LF Tracy: A Unified Single-Pipeline Paradigm for Salient Object Detection in Light Field Cameras
Abstract
Leveraging rich information is crucial for dense prediction tasks. Light field (LF) cameras are instrumental in this regard, as they allow data to be sampled from various perspectives. This capability provides valuable spatial, depth, and angular information, enhancing scene-parsing tasks. However, we have identified two overlooked issues for the LF salient object detection (SOD) task. (1): Previous approaches predominantly employ a customized two-stream design to discover the spatial and depth features within light field images. The network struggles to learn the implicit angular information between different images due to a lack of intra-network data connectivity. (2): Little research has been directed towards the data augmentation strategy for LF SOD. Research on inter-network data connectivity is scant. In this study, we propose an efficient paradigm (LF Tracy) to address those issues. This comprises a single-pipeline encoder paired with a highly efficient information aggregation (IA) module ( parameters) to establish an intra-network connection. Then, a simple yet effective data augmentation strategy called MixLD is designed to bridge the inter-network connections. Owing to this innovative paradigm, our model surpasses the existing state-of-the-art method through extensive experiments. Especially, LF Tracy demonstrates a improvement over previous results on the latest large-scale PKU dataset. The source code is publicly available at: https://github.com/FeiBryantkit/LF-Tracy.
Keywords:
Light field camera salient object detection neural network scene parsing.1 Introduction
The objective of SOD lies in mimicking human visual attention mechanisms to accurately identify the most conspicuous objects or regions in a variety of visual contexts. In particular, SOD plays a dual role: it not only aids agents in discerning the most striking and important elements in visual scenarios but also plays a pivotal role in several downstream tasks, including object detection, segmentation, and other dense prediction tasks [29, 2].
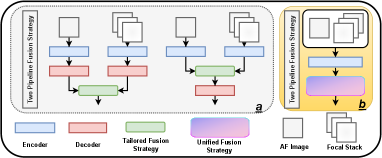
Within the SOD community, the current 2D-based methods [23, 6] rely on the powerful feature extraction capabilities of Convolutional Neural Networks and Transformers, coupled with finely crafted decoders, to achieve impressive results. Meanwhile, a rich array of 3D methods [27, 3] have been introduced by utilizing depth or thermal information to boost the result. Given that information from various domains aids neural networks in more effectively learning scene features, LF cameras have been introduced [18]. LF camera is capable of capturing spatial, depth, and angular information. However, two significant challenges are neglected.
One: Lacking Intra-network Data Connectivity. The existing datasets for LF cameras consist of post-processed All-Focused (AF) images and Focal Stacks (FS) [22, 41, 38, 17]. AF images are full of texture information. FS images refer to images that include angular and depth information. The asymmetric data construction enriches the geometric information captured by LF cameras.

However, the implicit angular details cannot be directly utilized; they can only be obtained by exploring the latent relationships between images. While effectively utilizing depth and spatial information enhances the network’s ability to understand scenes, the current two-stream approach (Fig. 1(a)) neglects essential linkages among various images and disregards the angular information flow throughout the network, resulting in smaller searching space. As illustrated in Fig. 2, the high-dimensional data visualization (i.e., TSNE) is conducted to demonstrate the search space of features. The search space of SFS (single-pipeline, focal stack) and SAF (single-pipeline, all-focused image) is significantly larger than that of the two-stream method.
Furthermore, in using a single-pipeline encoder, while different images can guide the network to learn angular features, merging the unfocused segments in AF image with all-focused data in FS images results in feature contamination within the feature space, significantly undermining the network’s discriminative capabilities. Hence, one of the key points of our work is “how to leverage angular information while circumventing the alignment issues brought about by varying shooting viewpoints?”.

Two: Lacking Inter-network Data Connectivity. Although researchers in the LF community enhance the understanding of scenes by introducing depth information (Focal Stack), existing works still adhere to the conventional RGB-D fusion structures [5, 4], employing common data augmentation (DA) strategies. Those methods isolatedly excavate the angular features and bury the relationship between different LF representations since there is no data interaction before the training process [33]. Therefore, another key point of our work is “developing a novel DA strategy specifically for the LFSOD task to bridge a connection between various LF data sources before the training process”. Fig. 3 indicates a statistical result through the MixLD strategy. Before applying data augmentation, although a certain degree of data similarity between AF and FS can be observed from figures Fig. 3(a) and Fig. 3(b), there are still considerable differences in data within the range of pixels. However, after DA, by analyzing the distribution of the phase spectrum (Fig. 3(c)) and calculating its similarity with the central figure in the frequency domain (Fig. 3(f)), it can be seen that information has been aggregated.
In this work, we propose a novel paradigm (LF Tracy) to overcome the aforementioned challenges. Firstly, a single-pipeline framework in Fig. 1(b) is established to achieve the intra-network data connectivity. By learning different LF representations from a comprehensive perspective through a single backbone, our network can fully utilize the information from LF images rather than conducting separate feature extraction for LF representations. Furthermore, a simple yet IA model is performed within LF Tracy to effectively align and fuse the coupled features through the same backbone. Moreover, a simple data augmentation strategy called MixLD is introduced to establish inter-network data connectivity.
To demonstrate the efficiency of the proposed LF Tracy paradigm, comprehensive experiments are conducted on the large-scale PKU dataset [17], which comprises samples from both terrestrial and aquatic environments, and the LFSOD datasets [22, 41, 38]. By employing this paradigm (), our network achieved the state-of-the-art performance compared with previous works. Specifically, on the PKU dataset, our work achieved a improvement in accuracy, fully validating the effectiveness of our network.
At a glance, we deliver the following contributions:
-
•
We propose a single-stream SOD paradigm from scratch, bridging the inter-network and intra-network data connectivity.
-
•
We have designed a low-parameter Information Aggregation (IA) Module that uncovers angular information while avoiding feature aliasing. Furthermore, we introduce a data augmentation strategy, namely MixLD, to establish inter-network data connectivity.
-
•
An in-depth analysis is conducted to evaluate the performance of the single stream network under different hyper-parameters and module combinations.
-
•
Our method achieves top performance on three LF datasets and one large-scale PKU dataset, which comprises over images.
2 Related Work
Discovering and connecting the spatial, depth, and angular information of LF is essential for designing an efficient SOD neural network. Therefore, we will discuss the utilization of light field information from two aspects: Intra-network Data Connectivity in Sec. 2.1 and Inter-network Data Connectivity in Sec. 2.2. Lastly, preliminaries related to LF imaging are introduced in the appendix.
2.1 Intra-network Data Connectivity
The SOD task can be traced back to rule-based methodologies, which predominantly relied on visual attributes such as color, contrast, and spatial distribution to ascertain salient areas in images. In recent years, there has been a paradigm shift in the SOD community towards leveraging deep learning paradigms. Specifically, MENet [31] introduced iterative refinement and frequency decomposition mechanisms to improve detection accuracy. By utilizing transformer and multi-scale refinement architecture, Wang et al. [9] used high- and low-resolution images to achieve SOD. Furthermore, Zhang et al. [7] implemented SOD for panoramic images. Apart from those single-modality SOD networks, depth information is introduced to enhance performance, whereas multi-model fusion strategies [3, 8] are employed for RGB and thermal data.
For the SOD task of LF, Wang et al. [28] implemented a dual-pipeline neural network in the SOD community. Since then, the two-stream approach [21] for processing LF images has stood in a leading position in this field. Typically, this involves employing one backbone for processing AF images and another for FS images or the depth image extracted from LF sub-aperture images. Although the two-stream approach has seen considerable advancement in various tasks [36], it is typically applied to modalities that are isolated, such as depth and RGB images. For light field cameras, the depth, angular, and spatial information are embedded across different representations, i.e., AF images and FS images. Processing these images in an isolated manner buries the angular features of light field cameras, and thus remains a sub-optimal method [33].
2.2 Inter-network Data Connectivity
Data augmentation (DA) has been thoroughly explored in various vision tasks such as image recognition, image classification, and semantic segmentation, proving effective in enhancing network performance and mitigating the issue of overfitting. The traditional data augmentation strategies can be roughly divided into five categories based on the adjusted purpose. 1) Flipping the image along its vertical and horizontal axis is a typical technique for increasing the diversity of data available for training. Furthermore, rotating an image at a certain angle is also a contributing factor. 2) Color jitter simulates images under different lighting and camera settings, enabling the trained model to better adapt to various scenarios. 3) Cutout [10] is introduced to drought or mismatch part of pixel-level information between neighboring pixels to increase the discrimination capability of the network. 4) Beyond deep learning, several works [11, 35] introduced machine learning-based strategies to boost the network capability. 5) Mixing-based methods [33, 15] leverage information from multiple images by generating blended input images.
Those methods demonstrate noticeable performance for the single image in the augmentation community. However, for light field cameras, the subtle angular information hidden within the interplay of multiple images cannot be captured through DA applied to individual images alone. Thus, establishing data connectivity across networks becomes crucial.
3 Methodology
This section introduces a comprehensive overview of our proposed paradigm, designed for the LFSOD task. Firstly, the framework’s architecture is meticulously expounded in Sec. 3.1. Additionally, in Sec. 3.2, we introduce a simple yet fusion module, which is pivotal for efficiently aggregating Light Field features. Last but not least, Sec. 3.3 delves into our innovative DA Strategy.
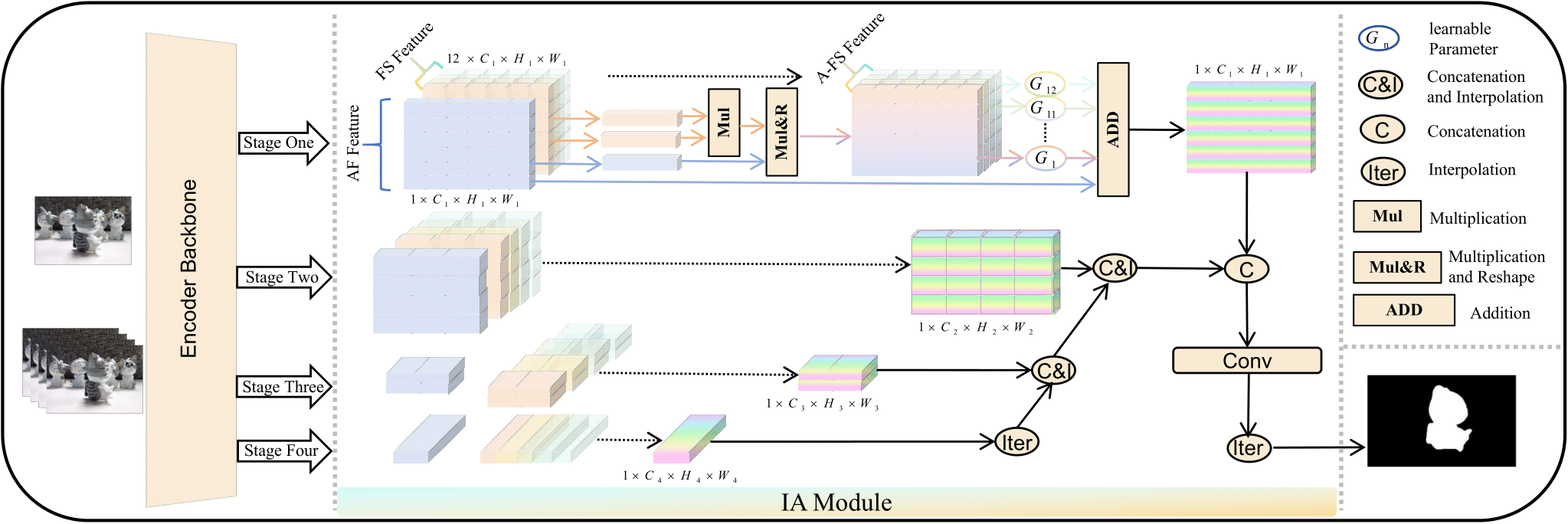
3.1 Proposed LF Tracy Framework
As shown in Fig. 4, the proposed network has two components: a four-stage encoder providing rich multi-dimensional information from different asymmetric data and the IA Module. The IA Module serves a dual purpose: 1) It overcomes the mismatching between the features established in-network connectivity through the same encoder block. 2) It can realign these features before sending them to the prediction head. The AFttention image and FSttention stack are described separately to provide a more intuitive description of the information flow and interaction process. The AFttention image and FSttention stack indicate the data source after MixLD. Furthermore, for simplicity, the following description is based on the stage one, which is the same for the other three stages. Especially, by applying the encoder block, the images are transferred into AF features and FS features . After applying the IA Module, the features are aggregated into one feature , which contains all spatial, angular, and depth information. After four stages, there is a set of feature maps with channel dimension . Only is described in detail here, as the processes for the other dimensions are identical. Furthermore, at the training stage, to cooperate with the structure loss [12] calculation, is also passed through one convolutional layer to compress channel information, as in Eq. (1).
| (1) |
where indicates the convolutional layer with input channel and output channel one. denotes the feature after merging at the first stage. Furthermore, drawing upon the structure loss as outlined in [32], we have integrated the Tversky Loss [26] into our training process to improve supervision during training, specifically targeting a reduction in false positives and negatives.
3.2 Information Aggregation: IA Module
To fuse the implicit angular, explicit spatial, and depth information from asymmetric data, we introduce a simple IA Module that follows a two-step interaction process. Firstly, given single feature , the FS-guided Querry and Key are generated through their respective convolutional layer. Through matrix multiplication, the attention map is obtained. The attention map integrates a broader context into the aggregation of local features and enhances the representative capability of the focus part. Furthermore, applying the third convolutional layer to , the AF image guided Value is generated, as in Eq. (2)-(5). Given that the SOD task is sensitive to hyper-parameters and module design, we adopt a dimension reduction method for Query and Key. For more details on dimension reduction, please refer to Sec. 5.2.
| (2) | |||
| (3) | |||
| (4) | |||
| (5) |
The tokens , which contains information from certain focal images, is obtained by multiplication of attention map and Value, as in Eq. (6).
| (6) |
After obtaining the tokens, the A-FS features are generated by applying the reshape operation. Note that the number of images has remained unchanged until now. This operation aims to enhance the spatial information at the corresponding depth by guiding the information from the FS image and, with the help of AF features, establish a connection between the global AF and FS information. Secondly, we introduce a set of leanable parameters to calculate the contribution of different FS features. To further enhance the spatial context information, a submission is undertaken, and the final result is obtained as in Eq. (7).
| (7) |
Given multi-scale features , interpolation and concatenation are conducted. Finally, by applying the convolutional layer following an interpolation, the mask is compressed and sent to the prediction head.
3.3 Data Augmentation Strategy: MixLD
As depicted in Fig. 5, the primary objective of the specific data augmentation strategy for the LFSOD task is to amalgamate distinct representations inherent in light field camera, namely, AF image , FS , and implicit angular information. This strategy is methodically partitioned into two discrete phases, each targeting specific aspects of the integration process. Initially, a non-intrusive approach is employed to integrate angular and depth information into the composite AF image while preserving the integrity of spatial data dimensions. Specifically, the data augmentation strategy can be described as following steps:
Firstly: (FS2AF) Following the FS setting [25], one FS slice with dimension is randomly selected with a likelihood of . This FS image is then subjected to a pixel-level fusion process, meticulously blending it into the AF image representation, as shown in Eq. (8).
| (8) |

where denotes the degree of blending and indicates the quantities of focal images. indicates the AF image after blending, i.e., AFttention image. In MixLD, indicates no blending and indicates that the AF Image is completely replaced. Only the AF image is altered during this process, while the FS images remain unchanged. Meanwhile, this procedure is not conducted for each interaction.
Secondly: (AF2FS) The AFttention image is integrated into all the FS images with a probability of , as in Eq. (9).
| (9) |
where denotes also a super parameter for the degree of blending in stage two and denotes the quantities of focal images. indicates the FS after blending i.e., FSttention stack. This integration carried out with a fusion probability of instead of , aims to make it more possible to enrich the FS with additional information. By blending the AF image into the FS images, each focal image retains its inherent depth information, gains implicit angular insights from the other focal image, and enhances its spatial geometric information from the AF image. Furthermore, the AFttention image and FSttention stack are fed into the network. It is important to emphasize that both phases (FS2AF and AF2FS) of MixLD are conducted randomly. It is possible for data interaction to occur in only one phase, while the other remains non-interactive.
It is precisely through this form of blending that the neural network while learning the inherent AF and FS information, can break out of the conventional framework to learn implicit angular information. For detailed algorithms, please refer to the pseudocode presented in the Appendix.
4 Experiments
To effectively demonstrate the efficacy of the approach, we showcase the quantitative result and qualitative results on different datasets. Firstly, we introduce the experimental setup in Sec. 4.1. Secondly, in Sec. 4.2, we present a quantitative comparison with other methods. Thirdly, in Sec. 4.3, we showcase the visual results of the method, along with a visual comparison with previous approaches.
4.1 Implementation Details
Datasets: The experiments are conducted following the benchmark proposed by the PKU team [17]. The datasets involve traditional LFSOD datasets, which include LFSD [22], DUT-LF [41], HFUT [38] and a large-scale PKU dataset [17]. The images within the PKU dataset are sourced from terrestrial and aquatic environments. Two experiment strategies are conducted: I) training on DUT-LF HFUT, images, and evaluation on the whole LFSD dataset, the DUT-LF testing dataset, and HFUT testing dataset; II) training and testing on the PKU-LF dataset. PKU-LF dataset contains more than images. For the ablation study, the experiments are based on experiment strategy one.
Setting Details: The image size for all the datasets is . Each scene is structured to contain exactly focal slices to meet specific coding requirements. This is achieved by strategically duplicating focal slices in the original order. Data augmentation is applied with Flipping, Cropping, Rotating, and MixLD for the training process. The blending parameter are set into and , respectively. The AdamW optimizer with a learning rate of and weight decay of is adapted for training. All the experiments are conducted on one A6000 GPU with a batch size of . The training epochs are limited to .
Evaluation Metrics: To analyze the results of different methods, we employ mean absolute error (MAE) [24] for a fair comparison. For F-measure () [1], E-measure () [12], S-measure (), we compare them with the previously best methods.
Methods LFNet SSF D3Net ATSA UCNet ESCNet JLDCF MEANet GFRNet STSA1 STSA2 STSA3 Ours Gain [40] [42] [13] [39] [37] [43] [16] [20] [34] [17] TIP20 CVPR20 TNNLS21 ECCV21 TPAMI22 TIP22 TPAMI22 Neuc22 ICME23 TPAMI23 LFSD .092 .067 .095 .068 .072 n.a. .070 .077 .065 .067 .065 .062 .046 26% HFUT .096 .100 .091 .084 .090 .090 .075 .072 .072 .067 .072 .057 .056 2% DUT-LF .055 .050 .083 .041 .081 .061 .058 .031 .026 .033 .030 .027 .023 12% PKU-LF n.a. .062 .067 .045 .070 n.a. .049 n.a. n.a. .047 .042 .035 .027 23%
4.2 Quantitative Results
To verify the efficiency of the approach, we compare the designed network with existing methods. Table 1 shows that the best performance of the proposed approach significantly outperforms existing methods across the LFSD series dataset [22, 41, 38] and PKU dataset [17] on MAE. Due to the variability in performance across different evaluation metrics and datasets, we follow the benchmark provided by the PKU team [17].
| Dataset | Metrics | PreV | Our | Gain |
|---|---|---|---|---|
| LFSD [22] | .862 [4] | .896 | 3.9% | |
| .902 [17] | .912 | 1.1% | ||
| .864 [14] | .902 | 4.4% | ||
| HFUT [38] | .771 [17] | .769 | 0.3% | |
| .864 [17] | .865 | 0.1% | ||
| .810 [17] | .833 | 0.1% | ||
| DUT-LF [41] | .906 [17] | .936 | 3.3% | |
| .954[17] | .957 | 0.3% | ||
| .911[17] | .938 | 3.0% |
The proposed method significantly surpasses this integrated benchmark. The network’s performance is most effectively proved, particularly with the large-scale and richly varied PKU dataset. By establishing the pre-network connectivity and the in-network connectivity of LF data, the network reconnects the intrinsic relationships between different light field camera images, achieving a improvement in MAE compared with STSA3. It should be noted that the training dataset of STSA3 is an extension dataset (DUT-LF HFUT PKU-LF). We used the PKU-LF dataset, and the network performance still exceeded by 23%. In Table 2, we perform a comparison in terms of other evaluation criteria following PKU team [17]. While other networks may perform well in certain respects, LF Tracy still surpasses previous methods on a majority of metrics. This fully demonstrates the network’s superior comprehensive perception capabilities without being data-dependent.
4.3 Qualitative Results
It can be seen from Fig. 7 that the LF Tracy achieves outstanding accuracy across different scenarios by establishing intra-network and inter-network connectivity. Whether dealing with a single scene or complex scenarios, the network delivers excellent visualization results. Especially, for transparent backboards under varying lighting conditions, the network identifies the object through efficient information processing. Meanwhile, thin structures have always been a challenging issue in SOD tasks, yet the network has successfully identified both the necks of animals and the slender support poles of basketball hoops. Furthermore, the visual comparison results demonstrate the method’s superiority, as in Fig. 7. The proposed network accurately identifies the locations of objects, and notably, it precisely identifies challenging boundaries and lines. For the images in the middle row, the area with two pedestrians walking side by side is particularly challenging to discern. The varied colors and textures of their clothing present a significant challenge to the network. While other methods show numerous errors in this region, the proposed network achieves accurate identification.


5 Ablation Studies
In this section, several ablation studies are conducted to showcase the process of designing the network from scratch. Firstly, in Sec. 5.1, the experiments are carried out to comprehensively examine the effects of various components incorporated in the methods. Sec. 5.2 showcases an in-depth analysis for the IA Module and FS Stack. Sec. 5.3 investigates the performance of different backbones for the SOD task. Sec. 5.4 demonstrated the in-depth analysis for MixLD.
5.1 Ablation Study for the Approach
In the experimental analysis, as shown in Table. 3, we ablated components of the approach to assess their contributions. The optimal performance achieved an MAE of . Firstly, eliminating the data augmentation strategy MixLD resulted in a performance decrease, and adapting CutMib [33] has few contributions to the performance. This indicates the necessity of MixLD to connect the different data before sending them into the network. After that, we ablate the core component of the network, the IA module, and the multi-scale features are directly fused. The MAE dramatically increased. The observed significant disparity of highlights the effectiveness of the IA module. This module is integral for effectively realigning and managing the data imbalance across diverse sources. In particular, it is pivotal in reducing data mismatching between LF and AF images, facilitating more effective data integration, and improving accuracy with one stream encoder. Finally, without FS, the result is further reduced.
| Model | Our | w/o. MixLD | w. CutMib | w/o. IA | w/o. LF |
| MAE | .046 | .052 | .051 | .332 | .057 |
Parameters Analysis: The total Parameters of the designed LF Tray are . After removing the first stage in the IA module, the parameters decrease to . Furthermore, removing the entire IA module, the parameters fall into . With only 6 parameters, the network is capable of intra-network data connections and efficient feature fusion. GFlops and FPS: When processing 12 FS images, i.e., handling a total of 13 light field images in a single training flow, the GFLOPs and FPS are 104.13 and 4.28, respectively. Without the IA module, these values are 84.8 GFLOPs and 4.73 FPS.
5.2 In-depth analysis for the IA Module and FS Stack
To demonstrate the contribution of the FS stack and the alignment and fusion capabilities of the IA module for asymmetric data, the ablation studies are conducted from three different aspects.
| Stack Size | 2 | 3 | 5 | 12 |
|---|---|---|---|---|
| w/o. IA | .137 | .141 | .205 | .332 |
| w. IA | .051 | .051 | .049 | .046 |
➀ Focal Stack Images: We compared the discrimination ability of the network with and without the IA module, using , , , and FS images, respectively. As indicated in Table. 4, without the IA module, continuously stacking FS images does not enhance the network’s capability; rather, it negatively impacts the network. With the addition of the IA module, the focused range and implicit angular information in the FS are utilized, increasing the network’s discrimination ability.
➁ Fusion strategy in IA module: In Table 6, four different fusion strategies are compared. Firstly, we introduced an attention-based feature interaction process, accompanied by a set of learnable parameters, to achieve the fusion of information from different data sources. Then, we replaced this process with deformable cross attention [44]. Subsequently, we directly add the features point by point. Finally, we utilized cross-attention for feature interaction, directly adding the interacted feature maps. Although the point-by-point addition method has achieved significant results in semantic segmentation tasks, it does not work effectively for SOD tasks. Likewise, the method of deformable cross attention also did not surpass the method we proposed.
| Strategy | A&PD | DA | ADD | A&D |
| MAE | .046 | .056 | .332 | .048 |
| R&Rate | 1 | |||
|---|---|---|---|---|
| MAE | .050 | .049 | .046 | .050 |
➂ Reduction rate: Last but not least, a set of experiments are conducted to deeply access the better hyper-parameters within IA module. Inspired by [19], the dimensions of the Query and Key are compressed in the IA module. Four different reduction rates are chosen. As shown in Table 6, over-reducing or under-reducing the channel can lead to performance degradation. The best option is to reduce the query and key dimensions to of the original size.
5.3 Selection of Various Backbones
| Backbone | B0 | B1 | B2 | B4 |
|---|---|---|---|---|
| PVTv2 [30] | .120 | .097 | .072 | .087 |
| AgentPVT [19] | .153 | .137 | .142 | .145 |
We conducted a series of experiments based on traditional datasets to assess the optimal feature extraction backbone. The PVTv2 [30] and the agent attention [19] are selected. To prevent pre-trained weights from causing an unfair comparison in the selection of backbones, we conducted experiments for epochs without pre-trained weights. Table 7 shows that the agent attention is ineffective for the dataset, and the performance on the LFSOD dataset does not improve with the increase in the number of parameters. Due to this reason, we have chosen PVTv2 as the backbone.
5.4 In-depth analysis for MixLD
Interaction probability between texture and depth information: In determining the optimal combination for incorporating depth information into AF images (FS2AF) and augmenting each FS image with texture information (AF2FS). Several experiments are designed with occurrence probabilities set at 0.1, 0.5, and 0.9. From the Table. 9, it can be seen that: ➀ Assigning low occurrence probabilities (0.1) to both FS2AF and AF2FS minimally impacts the experimental outcomes, yet the performance metrics are analogous to those achieved with the CutMix augmentation technique. ➁ Excessive integration of depth information into AF images (probability set at 0.9 for FS2AF) leads to a significant loss of spatial information, affecting the network’s performance. ➂ While injecting spatial information into FS images improves the network’s ability to discriminate, excessive fusion can damage the valuable depth cues.
| Selection Rate | FS2AF | ||||
|---|---|---|---|---|---|
| 0.1 | 0.5 | 0.9 | |||
| AF2FS | 0.1 | 0.51 | 0.55 | 0.57 | |
| 0.5 | 0.46 | 0.49 | 0.54 | ||
| 0.9 | 0.49 | 0.52 | 0.59 | ||
| 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | |
|---|---|---|---|---|---|
| MAE | .053 | .049 | .046 | .073 | .142 |
Blending rate analysis: To explore the optimal blending ratio of AF image and FS. We altered the parameter in the first step, which involves blending one FS slice into AF images. Furthermore, in the second step, the parameter is adjusted to merge the blended AF image into FS. Due to the various combinations of - pair, we only experimented with a few combinations based on . As shown in Table 9, the optimal outcome is achieved with a blending rate of . Notably, deviations from this ratio, either by increasing or decreasing the blending rate, result in a discernible decline in performance.
6 Conclusion
Contribution: In this paper, we present a unified single-stream method (LF Tracy) for salient object detection, bridging the inter-network and intra-network data connectivity. First, we have designed an efficient IA module. This module effectively addresses the feature mismatching of different LF representations. In combination with a single-pipeline encoder, it enables intra-network data connectivity. Uniquely, our study tests the network’s performance and achieves leading results on four distinct datasets. Second, we propose a data augmentation strategy for saliency object detection, specifically targeting inter-network connectivity. This method facilitates interaction among different channels of data, enhancing the network’s discriminative ability.
Limitation and Further Work: The task of salient object detection is sensitive to the choice of backbone, which sets it apart from other dense prediction tasks, such as semantic segmentation. Establishing a unified pixel-wise prediction framework is challenging and requires investigation in future work.
Acknowledgment: This work was supported in part by the National Natural Science Foundation of China (No. 62473139), in part by Helmholtz Association of German Research Centers, in part by the MWK through the Cooperative Graduate School Accessibility through AI-based Assistive Technology (KATE) under Grant BW6-03, and in part by Hangzhou SurImage Technology Co. Ltd.
References
- [1] Achanta, R., Hemami, S., Estrada, F., Susstrunk, S.: Frequency-tuned salient region detection. In: Proc. CVPR (2009)
- [2] Borji, A., Itti, L.: State-of-the-art in visual attention modeling. IEEE Transactions on Pattern Analysis and Machine Intelligence (2013)
- [3] Chen, G., et al.: Modality-induced transfer-fusion network for RGB-D and RGB-T salient object detection. IEEE Transactions on Circuits and Systems for Video Technology (2022)
- [4] Chen, G., et al.: Fusion-embedding siamese network for light field salient object detection. IEEE Transactions on Multimedia (2023)
- [5] Chen, Y., Li, G., An, P., Liu, Z., Huang, X., Wu, Q.: Light field salient object detection with sparse views via complementary and discriminative interaction network. IEEE Transactions on Circuits and Systems for Video Technology (2023)
- [6] Chen, Z., Xu, Q., Cong, R., Huang, Q.: Global context-aware progressive aggregation network for salient object detection. In: Proc. AAAI (2020)
- [7] Cong, R., Huang, K., Lei, J., Zhao, Y., Huang, Q., Kwong, S.: Multi-projection fusion and refinement network for salient object detection in 360° omnidirectional image. IEEE Transactions on Neural Networks and Learning Systems (2023)
- [8] Cong, R., et al.: Does thermal really always matter for RGB-T salient object detection? IEEE Transactions on Multimedia (2023)
- [9] Deng, X., Zhang, P., Liu, W., Lu, H.: Recurrent multi-scale transformer for high-resolution salient object detection. In: Proc. MM (2023)
- [10] DeVries, T., Taylor, G.W.: Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552 (2017)
- [11] Ekin, B., Dandelion, V., Le, Q.V.: AutoAugment: Learning augmentation policies from data. In: Proc. CVPR (2019)
- [12] Fan, D.P., Cheng, M.M., Liu, Y., Li, T., Borji, A.: Structure-measure: A new way to evaluate foreground maps. In: Proc. ICCV (2017)
- [13] Fan, D.P., Lin, Z., Zhang, Z., Zhu, M., Cheng, M.M.: Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Transactions on Neural Networks and Learning Systems (2021)
- [14] Fan, D.P., Zhai, Y., Borji, A., Yang, J., Shao, L.: BBS-Net: RGB-D salient object detection with a bifurcated backbone strategy network. In: Proc. ECCV (2020)
- [15] Florea, C., Vertan, C., Florea, L.: SoftClusterMix: Learning soft boundaries for empirical risk minimization. Neural Computing and Applications (2023)
- [16] Fu, K., Fan, D.P., Ji, G.P., Zhao, Q., Shen, J., Zhu, C.: Siamese network for RGB-D salient object detection and beyond. IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
- [17] Gao, W., Fan, S., Li, G., Lin, W.: A thorough benchmark and a new model for light field saliency detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (2023)
- [18] Georgiev, T., Intwala, C.: Light field camera design for integral view photography. Adobe System, Inc., Technical Report (2006)
- [19] Han, D., Ye, T., Han, Y., Xia, Z., Song, S., Huang, G.: Agent attention: On the integration of softmax and linear attention. In: Proc. ECCV (2024)
- [20] Jiang, Y., Zhang, W., Fu, K., Zhao, Q.: MEANet: Multi-modal edge-aware network for light field salient object detection. Neurocomputing (2022)
- [21] Jing, D., Zhang, S., Cong, R., Lin, Y.: Occlusion-aware bi-directional guided network for light field salient object detection. In: Proc. MM (2021)
- [22] Li, N., Ye, J., Ji, Y., Ling, H., Yu, J.: Saliency detection on light field. In: Proc. CVPR (2014)
- [23] Pang, Y., Zhao, X., Zhang, L., Lu, H.: Multi-scale interactive network for salient object detection. In: Proc. CVPR (2020)
- [24] Perazzi, F., Krähenbühl, P., Pritch, Y., Hornung, A.: Saliency filters: Contrast based filtering for salient region detection. In: Proc. CVPR (2012)
- [25] Piao, Y., Jiang, Y., Zhang, M., Wang, J., Lu, H.: PANet: Patch-aware network for light field salient object detection. IEEE Transactions on Cybernetics (2023)
- [26] Salehi, S., Erdogmus, D., Gholipour, A.: Tversky loss function for image segmentation using 3D fully convolutional deep networks. In: Proc. MLMI@MICCAI (2017)
- [27] Sun, F., Ren, P., Yin, B., Wang, F., Li, H.: CATNet: A cascaded and aggregated transformer network for RGB-D salient object detection. IEEE Transactions on Multimedia (2023)
- [28] Wang, T., Piao, Y., Li, X., Lu, H.: Deep learning for light field saliency detection. In: Proc. ICCV (2019)
- [29] Wang, W., Shen, J., Porikli, F.: Saliency-aware geodesic video object segmentation. In: Proc. CVPR (2015)
- [30] Wang, W., et al.: PVT v2: Improved baselines with pyramid vision transformer. Computational Visual Media (2022)
- [31] Wang, Y., Wang, R., Fan, X., Wang, T., He, X.: Pixels, regions, and objects: Multiple enhancement for salient object detection. In: Proc. CVPR (2023)
- [32] Wei, J., Wang, S., Huang, Q.: F3Net: Fusion, feedback and focus for salient object detection. In: Proc. AAAI (2020)
- [33] Xiao, Z., Liu, Y., Gao, R., Xiong, Z.: CutMIB: Boosting light field super-resolution via multi-view image blending. In: Proc. CVPR (2023)
- [34] Yuan, B., Jiang, Y., Fu, K., Zhao, Q.: Guided focal stack refinement network for light field salient object detection. In: Proc. ICME (2023)
- [35] Zhang, C., Li, X., Zhang, Z., Cui, J., Yang, B.: BO-Aug: learning data augmentation policies via bayesian optimization. Applied Intelligence (2023)
- [36] Zhang, J., et al.: Delivering arbitrary-modal semantic segmentation. In: Proc. CVPR (2023)
- [37] Zhang, J., et al.: Uncertainty inspired RGB-D saliency detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
- [38] Zhang, J., Wang, M., Lin, L., Yang, X., Gao, J., Rui, Y.: Saliency detection on light field: A multi-cue approach. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) (2017)
- [39] Zhang, M., Fei, S.X., Liu, J., Xu, S., Piao, Y., Lu, H.: Asymmetric two-stream architecture for accurate RGB-D saliency detection. In: Proc. ECCV (2020)
- [40] Zhang, M., Ji, W., Piao, Y., Li, J., Zhang, Y., Xu, S., Lu, H.: LFNet: Light field fusion network for salient object detection. IEEE Transactions on Image Processing (2020)
- [41] Zhang, M., Li, J., Wei, J., Piao, Y., Lu, H.: Memory-oriented decoder for light field salient object detection. In: Proc. NeurIPS (2019)
- [42] Zhang, M., Ren, W., Piao, Y., Rong, Z., Lu, H.: Select, supplement and focus for RGB-D saliency detection. In: Proc. CVPR (2020)
- [43] Zhang, M., Xu, S., Piao, Y., Lu, H.: Exploring spatial correlation for light field saliency detection: Expansion from a single view. IEEE Transactions on Image Processing (2022)
- [44] Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable DETR: Deformable transformers for end-to-end object detection. In: Proc. ICLR (2021)