[2,5]\fnmTao \surLin
[3,4]\fnmHongyu \surChen
1]\orgnameZhejiang University, \orgaddress\cityHangzhou, \postcode310030, \stateZhejiang, \countryChina
2]\orgdivDepartment of Computer Science and Engineering, School of Engineering, \orgnameWetlake University, \orgaddress\cityHangzhou, \postcode310030, \stateZhejiang, \countryChina
3]\orgdivDepartment of Chemistry, School of Science and Key Laboratory for Quantum Materials of Zhejiang Province, \orgnameWetlake University, \orgaddress \cityHangzhou, \postcode310030, \stateZhejiang, \countryChina
4]\orgdivInstitute of Natural Sciences, \orgnameWestlake Institute for Advanced Study, \orgaddress\cityHangzhou, \postcode310024, \countryChina
5]\orgdivResearch Center for Industries of the Future, \orgnameWetlake University, \orgaddress\cityHangzhou, \postcode310030, \stateZhejiang, \countryChina
Leveraging large language models for nano synthesis mechanism explanation: solid foundations or mere conjectures?
Abstract
With the rapid development of artificial intelligence (AI), large language models (LLMs) such as GPT-4 have garnered significant attention in the scientific community, demonstrating great potential in advancing scientific discovery. This progress raises a critical question: are these LLMs well-aligned with real-world physicochemical principles? Current evaluation strategies largely emphasize fact-based knowledge, such as material property prediction or name recognition, but they often lack an understanding of fundamental physicochemical mechanisms that require logical reasoning. To bridge this gap, our study developed a benchmark consisting of 775 multiple-choice questions focusing on the mechanisms of gold nanoparticle synthesis. By reflecting on existing evaluation metrics, we question whether a direct true-or-false assessment merely suggests conjecture. Hence, we propose a novel evaluation metric, the confidence-based score (c-score), which probes the output logits to derive the precise probability for the correct answer. Based on extensive experiments, our results show that in the context of gold nanoparticle synthesis, LLMs understand the underlying physicochemical mechanisms rather than relying on conjecture. This study underscores the potential of LLMs to grasp intrinsic scientific mechanisms and sets the stage for developing more reliable and effective AI tools across various scientific domains.
keywords:
Large langauge models, evaluation, physicochemical mechanisms, c-score1 Introduction
Achieving precise synthesis has long been a dream for materials chemists. This involves using a range of controllable material synthesis techniques to create materials with specific structures and properties based on the underlying physicochemical mechanisms. [1, 2, 3, 4] To overcome the limited scope of each set of synthetic conditions, building connection across a wide range of methods and scenarios is crucial. [5, 6] This would expand the feasibility and adaptability of synthetic processes, ultimately enabling the tailored production of materials to meet specific scientific and technological requirements. [7, 8, 9]
Standing at the forefront of the times, designing cutting-edge deep learning methods combined with existing knowledge is one of the most promising methods to achieve controllable material synthesis. [10, 11, 12] It is important to note that all literature are written in human languages. In this context, large language models (LLMs), such as GPT-4, are promising solution to complex problems. It has demonstrated exceptional results in autonomous biological and chemical synthesis experiments, amongst other domains, because of their learning ability. [13, 14, 15, 16, 17, 18, 19] Despite efforts to let LLMs deal with synthesis tasks, a critical question remains: do these LLMs grasp the realworld physicochemical principles? Solid foundations or mere conjectures?

Among existing investigations, the common and straightforward approach for answering this question is fact-based evaluation, which can measure the learning performance of the model. [20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30]. Meanwhile, evaluating the cognitive logic behind the principles is far more challenging yet essential for addressing key scientific issues. [31] For instance, Alexander Fleming observed that bacteria could not survive where mold grew—a simple fact. Yet, this correlation alone could not explain why the mold inhibited bacterial growth. Through reasoning, Fleming discovered the penicillin. This case underlines the critical role of reasoning in scientific research.
Inspired by the research of nanomaterial synthesis, we embark on a feasibility study regarding whether LLMs can truly comprehend underlying physicochemical principles. Specifically, we construct 775 expert-level test questions, covering six primary methods of gold nanoparticle synthesis and six major categories of nanomaterial structures, to thoroughly assess the capabilities of current LLMs, more details are shown in Method section. In this work, our contribution encompasses the following key elements, also shown in Figure 1:
-
1.
We propose a synthetic mechanistic descriptor, grouped by initial conditions, variable adjustments, and experimental observations, to deal with the material synthesis mechanism study.
-
2.
A benchmark of gold nanoparticle synthesis mechanisms, including 775 multiple selection questions focusing on synthesis experiments, is built by using the descriptor.
-
3.
A confidence-based score (c-score) is introduced, offering an interpretable measurement of LLMs to understand complex synthesis mechanisms.
2 Method
2.1 Preparation of datasets

The dataset for evaluation was meticulously selected from high-quality papers boasting an IF 15, with a particular emphasis on synthesis methods for controlling the structure of gold nanoparticles. To ensure the relevance and quality of the papers to meet the theme of gold nanoparticle synthesis, we manually reviewed over 220 articles from a diverse range of publishers and esteemed scientific journals. Each paper underwent a process of key experimental information extraction, leading to the summarization and collection of 775 experimental records, categorized under a condition-observation-mechanism fashion. This structure serves as a descriptor for expressing any controlled experiment and is a usual loop for discovering synthesis principles. This systematic design not only enabled the creation of a unified framework of descriptors to assist in compiling test questions, but also, given the unstructured nature of mechanistic expression in nanomaterial synthesis, emphasized the importance of using average sampling in the design of the evaluation set. In this approach, the dataset distribution and cases are shown in Figure 2, and we address three pivotal issues and challenges:
-
1.
The keywords classification of evaluation content and the synthesis of knowledge for uniform sampling in this domain.
-
2.
The precise extraction of conclusions and the completeness of experiment conditions in each report.
-
3.
The completeness of correlation between experimental conclusions and mechanisms of nanomaterial synthesis.
Regarding the keywords classification issue, our evaluation perspective is based on either material synthesis methods or material morphology. The former category predominantly focuses on the seed-mediated synthesis method, a commonly utilized approach for synthesizing nanoparticles with complex structures. The latter category emphasizes mechanisms more generally applicable to nanocyrstals, rod-shaped particles, and some unmarked systems, with their distribution illustrated in Figure 2a. Two distributions of the data indicate a wide range knowledge points of gold nanoparticle synthesis considered in this work.
For the insight extraction problem, we employed cue word engineering in conjunction with predefined descriptors to extract the descriptions of synthesis experiments from each paper. This was achieved by using pre-defined prompts and then, manual checking. It was determined that for each report, on average, experimental report included five particularly relevant initial conditions and three sets of experimental setups, such as the increase or decrease of certain parameters, the presence or absence thereof, along with a corresponding number or more of observations leaning towards conclusions, as shown in Figure 2b, each point represents a scientific report. To facilitate easier visualization, we applied a jittering technique, meaning that each point was moved slightly by adding a small random values to the integer coordinates.
For mechanism completeness, we posit that accurate division based on mechanistic tendencies can significantly enhance the precision of model evaluation. However, considering the inherent bias in dividing mechanisms—where a handful of studies fail to report complete and comprehensive descriptions of mechanisms compared to the average, and there exists a wide variance in the interpretation of complete mechanisms. To illustrate this point, we employ the GPT-4 via OpenAI API to model in conjunction with cue words for a more detailed division of mechanistic tendencies. Previous research has indicated that there is no large gap in evaluation between humans and LLMs even in the specific area of material science. Meanwhile, we also confirmed that 775 questions are almost making the accuracy converged for evaluating LLMs according to their performance in this task, see supplementary information (Figure S1) for more details. Furthermore, we discovered that the utilization of cue word engineering with the GPT-4 model enables rapid acquisition of summaries for nanomaterials papers, which is also demonstrated in existing work. [32, 33, 16]
Furthermore, we discovered that the utilization of cue word engineering with the GPT-4 model enables rapid acquisition of summaries for nanomaterials papers, which is also demonstrated in another work. [34] This capability extends even to articles that do not contain experimental data (such as literature reviews, opinions, and comments), wherein GPT-4 provides feedback indicating the absence of extractable content, thereby demonstrating GPT-4’s honesty in responding to user queries.
Ultimately, we can rephrase this refined condition-observation pair-wise data into a standardized format of questions and options with the gold answer using the GPT-4 along with predefined instructions, one case is shown in Figure 2c. These are formatted as multiple-choice questions with four options. Notably, sampling analyses have shown that the powerful paraphrasing capabilities of GPT-4 enable it to convert these data into equivalent test questions smoothly. Furthermore, we can filter, adjust and summarize them through modifications of cue words as deemed appropriate. For detailed methodologies on the aforementioned cue word engineering, and prompt with instructions, please refer to the supplementary information (Note S1).
2.2 LLM Baselines
We choose multiple existing models with different architectures and features for comparison, to better consider the inner design differences.
Vicuna Paradigm. Vicuna represents a pioneering effort within the open-source community. This model, conceptualized and refined by LMSYS, undergoes an extensive fine-tuning process leveraging the LLaMA series models [35], trained on a dataset comprising 70,000 user-generated dialogs. Furthermore, Vicuna is distinguished as one of the preeminent models within the subset of LLaMA-2 fine-tuned models (for vicuna-v1.3 and v1.5 versions), attributed to its superior training quality and the voluminous corpus of data it utilizes. [36]
Mistral and Mixtral architectures. Developed by Mistral.AI, these models represent two distinct approaches within the field of AI. The Mistral model integrates a Grouped-Query Attention mechanism to enhance inference speed and employs Sliding Window Attention to efficiently manage extended sequences with reduced computational demands. Conversely, the Mixtral model adopts an innovative architecture characterized by a high-quality Sparse Mixture of Experts. This decoder-only framework enables the feedforward block to select from eight unique parameter groups, with a router network at each layer determining the optimal combination of two groups, known as experts, to process each token and amalgamate their outputs in an additive fashion. [37, 38]
Qwen series. These models are meticulously fine-tuned using a dataset curated to align with a diverse range of tasks, including conversation, tool utilization, agency, and safety protocols. A notable distinction of the Qwen models lies in their token representation capacity. The 7B model processes 2.4 trillion tokens, while the 14B model handles 3.0 trillion tokens. This positions Qwen at the pinnacle of token representation capabilities compared to other models in its category. [39]
Gemma framework. The Gemma model encapsulates a series of lightweight, cutting-edge open-source models that draw from the same foundational research and technological advancements underpinning the Gemini models. This lineage of models is celebrated for their formidable performance metrics, notably in comparison to the GPT-4 model. [40]
Other framewroks. In the evaluation of models including, but not limited to, GPT-4 (gpt-4-0125-preview) and Claude 3 (claude-3-ops-20240229), our analysis endeavors to assess them based upon their sophisticated capabilities in solving general problems. It is pertinent to note that these models are not made available as open-source; nevertheless, they are developed through the training on extensive corpuses of data, encompassing a wide array of domains. This approach underscores the depth and breadth of knowledge these models can potentially harness, despite the proprietary nature of their development methodologies. In addition, Gemini is not considered due to its accessibility, thus, we use Gemma for a case to test its behavior. [13]
2.3 Evaluation metrics
The most direct metric for evaluation is the use of accuracy to assess the comprehensive performance of models across a certain number of test questions, with higher scores indicating stronger capabilities. This is widely used in various tasks, and benefits from a design similar to that of comprehensive human knowledge tests, directly aiming at the logical reasoning and knowledge understanding abilities of language models through a multiple-choice question format. [41, 42]
In this work, we aim for the model to answer the question with confidence, reflecting a quantitative understanding of the intrinsic sequential logic in material synthesis. Thus, we further evaluate LLMs by introducing the c-score with knowledge probing techniques, and more designing details are shown in the results section. Here we treat statistical accuracy, with the counting of true-or-false, as a baseline metric to evaluate the comprehensive capabilities of models, to explore their performance relative to random guessing.
To sum up, two perspectives with the proposed benchmark are illustrated regarding whether LLMs understand physicochemical principles, i.e., true-or-false-based accuracy, and ensure the discernment of correct answers, i.e., confidence-based score, as shown in Figure 2d. To achieve this, with a preliminary study of temperature effects on LLMs for examining the degree of stability, we use both intuitive accuracy and c-score to judge the capabilities of models in recognizing physicochemical principles.

3 Results
3.1 Temperature Effect Analysis

Language models based on the transformer architecture predict the next token through an autoregressive approach and iteratively generate the output for an entire sentence. This method also allows for the adjustment of the probability distribution of the final predicted token.
The decision to adjust the probability distribution using the temperature setting in language models is inspired by statistical thermodynamics, where a higher temperature signifies a greater likelihood of overcoming energy barriers. In probability models, logits function as a representation of kinetic energy. Low temperatures lead to a more concentrated distribution of values, whereas higher temperatures yield a dispersed distribution. The introduction of temperature into logits facilitates temperature sampling, which, upon being fed into the Softmax function, yields sampling probabilities.
To examine the degree of stability, we investigated the impact of different temperatures on the performance of language models. We uniformly selected five temperature values ranging from 0 to 1, specifically 0.1, 0.3, 0.5, 0.7 and 0.9, to conduct controlled experiments. As demonstrated in the Figure 4, there is a trend of precision decline in models as temperature increases, with certain models exhibiting more complex fluctuations. For instance, both claude-3-ops-20240229, gpt-4-0125-preview, Mixtral-8x7B-Instruct-v0.1, Mistral-7B-Instuct-v0.2 and gpt-3.5-turbo showed a trend where accuracy initially decreased and then increased as the temperature slightly rose.
From the final outcomes, it is evident that temperature exerts a patterned influence on the performance of language models. Although there remains a possibility of incorrect responses, extensive statistical evidence suggests that their overall performance is marginally superior to that observed at higher temperatures, demonstrating an assured stability.
3.2 Results of Accuracy with Temperature
It is widely recognized that the capabilities of language models are predicated upon two distinct phases: pre-training and fine-tuning. On one hand, the method of pre-training is acknowledged to endow models with an understanding of context. Since it necessitates that language models predict masked words by comprehending the context (or the surrounding words), to elucidate, when describing a dog, one needs to employ descriptions such as a tailed mammal, mankind’s best friend, etc., leveraging context to grasp the meaning of dog. On the other hand, the fine-tuning process equips language models with a degree of obedience to instructions and the ability for sustained dialogue, with its efficacy contingent upon the volume, variety of the final dataset, and the process of the model fine-tuning.
Contemporary large language models rely on the aforementioned pre-training and fine-tuning learning processes. Consequently, multiple-choice questions serve as one of the effective methods to evaluate the level of reasoning ability of the language model in a specific domain. This implies that the language model needs to provide answers according to the domain knowledge learned during the pre-training phase and the comprehensive abilities acquired during the fine-tuning phase, as required by the question.
The content we aim to evaluate primarily unfolds from two aspects:
-
1.
The themes encompassed by the multiple-choice questions represent the knowledge being assessed, aiming to evaluate the understanding of the model in terms of the concepts and semantics demonstrated within the sentences.
-
2.
This question format supports both the different mechanisms expression and the examination of the language model’s logical reasoning abilities, assessing whether it can answer based on the fundamental principles of gold nanoparticle synthesis.
In order to obtain the binary accuracy of the model, for each multiple-choice questions, one point will be given to the model if it selected the gold answer, otherwise zero. This process will also be repeated with different temperature settings, i.e., from 0.1 to 0.9 with 5 steps. Finally, the average score of each model will be ranked.
As illustrated in Figure 3a, all models significantly surpass the random guessing baseline of 25% with a remarkable margin, consistent with their capabilities in general tasks.
It is worth noting that Claude and GPT-4 are the best performing models in this evaluation, with accuracies of 84.8% and 80.5%, respectively. The other open source models are not very competitive, with accuracies around 70% or lower, showing a huge gap with the top two. Specifically, Claude and GPT-4 have outstanding performance on a wide range of benchmarks due to their excellent training. The open source models may perform relatively poorly due to a variety of reasons such as the type and quality of training data and model size. Among them, the Mixtral-8x7B model performs slightly better than all other open-sourced models tested, with an accuracy of about 70.4%. Gemma has an accuracy of about 44.7%, which is the last one in our evaluation. However, its accuracy is still much higher than 25% (random guess). In addition, the accuracy of other models is in the middle level, their accuracy values can be found in the supplementary information (Table S1). To sum up, we believe that all of these tested LLMs can explain some physicochemical principles, whether basic or complex, showing future potential in explaining synthetic mechanisms.
3.3 Results of C-scores with Temperature

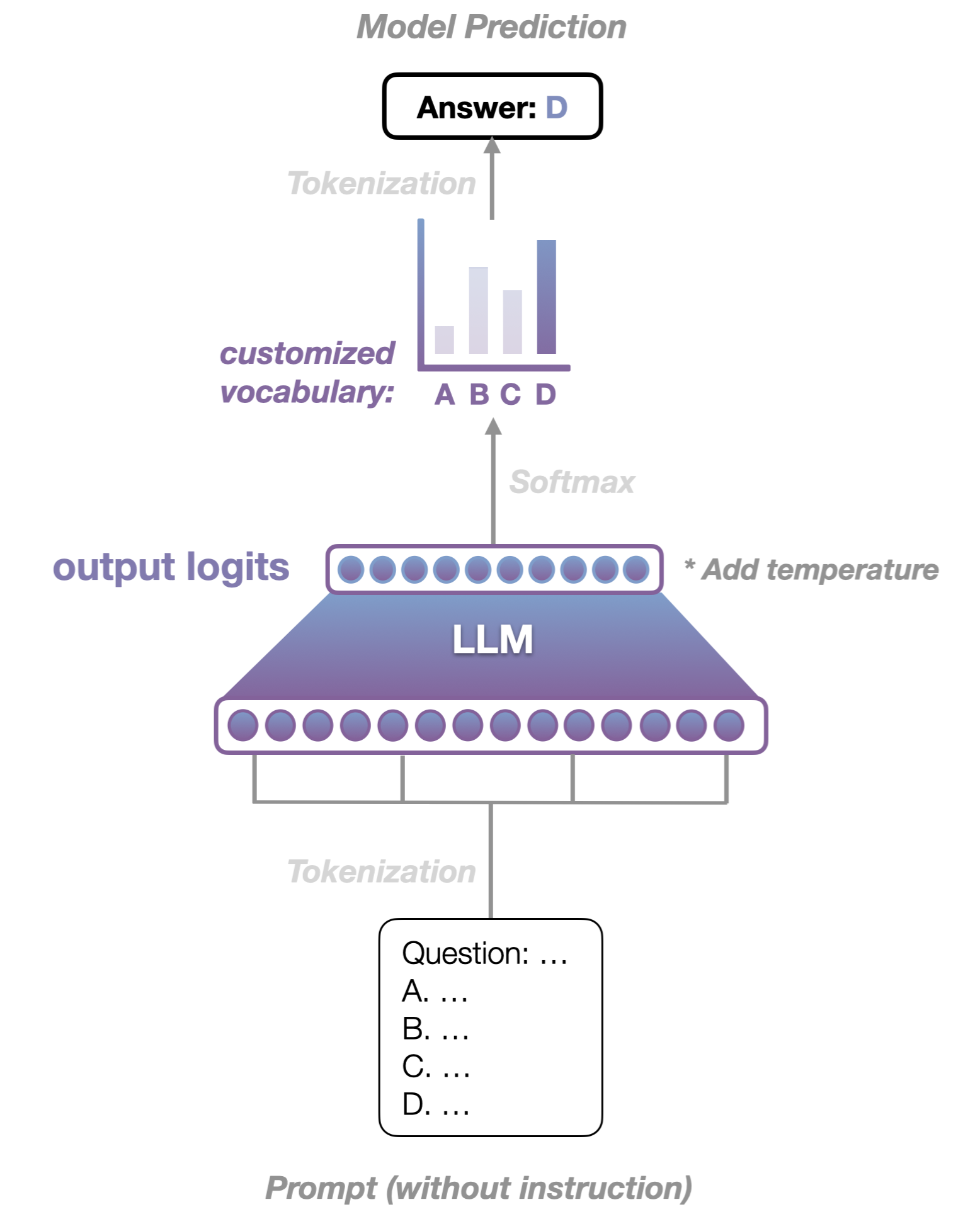
Knowledge probing is a method designed to assess the capacity of language models, such as those in the GPT series, to understand and recall specific knowledge domains. This technique evaluates the model’s comprehension by analyzing the probability distribution of tokens corresponding to the logits in the model’s output. Since the prediction of the next token is governed by the distribution of logits and transformed by the Softmax function, each token is assigned a probability. Our focus is directed towards a subset of tokens with higher probabilities rather than a singular output result, as illustrated in Figure 5. Typically, a sharper distribution of predicted token probabilities indicates a higher certainty in the model response, and vice versa. This design enables an analysis of the model’s responses to varied queries, discerning whether they are grounded in solid theoretical understanding or merely speculative guesses.
In our study, we examine the distribution at the logits layer before the model responses, which is considered an indicator of confidence, to better address the aforementioned question. We further assess this by combining previous accuracy metrics with c-score. In past multiple-choice assessments, the final answer of the model is assumed to be chosen with 100% confidence, meaning that either True or False only. This inspires us to measure its capabilities directly by the percentage of the gold answer’s confidence, even the model chooses the drinkable gold answer. We here evaluate the overall confidence using the formulated c-score, which quantifies the confidence level assigned to each correct answer, as detailed in the E.q. 1:
| (1) |
where is the probability (or confidence) of gold answer regarding the i-th question and is for other options. The probability of all options (assume four here) is normalized exponentially and N is the number of all questions.
Specifically, based on the evaluation of accuracy, we further evaluate the top-5 ranked open-source models with c-score for efficient comparison, considering only models that excel in the benchmark. These models represent typical scales in the open-source community. The evaluation process will also be repeated with different temperature settings, as mentioned before (0.1, 0.3, 0.5, 0.7 and 0.9). Finally, the average c-scores of top-5 models will be ranked for discussion due to their competitive performances.
Regarding the results, as shown in Figure 3, the Vicuna-33B exhibits a lower level of performance, whereas the other models showed slight improvements in the c-score compared to accuracy. In detail, the c-score of Mixtral-8x7B improves by about 8% compared to the accuracy, while the c-score of Vicuna-33B decreases by about 6%. This indicates a clear confidence difference between the two models. Similarly, Vicuna-13B, Mistral-7B and Vicuna-7B demonstrate remarkable differences between accuracy and c-scores. The results indicate that the c-score effectively measures the ability of LLMs in gold nanoparticle synthesis tasks in an interpretable manner. Such metrics suggest that utilizing c-score allows for a more appropriate assessment of language models compared with pure accuracy, revealing insights distinct from traditional accuracy statistics.
For a direct view of the knowledge probing, we showcase a probing result in Figure 6, where we consider the temperature effects, which are represented by the error bar. Here, option A is correct, because the higher the supersaturation (reduction rate), the more unbalanced the growth of the gold particle morphology will be, and thus a nanoparticle morphology with a high-index crystal face or high curvature will be developed. Options B, C, and D have opposite statements. For each model tested, except for option B, there is a tendency to choose A, C, and D – with a higher confidence. Among them, Mistral-7B has a confidence of nearly 100% for the correct option A, and a tendency for other options is almost 0. This result shows that the model has sufficient and solid learning of this knowledge point, and can distinguish the nanosynthesis logic involved in this question, while other models are more confused. One possible reason is that the model is interfered by certain keywords, resulting in a confidence level of about 50%. Some other examples of knowledge probing are in supplementary information (Note S2).
4 Related Work
In the field of materials science, existing datasets predominantly support tasks focused on factual knowledge, such as named entity recognition and classification. [20, 21, 22, 43] Researchers utilize these datasets to benchmark the performance of language models in the materials domain.
Previously, three key chemistry-related capabilities in LLMs, understanding, reasoning, and explaining have been identified, and a benchmark containing eight chemistry tasks has been established. [28] Meanwhile, the potential of large language models to perform scientific synthesis, inference, and explanation across many domains for scientific discovery has been discussed, although this approach is based solely on knowledge graph inference. [29] To expend the task diversity, LLMs such as GPT-3 have been benchmarked on datasets spanning the chemical space, including molecules, materials, and reactions, across diverse tasks such as classification, regression, and inverse design. [27] With the continuous growing of the LLMs, a dataset of 650 challenging questions from the materials domain, requiring the knowledge and skills of a materials science student who has completed their undergraduate degree, has been curated. [23]
While significant progress has been made in benchmarking, there remains a need for more comprehensive evaluations that encompass the full spectrum of capabilities required for advanced scientific applications. This includes the ability to reason about mechanisms and the fundamental rules of physics and chemistry. Our study developed a benchmark consisting of 775 multiple-choice questions focusing on the mechanisms of gold nanoparticle synthesis and propose a novel evaluation metric, the confidence-based score (c-score), which probes the output logits to derive the precise probability for the correct answer.
5 Conclusion
In this study, we introduced a novel evaluation method for assessing LLMs in the context of materials science, specifically focusing on the synthesis of gold nanoparticles. Our approach encompassed the development of 775 multiple-choice questions addressing both synthesis methods and morphological structures. By employing knowledge probing and confidence scores (c-scores), we evaluated a range of mainstream open-source and closed-source LLMs. The results of our evaluation demonstrate that c-scores are more effective in discerning whether LLMs’ contributions to the synthesis tasks are rooted in an understanding of the physicochemical mechanisms, rather than mere recall of information. This finding underscores the importance of assessing the models’ comprehension and logical reasoning abilities, which are crucial for facilitating genuine scientific discoveries. In conclusion, our study not only highlights the potential of LLMs in advancing materials science but also sets a precedent for the rigorous evaluation of their scientific and logical reasoning capabilities. The insights gained from this research can inform the development of more sophisticated models that are capable of making meaningful contributions to scientific discovery.
Data and code availability
The dataset created for this study, along with the testing code, is available in the GitHub repository at https://github.com/Dandelionym/llm_for_mechanisms.git. This repository contains all relevant data and scripts necessary to replicate our experiments and results.
References
- \bibcommenthead
- Li et al. [2014] Li, N., Zhao, P., Astruc, D. Anisotropic gold nanoparticles: synthesis, properties, applications, and toxicity. Angewandte Chemie 53 7, 1756–89 (2014)
- Yang et al. [2022] Yang, R.X. et al. Big data in a nano world: A review on computational, data-driven design of nanomaterials structures, properties, and synthesis. ACS Nano 16, 19873–19891 (2022)
- Sun and Xia [2002] Sun, Y., Xia, Y. Shape-controlled synthesis of gold and silver nanoparticles. Science 298, 2176–2179 (2002)
- Tang et al. [2020] Tang, B. et al. Machine learning-guided synthesis of advanced inorganic materials. Materials Today 41, 72–80 (2020)
- Szymanski et al. [2021] Szymanski, N.J. et al. Toward autonomous design and synthesis of novel inorganic materials. Materials Horizons 8(8), 2169–2198 (2021)
- Wang et al. [2023] Wang, H. et al. Scientific discovery in the age of artificial intelligence. Nature 620, 47–60 (2023)
- Xia et al. [2009] Xia, Y., Xiong, Y., Lim, B., Skrabalak, S.E.: Shape-controlled synthesis of metal nanocrystals: simple chemistry meets complex physics? Angewandte Chemie 48 1, 60–103 (2009)
- Wang et al. [2010] Wang, F. et al. Simultaneous phase and size control of upconversion nanocrystals through lanthanide doping. Nature 463, 1061–1065 (2010)
- Xing et al. [2009] Xing, S. et al. Highly controlled core/shell structures: tunable conductive polymer shells on gold nanoparticles and nanochains. Journal of Materials Chemistry 19, 3286–3291 (2009)
- So et al. [2020] So, S., Badloe, T., Noh, J.-K., Bravo-Abad, J., Rho, J.: Deep learning enabled inverse design in nanophotonics. Nanophotonics 9, 1041–1057 (2020)
- Choudhary et al. [2021] Choudhary, K. et al. Recent advances and applications of deep learning methods in materials science. npj Computational Materials 8, 1–26 (2021)
- Tao et al. [2021] Tao, H., Wu, T., Aldeghi, M., Wu, T. C., Aspuru-Guzik, A., Kumacheva, E. Nanoparticle synthesis assisted by machine learning. Nature reviews materials 6(8), 701–716 (2021)
- Achiam et al. [2023] Achiam, O.J. et al. Gpt-4 technical report. Preprint at https://arxiv.org/abs/2303.08774 (2023).
- Xiao et al. [2023] Xiao, Z., Li, W., Moon, H., Roell, G. W., Chen, Y., Tang, Y. J. Generative Artificial Intelligence GPT-4 Accelerates Knowledge Mining and Machine Learning for Synthetic Biology. ACS Synthetic Biology 12(10), 2973–2982 (2023).
- AI4Science and Quantum [2023] AI4Science, M. R., Quantum, M. The impact of large language models on scientific discovery: a preliminary study using gpt-4. Preprint at https://arxiv.org/abs/2311.07361 (2023)
- Zheng et al. [2023] Zheng, Z., Rong, Z., Rampal, N., Borgs, C., Chayes, J. T., Yaghi, O. M. A gpt-4 reticular chemist for guiding mof discovery. Angewandte Chemie 62(46), e202311983 (2023)
- Guo et al. [2023] Guo, T. et al. What can large language models do in chemistry? a comprehensive benchmark on eight tasks. Neural Information Processing Systems Advances in Neural Information Processing Systems 36 59662–59688 (2023).
- Bran et al. [2023] Bran, A. M., Cox, S., Schilter, O., Baldassari, C., White, A. D., Schwaller, P. Augmenting large language models with chemistry tools. Nature Machine Intelligence 1–11 (2024).
- Pyzer-Knapp et al. [2022] Pyzer-Knapp, E. O. et al. Accelerating materials discovery using artificial intelligence, high performance computing and robotics. npj Computational Materials 8(1), 84 (2022)
- Weston et al. [2019] Weston, L. et al. Named entity recognition and normalization applied to large-scale information extraction from the materials science literature. Journal of chemical information and modeling 59(9), 3692–3702 (2019)
- Cruse et al. [2022] Cruse, K. et al. Text-mined dataset of gold nanoparticle synthesis procedures, morphologies, and size entities. Scientific data 9(1), 234 (2022)
- Venugopal et al. [2021] Venugopal, V., Sahoo, S., Zaki, M., Agarwal, M., Gosvami, N.N., Krishnan, N.A. Looking through glass: Knowledge discovery from materials science literature using natural language processing. Patterns 2(7) (2021)
- Zaki et al. [2024] Zaki, M., Krishnan, N.A. Mascqa: investigating materials science knowledge of large language models. Digital Discovery 3(2), 313–327 (2024)
- Jablonka et al. [2023] Jablonka, K.M. et al. 14 examples of how llms can transform materials science and chemistry: a reflection on a large language model hackathon. Digital Discovery 2(5), 1233–1250 (2023)
- Zheng et al. [2023] Zheng, Z., Zhang, O., Borgs, C., Chayes, J.T., Yaghi, O.M. Chatgpt chemistry assistant for text mining and the prediction of mof synthesis. Journal of the American Chemical Society 145(32), 18048–18062 (2023)
- Kang and Kim [2023] Kang, Y., Kim, J. Chatmof: An autonomous ai system for predicting and generating metal-organic frameworks. Preprint at https://arxiv.org/abs/2308.01423 (2023)
- Jablonka et al. [2024] Jablonka, K.M., Schwaller, P., Ortega-Guerrero, A., Smit, B. Leveraging large language models for predictive chemistry. Nature Machine Intelligence. 6(2) 161–169 (2024)
- Guo et al. [2023] Guo, T. et al. What can large language models do in chemistry? a comprehensive benchmark on eight tasks. Advances in Neural Information Processing Systems 36, 59662–59688 (2023)
- Zheng et al. [2023] Zheng, Y. et al. Large language models for scientific synthesis, inference and explanation. Preprint at https://arxiv.org/abs/2310.07984 (2023)
- Thawani et al. [2020] Thawani, A.R. et al. The photoswitch dataset: a molecular machine learning benchmark for the advancement of synthetic chemistry. Preprint at https://arxiv.org/abs/2008.03226 (2020)
- Chang et al. [2024] Chang, Y. et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology 15(3), 1–45 (2024)
- Clark et al. [2021] Clark, E., August, T., Serrano, S., Haduong, N., Gururangan, S., Smith, N.A. All that’s’ human’is not gold: Evaluating human evaluation of generated text. Preprint at https://arxiv.org/abs/2107.00061 (2021)
- Chiang and Lee [2023] Chiang, C.-H., Lee, H.-y. Can large language models be an alternative to human evaluations?. Preprint at https://arxiv.org/abs/2305.01937 (2023)
- Rampal et al. [2024] Rampal, N. et al. Single and multi-hop question-answering datasets for reticular chemistry with gpt-4-turbo. Preprint at https://arxiv.org/abs/2405.02128 (2024)
- Touvron et al. [2023] Touvron, H. et al. Llama: Open and efficient foundation language models. Preprint at https://arxiv.org/abs/2302.13971 (2023)
- Chiang et al. [2023] Chiang, W.-L. et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems. 36, (2023)
- Jiang et al. [2023] Jiang, A.Q. et al. Mistral 7b. Preprint at https://arxiv.org/abs/2310.06825 (2023)
- Jiang et al. [2024] Jiang, A.Q. et al. Mixtral of experts. Preprint at https://arxiv.org/abs/2401.04088 (2024)
- Bai et al. [2023] Bai, J. et al. Qwen technical report. Preprint at https://arxiv.org/abs/2309.16609 (2023)
- Team et al. [2023] Team, G. et al. Gemini: a family of highly capable multimodal models. Preprint at https://arxiv.org/abs/2312.11805 (2023)
- Laskar et al. [2023] Laskar, M.T.R., Bari, M.S., Rahman, M., Bhuiyan, M.A.H., Joty, S.R., Huang, J. A systematic study and comprehensive evaluation of chatgpt on benchmark datasets Preprint at https://arxiv.org/abs/2305.18486 (2023)
- Singhal et al. [2023] Singhal, K. et al. Large language models encode clinical knowledge. Nature 620(7972), 172–180 (2023)
- Kim et al. [2017] Kim, E. et al. Materials synthesis insights from scientific literature via text extraction and machine learning. Chemistry of Materials 29(21), 9436–9444 (2017)