Learning to Regrasp by Learning to Place
Abstract
In this paper, we explore whether a robot can learn to regrasp a diverse set of objects to achieve various desired grasp poses. Regrasping is needed whenever a robot’s current grasp pose fails to perform desired manipulation tasks. Endowing robots with such an ability has applications in many domains such as manufacturing or domestic services. Yet, it is a challenging task due to the large diversity of geometry in everyday objects and the high dimensionality of the state and action space. In this paper, we propose a system for robots to take partial point clouds of an object and the supporting environment as inputs and output a sequence of pick-and-place operations to transform an initial object grasp pose to the desired object grasp poses. The key technique includes a neural stable placement predictor and a regrasp graph based solution through leveraging and changing the surrounding environment. We introduce a new and challenging synthetic dataset for learning and evaluating the proposed approach. We demonstrate the effectiveness of our proposed system with both simulator and real-world experiments. More videos and visualization examples are available on our project webpage https://sites.google.com/view/regrasp.
Keywords: Regrasping, Object Placement, Robotic Manipulation
1 Introduction
“Regrasping must be performed whenever a robot’s grasp of an object is not compatible with the task it must perform.” [1]
Through regrasping, an object can be picked up initially, placed down on an intermediate stable state possibly supported by a second object or the environment geometry, and then be grasped in a target pose and position. Regrasping is a common daily task and plays a crucial role in connecting various manipulation operations to solve complex long-horizon tasks. For example, when assembling parts to an IKEA chair, we may need to pick-and-place these parts several times to find appropriate orientations before mating and putting them together. When preparing the food, we may need to pick-and-place the knife and spatula several times to find the desired grasp poses for tool usages. The ability of a robot to regrasp a wide variety of objects is of tremendous importance for many application domains such as manufacturing or domestic services. However, the large diversity of geometry in everyday objects and the high dimensionality of the state and action space make this a challenging manipulation task. In this paper, we enable a robot to construct a sequence of pick-and-place operations to achieve various desired grasp poses.
Picking objects, or grasping, has attracted great attention in robotics [2, 3, 4, 5, 6, 7]. In contrast, regrasping, which is generating the sequence of pick-and-place operations, has received considerably less attention. Early work [1, 8] builds a Grasp-Placement (GP) to search for regrasp sequences. It first fills valid grasp and placement pairs in the GP table and then searches the table to find a sequence of pick-and-place motion. There are many works following this direction [9, 10, 11]. It usually requires a full observability of the environment and takes a significantly long time before finding a solution given the high-dimensionality of the searching space. Jiang et al. [12] use Support Vector Machines with hand-designed features to score the placement suitability of candidate poses and they focus on the object placement. In this paper, we propose a novel stable object pose prediction model with deep-learned features extracted directly from the raw point clouds and consider both picking and placing operations for regrasping tasks.
Taking as inputs partial observations of the object to regrasp and the surrounding environment, our system predicts a pick-and-place sequence to reach the desired object grasp poses as the output. The system contains a learned object placement module that is able to efficiently generate a diverse set of valid object poses for placement, and a regrasp framework that autonomously creates a regrasp graph to search for desired grasp poses by leveraging and changing the surrounding environment.
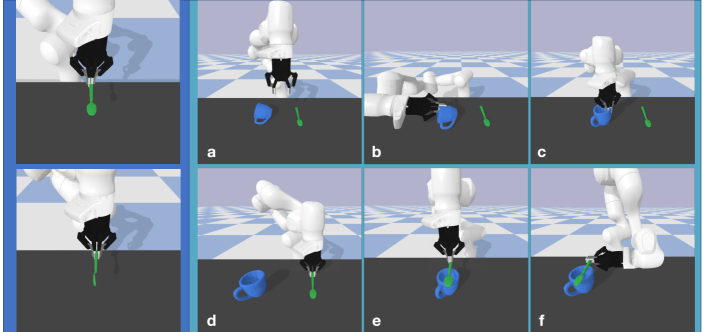
Our primary contributions are: 1) proposing a novel manipulation system that enables robots to regrasp a diverse set of objects through actively leveraging and changing the surrounding environment, 2) introducing a learning-based model to predict stable object placement poses; 3) generating an annotated dataset for object regrasping tasks and conducting extensive experiments to demonstrate the effectiveness of our proposed approach.
2 Related Work
We review literature related to the two key components in our approach - predicting object placement and planning regrasp graph, and describe how we are different from previous works.
2.1 Object Placement
Pick-and-place is one of the most common robotic manipulation tasks. Picking objects, or grasping, has attracted great attention in robotics. For a broader review of the field on data-driven grasp synthesis, we refer to [13, 7]. In contrast, object placement, which is the process of deciding where and how to place an object, has received considerably less attention. Harada et al. [14] presented an object placement planner to find object placement poses by matching planar surface patches on the object with planar surface patches in the environment. Haustein et al. [15] introduced a motion planning algorithm for robots to place a grasped object in a cluttered environment. Jiang et al. [12] employed Support Vector Machines with hand-designed features to score the placement suitability of candidate poses. Unlike these works either requiring full observability or relying on hand-crafted feature engineering, we propose an end-to-end approach with deep-learned features extracted directly from the raw point clouds.
2.2 Regrasp for Object Reorientation
Early works [1, 8] build Grasp-Placement (GP) to search for regrasp sequences, by solving the inverse kinematics, checking all collisions to remove invalid grasp-placement pairs, filling them in the GP table, and finally searching within the table to find a sequence of pick-and-place motion. There are many works following this direction. Rohrdanz and Wahl [9] improved the efficiency of regrasp planning using an evaluated breadth-first-search, rated grasp, and placement quantities. Stoeter et al. [10] replaced the GP table with a space of compatible grasp-placement-grasp triplet and searches this space to find a sequence of pick-and-place motion. Regrasp is also studied in the context of task and motion planning (TAMP). Lozano-Pérez and Kaelbling [16] presented a framework where a symbolic planner plans a sequence of high-level sub-tasks and a constraint satisfaction problem solver plans low-level operations. A regrasp plan is composed of a symbolic pick-and-place sequence and a set of geometrically feasible placements, grasps, and paths, which requires a precise full observability of the entire system.
Wan et al. [11] presented a regrasp planning component for object reorientation. Given the initial and goal pose of an object, the regrasp planning component finds a sequence of robot postures and grasp configurations that reorient the object from the initial pose to the goal pose. Raessa et al. [17] presented a hierarchical motion planner for planning the manipulation motion to re-pose long and heavy objects. They developed a graph-based planning system that combines both regrasp and in-hand manipulation motion considering external support surfaces. Cao et al. [18] increased the reorientation capability of a pick-and-place regrasp by adding a vertical pin on the working surface and using it as the intermediate location for regrasping. The work most related to ours is [19] where they developed a regrasp planning algorithm considering intermediate stable states on fixture such as box baskets. Unlike these planning based approaches, our learning-based approach do not require full observability and learn features directly from raw sensory data. Our approach also allows robots to actively change other objects in the environment to create extra supports. Besides regrasping, object reorientation can also be achieved through in-hand manipulation [20, 21, 22] or dual-arm manipulation [23, 24].
3 Problem Definition
In this section, we formulate the object regrasping problem and introduce necessary concepts we use. Note that there may be various other ways to parameterize the same problem.
We consider a single-arm robot equipped with a two-fingered robotic hand. However, our proposed pipeline can be applied to many other settings, such as multi-arm robots or dexterous robotic grippers, to enhance their manipulation performances. We assume that the segmentation of all objects within the surrounding environments is provided and the objects are graspable for the robotic hand. Note that our approach could also be extended to movable but ungraspable objects in the surrounding environment leveraging non-prehensile manipulation processes such as pushing.
Notations.
Let denote the set of objects in the scene, including the target object , supporting objects , and the ground . We use , , and to denote the robotic hand, the robot, and the robot configuration respectively. Each object and the robotic hand has its own local coordinate frame and . Their pairwise relative transformations are also known. Let and denote the 6D poses of the object and the robotic hand in the world frame .
Grasping Operation.
A grasp pose of an object is parameterized by two contact points on the object surface and an approaching direction of the robotic hand . All three vectors are described in the object local frame . A grasping operation depends on the grasp pose , the object pose in the world frame , the surrounding environment , and the robot’s configuration . A grasping operation is valid if the contact points are in force-closure, reachable by the robot, and occurring no collision in the process. A valid grasp attaches the object to the robotic hand , and hence its 6D pose in the world frame can change as the robotic hand moves. We assume all objects, including the supporting objects , can be grasped, since the robot may rearrange the environment in various ways to support the target object finally.
Placement Operation.
When an object is placed stably on a surrounding environment, we use its global world pose to describe its placement pose. A placement operation of the object depends on the placement pose , the surrounding environment , and the robot’s configuration . The placement operation is valid if 1) the placement pose is reachable by the robot, 2) there is no collision, and 3) the object remains stable after the robotic hand releases the object. A valid placement detaches the object from the robotic hand. Its 6D pose in the world frame remains when the robot moves away.
The Regrasping Problem.
The problem of regrasping object is defined as finding a sequence of valid grasping operations and placement operations over all objects to reach a target grasp pose for the target object .
4 Technical Approach
In this section, we introduce our regrasping pipeline, consisting of a plan searching algorithm over a regrasp graph (Fig. 2) and a deep-learned model for stable pose placement prediction (Fig. 3).
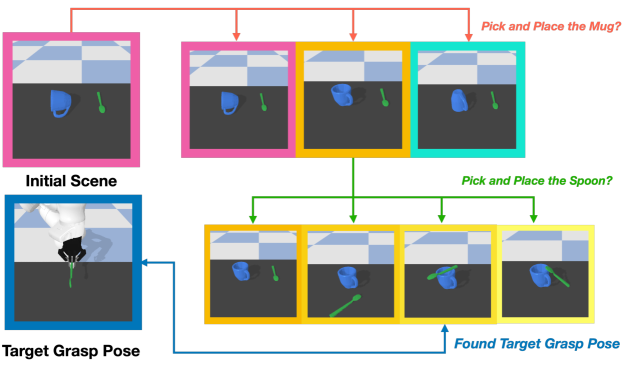
4.1 Regrasp Graph Construction and Searching
A regrasping problem solves a sequence of valid grasping and placement operations to reach a target grasp pose of the object . We also allow robots to change other objects’ poses by applying several intermediate grasping-and-placing operations, since changing the poses of other objects rearranges the environment and may provide extra supports that can increase the number of valid grasping operations for the target object . Below, we describe in details how to construct a regrasp graph and run a searching algorithm over it to figure out a plan.
Graph Construction.
Our system creates and leverages a regrasp graph to solve the regrasping problem. Each node in the regrasp graph includes stable poses for all objects . An edge connects two nodes and , if there is one and only one object whose stable pose is changed between the two nodes, and there exists a valid pair of grasping operation and placement operation that transform the object’s stable pose. The edge indicates that the robot can first grasp the object from its stable pose under one node and then place it at the stable pose in the other node.
Initially, all objects are stably placed in the scene. All objects’ initial poses define the first node in the regrasp graph. For each object , we use a deep-learned stable object placement pose prediction model (Sec. 4.2) to estimate the object’s alternative stable poses under the current surrounding environment. Each alternative stable pose of the object , along with other objects’ stable poses, leads to a new node in the regrasp graph. Whenever a new node is created, our system checks whether there are edges connecting it to the rest nodes and add these edges to the graph.
Graph Searching.
Leveraging the constructed regrasp graph, the solution of a regrasp problem is a path from a starting node to a target node that contains a stable object placement pose allowing a valid grasping operation to achieve the target grasp pose for the target object . We use depth-first-search algorithm to search for a valid path.
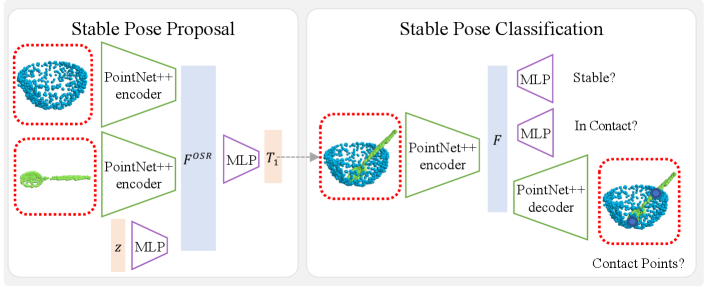
4.2 Stable Object Poses Prediction
We train a neural network to predict stable object placement poses under diverse surrounding environments. Estimating stable placement poses for a wide variety of objects with diverse and complicated geometry is a challenging task. It requires very accurate pose predictions, since a slight error may easily result in an undesired object falling or penetration between the object and its surrounding environment. Hence, we design a two-stage pipeline (Fig. 3) that first predicts diverse rough poses and then refines to obtain more accurate results. We describe the detailed network designs below.
Stable Poses Proposal.
Given an object and a static surrounding environment , we first train a generative model that learns to propose a diverse set of poses for the object to be stably placed in the environment .
Fig. 3 (left) illustrates the inputs, outputs, and design overview for this network. In our implementation, we represent both the partial observations of the object and surrounding environment , captured by the robot’s RGB-D camera, as 3D point clouds consisting of points. We first employ two PointNet++ encoders [26] to extract global point cloud features and . To propose multiple solutions to the stable poses of the object , we sample a random Gaussian noise as an additional input and use an Multilayer perceptron (MLP) to extract a feature . We concatenate , , and to produce a single joint feature and finally employ another MLP to decode a final 6-DoF pose for the object . For brevity, we omit the subscripts denoting the global world coordinate, indicating the environment, and the superscript representing the shape in the following paragraph. The 6-DoF pose is composed of a 3D translation and a 3D orientation. For the orientation part, we adopt the axis-angle representation, which has been shown to be effective for pose prediction task [27].
Sampling different Gaussian noises , we obtain a diverse set of pose predictions . Provided with a ground-truth list of stable poses generated by running several random interaction trials in physical simulation, we define a loss to train our pose prediction outputs.
| (1) |
where measures the distance between two 6-DoF poses. We implement as the average distance between the corresponding points of the object point clouds after applying the two poses.
Stable Pose Classification and Refinement.
We train a model to classify the stability of the sampled poses. For each predicted pose , we first concatenate the transformed object point cloud with the surrounding environment point cloud . Then, we augment this combined point cloud with one extra 1D arrays of ones and zeros, to indicate if a point belongs to or , along the XYZ dimension to form a tensor of shape . With this augmented input, a straightforward method for stable classification would be using a PointNet++ [26]. However, we find that this naive approach does not provide satisfying results due to the intrinsic difficulty of analyzing stability among two separate geometry components.
To facilitate learning, we propose to solve this problem via a multi-task supervised learning approach. After obtaining the feature from the PointNet++ backbone, we have three task branches that perform stable classification, contact classification, and contact point regression simultaneously. For contact point regression, we use a PointNet++ decoder to regress the 3D offset from each point of the input point cloud to its nearest ground-truth contact point with a loss defined as:
| (2) |
Here denotes the input point clouds including the transformed object point cloud and the environment point cloud . Based on the predicted pose, we calculate the nearest ground truth stable pose from Eqn. 1 and collect the corresponding contact point sets between the object and the environment in the simulation denoted as . We implement as smooth loss. We also adopt a variance loss similar to [27] to reduce the variance of the group {} that correspond to the same contact point. We train two MLP classifiers for stable pose and contact classification with losses denoted as and respectively. Our total loss is defined as:
| (3) |
where and are standard binary cross entropy losses.
Leveraging the above stable pose classifier function denoted as , we apply CEM [25] to search for a locally optimal goal pose starting from the initial predicted poses. We first apply the predicted transformation to the object point cloud to get a point cloud . A point in the CEM searching action space is a 6D transformation which transforms the object point cloud into . A point in the CEM state space is the transformed object point cloud along with the surrounding environment point cloud . When selecting the action , we run a derivative-free optimization method CEM [25] to search within the 6D pose space to find a 6D transformation associated with the highest score in the value model .
| (4) |
The 6D pose associated with is the final stable placement pose produced by our model.
4.3 Object Grasping
In this subsection, we describe how our system performs valid grasping operations. Recall that a grasp pose of the object is parameterized by two contact points on the object surface and an approaching direction of the robotic hand . We adopt UniGrasp [6], an efficient data-driven grasp synthesis method, to generate a list of valid grasp poses of the object . UniGrasp learns a deep neural network to select a set of contact points from the input point cloud of the object . We refer to Shao et al. [6] for more detailed description of the method. Given two contact points and , we calculate a plane perpendicular to the line segment of the two contact points intersecting at the middle point of the line segment. We then consider 36 approaching directions evenly distributed within the plane, which produces 36 potential grasp poses. For each grasp pose , we solve the inverse kinematics of the robot. If there is no valid inverse kinematic solution or there are collisions in all possible approaching directions, we drop the contact point pair and continue checking for the next pair of contact points. We keep running this process until we find a valid grasping operation if there exists one.
5 Experiments
In this work, we develop a learning framework for robots to learn to regrasp objects. Our experiments focus on evaluating the following questions: (1) How effective is our proposed learning-to-place approach compared to other baselines? (2) Whether our proposed learning-to-regrasp pipeline can find good solutions to the object regrasping problem? (3) Whether the multi-task learning for contact point predictions we use in Sec. 4.2 is useful or not? (4) Whether our proposed pipeline is robust to various sources of noises (e.g. object segmentation, sensing, dynamics)? Please refer to supplementary materials for experiments associated with (3) and (4), ablation study, and failure cases analysis.
Dataset.
We construct a dataset containing 50 objects (i.e., spoon, fork, hammer, wrench, etc.) and 30 supporting items (i.e., mug, box, bowl). We then split these objects and supporting items into training and test sets. No test objects and supporting items have been seen during training. We generate 249 pairs from the training set of objects and supporting items, and 38 pairs from the test. We collect the placement data for supporting items by randomly placing the supporting items with respect to the initial environment (i.e., the ground), and running the simulation to check whether the supporting items keep static. To make the stable placement robust to variant dynamics and geometry, we randomize the dynamic parameters including friction, mass, and external forces. We describe the details in the supplementary. In total, we generate around one million poses for training set and 15 thousand poses for testing set. We visualize the data in supplementary material.
Settings.
We first set up the simulation environment in PyBullet [28] for evaluating our full pipeline on synthetic data. We load the object at the predicted pose and check if there is collision and whether the object is stable. We then evaluate the regrasping task on a real robot system.
5.1 Object Stable Placement
We evaluate our proposed framework on learning stable placement poses in this subsection.
| method |
|
|
|
|
|
|
|
|
mean | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Random | 0.000 | 0.001 | 0.109 | 0.039 | 0.000 | 0.000 | 0.000 | 0.012 | 0.020 | ||||||||||||||||
| Jiang et al. [12] | 0.037 | 0.080 | 0.201 | 0.113 | 0.047 | 0.018 | 0.125 | 0.092 | 0.089 | ||||||||||||||||
| Jiang et al. [12] + heuristic | 0.175 | 0.041 | 0.437 | 0.852 | 0.603 | 0.013 | 0.128 | 0.000 | 0.281 | ||||||||||||||||
| Ours | 0.869 | 0.848 | 0.894 | 0.911 | 0.905 | 0.674 | 0.834 | 0.829 | 0.845 |
| method |
|
|
|
|
|
|
|
|
mean | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jiang et al. [12] + heuristic | 2.500 | 1.000 | 28.000 | 28.333 | 10.333 | 2.000 | 4.250 | 0.000 | 9.552 | ||||||||||||||||
| Ours | 16.900 | 18.100 | 45.850 | 49.100 | 52.133 | 14.500 | 15.750 | 12.450 | 28.098 |
Evaluation of Object Placement Accuracy.
Our pipeline samples and refines 128 poses for each object and supporting item pair. We use the pose classifier to estimate the scores for these 128 poses and use a threshold of 0.8 to filter out the poses with low scores. To verify the remaining poses, we run a forward simulation in PyBullet [28] to check whether the objects at these poses are stable. The results of the stable placement accuracy for each category are reported in Table 1.
We first adopt a baseline (Random) which is based on a random pose sampling strategy. The rotation value is sampled from SO(3) uniformly, and translation value is uniformly sampled within this region of [, , +0.02] in the supporting item’s local frame, where is determined by the maximal height of each supporting item. We use the meter as the unit of translation value throughout the experiment section.
We slightly modify the approach in [12] to work in our setting and use it as another baseline ( Jiang et al. [12] ), in which a stable pose classifier is learned based on hand crafted features. We randomly sample 128 poses in the local frame of the supporting environment, and classify these poses using the stable pose classifier. We evaluate the accuracy of these stable poses in PyBullet [28] and report the results in Table 1. The results suggest that even with random sampled poses, a simple classifier with hand-craft feature can improve the stable placement accuracy. We also design another baseline that adopts heuristic rules for pose sampling but with the same classifier from [12]. For this baseline ( Jiang et al. [12] + heuristic), the object translation in the horizontal dimensions (XY dimensions) is sampled in the radius of and the translation in the gravity dimension (Z dimension) is determined by , where and are the radius and maximal height of supporting item respectively. We additionally rotate the object to make the longest axis of the object horizontally. While this baseline can achieve some reasonable results in easy situations when the supporting item has a nearly flat horizontal surface (i.e., box-wrench, box-spatula), it perform worse with supporting items with complicated geometry (i.e., bowl, mug). The results demonstrate that a good pose proposal algorithm is also of great importance to the success of stable object placement. With carefully designed stable pose proposal network and stable pose classifier network, our framework achieves the best results over all the approaches.
Evaluation of Object Placement Diversity.
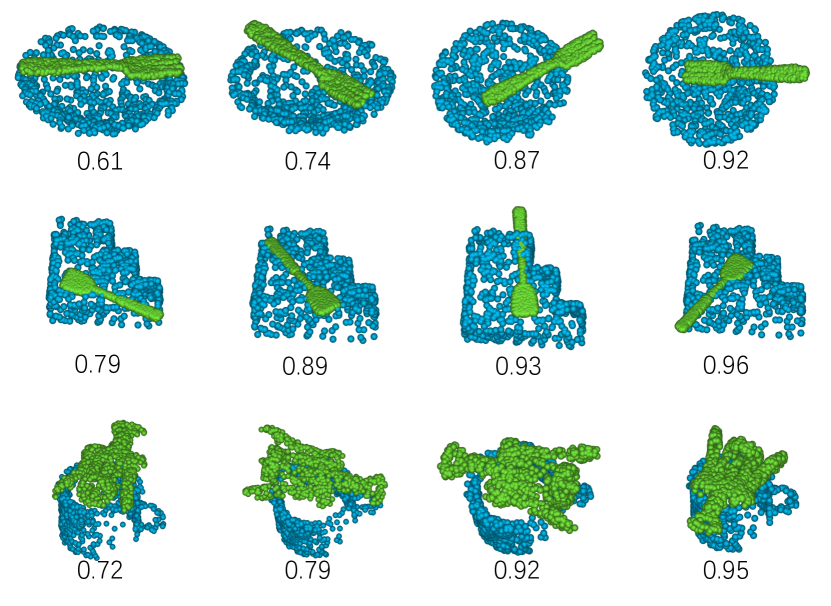
We evaluate whether the pose proposal network can generate a reasonable distribution of the stable poses for placing the object over the supporting items. A diversifying stable pose distribution is crucial for the success of finding desirable regrasping solutions. For each input object and supporting item pair, we draw 128 poses from the proposal network, and transform the candidate object to the proposed stable poses. The qualitative results are presented in Fig. 4. Our visualization demonstrates that our proposed stable poses yield diverse object placements.
To quantitatively measure the diversity of the stable object placements, we define two poses as two different poses if their translation difference is larger than and the rotation angle between them is larger than . In our experiment, and are set to be and respectively. We report the average number of different stable object placements in Table 2. The results showing that although random uniform sampling combined with heuristic rules can generate diverse stable poses for some easier environment (i.e., boxes with flattened surface), it can not handle complicated geometry. Our proposed method outperforms the baseline by a large margin.
5.2 Object Regrasping Performance
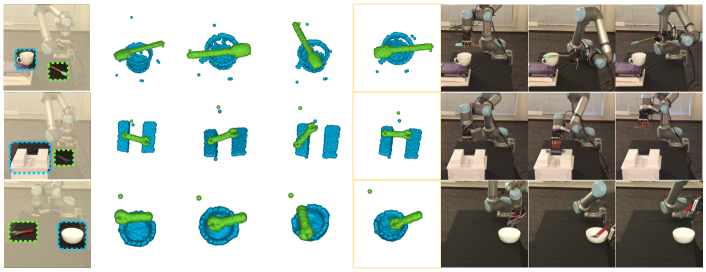
We evaluate the performance of our model in real-world experiments on everyday objects. We first test the pose proposal network on point clouds from Intel RealSense RGB-D camera. Utilizing the camera matrix, we can reconstruct a 3D point cloud. The point clouds are fed into our model to predict stable placement poses. We then run Unigrasp [6] to generate a list of valid grasp poses and search for the desired target poses based on the pipeline described in Sec. 4. The generated stable placements and several key frames of the regrasping process are visualized in Fig 5. For more results on the regrasping experiments, please refer to our supplementary material.
6 Conclusion
We present a system that can regrasp a diverse set of everyday objects to desired grasp poses for various manipulation tasks. Our system learns to predict the stable placement of objects based on partial point clouds of the object and the surrounding environments. The system also creates a regrasp graph and allows robots to leverage and actively change other objects’ poses to provide extra supports. We demonstrate the effectiveness of our system on both challenging synthetic dataset and in real world regrasping tasks. Currently our system only takes raw vision sensory data as inputs. For future work, we would like to explore how to incorporate other modalities such as force or tactile signals in our system.
Acknowledgments
We would like to thank the UnitX company (https://www.unitxlabs.com) for providing us the UR5 robot arm used in the real robot experiments. We thank Shenli Yuan for helping us set up the customized two-fingered gripper, and Hongzhuo Liang for helping us set up the network configuration.
7 Appendix
In this appendix, we evaluate whether the multi-task learning for contact point predictions is useful or not and how the score threshold affects the performance of stable object placement. Then we report how we generate and annotate the dataset used in this work. We describe the regrasping experiments in the simulation and the real world. We further investigate whether our proposed pipeline is robust to various sources of noises (e.g., object segmentation, depth camera noise, object dynamics). Lastly, we conduct failure cases analysis and report the computational costs.
A. Additional Experiments on Object Stable Placement
A1. Does Multi-task Learning Help?
| Task Combination | Contact Acc. | Contact Prec. | Stable Acc. | Stable Prec. |
|---|---|---|---|---|
| stable | N/A | N/A | 0.888 | 0.890 |
| stable + contact | 0.925 | 0.977 | 0.918 | 0.906 |
| stable + contact + offset (ours) | 0.945 | 0.981 | 0.912 | 0.910 |
To verify the usefulness of the multi-task joint learning framework, we adopt the same network architecture but with different combinations of task losses. The quantitative results on the test set are shown in Table 3. We use the accuracy and precision metrics to measure the performance of each model. While the model trained with only stable loss reaches a reasonable performance, adding auxiliary losses improves the stable precision from 0.906 to 0.910. Our experiments demonstrate that the contact prediction and contact offset regression are beneficial to the stable pose learning task. This is reasonable because a strong correlation between each subtask eases the joint learning process: 1) for all stable poses, the placed object must have contact points with the supporting environment, and 2) the offset from the support and the object should be consistent with each other.
A2. Different Score Threshold.
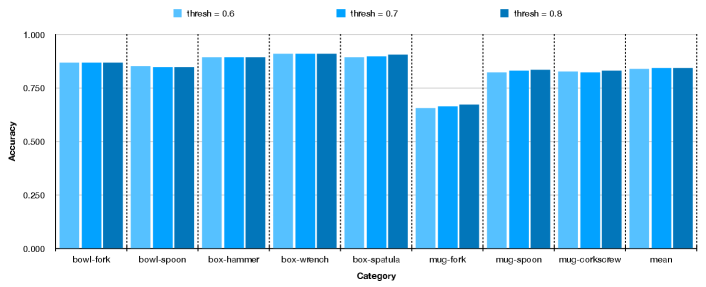
We evaluate how different score threshold will affect the accuracy of the proposed stable placements, the results are presented in Fig 6. While observing that filtering out the generated poses using higher thresholds will generally lead to better accuracy of stable placement, we do not consider a too harsh threshold because it will remove all the poses. We choose the threshold to be 0.8 for best practice.
B. Dataset
We construct a dataset containing 50 objects (i.e., spoon, fork, hammer, wrench, etc.) and 30 supporting items (i.e., mug, box, bowl). We then split these objects and supporting items into training and test sets. We generate 249 pairs from the training set of objects and supporting items, and 38 pairs from the test. For each pair of object-supporting item, the initial placement poses are generated by sampling different object poses with respect to the supporting item in PyBullet, and running a forward simulation to see if it remains stable. We collect the placement data for supporting items by randomly placing the supporting items with respect to the initial environment (i.e., the ground), and running the simulation to check whether the supporting items keep static. To make the stable placement robust to variant dynamics and geometry, we randomize the dynamic parameters including friction, mass, and external forces. For each round of simulation, we randomly scale the object mass by [0.9, 1.1], and we randomly select the gravity in the range [, , -9.81 ] for approximating the perturbations in the real environment, we also sample the lateral friction, spinning friction, and rolling friction in the range of [0.3, 0.7]. In total, we generate 1,050,884 poses for training items and 15,105 poses for testing items. Some stable object placements from our dataset are visualized in Fig 7.

C. Regrasping Simulation Experiments
Leveraging the stable pose prediction model and object grasping model, we evaluate the regrasping performance of our proposed system. We randomly select multiple objects from our dataset when creating each initial manipulation scene. These objects are placed stably, except that the robot might grasp one object. In each scene, there is one regrasp query, which is a target grasp pose of one object, for our system to accomplish.
In total, we have 30 scenes as the test set. Our system generates the regrasp graph by predicting the stable poses of each object and checking whether there are edges connecting two nodes. The regrasp task is considered successful if our system finally finds the target regrasp poses. We report the average success rate among the test scenes. We adopt a baseline approach by replacing our object placement prediction model with the baseline method (Random) and keeping the same rest settings. Our proposed pipeline achieves 83.3% success rate while the baseline does not have any successful case.
D. Regrasping Real World Experiments
We mount a two-fingered customized gripper onto a ur5 shown in the video on the project webpage https://sites.google.com/view/regrasp. A realsense camera is mounted at the robot’s wrist and its relative transformation to the end-effector is calibrated. We gather raw point clouds from the realsense camera leveraging its calibrated intrinsic camera parameters. In the current setting, we use the black color cloth to get object segmentation. Other segmentation approaches could also be adopted. These point clouds are fed into our model to predict stable poses. We run position control to move and place the object at its predicted pose. The video currently plays at 4x speed.
E. Generalization and Robustness
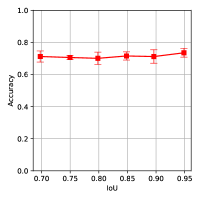
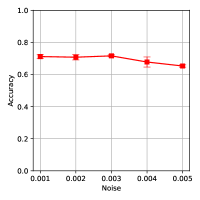
Our pipeline assumes the object and support can be segmented from the background using off-the-shelf methods [29, 30, 31]. Considering the noise induced by the perceptual algorithm and real sensor, we also add gaussian noise on point clouds during training to make the models more robust to outliers. For evaluation of the tolerance on segmentation errors, we first test our pipeline under different IoUs using simulation data (the ground-truth segmentation mask is randomly expanded or cropped), the performance is shown in Fig 8. To quantify the robustness of our models to sensor noise, we add Gaussian noise with different standard deviation to the input point clouds. The results suggest that our trained models can resist segmentation noise and sensor noise in a reasonable range.
To mitigate the uncertainties related to the object dynamics, we add various perturbations when annotating the stable poses during the data generation stage. In the real-world execution, we would prefer the stable object placement object that a small neighborhood of the specific stable pose remains stable according to the stable pose classifier. This specific stable pose is helpful during the real-world execution when the noise in robot actuation may lead to alignment errors between the object and the surrounding environments.

F. Failure Cases and More Result Analysis
F1. Stable Pose Prediction Module.
Our model takes raw point clouds of the object and surrounding environment along with random variables as inputs, and outputs a list of stable poses. However, these poses can not be 100% accuracy, the failure cases are shown in Fig. 9. We analyze that some predicted poses might be sensitive to tiny perturbation, or missing parts of the depth scans, these predicted poses might result in slight collisions between the object and the surrounding environments. These failure cases could be mitigated if force/tactile sensors are leveraged to produce closed-loop manipulation policies.
F2. Entire Regrasping Pipeline.
The regrapsing task is quite challenging. A typical regrasping process includes the object placement stage and the object regrasping stage.
During the object placement stage, when the robot is placing the object (for example, a spoon) into the supporting item (for example, a bowl), the final object pose might be stable but different from the predicted desired pose. The 6D pose of the supporting item might also change when receiving external forces in the process. These changes in the object and supporting item’s 6D poses might ruin the following regrasping stage. For example, the spoon might fall into the bottom of the bowl, which makes the spoon’s regrasping process impossible.
In the object regrasping stage, the robot might fail to find a feasible collision-free approach plan. Given that the robot finds a collision-free approach, the grasping process might still fail due to sensor noise, friction. In the regrasping stage, although the object is already at a stable pose, it might still be sensitive to external perturbations resulting in failure grasps. The most failure cases are caused by the false stable object pose predictions.
G. Computational Costs of the ReGrasping Pipeline
Our system creates and maintains a regrasp graph to tackle the regrasping problem. Each node represents a list of all objects’ stable poses in the scene, and each edge indicates that there is one regrasping operation to change from a list of stable poses to another list of stable poses.
In daily tasks such as regrasping spoons and forks, the regrasping process usually happens between two or three objects. In our cases, there are two or three objects in the scene. It takes one or two second to generate 128 predicted stable poses per object and 0.5 to 1 second to predict each object’s grasping parameters. It takes 5 to 10 seconds to construct the nodes in our cases and around 30 seconds to generate the edges. Since the regrasp graph in our experiments is relatively small, it takes less than one second to search the graph.
References
- Tournassoud et al. [1987] P. Tournassoud, T. Lozano-Perez, and E. Mazer. Regrasping. In Proceedings. 1987 IEEE International Conference on Robotics and Automation, volume 4, pages 1924–1928, 1987. doi:10.1109/ROBOT.1987.1087910.
- Sahbani et al. [2012] A. Sahbani, S. El-Khoury, and P. Bidaud. An overview of 3d object grasp synthesis algorithms. Robotics and Autonomous Systems, 60(3):326–336, 2012. ISSN 0921-8890. doi:https://doi.org/10.1016/j.robot.2011.07.016. URL https://www.sciencedirect.com/science/article/pii/S0921889011001485. Autonomous Grasping.
- Mahler et al. [2017] J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. 2017.
- Mahler et al. [2019] J. Mahler, M. Matl, V. Satish, M. Danielczuk, B. DeRose, S. McKinley, and K. Goldberg. Learning ambidextrous robot grasping policies. Science Robotics, 4(26):eaau4984, 2019.
- Lenz et al. [2015] I. Lenz, H. Lee, and A. Saxena. Deep learning for detecting robotic grasps. The International Journal of Robotics Research, 34(4-5):705–724, 2015. doi:10.1177/0278364914549607. URL https://doi.org/10.1177/0278364914549607.
- Shao et al. [2020] L. Shao, F. Ferreira, M. Jorda, V. Nambiar, J. Luo, E. Solowjow, J. A. Ojea, O. Khatib, and J. Bohg. Unigrasp: Learning a unified model to grasp with multifingered robotic hands. IEEE Robotics and Automation Letters, 5(2):2286–2293, 2020.
- Bohg et al. [2014] J. Bohg, A. Morales, T. Asfour, and D. Kragic. Data-driven grasp synthesis—a survey. IEEE Transactions on Robotics, 30(2):289–309, April 2014. ISSN 1552-3098. doi:10.1109/TRO.2013.2289018.
- Lozano-Pérez et al. [1992] T. Lozano-Pérez, J. L. Jones, P. A. O’Donnell, and E. Mazer. Handey: A Robot Task Planner. MIT Press, Cambridge, MA, USA, 1992. ISBN 0262121727.
- Rohrdanz and Wahl [1997] F. Rohrdanz and F. Wahl. Generating and evaluating regrasp operations. In Proceedings of International Conference on Robotics and Automation, volume 3, pages 2013–2018 vol.3, 1997. doi:10.1109/ROBOT.1997.619165.
- Stoeter et al. [1999] S. Stoeter, S. Voss, N. Papanikolopoulos, and H. Mosemann. Planning of regrasp operations. In Proceedings 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), volume 1, pages 245–250 vol.1, 1999. doi:10.1109/ROBOT.1999.769979.
- Wan et al. [2019] W. Wan, H. Igawa, K. Harada, H. Onda, K. Nagata, and N. Yamanobe. A regrasp planning component for object reorientation. Autonomous Robots, 43(5):1101–1115, 2019.
- Jiang et al. [2012] Y. Jiang, M. Lim, C. Zheng, and A. Saxena. Learning to place new objects in a scene. The International Journal of Robotics Research, 31(9):1021–1043, 2012.
- Sahbani et al. [2012] A. Sahbani, S. El-Khoury, and P. Bidaud. An overview of 3d object grasp synthesis algorithms. Robotics and Autonomous Systems, 60(3):326 – 336, 2012. ISSN 0921-8890. Autonomous Grasping.
- Harada et al. [2014] K. Harada, T. Tsuji, K. Nagata, N. Yamanobe, and H. Onda. Validating an object placement planner for robotic pick-and-place tasks. Robotics and Autonomous Systems, 62(10):1463–1477, 2014. ISSN 0921-8890. doi:https://doi.org/10.1016/j.robot.2014.05.014. URL https://www.sciencedirect.com/science/article/pii/S0921889014001092.
- Haustein et al. [2019] J. A. Haustein, K. Hang, J. Stork, and D. Kragic. Object placement planning and optimization for robot manipulators. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7417–7424, 2019. doi:10.1109/IROS40897.2019.8967732.
- Lozano-Pérez and Kaelbling [2014] T. Lozano-Pérez and L. P. Kaelbling. A constraint-based method for solving sequential manipulation planning problems. In 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3684–3691, 2014. doi:10.1109/IROS.2014.6943079.
- Raessa et al. [2021] M. Raessa, W. Wan, and K. Harada. Planning to repose long and heavy objects considering a combination of regrasp and constrained drooping. Assembly Automation, 2021.
- Cao et al. [2016] C. Cao, W. Wan, J. Pan, and K. Harada. Analyzing the utility of a support pin in sequential robotic manipulation. In 2016 IEEE International Conference on Robotics and Automation (ICRA), pages 5499–5504. IEEE, 2016.
- Ma et al. [2018] J. Ma, W. Wan, K. Harada, Q. Zhu, and H. Liu. Regrasp planning using stable object poses supported by complex structures. IEEE Transactions on Cognitive and Developmental Systems, 11(2):257–269, 2018.
- Xue et al. [2008] Z. Xue, J. M. Zoellner, and R. Dillmann. Planning regrasp operations for a multifingered robotic hand. In 2008 IEEE International Conference on Automation Science and Engineering, pages 778–783, 2008. doi:10.1109/COASE.2008.4626569.
- Chavan-Dafie and Rodriguez [2018] N. Chavan-Dafie and A. Rodriguez. Regrasping by fixtureless fixturing. In 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), pages 122–129, 2018. doi:10.1109/COASE.2018.8560381.
- Yuan et al. [2020] S. Yuan, L. Shao, C. L. Yako, A. Gruebele, and J. K. Salisbury. Design and control of roller grasper v2 for in-hand manipulation. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020.
- Cruciani et al. [2019] S. Cruciani, K. Hang, C. Smith, and D. Kragic. Dual-arm in-hand manipulation and regrasping using dexterous manipulation graphs. arXiv preprint arXiv:1904.11382, 2019.
- Saut et al. [2010] J.-P. Saut, M. Gharbi, J. Cortés, D. Sidobre, and T. Siméon. Planning pick-and-place tasks with two-hand regrasping. In 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4528–4533. IEEE, 2010.
- Rubinstein and Kroese [2004] R. Y. Rubinstein and D. P. Kroese. The Cross Entropy Method: A Unified Approach To Combinatorial Optimization, Monte-Carlo Simulation (Information Science and Statistics). Springer-Verlag, Berlin, Heidelberg, 2004. ISBN 038721240X.
- Qi et al. [2017] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv preprint arXiv:1706.02413, 2017.
- Shao et al. [2018] L. Shao, P. Shah, V. Dwaracherla, and J. Bohg. Motion-based object segmentation based on dense rgb-d scene flow. IEEE Robotics and Automation Letters, 3(4):3797–3804, Oct 2018. ISSN 2377-3766. doi:10.1109/LRA.2018.2856525.
- Coumans and Bai [2016–2019] E. Coumans and Y. Bai. Pybullet, a python module for physics simulation for games, robotics and machine learning. http://pybullet.org, 2016–2019.
- He et al. [2017] K. He, G. Gkioxari, P. Dollár, and R. Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- Long et al. [2015] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015.
- Tremeau and Borel [1997] A. Tremeau and N. Borel. A region growing and merging algorithm to color segmentation. Pattern recognition, 30(7):1191–1203, 1997.