Local Routing in a Tree Metric 1-Spanner
Abstract
Solomon and Elkin [14] constructed a shortcutting scheme for weighted trees which results in a 1-spanner for the tree metric induced by the input tree. The spanner has logarithmic lightness, logarithmic diameter, a linear number of edges and bounded degree (provided the input tree has bounded degree). This spanner has been applied in a series of papers devoted to designing bounded degree, low-diameter, low-weight -spanners in Euclidean and doubling metrics. In this paper, we present a simple local routing algorithm for this tree metric spanner. The algorithm has a routing ratio of 1, is guaranteed to terminate after hops and requires bits of storage per vertex where is the maximum degree of the tree on which the spanner is constructed. This local routing algorithm can be adapted to a local routing algorithm for a doubling metric spanner which makes use of the shortcutting scheme. ††A preliminary version of this paper appeared in the proceedings of COCOON’20 [6].
1 Introduction
Let be a weighted tree. The tree metric induced by , denoted , is the complete graph on the vertices of where the weight of each edge is the weight of the path connecting and in . For , a -spanner for a metric is a subgraph of the complete graph on such that every pair of distinct points is connected by a path in of total weight at most . We refer to such paths as -spanner paths. A -spanner has diameter if every pair of points is connected by a -spanner path consisting of at most edges. Typically, -spanners are designed to be sparse, often with a linear number of edges. The lightness of a graph is the ratio of its weight to the weight of its minimum spanning tree. Solomon and Elkin [14] define a 1-spanner for tree metrics. Given an vertex weighted tree of maximum degree , the 1-spanner has edges, diameter, lightness and maximum degree bounded by . While being an interesting construction in its own right, this tree metric 1-spanner has been used in a series of papers as a tool for reducing the diameter of various Euclidean and doubling metric spanner constructions [2, 7, 9, 14, 15].
Once a spanner has been constructed, it becomes important to find these short paths efficiently. A local routing algorithm for a weighted graph is a method by which a message can be sent from any vertex in to a given destination vertex. The successor to each vertex on the path traversed by the routing algorithm must be determined using only knowledge of the destination vertex, the neighbourhood of and possibly some extra information stored at . The efficiency of a routing algorithm is measured by the distance a message needs to travel through a network before reaching its destination as well as by the storage requirements for each vertex. There is a great deal of work on local routing algorithms in the literature. The difficulty of designing a good local routing algorithm clearly depends on the properties of the underlying network. Some authors have designed algorithms for very general classes of networks. For example, the algorithm of Chan et al. [8] works in any network although its quality depends on the induced doubling dimension. Many authors have focused on highly efficient algorithms for specific classes of networks. For example, there has been a line of research into routing algorithms for various classes of planar graphs [4, 5]. Support for efficient local routing algorithms is a desirable feature in a spanner and in some recent papers, researchers have designed spanners which simultaneously achieve support for efficient local routing with other properties. See, for example, the work of Ashvinkumar et al. [3].
There appears to be little work in the literature in designing spanners which achieve both support for local routing as well as low diameter. Given a spanner with diameter , it is natural to require that a local routing algorithm on this spanner match this diameter, i.e., the algorithm should be guaranteed to terminate after at most hops. Abraham and Malkhi [1] give a construction, for any , of a -spanner for points in two dimensional Euclidean space with an accompanying routing algorithm. The diameter of the routing algorithm is with high probability where is the quotient of the largest and smallest inter-point distances. The routing algorithm has routing ratio , with high probability, for points on a uniform grid.
In this paper, we demonstrate that the 1-spanner construction of Solomon and Elkin [14] supports a local routing algorithm with diameter in the worst case. In Section 4, we show that this routing algorithm can be adapted to a class of doubling metric -spanners which employ the 1-spanner construction to achieve low diameter while retaining low weight and low degree.
2 The Model
A local routing algorithm for a weighted graph is a distributed algorithm in which each vertex is an independent processor. At the beginning of a round, a node may find that it has received a message. If a message is received, the algorithm decides to which neighbour the message should be forwarded. The following information is available to each vertex in :
-
1.
A header contained in the message.
-
2.
The label of as well as labels of neighbouring vertices.
The message header stores the label of the destination vertex as well as other information if required by the routing algorithm. The labels are used not only as unique identifiers of vertices but may also store additional information if required. The labels of vertices are computed in a pre-processing step before the algorithm is run. Our model does not consider the running time of computation performed at each vertex in each round and so we do not specify the type of data structure used for headers and labels. The routing decision made at each vertex is deterministic. A routing algorithm is evaluated on the basis of the following quality measures.
-
•
Routing Ratio. Given two vertices , of , let denote the shortest path distance from to and let denote the total length of the path traversed by the routing algorithm when routing from to . The routing ratio is defined to be .
-
•
Diameter. A routing algorithm is said to have diameter if a message is guaranteed to reach its destination after traversing at most edges.
-
•
Storage. A bound on the number of bits stored at vertices and in message headers.
3 Local Routing in Tree Metrics
In this section we present a slightly modified version of the tree metric 1-spanner of Solomon and Elkin [14]. We then present our routing algorithm for this spanner and show that it has a routing ratio of 1.
3.1 The Spanner
In this section we describe the tree metric 1-spanner construction of Solomon and Elkin [14].
We first define some notation used in this section. will denote a weighted, rooted tree and will denote its weight. Given a graph , and denote its vertex and edge sets respectively. The root of is denoted and denotes the number of children of . As in the notation of [14], the children of a vertex are denoted and denotes the parent of a vertex . The lowest common ancestor of two vertices will be denoted by . Given , denotes the unique path from to in . Given , will denote the subtree of rooted at .
The shortcutting procedure selects a constant number of cut vertices in the tree whose removal results in a forest of trees which are at most a constant fraction of the size of the input tree. The spanner is obtained by building the complete graph on these cut vertices and recursively applying the procedure to all subtrees obtained by removing the cut vertices. We note that the original construction appearing due to Solomon and Elkin [14] actually builds a low diameter spanner on the cut vertices rather than the complete graph.
We first outline the method by which the cut vertices are selected. We assume that among all subtrees rooted at children of a vertex , the subtree rooted at the leftmost vertex is the largest. That is, , for all .
For an integer , we call a vertex -balanced if . We label an edge of as leftmost if or . Let denote the path of maximum length from to some descendant of which includes only leftmost edges. We say the last vertex on is the leftmost vertex in and we denote it by . We define . The construction we describe involves taking subtrees of an input tree. These subtrees inherit the ‘leftmost’ labelling of the input tree so it may be the case that . If there is a -balanced vertex along , we denote the first such vertex by . Otherwise, .
Given a rooted tree and a positive integer , we define a set of vertices as follows. Set . If , is defined to be . Otherwise,
Let be a positive integer. We define a set of vertices
where . (See Figure 1 for an example.) The spanner is constructed via the following recursive procedure which takes as input a tree and an integer parameter . Initialize the spanner as . Compute the set , with respect to , and add the edges of the complete graph on to . Denote by the forest obtained by removing the vertices in , along with all incident edges, from . Recursively run the algorithm on all trees in the forest and add the resulting edges to . Note that the parameter is passed down to recursive calls of the algorithm while the parameter is recomputed based on the size of the subtree on which the algorithm is called. The following lemmas are established by Solomon and Elkin [14]:
Lemma 3.1.
For , the set contains at most vertices.
Lemma 3.2.
Each tree in the forest has size at most .
In particular, Lemma 3.2 implies that the recursion depth of the spanner construction algorithm is for .

Solomon and Elkin [14] show that the graph resulting from a slightly more elaborate version of this shortcutting scheme has weight . Their scheme differs from what we have presented in that instead of building the complete graph on the set of cut vertices , they build a certain 1-spanner with edges and diameter where is the inverse Ackermann function. Since we consider the parameter to be constant, this modification does not affect the weight bound of the construction.
Theorem 3.1 ([14]).
Let be a weighted rooted tree and let be a positive integer, . The graph obtained by applying the algorithm described above to using the parameter is a 1-spanner for the tree metric induced by . Moreover, has diameter bounded by , weight bounded by and maximum degree bounded by where is the maximum degree of .
Let be the spanner resulting from running the algorithm described above on some tree with respect to the parameter . We define canonical subtrees of with respect to to be the subtrees computed during the course of the construction of . Canonical subtrees are defined recursively as follows. As a base for the recursive definition, the input tree is considered to be a canonical subtree with respect to and . Suppose is a canonical subtree with respect to and . Then each tree in the forest is a canonical subtree with respect to and . We speak of canonical subtrees without reference to the parameters and when they are clear from the context. Given a vertex of , we denote by the canonical subtree for which . When a canonical subtree is small enough, and so it is clear that is well defined for each . We say that is the canonical subtree of and that is a cut vertex of .
We establish some technical properties of canonical subtrees which will be of use in the following section. We reword statement 4 in Corollary 2.17 from the paper of Solomon and Elkin [14] in Lemma 3.3 and prove it using our terminology for completeness.
Lemma 3.3.
Let be a canonical subtree of and let be the canonical subtree such that . There are at most two edges in with one endpoint in and the other outside . Moreover, any vertex of incident to a vertex outside must be or .
Proof.
We first need to establish the following claim.
Claim:
Let for some canonical subtree . Suppose is a descendant of where is some child of . If is the first -balanced vertex on the path from to the left most vertex in , then or is a descendant of .
Proof of claim:
By definition of the cut vertex procedure, is a member of the set . If , we are done so suppose . Every cut vertex in other than is contained in some for some child of . The claim follows.
We note that any edge with one endpoint in and the other outside must have its other endpoint in . In particular, the parent of must be an element of . Let be the parent of . Suppose there is a second edge from a vertex to a vertex in . Note that must be a child of for otherwise would contain a cycle. Then is a descendant of . Let be the first -balanced vertex on the path from to the left most vertex in . Note that . By the claim, either coincides with, or is a descendant of, . If the latter holds, the parent of cannot be a vertex in and so . Suppose there exists a third vertex which has a parent in . Then is a member of which is a descendant of and neither equal to, nor a descendant of, the vertex which is impossible given the claim. Since is the first -balanced vertex on the path from to the left most vertex in , must be the leftmost child of its parent. It follows that the parent of is . ∎
Lemma 3.4.
Let and be canonical subtrees such that and let be some vertex of . Let be the set of vertices in which are ancestors of . Let be the element of deepest in and let be the child of which is an ancestor of . Then . (See Figure 2.)
Proof.
Consider the path . Note that all vertices in lie on this path. It is easy to see that this path enters through . The vertex on this path preceding is a member of , and an ancestor of and therefore a member of . Since the predecessor of is clearly deeper than all other vertices in , the lemma follows. ∎
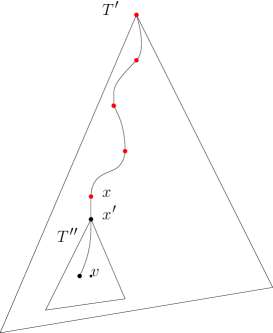
In the spanner, a vertex is connected to all vertices in . The following lemma ensures that in the routing algorithm described in the next section, under certain conditions, it is safe to make a ‘greedy’ choice from a subset of vertices in .
Lemma 3.5.
Let and be vertices in such that is not a vertex of . Let be the set of vertices in which are ancestors of . Suppose and let be the last vertex on the path from to which is contained in . Then . Moreover, is the deepest vertex in . (See Figure 3.)
Proof.
By Lemma 3.3, is either or . Since , is an ancestor which also implies is an ancestor of . Then is an ancestor of and it remains to be shown that is the deepest vertex in . Let be the deepest vertex in and suppose . The path from to must leave through either or . Since we also have that and since , we must have and . Then there would be two distinct paths from to , a contradiction since is a tree. The lemma follows. ∎

Lemma 3.6.
Let and be vertices of such that is a descendant of and is contained in . Let be the canonical subtree in the forest which contains and let be the set of vertices in which are descendants of and ancestors of . Let be the element of which is highest in . Then either or is the parent of . (See Figure 4.)
Proof.
Note that . Let be the first vertex on which is contained in . By Lemma 3.3, . Let be the predecessor of on . Since is an ancestor of , is a child of . Since is a vertex outside connected to a vertex in , and hence . Clearly is also the highest vertex in and so and the lemma follows. ∎

3.2 Routing Algorithm
In this section, we describe a local routing algorithm for the spanner defined above. Throughout what follows, let denote the graph obtained when the algorithm of the previous section is applied to a weighted, rooted tree using a parameter . We first define the labels for vertices . We make use of the interval labelling scheme of Santaro and Khatib [13]. Let denote the rank of in a post-order traversal of . We define
We define the label of to be . The observation used in the routing algorithm of Santaro and Khatib [13] is that a vertex is a descendant of if and only if . Note that the label of each vertex can be computed in linear time in a single traversal of the tree.
Lemma 3.7.
In the labelling scheme outlined above, each vertex of stores bits of information.
Proof.
Since has vertices, for each , and are both integers in the interval and therefore require bits to be represented. By Theorem 3.1, each vertex of has at most neighbours in . Then, for any , we require bits to store and for each neighbour of . ∎
For our routing algorithm, no auxiliary data structure is required at each vertex and so the total storage requirement per vertex is bits. Our routing algorithm considers a number of cases depending on the labels of the current vertex and destination vertex . For convenience of analysis, in each case we specify two routing steps. For ease of exposition, we consider a vertex to be both a descendant and ancestor of itself.
Case 0: If is a neighbour of , route to .
Case 1:
is an ancestor of in . Let be the set of vertices in which are ancestors of . Let be the deepest element of . Route first to and then to the child of which is an ancestor of .
Case 2:
is a descendant of in . Let be the set of vertices in which are descendants of and ancestors of . Let be the highest vertex in . Route first to and then to its parent.
Case 3: is not an ancestor or descendant of . Let be the set of vertices in which are ancestors of and not ancestors of . If , we define to be the deepest vertex in and define to be the child of which is an ancestor of . Let be the set of vertices in which are ancestors of but not ancestors of . We define to be the highest vertex in .
Case 3 a): is empty. Route first to and then to the parent of .
Case 3 b): is non-empty. Route first to and then to .
The routing algorithm uses a greedy strategy. Given the destination vertex and neighbours due to tree edges and shortcut edges, the algorithm simply selects the edge that appears to make the most progress. It is not obvious that this strategy gives the desired diameter of the routing algorithm. Indeed, this bound would not hold if the shortcuts were arbitrary edges and hinges on the particular structure of the 1-spanner.
The arguments we make in our analysis will make use of certain integer sequences we assign to vertices of . Note that these sequences are used only for the analysis of the algorithm and are not part of the labelling scheme. We define a unique integer sequence for each canonical subtree computed during the course of the spanner construction. Each vertex will be assigned the sequence corresponding to the tree .
The integer sequence for each canonical subtree is defined recursively as follows. The input tree is given the empty sequence. Suppose is a canonical subtree which has already been associated with some sequence . Consider the forest . Each tree is associated with the sequence obtained by appending to . It is clear that every vertex of appears in for exactly one canonical subtree . Let denote the sequence assigned to the vertex . We refer to as the canonical sequence of .
Observe that if for two vertices we have that , by definition of the spanner construction algorithm, and must be cut vertices of the same canonical subtree of and are therefore connected by an edge in . The routing algorithm works by choosing a successor vertex so as to incrementally transform the canonical sequence of the current vertex into the canonical sequence of the destination vertex.
Lemma 3.8.
Let and be vertices of such that is an ancestor of . Consider the two vertices visited after executing the routing steps of Case 1 when routing from to . These vertices are on the path from to in . Moreover, these vertices are visited in the order they appear on this path.
Lemma 3.9.
Let and be vertices of such that is a descendant of . Consider the two vertices visited after executing the routing steps of Case 2 when routing from to . These vertices are on the path from to in . Moreover, these vertices are visited in the order they appear on this path.
Lemma 3.10.
Let and be vertices of such that is not an ancestor or a descendant of . Suppose the set , as defined in Case 3 of the routing algorithm, is empty. Consider the vertices visited after executing Case 3 a) of the routing algorithm. These vertices are on the path from to the . Moreover, these vertices are visited by the routing algorithm in the order they appear on this path.
Proof.
Let be the first vertex visited in Case 3 a) and let be the second. Then is the vertex and is its parent. Since is, by definition, not an ancestor of , it lies on the path from to and is not equal to . Since is the parent of , it is clearly the next vertex on . ∎
Lemma 3.11.
Let and be vertices of such that is not an ancestor or descendant of . Suppose the set , as defined in Case 3 of the routing algorithm, is non-empty. Consider the vertices visited after executing Case 3 b) of the routing algorithm. These vertices are on the path from to . Moreover, these vertices are visited in the order they appear on this path.
Proof.
Let be the first vertex visited in Case 3 b) and let be the second. is an ancestor of which is not an ancestor of . It follows that is a descendant of . By definition of Case 3 b), is the child of which is an ancestor of . It is clear that is the successor to on the path . The lemma follows. ∎
Lemma 3.12.
Let and be vertices of and let . Suppose the routing steps of a single case of the routing algorithm are executed and vertices and are visited. Then there are indices such that and .
Using Lemma 3.12, we can show the routing algorithm has a routing ratio of 1.
Theorem 3.2.
Let and be vertices of . Let denote the length of the path from to in . The routing algorithm described above is guaranteed to terminate after a finite number of steps and the length of the path traversed is exactly .
Proof.
Lemma 3.12 implies that the vertices visited when any case of the routing algorithm is executed are on the path from the current vertex to the destination and they are explored in the order they appear on the path. Each case leads to at least one new vertex being explored. If is the path from to in , the arguments made above imply that the path traversed by the routing algorithm is of the form where , i.e., is a sub-sequence of . In the tree metric , the weight of the edge is by definition equal to the weight of the path and so the theorem follows. ∎
We now argue that the routing algorithm is guaranteed to terminate after traversing edges. To this end, we first prove the following lemma.
Lemma 3.13.
Let and be vertices of such that is either an ancestor or a descendant of . Let be the vertex reached after executing the routing steps of either Case 1 or Case 2 when routing from to . Then the following statements hold:
-
1.
If is a prefix of , then . Moreover, either or is a prefix of .
-
2.
If is a prefix of , then . Moreover, either or is a prefix of .
-
3.
Suppose and share a common prefix of length . Then . Moreover, either or is a prefix of
Proof.
We begin with the first statement. Suppose is a prefix of . Then contains . Let be the canonical subtree in the forest which contains . By definition, the canonical sequence of any cut vertex of can be obtained by appending some integer to . Since is contained in , the canonical sequence associated to is a prefix of . Then it is sufficient to show that . Suppose is an ancestor of so that the algorithm executes the routing steps of Case 1. Recall that in Case 1 the set is defined as the set of vertices in which are ancestors of and the vertex is defined as the deepest vertex in . Then by definition of Case 1, is the child of which is an ancestor of . By Lemma 3.4, . Since , the statement of the lemma follows in this case. Now suppose is a descendant of so that the algorithm executes the routing steps of Case 2. Recall that in Case 2, is defined to be the set of vertices in which are descendants of and ancestors of and is defined to be the highest vertex in . By definition of Case 2, the algorithm routes to and then to the parent of . Then is the parent of . By Lemma 3.6, . Since , the first statement of the lemma holds in this case.
We now address the second and third statements of the lemma. Suppose is not a prefix of . Let be the longest common prefix of and . Then either or is a prefix of . Let be the canonical subtree corresponding to the canonical sequence . Observe that contains . Let be the canonical subtree such that . Then either or contains . Note that the canonical sequence of any cut vertex of is a prefix of . Moreover, for any canonical sequence of a cut vertex in , either or is a prefix of . We claim that . When is a prefix of , we see this implies the second statement. When and share a prefix of length , we see that our claim implies the third statement.
We now prove the claim. Suppose that is an ancestor of so that the algorithm executes the routing steps of Case 1. Let and be as defined in Case 1. Then is the child of which is an ancestor of . By Lemma 3.5, is the last vertex on the path from to which is contained in . Since is an ancestor of and is both a child of and ancestor of , it is clear that is the next vertex on . Since is a vertex outside connected to a vertex in , we see that and so the claim holds in this case. Suppose now that is a descendant of so that the algorithm executes the routing steps of Case 2. Let and be as defined in Case 2. Note that since is a descendant of , must also be a descendant of . Then . Since must be the highest vertex in , we see that . Since the parent of is clearly a member of , the claim holds. This completes the proof of the lemma.
∎
Note that if is an ancestor (resp. descendant) of , then by Lemma 3.12 the vertex reached after executing the steps of Case 1 (resp. Case 2) will also be an ancestor (resp. descendant) of .
Lemma 3.14.
Suppose and in are such that is an ancestor or descendant of in . Then, when routing from to , the routing algorithm reaches after traversing edges.
Proof.
Suppose that is an ancestor of (the argument in the case where is a descendant of is symmetric) and let be the maximum length of the canonical sequence of any vertex of . Note that by Lemma 3.2, each canonical subtree is at most times the size of its smallest containing canonical subtree and so the recursion depth is at most which, by definition of canonical sequences, implies . If is a prefix of , by Lemma 3.13, the routing steps executed in a single iteration of Case 1 traverse at most two edges and lead to a vertex which is an ancestor of and for which is a prefix of strictly longer than . Then after traversing at most edges, the routing algorithm will reach . An analogous argument can be made in the case where is a prefix of .
Assume that and have a common prefix of length . By Lemma 3.13, after traversing at most edges, the algorithm reaches a vertex which is an ancestor of and is such that is a prefix of . By the argument made above, after traversing at most another edges, the routing algorithm reaches . Then in all cases, after traversing at most edges, the algorithm reaches its destination. This completes the proof of the lemma.
∎
Consider the case where is neither an ancestor nor a descendant of . The following lemma shows that in this case, the algorithm either routes to a vertex on the path or it follows the routing steps that would be executed if the algorithm were routing from to .
Lemma 3.15.
Let and be vertices of such that . Suppose that the set as defined in Case 3 is empty so that the algorithm executes the routing steps of Case 3 a) when routing from to . The same steps would be performed when routing from to .
Proof.
Recall the set in Case 3 is defined as the set of ancestors of which are not ancestors of . Consider Case 2 when routing from to . The set in Case 2 is defined as the set of ancestors of which are descendants of . Since an ancestor of is a descendant of if and only if it is not an ancestor of , we see that . In Case 3 a) the algorithm routes to the highest vertex in and then its parent. In Case 2 the algorithm routes to the highest vertex in and then its parent. We see the algorithm executes the same routing steps in both cases and so the lemma follows. ∎
Theorem 3.3.
Let and be vertices in . The routing algorithm reaches when routing from after traversing at most edges.
Proof.
Lemma 3.14 implies the theorem when is an ancestor or descendant of . Then we need only consider the case where is neither an ancestor nor descendant of . Suppose the algorithm executes the steps of Case 3 a) at some point when routing from to . Let be the current vertex after the steps of Case 3 a) are executed. Then is an ancestor of and so the algorithm will reach after traversing another edges. It remains to argue that edges are traversed before the current vertex is an ancestor of . By Lemma 3.15 and Lemma 3.14, the algorithm either executes the steps of Case 3 a) or reaches after traversing edges. This completes the proof of the theorem. ∎
4 Routing in a Doubling Metric Spanner
The 1-spanner of the previous section was designed to be a tool for reducing the diameter of Euclidean spanners without compromising bounds on degree and weight. It has been applied in a series of papers on various constructions of spanners of doubling metrics. The doubling dimension of a metric is the smallest number such that, for any , any ball of radius can be covered by at most balls of radius . An -point metric is said to be doubling if the doubling dimension is constant in . The class of doubling metrics contains the class of Euclidean metrics as -dimensional Euclidean metrics can be shown to have doubling dimension . The spanners for doubling and Euclidean metrics to which the 1-spanner shortcutting scheme has been applied are all based on some variety of hierarchical decomposition of the input point set. In particular, spanners based on the dumbbell trees of Arya et al. [2] and the net tree approach [10, 12] have been proposed. We will show that the routing algorithm described in the previous section can be extended to a routing algorithm on a low diameter doubling metric -spanner based on the net tree.
4.1 A net tree based spanner
The spanner we describe here is a simplified version of the spanner described by Chan et al. [7]. The starting point of their construction is based on the spanner of Gao et al. [10].
In this section, will denote an -point doubling metric. Let denote the doubling dimension of . We assume without loss of generality that the distance between the closest pair of points in is 1.
Definition 4.1.
For , a subset is said to be an -net for if
-
•
for all distinct pairs of points .
-
•
For all , there exists such that .
The first step of the construction is to compute a certain sequence of nets. Specifically, we compute a nested sequence of sets where is a -net of and is the largest inter-point distance among pairs of points in . Note that consists of a single point. An efficient method for computing such a sequence of nets is given by Har-Peled and Mendel [12]. Next, we describe the so-called net tree which we denote . The net tree has a node at level- for each point in the set . If a level- node corresponds to a point , we say that is the representative of and write . Note that a given point in can be the representative of multiple nodes in . The root of the tree corresponds to the singleton set and the leaves of are in one-to-one correspondence with the points of . The parent of each node at level- is a node at level-() for which . The constant doubling dimension of immediately implies that nodes in have a constant number of children. The tree induces a graph on in the natural way, i.e., each edge corresponds to the edge . For a point , we also use to denote the leaf of which has as its representative. Given a leaf , we denote by the level- ancestor of in . Given two nodes , we define . The graph as currently defined is not a -spanner for . To guarantee a spanning ratio, certain cross edges are added at each level. Fix a constant . For each pair of level- points for which , we add the cross edge to . If we make a sufficiently large choice of , the graph resulting from the addition of these cross edges to can be shown to be a -spanner for . The following theorem is established in the proof of Theorem 3.2 in [10].
Theorem 4.1.
Let be points in and let be the smallest integer such that the level- ancestors of and are connected by a cross edge. Consider the path in obtained by climbing from to its level- ancestor, taking the cross edge to the level- ancestor of and descending to . Then the path in corresponding to this path has total length .
The maximum degree of the spanner as described above is as some points in may represent many nodes in . Gottlieb and Roddity [11] devised a technique to reduce the degree bound to by carefully reassigning representatives.
The depth of the net tree is . In particular, if is not bounded by a polynomial in , the net tree may have linear depth and so the diameter of the spanner may be linear. We say a subtree of is light if it has height . Chan et al. [7] show that by applying the tree metric construction of the previous section to all light subtrees of , it is possible to reduce the diameter of the spanner to without increasing the asymptotic bound on the weight. Chan et al. [7] show that the weight of the spanner, after shortcuts are added, is at most , where is a minimum spanning tree of . Chan et al. [7] make additional modifications to ensure fault tolerance although we will not work with this version of the spanner.
To summarise, the spanner we work with has -stretch, degree, weight and diameter.
For the remainder of this section, will denote the net tree with cross edges and shortcuts. denotes the constant degree spanner of induced by . Our routing algorithm will make use of the following property of the spanner .
Lemma 4.1.
For , the smallest integer such that the level- ancestors of and are guaranteed to be joined by a cross edge lies in the interval
Proof.
Lemma 4.1 in the paper of Gao et al. [10] implies that if is a cross edge, then is a cross edge for all . Then is the unique integer for which is a cross edge and is not. Observe that for , we have . By definition of the net tree, . By the triangle inequality we have and so Then by the construction of the spanner, there is no cross edge between and . A similar argument shows that for , and so there is guaranteed to be a cross edge between and . Then since is not a cross edge for and is guaranteed to be a cross edge for , the lemma follows. ∎
Note that the length of the interval computed in Lemma 4.1 is . This fact is needed to establish a bound on the diameter of the routing algorithm we present in the next section.
4.2 Labelling Scheme and Routing Algorithm
Gottlieb and Roddity [11] show it is possible to route in the net tree in their construction while taking care to use the first available cross edge. This algorithm has a routing ratio of and the required labels are short as a result of the degree bound. We apply their method to the version of the spanner have described although we make use of our 1-spanner routing algorithm whenever the message passes through short subtrees so as to take advantage of the available shortcuts. We first describe the labels of . Since each point in is the representative of multiple nodes in , the label of will contain the labels of all nodes for which . Note that there is a constant number of such nodes in for each .
Initially, each node is labelled with the interval , the same labelling scheme used in our 1-spanner routing algorithm. Next, for each light subtree of , we label the vertices of with the labels required for the 1-spanner routing algorithm on .
When routing from a point to a point in , in order to obtain a routing ratio, the algorithm must make use of the first cross edge connecting ancestors of and . Since we make use of shortcuts, there is a danger the algorithm may ‘overshoot’ the correct level. Therefore, the algorithm requires a means to estimate the level of the tree containing a viable cross edge, i.e., the algorithm should be able to locally compute the interval of Lemma 4.1. If is a Euclidean metric, the distance can be computed if the labels of the points store their coordinates. However, if is an arbitrary doubling metric, it is not obvious how to achieve this goal. For , a -ADLS is a labeling of points in a metric space that allows approximation of pairwise distances to within a factor of . That is, given the labels of points and in a -ADLS, we are able to compute a value such that
Har-Peled and Mendel [12] give a -ADLS for doubling metrics in which each label consists of at most bits. If we work with a -ADLS rather than exact distances, the interval of Lemma 4.1 becomes
Note that the length of this interval is still .
To summarize, the label of each point contains:
-
•
The label of in a -ADLS for .
-
•
The label of each node for which .
Since the degree of the spanner is bounded by , we obtain the following bound on the storage of our labelling scheme.
Lemma 4.2.
In the labelling scheme for the spanner defined above, each label requires at most bits of storage, where .
We now describe the routing algorithm for the spanner . Let be the current vertex and be the destination. Since each point of is the representative of multiple vertices in , the message header stores a bit variable to keep track of the current position in . Suppose the current position is a vertex with representative . When we say the algorithm routes to a neighbour of , we mean the message is forwarded to a neighbour of in such that . Throughout the following, will denote the current position of the algorithm in and will denote the leaf in corresponding to the destination vertex in .
The algorithm operates in the following distinct states.
Initialization: Using the ADLS labels stored in the labels of and , a -approximation of is computed. Let denote this approximation. The integer is stored in the message header as the cross edge target level.
Ascending: In this state, the current position of the message in is at a level lower than . Suppose is in a light subtree. Then we use our 1-spanner routing algorithm to route towards the level- ancestor of . Otherwise, we simply route to the parent of .
Searching for a cross edge: In this state, is at level or higher in . If is connected by a cross edge to an ancestor of , the algorithm routes to this ancestor. Otherwise, the algorithm routes to the parent of .
Descending: In this state, is an ancestor of in . If is in a light subtree, the algorithm routes towards using our 1-spanner routing algorithm. Otherwise, the algorithm routes to the child of which is an ancestor of .
Theorem 4.2.
The routing ratio of the algorithm defined above has routing ratio and diameter .
Proof.
Observe that the path traversed when routing from to by the algorithm differs from the spanning path described in Theorem 4.1 only by the shortcuts taken on sections of the path which pass through light subtrees. Since these shortcuts cannot increase the length of the path, the first statement of the theorem follows.
To prove the second statement, we bound the number of vertices visited in each state. In the ascending state, at most vertices are visited in a light subtree since the 1-spanner routing algorithm has diameter. Since there are at most levels of the net tree higher than level , at most vertices are visited by the algorithm outside a light subtree. The same arguments hold for the descending state. Note that the level at which to begin the search for a cross edge determined in the initialization state is at most a constant number of levels lower that the lower endpoint of the interval of Lemma 4.1. Since the length of the interval in Lemma 4.1 has constant length, the second statement of the theorem follows. ∎
5 Conclusion
We have shown that a simplified version of the logarithmic diameter tree metric 1-spanner of Solomon and Elkin [14] supports a local routing algorithm of routing ratio 1 and logarithmic diameter. We have also shown that this algorithm can be used to route in a spanner for doubling metrics which uses the shortcutting scheme to achieve a low diameter while maintaining low weight and low degree.
References
- [1] Ittai Abraham and Dahlia Malkhi. Compact routing on Euclidian metrics. In Proceedings of the 23rd Annual ACM Symposium on Principles of Distributed Computing, pages 141–149, 2004.
- [2] Sandeep Kumar Arya, Gautam Das, David M. Mount, Jeffrey S. Salowe, and Michiel H. M. Smid. Euclidean spanners: short, thin, and lanky. In Proceedings of the 27th Annual ACM Symposium on Theory of Computing, 1995.
- [3] Vikrant Ashvinkumar, Joachim Gudmundsson, Christos Levcopoulos, Bengt J. Nilsson, and André van Renssen. Local routing in sparse and lightweight geometric graphs. In Proceedings of the 30th International Symposium on Algorithms and Computation, volume 149 of LIPIcs, pages 30:1–30:13, 2019.
- [4] Prosenjit Bose, Andrej Brodnik, Svante Carlsson, Erik Demaine, Rudolf Fleischer, Alejandro López-Ortiz, Pat Morin, and J. Munro. Online routing in convex subdivisions. International Journal of Computational Geometry & Applications, 12(4):283–296, 2002.
- [5] Prosenjit Bose, Rolf Fagerberg, André Renssen, and Sander Verdonschot. Optimal local routing on Delaunay triangulations defined by empty equilateral triangles. SIAM Journal on Computing, 44(6):1626–1649, 2015.
- [6] Milutin Brankovic, Joachim Gudmundsson, and André van Renssen. Local routing in a tree metric 1-spanner. In Computing and Combinatorics. COCOON 2020. Lecture Notes in Computer Science, vol 12273., pages 174–185. Springer International Publishing, 2020.
- [7] T. Chan, M. Li, L. Ning, and S. Solomon. New doubling spanners: Better and simpler. SIAM Journal on Computing, 44(1):37–53, 2015.
- [8] T.-H. Hubert Chan, Anupam Gupta, Bruce M. Maggs, and Shuheng Zhou. On hierarchical routing in doubling metrics. ACM Transactions on Algorithms, 12(4):55:1–55:22, 2016.
- [9] Michael Elkin and Shay Solomon. Optimal Euclidean spanners: Really short, thin and lanky. In Proceedings of the 45th Annual ACM Symposium on Theory of Computing, pages 645–654, 2013.
- [10] Jie Gao, Leonidas J. Guibas, and An Nguyen. Deformable spanners and applications. Computational Geometry, 35(1):2–19, 2006.
- [11] Lee-Ad Gottlieb and Liam Roditty. Improved algorithms for fully dynamic geometric spanners and geometric routing. In Proceedings of the 19th Annual ACM-SIAM Symposium on Discrete Algorithms, page 591–600, 2008.
- [12] Sariel Har-Peled and Manor Mendel. Fast construction of nets in low-dimensional metrics and their applications. SIAM Journal on Computing, 35(5):1148––1184, 2006.
- [13] N. Santoro and R. Khatib. Labelling and implicit routing in networks. The Computer Journal, 28(1):5–8, 1985.
- [14] S. Solomon and M. Elkin. Balancing degree, diameter, and weight in Euclidean spanners. SIAM Journal on Discrete Mathematics, 28(3):1173–1198, 2014.
- [15] Shay Solomon. From hierarchical partitions to hierarchical covers: Optimal fault-tolerant spanners for doubling metrics. In Proceedings of the 46th Annual ACM Symposium on Theory of Computing, page 363–372, 2014.