Learning to Rearrange with Physics-Inspired Risk Awareness
Abstract
Real-world applications require a robot operating in the physical world with awareness of potential risks besides accomplishing the task. A large part of risky behaviors arises from interacting with objects in ignorance of affordance. To prevent the agent from making unsafe decisions, we propose to train a robotic agent by reinforcement learning to execute tasks with an awareness of physical properties such as mass and friction in an indoor environment. We achieve this through a novel physics-inspired reward function that encourages the agent to learn a policy discerning different masses and friction coefficients. We introduce two novel and challenging indoor rearrangement tasks – the variable friction pushing task and the variable mass pushing task – that allow evaluation of the learned policies in trading off performance and physics-inspired risk. Our results demonstrate that by equipping with the proposed reward, the agent is able to learn policies choosing the pushing targets or goal-reaching trajectories with minimum physical cost, which can be further utilized as a precaution to constrain the agent’s behavior in a safety-critic environment.
I Introduction
There has been significant recent advances in applying reinforcement learning algorithms to a variety of domains ranging from playing games [1] [2] to solving navigation and manipulation tasks in simulation environments [3, 4, 5, 6, 7, 8]. However, in many real-world robotic problems, avoiding risky behaviors in deployment is as crucial as optimizing the task objective. There is a rich body of prior work on safe RL [9] defining risk and enforcing safety from various perspectives, such as imposing constraints on state-action space [10] and value functions [11, 12], restricting the policies to be close to safe demonstrations [13, 14], etc. Motivated by the fact that many damage outcomes (e.g. falling down, dropping an object) are induced by the physical process of robot interacting with environments, we consider to model the risk in terms of physical cost over the trajectories. Besides collisions with the obstacles, physical properties such as the frictions of terrains and weights of the objects are also informative learning signals for the agent to assess the risk of its behaviors. However, these factors have not been sufficiently captured by the goal states defining the success of the classical navigation and manipulation tasks [15, 5, 6, 16, 17].
To this end, we study how to incorporate physical cost into the reward function to guide the policy learning in indoor rearrangement tasks. We build two novel and challenging tasks featuring a wheeled robot pushing boxes to goal regions with physically variant properties (Fig. 1). Accomplishing these tasks requires the agent to minimize its physical cost besides reaching the successful states. Our experiments have shown that the learned policies under this new reward function are able to stably distinguishing between different masses and frictions.

II Physical Cost
To estimate the physical cost in an arrangement task, we compute the amount of virtual physical work the agent spends on pushing an object to move on a floor/table at each time step as
where and are the object mass and the friction coefficient between the box and the floor/table. The contact surface has width , length , with . The object displacement of time step is and the object rotates around its z-axis by an angle of . All physical quantities involved here can be either obtained from the simulator or measured in the real-world irregardless of the robot platforms.
We then normalize by its running bounds to get step physical cost relative to all history steps the agent has taken so far, i.e. . Similarly, for any successful trajectory , we define its episode physical cost as , which is normalized over the episode physical cost of all successful episodes so far. and will be used in our reward function to measure the physical expense of an action or action sequence.
III Physics-Aware Indoor Rearrangement Tasks
We experiment in the 3D simulated environments built upon classroom scenes from OpenRooms dataset [18] by integrating Bullet [19] physics engine and iGibson’s renderer [3]. Our tasks are performed by a simulated two-wheeled Fetch robot [20] under joint space control with abilities other than locomotion disabled. The robot has a state space of 3D positions and orientations of itself and the interactive objects. It has four discrete actions: (move forward), (turn left), (turn right) and (stop), where parameter is the maximum value of the robot’s wheel angular velocity.
III-A Variable Friction Pushing Task
In this task, the agent and a box (10 kg) are initialized on a two-band floor. The red and blue bands have friction coefficients 0.2 and 0.8 respectively (Fig. 1). The agent’s objective is to push the box to the target rectangular region located on the other band along the most efficient trajectory without collision with any obstacles. This is taught by a physics-inspired reward function:
where and in practice. By weighting the constant pushing reward with step physical cost , the agent tends to find the most physically efficient way rather than the fastest way.
III-B Variable Mass Pushing Task
In this task, the agent and two boxes are initialized in a circular region. The two boxes have the same shape, size and distance to the agent, but with different materials and weights (10 kg and 50 kg respectively) (Fig. 1). The objective of the agent is to push at least one box outside the circle. With the physics-inspired reward defined below, the agent is learning to choose a lighter box to push:
where , in practice. Weighting the succeed reward with the episode physical cost informs the agent to choose a policy succeeding in task at the minimum physical cost.
IV Experiments and Results
We trained the agents using proximal policy optimization (PPO) [21] algorithms and evaluated the learned policies on the proposed tasks to answer the following questions:
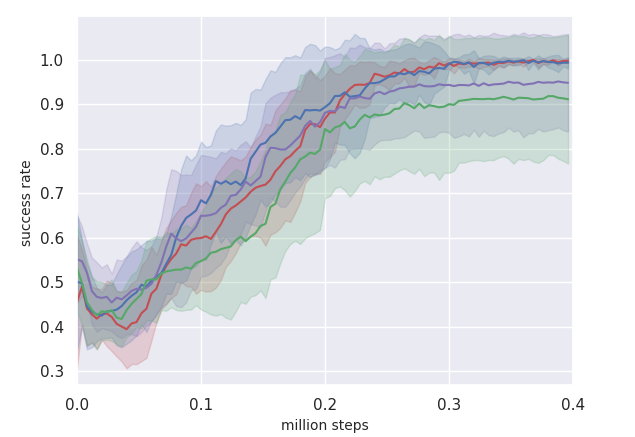
Does our physics-inspired reward function correctly guide the agent to learn a physically efficient policy? We compare the policies learned with (Blue) and without (Red) the physical cost in Fig. 2 and 3. The policies learned under the physics-inspired reward function has a clear drop on the mean energy cost of the successful episodes while converges to same near optimal success rate.
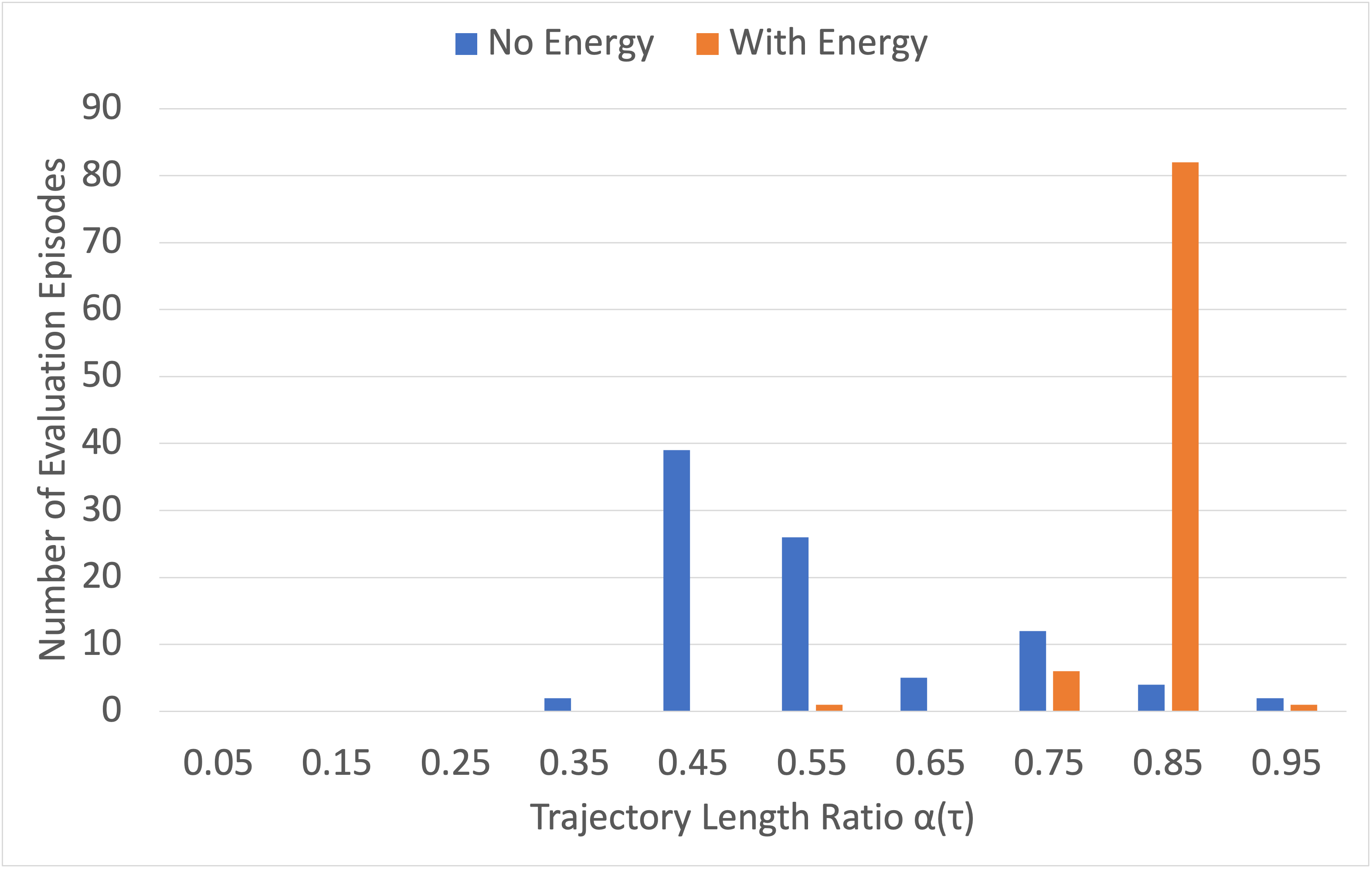
Does the policy learned under physics-inspired reward function reflect the agent’s awareness of mass and friction? We examine the distributions of evaluation trajectories on the preferences over low vs. high friction in Fig. 5 and light vs. heavy box in Fig. 5 with or without physical cost. The policy learned with physical cost has shown a clear preference while the counterpart without physical cost made the decision with nearly equal probabilities.
How does our definition of physical cost compare to other design strategies on learning successful and efficient policies? We ablate our physical cost to understand the role of the following factors: (1) Using pushing energy instead of robot output energy. (2) Normalizing the cost by running bounds instead of fixed bounds, which are estimated according to extra prior knowledge about the environment and the task. The comparisons of the training curves over the combinations of these factors are shown in Fig. 2 and 3. We observe that in most cases, removing either of these factors will lead to a drop in success rate or physical efficiency.




V Future work
Our work made a step towards learning physics-aware policies which are responsive to different masses and frictions. Potential future works include: (1) Extending the method to vision-based RL for better generalization of the physical risk. (2) Transferring the physics-inspired policies, value functions, experiences to downstream safe-critic tasks to avoid risky behaviors such as falling down on slippery floor, pushing unmovable objects, etc.
Acknowledgments
We thank NSF CAREER 1751365, CHASE-CI and generous gifts from Adobe, Google and Qualcomm.
References
- [1] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of go with deep neural networks and tree search,” Nature, vol. 529, pp. 484–503, 2016. [Online]. Available: http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
- [2] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. A. Riedmiller, A. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [3] B. Shen, F. Xia, C. Li, R. Martın-Martın, L. Fan, G. Wang, S. Buch, C. D’Arpino, S. Srivastava, L. P. Tchapmi, K. Vainio, L. Fei-Fei, and S. Savarese, “iGibson: A simulation environment for interactive tasks in large realistic scenes,” arXiv preprint, 2020.
- [4] E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, D. Gordon, Y. Zhu, A. Gupta, and A. Farhadi, “Ai2-thor: An interactive 3d environment for visual ai,” 2019.
- [5] Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik, D. Parikh, and D. Batra, “Habitat: A Platform for Embodied AI Research,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [6] F. Xiang, Y. Qin, K. Mo, Y. Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y. Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su, “SAPIEN: A simulated part-based interactive environment,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [7] Y. Zhu, J. Wong, A. Mandlekar, and R. Martín-Martín, “robosuite: A modular simulation framework and benchmark for robot learning,” in arXiv preprint arXiv:2009.12293, 2020.
- [8] D. Batra, A. X. Chang, S. Chernova, A. J. Davison, J. Deng, V. Koltun, S. Levine, J. Malik, I. Mordatch, R. Mottaghi, M. Savva, and H. Su, “Rearrangement: A challenge for embodied AI,” 2020.
- [9] J. Garcıa and F. Fernández, “A comprehensive survey on safe reinforcement learning,” Journal of Machine Learning Research, vol. 16, no. 1, pp. 1437–1480, 2015.
- [10] J. García and F. Fernández, “Safe exploration of state and action spaces in reinforcement learning,” CoRR, vol. abs/1402.0560, 2014. [Online]. Available: http://arxiv.org/abs/1402.0560
- [11] A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS’20. Red Hook, NY, USA: Curran Associates Inc., 2020.
- [12] K. Srinivasan, B. Eysenbach, S. Ha, J. Tan, and C. Finn, “Learning to be safe: Deep RL with a safety critic,” CoRR, vol. abs/2010.14603, 2020. [Online]. Available: https://arxiv.org/abs/2010.14603
- [13] P. Abbeel, A. Coates, and A. Y. Ng, “Autonomous helicopter aerobatics through apprenticeship learning,” The International Journal of Robotics Research, vol. 29, no. 13, pp. 1608–1639, 2010. [Online]. Available: https://doi.org/10.1177/0278364910371999
- [14] D. S. Brown, R. Coleman, R. Srinivasan, and S. Niekum, “Safe imitation learning via fast bayesian reward inference from preferences,” CoRR, vol. abs/2002.09089, 2020. [Online]. Available: https://arxiv.org/abs/2002.09089
- [15] Y. Jiang, S. Gu, K. Murphy, and C. Finn, “Language as an abstraction for hierarchical deep reinforcement learning,” CoRR, vol. abs/1906.07343, 2019. [Online]. Available: http://arxiv.org/abs/1906.07343
- [16] T. Yu, D. Quillen, Z. He, R. Julian, A. Narayan, H. Shively, A. Bellathur, K. Hausman, C. Finn, and S. Levine, “Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,” 2021.
- [17] Y. Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” CoRR, vol. abs/1609.05143, 2016. [Online]. Available: http://arxiv.org/abs/1609.05143
- [18] Z. Li, T.-W. Yu, S. Sang, S. Wang, M. Song, Y. Liu, Y.-Y. Yeh, R. Zhu, N. Gundavarapu, J. Shi, S. Bi, Z. Xu, H.-X. Yu, K. Sunkavalli, M. Hašan, R. Ramamoorthi, and M. Chandraker, “OpenRooms: An end-to-end open framework for photorealistic indoor scene datasets,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [19] “Bullet real-time physics simulation,” 2018. [Online]. Available: https://pybullet.org/wordpress/
- [20] M. Wise, M. Ferguson, D. King, E. Diehr, and D. Dymesich, “Fetch & freight: Standard platforms for service robot applications,” in 2016 International Joint Conference on Artificial Intelligence, 2016.
- [21] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017.