Less is More: A Lightweight and Robust Neural Architecture for Discourse Parsing
Abstract
Complex feature extractors are widely employed for text representation building. However, these complex feature extractors make the NLP systems prone to overfitting especially when the downstream training datasets are relatively small, which is the case for several discourse parsing tasks. Thus, we propose an alternative lightweight neural architecture that removes multiple complex feature extractors and only utilizes learnable self-attention modules to indirectly exploit pretrained neural language models, in order to maximally preserve the generalizability of pre-trained language models. Experiments on three common discourse parsing tasks show that powered by recent pretrained language models, the lightweight architecture consisting of only two self-attention layers obtains much better generalizability and robustness. Meanwhile, it achieves comparable or even better system performance with fewer learnable parameters and less processing time.
1 Introduction
Discourse Parsing derives a form of discourse structure that may consist of roles of individual sentences, relations between sentences, or relations between a sentence and a larger text unit, and the derived discourse are widely useful for many NLP applications Yu et al. (2020); Meyer and Popescu-Belis (2012); Ji et al. (2016). We focus on three discourse parsing tasks in this paper, news discourse profiling Choubey et al. (2020), RST (Rhetorical Structure Theory) style and PDTB (Penn Discourse Treebank) style discourse parsing tasks Mann and Thompson (1988); Prasad et al. (2008).

Like many other NLP systems, neural discourse parsing models often employ complex feature extractors on top of neural language models for text representation building. Existing discourse parsing models are mainly based on the heavy use of feature extractors, while the data used for training is limited, which might lead to instability and quick overfitting. For instance, in the task of news discourse profiling, Choubey et al. (2020); Choubey and Huang (2021) use two Long Short-Term Memory networks (LSTMs) Hochreiter and Schmidhuber (1997) with self-attention modules to obtain discourse-aware sentence embeddings. For RST style discourse parsing, Kobayashi et al. (2020); Koto et al. (2021); Yu et al. (2022) use several LSTM or transformer Chorowski et al. (2015) layers for building sentence representations. For PDTB style discourse parsing, Dai and Huang (2018); Bai and Zhao (2018); Liu et al. (2021); Munir et al. (2021) also use LSTM layers and transformer layers, some of them further use additional convolution layers or extra memory bank to create sentence embeddings.
However, these complex models are often prone to overfitting, presumably because their complex feature extractors need large datasets to train, but discourse parsing tasks often lack annotated data. Take the news discourse profiling task as an example, as shown in Figure 1, the two previous models Choubey et al. (2020); Choubey and Huang (2021) both overfit the training data and generalize poorly to the unseen validation data. This is visually reflected by the large gaps between training loss and validation loss curves. Both models can fit perfectly with the training data and achieve near to zero training loss after only several epochs of training while their validation losses are clearly higher and continue to increase dramatically with further training. Overfitting with the training data increases the risk that the models perform even worse for future new data and it also makes model tuning sensitive to hyperparameters and randomness.
Thus, we propose an alternative lightweight neural architecture that removes multiple complex feature extractors and only utilizes two well-designed learnable self-attention modules to indirectly exploit pretrained neural language models (PLMs) and build properly integrated sentence embeddings relevant to a particular discourse-level prediction task. To maximally keep the generalization ability of PLMs, their weights are fixed all the time and only parameters of self-attention layers are to be learned. In these two self-attention layers, the output vectors of each feature extractor are never used directly as inputs to the next layer but only serve as the weights to linearly combine the word embeddings from PLMs. By doing so, this simple model is restricted to spoiling the generalization ability of PLMs or fitting with training data. Thus it is expected to perform similarly on future new data and mitigates the overfitting and instability problems. As shown in Figure 1, the validation loss of our simplified model remains stable over the training epochs and the gap between its training and validation losses is kept small, indicating the robustness and generalizability of our model.
We refer to our simple self-attention-based model as LiMNet, where LiM stands for Less is More. In this model, all complex feature extractors are removed from the encoder and two well-designed self-attention modules Bahdanau et al. (2014); Chorowski et al. (2015) are utilized to obtain a local sentence embedding 111We call both Elementary Discourse Unit embeddings in RST and Discourse Unit embeddings in PDTB as sentence embeddings and do not distinguish them strictly. and sentence-specific complementary information from the discourse. These two embeddings of different receptive fields are fused together and then sent to the task-specific predictors. It is worth noting that the resulting fused sentence embeddings can be perceived as the linear combination of word embeddings sourced from PLMs, thereby retaining their inherent generalizability. Extensive experiments and analysis on three discourse parsing tasks including news discourse profiling, RST style and PDTB style discourse parsing, show that LiMNet largely prevents the overfitting problem and gains more robustness. Meanwhile, powered by recent PLMs, our simple model achieves comparable or even better system performance with fewer learnable parameters and less processing time. This holds significant implications for the ongoing evolution of PLMs, as the fine-tuning of these models becomes increasingly challenging, thereby highlighting the potential of our proposed LiMNet model.
The contributions of this paper are twofold :
-
•
To our best knowledge, we are the first to propose to reduce overfitting by removing complex feature extractors and exploiting pretrained language models in an indirect manner for discourse parsing tasks.
-
•
Our model is simple yet effective, it alleviates the potential overfitting problem and becomes more robust to randomness. Besides, it achieves promising performance on three discourse parsing tasks with less processing time, and fewer learnable parameters.
2 Discourse Parsing Tasks and Models
In this section, we introduce the tasks and models in neural discourse parsing that we focus on and compare the differences between baseline models and our model.
2.1 News Discourse Profiling
News Discourse Profiling Choubey et al. (2020) is a task focusing on the role of each sentence in news articles Van Dijk (1986, 2013); Pan and Kosicki (1993). It aims to understand the whole discourse at a higher level by identifying the main event with supporting content.
Baseline: We use Choubey et al. (2020) as our baseline model as shown in Figure 2(a). The first feature extractor with a self-attention module is used upon word embeddings to calculate sentence embeddings, and the second is used to obtain document embedding. Then the final output vector for each sentence is calculated by the combination of sentence embedding and document embedding.
Updated Baseline: For a fair comparison, we utilize word embeddings from T5 Raffel et al. (2020) language model as the input while the model structure keeps unchanged. Further experiments are conducted in ablation studies to explore the effects of different language models.
Our model: As discussed above, introducing extra feature extractors requires more data for training while discourse parsing tasks often lack annotated data, which leads to quick overfitting on training data. Thus we remove the word-level and sentence-level Bi-LSTM layers in the baseline and only utilize self-attention modules to better exploit the pretrained language model, shown in Figure 2(d). Specifically, the first self-attention module is used to build representative local sentence embeddings similar to the baseline. The second self-attention module is utilized to calculate the global sentence shifts, aiming to model global contextual information for each sentence. This simplification not only alleviates the overfitting problem but also reduces the number of learnable parameters and processing time simultaneously.

2.2 RST Discourse Parsing
The purpose of Rhetorical Structure Theory based Discourse Parsing (RST) Mann and Thompson (1988); Carlson et al. (2001) is to present a discourse by using a hierarchical rhetorical tree, where each leaf represents an elementary discourse unit (EDU).
Baseline: We use Koto et al. (2021) (the LSTM version, their best-performing model structure222In their paper, the performance of LSTM-based model is better than transformer-based model.) as our baseline model with a standard decoder as shown in Figure 2(b). The first feature extractor followed by an average pooling is utilized upon the concatenation of word and part-of-speech embeddings in each elementary discourse unit. The second feature extractor is utilized upon the syntax features from Dozat and Manning (2017). The sentence embeddings are obtained by combining the above embeddings with additional paragraph boundary features.
Updated Baseline: We update the baseline to support the T5 language model and discard the POS embeddings, syntax features, and the LSTM applied to syntax features. In the updated baseline, the first Bi-LSTM layer with average pooling is used upon input T5 word embeddings for local sentence construction. And another Bi-LSTM layer is utilized to model contextual relation and the paragraph boundary features are added to the output.
Our model: Our model uses the same word embeddings as the updated baseline but replaces all the LSTM layers with self-attention modules, as shown in Figure 2(d). For the discourse unit segmentation step, we use the same decoder as in their experiments.

2.3 PDTB Discourse Parsing
Penn Discourse Treebank based Discourse Parsing (PDTB)Prasad et al. (2008) focuses more on the relation between local discourse units.
Baseline: Most of the PDTB models only consider the relation between adjacent arguments and neglect the global contextual relation of the whole discourse. Dai and Huang (2018) is the first context-aware method that models the inter-dependencies between discourse units at the paragraph level. The input of this model is the continuous discourse units (DUs) in the same paragraph instead of a single DU pair. Thus we choose Dai and Huang (2018) as our PDTB baseline where a word-level Bi-LSTM followed by a max pooling is utilized to construct the sentence representations. Then a second Bi-LSTM is further utilized upon the obtained sentence embeddings to obtain the final vector output, as shown in Figure 2(c).
Updated Baseline: We utilize word embeddings from the T5 language model as the input while the baseline model keeps unchanged. Specifically, the whole discourse is sent to the T5 model for capturing global contextual information and the discourse units that need to be predicted are sent to the model at the paragraph level.
Our model: Our model uses the same word embeddings as an updated baseline. But our model discards all the LSTM layers and utilizes self-attention modules instead, as shown in Figure 2(d).
3 LiMNet
We design LiMNet that removes additional feature extractors and utilizes only self-attention mechanisms to obtain meaningful sentence embeddings indirectly. As shown in Figure 3, the input document will be first sent to the pretrained language model to get all the contextual word embeddings. Upon these word embeddings, two self-attention modules are implemented to calculate the local sentence embedding and global sentence shift for each sentence. Then the mixed sentence embeddings obtained by adding the previous two embeddings, which can be regarded as the linear combination of pretrained word embeddings, will be sent to the task-specific predictors.
Word Embedding: Pretrained language models Peters et al. (2018); Devlin et al. (2019) have been widely used in recent NLP tasks, which provide meaningful word embeddings for downstream tasks. These language models are mostly trained on large unannotated corpora, which greatly exceed the annotated data used for downstream tasks. In neural discourse parsing tasks, we find the finetuning on the language models and using additional complex feature extractors might spoil the generalization ability of pretrained language models and causes performance instability and quick overfitting problems. To preserve the generalization ability of pretrained language models, we fix their weights in all the experiments and utilize self-attention modules to better exploit them indirectly. In our model, the final sentence embeddings are the linear combination of word embeddings of PLMs, thus preserving their generalization ability. As we mainly experiment on discourse-level tasks, we choose T5 Raffel et al. (2020) as our language model because it supports long input while many other language models only support inputs up to tokens.
Local Sentence Embedding: For discourse-level tasks, getting meaningful sentence embeddings is fundamental. Previous models utilize word-level feature extractors followed by a combination method for getting sentence embeddings. Striving for building further simplified models, we use only a self-attention module to calculate local sentence embeddings. Specifically, two feed forward networks (FFN), with a tanh function in between, are utilized upon each word embedding to obtain a scalar representing the importance of this word. Then a softmax function is applied to get the normalized attention weights and the final local sentence embedding is simply the weighted sum of word embeddings.
Suppose the sentence in discourse has words. represents the word embedding of the word of the sentence. represents the self-attention weight for calculating local sentence embeddings. represents the learnable weights for deriving the importance of a word, including learnable FFN and a tanh in between. Then the local sentence embedding for the sentence can be calculated as follows:
| (1) | |||
| (2) |
Global Sentence Shift: Obtaining only local sentence embeddings is insufficient for performing discourse-level tasks. Most existing models implement additional discourse-level feature extractors to further incorporate broader discourse-level contexts. In addition, each sentence might require specific complementary discourse information to enrich its representation. To this end, we implement another self-attention module to learn the global shift for each sentence.
Specifically, Suppose there are sentences in a discourse, to obtain the global shift for the sentence, differences between its local sentence embedding and all the word embeddings in the discourse are calculated by subtraction. These new vectors represent the shifts between this particular sentence embedding and all other word embeddings. Then another self-attention module is implemented upon these sentence shift vectors, and thus the global sentence shift vector of this specific sentence is obtained. The global sentence shifts is calculated as follows:
| (3) | |||
| (4) |
where represents self-attention weight of word embedding for calculating global sentence shift of the sentence. represents the learnable weights for capturing global sentence shift, including feed forward networks and a tanh function in between.
The aforementioned equations reveal that both local sentence embeddings and their corresponding global sentence shifts are derived as linear combinations of word embeddings. Then the final mixed sentence embeddings are obtained by adding global shifts to local sentence embeddings notated as , which also constitutes a linear combination of word embeddings. Such a formulation ensures the maximal preservation of the generalizability inherent in PLMs. These mixed embeddings are then directed toward the task-specific predictors for subsequent processing, thus maintaining the original structure and broad applicability of the PLMs within our model.
| Macro | Micro | Efficiency | |||||
| Precision | Recall | F1 | F1 | Para(M) | Train(s) | Infer(s) | |
| Choubey et al. (2020) (Baseline) | |||||||
| Choubey and Huang (2021) | |||||||
| Choubey et al. (2020) w/ T5 (Updated Baseline) | |||||||
| Choubey and Huang (2021) w/ T5 | |||||||
| LiMNet (ours) | |||||||
4 Evaluation
4.1 Dataset
News Discourse Profiling: We use the NewsDiscourse dataset Choubey et al. (2020), which consists of news articles ( sentences). Each sentence in this corpus is labeled with one of eight content types reflecting the discourse role it plays in reporting a news story following the news content schemata proposed by Van Dijk Van Dijk (1985, 1988). For a fair comparison, we use the same division of dataset as Choubey et al. (2020); Choubey and Huang (2021), which has documents for training, documents for validation and documents for testing.
RST Discourse Parsing: We use the English RST Discourse Treebank Carlson et al. (2001), which is based on the Wall Street Journal portion of the Penn Treebank Marcus et al. (1993). It contains documents for training, and documents for testing. For a fair comparison, we use the same validation set as Koto et al. (2021) and Yu et al. (2018), which contains documents from the training set.
PDTB Discourse Parsing: We use the Penn Discourse Treebank v2.0 Prasad et al. (2008), containing k annotated discourse relations in Wall Street Journal (WSJ) articles. We use the dataset partition same as Dai and Huang (2018) and Rutherford and Xue (2015), where sections - are training set, sections - are test set, and sections - are validation set. In this work, we focus on top-level discourse relations.
4.2 Implementation Details
All experiments are implemented in PyTorch platform Paszke et al. (2019) and all the training and inference times are calculated by using NVIDIA GeForce RTX 3090 graphic card. We use t5-large Raffel et al. (2020) from huggingface Wolf et al. (2019) as our pretrained language model in all the models. The weights of pretrained language model are fixed all the time without finetuning. For each model of a different task, we follow the same configuration of the original baselines. News Discourse Profiling models are trained using Adam optimizer Kingma and Ba (2014) with the learning rate of for epochs. RST models are trained using Adam optimizer Kingma and Ba (2014) with the learning rate of , epsilon of , and gradient accumulation of for epochs. PDTB models are trained using Adam optimizer Kingma and Ba (2014) with the learning rate of for epochs. The dropout rates Srivastava et al. (2014) of all the models are set to . We run each model for rounds using different seeds and report the averaged performance to alleviate the influence of randomness.
4.3 Results on News Discourse Profiling
As shown in Table 1, our model has the best performance on all of the evaluation metrics (macro P/R/F and micro F1 score). In addition to the Baseline model Choubey et al. (2020) and its T5 version (Updated Baseline), our model also outperforms Choubey and Huang (2021) which additionally uses subtopics structures to guide sentence representation building in an actor-critic framework and its T5 version. It is impressive that the linear combination of word embeddings is so powerful that it outperforms those models with multiple additional feature extractors. Compared with previous models, our model has fewer parameters and less training and inference time, indicating the efficiency of our model. The calculation of all sentence embeddings in our model can be done in parallel, leading to large increases in speed. In parentheses are the standard deviations of different models on random runs, where we can see the standard deviation of our model is much less than the previous two models (T5 version), indicating the robustness of our model to randomness. In addition, as shown in Figure 4(a), the Updated Baseline is prone to overfitting quickly while our model keeps the training and validation loss similar, indicating the better generalization ability of our model to unseen data used for validation.
| Original Parseval | RST Parseval | Efficiency | |||||||||
| S | N | R | F | S | N | R | F | Para(M) | Train(s) | Infer(s) | |
| Hayashi et al. (2016) | - | - | - | ||||||||
| Li et al. (2016) | - | - | - | ||||||||
| Braud et al. (2017) | - | - | - | ||||||||
| Yu et al. (2018) | - | - | - | ||||||||
| Mabona et al. (2019) | - | - | - | - | - | - | - | ||||
| Kobayashi et al. (2020) | - | - | - | - | - | - | - | - | |||
| Zhang et al. (2020) | - | - | - | - | - | - | - | ||||
| Koto et al. (2021) | - | - | - | ||||||||
| Koto et al. (2021)(Baseline) | |||||||||||
| Updated Baseline | |||||||||||
| LiMNet (ous) | |||||||||||
| Deviation (Updated Baseline) | - | - | - | ||||||||
| Deviation (LiMNet) | - | - | - | ||||||||
| Implicit | Efficiency | ||||
| Macro | Acc | Para(M) | Train(ms) | Infer(ms) | |
| Shi and Demberg (2019) | - | - | - | ||
| Guo et al. (2020) | - | - | - | ||
| Dai and Huang (2019) | - | - | - | ||
| Nguyen et al. (2019) | - | - | - | - | |
| Varia et al. (2019) | - | - | - | ||
| Wu et al. (2020) | - | - | - | ||
| He et al. (2020) | - | - | - | ||
| Kishimoto et al. (2020) | - | - | - | ||
| Zhang et al. (2021) | - | - | - | - | |
| Dai and Huang (2018) | |||||
| Updated baseline | |||||
| LiMNet (ours) | |||||
| Deviation (Updated Baseline) | - | - | - | ||
| Deviation (LiMNet) | - | - | - | ||
4.4 Results on RST Discourse Parsing
As shown in Table 2, the Updated Baseline model achieves the best performance and outperforms the previous methods across all metrics. Meanwhile, our model achieves the second-best performance on all the metrics except one and the differences from the best performance are kept low. These results are also encouraging considering LiMNet due to its efficiency: it has less than half of the learnable parameters and needs less processing time. The last two rows present the standard deviation of Updated Baseline and our model on random runs, where the standard deviations of our model are much less than baseline models, indicating the robustness of our model to randomness. In addition, as shown in Figure 4(b), the Updated Baseline is prone to overfitting due to its heavy feature extractors, where its validation loss curve begins to increase dramatically from around the epoch while its training loss curve still decreases. On the contrary, our model LiMNet keeps the validation loss low throughout the training process, indicating the better generalization ability of our model to unseen data used for validation.
4.5 Results on PDTB Discourse Parsing
As shown in Table 3, compared with the baseline model Dai and Huang (2018), the updated baseline greatly improves the performance on implicit discourse relation classification. Meanwhile, LiMNet achieves even better results on both macro F1 and accuracy metrics, in spite of the efficiency of LiMNet since it has fewer parameters than the updated baseline and LiMNet requires less training time and less inference time. The last two rows present the standard deviation of Updated Baseline and our model on random runs, where the standard deviations of our model are much less than baseline models, indicating the robustness of our model to randomness. As shown in Figure 4(c), the updated baseline is more prone to overfitting than the baseline model, where its validation loss curve first decreases but then increases even more dramatically. However, after removing the feature extractors from the updated baseline, LiMNet largely reduces overfitting, indicating the better generalization ability.

4.6 Performance Analysis
From the empirical studies undertaken333The ablation experiments on model structure, the effect of using different PLM transformer layers on the task of news discourse profiling are further illustrated in the Appendix., our simple model architecture outstrips baseline models across multiple aspects on three distinct discourse parsing tasks. The source of these advancements lies in the indirect leveraging of PLMs. In contrast to most of the existing studies that resort to the utilization of complex feature extractors, which are intended to transform pretrained embeddings into intricate hidden spaces. Our method focuses on learning how to amalgamate existing word embeddings, which in turn ensures the stability of our model. The output representations produced by our model constitute a linear combination of static pretrained word embeddings, thereby safeguarding the inherent generalization capacity of PLMs from degradation. Moreover, given the ongoing advancement of PLMs, finetuning these models is becoming increasingly arduous. In such circumstances, a model like ours may offer a viable alternative. As PLMs continue to evolve, our model is poised to persistently preserve and maximally harness their intrinsic capabilities, which should lead to progressively better performance due to improved utilization of PLMs.
5 Related Work
5.1 Overfitting
In NLP community, transfer learning Shao et al. (2014); Weiss et al. (2016) and pretraining Erhan et al. (2010); Qiu et al. (2020) are widely used. Pretrained language models Pennington et al. (2014); Peters et al. (2018); Devlin et al. (2019); Clark et al. (2020); Lan et al. (2020); Liu et al. (2019) have been widely used in recent NLP tasks, which provide general and representative word embeddings for downstream tasks. Though augmenting parameters increases the performance of various tasks, a great number of parameters may cause overfitting Cawley and Talbot (2007); Tzafestas et al. (1996).
5.2 Robustness of Finetuned Models
The fine-tuning process of these models often displays instability, leading to significantly different performances even with identical settings Lee et al. (2019); Zhu et al. (2020); Dodge et al. (2020); Pruksachatkun et al. (2020); Mosbach et al. (2021). Some research suggests controlling the Lipschitz constant through various noise regularizations Arora et al. (2018); Sanyal et al. (2020); Aghajanyan et al. (2021); Hua et al. (2021). Theoretical analysis of fine-tuning paradigms like full fine-tuning Devlin et al. (2019) and head tuning or linear probing Peters et al. (2019); Kumar et al. (2022) has been explored, which provide insights into how modifying factors such as the training sample size, iteration number, or learning rate could enhance the stability of the fine-tuning process Wei et al. (2021); Kumar et al. (2022); Mosbach et al. (2021); Hua et al. (2021).
6 Conclusions
We propose to remove additional complex feature extractors and utilize self-attention modules to make good use of the pretrained language models indirectly and retain their generalization abilities. Extensive experiments and analysis on three discourse parsing tasks show that our simplified model LiMNet largely prevents the overfitting problem. In the meantime, our model achieves comparable or even better system performance with fewer learnable parameters and less processing time. Beyond the confines of neural discourse parsing, LiMNet’s architecture is task-agnostic. With appropriate task-specific decoders, it can be seamlessly adapted to a variety of tasks, thereby enhancing their generalizability and stability. This underscores the versatility and potential of our neural architecture across a broader spectrum of applications.
Limitations
One acknowledged limittaion of our approach lies in its current inability to surpass the state-of-the-art performance benchmarks in RST and PDTB discourse parsing. However, the primary impetus behind this work is not to design a model structure that achieves superior performance. Rather, it is to develop a simple and robust model capable of indirectly harnessing the capabilities of PLMs, with the goal of mitigating potential overfitting issues within the domain of discourse parsing tasks. Despite not reaching the performance levels of current state-of-the-art systems, our model exhibits superior generalizability and stability, achieved with fewer learnable parameters and less processing time. Looking ahead, as the development of PLMs continues unabated, our model is well-positioned to retain and optimally utilize the intrinsic potential of these models. This approach, we anticipate, will progressively yield improved performance due to the enhanced integration of evolving PLMs.
References
- Aghajanyan et al. (2021) Armen Aghajanyan, Akshat Shrivastava, Anchit Gupta, Naman Goyal, Luke Zettlemoyer, and Sonal Gupta. 2021. Better fine-tuning by reducing representational collapse. In International Conference on Learning Representations.
- Arora et al. (2018) Sanjeev Arora, Rong Ge, Behnam Neyshabur, and Yi Zhang. 2018. Stronger generalization bounds for deep nets via a compression approach. In International Conference on Machine Learning, pages 254–263. PMLR.
- Bahdanau et al. (2014) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Bai and Zhao (2018) Hongxiao Bai and Hai Zhao. 2018. Deep enhanced representation for implicit discourse relation recognition. In Proceedings of the 27th International Conference on Computational Linguistics, pages 571–583, Santa Fe, New Mexico, USA. Association for Computational Linguistics.
- Braud et al. (2017) Chloé Braud, Maximin Coavoux, and Anders Søgaard. 2017. Cross-lingual RST discourse parsing. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 292–304, Valencia, Spain. Association for Computational Linguistics.
- Carlson et al. (2001) Lynn Carlson, Daniel Marcu, and Mary Ellen Okurovsky. 2001. Building a discourse-tagged corpus in the framework of Rhetorical Structure Theory. In Proceedings of the Second SIGdial Workshop on Discourse and Dialogue.
- Cawley and Talbot (2007) Gavin C Cawley and Nicola LC Talbot. 2007. Preventing over-fitting during model selection via bayesian regularisation of the hyper-parameters. Journal of Machine Learning Research, 8(4).
- Chorowski et al. (2015) Jan K Chorowski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyunghyun Cho, and Yoshua Bengio. 2015. Attention-based models for speech recognition. In Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc.
- Choubey and Huang (2021) Prafulla Kumar Choubey and Ruihong Huang. 2021. Profiling news discourse structure using explicit subtopic structures guided critics. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 1594–1605, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Choubey et al. (2020) Prafulla Kumar Choubey, Aaron Lee, Ruihong Huang, and Lu Wang. 2020. Discourse as a function of event: Profiling discourse structure in news articles around the main event. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5374–5386, Online. Association for Computational Linguistics.
- Clark et al. (2020) Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. 2020. ELECTRA: Pre-training text encoders as discriminators rather than generators. In ICLR.
- Dai and Huang (2018) Zeyu Dai and Ruihong Huang. 2018. Improving implicit discourse relation classification by modeling inter-dependencies of discourse units in a paragraph. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 141–151, New Orleans, Louisiana. Association for Computational Linguistics.
- Dai and Huang (2019) Zeyu Dai and Ruihong Huang. 2019. A regularization approach for incorporating event knowledge and coreference relations into neural discourse parsing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2976–2987, Hong Kong, China. Association for Computational Linguistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dodge et al. (2020) Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah A. Smith. 2020. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. ArXiv, abs/2002.06305.
- Dozat and Manning (2017) Timothy Dozat and Christopher D. Manning. 2017. Deep biaffine attention for neural dependency parsing. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings.
- Erhan et al. (2010) Dumitru Erhan, Aaron Courville, Yoshua Bengio, and Pascal Vincent. 2010. Why does unsupervised pre-training help deep learning? In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 201–208. JMLR Workshop and Conference Proceedings.
- Guo et al. (2020) Fengyu Guo, Ruifang He, Jianwu Dang, and Jian Wang. 2020. Working memory-driven neural networks with a novel knowledge enhancement paradigm for implicit discourse relation recognition. Proceedings of the AAAI Conference on Artificial Intelligence, 34:7822–7829.
- Hayashi et al. (2016) Katsuhiko Hayashi, Tsutomu Hirao, and Masaaki Nagata. 2016. Empirical comparison of dependency conversions for RST discourse trees. In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 128–136, Los Angeles. Association for Computational Linguistics.
- He et al. (2020) Ruifang He, Jian Wang, Fengyu Guo, and Yugui Han. 2020. TransS-driven joint learning architecture for implicit discourse relation recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 139–148, Online. Association for Computational Linguistics.
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780.
- Hua et al. (2021) Hang Hua, Xingjian Li, Dejing Dou, Chengzhong Xu, and Jiebo Luo. 2021. Noise stability regularization for improving BERT fine-tuning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3229–3241, Online. Association for Computational Linguistics.
- Ji et al. (2016) Yangfeng Ji, Gholamreza Haffari, and Jacob Eisenstein. 2016. A latent variable recurrent neural network for discourse-driven language models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 332–342, San Diego, California. Association for Computational Linguistics.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kishimoto et al. (2020) Yudai Kishimoto, Yugo Murawaki, and Sadao Kurohashi. 2020. Adapting BERT to implicit discourse relation classification with a focus on discourse connectives. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 1152–1158, Marseille, France. European Language Resources Association.
- Kobayashi et al. (2020) Naoki Kobayashi, Tsutomu Hirao, Hidetaka Kamigaito, Manabu Okumura, and Masaaki Nagata. 2020. Top-down rst parsing utilizing granularity levels in documents. Proceedings of the AAAI Conference on Artificial Intelligence, 34(05):8099–8106.
- Koto et al. (2021) Fajri Koto, Jey Han Lau, and Timothy Baldwin. 2021. Top-down discourse parsing via sequence labelling. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 715–726, Online. Association for Computational Linguistics.
- Kumar et al. (2022) Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang. 2022. Fine-tuning can distort pretrained features and underperform out-of-distribution. In International Conference on Learning Representations.
- Lan et al. (2020) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2020. Albert: A lite bert for self-supervised learning of language representations. In International Conference on Learning Representations.
- Lee et al. (2019) Cheolhyoung Lee, Kyunghyun Cho, and Wanmo Kang. 2019. Mixout: Effective regularization to finetune large-scale pretrained language models. CoRR, abs/1909.11299.
- Li et al. (2016) Qi Li, Tianshi Li, and Baobao Chang. 2016. Discourse parsing with attention-based hierarchical neural networks. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 362–371, Austin, Texas. Association for Computational Linguistics.
- Liu et al. (2021) Xin Liu, Jiefu Ou, Yangqiu Song, and Xin Jiang. 2021. On the importance of word and sentence representation learning in implicit discourse relation classification. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI’20.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692.
- Mabona et al. (2019) Amandla Mabona, Laura Rimell, Stephen Clark, and Andreas Vlachos. 2019. Neural generative rhetorical structure parsing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2284–2295, Hong Kong, China. Association for Computational Linguistics.
- Mann and Thompson (1988) William C Mann and Sandra A Thompson. 1988. Rhetorical structure theory: Toward a functional theory of text organization. Text-interdisciplinary Journal for the Study of Discourse, 8(3):243–281.
- Marcus et al. (1993) Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. 1993. Building a large annotated corpus of English: The Penn Treebank. Computational Linguistics, 19(2):313–330.
- Meyer and Popescu-Belis (2012) Thomas Meyer and Andrei Popescu-Belis. 2012. Using sense-labeled discourse connectives for statistical machine translation. In Proceedings of the Joint Workshop on Exploiting Synergies between Information Retrieval and Machine Translation (ESIRMT) and Hybrid Approaches to Machine Translation (HyTra), pages 129–138, Avignon, France. Association for Computational Linguistics.
- Mosbach et al. (2021) Marius Mosbach, Maksym Andriushchenko, and Dietrich Klakow. 2021. On the stability of fine-tuning {bert}: Misconceptions, explanations, and strong baselines. In International Conference on Learning Representations.
- Munir et al. (2021) Kashif Munir, Hongxiao Bai, Hai Zhao, and Junhan Zhao. 2021. Memorizing all for implicit discourse relation recognition. ACM Trans. Asian Low-Resour. Lang. Inf. Process., 21(3).
- Nguyen et al. (2019) Linh The Nguyen, Linh Van Ngo, Khoat Than, and Thien Huu Nguyen. 2019. Employing the correspondence of relations and connectives to identify implicit discourse relations via label embeddings. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4201–4207, Florence, Italy. Association for Computational Linguistics.
- Pan and Kosicki (1993) Zhongdang Pan and Gerald M Kosicki. 1993. Framing analysis: An approach to news discourse. Political communication, 10(1):55–75.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, Doha, Qatar. Association for Computational Linguistics.
- Peters et al. (2018) Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 2227–2237, New Orleans, Louisiana. Association for Computational Linguistics.
- Peters et al. (2019) Matthew E. Peters, Sebastian Ruder, and Noah A. Smith. 2019. To tune or not to tune? adapting pretrained representations to diverse tasks. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), pages 7–14, Florence, Italy. Association for Computational Linguistics.
- Prasad et al. (2008) Rashmi Prasad, Nikhil Dinesh, Alan Lee, Eleni Miltsakaki, Livio Robaldo, Aravind Joshi, and Bonnie Webber. 2008. The penn discourse treebank 2.0. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08).
- Pruksachatkun et al. (2020) Yada Pruksachatkun, Jason Phang, Haokun Liu, Phu Mon Htut, Xiaoyi Zhang, Richard Yuanzhe Pang, Clara Vania, Katharina Kann, and Samuel R. Bowman. 2020. Intermediate-task transfer learning with pretrained language models: When and why does it work? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5231–5247, Online. Association for Computational Linguistics.
- Qiu et al. (2020) Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. 2020. Pre-trained models for natural language processing: A survey. Science China Technological Sciences, 63(10):1872–1897.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- Rutherford and Xue (2015) Attapol Rutherford and Nianwen Xue. 2015. Improving the inference of implicit discourse relations via classifying explicit discourse connectives. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 799–808, Denver, Colorado. Association for Computational Linguistics.
- Sanyal et al. (2020) Amartya Sanyal, Philip H. Torr, and Puneet K. Dokania. 2020. Stable rank normalization for improved generalization in neural networks and gans. In International Conference on Learning Representations.
- Shao et al. (2014) Ling Shao, Fan Zhu, and Xuelong Li. 2014. Transfer learning for visual categorization: A survey. IEEE transactions on neural networks and learning systems, 26(5):1019–1034.
- Shi and Demberg (2019) Wei Shi and Vera Demberg. 2019. Learning to explicitate connectives with Seq2Seq network for implicit discourse relation classification. In Proceedings of the 13th International Conference on Computational Semantics - Long Papers, pages 188–199, Gothenburg, Sweden. Association for Computational Linguistics.
- Srivastava et al. (2014) Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(56):1929–1958.
- Tzafestas et al. (1996) SG Tzafestas, PJ Dalianis, and G Anthopoulos. 1996. On the overtraining phenomenon of backpropagation neural networks. Mathematics and computers in simulation, 40(5-6):507–521.
- Van Dijk (1985) Teun A Van Dijk. 1985. Structures of news in the press. Discourse and communication: New approaches to the analysis of mass media discourse and communication, 10:69.
- Van Dijk (1986) Teun A Van Dijk. 1986. 5news schemata.
- Van Dijk (1988) Teun A Van Dijk. 1988. News analysis. Case Studies of International and National News in the Press. New Jersey: Lawrence.
- Van Dijk (2013) Teun A Van Dijk. 2013. News as discourse. Routledge.
- Varia et al. (2019) Siddharth Varia, Christopher Hidey, and Tuhin Chakrabarty. 2019. Discourse relation prediction: Revisiting word pairs with convolutional networks. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, pages 442–452, Stockholm, Sweden. Association for Computational Linguistics.
- Wei et al. (2021) Colin Wei, Sang Michael Xie, and Tengyu Ma. 2021. Why do pretrained language models help in downstream tasks? an analysis of head and prompt tuning. In Advances in Neural Information Processing Systems.
- Weiss et al. (2016) Karl Weiss, Taghi M Khoshgoftaar, and DingDing Wang. 2016. A survey of transfer learning. Journal of Big data, 3(1):1–40.
- Wolf et al. (2019) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. 2019. Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771.
- Wu et al. (2020) Changxing Wu, Chaowen Hu, Ruochen Li, Hongyu Lin, and Jinsong Su. 2020. Hierarchical multi-task learning with crf for implicit discourse relation recognition. Knowledge-Based Systems, 195:105637.
- Yu et al. (2020) Lei Yu, Laurent Sartran, Wojciech Stokowiec, Wang Ling, Lingpeng Kong, Phil Blunsom, and Chris Dyer. 2020. Better document-level machine translation with Bayes’ rule. Transactions of the Association for Computational Linguistics, 8:346–360.
- Yu et al. (2018) Nan Yu, Meishan Zhang, and Guohong Fu. 2018. Transition-based neural RST parsing with implicit syntax features. In Proceedings of the 27th International Conference on Computational Linguistics, pages 559–570, Santa Fe, New Mexico, USA. Association for Computational Linguistics.
- Yu et al. (2022) Nan Yu, Meishan Zhang, Guohong Fu, and Min Zhang. 2022. RST discourse parsing with second-stage EDU-level pre-training. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4269–4280, Dublin, Ireland. Association for Computational Linguistics.
- Zhang et al. (2020) Longyin Zhang, Yuqing Xing, Fang Kong, Peifeng Li, and Guodong Zhou. 2020. A top-down neural architecture towards text-level parsing of discourse rhetorical structure. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6386–6395, Online. Association for Computational Linguistics.
- Zhang et al. (2021) Yingxue Zhang, Fandong Meng, Peng Li, Ping Jian, and Jie Zhou. 2021. Context tracking network: Graph-based context modeling for implicit discourse relation recognition. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1592–1599, Online. Association for Computational Linguistics.
- Zhu et al. (2020) Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, and Jingjing Liu. 2020. Freelb: Enhanced adversarial training for natural language understanding. In International Conference on Learning Representations.
Appendix A Ablation Study for Model Components
A series of ablation experiments were conducted on the news discourse profiling task to examine the functional significance of each module within LiMNet.
As shown in Table 4, LiMNet w/o Global represents the model in which the calculation of global sentence shift is removed and the local sentence embeddings are sent to the prediction layer directly. This modification led to a minor increment in precision but resulted in a substantial decline in recall, consequently lowering the overall F1 score. Such results underscore the criticality of the global shifts in providing necessary information for the linear combination of word embeddings.
The variant LiMNet w/o Local symbolizes a model wherein the computation of local sentence embeddings is replaced by an average pooling operation. This removal of the sentence-level self-attention module precipitated a significant downturn in both precision and recall metrics. Given that the computation of global sentence shifts is contingent on local sentence embeddings, it is clear that an effective local embedding is paramount to the overall system performance.
LiMNet w/o Either represents a model where the computations for both local and global embeddings are excised. In this model, the only learnable component is the FFN in the final prediction layer. The performance of this model presents the inherent representational capabilities of the T5 language model and illuminates the necessity of integrating supplementary neural structures with fixed PLMs. The results demonstrate that in the absence of these additional neural structures, even powerful PLMs such as T5 are unable to yield satisfactory performance when using only their word embeddings.
In summary, the ablation analysis underscores the utility of each self-attention module within LiMNet and affirms its ability to efficiently harness underlying PLMs to generate task-relevant text representations.
| Macro | Micro | |||
|---|---|---|---|---|
| Precision | Recall | F1 | F1 | |
| LiMNet | ||||
| LiMNet w/o Global | ||||
| LiMNet w/o Local | ||||
| LiMNet w/o Either | ||||
| Updated Baseline | LiMNet | |||||||
|---|---|---|---|---|---|---|---|---|
| Macro | Micro | Macro | Micro | |||||
| Precision | Recall | F1 | F1 | Precision | Recall | F1 | F1 | |
| w/ ELMo Peters et al. (2018) | ||||||||
| w/ BERT Devlin et al. (2019) | ||||||||
| w/ RoBERTa Liu et al. (2019) | ||||||||
| w/ T5 Raffel et al. (2020) | ||||||||
Appendix B Effects of Different Language Models
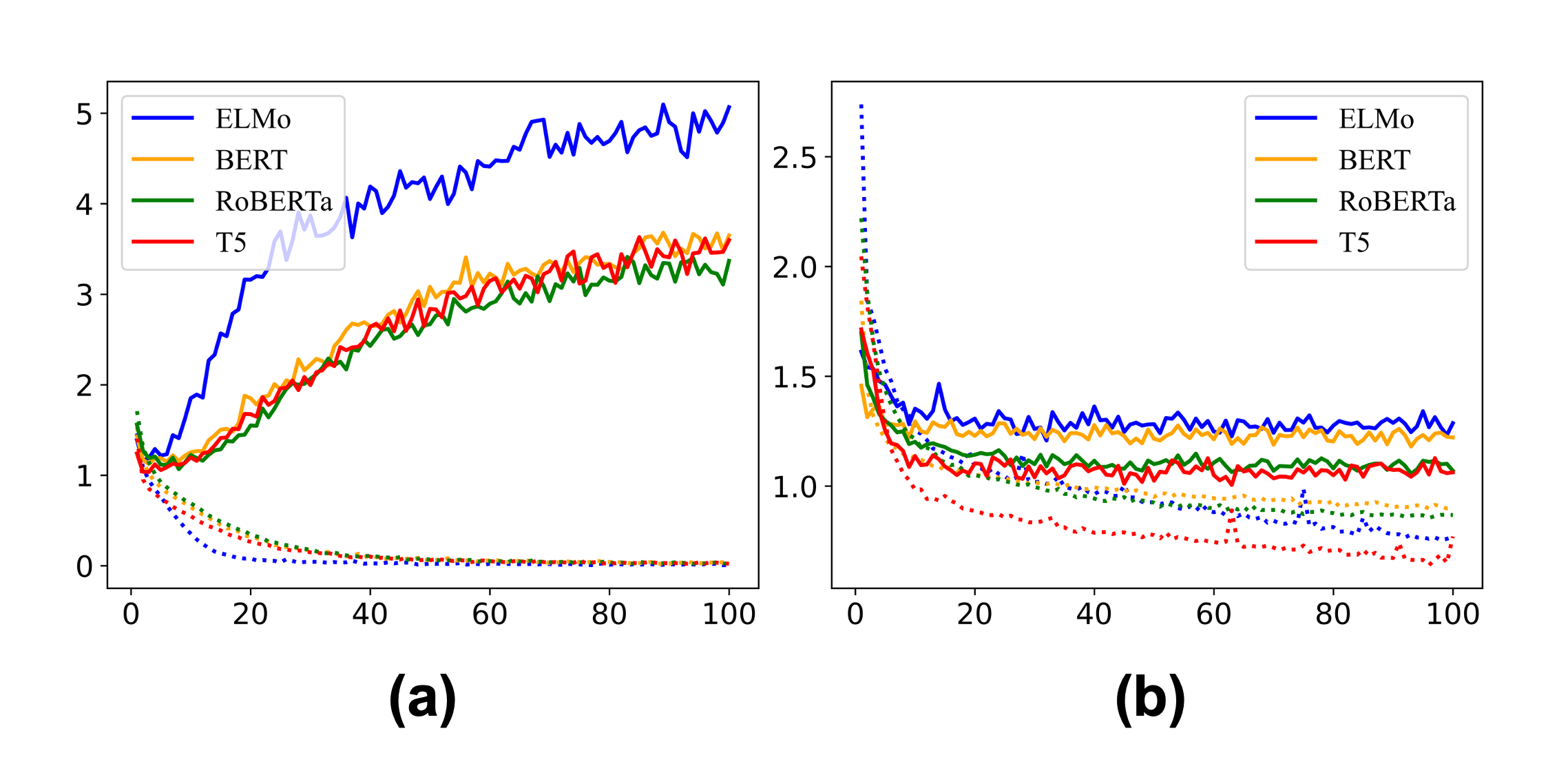
We also delved deeper into examining the impact of employing various PLMs without finetuning on the task of news discourse profiling. Table 5 presents the results of using a series of PLMs for our baseline model and LiMNet. Based on the macro F1 metric, our simple neural architecture LiMNet outperforms the baseline model on three pretrained language models, ELMo, RoBERTa and T5, and both models performed comparably on the remaining language model BERT. More specifically, LiMNet achieves higher precision across all the language models, but the recall of LiMNet is a little lower on two language models BERT and RoBERTa. Meanwhile, based on the micro F1 metric, LiMNet consistently outperforms the baseline model across all the language models. Furthermore, an intriguing observation was that the performance disparity between our LiMNet model and the baseline models widened with the use of superior PLMs. This phenomenon can be reasonably attributed to the fact that our model leverages PLMs indirectly, thus retaining their generalization capabilities while simultaneously being constrained by their inherent capacities.
Furthermore, Figure 5 delineates the evolution of the training and validation loss curves for both the baseline models and LiMNet models employing various pretrained language models. Upon inspection, it is observed that for each language model, the disparities between the training and validation loss widen rapidly over the course of the training epochs. This phenomenon is indicative of a propensity for overfitting within the baseline models. Conversely, the validation loss within the LiMNet models remains relatively stable, and the gaps between their training and validation losses are consistently narrow. These observations affirm the capacity of the LiMNet models to maintain the generalizability inherent in pretrained language models. The consistency of the generalization capability of our LiMNet model across disparate PLMs underscores its effectiveness in counteracting overfitting issues, thereby further attesting to the robustness of our model architecture.
Appendix C Effects of Finetuning Language Models
In this section, we investigate the impact of unfixed pretrained language models that are updated during training for the news discourse profiling task, as demonstrated in Table 6. Compared with experiments involving fixed language models, the finetuning process substantially enhances the final performance metrics. Although the paradigm of finetuning the entire PLM on downstream tasks is a widely adopted practice, it is susceptible to potentially severe overfitting issues when dealing with tasks characterized by limited data availability. This phenomenon is starkly illustrated in Figure 6 (a), which demonstrates the rapid overfitting to training data by models with unfixed PLMs, thereby creating a substantial divergence between training and validation loss. In comparison to our proposed LiMNet, finetuning PLMs configures their weights to fit specific downstream tasks, potentially compromising their generalization abilities. Furthermore, as PLMs continue to increase in size, finetuning the entirety of these PLMs becomes increasingly challenging. In such a context, our model, which more effectively leverages the fixed PLM, may prove to be increasingly beneficial.444We do not demonstrate that our approach is superior to the current approaches where the PLMs are updated, especially when comparing the performance scores. However, we would like to highlight our contributions to alleviating the overfitting problem and making the model lightweight by fixing the PLMs.
| Macro | Micro | |||
|---|---|---|---|---|
| Precision | Recall | F1 | F1 | |
| BERT | ||||
| RoBERTa | ||||
| Longformer | ||||
| Ours | ||||

| Macro | Micro | |||
| Precision | Recall | F1 | F1 | |
| 1 Trans Only | ||||
| 2 Trans Only | ||||
| 3 Trans Only | ||||
| SA + 1 Trans | ||||
| SA + 2 Trans | ||||
| SA + 3 Trans | ||||
| Ours | ||||
Appendix D Effects of Transformer Layer
We also provide the experimental results where transformer layers are utilized in replace of our self-attention modules on the task of news discourse profiling as shown in Table 7. x Trans Only represents the model where transformer layer with default configuration is utilized upon extracted word embeddings. Then average pooling is implemented to obtain the final sentence embeddings. A considerable performance decline is observed when juxtaposed with our proposed method. Moreover, as shown in Figure 6 (b), our model is still more stable than directly using transformer layers. An additional observation is that the incorporation of more transformer layers results in a slight escalation in both performance and standard deviation, thus indicating a reduction in robustness. In contrast to a transformer layer, where an FFN is employed to obtain requisite features for the subsequent layer directly, our model’s self-attention layer simply learns scalars for composing the word embeddings. This indirect approach circumvents potential adverse effects on word embeddings and thereby preserves their generalizability.
Another group of variant models is denoted as SA + x Tran, wherein transformer layers are applied on top of local sentence embeddings produced by our self-attention module. A significant performance increase is observed when comparing SA + x Tran to x Trans Only, thereby demonstrating a more effective exploitation of pretrained language models. Nevertheless, our method continues to achieve the highest performance and lowest standard deviation, affirming both the effectiveness of our model in utilizing pretrained language models and the stability of our method. Figure 6 (c) provides the loss curves corresponding to each model.