Leveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval
Abstract
Interactive and non-interactive model are the two de-facto standard frameworks in vector-based cross-lingual information retrieval (V-CLIR), which embed queries and documents in synchronous and asynchronous fashions, respectively. From the retrieval accuracy and computational efficiency perspectives, each model has its own superiority and shortcoming. In this paper, we propose a novel framework to leverage the advantages of these two paradigms. Concretely, we introduce semi-interactive mechanism, which builds our model upon non-interactive architecture but encodes each document together with its associated multilingual queries. Accordingly, cross-lingual features can be better learned like an interactive model. Besides, we further transfer knowledge from a well-trained interactive model to ours by reusing its word embeddings and adopting knowledge distillation. Our model is initialized from a multilingual pre-trained language model M-BERT, and evaluated on two open-resource CLIR datasets derived from Wikipedia and an in-house dataset collected from a real-world search engine. Extensive analyses reveal that our methods significantly boost the retrieval accuracy while maintaining the computational efficiency. 111Our codes are released on https://github.com/wutangA/Semi-Interactive-CLIR.
1 Introduction
Conventional cross-lingual information retrieval (CLIR) system mainly separates two stages, i.e., query translation and monolingual information retrieval (Sun, Sia, and Duh 2020; Zhou et al. 2012; Sabet et al. 2019; Li et al. 2020; Yao et al. 2020a). On the contrary, vector-based CLIR (V-CLIR) (Vulic and Moens 2015; Yarmohammadi et al. 2019) employs neural networks to encode input texts and score their associated similarity with end-to-end training, thus avoiding the problem of error propagation in translation-based systems (Wu and He 2010; Bosca and Dini 2010).
A widely used neural-based retrieval framework is deep relevance matching model (DRMM, Guo et al. 2016), which is built upon a unified semantic matching model to generate embeddings for queries and documents. In this paradigm, features of query and document are directly interacted at the representation learning time (being called as interactive mechanism, as shown in Figure 1 (a)), leading to promising results in a variety of information retrieval tasks (Mikolov et al. 2013; Bojanowski et al. 2017). However, in a real-world search engine, a user query has to match with millions of documents in database. When performing the interactive framework, for each query, massive real-time computations have to be carried out for obtaining joint representations.
Towards approaching this problem, existing V-CLIR systems are mainly built with a non-interactive architecture (Huang et al. 2013; Reimers and Gurevych 2019; Lu, Jiao, and Zhang 2020), as shown in Figure 1 (b). This model encodes queries and documents asynchronously, making the offline learning of document representations available. In this way, each query only requires to be encoded once during online inference. Despite its superiority on computational efficiency, such kind of architecture lacks in feature fusion among queries and documents, further raising the difficulty of cross-lingual semantic matching (Reimers and Gurevych 2019; Lu, Jiao, and Zhang 2020). It can be said that how to build a fast yet high-quality deep semantic matching model to enhance V-CLIR still remains a great challenge.


A natural question arises: Is it possible to leverage the advantages of interactive and non-interactive mechanisms simultaneously? In this paper, we propose a novel model named semi-interactive mechanism, as visualized in Figure 1 (c). Concretely, our model is built upon a non-interactive framework to maintain the computational efficiency. In order to narrow the distance between the latent spaces of cross-lingual queries and documents, we fuse the information of a document with its associated multilingual queries, which can be either ready-made or collected from the search log. The representation of document therefore contains rich multilingual contexts. To further leverage the advantage of interactive mechanism, we set a well-trained interactive model as teacher and transfer its knowledge to our model by reusing word embeddings and adopting knowledge distillation at the training time (Sanh et al. 2019; Sun et al. 2019). With these enhancements, the proposed model is able to preserve the online inference speed like a non-interactive model, in the meanwhile, fill the quality gap to its interactive counterpart.
Following the common settings (Yilmaz et al. 2019; Jiang et al. 2020), we build our approach upon a multilingual pre-trained language model – M-BERT (Devlin et al. 2019). The training set is constructed from a large-scale CLIR dataset – WikiCLIR (Sasaki et al. 2018), for Russian-to-English, Spanish-to-English, Portuguese-to-English, French-to-English and Arabic-to-English document retrieval. Our model is examined on both semantic similarity tasks collected from WikiCLIR and document search tasks provided in MULTI-8 (Sun and Duh 2020). Empirical results demonstrate that the proposed semi-interactive mechanism and knowledge transferring progressively improve the retrieval accuracy over non-interactive baseline and marginally drop the inference speed. In addition, we conduct experiments on a real-world search engine. Our model still significantly outperforms non-interactive based approach. Our visualization of representation distribution reveal that the proposed model can approximately transform both query and document representations to a standard orthogonal basis (Su et al. 2021), leading to more discriminative representations for similarity computation.
Major contributions of our work are three-fold:
-
•
We introduce a novel semi-interactive mechanism, offering V-CLIR model ability to combine the advantages of interactive and non-interactive paradigms.
-
•
We propose to transfer knowledge from a well-trained interactive model, thus boosting the retrieval quality of a non-interactive model.
-
•
Extensive analyses indicate the universal-effectiveness of our work and verify that our model is able to learn better representation for multilingual texts.
2 Preliminary
2.1 Cross-Lingual Information Retrieval
CLIR has attracted increasing interests over the past decades. The main challenge is to bridge the language discrepancy between user queries and documents (Nie 2010). Most of existing approaches use translation based technique, which first calls a machine translation (MT) model to translate either queries or documents into the same language (Levow, Oard, and Resnik 2005; Martino et al. 2017), the translation results are then passed to a monolingual IR system. However, such kind of framework requires huge amounts of parallel data, which is scarce for many language pairs and domains in low-resource. In addition, the search results are directly affected by translation accuracy.
With this point, researches start to explore vector-based IR methods (Nigam et al. 2019; Mitra and Craswell 2018; Tai, Ren, and Kita 2002; Mihalcea, Corley, and Strapparava 2006; Bi et al. 2020; Yao et al. 2020b) without the need to build MT systems. In this context, queries and documents are represented as vectors for similarity computation.
2.2 Vector-Based Retrieval Models
Vector-based IR model can be divided into two directions: interactive and non-interactive models.
Interactive Mechanism
Deep relevance matching model (DRMM, Guo et al. 2016) and kernel-based neural ranking model (Xiong et al. 2017, KNRM,) are two representatives under interactive framework. These approaches concatenate and feed query-document pairs into a unified deep neural encoder to learn their representations for semantic matching, as shown in Figure 1(a). Accordingly, features in query and document are interacted and fused, resulting in promising quality on a variety of IR tasks (McDonald, Brokos, and Androutsopoulos 2018). Recent studies further initialize the encoder with large-scale pre-trained language model, such as BERT (Devlin et al. 2019), which brings better model abilities on representation learning and relevance scoring (Jiang et al. 2020). Specifically, given the input token embeddings of a query Q and a document D, the interactive model first encodes them into hidden states:
| (1) |
where indicates the BERT model, represents the concatenation of inputs. Then, a non-linear active function is adopted to calculate the relevance score s over the mean of the output hidden states :
| (2) |
Non-Interactive Mechanism
Contrary to the synchronous encoding procedure in interactive architecture, the representations of queries and documents in non-interactive architecture (Figure 1(b)) are encoded asynchronously (Huang et al. 2013; Shen et al. 2014; Reimers and Gurevych 2019; Lu, Jiao, and Zhang 2020). It employs two encoders for query and document representation learning, respectively. Formally, the representations of query and document are calculated in a separate manner:
| (3) |
A cosine function is assigned for the similarity calculation:
| (4) |
Training
The parameters of both interactive and non-interactive models are optimized by minimizing the cross-entropy loss over the training set:
| (5) |
where denotes the groundtruth relevance label of Q and D.
3 Methodology
3.1 Motivation
To find the most similar document of Q in a collection of millions documents, interactive model has to recompute the joint representation millions times for all the documents. This massive computational overhead makes it unsuitable for real-word search engine (Zhang and Zhai 2015). The superiority of non-interactive architecture lies in the fast online inference. Nevertheless, the lack of interaction between Q and D may cause biases between latent vectors, raising the difficulty on semantic matching. In particular, Q and D in different languages further deteriorate this problem, resulting in unsatisfied retrieval quality.
Accordingly, our goal is to leverage the advantages of interactive and non-interactive models. In this work, we handle this problem from two aspects:
-
•
From the model perspective, we propose semi-interactive module (Figure 1(c)) to encode the representation of a document with its relevant multilingual queries. In this way, multilingual features can be supplemented into the document representation.
-
•
From the optimization perspective, we introduce knowledge transfer methods, in which a well-trained interactive model is regarded as teacher. We reuse its word embeddings and distill its knowledge to our model.
3.2 Semi-Interactive Mechanism
One principle of our model is to maintain the inference speed, in the meanwhile, improve retrieval quality. To this end, we build the proposed model upon a non-interactive architecture. A natural solution to alleviate the discrepancy between latent spaces of query and document is to enhance the document representations with cross-lingual features. Specifically, we propose to provide multilingual contexts for the document encoder. In this way, cross-lingual properties are incorporated at the representation learning time, thus producing more informative representations. More importantly, since each document and its associated contexts can be encoded offline, the computational efficiency is still preserved. We serve the multilingual keywords or queries that is relevant to the document as its multilingual contexts.
As shown in Figure 2, given relevant queries for the document D, where () denotes the -th relevant query, the document encoder produces joint representations by modifying Equation 3 as following:
| (6) |
In this paper, we set as default according to ablation study as Section 5.2 described.
Collecting Relevant Queries
Several potential manners can collect relevant multilingual queries:
-
•
Ready-Made Queries. Several documents have already provided multilingual summarization or keywords. For example, the dataset WikiCLIR (Sasaki et al. 2018) collects large amount of pages of Wikipedia, each of which links with multilingual relevant keywords. For simplification, we can directly collect ready-made relevant queries labeled as “relevant” for each document.
-
•
Mining-Based Queries. For an existing cross-lingual search engine (no matter translation-based or vector-based), the relevant queries for each document can be extracted according to its clickthrough data. The click behavior reflects users’ interests and the latent semantic relationships between the input queries and the clicked documents (Radlinski, Kurup, and Joachims 2008; Ma et al. 2008). We can collect Top queries according to the click-through rate (CTR).
A special circumstances is that there is neither off-the-rack multilingual relevant queries, nor search log. In this paper, we do not take attention into this case, because a vector-based CLIR system even can not be well-trained without large-scale cross-lingual annotated data, letting alone considering the trade-off between efficiency and quality. Despite of that, several few-shot learning approaches in IR contexts can be carried out to handle this problem, such as generating pseudo data using MT (Chidambaram et al. 2019; Yang et al. 2020) and searching associated queries using a preliminary retrieval system (Litschko et al. 2018).

3.3 Knowledge Transfer
Another promising direction is to transfer knowledge from the well-trained interactive model to the non-interactive one. As interactive architecture benefits to the representation learning and relevance scoring, we treat it as a teacher to assist the training of non-interactive models. Our model profits from the teacher model in two aspects: 1) initializing word embeddings of our model with that of teacher model and 2) distilling prediction distribution of teacher model to ours.
Reusing Word Embeddings
The distribution of word embeddings immediately affects the final representations, therefore plays a critical role in neural-based natural language understanding tasks (Levy and Goldberg 2014; Kusner et al. 2015). As cross-lingual queries and documents are jointly encoded by the interactive model, word embeddings have relatively less discrepancy caused by distinct languages. As a result, we reuse the well-trained word embedding layer of the teacher model to initialize that of non-interactive models. We expect this can carry a better initialization for model parameters, thus contribute to the subsequent training procedure.
Knowledge Distillation
Knowledge distillation approach (Ba and Caruana 2014; Hinton, Vinyals, and Dean 2015) enables the transfer of knowledge from a teacher model to a student model, which is improved in the process. Here, we exploit knowledge distillation to guide both non-interactive and semi-interactive model to learn the probability distribution output by a well-trained interactive model. Specifically, given the relevance probability predicted by the teacher model, the goal of distillation is to force our model to fit the probability distribution of the teacher:
| (7) |
The final loss can be formally expressed as:
| (8) |
where is the conventional cross-entropy loss as defined in Equation 5. denotes a factor to balance the two loss, which is set to 0.7 as default according to ablation study as Section 5.2 described.
Recent studies (Tang et al. 2019; Lu, Jiao, and Zhang 2020; Izacard and Grave 2020) has successfully adopted such kind of methods to the area of monolingual IR. For example, Tang et al. (2019) and Lu, Jiao, and Zhang (2020) distill knowledge from the pre-trained language model BERT to a BiLSTM-based model and a non-interactive model, respectively. Contrast with these researches, we are the first to distill knowledge from a interactive model to the semi-interactive one, and examine the effectiveness of knowledge distillation under the cross-lingual scenario. Besides, the input of teacher model and student model are same in prior studies, while ours are different.
4 Experiment Setting
We examine our methods on both semantic similarity task and document search task. In this section, we describe the experimental setting in detail.
| Direction | Training | Validation | Testing | ||||
|---|---|---|---|---|---|---|---|
| WikiCLIR | WikiCLIR |
|
|
||||
| RuEn | 2.2M | 30.0K | 60.0K | 100.0K | |||
| EsEn | 2.8M | 30.0K | 60.0K | 100.0K | |||
| FrEn | 5.0M | 30.0K | 60.0K | 100.0K | |||
| PtEn | 1.6M | 30.0K | 60.0K | - | |||
| ArEn | 0.4M | 30.0K | 60.0K | 100.0K | |||
| DeEn | - | - | - | 100.0K | |||
| JaEn | - | - | - | 100.0K | |||
| ZhEn | - | - | - | 100.0K | |||
| Total | 12.0M | 150.0K | 300.0K | 700.0K | |||
4.1 Training and Validation Set
WikiCLIR (Sasaki et al. 2018) is a large-scale CLIR dataset collected from Wikipedia which has provided positive and negative samples. We construct our training and validation set on English (En) document and five multilingual queries in Russian (Ru), Spanish (Es), French (Fr), Portuguese (Pt) as well as Arabic (Ar). For each language pair, we randomly select 0.4M to 5.0M (M = million) samples as the training set, covering low-resource and high-resource language directions. And 60K (K = thousand) samples are extracted as the validation set for each language direction. The statistics of the used datset is concluded in Table 1. Each document in WikiCLIR has been linked to multiple multilingual queries, we randomly collect ready-made relevant queries labeled as “relevant” for each document in the proposed semi-interactive mechanism. Finally, each sample is formed as: . To cope with the pre-trained language model M-BERT, all the queries and documents are preprocessed following Devlin et al. (2019), the first token is a special classification token ([CLS]) and the document and relevant queries are concatenated with a special token ([SEP]).
4.2 Evaluation Tasks and Metrics
Semantic Similarity
Semantic similarity tasks aim to predict whether query and document are semantically relevant or not. We evaluate our methods on WikiCLIR in five languages: Russian (Ru), Spanish (Es), French (Fr), Portuguese (Pt) as well as Arabic (Ar). For each language pair, we randomly extract 30K samples as the test set. To evaluate the performance, we use the area under the curve (AUC, Lydick, Epstein, and White 1995). Moreover, in order to verify the effectiveness of mining queries from search log, we also conduct a group of experiments on a dataset collected from a real-world search engine, as described in Section 5.4.
| Model | RuEn | EsEn | PtEn | FrEn | ArEn | AVG | Inf.Time(ms) |
|---|---|---|---|---|---|---|---|
| Interact | 90.71 | 96.57 | 96.56 | 96.37 | 90.86 | 94.86 | 45.8 |
| Non-Interact | 77.83 | 80.91 | 79.94 | 80.70 | 80.20 | 78.92 | 8.4 |
| + KT | 79.57 | 83.96 | 82.60 | 83.82 | 78.66 | 81.71 | 8.4 |
| Semi-Interact | 8.9 | ||||||
| + KT | 8.9 |
| Model | Supervised | Unsupervised | |||||
|---|---|---|---|---|---|---|---|
| RuEn | EsEn | FrEn | ArEn | DeEn | ZhEn | JaEn | |
| (Sun and Duh 2020) | 0.7100 | 0.7600 | 0.7600 | 0.6000 | 0.7500 | 0.6300 | 0.7100 |
| Interact | 0.7717 | 0.7954 | 0.8050 | 0.7458 | 0.7579 | 0.7478 | 0.7504 |
| Non-Interact | 0.7052 | 0.6957 | 0.6965 | 0.7135 | 0.6669 | 0.7001 | 0.7062 |
| + KT | 0.7101 | 0.6989 | 0.6982 | 0.7203 | 0.6736 | 0.7024 | 0.7100 |
| Semi-Interact | |||||||
| + KT | |||||||
Document Search
This task is to rank candidate documents by relevance with respect to a multilingual query. Here, we use the test data of MULTI-8 (Sun and Duh 2020) to further evaluate our proposed methods. MULTI-8 is also constructed from Wikipedia but allows for more finergrained levels of relevance. We evaluate our methods on seven multilingual queries (Arabic (Ar), German (De), Spanish (Es), French (Fr), Japanese (Ja), Russian (Ru), and Chinese (Zh)) with each language pair contains 100K samples. Following the default setting in Sun and Duh (2020), we calculate normalized discounted cumulative gain (NDCG, Järvelin and Kekäläinen 2002) to evaluate the search performance.
4.3 Implementation Details
We implement our model and the associated baselines upon Tensorflow. In order to preliminarily map different languages into the same latent space, all the encoders are initialized by the pre-trained cross-lingual language model M-Bert (Devlin et al. 2019).222https://github.com/google-research/bert We follow Lu, Jiao, and Zhang (2020) to build each model with 6 layers in encoders. For the model training, we use Adam optimizer (Kingma and Ba 2015) and set learning rate to 3e-5 with 8K warmup steps. Besides, dropout rate is set to a constant of 0.1 to enhance the model robustness. We train our model on a single Tesla P100 GPU with a mini-batch consisting of 1,024 samples. The training of each model is early-stopped to maximize AUC on the validation set. Other hyper-parameters are assigned with the common finetune configurations described in Devlin et al. (2019). We compare following models:
-
•
Interact: We first build an interactive model as baseline and teacher model. Since there are few studies explore V-CLIR, we build the model following Jiang et al. (2020). Contrary to previous study, we initialize the encoder using multilingual BERT rather than the monolingual version (Devlin et al. 2019).
-
•
Non-Interact: We borrow the advanced monolingual vector-based IR model (Reimers and Gurevych 2019) into the CLIR task as our non-interactive baseline.
-
•
Ours: We examine the proposed semi-interactive mechanism (Semi-Interact) and knowledge transfer method (KT). Considering the former, we randomly select relevant queries for each document. For the latter, we set to 0.7 as default.
5 Results
5.1 Main Results
Results on Semantic Similarity
As shown in Table 2, our model significantly outperforms the non-interactive baseline across different language pairs, demonstrating the universal-effectiveness of the proposed method. In the meanwhile, our model yields over 4 times faster than its interactive counterpart at the inference time.
Concretely, although interactive model outperforms non-interactive model, it significantly increases the inference time and fails to be employed in a real-world IR system. We regard this model as an upper limit of retrieval quality. The proposed semi-interactive mechanism narrows the accuracy gap, which confirms our hypothesis that supplementing the document representation with its relevant multilingual contexts is conductive to V-CLIR. Moreover, the interactions among multilingual queries and documents of our approach are able to be conducted offline, maintaining the superiority of non-interactive model on processing speed.
We assess knowledge transferring on non- and semi-interactive models. Both the models boost the retrieval performance, indicating that transferring knowledge from a well-trained interactive model to non-interactive models is able to narrow the quality gaps among them. Besides, our results demonstrate that the Semi-Interact and KT are complementary to each other, progressively benefiting to the cross-lingual semantic matching.
Results on Document Search
Table 3 shows the NDCG@10 of different models on MULTI-8 document search tasks. Similar to semantic similarity tasks, our method yields consistently better results across language pairs. As a superiority of pre-trained multilingual language model lies in its ability on knowledge transferring, we can transfer knowledge from high-resource languages to low-resource ones in the downstream tasks. Accordingly, we conduct three retrieval tasks that are not considered at the training time. As seen, the proposed methods yield considerable performance on both the three tasks. It is encouraging to see that, although we do not enhance documents with relevant queries in these three languages, the improvements are still preserved on these tasks.
5.2 Ablation Study
In this section, we conduct ablation study of different components on WikiCLIR semantic similarity tasks. We report the average score for simplification.
Effects of the Number of Relevant Queries
We plot Figure 3 (a) to show the effects of the number of relevant queries added to document representation. Specifically, via incorporating queries (N 0), the relevance accuracy increases, confirming that the associated queries are helpful for the document representation learning. We observe that the number with 3 is superior to other settings. When the number of queries goes up (N 3), the classification performance inversely drops. One possible reason is that the conventional semantic meaning of the document may be potentially overlooked when complementing superfluous multilingual queries. This results in biases in document representations and raises the difficulty on relevance prediction.

| Model | Training | ||
|---|---|---|---|
| ✓ | ✗ | ||
| Testing | ✓ | 84.04 | 78.76 |
| ✗ | 79.97 | 78.92 | |
Usage of Semi-Interactive Mechanism
We verify the effect of semi-interactive on different stages, i.e. training and inference. As shown in Table 4, we found that exploiting relevant queries at the training time can consistently improve the performance, no matter relevant queries are utilized or not during inference. When adapting semi-interactive mechanism only in inference, the performance marginally changes. We attribute these to the fact that complementing multilingual contexts during training benefits the representation learning. Our results suggest that carrying out our method on both training and inference stages performs best.
Effects of Factor in Distillation
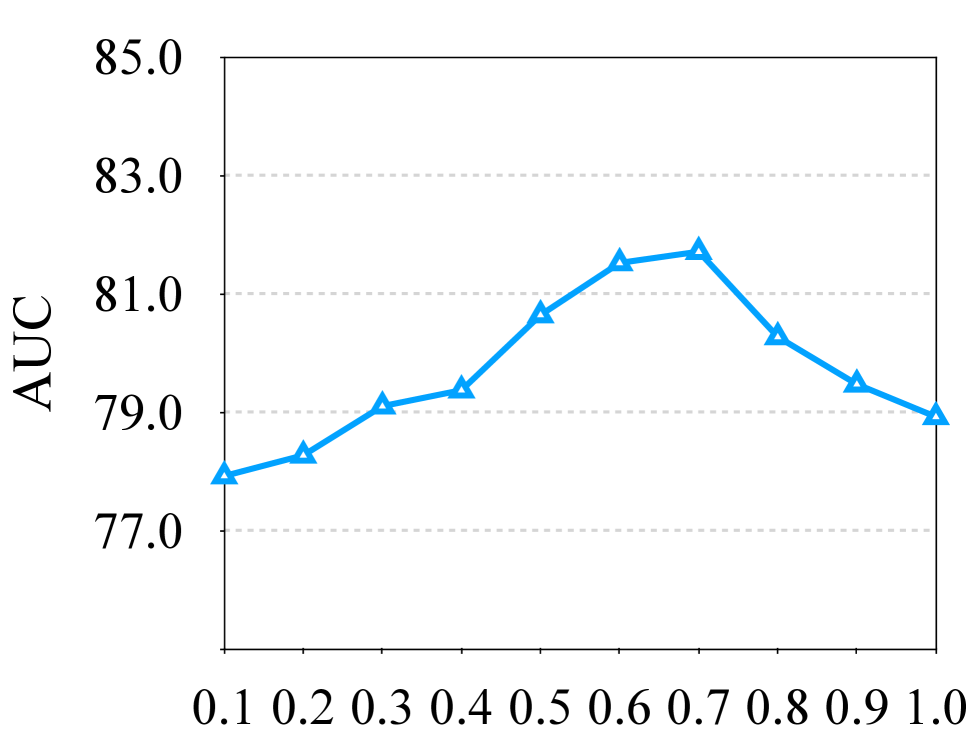
Figure 3 (b) visuals the effects of the factor used in loss function at knowledge distilling time. Our results reveal that the weight significantly affect the performance. A small makes the teacher model plays a dominate role during training time, while too large values result in less affects from the distillation procedure. Weight with 0.7 is the best configuration to balance the learning from the groundtruth and the teacher model.
Effectiveness of Knowledge Transferring Strategies
We further conduct experiments to examine knowledge transferring strategies. As shown in Table 5, reusing teacher model word embeddings (Initialize) and knowledge distillation (Distillation) improve the relevance quality separately and are complementary to each other. These results verify again that transferring knowledge from interactive model is facilitate to the representation learning and relevance scoring of non-interactive model.
| Model | AUC |
|---|---|
| Semi-Interact | 84.04 |
| + Initialize | 88.33 |
| + Distillation | 87.54 |
| + Initialize + Distillation | 89.26 |
5.3 Representation Visualization
A natural question is why and how the proposed mechanism boosts the model performance. We pay our attention into the representation learning of queries and documents. Su et al. (2021) and Gao et al. (2019) pointed out that sentence embeddings not in a standard orthogonal basis cause poor performance of semantic similarity tasks, especially for the BERT-like models.
For a more intuitive comparison, we randomly select 10K query and document representations from our training set, and project them into a 3-dimensional space using principal component analysis (PCA, Abdi and Williams 2010). As shown in Figure 4, the representations learnt from interactive model (Figure 4(a)) are diversely distributed around the origin using PCA projection. In contrast, the representations in non-interactive model (Figure 4(b)) degenerated into a narrow boundary, which means that the representations do not have enough capacity to model the diverse semantics in natural languages (Yang et al. 2017; McCann et al. 2017). Furthermore, we find the representations of semi-interactive (Figure 4(c)) are gradually distributed to the origin, which is more obviously while applying transferring knowledge methods (Figure 4(d)).




5.4 Mining Relevant Queries from Search Log
All the above experiments are based on ready-made queries provided in Wiki pages. We are interested at the effectiveness of the proposed semi-interactive mechanism in a real-world search engine where off-the-rack multilingual relevant queries for each document are not available.
To this end, we examine our method on our in-house dataset extracted from a real-world search engine Alibaba.com. 333Note that, we cannot release the data, we report this results to illustrate the effectiveness of our approach in a real-world scenario. Readers can re-produce our results using the open-released dataset described in Section 4.1. Specifically, we conduct experiments on Russian-to-English and Spanish-to-English semantic similarity tasks. Query-title training pairs are collected from the search logs, resulting in 1 million training samples for each task. For each query, we randomly sample documents from the document pool as negatives, while using the one user clicked as positive. The test set is extracted from training data and manually checked by bilingual experts, resulting in 30K samples for each directions. We select top 3 multi-lingual queries for each document according to clickthrough data (as described in Section 3.2)).
As shown in Table 6, our model significantly outperforms non-interactive based approach over 7 AUC in average. The results confirm the effectiveness of our method when mining relevant queries from search log.
| Model | RuEn | EsEn | AVG |
|---|---|---|---|
| Interact | 84.96 | 85.67 | 85.38 |
| Non-Interact | 68.54 | 69.83 | 69.65 |
| + KT | 69.90 | 70.64 | 70.39 |
| Semi-Interact | 72.97 | 73.42 | 73.21 |
| + KT | 75.66 | 77.63 | 76.90 |
6 Conclusion
In this paper, we provide insights on how to leverage the advantages of interactive model and non-interactive model for vector-based CLIR. Via supplementing multilingual features into document representation and transferring knowledge from a well-trained interactive model, the proposed model yields significant improvements over the conventional non-interactive model, while preserving its advantage with respect to computational efficiency. Our in-depth analyses further suggest that 1) the proposed strategies can tackle the representation degeneration problem in non-interactive models, thus obtaining discriminative representations; and 2) both of ready-made queries and mined queries are effect for supplementing multilingual features to documents.
Several directions are worth to be explored in future. An interesting problem is to explore more effective approaches to collect multilingual queries, especially for few-shot tasks, e.g. generating associated multilingual queries using text summarization (Gambhir and Gupta 2017; Liu and Lapata 2019). Another potential direction is to select queries with a more flexible manner such as using a dynamic routing layer (Sabour, Frosst, and Hinton 2017; Li et al. 2019).
References
- Abdi and Williams (2010) Abdi, H.; and Williams, L. J. 2010. Principal component analysis. Wiley interdisciplinary reviews: computational statistics.
- Ba and Caruana (2014) Ba, J.; and Caruana, R. 2014. Do Deep Nets Really Need to be Deep? In NIPS.
- Bi et al. (2020) Bi, T.; Yao, L.; Yang, B.; Zhang, H.; Luo, W.; and Chen, B. 2020. Constraint Translation Candidates: A Bridge between Neural Query Translation and Cross-lingual Information Retrieval. CoRR.
- Bojanowski et al. (2017) Bojanowski, P.; Grave, E.; Joulin, A.; and Mikolov, T. 2017. Enriching Word Vectors with Subword Information. In TACL.
- Bosca and Dini (2010) Bosca, A.; and Dini, L. 2010. Language Identification Strategies for Cross Language Information Retrieval. In CLEF.
- Chidambaram et al. (2019) Chidambaram, M.; Yang, Y.; Cer, D.; Yuan, S.; Sung, Y.; Strope, B.; and Kurzweil, R. 2019. Learning Cross-Lingual Sentence Representations via a Multi-task Dual-Encoder Model. In ACL.
- Devlin et al. (2019) Devlin, J.; Chang, M.; Lee, K.; and Toutanova, K. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT.
- Gambhir and Gupta (2017) Gambhir, M.; and Gupta, V. 2017. Recent automatic text summarization techniques: a survey. Artif. Intell. Rev.
- Gao et al. (2019) Gao, J.; He, D.; Tan, X.; Qin, T.; Wang, L.; and Liu, T. 2019. Representation Degeneration Problem in Training Natural Language Generation Models. In ICLR.
- Guo et al. (2016) Guo, J.; Fan, Y.; Ai, Q.; and Croft, W. B. 2016. A deep relevance matching model for ad-hoc retrieval. In CLKM.
- Hinton, Vinyals, and Dean (2015) Hinton, G. E.; Vinyals, O.; and Dean, J. 2015. Distilling the Knowledge in a Neural Network. CoRR.
- Huang et al. (2013) Huang, P.; He, X.; Gao, J.; Deng, L.; Acero, A.; and Heck, L. P. 2013. Learning deep structured semantic models for web search using clickthrough data. In CIKM.
- Izacard and Grave (2020) Izacard, G.; and Grave, E. 2020. Distilling Knowledge from Reader to Retriever for Question Answering. arXiv.
- Järvelin and Kekäläinen (2002) Järvelin, K.; and Kekäläinen, J. 2002. Cumulated gain-based evaluation of IR techniques. ACM.
- Jiang et al. (2020) Jiang, Z.; El-Jaroudi, A.; Hartmann, W.; Karakos, D. G.; and Zhao, L. 2020. Cross-lingual Information Retrieval with BERT. In LREC.
- Kingma and Ba (2015) Kingma, D. P.; and Ba, J. 2015. Adam: A Method for Stochastic Optimization. In ICLR.
- Koehn (2004) Koehn, P. 2004. Statistical Significance Tests for Machine Translation Evaluation. In EMNLP.
- Kusner et al. (2015) Kusner, M.; Sun, Y.; Kolkin, N.; and Weinberger, K. 2015. From word embeddings to document distances. In ICML.
- Levow, Oard, and Resnik (2005) Levow, G.; Oard, D. W.; and Resnik, P. 2005. Dictionary-based techniques for cross-language information retrieval. Inf. Process. Manag.
- Levy and Goldberg (2014) Levy, O.; and Goldberg, Y. 2014. Dependency-based word embeddings. In ACL.
- Li et al. (2020) Li, J.; Liu, C.; Wang, J.; Bing, L.; Li, H.; Liu, X.; Zhao, D.; and Yan, R. 2020. Cross-Lingual Low-Resource Set-to-Description Retrieval for Global E-Commerce. In AAAI.
- Li et al. (2019) Li, J.; Yang, B.; Dou, Z.-Y.; Wang, X.; Lyu, M. R.; and Tu, Z. 2019. Information Aggregation for Multi-Head Attention with Routing-by-Agreement. In NAACL.
- Litschko et al. (2018) Litschko, R.; Glavas, G.; Ponzetto, S. P.; and Vulic, I. 2018. Unsupervised Cross-Lingual Information Retrieval Using Monolingual Data Only. In SIGIR.
- Liu and Lapata (2019) Liu, Y.; and Lapata, M. 2019. Text Summarization with Pretrained Encoders. In EMNLP-IJCNLP.
- Lu, Jiao, and Zhang (2020) Lu, W.; Jiao, J.; and Zhang, R. 2020. TwinBERT: Distilling Knowledge to Twin-Structured Compressed BERT Models for Large-Scale Retrieval. In CIKM.
- Lydick, Epstein, and White (1995) Lydick, E.; Epstein, R. S.; and White, D. H. J. 1995. Area under the curve: A metric for patient subjective responses in episodic diseases. Quality of Life Research.
- Ma et al. (2008) Ma, H.; Yang, H.; King, I.; and Lyu, M. R. 2008. Learning latent semantic relations from clickthrough data for query suggestion. In CIKM.
- Martino et al. (2017) Martino, G. D. S.; Romeo, S.; Barrón-Cedeño, A.; Joty, S. R.; Màrquez, L.; Moschitti, A.; and Nakov, P. 2017. Cross-Language Question Re-Ranking. In SIGIR.
- McCann et al. (2017) McCann, B.; Bradbury, J.; Xiong, C.; and Socher, R. 2017. Learned in translation: Contextualized word vectors. arXiv.
- McDonald, Brokos, and Androutsopoulos (2018) McDonald, R. T.; Brokos, G.; and Androutsopoulos, I. 2018. Deep Relevance Ranking using Enhanced Document-Query Interactions. In EMNLP.
- Mihalcea, Corley, and Strapparava (2006) Mihalcea, R.; Corley, C. D.; and Strapparava, C. 2006. Corpus-based and Knowledge-based Measures of Text Semantic Similarity. In AAAI.
- Mikolov et al. (2013) Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G. S.; and Dean, J. 2013. Distributed representations of words and phrases and their compositionality. In NIPS.
- Mitra and Craswell (2018) Mitra, B.; and Craswell, N. 2018. An Introduction to Neural Information Retrieval. FTIR.
- Nie (2010) Nie, J.-Y. 2010. Cross-language information retrieval. Synthesis Lectures on Human Language Technologies.
- Nigam et al. (2019) Nigam, P.; Song, Y.; Mohan, V.; Lakshman, V.; Ding, W. A.; Shingavi, A.; Teo, C. H.; Gu, H.; and Yin, B. 2019. Semantic Product Search. In SIGKDD.
- Radlinski, Kurup, and Joachims (2008) Radlinski, F.; Kurup, M.; and Joachims, T. 2008. How does clickthrough data reflect retrieval quality? In CIKM.
- Reimers and Gurevych (2019) Reimers, N.; and Gurevych, I. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In EMNLP-IJCNLP.
- Sabet et al. (2019) Sabet, A.; Gupta, P.; Cordonnier, J.; West, R.; and Jaggi, M. 2019. Robust Cross-lingual Embeddings from Parallel Sentences. CoRR.
- Sabour, Frosst, and Hinton (2017) Sabour, S.; Frosst, N.; and Hinton, G. E. 2017. Dynamic routing between capsules. NIPS.
- Sanh et al. (2019) Sanh, V.; Debut, L.; Chaumond, J.; and Wolf, T. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv.
- Sasaki et al. (2018) Sasaki, S.; Sun, S.; Schamoni, S.; Duh, K.; and Inui, K. 2018. Cross-lingual learning-to-rank with shared representations. In NAACL-HLT.
- Shen et al. (2014) Shen, Y.; He, X.; Gao, J.; Deng, L.; and Mesnil, G. 2014. Learning semantic representations using convolutional neural networks for web search. In WWW.
- Su et al. (2021) Su, J.; Cao, J.; Liu, W.; and Ou, Y. 2021. Whitening Sentence Representations for Better Semantics and Faster Retrieval. CoRR.
- Sun et al. (2019) Sun, S.; Cheng, Y.; Gan, Z.; and Liu, J. 2019. Patient Knowledge Distillation for BERT Model Compression. In EMNLP-IJCNLP.
- Sun and Duh (2020) Sun, S.; and Duh, K. 2020. CLIRMatrix: A massively large collection of bilingual and multilingual datasets for Cross-Lingual Information Retrieval. In EMNLP.
- Sun, Sia, and Duh (2020) Sun, S.; Sia, S.; and Duh, K. 2020. CLIReval: Evaluating Machine Translation as a Cross-Lingual Information Retrieval Task. In ACL.
- Tai, Ren, and Kita (2002) Tai, X.; Ren, F.; and Kita, K. 2002. An information retrieval model based on vector space method by supervised learning. Inf. Process. Manag.
- Tang et al. (2019) Tang, R.; Lu, Y.; Liu, L.; Mou, L.; Vechtomova, O.; and Lin, J. 2019. Distilling task-specific knowledge from bert into simple neural networks. arXiv.
- Vulic and Moens (2015) Vulic, I.; and Moens, M. 2015. Monolingual and Cross-Lingual Information Retrieval Models Based on (Bilingual) Word Embeddings. In SIGIR.
- Wu and He (2010) Wu, D.; and He, D. 2010. A study of query translation using google machine translation system. In IEEE.
- Xiong et al. (2017) Xiong, C.; Dai, Z.; Callan, J.; Liu, Z.; and Power, R. 2017. End-to-end neural ad-hoc ranking with kernel pooling. In SIGIR.
- Yang et al. (2020) Yang, Y.; Cer, D.; Ahmad, A.; Guo, M.; Law, J.; Constant, N.; Ábrego, G. H.; Yuan, S.; Tar, C.; Sung, Y.; Strope, B.; and Kurzweil, R. 2020. Multilingual Universal Sentence Encoder for Semantic Retrieval. In ACL.
- Yang et al. (2017) Yang, Z.; Dai, Z.; Salakhutdinov, R.; and Cohen, W. W. 2017. Breaking the softmax bottleneck: A high-rank RNN language model. arXiv.
- Yao et al. (2020a) Yao, L.; Yang, B.; Zhang, H.; Chen, B.; and Luo, W. 2020a. Domain Transfer based Data Augmentation for Neural Query Translation. In Scott, D.; Bel, N.; and Zong, C., eds., COLING.
- Yao et al. (2020b) Yao, L.; Yang, B.; Zhang, H.; Luo, W.; and Chen, B. 2020b. Exploiting Neural Query Translation into Cross Lingual Information Retrieval. CoRR.
- Yarmohammadi et al. (2019) Yarmohammadi, M.; Ma, X.; Hisamoto, S.; Rahman, M.; Wang, Y.; Xu, H.; Povey, D.; Koehn, P.; and Duh, K. 2019. Robust Document Representations for Cross-Lingual Information Retrieval in Low-Resource Settings. In MT.
- Yilmaz et al. (2019) Yilmaz, Z. A.; Wang, S.; Yang, W.; Zhang, H.; and Lin, J. 2019. Applying BERT to document retrieval with birch. In EMNLP-IJCNLP.
- Zhang and Zhai (2015) Zhang, Y.; and Zhai, C. 2015. Information retrieval as card playing: A formal model for optimizing interactive retrieval interface. In SIGIR.
- Zhou et al. (2012) Zhou, D.; Truran, M.; Brailsford, T. J.; Wade, V.; and Ashman, H. 2012. Translation techniques in cross-language information retrieval. ACM Comput. Surv.