Learning to Rank for Active Learning: A Listwise Approach
Abstract
Active learning emerged as an alternative to alleviate the effort to label huge amount of data for data-hungry applications (such as image/video indexing and retrieval, autonomous driving, etc.). The goal of active learning is to automatically select a number of unlabeled samples for annotation (according to a budget), based on an acquisition function, which indicates how valuable a sample is for training the model. The learning loss method is a task-agnostic approach which attaches a module to learn to predict the target loss of unlabeled data, and select data with the highest loss for labeling. In this work, we follow this strategy but we define the acquisition function as a learning to rank problem and rethink the structure of the loss prediction module, using a simple but effective listwise approach. Experimental results on four datasets demonstrate that our method outperforms recent state-of-the-art active learning approaches for both image classification and regression tasks.
I Introduction
There are many applications nowadays, such as image/video indexing and retrieval, autonomous driving, etc. which require a huge amount of labeled data. Manual annotation of this data is time consuming and prohibitively expensive since it involves human resources [1]. As a result, active learning emerged as an alternative to make this process more manageable.
Active learning attempts to overcome the labeling bottleneck by automatically selecting the most valuable data to be annotated by human experts. Active learning assumes the existence of a small labeled dataset and a fixed budget to annotate the unlabeled samples. The goal of active learning is to automatically select a number of unlabeled samples (according to the budget) for annotation, based on an acquisition function (also known as ‘query function’) which indicates how valuable a sample is for training the model. The underlying assumption is that some data samples provide more valuable information than others, so that when labeled and used for training, they improve the model performance by decreasing the number of annotations. In this way, the active learner aims to achieve high accuracy using as few labeled instances as possible, thereby minimizing the cost of obtaining labeled data. Active learning has been successfully applied to several computer vision applications, such as: image classification [2, 3], object detection [4, 5], Visual Question Answering (VQA) [6], remote sensing [7] and action localization [8].
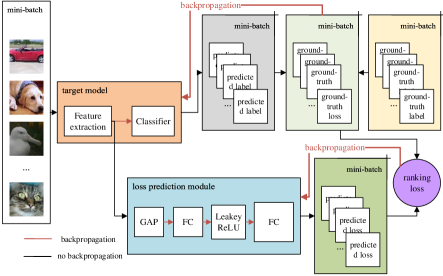
How to define and select the most valuable data - i.e. the query strategy - is the main research topic of active learning. In the current work, we follow the idea of learning to predict a loss from [9] as this method is task-agnostic and effective. This method learns to predict the loss of unlabeled input sample, and uses the predicted loss as a measure of uncertainty. Besides, unlike for instance the entropy method, which only suits classification problems, the learning loss method suits a variety of loss based deep learning problems, e.g. image classification, object detection and human pose estimation.
The overall architecture of the proposed method is depicted in Fig. 1, for an image classification problem, but it could be easily adapted for regression problems as well. The motivation for training the loss prediction module (the blue box) is to minimize the errors of predicted losses (dark green box) and ground-truth losses (light green box). A ground-truth loss is calculated by a loss function using the predicted label (gray box) of target model (orange box) and the ground-truth label (yellow box).
However, the learning loss based active learning problem is actually a ranking problem (the purple circle). We clarify this aspect in subsection III-A and demonstrate that the loss prediction module should be trained by minimizing the ranking error.
Although our approach has been inspired by [9], it is different in the following aspects (more details in subsection III-C): (i) from the target model (orange box) we extract only the features of the last convolutional layer to be processed by the rest of the pipeline, since it showed to improve the performance; (ii) in the loss prediction module (blue box) we used an improved, more explicit method to rank the predicted losses which takes into account the list (of losses) structure (iii) regarding training, we stop the ranking loss gradient to backpropagate to the target model and we separate the two losses (ranking loss and the target loss), so the loss prediction module and target model are trained separately. This is better, because the gradient from the loss prediction module does not influence the target model.
We validate our proposed framework on four datasets: CIFAR-10 [10] and CelebA [11] for classification tasks, and MPII dataset [12] for human pose estimation and ShanghaiTech Part_B dataset [13] for crowd counting for regression tasks. Experimental results demonstrate that our algorithm, learning to rank for active learning (L2R-AL), outperforms state-of-the-art methods such as: core-set [14], learning loss for active learning (LL4AL) [9], entropy method [15] and Variational Adversarial Active Learning (VAAL).
To summarize, the main contributions are:
-
•
we demonstrate the learning loss based active learning method is actually a learning to rank problem
-
•
we use an improved ranking method for predicted losses (the listwise approach)
-
•
we show that although for classification tasks entropy method dominates other active learning approaches (including ours), for regression tasks our approach holds the best performance when compared with current state-of-the art methods
II Related Work
II-A Active Learning
Most of the active learning strategies are pool-based approaches, which can be further divided into the following categories, depending on the query function: informativeness [16, 17], representativeness [18, 14], hybrid [19, 20] and performance-based [21, 22, 23].
Among all the above approaches, informativeness-based approaches are the most successful ones, with uncertainty being the most used selection criteria used in both bayesian [24] and non-bayesian frameworks [25]. The entropy method [15, 26] calculates the entropy value of class posterior probabilities to define uncertainty, and data with the highest entropy is viewed as the most uncertain. Despite the query strategy is very simple, this method performs remarkably well for classification problems. However, this method is not suitable for regression problems and people need to design specific uncertainty metrics as shown in [9].
The query-by-committee [27, 28] is another popular active learning strategy, which alleviates many disadvantages of uncertainty sampling. For instance, uncertainty sampling tends to be biased towards the actual learner and it may miss important examples which are not in the sight of the estimator. The committee issues multiple hypotheses and the instance with highest consensus is viewed as the most informative. This motivation is simple and clear, however, for current DNNs, training a committee has high computational cost.
In the era of big data and deep learning, it has been proven in [14] that classical approaches as mentioned earlier, do not scale well to large datasets. Therefore, recently, the attention has been shifted towards deep active learning, with adversarial strategies being one of the most popular techniques [29].
The authors of core-set approach [14] define the problem of active learning as core-set selection where the problem becomes a K-center problem which can be solved by using a greedy approximation method. Empirical results showed state-of-the-art performance, but the query strategy is computationally expensive.
Recently, [9] has introduced a novel and task-agnostic active learning method. The authors attach a loss prediction module to the target network, and learn to predict target model’s losses of unlabeled samples. The data with highest predicted loss is viewed as the most uncertain and informative. The experimental results demonstrate that their method consistently outperforms the previous methods over the tasks. They learn the loss prediction module by considering the differences between pairs of loss predictions. However, the batch size of their method must be an even number and they only consider the neighbouring data pairs, neglecting the overall list relationship.
The VAAL (Variational Adversarial Active Learning) approach [30] learns a latent space using a variational autoencoder (VAE) [31] and an adversarial network trained to discriminate between labeled and unlabeled data. Samples predicted as “unlabeled” with the lowest confidence is sent to the oracle. They demonstrate state-of-the-art results. However, training the VAE and the discriminator requires high computational cost, and the hyperparameters may be sensitive.
In our paper, our active learning algorithm is based on the learning loss strategy of [9]. Instead of trying to minimize mean square error of predicted losses and ground-truth losses, we define the problem as a learning to rank problem. We use a listwise approach to train the loss prediction module. Besides, we have further studied the architecture of loss prediction module. The detailed architecture of our algorithm can be seen in the next section.
II-B Learning to Rank
The central problem of many tasks in information retrieval (IR) and natural language processing (NLP) is ranking, including document retrieval, question answering, meta-search, online advertisement, collaborative filtering, machine translation and so on [32]. Learning to rank means performing a ranking using machine learning techniques. [33] learns to identify a ranked list of related news articles which the user would like to read afterwards. Besides, learning to rank techniques are central to question answering systems for questions are matched against an extensive database to find the most relevant answer [34]. Furthermore, [35] uses learning to rank for fault localization in software debugging.
Learning to rank has two components: a learning system and a ranking system [32]. In the learning system, for each request, there is a set of offerings and there is a true ranking list on the offerings. The ranking system receives a subset of new offerings and assigns scores to them, where the system uses the ranking model trained by the learning system. Then the ranking list is obtained with the scores.
The authors of [36] group learning to rank problems into three approaches: the pointwise approach, the pairwise approach, and the listwise approach. The pointwise approach assumes that each instance in the training data has a numerical or ordinary score, then it can be approximated by a regression problem: given a single query, predict its score. In the pairwise approach, ranking is transformed into a pairwise classification or pairwise regression. A major limitation of the pointwise and pairwise ranking approaches is that the group structure is ignored [32]. The listwise approach instead tries to optimize the value of an evaluation metric. The most commonly used metrics include: mean average precision (MAP), Spearman’s rank correlation [37], normalized discounted cumulative gain (NDCG) [38], etc. The listwise approach is difficult in the context of deep learning end-to-end architecures because most of the metrics are not differentiable with respect to ranking model’s parameters, so surrogate functions are used. In practice, listwise approach often outperforms pairwise and pointwise approaches, and this is supported by a large scale of experiments [39].
In this paper, we will demonstrate that the loss prediction based active learning algorithm actually is a learning to rank problem, which can be seen in subsection III-A. The proposed active learning algorithm adopts a listwise approach to train the loss prediction module. In the subsection III-B, we will describe the surrogate method we use in the listwise approach.
III Learning to rank for active learning
Let represents the target model, e.g., an image classification model or a regression model. For a mini-batch of training data of size , these training data has ground-truth labels . The model generates predicted labels , and we can calculate ground-truth losses with these data. For learning loss based active learning, let represent the loss prediction module which generates predicted losses . During training, we train with the ground-truth losses, and during the querying of data for labeling by the oracle, a set of unlabeled instances with highest predicted losses are selected. The aim is to learn the parameters of the loss prediction module, , in order to predict higher loss scores for unlabeled instances which it is more uncertain about.
III-A Why Learning to Rank
The query strategy of [9] consists of choosing a set of samples with high predicted losses. Learning the loss prediction module by mean square error (MSE) with the ground-truth losses is a simple idea. However, the authors said they failed to learn a good loss prediction module with MSE: the scale of the real loss decreases overall with target model’s learning, so the loss prediction module would adapt roughly to the scale rather than fitting to the exact value. Their solution is to calculate the loss of loss prediction module by comparing pairs of values, i.e. they adopt a pairwise ranking approach. For a mini-batch whose size is , they make data pairs and consider the difference between each pair of predicted losses and ground-truth losses thus discarding the overall scale changes [9].
However, we demonstrate that the problem is not only that the scale of loss changes, but also that the loss prediction module should be trained with ranking loss. Fig. 2 shows an example of why MSE is not optimal for training the learning loss module (G-T represents ground-truth). The ‘Active learning system 1’ has lower MSE value but it recommends wrong data with highest uncertainty, whereas the ‘Active Learning system 2’ recommends right data although its MSE value is higher. This is because ‘System 2’ predicts the right ranks for the unlabeled data. This scenario motivates us to use a better ranking scheme, based on the listwise approach.

III-B A Sorting Deep Net to Learn Ranking Loss Surrogates
Many tasks are evaluated using non-differentiable metrics such as mean average precision or Spearman’s rank correlation [37]. However, it is hard for us to use them as objective functions to train learning models for they are not differentiable. There are surrogate approaches but it is not easy to propose good surrogate functions [40].
Recently, [40] proposes a method to learn to optimize such non-differentiable metrics. They use a deep neural network as a sorter to approximate the ranking function. It is pretrained with synthetic values and their ground-truth ranks. This sorter can then be combined with an existing model (e.g. loss prediction module) and converts the value list given by the model into ranking list. Then the ranking loss between the predicted ranks and ground-truth ranks can be calculated and backpropagated through the differentiable sorter and used to update the weights of the model.
III-C The Architecture of Proposed Algorithm
As demonstrated above, we want to minimize the ranking error between the predicted losses and ground-truth losses. Let us consider the ranking function which converts the ground-truth losses into ground-truth ranks . The function also converts the predicted losses into predicted ranks . For a mini-batch of input data with size , the aim is to learn the parameters for:
| (1) |
where is a metric that calculates the error between two ranking loss lists.
However, the ranking function is not differentiable so the error as shown in (1) cannot be backpropagated to update . As described in III-B, [40] proposes a differentiable sorter to learn approximations of the rank vector . In this paper, we adopt this method to active learning, aiming to minimize the error between predicted losses and ground-truth losses in the ranking space. Fig. 3 shows the solution to this problem.

Fig. 1 shows the whole architecture of the proposed algorithm for image classification problems, where the predicted loss, ranking loss and ground-truth loss consist of Fig. 3. The architectures for other kinds of problems are similar, i.e. for regression.
In [9], they take the features that are extracted between the mid-level blocks of the target model. However, we use the outputs of last block before the fully-connected layer from the target model as the features of input instances, as we find this method is more effective than using features from all mid-level blocks, and extracting and concatenating features from all blocks is not efficient for very deep neural networks. Besides, using the output of last block as feature is widely adopted in applications, e.g., image captioning [41].
The ranking loss backpropagates to the loss prediction module and updates its parameters . In [9], the ranking loss and the target model’s loss are combined with a hyperparameter, and the gradient from ranking loss backpropagates to the target model for some epochs. This will influence the target model’s performance because the loss prediction module and target model are two different optimization problems. Besides, searching for an optimal hyperparameter is also difficult.
In this paper, we stop the ranking loss gradient to the target model and we separate the two losses, removing the hyperparameter, so the loss prediction module and target model are trained separately. The loss prediction module is only used to choose the most uncertain unlabeled instances to be labeled by the oracle. This is another difference with respect to [9].
The loss prediction module consists (see Fig. 1, the blue box) of a global average pooling (GAP) layer, a fully-connected layer, a Leaky ReLU activation function and another fully-connected layer. The GAP is used to decrease the feature scale, as many CNNs do, e.g., ResNet [42] also contains a GAP before the fully-connected layer. We use a Leaky ReLU activation function as this is effective and converges faster. The two fully-connected layers are the core of this module, and they are learned to predict the losses of unlabeled instances by minimizing the ranking loss. [9] also uses a GAP layer and a fully-connected layer to decrease the feature scale, then concatenate them to another fully-connected layer to predict the loss.
III-D Loss Functions
For a mini-batch with size , the loss of target model is:
| (2) |
For the loss prediction module, we use a pretrained differentiable sorter to convert the predicted losses to ranking list, and use MSE as the metric to calculate the error of the predicted ranks and ground-truth ranks. As shown in [40], this method approximates the Spearman’s rank correlation, which is a metric that measures the differences between two lists in ranking space.
For the predicted loss list and the ground-truth loss list , each with size . The Spearman’s rank correlation [37] is defined as:
| (3) |
The range of this metric is from -1 to 1. If the predicted ranks are same as the ground-truth ranks in every dimension, the value is 1, otherwise -1. Our aim is to maximize (3), this equals to:
| (4) |
As discussed, we use an pretrained differentiable sorter to approximate . Let represent the sorter, then the ranking loss of becomes:
| (5) |
Note that the sorter is pretrained independently on specific synthetic data.
For a mini-batch with size , then the ranking loss of this batch is:
| (6) |
III-E Query Strategy
In this work we adopt the standard methodology used in active learning literature, i.e. we divide the available labeling budget in cycles. After the loss prediction module is trained in each cycle, it is used to select the unlabeled samples which are sent to the oracle for labeling. Since we are only interested in predicted losses, the query strategy does not require the ranking procedure. Thus, for a given mini-batch, the loss prediction module outputs a list of predicted losses. The higher the loss is, the higher the rank is in this list. The query strategy of the proposed algorithm is choosing the instances with highest predicted losses, which equals to highest predicted ranks (i.e. highest uncertainty)
IV Experiments
In this section, we show the results of the proposed active learning algorithm on two image classification tasks using CIFAR-10 [10], and CelebA [11] datasets, and two regression tasks using MPII [12] and ShanghaiTech Part_B [13] datasets.
For all experiments, we choose the bidirectional GRU sorter to rank the losses111https://github.com/technicolor-research/sodeep. We train the GRU sorter with synthetic data according to the code of [40]. The synthetic training data consists of vectors of randomly generated scalars, associated with their ground-truth rank vectors. We train the sorter for 400 epochs, using a sequence length of 64, for the case of image classification task. For regression task, we use a sequence length of 32 for the MPII dataset and a sequence length of 4 for ShanghaiTech Part_B dataset. Afterwards, we fix its parameters and use it to convert the predicted losses into a ranking list.
We implement our algorithm and comparing methods in PyTorch [43].
IV-A Experiment on CIFAR-10
Implementation details. We use the 18-layer residual network (ResNet-18) [42] as the target model for image classification. The batch size is 64. CIFAR-10 dataset contains 50000 training images and 10000 test images. Active learning algorithms begin from an initial labeled set and continue to be trained for several cycles. At each cycle the query strategy selects some unlabeled instances to be labeled by the oracle and add them to the labeled set. Afterwards, the target model is trained again.
In each active learning cycle, the active learning algorithms query instances for labeling from a random subset rather than the whole unlabeled pool. Subset size is set to 10000 for CIFAR-10. We begin the active learning cycle with 1000 labeled instances, and in each cycle, we continue to train the target model by adding 1000 labeled instances. We train the target model for 10 cycles.
We use the SGD optimizer to train the target model ResNet-18 of all the active learning algorithms for 150 epochs on training set, with initial learning rate of 0.1. After 120 epochs, the learning rate is decreased to 0.01. The momentum and the weight decay are 0.9 and 0.0005 respectively. We train the loss prediction modules of our algorithm and learning loss approach [9] with Adam optimizer with a learning rate of 1e-3 for 150 epochs. The parameter of Leaky ReLU is 0.01.
Comparing algorithms. We compare the proposed ranking based active learning algorithm (L2R-AL) with three state-of-the-art approaches: core-set approach [14], VAAL [30], and Learning loss for Active Learning (LL4AL) [9], and two baselines: random method and entropy method [15].
For core-set approach, we use the -Center-Greedy algorithm in [14] in accordance with [9]. For VAAL approach, we use their official released code, and the VAE latent dimension is 32. We train the VAE with Adam optimizer with a learning rate of 5e-4 as the authors do.
We use the same augmentation scheme as shown in [9], including 3232 size random crop from 3636 zero-padded images, random horizontal flip, and normalize images using the channel mean and standard deviation vectors estimated over the training set.
Results. Fig. 4 shows the different active learning algorithms’ average accuracies of 5 runs on the test set. For each run, different algorithms have the same random seed for selecting the initial labeled set and the subset in each cycle.

Our algorithm is noted as L2R-AL and it shows higher image classification accuracies than others. In the last active learning cycle, the random query strategy obtains a 87.72% accuracy while the VAAL method achieves 87.11%. We use the default hyperparameters of the VAAL official code but fail to get a better result. LL4AL achieves a higher result than the core-set approach: 90.45% and 89.47% respectively. In the last several cycles, the entropy method performs similarly good as our algorithm. In the last cycle, the entropy method achieves 90.64% and our algorithm achieves a 90.95% result. The results shows that the proposed learning to rank active learning algorithm achieves better results than the other state-of-the-art comparing algorithms for CIFAR-10 problem.
Besides, we want to show the ranking comparisons of our approach and LL4AL for each cycle. We use the Spearman’s rank correlation [37] to calculate the ranking effect of predicted losses and the ground-truth losses on the test set, as Fig. 5 shows. The ‘Rank-all-features’ represents the active learning method that uses the same loss prediction module as the LL4AL approach with features from all mid-level blocks but trained with our proposed ranking method. We can see that our approach achieves the highest ranking result on the test set, especially in the beginning cycles. In the last cycle, it achieves 0.977 compared with 0.971 of the learning loss approach and 0.975 of the ‘Rank-all-features’. This result shows that the proposed L2R-AL not only has better loss function for training, but also has better architecture of loss prediction module.

IV-B Experiment on CelebA
Implementation details. CelebA is a more challenging dataset which consists of 40 face attributes. This dataset contains 162770 training images and 19962 test images. The subset size is 20000. We choose the gender classification problem as image classification task using the male/female attribute. We resize all the images to 6464 pixels and normalize them.
We train the target model and loss prediction modules with SGD optimizer for 100 epochs with initial learning rate of 0.1. After 80 epochs, the learning rate is decreased to 0.01.
Comparing algorithms. We use the same comparing algorithms as the experiment on CIFAR-10. The VAE latent dimension of VAAL is 64. We begin the active learning cycle with 100 labeled instances, and in each cycle, we add another 100 labeled instances. The other settings are in accordance with CIFAR-10.
Results. Fig. 6 shows the gender classification results on test set of 5 runs. Our algorithm is marked as the blue one and we can see it shows better results than the comparing algorithms before the fifth cycle and then entropy method performs better. In the last cycle, our algorithm achieves a 91.76% result, compared with core-set’s 91.02%, LL4AL’s 91.11%, random approach’s 90.67%, VAAL’s 89.29% and entropy method’s 92.25%. The entropy method is upper bound for this classification problem and our proposed algorithm outperforms the other algorithms.

The results of these two image classification tasks demonstrate that our algorithm outperforms the other state-of-the-art approaches and the random baseline. However, in the case of entropy, the results show it dominates all other active learning approaches (including ours). It’s worth to mention this aspect, since entropy method is seldomly used as a baseline in the active learning literature. This could be explained by the fact that entropy is a very good measure for uncertainty of classification.
IV-C Experiment on Human Pose Estimation
Implementation details. We implement active learning algorithms on human pose estimation problem and choose a simple baseline method [44] for this regression problem. In accordance with [9], we use the MPII dataset [12] and follow the same splits: the training set consists of 22,246 poses from 14,679 images and the test set consists of 2,958 poses from 2,729 images. The subset size for using query strategy is 5000, which is same as [9]. By default, the input size is cropped to pixels. We use the default optimizer of their official code as shown in their paper [44] to train the target model: an Adam optimizer with initial learning rate 1e-3. The target model and the loss prediction modules are trained for 140 epochs. We use the SGD optimizer to train the loss prediction modules with an initial learning rate of 5e-2, and after 110 epochs, it is decreased to 5e-3. We use the default target model which simply adds a few deconvolutional layers over the last convolution stage in the ResNet-50. The features are extracted before the deconvolutional layers of the target model.
We use the standard evaluation metric for this problem: [email protected] [12] which measures the percentage of predicted key-points falling within a threshold distance 0.5 to the ground truth, where the distance is normalized by a fraction of the head size. We begin with 200 labeled instances, and in each cycle, we add another 200 labeled instances, and stop training after 1000 labeled instances. The batch size is 32. The other settings are in accordance with the image classification tasks.
Comparing algorithms. We compare our algorithm with core-set [14], LL4AL[9] and two baselines: random method and entropy method [15].
For entropy method, we use the same approach as [9]: applying the softmax to each heatmap to get an entropy for each body part, then averaging all of the entropy values.
Results. Fig. 7 shows the average [email protected] comparisons of 5 runs. When the number of labeled instances is 600 or more, our algorithm achieves higher performance. In the last active learning cycle, our approach obtains 69.37% result. By comparison, the core-set approach obtains 68.53%, the LL4AL approach obtains 68.27%, the random baseline obtains 67.41%, and the entropy baseline achieves 67.08%, respectively. Our algorithm achieves the highest result and the entropy method fails to query the informative instances for this problem.

IV-D Experiment on Crowd Counting
Implementation details. We implement active learning algorithms on crowd counting problem and choose an open source PyTorch code222https://github.com/gjy3035/C-3-Framework for this regression problem. We use ShanghaiTech Part_B [13] dataset, which has 400 and 316 images for training and testing, respectively.
As the training set only has 400 images, the active learning algorithms query from the set directly without using subset. The target model and loss prediction module are trained for 100 epochs with the open source code’s default optimizer: Adam optimizers with initial learning rate 1e-5. We choose the pretrained ResNet-50 based target model which is changed after the third layer with decoder and deonvolutional layers, as the authors [45] have shown its good results. The features are extracted before the decoder layers of the target model and input to the loss prediction module.
We begin with 20 labeled instances, and in each cycle, we add another 20 labeled instances, and stop training after 100 labeled instances. The batch size is 4. The other settings are in accordance with the image classification problems.
Comparing algorithms. Same as in the the experiment on human pose estimation and applying the softmax to the output density map for entropy method.
Results. Fig. 8 shows the comparisons in performance for the aforementioned algorithms, using MAE as evaluation metric. In this case, it measures the mean average error of predicted number and ground-truth number of persons. The result is an average over 5 runs. We can see that the proposed algorithm L2R-AL achieves lower errors than the comparing algorithms. In the last cycle, the MAE of our algorithm is 10.43, the LL4AL approach is 10.73, the core-set approach 10.98, the random approach is 11.28, and the entropy method is 15.04. We can see that our approach achieves the lowest error while the entropy method fails to query the informative instances too and is not effective for regression problems.

The above experiment results show that entropy method is still the outstanding approach for classification problems, but our algorithm also can match with it and outperforms the other algorithms. For regression problems, the entropy method fails and our algorithm achieves the best results.
V Conclusion
In this paper, we propose a learning loss based method for active learning which is task-agnostic: it attaches a module to learn to predict the target loss of unlabeled data, and select data with the highest loss for labeling. Furthermore, we demonstrate that learning loss based active learning algorithm actually is a learning to rank problem. We use a simple and effective listwise approach to train the loss prediction module by optimizing the Spearman’s rank correlation metric. We validate the proposed approach on two tasks: image classification (CIFAR-10, CelebA) and regression (MPII, ShanghaiTech Part_B). The experimental results show that our algorithm outperforms recent state-of-the-art active learning algorithms.
Acknowledgment
The authors want to thank CERCA Program of Generalitat de Catalunya and Spanish project PID2019-104174GB-I00 (MINECO). Minghan Li acknowledges the Chinese Scholarship Council (CSC) grant No.201906960018.
References
- [1] B. Settles, Active learning. Morgan Claypool, 2012.
- [2] A. Joshi, F. Porikli, and N. Papanikolopoulos, “Scalable active learning for multiclass image classification,” IEEE Trans. on PAMI, vol. 34, no. 11, pp. 2259–2273, 2012.
- [3] E. Gavves, T. Mensink, T. Tommasi, , C. Snoek, and T. Tuytelaars, “Active transfer learning with zero-shot priors: Reusing past datasets for future tasks,” in Proc. of ICCV, 2015, pp. 2731–2739.
- [4] J. Zolfaghari Bengar, A. Gonzalez-Garcia, G. Villalonga, B. Raducanu, H. Habibi Aghdam, M. Mozerov, A. M. Lopez, and J. van de Weijer, “Temporal coherence for active learning in videos,” in Proc. of ICCVW, 2019.
- [5] H. H. Aghdam, A. Gonzalez-Garcia, J. v. d. Weijer, and A. M. López, “Active learning for deep detection neural networks,” in Proc. of ICCV, 2019, pp. 3672–3680.
- [6] X. Lin and D. Parikh, “Active learning for visual question answering: An empirical study,” arXiv preprint arXiv:1711.01732, 2017.
- [7] C. Deng, X. Liu, C. Li, and D. Tao, “Active multi-kernel domain adaptation for hyperspectral image classification,” Pattern Recognition, vol. 77, pp. 306–315, 2018.
- [8] F. Heilbron, J.-Y. Lee, H. Jin, and Ghanem, “What do i annotate next? an empirical study of active learning for action localization,” in Proc. of ECCV, 2018, pp. 212–229.
- [9] D. Yoo and I. S. Kweon, “Learning loss for active learning,” in Proc. of CVPR, 2019, pp. 93–102.
- [10] A. Krizhevsky, “Learning multiple layers of features from tiny images,” Master’s thesis, Computer Science Department, University of Toronto, 2009.
- [11] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proc. of ICCV, 2015, pp. 3730–3738.
- [12] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” in Proc. of CVPR, 2014, pp. 3686–3693.
- [13] Y. Zhang, D. Zhou, S. Chen, S. Gao, and Y. Ma, “Single-image crowd counting via multi-column convolutional neural network,” in Proc. of CVPR, 2016, pp. 589–597.
- [14] O. Sener and S. Savarese, “Active learning for convolutional neural networks: A core-set approach,” in Proc. of ICLR, 2018.
- [15] X. Li and Y. Guo, “Adaptive active learning for image classification,” in Proc. of CVPR, 2013, pp. 859–866.
- [16] Y. Guo, “Active instance sampling via matrix partition,” in Proc. of NeurIPS, 2010.
- [17] W. Cai, Z. Y., S. Zhou, W. Wang, C. Ding, and X. Gu, “Active learning for support vector machines with maximum model change,” in Machine Learning and Knowledge Discovery in Databases, 2014, pp. 211–226.
- [18] P. Saito, C. Suzuki, J. Gomes, P. d. Rezende, and A. Falcao, “Robust active learning for the diagnosis of parasites,” Pattern Recognition, vol. 48, no. 11, pp. 3572–3583, 2015.
- [19] S.-J. Huang, R. Jin, and Z.-H. Zhou, “Active learning by querying informative and representative examples,” IEEE Trans. on PAMI, vol. 10, no. 36, pp. 1936–1949, 2014.
- [20] Y. Yang and M. Loog, “A variance maximization criterion for active learning,” Pattern Recognition, vol. 78, pp. 358–370, 2018.
- [21] Q. Gu, T. Zhang, C. Ding, and J. Han, “Selective labeling via error bound minimization,” in Proc. of NeurIPS, 2012.
- [22] W. Fu, M. Wang, S. Hao, and X. Wu, “Scalable active learning by approximated error reduction,” in Proc. of KDD, 2018, pp. 1396–1405.
- [23] Y. Yang and M. Loog, “A benchmark and comparison of active learning for logistic regression,” Pattern Recognition, vol. 83, pp. 401–405, 2018.
- [24] Y. Gal, R. Islam, and Z. Ghahramani, “Deep bayesian active learning with image data,” in Proc. of ICML, 2017, pp. 1183–1192.
- [25] Y. Yang, Z. Ma, F. Nie, X. Chang, and A. Hauptmann, “Multi-class active learning by uncertainty sampling with diversity maximization,” IJCV, vol. 113, no. 2, pp. 113–127, 2015.
- [26] A. J. Joshi, F. Porikli, and N. Papanikolopoulos, “Multi-class active learning for image classification,” in Proc. of CVPR, 2009, pp. 2372–2379.
- [27] H. S. Seung, M. Opper, and H. Sompolinsky, “Query by committee,” in Proceedings of the fifth annual workshop on Computational learning theory, 1992, pp. 287–294.
- [28] W. H. Beluch, T. Genewein, A. Nürnberger, and J. M. Köhler, “The power of ensembles for active learning in image classification,” in Proc. of CVPR, 2018, pp. 9368–9377.
- [29] Y. Deng, K. Chen, Y. Shen, and H. Jin, “Adversarial active learning for sequence labeling and generation,” in Proc. of IJCAI, 2018, pp. 4012–4018.
- [30] S. Sinha, S. Ebrahimi, and T. Darrell, “Variational adversarial active learning,” in Proc. of ICCV, 2019, pp. 5972–5981.
- [31] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [32] H. Li, “Learning to rank for information retrieval and natural language processing,” Synthesis Lectures on Human Language Technologies, vol. 4, no. 1, pp. 1–113, 2011.
- [33] Y. Lv, T. Moon, P. Kolari, Z. Zheng, X. Wang, and Y. Chang, “Learning to model relatedness for news recommendation,” in Proceedings of the 20th international conference on World wide web, 2011, pp. 57–66.
- [34] Y. Tay, M. C. Phan, L. A. Tuan, and S. C. Hui, “Learning to rank question answer pairs with holographic dual lstm architecture,” in Proc. of SIGIR, 2017, pp. 695–704.
- [35] J. Xuan and M. Monperrus, “Learning to combine multiple ranking metrics for fault localization,” in 2014 IEEE International Conference on Software Maintenance and Evolution, 2014, pp. 191–200.
- [36] T.-Y. Liu et al., “Learning to rank for information retrieval,” Foundations and Trends in Information Retrieval, vol. 3, no. 3, pp. 225–331, 2009.
- [37] Y. Dodge, The concise encyclopedia of statistics. Springer Science & Business Media, 2008.
- [38] S. Chakrabarti, R. Khanna, U. Sawant, and C. Bhattacharyya, “Structured learning for non-smooth ranking losses,” in Proc. of SIGKDD, 2008, pp. 88–96.
- [39] N. Tax, S. Bockting, and D. Hiemstra, “A cross-benchmark comparison of 87 learning to rank methods,” Information processing & management, vol. 51, no. 6, pp. 757–772, 2015.
- [40] M. Engilberge, L. Chevallier, P. Pérez, and M. Cord, “Sodeep: a sorting deep net to learn ranking loss surrogates,” in Proc. of CVPR, 2019, pp. 10 792–10 801.
- [41] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in Proc. of ICML, 2015, pp. 2048–2057.
- [42] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. of CVPR, 2016, pp. 770–778.
- [43] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” 2017.
- [44] B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in Proc. of ECCV, 2018, pp. 466–481.
- [45] J. Gao, W. Lin, B. Zhao, D. Wang, C. Gao, and J. Wen, “C^ 3 framework: An open-source pytorch code for crowd counting,” arXiv preprint arXiv:1907.02724, 2019.