LiSnowNet: Real-time Snow Removal
for LiDAR Point Clouds
Abstract
LiDAR have been widely adopted to modern self-driving vehicles, providing 3D information of the scene and surrounding objects. However, adverser weather conditions still pose significant challenges to LiDARs since point clouds captured during snowfall can easily be corrupted. The resulting noisy point clouds degrade downstream tasks such as mapping. Existing works in de-noising point clouds corrupted by snow are based on nearest-neighbor search, and thus do not scale well with modern LiDAR which usually capture or more points at Hz. In this paper, we introduce an unsupervised de-noising algorithm, LiSnowNet, running faster than the state-of-the-art methods while achieving superior performance in de-noising. Unlike previous methods, the proposed algorithm is based on a deep convolutional neural network and can be easily deployed to hardware accelerators such as GPUs. In addition, we demonstrate how to use the proposed method for mapping even with corrupted point clouds.
I Introduction
LiDAR are classified as active sensors, emitting pulsed light waves and utilizing the returning pulse to calculate the distances between it and the surrounding objects. This makes LiDAR suitable during both daytime and nighttime, providing detailed 3D measurements of the surrounding scenes. Such measurements can be easily found in modern datasets [1, 2, 3, 4] as frame-by-frame point clouds, commonly sampled at Hz, and has been used for 3D object detection [5, 6], semantic segmentation [7, 8], and mapping [9].
Though LiDAR provide more accurate 3D measurements compared to radar, the measurements are prone to degrade under adverse weather conditions. Unlike radars, which see through fog, snowflakes and rain droplets, LiDAR are greatly affected by particles in the air [10, 11, 12]. Specifically during snowfall, the pulsed light waves hit the snowflakes and return to the sensor as ghost measurements, as shown in Fig. 1a and 1b. It is crucial to remove such measurements and unveil the underlying geometry of the scene for applications like mapping.
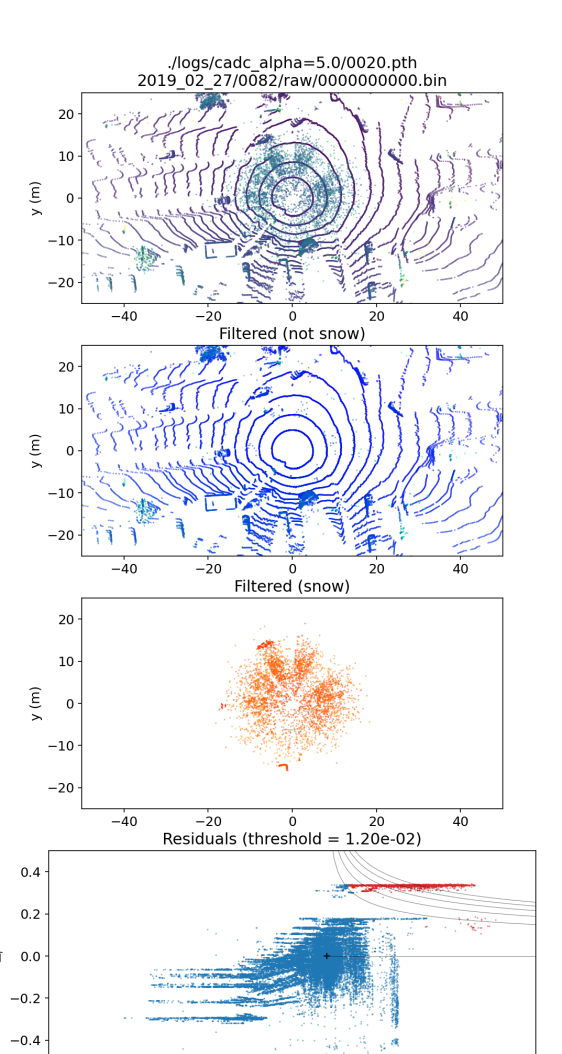

Recently, there is an increasing number of large-scale datasets containing adverse weather conditions. The most relevant ones are the CADC (CADC) Dataset [13] and the WADS (WADS) [14]. Denoising algorithms [11, 12] have also been developed alongside with them. To the best of our knowledge, all of the unsupervised de-noising algorithms are based on nearest neighbor search and have difficulty operating in real-time even with a moderate beam LiDAR (about points/frame). Therefore, it is critical to introduce an alternative formulation which does not rely on nearest neighbor search.
An alternative way to represent point clouds is using range images [15, 8], as shown in Fig. 2a and 2b. Each range image has two channels, and the pixel values are 1) the Euclidean distances in the body coordinate and 2) the intensities. With this representation, we can leverage common algorithms in image processing, including the FFT (FFT), the DWT (DWT), and the DoG (DoG) [16]. CNN with pooling, batch normalization [17] and dropout [18] can also be applied without any modification. More importantly, these operations can perform very efficiently on modern hardware such as GPUs.
However, developing a CNN for de-noising point clouds poses its own challenges. The most obvious one is that obtaining point-wise labels to isolate snowflakes from the scene is usually prohibitively expensive on large-scale datasets. Thus, the formulation needs to be either unsupervised or self-supervised to exploit unlabeled data. With this in mind, we propose a novel network, the LiSnowNet, which can be trained only with unlabeled point clouds.
We assume the noise-free range images are sparse under some transformation, and design loss functions that relies purely on quantifying the sparsity of the data. The norm is used as a proxy to sparsity, and encourages sparse coefficients during training. In addition, the DWT and the IDWT (IDWT) are used for down sampling and up scaling within the network instead of pooling and convolution transpose, respectively. The proposed network is evaluated on a subset of WADS [14], showing similar or superior performance in de-noising compared to other state-of-the-art methods while running times faster.
This paper is organized as follows: Section II lists related work in datasets with adverse weather conditions, existing de-noising methods, and backgrounds in compressed sensing with sparse representations. Section III goes through the formulation of the proposed network and loss functions in detail, including how we train the network in an unsupervised fashion. Section IV introduces the metrics for comparing the performance of the proposed network and other methods. Section V quantitatively shows the results of the aforementioned metrics, as well as qualitatively presents the resulting map from an off-the-shelf mapping algorithm. Lastly, Section VII summarizes the contributions and advantages of the proposed method.
II Related Work
II-A Datasets
Large-scale datasets for autonomous driving [1, 4, 3, 2] become more ubiquitous nowadays. Many of the recent ones contain LiDAR data collected during adverse weather conditions, targeting challenging scenarios like fog, rain, and snow.
[15] collected a dataset with points clouds in a weather-controlled climate chamber, simulating rain and fog in front of a vehicle. The dataset provides point-wise labels with three classes: clear, rain, and fog, where the “clear” points are the ones which are not caused by the adverse weather.
[13] published the CADC dataset which contains point clouds under various snow precipitation levels. The point clouds were collected from a top-mounted HDL-32e and were grouped into sequences where each sequence has about consecutive frames. Though the CADC dataset has 3D bounding boxes for vehicles and pedestrians, we do not use them in our work as the proposed method is designed to be unsupervised.
Recently [14] released the WADS with only point clouds which is significantly smaller than CADC. But unlike CADC, each point cloud in WADS has point-wise labels. There are classes, including “active falling snow” and “accumulated snow”.
Since the target application of the proposed network is snow removal, only CADC and WADS are used for training and evaluation.




II-B De-noising Point Clouds Corrupted by Snow
Similar to the proposed method, the WeatherNet [15] projects point clouds onto a spherical coordinate as range images, which we go into detail in Section III-A. With this representation and the dataset released alongside with the WeatherNet, they formulated the de-noising problem as supervised multi-class pixel-wise classification. The network is constructed by a series of LiLaBlock [19] and is trained with point-wise class labels. The WeatherNet is able to remove rain and fog, but it is unclear how it performs on snow. Additionally, training the WeatherNet requires point-wise label. This prevents the WeatherNet from taking advantage of large-scale unlabeled point cloud datasets such as CADC.
The 2D median filter is successful in removing salt and pepper noise. Once we convert point clouds into range images, we can apply the median filter to them. As shown in Fig. 2, the pixels corresponding to snow are relatively darker than their nearby pixels in both channels. They are darker in the distance channel because the background is further away from the ego vehicle; in addition, snowflakes tend to absorb the energy of the beams which results in dark pixels in the intensity channel. An asymmetrical median filter can be applied to remove just the “peppers” (i.e. snow, isolated dark pixels) while leaving other pixels untouched.
The DROR (DROR) [11] filter removes the noise by first constructing a tree, and count the number of neighbors of each point using dynamic search radii. The idea is that the density of the points from the scene is inversely proportional to the distance, while the density of the points from snowflakes follows a different distribution. The search radius of each point is dynamically adjusted by its distance to the LiDAR center accordingly. If a point does not have enough number of neighbors within its search radius, it is classified as an outlier (i.e. snow).
The DSOR (DSOR)[12] filter also relies on nearest neighbor search, but it calculates the mean and variance of relative distances given a fixed number of neighbors of each point. In other words, it estimates the local density around each point, and outliers can then be filtered out. DSOR is shown to be slightly faster than DROR while having a similar performance in de-noising.
Both DROR and DSOR require nearest neighbor search which prevents them from being real-time. A moderate LiDAR like the HDL‐64E generates around points at Hz. Querying this many points with a tree of this size takes hundreds of milliseconds on modern hardware. On the other hand, WeatherNet [15] and our method work with image-like data, which will be discussed later in Section III-A. Common tools in image processing, such as FFT, DWT, and CNN, can be applied directly and very efficiently on GPUs. This allows us to develop a real-time de-noising algorithm that runs orders of magnitude faster than DROR and DSOR.
We compare our method with DROR, DSOR, and a median filter in Section V, since their implementations are publicly available.
II-C Sparse Representations
Let be two signals in . The signal is said to be sparser than under a transformation if has more zero coefficients than . In other words,
| (1) |
where is the norm.
Though the norm directly quantifies the sparsity of a signal, using it in practice is problematic because it is not convex. Instead, the norm is widely used as a proxy to quantify sparsity and recover corrupted signals [20]. Thus we relax Eq. 1 and get
| (2) |
under some transformation , where is the norm.
The basic assumption of our work is that real-world clean signals are sparse under some transformation . Both DWT and FFT are known to generate sparse representations on real-world multi-dimensional grid data like audio and images, meaning that the Fourier and Wavelet coefficients of natural signals are mostly very close zero.
Typically, a signal corrupted by additive noise becomes less sparse in FFT and DWT than the underlying clean one. This is due to the fact that common noises, such as isolated spikes or Gaussian, have wide bandwidths in the frequency domain, as shown in Fig. 2c and 2d. Therefore de-noising is possible if the underlying clean signal is sufficiently sparse in Fourier or Wavelet. The de-noising can be formulated as maximizing the sparsity of the transformed signal.
Assuming that a noisy signal is roughly equally sparse under different transformations , we aim to solve
| (3) |
where is the underlying clean signal, is the norm, and is the weight keeping close to . The value is commonly set to be either or , depending on the structure of the noise: if the noise itself is sparse, and otherwise.
However, solving Eq. 3 directly is computationally intensive for any reasonably sized signal. Thus we propose to use a CNN to approximate the solution and use Eq. 3 as the groundwork of our loss functions. More details about our formulation can be found in Section III-B and III-C.


III Method
III-A Preprocessing
The first step is to convert point clouds into range images. Given a point in the th point cloud in the dataset and its corresponding intensity value , we calculate the following values:
| (4) |
where is the distance from the LiDAR center, is the inclination angle, and is the azimuth angle. By discretizing the inclination and azimuth angles within the FOV (FOV) of the LiDAR, we project each point within a point cloud onto a spherical coordinate, resulting a range image , where is the frame index, is the vertical resolution, and is the horizontal resolution. Throughout this paper is set to be the number of beams of the LiDAR and is set to be a constant . The first channel of the range image is the distance of each point, and the second channel is the corresponding intensity value .
The second step is to squash the range images to a proper scale. A key observation is that the ghost measurements mainly concentrate within a distance of meters, as shown in Fig. 1, whereas the maximum distance of a LiDAR easily exceeds meters. We scale the range images with an element-wise function , defined as
| (5) |
to amplify the relative importance of points near the ego vehicle while preserving its ordering in distances. The function also enhances the contrast between the noise and the scene in the intensity channel, since the intensity values of the snowflakes are almost always whereas the scene usually has positive intensity values.
Finally, not every pixel has a value due to the lack of points at certain directions like the sky and some transparent surfaces. The void pixels is processed with a series of operations, collectively denoted as , before entering the network. In sequence, the operations are:
-
1.
dilation to fill isolated void pixels.
-
2.
Filling the remaining void pixels with the value , where and are the row-wise mean and standard deviation, respectively.
-
3.
Subtraction with a DoG to reduce the amplitude of isolated noisy pixels.
-
4.
average pooling to smooth out the image.
III-B Network Architecture
The proposed network, LiSnowNet , is based on the MWCNN [21] with several key modifications. First, all convolution layers are replaced by residual blocks [22] with two circular convolution layers. In addition, a dropout layer is placed after the first ReLU activation in each residual block to further regularize the network. Lastly, the number of channels is dramatically reduced – the first level only has channels compared to the channels in MWCNN. The number of channels of the higher levels are also reduced proportionally. These modifications are critical for processing sparse representations (i.e. FFT and DWT coefficients) of panoramic range images in real-time.
The proposed network is designed to produce the residual image , satisfying
| (7) |
where is the de-noised range image representing the geometry of the underlying scene.
III-C Loss Functions
Let be the real-valued FFT and be the DWT with the Haar basis. With the formulation in Eq. 3 and 7, we designed three novel loss functions, two of which quantify the sparsity of the range image, while the third one quantifies the sparsity of the noise.
| (8) |
where is the number of point clouds in the training set, and is the element-wise absolute value.
Note that uses the log-magnitude of the Fourier coefficients. Since for some small , it prevents the network from focusing too much on the low-frequency part of the spectrum while pertaining the properties of the norm. The total loss function can thus be constructed as
| (9) |
where is a hyperparameter balancing the sparsity of the range image and the residual.
III-D Training
The network is trained on CADC and WADS with each dataset split into for training and for validation, where the minimum unit is a sequence. The batch size is and on the two datasets, respectively. Each training session runs epochs with the Adam optimizer and an initial learning rate of . The learning rate is updated at the end of each epoch with a learning decay of .
III-E Prediction
After the network is trained, the residual images are used for filtering. Let be the distance channel and be the intensity channel of the residual image at time . We define the decision boundary primarily in the residual space. A point with residuals and is classified as snow (i.e. positive) if it satisfies all the following conditions:
-
•
Being the foreground (i.e. is closer than nearby pixels).
-
•
Absorbing most of the energy of LiDAR beams (i.e. is darker than nearby pixels).
-
•
The residuals of are not sparse.
where and are the shape parameters of the primary decision boundary, and is a threshold value.
IV Evaluation
Quantitatively, the proposed network and other two state-of-the-art methods [11, 12] are evaluated with three common metrics for binary classification on a subset of WADS [14], since it is the only publicly available dataset containing point-wise labels with snow at the moment of writing this paper. Let be the number of true positive points, be the number of false positive points, and be the number of false negative points. The metrics are as follows:
-
•
Precision:
-
•
Recall:
-
•
IoU (IoU):
We also record the average runtime on a modern desktop computer with a Ryzen 2700X and an RTX 3060.
In addition, qualitative results in mapping with sequences of de-noised point clouds are presented. We use the RTK (RTK) poses from CADC and LeGO-LOAM (LeGO-LOAM) to demonstrate the effectiveness of building maps from de-noised point clouds. Both RTK and LeGO-LOAM are able to reconstruct the environment from the raw and de-noised point clouds, but the difference in the quality of the resulting map is significant.
V Results
Compared to the baselines, the proposed network (labeled as LiSnowNet-) yields similar or superior performance in de-noising, as shown in TABLE I. The recall is lower than DSOR, while the precision and IoU are noticeably higher than all other methods.
More importantly, our network is faster than DSOR and faster than DROR with about points per frame. Considering that the sampling rate of LiDAR are usually at Hz, the proposed method is the best one that can operate in real-time.
The de-noised point clouds also enable building clean maps using either poses from the RTK system or LeGO-LOAM, as shown in Fig. 4. LeGO-LOAM is able to generate near identical trajectories with both the raw and de-noised point clouds, but the map with the former shows a large number of ghost points above where the ego vehicle traveled. By contrast, resulting map with de-noise point clouds is much cleaner, containing a minimal amount of noise and faithfully reflecting the occupancy of the scene.






VI Ablation Study
| Optimal | Precision | Recall | IoU | |
|---|---|---|---|---|
| 0.9779 | 0.10 | 0.9363 | 0.9417 | 0.8840 |
| 0.9558 | 0.30 | 0.9378 | 0.9338 | 0.8783 |
| 0.9779 | 0.50 | 0.9249 | 0.9501 | 0.8812 |
| 0.9688 | 0.70 | 0.9457 | 0.9250 | 0.8768 |
| 0.9779 | 0.90 | 0.9444 | 0.9432 | 0.8928 |
VI-A versus
As stated in Section II-C, the norm widely is used as a proxy to sparsity of real-world signals. To further justify the usage of norm as oppose to some other common norms, such as the norm, we train the same network but replace the norm with the norm in the loss functions. We label the trained networks LiSnowNet- and LiSnowNet- to reflect the norm used during training, as shown in TABLE I.
We see that LiSnowNet- already performs better than DROR in all metrics. Using the norm brings further improvements in precision and IoU while keeping a similar recall. The results indicate that using the norm as a proxy to sparsity is more effective than using the norm.
VI-B FFT versus DWT
Both FFT and DWT are linear operators which are know to transform natural images to sparse representations in the frequency domain. The key difference is that FFT captures global features across the whole image, while DWT captures local features at various scales of the image.
We investigate the sensitivity of the contributions of individual transformation by varying the ratio of and in Eq. 9. The modified total loss thus becomes
| (10) |
where determines the relative contributions of FFT and DWT. We train the LiSnowNet using this loss function with five different values ranging from 0.1 to 0.9, as shown in TABLE II. The optimal is obtained by grid search for each value.
We see that the variations of the performance remain reasonably small, with the maximum difference being in recall. This number is way smaller than the variation between different methods presented in TABLE I, indicating that the proposed network is robust to the selection of sparse transformations if and are properly tuned.
VII Conclusions
We propose a deep CNN, LiSnowNet, for de-noising point clouds corrupted under adverse weather conditions. The proposed network can be trained without any labeled data, and generalizes well to multiple datasets. The network is able to process points under ms while yielding superior performance in de-noising compared to the state-of-the-art method. It also enhances the quality of down stream tasks such as mapping during snowfall.
References
- [1] Andreas Geiger, Philip Lenz, Christoph Stiller and Raquel Urtasun “Vision meets Robotics: The KITTI Dataset” In International Journal of Robotics Research (IJRR), 2013
- [2] Pei Sun et al. “Scalability in Perception for Autonomous Driving: Waymo Open Dataset” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
- [3] John Houston et al. “One Thousand and One Hours: Self-driving Motion Prediction Dataset” In CoRR abs/2006.14480, 2020 arXiv: https://arxiv.org/abs/2006.14480
- [4] Whye Kit Fong et al. “Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking” In arXiv preprint arXiv:2109.03805, 2021
- [5] Alex H Lang et al. “Pointpillars: Fast encoders for object detection from point clouds” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 12697–12705
- [6] Shaoshuai Shi et al. “From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network” In IEEE transactions on pattern analysis and machine intelligence IEEE, 2020
- [7] Ran Cheng, Ryan Razani, Yuan Ren and Liu Bingbing “S3Net: 3D LiDAR Sparse Semantic Segmentation Network” In arXiv preprint arXiv:2103.08745, 2021
- [8] Tiago Cortinhal, George Tzelepis and Eren Erdal Aksoy “SalsaNext: fast, uncertainty-aware semantic segmentation of LiDAR point clouds for autonomous driving” In arXiv preprint arXiv:2003.03653, 2020
- [9] Tixiao Shan and Brendan Englot “LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain” In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018, pp. 4758–4765 IEEE
- [10] Matti Kutila et al. “Automotive LIDAR sensor development scenarios for harsh weather conditions” In 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), 2016, pp. 265–270 DOI: 10.1109/ITSC.2016.7795565
- [11] Nicholas Charron, Stephen Phillips and Steven L. Waslander “De-noising of Lidar Point Clouds Corrupted by Snowfall” In 2018 15th Conference on Computer and Robot Vision (CRV), 2018, pp. 254–261 DOI: 10.1109/CRV.2018.00043
- [12] Akhil Kurup and Jeremy Bos “DSOR: A Scalable Statistical Filter for Removing Falling Snow from LiDAR Point Clouds in Severe Winter Weather”, 2021 arXiv:2109.07078 [cs.CV]
- [13] Matthew Pitropov et al. “Canadian adverse driving conditions dataset” In The International Journal of Robotics Research 40.4-5 SAGE Publications Sage UK: London, England, 2021, pp. 681–690
- [14] Jeremy P. Bos, Derek Chopp, Akhil Kurup and Nathan Spike “Autonomy at the end of the Earth: an inclement weather autonomous driving data set” In Autonomous Systems: Sensors, Processing, and Security for Vehicles and Infrastructure 2020 11415 SPIE, 2020, pp. 36 –48 International Society for OpticsPhotonics URL: https://doi.org/10.1117/12.2558989
- [15] Robin Heinzler, Florian Piewak, Philipp Schindler and Wilhelm Stork “CNN-based Lidar Point Cloud De-Noising in Adverse Weather” In IEEE Robotics and Automation Letters, 2020 DOI: 10.1109/LRA.2020.2972865
- [16] David Marr and Ellen Hildreth “Theory of edge detection” In Proceedings of the Royal Society of London. Series B. Biological Sciences 207.1167 The Royal Society London, 1980, pp. 187–217
- [17] Sergey Ioffe and Christian Szegedy “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift” In CoRR abs/1502.03167, 2015 arXiv: http://arxiv.org/abs/1502.03167
- [18] Yarin Gal and Zoubin Ghahramani “Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning” In Proceedings of The 33rd International Conference on Machine Learning 48, Proceedings of Machine Learning Research New York, New York, USA: PMLR, 2016, pp. 1050–1059 URL: https://proceedings.mlr.press/v48/gal16.html
- [19] Florian Piewak et al. “Boosting LiDAR-based Semantic Labeling by Cross-Modal Training Data Generation”, 2018 arXiv:1804.09915 [cs.CV]
- [20] Emmanuel J Candes, Michael B Wakin and Stephen P Boyd “Enhancing sparsity by reweighted l1 minimization” In Journal of Fourier analysis and applications 14.5 Springer, 2008, pp. 877–905
- [21] Pengju Liu, Hongzhi Zhang, Wei Lian and Wangmeng Zuo “Multi-level Wavelet Convolutional Neural Networks” In CoRR abs/1907.03128, 2019 arXiv: http://arxiv.org/abs/1907.03128
- [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun “Deep Residual Learning for Image Recognition” In CoRR abs/1512.03385, 2015 arXiv: http://arxiv.org/abs/1512.03385