LiCROcc: Teach Radar for Accurate Semantic Occupancy Prediction using LiDAR and Camera
Abstract
Semantic Scene Completion (SSC) is pivotal in autonomous driving perception, frequently confronted with the complexities of weather and illumination changes. The long-term strategy involves fusing multi-modal information to bolster the system’s robustness. Radar, increasingly utilized for 3D target detection, is gradually replacing LiDAR in autonomous driving applications, offering a robust sensing alternative. In this paper, we focus on the potential of 3D radar in semantic scene completion, pioneering cross-modal refinement techniques for improved robustness against weather and illumination changes, and enhancing SSC performance.Regarding model architecture, we propose a three-stage tight fusion approach on BEV to realize a fusion framework for point clouds and images. Based on this foundation, we designed three cross-modal distillation modules—CMRD, BRD, and PDD. Our approach enhances the performance in both radar-only (R-LiCROcc) and radar-camera (RC-LiCROcc) settings by distilling to them the rich semantic and structural information of the fused features of LiDAR and camera. Finally, our LC-Fusion (teacher model), R-LiCROcc and RC-LiCROcc achieve the best performance on the nuScenes-Occupancy dataset, with mIOU exceeding the baseline by 22.9%, 44.1%, and 15.5%, respectively. The project page is available at https://hr-zju.github.io/LiCROcc/.
Index Terms:
Sensor Fusion, Semantic Scene Completion, Knowledge DistillationI INTRODUCTION
Semantic Scene Completion (SSC), a crucial technology in autonomous driving, has garnered substantial attention for its ability to ground detailed 3D scene information. Cameras and LiDAR are the most prevalent sensors used for SSC tasks, each with strengths and limitations. The former provides rich semantic context but lacks depth information and is susceptible to lighting and weather conditions. The latter offers accurate 3D geometry but performs poorly when given highly sparse input, and is hindered for wide applications due to the high cost of dense LiDAR sensors. On the other hand, radar, a weather-resistant sensor gaining traction in autonomous driving, is valued for its automotive-grade design and affordability. Despite its robustness in diverse weather and lighting conditions, radar’s sparse and noisy measurements present significant challenges for SSC in large-scale outdoor scenarios.
Most of the research has recently focused mainly on radar-based detection [1, 2]. Only a few studies [3] have explored the application of radar sensors in the SSC task. However, they can only use radar to predict occupancy in very few categories or as a supplement to multi-modal inputs. In addition, we found that although the radar has inherent strengths against adverse weather conditions and illumination changes, as indicated in Tab. I and Fig. 1, there is still a significant performance gap between the radar-based and LiDAR/camera-based SSC approaches. To address the above challenge, in this work, we explore using radar as a core sensor for SSC and set a new sota regarding the performance.
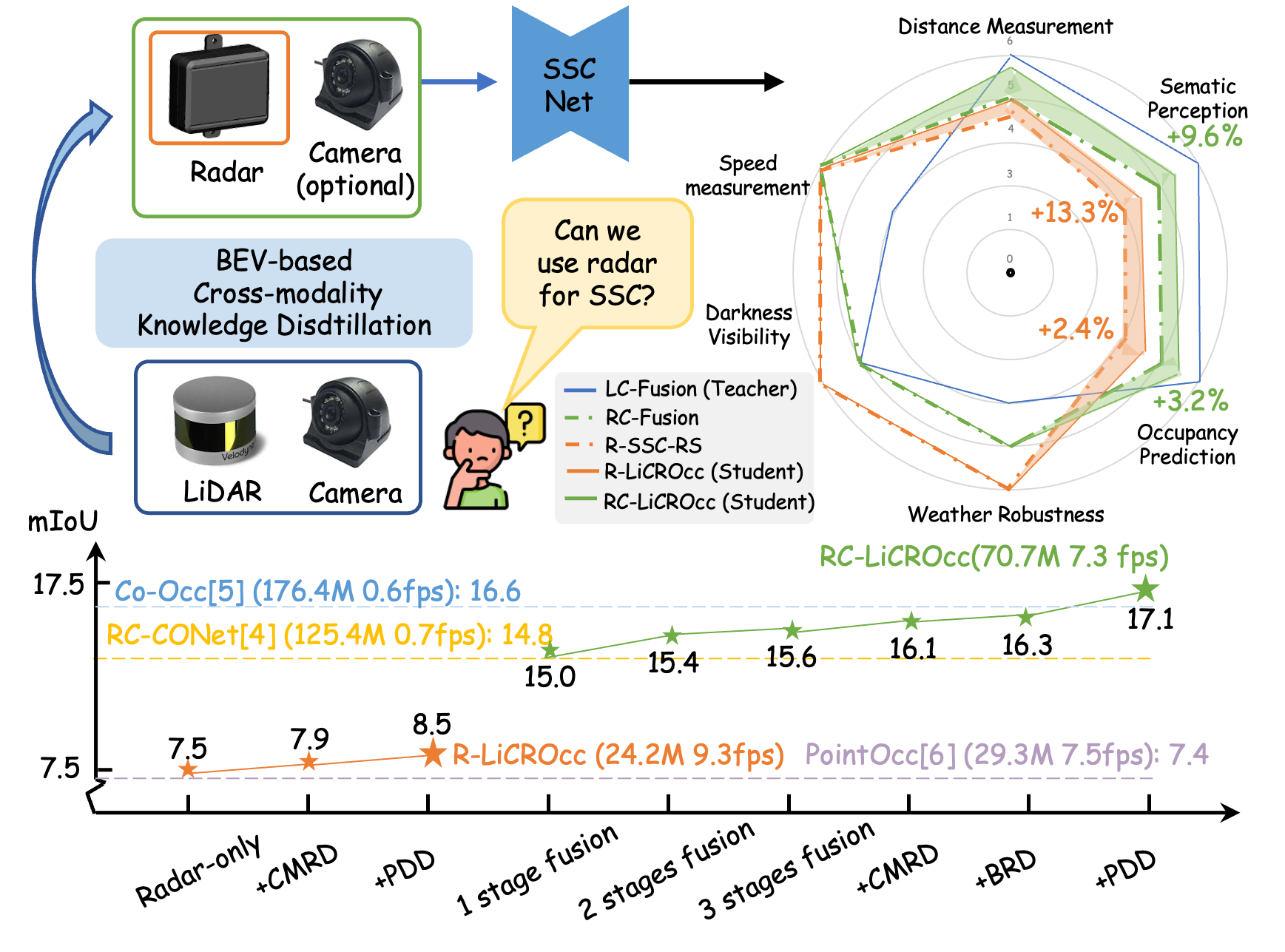
Initially, we establish a radar-based baseline R-SSC-RS inspired by [7]. However, due to the lack of intricate details, relying solely on radar sensors cannot achieve highly accurate and robust SSC. Therefore, to improve the performance of the radar-based SSC, we further design a camera-radar fusion network to fuse the rich semantic context of RGB images into radar in the BEV space effectively and efficiently. In this way, the radar SSC has been significantly improved.
Moreover, we have observed that LiDAR-camera fusion achieves superior performance in outdoor SSC, as illustrated in Fig. 1 and Tab. I, providing valuable guidance for radar feature learning. Therefore, we propose a fusion-based KD method to extract informative cues from a LiDAR-camera fusion network (Teacher) and transfer them to the radar-based baseline R-SSC-RS and radar-camera fusion network, resulting in our approaches R-LiCROcc and RC-LiCROcc.
We utilize the same architecture for both LiDAR-camera and radar-camera fusion networks. For the fusion-based KD module, we combine Cross-Model Residual Distillation (CMRD), BEV Relation Distillation (BRD), and Predictive Distribution Distillation (PPD) to hierarchically compel the student model to learn the feature representations and distributions of the teacher model. Through this proposed fusion-based KD module, our LiCROcc with radar alone (R-LiCROcc) achieves comparable results against camera-based methods. Additionally, LiCROcc approaches the performance of LiDAR-based methods by incorporating both radar and camera inputs (RC-LiCROcc) while maintaining robustness in adverse weather conditions and night vision capabilities.
To summarize, the main contributions are as follows:
-
•
We aim to improve radar for semantic scene completion while preserving real-world practicality, leveraging radar’s resilience to various weather conditions. We also establish radar-based benchmarks from LiDAR-based approaches, fostering radar-based SSC research, and consider a camera-radar fusion network for enhanced performance.
-
•
We resent a new framework, LiCROcc, which combines CMRD, BRD, and PPD modules to hierarchically force the student model to learn the feature representations and distributions of the teacher model.
-
•
Extensive experiments on the large-scale nuScenes-Occupancy [4] demonstrate the effectiveness of our proposed approaches.
II RELATED WORK
II-A 3D Semantic Scene Completion
LiDAR/Camera-based methods. LiDAR-based methods [8, 9, 7, 6, 10, 11, 12] use LiDARs for precise 3D semantic occupancy prediction. SSCNet [13] and UDNet [8] utilize 3D U-Nets but face computation overhead from empty voxels. LMSCNet [9] and SGCNet [14] improve efficiency with 2D CNNs and spatial group convolutions, respectively. Advanced methods focus on multi-view fusion [15], local implicit functions [16], knowledge distillation [10], and BEV representation [11, 7]. Recently, Pasco [12] further extends the SSC task with instance-level information to produce a richer 3D scene understanding. Camera-based methods [17, 18, 19, 20, 21, 22, 23] have become popular due to their rich visual cues and cost-effectiveness. Many methods have explored effective 3D scene representation learning for outdoor surrounding SSC. For instance, TPVFormer [17] introduces a tri-perspective view for detailed 3D structure representation. OccFormer [19] utilizes transformers for multi-scale voxel features. PanoOcc [21] achieves a unified occupancy representation for comprehensive 3D scene understanding.
Multi-modal methods [5, 4, 24] combines multi-source sensor data (e.g., images, LiDARs, and radars) to perform robust outdoor SSC. OpenOccupancy [4] provides a surrounding benchmark and establishes camera-based, LiDAR-based and LiDAR-camera baselines. Recently, radar perception [25, 26, 27, 28, 29] has garnered wide attention in multi-modal 3D detection task due to its cost-effectiveness, robustness against adverse weather conditions, and ability to detect distant objects. However, there are only a few works [24] to incorporate radar for outdoor SSC tasks. For instance, the recent OccFusion [24] devises a sensor fusion framework to integrate features from LiDARs, surround view images, and radars for robust and accurate SSC. We focus more on the distillation design of LC modes distilled to RC or R than on the direct fusion of multiple modes.
II-B Knowledge Distillation in Semantic Scene Completion
The concept of Knowledge Distillation (KD) was initially proposed for model compression and performance improvement in image classification tasks [30]. It has since been extended to other fields, such as 3D object detection [25, 31, 32], 3D segmentation [33, 34], and semantic scene completion [10, 35].
In SSC tasks, SCPNet [10] introduces Dense-to-Sparse Knowledge Distillation (DSKD) to transfer dense, relation-based semantic knowledge from a multi-LiDAR teacher to a single-LiDAR student, significantly boosting the representation learning of the student model. Similarly, MonoOcc [35] leverages knowledge distillation to transfer temporal information and visual cues to a monocular semantic occupancy framework. Different from the above methods that apply knowledge distillation in the same modality, our LiCROcc proposes fusion-based cross-modal knowledge distillation in a shared BEV space for outdoor SSC, passing informative cues from the LiDAR-camera features to the radar-camera features for performance improvement.
III METHODOLOGY
III-A Overview
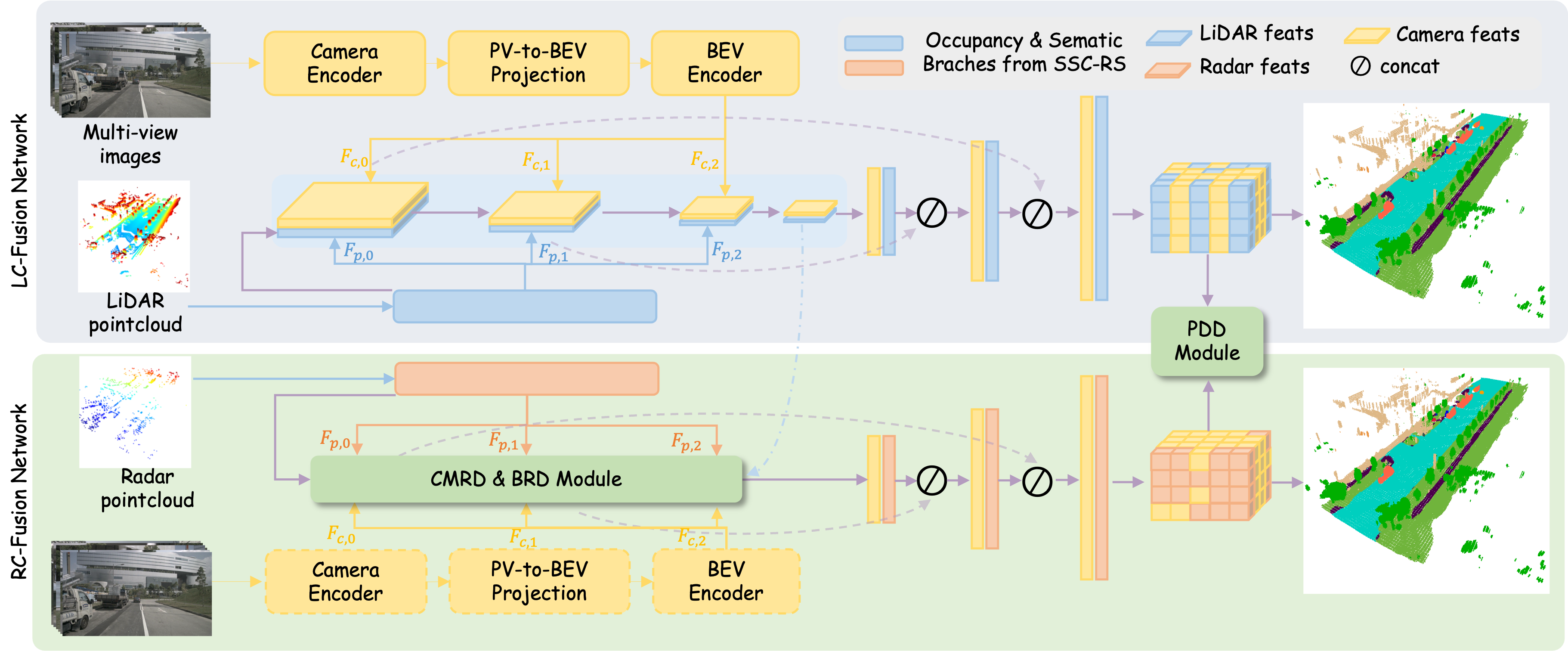
As mentioned above, we construct the radar-based baseline and design the radar-camera fusion network (the bottom part of Fig. 2) to boost the baseline’s performance. To leverage the guidance of detailed geometric structure and point representation in LiDAR-camera fusion, we further utilize the fusion-based KD (Section III-C) to transfer the knowledge from the LiDAR-camera fusion network (the top part of Fig. 2) to the radar-based baseline and radar-camera fusion network. We employ the same architecture, i.e., the multi-modal fusion network (Section III-B), to establish the above two fusion networks.
III-B Multi-modal Fusion Network
The multi-modal fusion network mainly consists of the image branch for extracting image features, the point branch for encoding LiDAR/radar points, and the multi-modal BEV fusion network for effectively and efficiently integrating point and image features hierarchically.
Image branch. Following FlashOcc [20], we propose to project surrounding image features to BEV space for subsequent processing, alleviating the memory overhead while maintaining the high accuracy of occupancy prediction. As shown in Fig. 2, the image branch mainly consists of three components: the camera encoder for image features, the PV-to-BEV projection layer for BEV representation of the 3D scene, and the BEV encoder for hierarchical BEV features , where that contain the rich semantic context. The extracted multi-scale BEV features are fed into the BEV fusion model to interact with the point features, which will be elaborated on below.
Point branch. Without losing generality, we adopt the recent BEV-based SSC-RS [7] as our point branch. This branch uses two independent branches for semantic and geometric encoding. The BEV fusion network with an ARF module [7] aggregates features from these branches, resulting in the final semantic scene completion. Due to its disentangled design, SSC-RS is lightweight and has strong representation ability, making it very suitable for use as the point branch. The point branch takes the LiDAR/radar point cloud and outputs the multi-scale BEV features , where . For LiDAR point cloud, the is in the range of . Moreover for the radar point cloud, is the concatenation of the coordinates, radar cross section , and the velocities compensated by the ego-motion.
Multi-modal BEV Fusion network. Due to the computational burden associated with 3D convolutions for dense feature fusion, we introduce a multi-modal bev fusion network, drawing inspiration from BEV perception tasks. This network efficiently combines semantically rich visual BEV representations , geometrically informative LiDAR features or weather-resistant radar features. To streamline the fusion process, we unify LiDAR or radar point cloud features with . Similarly to [7], our BEV fusion network employsa 2D convolutional U-Net architecture. Each residual block reduces the input feature resolution by a factor of 2 to maintain consistency with semantic/complementary features. Before each subsequent block, we integrate the previous stage’s with the current stage’s using ARF [7] to obtain , and then the scaled is fused to by addition. The decoder upsamples the encoder’s compressed features three times by a factor of two by skipping connections. The final decoder convolution generates the SSC prediction , where denotes the number of semantic classes. To represent the voxel-wise semantic occupancy probabilities, is reshaped into .
To train the proposed fusion model, cross-entropy loss is used to optimize the network. In addition, following [22], we also utilize affinity loss and to optimize the metrics in the scene and the class (i.e., geometric IoU, and semantic mIoU). Therefore, the BEV fusion loss function can be derived as:
| (1) |
III-C Fusion-based Knowledge Distillation Module
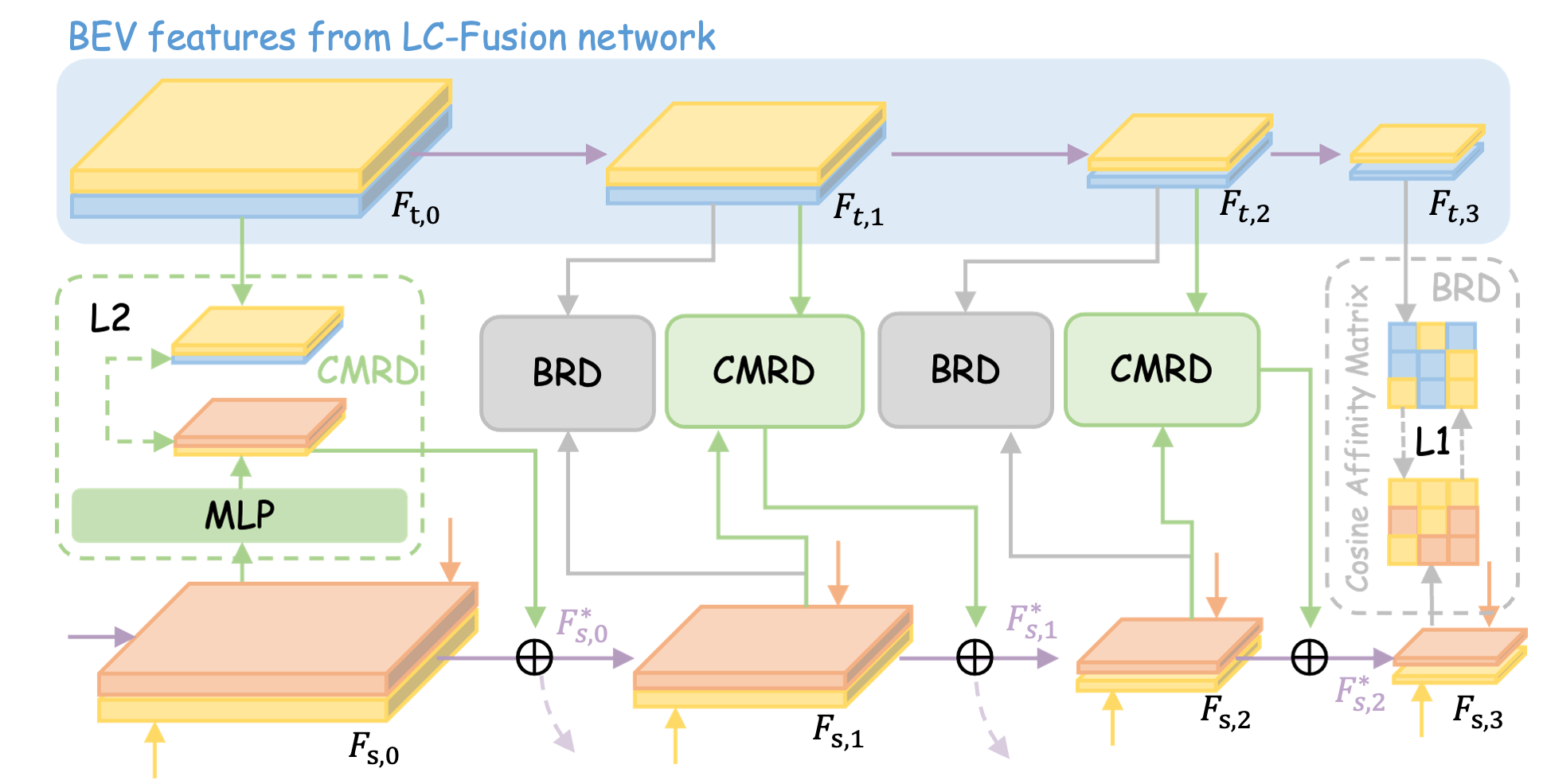
As shown in Fig. 2, our teacher and student model share the same network structure. Thanks to the fact that both the fusion and distillation processes are under BEV, the image branching of the student model is optional. In this section, we use to represent the four BEV features of the student model, and to represent the corresponding features of the teacher model (illustrated in light blue in Fig. 2 and Fig. 3).
III-C1 Cross-Model Residual Distillation
Camera and LiDAR fusion features contain rich semantic and geometric information. Compared to them, radar points are much sparser. The semantic information of radar is mainly derived from velocity measurements. Observing this gap, we believe the standard approach of directly forcing radar features to mimic multi-modal features may not work well [25], so we design a Cross-Model Residual Distillation module. Specifically, we use Eq. 3 to project student features onto a hidden space with the same dimensions. In that space, we bring the features of the student and teacher closer to each other by minimizing the cosine similarity (calculated by Eq. 4) between them and eventually add back to the original as an information complement, which avoids disturbing the intrinsic logic of the radar features compared to direct feature mimicry approaches. Moreover, radar possesses a distinct advantage over cameras and LiDAR regarding weather resilience and observation range. Our goal is for the student model to learn from the teacher’s strengths while maintaining its unique characteristics rather than simply copying the teacher. Based on the above, we utilize ARF to dynamically calculate the weights for integrating with . The procedure for feature transfer is outlined as follows:
| (2) | ||||
| (3) |
Assuming that is a feature indexed as on the feature map , the CMRD loss is formed as follows:
| (4) |
where =1 if there are labels on that pillar that are non-empty and non-noise, and otherwise. In other words, we constrain the feature similarity only on occupied locations. As shown in Fig. 3, we computed for and for , where the green dashed box shows the details of the computed loss.
III-C2 BEV Relation Distillation
We employ the CMRD for feature-level cross-modal distillation, which maintains the integrity of the student features while enriching them with additional teacher information. This section introduces a mechanism designed to uphold the consistency of scene-level geometric relationships. To achieve this, we employ a cosine similarity-based affinity matrix to compare teacher feature maps and student feature maps . Initially, the tensors and are defined in the space . We then transform these tensors into matrices with dimensions . The affinity matrix is computed using the following calculation:
| (5) |
where dentoes the cosine similarity at each element of the affinity matrix, denotes the -th feature in the feature map . To assess the scene-level information gap between the student and teacher model, we compute the L1 norm between their affinity matrices. The BRD loss is then defined as follows:
| (6) |
| Method | Input | Surround | IoU | mIoU |
barrier |
bicycle |
bus |
car |
const. veh. |
motorcycle |
pedestrian |
traffic cone |
trailer |
truck |
drive. suf. |
other flat |
sidewalk |
terrain |
manmade |
vegetation |
| MonoScene [22] | C | ✗ | 18.4 | 6.9 | 7.1 | 3.9 | 9.3 | 7.2 | 5.6 | 3.0 | 5.9 | 4.4 | 4.9 | 4.2 | 14.9 | 6.3 | 7.9 | 7.4 | 10.0 | 7.6 |
| TPVFormer [17] | C | ✓ | 15.3 | 7.8 | 9.3 | 4.1 | 11.3 | 10.1 | 5.2 | 4.3 | 5.9 | 5.3 | 6.8 | 6.5 | 13.6 | 9.0 | 8.3 | 8.0 | 9.2 | 8.2 |
| 3DSketch [36] | C&D | ✗ | 25.6 | 10.7 | 12.0 | 5.1 | 10.7 | 12.4 | 6.5 | 4.0 | 5.0 | 6.3 | 8.0 | 7.2 | 21.8 | 14.8 | 13.0 | 11.8 | 12.0 | 21.2 |
| AICNet [37] | C&D | ✗ | 23.8 | 10.6 | 11.5 | 4.0 | 11.8 | 12.3 | 5.1 | 3.8 | 6.2 | 6.0 | 8.2 | 7.5 | 24.1 | 13.0 | 12.8 | 11.5 | 11.6 | 20.2 |
| LMSCNet [9] | L | ✓ | 27.3 | 11.5 | 12.4 | 4.2 | 12.8 | 12.1 | 6.2 | 4.7 | 6.2 | 6.3 | 8.8 | 7.2 | 24.2 | 12.3 | 16.6 | 14.1 | 13.9 | 22.2 |
| JS3C-Net [38] | L | ✓ | 30.2 | 12.5 | 14.2 | 3.4 | 13.6 | 12.0 | 7.2 | 4.3 | 7.3 | 6.8 | 9.2 | 9.1 | 27.9 | 15.3 | 14.9 | 16.2 | 14.0 | 24.9 |
| C-CONet [4] | C | ✓ | 20.1 | 12.8 | 13.2 | 8.1 | 15.4 | 17.2 | 6.3 | 11.2 | 10.0 | 8.3 | 4.7 | 12.1 | 31.4 | 18.8 | 18.7 | 16.3 | 4.8 | 8.2 |
| L-CONet [4] | L | ✓ | 30.9 | 15.8 | 17.5 | 5.2 | 13.3 | 18.1 | 7.8 | 5.4 | 9.6 | 5.6 | 13.2 | 13.6 | 34.9 | 21.5 | 22.4 | 21.7 | 19.2 | 23.5 |
| PointOcc [6] | L | ✓ | 34.1 | 23.9 | 24.9 | 19.0 | 20.9 | 25.7 | 13.4 | 25.6 | 30.6 | 17.9 | 16.7 | 21.2 | 36.5 | 25.6 | 25.7 | 24.9 | 24.8 | 29.0 |
| M-CONet [4] | C&L | ✓ | 29.5 | 20.1 | 23.3 | 13.3 | 21.2 | 24.3 | 15.3 | 15.9 | 18.0 | 13.3 | 15.3 | 20.7 | 33.2 | 21.0 | 22.5 | 21.5 | 19.6 | 23.2 |
| Co-Occ [5] | C&L | ✓ | 30.6 | 21.9 | 26.5 | 16.8 | 22.3 | 27.0 | 10.1 | 20.9 | 20.7 | 14.5 | 16.4 | 21.6 | 36.9 | 23.5 | 25.5 | 23.7 | 20.5 | 23.5 |
| LC-Fusion (Ours) | C&L | ✓ | 34.9 | 24.7 | 29.6 | 20.5 | 22.2 | 26.4 | 15.7 | 24.5 | 27.3 | 21.8 | 18.1 | 21.8 | 35.9 | 22.8 | 25.0 | 25.1 | 27.8 | 30.5 |
| R-CONet [4] | R | ✓ | 17.0 | 5.9 | 6.3 | 0.6 | 3.4 | 9.4 | 0.9 | 0.9 | 1.0 | 1.7 | 2.3 | 3.9 | 24.2 | 8.8 | 11.4 | 8.6 | 6.1 | 4.2 |
| R-SSC-RS [7] | R | ✓ | 20.8 | 7.5 | 5.3 | 0.3 | 5.4 | 13.1 | 1.7 | 1.4 | 7.4 | 2.3 | 2.6 | 7.0 | 24.2 | 8.5 | 11.4 | 9.4 | 9.2 | 10.5 |
| PointOcc [6] | R | ✓ | 21.9 | 7.4 | 4.9 | 0.8 | 5.7 | 13.1 | 1.6 | 2.1 | 6.1 | 1.6 | 2.5 | 5.9 | 26.4 | 8.1 | 11.7 | 8.7 | 9.9 | 10.0 |
| R-LiCROcc (Ours) | R | ✓ | 21.3 | 8.5 | 8.1 | 0.9 | 6.4 | 13.6 | 2.3 | 2.7 | 7.9 | 2.7 | 3.3 | 7.6 | 24.3 | 11.2 | 13.1 | 10.7 | 10.6 | 11.0 |
| RC-CONet [4] | C&R | ✓ | 19.0 | 14.8 | 16.7 | 11.6 | 17.0 | 20.6 | 8.6 | 15.5 | 15.0 | 11.2 | 6.5 | 15.5 | 28.0 | 19.7 | 18.7 | 15.6 | 7.7 | 8.8 |
| Co-Occ [5] | C&R | ✓ | 24.2 | 16.6 | 18.6 | 12.6 | 18.1 | 23.0 | 6.4 | 16.5 | 15.2 | 11.2 | 7.0 | 15.3 | 34.3 | 21.9 | 23.0 | 19.6 | 10.3 | 12.0 |
| RC-Fusion (Ours) | C&R | ✓ | 25.2 | 15.6 | 14.6 | 10.4 | 16.4 | 20.5 | 9.5 | 15.0 | 15.5 | 10.0 | 7.0 | 15.0 | 32.2 | 18.5 | 20.3 | 18.3 | 11.6 | 14.8 |
| RC-LiCROcc (Ours) | C&R | ✓ | 26.0 | 17.1 | 18.6 | 11.9 | 17.1 | 21.6 | 11.1 | 15.5 | 16.7 | 11.5 | 8.8 | 16.0 | 34.1 | 20.9 | 21.9 | 19.7 | 12.8 | 15.9 |
where denote the affinity matrix of the student and teacher network bev feature maps, respectively. As shown in Fig. 3, we computed for and for , where the gray dashed box shows the details of the computed loss. To alleviate the computation burden, we resize all the BEV features of different scales to a smaller resolution and then compute . It is worth noting that BRD has only been used to distill to the radar-camera fusion for the student model.
III-C3 Predictive Distribution Distillation
Our work introduces a novel knowledge distillation method utilizing KL divergence. Specifically, we compute the KL divergence upon probabilities , where is introduced in Sec. III-B, predicted by teacher and student models. This measure captures the distribution discrepancy and is integrated into the distillation objective. By minimizing the KL divergence, the student model is encouraged to closely align its predictions with the teacher’s, thereby enhancing its predictive capabilities. The PDD loss can be computed as follows:
| (7) |
where is the predictive probability distribution of the student model and , the learning target, is the predictive probability distribution of the teacher model.
III-D Overall Loss Functions
During the training phase, we adopt a multi-task training strategy to guide the various components effectively. For 3D semantic scene completion, we utilize the loss. To enhance the distillation process, we combine three distillation components: , , and . Additionally, we retain the semantic () and occupancy () losses from SSC-RS [7] to supervise feature point cloud extraction. The overall loss function is represented as follows:
| (8) | ||||
where and are hyper-parameters.
IV EXPERIMENTS
In this section, we elaborate on the evaluation datasets and metrics (Sec. IV-A), implementation details (Sec. IV-B), and performance comparisons with state-of-the-art methods (Sec. IV-C). Additionally, we conduct ablation studies to demonstrate the effectiveness of the proposed fusion module (Sec. IV-D1) and distillation module (Sec. IV-D2). Finally, we provide experiments to ablate the impact of the observation distance (Sec. IV-D3) and the unique benefits of radar for semantic scene completion task (Sec. IV-D4).
IV-A Dataset and Metrics
Datasets. We evaluate our approach on the nuScenes-Occupancy [4] benchmark, which comprises 850 scenes (700 for training and 150 for validation) with 34,000 keyframes at the 3D volume with the size of . The dataset covers an area of -51.2 to 51.2 meters in the plane and -5 to 3 meters in the -axis. It provides the voxel annotations with 17 categories and a resolution.
Metrics. Following [13], we employ Intersection-over-Union (IoU) for scene completion (excluding semantics), and the mean Intersection-over-Union (mIoU) for semantic scene completion (no “noise” class), as the validation metrics.
IV-B Implementation Details
For LiDAR inputs, we concatenate 10 LiDAR sweeps as a keyframe similar to [4, 6]. We leverage a pre-trained ResNet50 [39] on ImageNet [40] as the image backbone to process the camera images with the input resolution of . During the training, we project the point cloud onto the camera view to provide depth supervision of the LSS [41]. For radar input, we adopt the preprocessing process in CRN [1], using radar scans stitched from 5 radar sensors of the car. For data augmentation, we randomly apply horizontal and vertical flips and cropping to the images. The point clouds are augmented by the random flipping on the -axis and -axis. We employ the AdamW optimizer with a weight decay of 0.01 and an initial learning rate of 2e-4. We use the cosine learning rate scheduler with linear warming up in the first 500 iterations. All experiments are conducted on 8 NVIDIA A100 GPUs with a total batch size 32 for 24 epochs.
| Input | stages | IoU | mIoU | Input | stages | IoU | mIoU |
| L | 0 | 34.4 | 22.1 | R | 0 | 20.8 | 7.5 |
| 1 | 34.0 | 23.4 | 1 | 24.7 | 15.0 | ||
| 2 | 34.2 | 23.7 | 2 | 24.9 | 15.4 | ||
| C&L | 3 | 34.9 | 24.7 | C&R | 3 | 25.2 | 15.6 |
IV-C Quantitative Results
Tab. I shows the comparison results of our method against the state-of-the-art methods on the nuScenes-Occupancy [4] benchmark. Compared with all previous methods, our LiCROcc achieves the best performance under the same configuration. For example, our LiDAR-camera fusion model LC-Fusion shows significant improvements, with a 23% increase in mIoU and an 18% increase in IoU compared to the baseline (M-CONet [4]). Meanwhile, LC-Fusion achieves the improvements of 3.3% and 2.3% in terms of mIoU and IoU scores over PointOCC [6], which emphasizes the effectiveness of our proposed multi-modal BEV fusion.
To comprehensively evaluate the effectiveness of our proposed method, we have modified several existing LiDAR-based and multi-modal methods (CONet [4], SSC-RS [7], PointOcc [6], and CoOCC [5]), to accommodate radar input, serving as our comparisons. As shown in the second part of Tab. I, our R-LiCROcc outperforms the second-best one (PointOcc) and the baseline (R-SSC-RS) by 13.3% on the mIoU scores, demonstrating the effectiveness of our proposed fusion-based knowledge distillation. We find the IoU score of our R-LiCROcc is slightly lower than PointOcc. We explain that this can be attributed to the fact that PointOcc projects features on three planes and uses a larger model, which may be more beneficial for occupancy prediction. For radar-camera fusion, we take CONet and CoOCC as our baselines. The results are presented in the third part of Tab. I and show that our radar-camera fusion version RC-Fusion has achieved comparable performance to these baselines. The proposed fusion-based knowledge distillation further boosts the performance by 1.5 and 0.8 in terms of mIoU and IoU. We also provide the visualization in Fig. 4 illustrates that our RC-LiCROcc and R-LiCROcc enable more complete scene completion and precise object segmentation.

IV-D Ablation Studies
We conduct a series of experiments to validate the proposed module and the potential of radar as a sensor for semantic scene completion tasks. All experiments are conducted under the same training configuration and evaluated according to nuScene-Occupancy [4] validation dataset.
IV-D1 Effect of Fusion Module
We investigate the impact of different fusion stages in the multi-modal BEV fusion network presented in III-B. The corresponding results are shown in Tab. II. “Stages=0” means only using the point cloud as input, which serves as the point-based baseline. From Tab. II, we can see that the multi-stage fusion strategy fuses BEV features at different scales and effectively improves the accuracy of the semantic scene completion.
IV-D2 Effect of Distillation Module
| Model | CMRD | BRD | PDD | IoU | mIoU |
| 20.8 | 7.5 | ||||
| ✓ | 21.7 | 7.9 | |||
| R-LiCROcc | ✓ | ✓ | 21.3 | 8.5 | |
| 25.2 | 15.6 | ||||
| ✓ | 25.3 | 16.1 | |||
| ✓ | ✓ | 25.6 | 16.3 | ||
| RC-LiCROcc | ✓ | ✓ | ✓ | 26.0 | 17.1 |
In this section, we delve into the individual contributions of different distillation components of our proposed fusion-based knowledge distillation. Detailed results are illustrated in Tab. III. We systematically evaluated the impact of these modules by incorporating them into two distinct configurations: R-LiCROcc (the first part in Tab. III) and RC-LiCROcc (the second part in Tab. III). Each configuration starts with a baseline model with any distillation module, to which we sequentially add our distillation modules to evaluate their efficacy.
Results in both parts of Tab. III show that CMRD, BRD, and PDD components significantly enhance the performance. Among these, PDD stands out with the most substantial boost, registering a 7.6% mIoU improvement for R-LiCROcc and a 4.9% mIoU improvement for RC-LiCROcc, underscoring its crucial role in cross-modal knowledge distillation.
IV-D3 Visual Field Benefits from KD
Radar’s inherent ability to penetrate objects and bypass foreground obstacles enables it to provide a wider field of view than LiDAR and camera sensors. However, the sparsity of radar point clouds increases with distance, which is particularly unfavorable for SSC, as shown in rows 2 and 3 of Tab. IV.
In order to further analyze the improvements brought by LiCROcc, we conducted a statistical analysis to evaluate the system’s effectiveness for semantic scene completion across various distance ranges, as detailed in Tab. IV. We measure the IoUs and mIoUs of the teacher model, the student model, and the R-LiCROcc at , , and for semantic scene complementation, respectively. Tab.IV reveals that knowledge distillation (KD) significantly enhances the student model’s performance, particularly in the short-range area. Interestingly, we found that when performing KD from LiDAR-camera fusion to radar-based models, the improvement in mIoU scores for the long-range area is much smaller than that for short- and medium-range areas. This observation suggests that the LiDAR-camera fusion loses its advantage as distance increases due to its relatively shorter visual range. It is worth noting that both the teacher and student models exhibit severe performance degradation in the long-range area, especially in the mIoU score. For example, the teacher model outperforms RC-LiCROcc by 10.96 mIoU within 20m. However, this advantage sharply drops to 3.76 points (almost 65% decrease) in the range.
| IoU | mIoU | ||||||
| Method | Modality | ||||||
| LC-Fusion (Teacher) | L+C | 49.0 | 23.69 | 12.01 | 34.62 | 14.85 | 4.98 |
| R-SSC-RS | R | 28.12 | 7.07 | 0.91 | 9.38 | 2.25 | 0.39 |
| R-LiCROcc (Student) | R | 27.87(-0.25) | 9.56(+2.49) | 0.81(-0.1) | 10.44(+1.06) | 3.26(+1.01) | 0.81(+0.42) |
| RC-Fusion | C+R | 35.79 | 10.56 | 1.75 | 21.75 | 6.39 | 1.02 |
| LiCROcc (Student) | C+R | 36.52(+0.73) | 11.67(+1.11) | 2.27(+0.52) | 23.66(+1.91) | 7.27(0.88) | 1.22(+0.2) |
| IoU | mIoU | ||||||||
| Method | Modality | ||||||||
| LC-Fusion (Teacher) | L+C | 35.22 | 34.28 | 33.52 | 34.16 | 24.91 | 24.08 | 16.43 | 12.69 |
| SSC-RS | L | 35.35 | 32.27 | 33.16 | 32.37 | 21.23 | 19.80 | 13.02 | 10.90 |
| C-CONet | C | 23.20 | 19.90 | 9.80 | 9.60 | 14.10 | 12.70 | 4.80 | 3.64 |
| R-SSC-RS | R | 21.25 | 19.27 | 18.90 | 17.01 | 7.55 | 7.15 | 5.35 | 4.30 |
| R-LiCROcc (Student) | R | 21.86(+0.61) | 20.10(+0.83) | 19.30(+0.4) | 17.27(+0.26) | 8.59(+1.04) | 7.10(-0.05) | 5.69(+0.34) | 4.74(+0.44) |
| RC-Fusion | R+C | 25.88 | 24.49 | 20.47 | 20.10 | 15.85 | 15.30 | 9.39 | 7.10 |
| RC-LiCROcc (Student) | R+C | 26.72(+0.84) | 25.12(+0.63) | 21.23(+0.76) | 20.67(+0.57) | 17.48(+1.63) | 16.69(+1.39) | 10.10(+0.71) | 8.02(+0.92) |
IV-D4 Weather Robustness from Radar
This study evaluates the performance of the radar-based methods in various weather conditions. Results detailed in Tab. V reveal that models’ performances fluctuate with changing weather scenarios (sunny daytime, rainy day, nighttime, and rainy night).
First, as shown in Tab. V, the weather properties of the three sensor types reveal varying degrees of robustness. The mIoU for radar decreases by only 3.25 from a clear day to a rainy night, while for LiDAR and camera, it decreases by 10.33 and 10.46 points, respectively. This indicates that radar is the most resilient to adverse weather and lighting conditions. In particular, during clear daylight hours, the teacher model achieves 16.32 higher than R-LiCROcc and 7.43 higher than RC-LiCROcc in terms of mIoU scores. However, in rainy night conditions, this advantage narrows to 7.95 and 5.26, respectively, with dominant performance decreasing by 51.3% and 29.2%. Additionally, it is evident that the rain in the nuScenes dataset is not particularly heavy, resulting in a less significant impact on the LiDAR point cloud than anticipated. Examining radar performance under a broader range of weather conditions is a focus of our future work.
Under sunny daytime conditions, the distillation effect yields the highest performance. The R-LiCROcc model demonstrates a 2.8% improvement in IoU and a 13.8% improvement in mIoU compared to the student model. Similarly, the RC-LiCROcc model achieves a 3.2% increase in IoU and a 10.3% increase in mIoU. This enhancement is attributed to the optimal performance of the teacher model under sunny conditions. Conversely, during rainy days and nights, the visibility of both the LiDAR and camera is compromised, leading to less pronounced enhancements for the student model. In fact, the performance of the R-LiCROcc model is slightly diminished in rainy weather.
V Conclusions and Future Work
In this paper, we investigate the utilization of radar in SSC task. We initially developed a fusion network that integrates point clouds and images, complemented by three distillation modules. By leveraging the strengths of radar while augmenting its performance on the SSC task, our approach achieves superior results across diverse settings. Moving forward, we plan to examine the SSC performance of additional radar types to substantiate our findings.
VI Acknowledgement
This work is partially supported by National Natural Science Foundation of China under grant U21A20484.
References
- [1] Youngseok Kim, Juyeb Shin, Sanmin Kim, In-Jae Lee, Jun Won Choi and Dongsuk Kum “Crn: Camera radar net for accurate, robust, efficient 3d perception” In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17615–17626
- [2] Yunfei Long, Abhinav Kumar, Daniel Morris, Xiaoming Liu, Marcos Castro and Punarjay Chakravarty “RADIANT: Radar-image association network for 3D object detection” In Proceedings of the AAAI Conference on Artificial Intelligence 37.2, 2023, pp. 1808–1816
- [3] Fangqiang Ding, Xiangyu Wen, Yunzhou Zhu, Yiming Li and Chris Xiaoxuan Lu “RadarOcc: Robust 3D Occupancy Prediction with 4D Imaging Radar” In arXiv preprint arXiv:2405.14014, 2024
- [4] Xiaofeng Wang, Zheng Zhu, Wenbo Xu, Yunpeng Zhang, Yi Wei, Xu Chi, Yun Ye, Dalong Du, Jiwen Lu and Xingang Wang “Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception” In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17850–17859
- [5] Jingyi Pan, Zipeng Wang and Lin Wang “Co-Occ: Coupling Explicit Feature Fusion With Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction” In IEEE Robotics and Automation Letters IEEE, 2024
- [6] Sicheng Zuo, Wenzhao Zheng, Yuanhui Huang, Jie Zhou and Jiwen Lu “Pointocc: Cylindrical tri-perspective view for point-based 3d semantic occupancy prediction” In arXiv preprint arXiv:2308.16896, 2023
- [7] Jianbiao Mei, Yu Yang, Mengmeng Wang, Tianxin Huang, Xuemeng Yang and Yong Liu “SSC-RS: Elevate LiDAR Semantic Scene Completion with Representation Separation and BEV Fusion” In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 1–8 IEEE
- [8] Hao Zou, Xuemeng Yang, Tianxin Huang, Chujuan Zhang, Yong Liu, Wanlong Li, Feng Wen and Hongbo Zhang “Up-to-Down Network: Fusing Multi-Scale Context for 3D Semantic Scene Completion” In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 16–23 IEEE
- [9] Luis Roldão, Raoul Charette and Anne Verroust-Blondet “LMSCNet: Lightweight Multiscale 3D Semantic Completion” In 3DV 2020-International Virtual Conference on 3D Vision, 2020
- [10] Zhaoyang Xia, Youquan Liu, Xin Li, Xinge Zhu, Yuexin Ma, Yikang Li, Yuenan Hou and Yu Qiao “SCPNet: Semantic Scene Completion on Point Cloud” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17642–17651
- [11] Xuemeng Yang, Hao Zou, Xin Kong, Tianxin Huang, Yong Liu, Wanlong Li, Feng Wen and Hongbo Zhang “Semantic segmentation-assisted scene completion for lidar point clouds” In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 3555–3562 IEEE
- [12] Anh-Quan Cao, Angela Dai and Raoul Charette “PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness”, 2023
- [13] Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva and Thomas Funkhouser “Semantic scene completion from a single depth image” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1746–1754
- [14] Jiahui Zhang, Hao Zhao, Anbang Yao, Yurong Chen, Li Zhang and Hongen Liao “Efficient semantic scene completion network with spatial group convolution” In Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 733–749
- [15] Ran Cheng, Christopher Agia, Yuan Ren, Xinhai Li and Liu Bingbing “S3cnet: A sparse semantic scene completion network for lidar point clouds” In Conference on Robot Learning, 2021, pp. 2148–2161 PMLR
- [16] Christoph B Rist, David Emmerichs, Markus Enzweiler and Dariu M Gavrila “Semantic scene completion using local deep implicit functions on lidar data” In IEEE transactions on pattern analysis and machine intelligence 44.10 IEEE, 2021, pp. 7205–7218
- [17] Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou and Jiwen Lu “Tri-perspective view for vision-based 3d semantic occupancy prediction” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9223–9232
- [18] Jianbiao Mei, Yu Yang, Mengmeng Wang, Junyu Zhu, Xiangrui Zhao, Jongwon Ra, Laijian Li and Yong Liu “Camera-based 3D Semantic Scene Completion with Sparse Guidance Network” In arXiv preprint arXiv:2312.05752, 2023
- [19] Yunpeng Zhang, Zheng Zhu and Dalong Du “OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction” In arXiv preprint arXiv:2304.05316, 2023
- [20] Zichen Yu, Changyong Shu, Jiajun Deng, Kangjie Lu, Zongdai Liu, Jiangyong Yu, Dawei Yang, Hui Li and Yan Chen “FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin” In arXiv preprint arXiv:2311.12058, 2023
- [21] Yuqi Wang, Yuntao Chen, Xingyu Liao, Lue Fan and Zhaoxiang Zhang “Panoocc: Unified occupancy representation for camera-based 3d panoptic segmentation” In arXiv preprint arXiv:2306.10013, 2023
- [22] Anh-Quan Cao and Raoul De Charette “Monoscene: Monocular 3d semantic scene completion” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 3991–4001
- [23] Jiawei Hou, Xiaoyan Li, Wenhao Guan, Gang Zhang, Di Feng, Yuheng Du, Xiangyang Xue and Jian Pu “FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird’s-Eye View and Perspective View” In arXiv preprint arXiv:2403.02710, 2024
- [24] Zhenxing Ming, Julie Stephany Berrio, Mao Shan and Stewart Worrall “OccFusion: A straightforward and effective multi-sensor fusion framework for 3D occupancy prediction” In arXiv preprint arXiv:2403.01644, 2024
- [25] Lingjun Zhao, Jingyu Song and Katherine A Skinner “CRKD: Enhanced Camera-Radar Object Detection with Cross-modality Knowledge Distillation” In arXiv preprint arXiv:2403.19104, 2024
- [26] Jisong Kim, Minjae Seong, Geonho Bang, Dongsuk Kum and Jun Won Choi “RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection” In arXiv preprint arXiv:2307.10249, 2023
- [27] Taohua Zhou, Junjie Chen, Yining Shi, Kun Jiang, Mengmeng Yang and Diange Yang “Bridging the view disparity between radar and camera features for multi-modal fusion 3d object detection” In IEEE Transactions on Intelligent Vehicles 8.2 IEEE, 2023, pp. 1523–1535
- [28] Youngseok Kim, Sanmin Kim, Jun Won Choi and Dongsuk Kum “Craft: Camera-radar 3d object detection with spatio-contextual fusion transformer” In Proceedings of the AAAI Conference on Artificial Intelligence 37.1, 2023, pp. 1160–1168
- [29] Ramin Nabati and Hairong Qi “Centerfusion: Center-based radar and camera fusion for 3d object detection” In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1527–1536
- [30] Geoffrey Hinton, Oriol Vinyals and Jeff Dean “Distilling the knowledge in a neural network” In arXiv preprint arXiv:1503.02531, 2015
- [31] Shengchao Zhou, Weizhou Liu, Chen Hu, Shuchang Zhou and Chao Ma “UniDistill: A Universal Cross-Modality Knowledge Distillation Framework for 3D Object Detection in Bird’s-Eye View” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5116–5125
- [32] Zehui Chen, Zhenyu Li, Shiquan Zhang, Liangji Fang, Qinhong Jiang and Feng Zhao “Bevdistill: Cross-modal bev distillation for multi-view 3d object detection” In arXiv preprint arXiv:2211.09386, 2022
- [33] Yuenan Hou, Xinge Zhu, Yuexin Ma, Chen Change Loy and Yikang Li “Point-to-voxel knowledge distillation for lidar semantic segmentation” In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8479–8488
- [34] Xu Yan, Jiantao Gao, Chaoda Zheng, Chao Zheng, Ruimao Zhang, Shuguang Cui and Zhen Li “2dpass: 2d priors assisted semantic segmentation on lidar point clouds” In European Conference on Computer Vision, 2022, pp. 677–695 Springer
- [35] Yupeng Zheng, Xiang Li, Pengfei Li, Yuhang Zheng, Bu Jin, Chengliang Zhong, Xiaoxiao Long, Hao Zhao and Qichao Zhang “Monoocc: Digging into monocular semantic occupancy prediction” In arXiv preprint arXiv:2403.08766, 2024
- [36] Xiaokang Chen, Kwan-Yee Lin, Chen Qian, Gang Zeng and Hongsheng Li “3d sketch-aware semantic scene completion via semi-supervised structure prior” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 4193–4202
- [37] Jie Li, Kai Han, Peng Wang, Yu Liu and Xia Yuan “Anisotropic convolutional networks for 3d semantic scene completion” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3351–3359
- [38] Xu Yan, Jiantao Gao, Jie Li, Ruimao Zhang, Zhen Li, Rui Huang and Shuguang Cui “Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion” In Proceedings of the AAAI Conference on Artificial Intelligence 35.4, 2021, pp. 3101–3109
- [39] Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun “Deep residual learning for image recognition” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
- [40] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li and Li Fei-Fei “Imagenet: A large-scale hierarchical image database” In 2009 IEEE conference on computer vision and pattern recognition, 2009, pp. 248–255 Ieee
- [41] Jonah Philion and Sanja Fidler “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d” In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, 2020, pp. 194–210 Springer