
LLM-based Conversational AI Therapist for Daily Functioning Screening and Psychotherapeutic Intervention via Everyday Smart Devices
Abstract.
Despite the global mental health crisis, access to screenings, professionals, and treatments remains high. In collaboration with licensed psychotherapists, we propose a Conversational AI Therapist with psychotherapeutic Interventions (CaiTI), a platform that leverages large language models (LLM)s and smart devices to enable better mental health self-care. CaiTI can screen the day-to-day functioning using natural and psychotherapeutic conversations. CaiTI leverages reinforcement learning to provide personalized conversation flow. CaiTI can accurately understand and interpret user responses. When the user needs further attention during the conversation, CaiTI can provide conversational psychotherapeutic interventions, including cognitive behavioral therapy (CBT) and motivational interviewing (MI). Leveraging the datasets prepared by the licensed psychotherapists, we experiment and microbenchmark various LLMs’ performance in tasks along CaiTI’s conversation flow and discuss their strengths and weaknesses. With the psychotherapists, we implement CaiTI and conduct 14-day and 24-week studies. The study results, validated by therapists, demonstrate that CaiTI can converse with users naturally, accurately understand and interpret user responses, and provide psychotherapeutic interventions appropriately and effectively. We showcase the potential of CaiTI LLMs to assist the mental therapy diagnosis and treatment and improve day-to-day functioning screening and precautionary psychotherapeutic intervention systems.
1. Introduction
Maintaining physical and mental health is crucial for quality of life, particularly for those living alone, experiencing early signs of mental illness, or requiring daily assistance. COVID-19 significantly impacted global mental health with high barriers to accessing mental health screenings and treatments, including home care (Talevi et al., 2020; House, 2022). There are a variety of smart wearables and smart devices to monitor physical and mental health (Nie et al., 2021; Morshed et al., 2019; Zhu et al., 2021). Human-Computer Interaction (HCI) researchers are actively working to improve wellness care for the general public and vulnerable population groups (Mishra, 2019; Pendse et al., 2021; Tlachac et al., 2022). Furthermore, with the growth of the Internet of Things (IoT) devices, the smart speaker market volume reached 200 million and there are more than 6.84 billion smartphones worldwide in 2023 (Statista, 2023; Explodingtopics, 2023). Recent advances in artificial intelligence (AI) and large language models (LLMs) further expanded the possibilities for intelligent health-oriented applications (Nie et al., 2021; Yunxiang et al., 2023; Nori et al., 2023; van Heerden et al., 2023; Dai et al., 2023).
While existing research primarily focuses on understanding emotional states or affective states as indicators of mental well-being (Zhou et al., 2018), therapists generally require more knowledge about patients’ daily activities and behaviors to accurately assess mental health (Helfrich et al., 2008; Bible et al., 2017). Therapists often rely on assessments such as the Daily Living Activities–20 (DLA-20) and the Global Assessment of Functioning (GAF) to screen day-to-day functions and mental health status (Clausen et al., 2016; Guze, 1995; Fu and Fu, 2022; Morshed et al., 2019). Most existing research efforts focus on screening for physical and mental well-being, with few addressing psychotherapeutic interventions. Psychotherapy refers to a range of interventions based on psychological theories and principles to address emotional and behavioral issues that impact mental health (Corey, 2013). (Nie et al., 2022) and (Zhou et al., 2018) propose conversational systems that provide preliminary consolation. While conversational systems and evidence-based treatments like Motivational Interviewing (MI) (Naar and Safren, 2017), Cognitive Behavioral Therapy (CBT) (Beck and Beck, 2011), and Dialectical Behavior Therapy (DBT) (Robins and Rosenthal, 2011) have been proposed, many lack personalization or user understanding (Schroeder et al., 2018; Sabour et al., 2022).
Although AI chatbots like ChatGPT show promise in addressing mental health concerns (Cay, 2023; cha, 2023), they often suffer from performance decline over time and limitations in psychotherapeutic considerations (red, 2023). Additionally, mental health applications see low usage rates in clinical settings (Chandrashekar, 2018; Torous et al., 2018). Smartphone-based tools may not be user-friendly for individuals with memory or vision impairments, especially the elderly (Mohadisdudis and Ali, 2014). As such, there is growing interest in exploring objective activity detection through ambient sensing and voice-based chatbots as more inclusive and effective approaches to mental health support.
Considering these limitations and opportunities, in collaboration with 4 licensed psychotherapists from a major mental health counseling institution with thousands of clients, we propose CaiTI, a conversational AI therapist that takes advantage of widely-owned smart devices for continuous screening of physical and mental health in a privacy-aware manner, while employing psychotherapeutic interventions (Figure 1). Our collaborating psychotherapists have identified several design requirements for CaiTI that can facilitate mental health self-care and assist in psychotherapeutic treatment for individuals: (i) provide comprehensive day-to-day functioning screenings and employ evidence-based psychotherapeutic interventions; (ii) facilitate natural conversation flow; (iii) ensure the quality of care by enabling the system to intelligently interpret user responses and, if necessary, guide the dialogue back toward the psychotherapeutic objectives when the user’s responses deviate; and (iv) the conversation format (using smartphones/smart speakers) should take into consideration individuals with visual impairments.
Realizing such a system poses several challenges. Primarily, the system must fit within the users’ lifestyles and habits, utilizing devices that users already own and prefer. It should facilitate communication through the user’s preferred modes—be it verbal or textual—while ensuring comprehensive screening and delivering effective psychotherapeutic interventions in a privacy-aware manner. Additionally, it is imperative that the system is easy to use for all individuals, regardless of their technical proficiency. Furthermore, the LLMs in CaiTI should effectively deliver conversational psychotherapy and must be carefully designed to both be user-friendly/accessible and capable of understanding, reasoning, and responding to an infinitely diverse number of user responses (including both YES/NO answers and open-ended responses). The design of CaiTI must effectively manage varied responses, translate therapists’ empirical techniques into a quality-controlled logical flow, and incorporate a recommendation system that dynamically personalizes itself to each user.
Building upon near-ubiquitous smart devices, CaiTI combines AI techniques, including LLMs, reinforcement learning (RL), and human-computer interaction (HCI) approaches with professional experiences from licensed psychotherapists. CaiTI screens the user along the 37 dimensions of day-to-day functioning proposed in (Nie et al., 2022) by conversing naturally with users with open-ended questions. CaiTI understands verbal and textual responses and activities of the user and employs conversation-based psychotherapeutic interventions. To summarize, the main contributions of this paper include:
-
•
CaiTI, an LLM-based conversational “AI therapist” that screens and analyzes the day-to-day functioning of users across 37 dimensions. Using the screening results, CaiTI provides appropriate empathic validations and psychotherapies depending on the physical and mental status of the user. CaiTI is accessible through widely available smart devices, including smartphones, computers, and smart speakers, and offers a versatile solution catering to the diverse requirements of the users whether they are indoors or outdoors.
-
•
To realize more intelligent and friendly human-device interaction, we leverage RL to personalize each user’s conversation experience during screening in an adaptive manner. CaiTI prioritizes the dimensions that concern psychotherapists more about each user based on his/her historical responses and brings up the dimensions in the order of priority during the conversation.
-
•
We design the conversation architecture of CaiTI with the therapists, which effectively incorporates Motivational Interviewing (MI) and Cognitive Behavioral Therapy (CBT) – two commonly used psychotherapeutic interventions administered by psychotherapists – to provide Psychotherapeutic Conversational Intervention in a natural way that closely mirrors the therapists’ actual practices.
-
•
To ensure the quality of care and effectiveness of the psychotherapy process and avoid the propagation of biases in AI algorithms and LLMs, CaiTI incorporates multiple task-specific LLM-based Reasonsers, Guides, and Validator during the psychotherapy process. Leveraging the task-specific conversation datasets prepared and labeled by the licensed psychotherapists, we experiment and microbenchmark the performance of different GPT- and Llama 2-based LLMs with few-shot prompts or fine-tuning in performing tasks along CaiTI’s. We will open-source: (i) the datasets prepared by the therapists to facilitate research in this area and (ii) the few-shot prompts we designed with the therapists.
-
•
In collaboration with licensed psychotherapists, we design, implement, and deploy a proof-of-concept prototype of CaiTI. Through real-world deployments with 20 subjects for up to 24 weeks, we demonstrate that CaiTI can accurately assess the user’s physical and mental status and provide appropriate and effective psychotherapeutic interventions. CaiTI has received positive feedback, endorsements, and validation from both licensed psychotherapists and subjects.
To the best of our knowledge, CaiTI is the first conversational “AI therapist” system that leverages smart home devices and LLMs to mimic the psychotherapists’ actual practices in clinical sessions and provides continuous monitoring and interaction with the integration of psychotherapies (MI and CBT).
2. Psychological Background
2.1. Psychological Assessment
People who experience mental health adjustment issues and disorders tend to face diminished capacity in professional or academic performance, maintaining social relationships, and self-care (Helfrich et al., 2008; Bible et al., 2017). Traditional screening tools, such as the Mental Status Examination (MSE), require clinicians to observe and assess people’s daily functioning, such as physical appearance and presentation, social interaction behaviors, and emotional expression (Trzepacz and Baker, 1993). Other widely used diagnostic assessments, such as the Adult ADHD Self-Report Scale (ASRS-v1.1), the Patient Health Questionnaire-9 (PHQ-9) for depression, and the General Anxiety Disorder-7 (GAD-7), which provide more specific screening options for specific mental health diagnoses, often include questions or items assessing daily functioning (Kroenke et al., 2001; El ASRS, 2009). For example, the PHQ-9 includes assessments of mood, sleep hygeine, and eating habits (Kroenke et al., 2001).
There are several psychological measurements designed to examine the day-to-day functioning of individuals to evaluate their mental health well-being, such as DLA-20 and GAF (Nie et al., 2022; DSM-IV-TR., 2000; Scott and Presmanes, 2001). DLA, which was developed to evaluate aspects of daily functioning affected by mental illnesses, includes 20 major categories for daily functioning. These categories include interpersonal communication, family relationships, personal hygiene, time management, and productivity at work (Scott and Presmanes, 2001). On the other hand, GAF, which was introduced in DSM-IV, employs an ordinal scale to evaluate an individual’s overall level of functioning (DSM-IV-TR., 2000). A lower GAF score indicates the presence of more significant symptoms and difficulties in social, occupational, and psychological functioning.
2.2. Psychotherapeutic Interventions
Clinicians using evidence-based practices (EBP) in psychology to guide interventions and treatment plans, taking into account relevant research on their clinical practices, have found that the use of EBP helps improve the quality and accountability of clinical practices (on Evidence-Based Practice et al., 2006; Spring, 2007). Some commonly used EBP include CBT, acceptance and commitment therapy (ACT), DBT, and MI. CBT is one of the most popular and commonly used psychological interventions. It focuses on challenging one’s cognitive distortions and subsequent behaviors to reduce existing mental health symptoms and improve overall mental well-being (Alford et al., 1997; Beck and Beck, 2011). CBT is found to be effective in a variety of diagnoses, such as mood disorders, Attention-deficit/hyperactivity disorder (ADHD), eating disorders, Obsessive-compulsive disorder, and Post-traumatic stress disorder (Clark et al., 2003; Roy-Byrne et al., 2005; Emilsson et al., 2011; Halmi et al., 2005; Walsh et al., 2004; Foa et al., 2005; Dickstein et al., 2013). CBT also shows promising results in preventative care that may not be tied to a specific diagnosis. It has been effective in various settings, including medical, work, and school environments (Moss-Morris et al., 2013; Tan et al., 2014; Miller et al., 2011). However, despite the abundant evidence of its effectiveness, CBT is associated with a high nonresponse rate, attributed to participants’ low motivation (Antony et al., 2005). During CBT, therapists assess the validity and utility of participants’ responses to understand their thought patterns and beliefs accurately (Sokol and Fox, 2019). Such an assessment involves identifying, challenging, and reframing cognitive distortions, such as overgeneralization, emotional reasoning, all-or-nothing thinking, catastrophizing, etc (Burns and Beck, 1999). CBT usually consists of the following steps:
-
(1)
Identify the Situation/Issue: Start by clearly identifying the situation or issue you want to work on.
-
(2)
Recognize Negative Thoughts: Think about the thoughts that go through your mind when you experience this issue. These are often automatic or subconscious thoughts that may be irrational or unhelpful. They can be self-critical, overly pessimistic, or unrealistic.
-
(3)
Challenge Negative Thoughts: Challenge means questioning the validity of these thoughts. Are there alternative, more balanced, or rational thoughts that might be more helpful in the situation?
-
(4)
Reframe Thoughts and Situations: Try to reframe your unhelpful thoughts and situations into more balanced, realistic, and constructive ones. This process is about changing the way you think about the situation, which can lead to changes in your emotions and behaviors.
To address issues related to low motivation, researchers have suggested using MI as a complementary approach alongside CBT (Marker and Norton, 2018; Naar and Safren, 2017; Arkowitz and Westra, 2004). There are four techniques to effectively implement MI (Miller and Rollnick, 2012):
-
(1)
Open-ended questions: Encouraging elaboration on responses, asking for examples, or exploring the implications of what’s been shared;
-
(2)
Affirmations: State strengths and help feel that changes are possible;
-
(3)
Reflective listening: (i) Simple reflection: repeating what the client has said, using slightly different words or phrases; (ii) Reframe reflection: listening to the client’s statements and then reflecting them back in a way that presents a new perspective or interpretation; and (iii) Affective reflection: recognizing, understanding, and reflecting back the emotional content of what the client expresses;
-
(4)
Summaries: Use summaries not only to encapsulate discussions but also to highlight progress.
MI is an evidence-based practice for substance use disorders and other addiction issues (Anton et al., 2006; Aarons et al., 2017). It is also found to be effective in helping people adapt to various situations, such as managing diabetes (Kertes et al., 2011; Channon et al., 2007; Chen et al., 2012). Growing research has shown that the combination of CBT and MI shows effectiveness in a variety of populations and for mental health adjustments (Merlo et al., 2010; Marker and Norton, 2018; Kertes et al., 2011; Arkowitz and Westra, 2004).
3. Related Work
3.1. Mental Wellness Self-Screening and Self-Care
There are various methods for mental health self-screening (Kruzan et al., 2022; Brown et al., 2016). While online help-seeking is preferred by many individuals (Gould et al., 2002), these tools provide a limited assessment based on closed-ended questions, potentially leading to omitting important details typically obtained from open-ended questions or in-person interactions (Screening, 2021; Onl, 2022). Besides the online tools, (Liu et al., 2022) proposed an AI-based self-administer online web-browser-based mental status examination (MSE). Recently, Experience Sampling Method (ESM) has been widely adopted by HCI researchers for various physical and mental health screening. ESM can be done automatically by sensors or by repeatedly prompting users to answer questions in their normal environments. For example, ESM is used for self-reporting Parkinson’s Disease symptoms, chronic pain, designing health technologies for Bipolar Disorder, etc (Vega et al., 2018; Adams et al., 2018; Matthews et al., 2015). Most wellness self-screening methods in the literature use close-ended questions and expect close-end results from the user, while CaiTI uses open-ended questions and allows the user to chat freely with any topic. And they usually only focus on particular dimensions of the day-to-day functioning or mental disorders instead of performing a comprehensive screening.
3.2. LLM-based Healthcare and Mental Healthcare
Large Language Models (LLMs) are pre-trained on vast datasets, which equip them with significant prior knowledge and enhanced reasoning skills. The recent state-of-the-art models, including GPT-4 (OpenAI, 2023b), GPT-3 (OpenAI, 2023a), Claude-3 (Anthropic, 2024), and Gemini 1.5 (Pichai and Hassabis, 2024), exhibt strong capability in reasoning over text. Consequently, recent research increasingly employs LLMs alongside various language, vision, or multimodal models to enable advanced applications in various domains without the need for additional training (Yin et al., 2023; Sharan et al., 2023; Deb et al., 2023). For example, IdealGPT combines two LLMs (GPT) with a vision-and-language model to enable a framework that iteratively decomposes vision-and-language reasoning, where the two LLMs are treated as Questioner and Reasoner (You et al., 2023). Additionally, research has shown that LLMs possess the ability to reason with and interpret IoT sensor data (Xu et al., 2023a).
Recently, transformer-based Large language foundation models, such as GPT-4 (Bubeck et al., 2023), PaLM 2 (Anil et al., 2023), and LLaMA2 (Touvron et al., 2023), have demonstrated superior performance across various medical-related NLP tasks. LLMs are used to enable various general healthcare applications. (Waisberg et al., 2023) showed that GPT-4 has the potential to help drive medical innovation, from aiding with patient discharge notes, summarizing recent clinical trials, and providing information on ethical guidelines. Moreover, Google introduced Med-PaLM and Med-PaLM 2(Singhal et al., 2023a, b), LLMs explicitly tailored for the medical domain, providing high-quality responses to medical inquiries.
Various works also exploit and evaluate the performance of LLMs for mental status classification and assessment. Researchers leveraged LLMs for mental health prediction via online text data and evaluated the capabilities of multiple LLMs on various mental health prediction tasks via online text data (Xu et al., 2023b; Radwan et al., 2024). In addition, (Jiang et al., 2023) leverages RoBERTa (Liu et al., 2019) and Llama-65b (Touvron et al., 2023) in the system for classifying psychiatric disorder, major depressive disorder, self-rated depression, and self-rated anxiety based on time-series multimodal features.
In addition to assessing and classifying the mental status of the user, researchers have investigated providing psychological consultations. For example, (Nie et al., 2022) leveraged GPT-3 to construct a home-based AI therapist that detects abnormalities in mental status and daily functioning and generates responses to console users. (Lai et al., 2023) proposed an AI-based assistive tool leveraging the WenZhong model, a pre-trained model trained on a Chinese corpus for question-answering in psychological consultation settings (Lai et al., 2023). Researchers also investigate the potential of ChatGPT in powering chatbots to simulate the conversations between psychiatrists and mentally disordered patients (Chen et al., 2023).
Only a few works in the literature focus on using LLM for MI or CBT, developing these psychotherapy systems, and evaluating them in real-world scenarios. (Kian et al., 2024) developed a GPT3.5-powered prompt-engineered socially assistive robot (SAR) that guides participants through interactive CBT at-home exercises. Their findings suggest that SAR-guided LLM-powered CBT may yield comparable effectiveness to traditional worksheet methods. However, this study solely focused on employing an LLM-based approach to simulate traditional worksheet-based CBT, without thoroughly examining the validity of user responses to the CBT exercises or ensuring users effectively engaged with the CBT.
4. System Architecture

Considering the design requirements presented in Section 1, CaiTI includes two main functionalities: day-to-day functioning screening and precautionary psychotherapeutic conversational interventions as shown in Figure 2. We adopt the 37 dimensions for day-to-day functioning screening proposed in (Nie et al., 2022). For screening, Converse with the User in a Natural Way consists of open-ended question generations and semantic analysis of user responses based on LLM. To facilitate precautionary interventions, following psychotherapists’ guidance, CaiTI effectively integrates the motivational interviewing (MI) and cognitive behavior therapy (CBT) processes into Psychotherapeutic Conversational Intervention. Considering the characteristics of MI and CBT, and the actual ways in which the therapists perform during clinical sessions, various MI techniques introduced in Section 2.2 are applied in different scenarios during the conversation, while the four-step CBT is performed at the end of each conversation session.

Each activity screened through conversation sensing results in a (Dimension, Score) pair. Therapists set 3 classes for Score based on their clinical practices (Score ), where (i) a score of 0 indicates that the user performs well in this dimension, (ii) a score of 1 indicates that the user has some problems in this dimension, but no immediate action is needed, and (iii) a score of 2 indicates a need for heightened attention from healthcare providers. Figure 3 shows the flow diagram of CaiTI’s components, and CaiTI stores the historical user data on the front-end devices owned by the user. Due to privacy concerns, CaiTI only conducts semantic analysis on the text of user input, although speech audio is informative (Salekin et al., 2017).
4.1. Conversation Principles and Underlying Rationale
Converse with the User in a Natural Way and the Psychotherapeutic Conversational Intervention modules of CaiTI are closely related to each other when CaiTI converses with the user. Based on the psychotherapists’ experience in dealing with thousands of clients, several factors are considered to shape the conversation process of CaiTI. First of all, when the therapist asks a question, some clients express a lot, while others do not respond to the question, but talk about other things (related to other dimensions). In addition, not all clients are patient enough to go through all dimensions that the therapist wants to check. Psychotherapists usually start to check on the dimensions that the clients didn’t do well in previous sessions and are more important for assessment. If clients have a problem in a dimension, the therapists usually follow up to hear more about this dimension and provide quick counseling and therapy addressing the specific issue. This mirrors the psychotherapist’s tendency to focus on one problematic dimension extensively rather than treating multiple dimensions at once.
Taking the professional experiences and common practices of the psychotherapists into consideration, to converse with the user in an efficient, intelligent, and natural way to screen physical and mental health status, CaiTI’s conversation process follows four guidelines:
-
(1)
Prioritize questions intelligently: CaiTI starts with the dimensions that concern therapists more, while personalizing the priority to each user and formulating questions based on his/her historical responses.
-
(2)
Understand the user input better: CaiTI checks if the user answers the question asked (Dimension_N), understands how well the user performs in this dimension and decides if follow-up questions and conversational interventions are needed.
-
(3)
Obtain more information through minimal questioning: CaiTI maps each user response to all possible dimensions to avoid redundant questions.
-
(4)
Guarantee the quality of psychotherapies: CaiTI intelligently interprets and reasons the user responses and, when needed, it steers and guides the conversation back to the psychotherapeutic goals if the user’s answers stray.

4.2. Conversation Generation, Analysis, and Psychotherapeutic Intervention
Figure 4 shows CaiTI’s process to converse with the user. Generally, MI therapies are conducted throughout the conversation, while CBT proceeds at the end of the conversation session. There are four modules in which the LLMs are involved: CaiTI Questioner, Response Analyzer, reflection-validation (R-V) process, and CBT process.
In particular, CaiTI asks one question for each dimension if CaiTI does not obtain any information in the dimension from the user’s previous responses. A model-free reinforcement learning algorithm, Q-learning, is used to decide the action (i.e., the next question) in the current state (i.e., the current question). For each dimension (Dimension_N), CaiTI Questioner formulates the question and uses the text-to-speech method to converse with the user through the front-end device. The front-end device generates the text of the user response (speech-to-text conversion is used if the user has voice input). The detailed implementation of the front-end device is described in Section 6.3.
CaiTI expects the user to chat freely with it and can deal with open-ended responses. CaiTI performs segmentation on the user response in to Segment(s). For each Segment, a LLM-based Response Analyzer, described in Section 5.2, is used to classify the Segment into (Dimension, Score). If CaiTI fails to classify the Segment into the format of (Dimension, Score), it asks the user to rephrase the answer. CaiTI logs the user response if CaiTI still fails to classify the rephrased Segment into the format of (Dimension, Score). Otherwise, CaiTI checks the Score no matter if this Segment is answering the question asked by CaiTI or not. If the user needs more attention in this dimension (Score ), CaiTI proceeds with a reflection-validation (R-V) process starting with asking for more information starting with a simple reflection in MI. An example of this process is presented in Figure 5.
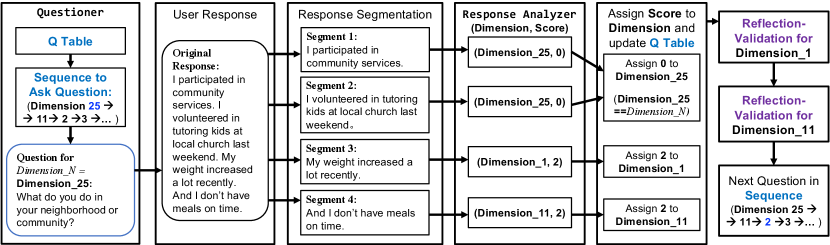
The R-V process is described in detail in Section 5.3 and demonstrated in Figure 8. To ensure the user provides follow-up information in the right direction, an R-V Reasoner and an R-V Guide are deployed. Based on the user response to the original and follow-up question, CaiTI provides validation, which includes affective reflection and affirmations in MI. Then, CaiTI assigns the Score to Dimension. After handling all Segment(s), CaiTI verifies whether the user does respond to the question asked by CaiTI in Dimension_N. In cases where a user does not answer the question asked by CaiTI (Dimension_N) but talks about something else, CaiTI asks the question in Dimension_N again.
After CaiTI enumerates all dimensions or the user wants to stop the session, CaiTI provides a summary of the chat session and asks the user to choose a dimension to work on for the CBT process. This CBT process includes the four steps outlined in Section 2.2. In particular, CaiTI identifies the situation and issue in the dimension the user chose based on the conversation history. Then, CaiTI leads the user to recognize (CBT Stage_1), challenge (CBT Stage_2), and reframe (CBT Stage_3) the negative thoughts in this situation. To ensure the effectiveness and quality of the CBT process, each CBT stage contains a Reasoner and a Guide (see Section 5.4).
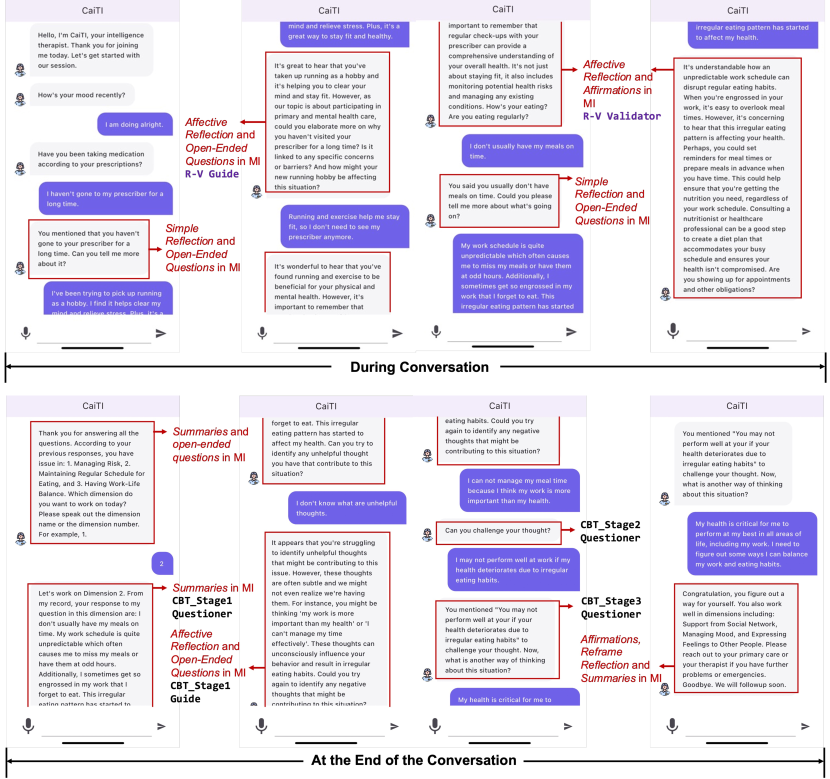
At the end, CaiTI generates a report that follows the same format as the therapists’ notes during their treatment sessions. Appendix A reports the details for the 37 dimensions used for day-to-day functioning screening, example questions from CaiTI, and sample responses from the users. Figure 6 shows the smartphone interface for CaiTI’s conversational chatbot, where the various psychotherapeutic interventions applied during different stages of the conversation are annotated.
As CaiTI provides comprehensive daily functioning screening, as presented in Appendix A, some of the dimensions, such as law-abiding, might be sensitive or uncomfortable for users. Therefore, CaiTI offers the option for users to manually select the dimensions to work on with the smartphone interface shown in Figure 7.

5. Method and LLM Microbenchmarks
The methods and LLMs leveraged in: (i) CaiTI’s Questioner, (ii) Response Analyzer, and (iii) task-specific Reasoners, Guides, and Validator during the psychotherapies (MI and CBT processes) are introduced in this section. To prevent the propagation of flaws or biases in LLMs, which may lead to ineffective or potentially harmful psychotherapy intervention, instead of leveraging models to handle all tasks during the psychotherapy process, CaiTI divides the tasks and employs different models to specifically handle each subtask.
Additionally, we present and discuss microbenchmarks comparing different GPT-based methods GPT-4(gpt-4) (OpenAI, 2023b) and GPT-3.5 Turbo (gpt-3.5-turbo-16k) (OpenAI, 2023a)) with Llama 2-based methods (Touvron et al., 2023). In particular, GPT-4, GPT-3.5 Turbo, Llama-2 13b, and Llama-2 7b possess parameter counts of over a trillion, more than one hundred billion, thirteen billion, and seven billion (Xu et al., 2023b). To carry out the microbenchmarks for LLMs, datasets were prepared and labeled by four licensed psychotherapists. These datasets were constructed based on their clinical experiences with clients, ensuring relevance and applicability to real-world therapeutic scenarios.
Considering the training dataset size for each task provided by the therapists, under the guidance from the therapists, we predominantly use few-shot prompting the system content in the chat completion in these LLMs to achieve the desired functions. Each prompt outlines: (i) the objectives; (ii) the information to be included in user content; and (iii) the desired goal and response format. The response format for Reasoners will be “Decision: 0/1”, while it is “Analysis: XXX” for Guides and Validator. For Reasoners, Guides, and Validator, the prompt includes 3-4 examples encompassing user content alongside corresponding system responses that adhere to the specified format. The examples for Response Analyzer is slightly different and illustrated in Section 5.2. We set the temperature as 0.7 in the LLMs to achieve varied rephrasings of the questions while maintaining certain constraints. The same prompt and hyperparameters are used for different LLMs. We fine-tune a GPT-3.5 Turbo model for Response Analyzer. The therapist also labeled and analyzed the output of Guides and Validator. We will open source the prompts we constructed as well as the datasets constructed by the psychotherapists. We did not conduct microbenchmark tests on basic LLM tasks such as the Rephraser and ReflectiveSummarizer. The former task involves structural rather than semantic rephrasing, while the latter repeats and converts statements from the first person to the third person.
5.1. CaiTI’s Questioner
CaiTI’s Questioner drives the conversations based on Epsilon-Greedy Q-learning and a GPT-based “Rephraser”. To make the conversation more natural, psychotherapists provide a set of questions they typically ask in each dimension (7 to 11 sample questions). We prompt a GPT-4-based Rephraser (OpenAI, 2023b) to rephrase these questions (structurally instead of semantically) when asking questions.
Each dimension has one related question. The Q-learning agent has 39 states (37 questions, start, and end). We set the learning rate and discount factor to 0.1 and 0.9, respectively. The probability of selecting the best action is set as . The therapists determine the initial Q-values for the Q-table based on their empirical evaluation of the “importance” of the dimensions. The Q-value, represents the expected future rewards that can be obtained by taking a given action (next question) in a given state (current question). The Score based on the analysis of user responses is the reward earned in that state.
5.2. Response Analyzer
When the user responds to the question asked by CaiTI, CaiTI first segments the response into individual sentences. For each segmented sentence, CaiTI classifies it into (Dimension, Score), where there are 37 dimensions and 3 scores (Score ) – a total number of 111 classes. In addition, we define 5-class general responses to express Yes, No, Maybe, Question, and Stop (e.g., “Yes”, “I don’t know”, “Stop”, “Maybe”, and “I don’t understand your question”) as well as a mapping table between the Scores and general responses for each dimension. For example, the Score of “Yes” is 0 to the question “Are you showing up for work or school?” in Managing Work/School, while it is 2 to the question “Do you often drink alone?” in Alcohol Abuse.
Since CaiTI asks open-ended questions, user responses are infinitely diverse (YES/NO answers or open-ended responses). With a Score of 2, CaiTI will conduct the psychotherapeutic conversational intervention. Otherwise, CaiTI will ask the next question based on the Q table. When CaiTI meets out-of-context responses, it asks the user to rephrase and follow the process illustrated in Figure 4.
5.2.1. Microbenchmark – Response Analyzer
To the best of our knowledge, no dataset exists with responses to these questions in the 37 dimensions. Therefore, psychotherapists create a dataset, which includes: (i) 6,950 user responses sample with the (Dimension, Score) labeled by the therapists, and (ii) 300 5-class general responses to express Yes, No, Maybe, Question, and Stop. Note that one user response may have one or more (Dimension, Score). As such, there are 7,000 (Dimension, Score) for the 6,950 responses. The number of responses per dimension is 103 to 177.
The datasets are split into 90% and 10% for training and testing set to fine-tune and evaluate the GPT-3.5 Turbo model (gpt-3.5-turbo is recommended by OpenAI for fine-tuning task (OpenAI, 2023c)). For a fair comparison, the same testing set is used to evaluate the performance of the LLMs with few-shot prompt. Therapists select 2-5 examples for each score in each dimension from the training set to construct the few-shot system content prompt. The constructed prompt contains around 8,140 tokens. As shown in Table 1, the prompt GPT-4 model has comparable performance to the fine-tuned GPT-3.5-Turbo model. Llama-based models perform less ideal in correctly classifying the Dimension and Score. In particular, Llama-based models have issues identifying the responses that don’t need further attention (Score = 0 and 1).
| Score Accuracy | Dimension Accuracy | General Response Accuracy | |
|---|---|---|---|
| Fine-tune GPT-3.5-Turbo | 95.58% | 96% | 93.75% |
| Prompt GPT-4 | 94.43% | 95.14% | 95.85% |
| Prompt GPT-3.5 Turbo | 92.81% | 94.14% | 96.14% |
| Prompt Llama-2-13b | 54.39% | 59.42% | 63.33% |
| Prompt Llama-2-7b | 55.11% | 48.63% | 53.33% |
5.3. Reflection-Validation Reasoner, Guide, and Validator
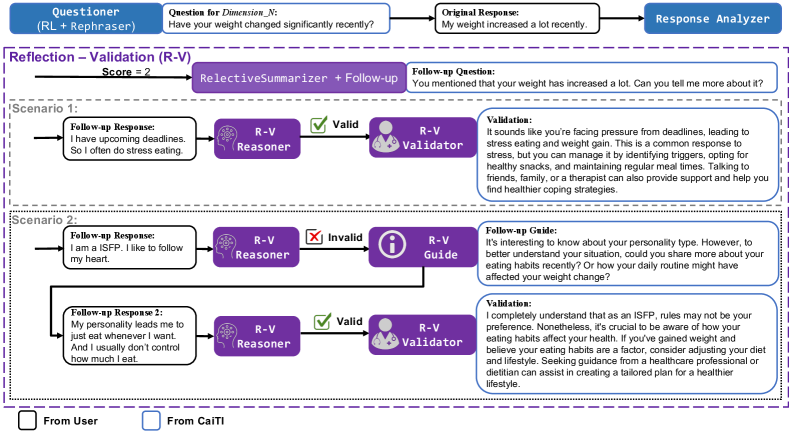
As depicted in Section 4.2 and Figure 4, during the conversation screening process, if the user’s response includes situations that require further attention (with Score = 2), CaiTI will pose a follow-up question to gather more information about the contributing factors to this situation. The follow-up question would start with the simple reflection in MI, a technique where the psychotherapist or counselor mirrors what the client has said. A GPT-4-based ReflectiveSummarizer is prompted to provide the simple reflection, which essentially rephrases or repeats the client’s own words, altering any self-references from the first person to the third person (OpenAI, 2023b).
The follow-up question initiates a reflection-validation (R-V) process to provide effective empathic validation and support. Given that follow-up responses from the user are open-ended and have infinite possibilities, CaiTI incorporates a R-V Reasoner to determine whether the follow-up response is related to the original response or the question asked in the current state. As illustrated in Scenario 1 in Figure 8, CaiTI will offer empathic validation if the user provides a valid follow-up response. Otherwise, the R-V Guide will assist the user in providing a follow-up response that more accurately describes the situation at hand before proceeding to empathic validation (Scenario 2 in Figure 8).
With a valid follow-up response, a R-V Validator is used to provide empathic validation and support to the user, which incorporates the affective reflection and affirmation techniques in MI. These two techniques aim at demonstrating empathy and understanding of the client’s feelings, creating a supportive environment that validates the client’s experiences and feelings, and fostering a deeper connection.
5.3.1. Microbenchmark – Reflection-Validation Reasoner, Guide, and Validator
Therapists provide us with 593 example follow-up responses for the original responses that need further attention (Score = 2). Within these 593 responses, 244 follow-up responses are invalid (1: Invalid), which trigger R-V Guides before prompting the R-V Validators. In addition, 6 examples for R-V Guides and R-V Validators are given by the psychotherapists to construct the prompts. As the output of R-V Guide and R-V Validator are open-ended, therapists label the 244 R-V Guides and 593 R-V Validators generated by each of the 4 prompt-based LLM models.
Table 2 presents the performance metrics of R-V Reasoner, R-V Guide, and R-V Validator across the four LLM models, where we prompted the system content in the chat completion functionality. The data presented in Table 2 illustrate that methods based on Llama demonstrate inferior reasoning capabilities in assessing the validity of a follow-up response in relation to the original question and response within the given context. Typically, Llama-based approaches are prone to inaccurately classifying valid follow-up responses as invalid. Additionally, the GPT-based method demonstrates a remarkable capability in accurately identifying all invalid responses, evidenced by its complete absence of false-negative errors (the misclassification of invalid responses as valid).
R-V Guides generated by GPT-based methods also outperform those generated by Llama-based methods. Therapists point out that the major issue for Llama-based Guides is they sometimes get confused or distracted by the irrelevant follow-up answer and reorient from the original dimension to ask about contents mentioned in the follow-up. This phenomenon is more obvious in the Guides generated by Llama-2-13b. Therapists also observe that Llama-based Guides cannot capture all the points in the user response, often focusing only on one aspect.
Moreover, the empathic validations generated by the Llama-based R-V Validators are substandard in quality control. In particular, Llama-based R-V Validators perform poorly in following the objectives and format specified in the few-shot prompt. Some outputs included excessive small talk, some focused on follow-up responses that were irrelevant to the target dimension that was the primary focus of the discussion, and some failed to provide reflection or affirmation. For example, one output generated by Llama-2-13b R-V Validator engaged in questions aiming to problem solve based on the user’s responses, rather than offering empathetic validation as intended, which deviates significantly from the expected function of providing empathetic support. As indicated in Table 2, GPT-based R-V Validators deliver more regulated and superior quality empathic validations, largely conforming to the prompt’s requirements. However, a minor number of empathic validations by GPT-based R-V Validators encounter issues such as the use of inappropriate words or tones, or overinterpreting the feeings and emotions in user responses.
| Prompted | R-V Reasoner | R-V Guide | R-V Validator | ||
|---|---|---|---|---|---|
| Models | Accuracy | Precision | Recall | Accuracy | Accuracy |
| GPT-4 | 97.8% | 94.94% | 100% | 94.67% | 96.79% |
| GPT-3.5 Turbo | 97.3% | 93.85% | 100% | 95.08% | 95.95% |
| Llama-2-13b | 69.3% | 68.7% | 84.5% | 68.85% | 83.47% |
| Llama-2-7b | 74.54% | 65.76% | 70.50% | 75.00 % | 63.52% |
5.4. Cognitive Behavioral Therapy Reasoner and Guide
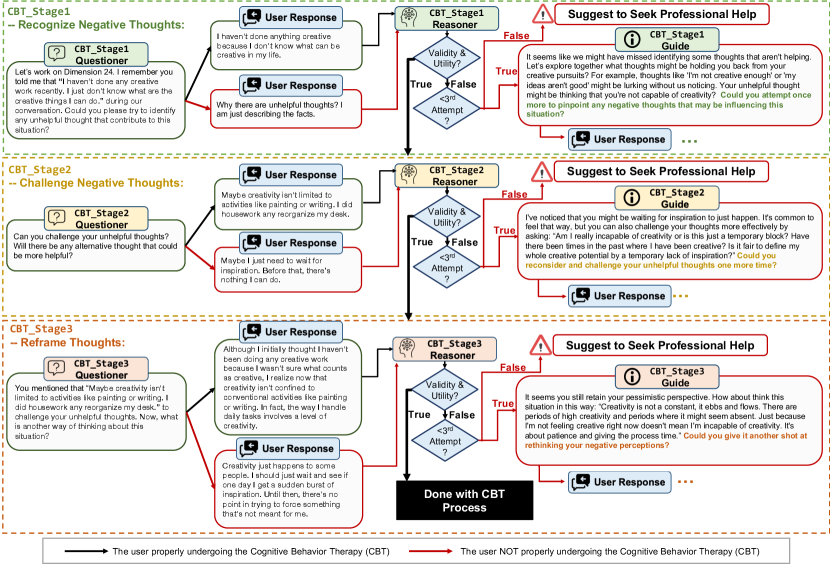
As described in Section 2.2 and Section 4.2, the CBT process usually includes four steps and CaiTI completes the first step – identifying the situation and issues – for the user based on the historical user responses in the current conversation session. As such, there are three stages remaining: recognizing the negative thoughts (CBT_Stage1), challenging the negative thoughts (CBT_Stage2), and reframing the thoughts and the situations (CBT_Stage3). As the three stages target at different objectives, there are a Questioner, Reasoner, and Guide in each stage.
Figure 9 shows the pipeline for the three-stage CBT process. In each stage, the Questioner poses questions aligned with that stage’s specific objectives. The Reasoner then evaluates the user’s response for its validity and utility. CaiTI progresses to the next stage if the response is deemed valid. If not, the Guide aids the user in crafting a valid response by identifying issues in the current response and suggesting possible improvements for a valid answer. If the user does not provide a valid response after two attempts, CaiTI will conclude the CBT process and recommend that the user seek professional assistance for a more effective and valid CBT experience.
Therapists also point out that an acceptable response involves identifications of cognitive distortion, such as polarized thinking, overgeneralization, emotional reasoning, catastrophizing, and jumping to conclusions. The Reasoner is tasked with recognizing responses containing cognitive distortions as valid, especially for CBT_Stage1 Reasoner. Meanwhile, if the response with cognitive distortions is invalid (e.g., not relevant to the situation), the Guide must take these distortions into account when assisting the user in formulating a valid response.
5.4.1. Microbenchmark – Cognitive Behavioral Therapy Reasoner and Guide
Psychotherapists provide us with 146 example situations within the 37 dimensions and the three-stage CBT responses for each situation. In addition, they label the validity of each response (0: Valid, 1: Invalid). In particular, there are 15, 17, and 33 responses that are invalid and need “Guide” in CBT_Stage1, CBT_Stage2, and CBT_Stage3, respectively. With guidance from therapists, we developed system content prompts to evaluate whether users can identify, challenge, and reframe negative thoughts effectively for CBT_Stage1 Reasoner, CBT_Stage2 Reasoner, and CBT_Stage3 Reasoner. And the performances of these CBT Reasoners using different LLMs are listed in Table 3. The user content for each stage encompasses all responses from the user and CaiTI within the current stage as well as from preceding stages. Overall, the performance for CBT_Stage3 is higher. GPT-3.5 Turbo has comparable performance to GPT-4, while both GPT-based models significantly outperform the Llama-2-based models in reasoning.
| Prompted | CBT_Stage1 Reasoner | CBT_Stage2 Reasoner | CBT_Stage3 Reasoner | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | Accuracy | Precision | Recall | Accuracy | Precision | Recall | Accuracy | Precision | Recall |
| GPT-4 | 95.89% | 72.68% | 93.33% | 95.21% | 72% | 100% | 99.32% | 100% | 96.97% |
| GPT-3.5 Turbo | 95.21% | 83.33% | 66.67% | 94.52% | 90.91% | 58.82% | 95.89% | 100% | 82.35% |
| Llama-2-13b | 67.81% | 23.33% | 93.33% | 91.1% | 59.09% | 76.47% | 96.58% | 96.67% | 87.88% |
| Llama-2-7b | 69.86% | 10.81% | 26.67% | 88.36% | 50% | 29.41% | 81.51% | 58.33% | 63.64% |
As mentioned before, CBT Guide needs to be aware of cognitive distortions and point them out to guide effectively. According to psychotherapists’ experiences, identifying unhelpful thoughts is the most challenging stage within the three stages of the CBT process, with the highest probability of containing cognitive distortions and less information obtained from the user in this stage. Table 4 shows the performance of different LLMs in providing appropriate CBT Guide when responses are invalid in the three CBT stages. In general, using the same prompt, GPT-3.5 Turbo performs the best, even outperforming GPT-4. Therapists comment that “GPT-4 sometimes sounds like it is reading into the user’s feelings” instead of guiding the user objectively. Additionally, Llama-2-13b and Llama-2-7b show fairly good performance in CBT_Stage2 and CBT_Stage3, with very few instances of “overanalyzing” or “reading into emotions”. However, as previously mentioned, Llama models have comparably poor reasoning capabilities and struggle with processing more complex information, which might contribute to their inferior performance in CBT_Stage1.
| Prompted Models | CBT_Stage1 Guide | CBT_Stage2 Guide | CBT_Stage3 Guide |
|---|---|---|---|
| GPT-4 | 93.33% | 94.12% | 90.9% |
| GPT-3.5 Turbo | 100% | 100% | 96.97% |
| Llama-2-13b | 73.33% | 94.12% | 100% |
| Llama-2-7b | 73.33% | 100% | 93.93% |
5.5. Discussion and Observations on different LLMs
As illustrated in Section 5.2 to 5.4, overall, GPT-based models have higher performance compared to Llama-based models in achieving the desired functionalities in CaiTI and following the instructions specified in the few-shot prompts, especially in complex tasks, such as: (i) Response Analyzer, which needs to classify the user response into (Dimension, Score) (5 general response classes, 37 dimensions, and 3 scores), and (ii) different Reasonsers, R-V Guide and R-V Validator, where the user responses may span infinitely diverse spectrum and may not fall within the current conversation topic. Llama-based models had a hard time following the instructions in the few-shot prompts when the expressions from the user lacked logical consistency and with cognitive distortions.
Moreover, GPT-based models sometimes add their own interpretation of users’ feelings instead of providing an objective, matter-of-fact output based on the user responses. Llama-based models with few-shot prompts have more stable performance for CBT_Stage2 Guide and CBT_Stage3 Guide, where the user responses are more standard and controlled thanks to the filtering of CBT Reasoners and the tasks, challenging and reframing the negative thoughts, are more straight forward. These observations are expected, as GPT-based models have larger parameters and are pre-trained on a larger corpus of data. Indeed, there are methods that can further improve the quality of the outputs generated by these LLM models, which will be further discussed in Section 9.
6. Implementation and Study Design
In this section, we outline the subject recruitment procedures, describe the implementation, and detail the study design.
6.1. Subject Recruitment
20 subjects voluntarily participated (received informed consent from each subject) in our study (approved by the Institutional Review Board), including 10 men and 10 women between 18 and 40 years old from different races. All participants reported having normal hearing and cognition with no history of serious mental or physical illness. All subjects were either students or employed. Each subject was assigned a random subject ID (e.g., S01) for data identification.
6.2. LLMs Implementation
Considering the response time and computational resources requirement, the best performing LLM according to the microbenchmarks is implemented for different modules, as illustrated in Figure 9. As discussed in Section 5, different LLMs excel at handling different tasks in CaiTI’s conversation flow. For example, GPT-3.5 turbo is more suitable for providing guide and empathic validation, while GPT-4 is better at reasoning the validity and utility of user response.

6.3. Implementation
As mentioned in Section 1, to accommodate individuals with different needs and with possible memory or vision impairments, particularly the elderly, CaiTI is available in two physical form factors: a customized multi-platform app and a smart speaker (Amazon Alexa). CaiTI integrates custom Alexa Skills with an Amazon Echo device and a Flutter-based application, enabling flexible interaction through voice or text on multiple platforms such as Android, iOS, Windows, and macOS.
Figure 3 depicts the System’s architecture, highlighting the communication pathway where only the conversation text is transmitted between the user interfaces and the server. This design decision is implemented to mitigate the risk of compromising sensitive information that may be inherent in voice data. Voice interactions are facilitated by APIs such as the Alexa Skills Kit (Ale, 2023) and Google’s speech-to-text API (Spe, 2022). The server’s role is to handle all LLM-based tasks, including interpreting text inputs and generating appropriate follow-up questions or psychotherapeutic interventions that are then delivered to the user interface.
Figure 6 shows the smartphone interface for CaiTI’s conversation session, where the various psychotherapeutic interventions applied during different stages of the conversation are annotated. Figure 11 displays the home page of the CaiTI on a smartphone (Figure 11(a)), shows user interactions with CaiTI via voice commands using both the smartphone and an Amazon Echo during in-lab sessions (Figures 11(b) and 11(c)), and depicts a user at home interacting with the CaiTI through text input on a computer (Figure 11(d)).




6.4. Study Design
We first conducted a 14-day study with in-lab and at-home sessions for each subject. The subjects participated in the in-lab session on the first and last days. Afterward, 4 subjects voluntarily participated in a 24-week at-home longitudinal study. A licensed psychotherapist implemented bi-weekly PHQ-9 and GAD-7 assessments with these 4 subjects to measure the effectiveness of CaiTI. Figure 12 shows the modules and tasks implemented in each setup. Subjects were told they were able to unselect some dimensions if they felt uncomfortable through the smartphone interface shown in Figure 7, but they were encouraged to select all. All conversation sessions (user and CaiTI responses, Response Anayzer’s results, Reasoners’ results) are saved for evaluation purposes.

6.4.1. In-Lab Session
The scope of the study and a tutorial about CaiTI system are given at the first in-lab session after informed consent was obtained. During this session, subjects were informed that the dialogue with CaiTI would incorporate elements of psychotherapy. However, to prevent their responses from being influenced and to maintain uniformity in the user experience, the underlying principles and methodologies of the psychotherapies (Motivational Interviewing (MI) and Cognitive Behavioral Therapy (CBT)) were not disclosed. Then, each subject is asked to choose their favorite method (smartphone platform/laptop platform/Amazon Echo) to converse with CaiTI. At the end of every in-lab session, subjects evaluated the system and provided feedback. This evaluative data will be examined in detail in Section 8.
6.4.2. At-Home Session
Participants were requested to engage in dialogues with the CaiTI at their convenience, with a recommended frequency of once daily or, at a minimum, twice weekly. Among the cohort, four subjects agreed to extend their participation to a 24-week duration. These individuals had regular sessions with a licensed therapist throughout the study period. To evaluate the severity of depression and generalized anxiety disorder, the PHQ-9 and GAD-7 scales were administered bi-weekly, respectively. Psychotherapists closely monitored the participants to ascertain that involvement in the study did not exert any adverse effects on their daily lives.
7. System Evaluation
We combine all the logs from conversation sessions during the 14-day and 24-week study and evaluate CaiTI’s system performance in this section. There are 454 conversation sessions with 18,309 and 2,013 segments of subjects’ responses to CaiTI’s original and follow-up questions, respectively. Some subjects answered the question with more than one sentence (segment). There are 107 times when the subjects failed to provide valid follow-up responses at the first attempt and triggered R-V Guide. CaiTI provides 2,013 empathic validation and support sessions with R-V Validator.
As described in Section 5.4, CaiTI will conclude the CBT process, if the user does not provide a valid response after two attempts in each stage of the three-stage CBT process. There are 454 CBT sessions at the end of each conversation session. Among these CBT sessions, as shown in Table 5 3, 6, and 3 of the CBT sessions terminated (fail to provide valid or relevant responses within 3 attempts) in CBT_Stage1, CBT_Stage2, and CBT_Stage3, respectively. The number of user attempts in each CBT stage is shown in this table. As such, there are 33 CBT_Stage1 Guides, 44 CBT_Stage2 Guides, and 26 CBT_Stage3 Guides, respectively. And the CBT_Stage1 Reasoner, CBT_Stage2 Reasoner, and CBT_Stage3 Reasoner are called 487, 495, 474 times, respectively.

4 licensed psychotherapists label the ground truth of output generated by these Reasoners, Validator, and Guides to evaluate their performance. Specifically, each therapist individually labels the outputs, with the ground truth determined by the majority vote among their evaluations.
In general, during the study with subjects, the performances of various LLM-based functional modules were either better than or comparable to their performances on the datasets provided by psychotherapists during the microbenchmark experiments. This phenomenon is expected, since there is a lower probability for subjects to provide invalid or illogical responses compared to the proportion of “invalid” or “inappropriate” responses in the datasets provided by the therapists. Note that CaiTI is designed for precautionary screening, assistance, and conversational psychotherapeutic intervention, and it is not intended to replace the process of diagnosis or clinical treatment.
| CBT_Stage1 | CBT_Stage2 | CBT_Stage3 | |
|---|---|---|---|
| CBT Reasoner in Attempt 1 | 454 | 451 | 448 |
| CBT Guide in Attempt 1 | 23 | 37 | 21 |
| CBT Reasoner in Attempt 2 | 23 | 37 | 21 |
| CBT Guide in Attempt 2 | 10 | 7 | 5 |
| CBT Reasoner in Attempt 3 | 10 | 7 | 5 |
| Terminated in Attempt 3 | 3 | 6 | 3 |
7.1. Response Analyzer
The user responses to the original questions were divided into segments. Each response segment was classified into (Dimension, Score) pairs, with ground truth labeled by the therapists. Dimension classification accuracy (5 classes of general responses and 37 dimensions) reached 97.6%. Figure 13 presents the confusion matrix for the Score of the 7,989 segments with a 99.4% accuracy.
7.2. R-V Reasoner, R-V Guide, and R-V Validator
| R-V Reasoner | R-V Guide | R-V Validator | ||
| Accuracy | Precision | Recall | Accuracy | Accuracy |
| 97.97% | 70% | 98.99% | 95.32% | 96.57% |
During the 2,013 reflection-validation (R-V) process, R-V Reasoner and R-V Guide were activated 2,120 and 107 times, respectively. As shown in Table 6, CaiTI’s R-V Reasoner almost perfectly identifies all “invalid” follow-up responses from the user with only 1 exception. R-V Reasoner misclassified 42 valid follow-up responses as invalid, which is acceptable in the context of precautionary psychotherapeutic intervention, as it would guide the user to provide valid follow-up responses with better quality. In addition, R-V Guide achieved an accuracy of 96.57%, with only 5 guides being slightly not perfect. The causes for these 5 imperfect guides are overinterpreting the relationship between the follow-up response and the original response and missing some information from the user responses.
The therapists also checked all the 2,013 empathic validations and supports provided by the R-V Validator to the subjects through a majority vote, with 69 being slightly inappropriate. Specifically, when follow-up responses were too brief (under 3 words), CaiTI struggled to comprehend, leading to 24 improper empathic supports. 15 inappropriate instances resulted from inconsistencies between the subjects’ original and follow-up responses. Another 30 inappropriate validations are due to the GPT-based R-V Validator adding its own interpretation of user responses into the empathic validation. Overall, CaiTI effectively delivered empathic validation and support in over 96.5% of instances. Although there are concerns about bias in large language models, the fine-tuned models in this work perform well in user studies and exhibit minimal bias.
7.3. CBT Reasoner and CBT Guide
Table 7 illustrates the performance of CBT Reasoners and CBT Guides when handling the responses from subjects from all attempts during the three-stage CBT process. It is shown that CBT Reasoners in each stage have high accuracies in identifying the validity and utility of the user responses to meet the psychotherapeutic goal of the CBT process. The CBT Reasoners also achieve high recall, which demonstrates that it is extremely rare for CBT Reasoners to miss any user response that’s not valid or not related.
CBT_Stage1 Guide, CBT_Stage2 Guide, and CBT_Stage3 Guide generated only 3, 3, and 2 less ideal context to guide the subjects. The most common issues for these 8 suboptimal CBT Guides is that they tried to read minds and made excessive assumptions about the relationships of the user responses earlier in the CBT process. None of these suboptimal CBT Guides completely misguide the user or lead them in the wrong direction.
| CBT_Stage1 Reasoner | CBT_Stage2 Reasoner | CBT_Stage3 Reasoner | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | Accuracy | Precision | Recall | Accuracy | Precision | Recall |
| 99.38% | 93.39% | 96.88% | 98.78% | 88.64% | 97.5% | 99.57% | 100% | 92.85% |
| CBT_Stage1 Guide | CBT_Stage2 Guide | CBT_Stage3 Guide | ||||||
| Accuracy | Accuracy | Accuracy | ||||||
| 90.9% | 95.45% | 92.23% | ||||||
8. User Study
In this section, we present the quantitative and qualitative feedback of the 20 subjects who participated in our study (20 subjects participated in the 14-day study and 4 subjects extended to 24 weeks). We also organize and discuss the qualitative feedback and evaluations from the 4 psychotherapists working with us on this project.
8.1. User Adaptation Indicated by Device Usage
During the 24-week study, we meticulously tracked the number of conversation sessions each subject had per week with CaiTI. As illustrated in Figure 14, the data indicates that all four subjects engaged in dialogue with CaiTI with a frequency of 2 to 3 times daily. Notably, this consistent engagement over the course of the study suggests a sustained use of the system by the participants. The frequency of their interactions with CaiTI did not exhibit a significant decline over time, implying a stable user adaptation and a persistent incorporation of the system into their daily routines. This enduring engagement underlines the utility and user-friendliness of CaiTI, as well as its potential to maintain user interest and interaction over extended periods.

8.2. Quantitative Analysis
ChatBot Usability Scale (BUS-15) is a recently developed tool to assess end-users’ satisfaction with chatbots (Borsci et al., 2022). Taking BUS-15 into account, we devised the 10 aspects listed in Table 8. Subjects rated the system from 1 (poor) to 5 (excellent) for these 10 aspects on the first and last day of the experiment. In general, subjects gave high ratings to CaiTI. Most subjects thought positively of the conversations with CaiTI and were willing to recommend and continue using CaiTI in the future. Only one subject showed a slightly negative attitude towards CaiTI and gave low scores. This subjective thought that “the technology is too intelligent and makes me worried that AI might be playing a too important role in my daily life” (S19).
A Wilcoxon signed-rank test, a nonparametric statistical within-subject test commonly used in behavioral science (Shin et al., 2022), was performed to compare the subjects’ day-to-day functioning on the first and last days of the 14-day study based on their responses Score on all 37 dimensions (Score , described in Section 4). The test results show a statistically significant decrease in the dimensions with Score equal to 1 and 2 on the last day, as compared to the first day of the experiment (z = -2.68, p ¡ .01), showing a decrease in dimensions subjects reported with concerns functioning. This suggests an overall reduction in the dimensions that subjects reported as having functional concerns. The results indicate that the subjects’ day-to-day functioning may have improved during the experiment using CaiTI.
In a 24-week longitudinal study, 4 subjects completed additional GAD-7 and PHQ-9 assessments every two weeks. These tools evaluate the severity of anxiety and depression symptoms. With the small sample size (n=4), therapists reviewed the questionnaire results individually. During the study, two subjects improved from moderate-to-severe anxiety and depression to mild levels, initially facing difficulties in functioning but eventually reporting none. One subject progressed from mild to minimal anxiety and depression and reported no functional difficulties. The remaining participant exhibited fluctuating symptoms, ranging from mild to minimal, initially facing some difficulties in functioning, but reporting none by the study’s end. The findings of this study indicate that CaiTI was effective in reducing the severity of anxiety and depression, as well as enhancing daily functioning.
| Question Asked | Average Rating | |
|---|---|---|
| Day 1 | Day 14 | |
| How do you like CaiTI in general? | 4.3 | 4.45 |
| Are you willing to continue using CaiTI in the future? | 4.3 | 4.35 |
| Will you recommend CaiTI to others? | 4.2 | 4.55 |
| Do you think CaiTI’s functions are easily detectable? | 4.4 | 4.5 |
| Do you think CaiTI can understand you and chat with you naturally? | 4.35 | 4.5 |
| Do you like the interface design of CaiTI? | 4.6 | 4.2 |
| Do you think the wording used in CaiTI is appropriate? | 4.6 | 4.75 |
| Do you think the psychotherapies are helpful? | 4.65 | 4.6 |
| How do you feel about the response time from CaiTI? | 4.8 | 4.85 |
| Do you feel that the conversation flow of CaiTI is gradually tailoring to you? | N.A. | 4.75 |
8.3. Qualitative Evaluation from the Subjects and Therapists
8.3.1. Experiences and Feedback from Subjects
All 20 subjects who participated in the study found CaiTI to be valid and effective. Subjects see using CaiTI brings awareness to their mental health daily, which makes them feel they are “relying on the system to do the self-reflection work” (S10) every day. One of the subjects said: “I feel in good shape doing these check-ins every day, in between my weekly sessions with individual therapist” (S11). Subjects were also surprised about how well “CaiTI can understand me and makes me feel validated”(S17). One subject stated that:
“I think CaiTI does a pretty good job validating my feelings and encouraging me to be more active. I had a very positive experience with the comforting part. I also like the sensing part, as CaiTI knows what I am doing at home and directly provides help if needed. I don’t need to describe my daily routine and recall when I am with CaiTI. I need to do these annoying things during my therapist visits. I think CaiTI is a good add-on in mental healthcare” (S15).
Several subjects complimented on CaiTI’s interactiveness and stated “CaiTI is really plug-and-play and easy to use” (S01). Additionally, a large portion of subjects stated that they liked the way that CaiTI “talked” to them as “the conversation is very genuine” (S12). For example, one subject said:
“I feel like that I have a companion. When CaiTI talks to me through my Alexa, it listens and converses naturally and reminds me of parts of my therapy sessions. The system reformulates the questions it asks me every time. Also, I realize that if I use CaiTI more frequently, CaiTI is more attuned to me because it changes the way it asks the question according to my answers” (S02).
Subjects found the psychotherapies helpful, encouraging, and valuable. A subject said “I like the counseling part of the system. The tone is supportive and encouraging. The system really understands what I said to it and provides reasonable and applicable guides” (S08). In addition, a few subjects find the guidance (Guide feature) provided by CaiTI during the psychotherapies helpful.
“To be honest, I was not that familiar with what they called the CBT procedures at the end of each conversation. Initially, I did not know what are the “unhelpful thoughts” in my situations. But, you know, after hanging using CaiTI a few times, I started to get the hang of these helpful thinking strategies. I am getting more optimistic and better at boosting my own confidence, when I face challenges.” (S01).
A few subjects feel that “the consolation is not pointed enough” (S02), as it provides very general comments that are suitable for “everyone who has the same problem” (S02). They would like to have more personalized experiences with more targeted suggestions.
8.3.2. Comments from Therapists
4 psychotherapists approved of CaiTI, recognizing its potential for “combining physical and mental wellness screening and providing psychotherapeutic precautionary interventions in daily life for everyone” (T02). They provided positive feedback on the conversational daily functioning screening, the integration of psychotherapeutic techniques within the conversation flow, and the overall style of the dialogue. They approved the content and style of the system’s language: “CaiTI engaged me in conversations with effective content control. However, ChatGPT sometimes produced responses that are not up to clinical standards” (T01).
The therapists also saw the interventions being potentially used in addition to clinical treatment. They spoke posivitely of the empathic validation and support in the MI process and valued the significant influence of CaiTI’s Reasoner and Guide features in guiding and steering the user towards more adaptive thinking in the CBT process. They felt that the combination of reasoning and guidance not only prevents users from getting stuck in incorrect ways of thinking but also positively directs and facilitates gradual learning. This, in turn, can support overall mental health well-being, especially in the long term. They mentioned these designs could “enforce the effectiveness of CaiTI’s psychotherapy” (T03) and “provide just the right amount of guidance to support users in situations that require additional attention” (T01). One therapist stated:
“From my observations on the interactions between CaiTI and our subjects, I think the validation implementations of CBT and MI are appropriate. Although very few exchanges are not perfect if the responses from the subjects are ambiguous, CaiTI impresses me with emotionally supportive text formulation. I also answered questions in a way a few times to indicate daily functioning concerns to CaiTI during different sessions, and CaiTI came up with different ways to guide and help me to improve the situation.” (T02).
Most therapists found CaiTI to aid traditional psychotherapeutic processes, stating that more frequent data collection offers more insights between therapy sessions. “I would love to see some of my clients use this” (T04), one therapist commented. Another therapist mentioned:
“Doing everyday check-ins helps people in general to bring awareness to mental health in their everyday activities. Sometimes, I assign my clients homework to log their everyday activities, just for them to keep doing the work outside of therapy sessions. It would be great if more people can use this system daily and become more intentional in their daily routine“ (T02).
They also validated CaiTI’s use of reinforcement learning for conversation generation and “are surprised by how attentive CaiTI is and how good the flow of the conversation we have” (T04). Additionally, they offered suggestions for future enhancements, including adjustments to CaiTI’s audio tone.
9. Discussion and Future Work
As shown in Sections 7 and 8, CaiTI can effectively perform Converse with the User in a Natural Way, and provide Psychotherapeutic Conversational Intervention. The qualitative evaluations further attest to the system’s usability, the relevance and effectiveness of its psychotherapeutic content, the helpfulness of the guides, and the efficacy of the empathic validation it offers, making it a promising tool for personalized mental health care. Throughout the rest of this section, we summarize some of the current limitations and propose plans for future improvements and visions.
First of all, we will continue our collaboration with the psychotherapists, we plan to include real patients with different kinds and severity of mental disorders in longitudinal studies. We will evaluate how well CaiTI can assist the treatment provided by the therapists and improve the mental well-being of the patients.
Moreover, during the psychotherapy process, although CaiTI breaks the tasks down and leverages LLM-based Reasoners, Guides, and Validator to specifically handle each subtask, there is room to improve the accuracies of Reasoners and quality of Guides, and Validator. In particular, we plan to add step-by-step “system reasoners” (Chain-of-Thought) to evaluate if the Guides and Validators are suboptimal because of “reading user’s minds” and making excessive assumptions (Radhakrishnan et al., 2023). Additionally, we plan to investigate if further breaking down the tasks would improve the system’s performance. For example, we will investigate whether using two LLM modules for classifying Dimension and Score in Response Analyzer instead of one will improve the accuracy, and how this change affects the performance of different LLM models. We are aware that these modifications will increase the computational overhead for the system, yielding longer system response time and affecting the user experience. As such, we also plan to investigate the trade-off between the system complexity and user experiences in multiple aspects.
We see the potential of incorporating common wearable devices, such as smartwatches and smartphones, as potential platforms into CaiTI. In fact, around half of the subjects in this study actively use smart devices for health and fitness monitoring. We plan to leverage the health and fitness data analyzed by smartphones or smartwatches (e.g., Apple HealthKit data) as a source to perform activity detection with existing commercial smart home devices.
In addition, the smart home market is rapidly expanding with new sensors and devices. CaiTI has the potential to be one of the many applications commonly integrated into smart home ecosystems. As such, we plan to investigate how to take advantage of smart home sensors, devices, and robots to provide a more comprehensive and invasive screening of users’ daily functioning through smart sensors and various kinds of interactions and interventions through home robots or other devices. With omnipresent modules being included in CaiTI, to make users feel less “invasive”, we plan to make CaiTI plug-and-play. Users can turn on devices that make them feel comfortable at that moment, CaiTI can automatically discover available resources and generate execution pipelines to screen the wellness of the user and provide interventions if necessary.
Furthermore, equipping with the RL recommender as well as fine-tuned and few-shot prompted GPT-based models for conversation, conversational psychotherapeutic intervention generations, CaiTI can generate speech for conversation and lead the conversation flow in a more human-like way compared to other platforms. However, since CaiTI uses the text-to-speech API, the tone and inflection of the voice generated to “talk” to the user are still not entirely identical to what a real person would perform. A therapist commented: “It’s not exactly how a real person would speak in terms of the tone and inflection but I think that definitely will improve in time as you know text-to-speech and other natural language things become better and better. However, the content and style of the sentences and words are very much in line with what a typical person would say” (T04). We plan to investigate and incorporate deep learning methods using to add “emotion” to the audio output accordingly (Adigwe et al., 2018).
We have designed CaiTI to minimize bias by implementing several modules of LLMs tailored to specific tasks instead of relying on a single model. We acknowledge that despite our best efforts, all AI applications, including this one, are subject to potential bias and the ethical concerns of AI for psychotherapies still remain. Therefore, the intended application of CaiTI is primarily for precautionary day-to-day functioning screenings and psychotherapeutic interventions, aiming for better self-care and assisting the professional psychotherapy process.
10. Conclusion
In this work, collaborating with licensed psychotherapists, we propose CaiTI, a conversational “AI therapist” that leverages the LLMs and RL to screen and analyze the day-to-day functioning of the user across 37 dimensions and provides appropriate and effective psychotherapies, including MI and CBT, depending on the physical and mental status of the user through natural and personalized conversations. Accessible on common smart devices like smartphones, computers, and smart speakers, CaiTI provides a versatile solution for users, both indoors and outdoors.
To enhance care quality and psychotherapy effectiveness while minimizing AI biases, CaiTI employs specialized LLM-based Reasonsers, Guides, and Validator to provide psychotherapy during the conversation. By using conversation datasets annotated by licensed psychotherapists, we assess various GPT and Llama-2 LLMs’ performances through few-shot prompts or fine-tuning across different LLM-based tasks in CaiTI. Based on the assessment results and observations, we collaborate with the therapists to develop a proof-of-concept prototype of CaiTI and conduct 14-day and 24-week studies in real-world trials. The evidence gathered through our studies showcases CaiTI’s effectiveness in screening daily functioning and providing psychotherapies. Additionally, the empirical evidence underscores CaiTI’s capability in enhancing daily functioning and mental well-being. We see the potential for LLM-based conversational “AI therapists” to aid the traditional psychotherapy process and provide precautionary mental health and psychotherapeutic self-care to a larger population.
References
- (1)
- Onl (2022) 2022. Mental Health Tests, Quizzes, Self-Assessments, & Screening Tools. https://www.psycom.net/quizzes. [Online; accessed 16-August-2022].
- Spe (2022) 2022. Speech-to-Text. https://cloud.google.com/speech-to-text. [Online; accessed 24-April-2022].
- cha (2023) 2023. 3 things to know before talking to ChatGPT about your mental health. https://mashable.com/article/how-to-chat-with-chatgpt-mental-health-therapy.
- red (2023) 2023. Using ChatGPT as a therapist? https://www.reddit.com/r/ChatGPTPro/comments/126rtvb/using_chatgpt_as_a_therapist/
- Ale (2023) 2023. What is the Alexa Skills Kit? https://developer.amazon.com/en-US/docs/alexa/ask-overviews/what-is-the-alexa-skills-kit.html
- Aarons et al. (2017) Gregory A Aarons, Mark G Ehrhart, Joanna C Moullin, Elisa M Torres, and Amy E Green. 2017. Testing the leadership and organizational change for implementation (LOCI) intervention in substance abuse treatment: a cluster randomized trial study protocol. Implementation Science 12, 1 (2017), 1–11.
- Adams et al. (2018) Alexander T Adams, Elizabeth L Murnane, Phil Adams, Michael Elfenbein, Pamara F Chang, Shruti Sannon, Geri Gay, and Tanzeem Choudhury. 2018. Keppi: A tangible user interface for self-reporting pain. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. 1–13.
- Adigwe et al. (2018) Adaeze Adigwe, Noé Tits, Kevin El Haddad, Sarah Ostadabbas, and Thierry Dutoit. 2018. The emotional voices database: Towards controlling the emotion dimension in voice generation systems. arXiv preprint arXiv:1806.09514 (2018).
- Alford et al. (1997) Brad A Alford, Aaron T Beck, and John V Jones Jr. 1997. The integrative power of cognitive therapy.
- Anil et al. (2023) Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. 2023. Palm 2 technical report. arXiv preprint arXiv:2305.10403 (2023).
- Anthropic (2024) Anthropic. 2024. Introducing the next generation of Claude. https://www.anthropic.com/news/claude-3-family. Accessed: 2024-03-06.
- Anton et al. (2006) Raymond F Anton, Stephanie S O’Malley, Domenic A Ciraulo, Ron A Cisler, David Couper, Dennis M Donovan, David R Gastfriend, James D Hosking, Bankole A Johnson, Joseph S LoCastro, et al. 2006. Combined pharmacotherapies and behavioral interventions for alcohol dependence: the COMBINE study: a randomized controlled trial. Jama 295, 17 (2006), 2003–2017.
- Antony et al. (2005) Martin M Antony, Deborah Roth Ledley, and Richard G Heimberg. 2005. Improving outcomes and preventing relapse in cognitive-behavioral therapy. Guilford Press.
- Arkowitz and Westra (2004) Hal Arkowitz and Henny A Westra. 2004. Integrating motivational interviewing and cognitive behavioral therapy in the treatment of depression and anxiety. Journal of Cognitive Psychotherapy 18, 4 (2004), 337–350.
- Beck and Beck (2011) Judith S Beck and AT Beck. 2011. Cognitive behavior therapy: Basic and beyond. New York: Guilford (2011).
- Bible et al. (2017) Lisa J Bible, Kristin A Casper, Jennifer L Seifert, and Kyle A Porter. 2017. Assessment of self-care and medication adherence in individuals with mental health conditions. Journal of the American Pharmacists Association 57, 3 (2017), S203–S210.
- Borsci et al. (2022) Simone Borsci, Alessio Malizia, Martin Schmettow, Frank Van Der Velde, Gunay Tariverdiyeva, Divyaa Balaji, and Alan Chamberlain. 2022. The Chatbot usability scale: The design and pilot of a usability scale for interaction with AI-based conversational agents. Personal and ubiquitous computing 26, 1 (2022), 95–119.
- Brown et al. (2016) Menna Brown, Noelle O’Neill, Hugo van Woerden, Parisa Eslambolchilar, Matt Jones, Ann John, et al. 2016. Gamification and adherence to web-based mental health interventions: a systematic review. JMIR mental health 3, 3 (2016), e5710.
- Bubeck et al. (2023) Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712 (2023).
- Burns and Beck (1999) David D Burns and Aaron T Beck. 1999. Feeling good: The new mood therapy. (1999).
- Cay (2023) Yusuf Cay. 2023. How to use ChatGPT as your therapist or mental coach? https://chatgptplus.blog/use-chatgpt-as-your-therapist-or-mental-coach/
- Chandrashekar (2018) Pooja Chandrashekar. 2018. Do mental health mobile apps work: evidence and recommendations for designing high-efficacy mental health mobile apps. Mhealth 4 (2018).
- Channon et al. (2007) Sue J Channon, Michelle V Huws-Thomas, Stephen Rollnick, Kerenza Hood, Rebecca L Cannings-John, Carol Rogers, and John W Gregory. 2007. A multicenter randomized controlled trial of motivational interviewing in teenagers with diabetes. Diabetes care 30, 6 (2007), 1390–1395.
- Chen et al. (2023) Siyuan Chen, Mengyue Wu, Kenny Q Zhu, Kunyao Lan, Zhiling Zhang, and Lyuchun Cui. 2023. LLM-empowered Chatbots for Psychiatrist and Patient Simulation: Application and Evaluation. arXiv preprint arXiv:2305.13614 (2023).
- Chen et al. (2012) Shu Ming Chen, Debra Creedy, Huey-Shyan Lin, and Judy Wollin. 2012. Effects of motivational interviewing intervention on self-management, psychological and glycemic outcomes in type 2 diabetes: a randomized controlled trial. International journal of nursing studies 49, 6 (2012), 637–644.
- Clark et al. (2003) David M Clark, Anke Ehlers, Freda McManus, Ann Hackmann, Melanie Fennell, Helen Campbell, Teresa Flower, Clare Davenport, and Beverley Louis. 2003. Cognitive therapy versus fluoxetine in generalized social phobia: a randomized placebo-controlled trial. Journal of consulting and clinical psychology 71, 6 (2003), 1058.
- Clausen et al. (2016) Whitney Clausen, Shinobu Watanabe-Galloway, M Bill Baerentzen, and Denise H Britigan. 2016. Health literacy among people with serious mental illness. Community mental health journal 52, 4 (2016), 399–405.
- Corey (2013) Gerald Corey. 2013. Theory and practice of counseling and psychotherapy. Cengage learning.
- Dai et al. (2023) Ruixuan Dai, Thomas Kannampallil, Seunghwan Kim, Vera Thornton, Laura Bierut, and Chenyang Lu. 2023. Detecting Mental Disorders with Wearables: A Large Cohort Study. In Proceedings of the 8th ACM/IEEE Conference on Internet of Things Design and Implementation. 39–51.
- Deb et al. (2023) Aniruddha Deb, Neeva Oza, Sarthak Singla, Dinesh Khandelwal, Dinesh Garg, and Parag Singla. 2023. Fill in the blank: Exploring and enhancing LLM capabilities for backward reasoning in math word problems. arXiv preprint arXiv:2310.01991 (2023).
- Dickstein et al. (2013) Benjamin D Dickstein, Kristen H Walter, Jeremiah A Schumm, and Kathleen M Chard. 2013. Comparing response to cognitive processing therapy in military veterans with subthreshold and threshold posttraumatic stress disorder. Journal of Traumatic Stress 26, 6 (2013), 703–709.
- DSM-IV-TR. (2000) DSM-IV-TR. 2000. Diagnostic and statistical manual of mental disorders. American Psychiatric Association.
- El ASRS (2009) Conclusiones El ASRS. 2009. Adult ADHD Self-Report Scale (ASRS-v1. 1) symptom checklist in patients with substance use disorders. Actas Esp Psiquiatr 37, 6 (2009), 299–305.
- Emilsson et al. (2011) Brynjar Emilsson, Gisli Gudjonsson, Jon F Sigurdsson, Gisli Baldursson, Emil Einarsson, Halldora Olafsdottir, and Susan Young. 2011. Cognitive behaviour therapy in medication-treated adults with ADHD and persistent symptoms: a randomized controlled trial. BMC psychiatry 11, 1 (2011), 1–10.
- Explodingtopics (2023) Explodingtopics. 2023. How Many People Own Smartphones? (2024-2029). https://explodingtopics.com/blog/smartphone-stats
- Foa et al. (2005) Edna B Foa, Michael R Liebowitz, Michael J Kozak, Sharon Davies, Rafael Campeas, Martin E Franklin, Jonathan D Huppert, Kevin Kjernisted, Vivienne Rowan, Andrew B Schmidt, et al. 2005. Randomized, placebo-controlled trial of exposure and ritual prevention, clomipramine, and their combination in the treatment of obsessive-compulsive disorder. American Journal of psychiatry 162, 1 (2005), 151–161.
- Fu and Fu (2022) Baoyan Fu and XinXin Fu. 2022. Distributed Simulation System for Athletes’ Mental Health in the Internet of Things Environment. Computational Intelligence and Neuroscience 2022 (2022).
- Gould et al. (2002) Madelyn S Gould, Jimmie Lou Harris Munfakh, Keri Lubell, Marjorie Kleinman, and Sarah Parker. 2002. Seeking help from the internet during adolescence. Journal of the American Academy of Child & Adolescent Psychiatry 41, 10 (2002), 1182–1189.
- Guze (1995) Samuel B Guze. 1995. Diagnostic and statistical manual of mental disorders, (DSM-IV). American Journal of Psychiatry 152, 8 (1995), 1228–1228.
- Halmi et al. (2005) Katherine A Halmi, W Stewart Agras, Scott Crow, James Mitchell, G Terence Wilson, Susan W Bryson, and Helena C Kraemer. 2005. Predictors of treatment acceptance and completion in anorexia nervosa: implications for future study designs. Archives of general psychiatry 62, 7 (2005), 776–781.
- Helfrich et al. (2008) Christine A Helfrich, Glenn T Fujiura, and Violet Rutkowski-Kmitta. 2008. Mental health disorders and functioning of women in domestic violence shelters. Journal of interpersonal violence 23, 4 (2008), 437–453.
- House (2022) The White House. 2022. Reducing the Economic Burden of Unmet Mental Health Needs. https://www.whitehouse.gov/cea/written-materials/2022/05/31/reducing-the-economic-burden-of-unmet-mental-health-needs/
- Jiang et al. (2023) Zifan Jiang, Salman Seyedi, Emily Lynn Griner, Ahmed Abbasi, Ali Bahrami Rad, Hyeokhyen Kwon, Robert O Cotes, and Gari D Clifford. 2023. Multimodal mental health assessment with remote interviews using facial, vocal, linguistic, and cardiovascular patterns. medRxiv (2023), 2023–09.
- Kertes et al. (2011) Angela Kertes, Henny A Westra, Lynne Angus, and Madalyn Marcus. 2011. The impact of motivational interviewing on client experiences of cognitive behavioral therapy for generalized anxiety disorder. Cognitive and Behavioral Practice 18, 1 (2011), 55–69.
- Kian et al. (2024) Mina J Kian, Mingyu Zong, Katrin Fischer, Abhyuday Singh, Anna-Maria Velentza, Pau Sang, Shriya Upadhyay, Anika Gupta, Misha A Faruki, Wallace Browning, et al. 2024. Can an LLM-Powered Socially Assistive Robot Effectively and Safely Deliver Cognitive Behavioral Therapy? A Study With University Students. arXiv preprint arXiv:2402.17937 (2024).
- Kroenke et al. (2001) Kurt Kroenke, Robert L Spitzer, and Janet BW Williams. 2001. The PHQ-9: validity of a brief depression severity measure. Journal of general internal medicine 16, 9 (2001), 606–613.
- Kruzan et al. (2022) Kaylee Payne Kruzan, Jonah Meyerhoff, Theresa Nguyen, Madhu Reddy, David C Mohr, and Rachel Kornfield. 2022. “I Wanted to See How Bad it Was”: Online Self-screening as a Critical Transition Point Among Young Adults with Common Mental Health Conditions. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–16.
- Lai et al. (2023) Tin Lai, Yukun Shi, Zicong Du, Jiajie Wu, Ken Fu, Yichao Dou, and Ziqi Wang. 2023. Psy-llm: Scaling up global mental health psychological services with ai-based large language models. arXiv preprint arXiv:2307.11991 (2023).
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
- Liu et al. (2022) Yanchen Liu, Stephen Xia, Jingping Nie, Peter Wei, Zhan Shu, Jeffrey Andrew Chang, and Xiaofan Jiang. 2022. aiMSE: Toward an AI-Based Online Mental Status Examination. IEEE Pervasive Computing (2022).
- Marker and Norton (2018) Isabella Marker and Peter J Norton. 2018. The efficacy of incorporating motivational interviewing to cognitive behavior therapy for anxiety disorders: A review and meta-analysis. Clinical Psychology Review 62 (2018), 1–10.
- Matthews et al. (2015) Mark Matthews, Stephen Voida, Saeed Abdullah, Gavin Doherty, Tanzeem Choudhury, Sangha Im, and Geri Gay. 2015. In situ design for mental illness: Considering the pathology of bipolar disorder in mhealth design. In Proceedings of the 17th International Conference on Human-Computer Interaction with Mobile Devices and Services. 86–97.
- Merlo et al. (2010) Lisa J Merlo, Eric A Storch, Heather D Lehmkuhl, Marni L Jacob, Tanya K Murphy, Wayne K Goodman, and Gary R Geffken. 2010. Cognitive-behavioral therapy plus motivational interviewing improves outcome for pediatric obsessive-compulsive disorder: A preliminary study. Cognitive Behaviour Therapy 39, 1 (2010), 24–27.
- Miller et al. (2011) Lynn D Miller, Aviva Laye-Gindhu, Joanna L Bennett, Yan Liu, Stephenie Gold, John S March, Brent F Olson, and Vanessa E Waechtler. 2011. An effectiveness study of a culturally enriched school-based CBT anxiety prevention program. Journal of Clinical Child & Adolescent Psychology 40, 4 (2011), 618–629.
- Miller and Rollnick (2012) William R Miller and Stephen Rollnick. 2012. Motivational interviewing: Helping people change. Guilford press.
- Mishra (2019) Varun Mishra. 2019. From sensing to intervention for mental and behavioral health. In Adjunct Proceedings of the 2019 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2019 ACM International Symposium on Wearable Computers. 388–392.
- Mohadisdudis and Ali (2014) Hazwani Mohd Mohadisdudis and Nazlena Mohamad Ali. 2014. A study of smartphone usage and barriers among the elderly. In 2014 3rd international conference on user science and engineering (i-USEr). IEEE, 109–114.
- Morshed et al. (2019) Mehrab Bin Morshed, Koustuv Saha, Richard Li, Sidney K D’Mello, Munmun De Choudhury, Gregory D Abowd, and Thomas Plötz. 2019. Prediction of mood instability with passive sensing. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 3, 3 (2019), 1–21.
- Moss-Morris et al. (2013) Rona Moss-Morris, Laura Dennison, Sabine Landau, Lucy Yardley, Eli Silber, and Trudie Chalder. 2013. A randomized controlled trial of cognitive behavioral therapy (CBT) for adjusting to multiple sclerosis (the saMS trial): does CBT work and for whom does it work? Journal of consulting and clinical psychology 81, 2 (2013), 251.
- Naar and Safren (2017) Sylvie Naar and Steven A Safren. 2017. Motivational interviewing and CBT: Combining strategies for maximum effectiveness. Guilford Publications.
- Nie et al. (2021) Jingping Nie, Yanchen Liu, Yigong Hu, Yuanyuting Wang, Stephen Xia, Matthias Preindl, and Xiaofan Jiang. 2021. SPIDERS+: A light-weight, wireless, and low-cost glasses-based wearable platform for emotion sensing and bio-signal acquisition. Pervasive and Mobile Computing 75 (2021), 101424.
- Nie et al. (2022) Jingping Nie, Hanya Shao, Minghui Zhao, Stephen Xia, Matthias Preindl, and Xiaofan Jiang. 2022. Conversational AI Therapist for Daily Function Screening in Home Environments. In Proceedings of the 1st ACM International Workshop on Intelligent Acoustic Systems and Applications. 31–36.
- Nori et al. (2023) Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. 2023. Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv:2303.13375 (2023).
- on Evidence-Based Practice et al. (2006) APA Presidential Task Force on Evidence-Based Practice et al. 2006. Evidence-based practice in psychology. The American Psychologist 61, 4 (2006), 271–285.
- OpenAI (2023a) OpenAI. 2023a. GPT-3.5 Turbo. https://platform.openai.com/docs/models/gpt-3-5-turbo. Accessed: 2024-02-06.
- OpenAI (2023b) OpenAI. 2023b. GPT-4 and GPT-4 Turbo. https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo. Accessed: 2024-02-06.
- OpenAI (2023c) OpenAI. 2023c. What models can be fine-tuned? https://platform.openai.com/docs/guides/fine-tuning. Accessed: 2024-02-06.
- Pendse et al. (2021) Sachin R Pendse, Amit Sharma, Aditya Vashistha, Munmun De Choudhury, and Neha Kumar. 2021. “Can I Not Be Suicidal on a Sunday?”: Understanding Technology-Mediated Pathways to Mental Health Support. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–16.
- Pichai and Hassabis (2024) Sundar Pichai and Demis Hassabis. 2024. Our next-generation model: Gemini 1.5. https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/#sundar-note. Accessed: 2024-03-06.
- Radhakrishnan et al. (2023) Ansh Radhakrishnan, Karina Nguyen, Anna Chen, Carol Chen, Carson Denison, Danny Hernandez, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamilė Lukošiūtė, et al. 2023. Question decomposition improves the faithfulness of model-generated reasoning. arXiv preprint arXiv:2307.11768 (2023).
- Radwan et al. (2024) Ahmad Radwan, Mohannad Amarneh, Hussam Alawneh, Huthaifa I Ashqar, Anas AlSobeh, and Aws Abed Al Raheem Magableh. 2024. Predictive Analytics in Mental Health Leveraging LLM Embeddings and Machine Learning Models for Social Media Analysis. International Journal of Web Services Research (IJWSR) 21, 1 (2024), 1–22.
- Robins and Rosenthal (2011) Clive J Robins and M Zachary Rosenthal. 2011. Dialectical behavior therapy. Acceptance and mindfulness in cognitive behavior therapy: Understanding and applying the new therapies (2011), 164–192.
- Roy-Byrne et al. (2005) Peter P Roy-Byrne, Michelle G Craske, Murray B Stein, Greer Sullivan, Alexander Bystritsky, Wayne Katon, Daniela Golinelli, and Cathy D Sherbourne. 2005. A randomized effectiveness trial of cognitive-behavioral therapy and medication for primary care panic disorder. Archives of General Psychiatry 62, 3 (2005), 290–298.
- Sabour et al. (2022) Sahand Sabour, Wen Zhang, Xiyao Xiao, Yuwei Zhang, Yinhe Zheng, Jiaxin Wen, Jialu Zhao, and Minlie Huang. 2022. Chatbots for Mental Health Support: Exploring the Impact of Emohaa on Reducing Mental Distress in China. arXiv preprint arXiv:2209.10183 (2022).
- Salekin et al. (2017) Asif Salekin, Zeya Chen, Mohsin Y Ahmed, John Lach, Donna Metz, Kayla De La Haye, Brooke Bell, and John A Stankovic. 2017. Distant emotion recognition. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 1, 3 (2017), 1–25.
- Schroeder et al. (2018) Jessica Schroeder, Chelsey Wilkes, Kael Rowan, Arturo Toledo, Ann Paradiso, Mary Czerwinski, Gloria Mark, and Marsha M Linehan. 2018. Pocket skills: A conversational mobile web app to support dialectical behavioral therapy. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. 1–15.
- Scott and Presmanes (2001) Roger L Scott and Willa S Presmanes. 2001. Reliability and validity of the daily living activities scale: A functional assessment measure for severe mental disorders. Research on Social Work Practice 11, 3 (2001), 373–389.
- Screening (2021) MHA Screening. 2021. Take a Mental Health Test. https://screening.mhanational.org/screening-tools/. [Online; accessed 24-July-2022].
- Sharan et al. (2023) SP Sharan, Francesco Pittaluga, Manmohan Chandraker, et al. 2023. Llm-assist: Enhancing closed-loop planning with language-based reasoning. arXiv preprint arXiv:2401.00125 (2023).
- Shin et al. (2022) Joongi Shin, Michael A Hedderich, AndréS Lucero, and Antti Oulasvirta. 2022. Chatbots Facilitating Consensus-Building in Asynchronous Co-Design. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–13.
- Singhal et al. (2023a) Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. 2023a. Large language models encode clinical knowledge. Nature 620, 7972 (2023), 172–180.
- Singhal et al. (2023b) Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, et al. 2023b. Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617 (2023).
- Sokol and Fox (2019) Leslie Sokol and Marci Fox. 2019. The comprehensive clinician’s guide to cognitive behavioral therapy. Pesi.
- Spring (2007) Bonnie Spring. 2007. Evidence-based practice in clinical psychology: What it is, why it matters; what you need to know. Journal of clinical psychology 63, 7 (2007), 611–631.
- Statista (2023) Statista. 2023. Sales volume of the smart speakers industry Worldwide 2018-2028. https://www.statista.com/forecasts/1367982/smart-speaker-market-volume-worldwide
- Talevi et al. (2020) Dalila Talevi, Valentina Socci, Margherita Carai, Giulia Carnaghi, Serena Faleri, Edoardo Trebbi, Arianna di Bernardo, Francesco Capelli, and Francesca Pacitti. 2020. Mental health outcomes of the CoViD-19 pandemic. Rivista di psichiatria 55, 3 (2020), 137–144.
- Tan et al. (2014) Leona Tan, Min-Jung Wang, Matthew Modini, Sadhbh Joyce, Arnstein Mykletun, Helen Christensen, and Samuel B Harvey. 2014. Preventing the development of depression at work: a systematic review and meta-analysis of universal interventions in the workplace. BMC medicine 12, 1 (2014), 1–11.
- Tlachac et al. (2022) ML Tlachac, Ricardo Flores, Miranda Reisch, Rimsha Kayastha, Nina Taurich, Veronica Melican, Connor Bruneau, Hunter Caouette, Joshua Lovering, Ermal Toto, et al. 2022. StudentSADD: Rapid mobile depression and suicidal ideation screening of college students during the coronavirus pandemic. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 6, 2 (2022), 1–32.
- Torous et al. (2018) John Torous, Hannah Wisniewski, Gang Liu, Matcheri Keshavan, et al. 2018. Mental health mobile phone app usage, concerns, and benefits among psychiatric outpatients: comparative survey study. JMIR mental health 5, 4 (2018), e11715.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Trzepacz and Baker (1993) Paula T Trzepacz and Robert W Baker. 1993. The psychiatric mental status examination. Oxford University Press.
- van Heerden et al. (2023) Alastair C van Heerden, Julia R Pozuelo, and Brandon A Kohrt. 2023. Global mental health services and the impact of artificial intelligence–powered large language models. JAMA psychiatry 80, 7 (2023), 662–664.
- Vega et al. (2018) Julio Vega, Samuel Couth, Ellen Poliakoff, Sonja Kotz, Matthew Sullivan, Caroline Jay, Markel Vigo, and Simon Harper. 2018. Back to analogue: Self-reporting for Parkinson’s Disease. In Proceedings of the 2018 CHI conference on human factors in computing systems. 1–13.
- Waisberg et al. (2023) Ethan Waisberg, Joshua Ong, Mouayad Masalkhi, Sharif Amit Kamran, Nasif Zaman, Prithul Sarker, Andrew G Lee, and Alireza Tavakkoli. 2023. GPT-4: a new era of artificial intelligence in medicine. Irish Journal of Medical Science (1971-) (2023), 1–4.
- Walsh et al. (2004) B Timothy Walsh, Christopher G Fairburn, Diane Mickley, Robyn Sysko, and Michael K Parides. 2004. Treatment of bulimia nervosa in a primary care setting. American Journal of Psychiatry 161, 3 (2004), 556–561.
- Xu et al. (2023a) Huatao Xu, Liying Han, Mo Li, and Mani Srivastava. 2023a. Penetrative ai: Making llms comprehend the physical world. arXiv preprint arXiv:2310.09605 (2023).
- Xu et al. (2023b) Xuhai Xu, Bingshen Yao, Yuanzhe Dong, Hong Yu, James Hendler, Anind K Dey, and Dakuo Wang. 2023b. Leveraging large language models for mental health prediction via online text data. arXiv preprint arXiv:2307.14385 (2023).
- Yin et al. (2023) Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. 2023. A Survey on Multimodal Large Language Models. arXiv preprint arXiv:2306.13549 (2023).
- You et al. (2023) Haoxuan You, Rui Sun, Zhecan Wang, Long Chen, Gengyu Wang, Hammad A Ayyubi, Kai-Wei Chang, and Shih-Fu Chang. 2023. IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models. arXiv preprint arXiv:2305.14985 (2023).
- Yunxiang et al. (2023) Li Yunxiang, Li Zihan, Zhang Kai, Dan Ruilong, and Zhang You. 2023. Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge. arXiv preprint arXiv:2303.14070 (2023).
- Zhou et al. (2018) Hao Zhou, Minlie Huang, Tianyang Zhang, Xiaoyan Zhu, and Bing Liu. 2018. Emotional chatting machine: Emotional conversation generation with internal and external memory. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32.
- Zhu et al. (2021) Junyi Zhu, Jackson C Snowden, Joshua Verdejo, Emily Chen, Paul Zhang, Hamid Ghaednia, Joseph H Schwab, and Stefanie Mueller. 2021. EIT-kit: An electrical impedance tomography toolkit for health and motion sensing. In The 34th Annual ACM Symposium on User Interface Software and Technology. 400–413.
Appendix A Dimensions for Day-to-day Functioning Screening
This section presents the 37 dimensions proposed by (Nie et al., 2022) to screen day-to-day functioning. These dimensions are based on the Diagnostic and Statistical Manual of Mental Disorders (DSM)-IV and the Daily Living Activities–20 (DLA-20), two gold standards for mental health care providers. As mentioned in Section 5, for each dimension, therapists provide a set of sample questions. With the GPT-4-based Rephraser, CaiTI rephrases and formulates the questions when it converses with the user. Note that as some of the dimensions might be sensitive or uncomfortable for users, CaiTI offers the option for users to select the dimensions to work on manually through the smartphone interface. The 37 dimensions and the example questions asked by CaiTI are listed below:
-
(1)
Maintaining stable weight: “Have your weight changed significantly recently?”;
-
(2)
Managing mood: “How’s your mood recently?”;
-
(3)
Taking medication as prescribed: “Have you been taking medication according to your prescriptions?”;
-
(4)
Participating primary and mental health care: “Have you been seeing your doctor, therapist or case manager consistently?”;
-
(5)
Organizing personal possessions & doing housework: “Have you been doing house chores?”;
-
(6)
Talking to other people: “Have you been talking to other people?”;
-
(7)
Expressing feelings to other people: “Have you expressed feelings towards others?”;
-
(8)
Managing personal safety: “Have you been taking safety into consideration when making decisions?”;
-
(9)
Managing risk: “Have you taken any risk recently?”;
-
(10)
Following regular schedule for bedtime & sleeping enough: “How has your sleep been? Do you have a regular schedule for bedtime?”;
-
(11)
Maintaining regular schedule for eating: “How’s your eating? Are you eating regularly?”;
-
(12)
Managing work/school: “Are you showing up for work or school?”;
-
(13)
Having work-life balance: “How’s your work-life balance? Have you taken days off recently?”;
-
(14)
Showing up for appointments and obligations: “Are you showing up for appointments and other obligations?”;
-
(15)
Managing finance and items of value: “How’s your finances? Any concern with your spending habits?”;
-
(16)
Getting adequate nutrition: “How’s your nutrition? Are you eating healthy?”;
-
(17)
Problem solving and decision making capability: “Are you able to make decisions yourself?”;
-
(18)
Family support: “Do you feel supported by your family?”;
-
(19)
Family relationship: “How’s your relationship with your family members?”;
-
(20)
Alcohol abuse: “Do you often drink alone?”;
-
(21)
Tobacco abuse: “Do you smoke cigarettes or vape? And how frequent?”;
-
(22)
Other substances abuse: “Do you use any substance and what’s the frequency of using?”;
-
(23)
Enjoying personal choices for leisure activities: “What do you like to do when you have free time?”;
-
(24)
Creativity: “Have you done any creative work recently?”;
-
(25)
Participation in community: “What do you do in your neighborhood or community?”;
-
(26)
Support from social network: “Other than family members, who do you consider as your close support?”;
-
(27)
Relationship with friends and colleagues: “Do you hang out with friends or coworkers”;
-
(28)
Managing boundaries in close relationship: “Do you feel comfortable with your partner or partners if you have?”;
-
(29)
Managing sexual safety: “If you are sexually active, do you try to avoid risky sexual behaviors?”;
-
(30)
Productivity at work or school: “Are you productive at work or school?”;
-
(31)
Motivation at work or school: “How’s your motivation for work or school?”;
-
(32)
Coping skills to de-stress: “What kind of coping do you use to calm yourself?”;
-
(33)
Exhibiting control over self-harming behavior: “Do you have self-harming behaviours?”;
-
(34)
Law-abiding: “Have you been arrested recently?”;
-
(35)
Managing legal issue: “Do you have any legal issue recently?”;
-
(36)
Maintaining personal hygiene: “How’s your personal hygiene? Are you taking care of your personal hygiene?”;
-
(37)
Doing exercises and sports: “Have you recently exercised?”;
As mentioned in Section 4.1, users can freely chat with CaiTI using open-ended responses, including both deterministic YES/NO answers and detailed responses. For example, when CaiTI asks: “Do you often drink alone?”, the user can respond deterministically: “Yes, I drink alone.” or: “I drink alone almost every other night recently.”. CaiTI classifies both responses to Dimension Alcohol usage with Score of 2. With Score 2, CaiTI follows up and provides Psychotherapeutic Conversational Interventions starting by asking for more information. In addition, if the user says: “I don’t drink alone. But I like to drink with my friends when we hang out together.”, CaiTI segments the responses into two parts and classifies the first part to Dimension Alcohol usage with Score of 0, and the second part to Dimension Relationship with friends and colleagues with Score of 0.