Likelihood Ratio Confidence Sets for
Sequential Decision Making
Abstract
Certifiable, adaptive uncertainty estimates for unknown quantities are an essential ingredient of sequential decision-making algorithms. Standard approaches rely on problem-dependent concentration results and are limited to a specific combination of parameterization, noise family, and estimator. In this paper, we revisit the likelihood-based inference principle and propose to use likelihood ratios to construct any-time valid confidence sequences without requiring specialized treatment in each application scenario. Our method is especially suitable for problems with well-specified likelihoods, and the resulting sets always maintain the prescribed coverage in a model-agnostic manner. The size of the sets depends on a choice of estimator sequence in the likelihood ratio. We discuss how to provably choose the best sequence of estimators and shed light on connections to online convex optimization with algorithms such as Follow-the-Regularized-Leader. To counteract the initially large bias of the estimators, we propose a reweighting scheme that also opens up deployment in non-parametric settings such as RKHS function classes. We provide a non-asymptotic analysis of the likelihood ratio confidence sets size for generalized linear models, using insights from convex duality and online learning. We showcase the practical strength of our method on generalized linear bandit problems, survival analysis, and bandits with various additive noise distributions.
1 Introduction
One of the main issues addressed by machine learning and statistics is the estimation of an unknown model from noisy observations. For example, in supervised learning, this might concern learning the dependence between an input (covariate) and a random variable (observation) . In many cases, we are not only interested in an estimate of the true model parameter , but instead in a set of plausible values that could take. Such confidence sets are of tremendous importance in sequential decision-making tasks, where uncertainty is used to drive exploration or risk-aversion needs to be implemented, and covariates are iteratively chosen based on previous observations. This setting includes problems such as bandit optimization, reinforcement learning, or active learning. In the former two, the confidence sets are often used to solve the exploration-exploitation dilemma and more generally influence the selection rule (Mukherjee et al.,, 2022), termination rule (Katz-Samuels and Jamieson,, 2020), exploration (Auer,, 2002) and/or risk-aversion (Makarova et al.,, 2021).



When we interact with the environment by gathering data sequentially based on previous confidence sets, we introduce correlations between past noisy observations and future covariates. Data collected in this manner is referred to as adaptively gathered (Wasserman et al.,, 2020). Constructing estimators, confidence sets, and hypothesis tests for such non-i.i.d. data comes with added difficulty. Accordingly, and also for its importance in light of the reproducibility crisis (Baker,, 2016), the task has attracted significant attention in the statistics community in recent years (Ramdas et al.,, 2022).
Instead of deriving explicit concentration inequalities around an online estimator, we construct confidence sets implicitly defined by an inclusion criterion that is easy to evaluate in a computationally efficient manner and requires little statistical knowledge to implement. Roughly speaking, given a model that describes the conditional dependence of the observation given the covariate under parameter , we will build sets based on a weighted modification of the sequential likelihood ratio statistic (Robbins et al.,, 1972; Wasserman et al.,, 2020)
| (1) |
where is a running estimator sequence that we are free to choose, but which may only depend on previously collected data. Parameters for which this statistic is small, i.e., for which will be included in the set (and considered plausible). Examples of sets in a parametric and non-parametric setting are shown in Figure 1. The weighting terms are crucial for dealing with inherent irregularities of many conditional observation models but can be flexibly chosen. Classically, these are set to . The full exposition of our method with choice of estimators and weights is given in Section 2. Apart from being easy to use and implement, our approach also comes with performance guarantees. These sets maintain a provable coverage – a fact we establish using Ville’s inequality for supermartingales (Ville,, 1939), which is known to be essentially tight for martingales (see Howard et al.,, 2018, for a discussion). Therefore, in stark contrast to alternate methods, our confidence sequence is fully data-dependent, making it empirically tighter than competing approaches. Despite the rich history of sequential testing and related confidence sets going back to Wald, (1945) and Robbins et al., (1972), these sets have found little use in the interactive machine learning community, which is a gap we fill in the present paper.
Contributions
In this work, we revisit the idea of using likelihood ratios to generate anytime-valid confidence sets. The main insight is that whenever the likelihood of the noise process is known, the likelihood ratio confidence sets are fully specified. They inherit their geometry from the likelihood function, and their size depends on the quality of our estimator sequence. We critically evaluate the likelihood ratio confidence sets and, in particular, we shed light on the following aspects: Firstly, for generalized linear models, we theoretically analyze the geometry of the LR confidence sets under mild assumptions. We show their geometry is dictated by Bregman divergences of exponential families (Chowdhury et al.,, 2022). Secondly, we show that the size of the confidence set is dictated by an online prediction game. The size of these sets depends on a sequence of estimators that one uses to estimate the unknown parameter . We discuss how to pick the estimator sequence in order to yield a provably small radius of the sets, by using the Follow-the-Regularized-Leader algorithm, which implements a regularized maximum-likelihood estimator. We prove that the radius of the confidence sets is nearly-worst-case optimal, and accordingly, they yield nearly-worst-case regret bounds when used in generalized linear bandit applications. However, due to their data-dependent nature, they can be much tighter than this theory suggests. Thirdly, we analyze the limitations of classical (unweighted) LR sets when the underlying conditional observation model is not identifiable. In this case, the resulting (inevitable) estimation bias unnecessarily increases the size of the confidence sets. To mitigate this, we propose an adaptive reweighting scheme that decreases the effect of uninformed early bias of the estimator sequence on the size of the sets downstream. The reweighting does not affect the coverage guarantees of our sets and utilizes an elegant connection to (robust) powered likelihoods (Wasserman et al.,, 2020). Finally, thanks to the adaptive reweighting scheme, our sets are very practical as we showcase experimentally. We demonstrate that our method works well with exponential and non-exponential family likelihoods, and in parametric as well as in kernelized settings. We attribute their practical benefits to the fact that they do not depend on (possibly loose) worst-case parameters.
2 The Likelihood Method
The sequential likelihood ratio process (LRP) in (1) is a statistic that compares the likelihood of a given model parameter, with the performance of an adaptively chosen estimator sequence. As noted above, we generalize the traditional definition, which would have , and define a corresponding confidence set as
| (2) |
The rationale is that the better a parameter is at explaining the data from the true model , the smaller this statistic will be, thereby increasing its chances to be included in . When we construct , the sequence of , and cannot depend on the noisy observation . Formally, consider the filtration with sub--algebras . We require that and are -measurable. Under these very mild assumptions and with arbitrary weights , we can show coverage, i.e., our (weighted) confidence sets uniformly track the true parameter with probability .
Theorem 1.
The last statement follows by applying Ville’s inequality for super-martingales on . The proof closely follows Wasserman et al., (2020). While coverage is always guaranteed irrespective of the estimator sequence , we would like to make the sets as small as possible at fixed coverage, which we do by picking a well-predicting estimator sequence.
2.1 The Estimator Sequence Game
The specification of the LR process (LRP) allows us to choose an arbitrary estimator sequence . To understand the importance of the sequence, let us introduce to the definition of in (1), and divide by . This gives the equivalent formulation
We see that the predictor sequence does not influence the geometry of the confidence set, which is fully specified by the likelihood function. We also observe that the ratio on the right-hand side serves as a confidence parameter controlling the size (radius) of the confidence sets measured under the likelihood ratio distance to . If the confidence parameter goes to zero, only is in the set. The better the estimator sequence is at predicting the data, the smaller the inclusion threshold, and hence the smaller the sets will ultimately be. Specifically, taking the , we would like to minimize
| (3) |
The quantity corresponds to a regret in an online prediction game, as will become apparent below.
Online Prediction Game
Online optimization is a mature field in interactive learning (Cesa-Bianchi and Lugosi,, 2006; Orabona,, 2019). The general goal is to minimize a sequence of loss functions as in Eq. (3) and compete against a baseline, which typically is the best-in-hindsight prediction, or – in our case – given by the performance of the fixed parameter . Specifically, at every timestep , iteratively, the agent chooses an action based on , and a loss function is revealed. In most of the online optimization literature, can be chosen adversarially. In our prediction game, we know the whole form of loss function , as can be seen in (3), and not just . Opposed to traditional assumptions in online prediction, in our case, are non-adversarial, but have a stochastic component due to . Also, contrary to most instances of online prediction, we do not compare against the best-in-hindsight predictor, but instead, as this is more meaningful in our setting.
Online Optimization Algorithms
Generally, we seek an algorithm that incurs low regret. Here, we focus on Follow-the-Regularized Leader (FTRL), which corresponds exactly to using regularized maximum likelihood estimation, making it a natural and computationally practical choice. The update rule is defined in Alg. 1 (Line 3). While other algorithms could be considered, FTRL enjoys the optimal regret rate for generalized linear regression as we show later, and is easily implemented. In order to run the algorithm, one requires a sequence of strongly convex regularizers. For now, let us think of it as , which we use in practice. However, one can derive a tighter analysis for a slightly modified, time-dependent regularization strategy for generalized linear models as we show in Sec. 3.3.
2.2 Adaptive Reweighting: Choosing the Right Loss
There is yet more freedom in the construction of the LR, via the selection of the loss function. Not only do we select the predictor sequence, but also the weights of the losses via . This idea allows controlling the influence of a particular data point on the cumulative loss based on the value of . For example, if we know a priori that for a given our prediction will be most likely bad, we can opt out of using the pair by setting . Below we will propose a weighting scheme that depends on a notion of bias, which captures how much of the error in predicting is due to our uncertainty about (compared to the uncertainty we still would have knowing ). Sometimes this bias is referred to as epistemic uncertainty in the literature, while the residual part of the error is referred to as aleatoric. Putting large weight on a data point heavily affected by this bias might unnecessarily increase the regret of our learner (and hence blow up the size of the confidence set). Note that, conveniently, even if we put low weight (zero) on a data point, nothing stops us from using this sample point to improve the estimator sequence in the next prediction round. As we will show below, our reweighting scheme is crucial in defining a practical algorithm for Reproducing Kernel Hilbert Space (RKHS) models and in high signal-to-noise ratio scenarios. Since we do not know , our strategy is to compute an estimate of the bias of the estimator and its effect on the value of the likelihood function for a specific that we played. We use the value of the bias to rescale the loss via such that its effect is of the same magnitude as the statistical error (see Algorithm 1; we call this step bias-weighting).
Intuition
To give a bit more intuition, suppose we have a Gaussian likelihood. Then the negative log-likelihood of with weighting is proportional to . Now, if does not lie in the span of the data points used to compute , it is in general unavoidable to incur large error, inversely proportional to . To see this, let us decompose the projection onto as
| (4) |
where the first term represents the statistical error up to time , while the second, bias, is deterministic, and independent of the actual realization , depending only . Estimators with non-zero bias are biased. Plugging this into the likelihood function, we see that in expectation , where is the unavoidable predictive error in expectation (due to a noisy objective) and is a constant independent of . is the statistical error, and is independent of . Note that the bias term scales inversely with the variance, and leads to unnecessarily big confidence parameters for small .
In fact, the problem is that we use the likelihood to measure the distance between two parameters, but this is only a “good“ distance once the deterministic source of the error (bias) vanishes. For this reason, without weighting, the incurred regret blows up severely in low-noise settings. To counter this, we balance the deterministic estimation bias and noise variance via proper selection of . In this case, it turns out that ensures that the overall the scaling is independent of . While the choice of weights influences the geometry of the confidence sets, with a good data collection and estimation strategy the bias asymptotically decreases to zero, and hence the weights converge to .
Bias estimation
In order to generalize this rule beyond Gaussian likelihoods, we need a proper generalization of the bias. Our generalization is motivated by our analysis of generalized linear models, but the method can be applied more broadly. The role of the squared statistical error (variance) is played by the inverse of the smoothness constant of the negative log-likelihood functions , denoted by . This is the usual smoothness, commonly seen in the convex optimization literature. We consider penalized likelihood estimators with strongly convex regularizers (Alg. 1, line 3). For this estimator class, we define the bias via a hypothetical stochastic-error-free estimate , had we access to the expected values of the gradient loss functions (a.k.a. score). We use the first-order optimality conditions and the indicator function of the set , , to define the error-free-estimate , and the bias of the estimator as
| (5) |
where the expectation denotes a sequence of expectations conditioned on the prior filtration. This notion of bias coincides with the definition of bias in Eq. (4) for the Gaussian likelihood. This quantity cannot be evaluated in general, however, we prove a computable upper bound.
Theorem 2 (Bias estimate).
Let the negative log-likelihood have the form, , where is strongly-convex and let the regularizer be making the overall objective strongly convex. Then, defining , we can bound
| (6) |
The proof is deferred to App. A.3, and requires elementary convex analysis.
This leads us to propose the weighting scheme . We justify that this is a sensible choice by analyzing the confidence set on the GLM class in Section 3, which satisfies the smoothness and strong-convexity conditions. We show that this rule properly balances the stochastic and bias components of the error in the regret as in (3). However, this rule is more broadly applicable beyond the canonical representation of GLM or the GLM family altogether.
3 Theory: Linear Models
While the coverage (i.e., “correctness”) of the likelihood ratio confidence sets is always guaranteed, their worst-case size (affecting the “performance”) cannot be easily bounded in general. We analyze the size and the geometry of the LR confidence sequence in the special but versatile case of generalized linear models.
3.1 Generalized Linear Models
We assume knowledge of the conditional probability model , where the covariates , and the true underlying model parameter lies in a set . If is indexing (discrete) time, then is acquired sequentially, and the – subsequently observed – is sampled from an exponential family distribution parametrized as
| (7) |
Here, is referred to as the log-partition function of the conditional distribution, and is the sufficient statistic. The function is the base measure, and has little effect on our further developments, as it cancels out in the LR. Examples of commonly used exponential families (Gaussian, Binomial, Poisson or Weibull) with their link functions can be found in Table 1 in App. A.1.
In order to facilitate theoretical analysis for online algorithms, we make the following assumptions about the covariates and the set of plausible parameters .
Assumption 1.
The covariates are bounded, i.e., , and the set is contained in an -ball of radius . We will also assume that the log-partition function is strongly convex, that is, that there exists , and that is L-smooth, i.e. .
These assumptions are common in other works addressing the confidence sets of GLMs (Filippi et al.,, 2010; Faury et al.,, 2020), who remark that the dependence on is undesirable. However, in contrast to these works, our confidence sets do not use these assumptions in the construction of the sets. We only require these for our theoretical analysis. As these are worst-case parameters, the practical performance can be much better for our sets.
3.2 Geometry and Concentration
Before stating our results, we need to define a distance notion that the convex negative log-likelihoods induce. For a continuously differentiable convex function , we denote the Bregman divergence as The -regularized sum of log-partition functions is defined as
| (8) |
This function will capture the geometry of the LR confidence sets. The confidence set size depends mainly on two terms. One refers to a notion of complexity of the space referred to as Bregman information gain: , first defined by Chowdhury et al., (2022) as a generalization of the information gain of Srinivas et al., (2009), for Gaussian likelihoods. We will drop the superscript whenever the regularization is clear from context and simply refer to . This term appears because one can relate the decay of the likelihood as a function of the Bregman Divergence from with the performance of a (regularized) maximum likelihood estimator via convex (Fenchel) duality. In particular, if is a regularized MLE, will asymptotically scale as (cf. Chowdhury et al.,, 2022, for further discussion). For Gaussian likelihoods and , it coincides with the classical information gain independent of . The second term that affects the size is the regret of the online prediction game over rounds we introduced previously in (3). These two parts together yield the following result:
Theorem 3.
The set defined via the above divergence does not coincide with the LR confidence set. It is slightly larger due to a term involving (as in Eq. (8)). This is a technical consequence of our proof technique, where the gradient of needs to be invertible, and regularization is added to this end. We note that this can be chosen freely. Note that the theorem involves two confidence levels, and : is a bound on the Type I error – coverage of the confidence sets – while upper bounds the probability of a large radius – and is therefore related to the power and Type II error of a corresponding hypothesis test. The proof of the theorem is deferred to App. B.2.
To give more intuition on these quantities, let us instantiate them for the Gaussian likelihood case with . In this scenario, , and the (in this case symmetric) Bregman divergence is equal to , where , which means that our confidence sets are upper bounded by a ball in the same norm as those in the seminal work on linear bandits (Abbasi-Yadkori et al.,, 2011).
3.3 Online Optimization in GLMs: Follow the Regularized Leader
The size of the confidence sets in Theorem 3 depends on the regret of the online prediction game involving the estimator sequence. We now bound this regret when using the Follow-the-Regularized-Leader (FTRL) algorithm in this setting. This high probability bound is novel to the best of our knowledge and may be of independent interest. We state in a weight-agnostic manner first, and then with our particular choice. The latter variant uses a specifically chosen regularizer. In this case, we can track the contribution of each time-step towards the regret separately.
Theorem 4.
The regret bounds are optimal in the orders of , matching lower bounds of Ouhamma et al., (2021), as for linear models . Combining results of Thm. 4 with Thm. 3, we get a confidence parameter that scales with , for confidence sets of the form , which coincides with the best-known confidence sets in this setting in the worst-case (Abbasi-Yadkori et al.,, 2012). The requirement of global smoothness can be relaxed to smoothness over . With a more elaborate (but less insightful) analysis, we can show that we achieve a bound even in this case. The proofs of these results are deferred to App. C.4, App. C.5 and App. C.6 respectively.
Regret, Weighting and Estimation Bias
Interestingly, the term in Thm. 4 involving the (crude) proxy to the bias – the bound – is not scaled by the same factors as the other terms in the regret bound (10) and in Theorem 3. Namely, the prefactor is instead of . This extra dependence manifests itself in the unnecessary penalization through the estimation bias we introduced in Sec. 2.2, particularly in low-noise settings. We addressed this issue by picking the weights . While the above theorem holds for any valid weighting, it does not exhibit the possible improvement from using specific weights.
We argued earlier that the error in prediction should not be measured by the likelihood function if there is deterministic error, since initially, we are fully uncertain about the value of outside the span of previous observations. Of course, if our goal would be to purely pick weights to minimize , then would lead to zero regret and hence be optimal. However, the likelihood ratio would then be constant, and uninformative. In other words, the associated log-partition Bregman divergence in Theorem 3 would be trivial and not filter out any hypotheses. Clearly, some balance has to be met. With this motivation in mind, we proposed a nonzero weighting that decreases the regret contribution of the bias, namely . The advantage of this choice becomes more apparent when we use the regularizer to obtain the following result.
Theorem 5.
Let . Assume Assumption 1, and additionally that is -smooth everywhere in , and choose . Additionally, let the sequence of be such that, , where is the FTRL optimizer with the regularizer from Theorem 4 111 Note that corresponds to a regularized MLE that did observe the data pair .. Then, with probability the regret of FTRL (Alg. 1) satisfies for all
where .
One can see that for points where the information gain is large (corresponding to more unexplored regions of the space, where the deterministic source of error is then large), the weighting scheme will make sure that the multiplicative contribution of is mitigated, along with having the correct prefactor . The reader may wonder how this result is useful when we replace with the upper bound from Thm. 2. While instructive, our bound still only makes the bias proxy appear in front of the information gain , instead of the more desireable bias itself. In the latter case, we could also directly make use of the upper bound and get an explicit result only using an upper bound on the bias. We leave this for future work.
4 Application: Linear and Kernelized Bandits
Our main motivation to construct confidence sets is bandit optimization. A prototypical bandit algorithm – the Upper Confidence Bound (UCB) (Auer,, 2002) – sequentially chooses covariates in order to maximize the reward , where is the unknown pay-off function parametrized by . UCB chooses the action which maximizes the optimistic estimate of the reward in each round, namely
| (11) |
where is some confidence set for , and can be constructed with Algorithm 1 from the first data points. An important special case is when is linear (Abe and Long,, 1999) or modelled by a generalized linear model (Filippi et al.,, 2010). In that case, the inner optimization problem is convex as long as is convex. The outer optimization is tractable for finite . In the applications we consider, our confidence sets are convex, and we easily solve the UCB oracle using convex optimization toolboxes.
Extension to RKHS
We introduced the framework of LR confidence sets only for finite-dimensional Euclidean spaces. However, it can be easily extended to Reproducing Kernel Hilbert Spaces (RKHS) (Cucker and Smale,, 2002). The definition of the LR process in (1) is still well-posed, but now the sets are subsets of the RKHS, containing functions . An outstanding issue is how to use these sets in downstream applications, and represent them tractably as in Figure 1. Conveniently, even with infinite-dimensional RKHSs, the inner-optimization in (11) admits a Lagrangian formulation, and the generalized representer theorem applies (Schölkopf et al.,, 2001; Mutný and Krause,, 2021). In other words, we can still derive a pointwise upper confidence band as in terms of , leading to a -dimensional, tractable optimization problem.
We also point out that the weighting is even more paramount in the RKHS setting, as the bias never vanishes for many infinite dimensional Hilbert spaces (Mutný and Krause,, 2022). For this purpose, our weighting is of paramount practical importance, as we can see in Figure 2a), where the gray arrow represents the significant improvement from reweighting.
4.1 Instantiation of the Theory for Linear Bandits
Before going to the experiments, we instantiate our theoretical results from Sec. 3 to the important and well-studied special case of linear payoffs. In that case, and the agent observes upon playing action , where . We are interested in minimizing the so-called cumulative pseudo-regret, namely, , where refers to the optimal action. Using the set from (2) along with Theorem 3 and the FTRL result of Theorem 4 we can get a regret bound for the choice .
Theorem 6.
Let . For any , with probability at least , for all we have
Our results are optimal in both and up to constant and logarithmic factors. The proof is deferred to App. D, but is an instantiation of the aforementioned theorems, along with a standard analysis. There, we also compare to the seminal result of Abbasi-Yadkori et al., (2011), which does not suffer from the dependence on . We attribute this to the incurred bias in the absence of the reweighting scheme.
For the weighted likelihood ratio, we can obtain a result similar to the above, but multiplied by an upper bound on . This is undesirable, as our experiments will show that the reweighting scheme vastly improves performance. While this could be somewhat mitigated by using the Theorem 5 instead of Theorem 4 to bound the FTRL regret, a better result should be achievable using our weighting scheme that improves upon Theorem 6 and possibly even matches Abbasi-Yadkori et al., (2011) exactly in the worst-case. We leave this for future work.
4.2 Experimental Evaluation
In this subsection, we demonstrate that the practical applicability goes well beyond the Gaussian theoretical result from the previous subsection. In the examples below, we always use the UCB algorithm but employ different confidence sets. In particular, we compare our LR confidence sets for different likelihood families with alternatives from the literature, notably classical sub-family confidence sets (Abbasi-Yadkori et al.,, 2011; Mutný and Krause,, 2021), and the robust confidence set of Neiswanger and Ramdas, (2021). In practice, however, the radius of these confidence sets is often tuned heuristically. We include such sets as a baseline without provable coverage as well. The main take-home message from the experiments is that among all the estimators and confidence sets that enjoy provable coverage, our confidence sets perform the best, on par with successful heuristics. For all our numerical experiments in Figure 2, the true payoff function is assumed to be an infinite dimensional RKHS element. For further details and experiments, please refer to App. E.

Additive Noise Models
Suppose that is linear and we observe , where is additive noise, and is an element of a Hilbert space. We consider classical Gaussian noise as well as Laplace noise in Fig. 2[a), b)]. Notice that in both cases our confidence sets yield lower regret than any other provably valid method. In both cases they are performing as good as heuristic confidence sets with confidence parameter . The sub-Gaussian confidence sets of Abbasi-Yadkori et al., (2011) (AY 2011) are invalid for the Laplace distribution as it is not sub-Gaussian but only sub-Exponential. For this reason, we compare also with sub-exponential confidence sets derived similarly to those of (Faury et al.,, 2020). The confidence sets of (Neiswanger and Ramdas,, 2021) (NR 2021) perform similarly on Gaussian likelihood, but are only applicable to this setting, as their generalization to other likelihood families involves intractable posterior inference. We note also the difference between the unweighted LR and the weighted one. The examples in Fig. 2 use the true payoff functions , which we model as an element of a RKHS with squared exponential kernel lengthscale on , which is the baseline function no. 4 in the global optimization benchmark database infinity77 (Gavana,, 2021). Additional experiments can be found in App. E.
Poisson Bandits
A prominent example of generalized linear bandits (GLB) are Poisson bandits, where the linear payoff is scaled by an exponential function. We instantiate our results on a common benchmark problem, and report the results in Fig. 2d). We improve the regret of UCB for GLBs compared to two alternative confidence sets: one that uses a Laplace approximation with a heuristic confidence parameter, and one inspired by considerations in Mutný and Krause, (2021) (MK 2021), also with a heuristic confidence parameter. Note that we cannot compare directly to their provable results in their original form as they do not state them in the canonical form of the exponential family.
Survival Analysis
Survival analysis is a branch of statistics with a rich history that models the lifespan of a service or product (Breslow,, 1975; Cox,, 1997; Kleinbaum and Klein,, 2010). The classical approach postulates a well-informed likelihood model. Here, we use a specific hazard model, where the survival time is distributed with a Weibull distribution, parametrized by and . The rate differs for each configuration , and – which defines the shape of the survival distribution – is fixed and known. We assume that the unknown part is due to the parameter which is the quantity we build a confidence set around to use within the UCB Algorithm. In particular, the probability density of the Weibull distribution is . In fact, with , the confidence sets are convex and the UCB rule can be implemented efficiently.
Interestingly, this model admits an alternate linear regression formulation. Namely upon using the transformation , the transformed variables follow a Gumbel-type distribution, with the following likelihood that can be obtained by the change of variables . The expectation over allows us to express it as a linear regression problem since , where is the Euler-Mascheroni constant. More importantly, is sub-exponential. Hence, this allows us to use confidence sets for sub-exponential variables constructed with the pseudo-maximization technique inspired by Faury et al., (2020). More details on how these sets are derived can be found in App. E. However, these approaches necessarily employ crude worst-case bounds and as can be seen in Figure 2c) the use of our LR-based confidence sequences substantially reduces the regret of the bandit learner.
5 Related Work and Conclusion
Related Work
The adaptive confidence sequences stem from the seminal work of Robbins et al., (1972), who note that these sets have -bounded Type I error. The likelihood ratio framework has been recently popularized by Wasserman et al., (2020) for likelihood families without known test statistics under the name universal inference. This approach, although long established, is surprisingly uncommon in sequential decision-making tasks like bandits. This might be due to the absence of an analysis deriving the size of the confidence sets (Mutný and Krause,, 2021), a necessary ingredient to obtain regret bounds. We address this gap for generalized linear models. Another reason might be that practitioners might be interested in non-parametric sub-families – a scenario our method does not cover. That being said, many fields such as survival analysis (Cox,, 1997) do have well-informed likelihoods. However, most importantly, if used naively, this method tends to fail when one departs from assumptions that our probabilistic model is identifiable (i.e., even if ). We mitigate this problem by introducing the scaling parameters in Eq. (1) to deal with it.
Prevalent constructions of anytime-valid confidence intervals rely on carefully derived concentration results and for a specific estimator such as the least-squares estimator and noise sub-families such as sub-Gaussian, sub-Bernoulli and sub-Poisson Abbasi-Yadkori et al., (2011); Faury et al., (2020); Mutný and Krause, (2021). Their constructions involve bounding the suprema of collections of self-normalized stochastic processes (Faury et al.,, 2020; Mutný and Krause,, 2021; Chowdhury et al.,, 2022). To facilitate closed-form expressions, worst-case parameters are introduced that prohibitively affect the size of the sets – making them much larger than they need to be.
Chowdhury et al., (2022) use the exact form of the likelihood to build confidence sets for parameters of exponential families. However, their approach is restricted to exponential family distributions. They use self-normalization and mixing techniques to explicitly determine the size of the confidence set and do not use an online learning subroutine as we do here. Neiswanger and Ramdas, (2021) use likelihood ratios for bandit optimization with possibly misspecified Gaussian processes but is not tractable beyond Gaussian likelihoods. The relation between online convex optimization and confidence sets has been noted in so-called online-to-confidence conversions (Abbasi-Yadkori et al.,, 2012; Jun et al.,, 2017; Zhao et al.,, 2022), where the existence of a low-regret learner implies a small confidence set. However, these sets still use potentially loose regret bounds to define confidence sets. Our definition is implicit. We do not necessarily need a regret bound to run our method, as the radius will depend on the actual, instance-dependent performance of the learner.
Conclusion
In this work, we generalized and analyzed sequential likelihood ratio confidence sets for adaptive inference. We showed that with well-specified likelihoods, this procedure gives small, any-time valid confidence sets with model-agnostic and precise coverage. For generalized linear models, we quantitatively analyzed their size and shape. We invite practitioners to explore and use this very versatile and practical methodology for sequential decision-making tasks.
Acknowledgments and Disclosure of Funding
We thank Wouter Koolen and Aaditya Ramdas for helpful discussions as well as for organizing the SAVI workshop where these discussions took place. NE acknowledges support from the Swiss Study Foundation and the Zeno Karl Schindler Foundation. MM has received funding from the Swiss National Science Foundation through NFP75. This publication was created as part of NCCR Catalysis (grant number 180544), a National Centre of Competence in Research funded by the Swiss National Science Foundation.
References
- Abbasi-Yadkori et al., (2011) Abbasi-Yadkori, Y., Pál, D., and Szepesvari, C. (2011). Improved algorithms for linear stochastic bandits. In Advances in Neural Information Processing Systems, pages 2312–2320.
- Abbasi-Yadkori et al., (2012) Abbasi-Yadkori, Y., Pal, D., and Szepesvari, C. (2012). Online-to-confidence-set conversions and application to sparse stochastic bandits. In Lawrence, N. D. and Girolami, M., editors, Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, volume 22 of Proceedings of Machine Learning Research, pages 1–9, La Palma, Canary Islands. PMLR.
- Abe and Long, (1999) Abe, N. and Long, P. M. (1999). Associative reinforcement learning using linear probabilistic concepts. In ICML, pages 3–11. Citeseer.
- Auer, (2002) Auer, P. (2002). Using confidence bounds for exploitation-exploration trade-offs. Journal of Machine Learning Research, 3(Nov):397–422.
- Azoury and Warmuth, (1999) Azoury, K. S. and Warmuth, M. K. (1999). Relative loss bounds for on-line density estimation with the exponential family of distributions. Machine Learning, 43:211–246.
- Baker, (2016) Baker, M. (2016). 1,500 scientists lift the lid on reproducibility. Nature, 533:452–454.
- Breslow, (1975) Breslow, N. E. (1975). Analysis of survival data under the proportional hazards model. International Statistical Review / Revue Internationale de Statistique.
- Carpentier et al., (2020) Carpentier, A., Vernade, C., and Abbasi-Yadkori, Y. (2020). The elliptical potential lemma revisited. ArXiv, abs/2010.10182.
- Cesa-Bianchi and Lugosi, (2006) Cesa-Bianchi, N. and Lugosi, G. (2006). Prediction, Learning, and Games. Cambridge University Press, New York, NY, USA.
- Chowdhury et al., (2022) Chowdhury, S. R., Saux, P., Maillard, O.-A., and Gopalan, A. (2022). Bregman deviations of generic exponential families. arXiv preprint arXiv:2201.07306.
- Cox, (1997) Cox, D. R. (1997). Some remarks on the analysis of survival data. In Proceedings of the First Seattle Symposium in Biostatistics, pages 1–9. Springer.
- Cucker and Smale, (2002) Cucker, F. and Smale, S. (2002). On the mathematical foundations of learning. Bulletin of the American mathematical society, 39(1):1–49.
- Faury et al., (2020) Faury, L., Abeille, M., Calauzènes, C., and Fercoq, O. (2020). Improved optimistic algorithms for logistic bandits. In ICML2020: Proceedings of the 37th International Conference on International Conference on Machine Learning.
- Filippi et al., (2010) Filippi, S., Cappe, O., Garivier, A., and Szepesvári, C. (2010). Parametric bandits: The generalized linear case. In Advances in neural information processing systems, pages 586–594.
- Gavana, (2021) Gavana, A. (2021). infinity global optimization benchmarks and ampgo. http://infinity77.net/global_optimization/index.html#.
- Hazan, (2016) Hazan, E. (2016). Introduction to online convex optimization. Found. Trends Optim., 2:157–325.
- Hazan et al., (2006) Hazan, E., Agarwal, A., and Kale, S. (2006). Logarithmic regret algorithms for online convex optimization. Machine Learning, 69:169–192.
- Howard et al., (2018) Howard, S. R., Ramdas, A., McAuliffe, J., and Sekhon, J. (2018). Time-uniform chernoff bounds via nonnegative supermartingales. Probability Surveys, 17:257–317.
- Jun et al., (2017) Jun, K.-S., Bhargava, A., Nowak, R., and Willett, R. (2017). Scalable generalized linear bandits: Online computation and hashing. Advances in Neural Information Processing Systems, 30.
- Katz-Samuels and Jamieson, (2020) Katz-Samuels, J. and Jamieson, K. (2020). The true sample complexity of identifying good arms. In Chiappa, S. and Calandra, R., editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 1781–1791. PMLR.
- Kleinbaum and Klein, (2010) Kleinbaum, D. G. and Klein, M. (2010). Survival analysis, volume 3. Springer.
- Lattimore and Szepesvári, (2020) Lattimore, T. and Szepesvári, C. (2020). Bandit Algorithms. Cambridge University Press.
- Makarova et al., (2021) Makarova, A., Usmanova, I., Bogunovic, I., and Krause, A. (2021). Risk-averse heteroscedastic bayesian optimization. In Proc. Neural Information Processing Systems (NeurIPS).
- McCullagh, (2018) McCullagh, P. (2018). Generalized linear models. Chapman and Hall.
- Mukherjee et al., (2022) Mukherjee, S., Tripathy, A. S., and Nowak, R. (2022). Chernoff sampling for active testing and extension to active regression. In International Conference on Artificial Intelligence and Statistics, pages 7384–7432. PMLR.
- Mutný and Krause, (2021) Mutný, M. and Krause, A. (2021). No-regret algorithms for capturing events in poisson point processes. In Meila, M. and Zhang, T., editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 7894–7904. PMLR.
- Mutný and Krause, (2022) Mutný, M. and Krause, A. (2022). Experimental design of linear functionals in reproducing kernel hilbert spaces. In Proc. Neural Information Processing Systems (NeurIPS).
- Neiswanger and Ramdas, (2021) Neiswanger, W. and Ramdas, A. (2021). Uncertainty quantification using martingales for misspecified gaussian processes. In Feldman, V., Ligett, K., and Sabato, S., editors, Proceedings of the 32nd International Conference on Algorithmic Learning Theory, volume 132 of Proceedings of Machine Learning Research, pages 963–982. PMLR.
- Orabona, (2019) Orabona, F. (2019). A modern introduction to online learning.
- Ouhamma et al., (2021) Ouhamma, R., Maillard, O.-A., and Perchet, V. (2021). Stochastic online linear regression: the forward algorithm to replace ridge. In Neural Information Processing Systems.
- Ramdas et al., (2022) Ramdas, A., Grünwald, P., Vovk, V., and Shafer, G. (2022). Game-theoretic statistics and safe anytime-valid inference.
- Robbins et al., (1972) Robbins, H., Siegmund, D., et al. (1972). A class of stopping rules for testing parametric hypotheses. In Proceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, Volume 4: Biology and Health. The Regents of the University of California.
- Schölkopf et al., (2001) Schölkopf, B., Herbrich, R., and Smola, A. (2001). A generalized representer theorem. In Computational learning theory, pages 416–426. Springer.
- Srinivas et al., (2009) Srinivas, N., Krause, A., Kakade, S. M., and Seeger, M. W. (2009). Gaussian process optimization in the bandit setting: No regret and experimental design. In International Conference on Machine Learning.
- Ville, (1939) Ville, J.-L. (1939). Étude critique de la notion de collectif.
- Vovk, (2001) Vovk, V. (2001). Competitive on-line statistics. International Statistical Review, 69.
- Wainwright, (2019) Wainwright, M. J. (2019). High-dimensional statistics: A non-asymptotic viewpoint. Cambridge university press.
- Wald, (1945) Wald, A. (1945). Sequential tests of statistical hypotheses. Annals of Mathematical Statistics, 16:256–298.
- Wasserman et al., (2020) Wasserman, L. A., Ramdas, A., and Balakrishnan, S. (2020). Universal inference. Proceedings of the National Academy of Sciences, 117:16880 – 16890.
- Zhao et al., (2022) Zhao, H., Zhou, D., He, J., and Gu, Q. (2022). Bandit learning with general function classes: Heteroscedastic noise and variance-dependent regret bounds. ArXiv, abs/2202.13603.
Appendix A Proofs of Theorem 1 and 2
A.1 GLM Families
| Name | |||||
|---|---|---|---|---|---|
| Gaussian | |||||
| Poisson | |||||
| Binomial | |||||
| Weibull |
A.2 Proof of Theorem 1 (Coverage)
Proof.
Starting with
The second equality is due to the fact that only depends on through . Since is measurable by assumption, is a density, and if , the integral is equal to an exponential of the Rényi-divergence . The negativity of the exponent follows from and the non-negativity of the divergence. Note that in the "degenerate" case of , we can easily see that the integral is over a density (cancellation), and hence also bounded by . The last part of the statement follows easily by using Ville’s inequality for supermartingales. ∎
All the elements of the above proof appear in Wasserman et al., (2020) albeit separately, and not with time-varying powered robust likelihoods.
A.3 Proof of Theorem 2 (Bias)
We will need a gradient characterization of strong-convexity, which we prove in the following lemma.
Lemma 1 (Convexity: Gradient).
Defining
under the assumption and is -strongly convex, we have for any :
Proof.
We assume that is -strongly convex. Therefore, for any , we get the two inequalities
Adding these two together, we obtain
Observing that , we can equivalently write
This holds for any realization of , and hence taking expectations yields
Summing up over and using the definition of we get
∎
Notice that the estimator in Alg. 1 has to fulfil the KKT conditions. We will denote the condition for belonging to the set as , where is a squared and twice-differentiable norm (there are many choices beyond ). The KKT conditions are
| (12) | |||
where the second and third conditions represent a complementary slackness requirement. Notice that the system of these equations has a unique solution due to the strong-convexity of the objective, and has to attain a unique minimum on a compact convex subset of . Adding the same quantity on both sides of (12) yields
| (13) |
This line motivates the definition of the error-free estimator in (6), where is set to zero. We will also make use of a fundamental property of the score (gradient of log-likelihood), namely
| (14) |
A classical textbook reference for this is e.g. McCullagh, (2018) but any other classical statistics textbook should contain it. Using these observations, we can already prove Theorem 2.
Proof of Theorem 2.
Using the optimality conditions of , and , we obtain the following statements:
where in the last line we used the property (14). Now, notice that since we know is generating the data, the best possible explanation without enforcing the constraint and the regularization would be to set as the cross-entropy is minimized at this point, and the above is just the optimality condition for optimizing the cross-entropy between these two distribution. Of course, this is only in the absence of regularization or constraints i.e. . Now, with the regularization constraint, as the true lies inside the constraint , and both the regularization and constraints induce star-shaped sets, their effect is to make smaller in norm than . This holds generally for any which is a norm. As a consequence of this consideration, , and then the complementary slackness dictates that .
We can therefore proceed with this simplification. Let us use the shorthand and compute
| (15) |
It suffices to apply the Cauchy-Schwarz Inequality and invoke (15):
where in the last inequality we used , due to the regularizer, as explained above. ∎
GLM models
Appendix B Proof of Theorem 3 (Bregman Ball Confidence Set)
Proof sketch
We give a quick sketch of the proof. To bound the size of the sets, we will draw inspiration from the i.i.d. parameter estimation analysis of Wasserman et al., (2020) and separate out the likelihood ratio in a part that relates the true parameter with the estimator sequence (i.e. regret), and a part that is independent of the estimator and characterized by a supremum of a stochastic process. We want to show that any point which is far away from the true parameter will eventually not be included in the confidence set anymore. Defining as , we wish to show that for any far from , we have
which is equivalent to saying that . The second term corresponds to our notion of regret exactly (, as discussed above). The first term is what we will focus on. We will bound the supremum of for all sufficiently far away from . "Far away" will be measured in the Bregman divergence outlined above. Note that this quantity can be expected to be negative, in general, (especially for "implausible" parameters), since with enough data, should appear much more likely. Writing this ratio out, we will observe that it is equal to
At this point, it will be sufficient to bound the cross term (second term) over the whole of . We view this supremum as part of the Legendre Fenchel transform of the function :
and harness duality properties of the Bregman divergence, along with known concentration arguments (Chowdhury et al.,, 2022, Theorem A.1).
B.1 Technical Lemmas
We need to introduce the concept of Legendre functions:
Definition 1.
Let be a convex function and . Then, a function is called Legendre if it satisfies
-
1.
is non-empty.
-
2.
is differentiable and strictly convex on .
-
3.
for any sequence with for all and for some .
This means that the gradient has to blow up near the edge of the domain. Note as well that the boundary condition is vacuous if there is no boundary. Legendre functions have some nice properties, most importantly regarding the bijectivity of their gradients (see e.g. Lattimore and Szepesvári, (2020)):
Lemma 2.
For a Legendre function
-
1.
is a bijection between and with the inverse .
-
2.
for all .
-
3.
The Fenchel conjugate is also Legendre.
With this, we can prove a slightly extended result, that appears as Lemma 2.1. in Chowdhury et al., (2022).
Lemma 3.
For a Legendre function we have the identity
where we define .
Notational Shorthands
Remember the model (7), with log-partition function . We define and to denote the log-partition function and the response function of the same exponential family distribution, but parametrized by instead of . That this is a valid parametrization can easily be seen from the likelihood definition. Indeed, denote by the exponential family reward distribution with parameter . Then our model (7) can be seen to satisfy
Exponentiating the likelihood with a weighting gives rise to another exponential family distribution. We can see that
Note that this does not necessarily integrate to one, but it is easy to see that there is a normalization function that makes it integrate to one. Therefore, the following is a valid parametrization of an exponential family distribution:
Additionally, let be defined on (i.e. a Legendre Function). We will also define the estimator
This is a well-defined quantity because the gradient will be invertible, by Lemma 2 above.
Conveniently, Chowdhury et al., (2022) prove the following Theorem 7 using an elegant application of the method of mixtures.
Proposition 1 (Theorem 7 in Chowdhury et al., (2022)).
With probability , for all
where
Lastly, we will need the (one-argument) function
i.e. a shortcut for the Bregman divergence of at . We use this one-argument function as we will be interested in its dual. We will also need a lemma on the sub-homogeneity properties of this object.
Lemma 4.
Under Assumption 1, for and such that , we have for any
i.e. function is sub-homogeneous with contraction parameter on .
See Appendix B.3 for a proof.
B.2 Proof of Theorem 3
As mentioned in the main paper, our proof will show that all sufficiently far from will be excluded from eventually. Equation (B) in the main text specifies the exclusion criterion, i.e. if and only if
| (17) |
The second term is bounded by the regret of the online learner. And therefore, a sufficient condition for is
Henceforth, we will be interested in having an explicit set such that we can upper bound
| (18) |
This will imply that that , or in other words, . Without further ado, let us derive a more convenient form of the ratio in question
We can switch parametrizations as described above:
| (19) |
where we define .
is strictly convex whenever , and convex otherwise (it might also be strictly convex otherwise, corresponding to some cases where the span the full -dimensional Euclidean space and , which will be satisfied uniformly. We note that since , is, therefore, Legendre, and its gradient is invertible. We will relate our problem to this estimator via the duality properties developed above. First, note that by the well-known fact and by the definition of , we have
| (20) |
Now, we leverage the duality properties: We can write
| (21) |
where is simply the definition of the Legendre-Fenchel transform. Why did we do all this work? Well, we are interested in the supremum in Equation (18). It is sufficient to bound the supremum over all of terms of the form (see Equation (19))
While we could do a covering type argument (carefully relaxing the i.i.d. data assumptions typical in empirical process theory), it is much easier to relate this supremum to the estimator via duality.
With probability at least , Proposition 1 gives us a high-probability time-uniform bound on
and therefore, by plugging into Equation (21) and making the reparametrization for some positive , it gives us
Therefore, for all and all , the following holds:
Since , restricting our uniform bound over gives us :
Now, we note that under Assumption 1, Lemma 4 kicks in and we have for any and
| (22) |
Finally, we can use this in (19) to obtain
| (23) |
It remains to investigate the full likelihood ratio in (17):
| (24) |
Note that crucially for , we have
This is implied by
or, since , more compactly by
B.3 Proof of Technical Lemmas
First, we will prove Lemma 3. The proof exactly follows Chowdhury et al., (2022), we include it here for convenience because it is very short.
Proof.
By definition
Since is strictly convex and differentiable, first-order optimality conditions imply that the optimal satisfies ( is unconstrained). Since the gradient is invertible, we must have . If we plug this into the above, we have
∎
Now we prove Lemma 4. To this end, we will do a reduction to the one-dimensional case, and prove the one-dimensional result below.
Lemma 5.
Under Assumption 1, for any , any and any with
We prove that this implies the desired sublinearity of the full Bregman difference.
Proof.
(of Lemma 4). Let and be such that . We will first show that for any , is sublinear, and then the result follows by the linearity of the Bregman divergence. Define and . Then we have . Similarly we have . Hence we satisfy the premise of Lemma 5 and we deduce that
We also note that for ,
| (25) |
Therefore, by summing up the terms, we obtain
∎
Proof.
(Lemma 5) -Lipschitzness of implies smoothness of . Additionally, ’s existence implies strong convexity of . With this, we can write for any and with
Similarly,
Putting this together, we have
The question is therefore: when is ? Clearly, choosing makes for all . ∎
Appendix C FTRL Results: Proofs
C.1 Technical Lemmas I: Exponential Families
Lemma 6 (MGF for Exponential family).
Proof.
where the last step follows because the density of a new exponential family distribution with parameter also integrates to 1. ∎
C.2 Technical Lemmas II: Elliptical Potential Lemma
We will repeatedly use instantiations of the following key lemma, known as the elliptical potential lemma. We will use the version from Hazan et al., (2006). Other variants are stated in Abbasi-Yadkori et al., (2011) or Carpentier et al., (2020).
Lemma 7 (Lemma 11 in Hazan et al., (2006)).
Let be a sequence of vectors such that . Define . Then
We will also need a result where the time indices of the matrix are shifted. For this, note that if , then , and so we get . Under our conditions, it follows that
Corollary 1.
We have the following bounds:
and
Proof.
The first bound is trivial by instantiating . The second bound is by noting
∎
C.3 Technical Lemmas III: Supermartingales
Lemma 8 (Martingale Increment).
Proof.
First, using the form of the exponential family and and recalling that we obtain
which finishes the proof. The second statement follows by using -smoothness on the last equation and therefore noting that . ∎
Lemma 9.
(Sequential Mixing) Define the martingale process,
and recursively define the mixture martingale,
where is a probability distribution equal , , and . Then the following statements hold
-
•
is an adapted super-martingale with respect to the usual filtration.
-
•
.
where
Proof.
The first point follows from the fact that is deterministic conditioned on the sub--algebra (since makes use of but not ). Therefore, under mild regularity conditions
In other words, mixing does not affect the supermartingale properties. For the second point, we derive an explicit form of the mixture martingale. Note that we can write out
| (26) |
We can complete the square to obtain
The second term is the exponent of a exponent of a Gaussian integral with covariance , and therefore results in
Plugging this into (26) we get
By multiplying the individual steps, we can see that the determinant terms cancel in a telescoping product. This leads to the formulation
To conclude the proof, note that . ∎
Lemma 10.
Proof.
The statement, follows by applying Ville’s inequality for supermartingales, applying the logarithm, and rearranging. Namely,
∎
The following results allow us to upper bound the weighted regret by the unweighted regret:
Lemma 11 (Weighting Reduction).
Let be a sequence of vectors adapted to the filtration . Define
Then, is a non-negative super-martingale for any choice of adapted , and hence,
with probability for all .
Proof.
We have used here the definition of the Renyi-divergence and the fact that it is always non-negative, namely
for .222The case is trivial for us. The rest follows by the application of Ville’s inequality. ∎
C.4 FTRL Proof: the Unweighted Case
Proof of Theorem 4 (first part).
We define the function that FTRL minimizes in each step (to pick ) as, . We can rewrite this objective as
where we recall that333The term does not play any role in the regret nor the FTRL objective.
and we have introduced the shorthands
and
In essence, we have shifted some of the objective into what is commonly looked at as the regularizer. By a standard telescoping sum argument, we obtain for any
Now we use the strong-convexity of under the norm where ,
where in the second inequality we used that due to the first-order optimality conditions for convex constrained minimization. Lastly, we optimized the resulting quadratic function over (over ) to get a worst case bound involving the dual-norm.
Note that for the shorthands we defined above:
Using our previous observations and the definition of , we get for the overall regret:
The last line follows because of Lemma 7, and the second to last one follows because of Lemma 10. Notice that if we wish to deal with arbitrary weights , we can simply resort to Lemma 11 and bound the weighted case with the unweighted case. In that case, we incur an additional additive term. ∎
C.5 FTRL Analysis: the Weighted Case (Vovk-Azoury-Warmuth Forecaster)
Proof.
We define the function that FTRL minimizes in each step (to pick ) as with . We can rewrite this objective as
by introducing the shorthands
and (notice the difference in time index of the second sum when compared to the proof in the previous subsection):
In addition consider the objective from the classical FTRL analysis in Section C.4. It is not used to run the online algorithm, but is helpful in our analysis. With our new components, it is equal to
and its minimizer is . Also, consider a weighted version of the regularizer
which will be useful. We use a variant of a similar telescoping sum argument as in the previous proof of Section C.4. We specifically use as the comparator to compete against. Notice that we insert a telescoping sum involving the objective , which is not the objective that our estimator is minimizing:
In , we used the shorthands and definitions introduced above. In , we used the identity . Finally, for , recall that is the minimizer of , and hence, . Next, define . We will bound this term later.
Now, we use the strong-convexity of under the norm where , namely
We can then proceed as follows:
| (28) | |||||
where in the second to last line we used that for any , due to the optimality of for the FTRL objective. In the last line, we optimized over to get a worst-case bound on the quadratic function involving it. Also, note that for the shorthands we defined above:
Our goal here is to upper bound the overall regret:
| (29) | |||||
The first inequality follows by plugging in (28).
We return back to the term ,
| (30) |
where the second to last line is by the optimality of and the last one by the assumption in the theorem.
Carrying on with the analysis, i.e. with (29), we insert the definition of and obtain
In , we use and the Lipschitzness of . In , we use the definition of the weights. Finally, in (), we used Lemma 10 and (30). By substituting , we finish the proof. The event in Lemma 10 holds with probability , completing the proof. ∎
C.6 FTRL Analysis: Beyond Global Smoothness
In this subsection, we give alternative analysis which avoids the necessity to impose a global smoothness condition our likelihood; instead strong convexity within a bounded domain suffices, and we will only assume that
are sub-Exponential random variables, setting us apart from Zhao et al., (2022) which assume sub-Gaussianity. In particular, we can show the following theorem
Theorem 7.
With probability , uniformly over time , we have
where the universal constant hides all constants independent of and .
C.6.1 Lemmas
We state the following result on sub-Exponential random variables.
Proposition 2 (Theorem 2.13 in Wainwright, (2019)).
If is a centered sub-Exponential variable with some finite variance proxy, then there exist constants such that for any
By some careful union bounds (akin to a stitching argument), we can also provide upper bounds on anytime-valid upper bounds on the process .
Lemma 12.
For any sequence of sub-Exponential-variables, there exists a constant independent of such that
Proof.
(of Lemma 12) By Proposition 2, there exists such that we have for any fixed . Note that is satisfied for . Let us denote by the event all satisfy the inequality
For a single , this happens with probability at least . Therefore, by a union bound, as , we can bound the probability of the complement, namely . Now, by another union bound, we can conclude that
Now we also have for any in this range that and therefore, if holds, we have for any :
We can immediately see that this implies
as desired. ∎
C.6.2 Proof of Theorem 7
Our proof initially follows the FTRL regret bound proofs in the adversarial setting Hazan, (2016); Orabona, (2019). It also has overlap with the proof in Zhao et al., (2022). We define the function that FTRL minimizes in each step as (to pick )
for convenience. We initially use the same steps as in Theorem 4 to see that for any
Similarly to the proof of Theorem 4 in Appendix C.4 we bound these increments by the dual norm of the gradient of the objective.
| (31) |
Now we note that
Using properties of the exponential family, we deduce that
From here on out, we proceed more crudely than in our previous analyses, since we are only concerned with asymptotic behavior when and are large. Let us define
which is a model-dependent, deterministic quantity. Let us define the noise variables
We bound
Note that the are centered, independent sub-Exponential variables, and as such are guaranteed to satisfy
by Lemma 12. This tells us that conditional on this event, we can upper bound for any
for some constant independent of . By Lemma 7, there is thus a constant independent of and such that
with probability uniformly over .
Appendix D Regret Consequences for Stochastic Linear Bandits
As a corollary of our analysis, we provide the regret for stochastic linear bandits that use our confidence sets within the LinUCB algorithm.
Proof.
We proceed in two parts: first, we instantiate Theorem 3 and then we follow the classical regret analysis for stochastic linear bandits.
Specializing the Bregman divergence results
By Theorem 3, we know that for any , we have that with probability ,
| (32) |
for all , where and is the online convex optimization regret. We also recall that
In the Gaussian case, where . This implies that
where we have defined a weighted version of as and therefore the Bregman divergence is given by We can also see that the Bregman information gain is given by
These Gaussian integrals are straightforward to evaluate. We know that
Similarly,
Then, we can compute
In the unweighted case, with which we proceed, we have , that is we recover the classical upper bound on the information gain (Srinivas et al.,, 2009). To summarize, we have specialized the bound (32) to say that for any , we have (since )
Now, we instantiate the regret of the online learner using Theorem 4. With probability , uniformly over , we have
| (33) |
We get by chosing , and setting that
Linear bandit regret analysis
We are ready to proceed with the bandit analysis for the UCB Algorithm. We follow Lattimore and Szepesvári, (2020) and bound the pseudo-regret, letting be the optimal action. We bound the instantaneous regret at step as
The first inequality replaces by the upper confidence bound for action , which is valid with probability uniformly over time. Then, uses the fact that is chosen to maximize the upper confidence bound. Finally defines the UCB parameter . By Corollary 1, we have
Plugging all this together and using an -norm inequality, we get
To summarize and to justify why this bound holds with probability uniformly over time, note that we have bounded the probability of the FTRL bound (33) not holding for some by . Then, the probability of (32) not holding for some is at most . Finally, the anytime Type I error of our sets is also bounded by . A union bound therefore concludes the proof. ∎
D.1 Comparison to Abbasi-Yadkori et. al. (2011)
We compare our result to the one from Abbasi-Yadkori et al., (2011). Under the assumption that , they show that the regret satisfies
Observe that there is a reparametrization for the regularizer to get even more similar bounds. If we take for some , our bound reads as
Given that by Corollary 1, we have
we get almost matching bounds, up to an additional term blowing up the regret, which we attribute to the accumulation of bias without the reweighting scheme. The remaining differences are down to using slightly different versions of the elliptical potential lemma, trading off generality and tightness (Abbasi-Yadkori et al.,, 2011; Hazan et al.,, 2006; Lattimore and Szepesvári,, 2020).
Appendix E Experimental Details
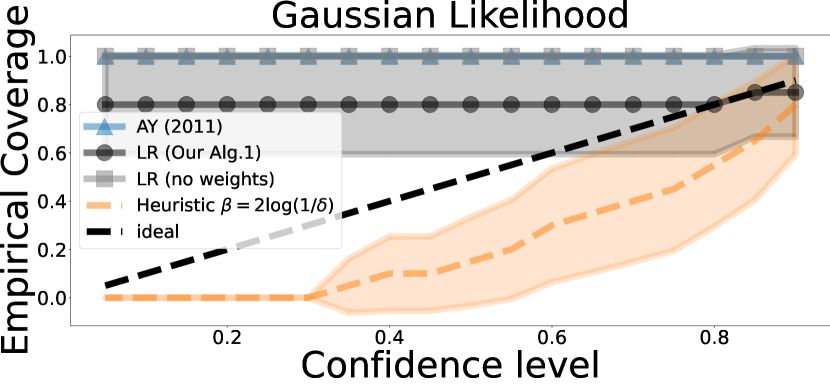
E.1 Calibration Plots
In Figure 3 we report the calibration of heuristics as well as other theoretically motivated works. The other theoretically motivated works are very pessimistic and are not appropriately calibrated. Note that one caveat of reporting calibration is that it is very much influenced by the data collection scheme in the sequential regime. In our case we use a bandit algorithm to collect the data. Arguably, in this setting, regret might be a better measure rather than looking at the calibration of the confidence sets. Additionally, the calibration depends on the true value . We report the results for zero parameter and a random parameter from a unit ball. We also report results for i.i.d. data.







E.2 Baselines and Details
In the following section, we describe the baseline we used in the comparison. The details of parameters used in the experiments can be found in Table 2. As there is no explicit statement for sub-exponential variables, we give a formal derivation in Appendix F.
E.2.1 Sub-Exponential Random Variables: Confidence Sets
For this baseline, we will assume a linear model with additive sub-exponential noise, namely that there is such that , where is -conditionally sub-exponential (Wainwright,, 2019). We let as usual
With this, one can prove the following time-uniform concentration result:
Proposition 3.
For any , the following holds:
where
E.2.2 Poisson Heuristics
We implement two heuristics. One is a Bayesian formulation due to the Laplace method, and one is due to considerations in Mutný and Krause, (2021) of how to construct a valid confidence set using the Fisher information. The Laplace method creates an ellipsoidal confidence set using the second-order information evaluated at the penalized maximum likelihood estimator. Namely, the second derivative of the likelihood evaluated at the maximum penalized likelihood is
We use this to define ellipsoidal confidence sets as . The other heuristic suggests using the worst-case parameter instead, namely
This method would have provable coverage with a proper confidence parameter. Its derivation is beyond the scope of this paper.
E.2.3 NR (2021)
This method follows from Neiswanger and Ramdas, (2021). Per se, this method was not developed to be versatile in terms of likelihood but instead provides a confidence set on , even if it originates from a misspecified prior. Nevertheless, it provides a likelihood-aware confidence sequence that is anytime-valid and doesn’t employ worst-case parameters, and hence is a good benchmark for our analysis. The confidence sets are of the form
where is the current log-evidence of the data given the Gaussian prior. For more information, see Neiswanger and Ramdas, (2021).
| Benchmark function | dim | Gaussian/Laplace / | ||||
|---|---|---|---|---|---|---|
| 1D | 1 | 0.06 | 4 | 1 | 0.15 | |
| Camelback | 2 | 0.2 | 2 | 1 | 0.10 |
E.3 Additive Models
We implemented two likelihoods, namely Gaussian and Laplace. We implemented the discretization of the domain , and in the implementation we used Nystrom features defined on providing the exact representation of the RKHS on the , The points were chosen to be on a uniform grid. Notice that for the regularized estimator, we chose the rule of thumb as is motivated in (Mutný and Krause,, 2022).
The laplace parameter was picked as likewise. Note that Laplace distribution is sub-exponential with parameters . We use or respectively for the value . Strictly speaking, the Laplace likelihood is not smooth, but a smoothed objective would most likely inherit a value depending on . As we maintain coverage with any choice of weighting, we do not risk invalidity by using a heuristic choice for .
E.4 Survival Analysis
We implemented the method exactly as specified, using the Weibull likelihood with parameter . Upon log-transformation, the Gumbel distribution is sub-exponential. To determine the parameter, consider the moment-generating function of the Gumbel distribution ( in the canonical parameterization):
hence, the sub-exponentiality parameter is , and we can use the above sub-exponential confidence sets with value . For the likelihood ratio code, we used , as this is the leading term of the Hessian of log-likelihood. The function is not smooth everywhere, but on a bounded domain, this turns out to be an appropriate scaling.
E.5 Poisson Bandits
In this case, we implemented a bandit game, where we used the parametrization , where is the RKHS evaluation operator, and is the unknown value.
We used , as this is the leading term of the Hessian of log-likelihood in this parametrization. The function is not smooth everywhere but on a bounded domain this is an appropriate scaling.
E.6 Additional Benchmark Functions
We focus on an additional baseline function: Camelback in 2D, a standard BO benchmark function. The results can be see in Figure 4.

Appendix F Proof of Proposition 3
Define and the shorthand
and the parametrized process
Lemma 13.
If is -conditionally sub-Exponential, then is a super-martingale on the ball with
Note that for (sub-Gaussian case), this recovers Lemma 20.2. in Lattimore and Szepesvári, (2020).
Proof.
It is easy to observe that for any , we have
For the first part, we can write
where in the last step we use that is -measurable. Now, as long as , we can apply our definition of conditional sub-Exponential noise to bound
From this we directly conclude
By Cauchy-Schwarz, a sufficient condition is as this implies (with our assumptions on the actions)
∎
In the following, will use this result to prove any-time confidence estimates for the parameter using the technique of pseudo-maximization, closely following Mutný and Krause, (2021).
Recall that is defined on the ball of radius . This allows us some freedom in choosing the radius of the ball on which we integrate. In particular, let be this radius. While we need , we can make larger by choosing larger (increasing only makes the set of noise distributions larger).
Ultimately, we wish to bound (following Lattimore and Szepesvári, (2020))
We can not control the second term, so we focus on the first: the self-normalized residuals. Via fenchel duality, one can motivate that the right object to study is the supremum of the martingale over all .444But that is in our case ill-defined. Define to be the martingale from above but with , i.e. no regularisation term. Similarly, let be the design matrix without the regularisation term. Slightly counterintuitively, we will study
where is the probability density function of a truncated normal distribution with inverse variance , that is with covariance matrix . By Lemma 20.3 in Lattimore and Szepesvári, (2020), is also a super-martingale with . Then we have
We will define the shorthand (by Taylor’s theorem), where , will be chosen later. We can lower bound by
| (34) | ||||
| (35) | ||||
| (36) | ||||
where in step (34) we used the change of variables . In (35) we use that if , then . Finally, in (36), we used Jensen’s inequality. The last inequality follows from symmetry. Note that we implicitly defined to be a truncated normal distribution with covariance matrix on the ball of radius .
This puts us in a position to put Ville’s inequality to good use:
We now wish to recover . Recall the definition of as the maximum over all in a ball of radius . Consequently, we can choose , which has norm bounded by . We have
which immediately yields
The only thing that remains is bounding .
We give the following Lemma that is a slightly generalized version of Mutný and Krause, (2021) and originally inspired by Faury et al., (2020).
Lemma 14.
The normalizing constants satisfy
We can use the bound from Lemma 14 to conclude that
We may now choose the parameters , and . Note that to get sub-Gaussian rates as in Abbasi-Yadkori, one needs to pick a regularization parameter of the order of .
Proof of Lemma 14
We give a proof of the Lemma for completeness, and because the additional generality makes for a slightly different proof, even though the bound stays the same.
Proof.
We have
Further we have
where . Note that and so . Therefore if , we have
Thus and
We may therefore bound
By a rather crude bound (as in any case) we get
We can put this together to obtain
∎