Limitation on the Student- Linear Regression Model
Abstract
For the outlier problem in linear regression models, the Student- linear regression model is one of the common methods for robust modeling and is widely adopted in the literature. To examine the model, it is important if a model recognizes outliers. This study provides the practically useful and quite simple conditions to ensure that the Student- linear regression model is robust against an outlier in the -direction.
Keywords: Outlier, Linear regression model, Regularly varying distributions, Bayesian modeling
1 Introduction
In regression analysis, outliers in a linear regression model can jeopardize the results by the ordinary least squares (OLS) estimator. The Student- linear regression model, designed as a linear regression model with the error term having t-distribution, is one of the common methods to solve the outlier problem (Lange et al., 1989). While the Student- linear regression model has been widely adopted, most studies apply it without careful theoretical consideration.
Bayesian robustness modeling using heavy tailed distributions, which include -distribution, provides the theoretical solution for the outlier problem. For a simple Bayesian model, when both the prior distribution and the likelihood of an observation are normal distributions, the posterior distribution is also a normal distribution, and the posterior mean is a weighted average of the mean of prior distribution and the observation. When the prior distribution and the observation are located far from each other and follow a normal distribution, the posterior distribution is far from both pieces of information; this is called . For example, when a single observation follows and the prior of the location parameter follows , then the posterior distribution follows . In this case, the posterior distribution is not suggested by either the prior distribution or the observation.
For this problem, Dawid (1973) formally provides the theoretical resolution of the conflict between the prior distribution and the data, also known as conflict of information. He uses the pure location model in which the scale parameter is given and clarifies how an outlier is automatically ignored in the posterior distribution when the outlier follows a heavy-tailed distribution. This result occurs because we believe the information about the prior distribution more than we believe the observation.
O’Hagan (1990) presents the concept of , which measures the degree of the tail’s information. As Andrade and O’Hagan (2006) mention, credence represents how much we are prepared to believe in one source of information rather than another in the case of conflict; it is represented by the index of a regularly varying function. Andrade and O’Hagan (2011) show that in a univariate model, many observations that are located close enough create a larger credence, which equals the sum of each credence of the observations. When an outlier is far from the group of non-outliers with the same heavy-tailed distribution, the information of the group of non-outliers creates larger credibility or credence. Thus, the posterior distribution is located closer to the non-outliers, and is robust against the outlier. Andrade and O’Hagan (2011) establish sufficient conditions for robust modeling against a single outlier in samples for a univariate model using regular variation theory. The sufficient condition requires the minimum number of non-outliers to be robust against an outlier. O’Hagan and Pericchi (2012) review previous studies on the resolution of the conflict.
O’Hagan (1988) applies heavy-tailed modeling to a Student- linear regression model without an intercept term under the pure location structure and demonstrates its robustness. For the model without the intercept term, the outlier unconditionally conflicts with non-outliers. Therefore, a univariate model can be directly applied. By contrast, as Peña et al. (2009) mention, we need to be careful about the outlier in the -direction for the model with an intercept term. Peña et al. (2009) show when the outliers in the -direction reach infinity, the result of a Student- linear model does not enable robustness. Peña et al. (2009) examine the phenomenon using Kullback–Leibler divergence, and propose a down-weighting method that assigns a lower weight to outliers. As Andrade and O’Hagan’s (2011) show the heavy-tail modeling using -distribution is a partial robust modeling. Thus the location-scale modeling completely cannot ignore outliers. Gagnon et al. (2020) theoretically develop a robust linear regression model using a super heavy tailed distribution, which is heavier than -distribution and provides a wholly robust modeling. He et al. (2021), Andrade (2022), and Gagnon and Hayashi (2023) provided theoretical consideration for the Student- linear regression model. Although the Student- linear regression model provides partial robustness, the model is widely applied. Thus, it is quite important to clarify how the model works as a robust model.
Our study investigates the conditions for the Student- linear model with an intercept term for an outlier in the -direction by extending Andrade and O’Hagan’s (2011) conditions. For this purpose, first, we investigate the range in which there is a conflict between an outlier and non-outliers, which is the necessary condition to apply heavy-tail modeling. Then, we clarify the condition of the model’s robustness.


Heavy-tail modeling as a resolution of a conflict between an outlier and non-outliers works when the outlier and the mean of the group of non-outliers are located far enough, and the sufficient condition for the number of non-outliers is satisfied. A linear regression model provides the mean of conditioned on . Thus, the conflict of information in a linear regression model with an intercept term occurs when an outlier is located far from the regression line, and non-outliers lie close to the regression line created from non-outliers.
The left panel in Figure 1 shows the case in which the outlier conflicts with the group of non-outliers. The figure shows that the outlier is located far from the regression line by OLS. In this case, the Student- linear regression model is robust against the outlier in the -direction. This is because the information of the conditional distribution of the outlier is less credible than that for the grouped non-outlier data, under the assumption of the same degrees of freedom of -distribution for all data, which represent . Non-outliers in the left panel of Figure 1 are close to each other and create a large credence, while the outlier does not belong to the regression line suggested by the grouped data and creates a small credence. Meanwhile, as shown in the right panel of Figure 1, when the outlier is in the -direction, which is called the leverage point, all data, including the outlier, are sufficiently close to the regression line, and create larger credence than the regression line without the outlier, which is presented by the dotted line in Figure 1. In this case, the straight line in the right panel of Figure 1 has larger credence than the dotted line does.
The rest of the paper is organized as follows. In Section 2, we provide the condition for the existence of conflict between an outlier and non-outliers in the Student- linear regression model. Section 3 shows the sufficient conditions for the Student- linear regression model. Section 4 presents simulation results in a simple linear regression model. Section 5 concludes.
2 Conflicting Information in the Student- Linear Regression Model
To examine the limitation of the robustness for the Student- linear model with an intercept term, we consider the following linear regression model. The dependent variable is an vector, the independent variable is an full-rank matrix, is a vector, and is an vector assumed to be independent and identically distributed:
| (1) |
where
Consider the residual of the result from OLS for the model in equation (1):
| (2) |
where
and subscripts and show a non-outlier and an outlier, respectively.
According to Cook and Weiberg (1982) and Chatterjee and Hadi (1988), the prediction or hat matrix, , is given by
| (3) |
Then the residual is defined as
| (4) |
The element of the hat matrix for the model with the intercept term, the ()-th element of , is described as
| (5) |
where
and .
In the model with the intercept term, for the diagonal elements, which are called , is the smallest value and 1 is the largest.
| (6) |
Mohammadi (2016) showed the range of the off-diagonal elements with the intercept term as follows:
| (7) |
Assume that the non-outliers are located close enough to the regression line. If the outlier moves away from the regression line and does so faster than the group of non-outliers does, then the residual reaches infinity as the outlier reaches infinity in the -direction. Since non-outliers create combined credence, if one of the non-outliers conflicts with the outlier, then the group of non-outliers conflicts with the outlier. As shown in Figure 1, when an outlier is located close enough to the group of non-outliers in the -direction, they conflict. Therefore, if the partial derivative of with respect to is larger than the partial derivative of the closest non-outlier’s residual, the outlier conflicts with the group of non-outliers.
We derived the relationship between the Hat matrix and the range of outliers in a linear regression model. Let th the observation be an outlier. Thus, represents the element of of an outlier.
| (8) |
where subscript is a non-outlier.
From the definition, the partial derivative of the residual of an outlier, , and the residual of a non-outlier, , with respect to outlier, , can be given as
| (9) |
and
| (10) |
To investigate the limitation in which an outlier conflicts with the group of non-outliers, this study examined the location of an outlier as the outlier goes to infinity in the -direction. To examine the condition, we first see if the observation is an outlier in the first stage and then derive the condition if the non-outliers create a group.
Lemma 1 If the following condition holds, the observation becomes an outlier in the linear regression model as :
| (11) |
Proof of Lemma 1
The condition that the observation becomes an outlier is expressed as the outlier moves away from the regression line, where the residual reaches infinity as the outlier reaches infinity in the -direction.
| (12) |
Substituting equations (9) and (10) into the condition (12), we have
| (13) |
Using (6), Lemma 1 is obtained.
∎
Lemma 2 If the following condition holds, the non-outliers create a group against the outlier as goes to infinity in the linear regression model.
| (14) |
Proof of Lemma 2
The outlier moves away from the regression line faster than the group of non-outliers. Therefore, if the partial derivative of with respect to is larger than the partial derivative of non-outlier residuals, non-outliers create a group against the outlier. To create a group of non-outliers, the following conditions are required:
| (15) |
When Lemma 1 holds, condition (i) in (15) holds: To satisfy condition (ii) in (15), we have
| (16) |
for . By the range of , Lemma 2 is obtained.
∎
Corollary 1 When the following condition holds, the property of idempotent and symmetric matrix is satisfied under the conditions Lemma 1 and Lemma 2.
| (17) |
Proof of Corollary 1
As Chatterjee and Hadi (1988) denoted, since a Hat matrix is idempotent and symmetric, can be written as
| (18) | |||||
By arranging (18), we have
| (19) |
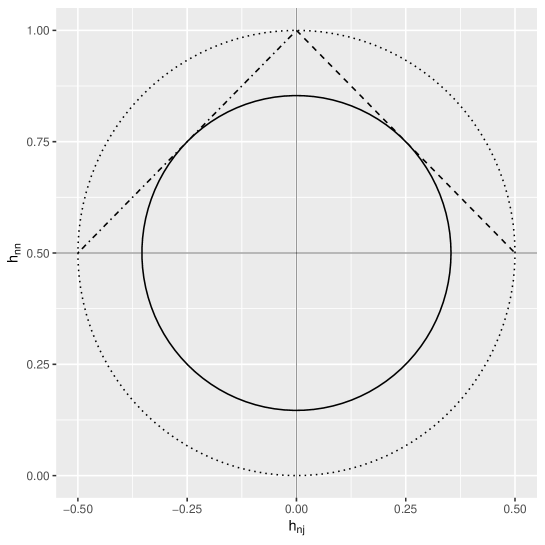
The dashed line and the dot-dashed line in Figure 2 show Lemma 1 and 2 based on the conditions (13) and (16). The dotted circle in Fig 2 shows the case with , which does not satisfy both Lemma 1 and 2 for . From the figure, is necessary greater than or equal to to satisfy the conditions of Lemma 1 and 2.
∎
3 Sufficient Conditions for Rejecting an Outlier in the Student- Linear Regression Model
This section investigates the sufficient conditions for a Student- linear regression model being robust based on Andrade and O’Hagan’s (2011) corollary 4, which shows the conditions for robustness against a single outlier out of samples in a univariate model. To examine the conditions for the Student- linear regression model, we adopt the independent Jeffreys priors derived by Fonseca et al. (2008, 2014) under the given degrees of freedom.
As shown in Andrade and O’Hagan (2006), the credence is defined as for , where presents that is regularly varying at with index . For a distribution, the credence of distribution with degrees of freedom is 1 (see Appendix A).
Assume all data, including a single outlier among observations, are -distributed with degrees of freedom, , , which has mean and scale parameter with degrees of freedom. As the -distribution is a location-scale family, the likelihood can be denoted as . is the -th row of .
For simplicity, assume all data have the same likelihood function and the non-outliers are close enough to the conditional mean . Consider the -th observation is an outlier.
Model
Theorem 1 Robustness of an outlier among observations
Consider observations in the present model, and Lemma 1 holds, in which the residual reaches infinity as goes to infinity. Then, the following condition holds: .
Then, the posterior distribution partially ignores the outlier:
| (20) |
where the superscript notation is used to indicate the omission of the -th observation.
Proof of Theorem 1
When scale parameter is given, the posterior distribution of in the model is as follows:
Applying transformation , which is a 1 vector, we obtain
| (22) |
When all elements of X are given and bounded, in is (1). Thus, as a function of , it is slowly varying,
| (23) |
Thus, the marginal posterior distribution of given information and becomes
| (24) |
Again, applying transformation produces the marginal posterior distribution of given information as
| (25) | |||
When non-outliers are located close enough to the regression line, Andrade and O’Hagan’s (2011) Proposition 1, which gives the convolution of regularly varying densities being distributed as the sum of them, , can be applied as and . Since for , when the residual reaches infinity as goes to the infinity, we obtain
| (26) |
Lemma 1 and 2 show the conditions for the residual reaching infinity as goes to infinity. Accordingly, the marginal posterior distribution for is
| (27) |
Next, consider the case in which goes to infinity. As a function of , the posterior distribution of takes the form of . Thus, by the relationship ,
| (28) |
From (24), we obtain
| (29) |
Thus, for the dominator of (28) to exist, must hold. ∎
3.1 Example
We consider the following case of a simple linear regression model with a single outlier:
| (30) |
From Lemma 1, we obtain the following condition:
| (31) | |||||
where .
By arranging the condition (31), we obtain the range as
| (32) |
Thus, when , we obtain the range for satisfying Lemma 1 as follows:
| (33) |
From Lemma 2, we obtain the following condition:
| (34) | |||||
By rearranging the above condition, we obtain the range as
| (35) |
Thus, when , we obtain the range for satisfying Lemma 2 as follows:
| (36) |
These results highlight that the robust range is wider, as the number of non-outliers is larger. In addition, when the independent variable of the outlier is located far from other data, there is no conflict of information, irrespective of the value of .
This subsection investigates the robustness performance in relation to the value of the outlier in the Student- linear regression model for simple linear regression. For robustness, the degrees of freedom of the -distributed errors need to be sufficiently small. Thus, we utilize three degrees of freedom, for the error term. We employ the independent Jeffreys priors; the priors of and have uniform distributions, and the prior distribution of is . By Theorem 5.1, the sufficient condition for -distribution with degrees of freedom is . Thus, in this model the condition becomes . The simulated observations are defined as . We set for the first simulation and for the second one. The error terms are generated from the normal distribution with mean 0 and variance 1. We move the outlier in the -direction, from -50 to 50, and set . The left panels of Figure 3 depict the simulated data we used for these simulations. The right panels of Figure 3 show the results of the numerical evaluation of the posterior mean of the parameter ; the upper right panel illustrates the result for , which satisfies the sufficient condition, and the lower right panel presents it for , which satisfies the condition. The results indicate that the Student- linear regression model is robust within the controllable range defined in Lemma 2, which is shown as the vertical dotted lines.




4 Concluding remarks
This study extended Andrade and O’Hagan’s (2011) condition
for resolving the outlier problem of the Student- linear regression model. The model treats outliers as a natural outcome of the data and does not remove them arbitrarily. The condition works when there is conflicting information between outliers and non-outliers. However, in a linear regression model, an outlier does not conflict with non-outliers when the outlier is located far from non-outliers in the -direction. Thus, we first clarified the range of the presence of conflicting information in a linear regression model. Then, we derived the sufficient condition for robustness of the Student- linear regression model in the above range. Future research should investigate the conditions for many outliers. Furthermore, it would be interesting to extend this study to a model with unknown degrees of freedom for the -distribution.
References
- [1] Andrade, J.A.A. (2022), On the robustness to outliers of the Student-t process, Scandinavian Journal of Statistics.
- [2] Andrade, J.A.A. and O’Hagan, A. (2006), Bayesian robustness modeling using regularly varying distribution. Bayesian Analysis 1, 169–188.
- [3] Andrade, J.A.A. and O’Hagan, A. (2011), Bayesian robustness modelling of location and scale parameters. Scandinavian Journal of Statistics 38(4), 691–711.
- [4] Bingham, N.H., Goldie, C.M., and Teugels, J.L. (1987), Regular Variation. Cambridge University Press, Cambridge.
- [5] Chatterjee, S. and Hadi, A.S. (1988), Sensitivity Analysis in Linear Regression. Wily, New York.
- [6] Cook, R. D. and Weisberg, S. (1982), Residuals and Influence in Regression. New York: Chapman and Hall.
- [7] Dawid, A.P. (1973), Posterior expectations for large observations. Biometrika 60(3), 664–667.
- [8] Fonseca, T.C.O., Ferreira, M.A.R., and Migon, H.S. (2008), Objective Bayesian analysis for the Student- regression model. Biometrika 95(2), 325–333.
- [9] Gagnon, P., Desgagné, A., and Bédard, M. (2020). A New Bayesian Approach to Robustness Against Outliers in Linear Regression. Bayesian Analysis 15, 389–414.
- [10] Gagnon, P. and Hayashi, Y. (2023), Theoretical properties of Bayesian Student-t linear regression. Statistics and Probability Letters 193, 109693.
- [11] He, D., Sun, D., and He, L. (2021), Objective Bayesian analysis for the 21 Student-t linear regression. Bayesian Analysis, 16, 129–145.
- [12] Lange, K.L., Little, R.J.A., and Taylor, J.M.G. (1989), Robust statistical modeling using the t distribution. Journal of the American Statistical Association 84(408), 881–892.
- [13] O’Hagan, (1988), A. Modelling with heavy tails. Bayesian Statistics 3, 345–359.
- [14] O’Hagan, A. (1990), On Outliers and Credence for Location Parameter Inference. Journal of the American Statistical Association , 85, pp.172–176.
- [15] O’Hagan, A. and Pericchi, L. (2012), Bayesian heavy-tailed models and conflict resolution: A review. Brazilian Journal of Probability and Statistics 26(4), 372–401, 2012.
- [16] Peña, D., Zamar, R., and Yan, G. (2009), Bayesian likelihood robustness in linear models. Journal of Statistical Planning Inference 139(7), 2196–2207, 2009.
- [17] Resnick, S.I. (2007), Heavy-tail Phenomena: Probabilistic and Statistical Modeling. Springer, New York.
Appendix A: Regularly varying functions
The tail behavior can be presented by the index of a regularly varying function. The index is defined as follows.
A positive measurable function is regularly varying at with index for an arbitrary positive .
| (A.1 ) |
We present it as in this study, and is called “slowly varying.” The regularly varying function can be presented as .
Using the property
| (A.2 ) |
we obtain the index for distribution with the degrees of freedom, , as
where .
Some properties of the regularly varying function used in this study are seen in Bingham et al. (1987) and Resnick (2007).