a Boolean -independent cube, there are with such that
By (32), is an independent draw from given . Thus, the variance of given is
∎