Learning to refer informatively by amortizing pragmatic reasoning
Abstract
A hallmark of human language is the ability to effectively and efficiently convey contextually relevant information. One theory for how humans reason about language is presented in the Rational Speech Acts (RSA) framework, which captures pragmatic phenomena via a process of recursive social reasoning (?, ?). However, RSA represents ideal reasoning in an unconstrained setting. We explore the idea that speakers might learn to amortize the cost of RSA computation over time by directly optimizing for successful communication with an internal listener model. In simulations with grounded neural speakers and listeners across two communication game datasets representing synthetic and human-generated data, we find that our amortized model is able to quickly generate language that is effective and concise across a range of contexts, without the need for explicit pragmatic reasoning.
Keywords: reference, pragmatics, rational speech acts, emergent communication
Introduction
When we refer to an object or situation using natural language, we easily generate an utterance that achieves a useful amount of information in the given context. Counterfactual reasoning about alternative utterances has been central to explanations of these pragmatic aspects of language (?, ?, ?). Yet these theories entail computations that appear slow and burdensome as cognitive processes, so how do we produce pragmatic utterances so easily?
One popular computational account of pragmatic reasoning is the Rational Speech Acts (RSA) model (?, ?). In RSA, speakers and listeners reason about the meaning of utterances by considering the other utterances that could have been produced, thus arriving at pragmatic interpretations that enrich literal semantics. In addition to referring expression generation (?, ?, ?), RSA has seen success in modeling a wide variety of phenomena, including scalar implicature, metaphor, hyperbole, and politeness (for a review, see ?, ?).
However, the successes of RSA have been in describing pragmatic language competence. In other words, within Marr’s (?) levels of analysis, RSA is a computational account of human language, describing only what is to be ideally computed, and not how humans produce language with limited resources. Indeed, the full computation specified by RSA involves reasoning over all possible utterances in context, which is intractable in all but the most trivial settings. Moreover, such computation is wasteful in that it is memoryless, and does not leverage past experience (?, ?).
The impracticality of explicit pragmatic reasoning has had implications for both theory and modeling. Linguists have argued that pragmatic phenomena such as scalar implicature (?, ?) and metaphor (?, ?) are conventionalized, becoming the default interpretation of utterances unless specifically cancelled by the speaker. Others have argued that during pragmatic reasoning, listeners may only consider a subset of relevant interpretations (?, ?, ?), or trade off between “slow” and “fast” processes (?, ?). In natural language processing, RSA-based models for pragmatic referring expression generation use approximate inference methods, either sampling a subset of possible utterances from a learned model (?, ?, ?) or reasoning incrementally (?, ?). Others use heuristics inspired from the psycholinguistics literature, with greedy and probabilistic search techniques to reduce the space of possible utterances (?, ?, ?).
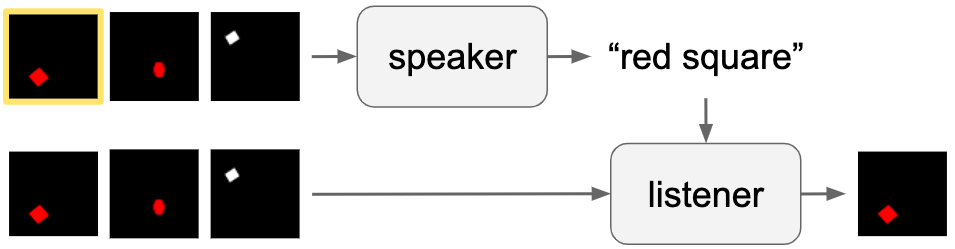
Given limited time and resources, it is indeed unlikely that we do exhaustive Bayesian reasoning every time we speak. An alternative is that experience with this slower reasoning process has led to amortized “habits of speech” that we use most of the time (?, ?). In this paper, we model this hypothesis through grounded language models that are trained with listeners in Lewis (?)-style communication games (Fig. 1), measuring the degree to which they learn to speak pragmatically. Our models are able to acquire desirable pragmatic behavior while being far more efficient than naive RSA-based approaches. This suggests that agents can internalize pragmatic language production processes, providing a plausible algorithmic account of human language production in resource-constrained settings and a promising avenue for the development of more efficient pragmatic language models.
How to Speak Informatively
We explore communication within Lewis-style signalling games (?) which allow us to analyze language use in grounded contexts. Formally, a reference game consists of a set of images , with one target image known only to the speaker. The speaker’s job is to produce an utterance which, when given to the listener, causes the listener to correctly identify (Fig. 1). Crucially, the ideal language for image changes depending on context. For example, in Fig. 1, it is not sufficient to simply say the color (“red”) or shape (“square”) of the target image; both must be provided to be unambiguous.
We consider a variety of speakers in this setting, each capturing different cognitive hypotheses about utterance production. The baseline naive speaker is a neural captioning model trained to generate observed descriptions of an image, completely ignoring context. To incorporate pragmatics, the naive speaker can be provided context objects as input, which we call the contextual speaker. In contrast, RSA-based speakers explicitly consider alternative utterances: the gold-standard Full RSA model does the complete reasoning process specified by RSA theory; the sample-rerank model approximates RSA by using a naive speaker to generate candidate utterances, reducing the space of alternatives. Our amortized speaker takes a different approach, training a context-aware language model with the RSA communication objective, without any pragmatic reasoning. The model is trained directly via backpropagation through a (white-box) internal listener model. In contrast, we also consider a REINFORCE speaker which learns from a sparser communicative reward signal given by a (black-box) external listener.
Naive speaker.
The naive speaker is a standard image captioning (IC) model trained to generate referring expressions that completely ignore context. Given a reference game , embeds with a convolutional neural network , and uses this embedding to initialize a recurrent neural network decoder (RNN-IC) which provides a probability distribution over utterances :
| (1) |
RNN-IC is trained with a standard language modeling objective with teacher forcing: given an image and ground-truth utterance , the loss of a predicted caption is
| (2) |
Contextual speaker.
The simplest way of incorporating context-sensitivity into is to condition it on the entire set of images as opposed to just . Given the same vision model , let be the embedding of the target image: . Let and be embeddings of the distractor images for : i.e. . Then our contextual speaker is trained identically to , except it is conditioned on the concatenation of all three embeddings:
| (3) |
RSA speakers
RSA speakers generate utterances with the goals of accurate and efficient communication. Accuracy is based on how a pretrained internal listener model will interpret the utterance. Given a reference game and a speaker utterance , represents the probability of target as proportional to the dot product between embeddings of and :
| (4) |
where is a CNN encoder (with the same architecture as ) and is an RNN encoder. These encoders will be trained from observed target-utterance pairs.
The speaker then chooses an utterance which maximizes the probability of the listener identifying , while also balancing the cost of the utterance :
| (5) |
When we can enumerate all possible utterances , we can compute Eq. 5 exactly, picking ; we call this model Full RSA () and treat it as an upper bound on the pragmatic quality of a speaker model. However, in many cases, there are an unbounded number of utterances to consider. Past work (?, ?, ?) uses the naive speaker as a proposal distribution from which a subset of utterances is sampled; exact inference is then performed with this subset. Since this involves sampling candidate utterances from then reranking them based on communicative utility, we refer to these approximations as sample-rerank models (). For both models, our cost function is simply a penalty linear in the length of the utterance: . We used a constant for , for , and for , and for , set .111Increasing resulted in little performance benefit.
Learning to produce informative utterances
Both versions of RSA speakers described so far generate informative utterances by explicitly considering alternatives, which can be slow and expensive. We next describe a model that amortizes this cost, learning to produce the utterances that RSA would prefer, without needing to explicitly consider alternatives at neither train nor test time.
Our amortized speaker has the same architecture as the naive contextual model , generating an utterance after encoding the target and distractors:
| (6) |
However, while is trained as an IC model to match observed utterances, is trained to directly optimize the RSA objective. Specifically, define the loss of a sampled caption as the listener surprisal plus the cost of the utterance:
| (7) |
Equation 7 looks similar to the RSA objective, Equation 5, but crucially omits the normalization term. This means we do not have to consider alternative utterances when training the model: for a fixed, pre-trained internal listener model , each optimization step consists of sampling an utterance from , evaluating the listener model, then updating the parameters to minimize . Note that unlike , utterances are evaluated solely via communicative utility, and not compared to observed language.
A technical problem with training this model is the need to estimate the gradient of given discrete sequences sampled by our speaker. We use the Gumbel-Softmax trick (?, ?), which gives differentiable “samples” from a categorical distribution by adding Gumbel noise and applying a softmax with a temperature . To ensure that receives discrete inputs, we use the (biased) straight-through estimator: the utterance is discretized in the forward pass, but treated as the original continuous sample in the backwards pass. A constant allowed our models to train successfully. Our differentiable cost function is implemented as a penalty on not predicting the end of sentence token, which increases by after each sampled token.
has an introspectable internal listener model that can be used for explicit pragmatic reasoning. Importantly, this means that the speaker model receives subtle word-by-word supervision during training. An alternative is an agent that has no internal listener model, but still attempts to maximize communication success by trial and error. We thus consider a reinforcement learning model, the REINFORCE speaker, , which is architecturally identical to , but trained with a black-box reward function rather than an explicit internal listener. A discrete utterance is sampled from as before. We simulate a referent choice from an external listener by selecting . receives a reward of +1 if the listener identifies the correct target and 0 otherwise222This is equivalent to stochastically sampling a reward from the RSA listener with a very low softmax temperature. A higher temperature led to more variance during training and overall worse performance.. The weights of are then updated via the REINFORCE gradient estimator (?, ?). From a reinforcement learning perspective, and have the same objective, but the former is model-free while the latter is model-based, with RSA as the model of communication.
Experiments
Datasets

We run experiments on two reference game datasets representing synthetic and human-generated data. ShapeWorld (?, ?) is an artificial dataset where each game consists a set of three images, each containing a single random shape with random color. Each game varies in the informativity of the utterance required for successful communication: either only the shape or color is sufficient, or both are needed (Fig. 2). This allows us to evaluate how our speakers modulate their utterances depending on the context. Our primary ShapeWorld dataset has 76000 games containing artificially generated utterances with a total vocabulary of 15 words. Additionally, to test systematic generalization to novel contexts, we constructed similar datasets where either a color (red), shape (square), or set of color-shape combinations (red circle, blue square, yellow ellipse, white circle, gray square) were held-out during training, but presented as targets in every test game.
Colors (?, ?) is a reference game dataset with real human language, where human speakers saw three patches of color and were asked to produce utterances that uniquely identify a target color. Here, contexts varied in their difficulty: either distractors were perceptually distinct from the target image (far) or were similar in color space (close) (Fig. 3). The language used in the 46000 games in this dataset is considerably more complex, with around 1400 unique vocabulary tokens; thus, reasoning over all possible utterances (as required by Full RSA) is infeasible.

Training and Model Details
We split each dataset into a training, validation, and test split of 60:15:1 on ShapeWorld and 42:3:1 on Colors. The training datasets for each task were further subdivided into thirds. 1/3 was used to train our speakers (and speaker-internal listener if used). The second 1/3 of the training data was used to train a validation listener: training was stopped after a speaker obtained maximum accuracy with this listener on the validation set. Finally, the last 1/3 was used to train evaluation listeners. The ultimate communicative accuracy of speaker models was evaluated with these evaluation listeners on the test set. These divisions ensured that speakers did not overfit to a single listener, and instead were evaluated for behavior that generalized across different listeners.
Models were trained for a maximum of 100 epochs with the Adam optimizer (?, ?) with a batch size of 32 and a learning rate of 0.001 for speakers and 0.01 for listeners. After training, the models with the highest validation accuracy were kept. RNNs (both encoders and decoders) are 100-d unidirectional Gated Recurrent Unit (GRU) RNNs (?, ?) with 50-d word embeddings learned from scratch, except for the contextual speakers , which have hidden size 300-d (since they consume 3 embeddings). The vision modules and are CNNs with 4 blocks, each block containing a 64-filter 3x3 convolutional layer, batch normalization, ReLU activation, and 2x2 max pooling. Given shapes and colors represented as input images, this produces 1024-d representations. In speakers, these are projected via a linear layer down to the GRU hidden size to initialize the GRU; for listeners, to compare image and text embeddings, we project the text representation into the 1024-d image space via a linear layer and use dot product to produce the target probability. Our code is available at https://github.com/juliaiwhite/amortized-rsa.
Results
We evaluate our speakers’ utterances (see Fig. 3 for examples) in several ways. First, language should be effective: it should serve its communicative goal of helping the listener correctly identify the target image. We measure communication success with our evaluation listeners on unseen reference games. Second, language should be concise, saying as much as needed, but no more. We measure this by examining how the length and content of the utterance changes depending on the difficulty of the contexts as specified in either dataset. Finally, language should be conventional: to cause minimal confusion to a listener, it should look like conventional, grammatical English. Because the ShapeWorld dataset uses completely artificial language, we measure conventionality on the Colors dataset only.333RSA and Amortized models used coherent one word utterances, e.g. “blue”, which due to the artificial nature of the dataset, did not exist in the training data (which had only “blue shape”). Thus, they had extremely low probability, making this evaluation nonsensical. As an imperfect proxy to conventionality, we measure the per-word probability of the utterances generated from our speakers, as reported by an unconditional language model trained on utterances in the training data.444Per-word probability avoids confounds with utterance length.
Efficacy.

All speaker models, except for the REINFORCE model , perform well above chance on both test datasets (Fig. 4) though there are significant differences between them. The naive baseline attains an accuracy of 73% for ShapeWorld and 67% for Colors. While the additional context given to results in some improvement, more substantial benefits come when models use pragmatic objectives. The sample-rerank model obtains much higher accuracy, only slightly behind in ShapeWorld and even outperforming the human utterances in Colors.555Human utterance accuracy is imperfect because utterances are evaluated with respect to a neural listener, not a human listener. Our listener model is an imperfect approximation for a human listener, but is still a reasonable measure of efficacy given that we measure accuracy across multiple separately-trained listeners. Most notably, our amortized model also performs very well, performing on par with in ShapeWorld and achieving the highest accuracy (94%) out of all the models tested for Colors. Meanwhile, the REINFORCE model struggles; it performs on par with for ShapeWorld and is unable to learn in the Colors setting.
Concision.

We quantify concision by measuring the speaker’s average utterance lengths for the different contexts of our reference game (Fig. 5). Analyzing utterance length within context, we see that RSA and the amortized model exhibit appropriately longer utterance lengths when both the shape and color are needed to identify the target image as opposed to either component separately. Looking more specifically at how the number of color and shape words per utterance differ based on the context, we see that in contexts where the shape is required, these models are less likely to say a color and vice versa.666Both RSA and amortized models also capture the well-attested tendency of humans to produce colors more often than shapes, all else being equal. This in turn follows from properties of the neural listener: a CNN is more accurate at detecting colors than shapes. This behavior is not reflected at all in the naive speaker , and is less pronounced in the contextual () and sample-rerank () models. In Colors, we see that humans tailor utterance length to game difficulty: for the difficult “close” contexts where colors were the same shade, utterances tended to be longer than the easier “far” contexts. Here, only the contextual speaker and amortized model demonstrate a similar significant difference in utterance length.
Conventionality.

Finally, we quantify the extent to which generated utterances reflect conventional language, with an unconditional language model trained on human utterances from the Colors dataset. We explore the probability per word of utterances generated by our speaker models (Fig. 6). Unsurprisingly, the naive and contextual speakers , which are trained with language-modeling objectives, have high probability. The sample re-rank model sees a major decrease in probability, as it re-ranks sampled utterances with respect to an internal listener, which does not necessarily favor the most probable utterance.
The amortized model is lower still: the communicative training objective results in language drift (see Fig. 3 for examples) whereby the model is able to sacrifice realism for communicative efficacy; this has been reported in similarly trained models (?, ?). It is unclear whether this reflects creative and acceptable, but unconventional, use of language, or malformed language that would be hard for humans to understand. Regardless, the language is not overfit to the amortized speaker’s internal listener, given its ability to generalize to listeners trained on separate data.
Inference Speed.


Fig. 7 depicts average utterance generation time across 100 games for ShapeWorld. , , , and are similarly fast, since they require only a single sample from an RNN. In contrast, and must evaluate a listener across many utterances, resulting in much higher inference times. While these results are merely suggestive—our RSA models can likely be optimized—they point to the large gap in compute requirements between online pragmatic reasoning and amortized utterance production.
Generalization.
Fig. 8 displays communication accuracy on the dataset variants with held-out colors, shapes, or combinations. The amortized model comes closest to the performance of Full RSA, followed by the sample-rerank and REINFORCE models. The contextual captioner’s poor performance here likely indicates that, where it captures pragmatic behavior, it does so primarily by memorization. This indicates that communication-based training is needed to produce pragmatic language in novel contexts.
Conclusion and Discussion
We explored several models for speech production in reference games and evaluated them with respect to pragmatic efficiency, concision, conventionality, and processing time. The Full RSA model represents the gold standard at a competence level, capturing nuances of pragmatic behavior and generalizing well. But it requires large, often intractable, processing costs. In contrast, our amortized RSA model achieves performance close to Full RSA, while being far more efficient.
The contextual speaker, , performs poorly with respect to efficacy and concision, though well with respect to convention. Because the contextual model matches our amortized model in architecture but uses a language modeling objective, we conclude that some aspects of pragmatic communication are unattainable by simply observing surface-level linguistic cues. Despite recent work showing that language models may implicitly learn pragmatic phenomena from sufficient data (?, ?), our simulations suggest that communication-based training is required for successful pragmatic communication, especially when generalizing to situations that have not been seen in the training distribution. The reinforcement learning approach provides a complementary contrast: it shared the communicative objective with the RSA models, but was forced to learn from the weaker signal of communicative success or failure. The poor performance of this model suggests that an internal model of the listener greatly helps communication-based training.
While common pragmatic behaviors may be amortized, our model must still learn from experience; highly novel situations may still require the full reasoning processes afforded by frameworks like RSA. Indeed, empirical evidence reports significant variability in processing time across instances of a pragmatic phenomenon (?, ?). To better model this variability, one interesting extension of the work presented here is a model which reverts from amortized computation back to more sophisticated reasoning procedures in novel situations. Such a model would operationalize the trade-off between slow explicit reasoning processes and fast amortized computation that motivates recent theories of language processing (?, ?) and amortized probabilistic inference (?, ?).
An intriguing connection is to models of emergent communication (?, ?, ?, ?). In order to ground our amortized speaker in actual language, the listener is pre-trained on real language and fixed. In most emergent communication models, either speaker and listener are co-trained from scratch, or in an attempt to ground the communication protocol, the speaker is pre-trained and/or given auxiliary language grounding tasks (?, ?).
In this paper we described an algorithmic model that forms “habits of pragmatic speech”, internalizing the explicit pragmatic reasoning of Rational Speech Acts models into a fast but flexible speaker. This represents one solution to the puzzle of pragmatic speech: How do we produce pragmatically useful utterances so easily and quickly?
Acknowledgments
We thank anonymous reviewers and Christopher Potts for insightful comments. This research was supported in part by DARPA under agreement FA8650-19-C-7923, an NSF Graduate Research Fellowship for JM, and the Office of Naval Research grant ONR MURI N00014-16-1-2007.
References
- Andreas KleinAndreas Klein Andreas, J., Klein, D. (2016). Reasoning about pragmatics with neural listeners and speakers. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1173–1182).
- Cho et al.Cho et al. Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y. (2014). Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1724–1734).
- Cohn-Gordon, Goodman, PottsCohn-Gordon et al. Cohn-Gordon, R., Goodman, N., Potts, C. (2019). An incremental iterated response model of pragmatics. In Proceedings of the Society for Computation in Linguistics (SCiL) 2019 (pp. 81–90).
- Degen, Hawkins, Graf, Kreiss, GoodmanDegen et al. Degen, J., Hawkins, R. D., Graf, C., Kreiss, E., Goodman, N. D. (2020). When redundancy is useful: A bayesian approach to “overinformative” referring expressions. Psychological Review.
- Degen TanenhausDegen Tanenhaus Degen, J., Tanenhaus, M. K. (2015). Processing scalar implicature: A constraint-based approach. Cognitive Science, 39(4), 667–710.
- Degen TanenhausDegen Tanenhaus Degen, J., Tanenhaus, M. K. (2019). Constraint-based pragmatic processing. In The Oxford handbook of experimental semantics and pragmatics.
- Fox KatzirFox Katzir Fox, D., Katzir, R. (2011). On the characterization of alternatives. Natural Language Semantics, 19(1), 87–107.
- Frank GoodmanFrank Goodman Frank, M. C., Goodman, N. D. (2012). Predicting pragmatic reasoning in language games. Science, 336(6084), 998–998.
- Gershman GoodmanGershman Goodman Gershman, S., Goodman, N. (2014). Amortized inference in probabilistic reasoning. In Proceedings of the Annual Meeting of the Cognitive Science Society (CogSci) (Vol. 36).
- Goodman FrankGoodman Frank Goodman, N. D., Frank, M. C. (2016). Pragmatic language interpretation as probabilistic inference. Trends in Cognitive Sciences, 20(11), 818-829.
- GriceGrice Grice, H. P. (1975). Logic and conversation. In P. Cole J. L. Morgan (Eds.), Syntax and semantics: Vol. 3: Speech acts. New York: Academic Press.
- Jang, Gu, PooleJang et al. Jang, E., Gu, S., Poole, B. (2017). Categorical reparameterization with gumbel-softmax. In International Conference on Learning Representations (ICLR).
- Kingma BaKingma Ba Kingma, D. P., Ba, J. (2014). Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR).
- Krahmer Van DeemterKrahmer Van Deemter Krahmer, E., Van Deemter, K. (2012). Computational generation of referring expressions: A survey. Computational Linguistics, 38(1), 173–218.
- Kuhnle CopestakeKuhnle Copestake Kuhnle, A., Copestake, A. (2017). ShapeWorld - a new test methodology for multimodal language understanding. arXiv preprint. doi: arXiv:1704.04517
- Lakoff JohnsonLakoff Johnson Lakoff, G., Johnson, M. (2008). Metaphors we live by. University of Chicago Press.
- Lazaridou, Peysakhovich, BaroniLazaridou et al. Lazaridou, A., Peysakhovich, A., Baroni, M. (2017). Multi-agent cooperation and the emergence of (natural) language. In International Conference on Learning Representations (ICLR).
- Lazaridou, Potapenko, TielemanLazaridou et al. Lazaridou, A., Potapenko, A., Tieleman, O. (2020). Multi-agent communication meets natural language: Synergies between functional and structural language learning. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL).
- LevinsonLevinson Levinson, S. C. (2000). Presumptive meanings: The theory of generalized conversational implicature. MIT Press.
- LewisLewis Lewis, D. (1969). Convention: A philosophical study. Cambridge, MA: Harvard University Press.
- Marr PoggioMarr Poggio Marr, D., Poggio, T. (1976). From understanding computation to understanding neural circuitry. Massachusetts Institute of Technology, Artificial Intelligence Laboratory.
- Monroe, Hawkins, Goodman, PottsMonroe et al. Monroe, W., Hawkins, R. X. D., Goodman, N. D., Potts, C. (2017). Colors in context: A pragmatic neural model for grounded language understanding. Transactions of the Association for Computational Linguistics (TACL), 5, 325–338.
- Mordatch AbbeelMordatch Abbeel Mordatch, I., Abbeel, P. (2018). Emergence of grounded compositional language in multi-agent populations. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Schuster, Chen, DegenSchuster et al. Schuster, S., Chen, Y., Degen, J. (2020). Harnessing the richness of the linguistic signal in predicting pragmatic inferences. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL).
- SearleSearle Searle, J. R. (1969). Speech acts: An essay in the philosophy of language (Vol. 626). Cambridge University Press.
- Sperber WilsonSperber Wilson Sperber, D., Wilson, D. (1986). Relevance: Communication and cognition (Vol. 142). Cambridge, MA: Harvard University Press.
- van Gompel, van Deemter, Gatt, Snoeren, Krahmervan Gompel et al. van Gompel, R. P., van Deemter, K., Gatt, A., Snoeren, R., Krahmer, E. J. (2019). Conceptualization in reference production: Probabilistic modeling and experimental testing. Psychological Review, 126(3), 345.
- WilliamsWilliams Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3-4), 229–256.