Localized Graph Collaborative Filtering
Abstract
User-item interactions in recommendations can be naturally denoted as a user-item bipartite graph. Given the success of graph neural networks (GNNs) in graph representation learning, GNN-based Collaborative Filtering (CF) methods have been proposed to advance recommender systems. These methods often make recommendations based on the learned user and item embeddings. However, we found that they do not perform well with sparse user-item graphs which are quite common in real-world recommendations. Therefore, in this work, we introduce a novel perspective to build GNN-based CF methods for recommendations which leads to the proposed framework Localized Graph Collaborative Filtering (LGCF). One key advantage of LGCF is that it does not need to learn embeddings for each user and item, which is challenging in sparse scenarios. Alternatively, LGCF aims at encoding useful CF information into a localized graph and making recommendations based on such graph. Extensive experiments on various datasets validate the effectiveness of LGCF, especially in sparse scenarios. Furthermore, empirical results demonstrate that LGCF provides complementary information to the embedding-based CF model which can be utilized to boost recommendation performance.
1 Introduction.
The rapid development of information technology has facilitated an explosion of information, and it has accentuated the challenge of information overload. Recommender systems aim to mitigate the information overload problem by suggesting a small set of items for users to meet their personalized interests. They have been widely adopted by various online services such as e-commerce and social media [15]. The key to build a personalized recommender system lies in modeling users’ preference on items based on their historical interactions (e.g., ratings and clicks), known as collaborative filtering (CF) [16]. In recommendation systems, the user-item interactions can naturally form a bipartite graph and GNNs have shown great potential to further improve the CF performance [19, 7]. GNNs are capable of capturing the CF signals encoded in the graph topology. Specifically, high-order user-item interactions can be explicitly captured by the stacked GNN layers, which contributes to learning expressive representations. For example, Neural Graph Collaborative Filtering (NGCF) [19] stacks several embedding propagation layers to explicitly encode the high-order connectivity in the user-item graph into the embedding process. LightGCN [7] simplifies the design for GNNs for recommendation by only including neighborhood aggregation while eliminating other operations such as feature transformation.


The key advantage of GNN-based CF methods is to learn both the embeddings and a GNN model by explicitly capturing the structural information in the user-item interaction graph. However, we empirically found that the improvement may no longer exist when the bipartite graph is very sparse. In Figure 1, we illustrate how the sparsity of user-item bipartite graph affects the performance of representative CF models including MF, NGCF and LightGCN. Specifically, we adjust the sparsity of the user-item graphs from two different commodity categories in the Tianchi dataset [1] by randomly removing edges from the original graph while not disrupting the graph connectivity. We use (i.e., the x-axis) to denote the sparsity of a bipartite graph where the larger is, the sparser the graph is. As shown in Figure 1, the performance of all the methods drops when the graph sparsity increases, in which GNN-based methods (NGCF and LightGCN) yield more dramatic performance reduction compared with MF. The inferior performance of GNN-based methods under the sparse setting could be attributed to the difficulty to learn high-quality user/item embeddings from limited user-item interactions. However, the user-item interaction graphs are often sparse in the real-world recommendation scenarios [2]. Thus, in this paper, we study how to alleviate the challenge of sparsity while enjoying the merits of high-order topological connectivity. Note that in this work, we focus on addressing the recommendation tasks solely based on the historical interactions following the previous works [19, 7]. Our motivation lies in learning CF signals from local structures of the user-item interaction graph, and the proposed model is called Localized Graph Collaborative Filtering (LGCF). Particularly, given a user and an item, LGCF makes predictions about their interaction based on their local structural context in the bipartite graph, rather than the user and item embeddings. Further comparisons and discussions between the traditional GNN-based CF methods and the proposed LGCF can be found in Appendix A.
To achieve the goal of LGCF, we face two main challenges: (1) how to construct the localized graph given two target nodes, and (2) how to capture the important CF information from the localized graph. To solve these two challenges, LGCF first samples a set of nodes for two target nodes from their neighborhoods, and then generates a localized graph with this node set and their edges. Next, LGCF adopts a GNN model to extract a graph representation for each localized graph. To better capture the graph topological information, LGCF generates a label for each node according to their topological importance in the localized graph, and takes the set of node labels as input attributes. Finally, LGCF makes predictions about the target user and item based on their corresponding localized graph representation.
The contributions of this paper are summarized as follows: (1) We study a new perspective to build GNN-based CF models for recommendations. Specifically, we aim at learning the recommendation related patterns in the localized graphs induced from the input bipartite graph, instead of learning user and item embeddings; (2) We propose Localized Graph Collaborative Filtering (LGCF) which utilizes a GNN model and minimum distances based node labeling function to generate graph representation for each user-item pair. In this way, we can encode the localized graph topological information and high order connectivity into the graph representation simultaneously; (3) We validate the effectiveness of LGCF on numerous real-world datasets. Especially, LGCF can achieve significantly better performance than representative GNN-based CF methods when user-item bipartite graphs are sparse.

2 Problem Statement.
A CF-based recommendation dataset can be formulated as a bipartite graph , in which denotes a set of users, is the set of items, and (e.g., ) indicates the edge set describing the historical interactions between users and items. Following previous works [19, 7], we assume that users and items have no content information. Given a candidate pair consisting of a target user and a potential item , we need to calculate a preference score to indicate how likely this potential item should be recommended to the target user. To solve this problem, we aim at learning a desirable score mapping function , which generates a preference score to make recommendations based on the historical interactions E.
3 The Proposed Framework.
In this section, we first give an overall description of the proposed framework, then detail its key modules, next introduce the optimization objective and finally discuss integration strategies with existing GNN-based CF methods. Note that compared to existing GNN-based recommendation methods, the mode size of LGCF is much smaller and is independent on the number of users and items. More details about the mode size analysis can be found in Appendix B.
The goal of LGCF is to learn CF-related knowledge for each user-item pair from its local structures in an interaction bipartite graph. To achieve this goal, it provides solutions to tackle two aforementioned obstacles – a local structure extraction to construct the localized graph for the user-item pair and a powerful model to capture the CF-related patterns from the localized graph. An overview of LGCF is illustrated in Figure 2. Specifically, given the input bipartite graph, LGCF first constructs the localized graphs centered with the target user and the target item. To preserve edges with rich CF information into the localized graph, we develop a localized graph construction method to efficiently generate the localized graphs. After that, LGCF labels the nodes within the localized graphs according to the topological positions relative to the target nodes. Then a GNN-based graph representation learning module will embed the high-order connectivity along with the node positional annotations simultaneously. Through this process, LGCF eliminates the traditional embedding-based strategy and effectively captures the critical CF-related patterns. Finally, the scoring function module calculates the preference score based on the learned graph representation. To sum up, there are three key modules in this framework: (1) the localized graph construction module that extracts a localized graph covering most edges related to a given user-item pair; (2) the localized graph representation learning module that learns recommendation related representations from the localized graph ; and (3) the scoring function module that computes a preference score based on the learned graph representation. Next we will detail each module.
3.1 Localized Graph Construction.
The localized graph construction module is designed to extract the localized graph covering the most important edges (i.e., collaborative filtering information) for a given user-item pair. We need to extract a localized graph for each user-item pair in the training process and the inference process, thus we aim to include the most representative edges for each pair with the consideration of scalability. To achieve these goals, we propose a localized graph construction as shown in Figure 3. This framework can be divided into three steps: (1) step 1 -random walk: we first take advantage of random walk with restart (RWR) [17] method to sample neighboring nodes for the user node and the item node. By using RWR, we can sample neighboring nodes which are different hops away from the center node. As a consequence, we can get a representative localized graph which captures abundant context information. Meanwhile, RWR is a sampling method in essence, thus it can naturally improve the scalability of the proposed LGCF. Specifically, given a user-item bipartite graph and a user-item pair , we perform a random walk on from the user node and the item node , respectively. Starting from the original node, each walk travels to one of the connected nodes iteratively with a uniform probability. In addition, there is a pre-defined probability for each walk to return to the starting node at each step. In this way, more neighboring nodes can be included in the walk. Via RWR, we can get two traces and for the user node and the item node , respectively. Each trace then can be denoted as a node subset, i.e., and . (2) step 2 - trace union: Next, we merge and into a union node subset . (3) step 3 - graph extraction: With this union node subset , we can extract a localized graph from the original user-item graph. Specifically, all the nodes in and all the edges among these nodes are extracted from the original graph to build a localized graph, which is denoted as . To conclude, consists of neighboring nodes of different hops away from and and thus preserves important collaborative filtering information for the given user-item pair .

3.2 Localized Graph Representation Learning.
This module aims at learning an overall representation for each user-item pair based on its extracted localized graph. We expect to encode the CF information and also the high-order connectivity related to a user-item pair into this representation. Therefore, we propose to use a graph neural network model since it can naturally capture the structural information and explicitly encode the high-order connectivity into the representation. Also, to further encode the topological information, we adopt a node labeling method to generate a positional label for each node based on its distance towards the user-item pair [24] where the node labels are considered as the input graph node attributes. Next, we will introduce the node labeling method and the adopted GNN model.
3.2.1 The Node Labeling Method.
Following the common setting from the previous works [19, 7], we do not assume that node attributes are available for LGCF. Instead, we generate a label for each node to indicate its unique role in the localized graph. Specifically, there are three expectations for the generated label. First, it is important to distinguish the target user and item from other nodes through the generated node labels, as the model should be aware of the target user-item pair. Second, for contextual nodes excluding the target user and item, they play different roles in the recommendation prediction considering their different relative position towards the target user and item. Thus, we need to distinguish these nodes via the generated node labels based on their positions; Finally, for the consistency of node labels, the closer the node is to both the target user and target item, the similar its label should be with that of the target ones. Therefore, we propose to use a node labeling method based on its distance to the user-item pair via Double-Radius Node Labeling (DRNL) [24] to generate a label for each node, and take the generated node labels as the input node attribute for the GNN model. The key motivations of DRNL are to distinguish the target user node and the item node from other nodes while preserving their relatively positional relations. Specifically, we first assign label to the target user node and the target item node to distinguish them from other nodes. Next, we assign labels to other nodes based on their minimum distances towards two target nodes on the extracted localized graph. Intuitively the closer the user or item node is to the target nodes, the more similar its label should be with that of the target nodes. For a specific node on the graph, we evaluate its distance towards the target user and the target item by summing up its minimum distances to these two nodes. Since we set the label of the target user and the target item as , we will also assign these nearby nodes labels with small values. In particular, given nodes and , if the distance between and the target nodes is smaller than that of , the label value of is supposed to be smaller than that of . If the distances are the same, the node with a smaller minimum distance to the target user or the target item should have a label with a smaller value. DRNL adopts a hashing function satisfying the criteria described above to compute node labels. The node labeling function for each node is summarized as follows:
| (3.1) |
where and denote the target user node and item node, respectively. () represents the minimum distance between nodes and (). is the sum of minimum distances which should be an odd due to the nature of the bipartite graphs.
3.2.2 The GNN Model.
For each user-item pair, we have extracted its localized graph , and it can be denoted as , where is the adjacency matrix of , and is the input node attributes generated by above node labeling method. It is natural to take advantage of a GNN model to learn an overall representation for each pair based on its localized graph , since GNNs have shown great potential in capturing complex patterns on graphs [20]. There are typically two key operations in a GNN model – the graph filtering operation to refine node representations and the graph pooling operation to abstract the graph-level representation from the node representations. In this work, we adopt graph convolutional filtering [11] as the graph filtering operation. Its process can be described as follows:
| (3.2) |
where denotes the node representations in the -th GNN layer, is the transformation matrix to be learned, represents the adjacency matrix with self-loops, is the diagonal degree matrix of and is the activation function. The node labels are set to be the input node representations . The graph pooling operation adopted by LGCF is sum pooling, which sums up representations all over the nodes for the graph-level representation. Its process can be denoted as follows:
| (3.3) |
where denotes the graph representation for the user-item pair and is the node representations outputted by the last layer. The overall process of the GNN model can be summarized as:
| (3.4) |
3.3 The Scoring Function.
The scoring function aims at giving a score for a user-item pair based on its corresponding localized graph representation . The higher the score is, the more likely the item should be recommended to the user. We use a single-layer linear neural network to model the scoring function in LGCF, which can be described as follows:
| (3.5) |
where is the transformation vector to be learned and is the sigmoid function.
3.4 Model Optimization.
In this work, we adopt the pairwise Bayesian Personalized Ranking (BPR) loss to train the framework. BPR loss is one of the most popular objective functions in recommendation tasks. It takes the relative order of the positive node pairs and negative node pairs where the positive node pairs are existent user-item node pairs observed in graphs, while the negative node pairs are non-existent user-item node pairs generated by negative sampling. Specifically, BPR assumes that the prediction scores of the positive node pairs should be larger than these of the corresponding negative ones. The objective function of our model is as follows:
| (3.6) |
where denotes the training data for the graph , is the set of the existent interactions between users and items in and indicates the set of the non-existent interactions. In this work, we adopt ADAM [10] to optimize the objective.
3.5 Integration with Embedding-based CF Methods.
LGCF aims at capturing the collaborative filtering information from a localized perspective by encoding the localized CF information into a subgraph level representation, while embedding-based GNN methods such as NGCF and LightGCN are to learn a set of user and item embeddings in the latent space based on all the user-item interactions. Therefore, LGCF provides a new perspective to build GNN based recommendations. As a consequence, LGCF is likely to provide complementary information to existing GNN based methods and integrating it with existing methods has the potential to boost the recommendation performance. In this subsection, we discuss strategies to combine LGCF with existing GNN based methods. In particular, we propose two strategies, i.e., LGCF-emb and LGCF-ens. Before we detail these strategies, we first denote the refined user and item embedding generated by embedding-based GNN methods as and , and the representation outputted by LGCG for a user-item pair as . In this work, we focus on how to integrate LGCF with LightGCN given the competitive performance of LightGCN.
3.5.1 LGCF-emb.
In LGCF-emb, we propose to directly concatenate the embeddings generated by LGCF and LightGCN, and then the scoring function takes the concatenated embedding as input to generate a score. Finally, the LGCF model and the LightGCN model are jointly trained by optimizing the objective function in Eq. 3.6. The concatenation process is summarized as follows:
| (3.7) |
where denotes element-wise multiplication and represents the concatenation operation.
3.5.2 LGCF-ens.
In LGCF-ens, we propose to combine LGCF and LightGCN in an ensemble way. Specifically, we conduct a weighted combination of the scores generated by LGCF and LightGCN. In addition, instead of joint training, we train LGCF and LightGCN, separately. The final score for a user-item pair can be computed as follows:
| (3.8) |
where denotes the scoring function in Eq 3.5 and can be either a predefined hyper-parameter or learnable parameter.
4 Experiment.
In this section, we conduct extensive experiments on various real-world datasets to validate the effectiveness of the proposed LGCF. Via experiments, we aim to answer the following questions: RQ1: How does LGCF perform compared with the state-of-the-art CF models on the sparse setting? RQ2: How does LGCF perform compared with the state-of-the-art CF models on the normal setting? RQ3: Can LGCF be complementary to the embedding-based GNN CF models? RQ4: How does the sparsity of data affect the performance of LGCF and other CF models?
In the following subsections, we will first introduce experimental settings, next design experiments to answer the above questions and we further probe to understand the working of LGCF.
4.1 Experimental Settings.
4.1.1 Datasets.
In our experiments, we have tested the proposed framework on twelve datasets, which are from three different real-world recommendation scenarios: Tianchi[1], Amazon[14] and MovieLens[6]. Specifically, we construct seven datasets corresponding to seven item categories from Tianchi and denote each of them as Tianchi-, where indicates the item category, two datasets from two item categories from Amazon and two datasets from two item categories from MovieLens. More details about these datasets can be found in the Appendix C. Note that it is common to extract a user-item interaction dataset based on the item category from a large recommendation dataset for evaluations that has been widely adopted by existing works [14, 19, 7].
4.1.2 Baselines and Evaluation Metrics.
We mainly compare the proposed method with LightGCN [7] and NGCF [19], which have empirically outperformed most recent CF-based models including NeuMF [8], PinSage [23] and HOP-Rec [22]. In addition, we also compare LGCF with one of the most classic factorization-based recommendation models – MF [12]. We use HR and NDCG as evaluation metrics in our experiments. More details about the baselines and evaluation details can be found in Appendix D.
| Tianchi | Amazon | MovieLens | |||||||||
| 685988 | 2798696 | 4527720 | 174490 | 61626 | 810632 | 3937919 | Beauty | Gift | War | Romance | |
| density | 0.0019 | 0.0106 | 0.0074 | 0.0036 | 0.0014 | 0.0019 | 0.0064 | 0.0121 | 0.0071 | 0.0113 | 0.0027 |
4.2 Performance in Sparse Scenarios.
The major motivation of LGCF is to improve the recommendation performance when there are a few user-item interactions or user-item interactions are sparse. Therefore, we start the evaluation by comparing the proposed method with baselines under the sparse setting, which correspondingly answers RQ1. Specifically, to obtain a sparse training user-item interaction bipartite graph, we randomly select as many interactions as possible as the validation set or the test set while ensuring no isolated nodes in the training set and no cold-start nodes in the validation set and the test set. After this process, the densities of the resulting sparse graphs are summarized in Table 1.
| HR() | Tianchi | Amazon | MovieLens | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 685988 | 2798696 | 4527720 | 174490 | 61626 | 810632 | 3937919 | Beauty | Gift | War | Romance | |
| MF | 28.42.3 | 19.84.9 | 25.43.1 | 27.01.7 | 15.61.2 | 25.21.9 | 38.75.2 | 64.37.4 | 12.70.3 | 55.83.0 | 57.71.0 |
| NGCF | 36.73.0 | 25.64.2 | 32.73.3 | 37.24.2 | 17.82.2 | 36.0 2.3 | 47.53.0 | 83.10.7 | 14.40.3 | 63.51.1 | 71.00.2 |
| LightGCN | 29.42.1 | 22.13.9 | 25.9 3.6 | 25.93.6 | 18.81.8 | 28.21.4 | 24.41.7 | 39.16.6 | 14.50.3 | 32.42.0 | 36.01.0 |
| LGCF | 65.30.4 | 39.70.6 | 60.21.0 | 66.20.5 | 41.63.0 | 60.70.2 | 61.60.2 | 88.00.4 | 32.42.0 | 81.10.5 | 82.7 1.2 |
The performance comparison on these sparse datasets is demonstrated in Table 3. We make the following observations: 1) The performance of LightGCN is worse than NGCF on most datasets. These results suggest that only neighborhood aggregation may not help embedding refinement in sparse scenarios; 2) LGCF outperforms other baselines on the sparse datasets significantly, which supports that capturing local structures is more effective than learning user and item embeddings in sparse scenarios. Meanwhile, this validates the effectiveness of LGCF in capturing CF information from local structures on sparse user-item bipartite graphs. More details about how the sparsity impacts the performance and why LGCF can improve the performance will be provided in the following subsections.
4.3 Performance in Normal Scenarios.
In the last subsection, we empirically demonstrated the superior of LGCF over the baseline methods in sparse scenarios. In this section, we further study how LGCF performs in normal settings where we ensure we have sufficient training data. To achieve the goal, we randomly select 90% of user-item interactions as the training set, and then divide the remaining interactions into the validation set and the test set equally. Since LGCF makes recommendations from a different perspective from LGCF and LightGCN, we also investigate if LGCF is complementary to them. These experiments aim to answer RQ2 and RQ3. The results are summarized in Table 3. It can be observed: 1) LGCF can often perform reasonably that achieves comparable performance with the baseline methods on most datasets; 2) LGCF-ens has shown significant performance improvement over both LGCF and LightGCN on most datasets. This demonstrates that LGCF indeed provides complementary information to embedding-based CF methods. Thus, there is a great potential to integrate these methods for the recommendation task; 3) LGCF-emb does not perform well on some datasets. It directly concatenates embeddings from LGCF and LightGCN. However, the embeddings from LGCF and LightGCN could be not aligned. Among the integration methods, LGCF-ens achieves consistent and better performance compared to LGCF-emb.
| HR() | Tianchi | Amazon | MovieLens | ||||||||
| 685988 | 2798696 | 4527720 | 174490 | 61626 | 810632 | 3937919 | Beauty | Gift | War | Romance | |
| MF | 57.33.0 | 22.03.0 | 43.94.1 | 41.63.3 | 22.34.6 | 70.7 1.6 | 38.75.3 | 93.71.4 | 44.24.1 | 72.01.7 | 77.70.5 |
| NGCF | 69.61.8 | 29.73.7 | 56.02.1 | 55.23.0 | 37.13.7 | 53.62.9 | 47.53.0 | 93.51.1 | 46.42.4 | 75.50.5 | 82.60.2 |
| LightGCN | 76.21.2 | 32.42.9 | 62.71.7 | 60.31.1 | 44.03.5 | 74.10.6 | 55.63.6 | 94.41.1 | 51.40.3 | 80.91.0 | 85.30.2 |
| LGCF | 76.91.2 | 49.32.5 | 59.31.7 | 63.43.5 | 46.95.6 | 71.22.3 | 55.71.6 | 91.52.5 | 36.96.1 | 65.512.9 | 77.35.6 |
| LGCF-emb | 72.17.1 | 46.33.1 | 54.15.9 | 62.43.7 | 50.03.0 | 71.03.1 | 57.83.0 | 92.62.0 | 36.68.3 | 64.77.6 | 81.52.8 |
| LGCF-ens | 76.81.1 | 44.84.1 | 62.73.3 | 67.3 2.1 | 54.52.4 | 74.91.0 | 61.72.1 | 94.70.7 | 52.81.0 | 87.50.4 | 88.50.4 |
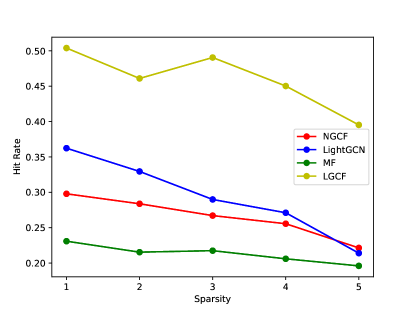



4.4 The Impact of Sparsity.
In this subsection, we further explore RQ4: how the sparsity of the training user-item bipartite graph affects the performance of different models. Specifically, we first randomly select 10% user-item interactions and split them equally into the validation set and the test set. Note that we constrain there are no cold-start users and items in the validation set and the test set. We take the remaining 90% interactions as the full training set, and denote its sparsity as . Next, we divide the full training set into two sets: the necessary set and the additional set. The necessary set consists of the minimum interactions to ensure all the users and items connected with at least one neighbor and the additional set includes the remaining interactions. We randomly select 20%, 40%, 60% and 80% of interactions from the additional set and exclude them from the full training set to increase the sparsity of the training user-item bipartite graphs. Here we denote the sparsity of these training graphs as , respectively. The performance of LGCF, LGCF-enz and the baseline methods are shown in Figure 4. (We have similar observations on most of datasets, and we select four of them to report due to the space limitation) We can observe that the performance of all the methods tends to decrease with the increase of graph sparsity. However, the performance drop of LightGCN and NGCF is relatively more significant than that of the proposed LGCF. LightGCN and LGCF typically perform comparably on the least sparse cases, and then the performance gap tends to increase with the graph sparsity raises. In addition, LGCF-enz is more robust to the sparsity change compared to LightGCN, which demonstrates that the integration of LGCF can help LightGCN reduce its sensitivity towards graph sparsity.
4.5 Further Probing.
In this subsection, we explore to further understand how LGCF works. As mentioned before, LGCF provides a new perspective to build GNN-based CF methods. Experimental results in Table 3 have demonstrated that LGCF is complementary to LightGCN. Thus, we first examine how LGCF is complementary to LightGCN for different types of user-item pairs. Moreover, localized graphs play a crucial role in LGCF. Therefore, we investigate if localized graphs for positive and negative pairs are distinguishable via case studies.
4.5.1 How is LGCF complementary to LightGCN.
To explore what kind of user-item pairs can benefit by integrating LGCF and LightGCN, we divide the test set in normal scenarios into different groups based on the average degree of the user and the item for a user-item pair. Specifically, we first sort all the user-item pairs in the test set in ascending order according to their average degree, and divide the sorted pairs into groups. We then train models on the same training set and test them on these groups. The performance of LightGCN, LGCF and LGCF-ens is shown in Figure 5. More results on different datasets can be found in Appendix E. We first note that the performance of all methods tends to increase when degree increases. In most cases, for all degree groups, LGCF-ens (or integrating LGCF and LightGCN) can boost the recommendation performance. This improvement is relatively more significant for groups with small degree. These results suggest that LGCF provides complementary information to LightGCN for all degree groups especially for these groups with small degree. This property has its significance in practice since how to make recommendations for user-item pairs with limited interactions is still a challenging problem in real-world recommender systems. In addition, this property makes the proposed method potentially computation-efficient for large-scale datasets, since we can first filter items that are less likely to be preferred by a given user based on embeddings and then leverage LGCF to rank the remaining items.


4.5.2 Localized Graphs.
The key to the success of LGCF is that the extracted localized graphs for positive and negative pairs are distinguishable. In other words, they have distinct structures. Thus, we visualize the extracted localized graphs for two positive user-item pairs and their corresponding negative pairs in Figure 6. Note that these two pairs are correctly predicted by LGCF, while wrongly predicted by LightGCN. For the figure, we observe that the localized graphs for positive pairs are substantially different from these of negative pairs, and thus LGCF can distinguish them and make correct predictions. These case studies not only validate the feasibility of using localized graphs for recommendations but also further demonstrate that recommendations via localized graphs are complementary to these via embeddings.




5 Related work.
Collaborative Filtering (CF) is one of the most popular techniques for recommendation [3]. Its core idea is to make predictions of a user’s preference by analyzing its historical interests. There are basically two types of CF methods: memory-based CF methods and model-based models. Memory-based CF methods aim at making predictions by memorizing its similar users’ (or items’) historical interactions [9]. Model-based CF methods [12] aim at predicting by inferring from an underlying model. With the rapid development of deep neural networks (DNNs), there are more and more works exploring incorporating DNN techniques into model-based CF methods [8, 21]. As DNN successfully generalizes to graphs, graph neural networks (GNNs) have drawn great attention. User-item interactions in recommendations can be naturally denoted as a bipartite graph. Thus, more and more works study how to utilize GNN techniques in model-based CF methods including HOP-Rec [22], PinSage [23], NGCF [19] and LightGCN [7]. Specifically, HOP-Rec [22] includes multi-hop connections into the MF method. PinSage [23] is developed based on GraphSage [5], and it can be directly applied in industry-level recommendations. NGCF [19] proposes to explicitly encode high-order connectivity into representation via graph filtering operation. LightGCN [7] simplifies the design of GNN specially for the recommendation task by eliminating feature transformation and activation function.
6 Conclusion.
In this paper, we propose a GNN-based CF model LGCF from a novel perspective for recommendations. It aims at encoding the collaborative filtering information into a localized graph representation. Different from existing embedding-based CF models, LGCF does not require learning embeddings for each user and item. Instead, it focuses on learning the recommendation-related patterns from the localized graph extracted from the input user-item interaction graph for a specific user-item pair. We have conducted extensive experiments to demonstrate the effectiveness of LGCF in recommendation tasks. In the future, we will explore other graph filter and pooling operations to learn the localized graph representations. In addition, we plan to explore some advanced techniques such as attention mechanism to further incorporate different types of GNN-based CF models.
References
- [1] User behavior data from taobao for recommendation. https://tianchi.aliyun.com/dataset/dataDetail?dataId=649&userId=1. Accessed May 23, 2021.
- [2] G. Adomavicius and A. Tuzhilin, Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions, IEEE transactions on knowledge and data engineering, 17 (2005), pp. 734–749.
- [3] C. C. Aggarwal, Model-based collaborative filtering, in Recommender systems, Springer, 2016, pp. 71–138.
- [4] H. Gao and S. Ji, Graph u-nets, in international conference on machine learning, PMLR, 2019.
- [5] W. L. Hamilton, R. Ying, and J. Leskovec, Inductive representation learning on large graphs, arXiv preprint arXiv:1706.02216, (2017).
- [6] F. M. Harper and J. A. Konstan, The movielens datasets: History and context, Acm transactions on interactive intelligent systems (tiis), 5 (2015).
- [7] X. He, K. Deng, X. Wang, Y. Li, Y. Zhang, and M. Wang, Lightgcn: Simplifying and powering graph convolution network for recommendation, in Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2020, pp. 639–648.
- [8] X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T.-S. Chua, Neural collaborative filtering, in Proceedings of the 26th international conference on world wide web, 2017, pp. 173–182.
- [9] T. Hofmann, Latent semantic models for collaborative filtering, ACM Transactions on Information Systems (TOIS), 22 (2004), pp. 89–115.
- [10] D. P. Kingma and J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980, (2014).
- [11] T. N. Kipf and M. Welling, Semi-supervised classification with graph convolutional networks, arXiv preprint arXiv:1609.02907, (2016).
- [12] Y. Koren, R. Bell, and C. Volinsky, Matrix factorization techniques for recommender systems, Computer, 42 (2009), pp. 30–37.
- [13] Y. Ma, S. Wang, C. C. Aggarwal, and J. Tang, Graph convolutional networks with eigenpooling, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019.
- [14] J. McAuley, Amazon product data. http://jmcauley.ucsd.edu/data/amazon/. Accessed May 23, 2021.
- [15] S. Okura, Y. Tagami, S. Ono, and A. Tajima, Embedding-based news recommendation for millions of users, in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017, pp. 1933–1942.
- [16] X. Su and T. M. Khoshgoftaar, A survey of collaborative filtering techniques, Advances in artificial intelligence, 2009 (2009).
- [17] H. Tong, C. Faloutsos, and J.-Y. Pan, Fast random walk with restart and its applications, in Sixth international conference on data mining (ICDM’06), IEEE, 2006, pp. 613–622.
- [18] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, Graph attention networks, arXiv preprint arXiv:1710.10903, (2017).
- [19] X. Wang, X. He, M. Wang, F. Feng, and T.-S. Chua, Neural graph collaborative filtering, in Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval, 2019, pp. 165–174.
- [20] K. Xu, W. Hu, J. Leskovec, and S. Jegelka, How powerful are graph neural networks?, arXiv preprint arXiv:1810.00826, (2018).
- [21] H.-J. Xue, X. Dai, J. Zhang, S. Huang, and J. Chen, Deep matrix factorization models for recommender systems., in IJCAI, vol. 17, Melbourne, Australia, 2017, pp. 3203–3209.
- [22] J.-H. Yang, C.-M. Chen, C.-J. Wang, and M.-F. Tsai, Hop-rec: high-order proximity for implicit recommendation, in Proceedings of the 12th ACM Conference on Recommender Systems, 2018, pp. 140–144.
- [23] R. Ying, R. He, K. Chen, P. Eksombatchai, W. L. Hamilton, and J. Leskovec, Graph convolutional neural networks for web-scale recommender systems, in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 974–983.
- [24] M. Zhang and Y. Chen, Link prediction based on graph neural networks, arXiv preprint arXiv:1802.09691, (2018).