Yerim [email protected]
\addauthorNur Suriza [email protected]
\addauthorSang-Chul [email protected]
\addinstitution
Department of Electrical
and Computer Engineering
Inha University
Incheon, South Korea
Local Feature Extraction from Salient Regions
Local Feature Extraction from Salient Regions by Feature Map Transformation
Abstract
Local feature matching is essential for many applications, such as localization and 3D reconstruction. However, it is challenging to match feature points accurately in various camera viewpoints and illumination conditions. In this paper, we propose a framework that robustly extracts and describes salient local features regardless of changing light and viewpoints. The framework suppresses illumination variations and encourages structural information to ignore the noise from light and to focus on edges. We classify the elements in the feature covariance matrix, an implicit feature map information, into two components. Our model extracts feature points from salient regions leading to reduced incorrect matches. In our experiments, the proposed method achieved higher accuracy than the state-of-the-art methods in the public dataset, such as HPatches, Aachen Day-Night, and ETH, which especially show highly variant viewpoints and illumination.
1 Introduction
Extracting and describing local features for matching is essential, especially in computer vision tasks that involve image matching, searching, tracking, and 3D reconstruction [Heinly et al.(2015)Heinly, Schonberger, Dunn, and Frahm, Svärm et al.(2016)Svärm, Enqvist, Kahl, and Oskarsson, Noh et al.(2017)Noh, Araujo, Sim, Weyand, and Han]. Feature matching focuses on three main phases when given two similar images are to be matched: feature detection, feature description, and feature matching [Lowe(2004), Cheng et al.(2014)Cheng, Leng, Wu, Cui, and Lu]. The primary goal of feature matching is to optimize matching accuracy while minimizing the memory footprint of earlier applications. The extracted features should be sparse, highly repeatable, and precise. Each image’s salient features, such as its corners, are initially recognized as interest points during the detection phase. Then, local descriptors are extracted based on the neighborhood regions of these interest points and used in the matching algorithms.
Classical approaches [Lowe(2004), Bay et al.(2006)Bay, Tuytelaars, and Van Gool] concentrate on the detect-then-describe method, where they first detect the points by analyzing the gradient of the image before describing the points with directional information. Furthermore, these approaches [Lowe(2004), Bay et al.(2006)Bay, Tuytelaars, and Van Gool] have shifted research trends by the emergence of deep learning methods [Tian et al.(2017)Tian, Fan, and Wu, Zagoruyko and Komodakis(2015), DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich]. Since deep convolutional neural networks (DCNNs) can automatically learn features, mimic traditional detector behaviors, and process complex images, CNN methods have achieved remarkable performance than before [Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan, Tian et al.(2020)Tian, Balntas, Ng, Barroso-Laguna, Demiris, and Mikolajczyk, Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls]. These data-driven methods concentrate on sparse points by leveraging descriptors’ information for corresponding points. At the same time, several networks [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich, Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] attempted to achieve better performance by influencing detection and description simultaneously, with improved repeatability and sparsity of detected points. Detector-free local feature matcher [Sun et al.(2021)Sun, Shen, Wang, Bao, and Zhou, Zhou et al.(2021)Zhou, Sattler, and Leal-Taixe] and a decoupled pipeline for a detection and description module were also studied [Li et al.(2022)Li, Wang, Liu, Ran, Xu, and Guo].
Despite these achievements, there is insufficient consideration for light and structure information in an image. Examining this information to robustly locate and define matched points, regardless of camera viewpoint or illumination variance, is critical. Nighttime images are challenging due to the uncertainties of light and structure [Sun et al.(2021)Sun, Shen, Wang, Bao, and Zhou]. When viewpoints change significantly, it is also difficult to match correctly [Balntas et al.(2017)Balntas, Lenc, Vedaldi, and Mikolajczyk]. Although some studies investigated this viewpoint and light information to apply in the local feature domain, they used only hand-crafted ways such as detecting corners or simply rotating features [Pautrat et al.(2020)Pautrat, Larsson, Oswald, and Pollefeys, Liu et al.(2019)Liu, Shen, Lin, Peng, Bao, and Zhou, Melekhov et al.(2020)Melekhov, Brostow, Kannala, and Turmukhambetov].
In this work, we propose a new strategy that uses both style and structure information to address the issue of mismatches in image variance. Specifically, we apply the concept of Instance Selective Whitening (ISW) loss, introduced by RobustNet [Choi et al.(2021)Choi, Jung, Yun, Kim, Kim, and Choo], where the features are transformed with implicit information about the style component to have robustness under variations in light. Since there are limitations in this idea and considers only the style factor, we revised ISW to consider the structure factor and apply it to the local feature field. Furthermore, we focus on salient points to reduce matching time.
Contributions. In this paper, we propose a framework that addresses the problems from a different light and structural information. We first extract features using Feature Map Generation (FMG) module. Then, Feature Map Transformation (FMT) module divides extracted features into two components: style and structure matrix. Each component independently learns the information gathered by the learned feature. Consequently, regardless of any changes in any component, the feature map will still select salient and matchable points. We introduce a loss function to maximize the influence of the structure information and minimize the style information in the feature map. The main contributions are summarized as follows:
-
•
We overcome the limitation of feature matching in image variance by distinguishing between structure- and style-dependent features and transforming the feature maps.
-
•
We propose Feature Map Transformation (FMT) module, exploiting an existing style transfer concept that concentrates only on style components, to transform the feature map while training to make it focus on salient features.
-
•
Extensive experiments on different benchmark datasets demonstrate that the proposed method can achieve high accuracy in matching tasks in a short time and with fewer parameters.
2 Related Work
Local feature learning. The joint learning of feature detectors and descriptors requires a unified network to construct feature maps and allows the two tasks to share the majority of computations for improved performance. DELF [Noh et al.(2017)Noh, Araujo, Sim, Weyand, and Han] proposed an image retrieval technique that learns local features as a by-product of a classification loss combined with an attention mechanism to improve performance on large-scale images. It outperforms images under changing light conditions but has limitations in terms of structural variation. SuperPoint [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich] suggested a method for learning from the manual annotation of significant points on simple images such as corners and edges. However, because of their low repeatability and descriptor accuracy, it has many outliers, so the matched points tend to be mistakenly judged. R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] has overcome this issue by learning the descriptor reliability in parallel with the detection and description phases and only selecting both repeatable and reliable keypoints with respect to the descriptor.
To find only the matchable points, D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler] proposed a describe-and-detect method for joint detection and description that uses a single CNN with shared weights. The detection is based on the entire channel’s local maxima and the shape map’s spatial dimensions. DISK [Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls] applied reinforcement learning on an end-to-end network inspired by D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler] that relied on policy gradients. Furthermore, ASLFeat [Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan] demonstrated significant improvement using a score map that used local shape estimation to select matching points.
Feature covariance. Previous research [Gatys et al.(2015)Gatys, Ecker, and Bethge, Gatys et al.(2016)Gatys, Ecker, and Bethge] proposed that image style information is considered via feature correlations such as a gram or a covariance matrix. Since then, feature correlation has been applied to several different research areas, including style transfer [Li et al.(2017)Li, Fang, Yang, Wang, Lu, and Yang], image-to-image translation [Cho et al.(2019)Cho, Choi, Park, Shin, and Choo], domain adaptation [Roy et al.(2019)Roy, Siarohin, Sangineto, Bulo, Sebe, and Ricci, Sun and Saenko(2016)], and network architecture [Luo(2017), Pan et al.(2019)Pan, Zhan, Shi, Tang, and Luo, Huang et al.(2018)Huang, Yang, Lang, and Deng]. Whitening transformation (WT) [Li et al.(2017)Li, Fang, Yang, Wang, Lu, and Yang, Cho et al.(2019)Cho, Choi, Park, Shin, and Choo, Pan et al.(2019)Pan, Zhan, Shi, Tang, and Luo], which eliminates feature correlation and assigns unit variance to each feature, aids in the removal of style information from the feature representations.
Since region-specific styles and region-invariant content are simultaneously written to the covariance vector of the feature maps, whitening all the correlation components reduce feature identification and distort the boundaries of objects [Li et al.(2017)Li, Fang, Yang, Wang, Lu, and Yang, Li et al.(2018)Li, Liu, Li, Yang, and Kautz]. RobustNet [Choi et al.(2021)Choi, Jung, Yun, Kim, Kim, and Choo] proposed the ISW loss, which extracted only the style information to solve the problem. We want to focus on style and structure information, so we modify the ISW loss to satisfy our objective.
3 Method
3.1 Feature Map Generation Module
Feature Map Generation (FMG) module first extracts the features of an image pair, and independently, which outputs two branches: descriptors and point extraction feature maps. The point extraction branch consists of two feature maps. One produces another with a 11 convolution layer; the former is a reliability map and the latter in repeatability map . The covariance matrix derived from the descriptor map is used to transform the feature map to focus on saliency with style and structure information. Then FMG module uses feature maps , , and to calculate the loss functions for repeatability and reliability. The FMG module’s network architecture differs from R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] but uses the same loss functions in this part. So only the architecture part will be described. The proposed method pipeline is shown in Figure 1.

As introduced in MobileNet [Howard et al.(2017)Howard, Zhu, Chen, Kalenichenko, Wang, Weyand, Andreetto, and Adam], depthwise separable convolution (DSC) is a factorization convolution method that significantly reduces computation and model size with new representations. Motivated by this, we used the DSC to focus on the salient area. Inspired by [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel, Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan], we adopt a modified L2Net [Tian et al.(2017)Tian, Fan, and Wu]—where the last layer is replaced by a set of three consecutive layers—in our backbone network to extract feature information from an image pair. Since the input images are image pairs, two backbone networks are needed. We use weight sharing in the DSC layer when adding it behind the backbone network to reduce the model weight. Furthermore, the relationship between descriptors and points of interest can be maintained by sharing the weights. The backbone network then generates three feature maps, by 2 normalization, by the element-wise square, and obtained from with a 11 convolution layer. In contrast to [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel], and come from the same branch since they depend on one another. We assumed that is a feature map that learns a point that reduces the matching distance, which might affect in high repeatability rate in . Therefore, the model weight gets lighter and develops more robust features through information sharing.
FMG module calculates the reliability loss, , to get discriminative feature points. Let be the local descriptor in each pixel of the image ; we then predict the individual reliability scores from and . Here, we specify the exact coordinate that corresponds to , knowing the ground truth correspondence mapping , where is the ground truth correspondence between image and . is compared with , where is extracted from . Then, average precision is used to calculate , optimized with a differentiable approximation [He et al.(2018)He, Lu, and Sclaroff, Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel], using .
In addition, FMG module calculates the repeatability loss, , for extracting repeatable feature points as in [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel]. It uses peakiness prediction and similarity between feature pairs from input pair images. For similarity, Let and be the repeatability maps corresponding to and . We set to be a map in which is transformed by the ground truth homography relationship between image pairs and . Because the prime objective is to predict keypoints with high repeatability, we train the network so that the positions of the local maxima in are covariant to the actual picture transformations, such as viewpoint structures or light shifts. Assuming that all the local maxima of coincide with the local maxima of , we define the loss function. The basic concept is to maximize the cosine similarity between and such that the two heatmaps are identical and their maxima identically coincide. The loss may remain at a particular constant that may terminate the learning process, so we prevent this using the peakiness prediction. The final repeatability loss is calculated by considering both similarity and the peakiness of the input image pair.
3.2 Feature Map Transformation Module
One problem with feature matching is structural perspective and lighting (style) differences. The style corresponds to noise, such as weather and light. Concentrating on the structure, which relates to the image’s point of view or the edges, can result in better results. Feature Map Transformation (FMT) module suppresses the style information by performing task adaptation and supplementing the existing WT loss with an extensive transformation. We improve the previous loss by including structural information to overcome the limitations of using only existing styles.
Style/Structure Covariance Matrix. Previous studies [Li et al.(2019)Li, Zhang, Yang, Liu, Song, and Hospedales, Choi et al.(2021)Choi, Jung, Yun, Kim, Kim, and Choo] claimed that applying WT to each instance of style transfer could successfully erase style information. WT is a linear transformation that equalizes the variance term in each channel to one and reduces the covariances between channels to zero. The intermediate feature map is , where is the number of channels, and and are the height and width of the feature map, respectively. The covariances between pairs of channels can be defined as follows:
| (1) |
where is a column vector of ones, and the and are the mean vector and covariance matrix, respectively. When the loss function is designed so that the elements of the covariance matrix decrease, the feature extraction is less affected by the style element in extracting features from the input image. This is because the feature map generation lacks the information of style elements. Based on this concept, we adopt a method of transforming feature maps using style elements. Furthermore, we use information about the structure, the leftover elements in the gram matrix beside style elements, to design the loss function in the direction of expansion rather than suppression.

Transformation Loss. In order to transform and manipulate feature maps using the aforementioned style and structure information, we introduce the FMT module which use feature map X to calculate . This is done since the descriptor has the most information among the three output feature maps from the FMG module. FMT module then separates style and structure characteristics from the feature representation’s higher-order statistics by selectively modifying each attribute differently. Replacing the old feature map X with a standardized feature map simplifies the optimization process of both the diagonal and off-diagonal elements of the covariance matrix simultaneously [Ulyanov et al.(2016)Ulyanov, Vedaldi, and Lempitsky, Choi et al.(2021)Choi, Jung, Yun, Kim, Kim, and Choo]. is a matrix made from the standardized feature map , and we define as follows:
| (2) |
After obtaining the covariance matrices and , we calculate the difference between the two matrices to produce matrix , as defined in Eq. 3. Matrix indicates the sensitivity of the corresponding covariance to the photometric transformation [Choi et al.(2021)Choi, Jung, Yun, Kim, Kim, and Choo]. Elements with a high variance value retain the style information, whereas elements with a low variance value retain the structure information. We use absolute value notation with vertical bars.
| (3) |
We cluster the style and structural components in equal amounts, using the mean value to determine the threshold for separating the two components. If a matrix element is greater than the threshold, that element is classified as a style factor, while the rest of the elements are classified as structural factors. This definition is established because the prominent factors of the matrix are assumed to imply the style factor [Choi et al.(2021)Choi, Jung, Yun, Kim, Kim, and Choo]. In this case, the style factor refers to changes in light or color, and the structural factor refers to complexities with many objects, edges, or viewpoints. The proposed loss function, is formulated as follows:
| (4) |
where and are the arithmetic mean and a mask matrix. and are masks that select style and structure values, and is element-wise multiplication. Finally, the total loss function can be represented by Eq. 5, with each weight are empirically tuned to the optimal ratio of 1:1:2. We define because the number of loss terms is three. We strengthen the argument that adding the transformation loss is superior in selecting only salient features when comparing the feature map of R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] with ours in Figure 2.
| (5) |
This aggregated loss function is used to select salient points to minimize the prediction of the less informative regions, such as the sky or ground. FMT is inducing the feature map transformation so that the proposed transformation loss function could extract robust features if the location where the image is taken is in the same place, regardless of the change in structure and style.
4 Experiment
4.1 Implementation details
Training. We apply Adam to optimize the network for 25 epochs with a fixed learning rate of 0.0001, a weight decay of 0.0005, and a batch size of 8 pairs of cropped images of 192 by 192 pixels, as in R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel]. Our experiment used the training dataset and ground-truth correspondences used in R2D2. Since our model uses the modified version of R2D2, we trained the network from scratch. Nonetheless, we fixed the patch size N used in the repeatability loss to 16 in all training parts to improve the performance of the transformation loss.
Testing. We used the sum of different scales of images to diversify the resolution of the feature maps at test time. The descriptors were interpolated at the modified locations. This multi-scale feature extraction enables the extraction of more tentative keypoints and provides improved localization.
Experiment Settings. This study used an NVIDIA GeForce RTX 3090 GPU and CUDA toolkit, version 11.2, with Python 3 and PyTorch 1.8 in the training environment.

MMA@3 Overall Illumi. Viewp. Hes.Aff. [Perd’och et al.(2009)Perd’och, Chum, and Matas] 56.24 51.35 60.79 DELF(new) [Noh et al.(2017)Noh, Araujo, Sim, Weyand, and Han] 49.43 89.73 12.02 SuperPoint [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich] 64.45 69.38 59.88 LF-Net [Ono et al.(2018)Ono, Trulls, Fua, and Yi] 53.01 57.31 49.02 D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler] 39.76 44.99 34.91 R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] 70.06 75.56 64.96 ASLFeat [Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan] 72.28 75.47 68.28 DISK [Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls] 75.34 79.43 71.53 Ours 78.41 83.22 73.94
4.2 Feature Matching
Quantitative Evaluation. We evaluated the performance of selecting meaningful points by calculating mean matching accuracy (MMA). If the distance between the converted point and the reference point exists within the threshold based on the ground truth homography metric, the converted point is classified as a correct conversion point. Figure 3 illustrates the comparisons on the H-Patches dataset [Balntas et al.(2017)Balntas, Lenc, Vedaldi, and Mikolajczyk], with MMA measured at various error thresholds. Figure 3 was drawn from the cache data provided by the D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler] repository. The comparison was performed with DELF [Noh et al.(2017)Noh, Araujo, Sim, Weyand, and Han], SuperPoint [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich], LF-Net [Ono et al.(2018)Ono, Trulls, Fua, and Yi] mono and multi-scale D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler], R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel], ASLFeat [Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan], DISK [Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls], and a hand-crafted Hessian affine detector with a RootSIFT descriptor [Perd’och et al.(2009)Perd’och, Chum, and Matas]. Our network denoted as "Ours" outperformed almost all state-of-the-art networks. Regarding illumination, DELF [Noh et al.(2017)Noh, Araujo, Sim, Weyand, and Han] outperformed our method since it identifies key points in a low-resolution feature map with a fixed grid. However, ours still exhibited the highest performance in terms of the five-pixel threshold because of the fixed grid of keypoints without spatial variation in this subgroup. The overall scores for the illumination dataset and viewpoints and their respective individual scores are presented in Table 1, with the MMA threshold set to 3.
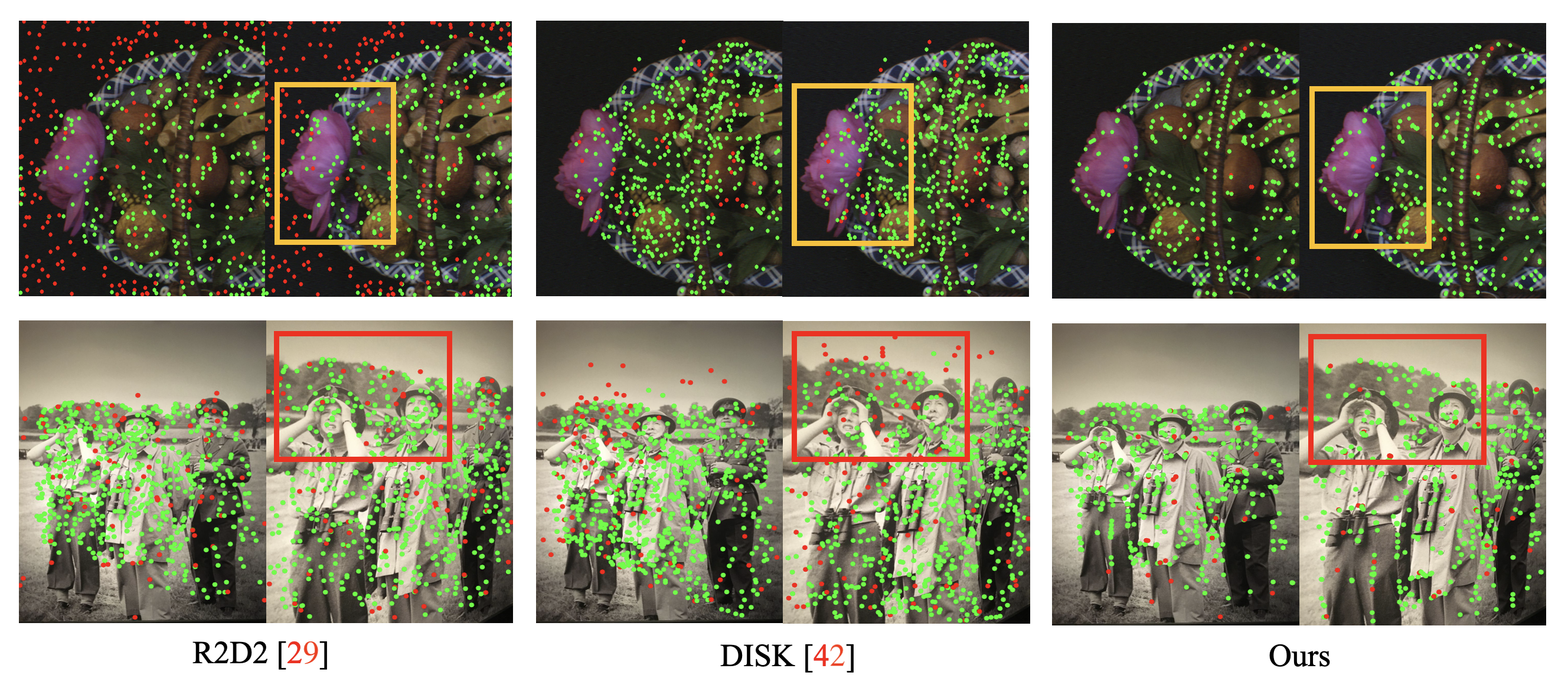
Qualitative Evaluation. Figure 4 shows the comparison between our baseline network R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] and the current state-of-the-art method DISK [Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls] with a severe change in illumination and viewpoint in the first and second row, respectively. The experiment was done with the nearest neighborhood matching with 3 points of error threshold. When we look at the yellow box, we see that we succeeded in focusing on structural information. The structurally less focused network failed to match in this part. In the red box, it can be seen that the error rate is lowered by focusing less on the background or natural objects corresponding to noise. The matching time is also shorter, shown in Figure 5.
4.3 Visual Localization
In a local reconstruction job [Sattler et al.(2017)Sattler, Torii, Sivic, Pollefeys, Taira, Okutomi, and Pajdla], we evaluate our technique on the Aachen Day-Night dataset v1.1 [Sattler et al.(2018)Sattler, Maddern, Toft, Torii, Hammarstrand, Stenborg, Safari, Okutomi, Pollefeys, Sivic, et al.] as in D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler]. In this section, we present the results of an optical localization task. Given the daytime photographs with known camera positions, our goal is to identify the nighttime image of the same area. The known location of the daytime photos in each set is used to triangulate the 3D structure of the scene after extensive feature matching. Finally, these 3D models are used to locate the query photographs taken at night. We followed the guidelines for Visual Localization Benchmark, for which we used our matches as input for a pre-defined visual localization pipeline based on COLMAP [Schonberger and Frahm(2016), Schönberger et al.(2016)Schönberger, Zheng, Frahm, and Pollefeys]. We also adopted hierarchical localization [Sarlin et al.(2019)Sarlin, Cadena, Siegwart, and Dymczyk] in every network for higher performance. This pipeline was then used to build an SfM model with the registered test photos. We used NetVlad [Arandjelovic et al.(2016)Arandjelovic, Gronat, Torii, Pajdla, and Sivic] for the global feature and the nearest neighborhood for matching. The percentages of properly localized photos under three error levels are reported in Table 2. Our results demonstrate our method’s strong generalization capabilities because of its high localization performance compared with SuperPoint [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich], D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler], R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] and DISK [Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls]. Our network performed fairly well when compared with matcher methods [Sun et al.(2021)Sun, Shen, Wang, Bao, and Zhou, Zhou et al.(2021)Zhou, Sattler, and Leal-Taixe].
Day Night 0.5m, 1m, 5m, 0.5m, 1m, 5m, SuperPoint [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich] 85.3 91.9 94.5 58.6 74.3 85.9 D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler] 81.6 89.3 96.2 62.8 80.6 92.7 R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] 89.9 95.4 98.4 69.6 85.9 96.3 DISK [Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls] - - - 72.3 86.4 97.9 Ours 90.4 96.1 98.9 72.3 89.0 96.9 LoFTR∗ [Sun et al.(2021)Sun, Shen, Wang, Bao, and Zhou] - - - 72.8 88.5 99.0 Patch2Pix∗ [Zhou et al.(2021)Zhou, Sattler, and Leal-Taixe] 86.4 93.0 97.5 72.3 88.5 97.9

4.4 3D Reconstruction
For 3D reconstruction evaluation, we used ETH-Microsoft Dataset [Schonberger et al.(2017)Schonberger, Hardmeier, Sattler, and Pollefeys] and for the evaluation protocols, we ran SfM algorithm by COLMAP [Schonberger and Frahm(2016), Schönberger et al.(2016)Schönberger, Zheng, Frahm, and Pollefeys]. In Table 3, we compare our method with the results presented in [Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan], but only the jointly learned models. Compared with other methods, since the number of matched points was less than 100K, we do not provide the comparison with R2D2 [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel]. For sparse reconstruction, we report the number of registered images ( Reg), the number of sparse points ( Sparse), tracked length (Track), and reprojection error (Reproj). Table 3 data shows that our network performs favorably against previous methods on the 3D reconstruction task. Furthermore, the number of registered images obtained the best value, and the number of sparse points also had the best or second-order value. It can be interpreted that the selection of salient points was made well.
Madrid Metropolis 1344 images Gendarmenmarkt 1463 images Tower of London 1576 images Reg Sparse Track Reproj Reg Sparse Track Reproj Reg Sparse Track Reproj SuperPoint [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich] 438 29K 9.03 1.02px 967 93K 7.22 1.03px 681 52K 8.67 0.96px D2-Net [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler] 495 144K 6.39 1.35px 965 310K 5.55 1.28px 708 287K 5.20 1.34px ASLFeat [Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan] 649 129K 9.56 0.95px 1061 320K 8.98 1.05px 846 252K 13.16 0.95px Ours 766 142K 8.13 1.19px 1316 516K 6.81 1.19px 1186 315K 8.63 1.21px
HPatches Aachen (Day) Aachen (Night) Overall Illum Viewp 0.5m, 2∘ 1m, 5∘ 5m, 10∘ 0.5m, 2∘ 1m, 5∘ 5m, 10∘ w/o 70.06 75.56 64.96 89.9 95.4 98.4 69.6 85.9 96.3 w/o 72.08 78.04 66.55 89.8 96.1 98.7 73.3 88.5 95.3 w/o 76.53 81.43 71.99 89.7 95.8 98.5 69.6 84.8 96.3 w/o DSC 76.89 81.95 72.19 89.9 95.3 98.2 69.1 85.9 93.7 w/ All 78.41 83.22 73.94 90.4 96.1 98.9 72.3 89.0 96.9
4.5 Ablation Studies
We validated the significance of the components that comprise our suggested transformation loss function by performing two ablation studies. We studied the presence of style and structural component losses to determine how each characteristic contributes to learning. and denote loss function that use same subscript in the masks of Eq. 4. The result in Table 4 reveals that the matching accuracy is not only influenced by the style factor but also by the structure factor. This experiment confirms the efficiency of ISW when applied to our method and its ability to provide additional information about the structure. Furthermore, ablation studies were conducted with and without DSC layer. The performance improved using DSC layer, with a model weight reduction of 2 MB.
5 Conclusion
We proposed a robust network using self-transformation loss, which transforms a feature map that contributes to the repeatability of local features. We separated structure and style characteristics by clustering the covariance vector and influenced the feature of each characteristic. The feature maps were unified to make two feature maps closer by reducing the light component and sharpening the structure component. Consequently, this step increases the repeatability of the points, reduces outliers, and assigns robustly matched descriptors. A comparison with similar research reveals that our method more effectively extracts robust matching points in various scenes. Nevertheless, the current work has limitations. Points tend to be retrieved by clustering them in a particular region. This analysis reveals that adaptively selecting from sparse points is a promising avenue for future research.
6 Acknowledgment
This work was supported in part by the National Research Foundation of Korea (NRF) under Grant NRF-2021R1A2C2010893 and in part by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) (No.RS-2022-00155915, Artificial Intelligence Convergence Innovation Human Resources Development (Inha University).
References
- [Arandjelovic et al.(2016)Arandjelovic, Gronat, Torii, Pajdla, and Sivic] Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016.
- [Balntas et al.(2017)Balntas, Lenc, Vedaldi, and Mikolajczyk] Vassileios Balntas, Karel Lenc, Andrea Vedaldi, and Krystian Mikolajczyk. Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5173–5182, 2017.
- [Bay et al.(2006)Bay, Tuytelaars, and Van Gool] Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. Surf: Speeded up robust features. In European conference on computer vision, pages 404–417. Springer, 2006.
- [Cheng et al.(2014)Cheng, Leng, Wu, Cui, and Lu] Jian Cheng, Cong Leng, Jiaxiang Wu, Hainan Cui, and Hanqing Lu. Fast and accurate image matching with cascade hashing for 3d reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–8, 2014.
- [Cho et al.(2019)Cho, Choi, Park, Shin, and Choo] Wonwoong Cho, Sungha Choi, David Keetae Park, Inkyu Shin, and Jaegul Choo. Image-to-image translation via group-wise deep whitening-and-coloring transformation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10639–10647, 2019.
- [Choi et al.(2021)Choi, Jung, Yun, Kim, Kim, and Choo] Sungha Choi, Sanghun Jung, Huiwon Yun, Joanne T Kim, Seungryong Kim, and Jaegul Choo. Robustnet: Improving domain generalization in urban-scene segmentation via instance selective whitening. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11580–11590, 2021.
- [DeTone et al.(2018)DeTone, Malisiewicz, and Rabinovich] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018.
- [Dusmanu et al.(2019)Dusmanu, Rocco, Pajdla, Pollefeys, Sivic, Torii, and Sattler] Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-net: A trainable cnn for joint detection and description of local features. arXiv preprint arXiv:1905.03561, 2019.
- [Gatys et al.(2015)Gatys, Ecker, and Bethge] Leon Gatys, Alexander S Ecker, and Matthias Bethge. Texture synthesis using convolutional neural networks. Advances in neural information processing systems, 28:262–270, 2015.
- [Gatys et al.(2016)Gatys, Ecker, and Bethge] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2414–2423, 2016.
- [He et al.(2018)He, Lu, and Sclaroff] Kun He, Yan Lu, and Stan Sclaroff. Local descriptors optimized for average precision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 596–605, 2018.
- [Heinly et al.(2015)Heinly, Schonberger, Dunn, and Frahm] Jared Heinly, Johannes L Schonberger, Enrique Dunn, and Jan-Michael Frahm. Reconstructing the world* in six days*(as captured by the yahoo 100 million image dataset). In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3287–3295, 2015.
- [Howard et al.(2017)Howard, Zhu, Chen, Kalenichenko, Wang, Weyand, Andreetto, and Adam] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [Huang et al.(2018)Huang, Yang, Lang, and Deng] Lei Huang, Dawei Yang, Bo Lang, and Jia Deng. Decorrelated batch normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 791–800, 2018.
- [Li et al.(2019)Li, Zhang, Yang, Liu, Song, and Hospedales] Da Li, Jianshu Zhang, Yongxin Yang, Cong Liu, Yi-Zhe Song, and Timothy M Hospedales. Episodic training for domain generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1446–1455, 2019.
- [Li et al.(2022)Li, Wang, Liu, Ran, Xu, and Guo] Kunhong Li, Longguang Wang, Li Liu, Qing Ran, Kai Xu, and Yulan Guo. Decoupling makes weakly supervised local feature better. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15838–15848, 2022.
- [Li et al.(2017)Li, Fang, Yang, Wang, Lu, and Yang] Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang. Universal style transfer via feature transforms. arXiv preprint arXiv:1705.08086, 2017.
- [Li et al.(2018)Li, Liu, Li, Yang, and Kautz] Yijun Li, Ming-Yu Liu, Xueting Li, Ming-Hsuan Yang, and Jan Kautz. A closed-form solution to photorealistic image stylization. In Proceedings of the European Conference on Computer Vision (ECCV), pages 453–468, 2018.
- [Liu et al.(2019)Liu, Shen, Lin, Peng, Bao, and Zhou] Yuan Liu, Zehong Shen, Zhixuan Lin, Sida Peng, Hujun Bao, and Xiaowei Zhou. Gift: Learning transformation-invariant dense visual descriptors via group cnns. Advances in Neural Information Processing Systems, 32, 2019.
- [Lowe(2004)] David G Lowe. Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2):91–110, 2004.
- [Luo(2017)] Ping Luo. Learning deep architectures via generalized whitened neural networks. In International Conference on Machine Learning, pages 2238–2246. PMLR, 2017.
- [Luo et al.(2020)Luo, Zhou, Bai, Chen, Zhang, Yao, Li, Fang, and Quan] Zixin Luo, Lei Zhou, Xuyang Bai, Hongkai Chen, Jiahui Zhang, Yao Yao, Shiwei Li, Tian Fang, and Long Quan. Aslfeat: Learning local features of accurate shape and localization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6589–6598, 2020.
- [Melekhov et al.(2020)Melekhov, Brostow, Kannala, and Turmukhambetov] Iaroslav Melekhov, Gabriel J Brostow, Juho Kannala, and Daniyar Turmukhambetov. Image stylization for robust features. arXiv preprint arXiv:2008.06959, 2020.
- [Noh et al.(2017)Noh, Araujo, Sim, Weyand, and Han] Hyeonwoo Noh, Andre Araujo, Jack Sim, Tobias Weyand, and Bohyung Han. Large-scale image retrieval with attentive deep local features. In Proceedings of the IEEE international conference on computer vision, pages 3456–3465, 2017.
- [Ono et al.(2018)Ono, Trulls, Fua, and Yi] Yuki Ono, Eduard Trulls, Pascal Fua, and Kwang Moo Yi. Lf-net: Learning local features from images. arXiv preprint arXiv:1805.09662, 2018.
- [Pan et al.(2019)Pan, Zhan, Shi, Tang, and Luo] Xingang Pan, Xiaohang Zhan, Jianping Shi, Xiaoou Tang, and Ping Luo. Switchable whitening for deep representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1863–1871, 2019.
- [Pautrat et al.(2020)Pautrat, Larsson, Oswald, and Pollefeys] Rémi Pautrat, Viktor Larsson, Martin R Oswald, and Marc Pollefeys. Online invariance selection for local feature descriptors. In European Conference on Computer Vision, pages 707–724. Springer, 2020.
- [Perd’och et al.(2009)Perd’och, Chum, and Matas] Michal Perd’och, Ondrej Chum, and Jiri Matas. Efficient representation of local geometry for large scale object retrieval. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 9–16. IEEE, 2009.
- [Revaud et al.(2019)Revaud, De Souza, Humenberger, and Weinzaepfel] Jerome Revaud, Cesar De Souza, Martin Humenberger, and Philippe Weinzaepfel. R2d2: Reliable and repeatable detector and descriptor. Advances in neural information processing systems, 32:12405–12415, 2019.
- [Roy et al.(2019)Roy, Siarohin, Sangineto, Bulo, Sebe, and Ricci] Subhankar Roy, Aliaksandr Siarohin, Enver Sangineto, Samuel Rota Bulo, Nicu Sebe, and Elisa Ricci. Unsupervised domain adaptation using feature-whitening and consensus loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9471–9480, 2019.
- [Sarlin et al.(2019)Sarlin, Cadena, Siegwart, and Dymczyk] Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. From coarse to fine: Robust hierarchical localization at large scale. In CVPR, 2019.
- [Sattler et al.(2017)Sattler, Torii, Sivic, Pollefeys, Taira, Okutomi, and Pajdla] Torsten Sattler, Akihiko Torii, Josef Sivic, Marc Pollefeys, Hajime Taira, Masatoshi Okutomi, and Tomas Pajdla. Are large-scale 3d models really necessary for accurate visual localization? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1637–1646, 2017.
- [Sattler et al.(2018)Sattler, Maddern, Toft, Torii, Hammarstrand, Stenborg, Safari, Okutomi, Pollefeys, Sivic, et al.] Torsten Sattler, Will Maddern, Carl Toft, Akihiko Torii, Lars Hammarstrand, Erik Stenborg, Daniel Safari, Masatoshi Okutomi, Marc Pollefeys, Josef Sivic, et al. Benchmarking 6dof outdoor visual localization in changing conditions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8601–8610, 2018.
- [Schonberger and Frahm(2016)] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016.
- [Schönberger et al.(2016)Schönberger, Zheng, Frahm, and Pollefeys] Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. In European Conference on Computer Vision, pages 501–518. Springer, 2016.
- [Schonberger et al.(2017)Schonberger, Hardmeier, Sattler, and Pollefeys] Johannes L Schonberger, Hans Hardmeier, Torsten Sattler, and Marc Pollefeys. Comparative evaluation of hand-crafted and learned local features. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1482–1491, 2017.
- [Sun and Saenko(2016)] Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. In European conference on computer vision, pages 443–450. Springer, 2016.
- [Sun et al.(2021)Sun, Shen, Wang, Bao, and Zhou] Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8922–8931, 2021.
- [Svärm et al.(2016)Svärm, Enqvist, Kahl, and Oskarsson] Linus Svärm, Olof Enqvist, Fredrik Kahl, and Magnus Oskarsson. City-scale localization for cameras with known vertical direction. IEEE transactions on pattern analysis and machine intelligence, 39(7):1455–1461, 2016.
- [Tian et al.(2017)Tian, Fan, and Wu] Yurun Tian, Bin Fan, and Fuchao Wu. L2-net: Deep learning of discriminative patch descriptor in euclidean space. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 661–669, 2017.
- [Tian et al.(2020)Tian, Balntas, Ng, Barroso-Laguna, Demiris, and Mikolajczyk] Yurun Tian, Vassileios Balntas, Tony Ng, Axel Barroso-Laguna, Yiannis Demiris, and Krystian Mikolajczyk. D2d: Keypoint extraction with describe to detect approach. In Proceedings of the Asian Conference on Computer Vision, 2020.
- [Tyszkiewicz et al.(2020)Tyszkiewicz, Fua, and Trulls] Michał Tyszkiewicz, Pascal Fua, and Eduard Trulls. Disk: Learning local features with policy gradient. Advances in Neural Information Processing Systems, 33:14254–14265, 2020.
- [Ulyanov et al.(2016)Ulyanov, Vedaldi, and Lempitsky] Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022, 2016.
- [Zagoruyko and Komodakis(2015)] Sergey Zagoruyko and Nikos Komodakis. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4353–4361, 2015.
- [Zhou et al.(2021)Zhou, Sattler, and Leal-Taixe] Qunjie Zhou, Torsten Sattler, and Laura Leal-Taixe. Patch2pix: Epipolar-guided pixel-level correspondences. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4669–4678, 2021.