LiFi: Towards Linguistically Informed Frame Interpolation
Abstract
In this work, we explore a new problem of frame interpolation for speech videos. Such content today forms the major form of online communication. We try to solve this problem by using several deep learning video generation algorithms to generate the missing frames. We provide examples where computer vision models despite showing high performance on conventional non-linguistic metrics fail to accurately produce faithful interpolation of speech videos. With this motivation, we provide a new set of linguistically-informed metrics specifically targeted to the problem of speech videos interpolation. We also release several datasets to test computer vision video generation models of their speech understanding.
1 Introduction
Video frame interpolation and extrapolation is the task of synthesizing new video frames conditioned on the context of a given video [1]. Contemporary applications of such interpolation are video playback software for increasing frame rates, video editing software for creating slow motion effects, and virtual reality software to decrease resource usage. From the early per-pixel phase-based shifting approaches such as by [2], current approaches have shifted to generating video frames using techniques like optical flow or stereo methods [1, 3]. These types of approaches typically involve two steps: motion estimation and pixel synthesis. While motion estimation is needed to understand the movement of different objects of the images across frames, pixel synthesis focuses on the generation of the new data.
A related task to video frame interpolation is talking face generation. Here, given an audio waveform, the task is to automatically synthesize a talking face [4, 5]. In recent times, these approaches have become popular with both academic and non-academic purposes [6]. While, on one hand, they are being used to extend speechreading models to low resource languages [7], on the other, many of them are also used to generate fake news and paid content as well.
The literature on talking face generation, as well as video interpolation and extrapolation use the conventional video quality metrics such as root mean squared (RMS) distance, structural similarity index, etc. to measure the quality of generated videos [8]. Although this evaluates the quality of generated pixels well, but none of the research works show how it translates to linguistically plausible video frames. This is important since speech being a linguistic problem,f cannot be solely addressed by non-linguistic metrics like RMS distance. The goal of this paper is to investigate how the different video interpolation and extrapolation algorithms are able to capture linguistic differences between the generated videos.
Speech as a natural signal is composed of three parts [9]: visual modality, audio modality and the context in which it was spoken (crudely the role played by language). Correspondingly, there are three tasks for modeling speech: speech-reading (or popularly known as lipreading) [7, 10], speech recognition (or ASR) [11] and language modeling [12]. The part of speech which is closest to the speech video generation task is the visual modality of speech; and visemes are the fundamental units of this part of speech. Calculating metrics such as mean squared error (MSE) over the whole video does not directly yield any information on these aspects of speech which makes us question the faithfulness of the thus attained reconstruction. Therefore, the focus of this work is to investigate video generation model’s understanding of the visual speech modality. To this end, we propose six tasks for looking at different aspects of the visual speech modality.
Hence, with this work, we try to make the following contributions:
1. We explore different video interpolation and extrapolation networks for usage on speechreading videos and propose a new auxiliary method of ROI loss using an visemic ROI unit for attaining faithful reconstructions.
2. For the first time in literature, we test the video frame generation algorithms on different aspects of speech such as visemic completion, generating prefix and suffix from context, word-level understanding, etc. These facets of language are critical to a model’s language understanding. We show that most of these networks are not able to capture the language aspect of a speech video.
3. We release six new challenge datasets corresponding to different language aspects. These have been verified automatically and manually and are meant to facilitate reproduction and follow-up testing and interpretation.
| Viseme | FCN3D | LSTM | FCN3D | Super |
|---|---|---|---|---|
| (ROI) | SloMo | |||
| Viseme Corruption | ||||
| @ | 0.8974 | 0.7489 | 0.9086 | 0.9660 |
| a | 0.8838 | 0.7410 | 0.9152 | 0.9566 |
| E | 0.8902 | 0.7425 | 0.9231 | 0.9656 |
| f | 0.8922 | 0.7465 | 0.9197 | 0.9617 |
| i | 0.8923 | 0.7387 | 0.9239 | 0.9761 |
| k | 0.8910 | 0.7434 | 0.9242 | 0.9684 |
| O | 0.9059 | 0.7513 | 0.9213 | 0.9558 |
| p | 0.8921 | 0.7415 | 0.9256 | 0.9715 |
| r | 0.8998 | 0.7446 | 0.9255 | 0.9731 |
| s | 0.8920 | 0.7497 | 0.9238 | 0.9662 |
| S | 0.8829 | 0.7398 | 0.9237 | 0.9556 |
| t | 0.8945 | 0.7443 | 0.9268 | 0.9702 |
| T | 0.9087 | 0.7436 | 0.9185 | 0.9771 |
| u | 0.8918 | 0.7503 | 0.8936 | 0.9395 |
| Model | SSIM | PSNR | SSIM | PSNR |
| Corruption | 40% | 75% | ||
| Random Corruption | ||||
| FCN3D | 0.9271 | 23.7161 | 0.8554 | 21.8354 |
| BDLSTM | 0.8119 | 21.6103 | 0.8199 | 22.3904 |
| FCN3D + ROI | 0.9326 | 28.3123 | 0.8654 | 24.7521 |
| Super SloMo | 0.9849 | 30.3459 | 0.9603 | 28.2660 |
| Prefix Corruption | ||||
| FCN3D | 0.7680 | 18.4513 | 0.5230 | 14.7208 |
| BDLSTM | 0.8119 | 21.6103 | 0.6288 | 17.6097 |
| FCN3D + ROI | 0.7721 | 19.6718 | 0.5208 | 15.3935 |
| Super SloMo | 0.8411 | 23.1864 | 0.7387 | 20.8218 |
| Suffix Corruption | ||||
| FCN3D | 0.7816 | 18.7518 | 0.5301 | 14.8344 |
| BDLSTM | 0.7682 | 20.4863 | 0.6281 | 17.8500 |
| FCN3D + ROI | 0.7774 | 19.7790 | 0.5161 | 15.3414 |
| Super SloMo | 0.8140 | 22.4334 | 0.6952 | 19.8319 |
2 Evaluation Methods
Most of the previous research on speech video reconstruction and interpolation focuses on conventional metrics like MSE, SSIM and PSNR, which although ensure good quality reconstructions [13, 3], can be misleading in terms of the nuances of the underlying dataset. Videos of the same person saying two different things can have fairly high values of the mentioned metrics thus indicating faithful reconstruction, which makes the evaluation difficult (Figures 1, 2)111We provide two examples in the Figures 1 and 2 and a few more in the Figure 5 in the Appendix.. We propose the following evaluation methods and corresponding datasets 222We make the datasets available at https://sites.google.com/view/yaman-kumar/speech-and-language/linguistically-informed-lrs-3-dataset. Training scripts for the models in Section 3.2 are available at https://github.com/midas-research/linguistically-informed-frame-interpolation/ (Table 3) for the speech videos to take into account the underlying language and speech information.
| Corruption Types | # Sp | # Ut | # WI | Vo |
|---|---|---|---|---|
| RandomFrame and | 4,004 | 31,982 | 356,940 | 17,545 |
| Extreme Sparsity | ||||
| Visemic | 2,883 | 6,152 | 338,207 | 16,663 |
| InterWord | 3,008 | 10,421 | 141,850 | 12,621 |
| IntraWord | 2,756 | 10,360 | 141,296 | 11,824 |
| Prefix and Suffix | 4,004 | 31,982 | 356,940 | 17,545 |
| POS Tagged Corruptions | 4,004 | 31,982 | 356,940 | 17,545 |
1. RandomFrame:
In this type of frame corruption, the frames at random timestamps are replaced with white noise. In a real scenario, the missing frames are dropped however the indices of the dropped frames are generally available [14]. To indicate the missing frames, we insert white noise images in their place. We do this type of corruption in two settings: 40% and 75% corruption rate. We call the 75% case as one with the extreme sparsity. A model that can work in such conditions can deal with extremely sparse speech videos and high dropping rates. Random corruption tests if the model effectively interpolates between different poses, facial expressions and probable word completions.
2. Visemic Corruption:
A viseme is a specific facial image corresponding to a particular sound [9]. In this type of corruption, we choose visemically equivalent sub-words in two or more words and corrupt the first viseme within the subword. For example, consider the words ‘million’ and ‘billion’, both are visemically equivalent. We corrupt the first common viseme - ‘p’ and show the results for such corruption in Table 5. The dataset also includes the cases where the visemic equivalence does not occur at the start of the word. For example, the first common viseme which is corrupted is ‘@’, in ‘Probably’ and ‘Possibly’, when the phonetic phrase “ebli” is spoken in both. The timestamps of specific phonemes are obtained through the Montreal Forced Aligner [15]. After that, the phonemes were converted to visemes. Through this type of corruption, we test the model’s knowledge of specific visemes given the context. We list the SSIM metrics after reconstructing each viseme is detailed in Table 8 of the Appendix.
3. InterWord and IntraWord Corruptions:
In this type of corruption, we corrupt 80% of approximately 20,000 unigram and bigram combinations. Corruption was done such that for a particular gram, 10% each of the prefix and suffix of the overall gram remains in the original state after the corruption. For example, consider the bigram ‘United States’, the corruption of this bigram results in ‘Un*********es’. A model that works well on such corruptions understands the context of the words well and is robust to corruptions during the transition from one word to another.
4. Prefix Completion:
For this corruption, we remove the start frames of a video. We do this for two levels of corruptions- a low level, 40% and a high level corruption (75%).
5. Suffix Completion:
Similar to the Prefix Completion test, we corrupt the ending frames from the sequence of input, which is also performed for 40% and 75% corruption. These two tests make sure that the model understands both the word start and word end and is not biased towards either. While predicting word start requires context from the previous word and the remaining part of the word, predicting the end of the word requires context from the prefix and the next word.
6. POS Tagged Corruptions: In this type of corruption, we identify nouns, pronouns, verbs, adjectives and determinants using Spacy’s English language POS tagger333https://spacy.io/api/tagger/. The corresponding timestamps for all such tagged words were obtained through MFA. Following this, we decided to corrupt these words for further study. For example, in a video from LRS3, the speaker says ‘The short answer to the question is that no, it’s not the same thing’. The POS tagger identifies the three words ‘answer’, ‘question’ and ‘thing’ as nouns. Thus all of the frames belonging to these three words were corrupted while inducing corruptions to nouns.
By introducing such corruptions, we test how well do the models understand semantic features of the language spoken. For example, for a particular model proper nouns may be more difficult to predict than pronouns. This test helps to bring such nuances into forefront.
3 Approach
 |
 |
| MSE: 0.0093898 PSNR: 20.273426 SSIM: 0.6174879 |
 |
 |
| MSE: 0.0088 PSNR: 20.5415 SSIM: 0.9521 |
| Metrics | Pretrain | Trainval | Test |
|---|---|---|---|
| # Speakers | 5091 | 4005 | 413 |
| # Utterances | 118,516 | 31,982 | 1321 |
| # Word instances | 3,894,800 | 807,375 | 9890 |
| Vocab | 51,211 | 17,546 | 2002 |
3.1 Dataset
We choose LRS3 dataset [16] for testing out the speech video frame generation models and making the six challenge sets as described in the last section. We chose LRS3 for this task since it has a high variety of speakers (5091), number of utterances (118k) and has longer average speech length. Other datasets are generally much less diverse both in terms of speakers and number and length of videos [17, 18]. In LRS3, the standard frame rates are 24, 30 and 60 fps. Therefore, we choose a standard frame rate of 32 to train our models and pad it with random noise. We train and evaluate our models using the LRS3 dataset with slight modifications, as explained in Table 4. We evaluate the models’ generated videos on MSE, SSIM and PSNR metrics [3].
| Corrupt Input | Ground Truth | Generated |
|---|---|---|
 |
 |
 |
 |
 |
| Model | SSIM | PSNR |
|---|---|---|
| Viseme Corruption for Viseme | ||
| FCN3D | 0.8385 | 18.5201 |
| BDLSTM | 0.7269 | 17.2827 |
| FCN3D + ROI | 0.9106 | 26.5401 |
| Super SloMo | 0.9129 | 25.2605 |
| Word Level Corruption | ||
| FCN3D | 0.8109 | 18.4554 |
| BDLSTM | 0.7411 | 18.066 |
| FCN3D + ROI | 0.8804 | 25.3279 |
| Super SloMo | 0.8800 | 24.5971 |
| Multi Word Corruption | ||
| FCN3D | 0.8064 | 19.6111 |
| BDLSTM | 0.7411 | 18.0665 |
| FCN3D + ROI | 0.8308 | 23.1354 |
| Super SloMo | 0.8481 | 23.8295 |
3.2 Models
We perform the tests on 4 different models. We perform the baseline tests on standard methods comprising of Convolutional Bi-Directional LSTM (BDLSTM) and Fully Convolutional Neural Network consisting of 3D convolutions (FCN3D). Further, we compare them with the proposed 3D Fully Convolutional Network with ROI unit. FCN3D have been heavily used in 3D image synthesis based tasks such as [13] while convolutional BDLSTM has been used for sequential image synthesis [19]. For the FCN3D model, we select a 3D Denoising auto-encoder based approach which has been known to be robust for video and 3D image synthesis related tasks [20, 21]. We also compare the results with NVIDIAs Super-Slo-Mo model [3] which is a state of the art method for interpolating frames with suitable modifications for the test suite.
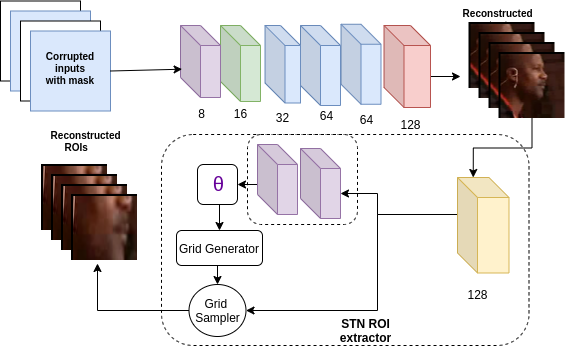
In this approach, we take a set of noisy frames as input and generate the denoised frames and train the network as a denoising autoencoder [22]. The network is expected to learn interpolations based on the available frames in the video sequence without any additional information. We test the model on two different percentages of corruptions and show the results for sparse reconstruction in the Figure 3. The network is trained with the corrupted frames with the original frames as the output. We tried for two kinds of losses, L1 and L2, since L2 is well known to produce blurring we define the reconstruction loss in equation 1.
| (1) |
where is the corrupted input image for an image in the set of images . The network learns to interpolate the missing frames based on the available set of uncorrupted frames.
3.2.1 Region of Interest (ROI) Unit
We noticed that all the models described before and their losses pay attention to images as a whole, where as, the speech videos have an important component in the form of visemes. Since there are no viseme centric losses in the conventional approaches, thus they largely are governed by other aspects of the images and not the visemes. To counter this problem, we propose an ROI loss which is calculated by computing the reconstruction loss computed between the ROI, i.e., the mouth region of the reconstructed output and ground truth. The mouth region is extracted using the facial landmarks obtained by the Blaze package [23].
From the facial landmarks, we extract the mouth region as a proxy for viseme for a particular frame and then compute the L1 loss between the mouth region extracted for the ground truth and the generated videos. This loss helps us understand the discrepancy that might arise when reconstruction is trained for full-frame instead of being trained on specific aspects like viseme for speech video reconstruction.
Further we introduce a new unit for extracting ROI from the reconstructed frames (as shown in the Figure 4). During the experiments we noticed that the the ROI extraction is performed best from the last three output channels. The ROI extraction unit consists of 2 convolutional layers and a spatial transformer layer proposed by [24]. They key idea is that the convolutional layers learn to focus on the ROI while the STN learns to extract only the mouth region. We show that the FCN3D model shows a much greater boost in terms of metrics for even sequential tasks such as prefix and suffix corruptions, coming close to the performance of that of bi-directional LSTMs for sequential reconstructions.
The ROI loss can be defined as:
| (2) |
where are the ground truth ROI features extracted from the frames and is the ROI stream of the architecture.
Thus the total loss during training is
| (3) |
However, for computing metrics we take into account only the reconstructed frames since ROI loss is only an auxiliary for frame reconstruction.
4 Results and Discussion
In this section, we present the experimental results for the models given in the Section 3.2 on the tests explained in the Section 2. Results of the test suite are given in the Table 2. We notice that for random corruption, though fully convolutional models beat bi-directional LSTM for low levels of noise, the bi-directional LSTMs gives a much better performance for longer sequential frame reconstructions. We see that the ROI extraction unit helps boost the performance of the FCN model. The ROI stream network helps attain a better PSNR and SSIM comparable with LSTM. This can be attributed to the model’s ability to focus more on visemes indirectly by learning a better reconstruction of the ROI for speech videos. The secondary stream is a very shallow network consisting of two convolutions and a spatial transformer which helps extract the mouth ROI from the already generated output. Thus, ROI loss further helps the network learn more about the visemic structure of the reconstruction and help attain better scores on the metrics.
We also show a quantitative comparison with Super SloMo [3]. Since Super SloMo only allows for the prediction of the contiguous frame we had to significantly modify the experimental setup to make any comparisons with it. The architecture did not allow the first and last frame of the batch from being corrupted. Therefore, though the quantitative results are the best for it, Super-Slomo suffers from severe experimental restrictions unlike the other models presented. In the case of continuous corruption, it will require the start and the end frames to reconstruct the intermediate ones, hence it is difficult to implement it in real time while taking into account the random nature of the noise/corruption.
If we look at the results on viseme and word-level datasets (Table 5), it can be seen that FCN3D with ROI outperforms SuperSlomo in terms of SSIM in word level corruption and PSNR for Viseme corruption attaining a PSNR of 26.54 against 25.2605 by Super SloMo. This is due to the smaller duration of corruption in these datasets as compared to those in Table 2. This is also likely to be the practical corruption distribution for realtime speech video streaming where networks like Super SloMo cannot function since they generate frames for only third time step between and (one of which may not exist). The proposed models are not restricted by this limitation and for the speech videos, capture a longer temporal context (not just the frames at timestamps and ) besides focusing on the mouth region using the ROI unit. As evident from Table 2 for random corruption FCN3D+ROI gives a high PSNR value of 24.75 beating BDLSTM and coming in close with Super SloMo with a PSNR value of 28.26, while LSTM outperforms FCN3D+ROI for prefix and suffix corruptions however with a smaller difference of 2.21, while Super SloMo outperforms both with a higher margin due to its ability to incorporate optical flow. This highlights a key limitation of such methods for speech video interpolation tasks due to their inability to capture context also reinforcing the need for a better test suite for a more faithful evaluation of speech video interpolation.
5 Conclusion
In this papaer, we demonstrate the necessity of a comprehensive linguistically-informed test suite that encompasses all the major aspects of speech in the task of speech video interpolation and reconstruction. We release six challenge datasets for this purpose. We also compare several different contemporary deep learning models for the different tasks proposed. We show the importance of incorporating visemic loss and provide a natural proxy to judge the visemic nature of reconstruction. In the future, we would like to cover more such linguistic aspects of speech. A parallel task would also be to take the audio-modality into account while reconstructing the corrupted and missing frames in video interpolation.
References
- [1] Z. Liu, R. A. Yeh, X. Tang, Y. Liu, and A. Agarwala, “Video frame synthesis using deep voxel flow,” in 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 4473–4481.
- [2] Simone Meyer, Oliver Wang, Henning Zimmer, Max Grosse, and Alexander Sorkine-Hornung, “Phase-based frame interpolation for video,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1410–1418.
- [3] Huaizu Jiang, Deqing Sun, Varun Jampani, Ming-Hsuan Yang, Erik Learned-Miller, and Jan Kautz, “Super slomo: High quality estimation of multiple intermediate frames for video interpolation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 9000–9008.
- [4] Rithesh Kumar, Jose Sotelo, Kundan Kumar, Alexandre de Brébisson, and Yoshua Bengio, “Obamanet: Photo-realistic lip-sync from text,” arXiv preprint arXiv:1801.01442, 2017.
- [5] Lele Chen, Zhiheng Li, Ross K Maddox, Zhiyao Duan, and Chenliang Xu, “Lip movements generation at a glance,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 520–535.
- [6] Olivia Solon, “The future of fake news: don’t believe everything you read, see or hear,” urlhttps://www.theguardian.com/technology/2017/jul/26/fake-news-obama-video-trump-face2face-doctored-content, 2017.
- [7] Yaman Kumar, Dhruva Sahrawat, Shubham Maheshwari, Debanjan Mahata, Amanda Stent, Yifang Yin, Rajiv Ratn Shah, and Roger Zimmermann, “Harnessing gans for zero-shot learning of new classes in visual speech recognition.,” in AAAI, 2020, pp. 2645–2652.
- [8] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004.
- [9] Dominic W Massaro and Jeffry A Simpson, Speech perception by ear and eye: A paradigm for psychological inquiry, Psychology Press, 2014.
- [10] Joon Son Chung and Andrew Zisserman, “Lip reading in the wild,” in Asian Conference on Computer Vision. Springer, 2016, pp. 87–103.
- [11] Dong Yu and Li Deng, AUTOMATIC SPEECH RECOGNITION., Springer, 2016.
- [12] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems, 2013, pp. 3111–3119.
- [13] Jelmer M Wolterink, Anna M Dinkla, Mark HF Savenije, Peter R Seevinck, Cornelis AT van den Berg, and Ivana Išgum, “Deep mr to ct synthesis using unpaired data,” in International workshop on simulation and synthesis in medical imaging. Springer, 2017, pp. 14–23.
- [14] Lawrence A Rowe, Ketan D Mayer-Patel, Brian C Smith, and Kim Liu, “Mpeg video in software: Representation, transmission, and playback,” in High-Speed Networking and Multimedia Computing. International Society for Optics and Photonics, 1994, vol. 2188, pp. 134–144.
- [15] Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger, “Montreal forced aligner: Trainable text-speech alignment using kaldi.,” in Interspeech, 2017, vol. 2017, pp. 498–502.
- [16] Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman, “Lrs3-ted: a large-scale dataset for visual speech recognition,” arXiv preprint arXiv:1809.00496, 2018.
- [17] Iryna Anina, Ziheng Zhou, Guoying Zhao, and Matti Pietikäinen, “Ouluvs2: A multi-view audiovisual database for non-rigid mouth motion analysis,” in 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). IEEE, 2015, vol. 1, pp. 1–5.
- [18] Shuang Yang, Yuanhang Zhang, Dalu Feng, Mingmin Yang, Chenhao Wang, Jingyun Xiao, Keyu Long, Shiguang Shan, and Xilin Chen, “Lrw-1000: A naturally-distributed large-scale benchmark for lip reading in the wild,” in 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019). IEEE, 2019, pp. 1–8.
- [19] Xiaoyu Xiang, Yapeng Tian, Yulun Zhang, Yun Fu, Jan P. Allebach, and Chenliang Xu, “Zooming slow-mo: Fast and accurate one-stage space-time video super-resolution,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020, pp. 3370–3379.
- [20] Chenyu You, Qingsong Yang, Hongming Shan, Lars Gjesteby, Guang Li, Shenghong Ju, Zhuiyang Zhang, Zhen Zhao, Yi Zhang, Wenxiang Cong, et al., “Structurally-sensitive multi-scale deep neural network for low-dose ct denoising,” IEEE Access, vol. 6, pp. 41839–41855, 2018.
- [21] John T Guibas, Tejpal S Virdi, and Peter S Li, “Synthetic medical images from dual generative adversarial networks,” arXiv preprint arXiv:1709.01872, 2017.
- [22] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol, “Extracting and composing robust features with denoising autoencoders,” in Proceedings of the 25th international conference on Machine learning, 2008, pp. 1096–1103.
- [23] Valentin Bazarevsky, Yury Kartynnik, Andrey Vakunov, Karthik Raveendran, and Matthias Grundmann, “Blazeface: Sub-millisecond neural face detection on mobile gpus,” 2019.
- [24] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al., “Spatial transformer networks,” in Advances in neural information processing systems, 2015, pp. 2017–2025.
6 Appendix
| Model | Corruption (%) | MSE | L1 | SSIM | PSNR |
|---|---|---|---|---|---|
| Random Corruption | |||||
| FCN3D | 75 | 0.008719796199 | 0.05576719156 | 0.7754931869 | 20.78947158 |
| BDLSTM | 75 | 0.00585898655 | 0.03845565588 | 0.8575272247 | 23.27513855 |
| FCN3D + ROI | 75 | 0.0042412771 | 0.03334277668 | 0.8654025606 | 24.75212616 |
| Super SloMo | 75 | 0.0032095665 | 0.01857670849 | 0.9603758130 | 28.26607934 |
| FCN3D | 40 | 0.004914738255 | 0.03917299796 | 0.8867508521 | 23.30322587 |
| BDLSTM | 40 | 0.004940670419 | 0.03570744986 | 0.8905155776 | 24.38299802 |
| FCN3D + ROI | 40 | 0.001789543358 | 0.02319063034 | 0.9326486659 | 28.31231905 |
| Super SloMo | 40 | 0.001827087549 | 0.01178585826 | 0.9849396967 | 30.34593392 |
| Prefix Corruption | |||||
| FCN3D | 75 | 0.03761557525 | 0.1411872019 | 0.4735313937 | 14.27897795 |
| BDLSTM | 75 | 0.01357646521 | 0.06795089568 | 0.6898999835 | 19.08365961 |
| FCN3D + ROI | 75 | 0.03076031727 | 0.1183280068 | 0.5208106449 | 15.39350073 |
| Super SloMo | 75 | 0.01147114887 | 0.0528111567 | 0.7387903618 | 20.82188895 |
| FCN3D | 40 | 0.0176491743 | 0.08077385376 | 0.7199462504 | 17.5958132 |
| BDLSTM | 40 | 0.007748413963 | 0.0462029091 | 0.8265586414 | 21.73186513 |
| FCN3D + ROI | 40 | 0.01163159572 | 0.05775547531 | 0.7721097014 | 19.67188354 |
| Super SloMo | 40 | 0.00629138803 | 0.03642695826 | 0.8411455717 | 23.1864927 |
| Suffix Corruption | |||||
| FCN3D | 75 | 0.036539371 | 0.1388430108 | 0.48635537 | 14.39668367 |
| BDLSTM | 75 | 0.01277490123 | 0.06604159133 | 0.6951813442 | 19.21521863 |
| FCN3D + ROI | 75 | 0.03108713292 | 0.1189973814 | 0.5161932313 | 15.34146382 |
| Super SloMo | 75 | 0.01606990903 | 0.0645460370 | 0.6952581282 | 19.83196098 |
| FCN3D | 40 | 0.01651665661 | 0.07831238874 | 0.7360948577 | 17.85544448 |
| BDLSTM | 40 | 0.006905819333 | 0.04328332246 | 0.8464001736 | 22.30525472 |
| FCN3D + ROI | 40 | 0.01134652429 | 0.05662384959 | 0.777493871 | 19.77901635 |
| Super SloMo | 40 | 0.01155048322 | 0.04815621729 | 0.8140604513 | 22.4334380 |
| Metrics | Train | Eval | Test |
|---|---|---|---|
| # Speakers | 5091 | 4005 | 413 |
| # Utterances | 118,516 | 31,982 | 1321 |
| # Word instances | 3,894,800 | 807,375 | 9890 |
| Vocab | 51,211 | 17,546 | 2002 |
| Avg. Video Length | XXX | XXX | XXX |
 |
 |
| MSE: 0.01086 |
| PSNR: 19.64074 |
| SSIM: 0.7619643 |
| Model | MSE | L1 | SSIM | PSNR |
| Viseme Corruption | ||||
| FCN3D | 0.01460618444 | 0.0568077997 | 0.83858460187 | 18.52015423 |
| BDLSTM | 0.02084208424 | 0.0828854019 | 0.72696408065 | 17.28277912 |
| FCN3D + ROI | 0.00229573487 | 0.0268876856 | 0.91065606555 | 26.54016680 |
| Super SloMo | 0.00377557111 | 0.0265828257 | 0.91293388146 | 25.26056400 |
| Word Level Corruption | ||||
| FCN3D | 0.01476183945 | 0.0596284348 | 0.81098916828 | 18.45544786 |
| BDLSTM | 0.01841032799 | 0.0762009256 | 0.74111890852 | 18.06654904 |
| FCN3D + ROI | 0.00313893227 | 0.0303552080 | 0.88049633604 | 25.32792884 |
| Super SloMo | 0.00426348229 | 0.0304555968 | 0.88005496244 | 24.59719328 |
| Multi Word Corruption | ||||
| FCN3D | 0.01131343627 | 0.0555250485 | 0.80642498433 | 19.61113891 |
| BDLSTM | 0.01841032808 | 0.0762009258 | 0.74111890912 | 18.06654899 |
| FCN3D + ROI | 0.00538372894 | 0.0382826699 | 0.83086033181 | 23.13544090 |
| Super SloMo | 0.00524661909 | 0.0348772242 | 0.84817349957 | 23.82953434 |